
Side Information Design in Zero-Error Coding for Computing


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Zero-Error Coding for Computing
1.2. Encoder’s Side Information Design
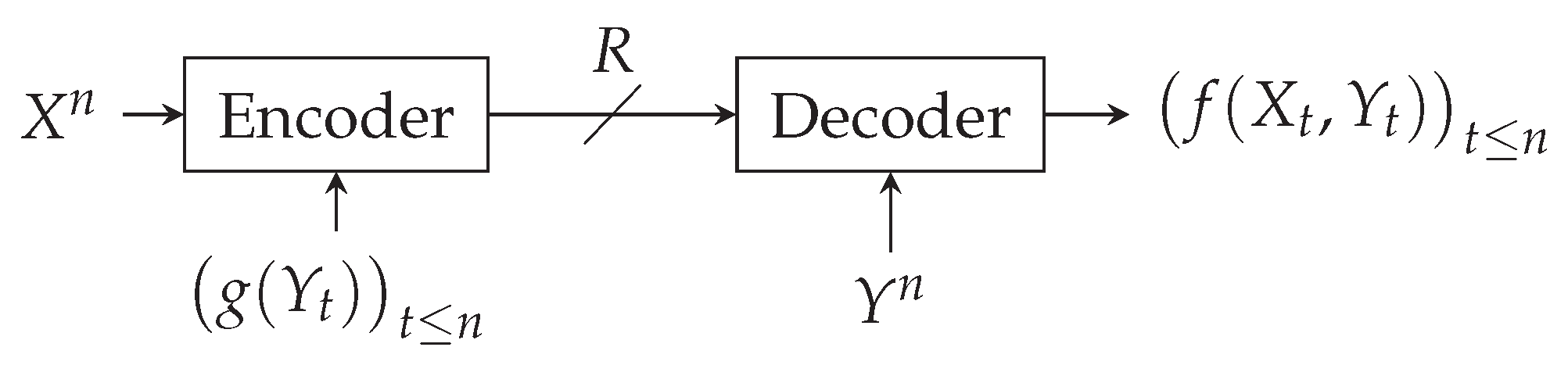
2. Formal Presentation of the Problem
- -
- Four finite sets , , , and a source distribution .
- -
- For all , is the random sequence of n copies of , drawn in an i.i.d. fashion using .
- -
- Two deterministic functions
- -
- An encoder that knows and sends binary strings over a noiseless channel to a decoder that knows and that wants to retrieve without error.
- -
- A time horizon and an encoding function such that is prefix-free.
- -
- A decoding function .
- -
- The rate is the average length of the codeword per source symbol,i.e., , where ℓ denotes the codeword length function.
- -
- n, , must satisfy the zero-error property:
3. Theoretic Results
3.1. General Case
- -
- as a set of vertices with distribution .
- -
- are adjacent if and there exists such thatwhere .
3.2. Pairwise Shared Side Information
- -
- as set of vertices with distribution ;
- -
- are adjacent if for some .
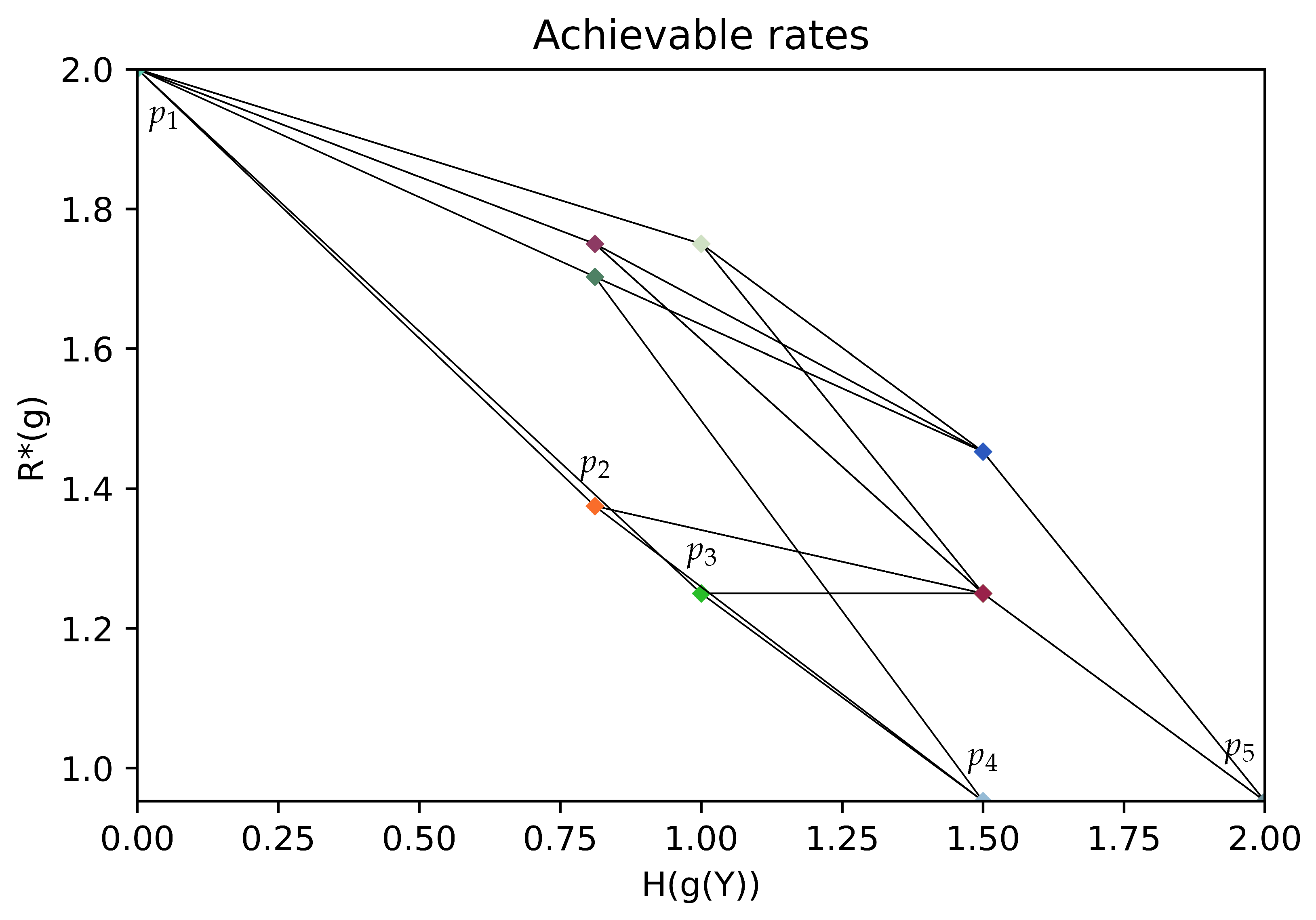
3.3. Example
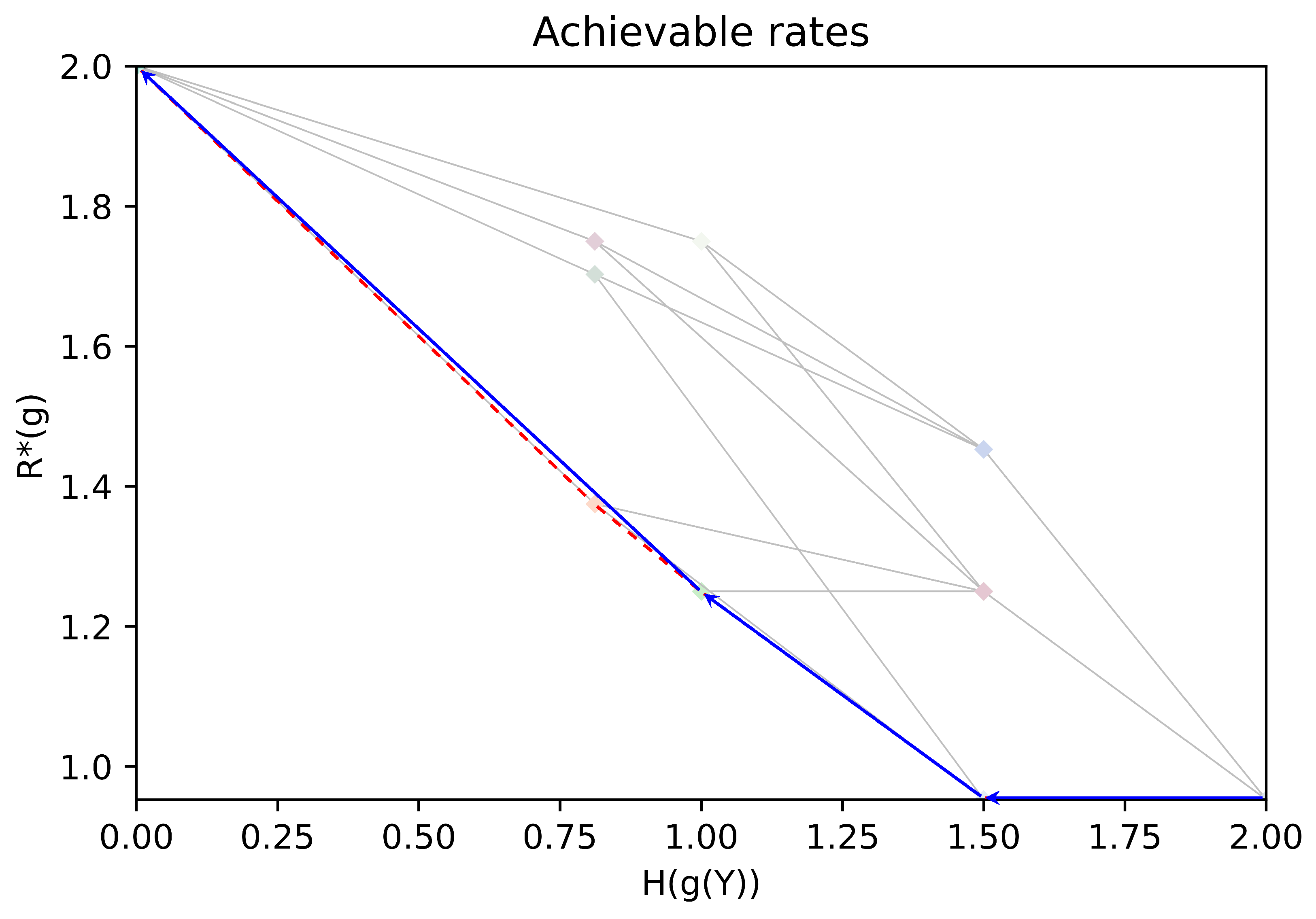
4. Optimization of the Encoder Side Information
4.1. Preliminary Results on Partitions
4.2. Greedy Algorithms Based on Partition Coarsening and Refining
| Algorithm 1 Greedy coarsening algorithm |
|
| Algorithm 2 Greedy refining algorithm |
|
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Proof of Theorem 2

- -
- as set of vertices;
- -
- are adjacent if for some .
Appendix A.2. Proof of Theorem 3
- -
- For all , ;
- -
- For all , .
Appendix A.3. Proof of Lemma A1
Appendix A.4. Proof of Lemma A3
Appendix A.5. Proof of Lemma A2
References
- Orlitsky, A.; Roche, J.R. Coding for computing. In Proceedings of the IEEE 36th Annual Foundations of Computer Science, Milwaukee, WI, USA, 23–25 October 1995; IEEE: Piscataway, NJ, USA, 1995; pp. 502–511. [Google Scholar]
- Duan, L.; Liu, J.; Yang, W.; Huang, T.; Gao, W. Video coding for machines: A paradigm of collaborative compression and intelligent analytics. IEEE Trans. Image Process. 2020, 29, 8680–8695. [Google Scholar] [CrossRef] [PubMed]
- Gao, W.; Liu, S.; Xu, X.; Rafie, M.; Zhang, Y.; Curcio, I. Recent standard development activities on video coding for machines. arXiv 2021, arXiv:2105.12653. [Google Scholar]
- Yamamoto, H. Wyner-ziv theory for a general function of the correlated sources (corresp.). IEEE Trans. Inf. Theory 1982, 28, 803–807. [Google Scholar] [CrossRef]
- Shayevitz, O. Distributed computing and the graph entropy region. IEEE Trans. Inf. Theory 2014, 60, 3435–3449. [Google Scholar] [CrossRef]
- Krithivasan, D.; Pradhan, S.S. Distributed source coding using abelian group codes: A new achievable rate-distortion region. IEEE Trans. Inf. Theory 2011, 57, 1495–1519. [Google Scholar] [CrossRef]
- Basu, S.; Seo, D.; Varshney, L.R. Hypergraph-based Coding Schemes for Two Source Coding Problems under Maximal Distortion. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Los Angeles, CA, USA, 21–26 June 2020. [Google Scholar]
- Malak, D.; Médard, M. Hyper Binning for Distributed Function Coding. In Proceedings of the 2020 IEEE 21st International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Atlanta, GA, USA, 26–29 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Feizi, S.; Médard, M. On network functional compression. IEEE Trans. Inf. Theory 2014, 60, 5387–5401. [Google Scholar] [CrossRef]
- Sefidgaran, M.; Tchamkerten, A. Distributed function computation over a rooted directed tree. IEEE Trans. Inf. Theory 2016, 62, 7135–7152. [Google Scholar] [CrossRef]
- Ravi, J.; Dey, B.K. Function Computation Through a Bidirectional Relay. IEEE Trans. Inf. Theory 2018, 65, 902–916. [Google Scholar] [CrossRef]
- Guang, X.; Yeung, R.W.; Yang, S.; Li, C. Improved upper bound on the network function computing capacity. IEEE Trans. Inf. Theory 2019, 65, 3790–3811. [Google Scholar] [CrossRef]
- Charpenay, N.; Le Treust, M.; Roumy, A. Optimal Zero-Error Coding for Computing under Pairwise Shared Side Information. In Proceedings of the 2023 IEEE Information Theory Workshop (ITW), Saint-Malo, France, 23–28 April 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 97–101. [Google Scholar]
- Alon, N.; Orlitsky, A. Source coding and graph entropies. IEEE Trans. Inf. Theory 1996, 42, 1329–1339. [Google Scholar] [CrossRef]
- Witsenhausen, H. The zero-error side information problem and chromatic numbers (corresp.). IEEE Trans. Inf. Theory 1976, 22, 592–593. [Google Scholar] [CrossRef]
- Körner, J. Coding of an information source having ambiguous alphabet and the entropy of graphs. In Proceedings of the 6th Prague Conference on Information Theory, Prague, Czech Republic, 19–25 September 1973; pp. 411–425. [Google Scholar]
- Tuncel, E.; Nayak, J.; Koulgi, P.; Rose, K. On complementary graph entropy. IEEE Trans. Inf. Theory 2009, 55, 2537–2546. [Google Scholar] [CrossRef]
- Csiszár, I.; Körner, J.; Lovász, L.; Marton, K.; Simonyi, G. Entropy splitting for antiblocking corners and perfect graphs. Combinatorica 1990, 10, 27–40. [Google Scholar] [CrossRef]
- Csiszár, I.; Körner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Charpenay, N.; Le Treust, M.; Roumy, A. Side Information Design in Zero-Error Coding for Computing. Entropy 2024, 26, 338. https://doi.org/10.3390/e26040338
Charpenay N, Le Treust M, Roumy A. Side Information Design in Zero-Error Coding for Computing. Entropy. 2024; 26(4):338. https://doi.org/10.3390/e26040338
Chicago/Turabian StyleCharpenay, Nicolas, Maël Le Treust, and Aline Roumy. 2024. "Side Information Design in Zero-Error Coding for Computing" Entropy 26, no. 4: 338. https://doi.org/10.3390/e26040338
APA StyleCharpenay, N., Le Treust, M., & Roumy, A. (2024). Side Information Design in Zero-Error Coding for Computing. Entropy, 26(4), 338. https://doi.org/10.3390/e26040338