
Intermediate Judgments and Trust in Artificial Intelligence-Supported Decision-Making


Abstract
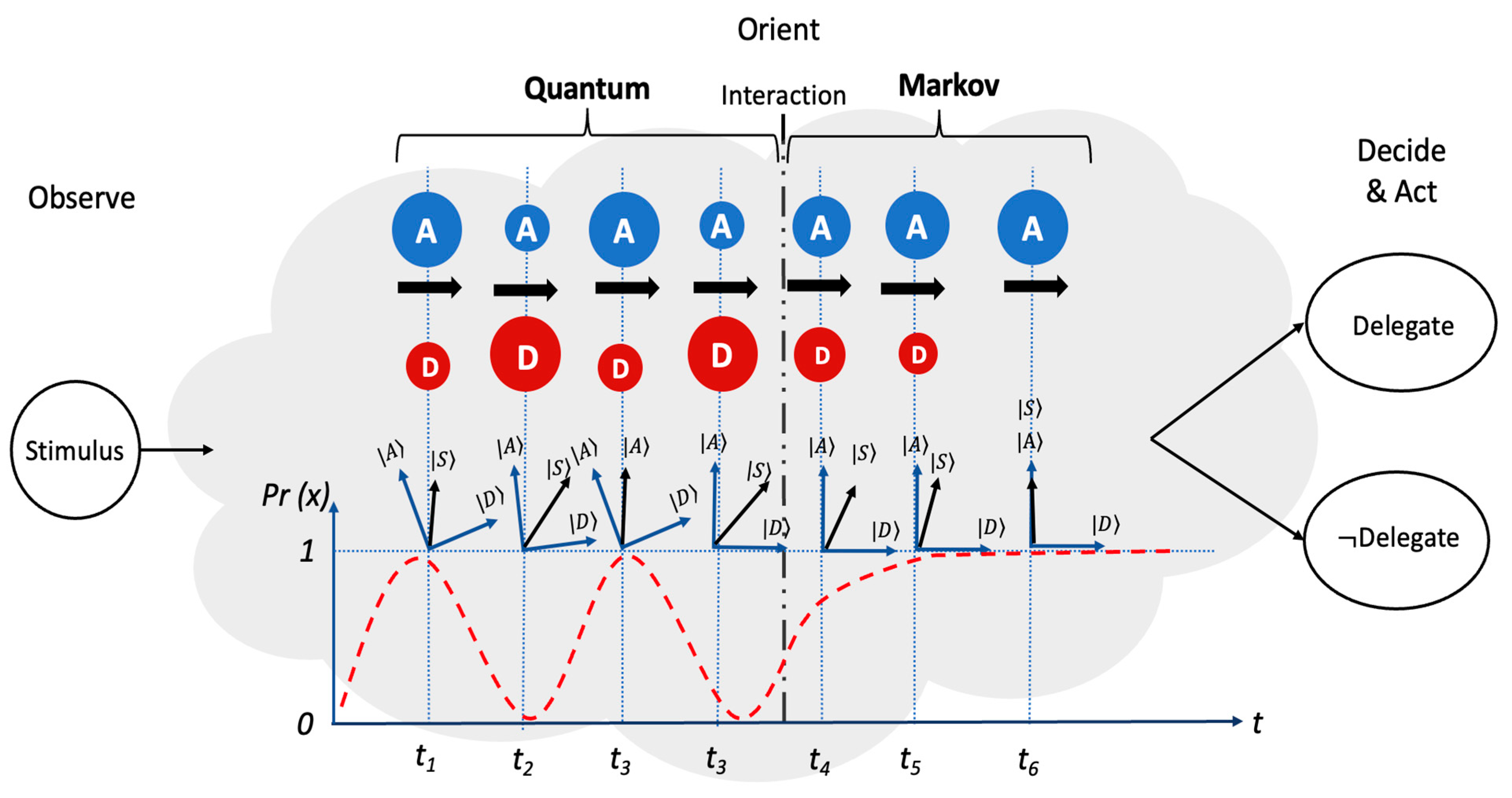
:1. Introduction
2. Background
2.1. Trust in AI for Decision-Making
2.2. Quantum Probability Theory
2.3. Modeling Human–AI Decision-Making with Quantum Probability
2.4. Quantum Open Systems Approach
2.5. Trust and Ontic Uncertainty
3. Methods
3.1. Participants
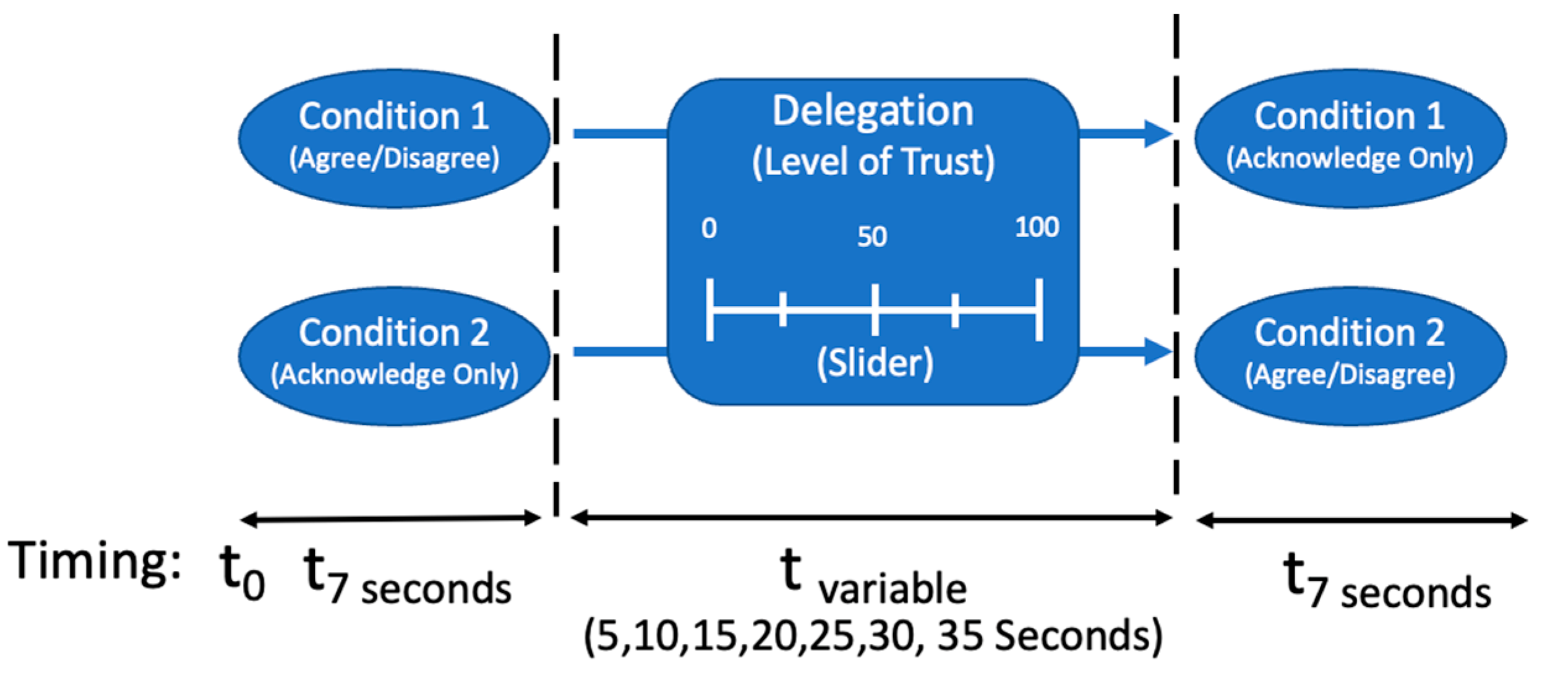
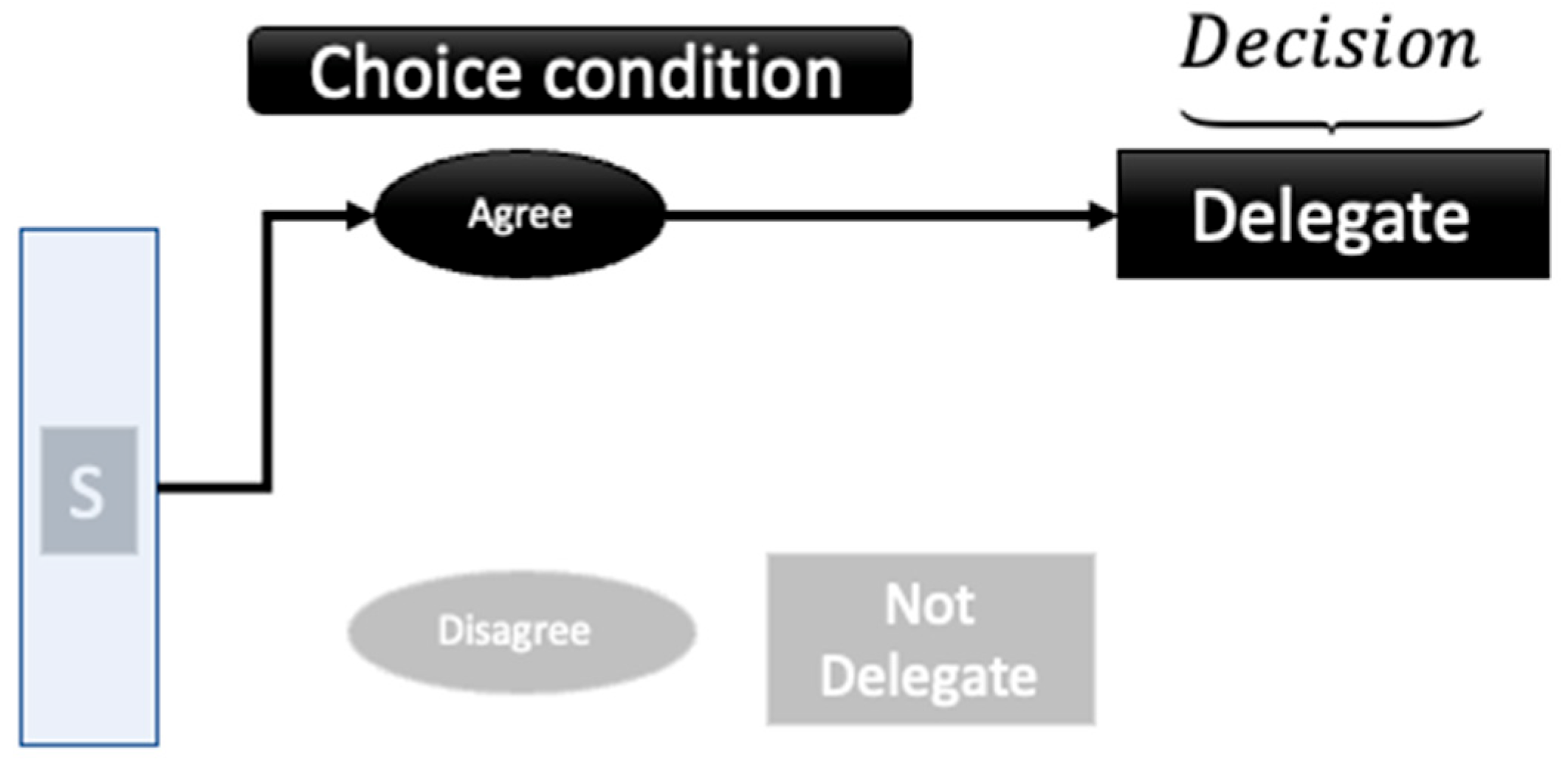
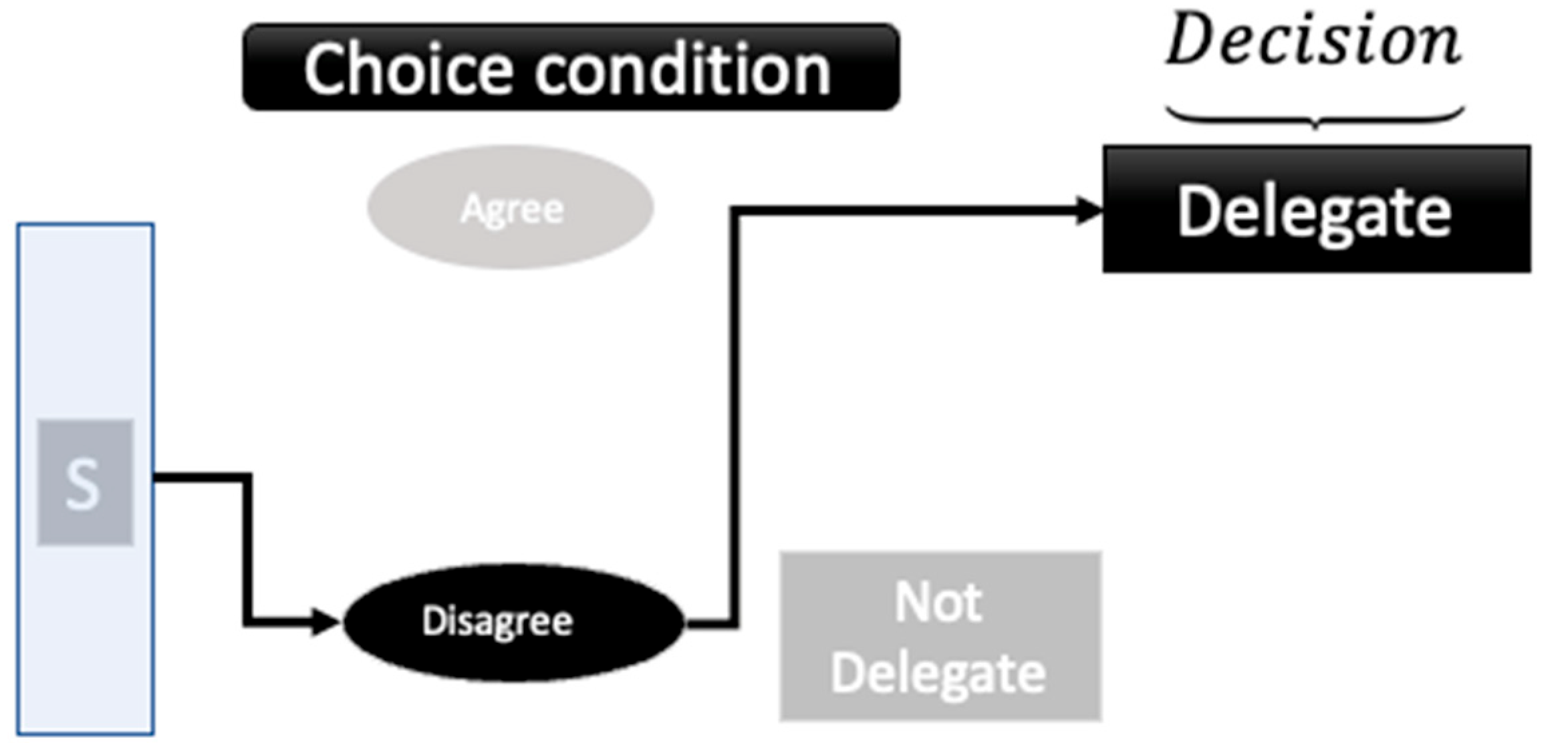
3.2. Overall Design
3.3. Experimental Procedure
4. Results
4.1. Modeling Delegation Strength with Quantum Open Systems to the Study Data
4.2. Comparison between Markov and Quantum Models
5. Quantum Open Systems
5.1. Quantum Open System Equation Components and Explanations
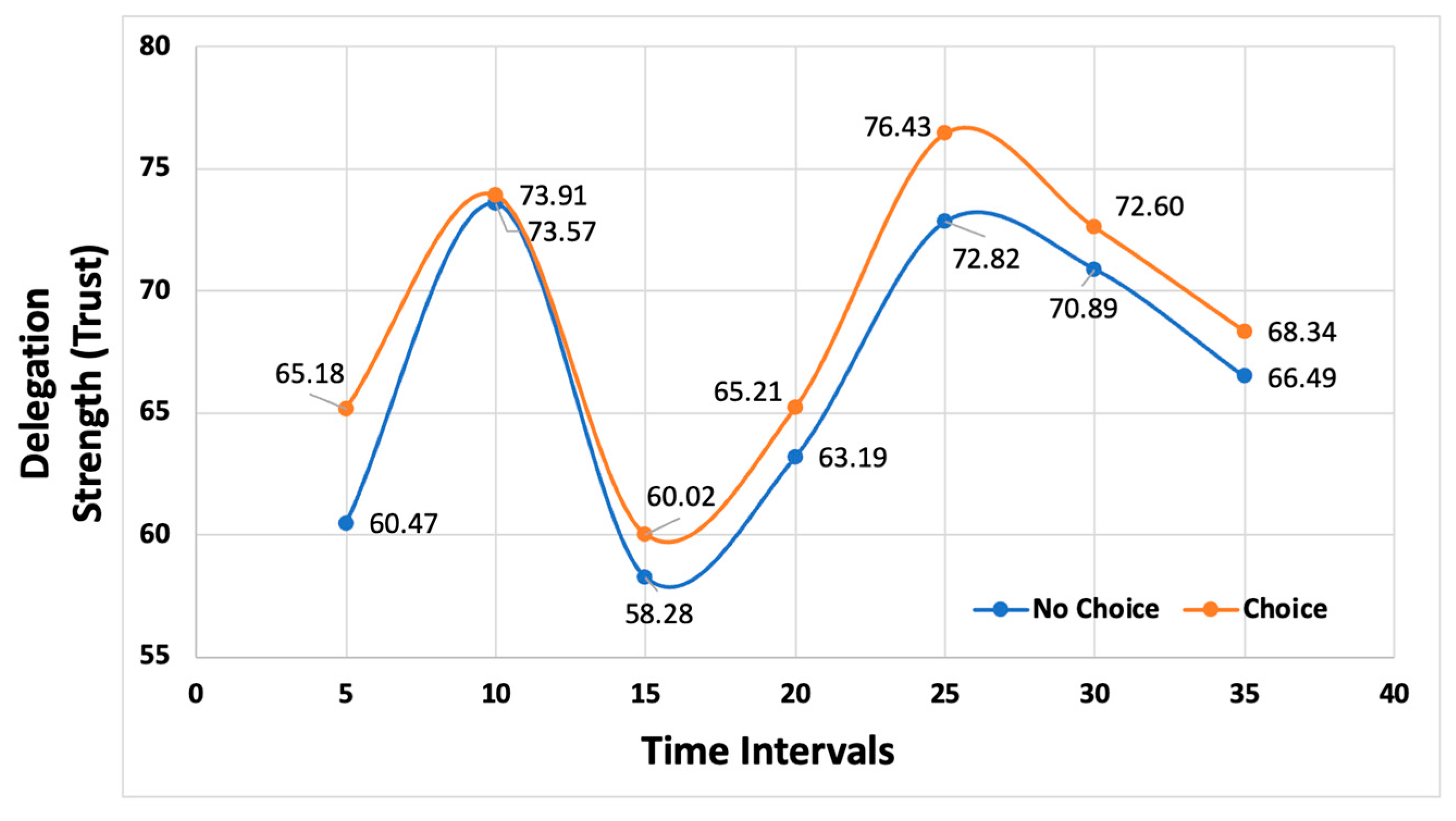
5.2. Exploratory Analysis
6. Discussion
6.1. Limitations
6.2. Future Research
7. Summary
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Fuchs, A.; Passarella, A.; Conti, M. Modeling, replicating, and predicting human behavior: A survey. ACM Trans. Auton. Adapt. Syst. 2023, 18, 4. [Google Scholar] [CrossRef]
- Waardenburg, L.; Huysman, M.; Sergeeva, A.V. In the land of the blind, the one-eyed man is king: Knowledge brokerage in the age of learning algorithms. Organ. Sci. 2022, 33, 59–82. [Google Scholar] [CrossRef]
- Denning, P.J.; Arquilla, J. The context problem in artificial intelligence. Commun. ACM 2022, 65, 18–21. [Google Scholar] [CrossRef]
- Blair, D.; Chapa, J.O.; Cuomo, S.; Hurst, J. Humans and hardware: An exploration of blended tactical workflows using john boyd’s ooda loop. In The Conduct of War in the 21st Century; Routledge: London, UK, 2021. [Google Scholar]
- Wrzosek, M. Challenges of contemporary command and future military operations|Scienti. Sci. J. Mil. Univ. Land Forces 2022, 54, 35–51. [Google Scholar]
- Bisantz, A.; Llinas, J.; Seong, Y.; Finger, R.; Jian, J.-Y. Empirical Investigations of Trust-Related Systems Vulnerabilities in Aided, Adversarial Decision Making. State Univ of New York at Buffalo Center of Multisource Information Fusion, Mar. 2000. Available online: https://apps.dtic.mil/sti/citations/ADA389378 (accessed on 30 April 2022).
- Hestad, D.R. A Discretionary-Mandatory Model as Applied to Network Centric Warfare and Information Operations. NAVAL POSTGRADUATE SCHOOL MONTEREY CA, Mar. 2001. Available online: https://apps.dtic.mil/sti/citations/ADA387764 (accessed on 30 April 2022).
- Marsh, S.; Dibben, M.R. The role of trust in information science and technology. Annu. Rev. Inf. Sci. Technol. 2002, 37, 465–498. [Google Scholar] [CrossRef]
- Kahneman, D. Thinking, Fast and Slow, 1st ed.; Farrar, Straus and Giroux: New York, NY, USA, 2013. [Google Scholar]
- Busemeyer, J.R.; Bruza, P.D. Quantum Models of Cognition and Decision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Thayyib, P.V.; Mamilla, R.; Khan, M.; Fatima, H.; Asim, M.; Anwar, I.; Shamsudheen, M.K.; Khan, M.A. State-of-the-Art of Artificial Intelligence and Big Data Analytics Reviews in Five Different Domains: A Bibliometric Summary. Sustainability 2023, 15, 4026. [Google Scholar] [CrossRef]
- Schneider, M.; Deck, C.; Shor, M.; Besedeš, T.; Sarangi, S. Optimizing Choice Architectures. Decis. Anal. 2019, 16, 2–30. [Google Scholar] [CrossRef]
- Susser, D. Invisible Influence: Artificial Intelligence and the Ethics of Adaptive Choice Architectures. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society; In AIES ’19; Association for Computing Machinery: New York, NY, USA, 2019; pp. 403–408. [Google Scholar] [CrossRef]
- Kvam, P.D.; Busemeyer, J.R.; Pleskac, T.J. Temporal oscillations in preference strength provide evidence for an open system model of constructed preference. Sci. Rep. 2021, 11, 8169. [Google Scholar] [CrossRef]
- Jayaraman, S.K.; Creech, C.; Robert, L.P., Jr.; Tilbury, D.M.; Yang, X.J.; Pradhan, A.K.; Tsui, K.M. Trust in av: An uncertainty reduction model of av-pedestrian interactions. In Companion of the 2018 ACM/IEEE International Conference on Human-Robot Interaction; In HRI’18; Association for Computing Machinery: New York, NY, USA, 2018; pp. 133–134. [Google Scholar] [CrossRef]
- Muir, B.M. Trust between humans and machines, and the design of decision aids. Int. J. Man-Mach. Stud. 1987, 27, 527–539. [Google Scholar] [CrossRef]
- Lee, J.; Moray, N. Trust, control strategies and allocation of function in human-machine systems. Ergonomics 1992, 35, 1243–1270. [Google Scholar] [CrossRef] [PubMed]
- Xu, A.; Dudek, G. Optimo: Online probabilistic trust inference model for asymmetric human-robot collaborations. In Proceedings of the Tenth Annual ACM/IEEE International Conference on Human-Robot Interaction; In HRI ’15; Association for Computing Machinery: New York, NY, USA, 2015; pp. 221–228. [Google Scholar] [CrossRef]
- Baylis, L.C. Organizational Culture and Trust within Agricultural Human-Robot Teams. Doctoral dissertation, Grand Canyon University, United States—Arizona. 2020. ProQuest Dissertations and Theses Global. Available online: https://www.proquest.com/docview/2459643625?pq-origsite=gscholar&fromopenview=true&sourcetype=Dissertations%20&%20Theses (accessed on 11 October 2021).
- Lewis, M.; Li, H.; Sycara, K. Chapter 14—Deep learning, transparency, and trust in human robot teamwork. In Trust in Human-Robot Interaction; Nam, C.S., Lyons, J.B., Eds.; Academic Press: Cambridge, MA, USA, 2021; pp. 321–352. [Google Scholar] [CrossRef]
- Cummings, M.L.; Huang, L.; Ono, M. Chapter 18—Investigating the influence of autonomy controllability and observability on performance, trust, and risk perception. In Trust in Human-Robot Interaction; Nam, C.S., Lyons, J.B., Eds.; Academic Press: Cambridge, MA, USA, 2021; pp. 429–448. [Google Scholar] [CrossRef]
- Barnes, M.J.; Chen, J.Y.C.; Hill, S. Humans and Autonomy: Implications of Shared Decision-Making for Military Operations. Human Research and Engineering Directorate, ARL, Aberdeen Proving Ground, MD, Technical ARL-TR-7919 2017. Available online: https://apps.dtic.mil/sti/citations/tr/AD1024840 (accessed on 12 April 2024).
- Glikson, E.; Woolley, A.W. Human trust in artificial intelligence: Review of empirical research. Acad. Manag. Ann. 2020, 14, 627–660. [Google Scholar] [CrossRef]
- Schaefer, K.E.; Perelman, B.; Rexwinkle, J.; Canady, J.; Neubauer, C.; Waytowich, N.; Larkin, G.; Cox, K.; Geuss, M.; Gremillion, G.; et al. Human-autonomy teaming for the tactical edge: The importance of humans in artificial intelligence research and development. In Systems Engineering and Artificial Intelligence; Lawless, W.F., Mittu, R., Sofge, D.A., Shortell, T., McDermott, T.A., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 115–148. [Google Scholar] [CrossRef]
- Cotter, J.E.; O’Hear, E.H.; Smitherman, R.C.; Bright, A.B.; Tenhundfeld, N.L.; Forsyth, J.; Sprague, N.R.; El-Tawab, S. Convergence across behavioral and self-report measures evaluating individuals’ trust in an autonomous golf cart. In Proceedings of the 2022 Joint 12th International Conference on Soft Computing and Intelligent Systems and 23rd International Symposium on Advanced Intelligent Systems (SCIS&ISIS), Charlottesville, VA, USA, 28–29 April 2022. [Google Scholar] [CrossRef]
- Araujo, T.; Helberger, N.; Kruikemeier, S.; de Vreese, C.H. In AI we trust? Perceptions about automated decision-making by artificial intelligence. AI Soc. 2020, 35, 611–623. [Google Scholar] [CrossRef]
- Basu, C.; Singhal, M. Trust dynamics in human autonomous vehicle interaction: A review of trust models. In AAAI Spring Symposia; AAAI Press: Palo Alto, CA, USA, 2016. [Google Scholar]
- Khawaji, A.; Zhou, J.; Chen, F.; Marcus, N. Using galvanic skin response (gsr) to measure trust and cognitive load in the text-chat environment. In Proceedings of the 33rd Annual ACM Conference Extended Abstracts on Human Factors in Computing Systems; In CHI EA ’15; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1989–1994. [Google Scholar] [CrossRef]
- Hergeth, S.; Lorenz, L.; Vilimek, R.; Krems, J.F. Keep your scanners peeled: Gaze behavior as a measure of automation trust during highly automated driving. Hum. Factors 2016, 58, 509–519. [Google Scholar] [CrossRef] [PubMed]
- Tenhundfeld, N.L.; de Visser, E.J.; Haring, K.S.; Ries, A.J.; Finomore, V.S.; Tossell, C.C. Calibrating trust in automation through familiarity with the autoparking feature of a tesla model x. J. Cogn. Eng. Decis. Mak. 2019, 13, 279–294. [Google Scholar] [CrossRef]
- Huang, L.; Cooke, N.J.; Gutzwiller, R.S.; Berman, S.; Chiou, E.K.; Demir, M.; Zhang, W. Chapter 13—Distributed dynamic team trust in human, artificial intelligence, and robot teaming. In Trust in Human-Robot Interaction; Nam, C.S., Lyons, J.B., Eds.; Academic Press: Cambridge, MA, USA, 2021; pp. 301–319. [Google Scholar] [CrossRef]
- Chien, S.-Y.; Sycara, K.; Liu, J.-S.; Kumru, A. Relation between trust attitudes toward automation, hofstede’s cultural dimensions, and big five personality traits. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2016, 60, 841–845. [Google Scholar] [CrossRef]
- Chien, S.Y.; Lewis, M.; Sycara, K.; Kumru, A.; Liu, J.-S. Influence of culture, transparency, trust, and degree of automation on automation use. IEEE Trans. Hum.-Mach. Syst. 2020, 50, 205–214. [Google Scholar] [CrossRef]
- Wojton, H.M.; Porter, D.; Lane, S.; Bieber, C.; Madhavan, P. Initial validation of the trust of automated systems test (TOAST). J. Soc. Psychol. 2020, 160, 735–750. [Google Scholar] [CrossRef]
- O’Neill, T.; McNeese, N.; Barron, A.; Schelble, B. Human-autonomy teaming: A review and analysis of the empirical literature. Hum. Factors J. Hum. Factors Ergon. Soc. 2022, 64, 904–938. [Google Scholar] [CrossRef] [PubMed]
- Palmer, G.; Selwyn, A.; Zwillinger, D. The ‘trust v’: Building and measuring trust in autonomous systems. In Robust Intel-ligence and Trust in Autonomous Systems; Mittu, R., Sofge, D., Wagner, A., Lawless, W.F., Eds.; Springer: Boston, MA, USA, 2016; pp. 55–77. [Google Scholar] [CrossRef]
- Santos, L.O.B.d.S.; Pires, L.F.; van Sinderen, M. A Trust-Enabling Support for Goal-Based Services. In Proceedings of the 2008 9th International Conference for Young Computer Scientists, Zhangjiajie, China, 18–21 November 2008; pp. 2002–2007. [Google Scholar]
- Yousefi, Y. Data Sharing as a Debiasing Measure for AI Systems in Healthcare: New Legal Basis. In Proceedings of the 15th International Conference on Theory and Practice of Electronic Governance; In ICEGOV ’22; Association for Computing Machinery: New York, NY, USA, 2022; pp. 50–58. [Google Scholar]
- Pieters, W. Explanation and trust: What to tell the user in security and AI? Ethic-Inf. Technol. 2010, 13, 53–64. [Google Scholar] [CrossRef]
- Ferrario, A.; Loi, M. How Explainability Contributes to Trust in AI. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency; In FAccT ’22; Association for Computing Machinery: New York, NY, USA, 2022; pp. 1457–1466. [Google Scholar] [CrossRef]
- Boulanin, V. The Impact of Artificial Intelligence on Strategic Stability and Nuclear Risk, Volume i, Euro-Atlantic Perspectives. SIPRI, May 2019. Available online: https://www.sipri.org/publications/2019/other-publications/impact-artificial-intelligence-strategic-stability-and-nuclear-risk-volume-i-euro-atlantic (accessed on 8 July 2023).
- Chen, J.Y.C.; Barnes, M.J. Human–agent teaming for multirobot control: A review of human factors issues. IEEE Trans. Human-Machine Syst. 2014, 44, 13–29. [Google Scholar] [CrossRef]
- Crootof, R.; Kaminski, M.E.; Price, W.N., II. Humans in the loop. Vand. L. Rev. 2023, 76, 429. [Google Scholar] [CrossRef]
- Kollmann, T.; Kollmann, K.; Kollmann, N. Artificial leadership: Digital transformation as a leadership task between the chief digital officer and artificial intelligence. Int J. Bus. Sci. Appl. Manag. 2023, 18. Available online: https://www.business-and-management.org/library/2023/18_1--76-95-Kollmann,Kollmann,Kollmann.pdf (accessed on 12 April 2024).
- Castelfranchi, C.; Falcone, R. Trust and control: A dialectic link. Appl. Artif. Intell. 2000, 14, 799–823. [Google Scholar] [CrossRef]
- Aerts, D. Quantum structure in cognition. J. Math. Psychol. 2009, 53, 314–348. [Google Scholar] [CrossRef]
- Agrawal, P.M.; Sharda, R. Quantum mechanics and human decision making. SSRN 2010, 1–49. [Google Scholar] [CrossRef]
- Bruza, P.D.; Hoenkamp, E.C. Reinforcing trust in autonomous systems: A quantum cognitive approach. In Foundations of Trusted Autonomy; Abbass, H.A., Scholz, J., Reid, D.J., Eds.; In Studies in Systems, Decision and Control; Springer International Publishing: Cham, Switzerland, 2018; pp. 215–224. [Google Scholar] [CrossRef]
- Jiang, J.; Liu, X. A quantum cognition based group decision making model considering interference effects in consensus reaching process. Comput. Ind. Eng. 2022, 173, 108705. [Google Scholar] [CrossRef]
- Khrennikov, A. Social laser model for the bandwagon effect: Generation of coherent information waves. Entropy 2020, 22, 559. [Google Scholar] [CrossRef]
- Trueblood, J.S.; Busemeyer, J.R. A comparison of the belief-adjustment model and the quantum inference model as explanations of order effects in human inference. Proc. Annu. Meet. Cogn. Sci. Soc. 2010, 32, 7. [Google Scholar]
- Stenholm, S.; Suominen, K. Quantum Approach to Informatics; Wiley-Interscience: Hoboken, NJ, USA, 2005. [Google Scholar]
- Floridi, L. The Philosophy of Information; OUP: Oxford, UK, 2013. [Google Scholar]
- Pothos, E.M.; Busemeyer, J.R. Quantum cognition. Annu. Rev. Psychol. 2022, 73, 749–778. [Google Scholar] [CrossRef]
- Bruza, P.; Fell, L.; Hoyte, P.; Dehdashti, S.; Obeid, A.; Gibson, A.; Moreira, C. Contextuality and context-sensitivity in probabilistic models of cognition. Cogn. Psychol. 2023, 140, 101529. [Google Scholar] [CrossRef]
- Danilov, V.I.; Lambert-Mogiliansky, A.; Vergopoulos, V. Dynamic consistency of expected utility under non-classical (quantum) uncertainty. Theory Decis. 2018, 84, 645–670. [Google Scholar] [CrossRef]
- Danilov, V.; Lambert-Mogiliansky, A. Targeting in quantum persuasion problem. J. Math. Econ. 2018, 78, 142–149. [Google Scholar] [CrossRef]
- Roeder, L.; Hoyte, P.; van der Meer, J.; Fell, L.; Johnston, P.; Kerr, G.; Bruza, P. A Quantum Model of Trust Calibration in Human–AI Interactions. Entropy 2023, 25, 1362. [Google Scholar] [CrossRef] [PubMed]
- Epping, G.P.; Kvam, P.D.; Pleskac, T.J.; Busemeyer, J.R. Open system model of choice and response time. J. Choice Model. 2023, 49, 100453. [Google Scholar] [CrossRef]
- Humr, S.A.; Canan, M.; Demir, M. Temporal Evolution of Trust in Artificial Intelligence-Supported Decision-Making. In Human Factors and Ergonomics Society; SAGE Publications: Washington, DC, USA, 2023; Available online: https://journals.sagepub.com/doi/10.1177/21695067231193672 (accessed on 12 April 2024).
- Busemeyer, J.R.; Kvam, P.D.; Pleskac, T.J. Comparison of Markov versus quantum dynamical models of human decision making. WIREs Cogn. Sci. 2020, 11, e1526. [Google Scholar] [CrossRef] [PubMed]
- Busemeyer, J.R.; Wang, Z.; Lambert-Mogiliansky, A. Empirical comparison of Markov and quantum models of decision making. J. Math. Psychol. 2009, 53, 423–433. [Google Scholar] [CrossRef]
- Townsend, J.T.; Silva, K.M.; Spencer-Smith, J.; Wenger, M.J. Exploring the relations between categorization and decision making with regard to realistic face stimuli. Diagramm. Reason. 2000, 8, 83–105. [Google Scholar] [CrossRef]
- Yin, M.; Vaughan, J.W.; Wallach, H. Understanding the Effect of Accuracy on Trust in Machine Learning Models. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems; ACM: Glasgow, Scotland, 2019; pp. 1–12. [Google Scholar] [CrossRef]
- Yu, K.; Berkovsky, S.; Conway, D.; Taib, R.; Zhou, J.; Chen, F. Trust and Reliance Based on System Accuracy. In Proceedings of the 2016 Conference on User Modeling Adaptation and Personalization, Halifax, NS, Canada, 13–16 July 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 223–227. [Google Scholar] [CrossRef]
- Zhang, Y.; Liao, Q.V.; Bellamy, R.K.E. Effect of confidence and explanation on accuracy and trust calibration in AI-assisted decision making. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 295–305. [Google Scholar] [CrossRef]
- Defurne, M.; Jiménez-Argüello, A.M.; Ahmed, Z.; Albataineh, H.; Allada, K.; Aniol, K.A.; Bellini, V.; Benali, M.; Boeglin, W.; Bertin, P.; et al. A glimpse of gluons through deeply virtual compton scattering on the proton. Nat. Commun. 2017, 8, 1408. [Google Scholar] [CrossRef] [PubMed]
- Canan, M. Triple Coincidence Beam Spin Asymmetry Measurements in Deeply Virtual Compton Scattering. Ph.D. Thesis, Old Do-minion University, Norfolk, VA, USA, 2011. Available online: https://www.proquest.com/docview/869288549/abstract/D94ED849DAFD407EPQ/1 (accessed on 17 May 2024).
- Wang, Z.; Busemeyer, J.R. Interference effects of categorization on decision making. Cognition 2016, 150, 133–149. [Google Scholar] [CrossRef]
- Snow, L.; Jain, S.; Krishnamurthy, V. Lyapunov based stochastic stability of human-machine interaction: A quantum decision system approach. arXiv 2022, arXiv:2204.00059. [Google Scholar] [CrossRef]
- Khrennikova, P.; Haven, E.; Khrennikov, A. An application of the theory of open quantum systems to model the dynamics of party governance in the US political system. Int. J. Theor. Phys. 2013, 53, 1346–1360. [Google Scholar] [CrossRef]
- He, Z.; Jiang, W. An evidential dynamical model to predict the interference effect of categorization on decision making results. Knowl.-Based Syst. 2018, 150, 139–149. [Google Scholar] [CrossRef]
- Kvam, P.D.; Pleskac, T.J.; Yu, S.; Busemeyer, J.R. Interference effects of choice on confidence: Quantum characteristics of evidence accumulation. Proc. Natl. Acad. Sci. USA 2015, 112, 10645–10650. [Google Scholar] [CrossRef]
- Zheng, R.; Busemeyer, J.R.; Nosofsky, R.M. Integrating Categorization and Decision-Making. Cogn. Sci. 2023, 47, e13235. [Google Scholar] [CrossRef] [PubMed]
- Hawley, K.; Mares, A.L. Human performance challenges for the future force: Lessons from patriot after the second gulf war. In Designing Soldier Systems; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Snook, S.A. Friendly Fire: The Accidental Shootdown of U.S. Black Hawks over Northern Iraq; Princeton University Press: Princeton, NJ, USA, 2011. [Google Scholar] [CrossRef]
- Klein, G.A. A recognition-primed decision (RPD) model of rapid decision making. In Decision Making in Action: Models and Methods; Ablex Publishing: Westport, CT, USA, 1993; pp. 138–147. [Google Scholar]
- Endsley, M.R. Toward a Theory of Situation Awareness in Dynamic Systems. Hum. Factors J. Hum. Factors Ergon. Soc. 1995, 37, 32–64. [Google Scholar] [CrossRef]
- Tversky, A.; Kahneman, D. Judgment under Uncertainty: Heuristics and Biases. Science 1974, 185, 1124–1131. [Google Scholar] [CrossRef] [PubMed]
- Busemeyer, J.; Zhang, Q.; Balakrishnan, S.N.; Wang, Z. Application of quantum—Markov open system models to human cognition and decision. Entropy 2020, 22, 990. [Google Scholar] [CrossRef] [PubMed]
- Sloman, A. Predicting Affordance Changes: Steps towards Knowledge-Based Visual Servoing. 2007. Available online: https://hal.science/hal-00692046 (accessed on 5 July 2023).
- Sloman, A. Predicting Affordance Changes. 19 February 2018. Available online: https://www.cs.bham.ac.uk/research/projects/cogaff/misc/changing-affordances.pdf (accessed on 5 July 2023).
- Basieva, I.; Khrennikov, A. “What Is Life?”: Open Quantum Systems Approach. Open Syst. Inf. Dyn. 2022, 29, 2250016. [Google Scholar] [CrossRef]
- Ingarden, R.S.; Kossakowski, A.; Ohya, M. Information Dynamics and Open Systems: Classical and Quantum Approach, 1997th ed.; Springer: Boston, MA, USA, 1997. [Google Scholar]
- Martínez-Martínez, I.; Sánchez-Burillo, E. Quantum stochastic walks on networks for decision-making. Sci. Rep. 2016, 6, 23812. [Google Scholar] [CrossRef]
- Asano, M.; Ohya, M.; Tanaka, Y.; Basieva, I.; Khrennikov, A. Quantum-like model of brain’s functioning: Decision making from decoherence. J. Theor. Biol. 2011, 281, 56–64. [Google Scholar] [CrossRef]
- Blaha, L.M. Interactive OODA Processes for Operational Joint Human-Machine Intelligence. In NATO IST-160 Specialist’s Meeting: Big Data and Military Decision Making; NATO, July 2018; Available online: https://www.sto.nato.int/publications/STO%20Meeting%20Proceedings/STO-MP-IST-160/MP-IST-160-PP-3.pdf (accessed on 6 June 2023).
- van den Bosch, K.; Bronkhorst, A. Human-AI Cooperation to Benefit Military Decision Making. In NATO IST-160 Specialist’s Meeting: Big Data and Military Decision Making; NATO, July 2018; Available online: https://www.karelvandenbosch.nl/documents/2018_Bosch_etal_NATO-IST160_Human-AI_Cooperation_in_Military_Decision_Making.pdf (accessed on 6 June 2023).
- Arnold, V.; Collier, P.A.; Leech, S.A.; Sutton, S.G. Impact of intelligent decision aids on expert and novice decision-makers’ judgments. Account. Financ. 2004, 44, 1–26. [Google Scholar] [CrossRef]
- Jussupow, E.; Spohrer, K.; Heinzl, A.; Gawlitza, J. Augmenting medical diagnosis decisions? An investigation into physicians’ decision-making process with artificial intelligence. Inf. Syst. Res. 2021, 32, 713–735. [Google Scholar] [CrossRef]
- National Academies of Sciences, Engineering, and Medicine. Human-AI Teaming; The National Academies Press: Washington, DC, USA, 2022. [Google Scholar]
- Buchanan, M. Quantum Minds: Why We Think Like Quarks. New Scientist. Available online: https://www.newscientist.com/article/mg21128285-900-quantum-minds-why-we-think-like-quarks/ (accessed on 19 June 2023).
- Canan, M.; Demir, M.; Kovacic, S. A Probabilistic Perspective of Human-Machine Interaction. In Proceedings of the Hawaii International Conference on System Sciences, Virtual/Maui, HI, USA, 3–7 January 2022. [Google Scholar] [CrossRef]
- Demir, M.; Canan, M.; Cohen, M.C. Modeling Team Interaction and Decision-Making in Agile Human–Machine Teams: Quantum and Dynamical Systems Perspective. IEEE Trans. Hum.-Mach. Syst. 2023, 53, 720–730. [Google Scholar] [CrossRef]
- Lord, R.G.; Dinh, J.E.; Hoffman, E.L. A Quantum Approach to Time and Organizational Change. Acad. Manag. Rev. 2015, 40, 263–290. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categorize, Then Delegate Conditions | Delegate Only | ||||||
|---|---|---|---|---|---|---|---|
| Timing | Pr(A) | Pr(Del|A) | Pr(Dis) | Pr(Del|Dis) | TP (Del) Intermediate Judgment | Pr(Del) No Intermediate Judgment | Pr(Del) |
| 5 s | 0.7097 | 0.5966 | 0.2903 | 0.1389 | 0.4637 | 0.4118 | −0.0519 |
| 10 s | 0.8495 | 0.7089 | 0.1505 | 0.2143 | 0.6344 | 0.6097 | −0.0247 |
| 15 s | 0.6231 | 0.6173 | 0.3769 | 0.2143 | 0.4654 | 0.4559 | −0.0095 |
| 20 s | 0.6833 | 0.6042 | 0.3167 | 0.2360 | 0.4875 | 0.4926 | 0.0050 |
| 25 s | 0.8566 | 0.7225 | 0.1434 | 0.2895 | 0.6604 | 0.6182 | −0.0422 |
| 30 s | 0.8327 | 0.7143 | 0.1673 | 0.1556 | 0.6208 | 0.5941 | −0.0267 |
| 35 s | 0.7907 | 0.6716 | 0.2093 | 0.1296 | 0.5581 | 0.5257 | −0.0324 |
| Agree (A) | Disagree (DisA) | |
|---|---|---|
| Delegate (D) | a | b |
| Not Delegate (notD) | c | d |
| Delegate (D), | e |
| Not Delegate (notD), | f |
| Fit Parameters | |
|---|---|
| 390.45 | |
| 30.12 | |
| 5.95 | |
| 19.62 | |
| 0.21 | |
| Condition | SSE for Quantum Open System Models |
|---|---|
| Choice | 247.9605 |
| No Choice | 273.9648 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Humr, S.; Canan, M. Intermediate Judgments and Trust in Artificial Intelligence-Supported Decision-Making. Entropy 2024, 26, 500. https://doi.org/10.3390/e26060500
Humr S, Canan M. Intermediate Judgments and Trust in Artificial Intelligence-Supported Decision-Making. Entropy. 2024; 26(6):500. https://doi.org/10.3390/e26060500
Chicago/Turabian StyleHumr, Scott, and Mustafa Canan. 2024. "Intermediate Judgments and Trust in Artificial Intelligence-Supported Decision-Making" Entropy 26, no. 6: 500. https://doi.org/10.3390/e26060500
APA StyleHumr, S., & Canan, M. (2024). Intermediate Judgments and Trust in Artificial Intelligence-Supported Decision-Making. Entropy, 26(6), 500. https://doi.org/10.3390/e26060500