
Real-Time Classification of Invasive Plant Seeds Based on Improved YOLOv5 with Attention Mechanism

 and
and
Abstract
:1. Introduction
2. Materials and Methods
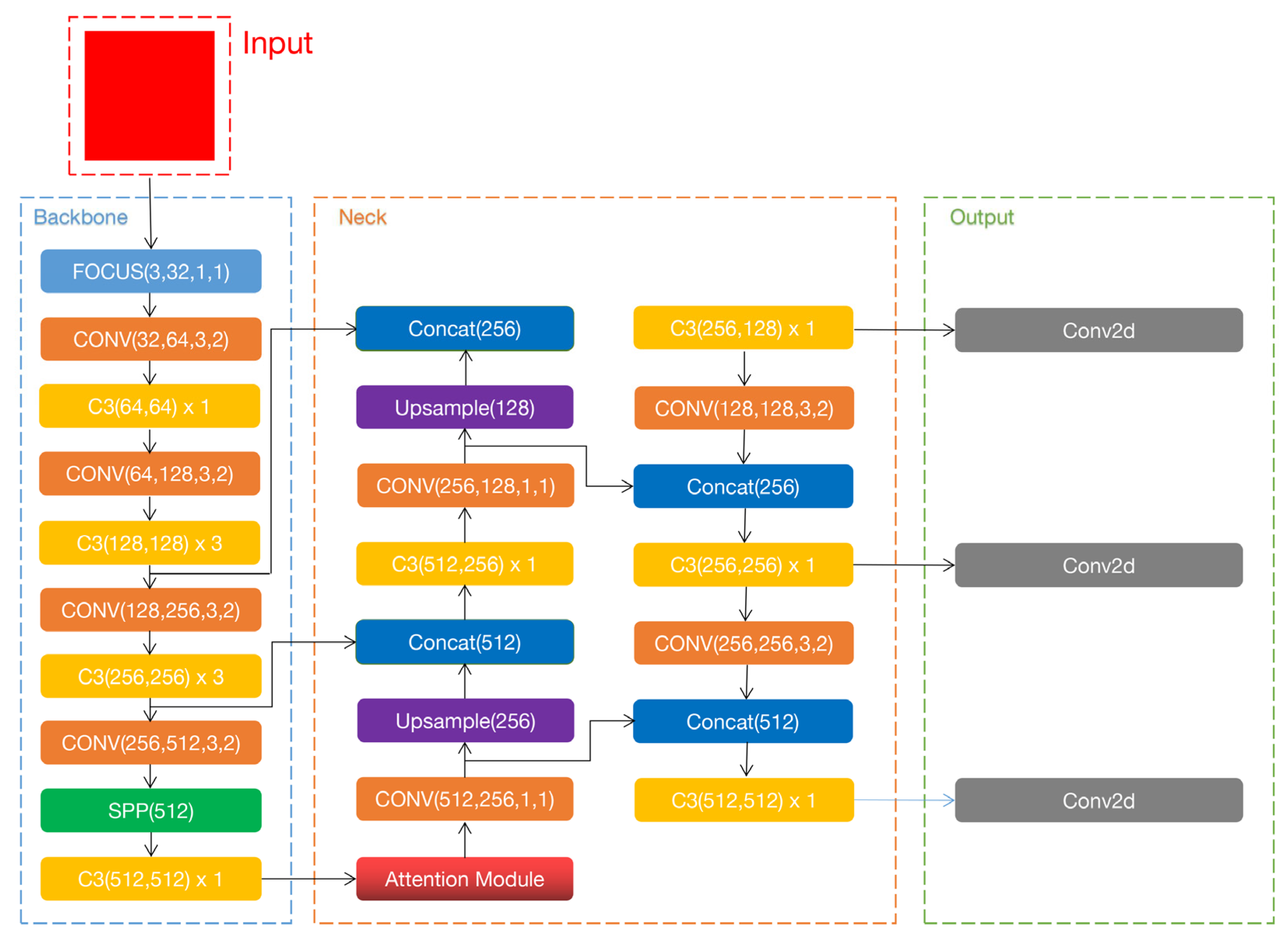
2.1. YOLOv5
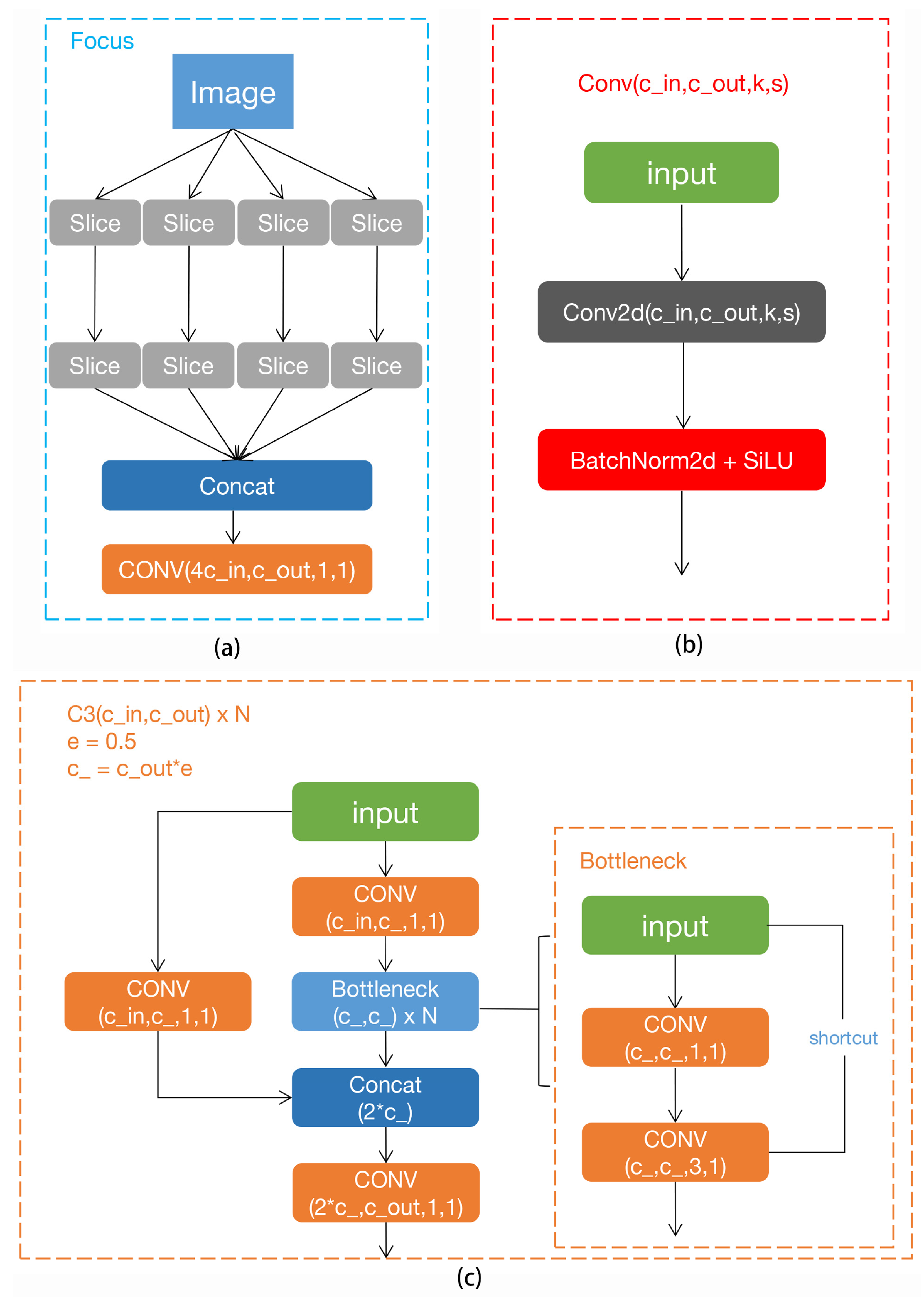
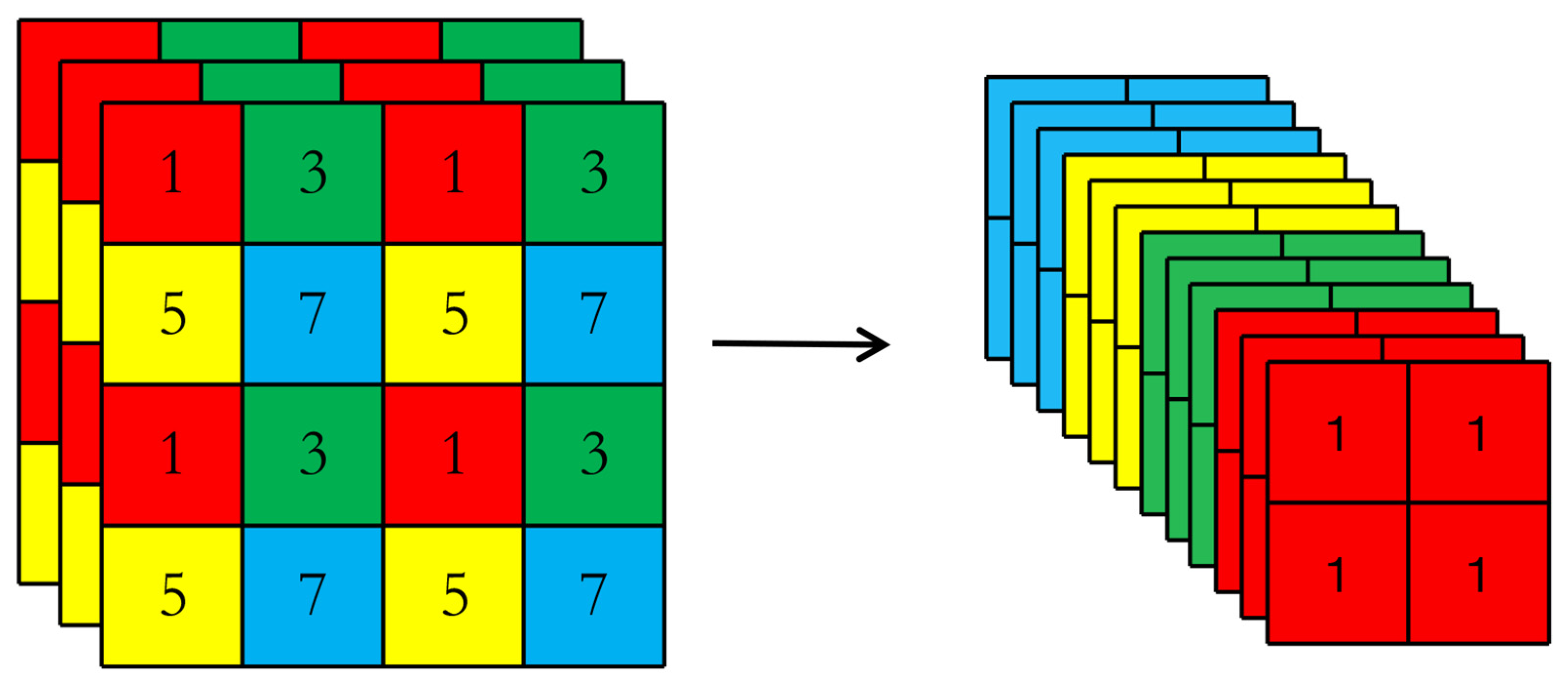
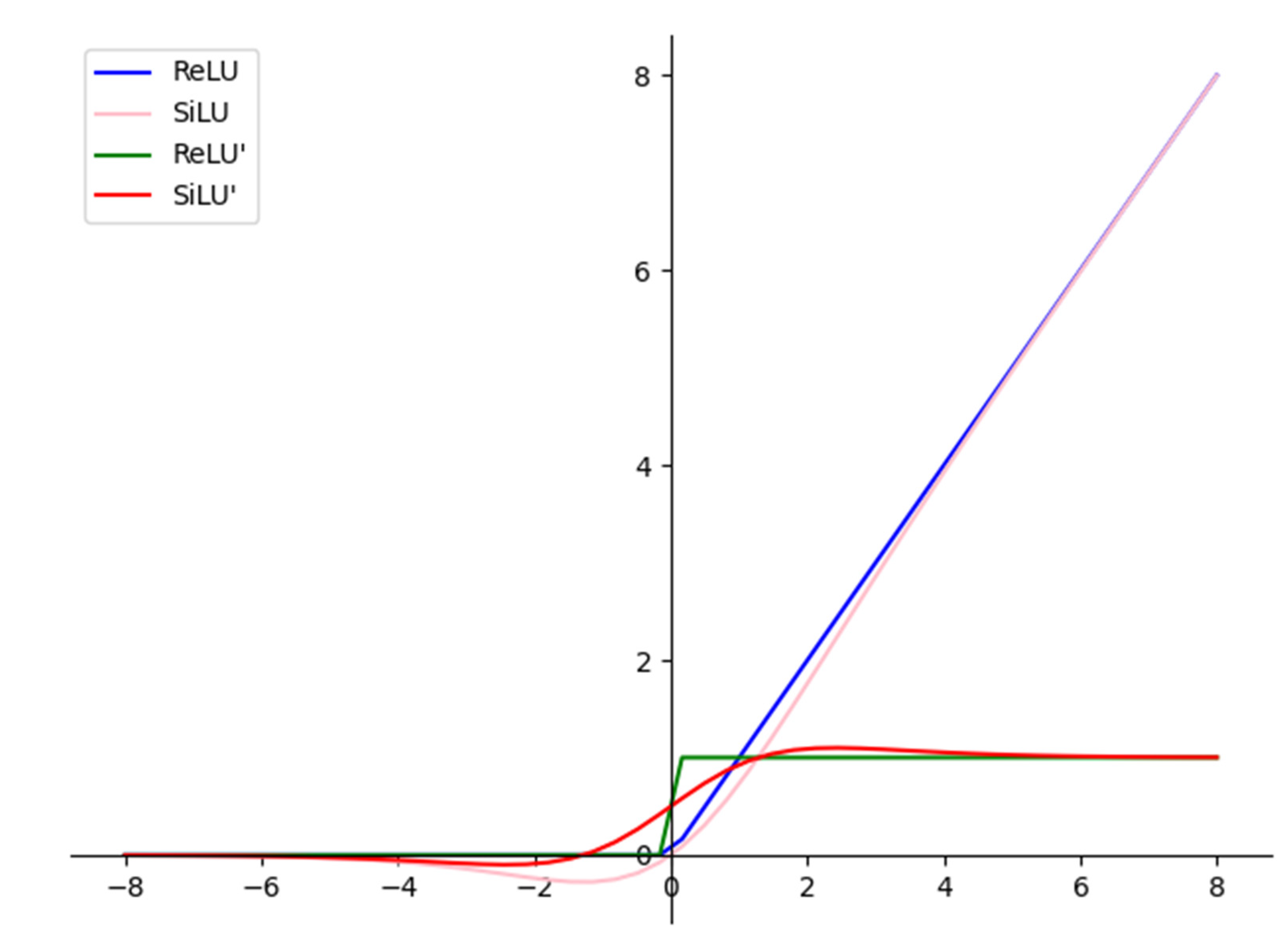
2.1.1. Input
2.1.2. Backbone
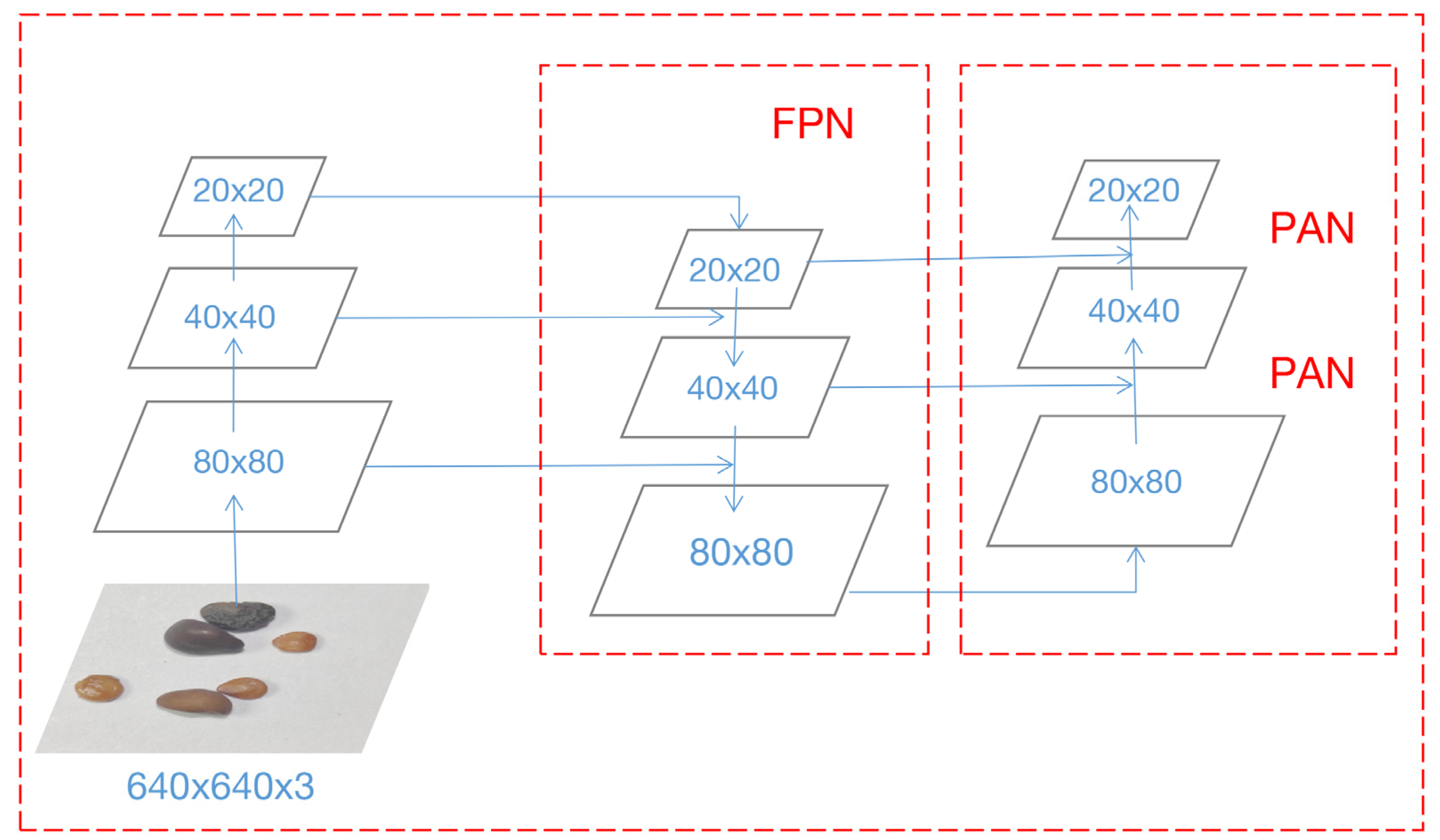
2.1.3. Neck
2.1.4. Output
2.2. Attention Mechanism
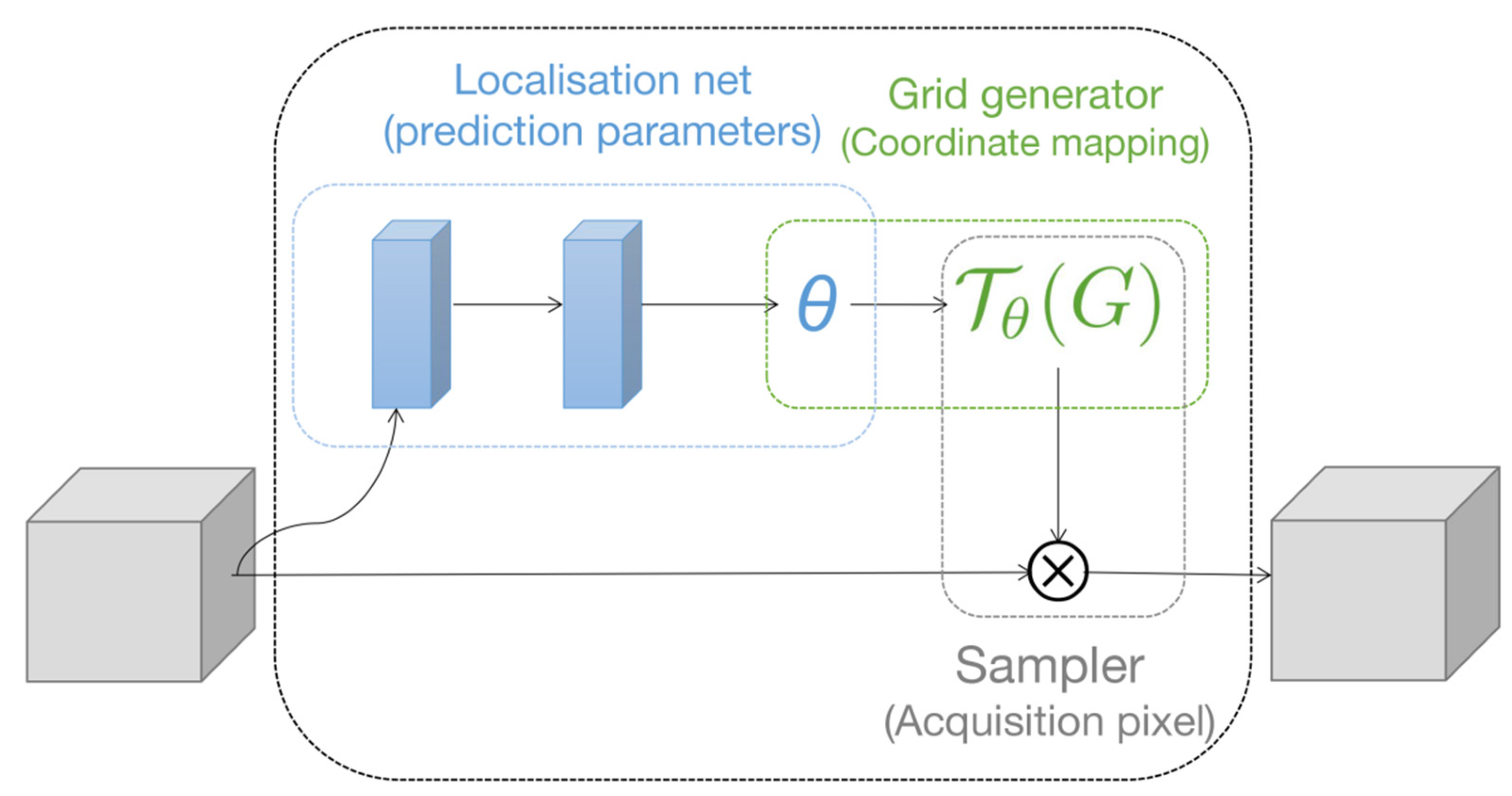
2.2.1. Spatial Attention Mechanism
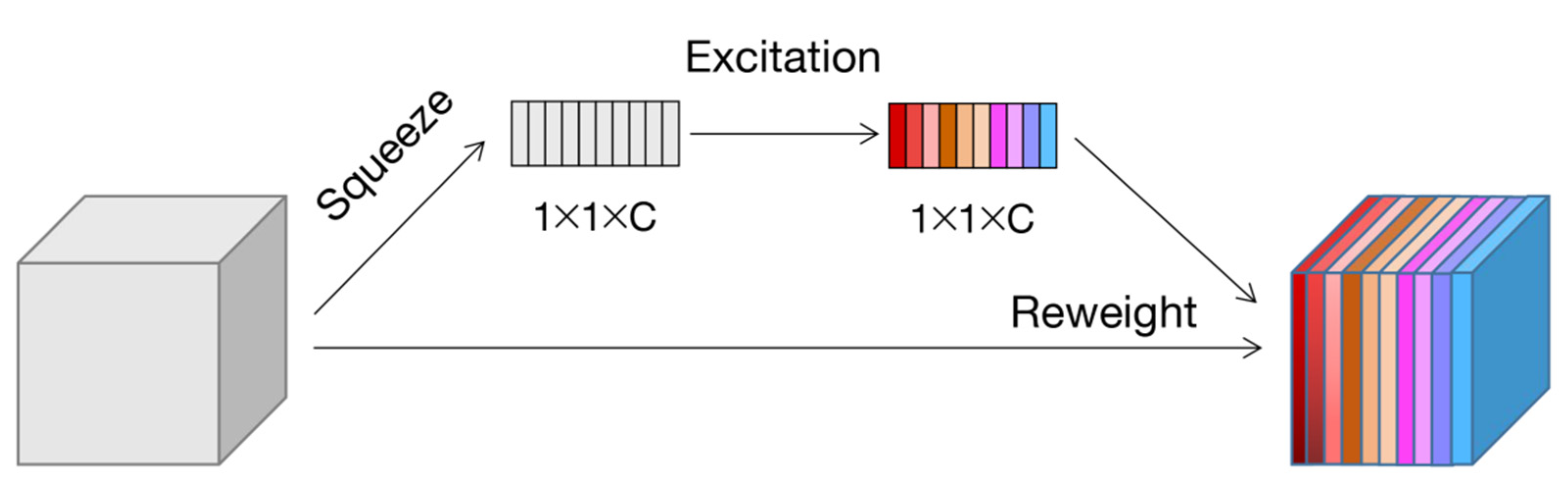
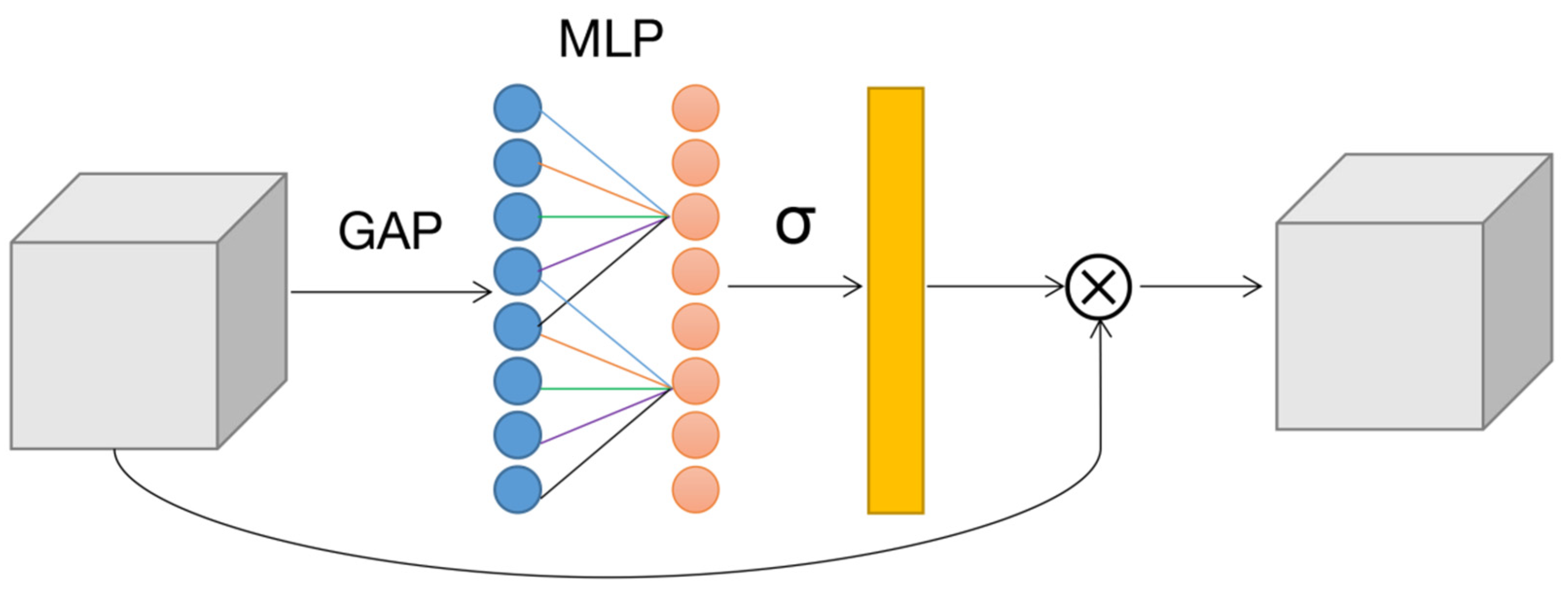
2.2.2. Channel Attention Mechanism
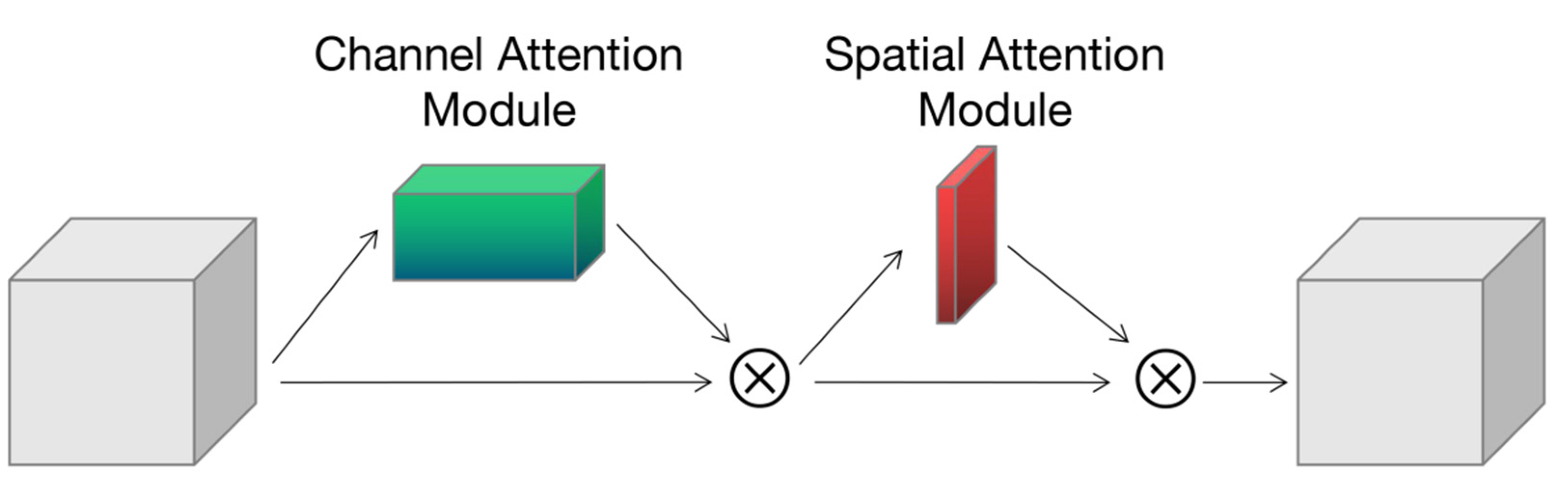
2.2.3. Mixed Attention Mechanism
3. Experiment
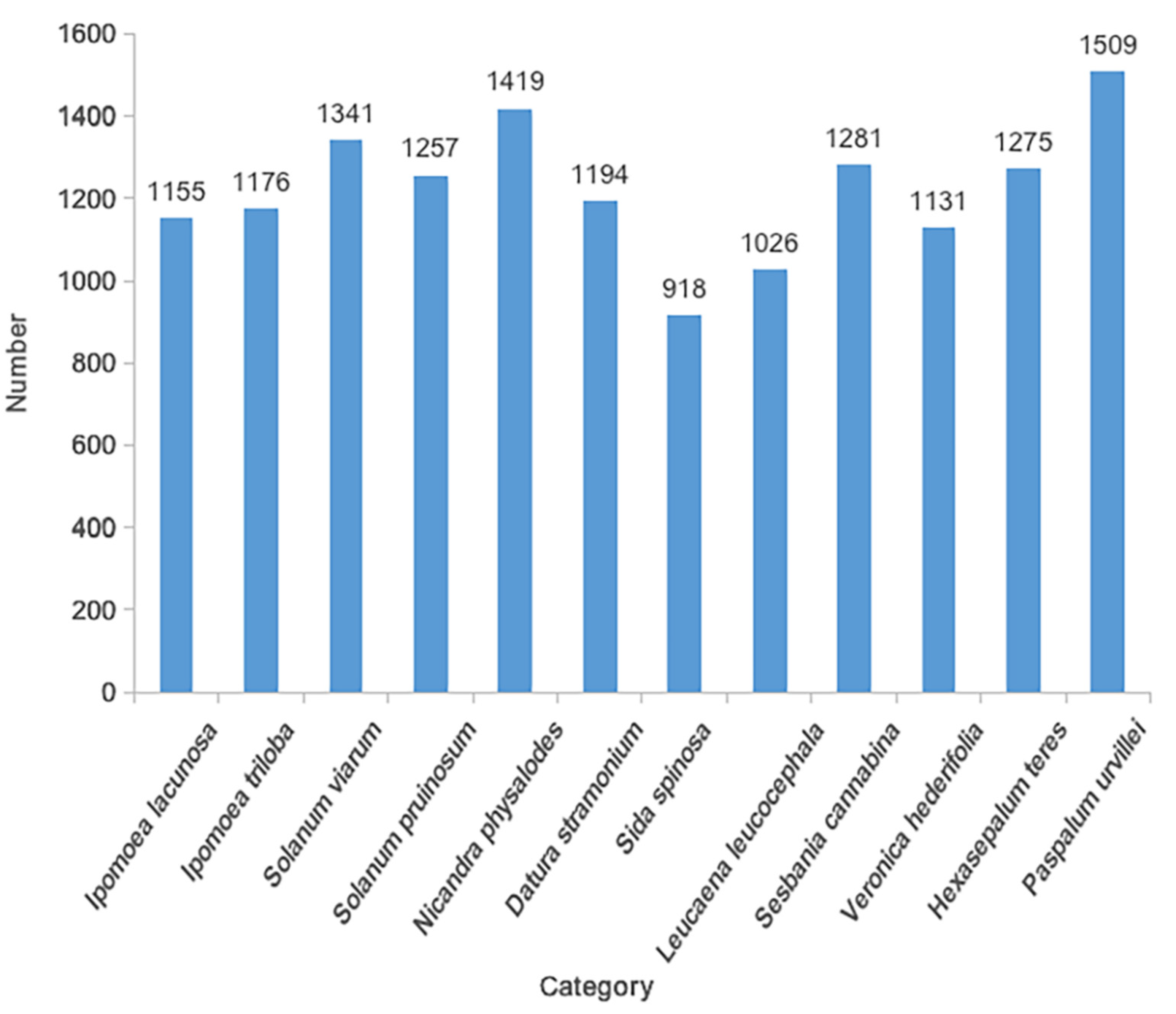
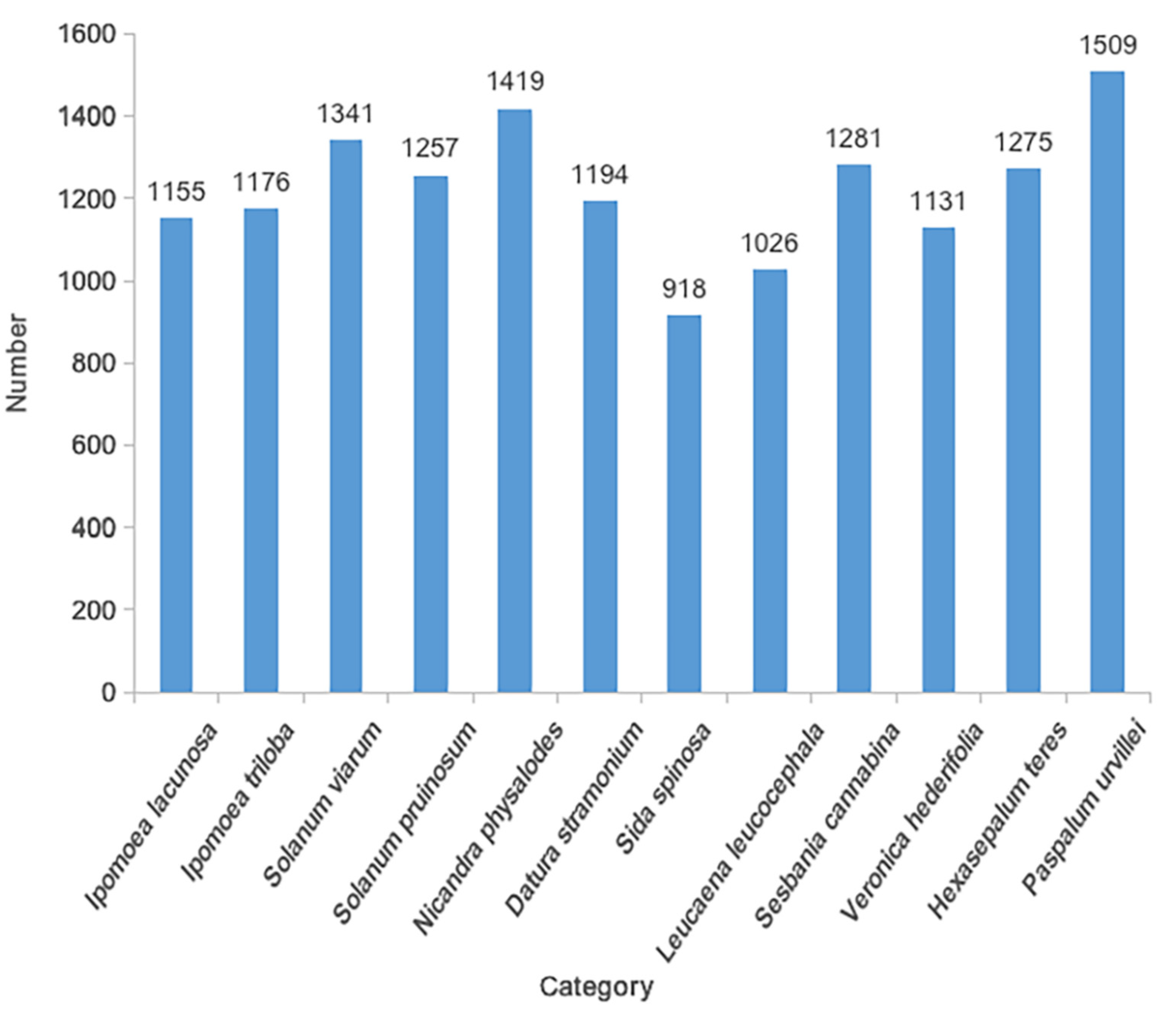
3.1. Invasive Plant Seed Data Set
3.2. Network Performance Evaluation
3.3. Experimental Implementations and Settings
3.4. Experimental Results and Analysis
4. Discussion
4.1. Potential Applications
4.2. Hyperparameter Exploration
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, H.; Qiang, S.; Han, Z.; Guo, J.; Huang, Z.; Sun, H.; He, S.; Ding, H.; Wu, H.; Wan, F. The status and causes of alien species invasion in China. Biodivers. Conserv. 2006, 15, 2893–2904. [Google Scholar] [CrossRef]
- Bulletin on China’s Ecological Environment in 2019. Available online: http://www.mee.gov.cn/hjzl/sthjzk/zghjzkgb/202006/P020200602509464172096.pdf (accessed on 1 April 2021).
- Zuo, Y.; Jiang, X.; Li, P.; Yu, W.D. Analysis of the present situation of intercepted weed seeds from American sorghum. J. Biosaf. 2017, 26, 307–310. [Google Scholar]
- Chtioui, Y.; Bertrand, D.; Dattée, Y.; Devaux, M.F. Identification of seeds by colour imaging: Comparison of discriminant analysis and artificial neural network. J. Sci. Food Agric. 1996, 71, 433–441. [Google Scholar] [CrossRef]
- Krizhevsky, B.A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 12 December 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Javanmardi, S.; Miraei Ashtiani, S.H.; Verbeek, F.J.; Martynenko, A. Computer-vision classification of corn seed varieties using deep convolutional neural network. J. Stored Prod. Res. 2021, 92, 101800. [Google Scholar] [CrossRef]
- Luo, T.; Zhao, J.; Gu, Y.; Zhang, S.; Qiao, X.; Tian, W.; Han, Y. Classification of weed seeds based on visual images and deep learning. Inf. Process. Agric. 2021, 2214–3173. [Google Scholar] [CrossRef]
- Loddo, A.; Loddo, M.; Di Ruberto, C. A novel deep learning based approach for seed image classification and retrieval. Comput. Electron. Agric. 2021, 187, 106269. [Google Scholar] [CrossRef]
- Kundu, N.; Rani, G.; Dhaka, V.S. Seeds Classification and Quality Testing Using Deep Learning and YOLO v5. In Proceedings of the International Conference on Data Science, Machine Learning and Artificial Intelligence, New York, NY, USA, 9–12 August 2021; pp. 153–160. [Google Scholar]
- GitHub. YOLOV5-Master. 2021. Available online: https://github.com/ultralytics/yolov5.git/ (accessed on 1 January 2021).
- Common Objects in Context Dataset. Available online: https://cocodataset.org (accessed on 1 February 2021).
- Hamerly, G.; Elkan, C. Learning the k in k-means. Adv. Neural Inf. Process. Syst. 2004, 16, 281–288. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef]
- Xavier, G.; Antoine, B.; Yoshua, B. Deep Sparse Rectifier Neural Networks Xavier. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Wang, C.Y.; Mark Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Hong Kong, 5–12 September 2014; pp. 346–361. [Google Scholar]
- Rezatofighi, S.H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.D.; Savarese, S. Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression. arXiv 2019, arXiv:1902.09630. [Google Scholar]
- Sønderby, S.K.; Sønderby, C.K.; Maaløe, L.; Winther, O. Recurrent Spatial Transformer Networks. arXiv 2015, arXiv:1509.05329. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 18–21 June 2018; pp. 7132–7148. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14 June 2020. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 6 October 2018; pp. 3–19. [Google Scholar]
- GitHub. labelImg. 2021. Available online: https://github.com/tzutalin/labelImg.git/ (accessed on 1 February 2021).
- Zhu, L.; Geng, X.; Li, Z.; Liu, C. Improving yolov5 with attention mechanism for detecting boulders from planetary images. Remote Sens. 2021, 13, 3776. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, X.; Yan, J.; Qiu, X.; Yao, X.; Tian, Y.; Zhu, Y.; Cao, W. A Wheat Spike Detection Method in UAV Images Based on Improved YOLOv5. Remote Sens. 2021, 13, 3095. [Google Scholar] [CrossRef]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Configuration |
|---|---|
| OS | CentOS 7.9 |
| GPU | Tesla K80 (24GB) |
| CPU | Intel(R) Xeon(R) CPU E5-2690 v2@3.00GHz |
| Framework | Pytorch 1.7.1 |
| Data annotation | LabelImg |
| Visualization | Tensorboard |
| Scientific Name | Family | Genus | Length (mm) | Width (mm) | Height (mm) |
|---|---|---|---|---|---|
| Ipomoea lacunosa L. | Convolvulaceae | Ipomoea | 4 ± 0.3 | 3.5 ± 0.3 | 2.9 ± 0.4 |
| Ipomoea triloba L. | Convolvulaceae | Ipomoea | 4.1 ± 0.5 | 3.1 ± 0.3 | 2.5 ± 0.3 |
| Solanum viarum Dunal | Solanaceae | Solanum | 2.3 ± 0.1 | 2 ± 0.1 | 0.7 ± 0.1 |
| Solanum pruinosum Dunal | Solanaceae | Solanum | 3 ± 0.2 | 2.3 ± 0.2 | 0.9 ± 0.1 |
| Nicandra physalodes (L.) Gaertner | Solanaceae | Nicandra | 1.7 ± 0.2 | 1.6 ± 0.1 | 0.6 ± 0.1 |
| Datura stramonium L. | Solanaceae | Datura | 3.5 ± 0.2 | 2.8 ± 0.1 | 1.4 ± 0.1 |
| Sida spinosa L. | Malvaceae | Sida | 2.2 ± 0.2 | 2 ± 0.2 | 1.5 ± 0.1 |
| Leucaena leucocephala (Lam.) de Wit | Fabaceae | Leucaena | 8.5 ± 0.5 | 5.4 ± 0.4 | 1.5 ± 0.2 |
| Sesbania cannabina (Retz.) Poir. | Fabaceae | Sesbania | 4 ± 0.5 | 2.4 ± 0.5 | 1.6 ± 0.2 |
| Veronica hederifolia L. | Plantaginaceae | Veronica | 2.2 ± 0.3 | 2 ± 0.3 | 1.6 ± 0.3 |
| Hexasepalum teres (Walter) J. H. Kirkbr. | Rubiaceae | Diodia | 3.4 ± 0.2 | 2.2 ± 0.2 | 1.6 ± 0.1 |
| Paspalum urvillei Steud. | Poaceae | Paspalum | 1.8 ± 0.3 | 1.3 ± 0.2 | 0.5 ± 0.1 |
| Multi-Class | Prediction | |||||||
|---|---|---|---|---|---|---|---|---|
| Class1 | Class2 | Class3 | Class4 | Class5 | Null | |||
| Real | class1 | TP1 | FN2 | FN3 | FN4 | FN5 | FN6 | |
| class2 | FP2 | TP2 | ||||||
| class3 | FP3 | TP3 | ||||||
| class4 | FP4 | TP4 | ||||||
| class5 | FP5 | TP5 | ||||||
| Null | FP6 | |||||||
| Hyperparameter | Image Size | Batch Size | Epoch | Optimizer | Learning Rate | Beta1 | Beta2 |
|---|---|---|---|---|---|---|---|
| Value/Type | 640 | 64 | 400 | Adam | 0.01 | 0.937 | 0.999 |
| Models | Params | Precision/% | Recall/% | F1-Score/% | mAP@.5 | mAP @.5:.95 | FPS |
|---|---|---|---|---|---|---|---|
| YOLOv5s | 7,093,209 | 93.02 | 89.28 | 91.06 | 90.65 | 80.40 | 32 |
| YOLOv5s+SE | 7,414,233 | 93.09 | 88.87 | 90.99 | 90.08 | 80.52 | 28 |
| YOLOv5s+CBAM | 7,137,121 | 92.83 | 89.52 | 91.22 | 90.83 | 81.16 | 29 |
| YOLOv5s+ECA | 7,283,164 | 93.96 | 90.11 | 91.94 | 91.67 | 82.77 | 29 |
| Category | YOLOv5s | YOLOv5s+SE | YOLOv5s+CBAM | YOLOv5s+ECA |
|---|---|---|---|---|
| Ipomoea lacunosa | 0.8904 | 0.8906 | 0.8976 | 0.9127 |
| Ipomoea triloba | 0.9056 | 0.9106 | 0.9214 | 0.9186 |
| Solanum viarum | 0.9440 | 0.9383 | 0.9398 | 0.9405 |
| Solanum pruinosum | 0.9170 | 0.9134 | 0.9087 | 0.9322 |
| Nicandra physalodes | 0.9071 | 0.9164 | 0.9180 | 0.9164 |
| Datura stramonium | 0.9153 | 0.9188 | 0.9090 | 0.9168 |
| Sida spinosa | 0.8921 | 0.8985 | 0.8966 | 0.8980 |
| Leucaena leucocephala | 0.9136 | 0.9028 | 0.9108 | 0.9182 |
| Sesbania cannabina | 0.8978 | 0.8890 | 0.9030 | 0.9076 |
| Veronica hederifolia | 0.9284 | 0.9258 | 0.9207 | 0.9406 |
| Hexasepalum teres | 0.9000 | 0.8934 | 0.9000 | 0.9120 |
| Paspalum urvillei | 0.9156 | 0.9214 | 0.9217 | 0.9187 |
| Number | Image Size | Batch Size | Learning Rate | Optimizer | Epoch | F1-Score |
|---|---|---|---|---|---|---|
| Exp1 | 640 | 64 | 0.01 | Adam | 400 | 91.94% |
| Exp2 | 320 | 64 | 0.01 | Adam | 400 | 90.54% |
| Exp3 | 640 | 32 | 0.01 | Adam | 400 | 91.26% |
| Exp4 | 640 | 64 | 0.1 | Adam | 400 | 71.23% |
| Exp5 | 640 | 64 | 0.001 | Adam | 400 | 91.10% |
| Exp6 | 640 | 64 | 0.01 | SGD | 400 | 90.92% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, L.; Yan, J.; Li, H.; Cao, X.; Ge, B.; Qi, Z.; Yan, X. Real-Time Classification of Invasive Plant Seeds Based on Improved YOLOv5 with Attention Mechanism. Diversity 2022, 14, 254. https://doi.org/10.3390/d14040254
Yang L, Yan J, Li H, Cao X, Ge B, Qi Z, Yan X. Real-Time Classification of Invasive Plant Seeds Based on Improved YOLOv5 with Attention Mechanism. Diversity. 2022; 14(4):254. https://doi.org/10.3390/d14040254
Chicago/Turabian StyleYang, Lianghai, Jing Yan, Huiru Li, Xinyue Cao, Binjie Ge, Zhechen Qi, and Xiaoling Yan. 2022. "Real-Time Classification of Invasive Plant Seeds Based on Improved YOLOv5 with Attention Mechanism" Diversity 14, no. 4: 254. https://doi.org/10.3390/d14040254
APA StyleYang, L., Yan, J., Li, H., Cao, X., Ge, B., Qi, Z., & Yan, X. (2022). Real-Time Classification of Invasive Plant Seeds Based on Improved YOLOv5 with Attention Mechanism. Diversity, 14(4), 254. https://doi.org/10.3390/d14040254