Abstract
Bitter peptides are small molecular peptides produced by the hydrolysis of proteins under acidic, alkaline, or enzymatic conditions. These peptides can enhance food flavor and offer various health benefits, with attributes such as antihypertensive, antidiabetic, antioxidant, antibacterial, and immune-regulating properties. They show significant potential in the development of functional foods and the prevention and treatment of diseases. This review introduces the diverse sources of bitter peptides and discusses the mechanisms of bitterness generation and their physiological functions in the taste system. Additionally, it emphasizes the application of bioinformatics in bitter peptide research, including the establishment and improvement of bitter peptide databases, the use of quantitative structure–activity relationship (QSAR) models to predict bitterness thresholds, and the latest advancements in classification prediction models built using machine learning and deep learning algorithms for bitter peptide identification. Future research directions include enhancing databases, diversifying models, and applying generative models to advance bitter peptide research towards deepening and discovering more practical applications.
1. Introduction
In vertebrates, taste is one of the fundamental physiological senses, helping organisms to select palatable foods and identify toxic and nutritious substances [1]. For a long time, the mainstream view of the scientific community has been that human taste can sense the five basic tastes of sour, sweet, bitter, salty, and fresh. A sixth taste, named the ammonium chloride taste, has been reported recently [2]. Bitterness typically arises from various substances such as polyphenols and alkaloids in food. Bitter peptides are produced from the breakdown of proteins under acidic, alkaline, or enzymatic conditions [3]. Most of these peptides are typically composed of no more than eight amino acids, and few contain more than ten. However, bitter peptides containing up to 39 amino acids have been described [4]. In food science, the presence of bitter peptides significantly impacts the taste perception of food products. Because of their unique amino acid composition and sequence structure, these short-chain peptides provide some benefits in humans, including antihypertensive, antidiabetic, antioxidant, antibacterial, and immunological effects [5]. Considering the bioactivity of bitter peptides, integrating them into everyday foods and beverages can lead to the development of functional foods that are both tasty and health-promoting, thus enhancing dietary quality and public health [6,7]. In biomedical research, bitter peptides have shown potential involvement in regulating the secretion of digestive enzymes, promoting gastrointestinal motility, and affecting the defensive mechanisms of the respiratory tract [8,9,10].
As early as 1953, Raadsveld et al. isolated bitter compounds from Gouda cheese and identified them as peptides, using human sensory evaluation to verify their bitterness [11]. Later, experiments by Murray and Baker found that treating casein with various proteases led to the accumulation of bitter peptides, and they successfully isolated and identified a specific bitter peptide [12,13,14]. Before the rise of bioinformatics, the identification of bitter peptides relied on a range of intricate experimental methods, each with its characteristics and limitations. (1) High-performance liquid chromatography (HPLC) and mass spectrometry (MS) offered precise separation and mass identification, but were costly and complex to operate [15]. (2) Synchrotron infrared and circular dichroism spectroscopy were used to explore peptide structures, providing deep insights into bitterness mechanisms; however, these techniques demanded a high sample quality and were technically complex [16,17,18,19,20]. (3) Amino acid sequence analysis provided the detailed identification of peptide structures, but was time-consuming and cumbersome [21]. (4) Cell-based sensory receptor assays allowed for direct evaluations of the bioactivity of bitter peptides [22], while animal behavioral experiments assessed bitterness through animal feeding preferences [23]. (5) Human sensory evaluation directly reflected consumer experience, but suffered from significant subjectivity. In summary, these experimental methods uniquely contributed to revealing the characteristics of bitter peptides, but faced challenges such as cost, efficiency, and implementation difficulty [24].
In recent years, with the rapid development of bioinformatics, significant progress has been made in bitter peptide research. BitterDB, databases containing bitter peptide information, have provided resources for research and development [25]. Researchers have developed various algorithms to predict and identify bitter peptides based on sequence using machine learning and deep learning techniques, significantly improving prediction accuracy [26]. Bioinformatics tools are widely applied to predict bitterness thresholds based on sequence [27,28,29,30]. Through molecular dynamics simulations and structure predictions, researchers can gain a deep understanding of the secondary structures of bitter peptides, revealing their functional properties [31,32,33,34]. These studies provide a solid theoretical foundation and technical support for bitter peptides in food science and drug development [35,36,37,38].
This review introduces the properties of bitter peptides, the mechanisms of bitterness generation, and their physiological functions and applications, highlighting research in bioinformatics related to bitter peptides, including bitter peptide databases, QSAR models, and predictive models (Figure 1). Furthermore, it provides an outlook on future research directions.
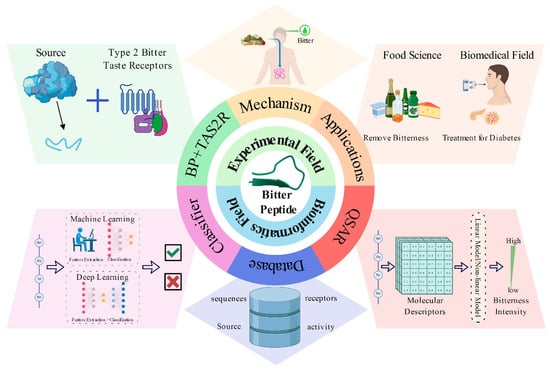
Figure 1.
A schematic diagram of the content covered in this review. It primarily includes two sections: experimental field and bioinformatics field. In the experimental section, we introduce bitter peptides (BPs) and taste receptors type 2 (TAS2Rs), the mechanisms of bitterness generation, and their applications. In the bioinformatics section, we discuss bitter peptide databases, QSAR models, and classification models.
2. Bitter Peptides
A bitter peptide is a flavor peptide produced by the hydrolysis of proteins in food through proteolytic enzymes. Flavor peptides are oligopeptides with a molecular mass of less than 3000 u, which can bind to corresponding taste receptors on the tongue to present characteristic flavors [39,40]. In food, based on the flavor-imparting action of flavor peptides, they can be divided into flavor precursor peptides and characteristic flavor peptides. Characteristic flavor peptides, including sweet peptides, sour peptides, bitter peptides, salty peptides, and umami peptides, have specific effects [41]. This review will focus on bitter peptides.
2.1. Sources of Bitter Peptides
Bitter peptides are widely found in everyday foods and primarily originate from three sources: (1) natural sources, which are peptides directly extracted from natural foods such as meats and dairy products; (2) fermentation production, where the presence of fermenting microbes in cheese, fermented fish products, and bean products produces bitter peptides; and (3) enzymatic production, which uses enzymes to process protein from raw materials (such as milk protein, soy protein, etc.) in industrial or laboratory settings, also resulting in the formation of bitter peptides [42,43,44,45,46]. These peptides are essentially hydrolyzed protein products. The exposure of hydrophobic amino acids within these peptides often stimulates the taste buds, causing bitterness. Generally, the more hydrophobic amino acids are exposed, the stronger this bitterness [47,48,49,50,51]. Additionally, the length of the peptide chain, the overall hydrophobicity, the sequence, and the amino acid composition also significantly affect bitterness [52].
2.2. Extraction of Bitter Peptides
Compared to the sources of bitter peptides, how to extract them is more important. There are different extraction methods for fermented products and non-fermented products. (1) In fermented products, proteins are enzymatically hydrolyzed into short peptides during fermentation. So, these peptides can be directly extracted. The typical extraction of peptides involves the following steps: first, the fermented product (such as cheese, soy sauce, or yogurt) is homogenized or ground to increase its surface area. Next, an appropriate solvent (such as water or a 50% ethanol solution) is used to extract the peptides, typically at 1:5 (sample, w/v). The extraction solution is stirred at 4 °C for 1–2 h to ensure thorough dissolution of the peptides. The mixture is centrifuged (10,000 rpm, 15 min) and filtered through a 0.22 µm membrane to remove solid impurities, yielding a short peptides solution [53]. (2) In non-fermented products, protein extraction is required first, followed by hydrolysis to produce short peptides. The extraction steps include grinding the sample (such as meat or grains) and dissolving the proteins in 0.1 M phosphate buffer (pH 7.0) at a ratio of 1:10 (sample, w/v). The solution is stirred at 4 °C for 2 h and sonicated (40 kHz, 10 min) to assist with extraction. The extracted sample is centrifuged (10,000 rpm, 20 min) and filtered (0.22 µm membrane) to obtain a purified protein solution. Subsequently, an appropriate enzyme (such as trypsin, at an enzyme-to-protein ratio of 1:100, w/w) is selected for hydrolysis at 37 °C for 4–24 h, or 6 M hydrochloric acid is added to hydrolysis at 110 °C for 24 h. The hydrolyzed product is then centrifuged, dialyzed, and concentrated to obtain short peptides [54,55].
The resulting supernatant obtained through the above methods can be directly analyzed using experimental techniques such as high-performance liquid chromatography (HPLC) and mass spectrometry (MS) or subjected to sequencing and bioinformatics methods (as discussed in Section 3) for further analysis to identify and characterize the composition and properties of bitter peptides.
2.3. Chemical and Physiological Mechanisms of Bitter Taste Perception
Understanding the diverse sources of bitter peptides has provided valuable insights into the factors that contribute to their distinct bitter taste. The main reason for the bitterness produced by protein hydrolysis is the formation of bitter peptides. The factors influencing the bitterness thresholds in bitter peptides include the hydrophobicity of the peptides, their sequence and number of amino acids, their composition, and the length and molecular weight of the peptide chains [52,56]. Bitter peptides generally contain several amino acids with hydrophobic side chains (such as phenylalanine, tyrosine, and tryptophan) [41,42,57]. In 1971, Ney et al. proposed the Q rule, primarily used to describe and predict the bitterness level of peptides by calculating the frequency of hydrophobic amino acid residues to obtain a Q value. Peptides with a Q value less than 1300 are not bitter, while those with a Q value greater than 1400 are bitter [58]. To date, the Q rule is a parameter still used to assess the relationship between the hydrophobicity of peptide chains and bitterness [46,59,60].
While the chemical properties of bitter peptides explain their origins, the physiological mechanisms by which animals perceive this taste are equally important. Exploring how the gustatory system processes these peptides sheds light on the complex interaction between their molecular structure and taste perception. The gustatory system is a complex physiological structure with taste buds associated with the nerve and brain structures. The tongue, the organ of the gustatory system, is covered with papillae, each harboring taste buds—the basic units of taste [61,62]. Taste buds contain various types of gustatory cells, such as Type I, II, III, and IV, which convert food stimuli into electrical signals that are transmitted to the brain to produce taste [63,64,65]. Specifically, bitter taste receptors (taste receptors type 2, TAS2Rs), part of the G protein-coupled receptor family, are predominantly expressed in Type II cells. They recognize ligands and transmit signals through a seven-transmembrane region and intracellular and extracellular loop structures. These receptors, which are expressed in diabetes in the oral cavity and extra-oral tissues, such as the gastrointestinal tract, airways, brain, and testes, demonstrate the extensive and complex functionality of the gustatory system [44,66,67,68,69,70,71,72].
When a bitter peptide binds to a TAS2R, it induces a conformational change and follows the dissociation of the α-subunit from the β- and γ-subunits of gustducin. This dissociation of subunits marks the initiation of two distinct signaling pathways [73,74,75,76]: (1) In the first pathway, the β- and γ-subunits activate phospholipase C β2 isoform (PLCβ2), which cleaves phosphatidylinositol 4,5-bisphosphate (PIP2) into diacylglycerol (DAG) and inositol 1,4,5-trisphosphate (IP3). IP3 then enters the endoplasmic reticulum (ER), where it binds to the IP3 receptor (IP3R), causing the release of Ca2+ from the ER into the cytoplasm. These concentration increases in intracellular Ca2+ activate the sodium-selective transmembrane transporters transient receptor potential melastatin 4 and 5 (TrpM4/5), leading to cell membrane depolarization. Depolarization activates voltage-gated sodium channels (VGNCs), further accelerating the depolarization. Upon reaching an action potential (AP), the calcium homeostasis modulator 1/3 (CALHM1/3) channels and pannexin 1 channels are activated and allow adenosine triphosphate (ATP) to be transported from the cytoplasm to the intercellular space. ATP is taken up by incoming neurons via P2X purinergic receptors 2/3 (P2X2/P2X3), further propagating the signal. (2) The second pathway involves the α-subunit of gustducin. α-gustducin reduces cAMP levels by activating phosphodiesterase (PDE), which hydrolyzes cyclic adenosine monophosphate (cAMP). This reduction in cAMP may decrease intracellular cyclic nucleotide monophosphate (cNMP) levels, thereby regulating protein kinases and subsequently modulating ion activity within the cell. Alternatively, cNMPs might directly regulate cNMP-gated ion channels, leading to membrane depolarization and the release of neurotransmitters [77,78,79]. These cellular responses ultimately lead to the transmission of neural signals, with bitter information being relayed from the gustatory receptor cells through the facial nerve and the glossopharyngeal nerve to the solitary tract nucleus (NTS) in the brainstem, then to the parabrachial nucleus (PbN), and finally to the gustatory cortex in the thalamus and cerebral cortex [80,81,82].
These detailed signal transduction pathways reveal the neural basis of bitter taste perception and highlight the potential role of bitter peptides in regulating physiological functions such as digestion and respiration, providing new perspectives for treating diseases related to these processes.
2.4. Functions and Applications of Bitter Peptides
Having explored the intricate mechanisms by which animals perceive bitterness through the gustatory system, these bitter peptides might offer significant health benefits. Current research on bitter peptides primarily focuses on food science and biomedicine [83].
In food science, bitter peptides can significantly influence the taste profile of a food product, prompting researchers to focus on optimizing production processes to control their levels. This optimization often involves adjusting fine-tuned enzymatic hydrolysis conditions, such as the pH, temperature, and enzyme-to-substrate ratios, to minimize the formation of bitterness-contributing peptides. There is a bell-shaped relationship between the degree of hydrolysis (DH) and bitterness intensity; controlling the DH can significantly affect the sensory quality of protein hydrolysates [84,85,86,87]. Moreover, based on the bioactivity of bitter peptides, researchers can develop functional foods that are both tasty and beneficial for health by incorporating these functional peptides into everyday foods and beverages. Various encapsulation techniques, such as spray drying, liposomes, ionic gelation, freeze-drying, and double emulsion solvent evaporation, can enhance their stability, bioavailability, and consumer acceptance. These methods help to protect these bioactive peptides from degradation, control their release, and mask undesirable flavors, making them suitable for use in food products [88,89].
In biomedicine, bitter peptides exhibit a range of functions through their interactions with bitter receptors located in various tissues, including the oral cavity, gastrointestinal and respiratory systems, pancreatic and ovarian tissues, and associated malignant tumors [90]. These interactions can regulate digestive enzyme secretion, promote gastrointestinal motility, and modulate respiratory defense mechanisms [41,91]. Building on these properties, researchers have developed microcapsules to encapsulate bitter peptides and other functional peptides, effectively masking their bitterness, preserving their antioxidant activity, and specifically targeting gastrointestinal bitter receptors to enhance therapeutic efficacy [92].
Moreover, bitter peptides are valuable for their antihypertensive, antidiabetic, antioxidative, antibacterial, and immune regulation properties. (1) Antihypertensive: Bitter peptides regulate blood pressure by inhibiting angiotensin-converting enzyme (ACE) and renin, while also enhancing the endothelial nitric oxide synthase (eNOS) pathway to increase the nitric oxide (NO) levels in blood vessels, thereby promoting vasodilation [93]. One study demonstrated that hydrolysates of bitter apricot protein, such as the peptide RPPSEDEDQE, exhibited ACE inhibitory activity and zinc-ion-chelating abilities by forming hydrogen bonds and undergoing hydrophobic interactions at multiple active sites of ACE. In spontaneously hypertensive rats, these peptides significantly reduced their blood pressure, although zinc chelation diminished their antihypertensive effect, indicating their potential in hypertension management [94,95,96]. Interesting, Val-Pro-Pro (VPP) and Ile-Pro-Pro (IPP) are two tripeptides found in fermented dairy products, known for their antihypertensive bioactivity, which primarily lower blood pressure by inhibiting the activity of ACE [97]. (2) Antidiabetic: Bitter peptides have shown significant potential in managing diabetes through various mechanisms. Studies have shown that mcIRBP-19-BGE can span the 50th–68th residues, enhance the binding of insulin and insulin receptors (IRs), stimulate the phosphorylation of phosphoinositide-dependent kinase-1 (PDK1) and protein kinase B (PKB), and induce the expression of glucose transporter 4, thus promoting glucose clearance [98,99,100,101]. In a clinical setting, a study involving 142 diabetic patients demonstrated that bitter melon peptide (BMP) treatment significantly reduced their glycated hemoglobin (HbA1c) levels starting from the second month, underscoring its therapeutic potential [98]. Furthermore, Pan et al. used the Health Belief Model to study the factors affecting BMP intake among 292 type 2 diabetes patients in Taiwan. They found that perceived susceptibility to diabetes complications and perceived benefits were key motivators for BMP consumption, with self-efficacy significantly enhancing the likelihood of intake [102]. Broader research on bitter peptides in herbal remedies can improve insulin sensitivity and manage blood sugar by inhibiting glucose absorption and boosting insulin receptor activity [39,40,103,104,105]. (3) Antioxidative properties: Bitter peptides exert antioxidant effects through scavenging free radicals, neutralizing reactive oxygen species, chelating transition metal ions, forming a physical barrier at the oil–water interface, and so on [106]. Numerous studies have demonstrated the antioxidant activities of protein hydrolysates and peptides. For instance, Carrillo et al. reported that the bitter peptides in casein hydrolysates effectively inhibited lipid peroxidation in olive oil by scavenging free radicals and neutralizing reactive oxygen species, highlighting their significant antioxidant potential [107]. Similarly, Li et al. found that the bitter peptides in whey isolate hydrolysates reduced protein oxidation in carp surimi by maintaining protein solubility, preserving Ca-ATPase activity, and minimizing structural changes during frozen storage [108,109]. (4) Antibacterial: Bitter peptides have shown significant potential as natural antimicrobial agents in various food applications. Filho et al. found that incorporating hydrolyzed cottonseed protein, rich in bitter peptides, into alginate films effectively inhibited the growth of Staphylococcus aureus by disrupting bacterial cell membranes and interfering with microbial metabolism, making these films a promising choice for active food packaging [110]. Similarly, Dang et al. discovered that antimicrobial peptides, including bitter peptides isolated from the edible insect Musca domestica, inhibited the growth of Staphylococcus aureus, Escherichia coli, Salmonella spp., and Listeria monocytogenes in chilled pork, significantly extending its shelf life by increasing its bacterial membrane permeability and causing cell lysis [111]. Ren et al. also demonstrated that adding catfish bone hydrolysates rich in bitter peptides could effectively suppress microbial growth in catfish sausages, enhancing their safety and prolonging their shelf life during ambient temperature storage [112]. (5) Immune regulation: Bitter peptides have emerged as promising agents in modulating immune responses. Some plant-derived bitter peptides, such as lunasin and soy-derived peptides, have been demonstrated to stimulate natural killer (NK) cells and enhance the phagocytic activity of macrophages. These peptides exert their immunomodulatory effects by activating immune cells and promoting cytokine production, strengthening the body’s innate immune response and providing enhanced protection against infections and diseases [113,114,115,116].
Therefore, research on bitter peptides has enhanced our understanding of the causes and regulation of bitterness in food and provided a scientific basis for developing new therapeutic methods. With advancements in food science and biotechnology, further exploring the multifunctionality and potential applications of bitter peptides will become a challenging and valuable field of study.
3. Research on Bitter Peptides in Bioinformatics
Bitter peptides are known for their ability to interact with taste receptors type 2 (TAS2Rs) in the mouth [117,118]. Therefore, studying and characterizing their bitterness thresholds is crucial, as this plays a significant role in drug development and nutritional research [94,104]. Although experimental methods are considered to be reliable for characterizing peptide bitterness, they are often time-consuming and expensive. Machine learning (ML) methods, known for their convenience and efficiency, are increasingly attracting attention in bioinformatics.
Significant progress has been made in studying bitter peptides, providing new perspectives and methodologies for peptide research in bioinformatics. Firstly, databases related to bitter peptides have been developed to store and manage the vast information on bitter peptides and their characteristics, offering valuable resources for researchers. Secondly, the quantitative structure–activity relationship (QSAR) and classification models for bitter peptides continue to be refined. These models use machine learning techniques to predict the activity and stability of bitter peptides, significantly enhancing research efficiency. The current research provides inspiration and methodological references for the study of bitter peptides and deepens our understanding of the bioactivity of peptides overall. In the future, bioinformatics is expected to develop more innovative technologies for studying bitter peptides.
3.1. Bitter Peptide Database
In bioinformatics research, databases play a crucial role. They provide vast data resources and offer tools for researchers to analyze and mine information, advancing scientific progress [119,120,121]. With more bitter peptides being discovered, researchers have constructed several databases by collecting and summarizing the bitter peptides reported in the literature. For example, the BIOPEP-UWM database contains information on bioactive peptides, including the sequences of bitter peptides and their activity information [122]; BitterDB focuses on bitter molecules and their receptors, featuring detailed descriptions of over 1000 bitter molecules, quantitative sensory data on bitterness thresholds, and toxicity information [123]; TastePeptidesDB includes the detailed sequences and taste characteristics of taste-active peptides [124]; and the database on cheese-derived bitter peptides focuses on the sequences and characteristics of bitter peptides in cheese [125]. These databases collectively provide essential resources for identifying and characterizing bitter peptides, developing prediction models, and designing functional foods and pharmaceuticals. Through these databases, researchers can perform data analyses more efficiently, uncover new scientific discoveries, and propel the development of bioinformatics and related fields. This demonstrates the importance of databases in bioinformatics research. Specific database information is shown in Table 1.

Table 1.
Bitter peptides related database.
3.2. Bitter Peptide Prediction Models
3.2.1. Bitter Peptide Quantitative Structure–Activity Relationship Models
Quantitative structure–activity relationship (QSAR) models are methods for predicting the biological activity of compounds by analyzing their molecular structures. This approach is based on the core principle that molecules with the same structures often exhibit similar biological activities or chemical properties [126,127,128,129,130]. This concept was systematically introduced by Corwin Hansch in the 1960s and applied in his studies on benzoic acid derivatives [131].
QSAR models integrate chemical and biological information with mathematical and statistical methods to develop a system that can predict the activity of unknown compounds. The general steps for building a QSAR model include first collecting data on compounds with known biological activities and chemical structures; secondly, calculating the molecular descriptors of the compounds, such as their topological indices, electronic characteristics, and geometric properties; thirdly, standardizing these molecular descriptors and removing redundant or highly correlated descriptors; then, selecting appropriate mathematical and statistical methods, such as multiple linear regression, support vector machines, or neural networks, to establish the QSAR model; and finally, evaluating the predictive performance and stability of the model using methods like cross-validation and external validation sets. These steps constitute the complete process of building QSAR models from data collection to application and aid in systematically predicting a compound’s biological activity [132,133,134].
Currently, several studies on QSAR models for bitter peptides have been published. These studies have utilized various datasets, molecular descriptors, and modeling methods, achieving notable results (Table 2). The development of these models has improved the predictive capability for the bitterness thresholds of bitter peptides and provided a theoretical basis for the design and development of new bitter peptides.
Table 2.
Bitter-peptide-related QSAR models.
There are significant trends in the evolution of QSAR models for bitter peptides. The first trend is that molecular descriptors have become increasingly complex and multidimensional. In early studies, Asao et al. used relatively simple descriptors, such as hydrophobicity, molecular size, and electronic properties [135]. Over time, researchers have introduced more complex descriptors, such as total hydrophobicity, residue count, and log mass values [136,137]. More recent studies, such as those by Wang et al. and Xu et al., have adopted more advanced and refined molecular modeling and alignment methods [117,138]. The second trend is that modeling methods have evolved from linear regression to nonlinear regression and machine learning techniques. Early research often used partial least squares regression (PLS) [139]. Recent years have seen the introduction of nonlinear models like support vector regression (SVR) [140], support vector machines (SVMs) [141,142,143], and artificial neural networks (ANNs) [144], significantly enhancing the models’ predictive power and stability. The third trend is model evaluation metrics seeing substantial improvements. Early models had relatively low coefficients of determination (R2) and root mean square errors of prediction (RMSEPs), but these metrics have significantly improved with in-depth research and improved methods. For instance, SVR models can achieve a high R2 (0.962) and a low RMSEP (0.123), demonstrating an excellent predictive performance. Overall, with the increasing complexity of molecular descriptors, the evolution of modeling methods, the enhancement of model evaluation metrics, and the expansion of dataset sizes, the development of bitter peptide QSAR models has shown increasingly strong predictive capabilities and application prospects.
3.2.2. Bitter Peptide Classification Prediction Models
Machine learning classification models are based on assigning input data to predefined categories and are widely applied across various fields [145,146,147]. The construction of classification models generally involves the following steps: First, collect and prepare the data, ensuring their quality and representativeness; second, preprocess the data, including cleaning, normalizing, and extracting features to enhance the model’s performance; then, select an appropriate classification algorithm, such as logistic regression, support vector machines, decision trees, random forests, k-nearest neighbors (k-NN), or neural networks in deep learning, and train the model; next, evaluate the model’s performance using cross-validation or an independent validation set, using metrics including accuracy (ACC), sensitivity (Sn), specificity (Sp), matthews correlation coefficient (MCC), and area under the receiver operating characteristic curve (ROC); and finally, apply the trained model to classify new data, and interpret and analyze the results. Machine learning classification models excel in classification tasks by learning complex patterns and relationships from large amounts of data, which are extensively used in fields such as medical diagnosis, image recognition, natural language processing, and financial risk assessment [148,149,150,151,152,153]. Below, we detail eight different bitter peptide classifiers, their methodologies, technical features, and performances in bitter peptide prediction, as shown in Table 3.
The development of bitter peptide classifiers from 2020 to 2024 significantly reflects the evolution from traditional statistical methods to deep learning technologies (Table 3). Initially, in 2020, the iBitter-SCM primarily utilized a scoring card method (SCM) based on dipeptide propensity, which, although simple to implement, had limited capabilities in handling complex biological sequence data [154]. In 2021, with the introduction of BERT4Bitter, classifiers began utilizing a combination of BERT [155] and LSTM [156], marking a significant turning point in bitter peptide classification technology—the transition from simple statistical feature extraction to complex neural network models, allowing for deeper and more automated feature extraction [157]. By 2022 and 2023, the technology continued to lean towards ensemble and deep learning. For example, MIMML adopted meta-learning and TextCNN, emphasizing the optimization of model structure and parameters through learning how to learn better [158]. iBitter-DRLF demonstrated how to extract more complex sequence features by integrating deep learning techniques (such as SSA, UniRep, and BiLSTM) and exhibited clear advantages in enhancing model generalizability and handling diverse biological data [4]. By 2024, the development of bitter peptide classifiers reached new heights with the introduction of CPM-BP, a LightGBM-based model incorporating in-depth features [159]. This trend indicates that classification technology is moving towards greater precision and efficiency. Besides improving the accuracy and efficiency of classifiers, these advancements have also improved their adaptability to the complexity and high dimensionality of biological datasets. This implies that future bitter peptide classification technology might explore more dynamic and adaptive machine learning methods. Overall, the developmental trajectory of bitter peptide classifiers reflects the rapid progress in technology and applications with bioinformatics, showcasing the successful translation from basic research to practical applications.
Table 3.
Bitter peptide classification prediction models.
Table 3.
Bitter peptide classification prediction models.
| Classifier | Dataset | Features | Algorithm | ACC | Sn | Sp | MCC | AUC | Publication | Reference |
|---|---|---|---|---|---|---|---|---|---|---|
| iBitter-SCM | BTP640: 320 BPs and 320 NBPs | AAC, DPC | SCM | 0.844 | 0.844 | 0.844 | 0.866 | 0.904 | July 2020 | [154] |
| BERT4Bitter | BTP640: 320 BPs and 320 NBPs | Original sequence | BERT + LSTM | 0.922 | 0.938 | 0.906 | 0.844 | 0.964 | February 2021 | [157] |
| iBitter-Fuse | BTP640: 320 BPs and 320 NBPs | AAC, DPC, PAAC, APAAC, AAI | SVM | 0.930 | 0.938 | 0.922 | 0.859 | 0.933 | August 2021 | [160] |
| MIMML | BTP640: 320 BPs and 320 NBPs | TextCNN | Meta-learning | 0.938 | 0.938 | 0.938 | 0.875 | 0.955 | January 2022 | [158] |
| iBitter-DRLF | BTP640: 320 BPs and 320 NBPs | SSA; UniRep; BiLSTM | LGBM | 0.944 | 0.922 | 0.977 | 0.899 | 0.977 | July 2022 | [4] |
| Bitter-RF | BTP640: 320 BPs and 320 NBPs | AAC, TPAAC, APAAC, ASDC, DPC, DDE, GAA, GDPC, SOCNumber, QSOrder1 | RF | 0.940 | 0.940 | 0.940 | 0.890 | 0.980 | January 2023 | [161] |
| Umami_YYDS | 129 BPs and 84 NBPs | 278 descriptor features | GTB | 0.896 | 0.917 | 0.875 | 0.792 | 0.980 | March 2023 | [124] |
| CPM-BP | BTP720: 360 BPs and 360 NBPs | Q, Q1, Q2, Q3, Q4, AH, N, C, Percentage-HAA, N-basic AA, LFIYWV-C, Percentage-FWY, P-X-C, RP | LightGBM | 0.903 | 0.891 | - | 0.816 | 0.905 | February 2024 | [159] |
Note: AAC: amino acid composition; DPC: dipeptide composition; PAAC: pseudo amino acid composition; APAAC: amphiphilic pseudo amino acid composition; AAI: Amino Acid Index; CNN: convolutional neural network; SSA: secondary structure assignment; UniRep: universal representation of protein sequences; BiLSTM: bidirectional long short-term memory; TPAAC: traditional pseudo amino acid composition; ASDC: adaptive skip dinucleotide composition; DDE: dipeptide deviation from expected mean; GAA: grouped amino acid composition; GDPC: grouped dipeptide composition; SOCNumber: sequence-order-coupling number; QSOrder1: quasi-sequence-order; Q: average hydrophobicity of peptides; Q1: percentage of the amino acids with value < 0 in peptides; Q2: percentage of the amino acids with value in range 0–1000 in peptides; Q3: percentage of the amino acids with value in range 1000–2000 in peptides; Q4: percentage of the amino acids with value in range 2000–3000 in peptides; AH: average hydrophobicity of peptides; N: hydrophobicity of amino acids located in the N-terminal of peptides; C: hydrophobicity of amino acids located in the C-terminal of peptides; Percentage-HAA: percentage of bitter-contributing amino acids (Ala, Phe, Gly, Ile, Leu, Met, Pro, Val, Tyr, and Trp) in peptides; N-basic AA: amino acids located in N-terminal of peptides were basic amino acids or not; LFIYWV-C: amino acids located in C-terminal of peptides were six kinds bitter-contributing amino acids (Leu, Phe, Ile, Tyr, Trp, and Val) or not; Percentage-FWY: percentage of three kinds of bitter-contributing amino acids (Phe, Trp, and Tyr) in peptides; P-X-C: amino acid P located in the second place from C-terminal of peptides or not; RP: adjacent RP in peptides or not; SCM: scoring card method; BERT: bidirectional encoder representations from transformers; LSTM: long short-term memory; LGBM: light gradient boosting machine; RF: random forest; GTB: gradient boosting; LightGBM: light gradient boosting machine.
The six classifiers built on the same dataset, BTP640, primarily employ machine learning or deep learning techniques. In traditional machine learning methods, features such as AAC and TPAAC, as mentioned in the table above, are manually extracted, chosen based on extensive experimental validation and varying in performance depending on the application scenario [124,161]. Some feature extraction methods might adversely affect classification effectiveness, requiring researchers to manually select and adjust these methods based on specific problems and perform feature screening to ensure that the chosen features achieve the optimal classifier performance [162,163,164]. Deep learning is superior for its performance and ability to implement an “end-to-end” processing workflow, meaning that users need to provide sequences to the deep learning model that can automatically perform feature extraction, model construction, and feature selection, outputting the results. Deep learning models continually iterate to optimize parameters, automatically constructing the best-suited model without the need for tedious manual settings like traditional machine learning. This increased level of automation significantly simplifies the model development process, demonstrating substantial advantages when handling complex biological data [165,166].
Overall, the progress of these models showcases the evolution from manual feature engineering to automated deep learning, reflecting the ongoing innovation and development in bitter peptide classification technology. This development has enhanced the performance and efficiency of classifiers and provides more powerful tools for future bioinformatics research.
3.2.3. Shift in Research Directions
Considering the two types of models, the research focus has shifted over time. Before 2020, researchers primarily focused on constructing QSAR models to study the bitterness thresholds of bitter peptides. After 2020, the direction shifted towards developing classification prediction models for determining whether a peptide possesses bitterness.
Several factors may be responsible for this change in research directions and goals. (1) Before 2020, the lack of dataset size and quality led researchers to focus more on quantifying the bitterness threshold for each bitter peptide. Over time, with more experimental data being accumulated, datasets increased in size and diversity, allowing researchers to better construct and validate classification models [167]. (2) Rapid advancements in machine learning and artificial intelligence technologies provided more tools and methods for classification models, which can handle large-scale data more efficiently and excel in dealing with nonlinear and complex relationships, enabling researchers to use these advanced technologies to more accurately predict and classify bitter peptides [168]. (3) The food industry and health sector increasingly demand the rapid identification of bitter peptides. Compared to merely quantifying its bitterness threshold, quickly determining whether a peptide is bitter is more practical for real-world applications, such as discovering new food additives, where the rapid screening of bitter peptides can significantly enhance development efficiency [169,170]. (4) Classification models generally outperform regression models in terms of computational and prediction efficiency, which can more quickly predict and classify bitter peptides from candidate sequences for industrial production and scientific research [171]. As research progresses, scientists are increasingly recognizing that understanding the classification attributes of bitter peptides (whether they are bitter peptides) is often more crucial than quantitatively analyzing their bitterness thresholds. Classification models can help to reveal the characteristic patterns of bitter peptides, guiding the design of peptides with specific or no bitterness characteristics.
4. Future Directions
4.1. Database Enhancement
Databases focused on bitter peptides encompass extensive sequence data and activity information, lacking comprehensive details about sources and functions. They will be updated and elevated with professional properties [122,123,124]. To expand the current databases, we can consider the following three aspects. (1) Diverse Data Sources: In addition to the bitter peptides produced during fermentation processes, it is also important to collect bitter peptides from other sources such as plant proteins and marine organisms to enrich the diversity of databases. (2) Integration of Multimodal Data: We should not only collect the sequences of bitter peptides, but also include their bitterness thresholds, structural information, important site details, and biological activity characteristics. (3) Establishment of a Regular Update System: A regular update should promptly incorporate the latest research findings and discoveries of bitter peptides to ensure that databases remain cutting-edge and practical. The above approach aligns with the way many established protein databases, such as the Protein Data Bank (PDB) and universal protein resource (UniProt), were constructed and are maintained [172,173].
Since bitter peptides have applications in the food and pharmaceutical industries, there is a need for the development of more specific databases. For example, the database of cheese-derived bitter peptides specifically includes bitter peptides produced during cheese fermentation [125]. The methods and maintenance strategies for building a specialized database for specific fields and a comprehensive bitter peptide database are fundamentally similar, with the primary difference being the focus of the information collected. For instance, a specialized database could be developed for bitter peptides in food science, emphasizing factors such as the sources of bitter peptides, their bitterness thresholds, their impacts on food taste, and their potential health benefits. Additionally, a separate database could be dedicated to bitter peptides with potential antidiabetic effects, concentrating on their therapeutic efficacy, specific mechanisms of action, and related data. These specialized databases would play a crucial role in food safety and disease research, facilitating researchers to efficiently utilize bitter peptides for various studies and practical applications.
4.2. Diversity of Models
4.2.1. Classification Models
Classification models for bitter peptides have achieved significant results in predicting their presence. However, due to the small datasets used to train these models, their generalization performance may not be ideal, limiting their effectiveness in practical applications. Future objectives should promote the robustness and practicality of these models and focus on several areas. (1) Building more comprehensive datasets is crucial for improving model generalization. Larger datasets provide more training samples to enhance a model’s learning capability and cover a diverse range of bitter peptide sequences and features, ensuring a more stable performance with different data types. Additionally, increasing the diversity in datasets, including bitter peptides from other sources and with other functions, will enable models to better adapt to various application scenarios [174,175,176]. (2) Employing more complex and advanced algorithms to construct classification models will enhance their performance. Existing models primarily rely on traditional machine learning methods and the initial applications of deep learning techniques. In the future, more cutting-edge deep learning architectures, such as the Transformer model and its variants, which excel in handling high-dimensional and complex feature data, could be beneficial. By integrating the advantages of multiple algorithms, more precise and robust classification models can be constructed [177,178,179]. (3) The robustness and interpretability of models are crucial for future research. In addition to improving prediction accuracy, it is essential to focus on the stability of models across different datasets and environments to ensure their reliability in practical applications. Furthermore, enhancing the interpretability of models, allowing researchers to understand the decision-making processes of these models, is crucial for advancing the depth of bitter peptide research [180,181,182].
4.2.2. Interaction Models
There are 25 bitter taste receptors with different structures and ligands in the human body, capable of binding distinct bitter peptides. Bitter taste receptors have a high level of specificity when binding to bitter peptides, meaning that not a single receptor can bind to all types of bitter peptides [183,184]. Physiological responses, including lowering blood pressure and the stimulation of gastrointestinal motility, are only triggered when a bitter peptide binds to its specific receptor. This underscores the interactions between bitter peptides and their specificity receptors. In this relationship, bitter receptors act as drug targets, with the bitter peptides serving as the drugs, effective only when the drug binds to its target [185,186]. In bioinformatics, there has been considerable research on protein and peptide interactions, such as studying protein–ligand binding characteristics through molecular docking and molecular dynamics simulations [187,188,189].
Thus, developing a model to predict the interactions between bitter peptides and receptors is crucial for future research. This model would help us better understand the interactions between bitter peptides and receptors and provide robust support for the development of targeted drugs. By constructing such a model, researchers can identify bitter peptides with specific physiological effects and design new pharmaceuticals or functional foods. In practice, developing these predictive models can utilize various technical approaches. For example, machine learning and deep learning algorithms can be employed in training with a vast amount of known data on bitter peptide–receptor bindings to build highly accurate prediction models [190,191,192,193]. Combining computational methods like molecular docking and molecular dynamics simulations can further validate and optimize prediction outcomes [194,195]. The integration of these methods will aid in developing more precise and reliable predictive models.
4.2.3. Generative Models
The concept of using generative models for simulating simple data distributions dates back to the 1950s [196]. However, it was not until the early 21st century, with significant improvements in computational power and the advent of the big data era, that generative models began to evolve and rapidly demonstrate their formidable potential. In recent years, generative models have made breakthroughs in many fields, such as the large language models exemplified by OpenAI’s GPT-4, which can generate text nearly indistinguishable from that produced by humans [197].
In bioinformatics, generative models have also played a significant role. DeepMind’s AlphaFold model series is a milestone example, accurately predicting the three-dimensional structures of proteins through machine learning methods, advancing biomedical research and drug development. The successful application of AlphaFold demonstrates the potential of generative models in predicting complex biological structures [198,199]. The latest de novo protein generative models, such as ProGen [200] and ProteinGAN [201], can produce entirely new proteins not yet found in nature, providing new ideas and insights for protein design [202,203,204].
Constructing a specialized bitter peptide generative model is of tremendous application value, which could specifically provide the properties of bitter peptides, such as their solubility and stability, or combine two peptides with different functions to create multifunctional effects [205]. Further, it could generate bitter peptides with entirely new functions, opening up new research avenues. Developing bitter peptide generative models would be achieved in the following directions. Firstly, collecting and organizing more bitter peptide sequences and their related property data to establish a rich dataset. Secondly, employing advanced generative model algorithms, such as Generative Adversarial Networks (GANs) and Transformers, for model training and optimization [206,207,208]. Finally, although a comprehensive evaluation system to assess the quality of newly generated bitter peptides from generative models has yet to be established, several methods are currently available for this purpose, as follows: (1) utilizing structural prediction tools (such as AlphaFold and ESM Fold) to predict the structures of generated bitter peptides and comparing them with known bitter peptides to evaluate their structural similarity and potential functionality; (2) using tools (such as foldX and RoseTTA) to calculate the free energy and stability of the generated peptides, with lower-energy conformations typically being more stable, which helps to assess their bioactivity and stability; (3) employing molecular docking methods (such as AutoDock Vina and Dock) to study the interactions between the generated bitter peptides and specific receptors, identifying potential binding sites and affinities, thereby further supporting functional predictions; and (4) when feasible, cloning the genes of the generated bitter peptides into expression vectors and conducting in vitro or cell-based experiments to verify their actual functions, assessing whether they exhibit similar or superior characteristics compared to natural bitter peptides. We expect that bitter peptide generative models might accelerate research and applications that can provide new tools and methods for food science and pharmaceutical development.
4.3. Experimental Evaluation
Experimental validation has always been a crucial part of bioinformatics, serving as the best standard for assessing various model performances [209]. Accuracy and robustness can be evaluated in classification models using data from newly identified bitter and non-bitter peptides [149], while the validation process for generative models is more complex. Initially, the generated bitter peptides can be screened based on their physicochemical properties, such as their stability and solubility. Subsequently, these peptides are necessary to confirm their biological activity and functionality [200,210,211,212]. However, there is a lack of quantitative metrics to determine whether generated bitter peptides are superior to those in nature. Comparing the activity of bitter peptides under the same or optimized conditions may yield different conclusions [213,214]. Therefore, setting fair and reasonable evaluation standards is an issue that needs in-depth exploration.
Despite the current uncertainties in model validation structures, this remains an essential path for bioinformatics research. Future studies should continuously optimize experimental evaluation methods and establish a more scientific and systematic assessment system to more accurately gauge the merits of generative models. Such progress will aid in the development and applications of bioinformatics models and help to advance the field.
5. Conclusions
Bitter peptides are small molecular peptides produced during the hydrolysis of proteins, commonly found in everyday foods such as meats and dairy products. Their bitterness is primarily caused by the exposed hydrophobic amino acids within the peptides, which bind to G-protein-coupled bitter taste receptors, triggering complex signal transduction and ultimately forming the perception of bitterness in the brain. Apart from being extensively studied in food science for their taste characteristics, bitter peptides are also of significant research interest due to their various biological activities. Studies have shown that bitter peptides possess multiple health benefits, including antihypertensive, antidiabetic, antioxidant, antibacterial, and immune regulation properties, thus displaying broad application prospects in the biomedical field. Particularly in managing blood pressure and diabetes, bitter peptides have shown significant therapeutic potential. Therefore, research on bitter peptides enhances our understanding of the causes and regulation of food bitterness and provides a scientific basis for developing new therapies and improving public health. With advances in food science and biotechnology, the multifunctionality and potential applications of bitter peptides will become a valuable area of research.
We provide a detailed introduction to the research on bitter peptides in the field of bioinformatics, covering several aspects: (1) bitter peptide databases, which are crucial for research on bitter peptides; (2) QSAR models predicting the bitterness levels of peptides, characterizing bitter peptides using molecular descriptors, and employing simple regression algorithms to predict bitterness thresholds, which are important for studying the bitterness of peptides and for debittering processes in the food industry; and (3) predictive models for bitter peptides, extracting features through various means and building models with machine learning algorithms to predict whether a peptide is a bitter peptide, offering significant value to experimental researchers and food industry professionals. Despite significant progress in research on bitter peptides through bioinformatics, several challenges remain, including incomplete data, leading to a lack of diversity and limiting the comprehensiveness of databases, and the need for models with improved generalizability and robustness, especially with small sample datasets. Additionally, the complexity of the interactions between bitter peptides and taste receptors increases the difficulty in developing predictive models. The accuracy and efficacy of generative models urgently require a more scientific evaluation system. These challenges must be addressed through the continuous optimization of data collection, model construction, and experimental validation methods to advance bitter peptide research towards application-oriented directions.
Future research directions in bitter peptide studies primarily include four areas. First, enhancing bitter peptide databases, particularly developing specialized databases targeted at different application domains to improve research and application efficiency. Second, developing models with an advanced performance and interpretability by building larger datasets and employing advanced algorithms that can predict the interactions between bitter peptides and taste receptors to advance new drug development and functional food design. Third, exploring the application of generative models in bitter peptide research to produce peptides with specific or entirely new functions, which should accelerate research and applications. Finally, experimental evaluation will be crucial in validating model performance and establishing a scientific and systematic assessment system to propel the development of bioinformatics and biotechnology.
Author Contributions
S.L.: methodology, formal analysis, investigation, and writing—original draft preparation; T.S.: visualization; J.Y.: visualization; R.L.: investigation; H.L. and K.D.: supervision, project administration, writing—review and editing, and funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China (grant numbers 82130112, 62372090).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chandrashekar, J.; Hoon, M.A.; Ryba, N.J.; Zuker, C.S. The receptors and cells for mammalian taste. Nature 2006, 444, 288–294. [Google Scholar] [CrossRef] [PubMed]
- Liang, Z.; Wilson, C.E.; Teng, B.; Kinnamon, S.C.; Liman, E.R. The proton channel OTOP1 is a sensor for the taste of ammonium chloride. Nat. Commun. 2023, 14, 6194. [Google Scholar] [CrossRef] [PubMed]
- Maehashi, K.; Huang, L. Bitter peptides and bitter taste receptors. Cell. Mol. Life Sci. 2009, 66, 1661–1671. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Lin, X.; Jiang, Y.; Jiang, L.; Lv, Z. Identify Bitter Peptides by Using Deep Representation Learning Features. Int. J. Mol. Sci. 2022, 23, 7877. [Google Scholar] [CrossRef] [PubMed]
- Lee, R.J.; Cohen, N.A. Bitter and sweet taste receptors in the respiratory epithelium in health and disease. J. Mol. Med. 2014, 92, 1235–1244. [Google Scholar] [CrossRef]
- Jaggupilli, A.; Howard, R.; Upadhyaya, J.D.; Bhullar, R.P.; Chelikani, P. Bitter taste receptors: Novel insights into the biochemistry and pharmacology. Int. J. Biochem. Cell Biol. 2016, 77, 184–196. [Google Scholar] [CrossRef]
- Raksakulthai, R.; Haard, N.F. Exopeptidases and their application to reduce bitterness in food: A review. Crit. Rev. Food Sci. Nutr. 2003, 43, 401–445. [Google Scholar] [CrossRef]
- Chou, W.L. Therapeutic potential of targeting intestinal bitter taste receptors in diabetes associated with dyslipidemia. Pharmacol. Res. 2021, 170, 105693. [Google Scholar] [CrossRef]
- Erdmann, K.; Cheung, B.W.; Schröder, H. The possible roles of food-derived bioactive peptides in reducing the risk of cardiovascular disease. J. Nutr. Biochem. 2008, 19, 643–654. [Google Scholar] [CrossRef]
- Kok, B.P.; Galmozzi, A.; Littlejohn, N.K.; Albert, V.; Godio, C.; Kim, W.; Kim, S.M.; Bland, J.S.; Grayson, N.; Fang, M. Intestinal bitter taste receptor activation alters hormone secretion and imparts metabolic benefits. Mol. Metab. 2018, 16, 76–87. [Google Scholar] [CrossRef]
- Raadsveld, C.W. Bitter Compounds from Cheese. In Proceedings of the 13th International Dairy Congress, Hague, The Netherlands, 22–26 June 1953; Volume 2, p. 676. [Google Scholar]
- Murray, T.; Baker, B.E. Studies on protein hydrolysis. I.—Preliminary observations on the taste of enzymic protein-hydrolysates. J. Sci. Food Agric. 1952, 3, 470–475. [Google Scholar] [CrossRef]
- Carr, J.; Loughheed, T.; Baker, B.E. Studies on Protein Hydrolysis. IV.—Further Observations on the Taste of Enzymic Protein Hydrolysates. J. Sci. Food Agric. 1956, 7, 629–637. [Google Scholar] [CrossRef]
- Yan, K.; Lv, H.; Guo, Y.; Peng, W.; Liu, B. sAMPpred-GAT: Prediction of Antimicrobial Peptide by Graph Attention Network and Predicted Peptide Structure. Bioinformatics 2023, 39, btac715. [Google Scholar] [CrossRef] [PubMed]
- Ziaikin, E.; Tello, E.; Peterson, D.G.; Niv, M.Y. BitterMasS: Predicting Bitterness from Mass Spectra. J. Agric. Food Chem. 2024, 72, 10537–10547. [Google Scholar] [CrossRef]
- Windt, X.; Scott, E.L.; Seeger, T.; Schneider, O.; Asadi Tashvigh, A.; Bitter, J.H. Fourier transform infrared spectroscopy for assessing structural and enzymatic reactivity changes induced during feather hydrolysis. ACS Omega 2022, 7, 39924–39930. [Google Scholar] [CrossRef]
- Khan, E.; Mishra, S.K.; Kumar, A. Emerging methods for structural analysis of protein aggregation. Protein Pept. Lett. 2017, 24, 331–339. [Google Scholar]
- Hohlweg, W.; Kosol, S.; Zangger, K. Determining the orientation and localization of membrane-bound peptides. Curr. Protein Pept. Sci. 2012, 13, 267–279. [Google Scholar] [CrossRef]
- Meng, Q.; Guo, F.; Wang, E.; Tang, J. ComDock: A novel approach for protein-protein docking with an efficient fusing strategy. Comput. Biol. Med. 2023, 167, 107660. [Google Scholar] [CrossRef]
- Li, H.; Pang, Y.; Liu, B. BioSeq-BLM: A platform for analyzing DNA, RNA, and protein sequences based on biological language models. Nucleic Acids Res. 2021, 49, e129. [Google Scholar] [CrossRef]
- Kim, M.-R.; Choi, S.-Y.; Kim, C.-S.; Kim, C.-W.; Utsumi, S.; Lee, C.-H. Amino acid sequence analysis of bitter peptides from a soybean proglycinin subunit synthesized in Escherichia coli. Biosci. Biotechnol. Biochem. 1999, 63, 2069–2074. [Google Scholar] [CrossRef][Green Version]
- Hajfathalian, M.; Ghelichi, S.; García-Moreno, P.J.; Moltke Sørensen, A.-D.; Jacobsen, C. Peptides: Production, bioactivity, functionality, and applications. Crit. Rev. Food Sci. Nutr. 2018, 58, 3097–3129. [Google Scholar] [CrossRef] [PubMed]
- Beauchamp, G.K.; Mennella, J.A. Early flavor learning and its impact on later feeding behavior. J. Pediatr. Gastroenterol. Nutr. 2009, 48, S25–S30. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Li, C.; Chen, R.; Cao, D.; Zeng, X. Geometric Deep Learning for Drug Discovery. Expert Syst. Appl. 2023, 240, 122498. [Google Scholar] [CrossRef]
- Wiener, A.; Shudler, M.; Levit, A.; Niv, M.Y. BitterDB: A database of bitter compounds. Nucleic Acids Res. 2012, 40, D413–D419. [Google Scholar] [CrossRef]
- Huang, W.; Shen, Q.; Su, X.; Ji, M.; Liu, X.; Chen, Y.; Lu, S.; Zhuang, H.; Zhang, J. BitterX: A tool for understanding bitter taste in humans. Sci. Rep. 2016, 6, 23450. [Google Scholar] [CrossRef]
- Iwaniak, A.; Hrynkiewicz, M.; Bucholska, J.; Minkiewicz, P.; Darewicz, M. Understanding the nature of bitter-taste di-and tripeptides derived from food proteins based on chemometric analysis. J. Food Biochem. 2019, 43, e12500. [Google Scholar] [CrossRef] [PubMed]
- Rodgers, S.; Glen, R.C.; Bender, A. Characterizing bitterness: Identification of key structural features and development of a classification model. J. Chem. Inf. Model. 2006, 46, 569–576. [Google Scholar] [CrossRef]
- Zhong, V.W.; Kuang, A.; Danning, R.D.; Kraft, P.; Van Dam, R.M.; Chasman, D.I.; Cornelis, M.C. A genome-wide association study of bitter and sweet beverage consumption. Hum. Mol. Genet. 2019, 28, 2449–2457. [Google Scholar] [CrossRef]
- Wei, L.; He, W.; Malik, A.; Su, R.; Cui, L.; Manavalan, B. Computational prediction and interpretation of cell-specific replication origin sites from multiple eukaryotes by exploiting stacking framework. Brief. Bioinform. 2021, 22, bbaa275. [Google Scholar] [CrossRef]
- Acevedo, W.; González-Nilo, F.; Agosin, E. Docking and molecular dynamics of steviol glycoside–human bitter receptor interactions. J. Agric. Food Chem. 2016, 64, 7585–7596. [Google Scholar] [CrossRef]
- Oluyori, A.P.; Olanipekun, B.E.; Adeyemi, O.S.; Egharevba, G.O.; Adegboyega, A.E.; Oladeji, O.S. Molecular docking, pharmacophore modelling, MD simulation and in silico ADMET study reveals bitter cola constituents as potential inhibitors of SARS-CoV-2 main protease and RNA dependent-RNA polymerase. J. Biomol. Struct. 2023, 41, 1510–1525. [Google Scholar] [CrossRef] [PubMed]
- Kubota, T.; Kubo, I.J.N. Bitterness and chemical structure. Nature 1969, 223, 97–99. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Gao, X.; Zhang, H. BioSeq-Analysis2.0: An updated platform for analyzing DNA, RNA and protein sequences at sequence level and residue level based on machine learning approaches. Nucleic Acids Res. 2019, 47, e127. [Google Scholar] [CrossRef] [PubMed]
- Zeng, X.; Xiang, H.; Yu, L.; Wang, J.; Li, K.; Nussinov, R.; Cheng, F. Accurate prediction of molecular properties and drug targets using a self-supervised image representation learning framework. Nat. Mach. Intell. 2022, 4, 1004–1016. [Google Scholar] [CrossRef]
- Ren, X.; Wei, J.; Luo, X.; Liu, Y.; Li, K.; Zhang, Q.; Gao, X.; Yan, S.; Wu, X.; Jiang, X. HydrogelFinder: A Foundation Model for Efficient Self-Assembling Peptide Discovery Guided by Non-Peptidal Small Molecules. Adv. Sci. 2024, 11, 2400829. [Google Scholar] [CrossRef]
- Su, R.; Wu, H.; Xu, B.; Liu, X.; Wei, L. Developing a Multi-Dose Computational Model for Drug-Induced Hepatotoxicity Prediction Based on Toxicogenomics Data. IEEE-ACM Trans. Comput. Biol. Bioinform. 2019, 16, 1231–1239. [Google Scholar] [CrossRef]
- Liu, B. BioSeq-Analysis: A platform for DNA, RNA and protein sequence analysis based on machine learning approaches. Brief. Bioinform. 2019, 20, 1280–1294. [Google Scholar] [CrossRef]
- Suh, H.W.; Lee, K.B.; Kim, K.S.; Yang, H.J.; Choi, E.K.; Shin, M.H.; Park, Y.S.; Na, Y.C.; Ahn, K.S.; Jang, Y.P.; et al. A bitter herbal medicine Gentiana scabra root extract stimulates glucagon-like peptide-1 secretion and regulates blood glucose in db/db mouse. J. Ethnopharmacol. 2015, 172, 219–226. [Google Scholar] [CrossRef]
- Chandrasekaran, S.; Luna-Vital, D.; de Mejia, E.G. Identification and Comparison of Peptides from Chickpea Protein Hydrolysates Using Either Bromelain or Gastrointestinal Enzymes and Their Relationship with Markers of Type 2 Diabetes and Bitterness. Nutrients 2020, 12, 3843. [Google Scholar] [CrossRef]
- Jeruzal-Swiatecka, J.; Fendler, W.; Pietruszewska, W. Clinical Role of Extraoral Bitter Taste Receptors. Int. J. Mol. Sci. 2020, 21, 5156. [Google Scholar] [CrossRef]
- Iwaniak, A.; Hrynkiewicz, M.; Minkiewicz, P.; Bucholska, J.; Darewicz, M. Soybean (Glycine max) protein hydrolysates as sources of peptide bitter-tasting indicators: An analysis based on hybrid and fragmentomic approaches. Appl. Sci. 2020, 10, 2514. [Google Scholar] [CrossRef]
- Habibi-Najafi, M.B.; Lee, B.H. Bitterness in cheese: A review. Crit. Rev. Food Sci. Nutr. 1996, 36, 397–411. [Google Scholar] [CrossRef] [PubMed]
- Jiang, S.; Wang, X.; Yu, M.; Tian, J.; Chang, P.; Zhu, S. Bitter Peptides in Fermented Soybean Foods—A Review. Plant Foods Hum. Nutr. 2023, 78, 261–269. [Google Scholar] [CrossRef] [PubMed]
- Lemieux, L.; Simard, R. Bitter flavour in dairy products. II. A review of bitter peptides from caseins: Their formation, isolation and identification, structure masking and inhibition. Le Lait 1992, 72, 335–385. [Google Scholar] [CrossRef]
- Liu, X.; Jiang, D.; Peterson, D.G. Identification of bitter peptides in whey protein hydrolysate. J. Agric. Food Chem. 2014, 62, 5719–5725. [Google Scholar] [CrossRef]
- Cho, M.J.; Unklesbay, N.; Hsieh, F.-H.; Clarke, A.D. Hydrophobicity of bitter peptides from soy protein hydrolysates. J. Agric. Food Chem. 2004, 52, 5895–5901. [Google Scholar] [CrossRef]
- Ishibashi, N.; Ono, I.; Kato, K.; Shigenaga, T.; Shinoda, I.; OKAi, H.; Fukui, S. Role of the hydrophobic amino acid residue in the bitterness of peptides. Agric. Biol. Chem. 1988, 52, 91–94. [Google Scholar] [CrossRef]
- Acquah, C.; Di Stefano, E.; Udenigwe, C.C. Role of hydrophobicity in food peptide functionality and bioactivity. J. Food Bioact. 2018, 4, 88–98. [Google Scholar] [CrossRef]
- Xu, Q.; Hong, H.; Yu, W.; Jiang, X.; Yan, X.; Wu, J. Sodium chloride suppresses the bitterness of protein hydrolysates by decreasing hydrophobic interactions. J. Food Sci. 2019, 84, 86–91. [Google Scholar] [CrossRef]
- Fang, Y.; Xu, F.; Wei, L.; Jiang, Y.; Chen, J.; Wei, L.; Wei, D.-Q. AFP-MFL: Accurate identification of antifungal peptides using multi-view feature learning. Brief. Bioinform. 2023, 24, bbac606. [Google Scholar] [CrossRef]
- Fan, W.; Tan, X.; Xu, X.; Li, G.; Wang, Z.; Du, M. Relationship between enzyme, peptides, amino acids, ion composition, and bitterness of the hydrolysates of Alaska pollock frame. J. Food Biochem. 2019, 43, e12801. [Google Scholar] [CrossRef] [PubMed]
- Chourasia, R.; Chiring Phukon, L.; Abedin, M.M.; Padhi, S.; Singh, S.P.; Rai, A.K. Bioactive peptides in fermented foods and their application: A critical review. Syst. Microbiol. Biomanuf. 2023, 3, 88–109. [Google Scholar] [CrossRef]
- Franca-Oliveira, G.; Fornari, T.; Hernandez-Ledesma, B. A review on the extraction and processing of natural source-derived proteins through eco-innovative approaches. Processes 2021, 9, 1626. [Google Scholar] [CrossRef]
- Hewage, A.; Olatunde, O.O.; Nimalaratne, C.; Malalgoda, M.; Aluko, R.E.; Bandara, N. Novel extraction technologies for developing plant protein ingredients with improved functionality. Trends Food Sci. Technol. 2022, 129, 492–511. [Google Scholar] [CrossRef]
- Fu, Y.; Chen, J.; Bak, K.H.; Lametsch, R. Valorisation of protein hydrolysates from animal by-products: Perspectives on bitter taste and debittering methods: A review. Int. J. Food Sci. Technol. 2019, 54, 978–986. [Google Scholar] [CrossRef]
- Cui, Q.; Sun, Y.; Zhou, Z.; Cheng, J.; Guo, M. Effects of enzymatic hydrolysis on physicochemical properties and solubility and bitterness of milk protein hydrolysates. Foods 2021, 10, 2462. [Google Scholar] [CrossRef] [PubMed]
- Ney, K. Voraussage der bitterkeit von peptiden aus deren aminosäurezu-sammensetzung. Z. Lebensm.-Unters.-Forsch. 1971, 147, 64–68. [Google Scholar] [CrossRef]
- de Armas, R.R.; Díaz, H.G.; Molina, R.; González, M.P.; Uriarte, E. Stochastic-based descriptors studying peptides biological properties: Modeling the bitter tasting threshold of dipeptides. Bioorg. Med. Chem. 2004, 12, 4815–4822. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Aluko, R.E. Quantitative structure-activity relationship study of bitter di-and tri-peptides including relationship with angiotensin I-converting enzyme inhibitory activity. J. Pept. Sci. Off. Publ. Eur. Pept. Soc. 2007, 13, 63–69. [Google Scholar] [CrossRef]
- Diepeveen, J.; Moerdijk-Poortvliet, T.C.W.; van der Leij, F.R. Molecular insights into human taste perception and umami tastants: A review. J. Food Sci. 2022, 87, 1449–1465. [Google Scholar] [CrossRef]
- Pritchard, T.C.; Norgren, R. Gustatory system. In The Human Nervous System, 2nd ed.; Elsevier Inc.: Amsterdam, The Netherlands, 2003; pp. 1171–1196. [Google Scholar]
- Witt, M. Anatomy and development of the human taste system. Handb. Clin. Neurol. 2019, 164, 147–171. [Google Scholar] [PubMed]
- Just, T.; Stave, J.; Pau, H.W.; Guthoff, R. In vivo observation of papillae of the human tongue using confocal laser scanning microscopy. ORL J. Otorhinolaryngol. Relat. Spec. 2005, 67, 207–212. [Google Scholar] [CrossRef] [PubMed]
- Herness, S.; Zhao, F.L.; Kaya, N.; Shen, T.; Lu, S.G.; Cao, Y. Communication routes within the taste bud by neurotransmitters and neuropeptides. Chem. Senses 2005, 30 (Suppl. 1), i37–i38. [Google Scholar] [CrossRef]
- Reichling, C.; Meyerhof, W.; Behrens, M. Functions of human bitter taste receptors depend on N-glycosylation. J. Neurochem. 2008, 106, 1138–1148. [Google Scholar] [CrossRef]
- Behrens, M.; Meyerhof, W. Bitter taste receptor research comes of age: From characterization to modulation of TAS2Rs. Semin Cell Dev. Biol. 2013, 24, 215–221. [Google Scholar] [CrossRef]
- Venkatakrishnan, A.J.; Deupi, X.; Lebon, G.; Tate, C.G.; Schertler, G.F.; Babu, M.M. Molecular signatures of G-protein-coupled receptors. Nature 2013, 494, 185–194. [Google Scholar] [CrossRef] [PubMed]
- Pydi, S.P.; Singh, N.; Upadhyaya, J.; Bhullar, R.P.; Chelikani, P. The third intracellular loop plays a critical role in bitter taste receptor activation. Biochim. Biophys. Acta 2014, 1838, 231–236. [Google Scholar] [CrossRef]
- Froemke, R.C.; Poo, M.M.; Dan, Y. Spike-timing-dependent synaptic plasticity depends on dendritic location. Nature 2005, 434, 221–225. [Google Scholar] [CrossRef]
- Jaggupilli, A.; Singh, N.; De Jesus, V.C.; Gounni, M.S.; Dhanaraj, P.; Chelikani, P. Chemosensory bitter taste receptors (T2Rs) are activated by multiple antibiotics. FASEB J. 2019, 33, 501–517. [Google Scholar] [CrossRef]
- Harmon, C.P.; Deng, D.; Breslin, P.A.S. Bitter Taste Receptors (T2Rs) are Sentinels that Coordinate Metabolic and Immunological Defense Responses. Curr. Opin. Physiol. 2021, 20, 70–76. [Google Scholar] [CrossRef]
- Jalsevac, F.; Terra, X.; Rodriguez-Gallego, E.; Beltran-Debon, R.; Blay, M.T.; Pinent, M.; Ardevol, A. The Hidden One: What We Know About Bitter Taste Receptor 39. Front. Endocrinol. 2022, 13, 854718. [Google Scholar] [CrossRef] [PubMed]
- Tizzano, M.; Gulbransen, B.D.; Vandenbeuch, A.; Clapp, T.R.; Herman, J.P.; Sibhatu, H.M.; Churchill, M.E.; Silver, W.L.; Kinnamon, S.C.; Finger, T.E. Nasal chemosensory cells use bitter taste signaling to detect irritants and bacterial signals. Proc. Natl. Acad. Sci. USA 2010, 107, 3210–3215. [Google Scholar] [CrossRef] [PubMed]
- Yan, J.; Tong, H. An overview of bitter compounds in foodstuffs: Classifications, evaluation methods for sensory contribution, separation and identification techniques, and mechanism of bitter taste transduction. Compr. Rev. Food Sci. Food Saf. 2023, 22, 187–232. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Li, N.; Chen, F.; Zhang, J.; Sun, X.; Xu, L.; Fang, F. Review on the release mechanism and debittering technology of bitter peptides from protein hydrolysates. Compr. Rev. Food Sci. Food Saf. 2022, 21, 5153–5170. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.; Gumpper, R.H.; Liu, Y.F.; Kocak, D.D.; Xiong, Y.; Cao, C.; Deng, Z.J.; Krumm, B.E.; Jain, M.K.; Zhang, S.C.; et al. Bitter taste receptor activation by cholesterol and an intracellular tastant. Nature 2024, 628, 664–671. [Google Scholar] [CrossRef]
- Uchida, T. Taste Sensor Assessment of Bitterness in Medicines: Overview and Recent Topics. Sensors 2024, 24, 4799. [Google Scholar] [CrossRef]
- Kohanski, M.A.; Brown, L.; Orr, M.; Tan, L.H.; Adappa, N.D.; Palmer, J.N.; Rubenstein, R.C.; Cohen, N.A. Bitter taste receptor agonists regulate epithelial two-pore potassium channels via cAMP signaling. Respir. Res. 2021, 22, 31. [Google Scholar] [CrossRef]
- Gibbons, J.R.; Sadiq, N.M. Neuroanatomy, Neural Taste Pathway. In StatPearls; StatPearls Publishing LLC.: Treasure Island, FL, USA, 2024. [Google Scholar]
- Koizumi, A.; Nakajima, K.; Asakura, T.; Morita, Y.; Ito, K.; Shmizu-Ibuka, A.; Misaka, T.; Abe, K. Taste-modifying sweet protein, neoculin, is received at human T1R3 amino terminal domain. Biochem. Biophys. Res. Commun. 2007, 358, 585–589. [Google Scholar] [CrossRef]
- Fontanini, A. Taste. Curr. Biol. 2023, 33, R130–R135. [Google Scholar] [CrossRef]
- Pripp, A.; Ardo, Y. Modelling relationship between angiotensin-(I)-converting enzyme inhibition and the bitter taste of peptides. Food Chem. 2007, 102, 880–888. [Google Scholar] [CrossRef]
- Roy, G.M. The applications and future implications of bitterness reduction and inhibition in food products. Crit. Rev. Food Sci. Nutr. 1990, 29, 59–71. [Google Scholar] [CrossRef] [PubMed]
- Sun-Waterhouse, D.; Wadhwa, S.S. Industry-relevant approaches for minimising the bitterness of bioactive compounds in functional foods: A review. Food Bioprocess Technol. 2013, 6, 607–627. [Google Scholar] [CrossRef]
- Komai, T.; Kawabata, C.; Tojo, H.; Gocho, S.; Ichishima, E. Purification of serine carboxypeptidase from the hepatopancreas of Japanese common squid Todarodes pacificus and its application for elimination of bitterness from bitter peptides. Fish. Sci. 2007, 73, 404–411. [Google Scholar] [CrossRef]
- Tagliamonte, S.; Oliviero, V.; Vitaglione, P. Food bioactive peptides: Functionality beyond bitterness. Nutr. Rev. 2024, nuae008. [Google Scholar] [CrossRef] [PubMed]
- Li-Chan, E.C. Bioactive peptides and protein hydrolysates: Research trends and challenges for application as nutraceuticals and functional food ingredients. Curr. Opin. Food Sci. 2015, 1, 28–37. [Google Scholar] [CrossRef]
- Aguilar-Toalá, J.E.; Quintanar-Guerrero, D.; Liceaga, A.M.; Zambrano-Zaragoza, M.L. Encapsulation of bioactive peptides: A strategy to improve the stability, protect the nutraceutical bioactivity and support their food applications. RSC Adv. 2022, 12, 6449–6458. [Google Scholar] [CrossRef] [PubMed]
- Tang, W.; Wan, S.; Yang, Z.; Teschendorff, A.E.; Zou, Q. Tumor origin detection with tissue-specific miRNA and DNA methylation markers. Bioinformatics 2018, 34, 398–406. [Google Scholar] [CrossRef] [PubMed]
- Tuzim, K.; Korolczuk, A. An update on extra-oral bitter taste receptors. J. Transl. Med. 2021, 19, 440. [Google Scholar] [CrossRef]
- Rao, P.S.; Bajaj, R.K.; Mann, B.; Arora, S.; Tomar, S.K. Encapsulation of antioxidant peptide enriched casein hydrolysate using maltodextrin-gum arabic blend. J. Food Sci. Technol. 2016, 53, 3834–3843. [Google Scholar] [CrossRef]
- Aluko, R.E. Antihypertensive peptides from food proteins. Annu. Rev. Food Sci. Technol. 2015, 6, 235–262. [Google Scholar] [CrossRef]
- Qin, N.; Chen, C.; Zhang, N.; Song, L.; Li, Y.; Guo, L.; Liu, R.; Zhang, W. Bitter almond albumin ACE-inhibitory peptides: Purification, screening, and characterization in silico, action mechanisms, antihypertensive effect in vivo, and stability. Molecules 2023, 28, 6002. [Google Scholar] [CrossRef] [PubMed]
- Zhou, P.; Yang, C.; Ren, Y.; Wang, C.; Tian, F. What are the ideal properties for functional food peptides with antihypertensive effect? A computational peptidology approach. Food Chem. 2013, 141, 2967–2973. [Google Scholar] [CrossRef] [PubMed]
- Norris, R.; FitzGerald, R.J. Antihypertensive peptides from food proteins. In Bioactive Food Peptides in Health and Disease; Hernandez-Ledesma, B., Hsieh, C.C., Eds.; InTech: Rijeka, Croatia, 2013; pp. 45–72. [Google Scholar]
- Chakrabarti, S.; Wu, J. Milk-derived tripeptides IPP (Ile-Pro-Pro) and VPP (Val-Pro-Pro) promote adipocyte differentiation and inhibit inflammation in 3T3-F442A cells. PLoS ONE 2015, 10, e0117492. [Google Scholar] [CrossRef] [PubMed]
- Hsu, P.K.; Pan, F.F.C.; Hsieh, C.S. mcIRBP-19 of Bitter Melon Peptide Effectively Regulates Diabetes Mellitus (DM) Patients’ Blood Sugar Levels. Nutrients 2020, 12, 1252. [Google Scholar] [CrossRef]
- Zaky, A.A.; Simal-Gandara, J.; Eun, J.-B.; Shim, J.-H.; Abd El-Aty, A. Bioactivities, applications, safety, and health benefits of bioactive peptides from food and by-products: A review. Front. Nutr. 2022, 8, 815640. [Google Scholar] [CrossRef]
- Jahandideh, F.; Wu, J. Perspectives on the potential benefits of antihypertensive peptides towards metabolic syndrome. Int. J. Mol. Sci. 2020, 21, 2192. [Google Scholar] [CrossRef]
- Lo, H.-Y.; Li, C.-C.; Ho, T.-Y.; Hsiang, C.-Y. Identification of the bioactive and consensus peptide motif from Momordica charantia insulin receptor-binding protein. Food Chem. 2016, 204, 298–305. [Google Scholar] [CrossRef] [PubMed]
- Pan, F.; Hsu, P.K.; Chang, W.H. Exploring the Factors Affecting Bitter Melon Peptide Intake Behavior: A Health Belief Model Perspective. Risk Manag. Healthc. Policy 2020, 13, 2219–2226. [Google Scholar] [CrossRef]
- Chen, H.; Guo, J.; Pang, B.; Zhao, L.; Tong, X. Application of Herbal Medicines with Bitter Flavor and Cold Property on Treating Diabetes Mellitus. Evid. Based Complement. Alternat. Med. 2015, 2015, 529491. [Google Scholar] [CrossRef]
- Gao, Y.; Li, X.; Huang, Y.; Chen, J.; Qiu, M. Bitter melon and diabetes mellitus. Food Rev. Int. 2023, 39, 618–638. [Google Scholar] [CrossRef]
- Kwatra, D.; Dandawate, P.; Padhye, S.; Anant, S. Bitter melon as a therapy for diabetes, inflammation, and cancer: A panacea? Curr. Pharmacol. Rep. 2016, 2, 34–44. [Google Scholar] [CrossRef]
- Tkaczewska, J. Peptides and protein hydrolysates as food preservatives and bioactive components of edible films and coatings-A review. Trends Food Sci. Technol. 2020, 106, 298–311. [Google Scholar] [CrossRef]
- Carrillo, W.; Guzmán, X.; Vilcacundo, E. Native and heated hydrolysates of milk proteins and their capacity to inhibit lipid peroxidation in the zebrafish larvae model. Foods 2017, 6, 81. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Kong, B.; Xia, X.; Liu, Q.; Li, P. Inhibition of frozen storage-induced oxidation and structural changes in myofibril of common carp (Cyprinus carpio) surimi by cryoprotectant and hydrolysed whey protein addition. Int. J. Food Sci. Technol. 2013, 48, 1916–1923. [Google Scholar] [CrossRef]
- Pan, M.; Liu, K.; Yang, J.; Liu, S.; Wang, S.; Wang, S. Advances on food-derived peptidic antioxidants—A review. Antioxidants 2020, 9, 799. [Google Scholar] [CrossRef]
- de Oliveira Filho, J.G.; Rodrigues, J.M.; Valadares, A.C.F.; de Almeida, A.B.; de Lima, T.M.; Takeuchi, K.P.; Alves, C.C.F.; de Figueiredo Sousa, H.A.; da Silva, E.R.; Dyszy, F.H. Active food packaging: Alginate films with cottonseed protein hydrolysates. Food Hydrocoll. 2019, 92, 267–275. [Google Scholar] [CrossRef]
- Dang, X.; Zheng, X.; Wang, Y.; Wang, L.; Ye, L.; Jiang, J. Antimicrobial peptides from the edible insect Musca domestica and their preservation effect on chilled pork. J. Food Process. Preserv. 2020, 44, e14369. [Google Scholar] [CrossRef]
- Ren, X.Q.; Ma, L.Z.; Chu, J. Effect of catfish bone hydrolysate on the quality of catfish sausage during ambient temperature (37 °C) storage. Adv. Mater. Res. 2011, 236, 2886–2889. [Google Scholar] [CrossRef]
- Sosalagere, C.; Kehinde, B.A.; Sharma, P. Isolation and functionalities of bioactive peptides from fruits and vegetables: A reviews. Food Chem. 2022, 366, 130494. [Google Scholar] [CrossRef]
- Das, A.; Deka, D.; Banerjee, A.; Pathak, S. Therapeutic Role of Soybean-Derived Lunasin Peptide in Colon Cancer Treatment: A Recent Updates from Literature. In Therapeutic Proteins against Human Diseases; Springer: Berlin/Heidelberg, Germany, 2022; pp. 141–156. [Google Scholar]
- Paterson, S.; Fernandez-Tome, S.; Galvez, A.; Hernandez-Ledesma, B. Evaluation of the Multifunctionality of Soybean Proteins and Peptides in Immune Cell Models. Nutrients 2023, 15, 1220. [Google Scholar] [CrossRef]
- Casiano-Rivera, F.M.; Tung, C.-Y.; Chang, H.-C. Mechanisms of Gene Regulation by Soy Peptide Lunasin in Innate Immune Cells; IUPUI Research Day: Indianapolis, Indiana, 2015. [Google Scholar]
- Xu, B.; Chung, H.Y. Quantitative Structure-Activity Relationship Study of Bitter Di-, Tri- and Tetrapeptides Using Integrated Descriptors. Molecules 2019, 24, 2846. [Google Scholar] [CrossRef] [PubMed]
- Soltani, S.; Haghaei, H.; Shayanfar, A.; Vallipour, J.; Asadpour Zeynali, K.; Jouyban, A. QSBR study of bitter taste of peptides: Application of GA-PLS in combination with MLR, SVM, and ANN approaches. Biomed. Res. Int. 2013, 2013, 501310. [Google Scholar] [CrossRef]
- Zhang, Y.; Pan, X.; Shi, T.; Gu, Z.; Yang, Z.; Liu, M.; Xu, Y.; Yang, Y.; Ren, L.; Song, X.; et al. P450Rdb: A manually curated database of reactions catalyzed by cytochrome P450 enzymes. J. Adv. Res. 2024, 63, 35–42. [Google Scholar] [CrossRef] [PubMed]
- Ren, L.; Xu, Y.; Ning, L.; Pan, X.; Li, Y.; Zhao, Q.; Pang, B.; Huang, J.; Deng, K.; Zhang, Y. TCM2COVID: A resource of anti-COVID-19 traditional Chinese medicine with effects and mechanisms. Imeta 2022, 1, e42. [Google Scholar] [CrossRef]
- Gaulton, A.; Hersey, A.; Nowotka, M.; Bento, A.P.; Chambers, J.; Mendez, D.; Mutowo, P.; Atkinson, F.; Bellis, L.J.; Cibrián-Uhalte, E.; et al. The ChEMBL database in 2017. Nucleic Acids Res. 2017, 45, D945–D954. [Google Scholar] [CrossRef] [PubMed]
- Minkiewicz, P.; Iwaniak, A.; Darewicz, M. BIOPEP-UWM Database of Bioactive Peptides: Current Opportunities. Int. J. Mol. Sci. 2019, 20, 5978. [Google Scholar] [CrossRef]
- Dagan-Wiener, A.; Di Pizio, A.; Nissim, I.; Bahia, M.S.; Dubovski, N.; Margulis, E.; Niv, M.Y. BitterDB: Taste ligands and receptors database in 2019. Nucleic Acids Res. 2019, 47, D1179–D1185. [Google Scholar] [CrossRef] [PubMed]
- Cui, Z.; Zhang, Z.; Zhou, T.; Zhou, X.; Zhang, Y.; Meng, H.; Wang, W.; Liu, Y. A TastePeptides-Meta system including an umami/bitter classification model Umami_YYDS, a TastePeptidesDB database and an open-source package Auto_Taste_ML. Food Chem. 2023, 405, 134812. [Google Scholar] [CrossRef] [PubMed]
- Kuhfeld, R.F.; Eshpari, H.; Atamer, Z.; Dallas, D.C. A comprehensive database of cheese-derived bitter peptides and correlation to their physical properties. Crit. Rev. Food Sci. Nutr. 2023, 1–15. [Google Scholar] [CrossRef]
- Veerasamy, R.; Rajak, H.; Jain, A.; Sivadasan, S.; Varghese, C.P.; Agrawal, R.K. Validation of QSAR models-strategies and importance. Int. J. Drug Des. Discov. 2011, 3, 511–519. [Google Scholar]
- Tropsha, A. Best practices for QSAR model development, validation, and exploitation. Mol. Inform. 2010, 29, 476–488. [Google Scholar] [CrossRef] [PubMed]
- De, P.; Kar, S.; Ambure, P.; Roy, K. Prediction reliability of QSAR models: An overview of various validation tools. Arch. Toxicol. 2022, 96, 1279–1295. [Google Scholar] [CrossRef] [PubMed]
- Roy, K. Advances in QSAR Modeling; Springer: Cham, Switzerland, 2017; Volume 555. [Google Scholar]
- Tropsha, A.; Isayev, O.; Varnek, A.; Schneider, G.; Cherkasov, A. Integrating QSAR modelling and deep learning in drug discovery: The emergence of deep QSAR. Nat. Rev. Drug Discov. 2024, 23, 141–155. [Google Scholar] [CrossRef]
- Fujita, T.J. In memoriam Professor Corwin Hansch: Birth pangs of QSAR before 1961. J. Comput.-Aided Mol. Des. 2011, 25, 509–517. [Google Scholar] [CrossRef]
- Hopfinger, A.; Wang, S.; Tokarski, J.S.; Jin, B.; Albuquerque, M.; Madhav, P.J.; Duraiswami, C.J. Construction of 3D-QSAR models using the 4D-QSAR analysis formalism. J. Am. Chem. Soc. 1997, 119, 10509–10524. [Google Scholar] [CrossRef]
- Sahigara, F.; Mansouri, K.; Ballabio, D.; Mauri, A.; Consonni, V.; Todeschini, R.J.M. Comparison of different approaches to define the applicability domain of QSAR models. Molecules 2012, 17, 4791–4810. [Google Scholar] [CrossRef]
- Roy, K.; Kar, S.; Ambure, P.J.C.; Systems, I.L. On a simple approach for determining applicability domain of QSAR models. Chemom. Intell. Lab. Syst. 2015, 145, 22–29. [Google Scholar] [CrossRef]
- Asao, M.; Iwamura, H.; Akamatsu, M.; Fujita, T. Quantitative structure-activity relationships of the bitter thresholds of amino acids, peptides, and their derivatives. J. Med. Chem. 1987, 30, 1873–1879. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.-O.; Li-Chan, E.C.Y. Quantitative structure—Activity relationship study of bitter peptides. J. Agric. Food Chem. 2006, 54, 10102–10111. [Google Scholar] [CrossRef]
- Yin, J.; Diao, Y.; Wen, Z.; Wang, Z.; Li, M. Studying Peptides Biological Activities Based on Multidimensional Descriptors (E) Using Support Vector Regression. Int. J. Pept. Res. Ther. 2010, 16, 111–121. [Google Scholar] [CrossRef]
- Wang, F.; Zhou, B. Quantitative structure-activity relationship models for bitter-tasting tripeptides based on integrated descriptors. Struct. Chem. 2019, 31, 573–583. [Google Scholar] [CrossRef]
- Geladi, P.; Kowalski, B.R. Partial least-squares regression: A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Awad, M.; Khanna, R.; Awad, M.; Khanna, R. Support vector regression. In Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers; Springer: Berkeley, CA, USA, 2015; pp. 67–80. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Wang, Y.; Zhai, Y.; Ding, Y.; Zou, Q. SBSM-Pro: Support Bio-sequence Machine for Proteins. arXiv 2023, arXiv:2308.10275. [Google Scholar]
- Wang, Y.; Zhang, W.; Yang, Y.; Sun, J.; Wang, L. Survival Prediction of Esophageal Squamous Cell Carcinoma Based on the Prognostic Index and Sparrow Search Algorithm-Support Vector Machine. Curr. Bioinform. 2023, 18, 598–609. [Google Scholar] [CrossRef]
- Zou, J.; Han, Y.; So, S.-S. Overview of artificial neural networks. Artif. NeuralNetw. Methods Appl. 2009, 458, 14–22. [Google Scholar]
- Liu, S.; Liang, Y.; Li, J.; Yang, S.; Liu, M.; Liu, C.; Yang, D.; Zuo, Y. Integrating reduced amino acid composition into PSSM for improving copper ion-binding protein prediction. Int. J. Biol. Macromol. 2023, 244, 124993. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, S.; Li, X.; Liu, Y.; Zhu, X. NeuroPpred-SVM: A New Model for Predicting Neuropeptides Based on Embeddings of BERT. J. Proteome Res. 2023, 22, 718–728. [Google Scholar] [CrossRef] [PubMed]
- Zhu, H.; Hao, H.; Yu, L. Identifying disease-related microbes based on multi-scale variational graph autoencoder embedding Wasserstein distance. BMC Biol. 2023, 21, 294. [Google Scholar] [CrossRef]
- Sikander, R.; Ghulam, A.; Ali, F. XGB-DrugPred: Computational prediction of druggable proteins using eXtreme gradient boosting and optimized features set. Sci. Rep. 2022, 12, 5505. [Google Scholar] [CrossRef]
- Cunningham, M.; Pins, D.; Dezso, Z.; Torrent, M.; Vasanthakumar, A.; Pandey, A. PINNED: Identifying characteristics of druggable human proteins using an interpretable neural network. J. Cheminform. 2023, 15, 64. [Google Scholar] [CrossRef] [PubMed]
- Suresh, V.; Parthasarathy, S. SVM-PB-Pred: SVM based protein block prediction method using sequence profiles and secondary structures. Protein Pept. Lett. 2014, 21, 736–742. [Google Scholar] [CrossRef]
- Zhang, H.Q.; Liu, S.H.; Li, R.; Yu, J.W.; Ye, D.X.; Yuan, S.S.; Lin, H.; Huang, C.B.; Tang, H. MIBPred: Ensemble Learning-Based Metal Ion-Binding Protein Classifier. ACS Omega 2024, 9, 8439–8447. [Google Scholar] [CrossRef]
- Erickson, B.J.; Korfiatis, P.; Akkus, Z.; Kline, T.L. Machine learning for medical imaging. Radiographics 2017, 37, 505–515. [Google Scholar] [CrossRef] [PubMed]
- Jasti, V.D.P.; Zamani, A.S.; Arumugam, K.; Naved, M.; Pallathadka, H.; Sammy, F.; Raghuvanshi, A.; Kaliyaperumal, K. Computational technique based on machine learning and image processing for medical image analysis of breast cancer diagnosis. Secur. Commun. Netw. 2022, 2022, 1918379. [Google Scholar] [CrossRef]
- Charoenkwan, P.; Yana, J.; Schaduangrat, N.; Nantasenamat, C.; Hasan, M.M.; Shoombuatong, W. iBitter-SCM: Identification and characterization of bitter peptides using a scoring card method with propensity scores of dipeptides. Genomics 2020, 112, 2813–2822. [Google Scholar] [CrossRef]
- Tran, H.V.; Nguyen, Q.H. iAnt: Combination of Convolutional Neural Network and Random Forest Models Using PSSM and BERT Features to Identify Antioxidant Proteins. Curr. Bioinform. 2022, 17, 184–195. [Google Scholar] [CrossRef]
- Chen, J.; Zou, Q.; Li, J. DeepM6ASeq-EL: Prediction of Human N6-Methyladenosine (m6A) Sites with LSTM and Ensemble Learning. Front. Comput. Sci. 2022, 16, 162302. [Google Scholar] [CrossRef]
- Charoenkwan, P.; Nantasenamat, C.; Hasan, M.M.; Manavalan, B.; Shoombuatong, W. BERT4Bitter: A bidirectional encoder representations from transformers (BERT)-based model for improving the prediction of bitter peptides. Bioinformatics 2021, 37, 2556–2562. [Google Scholar] [CrossRef]
- He, W.; Jiang, Y.; Jin, J.; Li, Z.; Zhao, J.; Manavalan, B.; Su, R.; Gao, X.; Wei, L. Accelerating bioactive peptide discovery via mutual information-based meta-learning. Brief. Bioinform. 2022, 23, bbab499. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, S.; Zhang, X.; Yu, W.; Pei, X.; Liu, L.; Jin, Y. Identification and prediction of milk-derived bitter taste peptides based on peptidomics technology and machine learning method. Food Chem. 2024, 433, 137288. [Google Scholar] [CrossRef] [PubMed]
- Charoenkwan, P.; Nantasenamat, C.; Hasan, M.M.; Moni, M.A.; Lio, P.; Shoombuatong, W. iBitter-Fuse: A Novel Sequence-Based Bitter Peptide Predictor by Fusing Multi-View Features. Int. J. Mol. Sci. 2021, 22, 8958. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.F.; Wang, Y.H.; Gu, Z.F.; Pan, X.R.; Li, J.; Ding, H.; Zhang, Y.; Deng, K.J. Bitter-RF: A random forest machine model for recognizing bitter peptides. Front. Med. 2023, 10, 1052923. [Google Scholar] [CrossRef]
- Cai, J.; Luo, J.; Wang, S.; Yang, S. Feature selection in machine learning: A new perspective. Neurocomputing 2018, 300, 70–79. [Google Scholar] [CrossRef]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the 2014 Science and Information Conference, London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar]
- Pudjihartono, N.; Fadason, T.; Kempa-Liehr, A.W.; O’Sullivan, J.M. A review of feature selection methods for machine learning-based disease risk prediction. Front. Bioinform. 2022, 2, 927312. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Michelucci, U. Applied Deep Learning. In A Case-Based Approach to Understanding Deep Neural Networks; Springer: Berkeley, CA, USA, 2018. [Google Scholar]
- Kou, X.; Shi, P.; Gao, C.; Ma, P.; Xing, H.; Ke, Q.; Zhang, D. Data-Driven Elucidation of Flavor Chemistry. J. Agric. Food Chem. 2023, 71, 6789–6802. [Google Scholar] [CrossRef]
- Dutta, P.; Jain, D.; Gupta, R.; Rai, B. Classification of tastants: A deep learning based approach. Mol. Inform. 2023, 42, e202300146. [Google Scholar] [CrossRef]
- Dini, I.; Mancusi, A. Food Peptides for the Nutricosmetic Industry. Antioxidants 2023, 12, 788. [Google Scholar] [CrossRef]
- Amit, S.K.; Uddin, M.M.; Rahman, R.; Islam, S.R.; Khan, M.S. A review on mechanisms and commercial aspects of food preservation and processing. Agric. Food Secur. 2017, 6, 51. [Google Scholar] [CrossRef]
- Dreiseitl, S.; Ohno-Machado, L. Logistic regression and artificial neural network classification models: A methodology review. J. Biomed. Inform. 2002, 35, 352–359. [Google Scholar] [CrossRef] [PubMed]
- Burley, S.K.; Berman, H.M.; Kleywegt, G.J.; Markley, J.L.; Nakamura, H.; Velankar, S. Protein Data Bank (PDB): The single global macromolecular structure archive. Protein Crystallogr. Methods Protoc. 2017, 1607, 627–641. [Google Scholar]
- Consortium, U. UniProt: A worldwide hub of protein knowledge. Nucleic Acids Res. 2019, 47, D506–D515. [Google Scholar] [CrossRef]
- ElAbd, H.; Bromberg, Y.; Hoarfrost, A.; Lenz, T.; Franke, A.; Wendorff, M. Amino acid encoding for deep learning applications. BMC Bioinform. 2020, 21, 235. [Google Scholar] [CrossRef]
- Liu, J.; Yang, M.; Yu, Y.; Xu, H.; Li, K.; Zhou, X. Large language models in bioinformatics: Applications and perspectives. arXiv 2024, arXiv:2401.04155v1. [Google Scholar]
- Dias, A.C.; Jacomo, R.H.; Nery, L.F.A.; Naves, L.A. Effect size and inferential statistical techniques coupled with machine learning for assessing the association between prolactin concentration and metabolic homeostasis. Clin. Chim. Acta 2024, 552, 117688. [Google Scholar] [CrossRef] [PubMed]
- Siying, L. Researches Advanced in Deep Learning based Image Classification. Highlights Sci. Eng. Technol. 2022, 16, 178–187. [Google Scholar]
- Jain, S.M. Introduction to Transformers for NLP. In with the Hugging Face Library Models to Solve Problems; Springer: Berkeley, CA, USA, 2022. [Google Scholar]
- Von Oswald, J.; Niklasson, E.; Randazzo, E.; Sacramento, J.; Mordvintsev, A.; Zhmoginov, A.; Vladymyrov, M. Transformers learn in-context by gradient descent. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 35151–35174. [Google Scholar]
- Ross, A.; Doshi-Velez, F. Improving the adversarial robustness and interpretability of deep neural networks by regularizing their input gradients. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Crabbé, J.; van der Schaar, M. Evaluating the robustness of interpretability methods through explanation invariance and equivariance. Adv. Neural Inf. Process. Syst. 2023, 36, 71393–71429. [Google Scholar]
- Alvarez Melis, D.; Jaakkola, T. Towards robust interpretability with self-explaining neural networks. Adv. Neural Inf. Process. Syst. 2018, 31, 7786–7795. [Google Scholar]
- Thomas, A.; Sulli, C.; Davidson, E.; Berdougo, E.; Phillips, M.; Puffer, B.A.; Paes, C.; Doranz, B.J.; Rucker, J.B. The bitter taste receptor TAS2R16 achieves high specificity and accommodates diverse glycoside ligands by using a two-faced binding pocket. Sci. Rep. 2017, 7, 7753. [Google Scholar] [CrossRef]
- Upadhyaya, J.; Pydi, S.P.; Singh, N.; Aluko, R.E.; Chelikani, P. Bitter taste receptor T2R1 is activated by dipeptides and tripeptides. Biochem. Biophys. Res. Commun. 2010, 398, 331–335. [Google Scholar] [CrossRef] [PubMed]
- Lu, P.; Zhang, C.-H.; Lifshitz, L.M.; ZhuGe, R. Extraoral bitter taste receptors in health and disease. J. Gen. Physiol. 2017, 149, 181–197. [Google Scholar] [CrossRef] [PubMed]
- Depoortere, I. Taste receptors of the gut: Emerging roles in health and disease. Gut 2014, 63, 179–190. [Google Scholar] [CrossRef]
- Komiyama, Y.; Banno, M.; Ueki, K.; Saad, G.; Shimizu, K. Automatic generation of bioinformatics tools for predicting protein–ligand binding sites. Bioinformatics 2016, 32, 901–907. [Google Scholar] [CrossRef]
- Laurie, A.T.; Jackson, R.M. Q-SiteFinder: An energy-based method for the prediction of protein-ligand binding sites. Bioinformatics 2005, 21, 1908–1916. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, A.; Mam, B.; Sowdhamini, R. DEELIG: A deep learning approach to predict protein-ligand binding affinity. Bioinform. Biol. Insights 2021, 15, 11779322211030364. [Google Scholar] [CrossRef] [PubMed]
- Bertolazzi, P.; Guerra, C.; Liuzzi, G. Predicting protein-ligand and protein-peptide interfaces. Eur. Phys. J. Plus 2014, 129, 132. [Google Scholar] [CrossRef]
- Li, B.-Q.; Zhang, Y.-H.; Jin, M.-L.; Huang, T.; Cai, Y.-D. Prediction of protein-peptide interactions with a nearest neighbor algorithm. Curr. Bioinform. 2018, 13, 14–24. [Google Scholar] [CrossRef]
- Taherzadeh, G.; Yang, Y.; Zhang, T.; Liew, A.W.C.; Zhou, Y. Sequence-based prediction of protein–peptide binding sites using support vector machine. J. Comput. Chem. 2016, 37, 1223–1229. [Google Scholar] [CrossRef]
- Zhou, P.; Wen, L.; Lin, J.; Mei, L.; Liu, Q.; Shang, S.; Li, J.; Shu, J. Integrated unsupervised–supervised modeling and prediction of protein–peptide affinities at structural level. Brief. Bioinform. 2022, 23, bbac097. [Google Scholar] [CrossRef]
- Tu, G.; Fu, T.; Yang, F.; Yao, L.; Xue, W.; Zhu, F. Prediction of GluN2B-CT1290-1310/DAPK1 interaction by protein–peptide docking and molecular dynamics simulation. Molecules 2018, 23, 3018. [Google Scholar] [CrossRef] [PubMed]
- Singh, S.; Baker, Q.B.; Singh, D.B. Molecular docking and molecular dynamics simulation. In Bioinformatics; Elsevier: Amsterdam, The Netherlands, 2022; pp. 291–304. [Google Scholar]
- Mitzenmacher, M. A brief history of generative models for power law and lognormal distributions. Internet Math. 2004, 1, 226–251. [Google Scholar] [CrossRef]
- Baktash, J.A.; Dawodi, M. Gpt-4: A review on advancements and opportunities in natural language processing. arXiv 2023, arXiv:2305.03195. [Google Scholar]
- Abramson, J.; Adler, J.; Dunger, J.; Evans, R.; Green, T.; Pritzel, A.; Ronneberger, O.; Willmore, L.; Ballard, A.J.; Bambrick, J.; et al. Accurate structure prediction of biomolecular interactions with AlphaFold 3. Nature 2024, 630, 493–500. [Google Scholar] [CrossRef] [PubMed]
- Jumper, J.; Evans, R.; Pritzel, A.; Green, T.; Figurnov, M.; Ronneberger, O.; Tunyasuvunakool, K.; Bates, R.; Zidek, A.; Potapenko, A.; et al. Highly accurate protein structure prediction with AlphaFold. Nature 2021, 596, 583–589. [Google Scholar] [CrossRef]
- Madani, A.; Krause, B.; Greene, E.R.; Subramanian, S.; Mohr, B.P.; Holton, J.M.; Olmos, J.L., Jr.; Xiong, C.; Sun, Z.Z.; Socher, R.; et al. Large language models generate functional protein sequences across diverse families. Nat. Biotechnol. 2023, 41, 1099–1106. [Google Scholar] [CrossRef]
- Shin, J.E.; Riesselman, A.J.; Kollasch, A.W.; McMahon, C.; Simon, E.; Sander, C.; Manglik, A.; Kruse, A.C.; Marks, D.S. Protein design and variant prediction using autoregressive generative models. Nat. Commun. 2021, 12, 2403. [Google Scholar] [CrossRef]
- Strokach, A.; Kim, P.M. Deep generative modeling for protein design. Curr. Opin. Struct. Biol. 2022, 72, 226–236. [Google Scholar] [CrossRef]
- Mardikoraem, M.; Wang, Z.; Pascual, N.; Woldring, D. Generative models for protein sequence modeling: Recent advances and future directions. Brief. Bioinform. 2023, 24, bbad358. [Google Scholar] [CrossRef]
- Wu, Z.; Johnston, K.E.; Arnold, F.H.; Yang, K.K. Protein sequence design with deep generative models. Curr. Opin. Chem. Biol. 2021, 65, 18–27. [Google Scholar] [CrossRef]
- Notin, P.; Rollins, N.; Gal, Y.; Sander, C.; Marks, D. Machine learning for functional protein design. Nat. Biotechnol. 2024, 42, 216–228. [Google Scholar] [CrossRef] [PubMed]
- Lin, E.; Lin, C.-H.; Lane, H.-Y. De novo peptide and protein design using generative adversarial networks: An update. J. Chem. Inf. Model. 2022, 62, 761–774. [Google Scholar] [CrossRef] [PubMed]
- Repecka, D.; Jauniskis, V.; Karpus, L.; Rembeza, E.; Rokaitis, I.; Zrimec, J.; Poviloniene, S.; Laurynenas, A.; Viknander, S.; Abuajwa, W. Expanding functional protein sequence spaces using generative adversarial networks. Nat. Mach. Intell. 2021, 3, 324–333. [Google Scholar] [CrossRef]
- Lin, E.; Lin, C.-H.; Lane, H.-Y. Relevant applications of generative adversarial networks in drug design and discovery: Molecular de novo design, dimensionality reduction, and de novo peptide and protein design. Molecules 2020, 25, 3250. [Google Scholar] [CrossRef]
- Willmott, C.J.; Robeson, S.M.; Matsuura, K. A refined index of model performance. Int. J. Climatol. 2012, 32, 2088–2094. [Google Scholar] [CrossRef]
- Hsu, C.; Fannjiang, C.; Listgarten, J. Generative models for protein structures and sequences. Nat. Biotechnol. 2024, 42, 196–199. [Google Scholar] [CrossRef] [PubMed]
- Truong, T., Jr.; Bepler, T. PoET: A generative model of protein families as sequences-of-sequences. Adv. Neural Inf. Process. Syst. 2024, 36, 77379–77415. [Google Scholar]
- Yim, J.; Stärk, H.; Corso, G.; Jing, B.; Barzilay, R.; Jaakkola, T.S. Diffusion models in protein structure and docking. Wiley Interdiscip. Rev. Comput. Mol. Sci. 2024, 14, e1711. [Google Scholar] [CrossRef]
- Johnson, S.R.; Fu, X.; Viknander, S.; Goldin, C.; Monaco, S.; Zelezniak, A.; Yang, K.K. Computational scoring and experimental evaluation of enzymes generated by neural networks. Nat. Biotechnol. 2024, 1–10. [Google Scholar] [CrossRef]
- Wang, J.; Wang, X.; Chu, Y.; Li, C.; Li, X.; Meng, X.; Fang, Y.; No, K.T.; Mao, J.; Zeng, X. Exploring the Conformational Ensembles of Protein–Protein Complex with Transformer-Based Generative Model. J. Chem. Theory Comput. 2024, 20, 4469–4480. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).