1. Introduction
Nowadays, information and communication technology (ICT) systems play a crucial role in every area of business and people’s lives. At the same time, cyber-attacks on ICT systems are becoming more complex and are steadily increasing. Therefore, ICT systems need a very efficient network security solution. An intrusion detection (ID) system is one of the widely used tools for detecting various types of malicious attacks in the network. Initially, a substantial amount of work in the ID domain was done by John Anderson in 1980 [
1]. In most cases, an ID framework traces all interior and exterior packets in a network to find out if any of them have signs of interruption. A good-quality ID system can identify the characteristics of various cyberattacks’ actions and react automatically by sending out warnings. An ID is classified into three categories according to the network architecture: (1) network-based ID systems, which evaluate the contents of distinct packets to detect malicious network traffic behavior; (2) host-based ID systems, which evaluate the event log files of each host separately to determine malicious attacks; and (3) hybrid ID systems, which combine both host and network-based ID systems with better-quality security mechanisms [
2,
3,
4]. The classification and evaluation of collected network traffic packets are generally classified into anomaly detection, signature detection, and state protocol analysis. The signature detection technique utilizes the predefined patterns and filters that efficiently detect malicious attacks. The signature detection technique uses existing knowledge to identify malicious threats, which is why it is referred to as a knowledge-based approach. The signature recognition method attains a low false alarm rate (FAR) and high accuracy; however, it cannot detect a new attack in the network [
5]. The anomaly detection technique depends on heuristic methods to detect unknown attacks. However, the performance of the anomaly detection technique is effective and has a high false-positive rate. To overcome this issue, various organizations have used state protocol analysis, which combines the benefits of both signature and anomaly-based systems [
6]. Two main types of ID systems can be identified according to their deployment structure: distributed and non-distributed. The first type contains numerous ID subsystems, and these subsystems connect over a large network, known as distributed implementation, while a non-distributed structure, on the other hand, may be placed in a unique location, such as an open-source snort [
7].
Nowadays, statistical tests and threshold computing techniques are used in the current approaches to network intrusions in commercial markets. This statistical-test-based ID system depends on several traffic constraints, including packet arrival time, packet length, and network traffic flow size, on the model’s network traffic in a predefined time. These kinds of approaches may not be efficient due to the complex nature of malicious attacks that are occurring nowadays. So, the most efficient intelligent solution is required instead of these statistically based approaches. ML-based approaches have been extensively used in detecting several types of malicious attacks and ML techniques can assist the network administrator with taking the appropriate actions to prevent these malicious attacks in the network [
8]. Ensemble learning (EL) also helps us to boost the machine learning (ML) results by combining several models. Yong et al. [
9] used ensemble ML-based approaches for web shell attack detection in Internet of things (IoT) environments. To develop a secure IoT system, authors apply machine learning models to detect web shells to create safe solutions for IoT networks. Future ensemble ML algorithms, such as extremely randomized trees (ET), random forest (RF), and Voting, are used to increase the performances of these machine learning models. Folino et al. [
10] developed a novel ensemble-based deep learning framework for the analysis of non-stationary data, such as those that typically occur in IDS logs. The ability to design a better detection system is desired to achieve a higher detection rate, particularly when using ensemble learners. The choice of available base classifiers and the choice of available combiners are two major challenges when designing an ensemble. Tama et al. [
11] provide a comprehensive review of ensemble learning for intrusion detection systems. However, most conventional ML methods belong to the shallow learning category and are less focused on feature engineering and selection; they are unable to effectively solve the massive attack data classification problem that occurs in a real-world network application context. As dataset sizes increase continuously, multi-classification attack detection tasks will lead to reduced accuracy. So, ML is incompatible with intelligent evaluation and the forecasting prerequisites of high-dimensional learning with an enormous amount of data [
12]. Deep learning (DL) algorithms have recently gained popularity as powerful algorithms due to promising results in image processing, computer vision (CV), natural language processing (NLP), and other fields [
13]. DL is popular among researchers due to its two primary characteristics: hierarchical feature representations and learning long-term temporal pattern dependencies. Therefore, DL methods have recently been considered to increase the intelligence of ID techniques, although there is a shortage of research to benchmark such ML techniques with publicly existing datasets. In a nutshell, DL has a nonlinear structural design that enables high-quality learning for complex data analysis. The fast development of parallel computing technology has delivered an extensive hardware foundation for DL methods. The most popular problems with current ML-based models are: (1) these models have a high false-positive rate (FPR) with a larger range of malicious intrusions [
14]; (2) these models are not generalizable, as most of the existing ID systems miss novel attacks due to outdated ID datasets; and (3) state-of-the-art solutions are needed to maintain today’s quickly growing high-speed network traffic in a heterogeneous environment. These challenges are the motivation to develop a hybrid convolutional recurrent neural network-based ID system using a real-world dataset with a focus on evaluating the efficacy of ML and DL classifiers in the ID domain. As mentioned above, ID methods have their limitations; so, in our proposed ID system, we merge the two approaches to overwhelm their disadvantages and propose a new classical method combining the advantages of two approaches that have enhanced performance over traditional methods. To improve the learning capacity and performance of the ID system, we propose an improved IDS that consists of up-to-date DL methods, such as CNN, and classical ML, such as RNN. The important contributions of our research can be summarized as follows.
We developed the HCRNNIDS, which combines both deep and shallow models to reduce analytical overheads and maximize benefits. The proposed HCRNNIDS focuses on identifying whether network traffic behavior is normal or malicious because attacks can be classified into the corresponding intrusion class.
We address the problem of class imbalance that is common in ID data.
We equate the proposed method with popular ML approaches. The empirical outcomes express that the HCRNNIDS very appropriate for attack detection and can accurately identify the misuses in 97.75% of incidents with 10-fold cross-validation.
The output of the hybrid convolutional recurrent neural network-based network intrusion detection system is higher than that of traditional classification techniques when conducting experiments on the well-known and contemporary real-life CSE-CIC-IDS2018 dataset; it improves the accuracy of ID, thus providing a novel research method for ID.
To address the abovementioned challenge, we developed a hybrid convolutional recurrent neural network-based intrusion detection system (HCRNNIDS). The remainder of the article is arranged as follows. We introduce the background of the NID in
Section 2. In
Section 3, we provide an overview of the proposed HCRNNIDS structure as well as a comprehensive explanation of the ID data. The HCRNNIDS simulation is described in
Section 4. Lastly, the conclusion of our research is illustrated in
Section 5.
2. Related Work
During the last two decades, machine learning (ML) techniques have been used extensively in the network security domain because of their capability to extract the concealed information on the distinctions among malicious and normal behaviors [
15,
16,
17,
18]. So, the earlier researchers used various approaches based on conventional ML for intrusion detection (ID). Xu et al. [
19] applied K-nearest neighbors (K-NN) for anomaly ID, and evaluated the efficacy of the proposed ID system using the KDDCup ID dataset. Bhati et al. [
20] applied variants of support vector machine (SVM), such as quadratic, linear, fine, and medium Gaussian, to analyze the performance of SVM techniques using the NSL-KDD dataset. An integrated ID system was developed by Sumaiya et al. [
21] using correlation-based feature selection and an artificial neural network (ANN). The authors performed an experimental analysis on the UNSW-NB and NSL-KDD ID datasets. Similarly, a Random Forest (RF)-based ID system was presented by Waskle et al. [
22], and an ID system based on several classical ML classification methods was presented by Alqahtanet al. [
23]. However, prior techniques used in the domain of ID have poor classification efficiency, with a high FAR and a low DR in the ID system. Deep learning (DL) is a subset of ML that consists of several hidden layers used to obtain the deep network’s characteristics. Due to their deep structure and ability to learn the important features from the dataset on their own and produce an output, these techniques are more effective than ML [
24].
DL has grown in popularity in recent years and has been applied for intrusion detection (ID); studies have shown that DL outperforms conventional methods. The authors of [
25] use a DL method for flow-based anomaly ID based on a deep neural net (DNN), and the experimental results show that DL can be used for anomaly ID in a software-defined network. Nowadays, auto-encoders (AE), convolutional neural networks (CNNs), and deep neural networks (DNNs), as well as variants of these methods, are used for ID [
26]. Long-short-term-memory (LSTM) can be effective in the field of network security. Various LSTM deep-learning-based security policies have been investigated for ID [
27], classification and detection of malicious apps [
28], phishing exposure [
29], and time-dependent botnet ID [
30]. The ability to model the sequence is the primary benefit of a recurrent neural network (RNN) over a conventional network. Oliveira et al. [
31] developed an intelligent ID and classification framework using LSTM deep learning and evaluated the proposed framework by using the CIDDS-001 dataset to achieve a higher ID accuracy as compared with traditional ML approaches. The convolutional neural network (CNN) is another popular DL approach that learns directly from the dataset without requiring manual feature extraction algorithms. A typical CNN consists of convolutional, pooling fully connected, input, and output layers. Even though CNNs are widely used to analyze visual images, they can also be utilized in the field of security. For example, in IoT networks [
32], CNN-based models are used for ID, such as denial-of-service (DoS) ID [
33], and android malware [
34]. An auto-encoder (AE) [
35] is a kind of ANN that is applied to economically learn data codes in an unsupervised fashion. An AE aims to learn a representation for a dataset by training the network to disdain “noise” signals to reduce the number of dimensions. An auto-encoder has three components: encoder, message, and decoder. A deep AE can be used to construct a useful security model in cybersecurity. As a result, the AE-based feature learning (FL) model in cybersecurity outperforms other advanced algorithms. The AE-based FL model uses the fewest security features when compared with other sophisticated algorithms in cybersecurity. The model is more effective and functional, even in small spaces like the IoT, because of the rich and tiny latent representation of security features. [
36]. The authors in [
37] provide an AE-based FL prototype for security purposes, proving its effectiveness in malware classification and detection. The authors in [
38] propose a deep AE-based anomaly detection model. To create an effective ID model, the Restricted Boltzmann Machine (RBM) can be used. Yadigar et al. [
39] present a denial-of-service attack detection model and achieve a higher attack detection accuracy with a RBM. The summary of various approaches in the ID domain is given in
Table 1.
Recently, applications of the hybrid model have made various researchers attempt to develop an efficient and robust ID system in the cybersecurity domain. These ID systems have been found to be competent against malicious attacks as compared with separate conventional ML and DL-based ID systems [
52]. Wang et al. [
51] transformed two packets into an image and used the 2D-CNN to learn the characteristics of packet bytes while using the LSTM to learn the characteristics of the packet sequence, resulting in the simultaneous learning of two spacing and timing characteristics. Chencheng et al. [
53] developed a hybrid ID system for the evaluation of multiple types of flow features using a hybrid NN and tested the efficacy of the proposed hybrid ID system in real-time using the ISCX2012 ID dataset. Zeng et al. [
54] used a hybrid NN with a stack autoencoder (SAE) to evaluate the traffic features and chose the best feature vectors from the network traffic as label results. Hosseini et al. [
55] used a fusion-based method that combined an ANN and a SVM and tested it on the benchmark NSL-KDD dataset, where the SVM was used for feature selection and the ANN was used for attack classification.
Most of the researchers in the ID domain use simulated datasets, such as NSL-KDD or KDDcup99, but these kinds of ID databases cannot accurately represent the scenarios of realistic network traffic. Erhan et al. [
56] note that DDOS attacks are one of the most annoying types of malicious attacks for online activities on the internet. DDoS attacks are generally classified into two types: bandwidth depletion and resource depletion attacks. The authors created resource-depletion-type DDoS attacks and recorded the traffic from the backbone router’s mirror port of the Bogaziçi University network. This dataset contains both attack-free and attack traffic, making it appropriate for testing network-based DDoS detection methods. Attacks are directed at a single victim server that is linked to the campus’s backbone router. Damasevicius et al. [
57] developed an annotated real-world network flow dataset for network ID called LITNET-2020. It consists of modern network traffic and various types of malicious attacks that occurred over 10 months. This gives an advantage over synthetically created ID datasets because an artificial synthesis of traffic might lead to inaccurate network attack models and behaviors. It is essential to utilize realistic flow-based ID datasets to guarantee accurate valuation of techniques [
58]. As a result, in this study, the practical CSE CIC dataset was used to demonstrate a change from static datasets to dynamically created datasets that not only represent network traffic and log files at the time of the study, but can also be updated, reproduced, and extended.
3. Proposed Approach
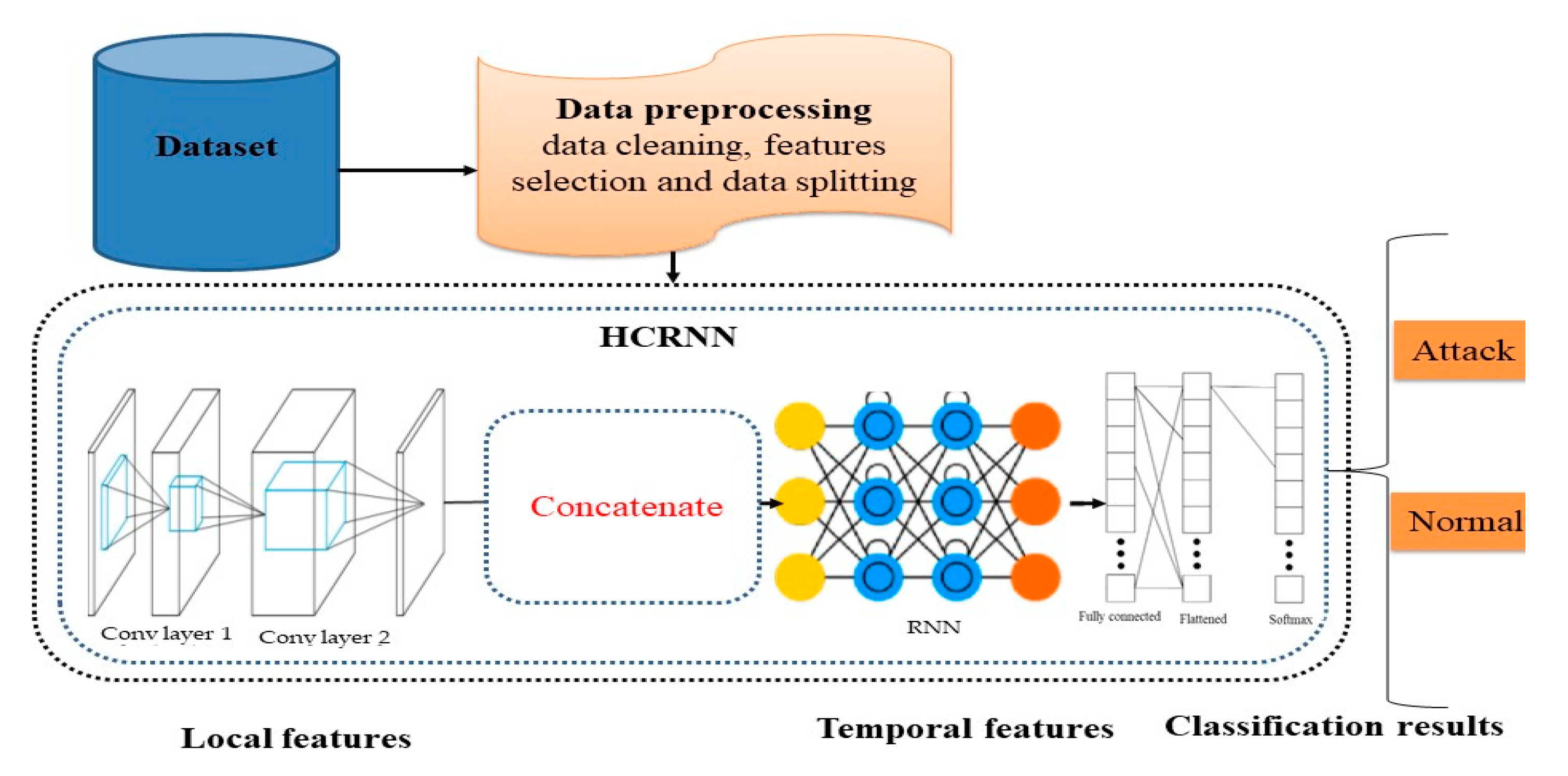
Figure 1 shows the ID system’s architecture. It consists of two learning steps, sketched as follows. In this approach, we proposed to construct an IDS using a HCRNN-based deep learning approach. Our proposed HCRNNIDS is economical in terms of computational complexity while using datasets with full features and offers improved accuracy with a minimal chance of a FAR.
3.1. Overview of the HCRNNIDS
HCRNN-based deep learning focuses on solving realistic ID problems with a big data processing framework. Due to a lack of time and space, resolving such a problem is not an easy job. Big data presently has huge, and increasing, volumes but needs an enormous amount of power, specialized resources, and a computational device to assist with the learning process that can handle the data competently.
HCRNN-based deep learning decreases these challenges by using a RNN with a CNN DL model. The source of the experiment is the key structure of the HCRNNIDS that exists here. The detail of the HCRNNIDS is depicted in
Figure 1.
The overview of the HCRNNIDS shows that a CNN has two fundamental components: (i) a feature extractor; and (ii) a classifier. The feature extractor consists of two layers called convolution and pooling layers. The extracted output, which is known as the feature map, becomes the input to the second component for the classification. This way, the CNN learns the local features very well. However, the weakness is that it misses the temporal dependency among important features. Therefore, to capture both spatial as well as temporal features more robustly, we introduced recurrent layers after the CNN layers. This way, we addressed the vanishing and exploding gradient problems effectively, which improves the capability to capture spatial and temporal dependencies and learn efficiently from variable extent sequences. In the HCRNN network, the input is initially processed by the CNN, and then the output of the CNN is passed through the recurrent layers to generate sequences at each timestep, which helps us model both spatial and temporal features. Then, the sequence vector is passed through a fully connected layer before being fed into a Softmax layer for the probability distribution over the classes. The network traffic was first organized and preprocessed in the data pre-processing part. During pre-processing, all necessary conversions were made that used or were helpful for the HCRNNIDS and IDS-supported data formats. In the original CSE CIC IDS2018, a few features, such as IP addresses and timestamps, have slight importance on whether the network traffic is benign or malicious. The timestamp features are used to record the time when malicious traffic happened and provide only slight support when training the process, so during the pre-processing phase we removed these kinds of features. As in an anomaly intrusion detection system (AIDS), most of the traffic is categorized based on the traffic behavior, and should not be biased, conflicting with the IP address, so we also removed the IP address characteristics. Data pre-processing operations were implemented using Pandas NumPy and Scikit-learn libraries developed for the Python programming language. The research community has drawn substantial attention to the class imbalance issue. The problem of a class imbalance is created by an insufficient data distribution; one class contains most of the samples, while others contain comparatively few. The classification problem becomes more complicated as the data dimensionality increases due to unbounded data values and unbalanced classes. Bedi et al. [
59] utilized several ML approaches to deal with the class imbalance issue. Thabtah et al. [
60] also evaluated various approaches to the class imbalance problem. Most data samples are targeted by most of the algorithms, which miss the minority data samples. As a result, minority samples appear irregularly but constantly. The main algorithms for solving an unbalanced data problem are data pre-processing and feature selection techniques, and every approach has both benefits and shortcomings. The ID dataset has a high-dimensional imbalance problem, including missing features of interest, missing feature values, and the sole existence of cumulative data. The data appear to be noisy, containing errors and outliers, and unpredictable, comprising discrepancies in codes or names. We used over-sampling to resolve the imbalance problem; this involved enlarging the number of instances in the minority class by arbitrarily replicating them to increase the presence of the minority class in the sample. Although this procedure carries some risk of overfitting, no information was lost, and the over-sampling approach was found to outperform the under-sampling alternative. After finishing the data pre-processing, we split the dataset into testing, training, and validation sets, which were 9, 90, and 1% of the initial network traffic, respectively. The training set was utilized for training, the validation set was applied for fast evaluation of the prototype during training, and the testing set was utilized for the final evaluation of the model. Furthermore, we discovered that the dataset included far too many samples of normal network traffic, which could easily distort the model’s classification preference.
3.2. Datasets
Since choosing proper ID data to assess the ID system plays a critical role, we selected the data before we performed the simulation of the proposed approach.
Explanation of the ID Data
Although numerous ID datasets are freely available, some of them contain old-fashioned, inflexible, under-verified, and irreproducible intrusions. To overcome these deficiencies and produce modern traffic patterns, the well-known CSE-CIC-DS2018 [
61] dataset was produced by the Amazon Web Services (AWS) platform. It contains various types of datasets used to evaluate anomaly-based techniques. The CSE-CIC-DS2018 intrusion dataset presents real-time network behavior and comprises several intrusion states. Moreover, it is distributed as a whole network encapsulates all of the inner network traces to calculate payloads for data packets. These characteristics of the CSE-CIC-DS2018 dataset bring us to utilize it for the proposed intrusion detection system in our research. It is expected that the proposed HCRNN-based ID system will result in a more rational and valuable direction in the network security domain.
This dataset contains several intrusion profiles that can be utilized in the security domain and apply to a wide range of network protocols and topologies. This dataset was enhanced by the IDS2017 criteria. IDS2018 is a publicly available dataset that currently has two profiles and seven intrusion methods. Several data states were gathered, and the unprocessed data were edited regularly. So, IDS2018 has 80 statistical properties, including packet length, volume, and number of bytes, that were calculated in forward and reverse mode. Finally, the dataset was made available to all researchers via the internet, with approximately 5 million records. The CSE-CIC IDS2018 dataset is accessible in two formats: PCAP and CSV. The CSV format is primarily used in AI, while the PCAP format is utilized to extract new features [
62,
63].
This CSE-CIC IDS2018 dataset contains seven different types of attacks:
Brute-force DOS attacks;
DDOS attacks;
Brute-force SSH;
Infiltration;
Heartbleed;
Web attacks; and
Botnet.
The dataset-attacking infrastructure consists of 50 computers, while the attacking companies consist of 30 servers and 420 terminals. CSE-CIC IDS2018 data signify the captured network traffic of AWS and a system log with 80 extracted attributes utilizing CICFlowMeter-V3. The size of the CSE-CIC IDS2018 dataset is around 400 GB, which is larger than that of CIC-IDS 2017.
Table 2 presents a few extracted features of the CSE-CIC2018 dataset.
We compared the sample size of the CSE-CICIDS2018 dataset with that of CICIDS2017. The results are displayed in
Table 3. The sample size of CSE-CICIDS2018 was significantly increased compared with the CICIDS 2017 ID dataset, particularly in the Botnet and Infiltration attacks, where it has risen by 143 and 4497, respectively. However, the number of Web Attacks available is extremely small (928) in CSE-CICIDS2018.
3.3. Experimental Details
We implemented the HCRNN method in Java with Deeplearning4j to validate the efficacy of the proposed ID scheme. The experiment was done on a cluster computer (64-bit, 32 GB RAM, 32-core processor, desktop computer Core I7). The software stack contained Java (JDK) 12, Deeplearning4j 1.0.0. alpha, and Spark v2.3.0. The deep learning (DL) algorithm was trained on an NVIDIA GTX 1080 Ti GPU with cuDNN support to increase the pipeline speed. To evaluate the output of the HCRNNIDS, we first had to divide the data into training and testing sets. To develop an effective HCRNNIDS, we used a training set and analyzed our ID approach with the testing set. To show the dominance of the proposed solution, we used the CSE-CIC-IDS2018 dataset with all its original features. The network traffic was mixed with malicious and non-malicious data, which were classified into malicious and non-malicious groups by the HCRNNIDS. The proposed method reduces the computational complexity by using extensive features from the CSE-CIC-IDS2018 dataset to achieve high ID accuracy and a low FAR value. Though 90% of the CSE-CIC-IDS2018 data were used for training purposes with 10-fold cross-validation, the model was evaluated on a 10% held-out dataset. During the training phase, first-order gradient-based optimization techniques, such as Adam, Ada Grad, RMSprop, and Ada Max, with varying learning rates were used to optimize the binary cross-entropy loss of the predicted network packet, and the actual network packet was optimized with different combinations of hyperparameters from a grid search and 10-fold cross-validation to train each model on the batch size. We observed the performance by adding Gaussian noise layers followed by convolutional and recurrent layers to improve the model generalization and reduce overfitting.
5. Conclusions and Future Work
In this article, the NIDS was formed using a HCRNN, which is effective in cybersecurity. We trained the ID system framework utilizing a CSE-CIC-DS2018 dataset. We executed the IDS using a few traditional classification techniques (LR, DT, XGB, etc.) and the HCRNN technique for the proposed ID system. To capture both spatial as well as temporal features more robustly, we introduced recurrent layers after the CNN layers. This way, we attempted to address the vanishing and exploding gradient problems effectively, which improves the capability to capture spatial and temporal dependencies and learn efficiently from variable extent sequences. The key reason for the proposed ID system based on DL classification is to combine the benefits of both anomaly-based (AB) and signature-based (SB) methods. The proposed ID system helps to reduce the computational complexity and results in an enhancement in accuracy and DR for intrusion detection.
Both traditional ML and deep learning methods were assessed using renowned classification metrics (DR, Accuracy, Precision, Recall, and F1 score). The simulation results show that the proposed HCRNNIDS can successfully realize the calcification of malicious attack events. The overall accuracy of the normal and other types of attacks reaches around 97.75% in the CSE-CIC-IDS2018 data. Based on the simulation results, we can conclude that one can achieve an effective security solution against malicious attacks using the HCNRNN deep learning model.
However, one possible limitation of the proposed approach is that we have tested the HCRNNIDS only on a single ID dataset. It will also be important to test it on a more recent dataset since the signature of the attached traffic often changes. We think that the proposed scheme can be extended, in the future, into many domains, such as anomalies, and misuses could be identified in various real image datasets in the IoT. We will focus on exploring various other deep learning methods with a feature extraction technique to learn knowledgeable data illustrations in the case of other ID issues in contemporary, realistic datasets.





{kind=link}