
BPT-PLR: A Balanced Partitioning and Training Framework with Pseudo-Label Relaxed Contrastive Loss for Noisy Label Learning

Abstract
:1. Introduction
- We propose an improved end-to-end training framework called BPT-PLR (Balanced Partitioning and Training framework with Pseudo-Label Relaxed contrastive loss) to address issues of noisy label learning (NLL) in DNNs, such as class imbalance in partitioned subsets and optimization conflicts between CRL losses and supervised losses. This framework enhances DNNs’ robustness to noisy labels and achieves superior performance.
- We introduce a novel class-level balanced selection method based on a two-dimensional Gaussian mixture model (GMM). This method first models both the semantic and class information of the data using a two-dimensional GMM and then utilizes a class-level balanced selection strategy based on the distribution of samples to partition the data. This ensures that the labeled subset after partitioning maintains class balance, thereby alleviating the impact of the long-tail issue on model accuracy.
- We incorporate the existing PLR loss into a semi-supervised learning (SSL) framework following previous work but further leverage it through oversampling techniques. This process enhances the model’s learning of semantic information from both labeled and unlabeled samples, thereby improving test performance.
- We demonstrate the effectiveness of BPT-PLR through extensive experiments on several classic datasets in the NLL field. Additionally, we validate the robustness of the two key processes proposed through ablation experiments.
2. Related Works
2.1. Recent Research on NLL
2.2. Recent Research on CRL
3. Algorithm
3.1. Balanced Partitioning Process
3.2. Semi-Supervised Oversampling Training Process
3.3. Calculation of Class Prototypes
3.4. Pseudo-Code
| Algorithm 1: Training process pseudo-code representation |
| Input: and ; epoch counter e = 0; sampling counter t = 0; while do: if : //enable Equation (2) only in the presence pf asymmetric noise labels pretrain the two networks on the whole dataset using Equations (1) and (2); if : for each network using Equation (18); //It is the same as PLReMix end if else: re-initialize the sampling counter t = 0; //execute the BP-GMM process using from Equation (3) to Equation (9) //for network m = 0 perform coarse data division using two-dimensional GMM (Equation (3) to Equation (4)); //It is the same as PLReMix perform the proposed class-level balanced selection on the coarse division results using (Equations (5)–(9)); //It is different from PLReMix ; //for network m = 1 perform coarse data division using two-dimensional GMM (Equations (3) and (4)); //It is the same as PLReMix perform the proposed class-level balanced selection on the coarse division results using (Equations (5)–(9)); //It is different from PLReMix ; //execute the SSO-PLR process for network m = 0 to 1: if : //oversampling strategy, it is different from PLReMix , respectively; perform label-refinement and co-guessing operation using Equation (10); //generate pseudo labels for all samples do Mixup augmentation for two mini-batches using Equation (12); //enhance model generalization and robustness calculate the SSL loss and PLR loss through Equations (13) and (15); perform backpropagation according to Formula (14) to update all parameters of current network; ; //the increment of t end if //all the unlabeled samples are completely sampled end for //update all the class prototypes, it is the same as PLReMix for network m = 0 to 1: estimate latent GT labels based on current network using Equations (19) and (20); perform momentum updates for the class prototypes belonging to the current network using Equation (21); end for ; //the increment of epoch counter e end while Output: with relatively low noise rates. |
4. Experiments
4.1. Datasets and Experimental Settings
4.2. Experiments on Synthetic Noisy Datasets
4.2.1. Results on CIFAR-10
4.2.2. Results on CIFAR-100
4.3. Experiments on Real-World Noisy Datasets
4.3.1. Results on Animal-10N
4.3.2. Results on Clothing1M
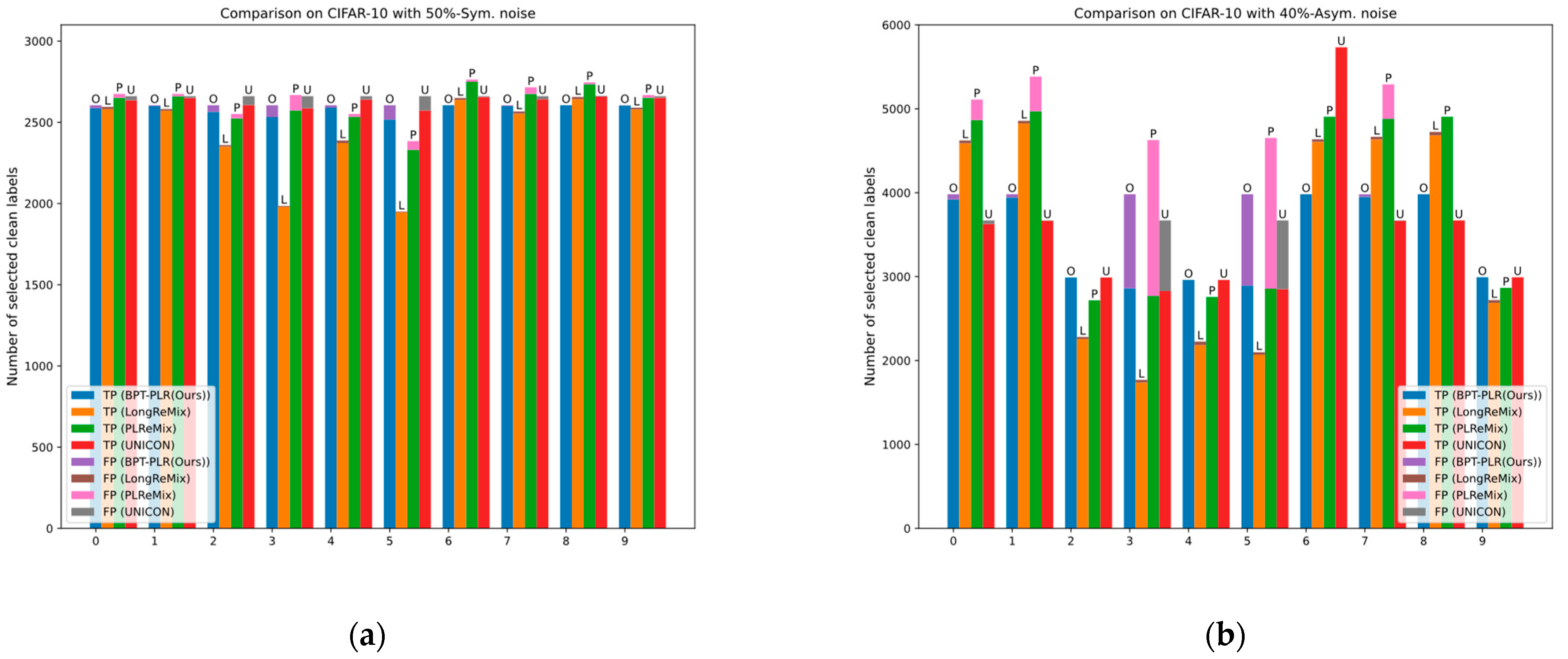
4.4. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, Y.; Wei, H.; Zhu, H.; Yu, D.; Xiong, H.; Yang, J. Exploiting cross-modal prediction and relation consistency for semi-supervised image captioning. IEEE Trans. on Cybernetics 2024, 54, 890–902. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Lee, F.F.; Wang, Y.G.; Ding, D.M.; Yao, W.; Chen, L.; Chen, Q. An joint end-to-end framework for learning with noisy labels. Appl. Soft Comput. 2021, 108, 107426. [Google Scholar] [CrossRef]
- Zhou, R.; Wang, J.; Xia, G.; Xing, J.; Shen, H.; Shen, X. Cascade residual multiscale convolution and mamba-structured UNet for advanced brain tumor image segmentation. Entropy 2024, 26, 385. [Google Scholar] [CrossRef]
- Zhou, J.; Li, Y.; Wang, M. Research on the threshold determination method of the duffing chaotic system based on improved permutation entropy and poincaré mapping. Entropy 2023, 25, 1654. [Google Scholar] [CrossRef] [PubMed]
- Gui, X.; Wang, W.; Tian, Z. Towards understanding deep learning from noisy labels with small-loss criterion. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Montreal, QC, Canada, 19–27 August 2021; pp. 2469–2475. [Google Scholar] [CrossRef]
- Li, J.; Socher, R.; Hoi, S. DivideMix: Learning with noisy labels as semi-supervised learning. In Proceedings of the 8th International Conference on Learning Representations (ICLR), Virtual, 26 April–1 May 2020. [Google Scholar]
- Liu, X.; Zhou, B.; Cheng, C. PLReMix: Combating noisy labels with pseudo-label relaxed contrastive representation learning. arXiv 2024, arXiv:2402.17589. in press. [Google Scholar]
- Cordeiro, F.R.; Sachdeva, R.; Belagiannis, V.; Reid, I.; Carneiro, G. LongReMix: Robust learning with high confidence samples in a noisy label environment. Pattern Recognit. 2023, 133, 109013. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhu, Y.; Yang, M.; Jin, G.; Zhu, Y.W.; Chen, Q. Cross-to-merge training with class balance strategy for learning with noisy labels. Expert Sys. With Applica. 2024, 249, 123846. [Google Scholar] [CrossRef]
- Natarajan, N.; Dhillon, I.S.; Ravikumar, P.; Tewari, A. Learning with noisy labels. In Proceedings of the 26th International Conference on Neural Information Processing Systems (NeurIPS), Lake Tahoe, NV, USA, 3-6 December 2012; Curran Associates Inc.: Red Hook, NY, USA, 2013; pp. 1196–1204. [Google Scholar]
- Zhang, Z.L.; Sabuncu, M. Generalized cross entropy loss for training deep neural networks with noisy labels. In Proceedings of the 32nd Annual Conference on Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 2–8 December 2018; pp. 8778–8788. [Google Scholar]
- Natarajan, N.; Dhillon, I.S.; Ravikumar, P.; Tewari, A. Cost-sensitive learning with noisy labels. J. Mach. Learn. Res. 2017, 18, 5666–5698. [Google Scholar]
- Qaraei, M.; Schultheis, E.; Gupta, P.; Babbar, R. Convex surrogates for unbiased loss functions in extreme classification with missing labels. In Proceedings of the Web Conference (WWW), Ljubljana, Slovenia, 19–23 April 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 3711–3720. [Google Scholar] [CrossRef]
- Schultheis, E.; Wydmuch, M.; Babbar, R.; Dembczynski, K. On missing labels, long-tails and propensities in extreme multi-label classification. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), Washington, DC, USA, 14–18 August 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 1547–1557. [Google Scholar] [CrossRef]
- Wang, Y.; Ma, X.; Chen, Z.; Luo, Y.; Yi, J.; Bailey, J. Symmetric cross entropy for robust learning with noisy labels. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 322–330. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond empirical risk minimization. In Proceedings of the 6th International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Ye, X.; Li, X.; Liu, T.; Sun, Y.; Tong, W. Active negative loss functions for learning with noisy labels. In Proceedings of the 37th Annual Conference on Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, 10–16 December 2023; Volume 36, pp. 6917–6940. [Google Scholar]
- Ma, X.; Huang, H.; Wang, Y.; Romano, S.; Erfani, S.; Bailey, J. Normalized loss functions for deep learning with noisy labels. In Proceedings of the 37th International Conference on Machine Learning (ICML), Virtual, 13–18 July 2020; pp. 6543–6553. [Google Scholar]
- Tanaka, D.; Ikami, D.; Yamasaki, T.; Aizawa, K. Joint optimization framework for learning with noisy labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, Utah, 18–22 June 2018; pp. 5552–5560. [Google Scholar] [CrossRef]
- Yi, K.; Wu, J. Probabilistic end-to-end noise correction for learning with noisy labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar] [CrossRef]
- Zhang, Y.; Zheng, S.; Wu, P.; Goswami, M.; Chen, C. Learning with feature-dependent label noise: A progressive approach. In Proceedings of the 9th International Conference on Learning Representations (ICLR), Virtual, 3–7 May 2021. [Google Scholar]
- Xu, C.; Lin, R.; Cai, J.; Wang, S. Label correction using contrastive prototypical classifier for noisy label learning. Inf. Sci. 2023, 649, 119647. [Google Scholar] [CrossRef]
- Huang, B.; Zhang, P.; Xu, C. Combining layered label correction and mixup supervised contrastive learning to learn noisy labels. Inf. Sci. 2023, 642, 119242. [Google Scholar] [CrossRef]
- Wang, L.; Xu, X.; Guo, K.; Cai, B.; Liu, F. Reflective learning with label noise. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 3343–3357. [Google Scholar] [CrossRef]
- Han, B.; Yao, Q.M.; Yu, X.R.; Niu, G.; Xu, M.; Hu, W.H.; Tsang, I.W.; Sugiyama, M. Co-teaching: Robust training of deep neural networks with extremely noisy labels. In Proceedings of the 32nd Annual Conference on Neural Information Processing Systems (NeurIPS), Montreal, Canada, 2–8 December 2018; Volume 31. [Google Scholar]
- Zhang, Q.; Lee, F.F.; Wang, Y.G.; Ding, D.M.; Yang, S.; Lin, C.W.; Chen, Q. CJC-net: A cyclical training method with joint loss and co-teaching strategy net for deep learning under noisy labels. Inf. Sci. 2021, 579, 186–198. [Google Scholar] [CrossRef]
- Liu, S.; Niles-Weed, J.; Razavian, N.; Fernandez-Granda, C. Early-learning regularization prevents memorization of noisy labels. In Proceedings of the 34th Annual Conference on Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020. [Google Scholar]
- Karim, N.; Rizve, M.N.; Rahnavard, N.; Mian, A.; Shah, M. UNICON: Combating label noise through uniform selection and contrastive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–23 June 2022; pp. 9666–9676. [Google Scholar] [CrossRef]
- Zhang, S.; Li, Y.; Wang, Z.; Li, J.; Liu, C. Learning with noisy labels using hyperspherical margin weighting. In Proceedings of the Association for the Advancement of Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 16848–16856. [Google Scholar] [CrossRef]
- Feng, C.W.; Ren, Y.L.; Xie, X.K. OT-Filter: An optimal transport filter for learning with noisy labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 16164–16174. [Google Scholar] [CrossRef]
- Li, Y.; Han, H.; Shan, S.; Chen, X. DISC: Learning from noisy labels via dynamic instance-specific selection and correction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 24070–24079. [Google Scholar] [CrossRef]
- Sun, X.; Zhang, S.; Ma, S. Prediction consistency regularization for learning with noise labels based on contrastive clustering. Entropy 2024, 26, 308. [Google Scholar] [CrossRef] [PubMed]
- Deng, L.; Yang, B.; Kang, Z.; Wu, J.; Li, S.; Xiang, Y. Separating hard clean samples from noisy samples with samples’ learning risk for DNN when learning with noisy labels. Complex Intell. Syst. 2024, 10, 4033–4054. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning (ICML), Virtual, 13–18 July 2020. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 9726–9735. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. In Proceedings of the 34th Annual Conference on Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020; Volume 33, pp. 18661–18673. [Google Scholar]
- Li, J.; Xiong, C.; Hoi, S. MoPro: Webly supervised learning with momentum prototypes. In Proceedings of the 9th International Conference on Learning Representations (ICLR), Virtual, 3–7 May 2021. [Google Scholar]
- Li, S.K.; Xia, X.B.; Ge, S.M.; Liu, T.L. Selective-supervised contrastive learning with noisy labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–23 June 2022; pp. 316–325. [Google Scholar] [CrossRef]
- Sachdeva, R.; Cordeiro, F.R.; Belagiannis, V.; Reid, I.; Carneiro, G. ScanMix: Learning from severe label noise via semantic clustering and semi-supervised learning. Pattern Recognit. 2023, 134, 109121. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Available online: http://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 28 May 2024).
- Xiao, T.; Xia, T.; Yang, Y.; Huang, C.; Wang, X. Learning from massive noisy labeled data for image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–12 June 2015; pp. 2691–2699. [Google Scholar] [CrossRef]
- Zhang, C.; Hsieh, M.; Tao, D. Generalization bounds for vicinal risk minimization principle. arXiv 2018, arXiv:1811.04351. in press. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Song, H.; Kim, M.; Lee, J.G. SELFIE: Refurbishing unclean samples for robust deep learning. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 5907–5915. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Wei, H.; Feng, L.; Chen, X.; An, B. Combating noisy labels by agreement: A joint training method with co-regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 13726–13735. [Google Scholar] [CrossRef]
- Xia, Q.; Lee, F.; Chen, Q. TCC-net: A two-stage training method with contradictory loss and co-teaching based on meta-learning for learning with noisy labels. Inf. Sci. 2023, 639, 119008. [Google Scholar] [CrossRef]
- Zhao, R.; Shi, B.; Ruan, J.; Pan, T.; Dong, B. Estimating noisy class posterior with part-level labels for noisy label learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle WA, USA, 17–21 June 2024; pp. 1–11. [Google Scholar]
- Wu, T.; Ding, X.; Zhang, H.; Tang, M.; Qin, B.; Liu, T. Uncertainty-guided label correction with wavelet-transformed discriminative representation enhancement. Neural Netw. 2024, 176, 106383. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Class Number | Training Number | Testing Number | Original Size | Cropped Size |
|---|---|---|---|---|---|
| CIFAR-10 | 10 | 50K | 10K | 32 32 | 32 32 |
| CIFAR-100 | 100 | 50K | 10K | 32 32 | 32 32 |
| Animal-10N | 10 | 50K | 5K | 64 64 | 64 64 |
| Clothing1M | 14 | 1M | 10K | 256 256 | 224 224 |
| Dataset | CIFAR-10 | CIFAR-100 | Clothing1M | Animal-10N |
|---|---|---|---|---|
| Backbone | PreAct ResNet-18 | ResNet-50 | VGG19-BN/9-layer CNN | |
| lr | 0.02 | 0.02 | 0.01 | 0.01 |
| Optimizer | SGD | SGD | SGD | SGD |
| Weight decay | 5 × 10−4 | 5 × 10−4 | 1 × 10−3 | 1 × 10−3 |
| Momentum | 0.9 | 0.9 | 0.9 | 0.9 |
| 64 | 64 | 64 | 128 | |
| 10 | 30 | 5 | 30 | |
| 400 | 400 | 80 | 200 | |
| 4 | 4 | 0.5 | 4 | |
| Methods | The Comparison of Test Accuracies (%) on CIFAR-10 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Symmetric Noise | Asymmetric Noise | |||||||||
| 20% | 50% | 80% | 90% | 10% | 20% | 30% | 40% | 49% | ||
| Standard CE | 86.8 | 79.4 | 62.9 | 42.7 | 88.8 | 86.1 | 81.7 | 76.1 | - | |
| Co-teaching [25] (18) | 86.5 | 76.1 | 25.4 | - | 87.2 | - | 84.7 | 75.7 | - | |
| Mixup [16] (18) | 95.6 | 87.1 | 71.6 | 52.2 | 93.3 | 88.0 | 83.3 | 77.7 | - | |
| PENCIL [20] (19) | 92.4 | 89.1 | 77.5 | 58.2 | 93.1 | 92.9 | 92.6 | 91.6 | - | |
| DivideMix [6] (20) | last | 95.7 | 94.4 | 92.9 | 75.4 | - | - | - | 92.1 | 76.3 |
| best | 96.1 | 94.6 | 93.2 | 76.0 | - | - | - | 93.4 | 84.7 | |
| ELR+ [27] (20) | 95.8 | 94.8 | 93.3 | 78.7 | 95.4 | 94.7 | 94.7 | 93.0 | - | |
| UNICON [28] (22) | 96.0 | 95.6 | 93.9 | 90.8 | 95.3 | - | 94.8 | 94.1 | 87.1 | |
| LongReMix [8] (23) | last | 96.0 | 94.8 | 93.3 | 79.1 | 95.4 | 94.1 | 93.5 | 94.3 | 77.8 |
| best | 96.3 | 95.1 | 93.8 | 79.9 | 95.6 | 94.6 | 94.3 | 94.7 | 84.4 | |
| OT-Filter [30] (23) | last | - | - | - | - | 95.2 | 94.9 | 94.5 | - | 87.7 |
| best | 96.0 | 95.3 | 94.0 | 90.5 | 95.6 | 95.2 | 94.9 | 95.1 | 88.6 | |
| DISC [31] (23) | last | - | - | - | 32.3 | 96.2 | 95.7 | 95.2 | - | 69.0 |
| best | 96.1 | 95.1 | 84.7 | 55.8 | 96.3 | 95.8 | 95.3 | 94.6 | 72.7 | |
| ScanMix [39] (23) | 95.7 | 93.9 | 92.6/93.5 | 90.3 | - | - | - | 93.4 | 87.1 | |
| RL † [24] (23) | last | - | 90.57 | - | 61.72 | 93.80 | 93.51 | 93.05 | 92.31 | - |
| best | - | 90.73 | - | 62.32 | 94.21 | 93.86 | 93.23 | 93.57 | - | |
| TPCR † [32] (24) | 93.2 | - | 86.9 | - | - | 93.3 | 92.3 | 91.0 | - | |
| Flat-PLReMix [7] (24) | last | 96.46 | 95.36 | 94.84 | 91.54 | - | - | - | 94.72 | 55.1 |
| best | 96.63 | 95.71 | 95.08 | 91.93 | - | - | - | 95.11 | 86.2 | |
| C2MT [9] (24) | last | 96.1 | 94.8 | 92.8 | - | 95.1 | 93.0 | 93.5 | 92.6 | - |
| best | 96.5 | 95.0 | 93.4 | - | 95.4 | 94.3 | 94.1 | 92.9 | - | |
| SLRLNL [33] (24) | 92.5 | - | 78.9 | - | - | 93.1 | 92.5 | 92.0 | - | |
| HMW+ [29] (24) | 93.5 | 95.2 | 93.7 | 90.7 | 93.5 | - | 94.7 | 93.7 | - | |
| BPT-PLR (Ours) | last | 96.89 | 96.03 | 95.45 | 93.84 | 96.61 | 96.49 | 95.63 | 95.51 | 89.49 |
| best | 97.00 | 96.16 | 95.66 | 94.07 | 96.76 | 96.68 | 95.82 | 95.66 | 89.66 | |
| Methods | Test Accuracy (%) on CIFAR-100 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Symmetric Noise | Asymmetric Noise | ||||||||
| 20% | 50% | 80% | 90% | 10% | 20% | 30% | 40% | ||
| Standard CE | 62.0 | 46.7 | 19.9 | 10.1 | 68.1 | 63.6 | 53.5 | 44.5 | |
| Co-teaching [25] (18) | 49.2 | 35.1 | 5.7 | - | 54.1 | - | 49.6 | 43.7 | |
| Mixup [16] (18) | 67.8 | 57.3 | 30.8 | 14.6 | 72.4 | 65.1 | 57.6 | 48.1 | |
| PENCIL [20] (19) | 69.4 | 57.5 | 31.1 | 15.3 | 76.1 | 68.9 | 59.3 | 48.3 | |
| PENCIL † [20] (19) | 73.86 | - | - | - | 75.93 | 74.70 | 72.52 | 63.61 | |
| DivideMix [6] (20) | 76.9/77.3 | 74.2/74.6 | 59.6/60.2 | 31.0/31.5 | 69.5 | 69.2 | 68.3 | 51.0 | |
| ELR+ [27] (20) | 77.6 | 73.6 | 60.8 | 33.4 | 77.4 | 75.5 | 75.1 | 74.0 | |
| UNICON [28] (22) | 78.9 | 77.6 | 63.9 | 44.8 | 78.2 | - | 75.6 | 74.8 | |
| OT-Filter [30] (23) | 76.7 | 74.6 | 61.8 | 42.8 | - | - | - | 76.5 | |
| DISC [31] (23) | 78.8 | 75.2 | 57.6 | - | 78.1/78.4 | 77.5/77.2 | 76.3/76.8 | 76.5 | |
| LongReMix [8] (23) | 77.5/77.9 | 74.9/75.5 | 61.7/62.3 | 30.7/34.7 | - | - | - | 54.9/59.8 | |
| ScanMix [39] (23) | 76.0/77.0 | 75.4/75.7 | 65.0/66.0 | 58.2/58.5 | - | - | - | - | |
| RL † [24] (23) | 78.79 | - | 49.81 | - | 79.72 | 79.20 | 79.04 | 76.50 | |
| TPCR † [32] (24) | 74.8 | - | 53.1 | - | - | 77.2 | 75.4 | 71.3 | |
| C2MT [9] (24) | 76.5/77.5 | 73.1/74.2 | 57.5/57.7 | - | 77.1/77.8 | 77.3/77.7 | 74.5/75.7 | - | |
| SLRLNL [33] (24) | 69.4 | - | 32.6 | - | - | 72.5 | 71.9 | 69.7 | |
| Flat-PLReMix [7] (24) | 77.78/77.95 | 77.31/77.78 | 68.76/68.41 | 49.44/50.17 | - | - | - | - | |
| HMW+ [29] (24) | 76.6 | 75.8 | 63.4 | 43.4 | 76.6 | - | 76.3 | 72.1 | |
| BPT-PLR (Ours) | last | 78.66 | 77.77 | 69.06 | 49.49 | 78.68 | 78.30 | 78.52 | 73.95 |
| best | 78.85 | 78.02 | 69.31 | 49.85 | 79.04 | 78.54 | 78.82 | 74.30 | |
| Methods | Test Accuracy (%) | |
|---|---|---|
| Training with 9-layer CNN | ||
| Standard | 82.68 | |
| Co-teaching [25] (18) | 82.43 | |
| JoCoR [46] (20) | 82.82 | |
| TCC-net [47] (23) | 83.22 | |
| C2MT [9] (24) | 84.30/84.76 | |
| Ours | last | 86.79 |
| best | 87.20 | |
| Training with Vgg-19N | ||
| Mixup [16] (18) | 82.7 | |
| SELFIE [44] (19) | 81.8 | |
| DivideMix [6] (20) | 85.35/86.20 | |
| OT-Filter [30] (23) | 85.5 | |
| DISC [31] (23) | 87.1 | |
| LongReMix [8] (23) | 86.88/87.22 | |
| TPCR † [32] (24) | 87.39 | |
| C2MT [9] (24) | 85.8/85.9 | |
| SLRLNL [33] (24) | 86.4 | |
| N-Flat-PLReMix [7] (24) | 87.27/88.0 | |
| HMW+ [29] (24) | 86.5 | |
| BPT-PLR (Ours) | last | 88.02 |
| best | 88.28 | |
| Methods | Test Accuracy (%) |
|---|---|
| Standard | 68.94 |
| Co-teaching * [25] (18) | 69.21 |
| CJC-net * [26] (21) | 72.71 |
| TCC-Net * [47] (23) | 70.46 |
| Co-teaching [25] (18) | 71.70 |
| PENCIL [20] (19) | 73.49 |
| Divide-Mix [6] (20) | 74.21 |
| ELR+ [27] (20) | 74.39 |
| ECMB [2] (21) | 73.29 |
| UNICON [28] (22) | 74.00 |
| LongReMix [8] (23) | 74.38 |
| ScanMix [39] (23) | 74.35 |
| DISC [31] (23) | 73.72 |
| OT-Filter [30] (23) | 74.50 |
| RL [24] (23) | 74.29 |
| C2MT [9] (24) | 74.45 |
| PLM [48] (24) | 73.30 |
| Ultra+ [49] (24) | 74.03 |
| N-Flat-PLReMix [7] (24) | 74.58 |
| SLRLNL [33] (24) | 74.15 |
| BPT-PLR (Ours) | 74.37 |
| Noise Types | Last/Best Test Accuracy (%) | |||||
|---|---|---|---|---|---|---|
| Modules | CIFAR-10 | |||||
| Rows | BP | OS | PLR | 80%-sym. | 40%-asym. | Average Accuracy |
| 1 | ✗ | ✗ | ✗ | 94.94/95.10 | 88.28/88.61 | 91.61/91.86 |
| 2 | ✓ | ✗ | ✗ | 95.14/95.31 | 94.67/94.78 | 94.91/95.04 |
| 3 | ✗ | ✓ | ✗ | 10.00/94.82 | 88.99/89.19 | 50.00/92.01 |
| 4 | ✗ | ✗ | ✓ | 94.72/94.98 | 79.94/94.55 | 87.33/94.77 |
| 5 | ✓ | ✓ | ✗ | 95.83/95.99 | 94.68/94.90 | 95.26/95.45 |
| 6 | ✓ | ✗ | ✓ | 95.06/95.18 | 95.37/95.54 | 95.22/95.36 |
| 7 | ✗ | ✓ | ✓ | 95.78/95.88 | 90.58/90.85 | 93.18/93.37 |
| 8 | ✓ | ✓ | ✓ | 95.77/95.95 | 95.51/95.69 | 95.64/95.82 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Jin, G.; Zhu, Y.; Wei, H.; Chen, Q. BPT-PLR: A Balanced Partitioning and Training Framework with Pseudo-Label Relaxed Contrastive Loss for Noisy Label Learning. Entropy 2024, 26, 589. https://doi.org/10.3390/e26070589
Zhang Q, Jin G, Zhu Y, Wei H, Chen Q. BPT-PLR: A Balanced Partitioning and Training Framework with Pseudo-Label Relaxed Contrastive Loss for Noisy Label Learning. Entropy. 2024; 26(7):589. https://doi.org/10.3390/e26070589
Chicago/Turabian StyleZhang, Qian, Ge Jin, Yi Zhu, Hongjian Wei, and Qiu Chen. 2024. "BPT-PLR: A Balanced Partitioning and Training Framework with Pseudo-Label Relaxed Contrastive Loss for Noisy Label Learning" Entropy 26, no. 7: 589. https://doi.org/10.3390/e26070589