1. Introduction
Nowadays, various types of sensors, such as Kinect sensor [
1], inertial motion units [
2], ultrasound range sensor [
2], GPS [
3], Radio Frequency Identification (RFID), laser scanners [
4] and remote sensor networks [
5], have been used to perceive the physical environment, and many promising solutions [
2,
6,
7] have been proposed to realize the effective mapping from the physical world to the cyberspace. Among them, RFID technology is one of the most promising technologies. Based on geometric mapping, it has been increasingly used in various application scenarios, such as intelligent exhibition halls, goods tracking and congestion detection in logistics and distribution [
8], abnormal activity detection and insecurity factor detection in access control, and so on.
In the grocery industry, when various items, not only returnable transport carts, trolleys and kegs, but also valuable products, are equipped with RFID tags, item-level RFID infrastructures are established [
9]. They can be utilized to realize a wide range of smart applications, e.g., auto check-outs [
9], item-level valuable merchandise tracking [
10], vendor managed inventory [
11], smart price tags [
9],
etc. [
12,
13]. Among them, one of the more attractive applications is tracking customers’ shopping paths. These paths can be captured based on identifying the moving trajectories of smart shopping carts/trolleys/keys which are tagged with RFID [
14]. Besides that, shopping carts/trolleys/keys featuring RFID readers can recognize valuable products put into the carts/trolleys/keys, if each valuable product is tagged with an RFID label. As a result, both the walking trajectories of customers and the corresponding purchase behaviors are automatically recorded in the RFID datasets, which are quite precious for mining in-depth knowledge about the shopping behaviors of customers.
Clearly, in the competitive retail climate, discovering insights from the shopping behaviors of customers and then turning these insights into promotion and customer care actions are crucial for enhancing retail business and service quality [
15]. Towards this vision, one fundamental work is to study customers’ shopping paths in conjunction with their purchasing behaviors. The quick development of in-door positioning [
6,
7,
16,
17,
18,
19,
20,
21,
22,
23] and data mining [
24,
25,
26,
27,
28,
29,
30,
31,
32] technologies sheds light on the above problem, and motivates us to consider building a bridge between RFID-based indoor mapping and advanced data mining techniques to explore customer’s shopping behavior in depth.
Consequently, in this study, we propose a framework for mining actionable navigation patterns using multi-source RFID data,
i.e., shopping path data and RFID-supported customers’ purchasing behavior data. Actionable navigation pattern [
24,
25] is very useful for understanding behaviors of customers and can be applied to various applications, such as customer navigation, active advertising and recommendations,
etc. In this framework, we first use the path graph to map the problem in the physical space to a problem in the cyber space, where shopping paths are represented by sequences of path segments. After the mapping between the physical space and the cyber space, the problem of RFID-based shopping path analytics is converted to sequential pattern analysis [
26], which has plenty of research in data mining field [
27,
28,
29,
30,
31,
32] for further reference.
This paper is organized as follows: first, we introduce indoor mapping technologies and related terms in
Section 2 and
Section 3, respectively. Then, in
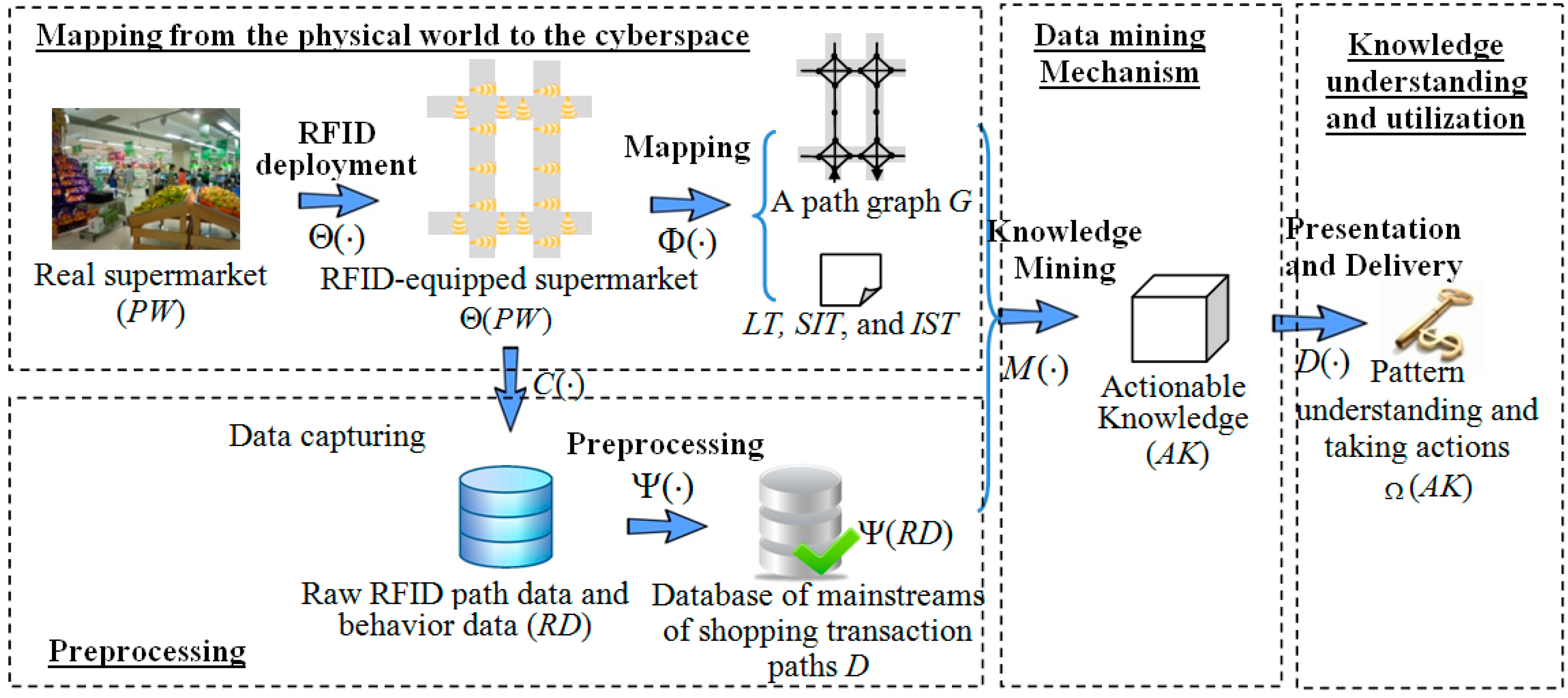
Section 4, the framework for mining multi-source in-door RFID data is presented, and four modules are discussed in detail, which are: (1) mapping from the physical space to the cyber space; (2) data preprocessing; (3) pattern mining and (4) knowledge understanding and utilization. In
Section 5, we address a key problem existing in the data preprocessing module, which is how to identify the mainstream shopping transaction paths while wiping out unnecessary redundant and repeated details. An algorithm which can filter two types of redundant patterns is also proposed. Then, a simulated shopping path generator is discussed in
Section 6, and the experimental evaluation of the algorithm is given in
Section 7. Finally, we discuss the contributions towards a real supermarket scenario and conclude our work in
Section 8 and
Section 9, respectively.
3. Materials for the Study
In this section, related concepts are defined, and the notations used in this study are summarized in
Table 1.
Definition 1. A path segment s is a directed edge associated with a direction symbol (s.dir), two terminal points (one is the start terminal point s.b and the other is the end terminal point s.e), and its length (s.l). The path segment only can be travelled from s.b to s.e. The reverse-order path segment of s is the path segment sharing the same edge with s but reverse direction, i.e., sreverse, where sreverse.dir and s.dir are reverse, sreverse.b equals s.e, sreverse.e equals s.b, and sreverse.l and s.l are equal.
Definition 2. A path graph G is a directed graph, i.e., G = (V, E), where V is the set of terminal points of path segments, and E is the set of path segments. Path graph G is an abstraction of the connections of path segments in a real field.
Definition 3. A shopping path SP is a sequence of path segments, SP = <s1, s2,…, sn>, where si+1.b = si.e and sj ∈ E, (1 ≤ i ≤ n−1, 1 ≤ j ≤ n). The beginning point and the ending point of SP can be represented as SP.b = s1.b and SP.e = sn.e.
Definition 4. There are several concepts related to shopping paths as given below:
(1) Given two shopping paths, i.e., SP = <s1, s2,…, sn> and SP' = (l≤n), if there exists i, such that = Si, = si+1, …, = si+l−1, then SP is a super-sequence of SP', and SP' is a subsequence of SP (denoted as SP' ⊂ SP). We also call that SP' is contained in SP.
(2) A navigation pattern NP means a subsequence of a shopping path.
(3) For a shopping path SP = <s1, s2,…,sk+1,…,sn>, the reverse-order path of SP is SPreverse =<sn,reverse,…,sk+1,reverse, sk,reverse,s2reverse, s1reverse>, where si,reverse (1≤i≤n) is the reverse-order path segment of si.
(4) Given a shopping path SP = <s1, s2,…,sk, sk+1,…,sn>, SPprefix = <s1, s2,…,sk>, is called a prefix of SP, and SPprefix = <sk+1, s2,…, sn> is called a suffix of SP, where 1≤k≤n.
(5) Given n shopping paths, i.e., SP1, SP2, …, SPn-1 and SPn, if SPi.e = SPi+1.b (1 ≤ i ≤ n−1) is satisfied, these shopping paths can be connected one after another, and the connection can be marked as SP1→SP2→…→SPn.
Table 1.
Notations.
| Notation | Description |
|---|
| s, si | A path segment |
| sreverse | The reverse-order path segment of s |
| si.b, si.e | The start terminal point, the end terminal point of si respectively |
| ti | Unit time per unit length spent in si |
| vi | A terminal point |
| Ti | The itemset purchased in si |
| G | A path graph |
| SP, SP', SQ | A shopping path |
| SP' ⊂ SP | SP is a super-sequence of SP', and SP' is a subsequence of SP |
| STP, STPprefix, STPsuffix | A shopping transaction path |
| Trans(STP) | Transforming STP to a shopping path |
| iitem | An item |
| iitem < STP | iitem is purchased in STP |
| D | A shopping transaction path database |
| Sitem, |Sitem| | A set of items, and the number of its elements respectively |
| Γs | The itemset sold in s |
| SIT | The Segment-Item Table |
| Eitem | The set of path segments that sell iitem |
| IST, LT, PT | The Item-segment table, the Length table, and the Path-set table respectively |
Definition 5. Given a shopping path SP, the connection between SP and its reverse-order path SPreverse (i.e., SP→SPreverse) forms a symmetric pattern. If SP.b = SP.e, SP is called a loop pattern. Given a loop pattern SP, if SP repeats n (n ≥ 2) times successively, i.e., SP→SP→…→SP, we call it a loop repeat pattern. Given a shopping paths, i.e., SP, we call the pattern SP→SPreverse→SP a palindrome-contained pattern.
Definition 6. A shopping transaction path is a sequence of triples, STP = <(s1,t1,T1), (s2,t2,T2), …, (sn,tn,Tn)>, where (si, ti, Ti) means that a shopper purchases the itemset Ti and spends ti unit time per unit length in the path segment si (1≤i≤n).
Definition 7. Given a shopping transaction path, i.e., STP = <(s1,t1,T1), (s2,t2,T2), …, (sn,tn,Tn)>, there are several concepts, which are relevant to shopping transaction paths, are given below:
(1) For simplicity, all si (1≤i≤n) are called the path segments of shopping transaction path STP.
(2) For a given item iitem, if iitem ∈ T1∪T2∪…∪Tn, we call iitem is purchased in STP, i.e., iitem < STP.
(3) Given a fragment of STP, i.e., STP' = <(sk,tk,Tk), (sk+1,tk+1,Tk+1), …, (sl,tl,Tl)>(1≤k≤l≤n), we called STP' a subsequence of STP, and STP' is contained in STP.
(4) STPprefix = <(s1,t1,T1), (s2,t2,T2), …, (sk,tk,Tk)>, is called a prefix of STP, where 1<k<n. STPsuffix = <(sk+1,tk+1,Tk+1), (sk+2,tk+2,Tk+2), …, (sn,tn,Tn)> is called a suffix of STP.
(5) Given a shopping transaction path, STP = <(s1,t1,T1), (s2,t2,T2), …, (sn,tn,Tn)>, if only path segments appear in STP, we transform it to a shopping path, SP = <s1, s2,…, sn>, which is called the shopping path of STP and denoted as SP = Trans(STP).
(6) Given n shopping transaction paths, i.e., STP1, STP2, …, STPn-1 and STPn, if Trans(STPi).e = Trans(STPi+1).b (1≤i≤n−1) is satisfied, these shopping transaction paths can be connected one after another, and the connection can be marked as STP1→STP2→…→STPn.
For example, STP = <(s1,1, Ø),(s2,0.8,Ø),(s3,8,{i1,i2}),(s4,0.8,Ø),(s5,5,{i3})> denotes that when the shopper visits s1, s2,…, s5 consecutively, he/she spends 1, 0.8, …, 5 unit time per unit length in these path segments respectively. Meanwhile, the shopper purchases {i1,i2} in s3 and purchases {i3} in s5. s1, s2,…, s5 are all path segments of STP. Among them, s1 is the first path segment of STP, s2 is the second one, …, and s5 is the last one. Because i1∈Ø∪Ø∪{i1,i2}∪Ø∪{i3}, we have i1 < STP. STP can be transformed to a shopping path, that is to say Trans(STP) = <s1, s2,…, s5>.
Definition 8. A mainstream of shopping path is a shopping path without containing any loop repeat or palindrome-contained subsequence pattern. A shopping transaction path STP is a mainstream of shopping transaction path, if Trans(STP) is a mainstream of shopping path.
Definition 9. A
Segment-Item Table (
SIT), maintaining the information of items sold in each path segment, is denoted as below:
where
si is a path segment,
Γsi is the itemset sold in
si (1≤
i≤
W), and
W is the total number of path segments.
Definition 10. An
Item-Segment Table (
IST), maintaining the information about the segments where each item is sold, is denoted as below:
where
iitem,j is an item,
Eitem,j is the set of path segments that sell
iitem,j (1≤
j≤
U), and
U is the total number of items.
Definition 11. A
Length Table (
LT), maintaining the length information of path segments, is denoted as below:
where
si is a path segment, and
si..l is the length of
si which can be obtained according to the length of normal trajectory of
si (1 ≤
i ≤
W).
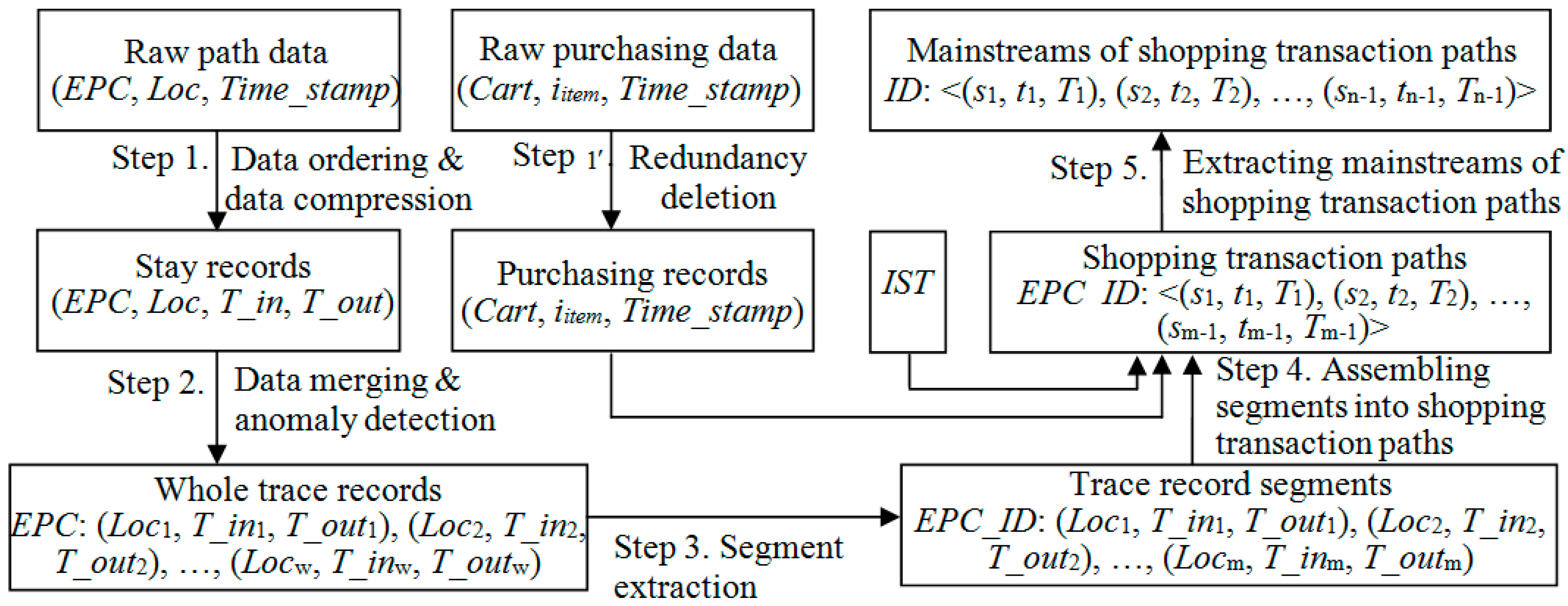
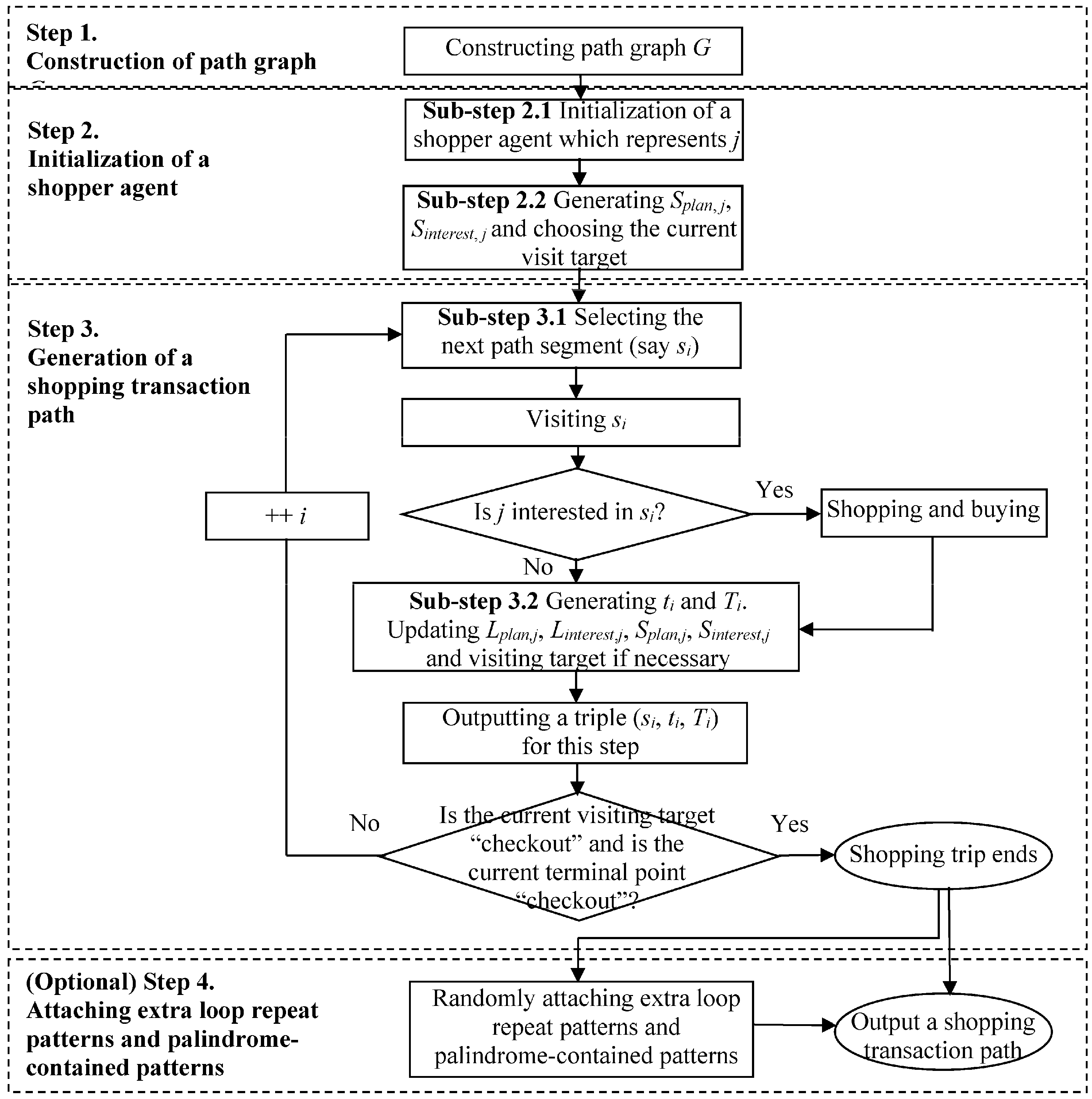
5. Algorithm for Identifying Mainstreams of Shopping Transaction Paths
The algorithm is an iterative process of filtering loop repeat patterns (i.e., Function LRP_Filtering(STP)) and palindrome-contained patterns (i.e., Function PCP_Filtering(STP)) for identifying mainstreams of shopping transaction path from shopping transaction paths, as shown in Algorithm 1.
| Algorithm 1 Identifying mainstreams of shopping transaction paths |
| Input: Shopping transaction paths DSTP |
| Output: Mainstreams of shopping transaction paths DMSTP |
| Method: |
For each shopping transaction path STP in DSTP do { while (loop repeat patterns and palindrome-contained patterns exist in STP) do { Call LRP_Filtering(STP) to filter loop repeat patterns Call PCP_Filtering(STP) to filter palindrome-contained patterns } Add STP to DMSTP } Return DMSTP.
|
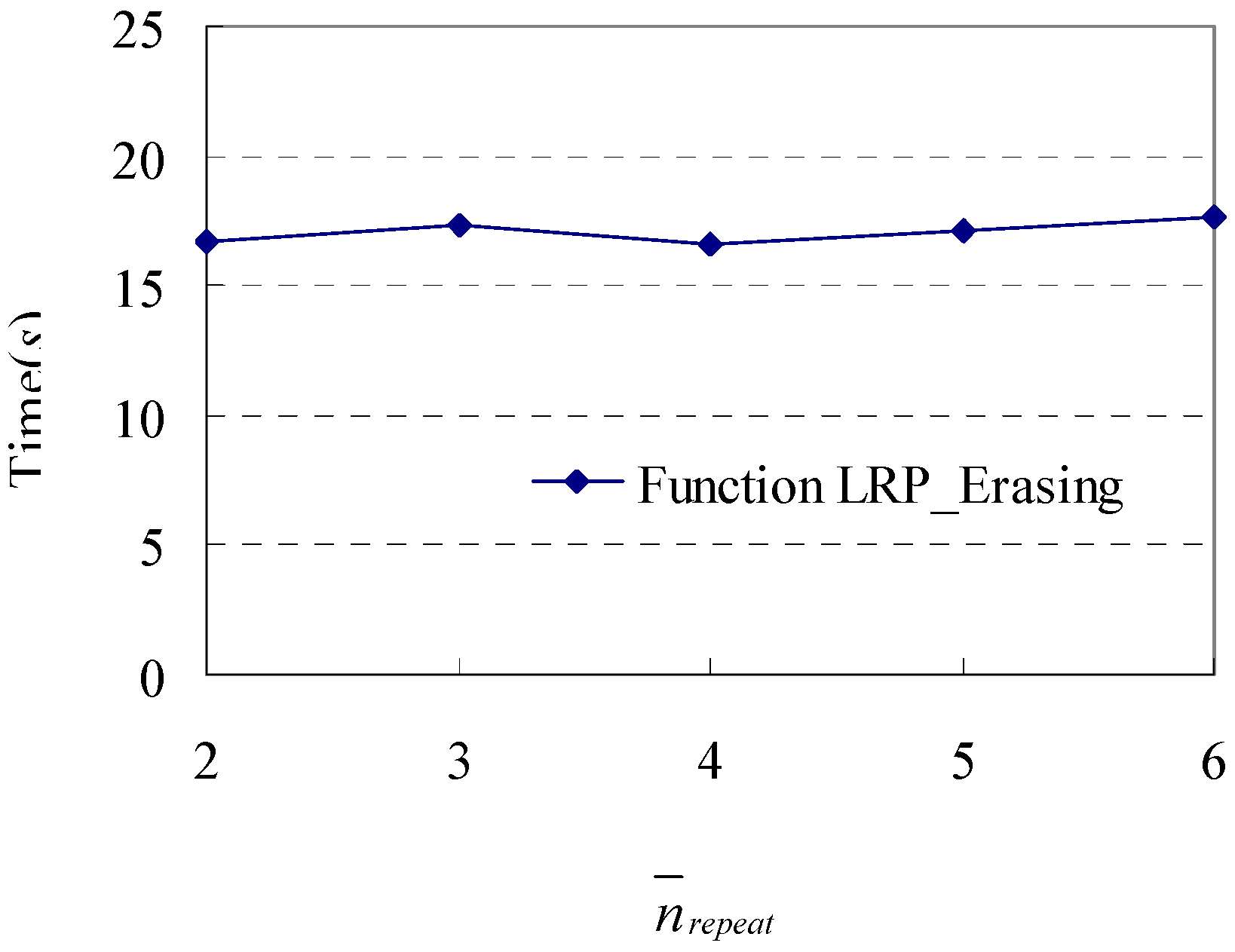
5.1. Function LRP_Filtering(STP)
Given a shopping transaction path STP = <(s0, t0, T0), (s1, t1, T1),…, (sn, tn, Tn)>, the process of filtering loop repeat patterns is an iterative procedure to find the start position of the loop (say µ) and the number of path segments in the loop (say λ), such that sµ+i = sµ+λ+i (i = 0,1,…, λ − 1; µ+λ+i ≤ n). If µ and λ satisfying the above conditions are found, the fragments <(sµ, tµ, Tµ),…, (sµ+λ-1, tµ+λ-1, Tµ+λ-1)> and <(sµ+λ, tµ+λ, Tµ+λ),…, (sµ+2λ-1, tµ+2λ-1, Tµ+2λ-1)> in STP form a loop repeat pattern. This procedure is given in sub-function Find_RepeatLoops(STP), and three data structures (i.e., path vector, hash table, and list of loop candidates) are used:
Definition 14. A path vector (say PV) is a vector of pair (s, pos), where s is a path segment and pos is the previous position of s in PV. A hash table (say HT) stores the current position (i.e., cur_pos_seg) for each path segment (i.e., s), and a hash function f is defined in HT, such that HT[f(s)] = cur_pos_seg. A list of loop candidates (say List) is a list of triple (b_pos, e_pos, cur_pos) representing a loop candidate (i.e., the fragment <PV[b_pos].s, PV[b_pos+1].s, …, PV[e_pos].s>), where cur_pos is the current matching position between b_pos and e_pos. Based on these definitions, we have the following Function LRP_Filtering(STP), where the key part is the sub-function Find_RepeatLoops(SP).
| Function. LRP_Filtering(STP) |
| Method: |
While repeat loop pattern is found, do{ (µ, λ, n_loops)←Find_RepeatLoops(trans(STP)) If repeat loop pattern is found, do { For STP, combine n_loops fragments, i.e., <(sµ, tµ, Tµ),…, (sµ+λ-1, tµ+λ-1, Tµ+λ-1)>, <(sµ+λ, tµ+λ, Tµ+λ),…, (sµ+2λ-1, tµ+2λ-1, Tµ+2λ-1)>, …, <(sµ + (n_loops-1) × λ, tµ+(n_loops-1)×λ, Tµ+(n_loops-1)×λ),…, (sµ+n_loops×λ-1, tµ+n_loops×λ-1, Tµ+n_loops×λ-1)>, to form a new STP according to Definition 12.} } Return STP
|
| Sub-Function. Find_RepeatLoops(SP) |
Initialize PV, HT and List as empty Suppose SP = <s0, s1, …, sn>. For each path segment si in SP, do { If si is a key in HT, let cur_pos_seg=HT[f(si)]; otherwise, insert a key-value pair (si, “null”) to HT and let cur_pos_seg=“null”. Push the pair (si, cur_pos_seg) onto PV, and get the position of this pair in PV (say new_cur_pos_seg). Set HT[f(si)] to be new_cur_pos_seg in HT. For each triple (b_pos, e_pos, cur_pos) in List, do { If PV[cur_pos+1].s equals to si, do { If (cur_pos+1) equals to e_pos, repeat loops are found. Let µ be b_pos, λ be e_pos-b_pos+1. Call n_loops←Test_RepeatLoops(SP, µ, λ, 2). Return the triple (µ,λ, n_loops) and exit this sub-function. Otherwise, let cur_pos++ and update this triple in List. } Else delete this triple from List. } If cur_pos_seg equals to new_cur_pos_seg-1, repeat loops are found. Let µ be cur_pos_seg and λ be 1. Call n_loops←Test_RepeatLoops(SP, µ, λ, 2). Return the triple (µ,λ, n_loops) and exit this sub-function. While cur_pos_seg isn’t “null”, do { Generate a candidate triple (cur_pos_seg, new_cur_pos_seg-1, cur_pos_seg) and add it to List. Let cur_pos_seg = PV[cur_pos_seg].pos.}} No repeat loop pattern is found. Return the triple (“null”, “null”, “null”).
|
| Sub-Function. Test_RepeatLoops(SP, µ, λ, n_loops) |
If μ + (n_loops + 1) × λ − 1 ≤ n and <sμ, sμ+1, …, sμ+λ-1> = <sμ+n_loops×λ, sμ+n_loops×λ+1, …, sμ+(n_loops+1)×λ-1>, n_loops++ and then call n_loops←Test_RepeatLoops(SP, µ, λ, n_loops). Return n_loops.
|
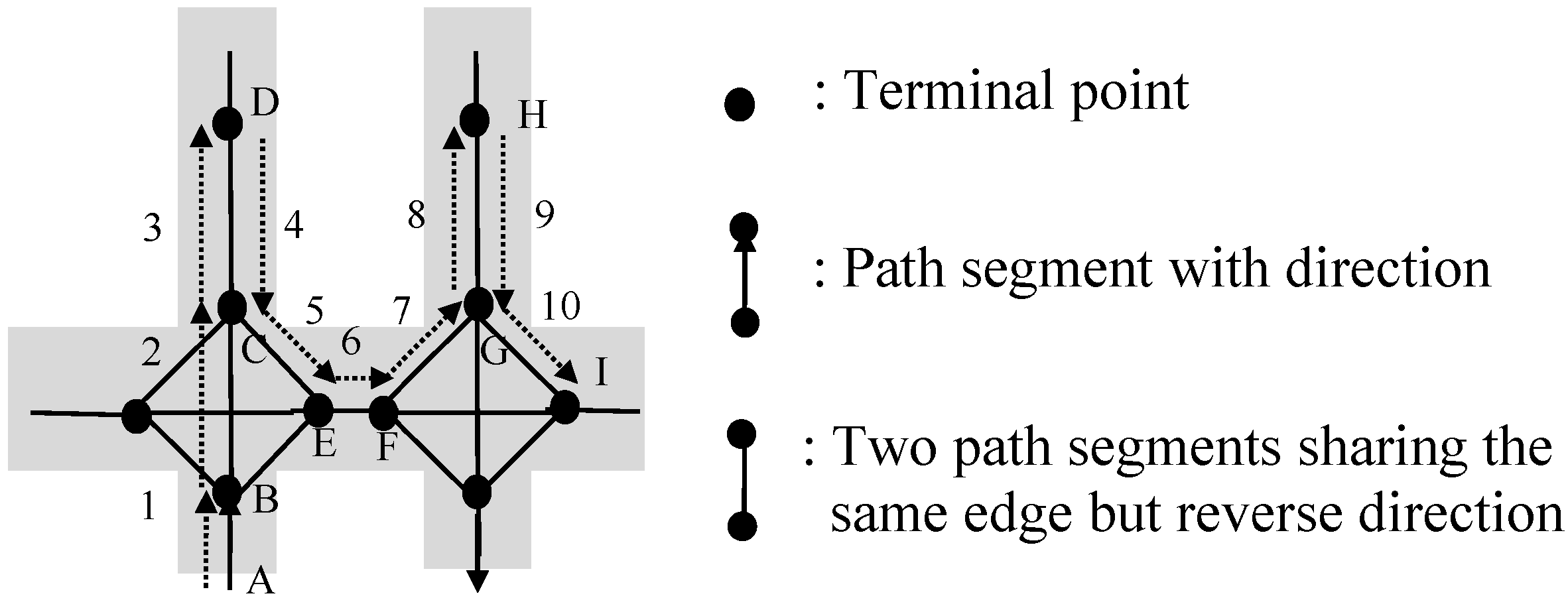
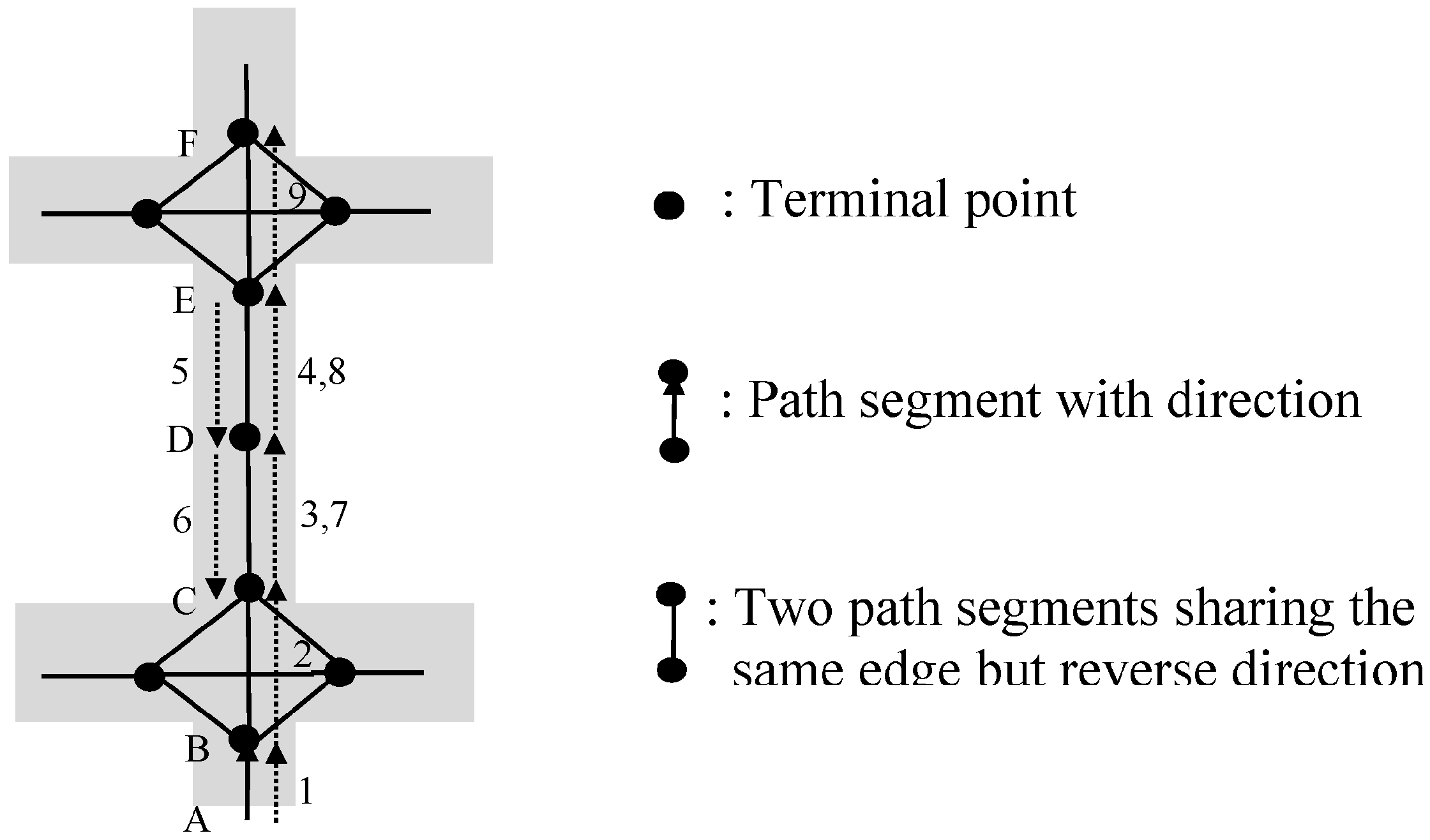
We use a running example to explain the running process of sub-function Find_RepeatLoops(SP). Given a shopping path SP = <EA, AB, BC, CD, DE, EA, AB, BE, EA, AB, BE, EG, GD, DK>, the function reads path segments in SP one by one, and the process of finding loop repeat pattern is shown below.
For the first path segment EA, EA cannot be found as a key in empty HT, so the key-value pair (EA, “null”) is inserted to HT, and the pair (EA, “null”) is pushed onto an empty PV. The position of this pair in PV is 0. Therefore, the value associated with EA is changed to 0 in HT. cur_pos_seg (which is “null”) doesn’t equal to new_cur_pos_seg-1 (which is -1). List still remains empty.
For the second path segment AB, similar operations are done. After operations, the key-value pair (AB, 1) is added in HT, and the pair (AB, “null”) is pushed onto PV.
Similarly, after reading the third path segment BC, the fourth CD, and the fifth DE, pairs (BC, 2), (CD, 3), (DE, 4) are inserted into HT, and pairs (BC, “null”), (CD, “null”), (DE, “null”) are pushed onto PV sequentially. Because cur_pos_seg keeps “null”, no candidate is generated.
For the sixth path segment EA, it is found as a key in HT and cur_pos_seg is 0, which is the position of previous EA in PV. Push the pair (EA, 0) onto PV and set the value associated with EA (i.e., HT[f(EA)]) to be 5 in HT. Because cur_pos_seg is not “null”, a candidate (0, 4, 0) is generated and added to List. And then, cur_pos_seg = PV[0].pos = “null”, so no candidate is generated here.
For the seventh path segment AB, the pair (AB, 1) is pushed onto PV and HT[f(AB)] is set as 6. Since there is a loop candidate (i.e., triple (0, 4, 0)) in List, we need to compare AB with the next path segment of this candidate (i.e., PV[0+1].s). Both of them are AB and they are matching, so we set this triple to be (0, 4, 1). Because cur_pos_seg is 1, a new candidate (1, 5, 1) is produced and there are two candidates in List now.
When reading the eighth one BE, the pair (BE, 7) is pushed onto PV and HT[f(BE)] is 7. For the candidate (0, 4, 1), the next path segment is PV[1+1].s=BC, which does not match BE. So this candidate should be deleted from List. For the candidate (1, 5, 1), the next path segment, i.e., PV[1+1].s=BC, does not match BE, so this candidate also needs to be pruned. No new candidate is generated, since cur_pos_seg equals to “null”.
For the ninth one EA, the pair (EA, 5) is added at the end of PV and the value associated with EA is set as 8 in HT. Similarly, two new candidates (5, 7, 5) and (0, 7, 0) are obtained and added to List.
Similarly, when reading the tenth path segment AB, the pair (AB, 6) is pushed onto PV and HT[f(AB)] is set as 9. For candidates, triple (5, 7, 5) becomes (5, 7, 6), and triple (0, 7, 0) is converted to (0, 7, 1). And two new candidates, i.e., triple (6, 8, 6) and triple (1, 8, 1), are generated.
When reading the eleventh one BE, the pair (BE, 7) is added at the end of PV and HT[f(BE)] is set as 10. For the candidate (5, 7, 6), the next path segment PV[6+1].s equals to BE, and is the last one in this candidate. Thus repeat loops are found, and µ, λ are 5, 3 respectively. And then, we call Test_RepeatLoops(SP, 5, 3, 2). Since <s5, s6, s7> (i.e., <EA, AB, BE>) are not equal to <s11, s12, s13> (i.e., <EG, GD, DK>), n_loops which equals 2 is returned. Thus, we have n_loops equals 2.
5.2. Function PCP_Filtering (STP)
Given a shopping transaction path STP = <(s0, t0, T0), (s1, t1, T1),…, (sn, tn, Tn)>, the procedure of filtering palindrome-contained patterns (i.e., STP1→STP2→STP3, where Trans(STP1), the reverse-order path of Trans(STP2), and Trans(STP3) are equal (say SP)) is an iterative process of finding the start position of palindrome-contained pattern (say µ), and the number of path segments of SP (say λ), such that sµ+i = sµ+2λ-i-1,reverse = sµ+2λ+i (i = 0,1,…, λ − 1; µ + 2λ + i ≤ n), where sµ+2λ-i-1,reverse is the reverse-order path segment of sµ+2λ-i-1. If µ and λ satisfying the above conditions are found, the connections of three fragments <(sµ, tµ, Tµ),…, (sµ+λ-1, tµ+λ-1, Tµ+λ-1)>, <(sµ+λ, tµ+λ, Tµ+λ),…, (sµ+2λ-1, tµ+2λ-1, Tµ+2λ-1)> and <(sµ+2λ, tµ+2λ, Tµ+2λ),…, (sµ+3λ-1, tµ+3λ-1, Tµ+3λ-1)> in STP form a palindrome-contained pattern. This procedure is presented in the sub-function Find_PCP(STP), and three data structures (i.e., vector of path segment, list of candidate, and list of candidate suffix) are adopted.
Definition 15. A vector of path segment (say V) stores path segments. Suppose a potential palindrome-contained pattern is SP→SPreverse→SP. A list of candidate (say LC) is a list of triple (b_pos, e_pos, cur_pos), and each triple represents a candidate SP (i.e., the fragment <V[b_pos], V[b_pos+1], …, V[e_pos]>), where cur_pos is the current matching position between b_pos and e_pos. A list of candidate suffix (say LCS) is a list of pair (inter_posi, e_posi), and each pair represents a candidate suffix of SP (i.e., the fragment <V[inter_posi], V[inter_posi+1], …, V[e_posi]> ).
Based on the above definition, we have the following Function PCP_Filtering (STP):
| Function. PCP_Filtering(STP) |
| Method: |
While palindrome-contained pattern is found, do{ (µ, λ)←Find_PCP(trans(STP)) If palindrome-contained pattern is found, do { For STP, combine fragments <(sµ, tµ, Tµ),…, (sµ+λ-1, tµ+λ-1, Tµ+λ-1)>, <(sµ+λ, tµ+λ, Tµ+λ),…, (sµ+2λ-1, tµ+2λ-1, Tµ+2λ-1)> and <(sµ+2λ, tµ+2λ, Tµ+2λ),…, (sµ+3λ-1, tµ+3λ-1, Tµ+3λ-1)> to form a new STP according to Definition 13.} } Return STP
|
| Sub-Function. Find_PCP(SP) |
Initialize V, LC and LCS as empty Suppose SP = <s0, s1, …, sn>. For each path segment si in SP, do { If V is not empty, do { Get the position of the last element of V (say cur_pos_seg), and compare the last element of V with si. If they are reverse-order, let variable reverse-order be true. Otherwise, let variable reverse-order be false. } Else let reverse-order be false. Push si onto V. For each candidate triple (b_pos, e_pos, cur_pos) in LC, do { If cur_pos is “null”, let cur_pos be b_pos; otherwise, let cur_pos be added by 1. Compare V[cur_pos] with si. If they are same, do { Let this triple be (b_pos, e_pos, cur_pos) and update it in LC. If cur_pos equals to e_pos, then a palindrome-contained pattern is found. Let µbe b_pos, λbe e_pos-b_pos+1, return the pair of µand λ, and exit this sub-function. } Else delete this candidate triple from LC. } For each pair (inter_posi, e_posi) in LCS, do { If inter_posi-1 0, and V[inter_posi-1] and si are reverse-order, set this pair as (inter_posi-1, e_posi) in LCS, and generate a new candidate (inter_posi-1, e_posi, “null”) in LC. Otherwise, delete this pair from LCS. } If reverse-order is true, do { Produce a candidate (cur_pos_seg, cur_pos_seg, “null”) and insert it to LC. Generate a candidate suffix (cur_pos_seg, cur_pos_seg) and add it to LCS. } } No palindrome-contained pattern is found. Return the pair of “null” and “null”.
|
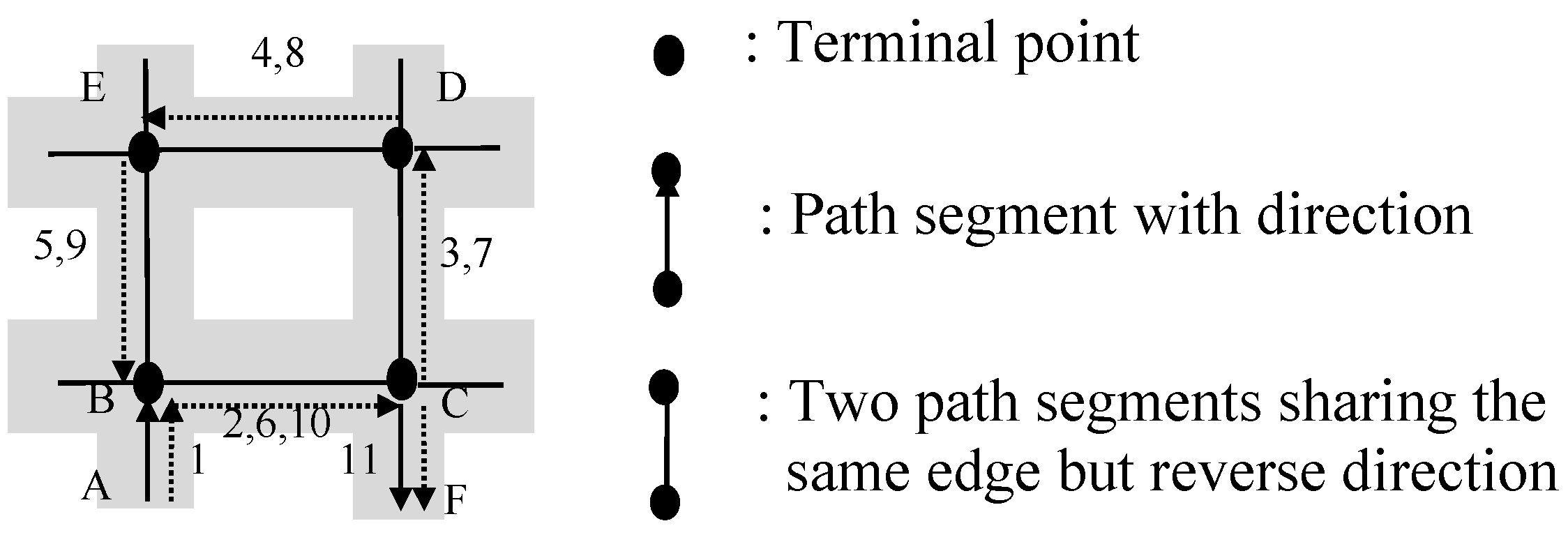
In the following, we illustrate a running example to show the running procedure of sub-function Find_PCP(SP). For instance, given a shopping path SP = <AB, BC, CD, DE, EF, FE, ED, DC, CD, DE, EF, FG>, its process of finding palindrome-contained pattern is as described below:
For the first path segment AB, simply let reverse-order be false and push AB onto V. When reading the second path segment BC, we compare the last element of V, which is AB, with BC. Because they are not reverse-order, reverse-order is false. Then, we push BC onto V.
Similarly, we push CD, DE, EF onto V. And no candidate or candidate suffix is generated.
For the sixth path segment FE, since the last element of V (EF) and FE are reverse-order, reverse-order is true. We push FE onto V. A candidate (4, 4, “null”) and a candidate suffix (4, 4) are generated.
When reading the seventh path segment ED, reverse-order is false, and ED is pushed onto V. For candidate (4, 4, “null”), we compare V[4] (EF) with ED and they do not match, so we delete this candidate from LC. For candidate suffix (4, 4), since V[3] (DE) is reverse-order path segment of ED, this candidate suffix becomes (3, 4) and a new candidate (3, 4, “null”) is generated.
When reading the eighth path segment DC, reverse-order is also false, and DC is pushed onto V. For candidate (3, 4, “null”), since V[3] (DE) and DC do not match we also prune this candidate from LC. For candidate suffix (3, 4), V[2] (CD) and DC are reverse-order, so this candidate suffix turns to (2, 4) and a new candidate (2, 4, “null”) is produced.
When reading the ninth path segment CD, reverse-order is true and CD is pushed onto V. For candidate (2, 4, “null”), since V[2] (CD) and CD match, this candidate turns to (2, 4, 2). For candidate suffix (2, 4), since V[1] (BC) and CD are not reverse-order, we delete this candidate suffix from LCS. Because reverse-order is true, a candidate (7, 7, “null”) and a candidate suffix (7, 7) are produced.
When reading the tenth one DE, reverse-order is false and DE is pushed onto V. For candidate (2, 4, 2), since V[3] (DE) and DE are matching, it turns to (2, 4, 3). For candidate (7, 7, “null”), it is deleted for mismatch. For candidate suffix (7, 7), since V[6] (ED) and DE are reverse-order, this candidate suffix becomes (6, 7) and a new candidate (6, 7, “null”) is added to LC.
Then for the eleventh one EF, reverse-order is also false and EF is pushed onto V. For candidate (2, 4, 3), since V[4] (EF) and EF are matching, this candidate becomes (2, 4, 4). Thus, a palindrome-contained pattern is found, and µ, λ are 2, 3 respectively.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












