MAB-Based Online Client Scheduling for Decentralized Federated Learning in the IoT

Abstract
1. Introduction
- This paper considers the client scheduling problem in DFL scenarios. Due to the heterogeneity of local computing and communication resources, as well as the time-varying nature of wireless channels, the total delay of each client in each round cannot be predicted. Thus, we formulate the client scheduling problem as a contextual combinatorial multi-armed bandit (CC-MAB) program [15].
- We propose an online client scheduling algorithm that estimates the delay of clients based on their contextual information during training and continuously updates the estimator according to the actual delay. Through theoretical analysis and algorithm parameter design, this algorithm can achieve asymptotic optimal performance in theory.
- Finally, through extensive experiments, we show that the algorithm can make asymptotically optimal client scheduling decisions, which is superior to existing algorithms in reducing the cumulative delay of the system.
2. Related Works
2.1. Client Scheduling in Centralized FL
2.2. Client Scheduling in DFL
3. System Model
3.1. DFL Process
3.2. Delay Model
4. Problem Formulation
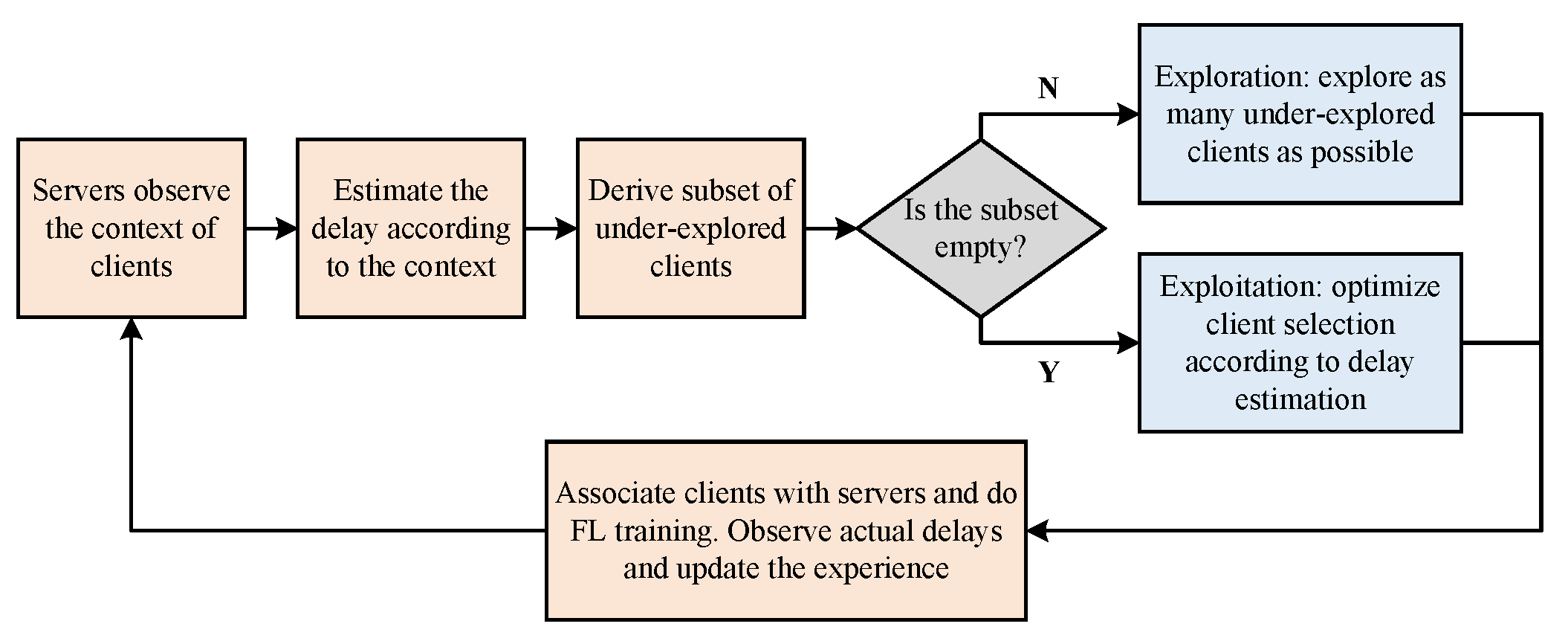
5. Algorithm Design
5.1. Delay Estimation Based on Contextual Information
5.2. Exploration and Exploitation
6. Key Parameter Design
6.1. Upper Bound of Regret
6.2. Parameter Design Based on the Upper Bound
7. Experimental Results
7.1. Simulation Setup
- Optimal client selection. In this method, the total delay of each client in each round of the system is known as a priority. When making decisions in each round, edge servers select the N clients with the smallest total delay in the covered cells to participate in training. Note that this method serves as the upper bound.
- -greedy client selection. This method employs a greedy metric to decide between exploration and exploitation. In the exploration round, each edge server randomly selects N clients from their covered cells to participate in training. In the exploitation round, each edge server selects the N clients with the minimum delay expectation to participate in training. This method does not utilize contextual information when making selection decisions, relying solely on randomness and delay-based selection. In this work, the value of is 0.3.
- Random client selection. At the beginning of each training round, each edge server randomly selects N clients from the corresponding cells to participate in the training.
7.2. Performance Analysis
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Proof of Theorem 1
References
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Niyato, D.; Dobre, O.; Poor, H.V. 6G Internet of Things: A Comprehensive Survey. IEEE Internet Things J. 2021, 9, 359–383. [Google Scholar] [CrossRef]
- Lampropoulos, G.; Siakas, K.; Anastasiadis, T. Internet of things (IoT) in industry: Contemporary application domains, innovative technologies and intelligent manufacturing. People 2018, 6, 109–118. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Majeed, I.A.; Kaushik, S.; Bardhan, A.; Tadi, V.S.K.; Min, H.K.; Kumaraguru, K.; Muni, R.D. Comparative assessment of federated and centralized machine learning. arXiv 2022, arXiv:2202.01529. [Google Scholar]
- Konečný, J.; Brendan McMahan, H.; Ramage, D.; Richtárik, P. Federated Optimization: Distributed Machine Learning for On-Device Intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar] [CrossRef]
- Zhao, P.; Jin, Y.; Ren, X.; Li, Y. A personalized cross-domain recommendation with federated meta learning. Multim. Tools Appl. 2024, 83, 71435–71450. [Google Scholar] [CrossRef]
- Hao, M.; Li, H.; Luo, X.; Xu, G.; Yang, H.; Liu, S. Efficient and Privacy-Enhanced Federated Learning for Industrial Artificial Intelligence. IEEE Trans. Ind. Inform. 2020, 16, 6532–6542. [Google Scholar] [CrossRef]
- Samarakoon, S.; Bennis, M.; Saad, W.; Debbah, M. Federated Learning for Ultra-Reliable Low-Latency V2V Communications. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–7. [Google Scholar]
- Yuan, B.; Ge, S.; Xing, W. A Federated Learning Framework for Healthcare IoT devices. arXiv 2020, arXiv:2005.05083. [Google Scholar]
- AbdulRahman, S.; Tout, H.; Ould-Slimane, H.; Mourad, A.; Talhi, C.; Guizani, M. A survey on federated learning: The journey from centralized to distributed on-site learning and beyond. IEEE Internet Things J. 2020, 8, 5476–5497. [Google Scholar] [CrossRef]
- Sun, Y.; Shao, J.; Mao, Y.; Wang, J.H.; Zhang, J. Semi-Decentralized Federated Edge Learning for Fast Convergence on Non-IID Data. In Proceedings of the 2022 IEEE Wireless Communications and Networking Conference (WCNC), Austin, TX, USA, 10–13 April 2022; pp. 1898–1903. [Google Scholar] [CrossRef]
- Beltrán, E.T.M.; Pérez, M.Q.; Sánchez, P.M.S.; Bernal, S.L.; Bovet, G.; Pérez, M.G.; Pérez, G.M.; Celdrán, A.H. Decentralized federated learning: Fundamentals, state of the art, frameworks, trends, and challenges. IEEE Commun. Surv. Tutor. 2023, 25, 2983–3013. [Google Scholar] [CrossRef]
- S Alsaffar, Q.; Ayed, L.B. Heterogeneous Resources in Infrastructures of the Edge Network Paradigm: A Comprehensive Review. Karbala Int. J. Mod. Sci. 2024, 10, 15. [Google Scholar] [CrossRef]
- Noaman, M.; Khan, M.S.; Abrar, M.F.; Ali, S.; Alvi, A.; Saleem, M.A. Challenges in integration of heterogeneous internet of things. Sci. Program. 2022, 2022, 8626882. [Google Scholar] [CrossRef]
- Qin, L.; Chen, S.; Zhu, X. Contextual combinatorial bandit and its application on diversified online recommendation. In Proceedings of the 2014 SIAM International Conference on Data Mining, SIAM, Philadelphia, PA, USA, 24–26 April 2014; pp. 461–469. [Google Scholar]
- WANG, L.; WANG, W.; LI, B. CMFL: Mitigating Communication Overhead for Federated Learning. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–9 July 2019; pp. 954–964. [Google Scholar] [CrossRef]
- Cho, Y.J.; Wang, J.; Joshi, G. Client Selection in Federated Learning: Convergence Analysis and Power-of-Choice Selection Strategies. arXiv 2020, arXiv:2010.01243. [Google Scholar]
- Ren, J.; He, Y.; Wen, D.; Yu, G.; Huang, K.; Guo, D. Scheduling for Cellular Federated Edge Learning With Importance and Channel Awareness. IEEE Trans. Wirel. Commun. 2020, 19, 7690–7703. [Google Scholar] [CrossRef]
- Chen, M.; Yang, Z.; Saad, W.; Yin, C.; Poor, H.V.; Cui, S. A Joint Learning and Communications Framework for Federated Learning Over Wireless Networks. IEEE Trans. Wirel. Commun. 2021, 20, 269–283. [Google Scholar] [CrossRef]
- Xu, B.; Xia, W.; Zhang, J.; Quek, T.Q.S.; Zhu, H. Online Client Scheduling for Fast Federated Learning. IEEE Wirel. Commun. Lett. 2021, 10, 1434–1438. [Google Scholar] [CrossRef]
- Slivkins, A. Introduction to multi-armed bandits. Found. Trends Mach. Learn. 2019, 12, 1–286. [Google Scholar] [CrossRef]
- Luo, S.; Chen, X.; Wu, Q.; Zhou, Z.; Yu, S. HFEL: Joint Edge Association and Resource Allocation for Cost-Efficient Hierarchical Federated Edge Learning. IEEE Trans. Wirel. Commun. 2020, 19, 6535–6548. [Google Scholar] [CrossRef]
- Wen, W.; Chen, Z.; Yang, H.H.; Xia, W.; Quek, T.Q.S. Joint Scheduling and Resource Allocation for Hierarchical Federated Edge Learning. IEEE Trans. Wirel. Commun. 2022, 21, 5857–5872. [Google Scholar] [CrossRef]
- Zhao, T.; Li, F.; He, L. DRL-Based Joint Resource Allocation and Device Orchestration for Hierarchical Federated Learning in NOMA-Enabled Industrial IoT. IEEE Trans. Ind. Inform. 2023, 19, 7468–7479. [Google Scholar] [CrossRef]
- Saadat, H.; Allahham, M.S.; Abdellatif, A.A.; Erbad, A.; Mohamed, A. RL-Assisted Energy-Aware User-Edge Association for IoT-based Hierarchical Federated Learning. In Proceedings of the 2022 International Wireless Communications and Mobile Computing (IWCMC), Dubrovnik, Croatia, 30 May–3 June 2022; pp. 548–553. [Google Scholar] [CrossRef]
- Xu, B.; Xia, W.; Zhang, J.; Sun, X.; Zhu, H. Dynamic Client Association for Energy-Aware Hierarchical Federated Learning. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Qu, Z.; Duan, R.; Chen, L.; Xu, J.; Lu, Z.; Liu, Y. Context-Aware Online Client Selection for Hierarchical Federated Learning. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 4353–4367. [Google Scholar] [CrossRef]
- Liu, W.; Chen, L.; Zhang, W. Decentralized Federated Learning: Balancing Communication and Computing Costs. IEEE Trans. Signal Inf. Process. Over Netw. 2022, 8, 131–143. [Google Scholar] [CrossRef]
- Yan, Z.H.; Li, D. Adaptive Decentralized Federated Learning in Energy and Latency Constrained Wireless Networks. arXiv 2024, arXiv:abs/2403.20075. [Google Scholar]
- Masmoudi, N.; Jaafar, W. OCD-FL: A Novel Communication-Efficient Peer Selection-based Decentralized Federated Learning. arXiv 2024, arXiv:abs/2403.04037. [Google Scholar] [CrossRef]
- Xie, H.; Xia, M.; Wu, P.; Wang, S.; Huang, K. Decentralized Federated Learning With Asynchronous Parameter Sharing for Large-Scale IoT Networks. IEEE Internet Things J. 2024, 11, 34123–34139. [Google Scholar] [CrossRef]
- Abed, Q.A. Study the Performance of Transmission Control Protocol Versions in Several Domains. J. Mach. Comput. 2023, 3, 517–522. [Google Scholar] [CrossRef]
- Ye, H.; Liang, L.; Li, G.Y. Decentralized Federated Learning With Unreliable Communications. IEEE J. Sel. Top. Signal Process. 2022, 16, 487–500. [Google Scholar] [CrossRef]
- Garcia, N.M.; Gil, F.; Matos, B.; Yahaya, C.; Pombo, N.; Goleva, R.I. Keyed user datagram protocol: Concepts and operation of an almost reliable connectionless transport protocol. IEEE Access 2019, 7, 18951–18963. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE Inst. Electr. Electron. Eng. 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Size of the area | 500 m × 500 m |
| Noise power spectral density | dBm/Hz |
| Uplink resource block bandwidth | 1 Mbps |
| Transmit power of clients | 10 mW |
| Transmit power of servers | 1 W |
| The data size of model parameters | |
| The computing capability | |
| The computational resource | |
| The number of active programs running on client | [0,10] |
| The maximum interval | 5 s |
| Batch size | 64 |
| Learning rate (MNIST / CIFAR-10) | 0.05/0.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Zhang, X.; Wang, S.; Wang, Y. MAB-Based Online Client Scheduling for Decentralized Federated Learning in the IoT. Entropy 2025, 27, 439. https://doi.org/10.3390/e27040439
Chen Z, Zhang X, Wang S, Wang Y. MAB-Based Online Client Scheduling for Decentralized Federated Learning in the IoT. Entropy. 2025; 27(4):439. https://doi.org/10.3390/e27040439
Chicago/Turabian StyleChen, Zhenning, Xinyu Zhang, Siyang Wang, and Youren Wang. 2025. "MAB-Based Online Client Scheduling for Decentralized Federated Learning in the IoT" Entropy 27, no. 4: 439. https://doi.org/10.3390/e27040439
APA StyleChen, Z., Zhang, X., Wang, S., & Wang, Y. (2025). MAB-Based Online Client Scheduling for Decentralized Federated Learning in the IoT. Entropy, 27(4), 439. https://doi.org/10.3390/e27040439