4.1. Data Sets
The considered locations (see
Table 1) are chosen to reflect the variation of climate conditions in Europe: Almeria in southern Spain is the driest and most sunny area in Europe with (in general) little influence of rain and clouds. Ulm, Germany, again, represents continental climate influenced by mountains (Alps) and rivers (Danube). Hull is a coastal town in northern England, which allows for the testing of the forecasting performance under windy and rapidly changing weather conditions. Eventually, we picked Rovaniemi in northern Finland, which is close to the Arctic Circle, to include a location with comparably cold climate and less sunshine. Besides global irradiation on the ground, i.e., the value to be forecasted, relative humidity, wind speed, temperature, pressure, and rainfall are included in the analysis (see
Table 2). This choice is based on previous research. Kreuzer et al. [
6], for example, showed that there is some significant interdependence between the individual input data sets, as these helped to improve the quality of short-term temperature forecasts. Hence, in turn, it should also be beneficial for irradiation forecasting. Besides, this choice represents our suggestion for an adequately large and diversified database. Including more data in general tends to improve forecasting quality but also increases problems related to data maintenance (missing data, errors etc.). Here, all data sets for all locations can be directly downloaded from www.soda-pro.com, which offers worldwide satellite-based climate data. This, in turn, means that our approach–combined with the software code on the mentioned GitHub account–can be easily transferred to any other location. For testing purposes we extend the above mentioned data set by the MSI—both current and future values. As this value is due to the movement of earth around the sun it can be calculated with high precision for any time of the year. There is a respective R package called solaR [
52].
The data available on
www.soda-pro.com (accessed on 21 May 2021) have been originally recorded by the United States National Aerospace Agency (NASA) and processed as MERRA-2 data set [
53]. Thereby, MERRA stands for Modern-Era Retrospective analysis for Research and Applications and includes several meteorological indicators such as wind or temperature for any location worldwide and different time steps such as hourly or daily, for example. The spatial resolution is
. For all chosen locations hourly data between 1 January 2016 and 30 November 2020 are obtained, which means we have 43,080 (multivariate) observations per data set.
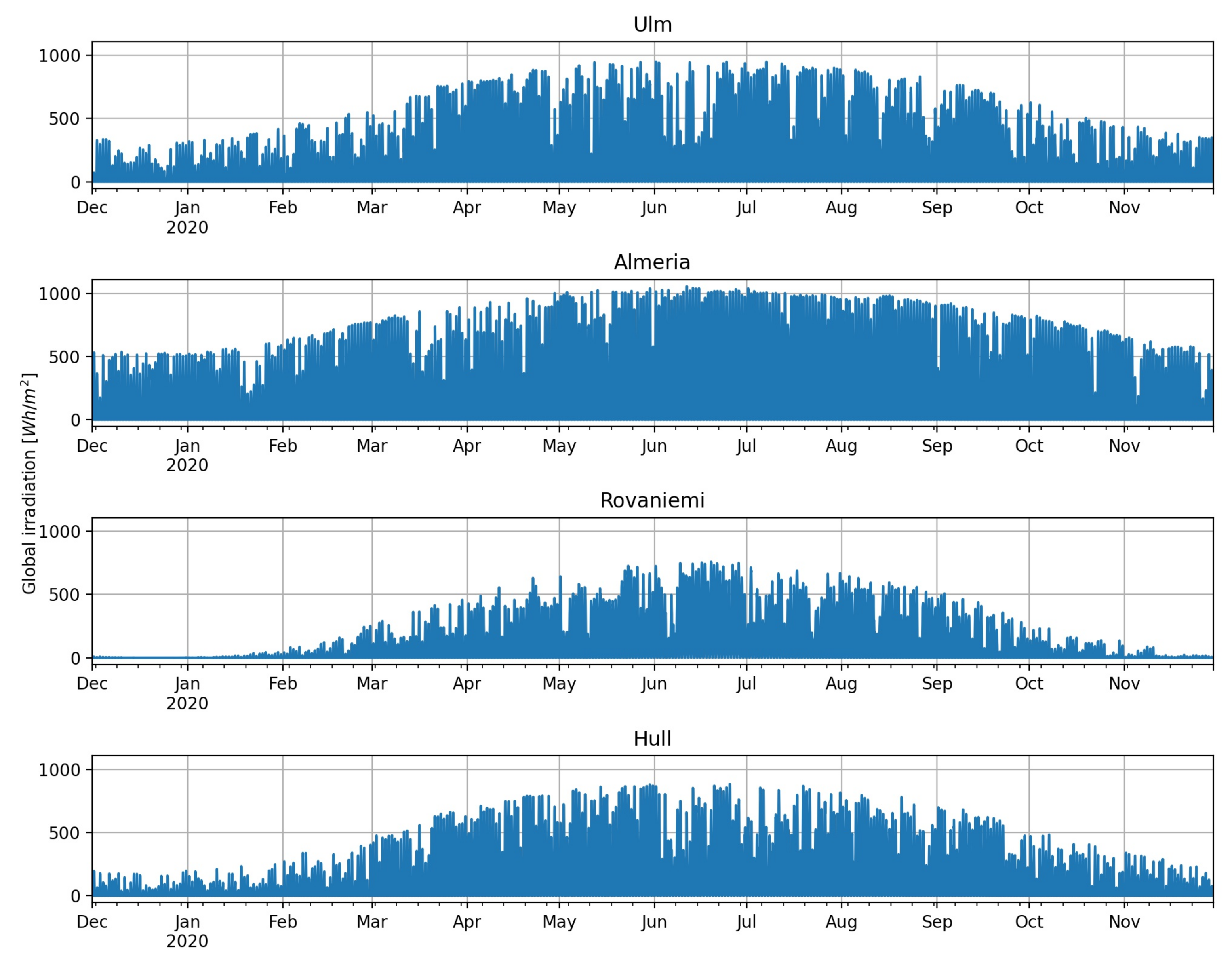
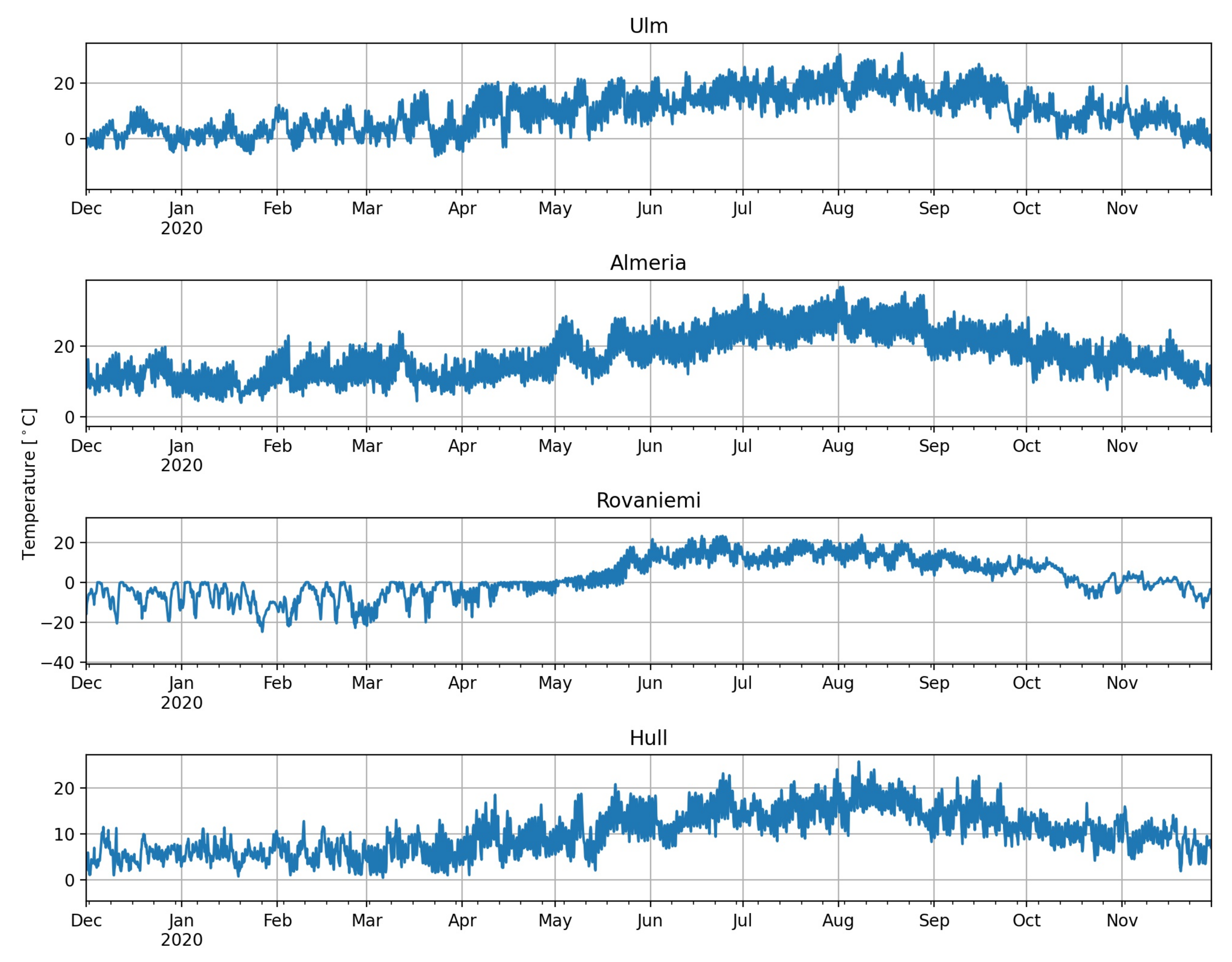
In total we have six univariate time series at four locations, and showing all data sets would simply be too much. Instead, to highlight some important features, we limit the visualisation to one year of solar irradiation and temperature data for all four locations, which are displayed in
Figure 2 and
Figure 3. For Ulm, as the most central location, we also plot one year of humidity, wind speed, pressure, and rainfall in
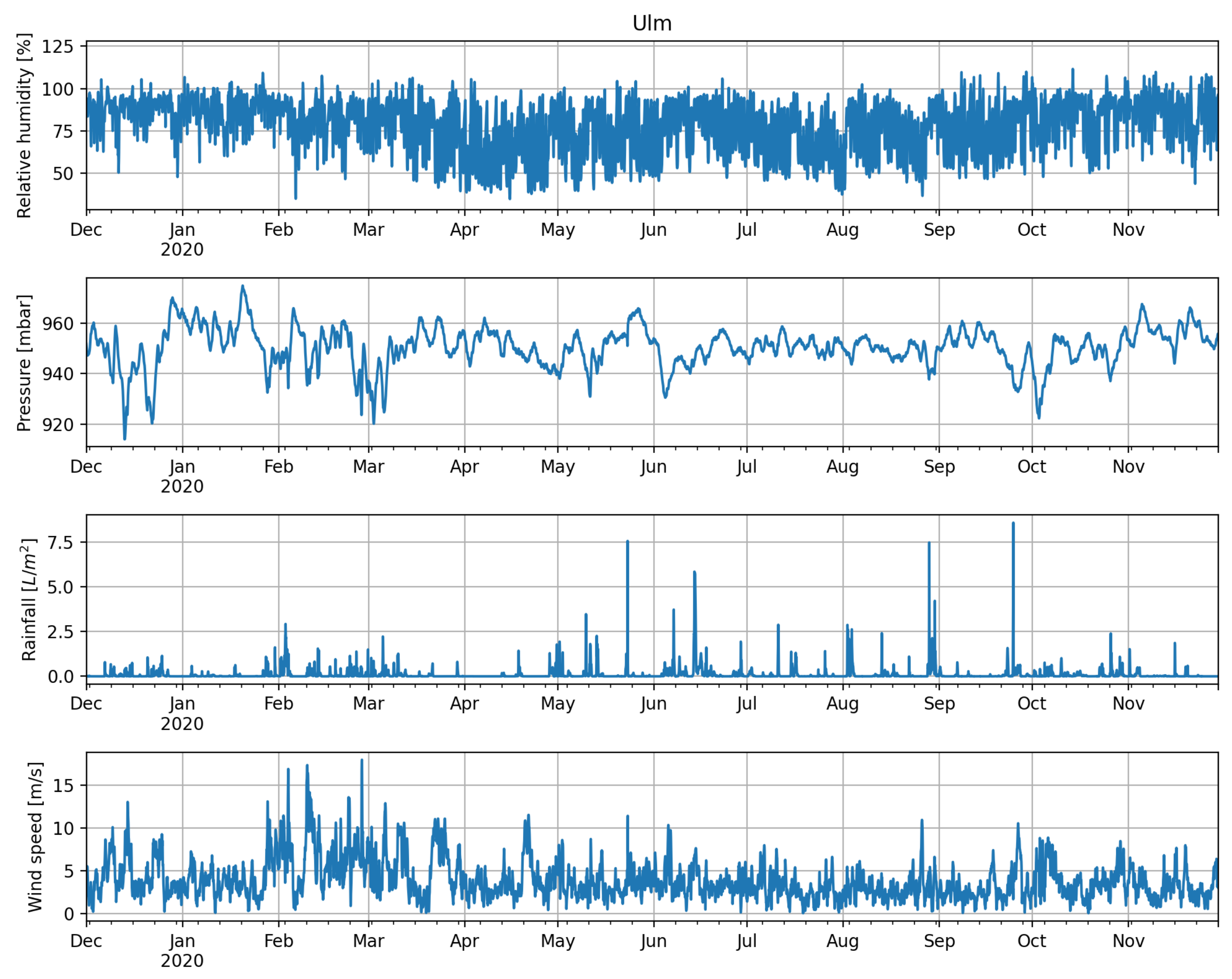
Figure 4. A visualization of the input data for all other locations can be found under the aforementioned GitHub link. Both global irradiation and temperature data show the expected annual swing, whereby the volatility of the irradiation data is considerably larger. Besides, irradiation levels are on average higher in Almeria and Ulm than in Rovaniemi and Hull. The same holds true for the temperature, where we see significantly larger oscillation during winter than during summer in Rovaniemi. Considering the other input factors for Ulm in
Figure 4, one might assume that the distribution of humidity is slightly asymmetric, whereas pressure shows comparably less variation. Wind speed is—compared to the other data sets—a fairly noisy time series with time-varying volatility. Rainfall shows hardly any annual pattern but some extreme solitary spikes. To sum up our observations: for each location we have six quite diverse data sets, whereby often we have to deal with some kind of instationarity, e.g., potentially time-varying seasonality, spikes, or time-dependent volatility. A forecasting model needs to consider all these aspects.
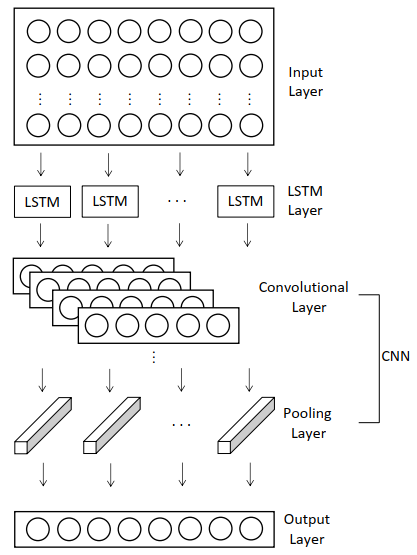
4.2. Model Architecture and Calibration
The objective of this article is to generate hourly solar irradiation forecasts. Models are chosen and calibrated to minimize the average expected error. In large part we based our architecture on the proposed models from related articles with similar objectives [
7,
33,
48]. Hence, we make use of their results, whereby we have to adapt the models to our setup. For example, Wang et al. [
7] used more LSTM units and two CNN layers (convolutional and max pooling layers) in their hybrid model. We fit the models to our data sets by trial and error where different setups are tested and the best one is chosen. Thereby one has to consider that including too many LSTM units may cause the network to adapt too much to a specific data set, which is called overfitting. Hence, in order to yield a trained NN that is able to handle new data points (which is the case in forecasting), we limit the number of LSTM units. For the convolutional part of the models we opted for a shallow architecture as we use 1D convolution. Based on that we evaluated the performance of different architectures and parameter combinations on the test set of a whole year and selected the best one. For example, we tested the effect of adding more convolutional layers, different amounts of kernels, different kernel sizes, and so on. The integration of max pooling layers was also investigated. Apart from that, layer order (whether LSTM or CNN first) does influence the NN setup. Thereby we found out that more convolutional kernels are needed if the data is convoluted first. The architecture and training parameters of all models considered here can be found in
Appendix A.
As input for the NNs, we use 24 time steps to predict the next 24 h. To train the NNs we first split the data into a training, validation, and test set. The training and validation sets are handed to the NNs, whereas the testing set is kept for evaluating the model’s performance against real data (out of sample testing). In order to see how the NN performs over the course of a whole year, the test set contains data for one year, which means 8760 h. For the remaining data set we follow Wang et al. [
7] and split it into
training data and
validation data, which is a common ratio in practice. Kreuzer et al. [
6], for example, use the same ratio. To be on the safe side we also tested other ratios like
vs.
but could not find significant differences. Apart from that, the time index is transformed with sine and cosine to catch the periodicity. This is done by fitting the day/year data to a sine/cosine oscillation by dividing the timestamp by the day/year. Then sine/cosine is applied and we obtain four variables, namely
day sine,
day cosine,
year sine, and
year cosine.
Moreover, for facilitating the NN data processing, we normalize all data by scaling each input factor to values between 0 and 1 using a MinMax scaler [
54]: Given a data sample
the scaled value
is calculated as follows:
where
and
.
4.4. Results and Performance Evaluation
Each model was trained for each location according to the process described in
Section 4.2. The trained NNs were then tested on hourly climate data from 1 December 2019 to 30 November 2020. In the context of a rolling time window we fed the realized input values (
Section 4.1) of the previous 24 h to the NNs in order to obtain irradiation forecasts for the upcoming 24 h. Results were compared to the true measured irradiation to obtain error values for each of the 24 forecasted hours. Eventually, having shifted the time window through the year, we obtained a vector of errors for each combination of forecasting horizon, model, and location. Eventually, these error vectors were evaluated and aggregated using the GoF measures described in
Section 4.3.
Given all results we can state that merging a CNN with an LSTM model does indeed improve the forecasting performance. However, it is not the precision but the model’s robustness regarding climate conditions that matters.
Before presenting the results for all tested locations we need to verify if and how adding the MSI to the input data set makes sense. Regarding test results we only discuss Ulm here, as the results for the other locations are very similar: adding the MSI to the input only slightly reduces forecasting errors as shown in
Table 3. Alternatively, as the MSI can be calculated for any location and any time over the year, we might add future MSI values (up to 24 h in advance) to the input set as well. Results from
Table 3 show that errors are not significantly smaller either. The performance even decreases for some models (see convLSTM). Hence, we only use the factors from
Table 2 and the MSI as input for all models.
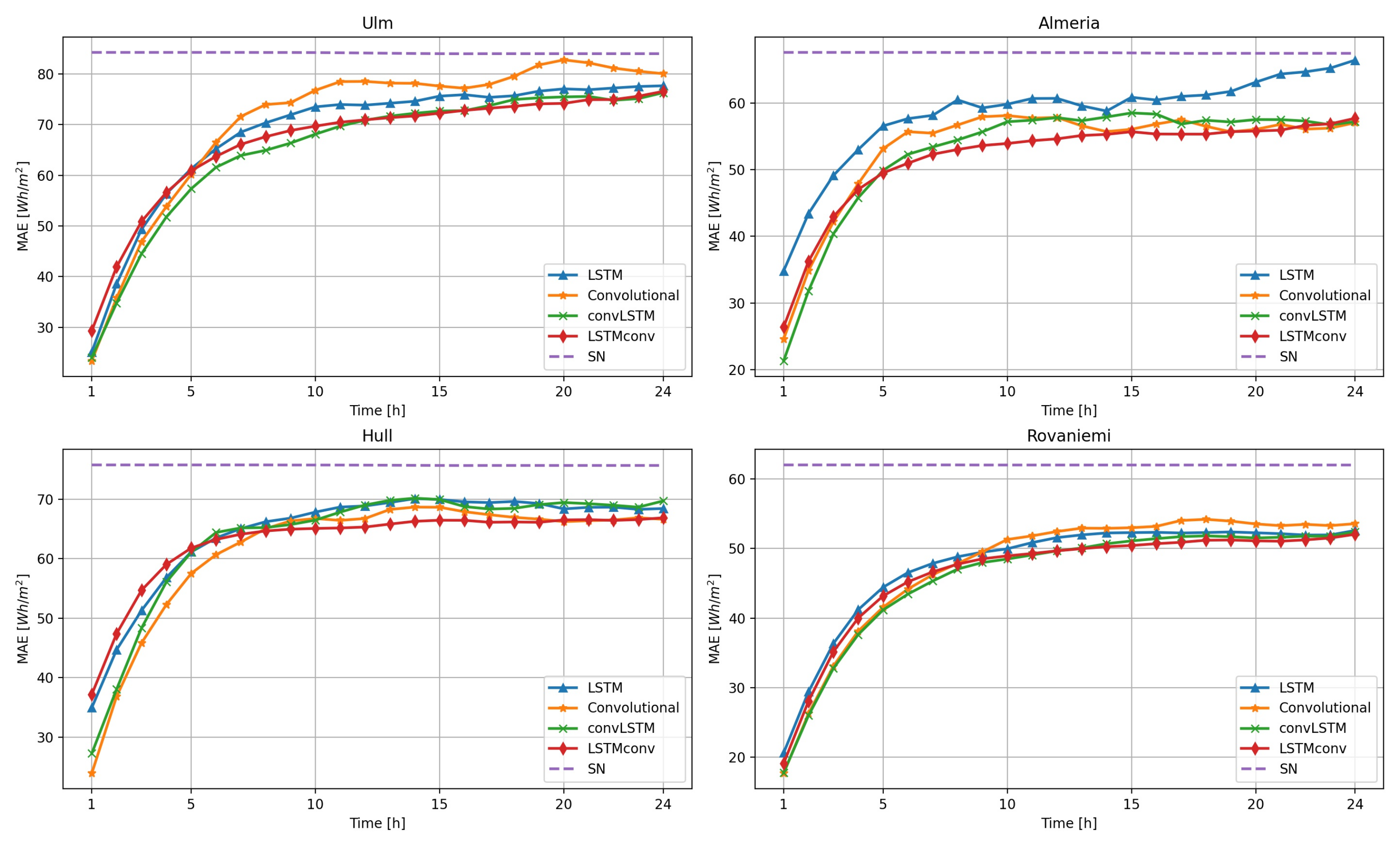
Having settled the issue if and how to include the MSI, we compute 24 h ahead forecasts for all locations and different neural network models, namely the LSTM network, the CNN, and both hybrid convLSTM and LSTMconv. The forecasts are evaluated using the GoF measures from
Section 4.3. Results for all four cities are displayed in
Figure 5, where the MAE for each individual hour of the 24 h ahead forecast is shown. The errors are thereby calculated based on the above described test set, i.e., for 8760 h from 1 December 2019 to 30 November 2020. From the graphic representation we can draw some major conclusions: First and foremost, except for the seasonal naive forecast, MAE values of the different NN models differ only slightly. In the first few hours the convolutional and convLSTM network perform the best. Later on the CNN is outperformed and overall the LSTMconv model seems to perform the best. The simple LSTM model has the worst performance, which is still close to the others. By comparing the cities we notice that here the main difference is the the error level. In Rovaniemi, where we have big seasonal differences (no solar irradiation in winter, all day irradiation in summer), the error is the lowest (MAE is roughly around 50 Wh/mM
2), whereas in Ulm with no specific seasonal pattern the network forecasts result in the largest errors (MAE is roughly around 75 Wh/m
2).
The aggregated results for all models and exemplary for the cities Ulm and Almeria are shown in
Table 4, whereby the best results are highlighted in bold letters. Values for Hull and Rovaniemi are given in
Appendix A. Thereby, results from
Table 4 just confirm the graphical observations. In general, combining an CNN with an LSTM model increases forecasting precision.
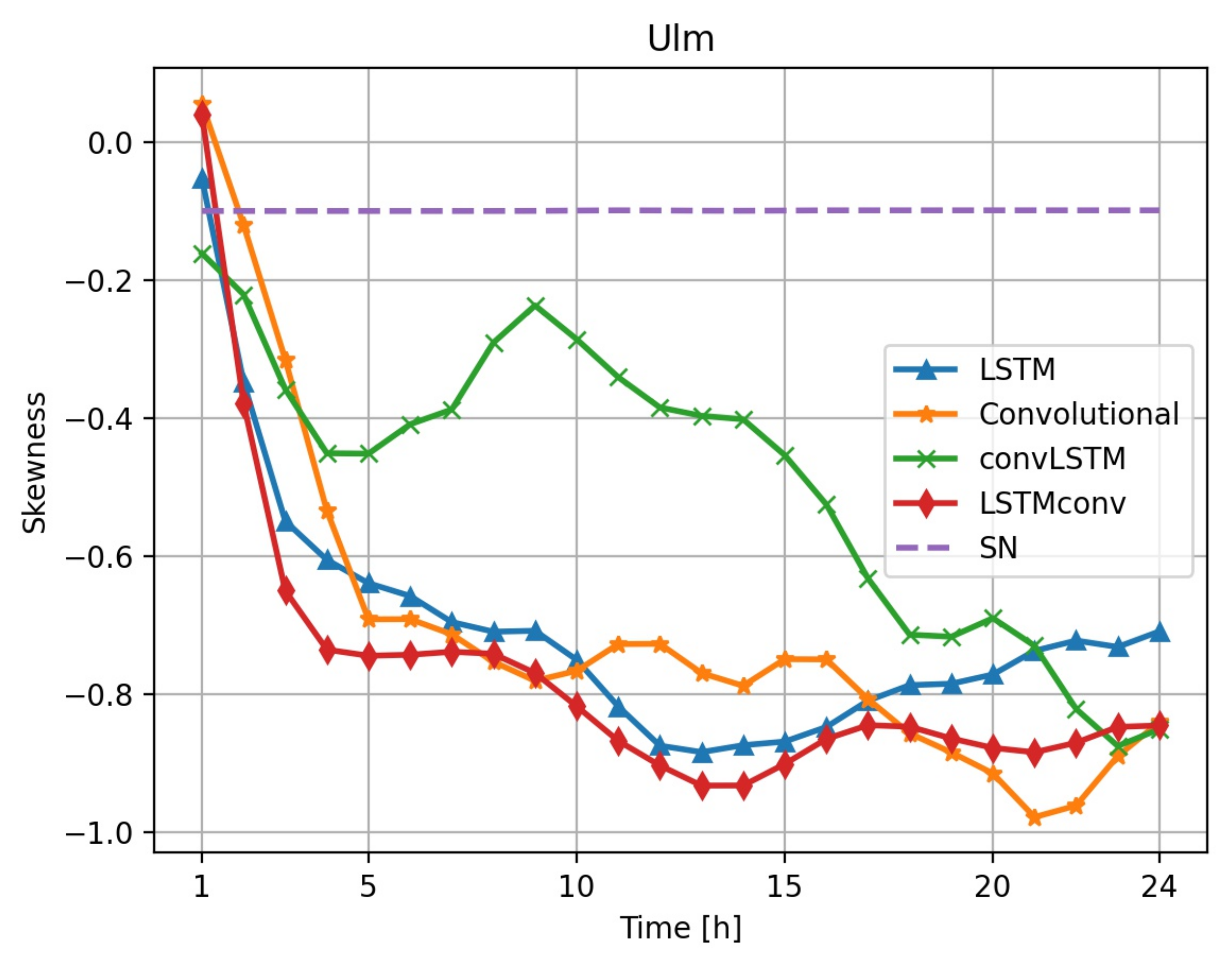
For more insight into the models’ performance we also consider some distributional properties. Thereby we see that, except for the convolutional model, all models are more or less unbiased. The bias of the naive forecast is closest to zero, whereas the convolutional model’s bias is positive. Hence, as the error is computed as true irradiation minus forecasted irradiation (
), the convolutional model tends to underestimate irradiation levels. Besides, at all locations and for all considered forecasting horizons we find that model errors are negatively skewed. In
Figure 6, where this fact is exemplarily shown for Ulm, we see a quite uniform behavior except for the convLSTM, which is still skewed. Negative skewness means that, when overestimating irradiation, the risk of missing the real value significantly is larger than when underestimating irradiation. The skewness is clearly visible in
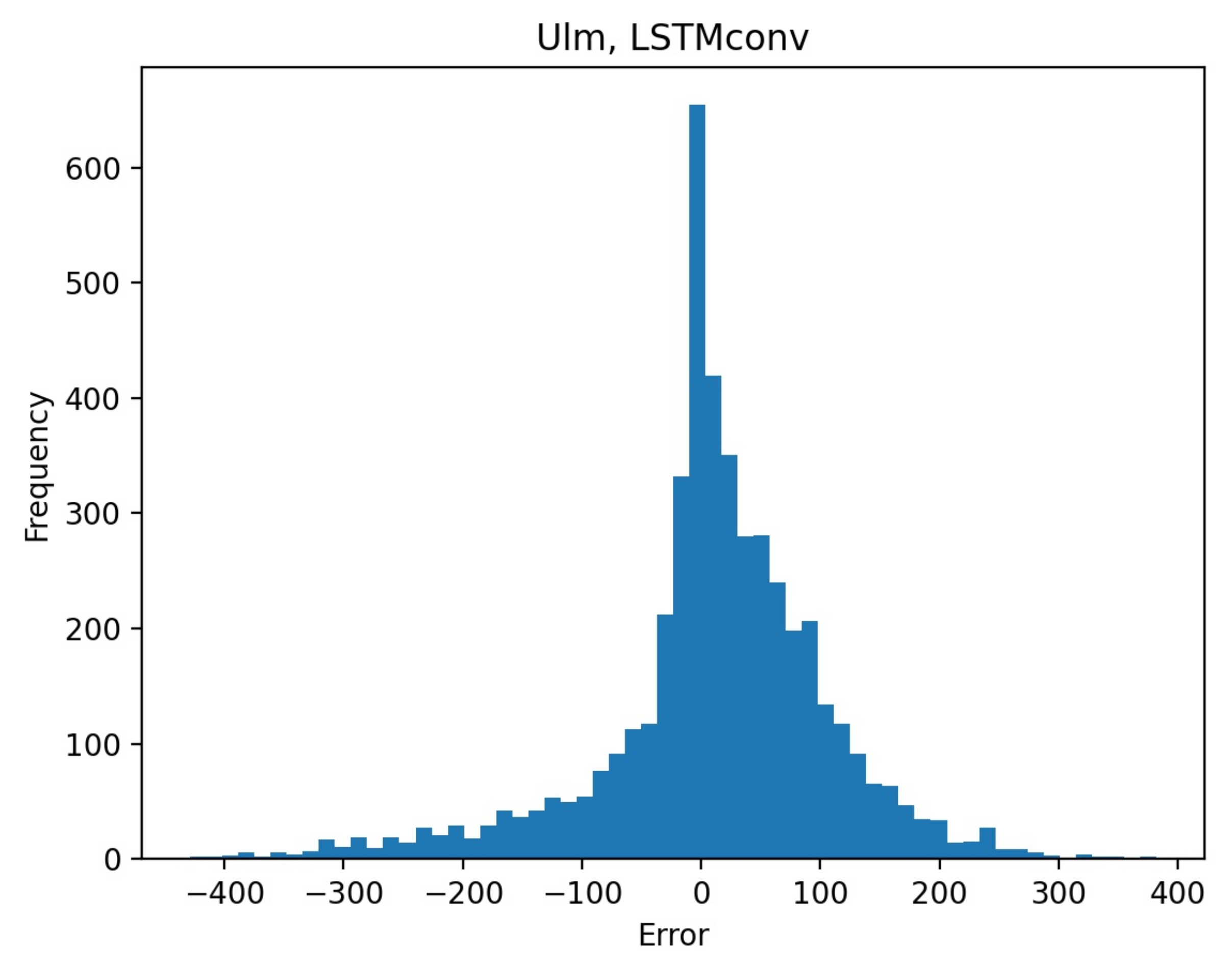
Figure 7 where the histogram of the six hour-ahead forecast for the LSTMconv model for Ulm is displayed.
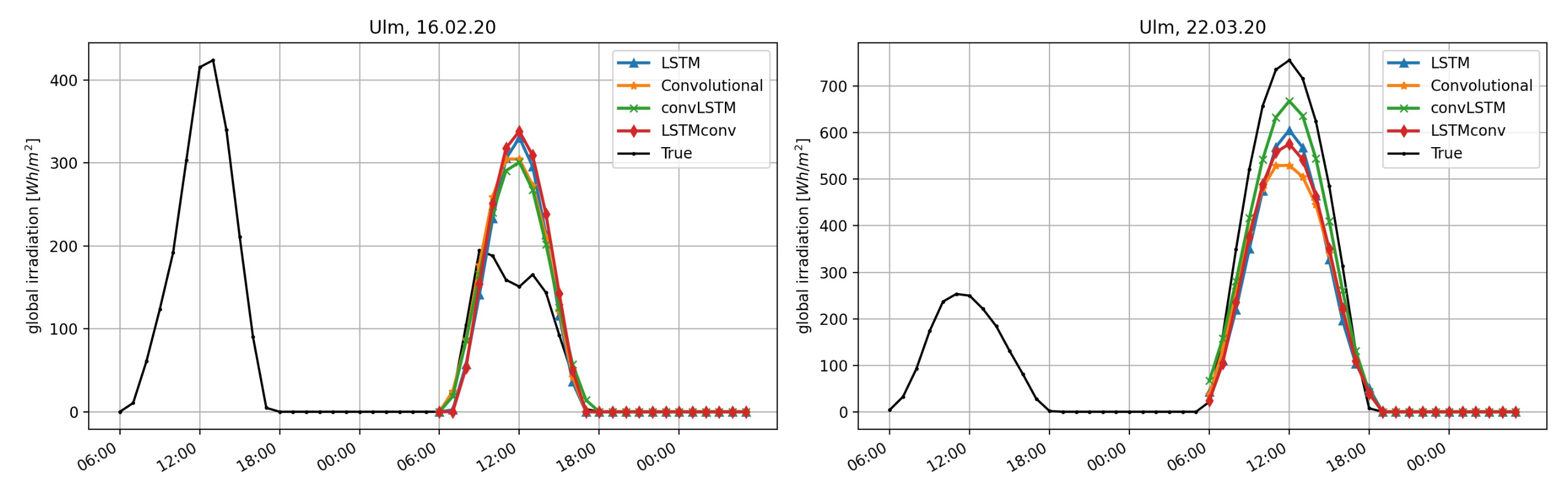
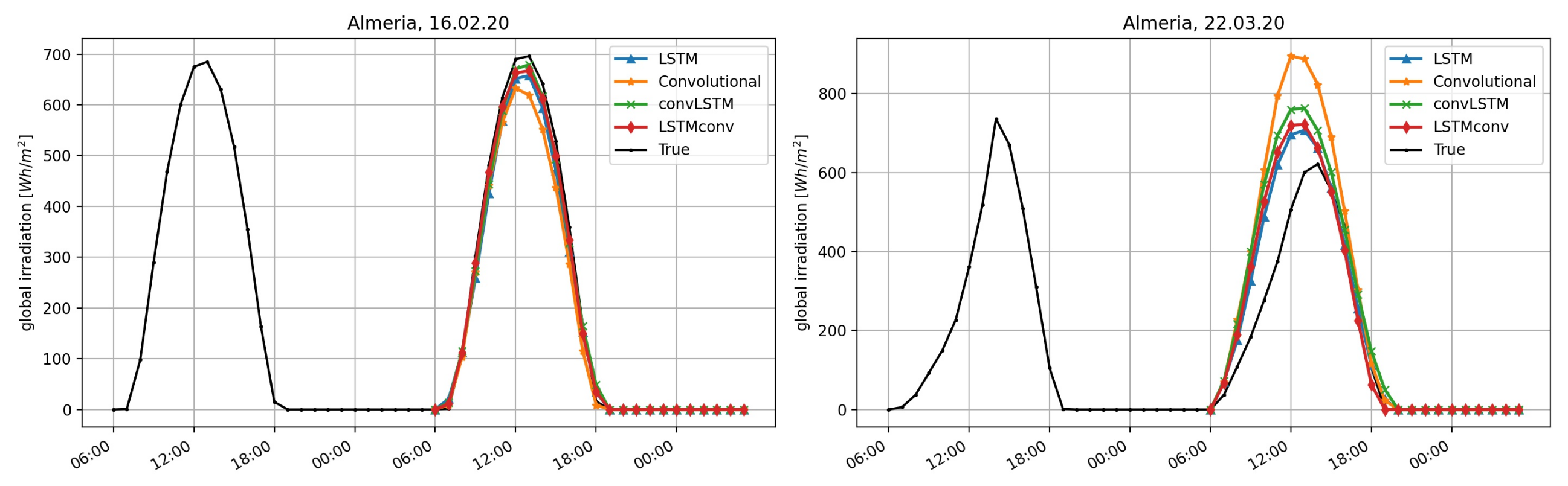
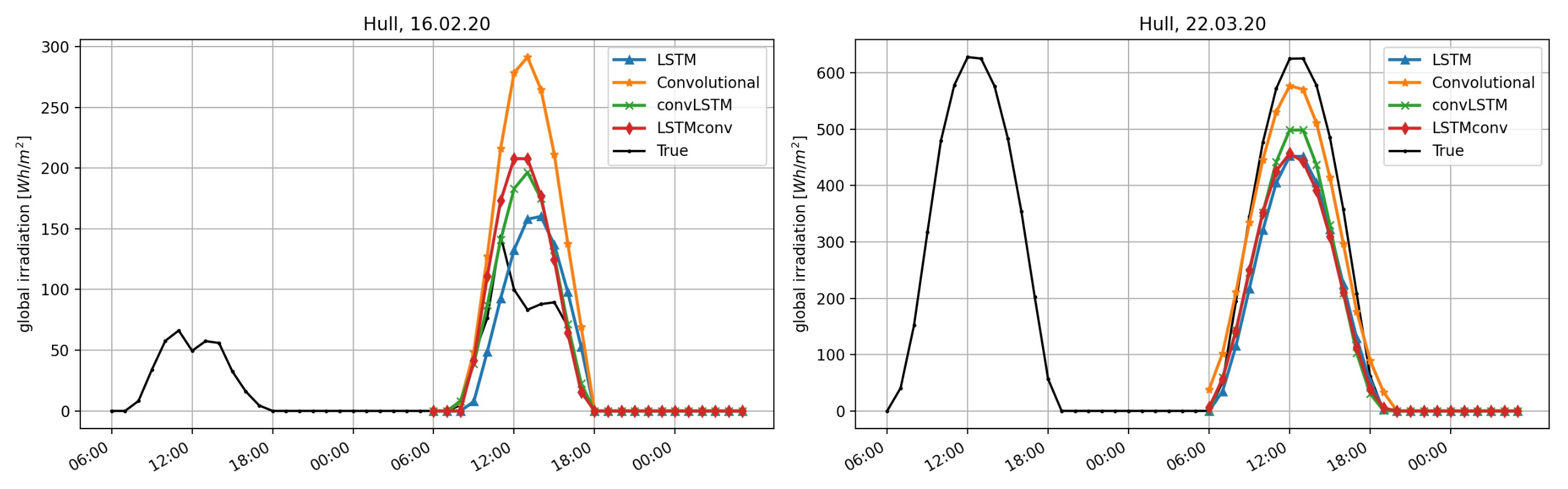
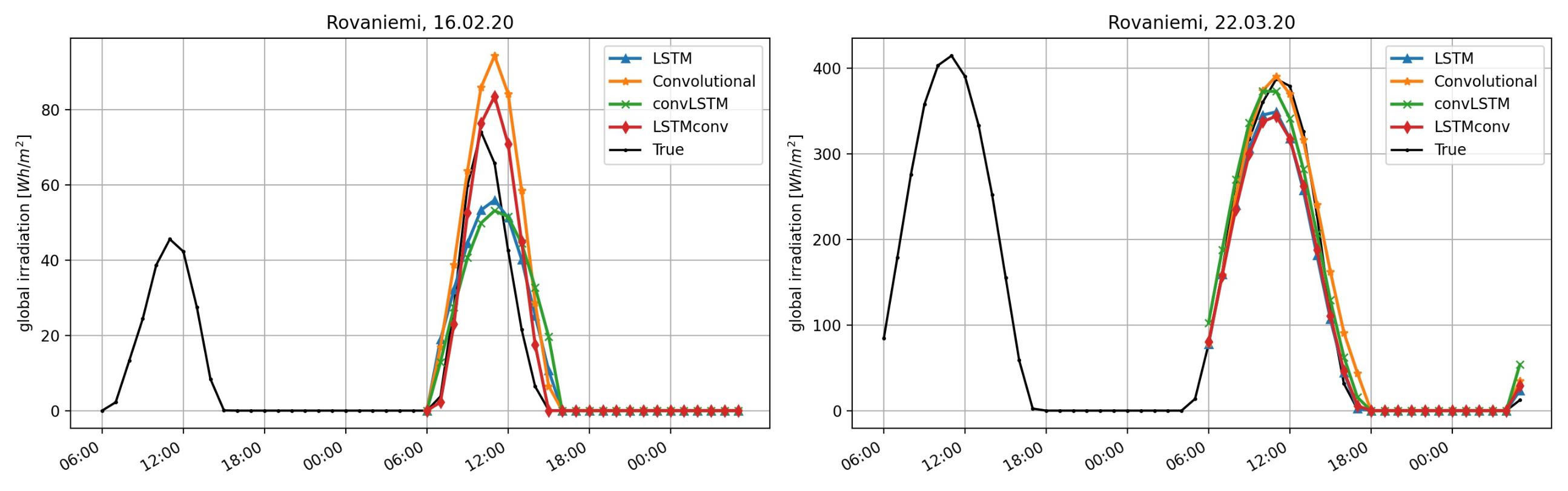
To visualize the models’ performance for two specific situations, we plot the forecasting results of each model in
Figure 8,
Figure 9,
Figure 10 and
Figure 11: A 24 h ahead forecast was computed for two days at 6 a.m. The right graphic shows the irradiation forecasts for 22 March 2020. For Ulm, for example, we see that even though the irradiation on the previous day (input data) is on a low level, all NNs are able to predict more or less the correct irradiation level. Nevertheless, the forecast is lower than the actual irradiation. On 16 February 2020 (left plot) there is a irradiation drop in Ulm around noon, which was not incorporated by any NN. The same can be seen for Hull in
Figure 10 on the left side. Interestingly, in
Figure 10 and
Figure 11, we see a rather diverse performance of the NN algorithms for 16 February 2020. In both cases the CNN was clearly overstimating sunshine levels. In Rovaniemi, the LSTMconv model produced the closest estimate, wherease LSTM and convLSTM signifcantly underestimated sunshine levels. The day in March seemed to be a fairly sunny day with no surprises and all models performed quite well for all locations except for Almeria, where no model was able to capture the seemingly asymmetric pattern with less sunshine in the morning hours.
To compare all locations with each other we eventually focus on the best model, namely the LSTMconv network. First we identify the mean solar irradiation for each location, whereby we only consider hours with positive values. Each MAE is then divided by this aggregated number and results are displayed in
Table 5, which confirms the assumption that the NNs perform better in sunny regions (e.g., Almeria) than in regions with unstable weather like Ulm or Hull. Without the adjustment, Rovaniemi has the lowest MAE, which is reasonable as during winter there is no sun and during summer there is comparably lesser sun than, say, in Almeria. Hence, it is reasonable to expect absolute differences to be smaller. Note that we could have alternatively computed the mean absolute percentage error, which divides the absolute error by the current irradiation level. However, as in the morning and in the evening irradiation levels are very small, this alternative error measure often produces extremely high error levels which significantly skews the total GoF measure. This is why we consider the adjusted MAE to be a better measure for comparison.
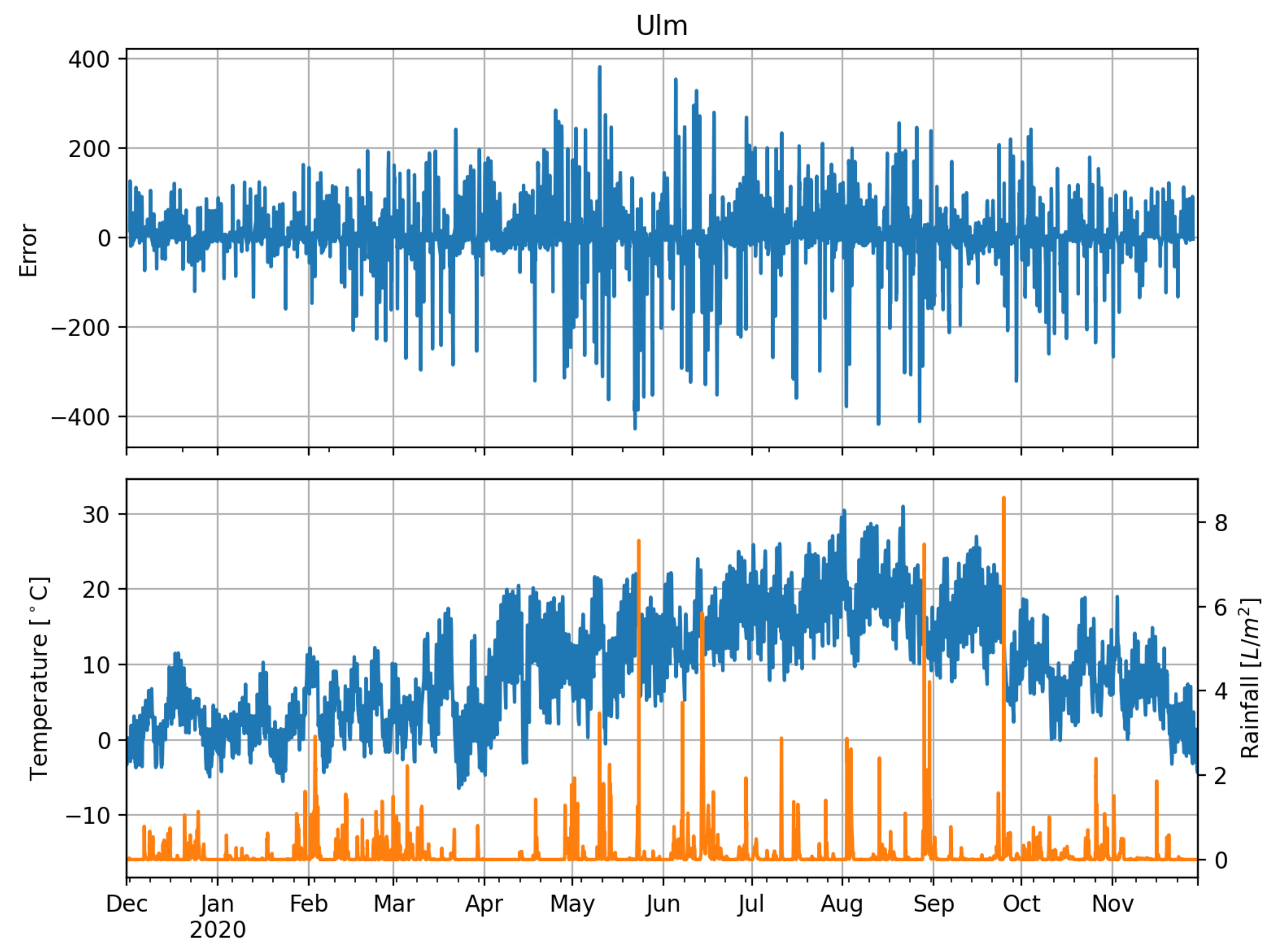
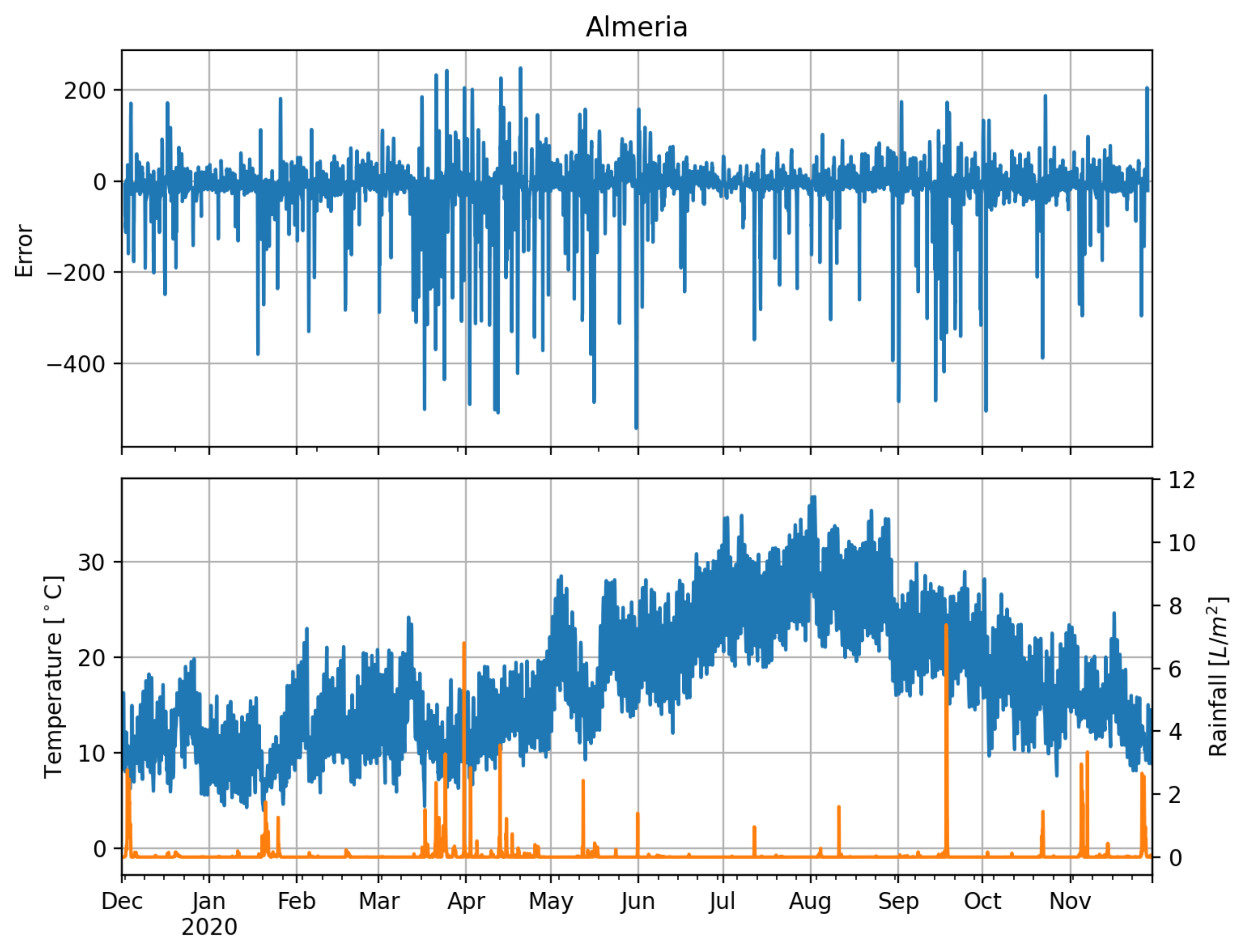
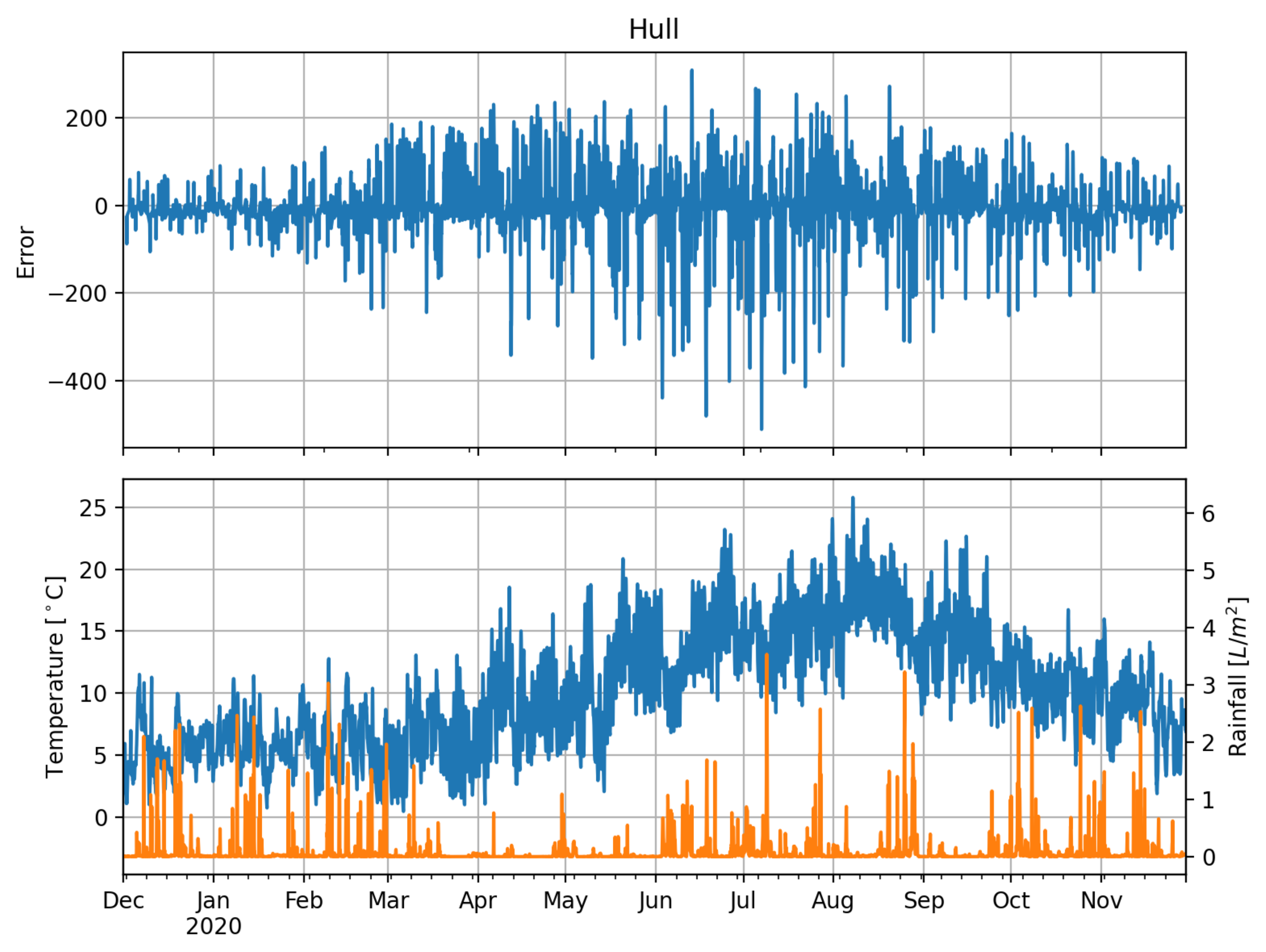
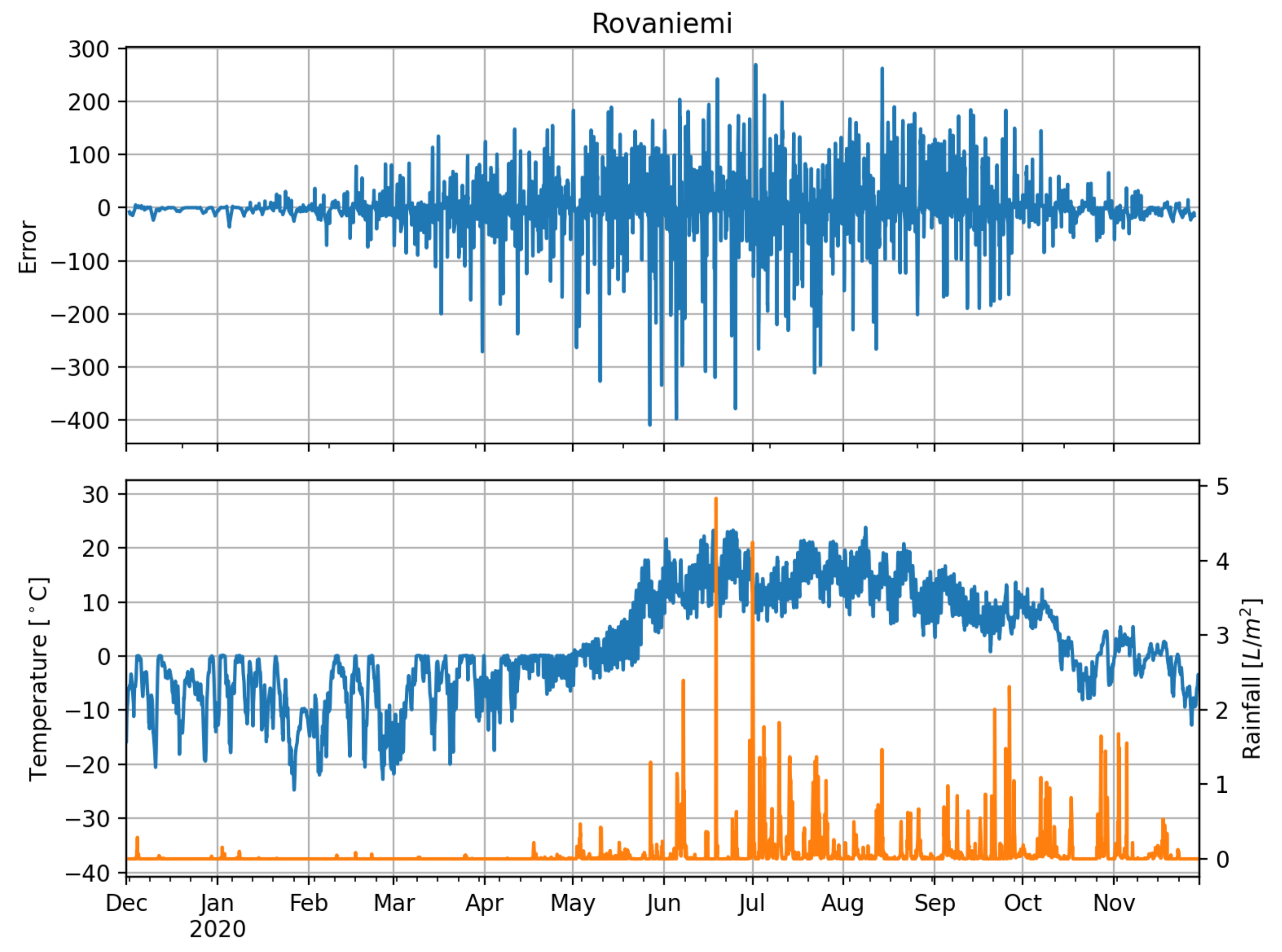
Having identified the LSTMconv as a model that performs good under all conditions, we eventually analyze the errors in the time domain, where we use
Figure 12,
Figure 13,
Figure 14 and
Figure 15 as graphical means to extract information about the model’s performance. Note that we limit our comparison to this model as it proves to be sufficient. The same conclusions can be drawn for the other NN models. The errors in Ulm show a distinct annual pattern with smaller absolute values in winter than in summer—which is not the case for Almeria. In fact, here it is the other way round. During July/August errors are comparably small whereas during April and May, where both temperature and precipitation indicate comparably cold and wet weather, error variation is larger than during the other months. Given the plot, Almeria errors are also skewed to the left but more distinctly than Ulm errors. Errors of Hull (
Figure 14) are low during winter season, which goes along with less sunshine, low temperatures, and comparatively a lot of rain. We see a distinct annual pattern in the forecasting error, which only partly coincides with the annual temperature swing. Eventually, Rovaniemi errors show the expected pattern: almost no errors during winter when it is dark anyway. Forecasting errors do not significantly coincide with the annual temperature swing or rainfall. As for Hull, errors seem to be mainly dependent on the annual swing of irradiation (compare
Figure 2).
To sum up our results: the LSTMconv neural network performs best in our case study across all tested locations. However, the advantage is small—especially when considering that the training process of the neural networks appeared to be not deterministic. This means that the results vary—albeit very little—when training the same network multiple times. Furthermore, the problem of the non-deterministic training process makes fine tuning of the neural networks quite hard. So, the LSTM seems like a good alternative; however, its performance for sunny Almeria is comparably worse. The CNN, again, has problems with the continental climate of Ulm but would be a feasible alternative for the other locations. Hence, the LSTMconv network is the best model not because it produces the best results but because it appears to be a rather versatile approach producing fairly good results in all tested climate conditions.
In terms of computational time, all networks are feasible for practical application as the training, which has to be done once a day or once a week, requires less then 30 min on a regular laptop.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














