1. Introduction
Information mining is a cycle that finds relevant patterns from a large amount of data. After collecting these data, text classification (which depends on the content and which dynamically classifies many texts from different fields on the internet) builds an innovative system, relationship, and decision through natural language processing (NLP) [
1]. Clustering, classification, information extraction, and information mining include various text preparation steps needing powerful data models because of inconsistencies and non-standard noise in digitized messages. In NLP, text arrangement is considered difficult because of the different types of information representation [
2].
Social media data mining is used to uncover hidden patterns and trends from social media network (SMN) platforms like Twitter, LinkedIn, Facebook, and others [
3]. There is unstructured content on social media—like tweets, comments, status updates—which is not only based on businesses, firms, and agencies but also have Public Protection Disaster Relief (PPDR) and DMSS-related information [
3].
De Oliveira et al. [
4] mention anonymous real-time data to generate information which allows sentiment analysis on a given subject and Gajjala et al. [
5] cite classification for sentiment analysis. Damaschk et al. [
6] analyzed multiclass text classification on noisy data. To improve the performance of DSS, Wang et al. [
7] used intelligent techniques for traffic prediction and Balbo and Pinson [
8] applied intelligent agents for transportation management. Learning methods includes supervised and unsupervised methods, Tzima and Mitkas [
9] for rule extraction, Herrero et al. [
10] for traffic risk analysis, and Yu et al. [
11] for traffic prediction. Zarei et al. [
12] also investigated the effects of learning methods in DSS based on historical data. Shadi et al. [
13] quote supervised and unsupervised learning decision support systems for incident management in an intelligent tunnel. Most of the research work examines only particular disasters or specific event analysis based on existing or scraping datasets, but comparative research on a decision support system that gives reliable information has not been extensively applied during a large or diverse set of crises. Aiming to provide real-time information for DMSS, this research provides data collecting and proposed methods for data cleaning and grouping, sentiment analysis, topic labeling for data categorization, chatbot application for sentence-based decision-making, unknown sentence prediction and decision, and finally DMSS from data visualization. Our novelty of this work is divergent from others because the model arranges user’s statements regarding the real-time situational information from any large or short corpus which encourages them to make an event analysis, visualization, informational data support by a chatbot, and DMSS. In addition, we experimented with short corpus data which gives informed decisions based on its authenticity. If the model gives an informational decision within a short dataset, it can provide also good accuracy and decisions among the larger ones. For this reason, we did evaluations with both short corpus (unsupervised) and larger corpus (supervised) chatbot in
Section 6 and shows their sentence accuracy label which is both cases (>98%). We achieved 96% and 99% accuracy in test and training datasets by using LSTM on a short corpus in the DL method. Moreover, the ML method using hyper-parameter in the dataset, a random forest algorithm increases data accuracy in the F1 score which is 2% (81–83%).
We used a completely different dataset for model verification, which is the Disaster corpus. The previous corpus contained 1635 sentences, whereas this corpus contains 10,875 sentences. Surprisingly, the data behavior that is employed in decision-making appears to be comparable in both circumstances. Furthermore, the deep learning LSTM model has an accuracy of over 98% in both Disaster and Covid scenarios.
In our system, we scraped Twitter SMN data where several data fields construct our model and visualize data in a user’s intended way. Keeping up information quality is a troublesome yet fundamental undertaking. To accomplish predictable and dependable information, the model should continually oversee information quality so they build authenticity and enable quicker which produce more proficient decisions. We applied semantic, syntactic, consistency, completeness, and uniqueness to maintaining data quality. After removing repetition and contradictory data, it decreases the original length of size and provides freshness, timeliness, and actuality. The measurement is the interaction that actualizes the metric to acquire the value on the dimension factor. In a similar example of our dataset which is Covid data, the dimension exactness, the accuracy factor, the distinction in data field metric can be assessed by an evaluator utilizing a data cleaning function. For dimensionality reduction and increasing model accuracy, our total dataset reducing 3590 rows to 1795 rows with seven topic labeling. We have applied the same methodology in the Disaster dataset for our model verification. The scraping classifier in
Section 4.1 has a Covid data field dimension which is based on the Twitter user’s statement.
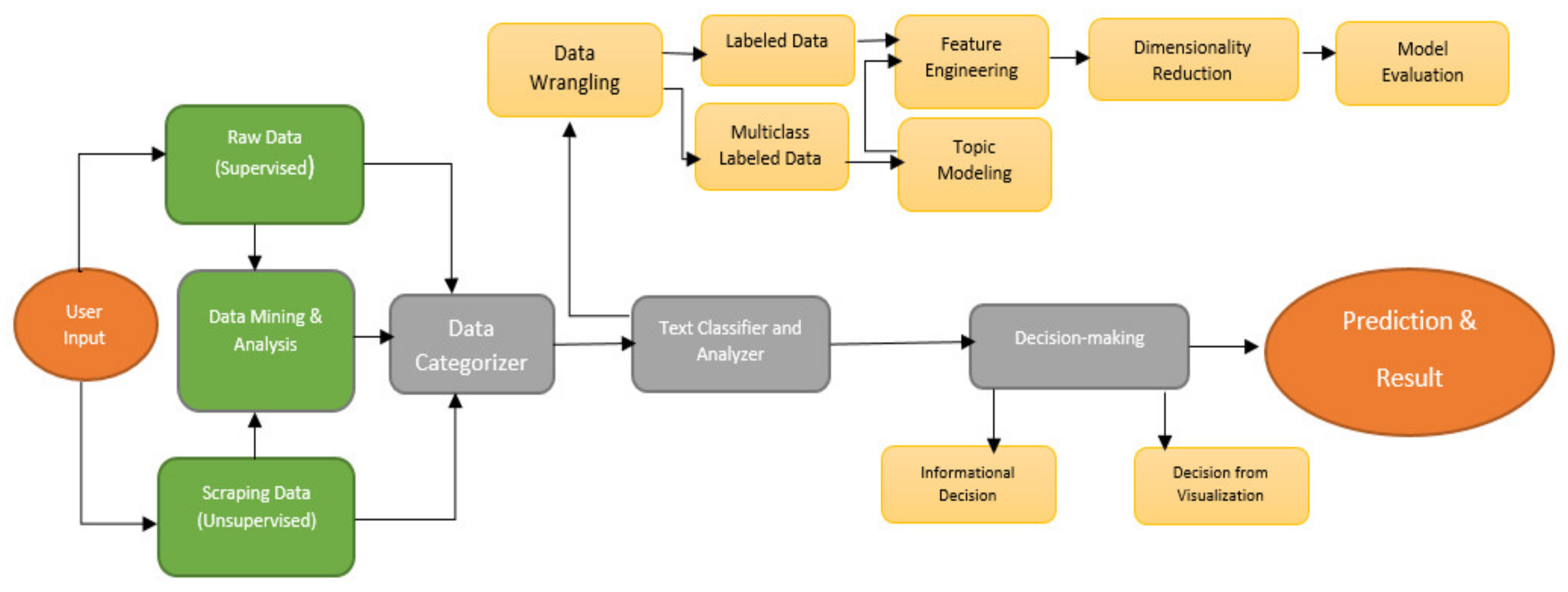
In supervised learning, there is a point at which we need to initially prepare the model with a previously existing, named dataset, much the same as showing a child how to differentiate between a seat and a table. We need to uncover disparities and similitudes. In contrast, unsupervised learning is tied to learning and predicting without a pre-named dataset. In the proposed RAIDSS model, there are two kinds of information input strategies: one is using labeled data, and the other is data mining. Users can input both types of information. Therefore, text classification is one of the most significant cycles for characterizing the user’s given info, choosing to order the data for unsupervised or supervised learning. If the data contain labeled information, then the text classifier and pre-processor execute data-wrangling extraction. After finishing a model assessment, the application takes the data for service and prediction. In contrast, if the information originates from Web scraping of various sources, numerous things (like data mining and analysis) need to be handled. The classifier’s objective should be to record clean information from the user and return the desired output. In discovering clean information segments, we need to conduct sentiment analysis to measure information execution and visualization. Topic modeling through Latent Dirichlet Allocation (LDA) and raw data conversion turn this unsupervised learning into a labeled dataset after information assembling, which provides structural performance and results.
We propose a real-time AI-based informational decision support system (RAIDSS) model for informational and DMSS systems in text classifications that include the following terminologies:
A filter cleaning text (FCT) methodology to scrape data cleaning and groupings;
A word generative probabilistic (WGP) method for highest word-frequency label selection;
A context-based chatbot application based on scraped datasets.
For the decision-making support system, the RAIDSS model visualizes data mining for the analysis of the topics (e.g., the current novel Covid and Disaster corpus); using Twitter data (namely tweets) for sentiment analysis; applying topic labeling for unsupervised and supervised learning (multi-class text classification); hyper-tuning data to provide robust application efficiency; visualizing data in various graphs, and comparing text classification methods. Finally, the chatbot provides an informational decision from among the supervised and unsupervised processes.
The remainder of this paper is organized as follows:
Section 2 presents related work from the literature.
Section 3 outlines the methodology of the working procedure in a system model. Data extraction and analysis determine if the corpus is supervised or unsupervised, which is discussed in
Section 4. In
Section 5, the text classifier assesses the model evaluation of both labeled and unlabeled data. Therefore, the chatbot takes the result of the assessment and gives an informational decision, as discussed in
Section 6. Finally, evaluations of the prediction and development of the decision-making results are in
Section 7.
2. Related Work
De Oliveira et al. [
4] cited an architecture designed to monitor and perform anonymous real-time searches in tweets to generate information allowing sentiment analysis. These results show, data extraction from SMN gives information in real-time and they measure sentiment analysis at a low cost of implementation. It assists to make smart decisions in several environments. This work pretty much similar to our work but they only focus on sentiment analysis whereas the RAIDSS model provides not only scraping and sentiment analysis but also gives chatbot informational decision, known and unknown sentence prediction, Topic data groupings, valid or invalid group data accuracy, and finally DMSS.
Damaschk et al. [
6] discussed methods of multiclass text classification on unstructured data which is one of our approaches to doing topic labeling for data grouping. Bevaola et al. [
14] mentioned how to use Twitter data to send warnings and identify crucial needs and responses in disaster communication. Milusheva et al. [
15] described how to transform an openly available dataset into resources for urban planning and development.
In text mining, Imran et al. [
16] proposed artificial intelligence for disaster response (AIDR), a platform to perform automatic text classification of crisis-related communications. AIDR classifies messages that people post during disasters into a set of user-defined categories of information. Above all, the whole process must ingest, process, and produce only credible information, in real-time or with low latency [
17]. In our RAIDSS model, data can be extracted from various sources, and pre-processing gives the exact user intention via the visualization and informational chatbot application.
Topic models have numerous applications in natural language processing. Numerous articles have been published on topic modeling approaches to different subjects, for example, social networks, software engineering, and linguistic sciences [
18]. Daud et al. [
19] presented a review of topic models with delicate bunching capacities in text corpora, exploring essential ideas and existing models that sequenced different classifications with boundary estimations (i.e., Gibbs sampling) and performance evaluation measures. Likewise, Daud et al. introduced a few uses of topic models for displaying text corpora and discussed a few open issues with future directions. In our case, topic modeling uses multiclass text classification that labels a significant corpus as a category.
Dang et al. [
20] reviewed the latest studies that employed deep learning (DL) to solve sentiment analysis problems, such as sentiment polarity. Models used term frequency-inverse document frequency (TF-IDF) and word embedding procedures on a series of datasets. Sentiment analysis comprises language preparation, text examination, and computational phonetics to recognize abstract sentiments [
21]. For the most part, new data entry samples have a similar category [
21]. Our model has an automated process for analyzing text data and sorting them into positive, negative, or neutral sentiments.
The semantic text-mining approach is significant for text classification. Škrlj et al. [
22] presented a practical semantic content–mining approach, which changes semantic data identified from a given set of documents into many novel highlights used for learning. Their proposed semantics-aware recurrent neural architecture (SRNA) empowers the system to obtain semantic vectors and raw text documents at the same time. This examination shows that the proposed approach beats a methodology without semantic information, with the highest exactness gained (up to 10% higher) from short reports. Our methodology also shows useful semantic content from a model of an application where unstructured data make up useful content.
Most text classification and document categorization frameworks can be deconstructed into four stages: feature extraction, dimension reduction, classifier choice, and assessment. Kowsari et al. [
23] talked about their survey and the structure and specialized usage of text classification frameworks. The initial input comprised a raw text dataset. Furthermore, Aggarwal et al. [
24] mentioned text informational indexes contained groupings of text from records that alluded to a data point (i.e., a document, or a portion of text) with several sentences to such an extent that each sentence incorporated word and letters that include a class value from a set of diverse discrete word lists. The RAIDSS model proposed by us also takes this action in a particular manner to improve the outcome from information extraction.
6. Informational Decision from Chatbot
For our model’s application, a chatbot provides a viable arrangement of the dataset. After concentrating the data by keyword, the user wants an informed decision based on the topic. There are two extensive variations of the chatbot: rule-based and self-learning. In a rule-based methodology, the bot responds to address dependence on certain principles that it is preparing. The principles characterized can be easy or complex. The bot can deal with fundamental questions, yet neglect complex ones. Self-learning bots are the ones that utilize some machine learning–based methodologies, and they are certainly more effective than rule-based bots [
39]. These bots have categorization that is either retrieval-based or generative. For our RAIDSS model, a retrieval-based chatbot is congenial and depends on respect for the question and answer based on knowledge from the model [
39]. We used a context-based chatbot that depends on respect for the user question and intense detection from the model.
The context-based chatbot is based on hyper-tuning dataset conditions, which structure the setting for an event, explanation, or thought and is (fundamentally, as far as it may be wholly comprehended) memory of all data about the users [
40]. Memory that has earlier data about the users is gradually updated as the conversation advances. So (for gaining context), states and transitions are assumed to be a vital job here. Considering intent, to play out actions, users utilize the chatbot, which recognizes these activities by intent classification. According to the intent of the user, we place our chatbot in a particular state [
41]. Transitions change the intent of the chatbot modes. There is an exchange mode starting with one state, then moving on to the next, which characterizes the discussions, and designs the chatbot. At the transition point, the chatbot requires a lot of data that belong to the same state. Due to the lack of data, it is harder to train the model. Neural networks work superbly at this stage, which is learning the context from the injected states.
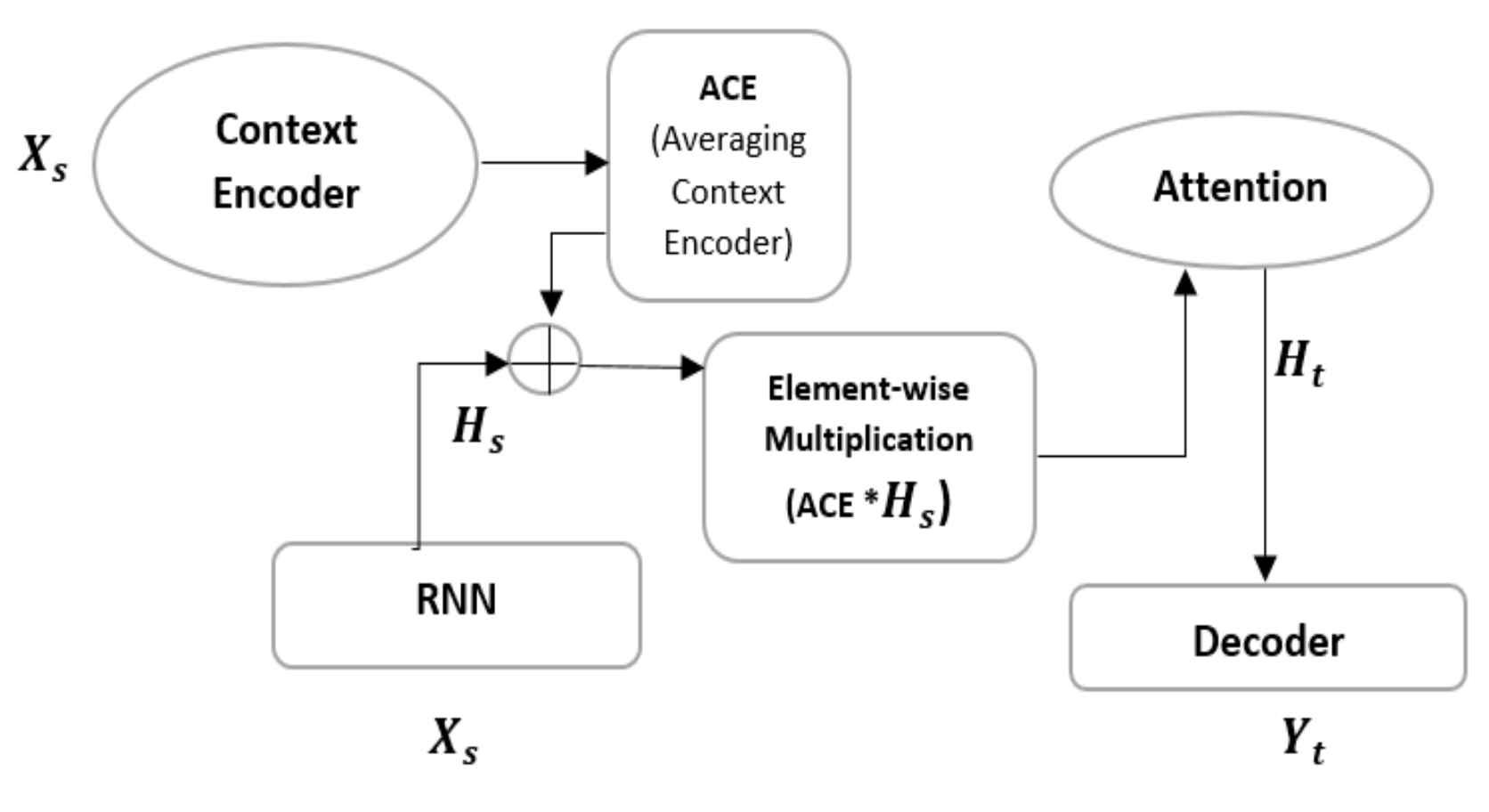
The RAIDSS functional chatbot model in
Figure 11 describes context working on encoding input
and aggregating output
through the averaging context encoder (
). Therefore, the training input layer,
, from the RNN and ACE do element-wise multiplications right before feeding into the attention layer,
. Finally, it decodes output layer
. The finite state machine uses this intent model input for text generation, which is a specific generative model. Each model will be generated based on the intended text, and will keep looping until the conversation stops.
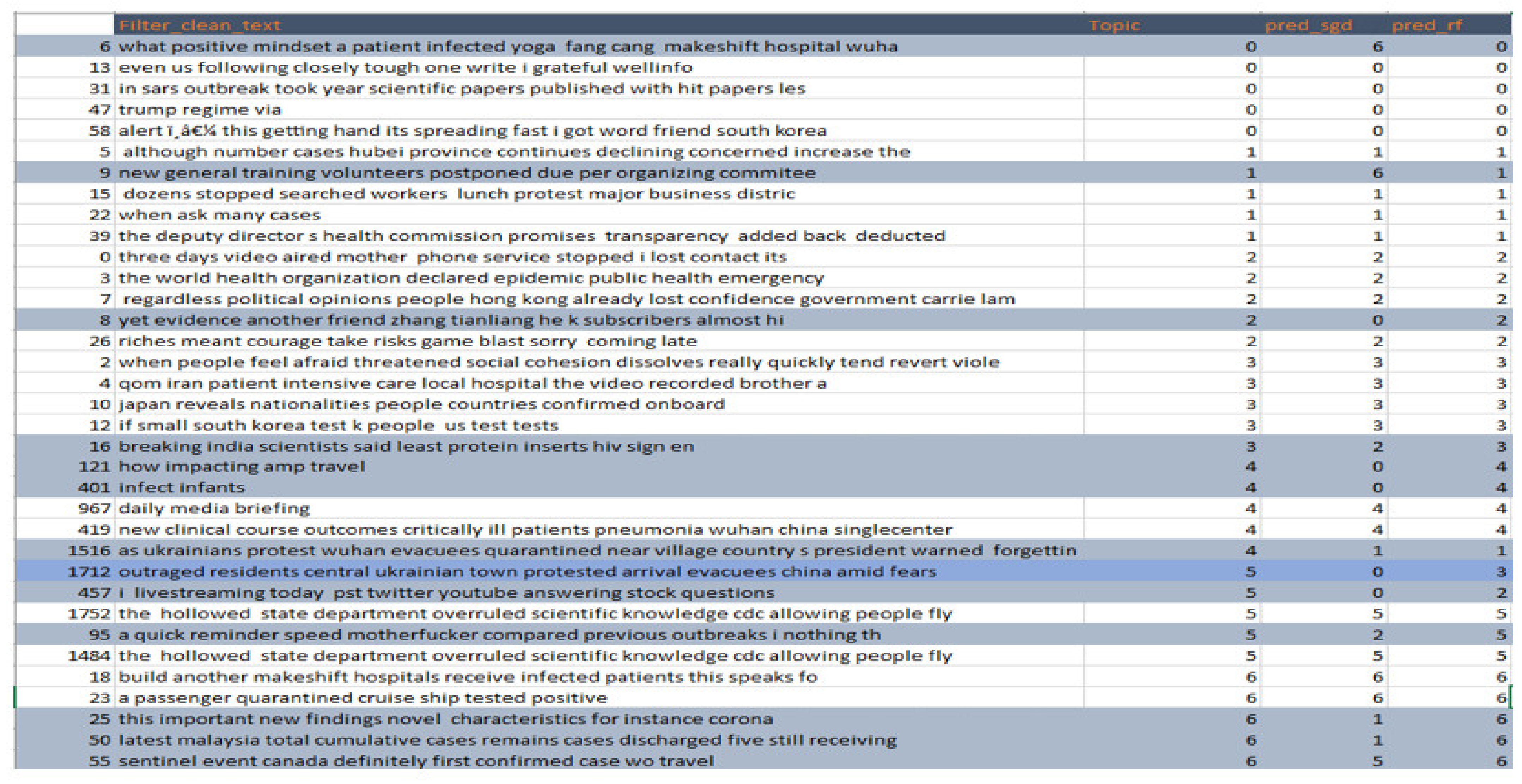
In
Figure 12, we experiment with COVID-19 scraped data in part (a) COVID-19 labeled data, and part (b) our scraping data, where both give an informed decision. Labeled data show more meaningful information than scraped data because of the data length and the given information. In contrast to both datasets, the unlabeled chatbot decision in
Figure 12b still gives an informative decision, though it has a noisy and small tweeter sentence.
Our chatbot goal was to show data behaviors in unsupervised learning. For verification of our model, we offer a disaster dataset chatbot in
Figure 13 which is in a large corpus. From the figure we can see that there has a piece of much relatable information along with disaster contents.
8. Conclusions
We have developed an approach, from data mining to decision-making results, that measures through an informed decision how well data are created under unsupervised and supervised learning, and which data answer the users’ questions. The RAIDSS model scraped a small dataset also a large dataset for verifications and processed the data input into a decision result. One of the goals of our research paper was to see how a small dataset behaved in our model when compared to a larger dataset. For this reason, we used the larger corpus, which included disaster-related data, to test our hypothesis. We can see that the accuracy of both datasets is nearly identical, and the behavior of the data in the chatbot is unaffected. However, its procedures give the overall output from a noisy dataset. As we tested both machine learning and deep learning models, exactness and forecasts were acceptable. Additionally, our application was applied to extract specific information from keywords, which showed amazing predictions and results. The DMSS from the RAIDSS model aims to identify, analyze, and synthesize various supervised and unsupervised data. We tested the COVID case and Disaster corpus from Twitter scrapes of public statement, which give adequate visualization in sentiment analysis, the topic labeling decisions, the chatbot decisions, and finally, known and unknown sentence predictions. We’ll use this model in the future to work on speech and image classifications, as well as how to construct decision-making results.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}