
Ultra-Reliable and Low-Latency Wireless Hierarchical Federated Learning: Performance Analysis †


Abstract
1. Introduction
- We propose an FBL approach for multi-antenna WHFL in the presence of PLS. In this approach, the feedback link is not only utilized for CSI transmission but also used to send the cloud server’s MMSE about the transmitted polluted data gradient back to the edge server. The key idea of the proposed scheme is to apply the modulo-lattice operation (MLO) [39] to eliminate the impact of feedback channel noise on the performance of the SK scheme [35], and further extend the SK-type scheme to a two-dimensional situation, which performs well in the SISO fading channel. Then further applying pre-coding, beamforming, and singular value decomposition (SVD) techniques to the extended scheme for the SISO case, the FBL coding scheme for the multi-antenna WHFL is obtained.
- We derive the achievable secrecy rate of our proposed scheme and characterize the relationship between PLS, privacy, and utility of our scheme. Moreover, given fixed decoding error probability and coding block length, we establish lower and upper bounds on the LDP noise variance that ensure certain privacy, utility, and secrecy levels of PLS.
2. Definitions, System Model and Main Results
2.1. WHFL System
2.2. Model Formulation
2.2.1. Privacy-Utility
2.2.2. Gradient Compression
2.2.3. Communication Model
2.3. Main Results
- The two-dimensional message mapping method, which maps the message to a complex codeword transmitted over the fading channels.
- An SVD-based pre-coding strategy that divides the MIMO channel into several parallel SISO channels.
- The two-dimensional modulo-lattice operation (MLO) that eliminates the impact of feedback channel noise on the performance of the SK scheme.
3. An FBL Approach for the MIMO WHFL
3.1. An FBL Approach for the MIMO WHFL
3.1.1. Channel Decomposition by SVD
3.1.2. Message Splitting
3.1.3. An FBL Scheme of Each Parallel Sub-Channel
4. An FBL Approach for the SIMO WHFL
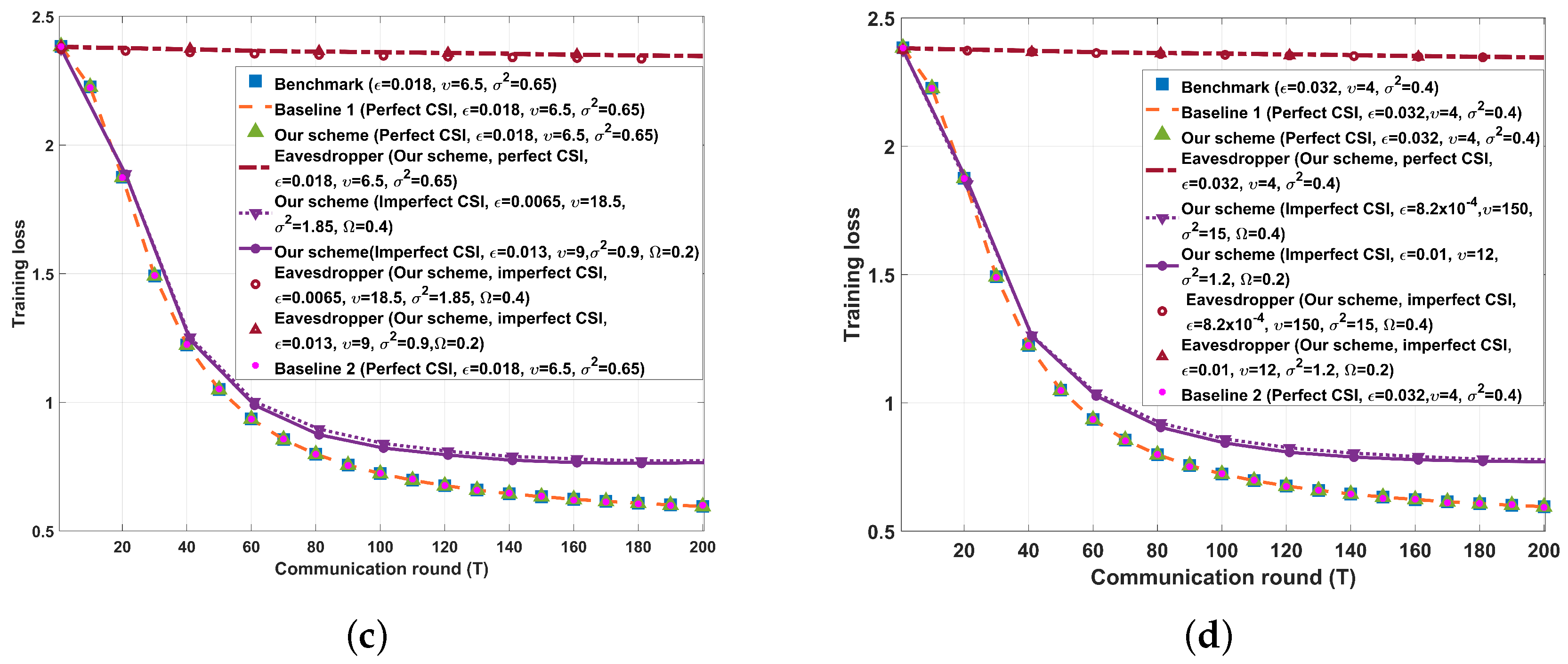
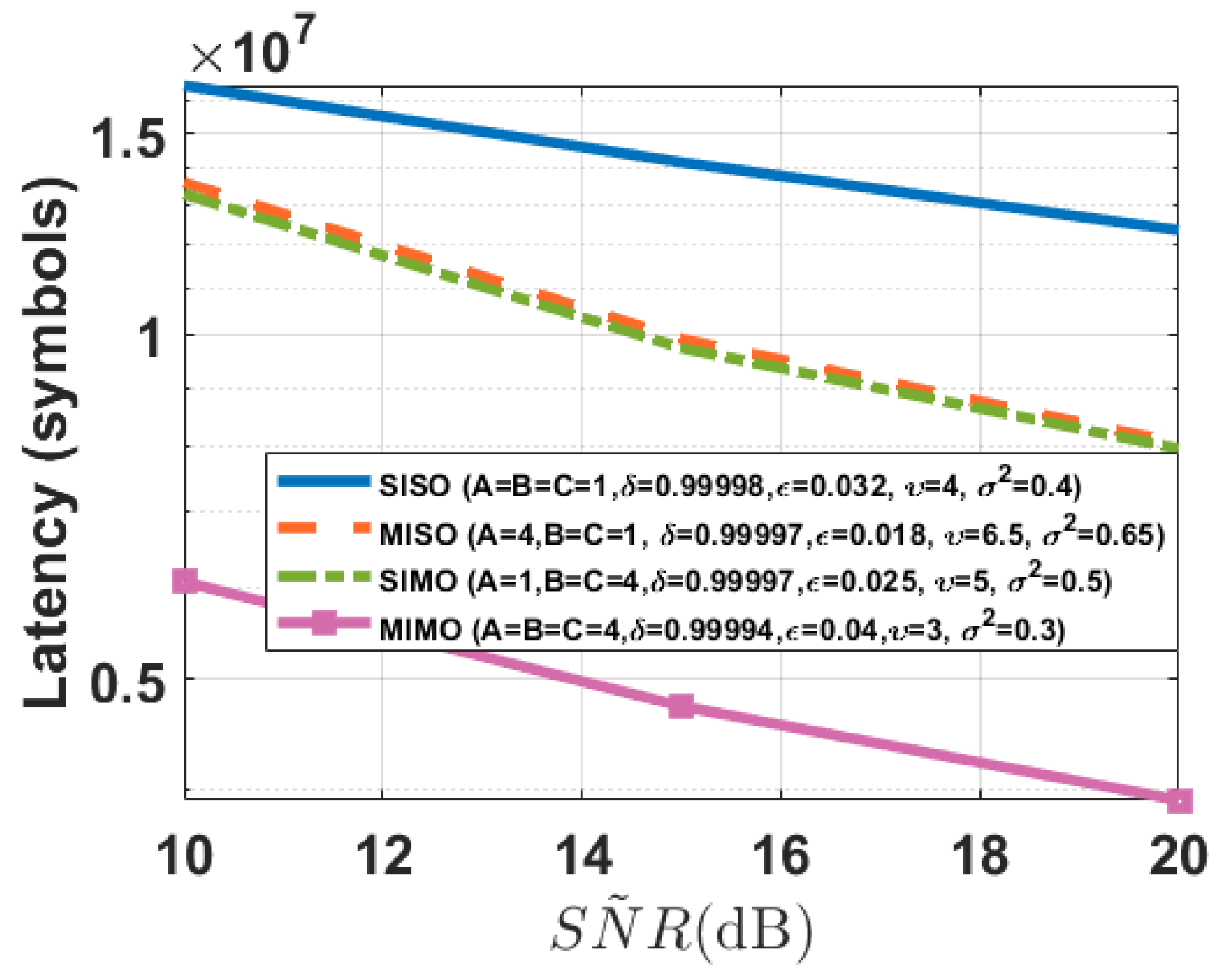
5. Simulation Results
5.1. Experimental Settings
- Benchmark (Perfect HFL): The perfectly aggregated HFL system can be achieved through error-free transmission, which serves as the benchmark accuracy in ideal settings.
- Baseline 2 (Frequency division multiple access (FDMA)-based WHFL with artificial noise (AN) [29]): In the FDMA-based WHFL system with AN, FDMA is employed to transmit gradient data from edge servers to the cloud server, targeting a bit error ratio of . Additionally, AN is added to the transmitted signals to prevent eavesdroppers from obtaining the true gradient data.
5.2. Experimental Results
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A. The Formal Proof of Theorem 1
Appendix A.1. Utility and Privacy Analysis
Appendix A.2. Decoding Error Probability and Convergence Analysis
- (1)
- A modulo-aliasing error occurs in the edge server at time instant , and it is defined as follows:where and are the real and imaginary parts of , respectively, and are the real and imaginary parts of , respectively.
- (2)
- A decoding error occurs in the cloud server at time instant , and it is defined as follows:where and are the real and imaginary parts of , respectively.
Appendix A.3. Security Analysis
References
- Zhu, G.; Liu, D.; Du, Y.; You, C.; Zhang, J.; Huang, K. Toward an Intelligent Edge: Wireless Communication Meets Machine Learning. IEEE Commun. Mag. 2020, 58, 19–25. [Google Scholar] [CrossRef]
- Yang, Z.; Chen, M.; Saad, W.; Hong, C.S.; Shikh-Bahaei, M. Energy Efficient Federated Learning Over Wireless Communication Networks. IEEE Trans. Wireless Commun. 2021, 20, 1935–1949. [Google Scholar] [CrossRef]
- Amiri, M.M.; Gündüz, D. Federated Learning Over Wireless Fading Channels. IEEE Trans. Wireless Commun. 2020, 19, 3546–3557. [Google Scholar] [CrossRef]
- Jin, R.; He, X.; Dai, H. Communication Efficient Federated Learning with Energy Awareness Over Wireless Networks. IEEE Trans. Wireless Commun. 2022, 21, 5204–5219. [Google Scholar] [CrossRef]
- Zhu, G.; Wang, Y.; Huang, K. Broadband Analog Aggregation for Low-Latency Federated Edge Learning. IEEE Trans. Wireless Commun. 2020, 19, 491–506. [Google Scholar] [CrossRef]
- Zhu, G.; Du, Y.; Gündüz, D.; Huang, K. One-Bit Over-the-Air Aggregation for Communication-Efficient Federated Edge Learning: Design and Convergence Analysis. IEEE Trans. Wireless Commun. 2021, 20, 2120–2135. [Google Scholar] [CrossRef]
- Elgabli, A.; Park, J.; Issaid, C.B.; Bennis, M. Harnessing Wireless Channels for Scalable and Privacy-Preserving Federated Learning. IEEE Trans. Commun. 2021, 69, 5194–5208. [Google Scholar] [CrossRef]
- Wen, H.; Wu, Y.; Yang, C.; Duan, H.; Yu, S. A Unified Federated Learning Framework for Wireless Communications: Towards Privacy, Efficiency, and Security. In Proceedings of the 2020 IEEE INFOCOM Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 6–9 July 2020; pp. 653–658. [Google Scholar]
- Seif, M.; Tandon, R.; Li, M. Wireless Federated Learning with Local Differential Privacy. In Proceedings of the 2020 IEEE International Symposium on Information Theory (ISIT), Los Angeles, CA, USA, 21–26 June 2020; pp. 2604–2609. [Google Scholar]
- Yuan, X.; Ni, W.; Ding, M.; Wei, K.; Li, J.; Poor, H.V. Amplitude-Varying Perturbation for Balancing Privacy and Utility in Federated Learning. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1884–1897. [Google Scholar] [CrossRef]
- Kim, M.; Günlü, O.; Schaefer, R.F. Federated Learning with Local Differential Privacy: Trade-Offs Between Privacy, Utility, and Communication. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Process (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2650–2654. [Google Scholar]
- Zhou, J.; Su, Z.; Ni, J.; Wang, Y.; Pan, Y.; Xing, R. Personalized Privacy-Preserving Federated Learning: Optimized Trade-off Between Utility and Privacy. In Proceedings of the 2022 IEEE Global Communications Conference (GLOBECOM), Rio de Janeiro, Brazil, 4–8 December 2022; pp. 4872–4877. [Google Scholar]
- Guo, S.; Su, Z.; Tian, Z.; Yu, S. Utility-Aware Privacy-Preserving Federated Learning through Information Bottleneck. In Proceedings of the 2022 IEEE International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Wuhan, China, 9–11 December 2022; pp. 680–686. [Google Scholar]
- Wang, B.; Chen, Y.; Jiang, H.; Zhao, Z. PPeFL: Privacy-Preserving Edge Federated Learning with Local Differential Privacy. IEEE Internet Things J. 2023, 10, 15488–15500. [Google Scholar] [CrossRef]
- Zhang, N.; Tao, M. Gradient Statistics Aware Power Control for Over-the-Air Federated Learning. IEEE Trans. Wireless Commun. 2021, 20, 5115–5128. [Google Scholar] [CrossRef]
- Liu, D.; Simeone, O. Privacy for Free: Wireless Federated Learning via Uncoded Transmission with Adaptive Power Control. IEEE J. Sel. Areas Commun. 2021, 39, 170–185. [Google Scholar] [CrossRef]
- Yang, K.; Jiang, T.; Shi, Y.; Ding, Z. Federated Learning via Over-the-Air Computation. IEEE Trans. Wireless Commun. 2020, 19, 2022–2035. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, J.; Song, S.H.; Letaief, K.B. Client-Edge-Cloud Hierarchical Federated Learning. In Proceedings of the 2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Luo, S.; Chen, X.; Wu, Q.; Zhou, Z.; Yu, S. HFEL: Joint Edge Association and Resource Allocation for Cost-Efficient Hierarchical Federated Edge Learning. IEEE Trans. Wireless Commun. 2020, 19, 6535–6548. [Google Scholar] [CrossRef]
- Liu, S.; Yu, G.; Chen, X.; Bennis, M. Joint User Association and Resource Allocation for Wireless Hierarchical Federated Learning with IID and Non-IID Data. IEEE Trans. Wireless Commun. 2022, 21, 7852–7866. [Google Scholar] [CrossRef]
- Wen, W.; Chen, Z.; Yang, H.H.; Xia, W.; Quek, T.Q.S. Joint Scheduling and Resource Allocation for Hierarchical Federated Edge Learning. IEEE Trans. Wireless Commun. 2022, 21, 5857–5872. [Google Scholar] [CrossRef]
- Shi, L.; Shu, J.; Zhang, W.; Liu, Y. HFL-DP: Hierarchical Federated Learning with Differential Privacy. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–7. [Google Scholar]
- Wainakh, A.; Guinea, A.S.; Grube, T.; Mühlhäuser, M. Enhancing Privacy via Hierarchical Federated Learning. In Proceedings of the 2020 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), Genoa, Italy, 7–11 September 2020; pp. 344–347. [Google Scholar]
- Feng, C.; Yang, H.H.; Hu, D.; Zhao, Z.; Quek, T.Q.S.; Min, G. Mobility-Aware Cluster Federated Learning in Hierarchical Wireless Networks. IEEE Trans. Wireless Commun. 2022, 21, 8441–8458. [Google Scholar] [CrossRef]
- Wyner, A.D. The Wire-Tap Channel. Bell Syst. Tech. J. 1975, 54, 1355–1387. [Google Scholar] [CrossRef]
- Yao, J.; Ansari, N. Secure Federated Learning by Power Control for Internet of Drones. IEEE Trans. Cognitive Commun. Netw. 2021, 7, 1021–1031. [Google Scholar] [CrossRef]
- Wang, T.; Li, Y.; Wu, Y.; Quek, T.Q.S. Secrecy driven Federated Learning via Cooperative Jamming: An Approach of Latency Minimization. IEEE Trans. Emerg. Topics Comput. 2021, 10, 1687–1703. [Google Scholar] [CrossRef]
- Qian, L.; Wu, W.; Lu, W.; Wu, Y.; Lin, B.; Quek, T.Q.S. Secrecy-Based Energy-Efficient Mobile Edge Computing via Cooperative Non-Orthogonal Multiple Access Transmission. IEEE Trans. Commun. 2021, 69, 4659–4677. [Google Scholar] [CrossRef]
- Yan, Z.; Li, D.; Zhang, Z.; He, J. Accuracy-Security Tradeoff with Balanced Aggregation and Artificial Noise for Wireless Federated Learning. IEEE Internet Things J. 2023, 10, 18154–18167. [Google Scholar] [CrossRef]
- Zhang, H.; Yang, C.; Dai, B. When Wireless Federated Learning Meets Physical Layer Security: The Fundamental Limits. In Proceedings of the IEEE INFOCOM Computer Communications Workshops (INFOCOM WKSHPS), New York, NY, USA, 2–5 May 2022; pp. 1–6. [Google Scholar]
- Durisi, G.; Koch, T.; Popovski, P. Toward Massive, Ultrareliable, and Low-Latency Wireless Communication with Short Packets. Proc. IEEE 2016, 104, 1711–1726. [Google Scholar] [CrossRef]
- Polyanskiy, Y.; Poor, H.V.; Verdu, S. Channel Coding Rate in the Finite Blocklength Regime. IEEE Trans. Inf. Theory 2010, 56, 2307–2359. [Google Scholar] [CrossRef]
- She, C.; Dong, R.; Gu, Z.; Hou, Z.; Li, Y.; Hardjawana, W.; Vucetic, B.; Song, L.; Yang, C. Deep Learning for Ultra-Reliable and Low-Latency Communications in 6G Networks. IEEE Netw. 2020, 34, 219–225. [Google Scholar] [CrossRef]
- Samarakoon, S.; Bennis, M.; Saad, W.; Debbah, M. Distributed Federated Learning for Ultra-Reliable Low-Latency Vehicular Communications. IEEE Trans. Commun. 2020, 68, 1146–1159. [Google Scholar] [CrossRef]
- Schalkwijk, J.; Kailath, T. A coding scheme for additive noise channels with feedback–I: No bandwidth constraint. IEEE Trans. Inf. Theory 1966, 12, 172–182. [Google Scholar] [CrossRef]
- Gunduz, D.; Brown, D.R.; Poor, H.V. Secret communication with feedback. In Proceedings of the 2008 International Symposium on Information Theory and Its Applications (ISITA), Auckland, New Zealand, 7–10 December 2008; pp. 1–6. [Google Scholar]
- Truong, L.V.; Fong, S.L.; Tan, V.Y.F. On Gaussian Channels with Feedback Under Expected Power Constraints and with Non-Vanishing Error Probabilities. IEEE Trans. Inf. Theory 2017, 63, 1746–1765. [Google Scholar] [CrossRef]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep Learning with Differential Privacy. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 303–318. [Google Scholar]
- Zamir, R. Lattice Coding for Signals and Network; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Zhi, K.; Pan, C.; Ren, H.; Wang, K.; Elkashlan, M.; Di Renzo, M.; Hanzo, L.; Schober, R.; Wang, J. Two-Timescale Design for Reconfigurable Intelligent Surface-Aided Massive MIMO Systems with Imperfect CSI. IEEE Trans. Inf. Theory 2022, 69, 3001–3033. [Google Scholar] [CrossRef]
- Schiessl, S.; Al-Zubaidy, H.; Skoglund, M.; Gross, J. Delay Performance of Wireless Communications with Imperfect CSI and Finite-Length Coding. IEEE Trans. Commun. 2018, 66, 6527–6541. [Google Scholar] [CrossRef]
- Chen, Z.J.; Hernandez, E.E.; Huang, Y.C.; Rini, S. DNN gradient lossless compression: Can GenNorm be the answer? In Proceedings of the 2022 IEEE International Conference on Communications (ICC), Seoul, Republic of Korea, 16–20 May 2022; pp. 407–412. [Google Scholar]
- Wang, W.; Ying, L.; Zhang, J. On the Relation Between Identifiability, Differential Privacy, and Mutual-Information Privacy. IEEE Trans. Inf. Theory 2016, 62, 5018–5029. [Google Scholar] [CrossRef]
- Sankar, L.; Rajagopalan, S.R.; Poor, H.V. Utility-Privacy Tradeoffs in Databases: An Information-Theoretic Approach. IEEE Trans. Inf. Forensics Secur. 2013, 8, 838–852. [Google Scholar] [CrossRef]
- Gamal, A.A.E.; Kim, Y.-H. Network Information Theory; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Han, S.; Xu, X.; Fang, S.; Sun, Y.; Cao, Y.; Tao, X.; Zhang, P. Energy Efficient Secure Computation Offloading in NOMA-Based mMTC Networks for IoT. IEEE Internet Things J. 2019, 6, 5674–5690. [Google Scholar] [CrossRef]
- Ng, D.W.K.; Lo, E.S.; Schober, R. Robust Beamforming for Secure Communication in Systems with Wireless Information and Power Transfer. IEEE Trans. Wireless Commun. 2014, 13, 4599–4615. [Google Scholar] [CrossRef]
- Tekin, E.; Yener, A. The Gaussian Multiple Access Wire-Tap Channel. IEEE Trans. Inf. Theory 2008, 54, 5747–5755. [Google Scholar] [CrossRef]
- Tse, D.; Viswanath, P. Fundamentals of Wireless Communication; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Welch, T.A. A technique of high-performance data compression. IEEE Comput. 1984, 17, 8–19. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Work | Privacy | Utility | PLS | Relationship between PLS, Privacy, and Utility | URLLC |
|---|---|---|---|---|---|
| [7,8,9,16,23] | ✓ | − | − | − | − |
| [10,11,12,13,14,22] | ✓ | ✓ | − | Relationship between Privacy and Utility | − |
| [26,27,28] | − | − | ✓ | − | − |
| [29] | − | ✓ | ✓ | Relationship between PLS and Utility | − |
| [30] | ✓ | ✓ | ✓ | Relationship between PLS-Privacy-Utility | − |
| [33,34] | − | − | − | − | ✓ |
| This Work | ✓ | ✓ | ✓ | Relationship between PLS-Privacy-Utility | ✓ |
| Number of Antennas | (MIMO) | (SIMO) | (MISO) | (SISO) |
|---|---|---|---|---|
| Our scheme (Perfect CSI) | (, , , ) | ) (, , , ) | (, , , ) | 2.6718 (bits/symbol) (, , , ) |
| Our scheme (Imperfect CSI, ) | (, , , ) | ) (, , , ) | (, , , ) | 2.6708 (bits/symbol) (, , , ) |
| Our scheme (Imperfect CSI, ) | (, , , ) | ) (, , , ) | (, , , ) | 2.6689 (bits/symbol) (, , , ) |
| Baseline 1 [26,28] (Perfect CSI) | (, , ) | (, , ) | (, , ) | (, , ) |
| Baseline 2 [29] (Perfect CSI) | (, , ) | (, , ) | (, , ) | (, , ) |
| Number of Antennas | (MIMO) (, , , ) |
(SIMO) , , , |
(MISO) (, , , ) |
(SISO) (, , , ) |
|---|---|---|---|---|
| dB (Perfect CSI) | ) | |||
| dB (Perfect CSI) | ) | |||
| dB (Perfect CSI) | ) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Xu, P.; Dai, B. Ultra-Reliable and Low-Latency Wireless Hierarchical Federated Learning: Performance Analysis. Entropy 2024, 26, 827. https://doi.org/10.3390/e26100827
Zhang H, Xu P, Dai B. Ultra-Reliable and Low-Latency Wireless Hierarchical Federated Learning: Performance Analysis. Entropy. 2024; 26(10):827. https://doi.org/10.3390/e26100827
Chicago/Turabian StyleZhang, Haonan, Peng Xu, and Bin Dai. 2024. "Ultra-Reliable and Low-Latency Wireless Hierarchical Federated Learning: Performance Analysis" Entropy 26, no. 10: 827. https://doi.org/10.3390/e26100827
APA StyleZhang, H., Xu, P., & Dai, B. (2024). Ultra-Reliable and Low-Latency Wireless Hierarchical Federated Learning: Performance Analysis. Entropy, 26(10), 827. https://doi.org/10.3390/e26100827