
Fusion of Raman and FTIR Spectroscopy Data Uncovers Physiological Changes Associated with Lung Cancer


Abstract
:1. Introduction
2. Results and Discussion
2.1. Model Performance
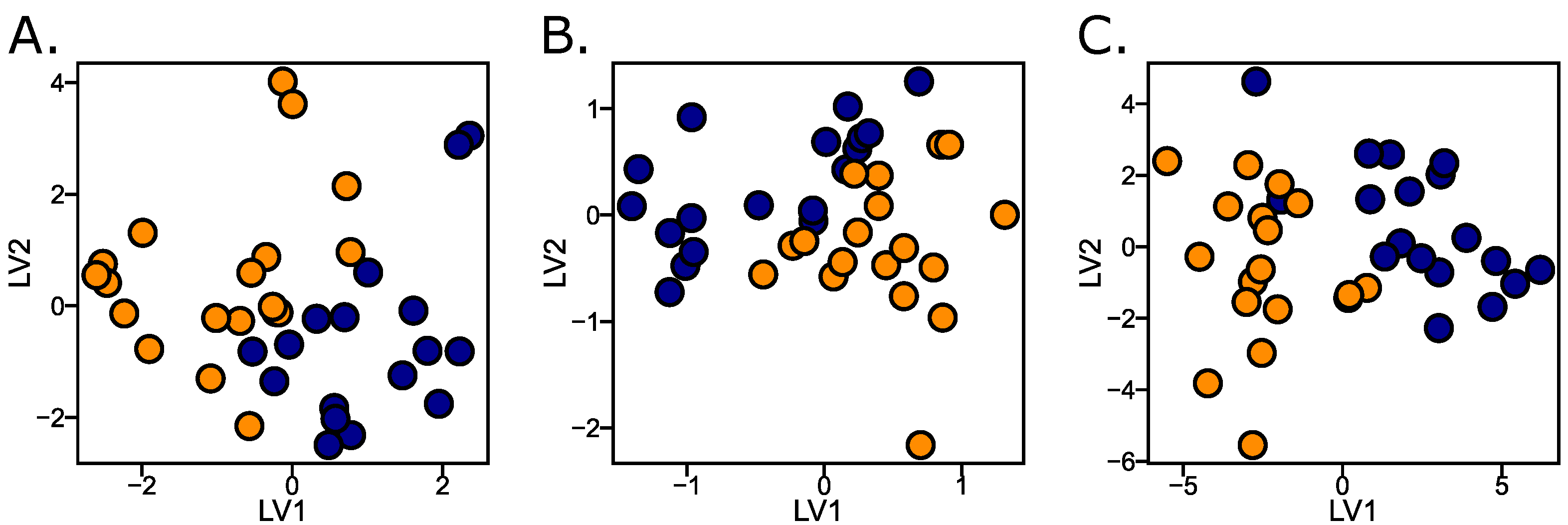
2.2. Graphical Representations
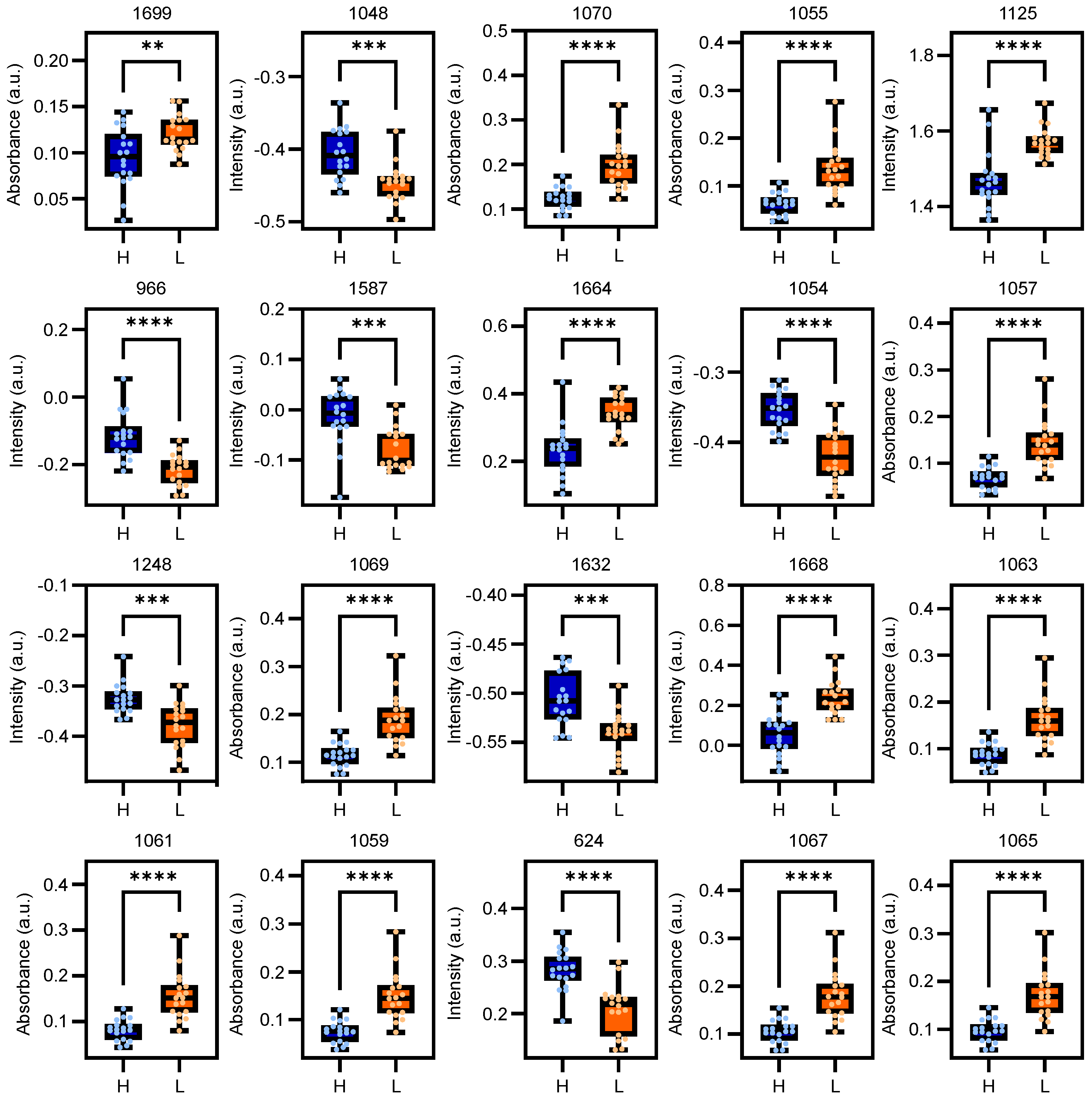
2.3. Biochemical Assignment
3. Materials and Methods
3.1. Sample Collection and Preparation
3.2. Data Collection and Preprocessing
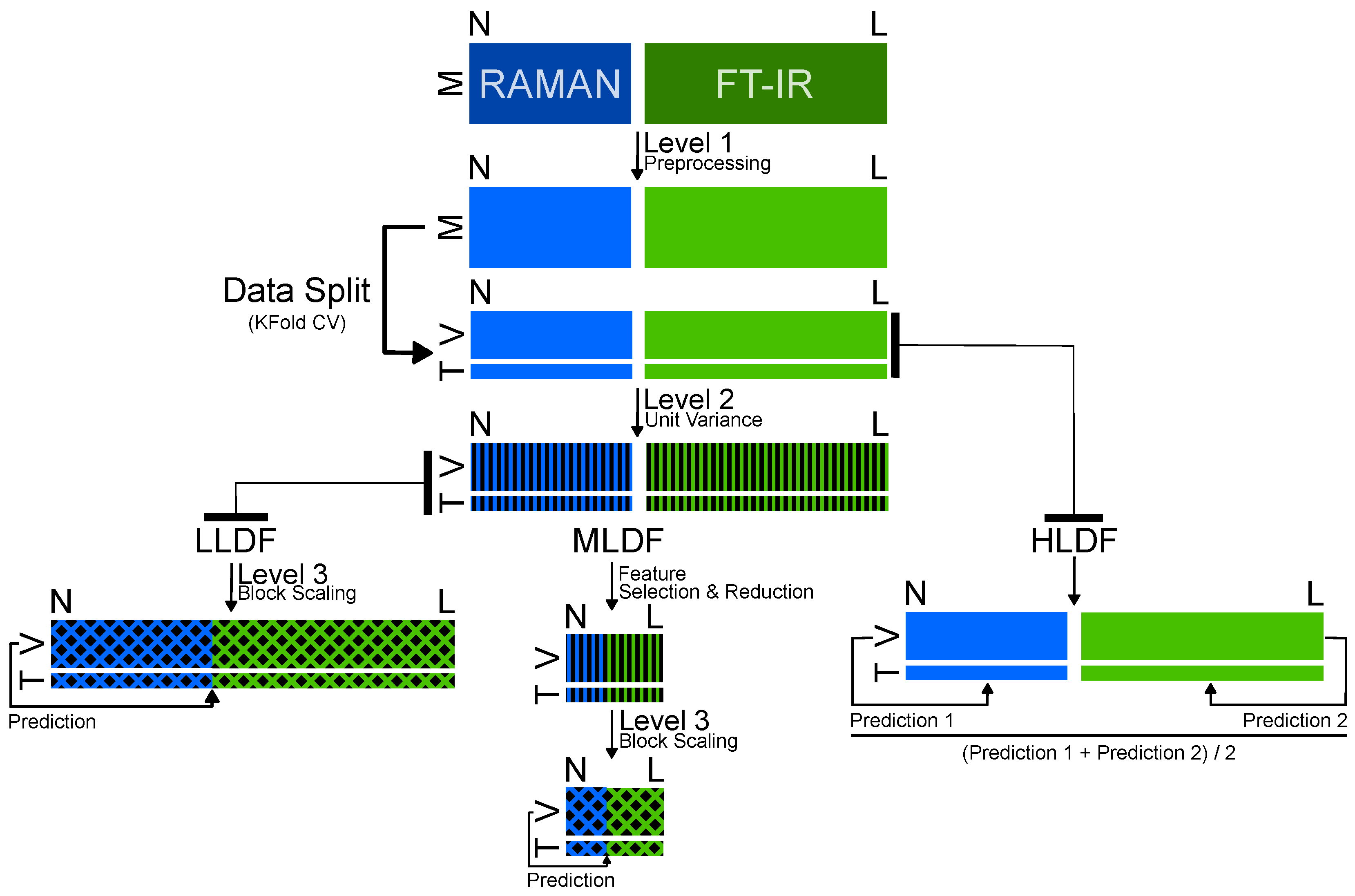
3.3. Data Fusion and Model Building
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chaitanya Thandra, K.; Barsouk, A.; Saginala, K.; Sukumar Aluru, J.; Barsouk, A. Epidemiology of lung cancer. Contemp. Oncol. WspółCzesna Onkol. 2021, 25, 45–52. [Google Scholar] [CrossRef]
- Youlden, D.R.; Cramb, S.M.; Baade, P.D. The International Epidemiology of Lung Cancer: Geographical Distribution and Secular Trends. J. Thorac. Oncol. 2008, 3, 819–831. [Google Scholar] [CrossRef]
- Thanoon, M.A.; Zulkifley, M.A.; Mohd Zainuri, M.A.A.; Abdani, S.R. A Review of Deep Learning Techniques for Lung Cancer Screening and Diagnosis Based on CT Images. Diagnostics 2023, 13, 2617. [Google Scholar] [CrossRef]
- Prabhakar, B.; Shende, P.; Augustine, S. Current trends and emerging diagnostic techniques for lung cancer. Biomed. Pharmacother. 2018, 106, 1586–1599. [Google Scholar] [CrossRef]
- Sultanbawa, Y.; Smyth, H.; Truong, K.; Chapman, J.; Cozzolino, D. Insights on the role of chemometrics and vibrational spectroscopy in fruit metabolite analysis. Food Chem. Mol. Sci. 2021, 3, 100033. [Google Scholar] [CrossRef]
- Balan, V.; Mihai, C.T.; Cojocaru, F.D.; Uritu, C.M.; Dodi, G.; Botezat, D.; Gardikiotis, I. Vibrational Spectroscopy Fingerprinting in Medicine: From Molecular to Clinical Practice. Materials 2019, 12, 2884. [Google Scholar] [CrossRef]
- Larkin, P. Chapter 1—Introduction: Infrared and Raman Spectroscopy. In Infrared and Raman Spectroscopy; Larkin, P., Ed.; Elsevier: Oxford, UK, 2011; pp. 1–5. [Google Scholar] [CrossRef]
- Hayes, E.; Greene, D.; O’Donnell, C.; O’Shea, N.; Fenelon, M.A. Spectroscopic technologies and data fusion: Applications for the dairy industry. Front. Nutr. 2023, 9, 1074688. [Google Scholar] [CrossRef]
- Cocchi, M. Chapter 1—Introduction: Ways and Means to Deal with Data from Multiple Sources. In Data Handling in Science and Technology; Cocchi, M., Ed.; Data Fusion Methodology and Applications; Elsevier: Amsterdam, The Netherlands, 2019; Volume 31, pp. 1–26. [Google Scholar] [CrossRef]
- Arévalo, L.A.; O’Brien, S.A.; Lopez, E.; Singh, G.P.; Seifert, A. Design and Development of a Bimodal Optical Instrument for Simultaneous Vibrational Spectroscopy Measurements. Int. J. Mol. Sci. 2022, 23, 6834. [Google Scholar] [CrossRef]
- Smolinska, A.; Engel, J.; Szymanska, E.; Buydens, L.; Blanchet, L. Chapter 3—General Framing of Low-, Mid-, and High-Level Data Fusion with Examples in the Life Sciences. In Data Handling in Science and Technology; Cocchi, M., Ed.; Data Fusion Methodology and Applications; Elsevier: Amsterdam, The Netherlands, 2019; Volume 31, pp. 51–79. [Google Scholar] [CrossRef]
- Azcarate, S.M.; Ríos-Reina, R.; Amigo, J.M.; Goicoechea, H.C. Data handling in data fusion: Methodologies and applications. TrAC Trends Anal. Chem. 2021, 143, 116355. [Google Scholar] [CrossRef]
- Hano, H.; Lawrie, C.H.; Suarez, B.; Lario, A.P.; Echeverría, I.E.; Mediavilla, J.G.; Cruz, M.I.C.; Lopez, E.; Seifert, A. Power of Light: Raman Spectroscopy and Machine Learning for the Detection of Lung Cancer. ACS Omega 2024, 9, 14084–14091. [Google Scholar] [CrossRef]
- Sinica, A.; Brožáková, K.; Brůha, T.; Votruba, J. Raman spectroscopic discrimination of normal and cancerous lung tissues. Spectrochim. Acta Part Mol. Biomol. Spectrosc. 2019, 219, 257–266. [Google Scholar] [CrossRef] [PubMed]
- Fadlelmoula, A.; Pinho, D.; Carvalho, V.H.; Catarino, S.O.; Minas, G. Fourier Transform Infrared (FTIR) Spectroscopy to Analyse Human Blood over the Last 20 Years: A Review towards Lab-on-a-Chip Devices. Micromachines 2022, 13, 187. [Google Scholar] [CrossRef]
- Bujok, J.; Gąsior-Głogowska, M.; Marszałek, M.; Trochanowska-Pauk, N.; Zigo, F.; Pavľak, A.; Komorowska, M.; Walski, T. Applicability of FTIR-ATR Method to Measure Carbonyls in Blood Plasma after Physical and Mental Stress. Biomed Res. Int. 2019, 2019, 2181370. [Google Scholar] [CrossRef]
- Vrtělka, O.; Králová, K.; Fousková, M.; Habartová, L.; Hříbek, P.; Urbánek, P.; Setnička, V. Vibrational and chiroptical analysis of blood plasma for hepatocellular carcinoma diagnostics. Analyst 2023, 148, 2793–2800. [Google Scholar] [CrossRef]
- Gajjar, K.; Trevisan, J.; Owens, G.; Keating, P.J.; Wood, N.J.; Stringfellow, H.F.; Martin-Hirsch, P.L.; Martin, F.L. Fourier-transform infrared spectroscopy coupled with a classification machine for the analysis of blood plasma or serum: A novel diagnostic approach for ovarian cancer. Analyst 2013, 138, 3917–3926. [Google Scholar] [CrossRef] [PubMed]
- Poon, K.W.C.; Lyng, F.M.; Knief, P.; Howe, O.; Meade, A.D.; Curtin, J.F.; Byrne, H.J.; Vaughan, J. Quantitative reagent-free detection of fibrinogen levels in human blood plasma using Raman spectroscopy. Analyst 2012, 137, 1807–1814. [Google Scholar] [CrossRef]
- Campos, M.P.; Reis, M.S. Data preprocessing for multiblock modelling—A systematization with new methods. Chemom. Intell. Lab. Syst. 2020, 199, 103959. [Google Scholar] [CrossRef]
- Silvestri, M.; Elia, A.; Bertelli, D.; Salvatore, E.; Durante, C.; Li Vigni, M.; Marchetti, A.; Cocchi, M. A mid level data-fusion strategy for the Varietal Classification of Lambrusco PDO wines. Chemom. Intell. Lab. Syst. 2014, 137, 181–189. [Google Scholar] [CrossRef]
- Mishra, P.; Roger, J.M.; Jouan-Rimbaud-Bouveresse, D.; Biancolillo, A.; Marini, F.; Nordon, A.; Rutledge, D.N. Recent trends in multi-block data analysis in chemometrics for multi-source data integration. TrAC Trends Anal. Chem. 2021, 137, 116206. [Google Scholar] [CrossRef]
- Shaffer, R.E. Multi- and Megavariate Data Analysis. Principles and Applications, I. Eriksson, E. Johansson, N. Kettaneh-Wold and S. Wold, Umetrics Academy, Umeå, 2001, ISBN 91-973730-1-X, 533pp. J. Chemom. 2002, 16, 261–262. [Google Scholar] [CrossRef]
- Ríos-Reina, R.; Callejón, R.M.; Savorani, F.; Amigo, J.M.; Cocchi, M. Data fusion approaches in spectroscopic characterization and classification of PDO wine vinegars. Talanta 2019, 198, 560–572. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Option | Data Fusion | Spectral Range for FTIR | Method | Data Range | Number of Features | Accuracy |
|---|---|---|---|---|---|---|
| 1 | No Fusion | Full | 1. Raman | 100% | 1015 | 0.8119 ± 0.0035 |
| 2. Raman (FS) | 5% | 51 | 0.8539 ± 0.0056 | |||
| 3. Raman (FR) | 6PCs | 6 | 0.8378 ± 0.0060 | |||
| 4. FTIR | 100% | 1868 | 0.7886 ± 0.0037 | |||
| 5. FTIR (FS) | 4% | 75 | 0.8425 ± 0.0058 | |||
| 6. FTIR (FR) | 8PCs | 8 | 0.7928 ± 0.0068 | |||
| FP | 7. FTIR | 100% | 727 | 0.7567 ± 0.0033 | ||
| 8. FTIR (FS) | 1% | 8 | 0.8419 ± 0.0057 | |||
| 9. FTIR (FR) | 5PCs | 5 | 0.7633 ± 0.0068 | |||
| 2 | LLDF | Full | 10. Raman + FTIR | 100% | 2883 | 0.8625 ± 0.0035 |
| 11. Raman + FTIR + FS | 6% | 173 | 0.9922 ± 0.0015 | |||
| 12. Raman + FTIR + FR | 6PCs | 6 | 0.8711 ± 0.0034 | |||
| FP | 13. Raman + FTIR | 100% | 1742 | 0.8592 ± 0.0037 | ||
| 14. Raman + FTIR + FS | 10% | 175 | 0.9497 ± 0.0039 | |||
| 15. Raman + FTIR + FR | 5PCs | 5 | 0.8681 ± 0.0031 | |||
| 3 | MLDF | Full | 16. Raman (FS) + FTIR (FS) | 5% + 4% | 126 | 0.8472 ± 0.0039 |
| 17. Raman (FR) + FTIR (FR) | 6PCs + 8PCs | 14 | 0.8425 ± 0.0034 | |||
| FP | 18. Raman (FR) + FTIR (FR) | 5% + 1% | 59 | 0.7972 ± 0.0035 | ||
| 19. Raman (FR) + FTIR (FR) | 6PCs + 5PCs | 11 | 0.8583 ± 0.0032 | |||
| 4 | HLDF | Full | 20. Raman + FTIR | 100% | 1015/1868 | 0.8383 ± 0.0024 |
| 21. Raman (FS) + FTIR (FS) | 5%/4% | 51/75 | 0.8131 ± 0.0023 | |||
| 22. Raman (FR) + FTIR (FR) | 6PCs\8PCs | 6/8 | 0.8383 ± 0.0024 | |||
| FP | 23. Raman + FTIR | 100% | 1015/727 | 0.8319 ± 0.0024 | ||
| 24. Raman (FS) + FTIR (FS) | 5%\1% | 51/8 | 0.7989 ± 0.0035 | |||
| 25. Raman (FR) + FTIR (FR) | 6PCs \5PCs | 6/5 | 0.8319 ± 0.0024 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hano, H.; Suarez, B.; Lawrie, C.H.; Seifert, A. Fusion of Raman and FTIR Spectroscopy Data Uncovers Physiological Changes Associated with Lung Cancer. Int. J. Mol. Sci. 2024, 25, 10936. https://doi.org/10.3390/ijms252010936
Hano H, Suarez B, Lawrie CH, Seifert A. Fusion of Raman and FTIR Spectroscopy Data Uncovers Physiological Changes Associated with Lung Cancer. International Journal of Molecular Sciences. 2024; 25(20):10936. https://doi.org/10.3390/ijms252010936
Chicago/Turabian StyleHano, Harun, Beatriz Suarez, Charles H. Lawrie, and Andreas Seifert. 2024. "Fusion of Raman and FTIR Spectroscopy Data Uncovers Physiological Changes Associated with Lung Cancer" International Journal of Molecular Sciences 25, no. 20: 10936. https://doi.org/10.3390/ijms252010936
APA StyleHano, H., Suarez, B., Lawrie, C. H., & Seifert, A. (2024). Fusion of Raman and FTIR Spectroscopy Data Uncovers Physiological Changes Associated with Lung Cancer. International Journal of Molecular Sciences, 25(20), 10936. https://doi.org/10.3390/ijms252010936