



SP-IGAN: An Improved GAN Framework for Effective Utilization of Semantic Priors in Real-World Image Super-Resolution


Abstract
1. Introduction
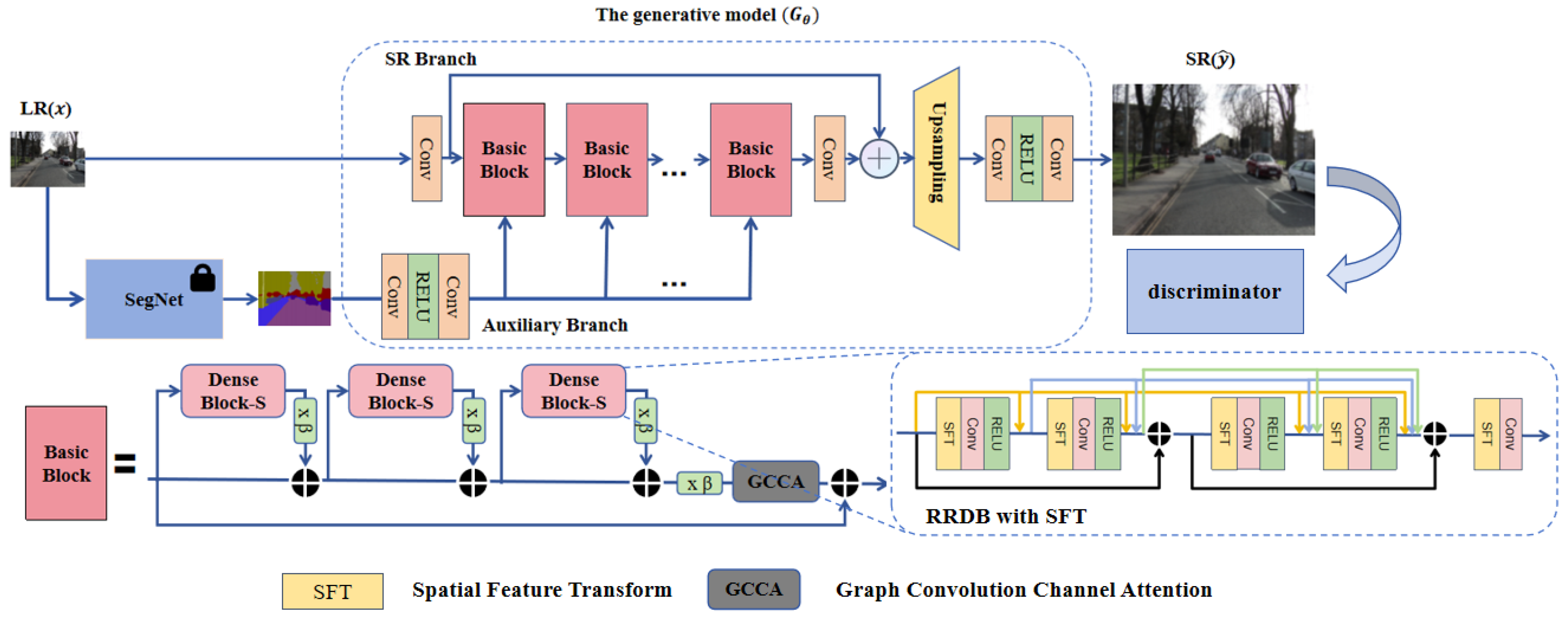
- The Spatial Feature Transform (SFT) layer is introduced into the Residual-in-Residual Dense Block (RRDB) module. The pre-trained segmentation network in the auxiliary branch accurately extracts regional semantic information, which is then conditioned and input into the RRDB module through the SFT layer via affine transformations. This provides the model with additional contextual semantic understanding, enhancing the correlation between texture information and category information, which leads to more accurate and semantically consistent texture reconstruction. Additionally, a Star-shaped Residual-in-Residual Dense Block (StarRRDB) [21] is employed, which offers higher network capacity compared to the RRDB module used in Real-ESRGAN. The design of StarRRDB is inspired by ESRGAN+ [22], providing greater flexibility and potential for the integration of the SFT layer and the subsequent GCCA module.
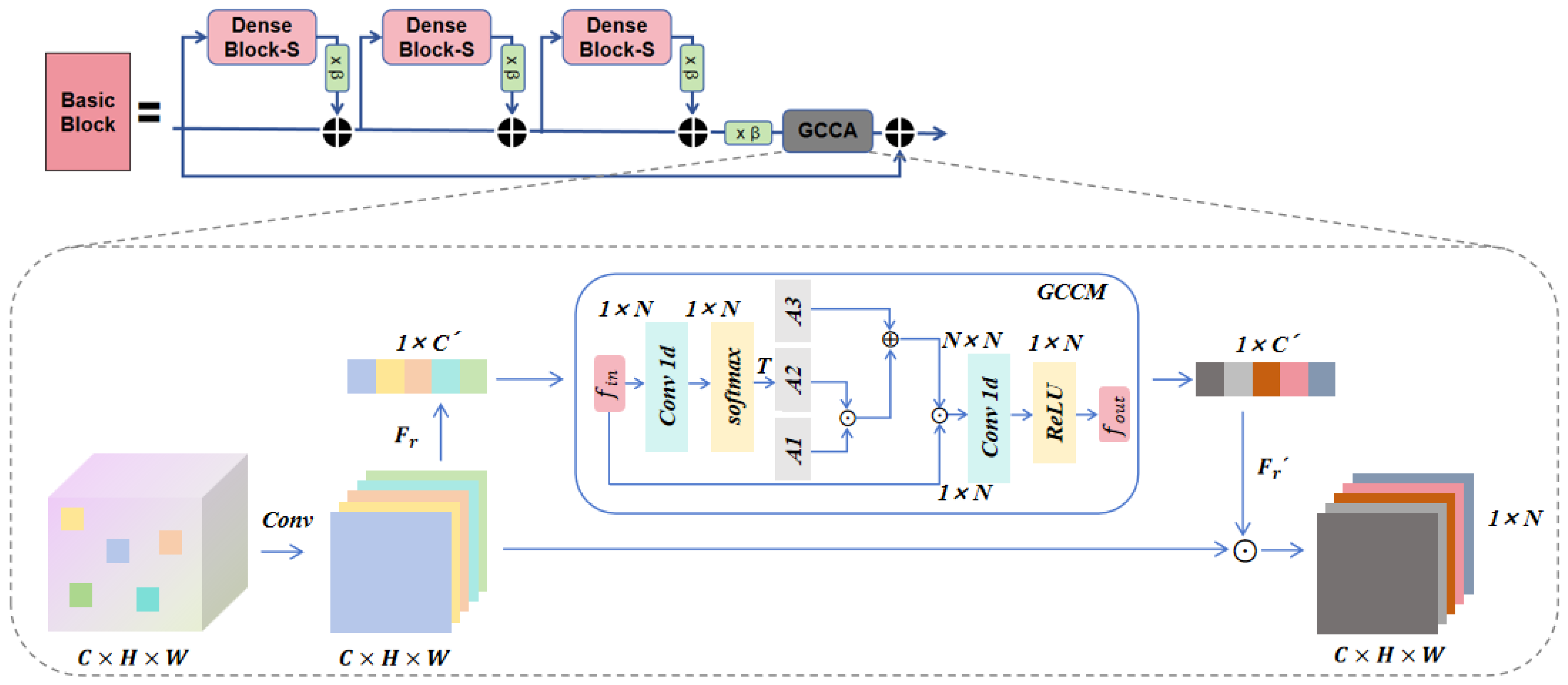
- The Graph Convolutional Channel Attention (GCCA) module enhances the RRDB module by transforming channel dependencies into adjacency relationships of feature vertices, thereby improving pixel correlation. The GCCA module draws on the theory of graph neural networks, focusing on the attention mechanism for feature interaction between channels. It effectively highlights key features, suppresses secondary features, reduces computational redundancy, and enhances the model’s ability to capture long-range dependencies.
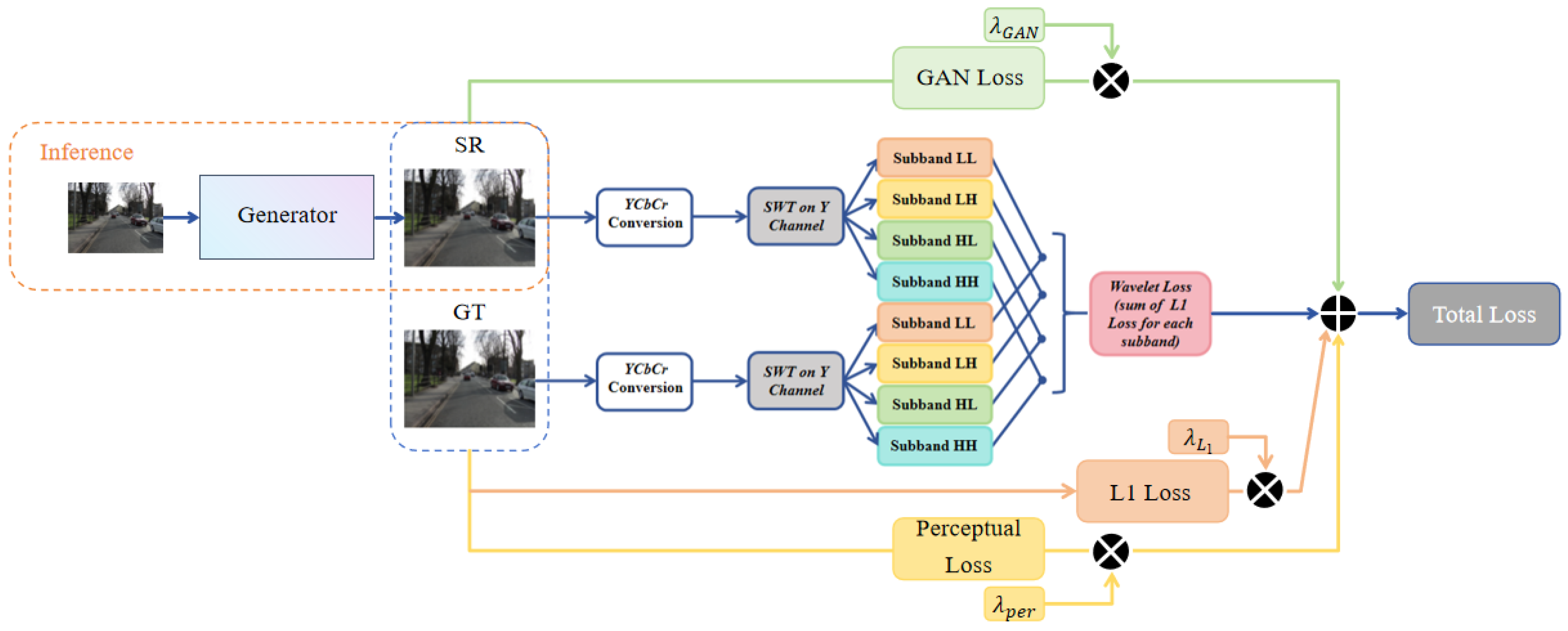
- Add the wavelet loss [23] to the overall loss function. Wavelet loss effectively captures high-frequency details that are often overlooked by conventional pixel-based loss functions. By combining wavelet loss with the standard GAN loss, the model can more accurately recover high-frequency components, thereby generating images with richer textures and finer details.
2. Related Work
2.1. Single-Image Super-Resolution Method Incorporating the Attention Mechanism
2.2. Single-Image Super-Resolution Method Incorporating Prior Information
3. Methods
3.1. Network Architecture
3.2. The RRDB Structure with the SFT Layer
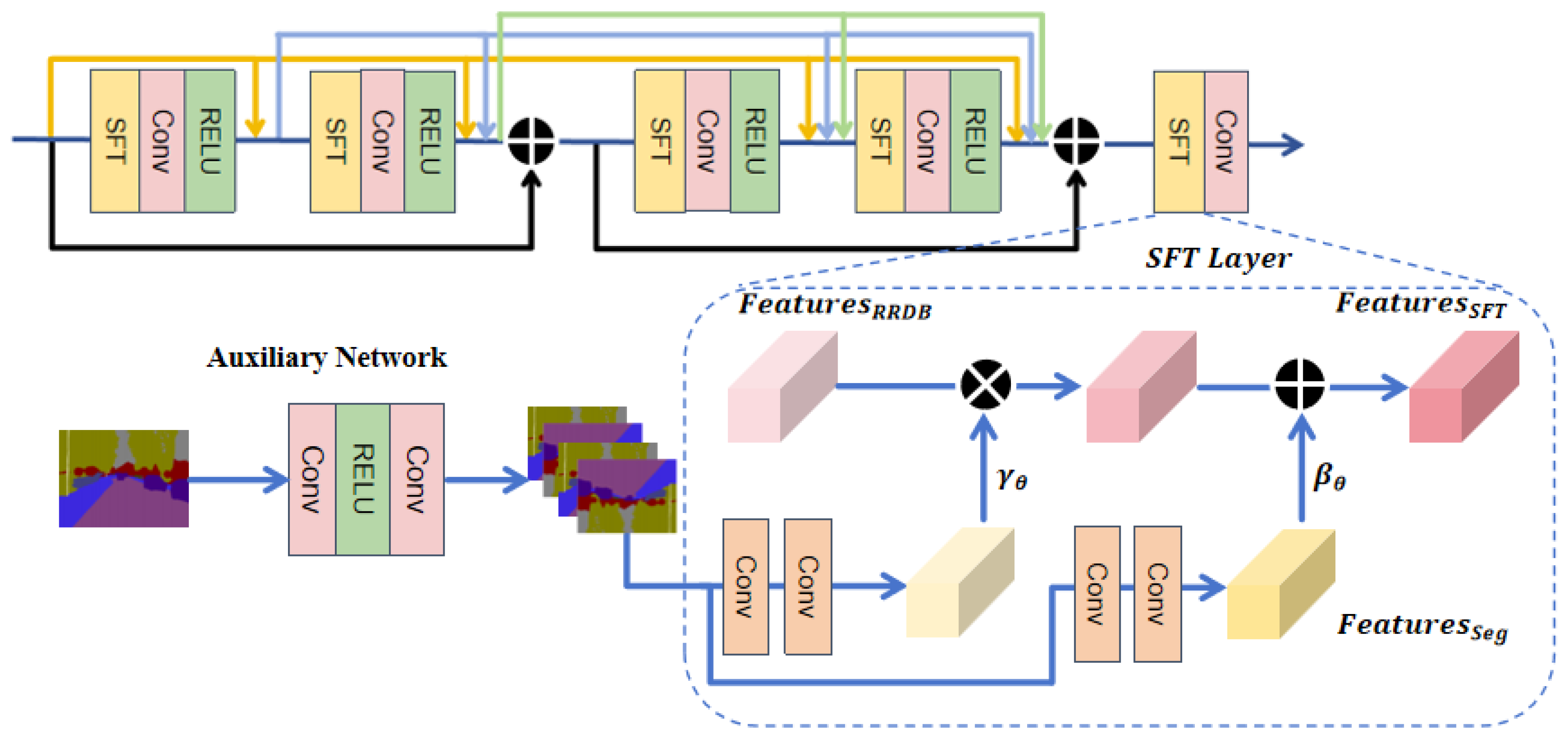
3.3. The RRDB Module Integrated with GCCA Attention
3.3.1. NL Operations
3.3.2. Graph Convolution Channel Attention (GCCA)
3.3.3. Graph Convolutional Channel Module (GCCM)
3.4. Loss Functions
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Implementation Details
4.1.3. Evaluation Index
4.2. The Effect of Low-Resolution Images on Segmentation Models
4.3. Effect of Different Priors on the Reconstruction Results
4.4. Comparison with State-of-the-Art Methods
4.4.1. Quantitative Results
4.4.2. Qualitative Results
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Al-Mekhlafi, H.; Liu, S. Single image super-resolution: A comprehensive review and recent insight. Front. Comput. Sci. 2024, 18, 181702. [Google Scholar] [CrossRef]
- Wang, P.; Bayram, B.; Sertel, E. A comprehensive review on deep learning based remote sensing image super-resolution methods. Earth Sci. Rev. 2022, 232, 104110. [Google Scholar] [CrossRef]
- Azam, N.; Yazid, H.; Rahim, S.A. Super Resolution with Interpolation-based Method: A Review. IJRAR Int. J. Res. Anal. Rev. (IJRAR) 2022, 9, 168–174. [Google Scholar]
- Ooi, Y.K.; Ibrahim, H. Deep Learning Algorithms for Single Image Super-Resolution: A Systematic Review. Electronics 2021, 10, 867. [Google Scholar] [CrossRef]
- Fu, K.; Peng, J.; Zhang, H.; Wang, X.; Jiang, F. Image super-resolution based on generative adversarial networks: A brief review. Comput. Mater. Contin. 2020, 64, 1977–1997. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Super-Resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Li, X.; Ren, Y.; Jin, X.; Lan, C.; Wang, X.; Zeng, W.; Wang, X.; Chen, Z. Diffusion Models for Image Restoration and Enhancement—A Comprehensive Survey. arXiv 2023, arXiv:2308.09388. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27 (NIPS 2014); MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In Proceedings of the 2018 European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, W.; Liu, Y.; Dong, C.; Qiao, Y. RANKSRGAN: Generative Adversarial Networks with Ranker for Image Super-Resolution. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 3096–3105. [Google Scholar]
- Schonfeld, E.; Schiele, B.; Khoreva, A. A U-Net Based Discriminator for Generative Adversarial Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8207–8216. [Google Scholar]
- Zhang, K.; Liang, J.; Van Gool, L.; Timofte, R. Designing a Practical Degradation Model for Deep Blind Image Super-Resolution. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4791–4800. [Google Scholar]
- Fritsche, M.; Gu, S.; Timofte, R. Frequency Separation for Real-World Super-Resolution. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 3599–3608. [Google Scholar]
- Wang, X.; Xie, L.; Dong, C.; Shan, Y. Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1905–1914. [Google Scholar]
- Wang, L.; Wang, Y.; Dong, X.; Xu, Q.; Yang, J.; An, W.; Guo, Y. Unsupervised Degradation Representation Learning for Blind Super-Resolution. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10581–10590. [Google Scholar]
- Vo, K.D.; Bui, L.T. StarSRGAN: Improving Real-World Blind Super-Resolution. arXiv 2023, arXiv:2307.16169. [Google Scholar]
- Rakotonirina, N.C.; Rasoanaivo, A. ESRGAN+: Further Improving Enhanced Super-Resolution Generative Adversarial Network. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3637–3641. [Google Scholar]
- Korkmaz, C.; Tekalp, A.M. Training Transformer Models by Wavelet Losses Improves Quantitative and Visual Performance in Single Image Super-Resolution. arXiv 2024, arXiv:2404.11273. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A Review on the Attention Mechanism of Deep Learning. Neurocomputing 2021, 452, 48–62. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 60–65. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-Order Attention Network for Single Image Super-Resolution. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar]
- Wang, X.; Yu, K.; Dong, C.; Loy, C.C. Recovering Realistic Texture in Image Super-Resolution by Deep Spatial Feature Transform. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 606–615. [Google Scholar]
- Park, S.H.; Moon, Y.S.; Cho, N.I. Perception-Oriented Single Image Super-Resolution Using Optimal Objective Estimation. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1725–1735. [Google Scholar]
- Park, S.H.; Moon, Y.S.; Cho, N.I. Flexible Style Image Super-Resolution Using Conditional Objective. IEEE Access 2022, 10, 9774–9792. [Google Scholar] [CrossRef]
- Ma, C.; Rao, Y.; Cheng, Y.; Chen, C.; Lu, J.; Zhou, J. Structure-preserving super resolution with gradient guidance. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7769–7778. [Google Scholar]
- Li, B.; Li, X.; Zhu, H.; Jin, Y.; Feng, R.; Zhang, Z.; Chen, Z. SeD: Semantic-Aware Discriminator for Image Super-Resolution. arXiv 2024, arXiv:2402.19387. [Google Scholar]
- Xiang, X.; Wang, Z.; Zhang, J.; Xia, Y.; Chen, P.; Wang, B. AGCA: An Adaptive Graph Channel Attention Module for Steel Surface Defect Detection. IEEE Trans. Instrum. Meas. 2023, 72, 5008812. [Google Scholar] [CrossRef]
- Chen, X.; Wang, X.; Zhou, J.; Qiao, Y.; Dong, C. Activating More Pixels in Image Super-Resolution Transformer. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22367–22377. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Zhou, D.; Hou, Q.; Chen, Y.; Feng, J.; Yan, S. Rethinking Bottleneck Structure for Efficient Mobile Network Design. In Computer Vision—ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part III 16; Springer International Publishing: Cham, Switzerland, 2020; pp. 680–697. [Google Scholar]
- Lin, M. Network in Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Aghelan, A.; Amiryan, A.; Zarghani, A.; Rouhani, M. IG-CFAT: An Improved GAN-Based Framework for Effectively Exploiting Transformers in Real-World Image Super-Resolution. arXiv 2024, arXiv:2406.13815. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | DF2K | OST300 | Set5 | BSD100 | |||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| ESRGAN [14] | 25.45 | 0.7570 | 24.87 | 0.7221 | 26.10 | 0.7781 | 23.22 | 0.7064 | |
| SFTGAN [29] | 25.53 | 0.7981 | 25.80 | 0.7881 | 26.82 | 0.7970 | 24.53 | 0.7153 | |
| Real-ESRGAN [19] | 26.88 | 0.8569 | 26.63 | 0.8553 | 27.55 | 0.8225 | 24.40 | 0.7521 | |
| BSRGAN [17] | ×2 | 26.21 | 0.8591 | 26.01 | 0.8621 | 26.12 | 0.8379 | 24.39 | 0.7560 |
| FxSR-PD [31] | 27.50 | 0.8811 | 27.20 | 0.8755 | 27.64 | 0.8530 | 25.36 | 0.7890 | |
| IG-CFAT [40] | 26.02 | 0.8520 | 25.45 | 0.7813 | 26.91 | 0.8024 | 24.11 | 0.7559 | |
| ours | 27.22 | 0.8951 | 27.31 | 0.8600 | 27.74 | 0.8561 | 26.01 | 0.7611 | |
| ESRGAN [14] | 22.56 | 0.6553 | 22.22 | 0.6844 | 23.65 | 0.6849 | 20.89 | 0.6281 | |
| SFTGAN [29] | 22.98 | 0.7255 | 22.82 | 0.7125 | 24.71 | 0.7051 | 21.74 | 0.6520 | |
| Real-ESRGAN [19] | 24.65 | 0.8200 | 25.10 | 0.8251 | 25.47 | 0.8091 | 23.51 | 0.7222 | |
| BSRGAN [17] | ×4 | 24.05 | 0.8012 | 24.35 | 0.8412 | 24.99 | 0.7538 | 22.97 | 0.6588 |
| FxSR-PD [31] | 25.15 | 0.8320 | 25.22 | 0.8505 | 25.66 | 0.8295 | 23.69 | 0.7583 | |
| IG-CFAT [40] | 24.19 | 0.7998 | 23.95 | 0.7764 | 24.22 | 0.7873 | 22.59 | 0.7023 | |
| ours | 25.20 | 0.8563 | 25.18 | 0.8520 | 25.51 | 0.8460 | 23.90 | 0.7619 | |
| ESRGAN [14] | 22.16 | 0.6463 | 21.35 | 0.5979 | 21.85 | 0.6251 | 20.66 | 0.5830 | |
| SFTGAN [29] | 22.75 | 0.7007 | 23.35 | 0.6896 | 24.01 | 0.6868 | 21.12 | 0.6258 | |
| Real-ESRGAN [19] | 24.56 | 0.7890 | 23.99 | 0.8036 | 25.03 | 0.7735 | 23.05 | 0.7272 | |
| BSRGAN [17] | ×8 | 23.85 | 0.7781 | 24.03 | 0.7890 | 24.47 | 0.7538 | 22.97 | 0.6588 |
| FxSR-PD [31] | 24.95 | 0.8097 | 25.12 | 0.8121 | 25.06 | 0.8055 | 23.28 | 0.7351 | |
| IG-CFAT [40] | 23.91 | 0.7769 | 23.85 | 0.7534 | 24.10 | 0.7624 | 22.31 | 0.6821 | |
| ours | 24.82 | 0.8211 | 24.91 | 0.8092 | 25.35 | 0.8350 | 23.58 | 0.7400 | |
| StarRRDB | GCCA | SFT | PSNR ↑ | SSIM ↑ | ||
|---|---|---|---|---|---|---|
| 1 | × | × | × | × | 24.65 | 0.8200 |
| 2 | ✓ | × | × | × | 24.68 | 0.8211 |
| 3 | ✓ | ✓ | × | × | 25.01 | 0.8421 |
| 4 | ✓ | ✓ | ✓ | × | 25.10 | 0.8489 |
| 5 | ✓ | ✓ | ✓ | ✓ | 25.20 | 0.8563 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, M.; Li, Z.; Liu, H.; Chen, Z.; Cai, K. SP-IGAN: An Improved GAN Framework for Effective Utilization of Semantic Priors in Real-World Image Super-Resolution. Entropy 2025, 27, 414. https://doi.org/10.3390/e27040414
Wang M, Li Z, Liu H, Chen Z, Cai K. SP-IGAN: An Improved GAN Framework for Effective Utilization of Semantic Priors in Real-World Image Super-Resolution. Entropy. 2025; 27(4):414. https://doi.org/10.3390/e27040414
Chicago/Turabian StyleWang, Meng, Zhengnan Li, Haipeng Liu, Zhaoyu Chen, and Kewei Cai. 2025. "SP-IGAN: An Improved GAN Framework for Effective Utilization of Semantic Priors in Real-World Image Super-Resolution" Entropy 27, no. 4: 414. https://doi.org/10.3390/e27040414
APA StyleWang, M., Li, Z., Liu, H., Chen, Z., & Cai, K. (2025). SP-IGAN: An Improved GAN Framework for Effective Utilization of Semantic Priors in Real-World Image Super-Resolution. Entropy, 27(4), 414. https://doi.org/10.3390/e27040414