
RNA-Binding S1 Domain in Bacterial, Archaeal and Eukaryotic Proteins as One of the Evolutionary Markers of Symbiogenesis

 , , and
, , and 
Abstract
:1. Introduction
2. Results and Discussion
2.1. Distribution of the S1 Domains in Eukaryotic, Archaeal and Bacterial Proteins
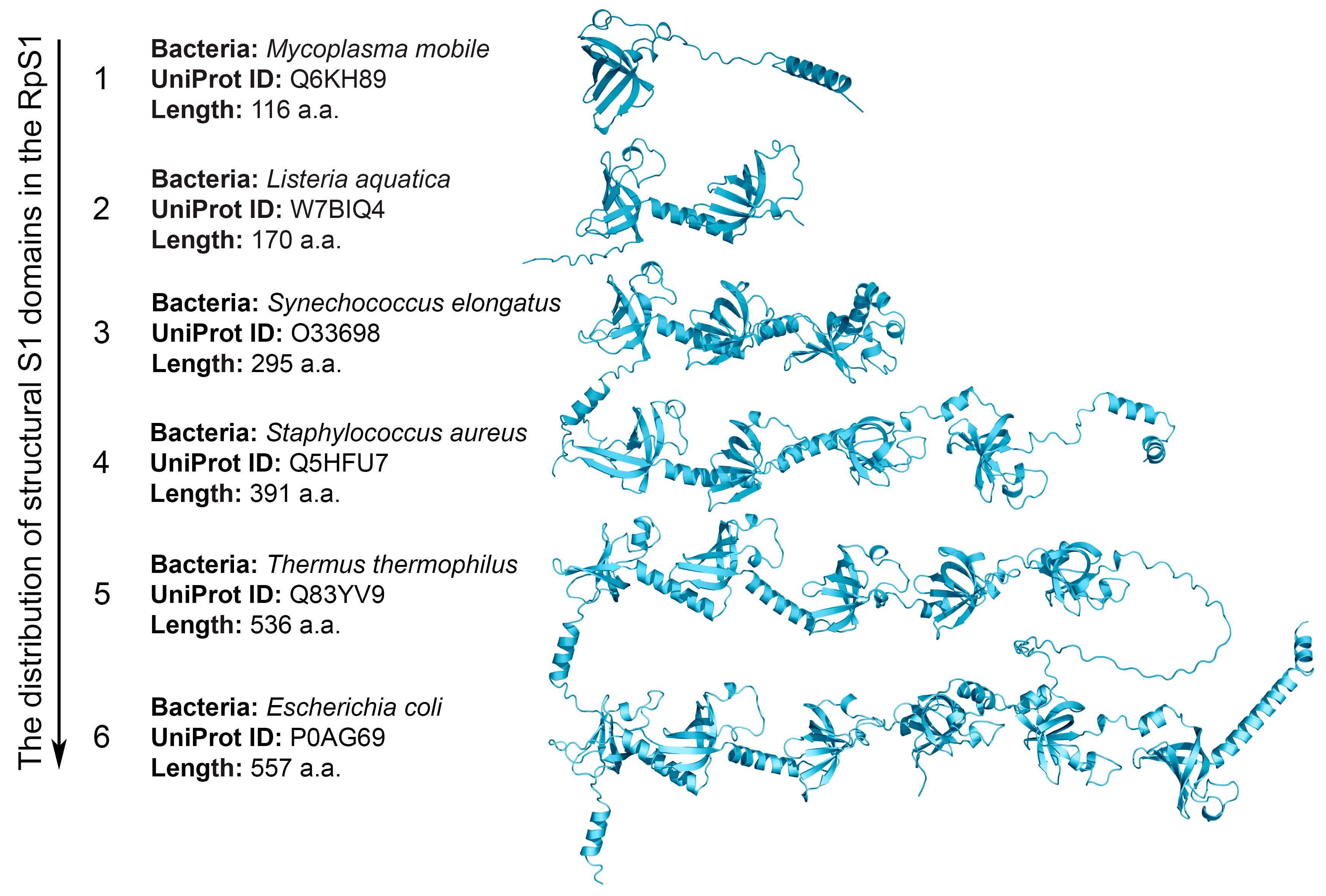
2.2. Structural S1 Domain Repeats
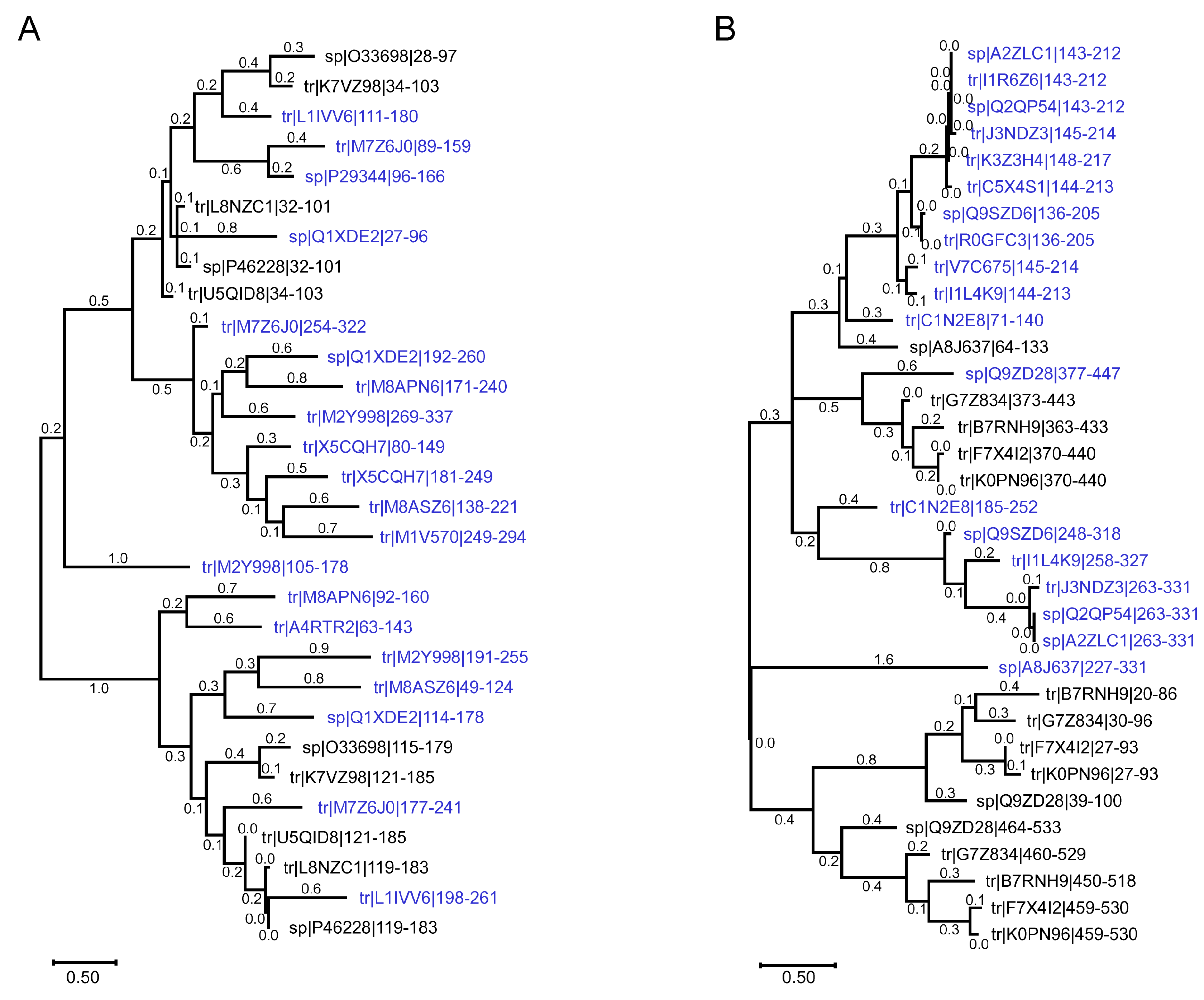
2.3. Chloroplast Ribosomal Protein S1
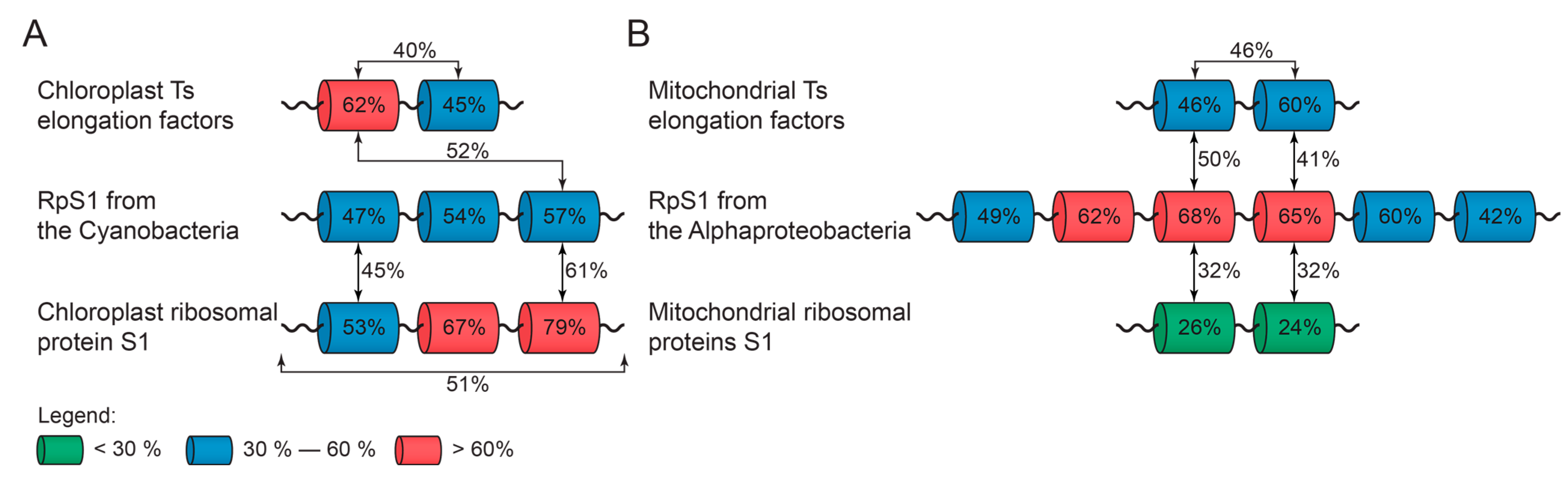
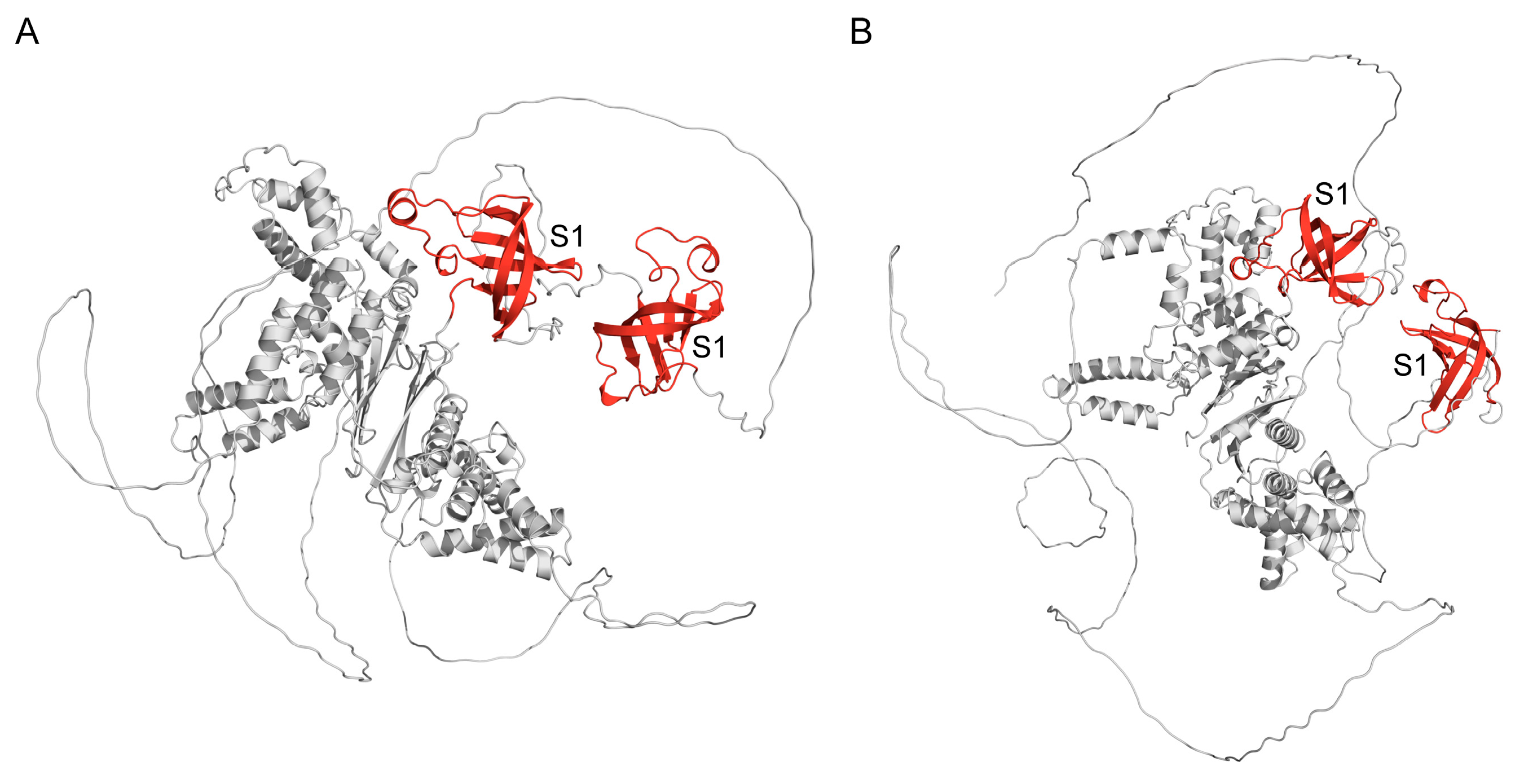
2.4. Elongation Factor Ts
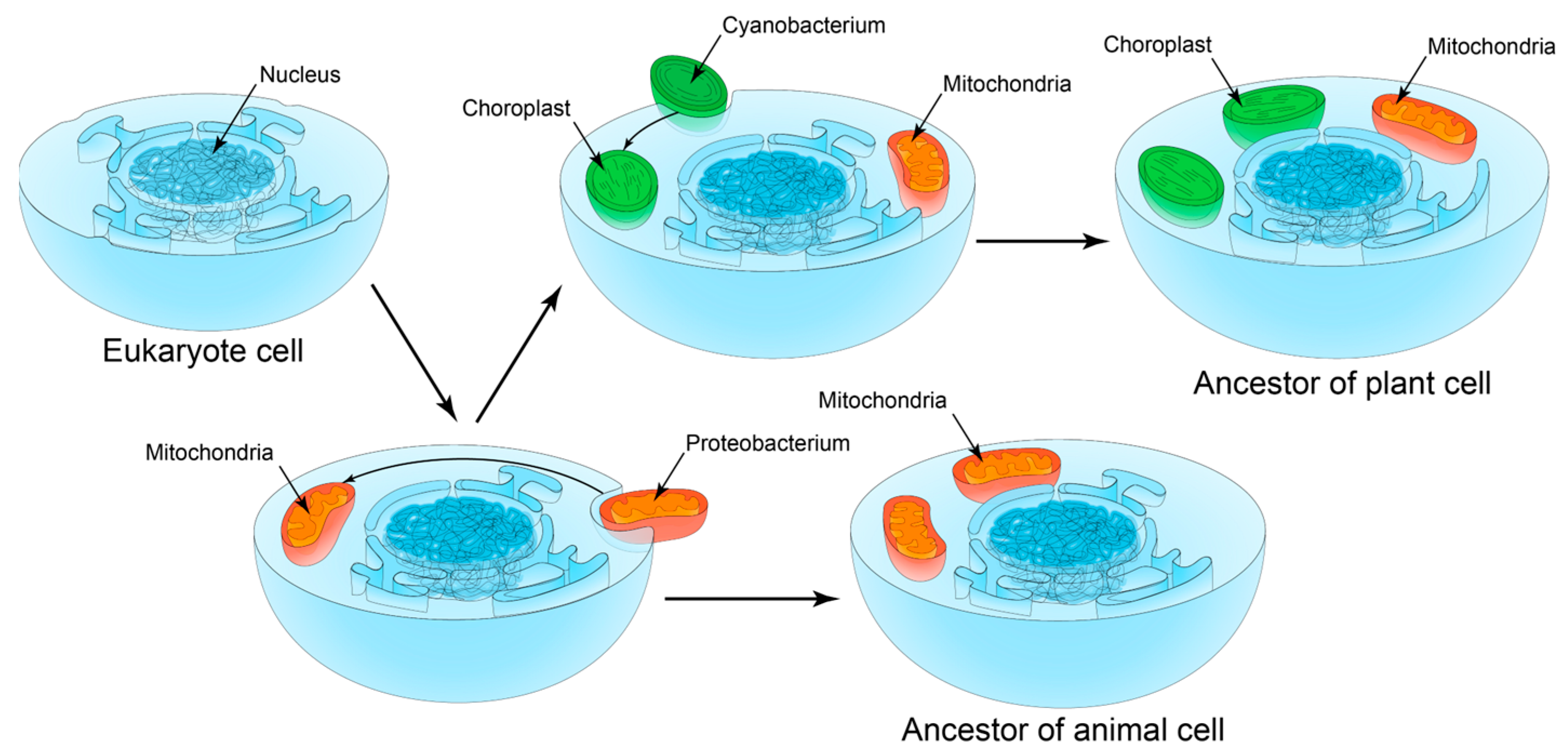
2.5. S1 Domain as One Evolutionary Marker of Symbiogenesis
3. Materials and Methods
3.1. Distribution of Proteins Containing the S1 Domain Among the Three Domains of Life
3.2. Number of Structural Repeats in Proteins
3.3. Realization
3.4. Alignment and Analysis of Sequences
3.5. Taxonomic Diversity
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Murzin, A.G. OB(oligonucleotide/oligosaccharide binding)-fold: Common structural and functional solution for non-homologous sequences. EMBO J. 1993, 12, 861–867. [Google Scholar] [CrossRef] [PubMed]
- Agrawal, V.; Kishan, K.V.R. OB-fold: Growing bigger with functional consistency. Curr. Protein Pept. Sci. 2003, 4, 195–206. [Google Scholar] [CrossRef] [PubMed]
- Deryusheva, E.I.; Machulin, A.V.; Selivanova, O.M.; Galzitskaya, O.V. Taxonomic distribution, repeats, and functions of the S1 domain-containing proteins as members of the OB-fold family. Proteins 2017, 85, 602–613. [Google Scholar] [CrossRef] [PubMed]
- Gribskov, M. Translational initiation factors IF-1 and eIF-2 alpha share an RNA-binding motif with prokaryotic ribosomal protein S1 and polynucleotide phosphorylase. Gene 1992, 119, 107–111. [Google Scholar] [CrossRef] [PubMed]
- Bycroft, M.; Hubbard, T.J.; Proctor, M.; Freund, S.M.; Murzin, A.G. The solution structure of the S1 RNA binding domain: A member of an ancient nucleic acid-binding fold. Cell 1997, 88, 235–242. [Google Scholar] [CrossRef] [PubMed]
- de Boer, P.; Vos, H.R.; Faber, A.W.; Vos, J.C.; Raué, H.A. Rrp5p, a trans-acting factor in yeast ribosome biogenesis, is an RNA-binding protein with a pronounced preference for U-rich sequences. RNA 2006, 12, 263–271. [Google Scholar] [CrossRef]
- Wower, I.K.; Zwieb, C.W.; Guven, S.A.; Wower, J. Binding and cross-linking of tmRNA to ribosomal protein S1, on and off the Escherichia coli ribosome. EMBO J. 2000, 19, 6612–6621. [Google Scholar] [CrossRef]
- Kutlubaeva, Z.S.; Chetverina, E.V.; Chetverin, A.B. The Contribution of Ribosomal Protein S1 to the Structure and Function of Qβ Replicase. Acta Naturae 2017, 9, 26–30. [Google Scholar] [CrossRef]
- Hajnsdorf, E.; Boni, I. V Multiple activities of RNA-binding proteins S1 and Hfq. Biochimie 2012, 94, 1544–1553. [Google Scholar] [CrossRef]
- Machulin, A.; Deryusheva, E.; Lobanov, M.; Galzitskaya, O. Repeats in S1 proteins: Flexibility and tendency for intrinsic disorder. Int. J. Mol. Sci. 2019, 20, 2377. [Google Scholar] [CrossRef]
- Deryusheva, E.I.; Machulin, A.V.; Matyunin, M.A.; Galzitskaya, O.V. Investigation of the relationship between the S1 domain and its molecular functions derived from studies of the tertiary structure. Molecules 2019, 24, 3681. [Google Scholar] [CrossRef] [PubMed]
- Machulin, A.; Deryusheva, E.; Selivanova, O.; Galzitskaya, O. The number of domains in the ribosomal protein S1 as a hallmark of the phylogenetic grouping of bacteria. PLoS ONE 2019, 14, e0221370. [Google Scholar] [CrossRef] [PubMed]
- Deryusheva, E.; Machulin, A.; Matyunin, M.; Galzitskaya, O. Sequence and evolutionary analysis of bacterial ribosomal S1 proteins. Proteins 2021, 89, 1111–1124. [Google Scholar] [CrossRef] [PubMed]
- Lane, N. Serial endosymbiosis or singular event at the origin of eukaryotes? J. Theor. Biol. 2017, 434, 58–67. [Google Scholar] [CrossRef] [PubMed]
- Savinov, A.B. Autocenosis and democenosis as individual- and population-level ecological categories in terms of symbiogenesis and systems approach. Russ. J. Ecol. 2011, 42, 179–185. [Google Scholar] [CrossRef]
- Sánchez-Baracaldo, P.; Raven, J.A.; Pisani, D.; Knoll, A.H. Early photosynthetic eukaryotes inhabited low-salinity habitats. Proc. Natl. Acad. Sci. 2017, 114, E7737–E7745. [Google Scholar] [CrossRef]
- Zhou, K.; Zhang, C.; Xia, J.; Yun, P.; Wang, Y.; Ma, T.; Li, Z. Albino seedling lethality 4; Chloroplast 30S Ribosomal Protein S1 is Required for Chloroplast Ribosome Biogenesis and Early Chloroplast Development in Rice. Rice 2021, 14, 47. [Google Scholar] [CrossRef]
- Martijn, J.; Vosseberg, J.; Guy, L.; Offre, P.; Ettema, T.J.G. Deep mitochondrial origin outside the sampled alphaproteobacteria. Nature 2018, 557, 101–105. [Google Scholar] [CrossRef]
- Gray, M.W.; Burger, G.; Lang, B.F. Mitochondrial Evolution. Science 1999, 283, 1476–1481. [Google Scholar] [CrossRef]
- Benelli, D.; Londei, P. Translation initiation in Archaea: Conserved and domain-specific features. Biochem. Soc. Trans. 2011, 39, 89–93. [Google Scholar] [CrossRef]
- MacNeill, S.A. The archaeal RecJ-like proteins: Nucleases and ex-nucleases with diverse roles in replication and repair. Emerg. Top. Life Sci. 2018, 2, 493–501. [Google Scholar] [CrossRef] [PubMed]
- Korkhin, Y.; Unligil, U.M.; Littlefield, O.; Nelson, P.J.; Stuart, D.I.; Sigler, P.B.; Bell, S.D.; Abrescia, N.G.A. Evolution of complex RNA polymerases: The complete archaeal RNA polymerase structure. PLoS Biol. 2009, 7, e1000102. [Google Scholar] [CrossRef]
- Werner, F.; Eloranta, J.J.; Weinzierl, R.O. Archaeal RNA polymerase subunits F and P are bona fide homologs of eukaryotic RPB4 and RPB12. Nucleic Acids Res. 2000, 28, 4299–4305. [Google Scholar] [CrossRef] [PubMed]
- Januszyk, K.; Lima, C.D. The eukaryotic RNA exosome. Curr. Opin. Struct. Biol. 2014, 24, 132–140. [Google Scholar] [CrossRef] [PubMed]
- Carpousis, A.J. The Escherichia coli RNA degradosome: Structure, function and relationship in other ribonucleolytic multienzyme complexes. Biochem. Soc. Trans. 2002, 30, 150–155. [Google Scholar] [CrossRef]
- Salah, P.; Bisaglia, M.; Aliprandi, P.; Uzan, M.; Sizun, C.; Bontems, F. Probing the relationship between gram-negative and gram-positive S1 proteins by sequence analysis. Nucleic Acids Res. 2009, 37, 5578–5588. [Google Scholar] [CrossRef]
- Deryusheva, E.I.; Machulin, A.V.; Selivanova, O.M.; Serdyuk, I.N. The S1 ribosomal protein family contains a unique conservative domain. Mol. Biol. 2010, 44, 642–647. [Google Scholar] [CrossRef]
- Frazão, C.; McVey, C.E.; Amblar, M.; Barbas, A.; Vonrhein, C.; Arraiano, C.M.; Carrondo, M.A. Unravelling the dynamics of RNA degradation by ribonuclease II and its RNA-bound complex. Nature 2006, 443, 110–114. [Google Scholar] [CrossRef]
- Pérébaskine, N.; Thore, S.; Fribourg, S. Structural and interaction analysis of the Rrp5 C-terminal region. FEBS Open Bio 2018, 8, 1605–1614. [Google Scholar] [CrossRef]
- Zaremba-Niedzwiedzka, K.; Caceres, E.F.; Saw, J.H.; Bäckström, D.; Juzokaite, L.; Vancaester, E.; Seitz, K.W.; Anantharaman, K.; Starnawski, P.; Kjeldsen, K.U.; et al. Asgard archaea illuminate the origin of eukaryotic cellular complexity. Nature 2017, 541, 353–358. [Google Scholar] [CrossRef]
- Liu, Y.; Makarova, K.S.; Huang, W.-C.; Wolf, Y.I.; Nikolskaya, A.N.; Zhang, X.; Cai, M.; Zhang, C.-J.; Xu, W.; Luo, Z.; et al. Expanded diversity of Asgard archaea and their relationships with eukaryotes. Nature 2021, 593, 553–557. [Google Scholar] [CrossRef] [PubMed]
- Da Cunha, V.; Gaia, M.; Gadelle, D.; Nasir, A.; Forterre, P. Lokiarchaea are close relatives of Euryarchaeota, not bridging the gap between prokaryotes and eukaryotes. PLoS Genet. 2017, 13, e1006810. [Google Scholar] [CrossRef] [PubMed]
- Da Cunha, V.; Gaia, M.; Nasir, A.; Forterre, P. Asgard archaea do not close the debate about the universal tree of life topology. PLoS Genet. 2018, 14, e1007215. [Google Scholar] [CrossRef] [PubMed]
- Yutin, N.; Wolf, M.Y.; Wolf, Y.I.; Koonin, E. V The origins of phagocytosis and eukaryogenesis. Biol. Direct 2009, 4, 9. [Google Scholar] [CrossRef] [PubMed]
- Bremer, N.; Tria, F.D.K.; Skejo, J.; Garg, S.G.; Martin, W.F. Ancestral State Reconstructions Trace Mitochondria but Not Phagocytosis to the Last Eukaryotic Common Ancestor. Genome Biol. Evol. 2022, 14, evac079. [Google Scholar] [CrossRef]
- Esser, C.; Ahmadinejad, N.; Wiegand, C.; Rotte, C.; Sebastiani, F.; Gelius-Dietrich, G.; Henze, K.; Kretschmann, E.; Richly, E.; Leister, D.; et al. A genome phylogeny for mitochondria among alpha-proteobacteria and a predominantly eubacterial ancestry of yeast nuclear genes. Mol. Biol. Evol. 2004, 21, 1643–1660. [Google Scholar] [CrossRef]
- Thiergart, T.; Landan, G.; Schenk, M.; Dagan, T.; Martin, W.F. An evolutionary network of genes present in the eukaryote common ancestor polls genomes on eukaryotic and mitochondrial origin. Genome Biol. Evol. 2012, 4, 466–485. [Google Scholar] [CrossRef]
- Pisani, D.; Cotton, J.A.; McInerney, J.O. Supertrees disentangle the chimerical origin of eukaryotic genomes. Mol. Biol. Evol. 2007, 24, 1752–1760. [Google Scholar] [CrossRef]
- Rivera, M.C.; Lake, J.A. The ring of life provides evidence for a genome fusion origin of eukaryotes. Nature 2004, 431, 152–155. [Google Scholar] [CrossRef]
- Kustatscher, G.; Collins, T.; Gingras, A.-C.; Guo, T.; Hermjakob, H.; Ideker, T.; Lilley, K.S.; Lundberg, E.; Marcotte, E.M.; Ralser, M.; et al. Understudied proteins: Opportunities and challenges for functional proteomics. Nat. Methods 2022, 19, 774–779. [Google Scholar] [CrossRef]
- Andrade, M.A.; Perez-Iratxeta, C.; Ponting, C.P. Protein repeats: Structures, functions, and evolution. J. Struct. Biol. 2001, 134, 117–131. [Google Scholar] [CrossRef] [PubMed]
- Deryusheva, E.; Machulin, A.; Galzitskaya, O. Structural, functional, and evolutionary characteristics of proteins with repeats. Mol. Biol. 2021, 55, 748–775. [Google Scholar] [CrossRef]
- Delucchi, M.; Schaper, E.; Sachenkova, O.; Elofsson, A.; Anisimova, M. A new census of protein tandem repeats and their relationship with intrinsic disorder. Genes 2020, 11, 407. [Google Scholar] [CrossRef] [PubMed]
- Bilgin Sonay, T.; Koletou, M.; Wagner, A. A survey of tandem repeat instabilities and associated gene expression changes in 35 colorectal cancers. BMC Genom. 2015, 16, 702. [Google Scholar] [CrossRef] [PubMed]
- Theriot, J.A. Why are bacteria different from eukaryotes? BMC Biol. 2013, 11, 119. [Google Scholar] [CrossRef]
- Björklund, A.K.; Ekman, D.; Elofsson, A. Expansion of protein domain repeats. PLoS Comput. Biol. 2006, 2, e114. [Google Scholar] [CrossRef]
- Dvořák, P.; Casamatta, D.A.; Poulíčková, A.; Hašler, P.; Ondřej, V.; Sanges, R. Synechococcus: 3 billion years of global dominance. Mol. Ecol. 2014, 23, 5538–5551. [Google Scholar] [CrossRef]
- Palenik, B.; Brahamsha, B.; Larimer, F.W.; Land, M.; Hauser, L.; Chain, P.; Lamerdin, J.; Regala, W.; Allen, E.E.; McCarren, J.; et al. The genome of a motile marine Synechococcus. Nature 2003, 424, 1037–1042. [Google Scholar] [CrossRef]
- Derelle, R.; Lang, B.F. Rooting the Eukaryotic Tree with Mitochondrial and Bacterial Proteins. Mol. Biol. Evol. 2012, 29, 1277–1289. [Google Scholar] [CrossRef]
- Cai, Y.C.; Bullard, J.M.; Thompson, N.L.; Spremulli, L.L. Interaction of mitochondrial elongation factor Tu with aminoacyl-tRNA and elongation factor Ts. J. Biol. Chem. 2000, 275, 20308–20314. [Google Scholar] [CrossRef]
- Cristodero, M.; Mani, J.; Oeljeklaus, S.; Aeberhard, L.; Hashimi, H.; Ramrath, D.J.F.; Lukeš, J.; Warscheid, B.; Schneider, A. Mitochondrial translation factors of Trypanosoma brucei: Elongation factor-Tu has a unique subdomain that is essential for its function. Mol. Microbiol. 2013, 90, 744–755. [Google Scholar] [CrossRef] [PubMed]
- Sagan, L. On the origin of mitosing cells. J. Theor. Biol. 1967, 14, 225–274. [Google Scholar] [CrossRef] [PubMed]
- Guerrero, R.; Margulis, L.; Berlanga, M. Symbiogenesis: The holobiont as a unit of evolution. Int. Microbiol. 2013, 16, 133–143. [Google Scholar] [CrossRef] [PubMed]
- Cavalier-Smith, T. Chloroplast Evolution: Secondary Symbiogenesis and Multiple Losses. Curr. Biol. 2002, 12, R62–R64. [Google Scholar] [CrossRef] [PubMed]
- Kloesges, T.; Popa, O.; Martin, W.; Dagan, T. Networks of Gene Sharing among 329 Proteobacterial Genomes Reveal Differences in Lateral Gene Transfer Frequency at Different Phylogenetic Depths. Mol. Biol. Evol. 2011, 28, 1057–1074. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, M. Phylogenomic Reconstruction Indicates Mitochondrial Ancestor Was an Energy Parasite. PLoS ONE 2014, 9, e110685. [Google Scholar] [CrossRef]
- Keeling, P.J. The Number, Speed, and Impact of Plastid Endosymbioses in Eukaryotic Evolution. Annu. Rev. Plant Biol. 2013, 64, 583–607. [Google Scholar] [CrossRef]
- Douzery, E.J.P.; Snell, E.A.; Bapteste, E.; Delsuc, F.; Philippe, H. The timing of eukaryotic evolution: Does a relaxed molecular clock reconcile proteins and fossils? Proc. Natl. Acad. Sci. USA 2004, 101, 15386–15391. [Google Scholar] [CrossRef]
- Arcus, V. OB-fold domains: A snapshot of the evolution of sequence, structure and function. Curr. Opin. Struct. Biol. 2002, 12, 794–801. [Google Scholar] [CrossRef]
- Bianco, P.R. OB-fold Families of Genome Guardians: A Universal Theme Constructed from the Small β-barrel Building Block. Front. Mol. Biosci. 2022, 9, 784451. [Google Scholar] [CrossRef]
- Amir, M.; Alam, A.; Ishrat, R.; Alajmi, M.F.; Hussain, A.; Rehman, M.T.; Islam, A.; Ahmad, F.; Hassan, M.I.; Dohare, R. A Systems View of the Genome Guardians: Mapping the Signaling Circuitry Underlying Oligonucleotide/Oligosaccharide-Binding Fold Proteins. OMICS J. Integr. Biol. 2020, 24, 518–530. [Google Scholar] [CrossRef] [PubMed]
- Neimark, H. Phylogenetic relationships between mycoplasmas and other prokaryotes. Mycoplasmas 1979, 1, 43–61. [Google Scholar]
- Koonin, E. V Origin of eukaryotes from within archaea, archaeal eukaryome and bursts of gene gain: Eukaryogenesis just made easier? Philos. Trans. R. Soc. Lond. B Biol. Sci. 2015, 370, 20140333. [Google Scholar] [CrossRef] [PubMed]
- Hulo, N.; Bairoch, A.; Bulliard, V.; Cerutti, L.; Cuche, B.A.; De Castro, E.; Lachaize, C.; Langendijk-Genevaux, P.S.; Sigrist, C.J.A. The 20 years of PROSITE. Nucleic Acids Res. 2008, 36, D245–D249. [Google Scholar] [CrossRef] [PubMed]
- Letunic, I.; Khedkar, S.; Bork, P. SMART: Recent updates, new developments and status in 2020. Nucleic Acids Res. 2021, 49, D458–D460. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain of Life | Number of Sequences Containing S1 Domain (Total Sequences) | Number of S1 Domains | Size of Proteins Containing the S1 Domain, a.a.r. | Name of the Shortest Protein (UniProt ID) | Name of the Longest Protein (UniProt ID) |
|---|---|---|---|---|---|
| Archaea | 1162 (1162) | 1 | 79–896 | Translation initiation factor IF-2 subunit alpha (D2EE74) | Archaea-specific RecJ-like exonuclease, contains DnaJ-type Zn finger domain protein (V4XD76) |
| Bacteria | 19,137 (24,142) | 1 | 36–1596 | RNA-binding S1 domain-containing protein (F3MV04) | Rne/Rng family ribonuclease (S3BLZ2) |
| 354 (24,142) | 2 | 113–2058 | Ribosomal protein S1 (F8XLB3) | Uncharacterized protein (W2CTN3) | |
| 449 (24,142) | 3 | 183–1864 | 30S ribosomal protein S1 (S2RAG1) | Uncharacterized protein (I9IS49) | |
| 1777 (24,142) | 4 | 279–850 | 30S ribosomal protein S1 (U5U0V0) | 4-hydroxy-3-methylbut-2-enyl diphosphate reductase (F9VK01) | |
| 418 (24,142) | 5 | 378–1008 | 30S ribosomal protein S1 (P14128) | RNA-binding S1 domain protein (F0S7A1) | |
| 2002 (24,142) | 6 | 485–932 | 30S ribosomal protein S1 (Q4ECF4) | 30S ribosomal protein S1 (B0VI92) | |
| 4 (24,142) | 7 | 600 | RNA-binding S1 domain protein (C7NE91) | ||
| 1 (24,142) | 8 | 681 | RNA-binding S1 domain protein (D1AGH2) | ||
| Eukaryota | 2486 (3263) | 1 | 52–3347 | Eukaryotic translation initiation factor 2 subunit 1 (P83268) | Ubiquitinyl hydrolase 1 (T1J6G6) |
| 247 (3263) | 2 | 99–2273 | Chloroplast ribosomal protein S1 (A1BQM4) | RNA helicase (T1IZH9) | |
| 111 (3263) | 3 | 263–3075 | 30S ribosomal protein S1, chloroplastic (Q1XDE2) | Pre-rRNA processing protein (F0VM47) | |
| 22 (3263) | 4 | 341–2871 | Uncharacterized protein (B9G786) | Pre-rRNA processing protein (S7W597) | |
| 22 (3263) | 5 | 812–2865 | Uncharacterized protein (F0ZDF8) | Pre-rRNA processing protein (S8GF05) | |
| 12 (3263) | 6 | 561–2366 | 30S ribosomal protein S1 (M3TEP3) | Uncharacterized protein (K0SL12) | |
| 10 (3263) | 7 | 861–1835 | Uncharacterized protein (I1BSM3) | Uncharacterized protein (R1E487) | |
| 21 (3263) | 8 | 771–2032 | cDNA FLJ61218, highly similar to RRP5 protein homolog (B4DES7) | Programmed cell death 11, putative (G0QXP6) | |
| 18 (3263) | 9 | 1210–2130 | rRNA biogenesis protein RRP5 (H1VL07) | Protein RRP5-like protein (S9WVU3) | |
| 49 (3263) | 10 | 1427–2437 | LOC779090 protein (A0JMT9) | Protein RRP5 like protein (M7BPG8) | |
| 135 (3263) | 11 | 1300–2245 | Part of small ribosomal subunit processosome (Contains u3 snorna) (I2K1K0) | Rrna biogenesis protein rrp5 (W7TCI2) | |
| 99 (3263) | 12 | 1431–2229 | Protein RRP5 homolog (H9EZV6) | Predicted protein (C1NA95) | |
| 17 (3263) | 13 | 1592–2018 | Uncharacterized protein (L1JFG5) | Uncharacterized protein (C1ECK5) | |
| 12 (3263) | 14 | 1789–2077 | Uncharacterized protein (R0G309) | Uncharacterized protein (K8EKT3) | |
| 2 (3263) | 15 | 1869–2384 | Uncharacterized protein (A4S384) | (spotted green pufferfish) hypothetical protein (Q4S7N9) |
| UniProt ID | Protein Name | Protein Size, a.a.r. | Number of S1 Domains | Source | Phylum, Class |
|---|---|---|---|---|---|
| Ribosomal protein S1 | |||||
| X5CQH7 | 30S plastidal ribosomal protein S1 | 329 | 2 | Tisochrysis lutea | Haptophyta |
| M2Y998 | 30S ribosomal protein S1 (Plastid) | 391 | 3 | Galdieria sulphuraria | Rhodophyta |
| M2XXH5 | 30S ribosomal protein S1 (Plastid) | 523 | 3 | Galdieria sulphuraria | Rhodophyta |
| M8CHE3 | 30S ribosomal protein S1, chloroplastic | 155 | 1 | Aegilops tauschii | Streptophyta |
| M7Z587 | 30S ribosomal protein S1, chloroplastic | 155 | 1 | Triticum urartu | Streptophyta |
| Q1XDE2 | 30S ribosomal protein S1, chloroplastic | 263 | 3 | Neopyropia yezoensis | Rhodophyta |
| P51345 | 30S ribosomal protein S1, chloroplastic | 263 | 3 | Porphyra purpurea | Rhodophyta |
| R7WGF8 | 30S ribosomal protein S1, chloroplastic | 268 | 1 | Aegilops tauschii | Streptophyta |
| M8APN6 | 30S ribosomal protein S1, chloroplastic | 324 | 2 | Triticum urartu | Streptophyta |
| M8ASZ6 | 30S ribosomal protein S1, chloroplastic | 343 | 2 | Triticum urartu | Streptophyta |
| M8CDW9 | 30S ribosomal protein S1, chloroplastic | 398 | 3 | Aegilops tauschii | Streptophyta |
| M7Z6J0 | 30S ribosomal protein S1, chloroplastic | 398 | 3 | Triticum urartu | Streptophyta |
| P29344 | 30S ribosomal protein S1, chloroplastic | 411 | 3 | Spinacia oleracea | Streptophyta |
| M0ZL57 | 30S ribosomal protein S1, chloroplastic | 411 | 3 | Solanum tuberosum | Streptophyta |
| M1A029 | 30S ribosomal protein S1, chloroplastic | 415 | 3 | Solanum tuberosum | Streptophyta |
| Q93VC7 | 30S ribosomal protein S1, chloroplastic | 416 | 3 | Arabidopsis thaliana | Streptophyta |
| W0RYL6 | Chloroplast 30S ribosomal protein S1 | 263 | 3 | Porphyridium purpureum | Rhodophyta |
| M1VII4 | Chloroplast ribosomal protein S1 | 447 | 3 | Cyanidioschyzon merolae | Rhodophyta |
| L1IVV6 | Ribosomal protein S1, chloroplastic | 404 | 3 | Guillardia theta | Cryptophyceae |
| M1V570 | Mitochondrial ribosomal protein S1 | 424 | 2 | Cyanidioschyzon merolae | Rhodophyta |
| A4RTR2 | Putative mitochondrial ribosomal protein S1 | 352 | 2 | Ostreococcus lucimarinus | Chlorophyta |
| Elongation factor Ts | |||||
| Q9SZD6 | Elongation factor Ts, chloroplastic | 953 | 2 | Arabidopsis thaliana | Streptophyta |
| Q2QP54 | Elongation factor Ts, chloroplastic | 1123 | 2 | Oryza sativa subsp. japonica | Streptophyta |
| A8J637 | Elongation factor Ts, chloroplastic | 1013 | 2 | Chlamydomonas reinhardtii | Chlorophyta |
| A2ZLC1 | Elongation factor Ts, chloroplastic | 1123 | 2 | Oryza sativa subsp. indica | Streptophyta |
| K3Z3H4 | Elongation factor Ts, mitochondrial | 988 | 2 | Setaria italica | Streptophyta |
| I1HXX8 | Elongation factor Ts, mitochondrial | 962 | 2 | Brachypodium distachyon | Streptophyta |
| C1N2E8 | Elongation factor Ts, mitochondrial | 844 | 2 | Micromonas pusilla | Chlorophyta |
| A9SG13 | Elongation factor Ts, mitochondrial | 899 | 2 | Physcomitrium patens | Streptophyta |
| W1NPM5 | Elongation factor Ts, mitochondrial | 1164 | 2 | Amborella trichopoda | Streptophyta |
| R0GFC3 | Elongation factor Ts, mitochondrial | 953 | 2 | Capsella rubella | Streptophyta |
| F6HH07 | Elongation factor Ts, mitochondrial | 1135 | 2 | Vitis vinifera | Streptophyta |
| I1R6Z6 | Elongation factor Ts, mitochondrial | 1123 | 2 | Oryza glaberrima | Streptophyta |
| B9RKL9 | Elongation factor Ts, mitochondrial | 972 | 2 | Ricinus communis | Streptophyta |
| M4D3M7 | Elongation factor Ts, mitochondrial | 1770 | 2 | Brassica rapa subsp. pekinensis | Streptophyta |
| I1L4K9 | Elongation factor Ts, mitochondrial | 1135 | 2 | Glycine max | Streptophyta |
| R7W2H4 | Elongation factor Ts, mitochondrial | 937 | 2 | Aegilops tauschii | Streptophyta |
| M5VUX8 | Elongation factor Ts, mitochondrial | 1010 | 2 | Prunus persic | Streptophyta |
| J3NDZ3 | Elongation factor Ts, mitochondrial | 1200 | 2 | Oryza brachyantha | Streptophyta |
| C1DZB9 | Elongation factor Ts, mitochondrial | 876 | 2 | Micromonas commoda | Chlorophyta |
| G7KPU0 | Elongation factor Ts, mitochondrial | 1054 | 2 | Medicago truncatula | Streptophyta |
| C5X4S1 | Elongation factor Ts, mitochondrial | 937 | 2 | Sorghum bicolor | Streptophyta |
| K8EFG1 | Elongation factor Ts, mitochondrial | 831 | 2 | Bathycoccus prasinos | Chlorophyta |
| M0ZU44 | Elongation factor Ts, mitochondrial | 1050 | 2 | Solanum tuberosum | Streptophyta |
| V7C675 | Elongation factor Ts, mitochondrial | 1134 | 2 | Phaseolus vulgaris | Streptophyta |
| I1J7Z7 | Elongation factor Ts, mitochondrial | 1133 | 2 | Glycine max | Streptophyta |
| V4MGB9 | Elongation factor Ts, mitochondrial | 979 | 2 | Eutrema salsugineum | Streptophyta |
| M7YWW3 | Elongation factor Ts, mitochondrial | 987 | 2 | Triticum urartu | Streptophyta |
| V4UQR1 | Elongation factor Ts, mitochondrial | 902 | 2 | Citrus clementina | Streptophyta |
| W9SL34 | Elongation factor Ts, mitochondrial | 1060 | 2 | Morus notabilis | Streptophyta |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deryusheva, E.I.; Machulin, A.V.; Surin, A.A.; Kravchenko, S.V.; Surin, A.K.; Galzitskaya, O.V. RNA-Binding S1 Domain in Bacterial, Archaeal and Eukaryotic Proteins as One of the Evolutionary Markers of Symbiogenesis. Int. J. Mol. Sci. 2024, 25, 13057. https://doi.org/10.3390/ijms252313057
Deryusheva EI, Machulin AV, Surin AA, Kravchenko SV, Surin AK, Galzitskaya OV. RNA-Binding S1 Domain in Bacterial, Archaeal and Eukaryotic Proteins as One of the Evolutionary Markers of Symbiogenesis. International Journal of Molecular Sciences. 2024; 25(23):13057. https://doi.org/10.3390/ijms252313057
Chicago/Turabian StyleDeryusheva, Evgenia I., Andrey V. Machulin, Alexey A. Surin, Sergey V. Kravchenko, Alexey K. Surin, and Oxana V. Galzitskaya. 2024. "RNA-Binding S1 Domain in Bacterial, Archaeal and Eukaryotic Proteins as One of the Evolutionary Markers of Symbiogenesis" International Journal of Molecular Sciences 25, no. 23: 13057. https://doi.org/10.3390/ijms252313057
APA StyleDeryusheva, E. I., Machulin, A. V., Surin, A. A., Kravchenko, S. V., Surin, A. K., & Galzitskaya, O. V. (2024). RNA-Binding S1 Domain in Bacterial, Archaeal and Eukaryotic Proteins as One of the Evolutionary Markers of Symbiogenesis. International Journal of Molecular Sciences, 25(23), 13057. https://doi.org/10.3390/ijms252313057