Abstract
For a finite field GF() with prime p and , one of the standard representations is matrices over GF(p) so that the arithmetic of GF() can be realized by the arithmetic among these matrices over GF(p). Based on the matrix representation of GF(), a conventional linear network coding scheme over GF() can be transformed to an L-dimensional vector LNC scheme over GF(p). Recently, a few real implementations of coding schemes over GF(), such as the Reed–Solomon (RS) codes in the ISA-L library and the Cauchy-RS codes in the Longhair library, are built upon the classical result to achieve matrix representation, which focuses more on the structure of every individual matrix but does not shed light on the inherent correlation among matrices which corresponds to different elements. In this paper, we first generalize this classical result from over GF( to over GF() and paraphrase it from the perspective of matrices with different powers to make the inherent correlation among these matrices more transparent. Moreover, motivated by this correlation, we can devise a lookup table to pre-store the matrix representation with a smaller size than the one utilized in current implementations. In addition, this correlation also implies useful theoretical results which can be adopted to further demonstrate the advantages of binary matrix representation in vector LNC. In the following part of this paper, we focus on the study of vector LNC and investigate the applications of matrix representation related to the aspects of random and deterministic vector LNC.
1. Introduction
The finite fields GF() with a prime of p and an integer of have been widely used in modern information coding, information processing, cryptography, and so on. Specifically, in the study of linear network coding (LNC), conventional LNC [1] transmits data symbols along the edges over GF(), and every outgoing edge of a node v transmits a data symbol that is a GF()-linear combination of the incoming data symbols to v. A general LNC framework called vector LNC [2] models the data unit transmitted along every edge as an L-dimensional vector of data symbols over GF(p). Correspondingly, the coding operations at v involve GF(p)-linear combinations of all data symbols in incoming data unit vectors and are naturally represented by matrices over GF(p).
Recently, many works [3,4,5,6,7] have shown that vector LNC has the potential to reduce extra coding overheads in networks relative to conventional LNC. In order to achieve vector LNC, a matrix representation of GF() [8] is matrices over GF(p) so that the arithmetic of GF() can be realized by the arithmetic among these matrices over GF(p). Based on the matrix representation of GF(), a conventional LNC scheme over GF() can be transformed to an L-dimensional vector LNC scheme over GF(p). In addition to the theory of LNC, many existing implementations of linear codes, such as the Cauchy-RS codes in the Longhair library [9] and the RS codes in the Jerasure library [10,11] and the latest release of the ISA-L library [12], also practically achieve arithmetic over GF() using matrix representation.
In order to achieve the matrix representation of GF(), a classical result obtained in [13] relies on polynomial multiplications to describe the corresponding matrix of an element over GF(). A number of current implementations and studies (see, e.g., [9,10,11,12,13,14,15]) utilize such a characterization to achieve the matrix representation of GF(). However, the characterization in the present form focuses more on the structure of every individual matrix and does not shed light on the inherent correlation between matrices that corresponds to different elements. As a result, in the aforementioned existing implementations, the corresponding binary matrix is either independently computed on demand or fully stored in a lookup table as an matrix over GF(2) in advance.
In the first part of this paper, we shall generalize the characterization of matrix representation from over GF( to over GF() and paraphrase it from the perspective of matrices with different powers so that the inherent correlation among these matrices will become more transparent. More importantly, this correlation motivates us to devise a lookup table to pre-store the matrix representation with a smaller size. Specifically, compared to the one adopted in the latest release of the ISA-L library [12], the table size is reduced by a factor of . Additionally, this correlation also implies useful theoretical results that can be adopted to further demonstrate the advantages of binary matrix representation in vector LNC. In the second part, we focus on the study of vector LNC and show the applications of matrix representation related to the aspects of random and deterministic coding. In random coding, we theoretically analyze the coding complexity of conventional and vector LNC via matrix representation under the same alphabet size . The comparison results show that vector LNC via matrix representation can reduce at least half of the coding complexity to achieve multiplications. Then, in deterministic LNC, we focus on the special choice of coding operations that can be efficiently implemented. In particular, we illustrate that the choice of primitive polynomial can influence the distributions of matrices with different numbers of non-zero entries and propose an algorithm to obtain a set of sparse matrices that can be good candidates for the coefficients of a practical LNC scheme.
This paper is structured as follows. Section 2 reviews the mathematical fundamentals of representations to an extension field GF(). Section 3 paraphrases the matrix representation from the perspective of matrices in different powers and then devises a lookup table to pre-store the matrix representation with a smaller size. Section 4 focuses on the study of vector LNC and shows the applications of matrix representation related to the aspects of random and deterministic coding. Section 5 summarizes this paper.
Notation. In this paper, every bold symbol represents a vector or a matrix. In particular, refers to the identity matrix of size L, and 0, 1, respectively, represent an all-zero or all-one matrix, whose size, if not explicitly explained, can be inferred in the context.
2. Preliminaries
In this section, we review three different approaches to express an extension field GF() with elements, where p is a prime. The first approach is the standard polynomial representation. Let denote an irreducible polynomial of degree L over GF(p) and be a root of . Every element of GF() can be uniquely expressed as a polynomial in over GF(p) with a degree less than L, and forms a basis GF() over GF(p). In particular, every can be uniquely represented in the form of with . In the polynomial representation, the element is expressed as the L-dimensional representative vector over GF(p). In order to further simplify this expression, can be written as the integer such that
where is the integer representation of , that is, where 1 is to be the multiplicative unit of GF(p).
The second approach is called the generator representation, which further requires to be a primitive polynomial such that is a primitive element, and all non-zero elements in GF() can be generated as . Thus, every non-zero is uniquely expressed as the integer subject to
The polynomial representation clearly specifies the additive structure of GF() as a vector space or a quotient ring of polynomials over GF(p) while leaving the multiplicative structure hard to determine. Meanwhile, the generator representation explicitly illustrates the cyclic multiplicative group structure of without clearly demonstrating the additive structure. It turns out that the addition operation and its inverse in are easy to implement based on the polynomial representation, while the multiplicative operations and its inverse in are easy to be implement based on the generator representation. In particular, for ,
where the operation ⊕ between two integers and means the component-wise p-ary addition between the p-ary expression , of them. This is the key reason that in practice both representations are always adopted interchangeably when conducting operations in GF().
Unfortunately, except for some special , such as , , there is not a straightforward way to establish the mapping between and without computation, and a built-in lookup table is always adopted in practice to establish the mapping between two types of representations. For instance, Table 1 lists the mapping between and for non-zero elements in with .

Table 1.
The mapping between and for non-zero in with .
By convention, elements in GF() are represented as . It takes L p-ary additions to compute . Based on the lookup table, it takes 3 lookups (which, respectively, map , to , and to ), 1 integer addition, and at most 1 modulo operation to compute . Meanwhile, it is worthwhile to note that the calculation of without the table follows the multiplication of polynomials and with coefficient vectors and , respectively, and finally falls into
where the computational complexity compared with the following matrix representation will be fully discussed in Section 4.
The third approach, which is the focus of this paper, is given by means of matrices called the matrix representation [8]. Let be the companion matrix of an irreducible polynomial of degree L over GF(p). In particular, if with ,
It can be easily verified that is the characteristic polynomial of , and according to the Cayley–Hamilton theorem, . As a result, forms a basis of GF() over GF(p), and for every with the representative vector based on the polynomial representation, the matrix representation of is defined as
If the considered further qualifies as a primitive polynomial, then similar to the role of the primitive element defined above, is also a multiplicative generator of all non-zero elements in GF(), that is, for all . One advantage for the matrix representation is that all operations in GF() can be realized by matrix operations over GF(p) among the matrices in such that there is no need to interchange between the polynomial and the generator representations in performing field operations. For more detailed discussions of representation of an extension field, please refer to [16].
Based on the polynomial representation and generator representation, even though the arithmetic over GF() can be efficiently realized by (3), (4) and a lookup table, it requires two different types of calculation systems, i.e., one over GF(p) and the other over integers. This hinders the deployment practicality in applications with resource-constrained edge devices, such as in ad hoc networks or Internet of Things applications. In comparison, the matrix representation of GF() interprets the arithmetic of GF() solely over the arithmetic over GF(p), so it is also a good candidate for realization of the efficient implementation of linear codes over GF() such as in [9,10,11,12,13].
3. Useful Characterization of the Matrix Representation
Let be a defined irreducible polynomial over GF(p) of degree L and let be a root of . When , a useful characterization of the matrix representation of (with respect to ) can be deduced based on the following classical result obtained in Construction 4.1 and Lemma 4.2 of [13]: For , the jth column in is equal to the binary expression of based on the polynomial representation. A number of implementations and studies (see, e.g., [9,10,11,12,13,14,15]) of linear codes utilize such characterization to achieve the matrix representation of GF(). However, the characterization in the present form relies on polynomial multiplications and focuses more on the structure of every individual . It does not explicitly shed light on the inherent correlation among of different . It turns out that in existing implementations, such as the Cauchy-RS codes in the Longhair library [9] and the RS codes in the Jerasure library [10,11], and the latest release of ISA-L library [12], is either independently computed on demand or fully stored in a lookup table as an matrix over GF(2) in advance.
In this section, we shall generalize the characterization of matrix representation from over GF( to over GF() and paraphrase it based on the interplay with the generator representation instead of the conventional polynomial representation so that the correlation among of different will become more transparent. From now on, we assume that is further qualified to be a primitive polynomial such that is a primitive element in . For simplicity, let , , denote the representative (column) vector of based on the polynomial representation. Then, the following theorem asserts that the matrix representation consists of L representative vectors with consecutive subscripts.
Theorem 1.
For , the matrix representation can be written as follows:
As , we omit the modulo- expressions on the exponent of and subscript of throughout this paper for brevity.
Proof.
First, the matrix can be characterized by multiplication iterations based on (6) as follows. When ,
where matrix . Further, when ,
The entries in (9) and (10) iteratively qualify
and
When , it can be easily checked that each vector in is a unit vector such that the only non-zero entry 1 of locates at th row. Therefore, , and (8) holds. When , consider with , i.e.,
Obviously, and (8) holds.
Assume when , (8) holds, i.e., . The Lth column vector of based on (9) corresponds to the representative vector of , that is, the matrix is equal to
It remains to prove, by induction, that As the column vectors indexed from 1th to th of matrix are exactly same as the ones indexed from 2th to Lth of , it suffices to show that the Lth column vector of corresponds to . The following is based on (13) and (14):
It can be easily checked that and with in calculated by (12) exactly consist of the representative vector of , i.e., . This completes the proof. □
The above theorem draws an interesting conclusion that every non-zero matrix in is composed of L representative vectors. Specifically, the first column vector of the matrix representation is the representative vector of , and its jth column vector, , corresponds to the representative vector of . For the case , even though the above theorem is essentially same as Construction 4.1 and Lemma 4.2 in [13], its expression with the interplay of generator representation allows us to further devise a lookup table to pre-store the matrix representation with a smaller size.
In this table, we store representative vectors with table size and arrange them based on the power order of with . Note that the first column of matrix can be indexed by vector or th column in this table, and the remaining columns of can be obtained via subsequent column vectors based on Theorem 1. As a result, although this table only stores vectors, it contains the whole matrix representations of due to the inherent correlation among . The following Example 1 shows the explicit lookup table of as an example.
Example 1.
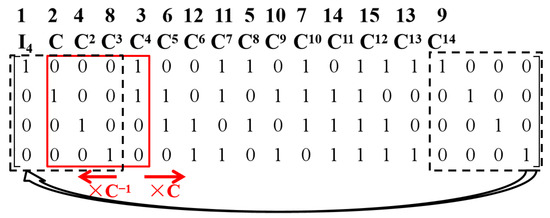
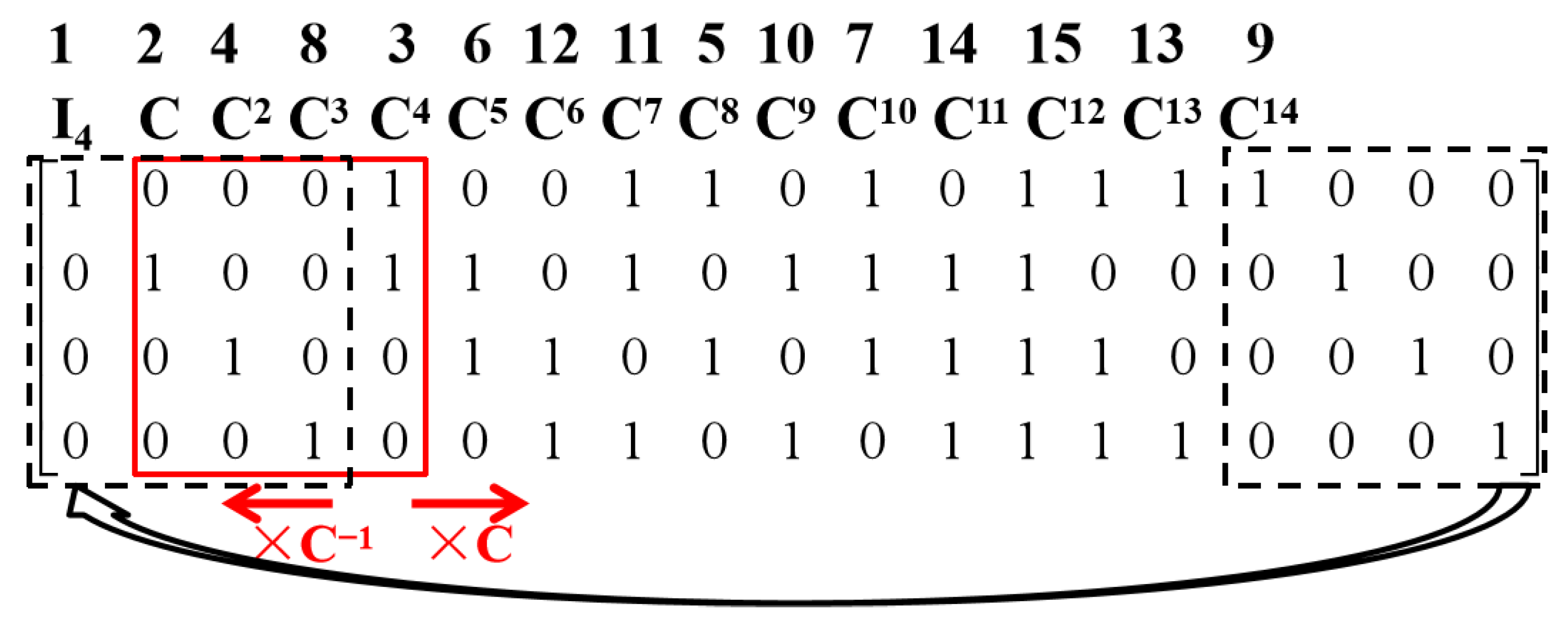
Consider the field GF() and primitive polynomial over GF(2). The companion matrix is written as follows:
Then, the lookup table to store matrix representation with is shown in Figure 1. In this figure, the solid “window” that currently represents the matrix can be slid to the right or left to generate with different i; meanwhile, the dashed box shows the cyclic property based on cyclic group .
Figure 1.
The lookup table to store the matrix representation with for the field GF() and primitive polynomial .
Recall that in the lookup table of the matrix representation adopted in the latest release of the ISA-L library [12], the matrix representation of every element in needs to be stored, so a total of p-ary elements need to be pre-stored. Compared with that, only an p-ary matrix needs to be stored in the new lookup table, so the table size is reduced by a factor of . Moreover, Theorem 1 implies the following useful corollaries of the matrix representation of .
Corollary 1.
Every vector in the vector space GF( exactly occurs L times as a column vector in matrices of .
Proof.
As forms a polynomial basis of GF() over GF(p), the representative vectors of matrices in are distinct. Consider a function . It can be easily checked that f is bijective, and exactly corresponds to the jth column vector of with . The zero vector of length L simply occurs L times in matrix . □
Corollary 2.
For every GF(), regardless of the choice of the primitive polynomial , the total number of zero entries in remains unchanged as .
The above two corollaries will be adopted to further demonstrate the advantages of binary matrix representation in vector LNC with .
4. Applications of Matrix Representation in Vector LNC
In this section, we focus on the study of vector LNC with binary matrices and show the applications of matrix representation related to the aspects of random and deterministic coding.
4.1. Computational Complexity Comparison in Random LNC
Herein, the coding coefficients of random LNC are randomly selected from GF(), which can provide a distributed and asymptotically optimal approach for information transmission, especially in unreliable or topologically unknown networks, such as wireless broadcast networks [17] or ad hoc network [18]. Recall that in polynomial and generator representations, the multiplication over GF() based on a lookup table requires two different types of calculation systems, so this table may not be utilized in resource-constrained edge devices. Therefore, under the same alphabet size , we first theoretically compare the random coding complexity between conventional LNC over and vector LNC over without lookup table, from the perspective of required binary operations.
To keep the same benchmark for complexity comparison, we adopt the following assumptions.
- We assume that an all-1 binary vector as information will multiply non-zero coding coefficients selected from and , which can be simulated as encoding process. The complexity is the total number of binary operations that multiplications take.
- We shall ignore the complexity of a shifting or permutation operation on the binary vector , which can be efficiently implemented.
- We only consider the standard implementation of multiplication in GF() by polynomial multiplication modulo and primitive polynomial with non-zero , instead of considering other advanced techniques such as the FFT algorithm [19].
We first consider the encoding scheme with coefficients selected from . Assume that is a root of and every element in GF() can be expressed as , where represents a polynomial over GF(2) with a degree less than L. An all-1 binary information vector can be expressed as . We can divide the whole encoding process into two parts: multiplication and addition. In the multiplication part, the complexity of shifting operations is ignored, and one polynomial in will modulo i times and take binary operations. Because every occurs times among all in GF(), it will take binary operations to compute . In the addition part, it takes binary operations to compute the additions between j binary vectors with distinct i. Note that the number of distinct with j non-zero terms is in GF(). Therefore, the traverse of will take an extra binary additions to compute . In total, the complexity of this scheme is shown as follows:
Next, we consider the encoding scheme with coefficients selected from , whose complexity of encoding process depends on the total number of 1 in with . In this framework, it is worthwhile to note that every in is full-rank and can extract a permutation matrix. Since the complexity of permutational operations is ignored, based on Proposition 2, the complexity of encoding process over is shown as follows:
For any primitive polynomial , . With , Table 2 lists the average number of binary operations per symbol in two schemes. Specifically, every value calculated by Equation (15) and (16) has divided the alphabet size , and we can find that in random coding, the vector LNC via matrix representation can theoretically reduce at least half of the coding complexity to achieve multiplications under the same alphabet size .
Table 2.
Average number of binary operations per symbol with parameter .
4.2. The Special Choices of Binary and Sparse
In addition to the random coding, a deterministic LNC where we pay a broader concern to reduce the computational complexity can also carefully design some special coding operations which can be efficiently implemented, such as circular shift [5,6] or permutation [7]. In this subsection, different from random choice of coefficients, we will carefully design the choices of binary primitive polynomial and sparse matrices in based on the unveiled properties in Sec. III. We illustrate that the choice of can influence the distributions of matrices with different numbers of non-zero entries. Then, based on a proper , an algorithm is proposed to obtain a subset of , which contains a series of relatively sparse matrices in .
When , the entries in representative vectors based on Equation (11) and (12) will, respectively, degenerate as follows:
and
with must be 1 in . Based on the above two equations, consider two adjacent representative vectors and . When the last entry in is equal to 0, the entries in follow
which means that can be generated by downward circular shift to . When the last entry equals 1, the entries in follow
Therefore, the difference between and in Hamming weight is no more than , where represents the number of non-zero in primitive polynomial .
Note that for the matrix representation of every GF(), the total number of 1 in is always regardless of the choice of binary . However, the value of will influence the distributions of sparse matrices in . Based on (17) and (18), we can intuitively deduce that with smaller , the sparse matrices in will be more concentrated distribution. Since the identity matrix with L non-zero entries is the sparsest full-rank matrix, we utilize Algorithm 1 to choose matrices in , which can be good candidates as coding coefficients of a practical coding scheme over GF().
| Algorithm 1 The choice of sparse matrices over GF() |
|
In Algorithm 1, the multiplications using or can be easily achieved by sliding the “window” right or left, respectively, as shown in Figure 1. Let denote this subset of and the matrices in can be written as with . Then, Table 3 lists the ratio of the total number of 1 between and with . We can find that the matrices, which are special choices using Algorithm 1, indeed contain less 1 than the other matrices in .
Table 3.
Ratio of total numbers of 1 between and .
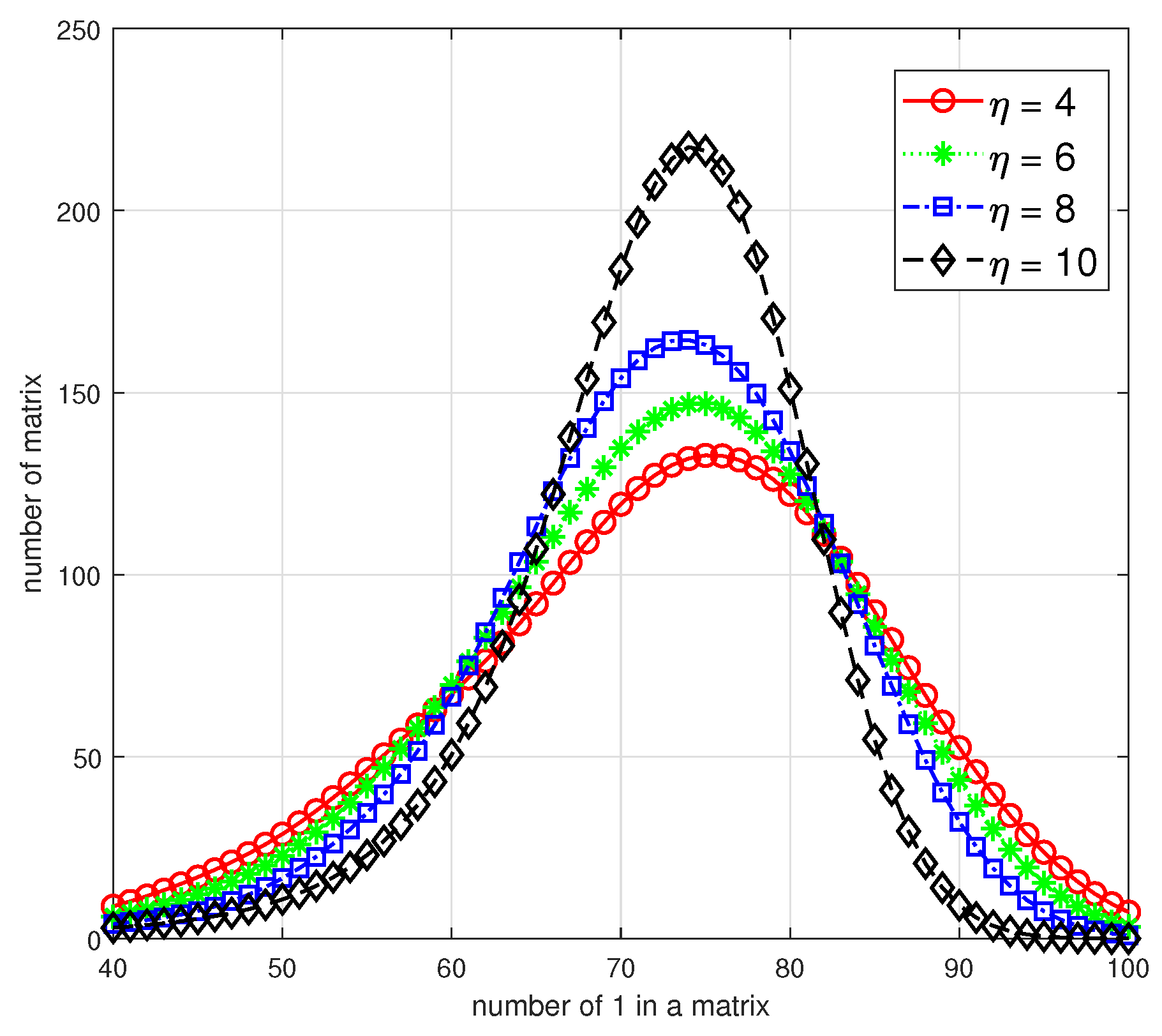
Moreover, in Figure 2, we numerically analyze the relationship between the number of 1 in each matrix and the corresponding number of matrices under the alphabet size . For all candidates of binary primitive polynomials, we choose four representative with different and the specific polynomials are shown as follows:
As all the matrices in are full-rank, the value range of the x-axis should be , and we restrict it to to highlight the distributions. These four curves illustrate that with increasing, the distribution variance of the number of 1 in a matrix will decrease, that is, the number of matrices with an average number of 1, i.e., 70–80, will increase and the number of relatively sparse or dense matrices will decrease. As a result, a smaller of not only infers a more concentrated distribution but also more amounts for sparse matrices in ; then, we can select parameter s according to practical requirements and obtain using Algorithm 1.
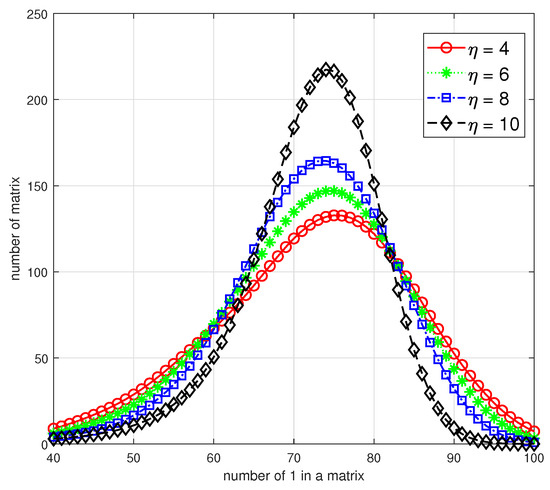
Figure 2.
The distribution of sparse matrices in with different .
5. Conclusions
Compared with the classical result, the paraphrase of matrix representation in this paper focuses more on inherent correlation among matrices and a lookup table to pre-store the matrix representation with a smaller size is devised. This work also identifies that the total number of non-zero entries in is a constant number, which motivates us to demonstrate the advantages of binary matrix representation in vector LNC. In the applications of matrix representation, we first theoretically demonstrate the vector LNC via matrix representation can reduce at least half of the coding complexity compared with conventional one over GF(). Then, we illustrate the influence of , i.e., the number of non-zero item in , on the amounts and distributions of sparse matrices in and propose an algorithm to obtain sparse matrices which can be good candidates as coding coefficients of a practical vector LNC scheme.
Author Contributions
Methodology, H.T.; Software, S.J.; Writing—original draft, H.T.; Writing—review & editing, H.L.; Visualization, W.L.; Supervision, Q.S.; Funding acquisition, Q.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partially supported by the National Natural Science Foundation of China under Grants U22A2005, 62101028 and 62271044, and by the Fundamental Research Funds for the Central Universities under Grant FRF-TP-22-041A1.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Li, S.-Y.R.; Yeung, R.W.; Cai, N. Linear network coding. IEEE Trans. Inf. Theory 2003, 49, 371–381. [Google Scholar] [CrossRef]
- Ebrahimi, J.B.; Fragouli, C. Algebraic algorithm for vecor network coding. IEEE Trans. Inf. Theory 2011, 57, 996–1007. [Google Scholar] [CrossRef]
- Sun, Q.T.; Yang, X.; Long, K.; Yin, X.; Li, Z. On vector linear solvability of multicast networks. IEEE Trans. Commun. 2016, 64, 5096–5107. [Google Scholar] [CrossRef]
- Etzion, T.; Wachter-Zeh, A. Vector network coding based on subspace codes outperforms scalar linear network coding. IEEE Trans. Inf. Theory 2018, 64, 2460–2473. [Google Scholar] [CrossRef]
- Tang, H.; Sun, Q.T.; Li, Z.; Yang, X.; Long, K. Circular-shift linear network coding. IEEE Trans. Inf. Theory 2019, 65, 65–80. [Google Scholar] [CrossRef]
- Sun, Q.T.; Tang, H.; Li, Z.; Yang, X.; Long, K. Circular-shift linear network codes with arbitrary odd block lengths. IEEE Trans. Commun. 2019, 67, 2660–2672. [Google Scholar] [CrossRef]
- Tang, H.; Zhai, Z.; Sun, Q.T.; Yang, X. The multicast solvability of permutation linear network coding. IEEE Commun. Lett. 2023, 27, 105–109. [Google Scholar] [CrossRef]
- Wardlaw, W.P. Matrix representation of finite field. Math. Mag. 1994, 67, 289–293. [Google Scholar] [CrossRef]
- Longhair: O(N2) Cauchy Reed-Solomon Block Erasure Code for Small Data. 2021. Available online: https://github.com/catid/longhair (accessed on 1 July 2024).
- Plank, J.S.; Simmerman, S.; Schuman, C.D. Jerasure: A Library in c/c++ Facilitating Erasure Coding for Storage Applications, Version 1.2; Technical Report CS-08-627; University of Tennessee: Knoxville, TN, USA, 2008. [Google Scholar]
- Luo, J.; Shrestha, M.; Xu, L.; Plank, J.S. Efficient encoding schedules for XOR-based erasure codes. IEEE Trans. Comput. 2014, 63, 2259–2272. [Google Scholar] [CrossRef]
- Intel® Intelligent Storage Acceleration Library. 2024. Available online: https://github.com/intel/isa-l/tree/master/erasurecode (accessed on 1 June 2024).
- Blomer, J.; Kalfane, M.; Karp, R.; Karpinski, M.; Luby, M.; Zuckerman, D. An XOR-Based Erasure-Resilient Coding Scheme; Technical Report TR-95-048; University of California at Berkeley: Berkeley, CA, USA, 1995. [Google Scholar]
- Plank, J.S.; Xu, L. Optimizing Cauchy Reed-Solomon codes for fault-tolerant network storage applications. In Proceedings of the Fifth IEEE International Symposium on Network Computing and Applications, Cambridge, MA, USA, 24–26 July 2006; pp. 173–180. [Google Scholar]
- Zhou, T.; Tian, C. Fast erasure coding for data storage: A comprehensive study of the acceleration techniques. ACM Trans. Storage (TOS) 2020, 16, 1–24. [Google Scholar] [CrossRef]
- Lidl, R.; Niederreiter, H. Finite Fields, 2nd ed.; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]
- Su, R.; Sun, Q.T.; Zhang, Z. Delay-complexity trade-off of random linear network coding in wireless broadcast. IEEE Trans. Commun. 2020, 68, 5606–5618. [Google Scholar] [CrossRef]
- Asterjadhi, A.; Fasolo, E.; Rossi, M.; Widmer, J.; Zorzi, M. Toward network coding-based protocols for data broadcasting in wireless ad hoc networks. IEEE Trans. Wirel. Commun. 2010, 9, 662–673. [Google Scholar] [CrossRef]
- Gao, S.; Mateer, T. Additive fast Fourier transforms over finite fields. IEEE Trans. Inf. Theory 2010, 56, 6265–6272. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).