
CAC: Confidence-Aware Co-Training for Weakly Supervised Crack Segmentation

Abstract
:1. Introduction
- A novel confidence-aware co-training framework is introduced for weakly supervised crack segmentation.
- Aiming at mitigating the effect of noisy pseudo-labels, a co-training mechanism is designed to iteratively refine the predicted pseudo-labels and accordingly learn a more robust crack segmentation model.
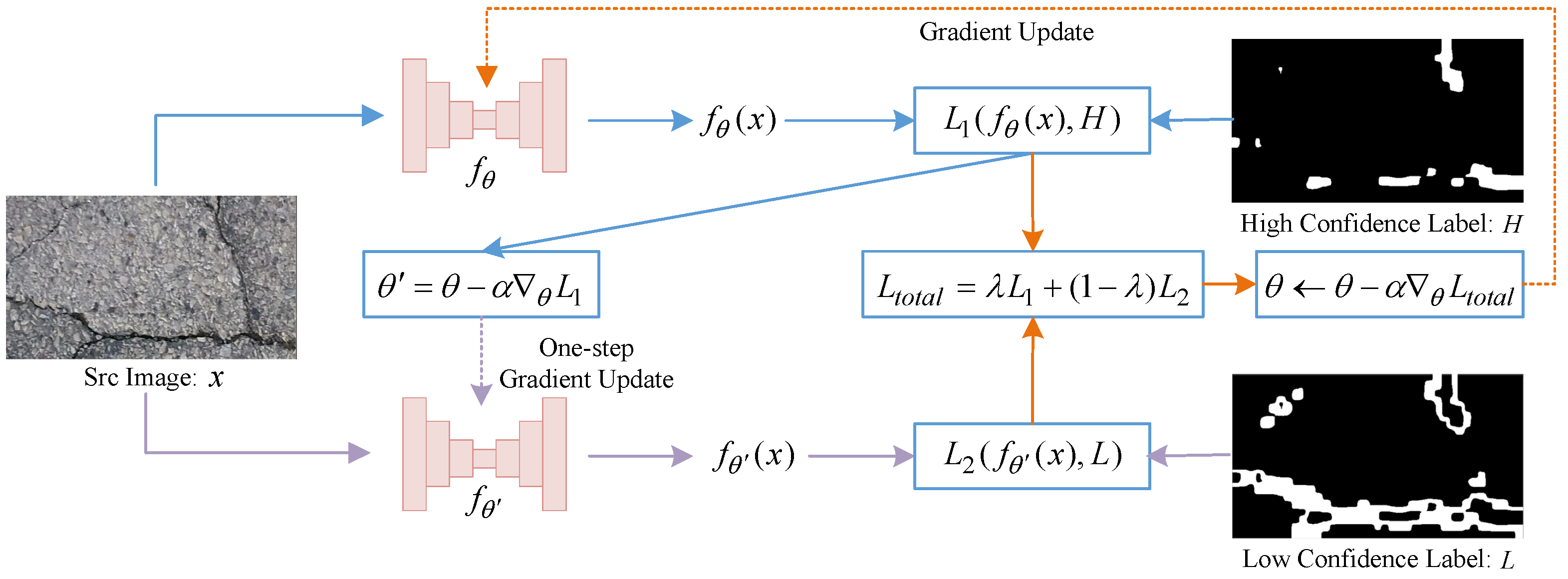
- A dynamic division strategy is proposed to handle the noisy pseudo-labels. Among them, the high-confidence pseudo-labels are utilized to optimize the initialization parameters and those with low-confidence enrich the diversity of crack samples.
- The effectiveness of the proposed CAC is demonstrated through extensive validation on three crack datasets: Crack500, DeepCrack, and CFD. The results showcase the superior performance of this approach compared to other state-of-the-art models.
2. Related Works
2.1. Fully Supervised Crack Segmentation Method
2.2. Weakly Supervised Crack Segmentation Methods
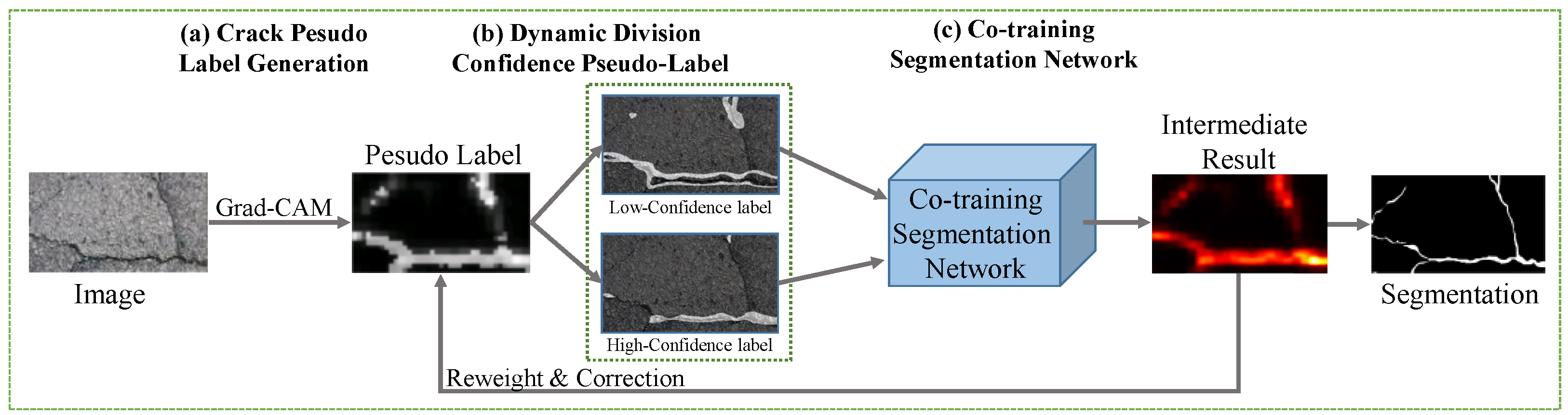
3. Methods
3.1. Overview
3.2. Crack Pseudo-Label Generation
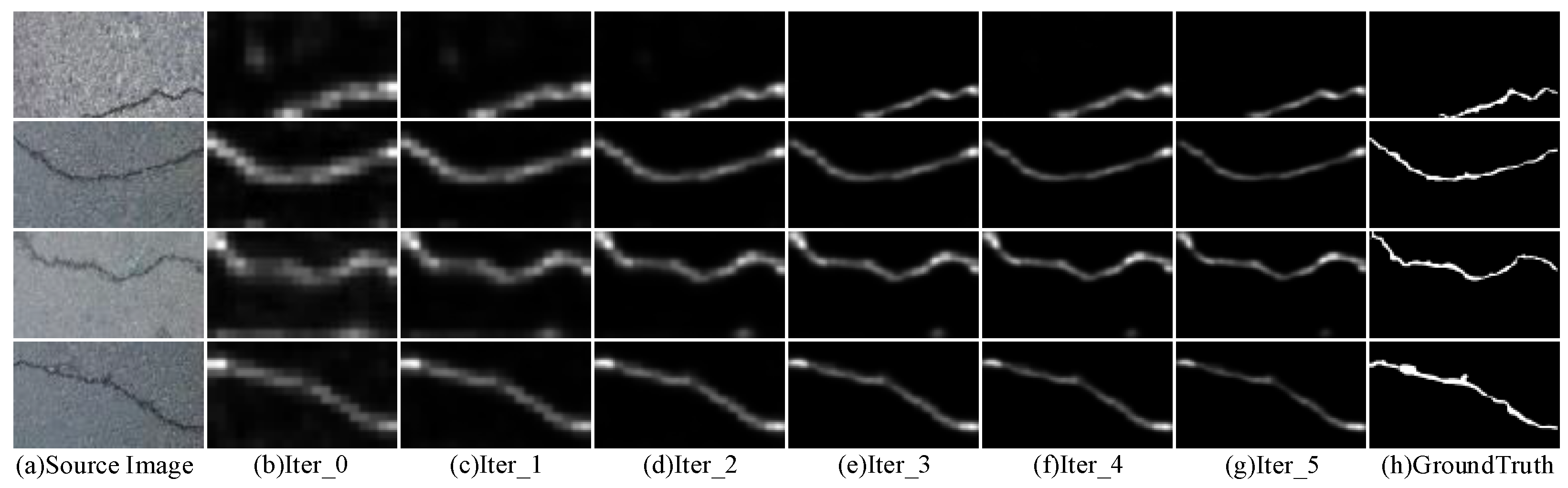
3.3. Dynamic Division of Confidence Pseudo-Labels
3.4. Co-Training of Segmentation Models
| Algorithm 1: CAC algorithm. |
 |
4. Experimental Results, Comparisons, and Analysis
4.1. Datasets
- Crack500 testing dataset [50]: This dataset consists of 1124 crack images. Crack500 is a pavement cracking dataset that is collected with a mobile phone on the campus of Temple University.
- CFD dataset [51]: It contains 118 crack images, each with a resolution of 320 × 480 pixels, which reflect urban road surface conditions in Beijing, China. This dataset includes various types of noise such as shadows, oil spots, and water stains.
- DeepCrack dataset [20]: This dataset comprises a total of 537 images, each with a resolution of 544 × 384 pixels. It includes crack data with multiple textures, scenes, and scales.
4.2. Evaluation Metrics
4.3. Implementation Details
4.3.1. Environment
4.3.2. Experimental Setting
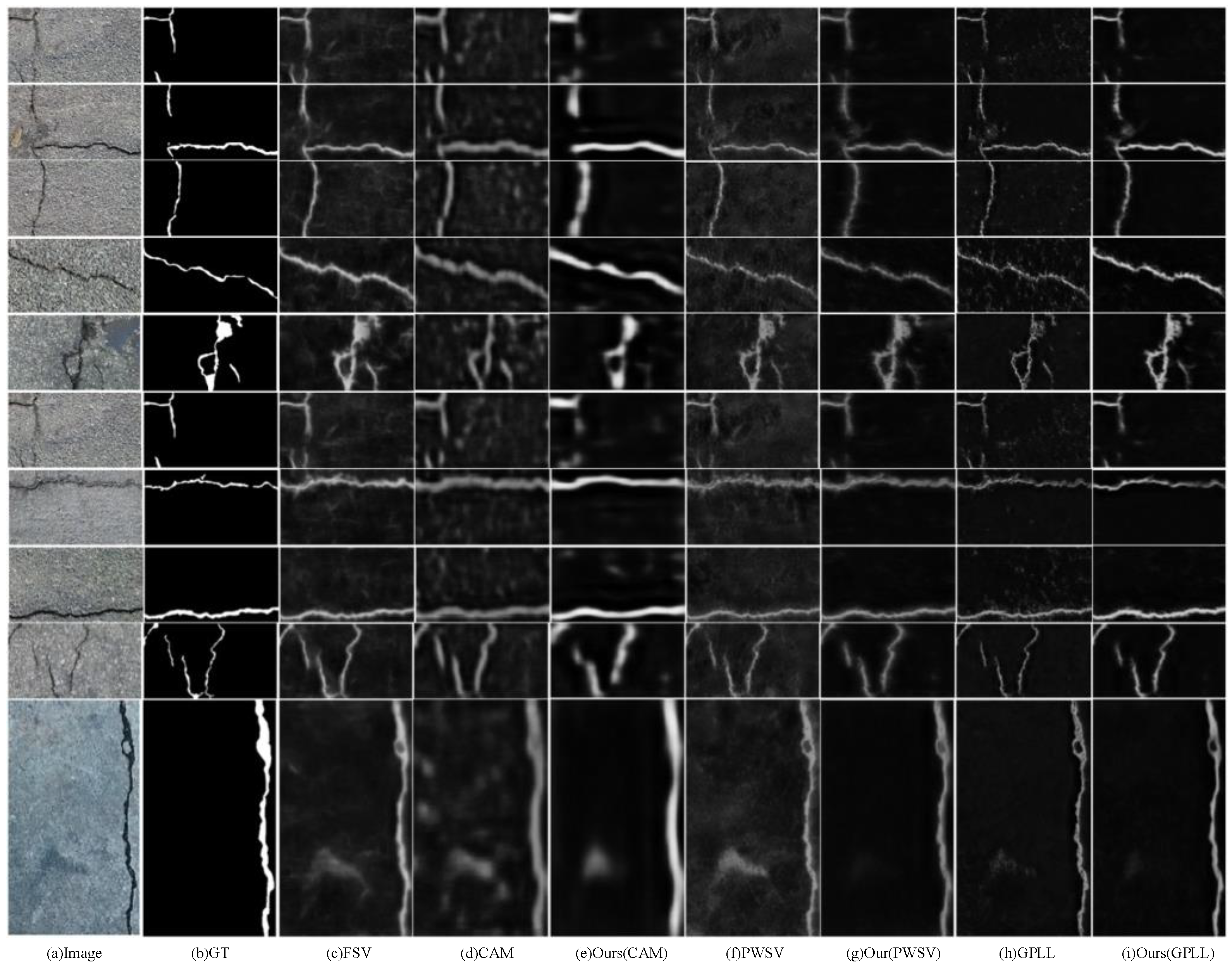
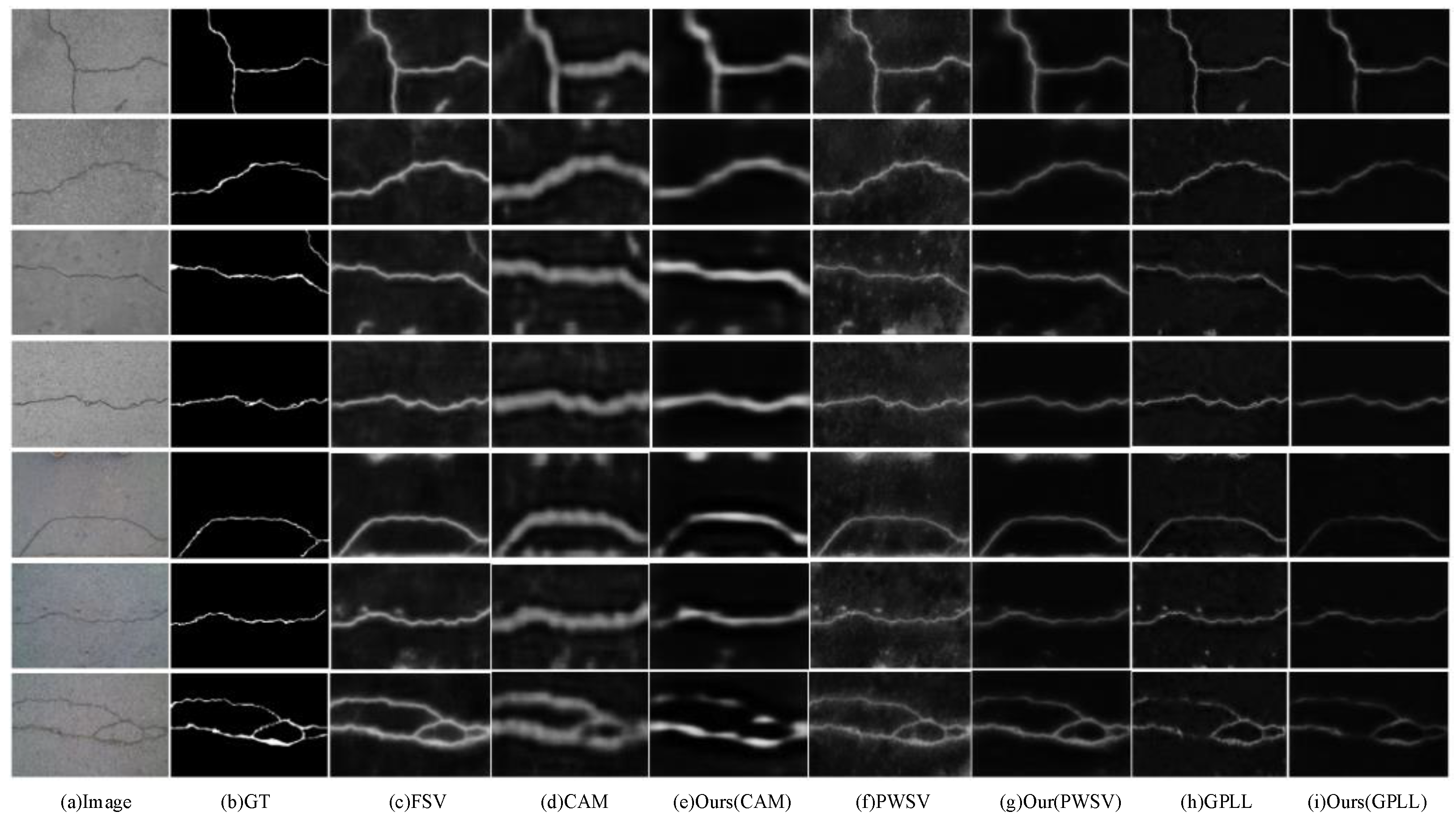
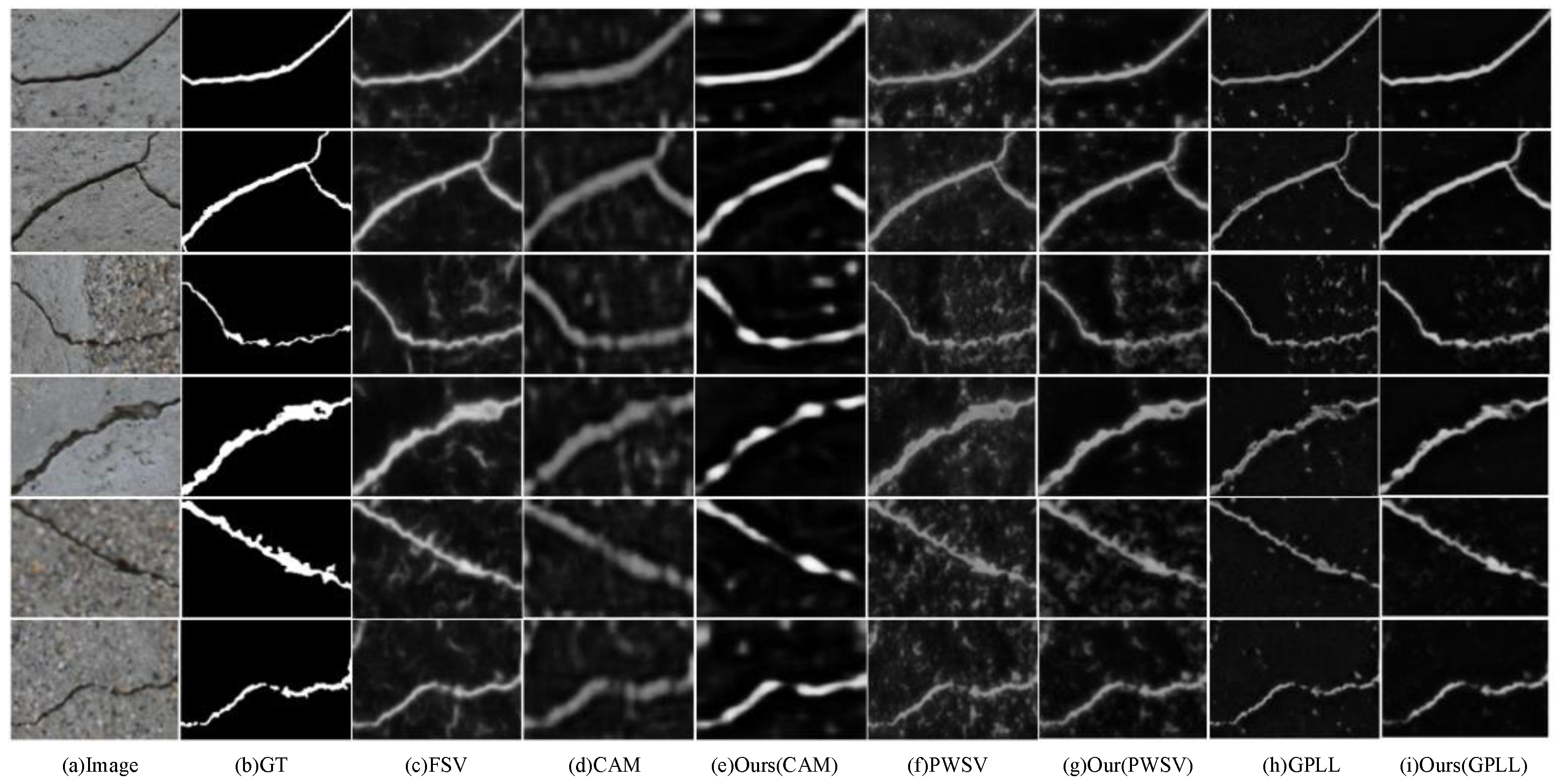
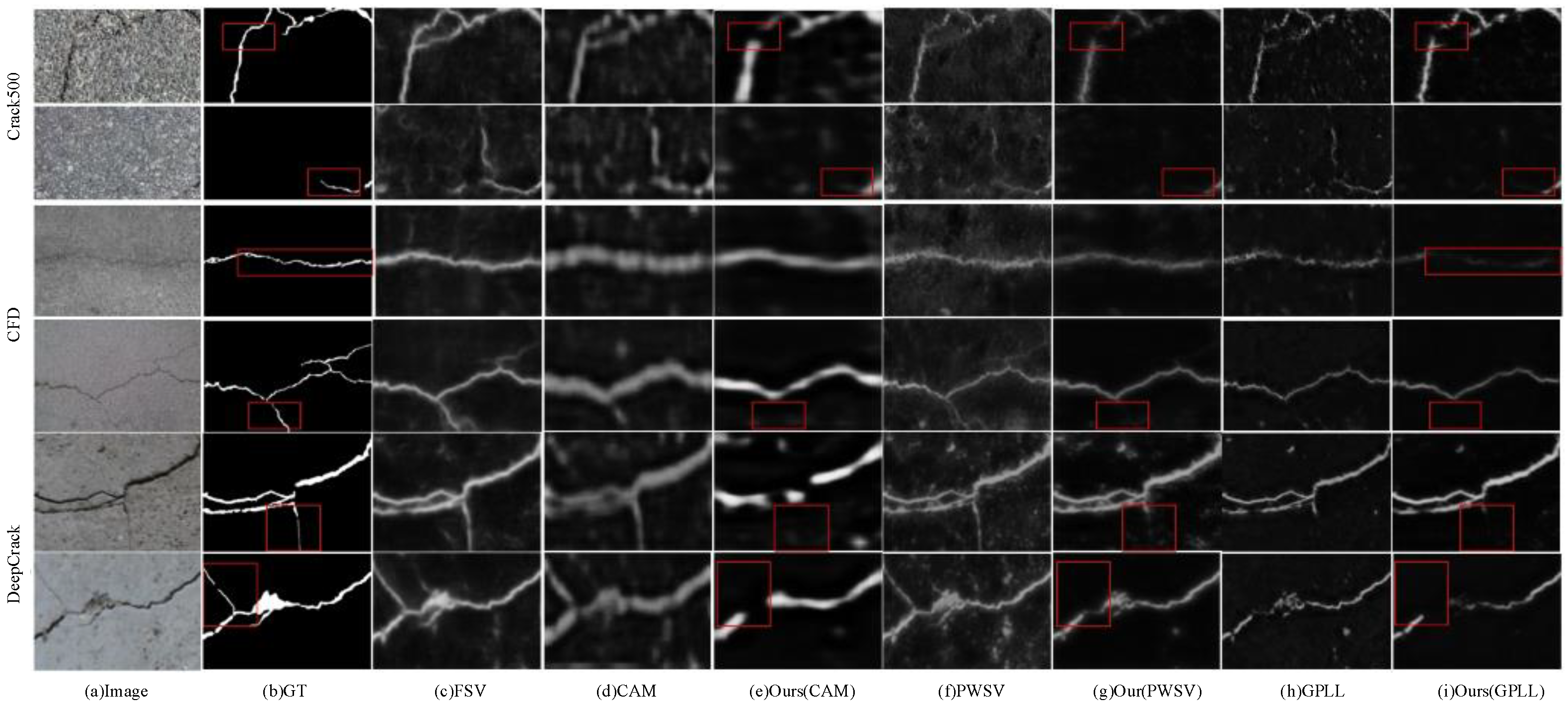
4.4. Evaluation on Crack500
4.5. Evaluation on CFD
4.6. Evaluation on DeepCrack
4.7. Model Performance Discussion and Summary
4.8. Ablation Experiments
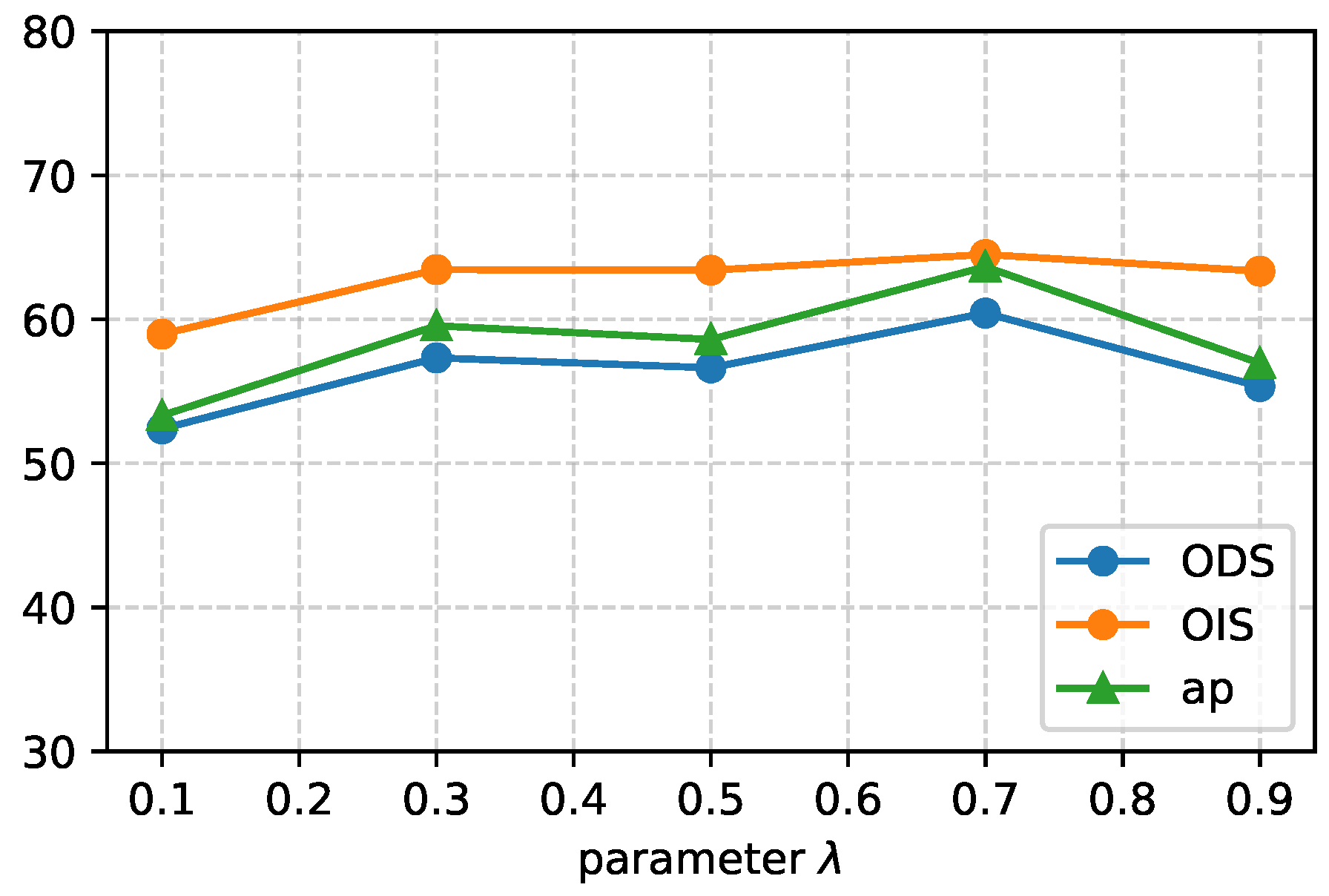
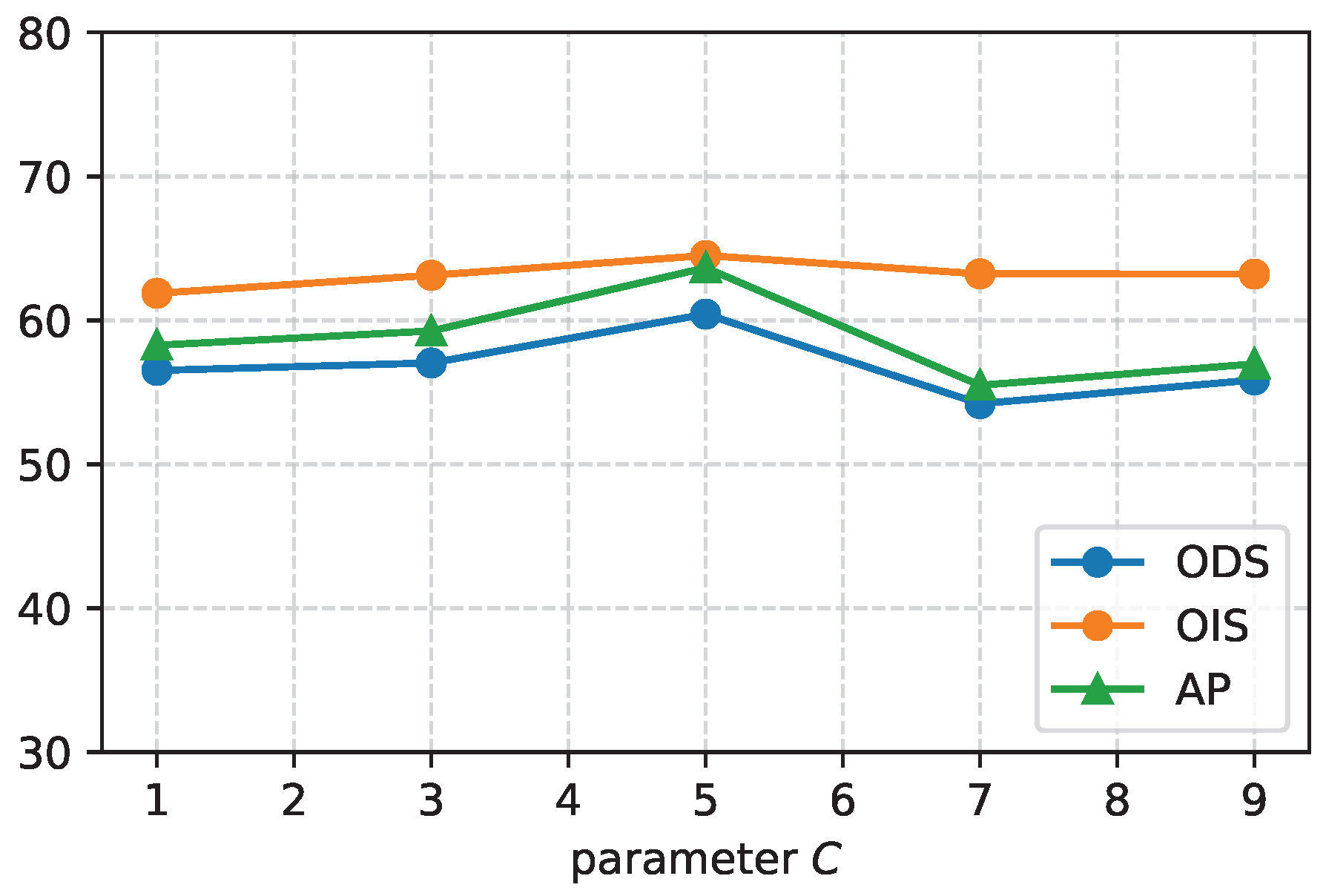
4.9. Parameter Experiments
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Munawar, H.S.; Hammad, A.W.A.; Haddad, A.; Soares, C.A.P.; Waller, S.T. Image-Based Crack Detection Methods: A Review. Infrastructures 2021, 6, 115. [Google Scholar] [CrossRef]
- Yu, X.; Kuan, T.W.; Tseng, S.P.; Chen, Y.; Chen, S.; Wang, J.F.; Gu, Y.; Chen, T. EnRDeA U-net deep learning of semantic segmentation on intricate noise roads. Entropy 2023, 25, 1085. [Google Scholar] [CrossRef]
- Zhong, J.; Huyan, J.; Zhang, W.; Cheng, H.; Zhang, J.; Tong, Z.; Jiang, X.; Huang, B. A deeper generative adversarial network for grooved cement concrete pavement crack detection. Eng. Appl. Artif. Intell. 2023, 119, 105808. [Google Scholar] [CrossRef]
- Ai, D.; Jiang, G.; Lam, S.K.; He, P.; Li, C. Computer vision framework for crack detection of civil infrastructure—A review. Eng. Appl. Artif. Intell. 2023, 117, 105478. [Google Scholar] [CrossRef]
- Wu, X.; Liu, X. Building crack identification and total quality management method based on deep learning. Pattern Recognit. Lett. 2021, 145, 225–231. [Google Scholar] [CrossRef]
- Taheri, S. A review on five key sensors for monitoring of concrete structures. Constr. Build. Mater. 2019, 204, 492–509. [Google Scholar] [CrossRef]
- Zhao, Y.; Yan, J.; Wang, Y.; Jing, Q.; Liu, T. Porcelain insulator crack location and surface states pattern recognition based on hyperspectral technology. Entropy 2021, 23, 486. [Google Scholar] [CrossRef] [PubMed]
- Ali, R.; Chuah, J.H.; Talip, M.S.A.; Mokhtar, N.; Shoaib, M.A. Automatic pixel-level crack segmentation in images using fully convolutional neural network based on residual blocks and pixel local weights. Eng. Appl. Artif. Intell. 2021, 104, 104391. [Google Scholar] [CrossRef]
- Ali, R.; Chuah, J.H.; Talip, M.S.A.; Mokhtar, N.; Shoaib, M.A. Crack segmentation network using additive attention gate-CSN-II. Eng. Appl. Artif. Intell. 2022, 114, 105130. [Google Scholar] [CrossRef]
- Al-Huda, Z.; Peng, B.; Algburi, R.N.A.; Alfasly, S.; Li, T. Weakly supervised pavement crack semantic segmentation based on multi-scale object localization and incremental annotation refinement. Appl. Intell. 2023, 53, 14527–14546. [Google Scholar] [CrossRef]
- Zhang, H.; Qian, Z.; Tan, Y.; Xie, Y.; Li, M. Investigation of pavement crack detection based on deep learning method using weakly supervised instance segmentation framework. Constr. Build. Mater. 2022, 358, 129117. [Google Scholar] [CrossRef]
- König, J.; Jenkins, M.D.; Mannion, M.; Barrie, P.; Morison, G. Weakly-Supervised Surface Crack Segmentation by Generating Pseudo-Labels Using Localization with a Classifier and Thresholding. IEEE Trans. Intell. Transp. Syst. 2022, 23, 24083–24094. [Google Scholar] [CrossRef]
- Dong, Z.; Wang, J.; Cui, B.; Wang, D.; Wang, X. Patch-based weakly supervised semantic segmentation network for crack detection. Constr. Build. Mater. 2020, 258, 120291. [Google Scholar] [CrossRef]
- Al-Huda, Z.; Peng, B.; Algburi, R.N.A.; Al-antari, M.A.; AL-Jarazi, R.; Zhai, D. A hybrid deep learning pavement crack semantic segmentation. Eng. Appl. Artif. Intell. 2023, 122, 106142. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Song, H.; Kim, M.; Park, D.; Shin, Y.; Lee, J.G. Learning from Noisy Labels with Deep Neural Networks: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 8135–8153. [Google Scholar] [CrossRef] [PubMed]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Xie, S.; Tu, Z. Holistically-Nested Edge Detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Liu, Y.; Cheng, M.M.; Hu, X.; Wang, K.; Bai, X. Richer Convolutional Features for Edge Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zou, Q.; Zhang, Z.; Li, Q.; Qi, X.; Wang, Q.; Wang, S. DeepCrack: Learning Hierarchical Convolutional Features for Crack Detection. IEEE Trans. Image Process. 2019, 28, 1498–1512. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, J.; He, Y. A novel U-shaped encoder–decoder network with attention mechanism for detection and evaluation of road cracks at pixel level. Comput.-Aided Civ. Infrastruct. Eng. 2022, 37, 1721–1736. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Sun, X.; Xie, Y.; Jiang, L.; Cao, Y.; Liu, B. DMA-Net: DeepLab with Multi-Scale Attention for Pavement Crack Segmentation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18392–18403. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, Y.; Song, K.; Liu, J.; Dong, H.; Yan, Y.; Jiang, P. RENet: Rectangular convolution pyramid and edge enhancement network for salient object detection of pavement cracks. Measurement 2021, 170, 108698. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Wang, W.; Su, C. Automatic concrete crack segmentation model based on transformer. Autom. Constr. 2022, 139, 104275. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhang, J.; Gong, C. Hybrid semantic segmentation for tunnel lining cracks based on Swin Transformer and convolutional neural network. Comput.-Aided Civ. Infrastruct. Eng. 2023, 38, 2491–2510. [Google Scholar] [CrossRef]
- Asadi Shamsabadi, E.; Xu, C.; Rao, A.S.; Nguyen, T.; Ngo, T.; da Costa, D.D. Vision transformer-based autonomous crack detection on asphalt and concrete surfaces. Autom. Constr. 2022, 140, 104316. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Hong, Y.; Lee, S.J.; Yoo, S.B. AugMoCrack: Augmented morphological attention network for weakly supervised crack detection. Electron. Lett. 2022, 58, 651–653. [Google Scholar] [CrossRef]
- Inoue, Y.; Nagayoshi, H. Crack Detection as a Weakly-Supervised Problem: Towards Achieving Less Annotation-Intensive Crack Detectors. In Proceedings of the 2020 25th International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2021. [Google Scholar]
- Rill-García, R.; Dokládalová, E.; Dokládal, P. Pixel-accurate road crack detection in presence of inaccurate annotations. Neurocomputing 2022, 480, 1–13. [Google Scholar] [CrossRef]
- Rill-García, R.; Dokladalova, E.; Dokládal, P. Syncrack: Improving Pavement and Concrete Crack Detection Through Synthetic Data Generation. In Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISAPP’22), Virtual, 8–10 February 2022. [Google Scholar]
- Rother, C.; Kolmogorov, V.; Blake, A. “GrabCut”: Interactive Foreground Extraction Using Iterated Graph Cuts. ACM Trans. Graph. 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Y.; Cheng, H.D. CrackGAN: Pavement Crack Detection Using Partially Accurate Ground Truths Based on Generative Adversarial Learning. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1306–1319. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Fan, R.; Bocus, M.J.; Zhu, Y.; Jiao, J.; Wang, L.; Ma, F.; Cheng, S.; Liu, M. Road Crack Detection Using Deep Convolutional Neural Network and Adaptive Thresholding. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium, Paris, France, 9–12 June 2019. [Google Scholar]
- Wang, H.; Li, Y.; Dang, L.M.; Lee, S.; Moon, H. Pixel-level tunnel crack segmentation using a weakly supervised annotation approach. Comput. Ind. 2021, 133, 103545. [Google Scholar] [CrossRef]
- Ahn, J.; Kwak, S. Learning Pixel-Level Semantic Affinity With Image-Level Supervision for Weakly Supervised Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ru, L.; Zhan, Y.; Yu, B.; Du, B. Learning Affinity From Attention: End-to-End Weakly-Supervised Semantic Segmentation With Transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Rong, S.; Tu, B.; Wang, Z.; Li, J. Boundary-Enhanced Co-Training for Weakly Supervised Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1525–1535. [Google Scholar] [CrossRef]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic Road Crack Detection Using Random Structured Forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Dollár, P.; Zitnick, C.L. Fast Edge Detection Using Structured Forests. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1558–1570. [Google Scholar] [CrossRef] [PubMed]
- Doyle, W. Operations useful for similarity-invariant pattern recognition. J. ACM 1962, 9, 259–267. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | |||
|---|---|---|---|
| FSV | 66.20 | 71.97 | 76.70 |
| CAM [46] | 53.12 | 56.86 | 49.89 |
| PWSV [13] | 56.54 | 63.73 | 65.13 |
| GPLL [12] | 45.04 | 56.69 | 45.46 |
| Ours (CAM) | 53.88 | 58.44 | 57.07 |
| Ours (PWSV) | 61.22 | 64.07 | 65.10 |
| Ours (GPLL) | 60.43 | 64.50 | 63.65 |
| Methods | |||
|---|---|---|---|
| FSV | 16.67 | 24.35 | 6.31 |
| CAM [46] | 23.16 | 17.52 | 14.07 |
| PWSV [13] | 8.56 | 14.46 | 7.72 |
| GPLL [12] | 18.74 | 19.41 | 14.88 |
| Ours (CAM) | 22.87 | 15.11 | 12.88 |
| Ours (PWSV) | 25.82 | 14.96 | 18.36 |
| Ours (GPLL) | 25.31 | 31.55 | 18.55 |
| Methods | |||
|---|---|---|---|
| FSV | 46.43 | 54.97 | 30.95 |
| CAM [46] | 44.88 | 52.43 | 37.33 |
| PWSV [13] | 37.05 | 43.95 | 44.31 |
| GPLL [12] | 65.97 | 73.19 | 72.28 |
| Ours (CAM) | 49.66 | 53.18 | 47.22 |
| Ours (PWSV) | 69.47 | 63.31 | 73.91 |
| Ours (GPLL) | 71.01 | 77.98 | 75.51 |
| Co-Training | Dynamical Division | |||
|---|---|---|---|---|
| 45.04 | 56.69 | 45.46 | ||
| ✓ | 56.86 | 63.74 | 59.09 | |
| ✓ | ✓ | 60.43 | 64.50 | 63.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, F.; Li, Q.; Li, X.; Liu, Y.; Wang, W. CAC: Confidence-Aware Co-Training for Weakly Supervised Crack Segmentation. Entropy 2024, 26, 328. https://doi.org/10.3390/e26040328
Liang F, Li Q, Li X, Liu Y, Wang W. CAC: Confidence-Aware Co-Training for Weakly Supervised Crack Segmentation. Entropy. 2024; 26(4):328. https://doi.org/10.3390/e26040328
Chicago/Turabian StyleLiang, Fengjiao, Qingyong Li, Xiaobao Li, Yang Liu, and Wen Wang. 2024. "CAC: Confidence-Aware Co-Training for Weakly Supervised Crack Segmentation" Entropy 26, no. 4: 328. https://doi.org/10.3390/e26040328