Abstract
Variational quantum algorithms (VQAs) have shown strong evidence to gain provable computational advantages in diverse fields such as finance, machine learning, and chemistry. However, the heuristic ansatz exploited in modern VQAs is incapable of balancing the trade-off between expressivity and trainability, which may lead to degraded performance when executed on noisy intermediate-scale quantum (NISQ) machines. To address this issue, here, we demonstrate the first proof-of-principle experiment of applying an efficient automatic ansatz design technique, i.e., quantum architecture search (QAS), to enhance VQAs on an 8-qubit superconducting quantum processor. In particular, we apply QAS to tailor the hardware-efficient ansatz toward classification tasks. Compared with heuristic ansätze, the ansatz designed by QAS improves the test accuracy from to . We further explain this superior performance by visualizing the loss landscape and analyzing effective parameters of all ansätze. Our work provides concrete guidance for developing variable ansätze to tackle various large-scale quantum learning problems with advantages.
1. Introduction
The successful exhibition of random quantum circuits sampling and Boson sampling over fifty qubits [1,2,3,4] evidences the potential of using current quantum hardware to address classically challenging problems. A leading strategy towards this goal is variational quantum algorithms (VQAs) [5,6], which leverage classical optimizers to train an ansatz that can be implemented on noisy intermediate-scale quantum (NISQ) devices [7]. In the past years, a growing number of theoretical studies have shown the computational superiority of VQAs in the regime of machine learning [8,9,10,11,12,13,14,15,16], quantum many-body physics [17,18,19,20], and quantum information processing [21,22,23]. On par with the achievements, recent studies have recognized some flaws of current VQAs through the lens of the trade-off between expressivity and learning performance [14,24]. That is, an ansatz with very high expressivity may encounter the barren plateau issues [25,26,27,28], while an ansatz with low expressivity could fail to fit the optimal solution [29]. With this regard, designing a problem-specific and hardware-oriented ansatz is of great importance to guarantee the good learning performance of VQAs and the precondition of pursuing quantum advantages.
Pioneered experimental explorations have validated the crucial role of ansatz when applying VQAs to accomplish tasks in different fields such as machine learning [30,31,32,33], quantum chemistry [19,34,35,36,37,38], and combinatorial optimization [39,40,41,42]. On the one side, envisioned by the no-free-lunch theorem [43,44], there does not exist a universal ansatz that can solve all learning tasks with optimal performance. To this end, myriad handcraft ansätze have been designed to address different learning problems [45,46,47]. For instance, the unitary coupled cluster ansatz and its variants attain superior performance in the task of estimating molecular energies [48,49,50,51]. Besides devising the problem-specific ansätze, another indispensable factor to enhance the performance of VQAs is the compatibility between the exploited ansatz and the employed quantum hardware, especially in the NISQ scenario [39]. Concretely, when the circuit layout of ansatz mismatches with the qubit connectivity, additional quantum resources, e.g., SWAP gates, are essential to complete the compilation. Nevertheless, these extra quantum resources may inhibit the performance of VQAs because of the limited coherence time and inevitable gate noise of NISQ machines. Considering that there are countless learning problems and diverse architectures of quantum devices [52,53,54], it is impractical to manually design problem-specific and hardware-oriented ansätze.
To enhance the capability of VQAs, initial studies have been carried out to seek feasible strategies of automatically designing a problem-specific and hardware-oriented ansatz with both good trainability and sufficient expressivity. Conceptually, the corresponding proposals exploit random search [55], evolutionary algorithms [56,57], deep learning techniques [58,59,60,61,62,63,64,65], and adaptive strategies [66,67,68] to tailor a hardware-efficient ansatz [19], i.e., inserting or removing gates, to decrease the cost function. In contrast with conventional VQAs that only adjust parameters, optimizing both parameters and circuit layouts enables the enhanced learning performance of VQAs. Meanwhile, the automatic nature endows the power of these approaches to address broad learning problems. Despite the prospects, little is known about the effectiveness of these approaches executed on real quantum devices.
In this study, we demonstrate the first proof-of-principle experiment of applying an efficient automatic ansatz design technique, i.e., quantum architecture search (QAS) scheme [69], to enhance VQAs on an 8-qubit superconducting quantum processor. In particular, we focus on data classification tasks and utilize QAS to pursue a better classification accuracy. To our knowledge, this is the first experimental study of multi-class learning. Moreover, to understand the noise-resilient property of QAS, we fabricate a controllable dephasing noisy channel and integrate it into our quantum processor. Assisted by this technique, we experimentally demonstrate that the ansatz designed by QAS is compatible with the topology of the employed quantum hardware and attains much better performance than the hardware-efficient ansatz [19] when the system noise becomes large. Experimental results indicate that under a certain level of noise, the ansatz designed by QAS achieves the highest test accuracy (), while other heuristic ansätze only reach accuracy. Additional analyses of loss landscape further explain the advantage of the QAS-based ansatz in both optimization and effective parameter space. These gains in performance suggest the significance of developing QAS and other automatic ansatz design techniques to enhance the learning performance of VQAs.
2. Materials and Methods
2.1. The Mechanism of QAS
The underlying principle of QAS is optimizing the quantum circuit architecture and the trainable parameters simultaneously to minimize an objective function. For elucidating, in the following, we elaborate on how to apply QAS to tailor the hardware-efficient ansatz (HEA). Mathematically, an N-qubit HEA yields a multi-layer structure, where the circuit layout of all blocks is identical, the l-th block consists of a sequence of parameterized single-qubit and two-qubits gates, and L denotes the block number. Note that our method can be generalized to prune other ansätze, such as the unitary coupled cluster ansatz [49] and the quantum approximate optimization ansatz [70].
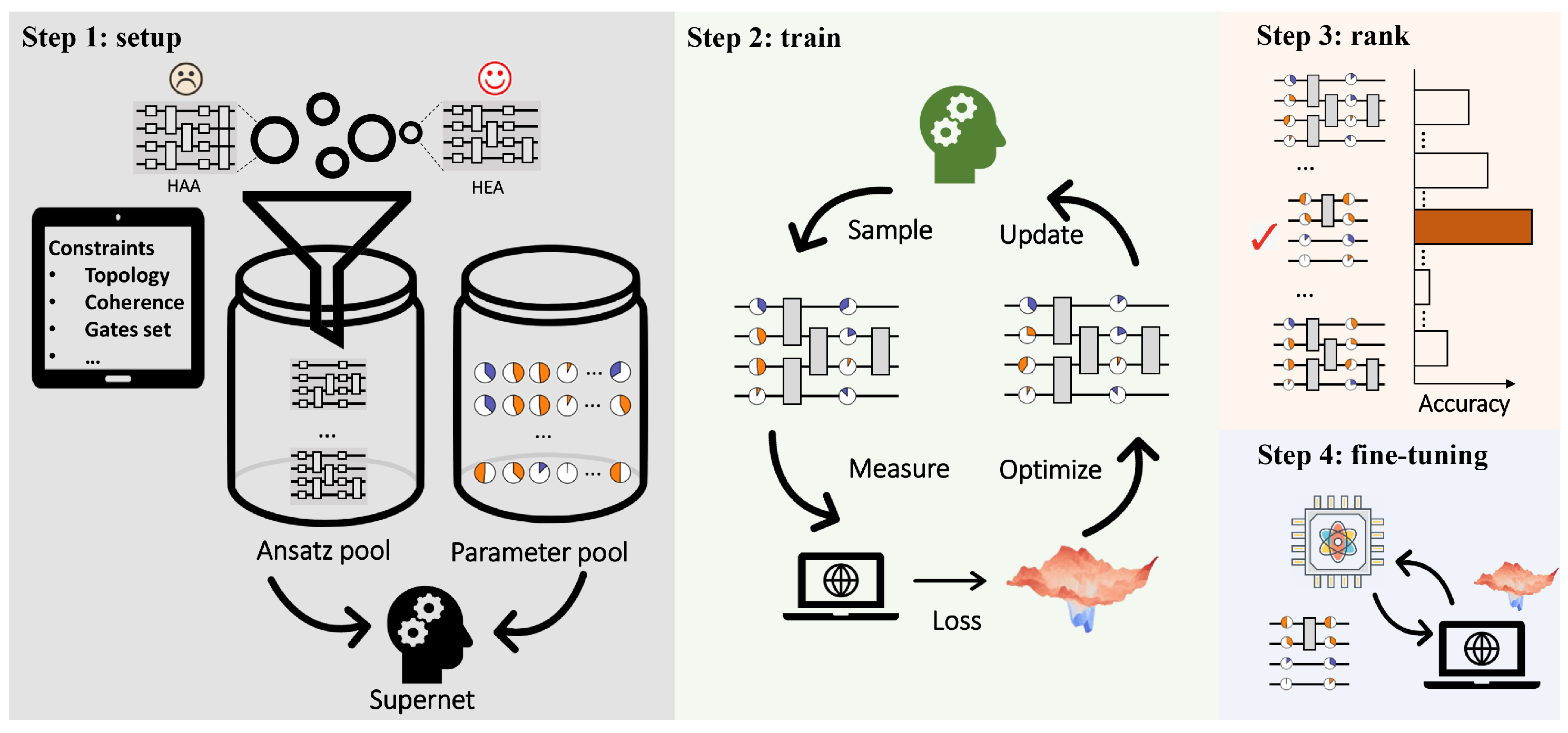
QAS is composed of four steps to tailor HEA and output a problem-dependent and hardware-oriented ansatz as shown in Figure 1. The first step is specifying the ansätze pool , collecting all candidate ansätze. Suppose that for can be formed by three types of parameterized single-qubit gates, i.e., rotational gates along three axes, and one type of two-qubits gates, i.e., CNOT gates. When the layout of different blocks can be varied by replacing single-qubit gates or removing two-qubit gates, the ansätze pool includes in total ansatz. Denote the input data as and an objective function as . The goal of QAS is finding the best candidate ansatz and its corresponding optimal parameters , i.e.,
where the quantum channel simulates the quantum system noise induced by .
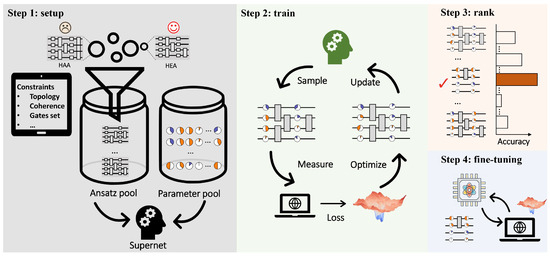
Figure 1.
Experimental implementation of QAS. The first step is to construct the ansätze pool which contains all candidate ansätze satisfying the hardware and physical constraints, such as hardware topology and maximal decoherence time. In the meantime, the parameter pool for all candidate ansätze is initialized in a layer-by-layer manner. The gate arrangement together with corresponding parameters constitutes the supernet. The second step is to sample ansatz from the supernet, measure the observable, calculate the loss, optimize the corresponding parameters based on the objective function, and update the parameters in the supernet. Repeat the above process until reaching the maximal number of iterations. Once the ansatz pool is well trained, the following steps are searching in , ranking according to performance, and selecting the optimal ansatz for fine-tuning.
The second step is optimizing Equation (1) with, in total, T iterations. As discussed in our technical companion paper [69], seeking the optimal solution is computationally hard since the optimization of is discrete and the size of and exponentially scales with respect to N and L. To conquer this difficulty, QAS exploits the supernet and weight-sharing strategy to ensure a good estimation of within a reasonable computational cost. Concisely, the weight-sharing strategy correlates parameters among different ansätze in to reduce the parameter space . As for supernet, it plays two significant roles, i.e., configuring the ansätze pool and parameterizing ansatz via the specified weight-sharing strategy. In doing so, at each iteration t, QAS randomly samples an ansatz and updates its parameters, with , and being the learning rate. Due to the weight-sharing strategy, the parameters of the unsampled ansätze are also updated.
The last two steps are ranking and fine-tuning. Specifically, once the training is completed, QAS ranks a portion of the trained ansätze and chooses the one with the best performance. The ranking strategies are diverse, including random searching and evolutionary searching. Finally, QAS utilizes the selected ansatz to fine-tune the optimized parameters with a few iterations. Refer to Ref. [69] for the omitted technical details of QAS.
2.2. Experimental Implementation
We implement QAS on a quantum superconducting processor to accomplish the classification tasks for the Iris dataset. Namely, the Iris dataset consists of three categories of flowers (i.e., ), and each category includes 50 examples characterized by 4 features (i.e., ). In our experiments, we split the Iris dataset into three parts, i.e., the training dataset , the validating dataset , and the test dataset with . The functionality of , , and is estimating the optimal classifier, preventing the classifier from being over-fitted, and evaluating the generalization property of the trained classifier, respectively.
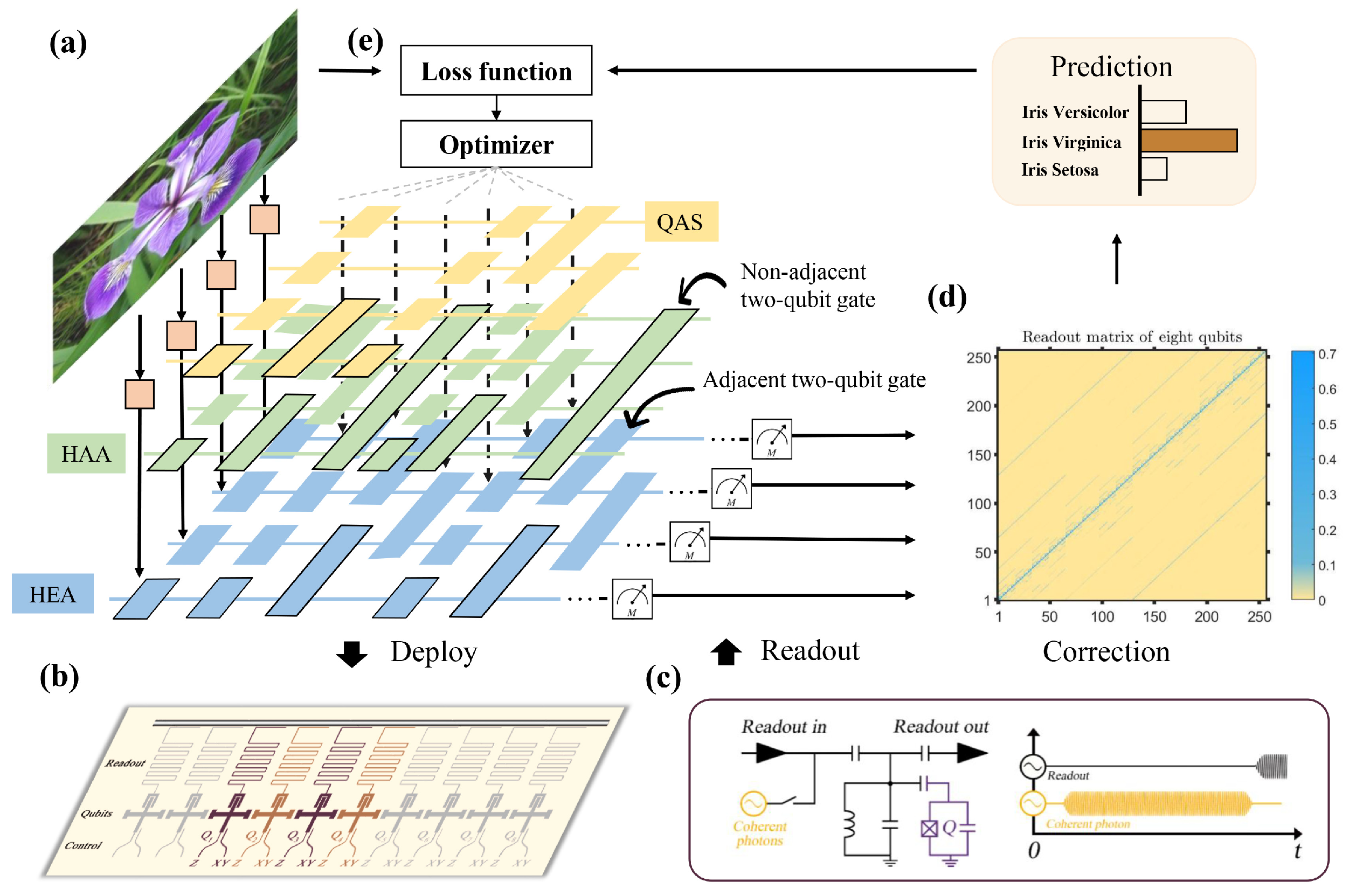
Our experiments are carried out on a quantum processor, including 8 Xmon superconducting qubits with a one-dimensional chain structure. As shown in Figure 2b, the employed quantum device is fabricated by sputtering an aluminum thin film onto a sapphire substrate. The single-qubit rotation gate () along X-axis (Y-axis) is implemented with a microwave pulse, and the Z rotation gate is realized by virtual Z gate [71]. The construction of the CZ gate is completed by applying the avoided level crossing between the high level states and or and . The calibrated readout matrix is shown in Figure 2d and the device parameters is summarized in Table A1 of Appendix A.
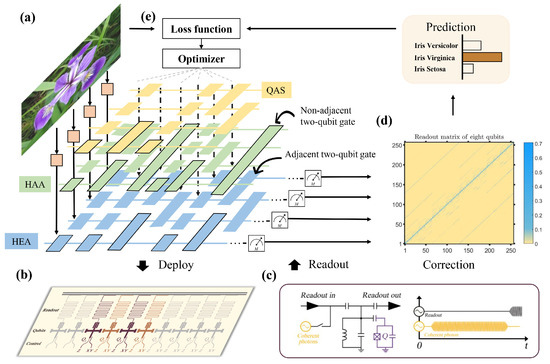
Figure 2.
Experimental setups. (a) The construction of quantum classifiers with the exploited three different ansätze, i.e., hardware-agnostic ansatz (HAA), hardware-efficient ansatz (HEA), and the ansatz searched by QAS, towards the Iris dataset. For all classifiers, the gate encoding method is adopted to embed the classical feature vector into the quantum state . After the interaction of with the ansatz , the generated state is measured by a fixed operator to obtain the prediction . (b) All three quantum classifiers are deployed on an 8-qubit superconducting processor with the chain topology. The activated qubits are highlighted by the purple color. (c,d) To suppress the system noise, error mitigation techniques of measurements are used in our quantum hardware. Namely, the collected measurement results are operated with a correction matrix to estimate the ideal results. Refer to the Method section for details. (e) A classical optimizer continuously updates the parameters in to minimize the discrepancy between the predictions of quantum classifiers and ground-truth labels indicated by the objective function.
We fabricate the controllable dephasing noise as a measurable disturbance to the quantum evolution. The operators for the noise channel can be written as and . is a constant, and the value of p can be tuned in our experiment by changing the average number of the coherent photons on the readout cavity’s steady state. The intensity of coherent photons is represented by the amplitude p of the curve shown on the AWGs.
The experimental implementation of the quantum classifiers is as follows. As illustrated in Figure 2a, the gate encoding method is exploited to load classical data into quantum states. The encoding circuit yields . To evaluate the effectiveness of QAS, three types of ansätze are used to construct the quantum classifier. The first two types are heuristic ansätze, which are the hardware-agnostic ansatz (HAA) and hardware-efficient ansatz (HEA). As depicted in Figure 2a, HAA is designed for a general paradigm and ignores the topology of specific quantum hardware platforms; HEA adapts to the quantum hardware constraints, where all inefficient two-qubit operators that connect two physically nonadjacent qubits are forbidden. The third type of ansatz refers to the output of QAS, denoted as . The mean square error between the prediction and real labels is employed as the objective function for all quantum classifiers. The noise rate of the dephasing channel p is set as 0, , and . We benchmark the test accuracy of these three ansätze HAA, HEA, and QAS, and explore whether QAS attains the highest test accuracy. Refer to Appendix B for more implementation details.
3. Results
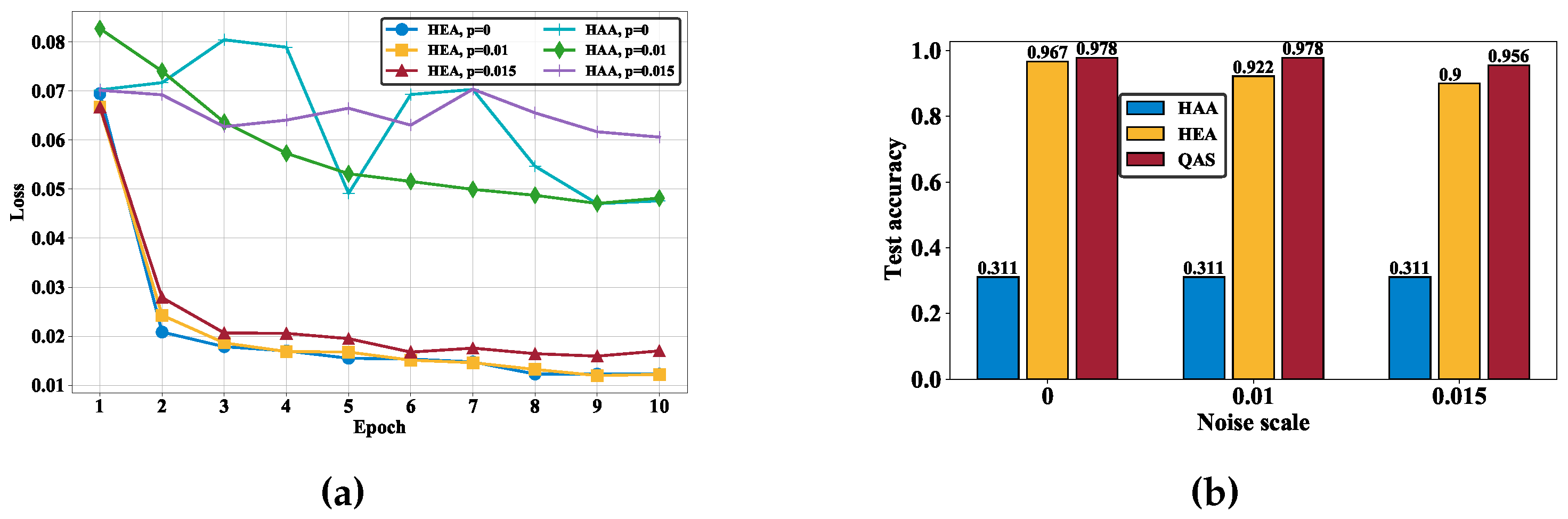
To comprehend the importance of the compatibility between quantum hardware and ansätze, we first examine the learning performance of the quantum classifiers with HAA and HEA under different noise rates. The achieved experimental results are demonstrated in Figure 3a. In particular, in the measure of training loss (i.e., the lower the better), the quantum classifier with the HEA significantly outperforms HAA for all noise settings. At the 10-th epoch, the training loss of the quantum classifier with HAA and HEA is and ( and ; and ) when (; ), respectively. In addition, the optimization of the quantum classifier with HAA seems to be divergent when . We further evaluate the test accuracy to compare their learning performance. As shown in Figure 3b, there exists a manifest gap between the two ansätze, highlighted by the blue and yellow colors. For all noise settings, the test accuracy corresponding to HAA is only 31.1%, whereas the test accuracy corresponding to HEA is at least 95.6%. These observations signify the significance of reconciling the topology between the employed quantum hardware and ansatz as the key motivation of this study. Specifically, the performance gap between HAA and HEA drives us to introduce QAS, which focuses on searching for the optimal quantum circuit architecture rather than iteratively updating gate parameters within a single, fixed architecture.
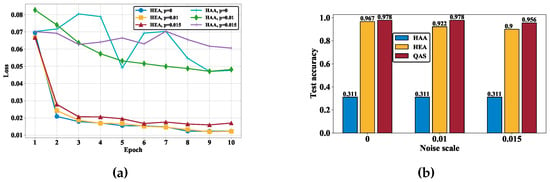
Figure 3.
The performance of quantum classifiers. (a) The training loss of quantum classifiers with the HAA and HEA ansätze under different noise settings. (b) The test accuracy achieved by HAA, HEA, and the ansatz searched by QAS under different noise settings.
We next experiment on QAS to quantify how it is a problem-specific and hardware-oriented design to enhance the learning performance of quantum classifiers. Concretely, as shown in Figure 3b, for all noise settings, the quantum classifier with the ansatz searched by QAS attains the best test accuracy compared to those of HAA and HEA. That is, when ( and ), the test accuracy achieved by QAS is ( and ), which is higher than HEA with ( and ). Notably, although the test accuracy is slightly decreased for the increased system noise, the strength of QAS becomes evident over the other two ansätze. In other words, QAS shows the advantages of simultaneously alleviating the effect of quantum noise and searching the optimal ansatz to achieve high accuracy. The superior performance validates the effectiveness of QAS in classification tasks.
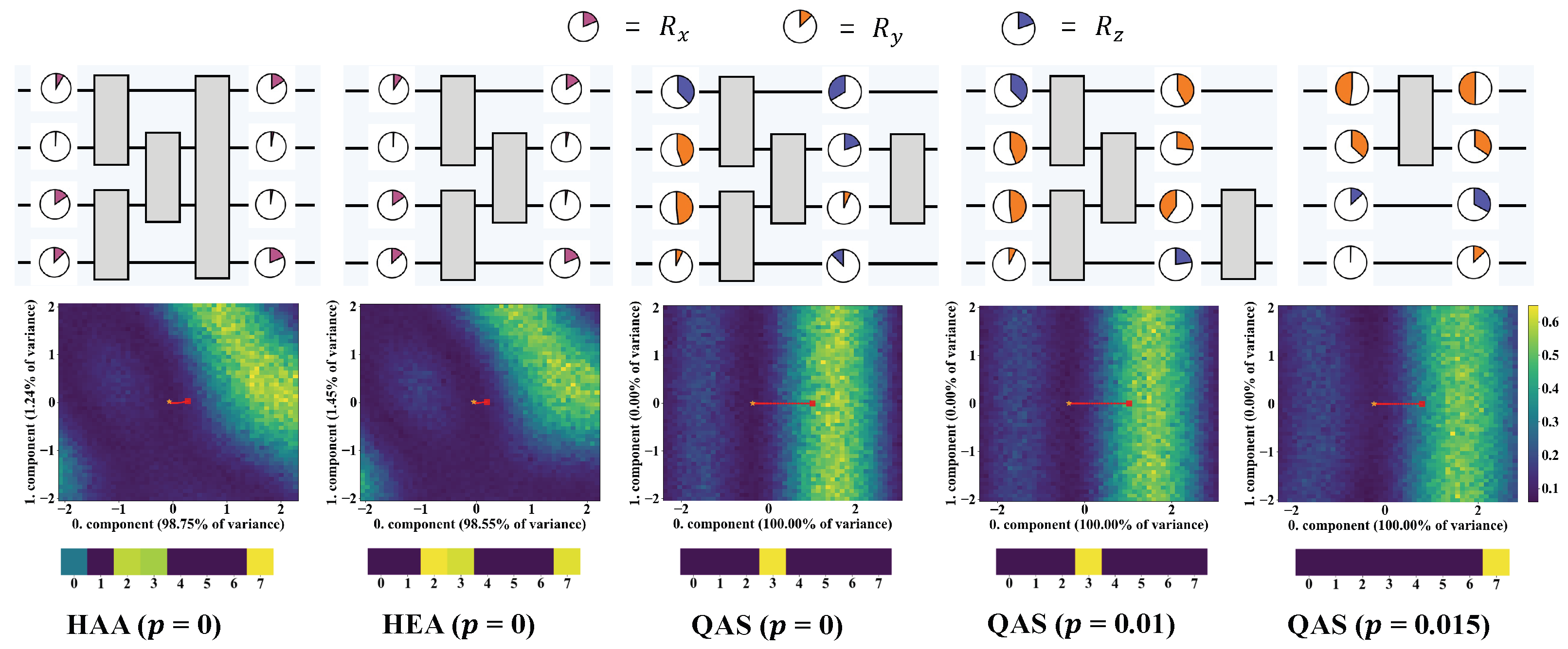
We last investigate the potential factors of ensuring the good performance of QAS from two perspectives, i.e., the circuit architecture and the corresponding loss landscape. The searched ansätze under three noise settings, HAA, and HEA are pictured at the top of Figure 4. Compared with HEA and HAA, QAS reduces the number of CZ gates with respect to the increased level of noise. When , QAS chooses the ansatz containing only one CZ gate. This behavior indicates that QAS can adaptively control the number of quantum gates to balance the expressivity and learning performance. We plot the loss landscape of HAA, HEA, and the ansatz searched by QAS in the middle row of Figure 4. To visualize the high-dimension loss landscape in a 2D plane, the dimension reduction technique, i.e., principal component analysis (PCA) [72] is applied to compress the parameter trajectory corresponding to each optimization step. After dimension reduction, we choose the obtained first two principal components that explain most of the variance as the landscape spanning vector. Refer to [73] and Appendix C for details. For HAA and HEA, the objective function is governed by both the 0-th component ( of variance for HAA, of variance for HEA) and 1-th component ( of variance for HAA, of variance for HEA). By contrast, for the ansätze searched by QAS, their loss landscapes totally depend on the 0-th component. Furthermore, the optimization path for QAS is exactly linear, while the optimization of HAA and HAA experiences a nonlinear curve. This difference reveals that QAS enables a more efficient optimization trajectory. As indicated in the bottom row of Figure 4, there is a major parameter that contributes the most to the 0-th component in the three ansätze searched by QAS, while HAA and HEA have to consider multiple parameters to determine the 0-th component. This phenomenon reflects that ansätze searched by QAS are prone to having a smaller effective parameter space, which leads to less noise accumulation and further stronger noise robustness. These observations can be treated as empirical evidence to explain the superiority of QAS.
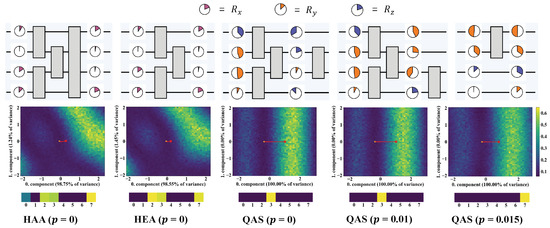
Figure 4.
The circuit architecture and corresponding loss landscape. The top row demonstrates the structure of HAA, HEA, and the ansatz searched by QAS under different noise settings. The color and angles refer to the gate type and corresponding parameter. The middle row visualizes the loss landscape of each ansatz with respect to the trained parameters based on the technique developed in [73]. The red line tracks the optimization path of loss during the 50 epochs. The linear path indicates that the loss landscape enjoys a simple structure and optimization is easy to converge. The bottom row shows the absolute value of the first row vector of the PCA transform matrix, which reflects the contribution of each parameter to the first component. Numbers 0–7 denote the parameter index.
4. Discussion
Our experimental results provide the following insights. First, we experimentally verify the feasibility of applying automatically designing a problem-specific and hardware-oriented ansatz to improve the power of quantum classifiers. Second, the analysis related to the loss landscape and the circuit architectures exhibits the potential of applying QAS and other variable ansatz construction techniques to compensate for the caveats incurred by executing variational quantum algorithms on NISQ machines.
Besides classification tasks, it is crucial to benchmark QAS and its variants towards other learning problems in quantum chemistry and quantum many-body physics. In these two areas, the employed ansatz is generally Hamiltonian dependent [48,49,74]. As a result, the way of constructing the ansatz pool should be carefully conceived. In addition, another important research diction is understanding the capabilities of QAS for large-scale problems. How to find the near-optimal ansatz among the exponential candidates is a challenging issue.
We note that although QAS can reconcile the imperfection of quantum systems, a central law to enhance the performance of variational quantum algorithms is promoting the quality of quantum processors. For this purpose, a promising area for future exploration is to delve into carrying out QAS and its variants on more types of quantum machines to accomplish more real-world generation tasks with potential advantages.
Author Contributions
Y.D. and H.Y. conceived the research. K.L. and Y.Q. designed and performed the experiment. Y.Q. and Y.D. performed numerical simulations. Y.Q., X.W., R.W., M.-J.H. and D.E.L. analyzed the results. All authors contributed to discussions of the results and the development of the manuscript. Y.Q., R.W., Y.D. and K.L. wrote the manuscript with input from all co-authors. Y.D., X.W., D.T. and R.W. supervised the whole project. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the NSFC of China (No. 12104056, No. 12104055, No. 12404558, Grant No. 12004042), the NSF of Beijing (Grant No. Z190012), and the Key-Area Research and Development Program of Guang Dong Province (Grant No. 2018B030326001).
Data Availability Statement
Data will be shared when there is a demand.
Acknowledgments
We appreciate the helpful discussion with Weiyang Liu and Guangming Xue.
Conflicts of Interest
Yang Qian, Xingyao Wu, Yuxuan Du and Dacheng Tao are employed by JD Explore Academy. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Appendix A. Experiment Setup
Appendix A.1. Device Parameters
The qubit parameters, length, and fidelity for the single- and two-qubit gates of our device are summarized in Table A1.
Appendix A.2. Electronics and Control Wiring
The device is installed in a cryogenic setup in a dilution refrigerator. The control and measurement electronics which are connected to the device are shown in Figure A1. The electronic control module is divided into six areas with different temperatures. The superconducting quantum device is installed at the base plate with a cryogenic environment of 10 mK. For each qubit, the frequency is tuned by a flux control line by changing the magnetic flux through the SQUID loop, and the flux is controlled by a constant current, which is generated by a voltage source and inductively coupled to the SQUID. Four attenuators are connected in the circuit in series to act as the thermal precipitator. The XY control for each qubit is achieved by up-converting the intermediate frequency signals with an analog IQ-mixer module. The drive pulse is provided by the multi-channel AWGs with a sample rate of 2 GSa/s.

Table A1.
Device parameters. and represent the qubit frequency and qubit anharmonicity, respectively. and are the longitudinal and transverse relaxation times, respectively. and are the average fidelity and length of the single-qubit gates. is the coupling strength between nearby qubits, and is the effective ZZ coupling strength. are the fidelity of the CZ gates calibrated by quantum process tomography, and are the length of the CZ gates.
Table A1.
Device parameters. and represent the qubit frequency and qubit anharmonicity, respectively. and are the longitudinal and transverse relaxation times, respectively. and are the average fidelity and length of the single-qubit gates. is the coupling strength between nearby qubits, and is the effective ZZ coupling strength. are the fidelity of the CZ gates calibrated by quantum process tomography, and are the length of the CZ gates.
| Parameter | Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (GHz) | |||||||||||||||
| (GHz) | |||||||||||||||
| () | |||||||||||||||
| () | |||||||||||||||
| () | 37 | 37 | 37 | 35 | 35 | 37 | 37 | 35 | |||||||
| () |
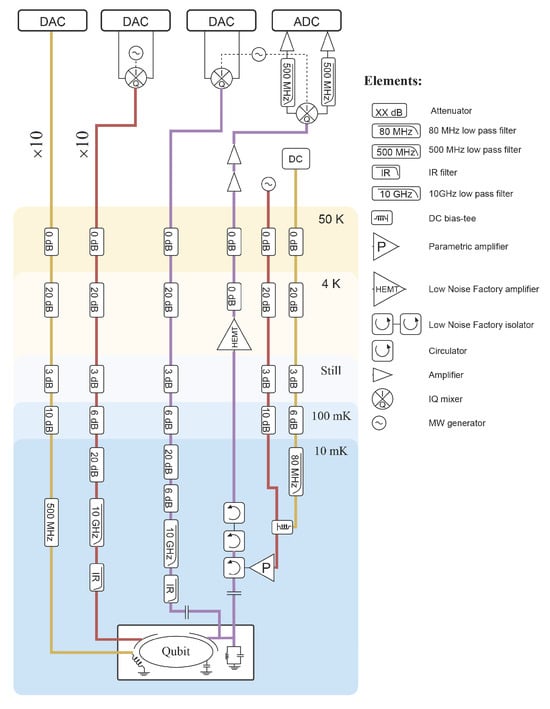
Figure A1.
Schematic diagram for the electronics and wiring setup for the superconducting quantum system.
Figure A1.
Schematic diagram for the electronics and wiring setup for the superconducting quantum system.
The qubit readout is performed by a readout control system with a sampling rate of 1 GSa/s. The readout pulse is up-converted to the frequency band of the readout cavity with the analog IQ-mixer and transmitted through the readout line with attenuators and low-pass filters to the chip. At the output side, the constant and alternating currents are combined by a bias-tee, amplified by the parametric amplifier, and connected to the readout line through a circulator at 10 mK, as well as a high-electron-mobility transistor (HEMT) at 4 K and two more amplifiers at room temperature. The amplified signals finally are digitized by an analog-to-digital converter.
Appendix A.3. Noise Setup
Due to the ac Stark effect, photon number fluctuations from the readout cavity can cause qubit dephasing [75]. We implement a pure dephasing noisy channel in our device. To every qubit, the noise photons are generated by a coherent source with a Lorentzian-shaped spectrum, which is centered at the frequency of . is the center frequency of the readout cavity, which is over-coupled to the feedline at the input and output port, and capacitively coupled to the Xmon qubit. The Hamiltonian system including the readout cavity and the qubit can be written as
where , and () is the Pauli operator for the X-mon qubit. (a) is the cavity photon creation (annihilation) operator. is the frequency between the ground and the first excited states of the qubit, and is the coupling strength between the qubit and the readout cavity.
By continuously sending the coherent photons to drive the readout cavity to maintain a coherent state, a noisy environment can be engineered. The noise channel can be described as the depolarization in the x-y plane of the Bloch sphere. The noise intensity can be tuned by changing the average number of coherent photons on the readout cavity’s steady state. The average number of photons is represented by the amplitude of the curve shown in the AWGs. Under different noise settings, the values of are shown in Table A2.
Table A2.
The transverse relaxation time under different noise settings.
Table A2.
The transverse relaxation time under different noise settings.
| Parameter | Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 |
|---|---|---|---|---|---|---|---|---|
| (s) | ||||||||
| (s) | ||||||||
| (s) | ||||||||
| (s) |
Appendix A.4. Readout Correction
The experimentally measured results of the final state for the eight qubits were corrected with a calibration matrix, which can be obtained in an experimental calibration process. The reconstruction process for readout results is based on Bayes’ rule. The colored schematic diagram for the calibration matrix is shown in Figure 2d. Assume that stands for the probability of obtaining a measured population when preparing a basis state . The calibration matrix is
If we prepare a state on n qubits, and the probability distribution of the prepared state in basis is , then we will obtain a measured state probability distribution as in the experiment. The relationship between the two probability distributions is
Sovling for P, we have
Appendix B. Implementation of Quantum Classifiers
In this section, we implement HAA, HEA, and QAS for the classification of the Iris dataset on the 8-qubit superconducting quantum processors with controllable dephasing noise. A detailed description of the dataset and hyper-parameters configuration is given below.
Appendix B.1. Dataset
The classification data employed in this paper are from the Iris dataset [76], which contains 150 instances characterized by 4 attributes and 3 categories. Each dimension of the feature vector is normalized to range . During training, the whole dataset is split into three parts, including the training set (60 samples), validation set (45 samples), and test set (45 samples). The sample distribution is visualized by selecting the first two dimensions of the feature vector. As shown in Figure A2, samples of class 1 and 2 cannot be distinguished by a linear classifier. It means that nonlinearity should be introduced into the quantum classifier to achieve higher classification accuracy.
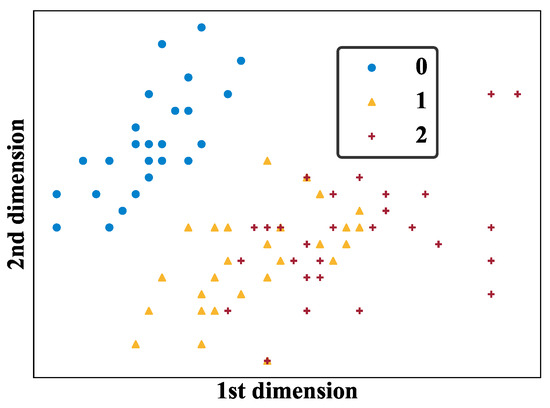
Figure A2.
The visualization of the Iris dataset based on its first two dimensions.
Figure A2.
The visualization of the Iris dataset based on its first two dimensions.
Appendix B.2. Objective Function and Accuracy Measure
Objective function. We adopt the mean square error (MSE) as the objective function for all quantum classifiers, i.e.,
where , O refers to the observable, denotes the unitary operator that embeds classical feature vector into the quantum circuit, and is the variational quantum circuit with the trainable parameters .
Definition of train, valid, and test accuracy. Given an example , the quantum classifier predicts its label as
The train (valid and test) accuracy aims to measure the differences between the predicted labels and true labels for examples in the training dataset (valid dataset and test dataset ), i.e., 3,
where denotes the size of a set.
Appendix B.3. Training Hyper-Parameters
The trainable parameters for all ansätze are randomly initialized following the uniform distribution . During training, the hyper-parameters are set as follows: the optimizer is stochastic gradient descent (SGD) [77], the batch size is 4, and the learning rate is fixed at . Specifically, the parameter shift rule [78] is applied to compute the gradient of the objective function with respect to a single parameter.
For QAS, we train 5 candidate supernets for 40 epochs to fit the training set. During the search phase, we randomly sample 100 ansatz and rank them according to their accuracy on the validation set. Finally, the ansatz with the highest accuracy is selected as the target ansatz. The ansätze pool is constructed as follows. For the single-qubit gate, the candidate set is . For the two-qubit gate, QAS automatically determines whether to apply gates to the qubit pair or not, discarding all other combinations, such as and . These nonadjacent qubits connections require more gates when running on the superconducting processor of 1-D chain topology, leading to bigger noise accumulation.
Appendix C. More Details of the Results
Appendix C.1. PCA Used in the Visualization of Loss Landscape
To visualize the loss landscape of HAA, HEA, and ansätze searched by QAS with respect to the parameter space, we apply principle component analysis (PCA) to the parameter trajectory collected in every optimization step and choose the first two components as the observation variable. To be concrete, given a sequence of trainable parameter vectors along the optimization trajectory , where T is the number of total optimization steps and denotes the parameter vector at the t-th step, we construct the matrix . Once we apply PCA to and obtain the first two principal components , the loss landscape with respect to trainable parameters can be visualized by performing a 2D scan for . Simultaneously, the projection vector of each component indicates the contribution of each parameter to this component, implying how many parameters determine the value of the objective function. Refer to [73] for details.
The optimization trajectory can provide certain information on the trainability and convergence of the employed ansatz in quantum classifiers. When the optimization path is exactly linear, it implies that the loss landscape is not intricate and the model can be easily optimized. On the contrary, the complicated nonlinear optimization curve indicates the difficulty of covering to the local minima.
Appendix C.2. Simulation Results
We conduct numerical experiments on classical computers to validate the effectiveness of QAS.
Dephasing noise. We simulate the dephasing noise channel as
where and represent the ideal quantum state (density matrix) and noisy quantum state affected by the dephasing channel, is the Pauli-Z operator, and is the noise strength, representing the probability of applying a Pauli-Z operator to the quantum state. In the experiments, the noise strength is set as , and the circuit layer L is set as . Each setting runs 10 times to suppress the effects of randomness.
Simulation results. As shown in Figure A3, QAS achieves the highest test accuracy over all noise and layer settings. When and , the performance gap between HEA () and QAS () is relatively small. With both the depth and noise strength increasing, HEA witnesses a rapid accuracy drop ( for and ). By contrast, the test accuracy for QAS with and is , which slightly decreases . This behavior accords with the results on the superconducting processor (the test accuracy of QAS running a superconducting device decreases from to when p increases from 0 to ; refer to Figure 3 for more details), further illustrating the advantage of QAS in error mitigation and model expressivity.
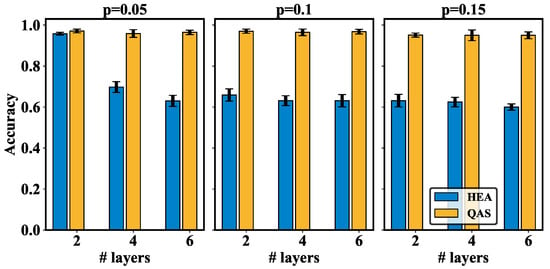
Figure A3.
The test accuracy achieved by HEA and QAS under various numbers of layers and noise strength when simulating on classical devices.
Figure A3.
The test accuracy achieved by HEA and QAS under various numbers of layers and noise strength when simulating on classical devices.
Appendix C.3. QAS in Quantum Approximate Optimization Algorithm (QAOA)
The quantum approximate optimization algorithm [41] is a variational quantum algorithm used to solve combinatorial optimization problems. In our work, QAOA is employed to search the maximum cut of an undirected graph. To this end, the system Hamiltonian generated from a graph with vertices V and edges E is given as
where is the Pauli-Z operator. Theoretically, the optimal partition is exactly deduced from the state , minimizing the expectation . In practice, the target state is approximated by following variation quantum circuit with depth p:
where the unitary gate is generated by the Hamiltonian , is usually selected as , , and are trainable parameters. Following the hybrid quantum–classical optimization scheme, we can asymptotically approach the solution by minimizing the expectation with infinite p.
Considering the system noise and limited qubit connectivity of quantum hardware, a natural generalization of is a generic unitary operator with free rotation axis [79] or more trainable parameters [80,81,82]. Inspired by the success of QAS in classification, we also apply QAS to automatically search the optimal mixer Hamiltonian to match the qubit connectivity and mitigate error.
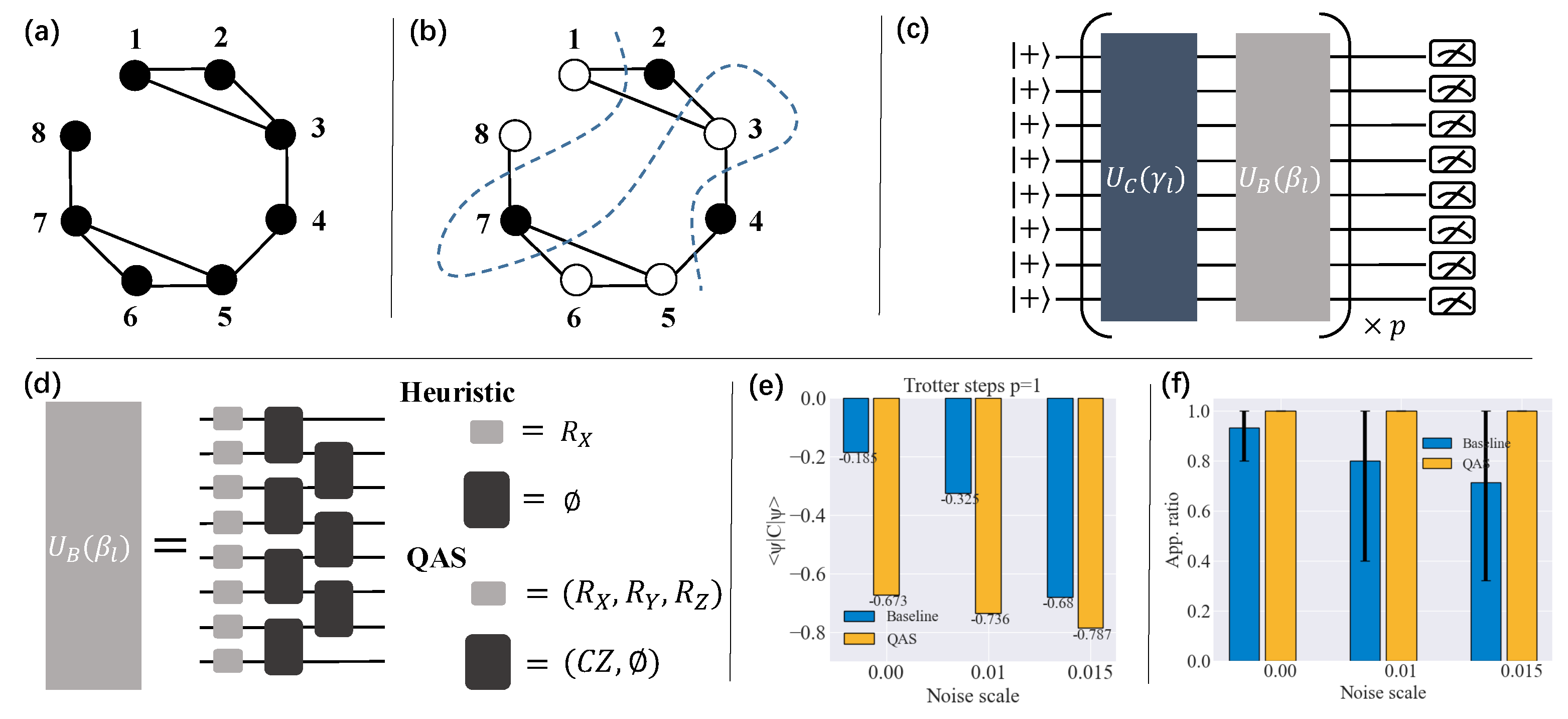
We study the 8-qubit system for the max-cut problem of graph with 8 vertices. Due to the chain connection of physical qubits, edges connecting vertices and with are discarded as shown in Figure A4a. The graph node indexed from 1 to 8 corresponds to the qubits from to . An optional graph partition achieving the maximum cut 7 is depicted in Figure A4b. Following the protocol of QAOA and the target graph, we employ the ansatz in Figure A4c to search the max-cut, where is generated by the system Hamiltonian C, and is generated by the mixer Hamiltonian. As drawn in Figure A4d, the heuristic layout of is described by , while QAS introduces more candidate Pauli operators and entangling gates to enhance the flexibility of . The performance of QAS for QAOA is demonstrated in Figure A4e,f. It is obvious that the mixer Hamiltonian searched by QAS achieves smaller loss than the vanilla mixer Hamiltonian for various trotter steps and noise scales, except for the extreme setting of and noise strength. We further measure the approximation ratio , where A is the graph cut solved by QAOA, and is the theoretical maximum cut. When corrupted by noise with increasing scales, the standard QAOA witnesses a gradual reduction in the average approximation ratio. Instead, the quantum ansatz generated by QAS can guarantee to find the optimal solution even when suffering from noise of intensity .
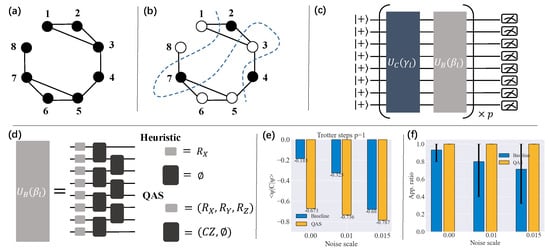
Figure A4.
Experimental results for the QAOA. (a) An instance of a graph with 8 vertices. (b) An optional partition achieving the max cut. (c) The QAOA circuit. (d) QAS helps design . (e) The loss comparison between standard QAOA (termed ‘baseline’) and QAS. (f) The approximation ratio achieved by standard QAOA and QAS.
Figure A4.
Experimental results for the QAOA. (a) An instance of a graph with 8 vertices. (b) An optional partition achieving the max cut. (c) The QAOA circuit. (d) QAS helps design . (e) The loss comparison between standard QAOA (termed ‘baseline’) and QAS. (f) The approximation ratio achieved by standard QAOA and QAS.
References
- Arute, F.; Arya, K.; Babbush, R.; Bacon, D.; Bardin, J.C.; Barends, R.; Biswas, R.; Boixo, S.; Brandao, F.G.; Buell, D.A.; et al. Quantum supremacy using a programmable superconducting processor. Nature 2019, 574, 505–510. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Bao, W.S.; Cao, S.; Chen, F.; Chen, M.C.; Chen, X.; Chung, T.H.; Deng, H.; Du, Y.; Fan, D.; et al. Strong quantum computational advantage using a superconducting quantum processor. Phys. Rev. Lett. 2021, 127, 180501. [Google Scholar] [CrossRef] [PubMed]
- Zhong, H.S.; Wang, H.; Deng, Y.H.; Chen, M.C.; Peng, L.C.; Luo, Y.H.; Qin, J.; Wu, D.; Ding, X.; Hu, Y.; et al. Quantum computational advantage using photons. Science 2020, 370, 1460–1463. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Q.; Cao, S.; Chen, F.; Chen, M.C.; Chen, X.; Chung, T.H.; Deng, H.; Du, Y.; Fan, D.; Gong, M.; et al. Quantum computational advantage via 60-qubit 24-cycle random circuit sampling. Sci. Bull. 2021, 67, 240–245. [Google Scholar] [CrossRef]
- Bharti, K.; Cervera-Lierta, A.; Kyaw, T.H.; Haug, T.; Alperin-Lea, S.; Anand, A.; Degroote, M.; Heimonen, H.; Kottmann, J.S.; Menke, T.; et al. Noisy intermediate-scale quantum algorithms. Rev. Mod. Phys. 2022, 94, 015004. [Google Scholar] [CrossRef]
- Cerezo, M.; Arrasmith, A.; Babbush, R.; Benjamin, S.C.; Endo, S.; Fujii, K.; McClean, J.R.; Mitarai, K.; Yuan, X.; Cincio, L.; et al. Variational quantum algorithms. Nat. Rev. Phys. 2021, 3, 625–644. [Google Scholar] [CrossRef]
- Preskill, J. Quantum computing in the NISQ era and beyond. Quantum 2018, 2, 79. [Google Scholar] [CrossRef]
- Abbas, A.; Sutter, D.; Zoufal, C.; Lucchi, A.; Figalli, A.; Woerner, S. The power of quantum neural networks. Nat. Comput. Sci. 2021, 1, 403–409. [Google Scholar] [CrossRef]
- Banchi, L.; Pereira, J.; Pirandola, S. Generalization in quantum machine learning: A quantum information standpoint. PRX Quantum 2021, 2, 040321. [Google Scholar] [CrossRef]
- Bu, K.; Koh, D.E.; Li, L.; Luo, Q.; Zhang, Y. Statistical complexity of quantum circuits. Phys. Rev. A 2022, 105, 062431. [Google Scholar] [CrossRef]
- Caro, M.C.; Datta, I. Pseudo-dimension of quantum circuits. Quantum Mach. Intell. 2020, 2, 14. [Google Scholar] [CrossRef]
- Caro, M.C.; Huang, H.Y.; Cerezo, M.; Sharma, K.; Sornborger, A.; Cincio, L.; Coles, P.J. Generalization in quantum machine learning from few training data. Nat. Commun. 2022, 13, 4919. [Google Scholar] [CrossRef]
- Du, Y.; Hsieh, M.H.; Liu, T.; You, S.; Tao, D. Learnability of Quantum Neural Networks. PRX Quantum 2021, 2, 040337. [Google Scholar] [CrossRef]
- Du, Y.; Tu, Z.; Yuan, X.; Tao, D. Efficient measure for the expressivity of variational quantum algorithms. Phys. Rev. Lett. 2022, 128, 080506. [Google Scholar] [CrossRef]
- Huang, H.Y.; Kueng, R.; Preskill, J. Information-theoretic bounds on quantum advantage in machine learning. Phys. Rev. Lett. 2021, 126, 190505. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.Y.; Broughton, M.; Mohseni, M.; Babbush, R.; Boixo, S.; Neven, H.; McClean, J.R. Power of data in quantum machine learning. Nat. Commun. 2021, 12, 1–9. [Google Scholar] [CrossRef]
- Huang, H.Y.; Kueng, R.; Torlai, G.; Albert, V.V.; Preskill, J. Provably efficient machine learning for quantum many-body problems. Science 2022, 377, eabk3333. [Google Scholar] [CrossRef] [PubMed]
- Endo, S.; Sun, J.; Li, Y.; Benjamin, S.C.; Yuan, X. Variational quantum simulation of general processes. Phys. Rev. Lett. 2020, 125, 010501. [Google Scholar] [CrossRef]
- Kandala, A.; Mezzacapo, A.; Temme, K.; Takita, M.; Brink, M.; Chow, J.M.; Gambetta, J.M. Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets. Nature 2017, 549, 242–246. [Google Scholar] [CrossRef]
- Pagano, G.; Bapat, A.; Becker, P.; Collins, K.S.; De, A.; Hess, P.W.; Kaplan, H.B.; Kyprianidis, A.; Tan, W.L.; Baldwin, C.; et al. Quantum approximate optimization of the long-range Ising model with a trapped-ion quantum simulator. Proc. Natl. Acad. Sci. USA 2020, 117, 25396–25401. [Google Scholar] [CrossRef]
- Cerezo, M.; Poremba, A.; Cincio, L.; Coles, P.J. Variational quantum fidelity estimation. Quantum 2020, 4, 248. [Google Scholar] [CrossRef]
- Du, Y.; Tao, D. On exploring practical potentials of quantum auto-encoder with advantages. arXiv 2021, arXiv:2106.15432. [Google Scholar]
- Carolan, J.; Mohseni, M.; Olson, J.P.; Prabhu, M.; Chen, C.; Bunandar, D.; Niu, M.Y.; Harris, N.C.; Wong, F.N.; Hochberg, M.; et al. Variational quantum unsampling on a quantum photonic processor. Nat. Phys. 2020, 16, 322–327. [Google Scholar] [CrossRef]
- Holmes, Z.; Sharma, K.; Cerezo, M.; Coles, P.J. Connecting ansatz expressibility to gradient magnitudes and barren plateaus. PRX Quantum 2022, 3, 010313. [Google Scholar] [CrossRef]
- McClean, J.R.; Boixo, S.; Smelyanskiy, V.N.; Babbush, R.; Neven, H. Barren plateaus in quantum neural network training landscapes. Nat. Commun. 2018, 9, 4812. [Google Scholar] [CrossRef]
- Cerezo, M.; Sone, A.; Volkoff, T.; Cincio, L.; Coles, P.J. Cost function dependent barren plateaus in shallow parametrized quantum circuits. Nat. Commun. 2021, 12, 1–12. [Google Scholar] [CrossRef]
- Pesah, A.; Cerezo, M.; Wang, S.; Volkoff, T.; Sornborger, A.T.; Coles, P.J. Absence of Barren Plateaus in Quantum Convolutional Neural Networks. Phys. Rev. X 2021, 11, 041011. [Google Scholar] [CrossRef]
- Grant, E.; Wossnig, L.; Ostaszewski, M.; Benedetti, M. An initialization strategy for addressing barren plateaus in parametrized quantum circuits. Quantum 2019, 3, 214. [Google Scholar] [CrossRef]
- Bravyi, S.; Kliesch, A.; Koenig, R.; Tang, E. Obstacles to variational quantum optimization from symmetry protection. Phys. Rev. Lett. 2020, 125, 260505. [Google Scholar] [CrossRef]
- Havlíček, V.; Córcoles, A.D.; Temme, K.; Harrow, A.W.; Kandala, A.; Chow, J.M.; Gambetta, J.M. Supervised learning with quantum-enhanced feature spaces. Nature 2019, 567, 209–212. [Google Scholar] [CrossRef]
- Huang, H.L.; Du, Y.; Gong, M.; Zhao, Y.; Wu, Y.; Wang, C.; Li, S.; Liang, F.; Lin, J.; Xu, Y.; et al. Experimental quantum generative adversarial networks for image generation. Phys. Rev. Appl. 2021, 16, 024051. [Google Scholar] [CrossRef]
- Peters, E.; Caldeira, J.; Ho, A.; Leichenauer, S.; Mohseni, M.; Neven, H.; Spentzouris, P.; Strain, D.; Perdue, G.N. Machine learning of high dimensional data on a noisy quantum processor. npj Quantum Inf. 2021, 7, 161. [Google Scholar] [CrossRef]
- Rudolph, M.S.; Toussaint, N.B.; Katabarwa, A.; Johri, S.; Peropadre, B.; Perdomo-Ortiz, A. Generation of high-resolution handwritten digits with an ion-trap quantum computer. Phys. Rev. X 2022, 12, 031010. [Google Scholar] [CrossRef]
- Arute, F.; Arya, K.; Babbush, R.; Bacon, D.; Bardin, J.C.; Barends, R.; Boixo, S.; Broughton, M.; Buckley, B.B.; Buell, D.A.; et al. Hartree-Fock on a superconducting qubit quantum computer. Science 2020, 369, 1084–1089. [Google Scholar]
- Robert, A.; Barkoutsos, P.K.; Woerner, S.; Tavernelli, I. Resource-efficient quantum algorithm for protein folding. npj Quantum Inf. 2021, 7, 38. [Google Scholar] [CrossRef]
- Kais, S. Introduction to quantum information and computation for chemistry. In Quantum Information and Computation for Chemistry; Wiley: Hoboken, NJ, USA, 2014; pp. 1–38. [Google Scholar]
- Wecker, D.; Hastings, M.B.; Wiebe, N.; Clark, B.K.; Nayak, C.; Troyer, M. Solving strongly correlated electron models on a quantum computer. Phys. Rev. A 2015, 92, 062318. [Google Scholar] [CrossRef]
- Cai, X.; Fang, W.H.; Fan, H.; Li, Z. Quantum computation of molecular response properties. Phys. Rev. Res. 2020, 2, 033324. [Google Scholar] [CrossRef]
- Harrigan, M.P.; Sung, K.J.; Neeley, M.; Satzinger, K.J.; Arute, F.; Arya, K.; Atalaya, J.; Bardin, J.C.; Barends, R.; Boixo, S.; et al. Quantum approximate optimization of non-planar graph problems on a planar superconducting processor. Nat. Phys. 2021, 17, 332–336. [Google Scholar] [CrossRef]
- Lacroix, N.; Hellings, C.; Andersen, C.K.; Di Paolo, A.; Remm, A.; Lazar, S.; Krinner, S.; Norris, G.J.; Gabureac, M.; Heinsoo, J.; et al. Improving the performance of deep quantum optimization algorithms with continuous gate sets. PRX Quantum 2020, 1, 110304. [Google Scholar] [CrossRef]
- Zhou, L.; Wang, S.T.; Choi, S.; Pichler, H.; Lukin, M.D. Quantum approximate optimization algorithm: Performance, mechanism, and implementation on near-term devices. Phys. Rev. X 2020, 10, 021067. [Google Scholar] [CrossRef]
- Hadfield, S.; Wang, Z.; O’Gorman, B.; Rieffel, E.G.; Venturelli, D.; Biswas, R. From the quantum approximate optimization algorithm to a quantum alternating operator ansatz. Algorithms 2019, 12, 34. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Poland, K.; Beer, K.; Osborne, T.J. No free lunch for quantum machine learning. arXiv 2020, arXiv:2003.14103. [Google Scholar]
- Gard, B.T.; Zhu, L.; Barron, G.S.; Mayhall, N.J.; Economou, S.E.; Barnes, E. Efficient symmetry-preserving state preparation circuits for the variational quantum eigensolver algorithm. npj Quantum Inf. 2020, 6, 10. [Google Scholar] [CrossRef]
- Ganzhorn, M.; Egger, D.J.; Barkoutsos, P.; Ollitrault, P.; Salis, G.; Moll, N.; Roth, M.; Fuhrer, A.; Mueller, P.; Woerner, S.; et al. Gate-efficient simulation of molecular eigenstates on a quantum computer. Phys. Rev. Appl. 2019, 11, 044092. [Google Scholar] [CrossRef]
- Choquette, A.; Di Paolo, A.; Barkoutsos, P.K.; Sénéchal, D.; Tavernelli, I.; Blais, A. Quantum-optimal-control-inspired ansatz for variational quantum algorithms. Phys. Rev. Res. 2021, 3, 023092. [Google Scholar] [CrossRef]
- Cao, Y.; Romero, J.; Olson, J.P.; Degroote, M.; Johnson, P.D.; Kieferová, M.; Kivlichan, I.D.; Menke, T.; Peropadre, B.; Sawaya, N.P.; et al. Quantum chemistry in the age of quantum computing. Chem. Rev. 2019, 119, 10856–10915. [Google Scholar] [CrossRef] [PubMed]
- Romero, J.; Babbush, R.; McClean, J.R.; Hempel, C.; Love, P.J.; Aspuru-Guzik, A. Strategies for quantum computing molecular energies using the unitary coupled cluster ansatz. Quantum Sci. Technol. 2018, 4, 014008. [Google Scholar] [CrossRef]
- Cervera-Lierta, A.; Kottmann, J.S.; Aspuru-Guzik, A. Meta-Variational Quantum Eigensolver: Learning Energy Profiles of Parameterized Hamiltonians for Quantum Simulation. PRX Quantum 2021, 2, 020329. [Google Scholar] [CrossRef]
- Parrish, R.M.; Hohenstein, E.G.; McMahon, P.L.; Martínez, T.J. Quantum computation of electronic transitions using a variational quantum eigensolver. Phys. Rev. Lett. 2019, 122, 230401. [Google Scholar] [CrossRef]
- Petit, L.; Eenink, H.; Russ, M.; Lawrie, W.; Hendrickx, N.; Philips, S.; Clarke, J.; Vandersypen, L.; Veldhorst, M. Universal quantum logic in hot silicon qubits. Nature 2020, 580, 355–359. [Google Scholar] [CrossRef] [PubMed]
- DiVincenzo, D.P. The physical implementation of quantum computation. Fortschritte Phys. Prog. Phys. 2000, 48, 771–783. [Google Scholar] [CrossRef]
- Devoret, M.H.; Schoelkopf, R.J. Superconducting circuits for quantum information: An outlook. Science 2013, 339, 1169–1174. [Google Scholar] [CrossRef] [PubMed]
- Cincio, L.; Rudinger, K.; Sarovar, M.; Coles, P.J. Machine learning of noise-resilient quantum circuits. PRX Quantum 2021, 2, 010324. [Google Scholar] [CrossRef]
- Chivilikhin, D.; Samarin, A.; Ulyantsev, V.; Iorsh, I.; Oganov, A.; Kyriienko, O. MoG-VQE: Multiobjective genetic variational quantum eigensolver. arXiv 2020, arXiv:2007.04424. [Google Scholar]
- Rattew, A.G.; Hu, S.; Pistoia, M.; Chen, R.; Wood, S. A domain-agnostic, noise-resistant, hardware-efficient evolutionary variational quantum eigensolver. arXiv 2019, arXiv:1910.09694. [Google Scholar]
- He, Z.; Chen, C.; Li, L.; Zheng, S.; Situ, H. Quantum Architecture Search with Meta-Learning. Adv. Quantum Technol. 2022, 5, 2100134. [Google Scholar] [CrossRef]
- Meng, F.X.; Li, Z.T.; Yu, X.T.; Zhang, Z.C. Quantum Circuit Architecture Optimization for Variational Quantum Eigensolver via Monto Carlo Tree Search. IEEE Trans. Quantum Eng. 2021, 2, 3103910. [Google Scholar] [CrossRef]
- Kuo, E.J.; Fang, Y.L.L.; Chen, S.Y.C. Quantum Architecture Search via Deep Reinforcement Learning. arXiv 2021, arXiv:2104.07715. [Google Scholar]
- Zhang, S.X.; Hsieh, C.Y.; Zhang, S.; Yao, H. Differentiable quantum architecture search. Quantum Sci. Technol. 2022, 7, 045023. [Google Scholar] [CrossRef]
- Zhang, S.X.; Hsieh, C.Y.; Zhang, S.; Yao, H. Neural predictor based quantum architecture search. Mach. Learn. Sci. Technol. 2021, 2, 045027. [Google Scholar] [CrossRef]
- Ostaszewski, M.; Trenkwalder, L.M.; Masarczyk, W.; Scerri, E.; Dunjko, V. Reinforcement learning for optimization of variational quantum circuit architectures. Adv. Neural Inf. Process. Syst. 2021, 34, 18182–18194. [Google Scholar]
- Pirhooshyaran, M.; Terlaky, T. Quantum circuit design search. Quantum Mach. Intell. 2021, 3, 25. [Google Scholar] [CrossRef]
- Lei, C.; Du, Y.; Mi, P.; Yu, J.; Liu, T. Neural Auto-designer for Enhanced Quantum Kernels. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Bilkis, M.; Cerezo, M.; Verdon, G.; Coles, P.J.; Cincio, L. A semi-agnostic ansatz with variable structure for variational quantum algorithms. Quantum Mach. Intell. 2023, 5, 43. [Google Scholar] [CrossRef]
- Grimsley, H.R.; Economou, S.E.; Barnes, E.; Mayhall, N.J. An adaptive variational algorithm for exact molecular simulations on a quantum computer. Nat. Commun. 2019, 10, 3007. [Google Scholar] [CrossRef] [PubMed]
- Tang, H.L.; Shkolnikov, V.; Barron, G.S.; Grimsley, H.R.; Mayhall, N.J.; Barnes, E.; Economou, S.E. qubit-ADAPT-VQE: An adaptive algorithm for constructing hardware-efficient ansätze on a quantum processor. PRX Quantum 2021, 2, 020310. [Google Scholar] [CrossRef]
- Du, Y.; Huang, T.; You, S.; Hsieh, M.H.; Tao, D. Quantum circuit architecture search for variational quantum algorithms. npj Quantum Inf. 2022, 8, 62. [Google Scholar] [CrossRef]
- Farhi, E.; Goldstone, J.; Gutmann, S. A quantum approximate optimization algorithm. arXiv 2014, arXiv:1411.4028. [Google Scholar]
- Mckay, D.C.; Wood, C.J.; Sheldon, S.; Chow, J.M.; Gambetta, J.M. Efficient Z-Gates for Quantum Computing. Phys. Rev. A 2017, 96, 022330. [Google Scholar] [CrossRef]
- Pearson, K. LIII. On lines and planes of closest fit to systems of points in space. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef]
- Rudolph, M.S.; Sim, S.; Raza, A.; Stechly, M.; McClean, J.R.; Anschuetz, E.R.; Serrano, L.; Perdomo-Ortiz, A. ORQVIZ: Visualizing High-Dimensional Landscapes in Variational Quantum Algorithms. arXiv 2021, arXiv:2111.04695. [Google Scholar]
- Peruzzo, A.; McClean, J.; Shadbolt, P.; Yung, M.H.; Zhou, X.Q.; Love, P.J.; Aspuru-Guzik, A.; O’brien, J.L. A variational eigenvalue solver on a photonic quantum processor. Nat. Commun. 2014, 5, 4213. [Google Scholar] [CrossRef] [PubMed]
- Yan, F.; Campbell, D.; Krantz, P.; Kjaergaard, M.; Kim, D.; Yoder, J.L.; Hover, D.; Sears, A.; Kerman, A.J.; Orlando, T.P.; et al. Distinguishing coherent and thermal photon noise in a circuit quantum electrodynamical system. Phys. Rev. Lett. 2018, 120, 260504. [Google Scholar] [CrossRef] [PubMed]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Kiefer, J.; Wolfowitz, J. Stochastic estimation of the maximum of a regression function. Ann. Math. Stat. 1952, 23, 462–466. [Google Scholar] [CrossRef]
- Mitarai, K.; Negoro, M.; Kitagawa, M.; Fujii, K. Quantum circuit learning. Phys. Rev. A 2018, 98, 032309. [Google Scholar] [CrossRef]
- Govia, L.; Poole, C.; Saffman, M.; Krovi, H. Freedom of mixer rotation-axis improves performance in the quantum approximate optimization algorithm. arXiv 2021, arXiv:2107.13129. [Google Scholar] [CrossRef]
- Farhi, E.; Goldstone, J.; Gutmann, S.; Neven, H. Quantum algorithms for fixed qubit architectures. arXiv 2017, arXiv:1703.06199. [Google Scholar]
- Bapat, A.; Jordan, S. Bang-bang control as a design principle for classical and quantum optimization algorithms. arXiv 2018, arXiv:1812.02746. [Google Scholar] [CrossRef]
- Yu, Y.; Cao, C.; Dewey, C.; Wang, X.B.; Shannon, N.; Joynt, R. Quantum Approximate Optimization Algorithm with Adaptive Bias Fields. arXiv 2021, arXiv:2105.11946. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).