
Global Semantic-Sense Aggregation Network for Salient Object Detection in Remote Sensing Images
 , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
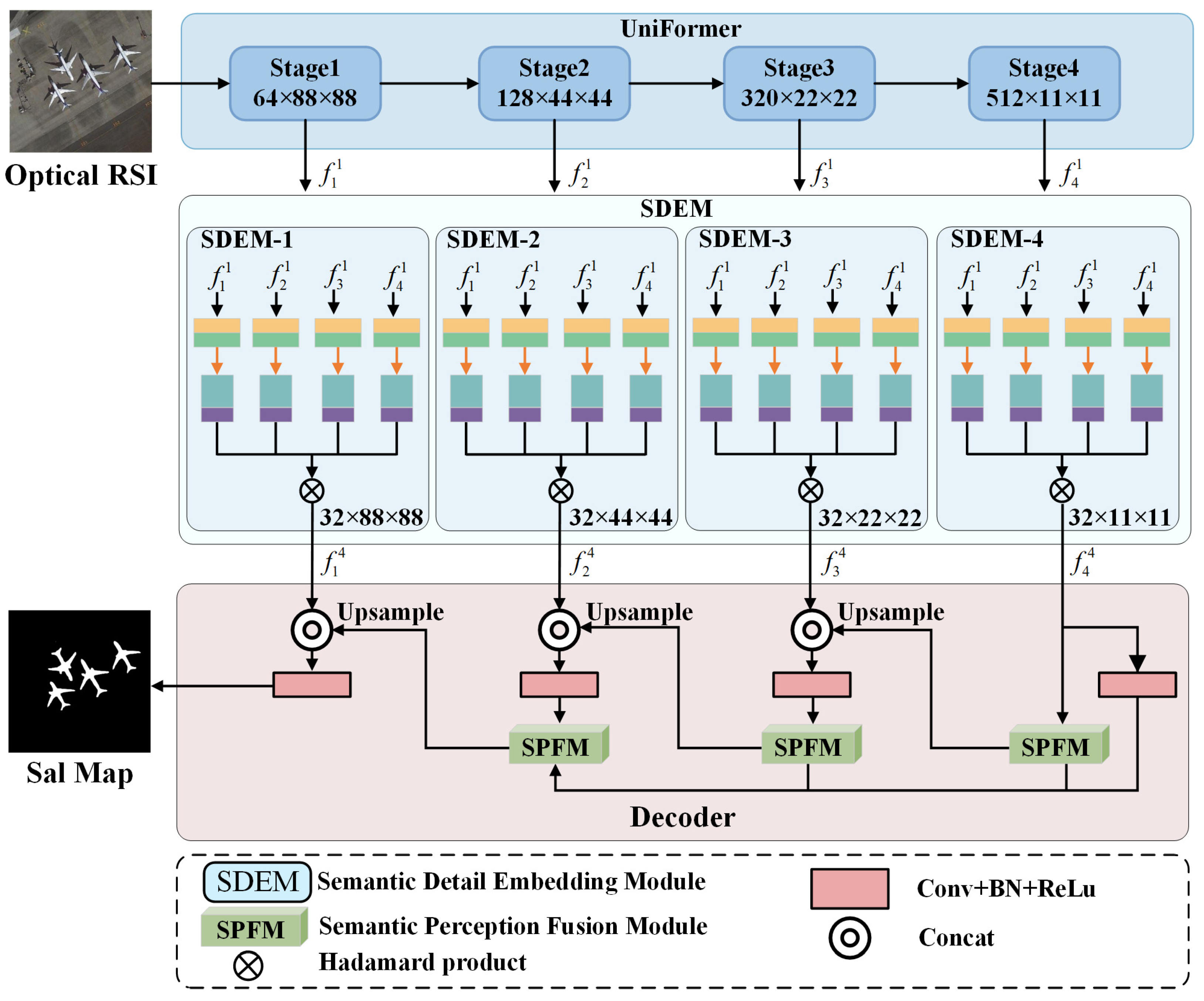
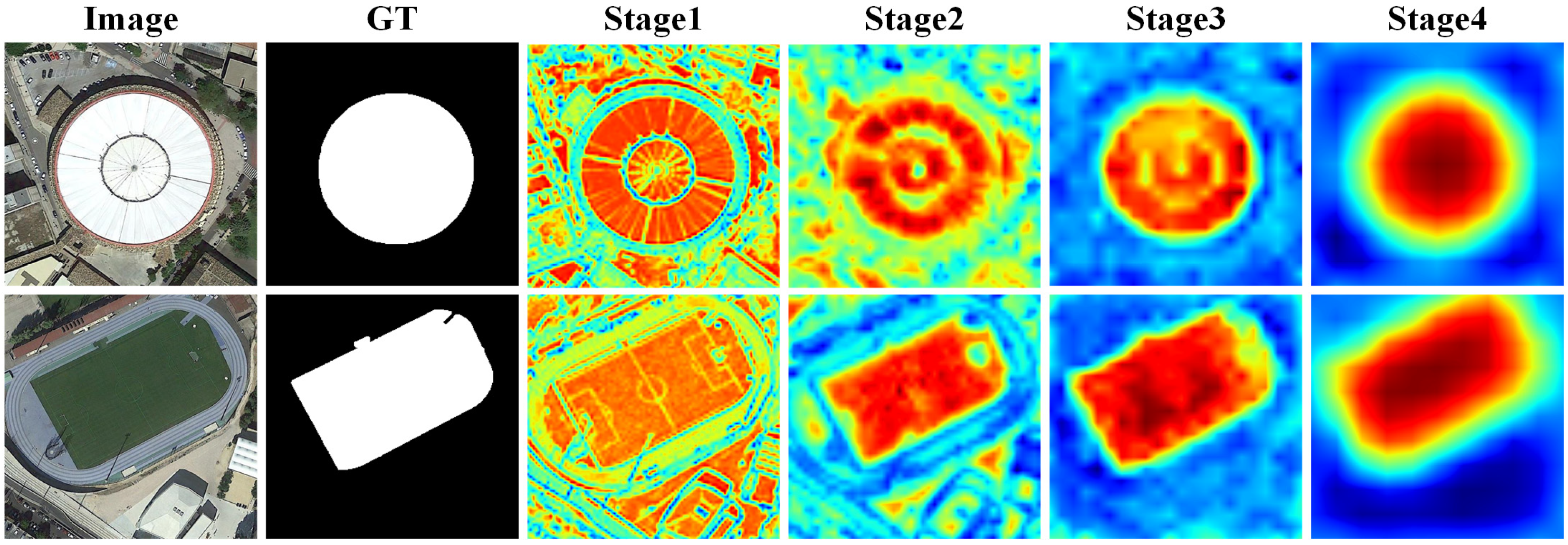
2.1. Network Overview
2.2. UniFormer
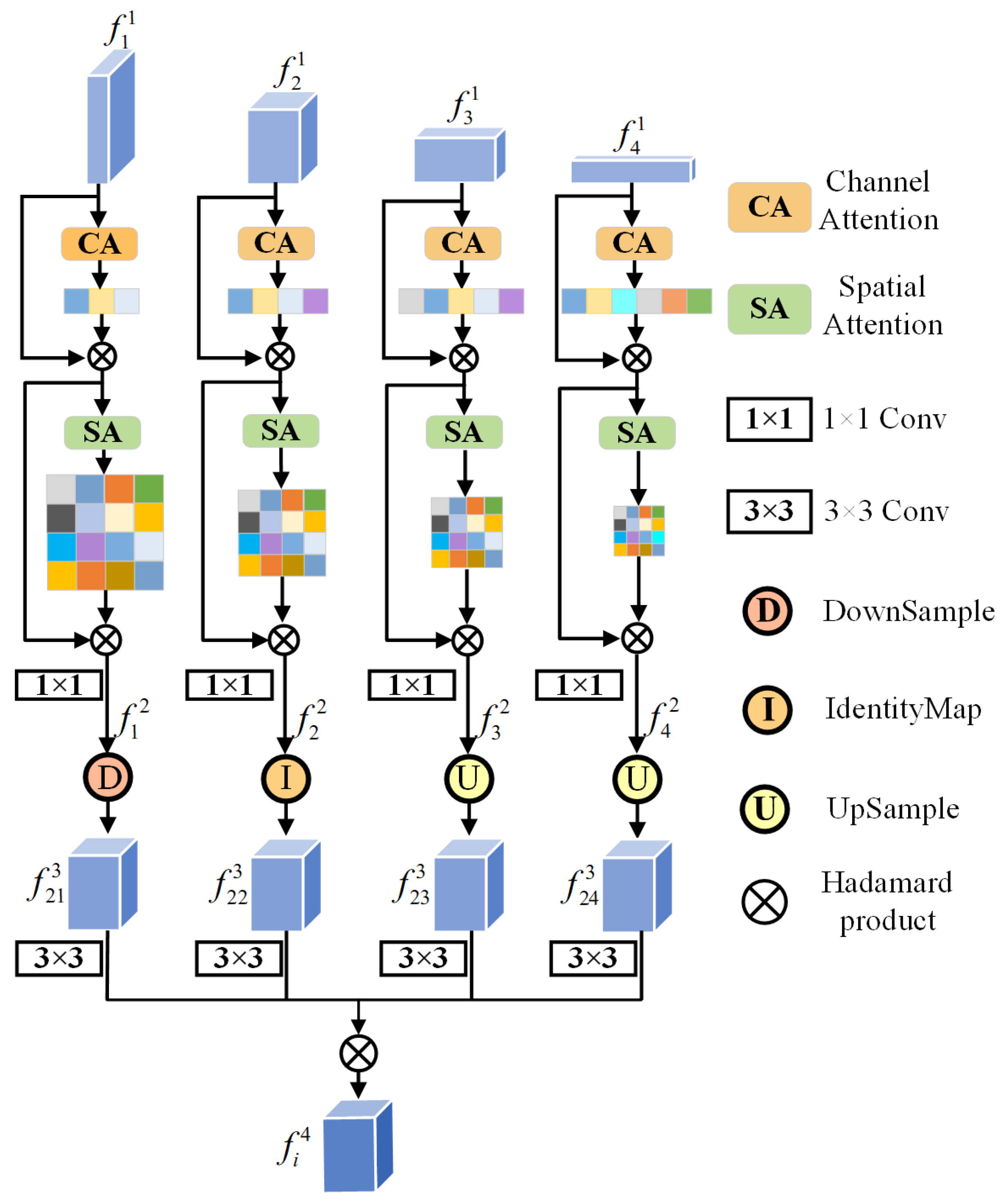
2.3. Semantic Detail Embedding Module (SDEM)
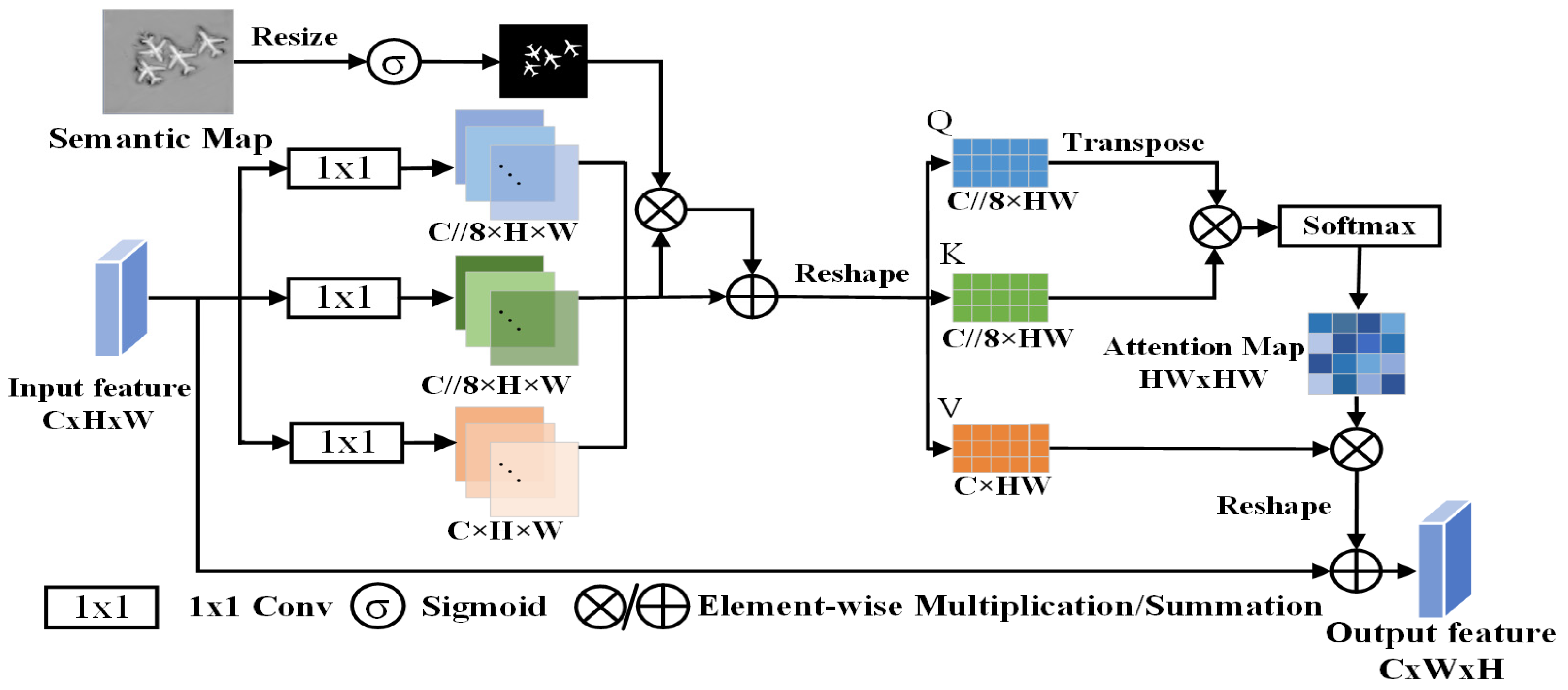
2.4. Semantic Perception Fusion Module (SPFM)
2.5. Loss Function
3. Results
3.1. Experimental Setup
3.2. Evaluation Metrics
3.3. Comparison with State-of-the-Art
3.3.1. Visual Comparison
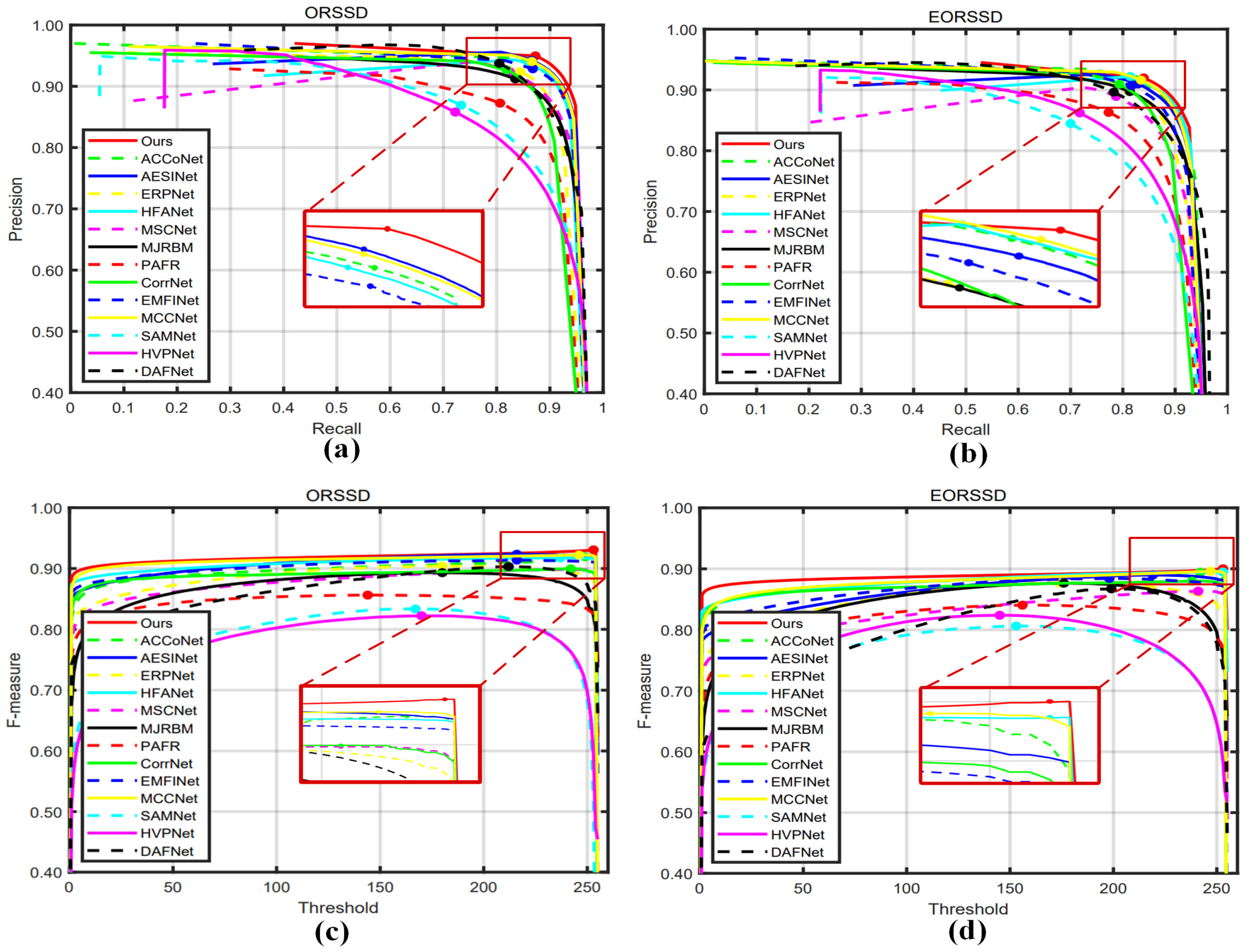
3.3.2. Quantitative Comparison
3.4. Ablation Studies
3.5. Computational Efficiency Experiment
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, L.; Wang, Q.; Chen, Y.; Zheng, Y.; Wu, Z.; Fu, L.; Jeon, B. CRNet: Channel-Enhanced Remodeling-Based Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Yan, R.; Yan, L.; Geng, G.; Cao, Y.; Zhou, P.; Meng, Y. ASNet: Adaptive Semantic Network Based on Transformer-CNN for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–16. [Google Scholar] [CrossRef]
- Gong, A.; Nie, J.; Niu, C.; Yu, Y.; Li, J.; Guo, L. Edge and Skeleton Guidance Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 7109–7120. [Google Scholar] [CrossRef]
- Quan, Y.; Xu, H.; Wang, R.; Guan, Q.; Zheng, J. ORSI Salient Object Detection via Progressive Semantic Flow and Uncertainty-aware Refinement. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–13. [Google Scholar] [CrossRef]
- Wen, D.; Huang, X.; Bovolo, F.; Li, J.; Ke, X.; Zhang, A.; Benediktsson, J.A. Change detection from very-high-spatial-resolution optical remote sensing images: Methods, applications, and future directions. IEEE Geosci. Remote Sens. Mag. 2021, 9, 68–101. [Google Scholar] [CrossRef]
- Wellmann, T.; Lausch, A.; Andersson, E.; Knapp, S.; Cortinovis, C.; Jache, J.; Scheuer, S.; Kremer, P.; Mascarenhas, A.; Kraemer, R. Remote sensing in urban planning: Contributions towards ecologically sound policies? Landsc. Urban Plan. 2020, 204, 103921. [Google Scholar] [CrossRef]
- Cong, R.; Qin, Q.; Zhang, C.; Jiang, Q.; Wang, S.; Zhao, Y.; Kwong, S. A weakly supervised learning framework for salient object detection via hybrid labels. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 534–548. [Google Scholar] [CrossRef]
- Song, K.; Huang, L.; Gong, A.; Yan, Y. Multiple graph affinity interactive network and a variable illumination dataset for RGBT image salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 3104–3118. [Google Scholar] [CrossRef]
- Zhou, X.; Shen, K.; Weng, L.; Cong, R.; Zheng, B.; Zhang, J.; Yan, C. Edge-guided recurrent positioning network for salient object detection in optical remote sensing images. IEEE Trans. Cybern. 2022, 53, 539–552. [Google Scholar] [CrossRef]
- Zheng, J.; Quan, Y.; Zheng, H.; Wang, Y.; Pan, X. ORSI Salient Object Detection via Cross-Scale Interaction and Enlarged Receptive Field. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Lin, W.; Ling, H. Multi-Content Complementation Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Zhang, X.; Lin, W. Lightweight Salient Object Detection in Optical Remote-Sensing Images via Semantic Matching and Edge Alignment. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–11. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Bai, Z.; Lin, W.; Ling, H. Lightweight Salient Object Detection in Optical Remote Sensing Images via Feature Correlation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Zeng, D.; Lin, W.; Ling, H. Adjacent Context Coordination Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Cybern. 2023, 53, 526–538. [Google Scholar] [CrossRef] [PubMed]
- Xu, C.; Ye, Z.; Mei, L.; Shen, S.; Sun, S.; Wang, Y.; Yang, W. Cross-Attention Guided Group Aggregation Network for Cropland Change Detection. IEEE Sens. J. 2023, 23, 13680–13691. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvt v2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Gao, L.; Liu, B.; Fu, P.; Xu, M. Adaptive Spatial Tokenization Transformer for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, J.; Yue, H.; Yin, X.; Zheng, S. Transformer guidance dual-stream network for salient object detection in optical remote sensing images. Neural Comput. Appl. 2023, 35, 17733–17747. [Google Scholar] [CrossRef]
- Li, K.; Wang, Y.; Zhang, J.; Gao, P.; Song, G.; Liu, Y.; Li, H.; Qiao, Y. Uniformer: Unifying convolution and self-attention for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12581–12600. [Google Scholar] [CrossRef] [PubMed]
- Xu, C.; Ye, Z.; Mei, L.; Yu, H.; Liu, J.; Yalikun, Y.; Jin, S.; Liu, S.; Yang, W.; Lei, C. Hybrid Attention-Aware Transformer Network Collaborative Multiscale Feature Alignment for Building Change Detection. IEEE Trans. Instrum. Meas. 2024, 73, 1–14. [Google Scholar] [CrossRef]
- Mei, L.; Yu, Y.; Shen, H.; Weng, Y.; Liu, Y.; Wang, D.; Liu, S.; Zhou, F.; Lei, C. Adversarial multiscale feature learning framework for overlapping chromosome segmentation. Entropy 2022, 24, 522. [Google Scholar] [CrossRef]
- Peng, Y.; Sonka, M.; Chen, D.Z. U-Net v2: Rethinking the Skip Connections of U-Net for Medical Image Segmentation. arXiv 2023, arXiv:2311.17791. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Maaz, M.; Shaker, A.; Cholakkal, H.; Khan, S.; Zamir, S.W.; Anwer, R.M.; Shahbaz Khan, F. Edgenext: Efficiently amalgamated cnn-transformer architecture for mobile vision applications. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 3–20. [Google Scholar]
- Mei, L.; Hu, X.; Ye, Z.; Tang, L.; Wang, Y.; Li, D.; Liu, Y.; Hao, X.; Lei, C.; Xu, C. GTMFuse: Group-Attention Transformer-Driven Multiscale Dense Feature-Enhanced Network for Infrared and Visible Image Fusion. Knowl. Based Syst. 2024, 293, 111658. [Google Scholar] [CrossRef]
- Han, C.; Wu, C.; Guo, H.; Hu, M.; Li, J.; Chen, H. Change guiding network: Incorporating change prior to guide change detection in remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 8395–8407. [Google Scholar] [CrossRef]
- Li, C.; Cong, R.; Hou, J.; Zhang, S.; Qian, Y.; Kwong, S. Nested Network With Two-Stream Pyramid for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9156–9166. [Google Scholar] [CrossRef]
- Zhang, Q.; Cong, R.; Li, C.; Cheng, M.-M.; Fang, Y.; Cao, X.; Zhao, Y.; Kwong, S. Dense attention fluid network for salient object detection in optical remote sensing images. IEEE Trans. Image Process. 2020, 30, 1305–1317. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Fan, D.-P.; Cheng, M.-M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Fan, D.-P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.-M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. arXiv 2018, arXiv:1805.10421. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Liu, Y.; Zhang, X.-Y.; Bian, J.-W.; Zhang, L.; Cheng, M.-M. SAMNet: Stereoscopically attentive multi-scale network for lightweight salient object detection. IEEE Trans. Image Process. 2021, 30, 3804–3814. [Google Scholar] [CrossRef]
- Liu, Y.; Gu, Y.-C.; Zhang, X.-Y.; Wang, W.; Cheng, M.-M. Lightweight salient object detection via hierarchical visual perception learning. IEEE Trans. Cybern. 2020, 51, 4439–4449. [Google Scholar] [CrossRef]
- Lin, Y.; Sun, H.; Liu, N.; Bian, Y.; Cen, J.; Zhou, H. A lightweight multi-scale context network for salient object detection in optical remote sensing images. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 238–244. [Google Scholar]
- Tu, Z.; Wang, C.; Li, C.; Fan, M.; Zhao, H.; Luo, B. ORSI Salient Object Detection via Multiscale Joint Region and Boundary Model. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Li, X.; Xu, Y.; Ma, L.; Huang, Z.; Yuan, H. Progressive Attention-Based Feature Recovery With Scribble Supervision for Saliency Detection in Optical Remote Sensing Image. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Zhou, X.; Shen, K.; Liu, Z.; Gong, C.; Zhang, J.; Yan, C. Edge-Aware Multiscale Feature Integration Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Zeng, X.; Xu, M.; Hu, Y.; Tang, H.; Hu, Y.; Nie, L. Adaptive Edge-Aware Semantic Interaction Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Zhao, J.; Jia, Y.; Ma, L.; Yu, L. Adaptive Dual-Stream Sparse Transformer Network for Salient Object Detection in Optical Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 5173–5192. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, Y.; Xiong, Z.; Yuan, Y. Hybrid feature aligned network for salient object detection in optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Li, G.; Bai, Z.; Liu, Z.; Zhang, X.; Ling, H. Salient object detection in optical remote sensing images driven by transformer. IEEE Trans. Image Process. 2023, 32, 5257–5269. [Google Scholar] [CrossRef]
- Khlifi, M.K.; Boulila, W.; Farah, I.R. Graph-based deep learning techniques for remote sensing applications: Techniques, taxonomy, and applications—A comprehensive review. Comput. Sci. Rev. 2023, 50, 100596. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | ORSSD [32] | |||||||
|---|---|---|---|---|---|---|---|---|
| SAMNet21 [38] | 0.8761 | 0.0217 | 0.8656 | 0.8818 | 0.9478 | 0.6843 | 0.7531 | 0.8137 |
| HVPNet21 [39] | 0.8610 | 0.0225 | 0.8471 | 0.8737 | 0.9320 | 0.6726 | 0.7396 | 0.7938 |
| DAFNet21 [33] | 0.9191 | 0.0113 | 0.9360 | 0.9539 | 0.9771 | 0.7876 | 0.8511 | 0.8928 |
| HFANet22 [46] | 0.9399 | 0.0092 | 0.9722 | 0.9712 | 0.9770 | 0.8819 | 0.8981 | 0.9112 |
| MSCNet22 [40] | 0.9227 | 0.0129 | 0.9584 | 0.9653 | 0.9754 | 0.8350 | 0.8676 | 0.8927 |
| MJRBM22 [41] | 0.9204 | 0.0163 | 0.9328 | 0.9415 | 0.9623 | 0.8022 | 0.8566 | 0.8842 |
| PAFR22 [42] | 0.8938 | 0.0211 | 0.9315 | 0.9268 | 0.9467 | 0.8025 | 0.8275 | 0.8438 |
| CorrNet22 [13] | 0.9201 | 0.0158 | 0.9543 | 0.9487 | 0.9575 | 0.8605 | 0.8717 | 0.8841 |
| EMFINet22 [43] | 0.9380 | 0.0113 | 0.9637 | 0.9657 | 0.9733 | 0.8664 | 0.8873 | 0.9019 |
| MCCNet22 [11] | 0.9445 | 0.0091 | 0.9733 | 0.9740 | 0.9805 | 0.8925 | 0.9045 | 0.9177 |
| ACCoNet23 [14] | 0.9418 | 0.0095 | 0.9694 | 0.9684 | 0.9754 | 0.8614 | 0.8847 | 0.9112 |
| AESINet23 [44] | 0.9427 | 0.0090 | 0.9704 | 0.9736 | 0.9817 | 0.8667 | 0.8975 | 0.9166 |
| ERPNet23 [9] | 0.9254 | 0.0135 | 0.9520 | 0.8566 | 0.9710 | 0.8356 | 0.8745 | 0.8974 |
| GeleNet23 [47] | 0.9451 | 0.0092 | 0.9816 | 0.9799 | 0.9859 | 0.9044 | 0.9123 | 0.9239 |
| ADSTNet24 [45] | 0.9379 | 0.0086 | 0.9785 | 0.9740 | 0.9807 | 0.8979 | 0.9042 | 0.9124 |
| Ours | 0.9491 | 0.0070 | 0.9807 | 0.9815 | 0.9864 | 0.8994 | 0.9095 | 0.9253 |
| Methods | EORSSD [33] | |||||||
|---|---|---|---|---|---|---|---|---|
| SAMNet21 [38] | 0.8622 | 0.0132 | 0.8284 | 0.8700 | 0.9421 | 0.6114 | 0.7214 | 0.7813 |
| HVPNet21 [39] | 0.8734 | 0.0110 | 0.8270 | 0.8721 | 0.9482 | 0.6202 | 0.7377 | 0.8036 |
| DAFNet21 [33] | 0.9166 | 0.0060 | 0.8443 | 0.9290 | 0.9859 | 0.6423 | 0.7842 | 0.8612 |
| HFANet22 [46] | 0.9380 | 0.0070 | 0.9644 | 0.9679 | 0.9740 | 0.8365 | 0.8681 | 0.8876 |
| MSCNet22 [40] | 0.9071 | 0.0090 | 0.9329 | 0.9551 | 0.9689 | 0.7553 | 0.8151 | 0.8539 |
| MJRBM22 [41] | 0.9197 | 0.0099 | 0.8897 | 0.9350 | 0.9646 | 0.7066 | 0.8239 | 0.8656 |
| PAFR22 [42] | 0.8927 | 0.0119 | 0.8959 | 0.9210 | 0.9490 | 0.7123 | 0.7961 | 0.8260 |
| CorrNet22 [13] | 0.9153 | 0.0097 | 0.9514 | 0.9445 | 0.9553 | 0.8259 | 0.8450 | 0.8597 |
| EMFINet22 [43] | 0.9284 | 0.0087 | 0.9482 | 0.9542 | 0.9665 | 0.8049 | 0.8494 | 0.8735 |
| MCCNet22 [11] | 0.9340 | 0.0073 | 0.9609 | 0.9676 | 0.9758 | 0.8302 | 0.8656 | 0.8884 |
| ACCoNet23 [14] | 0.9346 | 0.0081 | 0.9559 | 0.9622 | 0.9707 | 0.8248 | 0.8628 | 0.8846 |
| AESINet23 [44] | 0.9362 | 0.0072 | 0.9443 | 0.9618 | 0.9734 | 0.7908 | 0.8507 | 0.8820 |
| ERPNet23 [9] | 0.9210 | 0.0089 | 0.9228 | 0.9401 | 0.9603 | 0.7554 | 0.8304 | 0.8632 |
| GeleNet23 [47] | 0.9373 | 0.0075 | 0.9728 | 0.9740 | 0.9810 | 0.8648 | 0.8781 | 0.8910 |
| ADSTNet24 [45] | 0.9311 | 0.0065 | 0.9681 | 0.9709 | 0.9769 | 0.8532 | 0.8716 | 0.8804 |
| Ours | 0.9391 | 0.0053 | 0.9743 | 0.9784 | 0.9836 | 0.8657 | 0.8790 | 0.8937 |
| No. | Baseline | SDEM | SPFM | EORSSD [33] | ||
|---|---|---|---|---|---|---|
| 1 | √ | 0.9367 | 0.9804 | 0.8888 | ||
| 2 | √ | √ | 0.9412 | 0.9827 | 0.8923 | |
| 3 | √ | √ | 0.9396 | 0.9821 | 0.8905 | |
| 4 | √ | √ | √ | 0.9391 | 0.9836 | 0.8937 |
| Methods | Params (M) | FLOPs (G) |
|---|---|---|
| CorrNet | 4.086 | 21.379 |
| EMFINet | 95.086 | 176 |
| MCCNet | 67.652 | 114 |
| ACCoNet | 127 | 50.422 |
| ERPNet | 77.195 | 171 |
| GeleNet | 25.453 | 6.43 |
| Ours | 49.461 | 11.373 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Chen, X.; Yang, W.; Huang, J.; Sun, K.; Wang, Y.; Huang, A.; Mei, L. Global Semantic-Sense Aggregation Network for Salient Object Detection in Remote Sensing Images. Entropy 2024, 26, 445. https://doi.org/10.3390/e26060445
Li H, Chen X, Yang W, Huang J, Sun K, Wang Y, Huang A, Mei L. Global Semantic-Sense Aggregation Network for Salient Object Detection in Remote Sensing Images. Entropy. 2024; 26(6):445. https://doi.org/10.3390/e26060445
Chicago/Turabian StyleLi, Hongli, Xuhui Chen, Wei Yang, Jian Huang, Kaimin Sun, Ying Wang, Andong Huang, and Liye Mei. 2024. "Global Semantic-Sense Aggregation Network for Salient Object Detection in Remote Sensing Images" Entropy 26, no. 6: 445. https://doi.org/10.3390/e26060445
APA StyleLi, H., Chen, X., Yang, W., Huang, J., Sun, K., Wang, Y., Huang, A., & Mei, L. (2024). Global Semantic-Sense Aggregation Network for Salient Object Detection in Remote Sensing Images. Entropy, 26(6), 445. https://doi.org/10.3390/e26060445