Abstract
Video compression remains a challenging task despite significant advancements in end-to-end optimized deep networks for video coding. This study, inspired by information bottleneck (IB) theory, introduces a novel approach that combines IB theory with wavelet transform. We perform a comprehensive analysis of information and mutual information across various mother wavelets and decomposition levels. Additionally, we replace the conventional average pooling layers with a discrete wavelet transform creating more advanced pooling methods to investigate their effects on information and mutual information. Our results demonstrate that the proposed model and training technique outperform existing state-of-the-art video compression methods, delivering competitive rate-distortion performance compared to the AVC/H.264 and HEVC/H.265 codecs.
1. Introduction
Data compression is the science of reducing the amount of data used to convey information. It is important to ensure that the signal or data stream compressed represents only the information transmitted [1]. There are two types of compression techniques: (1) Lossless compression and (2) Lossy compression. Lossless compression is a class of data compression algorithms that allows the perfect reconstruction of the original data from the compressed data. Lossy compression (irreversible compression) is the class of data encoding methods that uses inexact approximations and partial data discarding to represent the data. Recently, advanced compression algorithms have been invented that focus on reducing data redundancy through predictive techniques. The spatial redundancy is the dependence between neighbouring pixels in each video frame; the temporal redundancy is a given motion compensation or dependence between consecutive video frames. The encoder uses these redundancies to predict future pixels. A better prediction ability improves a residual error. Therefore, fewer bits are required, and compression efficiency is improved [2]. The standardized video compression algorithm used for video coding is mainly based on discrete cosine transform (DCT) coding and motion compensation Video coding formats include the following features. MPEG (Moving Pictures Expert Group), MPEG2 is the basis for the Advanced Television Systems Committee (ATSC), Digital Television Standard and the European Digital Broadcast (DVB) implemented for both standard and high-definition transmissions around the world. MPEG4 is a method of defining the compression of audio and visual (AV) digital data. It is usually used for web (streaming media), Compact Disk (CD) distribution, voice (telephone, videophone) and broadcast television applications. AVC (Advanced Video Coding) or MPEG4 part 10 is the most commonly used format for recording, compressing, and distributing video content. One of the additional features of the AVC is Multiview Video Coding (MVC), also known as MVC 3D. It is a stereoscopic video coding standard for video compression that efficiently encodes video sequences captured simultaneously from multiple camera angles in a single video stream. HEVC (High-Efficiency Video Coding), also known as MPEG-H Part 2, is a video compression standard designed as a successor to the AVC [3]. The most viable alternative to DCT for image compression is Wavelet technology. Wavelet transform methods are considered the successors of Fourier analysis based on self-similarity [4]. They are very efficient in signal processing for denoising, cross-correlation, and data compressions, such as MPEG-4 and JPEG2000. The Joint Photographic Experts Group developed the JPEG2000 compression standard based on discrete wavelet transform (DWT) Multiwavelets are a generalization of scalar wavelets. The fundamental concept underlying everything related to wavelet analysis is multiresolution. Scalar wavelets use one scaling function for the coarse approximation and one wavelet function for the fine detail. Multiwavelets use several scaling functions, combining wavelet functions into function vectors. However, multiwavelets have not yet been used for video compression [5]. Wavelets can provide both frequency and location information. Wavelets can be viewed as a burst of energy with the dominant frequency. When a wavelet transform is applied, a sequence is walked across a sample sequence in a process known as convolution. The wavelet moves one sample at a time, and the convolution product evolves for each position. This idea of moving a wavelet over the image and picking out details shows how wavelets can give both frequency and location information, which behave like a high pass filter and extract the high-frequency detail of the image. The image is also convolved with the complementary scaling function that removes the high frequencies. The product of these actions is a set of wavelet coefficients representing the fine detail of the image, on the one hand; on the other hand, the image from which the fine detail has been removed [6]. Video compression can be improved by using neural networks. Neural networks can be used for pre-processing, post-processing, optimization, and segmentation algorithms. There is a lack of studies regarding neural network applications for reducing spatial and temporal redundancy in video encoding [3]. Neural networks are a core component of machine learning, where computers are trained to perform tasks by analyzing large sets of examples. Deep learning (DL), a specialized subset of machine learning, involves multi-layered neural networks that mimic the way the human brain ’learns’ from vast amounts of data. In each layer of the neural network, DL algorithms perform a series of calculations, making predictions and adjusting progressively to improve the accuracy of the outcomes over time. While deep learning has become a powerful tool for image classification, its application to image and video compression has been more limited [7]. Neural networks have shown great promise in video analysis but have so far contributed only incremental improvements to video encoding [3,7,8]. As Joy et al. [9] point out, recent advancements in deep learning-based video compression techniques suggest a potential paradigm shift in the field. These techniques show considerable promise in overcoming the limitations of traditional methods, with neural networks offering the potential for significant improvements in both compression efficiency and visual quality. Mochurad’s study [10] further emphasizes the potential of machine learning for video compression by comparing convolutional neural networks (CNNs) with conventional codecs. The study underscores the strengths of machine learning-based approaches, while also addressing their current limitations, paving the way for optimized neural network algorithms in future video compression technologies. Additionally, wavelet-based algorithms have shown strong performance in video compression, although there is still room for improvement in their application, particularly when combined with deep learning techniques. The Information Bottleneck (IB) principle is a fundamental concept in information theory that provides a framework for understanding the trade-off between compression and relevance preservation [11]. The central idea is to extract the most relevant information from an input variable while minimizing the information retained, effectively creating a compressed data representation. This principle has numerous applications in various fields, including machine learning, data analysis, and signal processing. The IB principle suggests that an optimal compression of an input variable X can be achieved by finding a compact representation T that preserves the relevant information about a target variable Y while discarding the irrelevant details. This is accomplished by minimizing the mutual information between X and T, while maximizing the mutual information between T and Y. The resulting compressed representation T can be used for various tasks, such as classification, prediction, or data storage and transmission. While the IB principle provides a solid theoretical foundation for deep neural network-based compression, its practical application presents several challenges. One of the main difficulties is balancing the trade-off between compression and reconstruction accuracy, as the network must learn to discard irrelevant information while preserving the essential features necessary for high-quality reconstruction. Another challenge lies in the complex and often non-linear relationships between input data and the target objective. With their expressive power, deep neural networks can potentially learn representations that deviate from the optimal IB solution, leading to suboptimal compression performance. Developing effective regularization techniques and optimization methods to ensure the network adheres to the IB principle is an active area of research. Additionally, applying the IB principle to deep neural networks is complicated by the inherent difficulty in estimating and optimizing the mutual information between the input, the compressed representation, and the target variable. Researchers are exploring various techniques, such as variational approximations and adversarial training, to overcome these challenges and improve the effectiveness of IB-based deep compression methods. This research aims to develop wavelet-based deep neural networks, utilize an information bottleneck-driven approach for video compression, and implement this novel approach to improve the existing video compression rates. We hope these powerful compression methods will be used in future codecs and become part of the new standards. Experimental results show that estimating and compressing motion information using our neural network-based approach can significantly improve compression performance. We introduce an open-source Tensorflow 2 implementation of the DVC model with an optical flow-based discrete wavelet transform.
2. Wavelet Theory
Wavelet was introduced by Jean Morlet in 1982. The Continues Wavelet Transform (CWT) [12]
The initial wavelet is called the mother wavelet. The mother wavelet is dilated with scale parameter s and is translated with parameter . Dilating wavelets makes it necessary to normalize the energy for different scales. This normalization is conducted by dividing the wavelet by a continuous wavelet series set of scaling functions plus the wavelet function is defined by
where is the scaling parameter and s is the shift parameter
The function is defined as:
When x is not the continuous variable, we define the signal as M number of samples (discrete time signal) The Discrete Wavelet Transform (DWT) is almost always applied in the form of a filter bank:
where is normalization. is like , j is like r and k is like s.
is called the “Approximation” and is called the “Details”. IDWT:
For the 2D case for images, the DWT is applied in both horizontal and vertical directions. The approximation and detail coefficients are defined as follows
where is the “Approximation” function and is the “Details” function. for horizontal, vertical, and diagonal directions. The DWT provides a hierarchical decomposition of the signal, making it a powerful tool for compression tasks by efficiently capturing multiscale information. Approximations and detailed coefficients for various wavelets are provided in Table 1.

Table 1.
Wavelet filter coefficients.
3. Information Bottleneck (IB)
The Information Bottleneck (IB) method offers a powerful framework for understanding and optimizing how information flows through neural networks, particularly in tasks like video compression, where both efficiency and accuracy are crucial [11]. In the context of video compression, the IB framework seeks to reduce the dimensionality of data while retaining the most relevant information for reconstruction, thus optimizing both compression rates and video quality. The basic idea IB method can be formulated as follows: Given input variable X, and output variable Y, the goal is to find a compressed representation T that retains maximal information about Y while being minimal in size.
The IB method formulates this as an optimization problem:
where:
- represents the compression cost of the mutual information between X and T.
- represents the relevance of the mutual information between T and Y.
- is a Lagrange multiplier that balances compression and relevance.
Entropy is the uncertainty of a single random variable. We can define conditional entropy as the entropy of a random variable given another random variable. The reduction in uncertainty due to another random variable is called mutual information. For random variables X and Y, this reduction is given by [13]:
Mutual Information measures the information shared between variables X and Y. In a deep neural network, each layer represents a transformation of the input X through the network. Mutual information and I can be tracked across layers to understand the information flow in neural networks better. By balancing the trade-off between compression and relevance, neural networks can be guided to learn efficient and effective representations.
4. Proposed Method
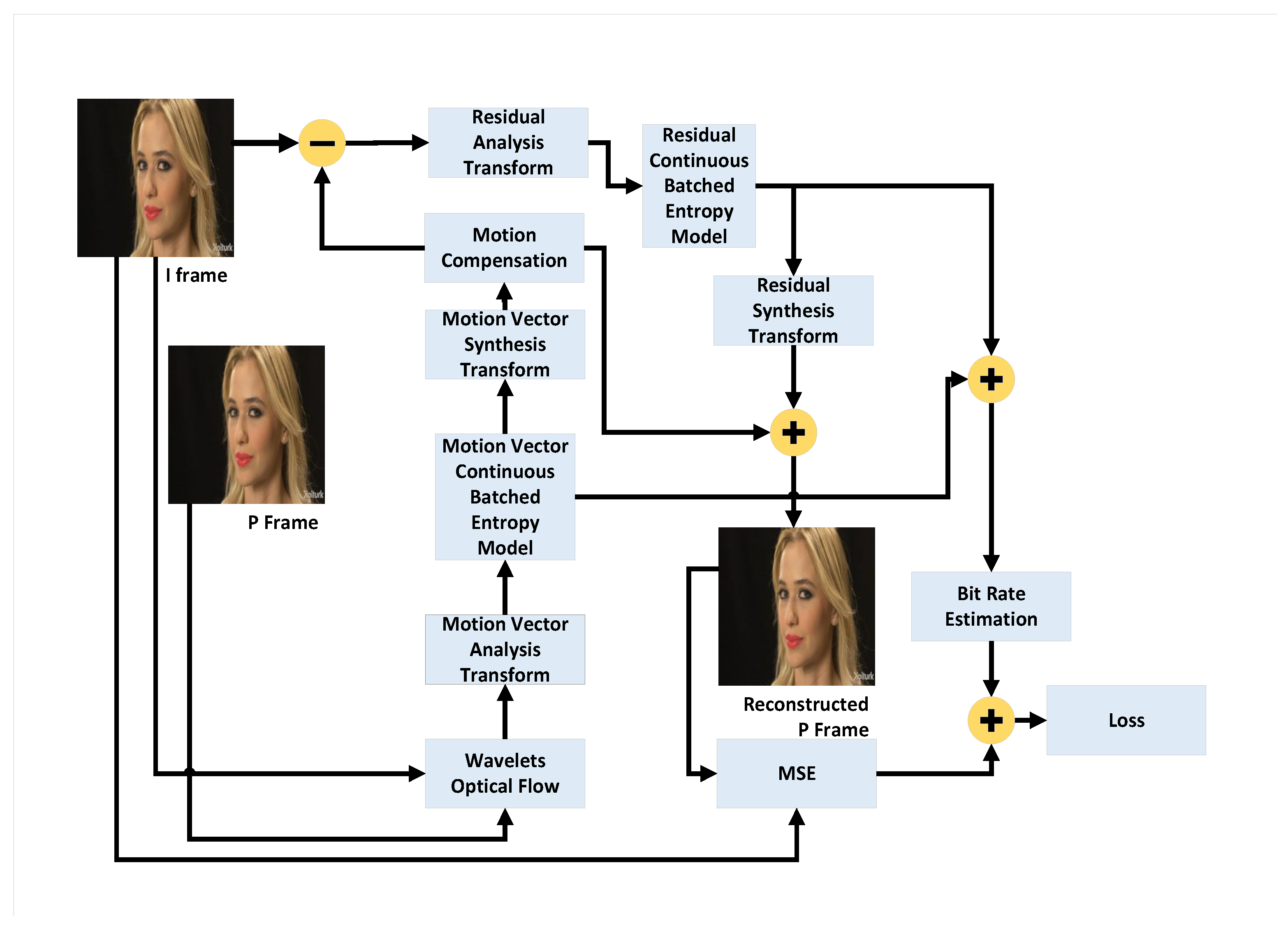
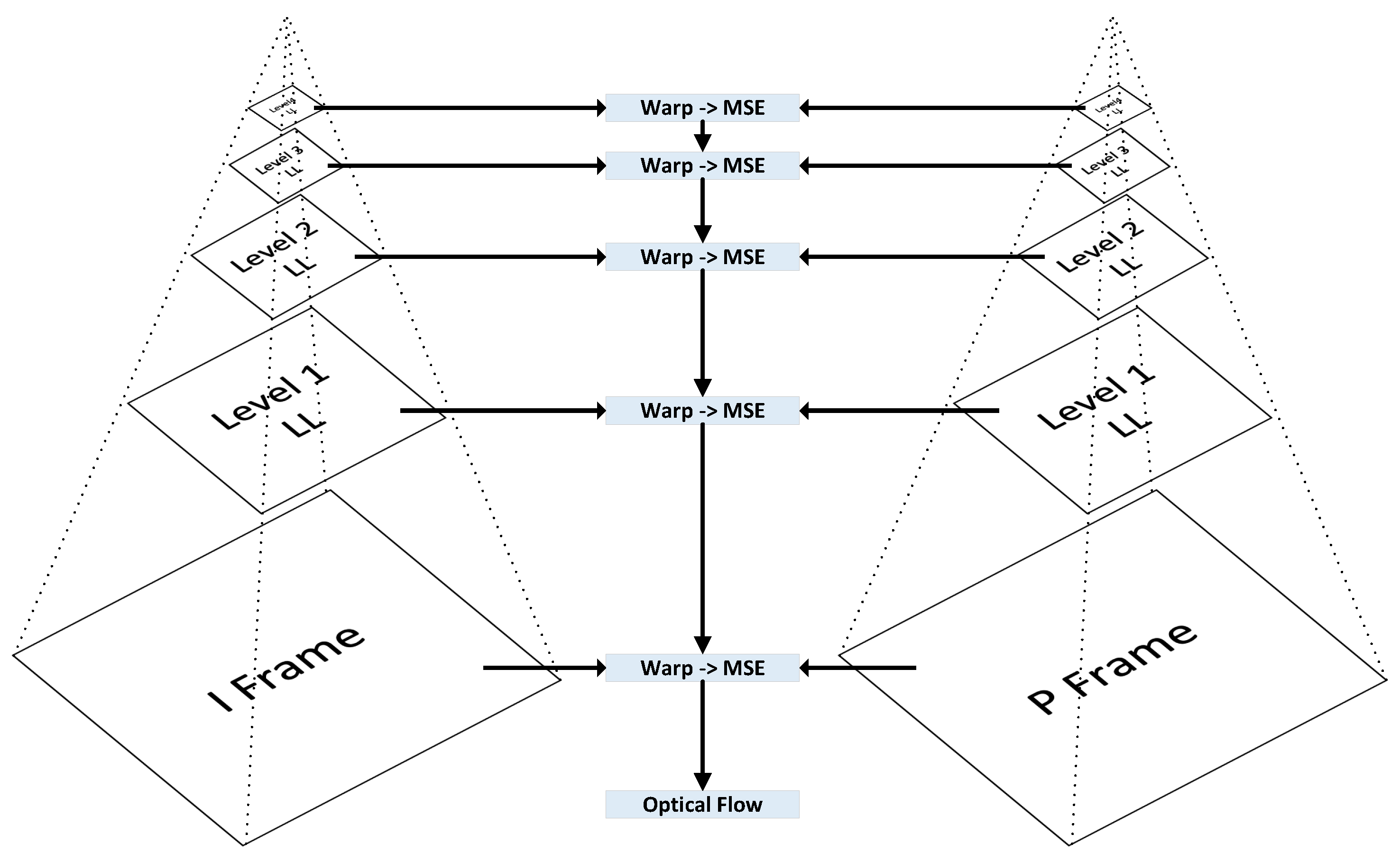
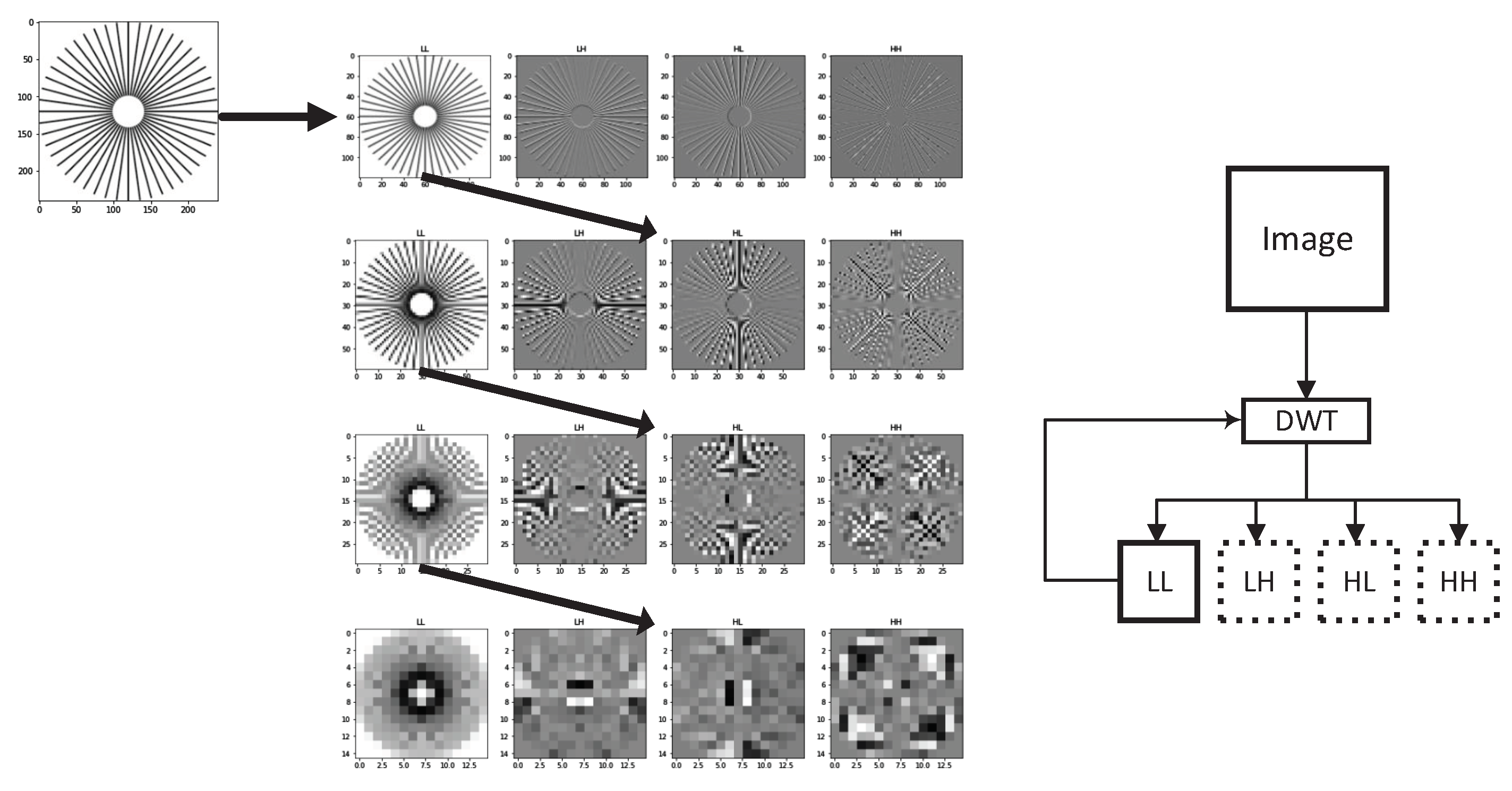
This section presents the implementation of our Information Bottleneck-Driven, Wavelet-based OpenDVC-IBW model, which builds upon the OpenDVC framework [14,15]. Our enhancement replaces the traditional Average Pooling layers with Discrete Wavelet Transform (DWT) layers. Pooling layers play a critical role in deep neural networks (DNNs), providing benefits that enhance the performance and efficiency of neural networks, particularly in compression tasks. The proposed method also incorporates an analysis of information flow and mutual information within the neural network. An overview of the end-to-end video compression framework is shown in Figure 1. Like traditional video compression methods, our model follows the predict-transform architecture. The structure of the Motion Vector (MV) encoder network, the residual encoder network, and the motion compensation network follows the design of the OpenDVC architecture. However, we leverage wavelet properties to perform motion estimation directly on the wavelet coefficients. In the MV network, motion estimation is conducted using a pyramid structure, as shown in Figure 2, to estimate motion between consecutive frames. We employ a coarse-to-fine motion estimation strategy, which has been successful in previous works [16]. Following the settings in OpenDVC, we use a five-level pyramid network. However, instead of AveragePooling2D layers, we integrate DWT layers. For each pyramid level, we utilize the output of the DWT, where only the coarse estimation (i.e., approximations) is used, and the finer details are discarded, as illustrated in Figure 3. The DWT layers were implemented in TensorFlow 2, with the full implementation available at https://github.com/Timorleiderman/tensorflow-wavelets (accessed on 1 August 2024). Our TensorFlow 2 implementation of the model can be found at https://github.com/Timorleiderman/OpenDVCW (accessed on 1 August 2024). The model’s input consists of two frames: an I-frame (the reference frame) and a P-frame (the frame to be coded). The output is the latent binary representation of the coded P-frame, generated by the context-adaptive entropy coder. The decoder takes the I-frame and the binary representation of the P-frame as inputs to decode the P-frame.
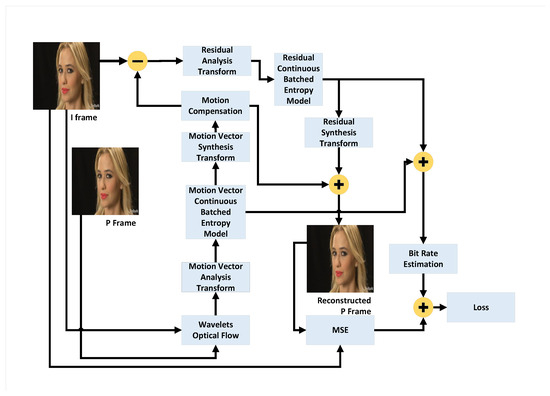
Figure 1.
High-Level framework of the OpenDVCW Network.
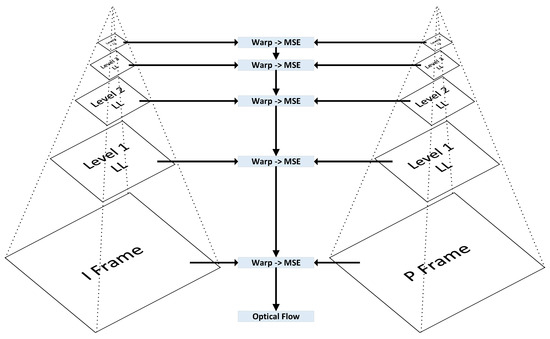
Figure 2.
Pyramid architecture of the optical flow estimation.
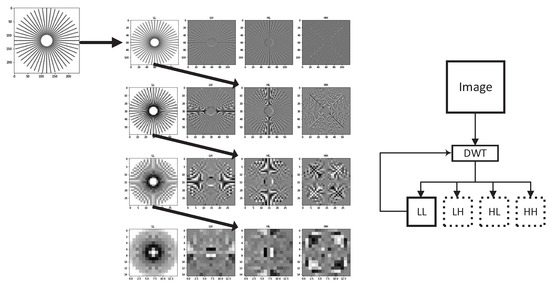
Figure 3.
Visualization of DWT as we apply the transform on the approximation on every iteration.
5. Training Strategy
The OpenDVCW network was trained on the Vimeo90k. The whole network is jointly trained in an end-to-end manner using the loss of
The is a hyperparameter, also called the Lagrange multiplier, is used to balance the rate and distortion loss. D is the distortion defined as the mean square error (MSE), and R indicates the bit rate of the motion vectors and residual, respectively; the bit rate can be estimated as the cross entropy of the probability function. The probability function is calculated via a differentiable entropy model by adding a uniformly distributed noise with a mean of 0 and a width of 1. The learning rate was initially set to . Cosine decay was used to lower the learning rate as the training progressed.
6. Experiments and Results
The experiment had two primary objectives. First, we assessed the network’s information and mutual information [17] flow by employing various wavelets at the pooling layer. Second, we evaluated the quality and performance of the video coding. We investigated the dependence of an Average Peak signal-to-noise ratio (PSNR) vs. Bits Per Pixel (BPP) for various wavelets implemented at the pooling layer of the end-to-end video compression framework shown in Figure 1. In addition, we have compared the performance of the proposed method AVC/H.264, HEVC/H.265 and VVC/H.266 encoders. We have studied the influence of various wavelets on information and mutual information. The experiment was conducted on the Lenna image. First, we performed the discrete wavelet transform and retained only the approximation coefficients, setting all the detail coefficients to zero. Next, we applied the inverse discrete wavelet transform and calculated the mutual information between the original image and the reconstructed one. Figure 4 presents the results of the calculated information at different decomposition levels for various mother wavelets.

Figure 4.
Calculated information on Lenna image for various mother wavelets.
Table 1 presents the information for various wavelets at the different decomposition levels. The calculated information depends on the mother wavelet and the decomposition level. Column 1 and column 2 are exactly the same because of the averaging pooling and Haar decomposition equivalence. At the higher decomposition levels, information is higher for db3 and sym3 than other mother wavelets shown in Table 1. Table 2 presents the calculated mutual information for the various wavelets. The mutual information was calculated using the method described by Kraskov et al. (2004) [17].
Table 2.
Entropy at each pyramid level of the decomposition for various mother wavelets.
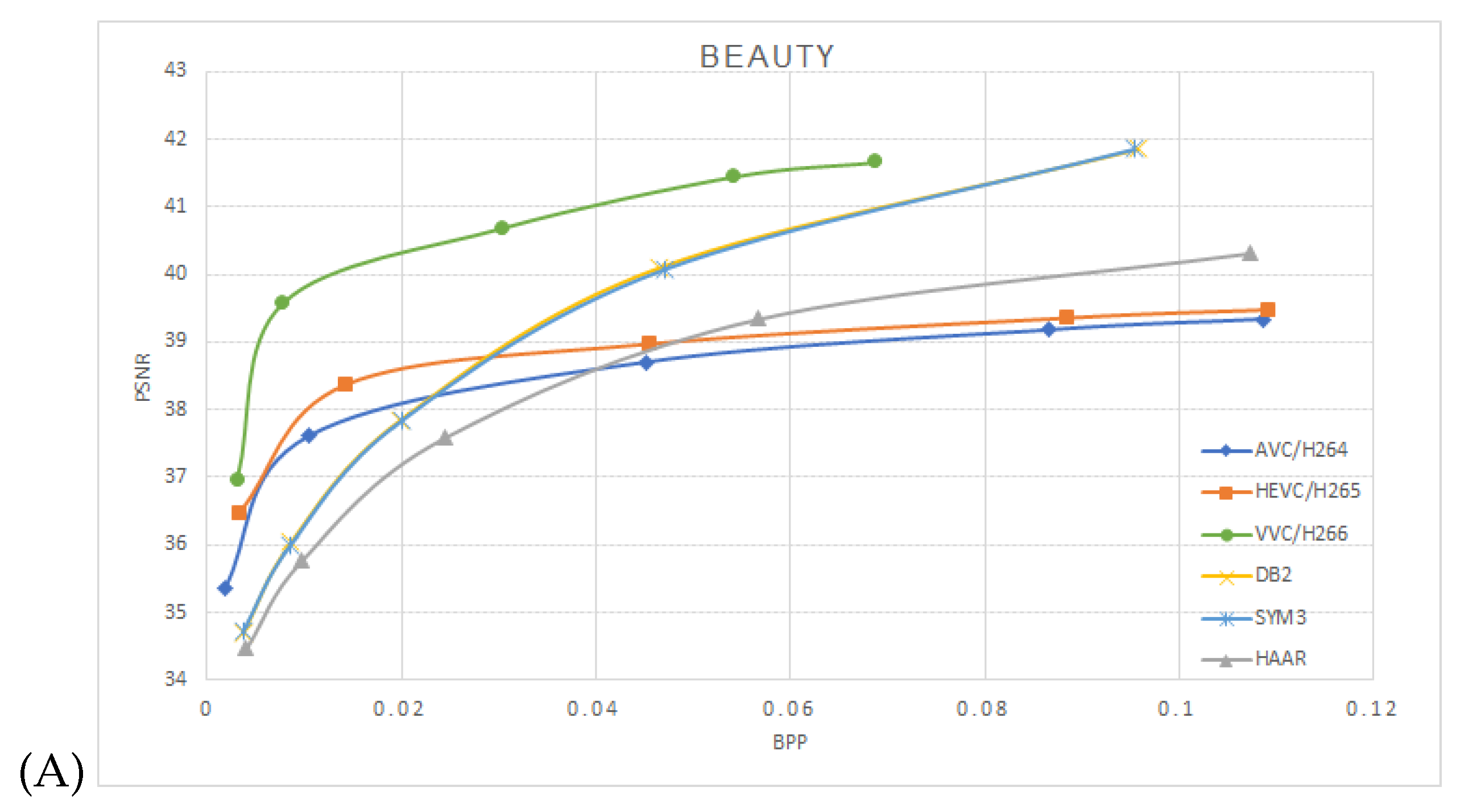
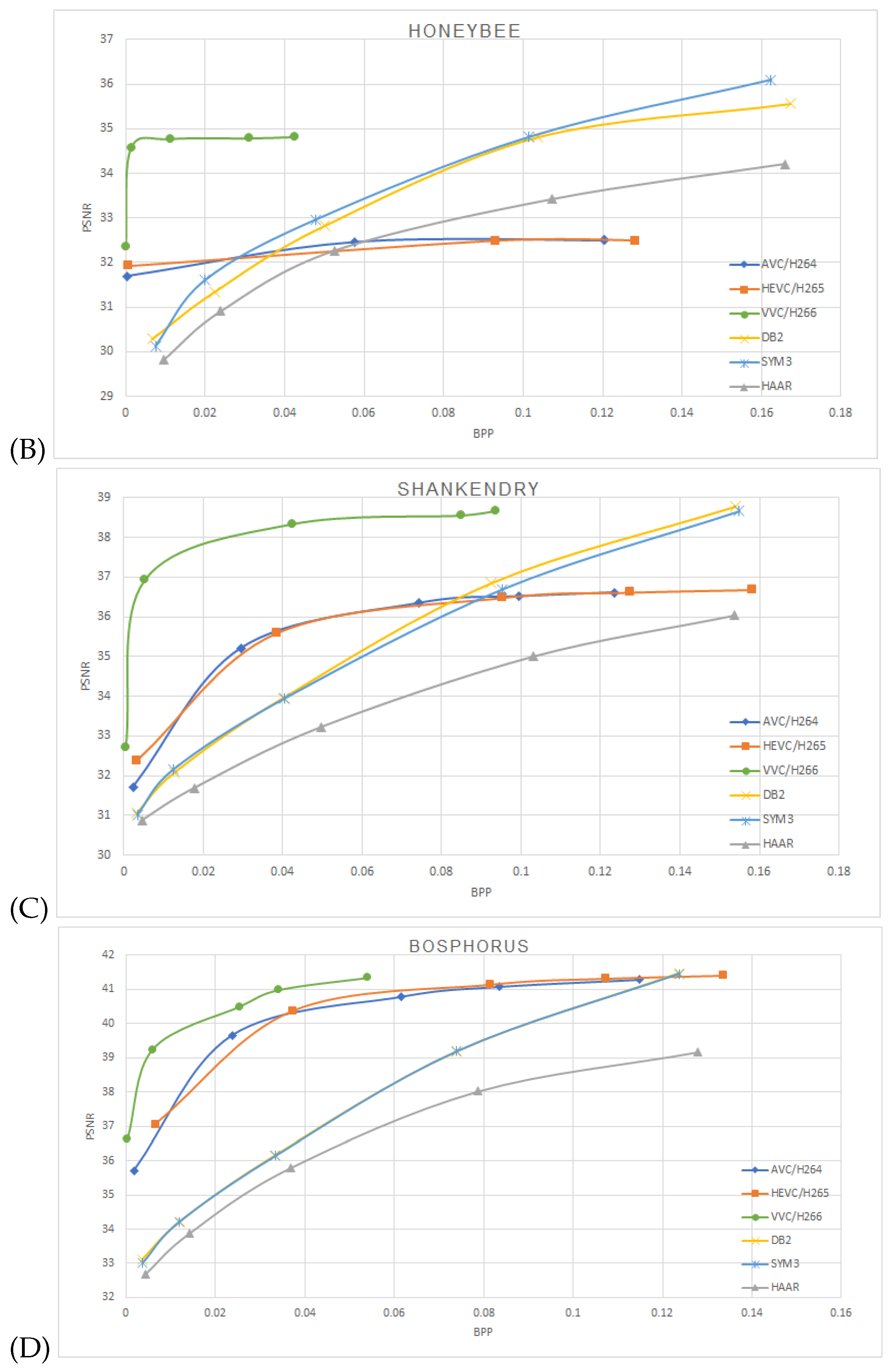
One can notice that the estimated mutual information between the network layers depends on the mother wavelets utilized at the pooling layer. The approximation coefficients used at the Haar wavelet’s layers are equivalent to averaging pooling layers. Utilizing db2 or sym3 wavelets increases the mutual information compared to the averaging pooling (Haar wavelet). We have used the Vimeo-90K dataset for the compression performance study to train our model. It consists of 89,800 video clips downloaded from vimeo.com, which cover various scenes and actions. It is designed for four video processing tasks: temporal frame interpolation, video denoising, video deblocking, and video super-resolution. BPG 444 [18] was used to compress I-frames in each video sequence with QP 22 27, 32, 37 and 42. The corresponding models were trained with lambda 65,536, 16,384 4096, 1024 and 256, respectively. A custom data generator was implemented to randomly sample two frames—“I-frame” and “P-frame” from the dataset. Then, the two frames were cropped to 240 × 240 resolution before they were fed into the model. We trained the network with mini-batches of 60,000 samples with 15 epochs. ADAM optimizer with cosine decay was used for the learning rate starting from . We then used Nvidia RTX 3060 with 12 GB GDDR6 to train the model, a process that lasted an average of about 24 h each. The proposed model was performed on the Open Ultra Video Group (UVG) dataset [19]. The UVG dataset is composed of 16 versatile 4K (3840 × 2160) test video sequences captured at 50/120 fps. The image sequence was resized to a 240 × 240 resolution to match the input size of the trained model. Compressed frames for AVC/H.264, HEVC/H.265, and VVC/H.266 were generated using libavcodec with libx264, libx265, and libvvenc, respectively. The encoders were configured with the “very fast” preset for AVC/H.264 and H.265, and the “faster” preset for H.266, consistent with the settings used in OpenDVC experiments. We trained the models HAAR-10k based on the Haar wavelet with 10,000 image pairs (I-Frame and P-Frame) with 15 epochs; HAAR-60k, DB2 (Daubechies 2) wavelet and SYM3 (Symlets 3) wavelet were trained with 60,000 image pairs. Figure 5 shows the average peak signal-to-noise ratio PSNR vs bits per pixel BPP on the encoded frames tested on the UVG dataset, A, B, C, and D are the video sequences Beauty, HoneyBee, ShakeNDry, and Bosphorous, respectively.
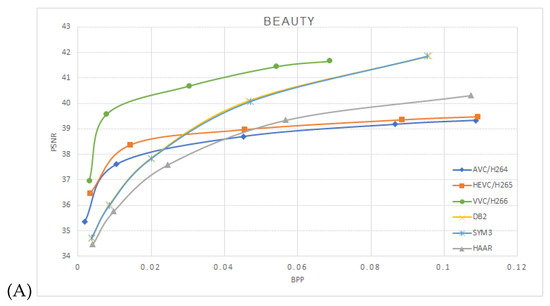
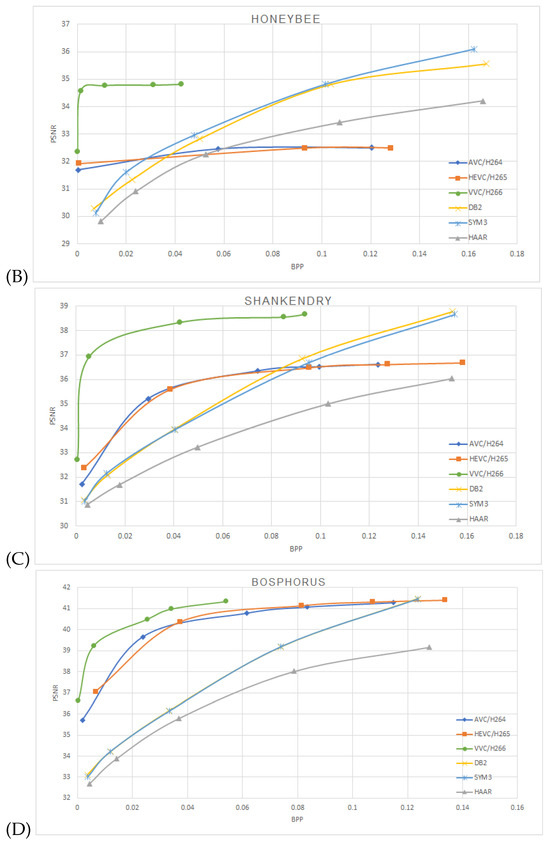
Figure 5.
Performance on the UVG dataset comparison between AVC/H.264, HEVC/H.265, VVC/H.266 and OpenDVCW with Db2, Sym3 and Haar wavelets for the DWT transform in the optical flow. (A)—Beauty, (B)—HoneyBee, (C)—ShakeNDry, (D)—Bosphorus.
7. Summary and Discussion
This paper proposes Information Bottleneck-Driven Deep Video Compression with Wavelet Transform. Our studies show that replacing the commonly used average pooling with wavelet transform-based pooling improves the performance of video compression rates. The improvement is particularly evident with wavelets, as they lead to higher mutual information between the layers. In terms of computational complexity, when using the HAAR wavelet, the complexity remains the same as in the original OpenDVC model, ensuring no additional computational overhead. However, using more complex wavelets can increase the computational cost. To balance performance and complexity, we opted to work with small filter taps like Daubechies (db2), (db3), and Symlet (sym3), which offer a good trade-off between accuracy and efficiency while keeping the computational complexity manageable. The proposed IBOpenDVCW network was carried out using TensorFlow 2. We have replaced the average pooling with DWT layers, implementing the pyramid algorithm for the optical flow estimation to obtain better quality and performance in video coding. The proposed network achieves equal or better results than the AVC/H.264, HEVC/H.265 and VVC/H.266 coders regarding BPP and PSNR. Increasing the dataset size and the number of epochs while training the model leads to better distortion rates. Future work may focus on developing and training the network with different kinds of wavelet families and researching and developing the network while using the discrete complex wavelet transform and accelerating the inference time. We have studied the mutual information between the layers for the different wavelets, as shown in Table 3. Additionally, the mutual information calculated for further wavelets is presented in Table 4.
Table 3.
Mutual Information for various mother wavelets.
Table 4.
More results for Mutual Information for various mother wavelets.
We can see that for coif3 wavelets, mutual information is higher than for db2, db3, and sym3. Further study is required to check the compression rate improvement for these wavelets. It is not obvious that the wavelets with higher mutual information will improve because of the potential trade-off between mutual information and accuracy. In summary, pooling layers play a crucial role in deep neural networks by reducing dimensionality, aiding in translation invariance, preventing overfitting, and abstracting features. The Information Bottleneck theory provides a theoretical framework for balancing compression and information retention in image and video compression tasks. The choice of pooling method can significantly influence the performance of a network, with various techniques are available depending on the application’s specific needs.
Author Contributions
The authors contributed equally to the work’s conceptualization and methodology. T.L. mainly investigated the case under the supervision of Y.B.E. All authors contributed equally to the result analysis. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Data is contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Symes, P. Digital Video Compression; Digital Video/Audio Series; McGraw-Hill: New York, NY, USA, 2004. [Google Scholar]
- Zhang, Z.; Shi, Y.; Toda, H.; Akiduki, T. A Study of a new wavelet neural network for deep learning. In Proceedings of the 2017 International Conference on Wavelet Analysis and Pattern Recognition (ICWAPR), Ningbo, China, 9–12 July 2017; pp. 127–131. [Google Scholar] [CrossRef]
- Ma, S.; Zhang, X.; Jia, C.; Zhao, Z.; Wang, S.; Wang, S. Image and Video Compression with Neural Networks: A Review. arXiv 2019, arXiv:1904.03567. [Google Scholar] [CrossRef]
- Shin, S. Industrial application of wavelet analysis. In Proceedings of the 2008 International Conference on Wavelet Analysis and Pattern Recognition, Hong Kong, China, 30–31 August 2008; Volume 2, pp. 607–610. [Google Scholar] [CrossRef]
- Keinert, F. Wavelets and Multiwavelets; Studies in Advanced Mathematics; CRC Press: Boca Raton, FL, USA, 2003. [Google Scholar]
- Graps, A. An introduction to wavelets. IEEE Comput. Sci. Eng. 1995, 2, 50–61. [Google Scholar] [CrossRef]
- Birman, R.; Segal, Y.; Hadar, O. Overview of Research in the field of Video Compression using Deep Neural Networks. Multimed. Tools Appl. 2020, 79, 11699–11722. [Google Scholar] [CrossRef]
- Sankaralingam, E.; Thangaraj, V.; Vijayamani, S.; Palaniswamy, N. Video Compression Using Multiwavelet and Multistage Vector Quantization 385 Video Compression Using Multiwavelet and Multistage Vector Quantization. Int. Arab J. Inf. Technol. 2009, 6, 385–393. [Google Scholar]
- Joy, H.; Kounte, M.R.; Chandrasekhar, A.; Paul, M. Deep Learning Based Video Compression Techniques with Future Research Issues. Wirel. Pers. Commun. 2023, 131, 2599–2625. [Google Scholar] [CrossRef]
- Mochurad, L. A Comparison of Machine Learning-Based and Conventional Technologies for Video Compression. Technologies 2024, 12, 52. [Google Scholar] [CrossRef]
- Tishby, N.; Zaslavsky, N. Deep learning and the information bottleneck principle. In Proceedings of the 2015 IEEE Information Theory Workshop (ITW), Jerusalem, Israel, 26 April–1 May 2015; pp. 1–5. [Google Scholar] [CrossRef]
- van Berkel, M.; Witvoet, G.; Nuij, P.; Steinbuch, M. Wavelets for Feature Detection: Theoretical Background; CST, Eindhoven University of Technology: Eindhoven, The Netherlands, 2010. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley Series in Telecommunications and Signal Processing; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Lu, G.; Ouyang, W.; Xu, D.; Zhang, X.; Cai, C.; Gao, Z. DVC: An End-to-end Deep Video Compression Framework. arXiv 2019, arXiv:1812.00101. [Google Scholar] [CrossRef]
- Yang, R.; Gool, L.V.; Timofte, R. OpenDVC: An Open Source Implementation of the DVC Video Compression Method. arXiv 2020, arXiv:2006.15862. [Google Scholar] [CrossRef]
- Ballé, J.; Laparra, V.; Simoncelli, E.P. End-to-end Optimized Image Compression. arXiv 2017, arXiv:1611.01704. [Google Scholar] [CrossRef]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [PubMed]
- Bellard, F. BPG Image Format. Available online: https://bellard.org/bpg/ (accessed on 28 June 2024).
- Mercat, A.; Viitanen, M.; Vanne, J. UVG dataset: 50/120fps 4K sequences for video codec analysis and development. In Proceedings of the MMSys ’20: Proceedings of the 11th ACM Multimedia Systems Conference, Istanbul, Turkey, 8–11 June 2020; pp. 297–302. [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).