Abstract
In most silent speech research, continuously observing tongue movements is crucial, thus requiring the use of ultrasound to extract tongue contours. Precisely and in real-time extracting ultrasonic tongue contours presents a major challenge. To tackle this challenge, the novel end-to-end lightweight network DAFT-Net is introduced for ultrasonic tongue contour extraction. Integrating the Convolutional Block Attention Module (CBAM) and Attention Gate (AG) module with entropy-based optimization strategies, DAFT-Net establishes a comprehensive attention mechanism with dual functionality. This innovative approach enhances feature representation by replacing traditional skip connection architecture, thus leveraging entropy and information-theoretic measures to ensure efficient and precise feature selection. Additionally, the U-Net’s encoder and decoder layers have been streamlined to reduce computational demands. This process is further supported by information theory, thus guiding the reduction without compromising the network’s ability to capture and utilize critical information. Ablation studies confirm the efficacy of the integrated attention module and its components. The comparative analysis of the NS, TGU, and TIMIT datasets shows that DAFT-Net efficiently extracts relevant features, and it significantly reduces extraction time. These findings demonstrate the practical advantages of applying entropy and information theory principles. This approach improves the performance of medical image segmentation networks, thus paving the way for real-world applications.
1. Introduction
Ultrasound technology, characterized by its cleanliness, safety, and cost-effectiveness, facilitates the imaging of the tongue and mouth. The precise extraction of tongue contours from these images assists physicians in monitoring the vocalization of patients with speech impairments due to diseases or speech disorders. It also serves as a reference for language pronunciation in sensitive contexts [1] and allows for the integration of tongue features as biological signals into silent speech interfaces [2]. Silent speech technology offers a means of communication for those who have lost their voice due to illness or accident. Additionally, it provides clear speech input in high-noise environments. In silent speech analysis, the accuracy of ultrasound tongue contour extraction directly impacts the precision of speech decoding. In essence, the extraction of ultrasonic tongue contours plays a critical role in ensuring effective language communication.
Research indicates that tongue contours serve as an invaluable foundation for the quantitative analysis of speech, with data obtained from these contours facilitating the advancement and comprehension of speech models [3,4]. Ultrasonic tongue contour extraction can dynamically capture the tongue’s position across various phonetic expressions and depict the movements responsible for sound transitions during articulation [5]. This process is integral to nearly all silent speech applications and has become an essential prerequisite. The precision of ultrasonic tongue contour extraction significantly impacts the overall accuracy of speech analysis tasks, while its real-time execution influences the process’s efficiency. Consequently, the identification of a method for ultrasonic tongue contour tracking that is both accurate and rapid is of paramount importance.
Currently, automatic tongue contour tracking presents significant challenges. In the context of ultrasonic tongue imaging, the process is persistently marred by high speckle noise [6]. Obstructions caused by the hyoid and jawbones sometimes impede ultrasound waves, while the tongue’s muscle fibers’ low reflectivity results in incomplete echo paths and sagittal contours [7]. Moreover, images capturing the soft tissue structure of the tongue during positional transformations often contain artifacts, thus rendering contours indiscernible [8]. From the extraction methodology standpoint, the precision of tongue contour delineation is heavily contingent upon the ultrasonic data’s quality and the chosen contour tracking algorithm [5]. Additionally, the extraction process’s speed is hampered by the inherently semiautomatic or manual nature of current methods. Prior research has seldom prioritized speed, and there are no established industry standards for it, with only a maximum speed of 29.8 frames per second (fps) for tongue contour extraction being reported.
A myriad of technologies, including active contour models [9,10,11,12], graph-based techniques [13], and machine learning approaches [14,15], have been employed for tracking tongue contours in ultrasonic imagery. Initially, these methods necessitated manual tagging for initialization, thus rendering real-time tracking by established software like EdgeTrak 1.0.0 [10] infeasible. The advent of deep learning (DL) has garnered significant interest, with convolutional neural networks [16] being recognized for their robust feature extraction capabilities, which are essential for tasks such as ultrasonic tongue contour tracking. Deep confidence networks and autoencoders have also demonstrated promising outcomes [17,18]. DeepLabv3 [19] has shown outstanding performance in the field of semantic segmentation. It effectively captures multiscale contextual information by using atrous convolution and atrous spatial pyramid pooling. This approach provides new methods for segmenting complex scenes, including medical images. Subsequent research highlighted a direct correlation between the efficacy of DL techniques and both the size of the training dataset and the model’s complexity [20,21]. This introduces a delicate balance between training sample volume and network parameter quantity. Achieving high-accuracy extractions mandates ample semantic and detailed information from segmentation networks [22]. Deepening network parameters and enhancing input image resolution for precise segmentation exponentially increases computational demand and diminishes efficiency [23]. Nevertheless, U-Net [24] has proven capable of delivering commendable segmentation outcomes in medical imagery without labeled training data, thus setting a benchmark in the field [25]. Despite this, its deep multilayer architecture significantly taxes computational resources during both training and testing phases. This poses a challenge for real-time ultrasonic tongue contour tracking.
Recent advancements in DL have increasingly emphasized attention mechanisms, which are celebrated for their efficient use of computational resources. The concept, inspired by the human attention system—a pivotal aspect of perception [26,27,28,29]—enables deep convolutional neural networks (DCNNs) to hasten the learning process, discern crucial features more effectively, and bolster model robustness [30]. For instance, Kaul et al. [31] introduced FocusNet, thus integrating attention with a fully convolutional network to segment medical images through feature maps from a distinct convolutional autoencoder. Additionally, incorporating an attention gate (AG) into U-Net’s skip connections has been suggested to refine pancreatic segmentation’s accuracy and sensitivity [32]. Hu et al. [33] explored channel response recalibration within SENet by explicitly modeling channel interdependencies. Similarly, Woo et al. [34] developed the Convolutional Block Attention Module (CBAM), a lightweight, nearly resource-neutral module capable of adaptively refining features from intermediate variables. In ultrasonic tongue contour extraction, the contour line is a minuscule portion of the entire image. Focusing on this target area not only speeds up training but also clarifies object representation and emphasizes detail [35]. Nonetheless, given the potential for fuzzy boundaries and irregular shapes in ultrasonic tongue images, relying solely on a singular attention mechanism might not suffice for effective tongue contour segmentation.
This study introduces a novel feature extraction network model, DAFT-Net, which is enhanced by entropy and information theory principles. It is designed to optimize both accuracy and efficiency, thus addressing the stated objectives, challenges, and technical frameworks. The primary contributions of this work include the following:
- The internal structure of U-Net has been meticulously reconfigured by eliminating one convolutional layer from each encoder and decoder block within the U-Net framework, thus significantly reducing computational demand.
- A novel attention learning module has been developed featuring a synergistic integration of the CBAM and AG modules. This module serves as a comprehensive attention mechanism with dual functionality, thus supplanting the traditional skip connections to enhance the network’s feature representation capabilities.
- The DAFT-Net model’s performance was rigorously evaluated against other neural networks using metrics such as Intersection over Union (IoU), loss, and processing time across three ultrasound datasets: the NS, TJU, and TIMIT datasets. The model achieved 94.93% accuracy and a processing speed of 34.55 ms per image on the NS dataset.
The rest of the manuscript is organized as follows: Section 2 describes the proposed DAFT-Net architecture and its components. Section 3 details the data and experimental details. Section 4 presents the experimental results and discussions. Section 5 validates the ablation experiments. Finally, Section 6 concludes the study and discusses future work.
2. Methods
Drawing inspiration from U-Net, Attention U-Net, the Spatial Attention Module, and Gate Attention, this paper introduces DAFT-Net. The network’s architecture is meticulously detailed in the sections that follow.
2.1. The Proposed DAFT-Net
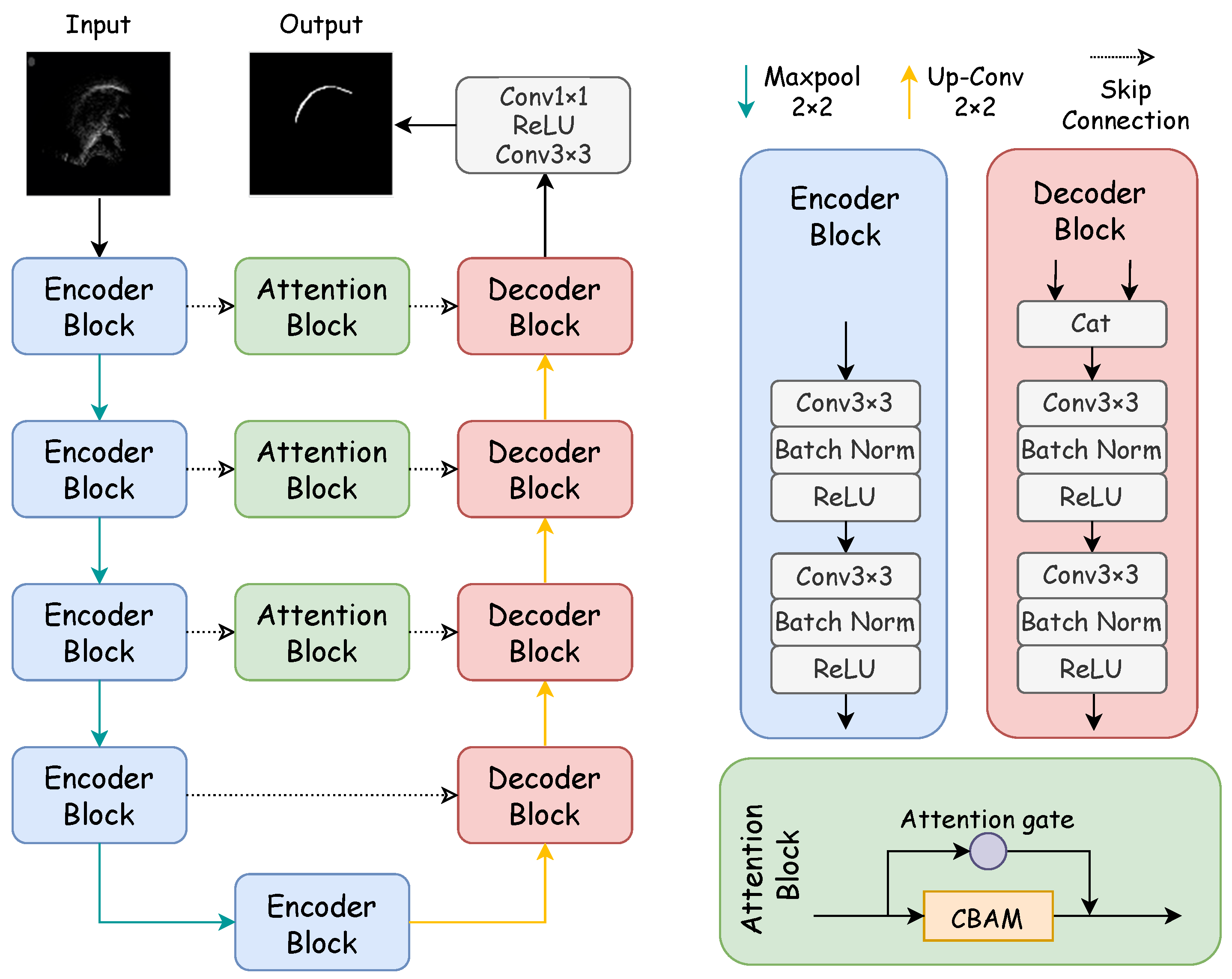
Figure 1 showcases the architecture of the proposed DAFT-Net, with its internal components to be elaborated in subsequent sections. Our method enhances DAFT-Net by integrating entropy-based optimization techniques, thus focusing on reducing data redundancy and improving feature selection through information-theoretic criteria. In DAFT-Net, we optimize feature selection by minimizing the mutual information of the network outputs. This ensures that the network focuses on the most important features and reduces data redundancy. Specifically, we introduce a mutual information-based regularization term in each attention module. This enables the network to automatically learn to reduce redundancy and highlight key features during the training process.
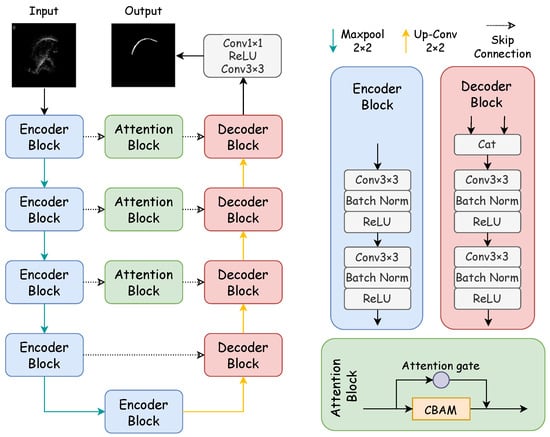
Figure 1.
Structure of the DAFT-Net network. The network is mainly composed of a coding path, decoding path, and comprehensive attention modules. The encoder block consists of two convolution blocks, while the decoding block is made up of a concatenation module and two convolution blocks. The concatenation module concatenates the features from the previous layer with the features of the encoder block at the same level. The attention block consists of an attention gate and CBAM.
Specifically, the network’s CBAM and AG modules are fine-tuned to minimize entropy, thus facilitating a more efficient encoding and decoding of ultrasound tongue images. This approach allows for a refined focus on relevant features, thus significantly improving the network’s performance in contour extraction tasks. Mirroring the structure of traditional U–encoder–decoder networks, DAFT-Net comprises an encoding path, a decoding path, and comprehensive attention modules. In Figure 1, rectangles of varying colors denote distinct modules: blue for the encoder module, pink for the decoder module—both forming the network’s symmetric structure—and green for the comprehensive attention module. Each convolution block within these modules consists of a convolutional layer (ConvBlock), a batch normalization layer (BN), and a rectified linear unit (ReLU).
In the encoding path, feature channels double with each downsampling step, thus paralleling the 2 × 2 transpose convolution upsampling in the decoding path, where the number of feature channels is halved. The comprehensive attention module first processes the encoded information. It refines the feature map across different scales while emphasizing noise filtration and elucidating spatial and channel relationships. By using attention mechanisms to filter features, the decoder can learn task-relevant features more effectively, thereby improving segmentation accuracy. The network culminates in a 1 × 1 convolution followed by a sigmoid activation function, thus producing the final segmentation map for the ultrasonic tongue contour.
2.2. Network Internal Design
2.2.1. U-Net
The U-Net architecture comprises an encoding path, a decoding path, and skip connections. Within the encoding path, each set of two convolutional layers is followed by a max pooling operation, thus utilizing a 2 × 2 window with a stride of two. Subsequent to every downsampling stage, the feature channels double. Conversely, the decoding path employs a 2 × 2 convolutional layer at each upsampling point, which is activated via a ReLU function. Moreover, each upsampling step integrates the corresponding feature map from the encoding path through skip connections, thus enhancing detail preservation. The network’s final layer features a 1 × 1 convolutional layer, thereby converting the 64-channel feature map into an output corresponding to the classification categories. The overall structure of the U-Net is depicted in Figure 1.
Within the U-Net framework, feature maps retrieved from the encoding path are concatenated with newly generated feature maps during the upsampling phase. This facilitates the fusion of feature images. This process ensures the maximal preservation of feature information through the downsampling stages of the encoding path, thereby enabling precise localization of the segmentation target. To address the challenge of learning from small datasets, data augmentation techniques are applied to expand the dataset before inputting it into the network. Specifically, transformer packages are used to adjust saturation, brightness, and contrast based on random probabilities. Additionally, random rotations and flips are applied to the training images to enhance variability and robustness. Consequently, this study adopts the U-Net architecture as the foundational model for ultrasonic tongue contour extraction.
2.2.2. U-Net Simplified Design
In the U-Net framework, the inclusion of two consecutive convolutional layers aims to expand the receptive field, thereby enhancing feature detection capabilities. However, these additional layers significantly increase the parameter count during the encoding and decoding stages, thus impacting the network’s inference speed. To enhance architectural efficiency without compromising accuracy, this study proposes a modification: the removal of one convolutional layer at each level within the codec convolution block of the original U-Net model. This adjustment maintains accuracy on par with the unaltered model. The architectural modifications are illustrated within the codec block structure depicted in Figure 1. The efficiency and effectiveness of this streamlined approach will be substantiated through ablation studies detailed in Section 5.
2.3. Integrated Attention Module
The integrated attention module, marked as the green block in Figure 1, stands as the cornerstone of this network model, thus incorporating both AG and CBAM modules. The fusion of these modules’ outputs enriches the U-Net with parallel encoded feature information, thereby refining the materials available for precise decoding tasks. The AG module reduces noisy and irrelevant responses typically introduced by skip connections. It prioritizes relevant information extracted at a coarse scale. It streamlines the merging of pertinent activations immediately before the concatenation process, thus enabling the selective activation of neurons for both propagation directions. By gleaning additional information from each encoded and decoded path within sub-AGs, it produces a refined output that bypasses the conventional joining process. The AG’s mechanism, akin to a nonlocal block, undergoes a linear transformation devoid of spatial constraints and employs downsampling to diminish the resolution of the feature map. This approach contributes to a reduction in both the parameter count and the computational demands of the network.
Conversely, the CBAM module focuses on dynamically accentuating or attenuating intermediate features to highlight the significance and placement of the target object accurately. Through its dual-attention mechanisms—channel and spatial—it analyzes an input image to yield complementary attention, thus concentrating on feature content and spatial location, respectively. Specifically, the channel attention hones in on the ultrasonic tongue contour, the primary subject of study, whereas the spatial attention zeroes in on pixel positions aligned with the distinct white sagittal tongue contour [35].
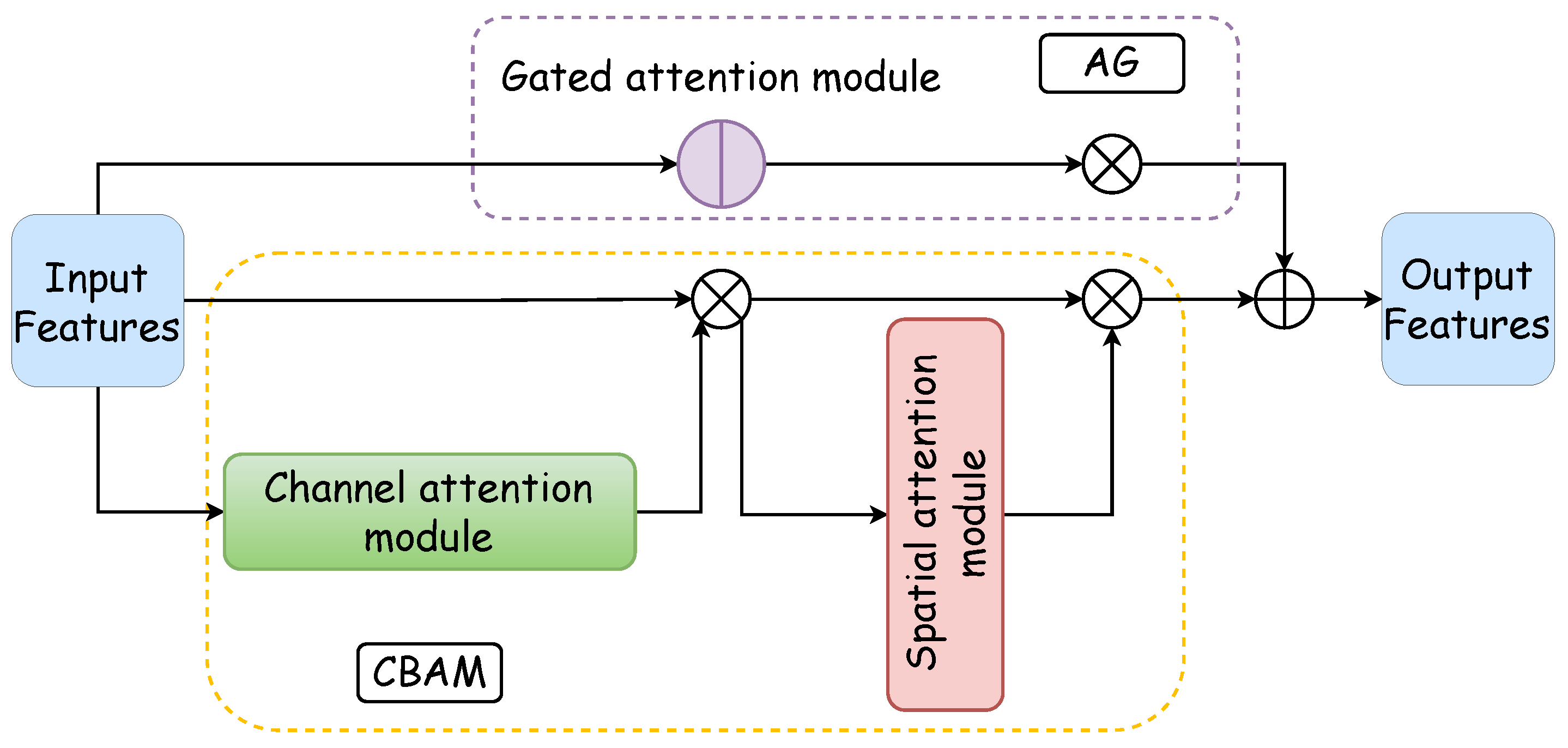
The integrated attention module, which is a parallel configuration of the AG and CBAM, excels in feature processing across distinct dimensions. Moreover, it achieves precise and swift feature localization through the synergistic interaction between the AG and the CBAM. Figure 2 illustrates the architecture of the integrated attention module: the purple box delineates the AG’s internal structure, the yellow dotted box outlines the CBAM’s internal makeup, the blue box represents the CBAM’s channel attention component, and the red box denotes the spatial attention segment of the CBAM. The functionality and design of these two pivotal internal modules of the integrated attention mechanism are expounded upon in the subsequent discussion.
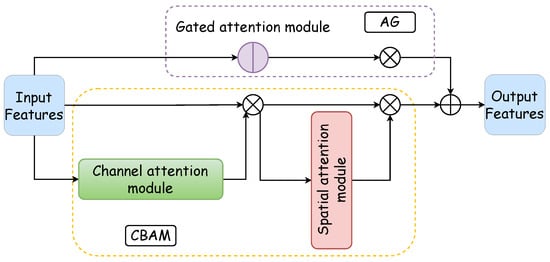
Figure 2.
Comprehensive attention module. The comprehensive attention module is composed of a gated attention module and a CBAM in a parallel manner. The CBAM consists of a channel attention module and a spatial attention module, thus forming a dual attention mechanism.
2.3.1. Gated Attention
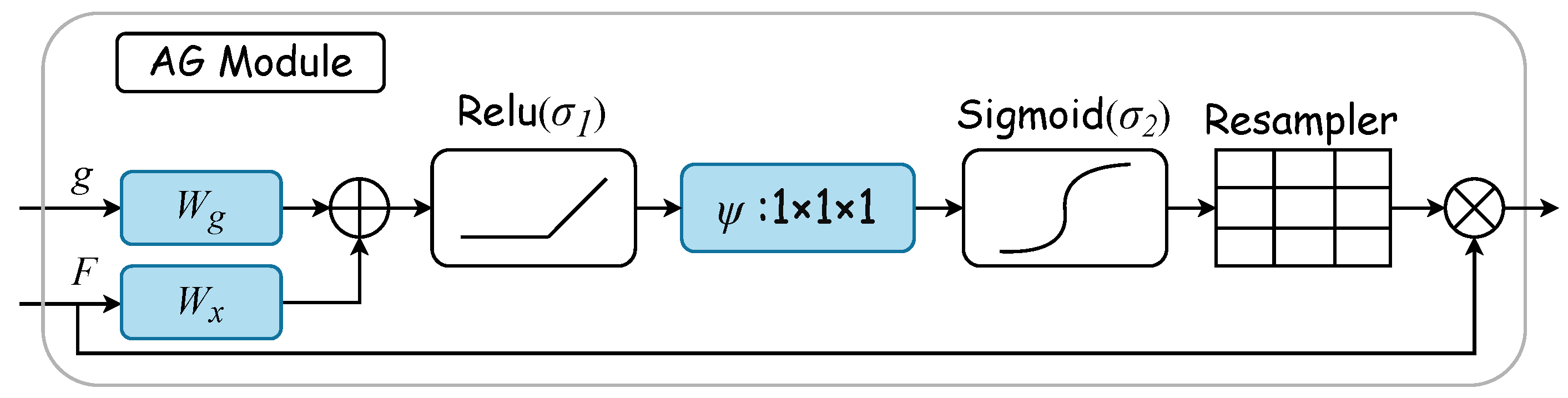
Gated attention mechanisms select specific spatial regions by analyzing contextual information alongside activations from gated signals , which are derived from a broader scale. The gating signal is a dynamically computed feature vector used to control the focus of the network’s attention. It determines the importance of each feature in the final feature map by considering contextual information. Figure 3 displays the AG attention module’s internal structure. Here, input features are modulated by a concern coefficient related to the resampling grid, with refinement achieved through trilinear interpolation. Trilinear interpolation is an efficient data upsampling technique. This technique interpolates in three-dimensional space to upscale low-resolution attention weights to match the size of high-resolution feature maps. The attention coefficient , ranging from 0 to 1, pinpoints critical image areas for focused analysis. The “attention coefficient” refers to the values computed by the attention gate mechanism to identify salient image regions and prune feature responses, thus preserving only the activations relevant to the specific task. For each pixel, the gated vector specifies the region of interest, as detailed in Equations (1) and (2). The ReLU function is denoted by , while represents the sigmoid activation function. Linear transformations and , along with an offset and , embody the AG’s parameter set. These transformations lead to a vector-based connection notation for cascaded features between and g within the intermediary space of . The AG’s output merges input elements with attention coefficients through elementwise multiplication, as formulaically represented in Equation (3). In this study, the AG calculates a singular scalar focus value for each pixel vector , with indicating the number of feature maps at layer l.
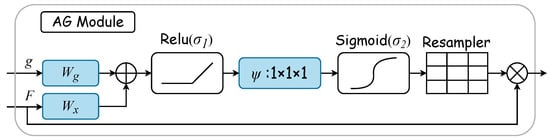
Figure 3.
AG module. The gated vector g specifies the region of interest. Linear transformations and , along with an offset , embody the AG’s parameter set. These transformations are executed via convolution across the input tensor’s channels, thus leading to a vector-based connection notation. The AG’s output merges input elements with attention coefficients through elementwise multiplication.
The AG module dynamically learns to focus on medical image structures of diverse shapes and sizes. It uses an AG-filtered model to emphasize features pertinent to specific tasks through implicit learning and attenuates irrelevant image areas [36]. In ultrasonic tongue contour extraction, the AG plays a crucial role in accentuating essential contours and diminishing nonessential pixels. Thus, integrating the AG into the extraction network is anticipated to substantially enhance network efficiency.
2.3.2. CBAM
Outlined within the yellow dotted box in Figure 2, the Convolutional Block Attention Module integrates a channel attention module with a spatial attention module. The channel attention mechanism formulates an attention map by exploring interchannel relationships. Initially, it synthesizes two distinct spatial context descriptors through the aggregation of feature map spatial information via average and maximum pooling, thus yielding the average pooling feature and the maximum pooling feature . These descriptors are then processed by a shared network, which is typically a multilayer perceptron (MLP) with a hidden layer, to produce a channel attention map . To optimize parameter efficiency, the hidden layer’s dimensionality is reduced to , with r denoting the reduction ratio. Subsequently, the outputs for each descriptor, obtained after passing through the shared network, are aggregated via elementwise summation. The formulation for channel attention is detailed in Equation (4), where denotes the sigmoid activation function, and and represent the MLP’s shared weights, with succeeded by the ReLU activation function. Figure 4 displays the schematic of the channel attention module.
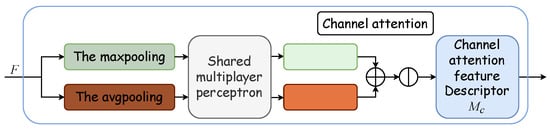
Figure 4.
Channel attention module. The channel attention module synthesizes two distinct spatial context descriptors through the aggregation of feature map spatial information via average and maximum pooling, thus yielding the average pooling feature and the maximum pooling feature . These descriptors are then processed by a shared multilayer perceptron (MLP) with a hidden layer to produce a channel attention map .
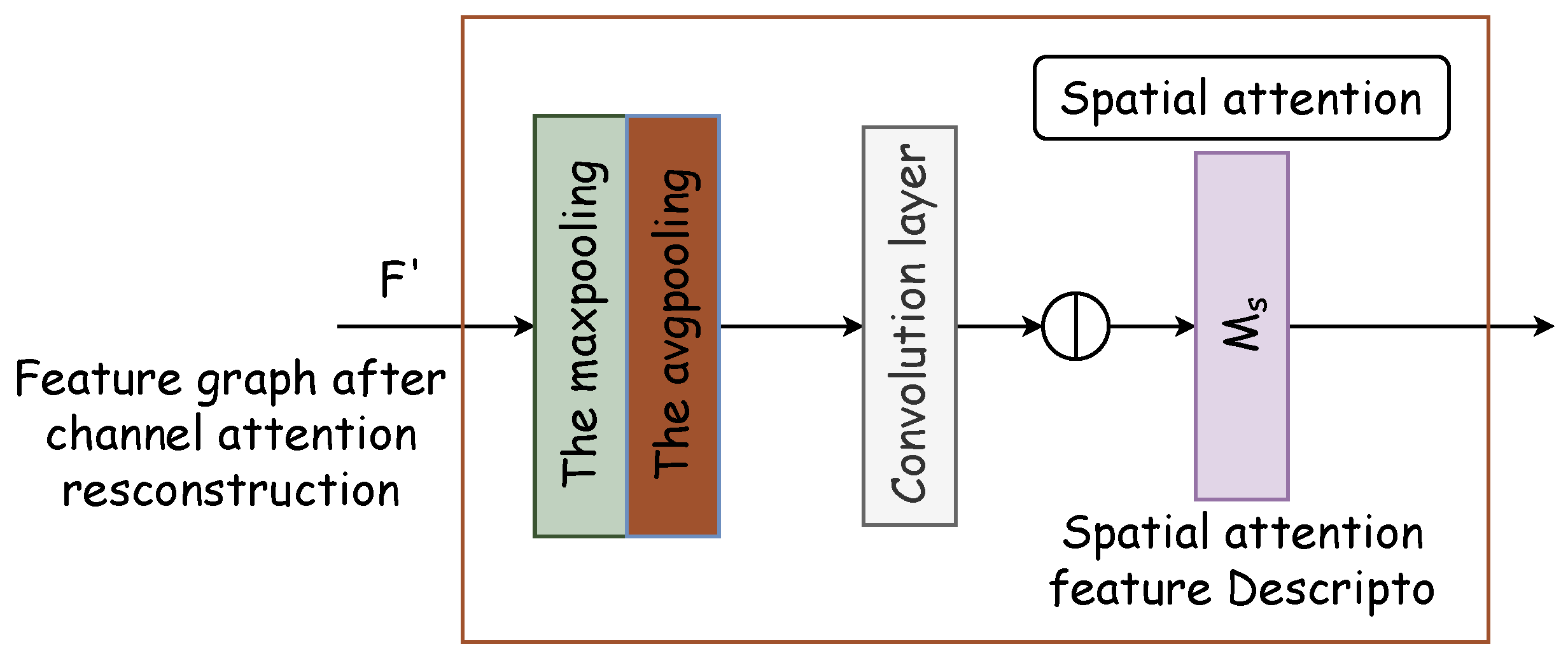
The spatial attention module generates a spatial attention map by leveraging the spatial relationships of features. It distinguishes itself from the channel attention by focusing on the locational information of the target features, thereby complementing channel attention. The spatial attention module’s internal architecture is depicted in Figure 5. Initially, two pooling operations compile the channel information of the feature map along the channel axis, thus producing the two-dimensional effective feature descriptors and . Subsequently, these descriptors are concatenated and processed through a standard convolutional layer to form a 2D spatial attention map , which designates areas to be highlighted or de-emphasized for feature extraction. The methodology for calculating spatial attention is delineated in Equation (5).
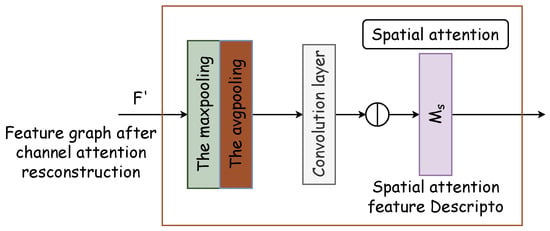
Figure 5.
Spatial attention module. Two pooling operations compile channel information of the feature map along the channel axis, thus producing two-dimensional effective feature descriptors and . Subsequently, these descriptors are concatenated and processed through a standard convolutional layer to form a 2D spatial attention map .
Within the network, the CBAM processes encoded information by addressing both the channel and spatial relationships, thus representing the features to be extracted through a feature vector. Unlike the original U-Net, where full-scale information is directly transferred to the decoding block via skip connections, the modified approach determines the key feature positions first. As a result, with CBAM integration, U-Net selectively channels crucial information to the decoding stage. It enables pixel reconstruction by combining significant feature information at this scale with decoding inputs from other scales to finalize the prediction. The CBAM not only expedites the decoding process but also enhances accuracy by pinpointing essential feature locations, thereby improving the precision of pixel recovery.
3. Experiment
3.1. Data Preparation
The dataset utilized in this study encompasses the NS dataset, TJU dataset, and TIMIT dataset. The NS dataset comprises 3926 video frames featuring two American English speakers: a male and a female enunciating “The North Wind and The Sun”. The TJU dataset originates from a laboratory at Tianjin University, which was collected from four male native Chinese speakers who recorded real-time ultrasound tongue videos in a professional noise-cancelling environment. The TIMIT dataset represents a comprehensive collection of continuous English speech recorded by native speakers from various regions across the United States, thus encompassing diverse dialects. Each dataset includes ultrasound frames that provide a midsagittal view of the tongue movement during speech, with a resolution of 480 pixels × 640 pixels. These ultrasound frames have been digitized as 2D matrices, where each column corresponds to the ultrasonic reflection intensity along a singular scan line. The ground truth masks have been manually drawn by experienced radiologists to ensure accurate labeling of tongue contours.
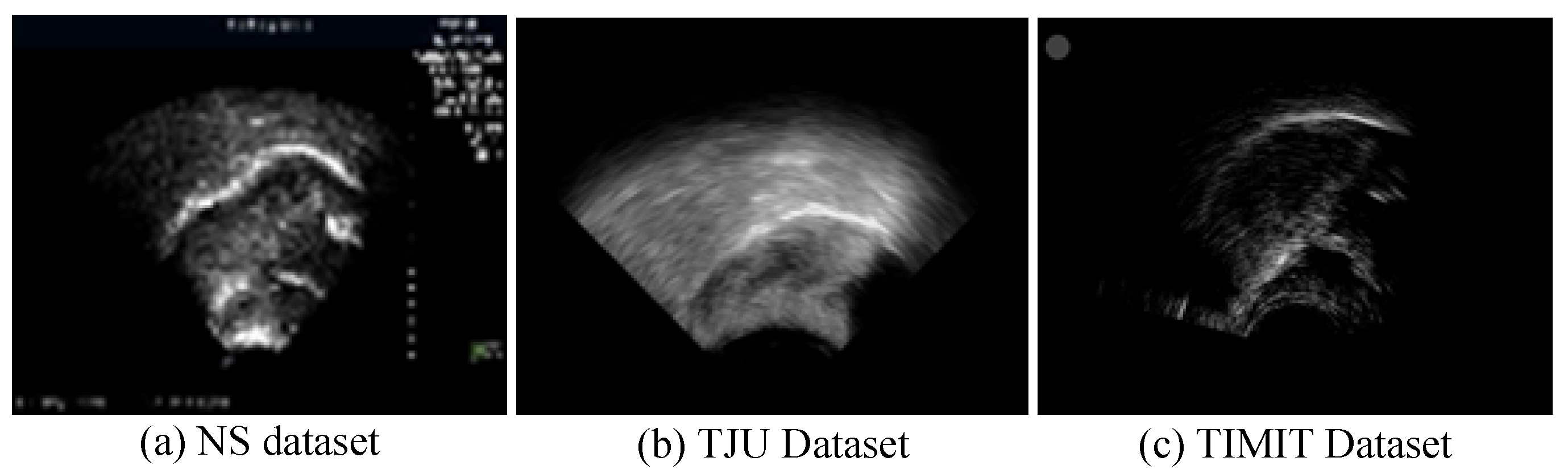
In ultrasound recordings, the tongue’s contour is delineated by the reflection of ultrasonic waves at the boundary between the tongue and the air above it, thus manifesting as a luminous band. Figure 6 displays ultrasound transducer imaging results, with (a) to (c) representing samples from the NS dataset, TJU dataset, and TIMIT dataset, respectively. The NS dataset features a white sagittal contour that stands out more clearly against the background than those in the other two datasets. In the TJU dataset, the tongue’s contour significantly merges with the surrounding oral cavity, thus making segmentation notably more challenging compared to the other datasets. Meanwhile, the TIMIT dataset’s tongue contour is slender and lacks uniform clarity along its entire length, thus posing difficulties in segmenting the complete tongue line. Although it is less blended with the oral environment, these characteristics still present challenges.
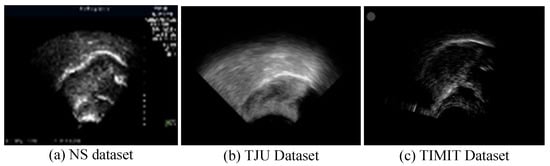
Figure 6.
Imaging results of the ultrasonic transducer, with (a–c) representing samples from the NS dataset, TJU dataset, and TIMIT dataset, respectively. The prominent line at the center represents the tongue’s lateral contour, thus extending from the tongue’s root on the left to its tip on the right.
3.2. Data Preprocessing
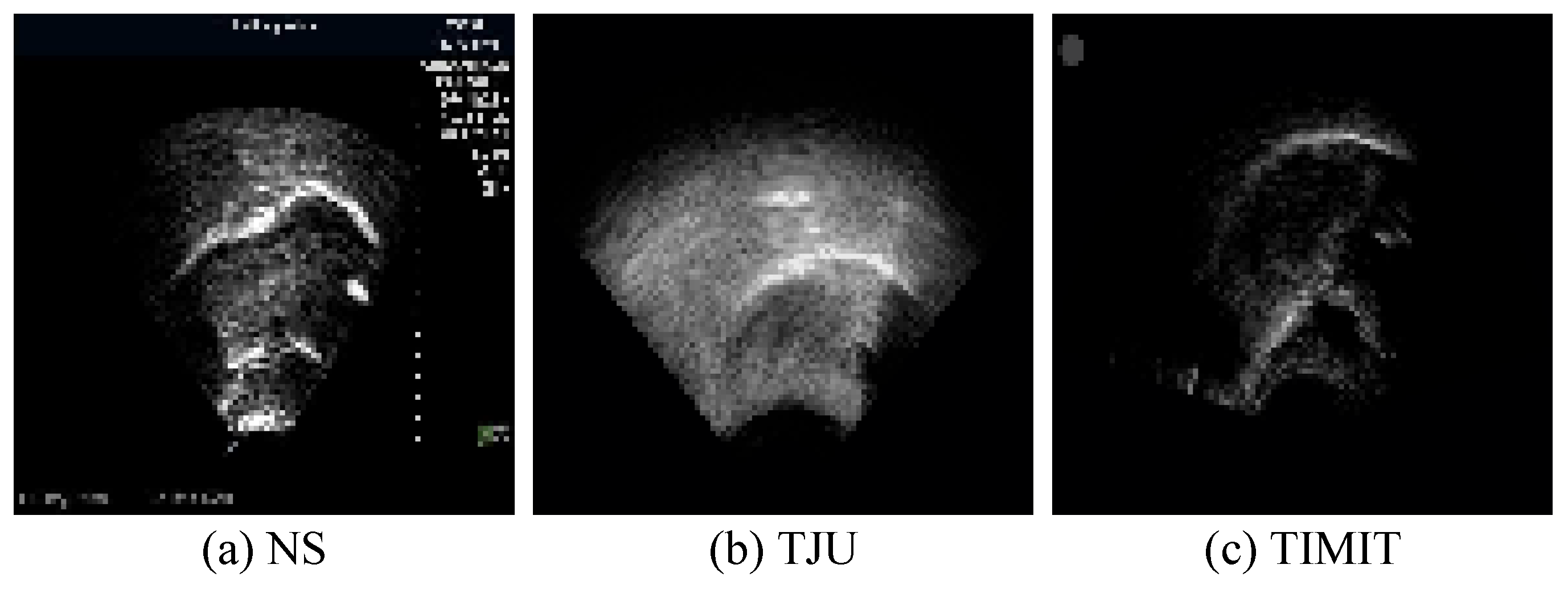
The white pixels delineating the tongue contour constitute merely 2% of the total pixels in each image. The absence of a clear reference for the tongue’s soft tissue structure results in contours characterized by burrs and discontinuities. This lack of smooth processing can adversely affect the accuracy of ultrasonic tongue contour extraction. To mitigate this, the datasets have been enriched with supplementary information, thereby ensuring that the ground truth encompasses more comprehensive knowledge. This enhancement significantly aids in refining feature extraction accuracy, thereby facilitating subsequent speech research endeavors. Additionally, to augment the datasets’ recognition rate within the network, data augmentation techniques were applied prior to network input. Specifically, transformer packages adjusted saturation, brightness, and contrast based on random probabilities, thus applying random rotations and flips to the training images. These augmentations were executed through the Compose and Oneof functions. Moreover, to enable precise feature extraction from ultrasonic datasets of various sizes and origins, uniform preprocessing was conducted before network training. For this experiment, the images across all datasets were resized to 96 pixels × 96 pixels. Figure 7 illustrates images from the tongue datasets following this preprocessing regimen.
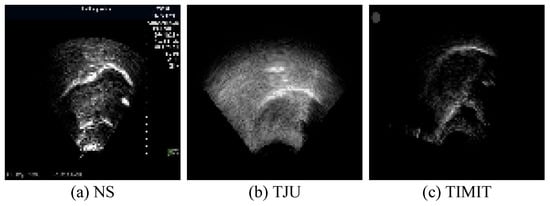
Figure 7.
Sample preprocessing results from the tongue datasets following the preprocessing operation.
3.3. Experimental Implement
The experiment was conducted on a high-performance NVIDIA Tesla V100 GPU training server equipped with 32 GB of video memory, an 8-core CPU, and 40 GB of system memory, thus ensuring a consistent hardware environment for both training and testing phases. The computational setup utilized the Windows 10 operating system, with Python 3.6 serving as the programming language. The design and debugging of the neural network architecture were performed within the PyTorch 1.6.0 framework, thus leveraging its extensive open-source resources.
3.4. Evaluation Metrics
In this study, loss, Intersection over Union (IoU), and processing time serve as metrics to evaluate the network’s segmentation efficacy.
Loss and IoU are crucial for assessing the precision of feature extraction in segmentation tasks. Loss, defined as binary crossentropy, quantifies the discrepancy between predicted outputs and actual targets. It is a fundamental metric in target detection, thus providing insight into the model’s performance. IoU, on the other hand, gauges the pixel-level congruence between the segmented tongue contour and the true mask, thus serving as a direct measure of segmentation accuracy. The loss calculation is described by Equation (6), where N denotes the total pixel count, denotes the true label, denotes the predicted label, and denotes the mapping function. The IoU’s formulation, shown in Equation (7), involves as the prediction, as the ground truth, c as each pixel, and as the mapping function. A smaller loss value and a larger IoU indicate enhanced segmentation precision.
In this study, the processing time was utilized to assess the network’s real-time performance capabilities. The experimental datasets consist entirely of image sets, analogous to frames in video processing, thus rendering the input to the network as static images, with the testing datasets also comprising image sets. Consequently, the time required to test a single image was chosen as a proxy for the network’s testing speed. This metric, denoted as Time, is measured in milliseconds and corresponds to the duration needed to process each image frame. Time not only reflects the speed at which segmentation tasks are completed but also serves as a critical metric for evaluating the network’s performance. Essentially, the shorter the processing time, the faster the image is processed, thus indicating superior real-time performance capabilities in practical applications.
3.5. Experiment Setting
The dataset distribution for the study was as follows: 50% for training, 20% for validation, and 30% for testing. The experiment utilized a batch_size of 32, a learning rate of 0.001, 100 iterations, a momentum of 0.9, and employed the Adam optimizer. An early stopping mechanism was incorporated to halt the training process using the validation set for monitoring. This ensured that the model achieving the lowest average loss on the validation set would be selected as the optimal model for further evaluation.
Given U-Net’s prevalence as a cornerstone medical segmentation network and a foundational model for numerous image recognition architectures, this study devised several comparative experiments centered around U-Net. It assessed the efficacy of Unet++, SA-UNet, and SegAN across the three datasets by examining loss, IoU, and time metrics to compare their accuracy and real-time feature extraction performance. Furthermore, to ascertain the contributions of the DAFT-Net network proposed in this research towards network simplification, the AG and CBAM modules were integrated to enhance U-Net’s functionality. This was followed by an ablation study to evaluate their impact.
4. Experimental Results and Discussion
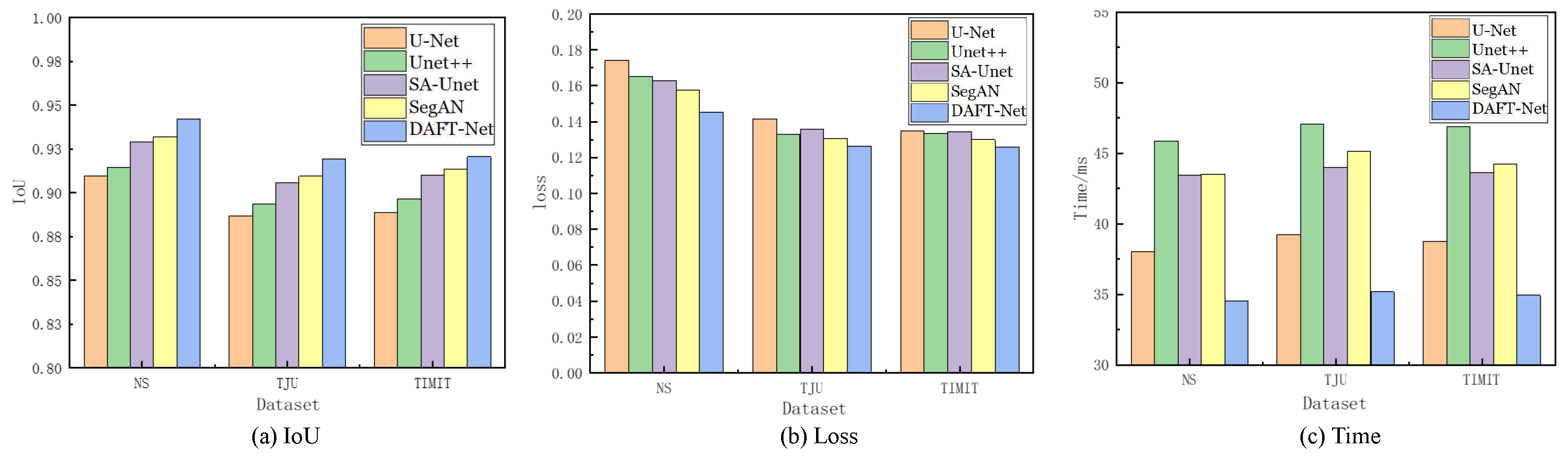
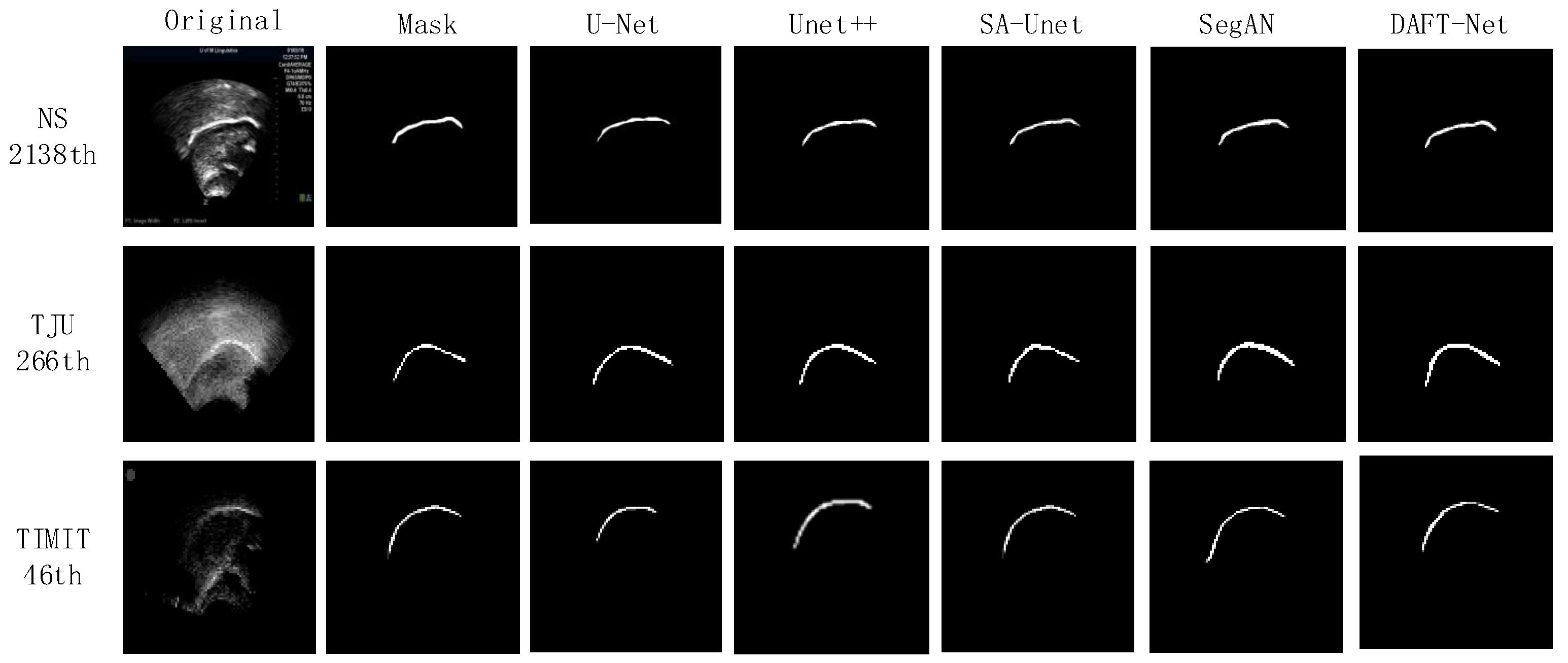
Using the U-Net network as a benchmark, UNet++, SA-UNet, and SegAN were included in comparative experiments. The comparative results are detailed in Table 1, where the IoU, loss, and Time metrics for each network across different datasets are enumerated. The and represent the ranking values according to quartiles for the methods with the highest IoU and the lowest loss values, as is similar to [37]. Figure 8 graphically illustrates these metrics for five networks across the three datasets via bar charts: (a) for IoU, (b) for loss, and (c) for Time. Figure 9 showcases the segmentation effects of the five networks arranged in a matrix of three rows and seven columns. A frame from each dataset was randomly selected for evaluation: frame 2138 from the NS dataset, frame 266 from the TJU dataset, and frame 46 from the TIMIT dataset. The first column presents the original sample images, the second column shows the corresponding mask images, and the third to seventh columns display the predictive outcomes from U-Net, UNet++, SA-UNet, SegAN, and DAFT-Net, respectively. This study conducted a comprehensive analysis of each network using these three metrics and segmentation effect diagrams, thus aiming to identify a network that balances high accuracy with rapid processing. Although the visual results of various methods appear similar, DAFT-Net had an advantage in enhancing edge definition. This is crucial for subsequent medical applications such as real-time speech analysis and speech disorder assessment.

Table 1.
Comparative experimental results of IoU, loss, and Time metrics between our DAFT-Net and other four compared methods on the NS, TIMIT, TJU datasets.
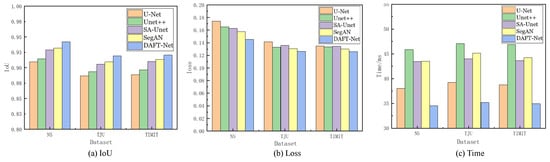
Figure 8.
Comparison of IoU, loss, and Time metrics for U-Net, UNet++, SA-UNet, SegAN, and DAFT-Net, respectively, across the NS, TIMIT, TJU datasets.
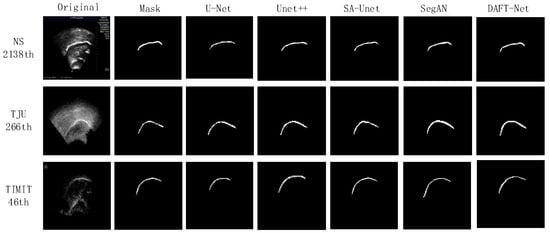
Figure 9.
Visual comparison results between our DAFT-Net and other four compared methods on the NS, TIMIT, TJU datasets.
Regarding the dataset performance, the five network groups ranked as follows: NS dataset > TIMIT dataset > TJU dataset. This ranking underscores the significant influence of dataset feature clarity on network extraction effectiveness. It also validates the anticipated challenges in feature extraction across the three datasets, as was predicted in Section 3.1.
The network comparison reveals that UNet++ enhanced U-Net by extending the selection of feature scales and enriching semantic information through a nested network structure. However, its fragmented and complex internal structure significantly increased the operational parameter count, thus presenting challenges for real-time ultrasonic tongue imaging applications. Notably, UNet++ demonstrated a 7.85 ms (20.64%) longer processing time on the NS dataset compared to U-Net, thus highlighting its limitations in real-time performance.
SA-UNet, on the other hand, reimagines U-Net by incorporating a spatial attention mechanism [36], thus showcasing how attention mechanisms can refine U-Net’s architecture. Despite its modest time improvement over U-Net, SA-UNet exceled in accuracy, thus underscoring the benefits of spatial attention in segmentation tasks.
SegAN, a generative adversarial network with segmentation capabilities, achieved stable feature extraction with minimal training samples. Nevertheless, the adversarial process, involving the generation of false samples to deceive the discriminator, prolonged the extraction timeline [38]. Compared to its counterparts, SegAN underperformed in the processing speed relative to U-Net, matched SA-UNet, and surpassed only UNet++. DeepLabv3 is based on atrous convolution and spatial pyramid pooling. As shown in Table 1, compared to non-UNet methods such as SegAN and DeepLabv3, our improved UNet-based method demonstrated greater advantages.
The approach introduced in this study involves integrating an attention gate module into the SA-UNet framework and substituting its original spatial attention mechanism with a CBAM that addresses both spatial and channel relations. While this adjustment ostensibly complicates the network’s architecture, it facilitates swift feature extraction—a capability substantiated by the experimental outcomes. The AG and CBAM modules primarily expedite the identification of crucial features, thereby enhancing segmentation and extraction processes. Despite their intricate functionality, the computational demand and resource consumption of these modules are minimal, thus owing to the efficiency of the internal connection and convolution operations. Consequently, this dual-module integration significantly refines the accuracy of ultrasonic tongue contour extraction without extending the network’s operational duration. Moreover, this streamlined network, augmented by the synergistic function of both attention modules, achieved notable segmentation speeds—94.23% accuracy within 34.55 ms/frame on the NS dataset, 91.95% accuracy within 35.17 ms/frame on the TJU dataset, and 92.06% accuracy within 34.93 ms/frame on the TIMIT dataset—thus demonstrating its efficacy in rapid segmentation tasks.
5. Ablation Experiment Validation
This paper streamlined the U-Net architecture by reducing its layers and incorporated both the AG and CBAM modules via a parallel configuration, thus resulting in the creation of DAFT-Net. The design process focused on three pivotal modifications: (1) layer reduction in U-Net; (2) integration of the AG module; and (3) integration of the CBAM module. To evaluate the individual impact of these components on the baseline U-Net network, dedicated ablation studies were conducted.
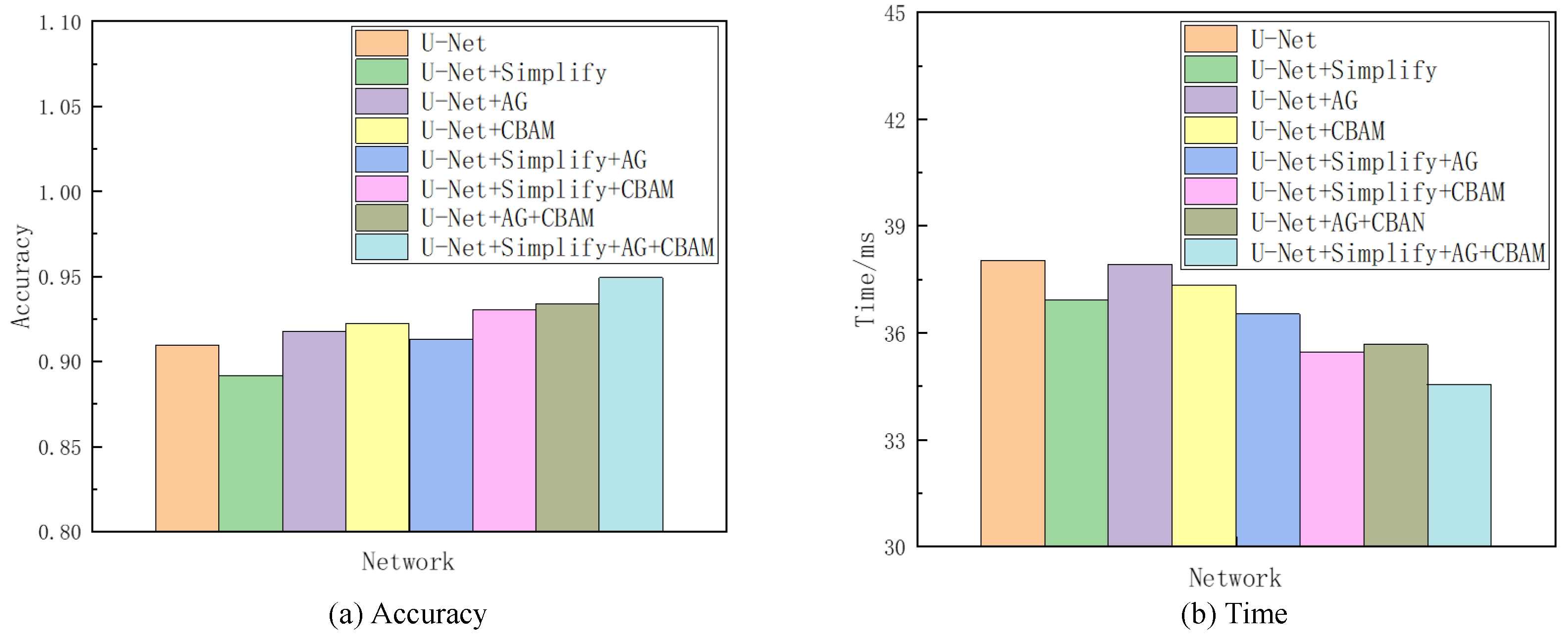
Given the superior segmentation performance on the NS dataset in terms of both accuracy and speed, as detailed in Section 4, it was selected as the reference for the subsequent ablation analysis. This investigation encompassed seven sets of comparative experiments. The network variant derived from U-Net by excising one convolutional layer at each codec level is denoted as “Simplify” in the analysis. Combining “Simplify”, AG, and CBAM with U-Net through all possible permutations yielded seven distinct networks, thus excluding the original U-Net. The evaluative focus of these models’ training and testing phases centered on discerning the contributory value of each element. This value was inferred from comparative analysis, with enhancements in accuracy and processing time being indicative of each component’s efficacy in augmenting the baseline network. Given the project’s emphasis on sagittal tongue contour segmentation, the IoU served as the primary metric for accuracy, while the Time metric quantified the duration each model took to process an identical ultrasonic image. Table 2 compiles the findings from this ablation study, and Figure 10 provides a visual comparative analysis through bar charts, thus showcasing each model’s performance on the NS dataset concerning accuracy and time. Additionally, visualization tests from various networks on frame 2138 of the NS dataset within this ablation framework are itemized in Table 3.
Table 2.
Ablation study of proposed modules on the NS dataset. Simplify denotes the network variant derived from U-Net by excising one convolutional layer at each encoder level. AG represents the Attention Gate module. The CBAM denotes the Convolutional Block Attention Module. The accuracy means the IoU metrics. The Time metric quantifies the duration each model takes to process an identical ultrasonic image.
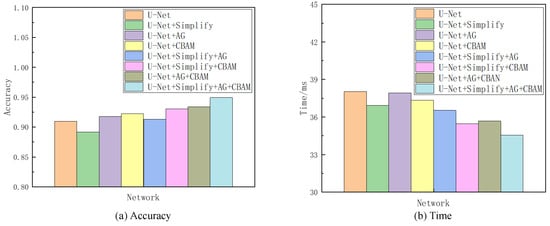
Figure 10.
Comparison of accuracy and Time metirics of the ablation experiments on the NS dataset.
Table 3.
Visualization test results of each network in the ablation experiments (with the 2138th frame of the NS dataset taken as an example). Simplify denotes the network variant derived from U-Net by excising one convolutional layer at each codec level. AG represents the Attention Gate module. The CBAM denotes the Convolutional Block Attention Module.
Referencing Table 2 and Table 3, as well as Figure 10, the Simplify version of U-Net exhibited a modest decline in accuracy by 1.8% compared to the original network. However, it showed a processing time improvement of 1.11 ms attributed to reduced convolutional layer parameters and computational load. This Simplify model strikes a good balance between accuracy and speed, thus demonstrating an overall superior performance in ultrasonic tongue contour extraction tasks relative to the original U-Net architecture. The integration of attention modules further enhances both accuracy and efficiency. Specifically, employing the AG module alone outperformed both Simplify and U-Net in terms of accuracy, with its processing time falling between the two. Utilizing the CBAM module independently yielded even better results in accuracy and time than using the AG module alone. Combining both attention modules surpassed the performance achieved with either module individually, with an accuracy increase of 1.6% and a 2.25 ms reduction in processing time compared to the AG module alone. Compared to the CBAM module alone, the dual-module approach improved the accuracy by 1.1% and reduced the processing time by 1.66 ms. The incorporation of Simplify with both modules markedly enhanced the metrics, thus showing a 5.87% improvement in accuracy and a 2.37 ms decrease in processing time compared to using Simplify alone.
The outcomes of the ablation studies underscore the practical viability of balancing accuracy and speed. U-Net, a well-established image segmentation network, exemplifies how a thoughtfully designed lightweight framework can ensure precise feature extraction. This paper advances the network’s architecture by streamlining the original structure and integrating a triple attention mechanism. The introduction of the Simplify, AG, and CBAM modules enhances U-Net’s already formidable capability in ultrasonic tongue contour extraction, thus highlighting the significant benefits of these strategic modifications.
The effectiveness of incorporating entropy and information theory into the DAFT-Net is evident in its improved performance. Our analysis highlights the network’s enhanced capability in reducing entropy and efficiently managing information, thus leading to more precise and faster tongue contour extraction. This advancement not only aligns with the theoretical expectations of entropy and information theory but also enhances the way these concepts are applied in medical image analysis.
6. Conclusions
This paper proposes a U-Net-based algorithm for ultrasonic tongue contour image segmentation, thus integrating Attention Gate and Convolutional Block Attention Modules empowered by entropy and information theory. Experimental findings across three datasets demonstrate that incorporating attention mechanisms enhances efficiency. This was achieved either by enhancing the original U-Net’s connectivity or by simplifying the network through reduced convolutional layers. These methods align with the objectives of entropy minimization and information maximization. The combined implementation of these modifications utilizes entropy-based and information-theoretic approaches to accelerate feature extraction and improves segmentation accuracy while conserving computational resources. If successfully applied to actual ultrasonic tongue contour extraction tasks, this method could significantly streamline collaboration with silent speech and other medical fields. It demonstrates the practical applicability of entropy and information theory in enhancing medical image processing. This breakthrough aligns with our research group’s objectives and marks a significant step forward in the interdisciplinary application of information theory and entropy to medical image analysis.
Author Contributions
Conceptualization, methodology, software, investigation, writing—original draft preparation, X.W.; writing—review and editing, H.L.; formal analysis, visualization, W.L., W.Z. and H.L.; supervision, project administration, W.L. and Q.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China [grant number 62272337]. We also thank the datasets provided by the Tianjin University Laboratory.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The NS and TIMIT datasets are datasets are publicly available on the network. The TJU dataset is provided by Tianjin University Laboratory and is not public at present.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Gilbert, J.M.; Gonzalez, J.A.; Cheah, L.A.; Ell, S.R.; Green, P.; Moore, R.K.; Holdsworth, E. Restoring speech following total removal of the larynx by a learned transformation from sensor data to acoustics. J. Acoust. Soc. Am. Express Lett. 2017, 141, EL307–EL313. [Google Scholar] [CrossRef] [PubMed]
- Ji, Y.; Liu, L.; Wang, H.; Liu, Z.; Niu, Z.; Denby, B. Updating the silent speech challenge benchmark with deep learning. Speech Commun. 2018, 98, 42–50. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, J. Improving Ultrasound Tongue Image Reconstruction from Lip Images Using Self-supervised Learning and Attention Mechanism. arXiv 2021, arXiv:2106.11769. [Google Scholar]
- McKeever, L.; Cleland, J.; Delafield-Butt, J. Using ultrasound tongue imaging to analyse maximum performance tasks in children with Autism: A pilot study. Clin. Linguist. Phon. 2022, 36, 127–145. [Google Scholar] [CrossRef] [PubMed]
- Eshky, A.; Cleland, J.; Ribeiro, M.S.; Sugden, E.; Richmond, K.; Renals, S. Automatic audiovisual synchronisation for ultrasound tongue imaging. Speech Commun. 2021, 132, 83–95. [Google Scholar] [CrossRef]
- Stone, M. A guide to analysing tongue motion from ultrasound images. Clin. Linguist. Phon. 2005, 19, 455–501. [Google Scholar] [CrossRef] [PubMed]
- Hsiao, M.Y.; Wu, C.H.; Wang, T.G. Emerging role of ultrasound in dysphagia assessment and intervention: A narrative review. Front. Rehabil. Sci. 2021, 2, 708102. [Google Scholar] [CrossRef] [PubMed]
- Cloutier, G.; Destrempes, F.; Yu, F.; Tang, A. Quantitative ultrasound imaging of soft biological tissues: A primer for radiologists and medical physicists. Insights Imaging 2021, 12, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Trencsényi, R.; Czap, L. Possible methods for combining tongue contours of dynamic MRI and ultrasound records. Acta Polytech. Hung. 2021, 18, 143–160. [Google Scholar] [CrossRef]
- Li, M.; Kambhamettu, C.; Stone, M. Automatic contour tracking in ultrasound images. Clin. Linguist. Phon. 2005, 19, 545–554. [Google Scholar] [CrossRef] [PubMed]
- Ghrenassia, S.; Ménard, L.; Laporte, C. Interactive segmentation of tongue contours in ultrasound video sequences using quality maps. In Proceedings of the Medical Imaging 2014: Image Processing, San Diego, CA, USA, 16–18 February 2014; SPIE: Bellingham, WA, USA, 2014; Volume 9034, pp. 1046–1052. [Google Scholar]
- Laporte, C.; Ménard, L. Robust tongue tracking in ultrasound images: A multi-hypothesis approach. In Proceedings of the Interspeech, Dresden, Germany, 6–10 September 2015; pp. 633–637. [Google Scholar]
- Xu, K.; Yang, Y.; Stone, M.; Jaumard-Hakoun, A.; Leboullenger, C.; Dreyfus, G.; Roussel, P.; Denby, B. Robust contour tracking in ultrasound tongue image sequences. Clin. Linguist. Phon. 2016, 30, 313–327. [Google Scholar] [CrossRef] [PubMed]
- Tang, L.; Hamarneh, G. Graph-based tracking of the tongue contour in ultrasound sequences with adaptive temporal regularization. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 154–161. [Google Scholar]
- Tang, L.; Bressmann, T.; Hamarneh, G. Tongue contour tracking in dynamic ultrasound via higher-order MRFs and efficient fusion moves. Med. Image Anal. 2012, 16, 1503–1520. [Google Scholar] [CrossRef] [PubMed]
- Fabre, D.; Hueber, T.; Bocquelet, F.; Badin, P. Tongue tracking in ultrasound images using eigentongue decomposition and artificial neural networks. In Proceedings of the Interspeech 2015-16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Berry, J.; Fasel, I. Dynamics of tongue gestures extracted automatically from ultrasound. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 557–560. [Google Scholar]
- Li, B.; Xu, K.; Feng, D.; Mi, H.; Wang, H.; Zhu, J. Denoising convolutional autoencoder based B-mode ultrasound tongue image feature extraction. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 7130–7134. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Li, G.; Chen, J.; Liu, Y.; Wei, J. wUnet: A new network used for ultrasonic tongue contour extraction. Speech Commun. 2022, 141, 68–79. [Google Scholar] [CrossRef]
- Nie, W.; Yu, Y.; Zhang, C.; Song, D.; Zhao, L.; Bai, Y. Temporal-spatial Correlation Attention Network for Clinical Data Analysis in Intensive Care Unit. IEEE Trans. Biomed. Eng. 2023, 71, 583–595. [Google Scholar] [CrossRef] [PubMed]
- Saha, P.; Liu, Y.; Gick, B.; Fels, S. Ultra2speech-a deep learning framework for formant frequency estimation and tracking from ultrasound tongue images. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, 4–8 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 473–482. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters–improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed]
- Nie, W.; Zhang, C.; Song, D.; Bai, Y.; Xie, K.; Liu, A.A. Chest X-ray Image Classification: A Causal Perspective. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Vancouver, BC, Canada, 8–12 October 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 25–35. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Ding, Q. Understanding and improving deep learning-based rolling bearing fault diagnosis with attention mechanism. Signal Process. 2019, 161, 136–154. [Google Scholar] [CrossRef]
- Nie, W.; Zhang, C.; Song, D.; Zhao, L.; Bai, Y.; Xie, K.; Liu, A. Deep reinforcement learning framework for thoracic diseases classification via prior knowledge guidance. Comput. Med. Imaging Graph. 2023, 108, 102277. [Google Scholar] [CrossRef] [PubMed]
- Eom, H.; Lee, D.; Han, S.; Hariyani, Y.S.; Lim, Y.; Sohn, I.; Park, K.; Park, C. End-to-end deep learning architecture for continuous blood pressure estimation using attention mechanism. Sensors 2020, 20, 2338. [Google Scholar] [CrossRef] [PubMed]
- Kaul, C.; Manandhar, S.; Pears, N. Focusnet: An attention-based fully convolutional network for medical image segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 455–458. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Tong, X.; Wei, J.; Sun, B.; Su, S.; Zuo, Z.; Wu, P. ASCU-Net: Attention gate, spatial and channel attention u-net for skin lesion segmentation. Diagnostics 2021, 11, 501. [Google Scholar] [CrossRef] [PubMed]
- Santamaría, J. Testing the Robustness of JAYA Optimization on 3D Surface Alignment of Range Images: A Revised Computational Study. IEEE Access 2024, 12, 19009–19020. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).