Artificial Neural Network Prediction of Retention of Amino Acids in Reversed-Phase HPLC under Application of Linear Organic Modifier Gradients and/or pH Gradients

Abstract
:1. Introduction
2. Results
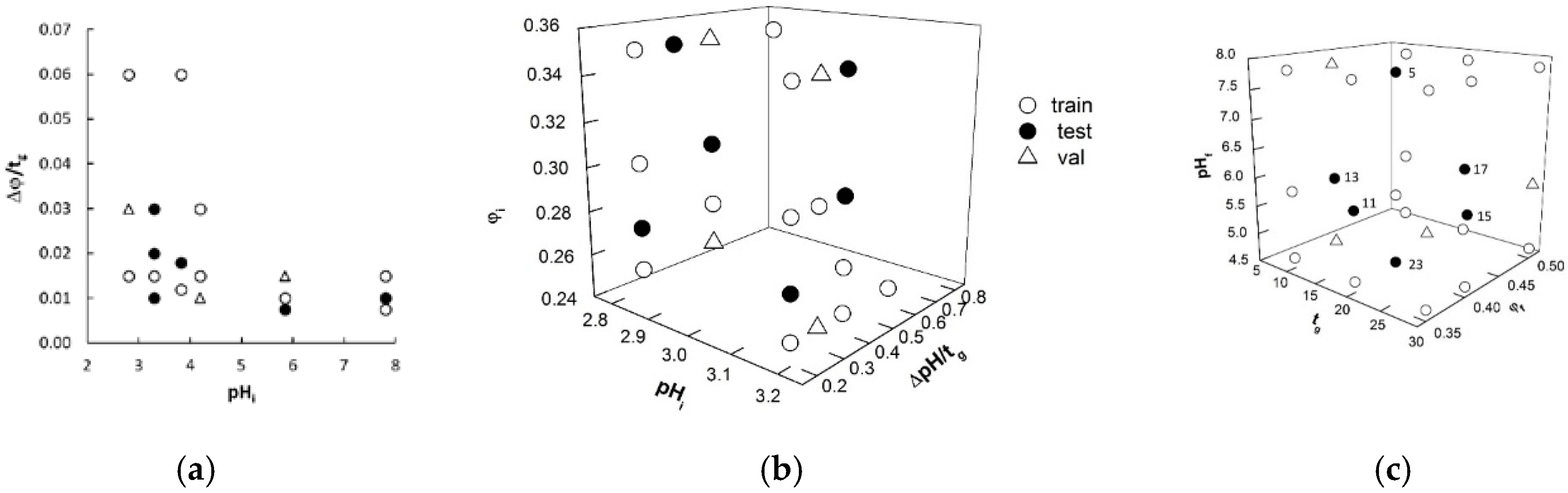
2.1. Identification of Model Variables and Data Subsets
2.2. ANN Modeling of Retention
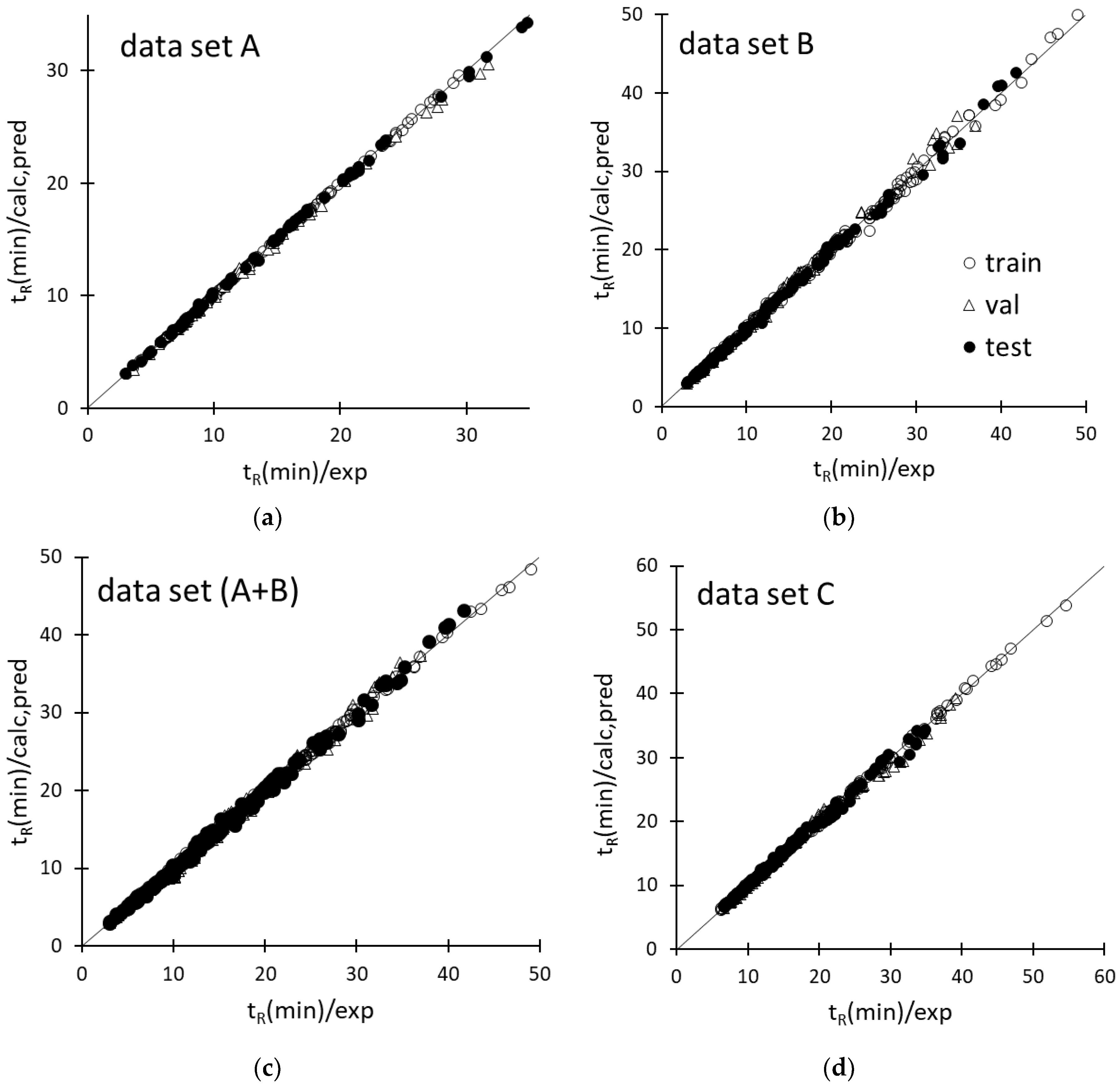
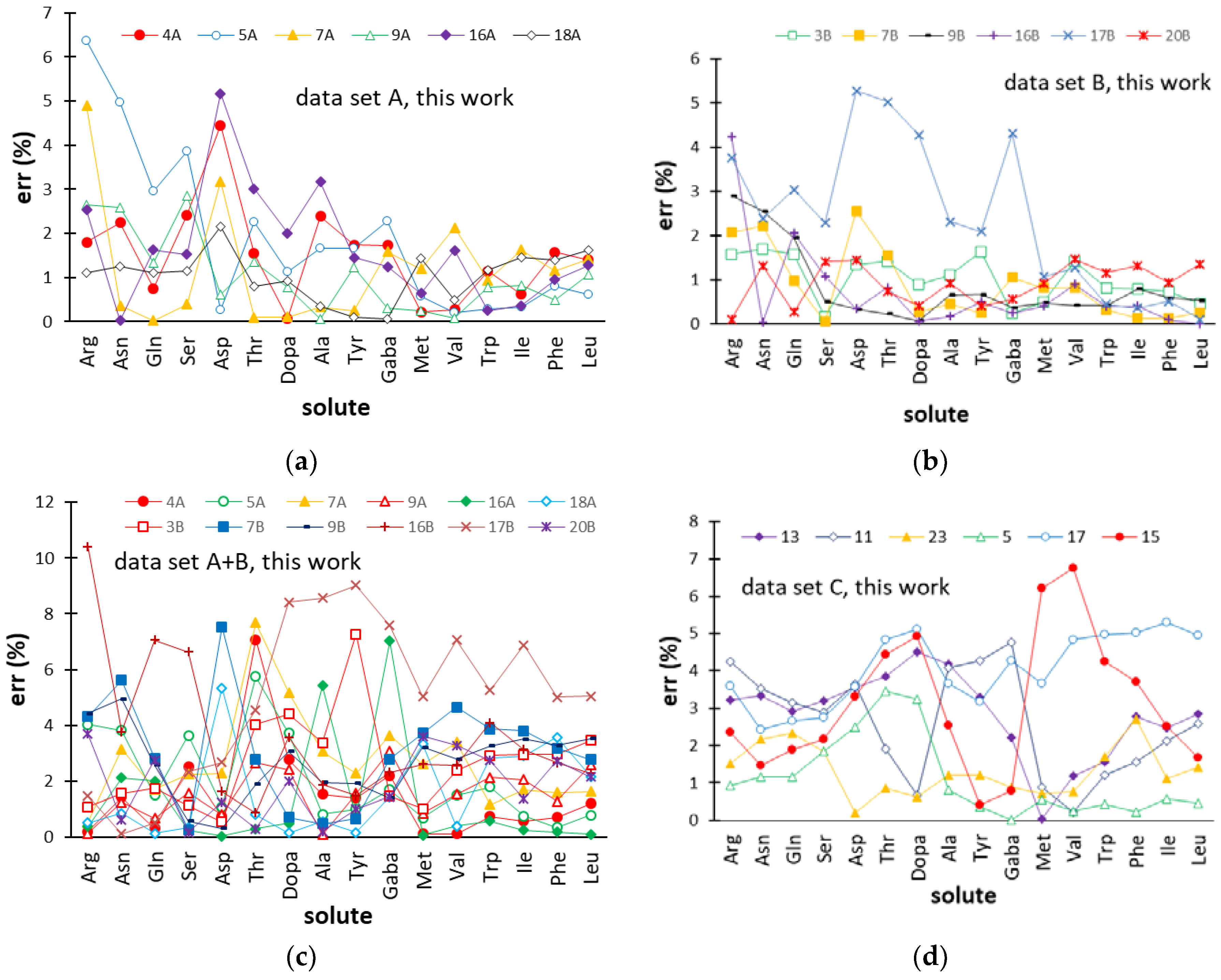
2.3. Predictive Performance of the ANN-Based Models
2.4. Comparison of the ANN-Based Models with Retention Models Based on the Solution of the Fundamental Equation of Gradient Elution
3. Methods
3.1. Retention Data
3.2. Artificial Neural Network Modelling
4. Conclusions
Funding
Conflicts of Interest
References
- Fekete, S.; Veuthey, J.L.; Guillarme, D. New trends in reversed-phase liquid chromatographic separations of therapeutic peptides and proteins: Theory and applications. J. Pharm. Biomed. Anal. 2012, 69, 9–27. [Google Scholar] [CrossRef] [PubMed]
- Domínguez-Álvarez, J.; Mateos-Vivas, M.; Rodríguez-Gonzalo, E.; García-Gómez, D.; Bustamante-Rangel, M.; Delgado Zamarreño, M.M.; Carabias-Martínez, R. Determination of nucleosides and nucleotides in food samples by using liquid chromatography and capillary electrophoresis. TrAC Trends Anal. Chem. 2017, 92, 12–31. [Google Scholar] [CrossRef]
- Mazzeo, P.; Di Pasquale, D.; Ruggieri, F.; Fanelli, M.; D’Archivio, A.A.; Carlucci, G. HPLC with diode-array detection for the simultaneous determination of di(2-ethylhexyl)phthalate and mono(2-ethylhexyl)phthalate in seminal plasma. Biomed. Chromatogr. 2007, 21, 1166–1171. [Google Scholar] [CrossRef] [PubMed]
- D’Archivio, A.A.; Maggi, M.A.; Ruggieri, F.; Carlucci, M.; Ferrone, V.; Carlucci, G. Optimisation by response surface methodology of microextraction by packed sorbent of non steroidal anti-inflammatory drugs and ultra-high performance liquid chromatography analysis of dialyzed samples. J. Pharm. Biomed. Anal. 2016, 125, 114–121. [Google Scholar] [CrossRef] [PubMed]
- Fanali, S.; Haddad, P.R.; Poole, C.F.; Schoenmakers, P.; Lloyd, D. Liquid Chromatography: Fundamentals and Instrumentation; Elsevier: Amsterdam, The Netherlands, 2013; ISBN 9780124158078. [Google Scholar]
- Jandera, P.; Churáček, J. Gradient elution in liquid chromatography. II. Retention characteristics (retention volume, band width, resolution, plate number) in solvent-programmed chromatography—Theoretical considerations. J. Chromatogr. A 1974, 91, 223–235. [Google Scholar] [CrossRef]
- Kaliszan, R.; Wiczling, P.; Markuszewski, M.J. pH Gradient Reversed-Phase HPLC. Anal. Chem. 2004, 76, 749–760. [Google Scholar] [CrossRef]
- Poole, C.F.; Lenca, N. Applications of the solvation parameter model in reversed-phase liquid chromatography. J. Chromatogr. A 2017, 1486, 2–19. [Google Scholar]
- Vitha, M.; Carr, P.W. The chemical interpretation and practice of linear solvation energy relationships in chromatography. J. Chromatogr. A 2006, 1126, 143–194. [Google Scholar] [CrossRef]
- Torres-Lapasió, J.R.; García-Alvarez-Coque, M.C.; Rosés, M.; Bosch, E.; Zissimos, A.M.; Abraham, M.H. Analysis of a solute polarity parameter in reversed-phase liquid chromatography on a linear solvation relationship basis. Anal. Chim. Acta 2004, 515, 209–227. [Google Scholar] [CrossRef]
- Cela, R.; Ordoñez, E.Y.; Quintana, J.B.; Rodil, R. Chemometric-assisted method development in reversed-phase liquid chromatography. J. Chromatogr. A 2013, 1287, 2–22. [Google Scholar] [CrossRef]
- Andrés, A.; Téllez, A.; Rosés, M.; Bosch, E. Chromatographic models to predict the elution of ionizable analytes by organic modifier gradient in reversed phase liquid chromatography. J. Chromatogr. A 2012, 1247, 71–80. [Google Scholar] [CrossRef] [PubMed]
- Fasoula, S.; Zisi, C.; Gika, H.; Pappa-Louisi, A.; Nikitas, P. Retention prediction and separation optimization under multilinear gradient elution in liquid chromatography with Microsoft Excel macros. J. Chromatogr. A 2015, 1395, 109–115. [Google Scholar] [CrossRef] [PubMed]
- Pappa-Louisi, A.; Zisi, C. A simple approach for retention prediction in the pH-gradient reversed-phase liquid chromatography. Talanta 2012, 93, 279–284. [Google Scholar] [CrossRef]
- Zisi, C.; Fasoula, S.; Nikitas, P.; Pappa-Louisi, A. Retention modeling in combined pH/organic solvent gradient reversed-phase HPLC. Analyst 2013, 138, 3771–3777. [Google Scholar] [CrossRef] [PubMed]
- Fasoula, S.; Zisi, C.; Nikitas, P.; Pappa-Louisi, A. Retention prediction and separation optimization of ionizable analytes in reversed-phase liquid chromatography under organic modifier gradients in different eluent pHs. J. Chromatogr. A 2013, 1305, 131–138. [Google Scholar] [CrossRef] [PubMed]
- Héberger, K. Quantitative structure-(chromatographic) retention relationships. J. Chromatogr. A 2007, 1158, 273–305. [Google Scholar] [CrossRef] [PubMed]
- D’Archivio, A.A.; Incani, A.; Ruggieri, F. Retention modelling of polychlorinated biphenyls in comprehensive two-dimensional gas chromatography. Anal. Bioanal. Chem. 2011, 399, 903–913. [Google Scholar] [CrossRef]
- D’Archivio, A.A.; Maggi, M.A.; Mazzeo, P.; Ruggieri, F. Quantitative structure-retention relationships of pesticides in reversed-phase high-performance liquid chromatography based on WHIM and GETAWAY molecular descriptors. Anal. Chim. Acta 2008, 628, 162–172. [Google Scholar] [CrossRef]
- D’Archivio, A.A.; Maggi, M.A.; Ruggieri, F. Multiple-column RP-HPLC retention modelling based on solvatochromic or theoretical solute descriptors. J. Sep. Sci. 2010, 33, 155–166. [Google Scholar] [CrossRef]
- D’Archivio, A.A.; Giannitto, A.; Maggi, M.A. Cross-column prediction of gas-chromatographic retention of polybrominated diphenyl ethers. J. Chromatogr. A 2013, 1298, 118–131. [Google Scholar] [CrossRef]
- D’Archivio, A.A.; Incani, A.; Ruggieri, F. Cross-column prediction of gas-chromatographic retention of polychlorinated biphenyls by artificial neural networks. J. Chromatogr. A 2011, 1218, 8679–8690. [Google Scholar] [CrossRef] [PubMed]
- D’Archivio, A.A.; Giannitto, A.; Maggi, M.A.; Ruggieri, F. Cross-column retention prediction in reversed-phase high-performance liquid chromatography by artificial neural network modelling. Anal. Chim. Acta 2012, 717, 52–60. [Google Scholar] [CrossRef] [PubMed]
- Fatemi, M.H.; Abraham, M.H.; Poole, C.F. Combination of artificial neural network technique and linear free energy relationship parameters in the prediction of gradient retention times in liquid chromatography. J. Chromatogr. A 2008, 1190, 241–252. [Google Scholar] [CrossRef] [PubMed]
- Golubović, J.; Protić, A.; Otašević, B.; Zečević, M. Quantitative structure-retention relationships applied to development of liquid chromatography gradient-elution method for the separation of sartans. Talanta 2016, 150, 190–197. [Google Scholar] [CrossRef] [PubMed]
- Barron, L.P.; McEneff, G.L. Gradient liquid chromatographic retention time prediction for suspect screening applications: A critical assessment of a generalised artificial neural network-based approach across 10 multi-residue reversed-phase analytical methods. Talanta 2016, 147, 261–270. [Google Scholar] [CrossRef] [PubMed]
- D’Archivio, A.A.; Maggi, M.A.; Ruggieri, F. Prediction of the retention of s-triazines in reversed-phase high-performance liquid chromatography under linear gradient-elution conditions. J. Sep. Sci. 2014, 37, 1930–1936. [Google Scholar] [CrossRef] [PubMed]
- D’Archivio, A.A.; Maggi, M.A.; Ruggieri, F. Artificial neural network prediction of multilinear gradient retention in reversed-phase HPLC: Comprehensive QSRR-based models combining categorical or structural solute descriptors and gradient profile parameters. Anal. Bioanal. Chem. 2015, 407, 1181–1190. [Google Scholar] [CrossRef]
- Todeschini, R.; Ballabio, D.; Grisoni, F. Beware of Unreliable Q2! A Comparative Study of Regression Metrics for Predictivity Assessment of QSAR Models. J. Chem. Inf. Model. 2016, 56, 1905–1913. [Google Scholar] [CrossRef]
- Marini, F.; Bucci, R.; Magrì, A.L.; Magrì, A.D. Artificial neural networks in chemometrics: History, examples and perspectives. Microchem. J. 2008, 88, 178–185. [Google Scholar] [CrossRef]
- Svozil, D.; Kvasnička, V.; Pospíchal, J. Introduction to multi-layer feed-forward neural networks. Chemometr. Intell. Lab. Syst. 1997, 39, 43–62. [Google Scholar] [CrossRef]
- Lopez, R. Open NN: An Open Source Neural Networks C++ Library. 2014; Available online: http://opennn.cimne.com/ (accessed on 20 January 2019).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Gradient Code | Subset a | pHi | ΔpH/tg | φi | Δφ/tg |
|---|---|---|---|---|---|---|
| A | 1A | train | 2.8 | 0 | 0.20 | 0.06 |
| 2A | val | 2.8 | 0 | 0.20 | 0.03 | |
| 3A | train | 2.8 | 0 | 0.20 | 0.015 | |
| 4A | test | 3.3 | 0 | 0.20 | 0.03 | |
| 5A | test | 3.3 | 0 | 0.20 | 0.02 | |
| 6A | train | 3.3 | 0 | 0.20 | 0.015 | |
| 7A | test | 3.3 | 0 | 0.20 | 0.01 | |
| 8A | train | 3.82 | 0 | 0.20 | 0.06 | |
| 9A | test | 3.82 | 0 | 0.20 | 0.018 | |
| 10A | train | 3.82 | 0 | 0.20 | 0.012 | |
| 11A | train | 4.2 | 0 | 0.20 | 0.03 | |
| 12A | train | 4.2 | 0 | 0.20 | 0.015 | |
| 13A | val | 4.2 | 0 | 0.20 | 0.01 | |
| 14A | val | 5.85 | 0 | 0.20 | 0.015 | |
| 15A | train | 5.85 | 0 | 0.20 | 0.01 | |
| 16A | test | 5.85 | 0 | 0.20 | 0.0075 | |
| 17A | train | 7.8 | 0 | 0.20 | 0.015 | |
| 18A | test | 7.8 | 0 | 0.20 | 0.01 | |
| 19A | train | 7.8 | 0 | 0.20 | 0.0075 | |
| B | 1B | train | 2.8 | 0.79 | 0.35 | 0 |
| 2B | val | 2.8 | 0.527 | 0.35 | 0 | |
| 3B | test | 2.8 | 0.395 | 0.35 | 0 | |
| 4B | train | 2.8 | 0.263 | 0.35 | 0 | |
| 5B | val | 2.8 | 0.527 | 0.25 | 0 | |
| 6B | train | 2.8 | 0.527 | 0.27 | 0 | |
| 7B | test | 2.8 | 0.527 | 0.30 | 0 | |
| 8B | train | 2.8 | 0.263 | 0.25 | 0 | |
| 9B | test | 2.8 | 0.263 | 0.27 | 0 | |
| 10B | train | 2.8 | 0.263 | 0.30 | 0 | |
| 11B | train | 3.2 | 0.580 | 0.25 | 0 | |
| 12B | train | 3.2 | 0.387 | 0.25 | 0 | |
| 13B | val | 3.2 | 0.290 | 0.25 | 0 | |
| 14B | train | 3.2 | 0.193 | 0.25 | 0 | |
| 15B | train | 3.2 | 0.387 | 0.27 | 0 | |
| 16B | test | 3.2 | 0.387 | 0.30 | 0 | |
| 17B | test | 3.2 | 0.387 | 0.35 | 0 | |
| 18B | train | 3.2 | 0.290 | 0.30 | 0 | |
| 19B | val | 3.2 | 0.290 | 0.35 | 0 | |
| 20B | test | 3.2 | 0.193 | 0.27 | 0 | |
| 21B | train | 3.2 | 0.193 | 0.30 | 0 | |
| 22B | train | 3.2 | 0.193 | 0.35 | 0 |
| Data Set | Network Topology | Learning Epochs | Training | Validation | Test | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R2 | SEC | mean(%) | max(%) | Q2 | SEP | mean(%) | max(%) | Q2 | SEP | mean(%) | max(%) | |||
| A | 18-14-1a | 251 | 0.9999 | 0.06 | 0.3 | 1.6 | 0.9906 | 0.37 | 1.6 | 7.4 | 0.9984 | 0.22 | 1.4 | 6.4 |
| B | 19-21-1 | 63 | 0.9980 | 0.46 | 0.7 | 4.1 | 0.9778 | 0.78 | 1.4 | 4.1 | 0.9949 | 0.48 | 1.1 | 5.3 |
| A+B | 20-23-1 | 286 | 0.9993 | 0.23 | 1.2 | 6.3 | 0.9939 | 0.65 | 3.3 | 12.6 | 0.9799 | 0.48 | 2.5 | 10.4 |
| C | 19-18-1 | 125 | 0.9994 | 0.22 | 1.0 | 4.2 | 0.9938 | 0.72 | 2.6 | 6.9 | 0.9958 | 0.59 | 2.5 | 6.8 |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
D’Archivio, A.A. Artificial Neural Network Prediction of Retention of Amino Acids in Reversed-Phase HPLC under Application of Linear Organic Modifier Gradients and/or pH Gradients. Molecules 2019, 24, 632. https://doi.org/10.3390/molecules24030632
D’Archivio AA. Artificial Neural Network Prediction of Retention of Amino Acids in Reversed-Phase HPLC under Application of Linear Organic Modifier Gradients and/or pH Gradients. Molecules. 2019; 24(3):632. https://doi.org/10.3390/molecules24030632
Chicago/Turabian StyleD’Archivio, Angelo Antonio. 2019. "Artificial Neural Network Prediction of Retention of Amino Acids in Reversed-Phase HPLC under Application of Linear Organic Modifier Gradients and/or pH Gradients" Molecules 24, no. 3: 632. https://doi.org/10.3390/molecules24030632
APA StyleD’Archivio, A. A. (2019). Artificial Neural Network Prediction of Retention of Amino Acids in Reversed-Phase HPLC under Application of Linear Organic Modifier Gradients and/or pH Gradients. Molecules, 24(3), 632. https://doi.org/10.3390/molecules24030632