
Adaptive Energy-Efficient Target Detection Based on Mobile Wireless Sensor Networks

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Studies
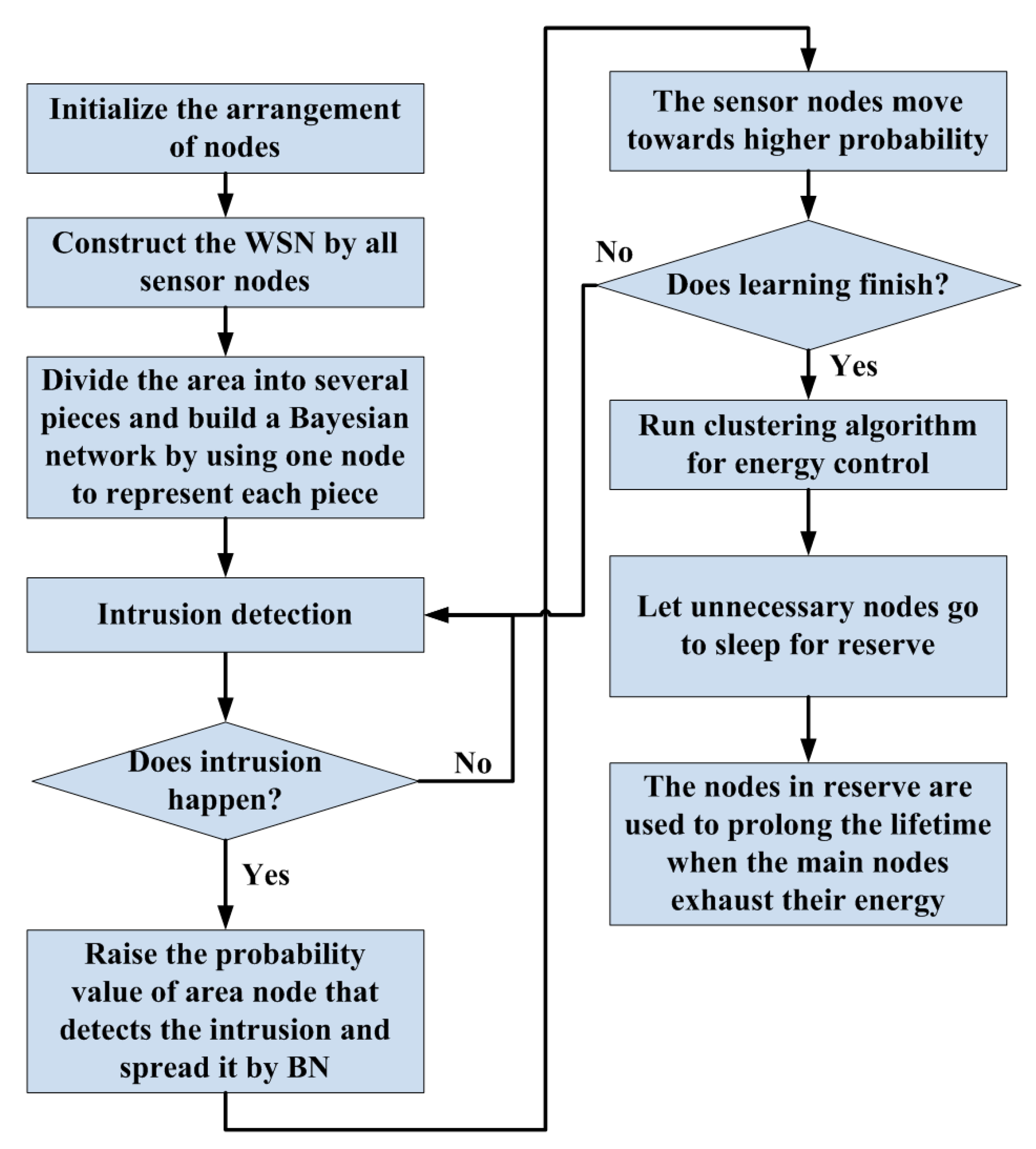
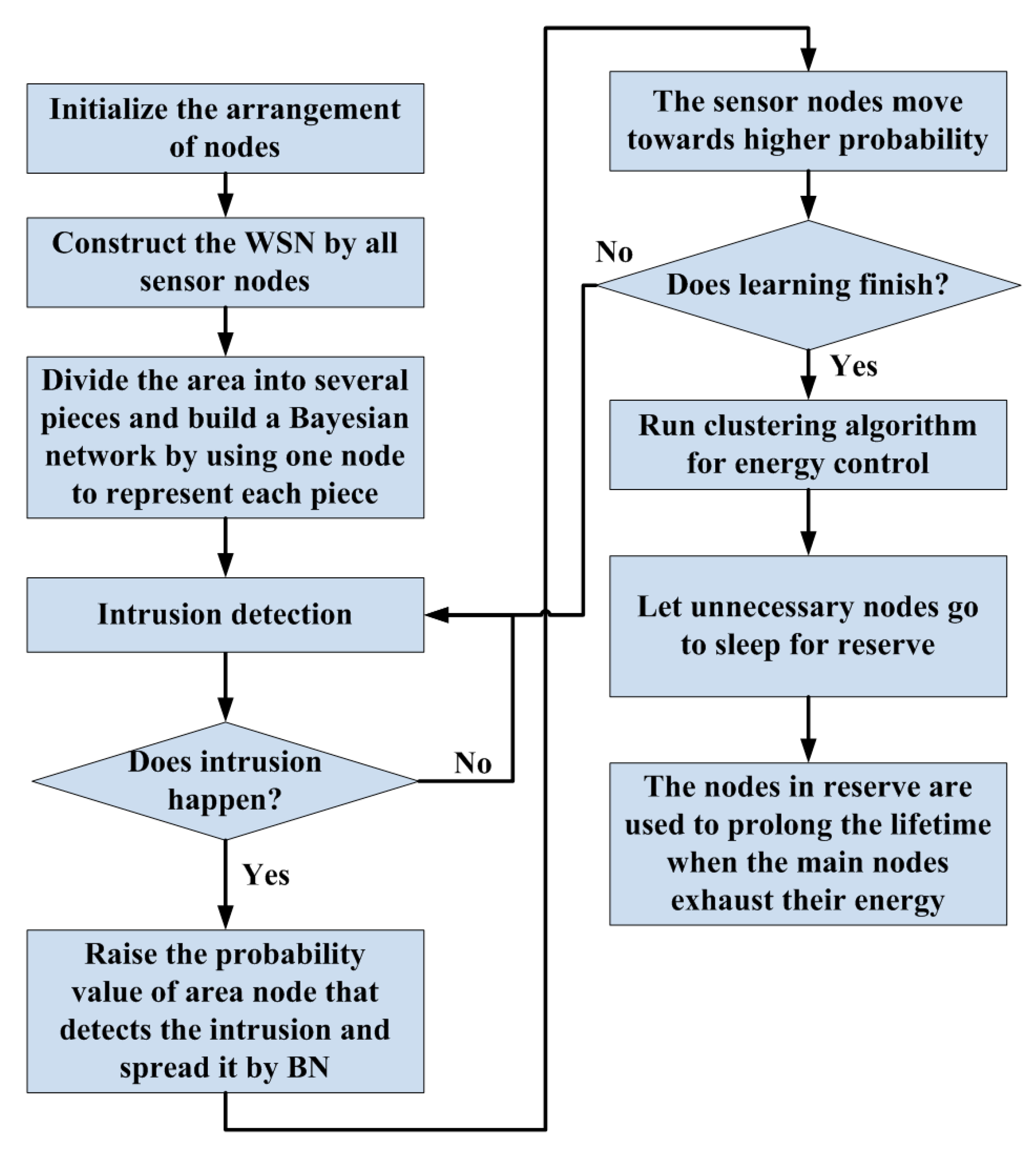
3. Adaptive Learning Procedure
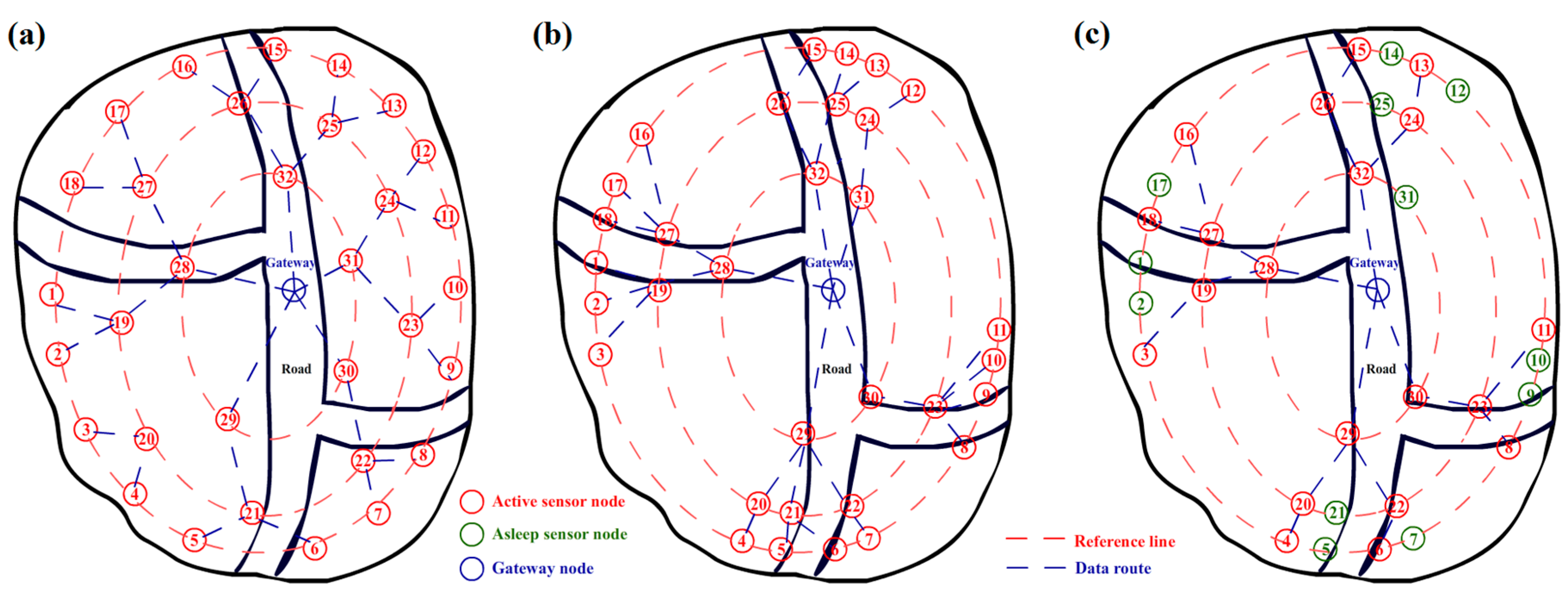
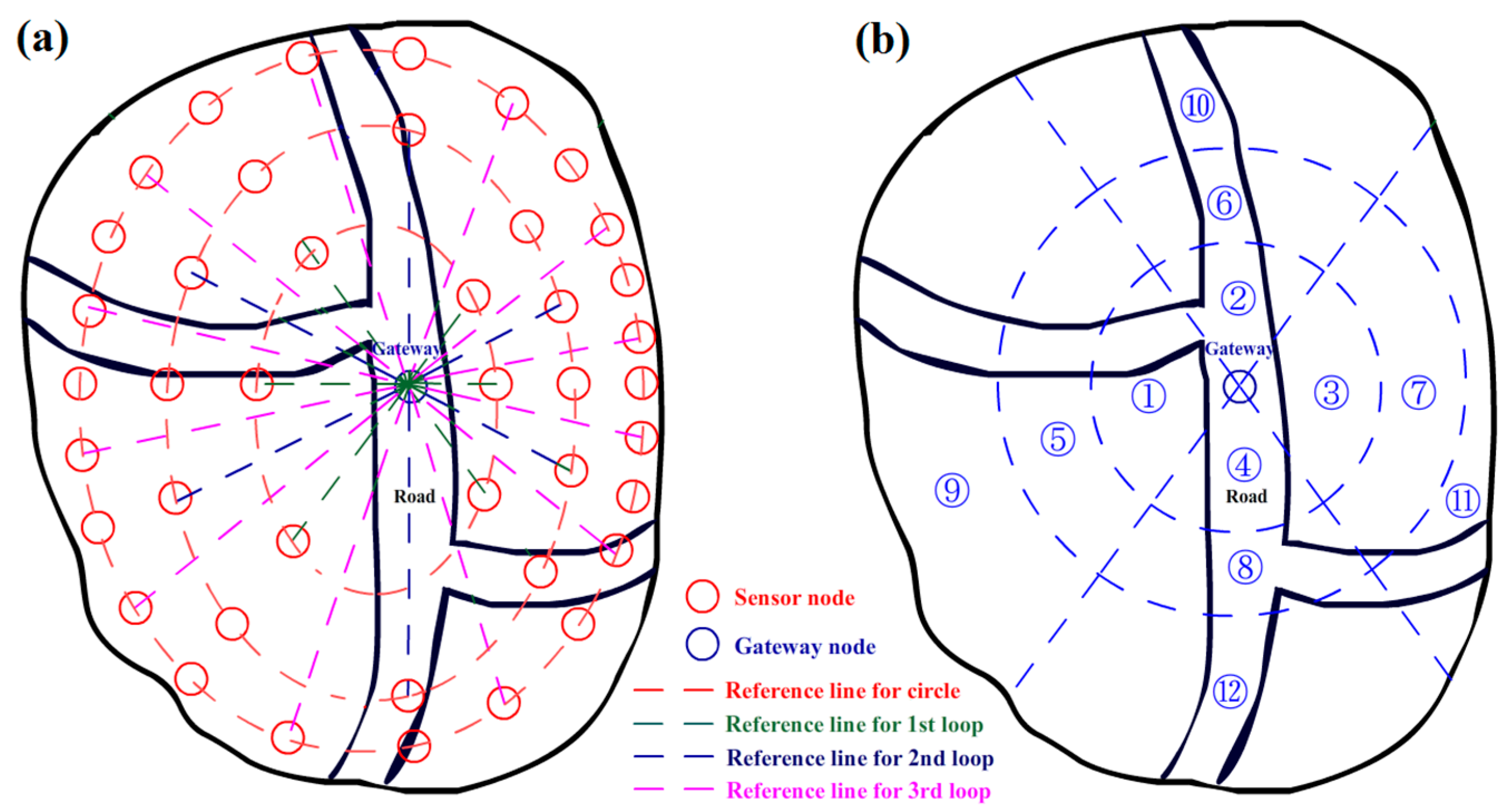
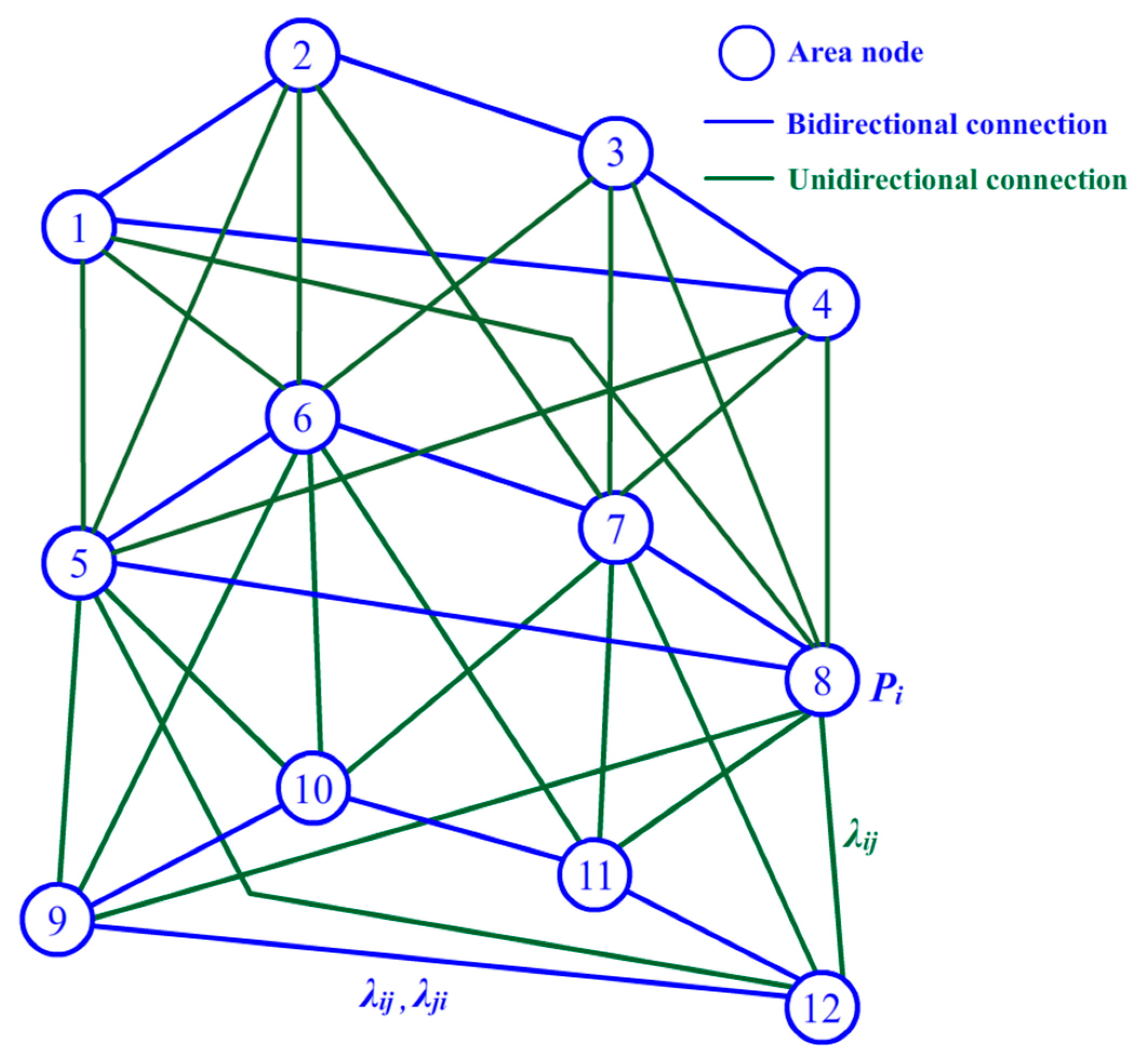
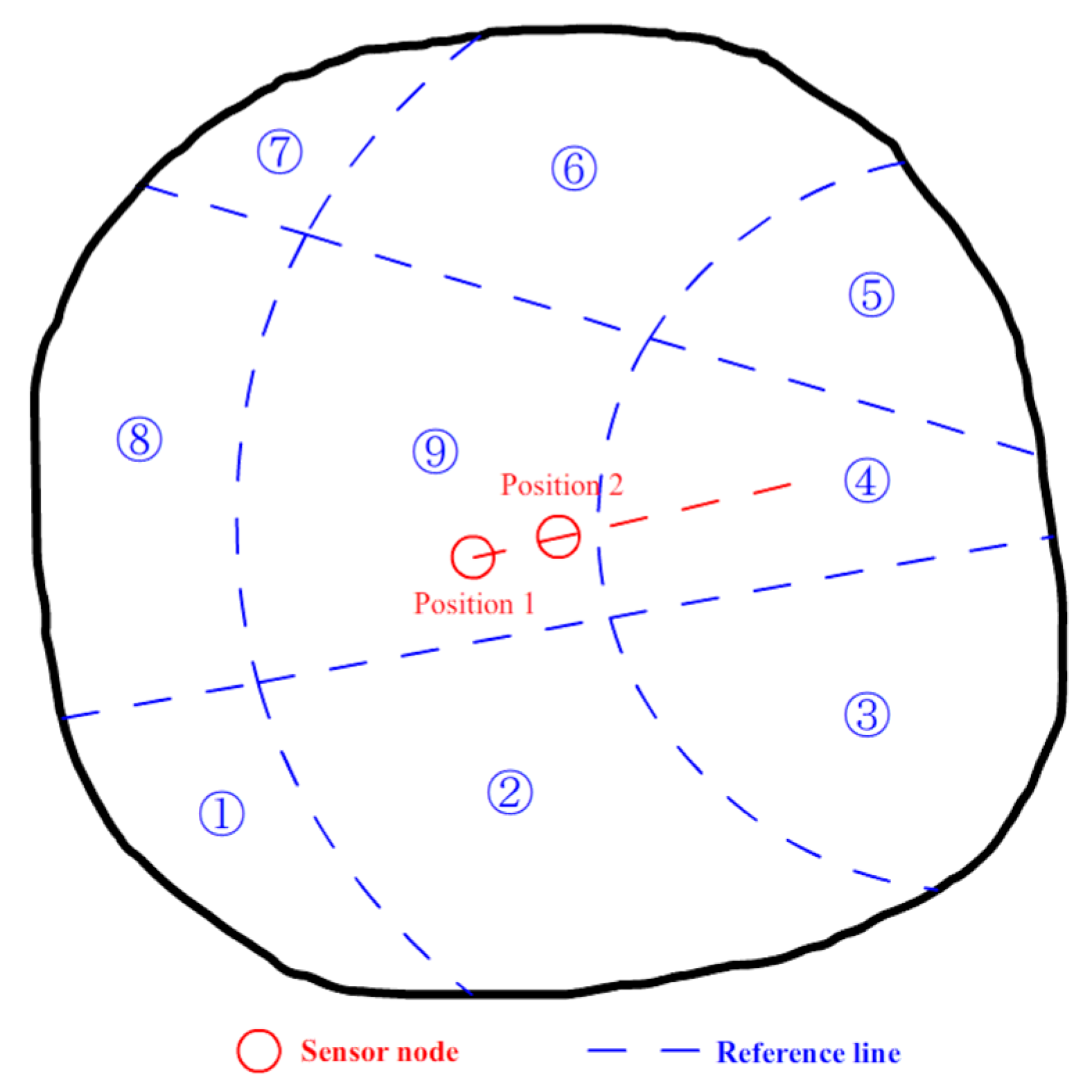
3.1. Initial Arrangement
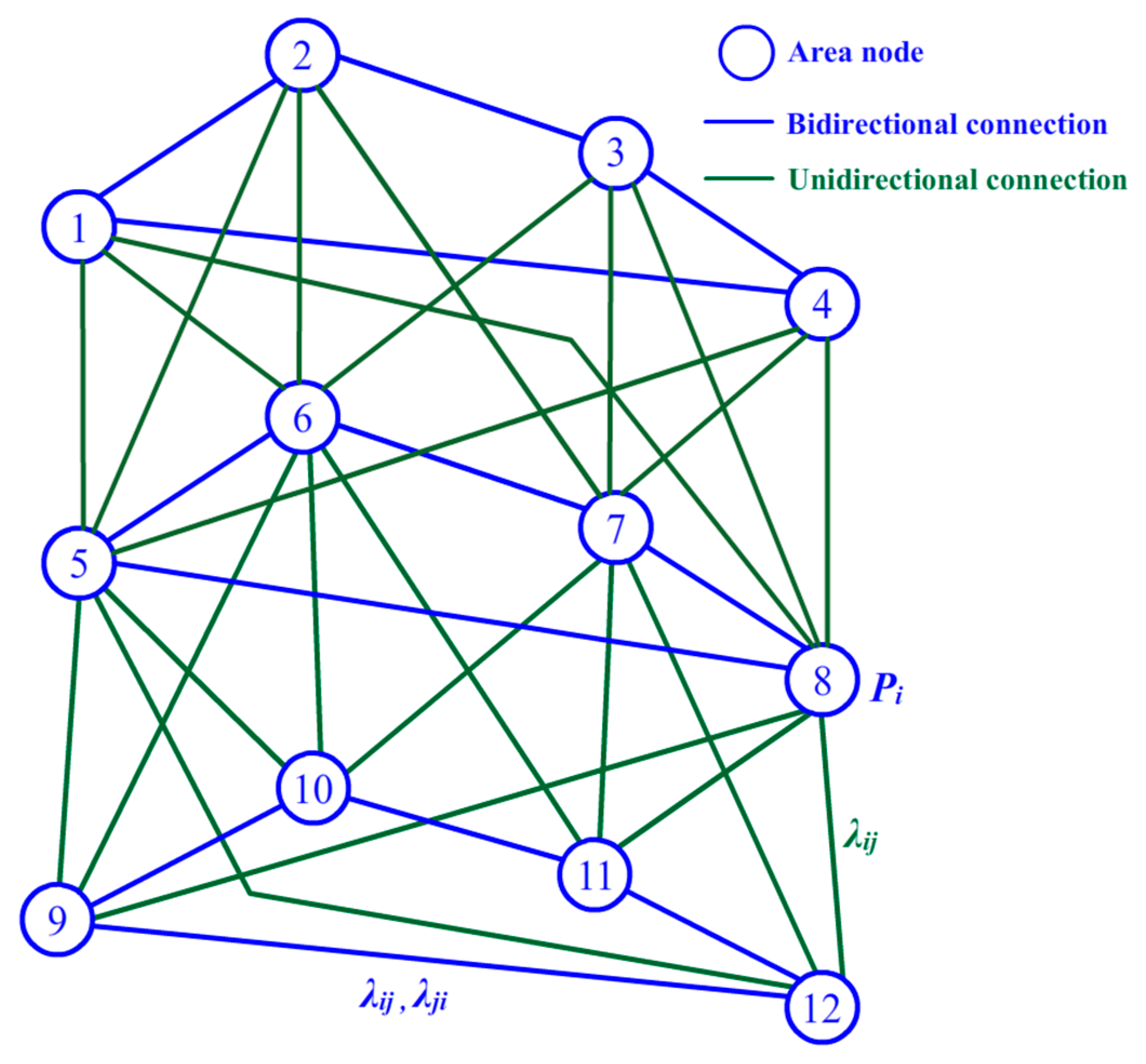
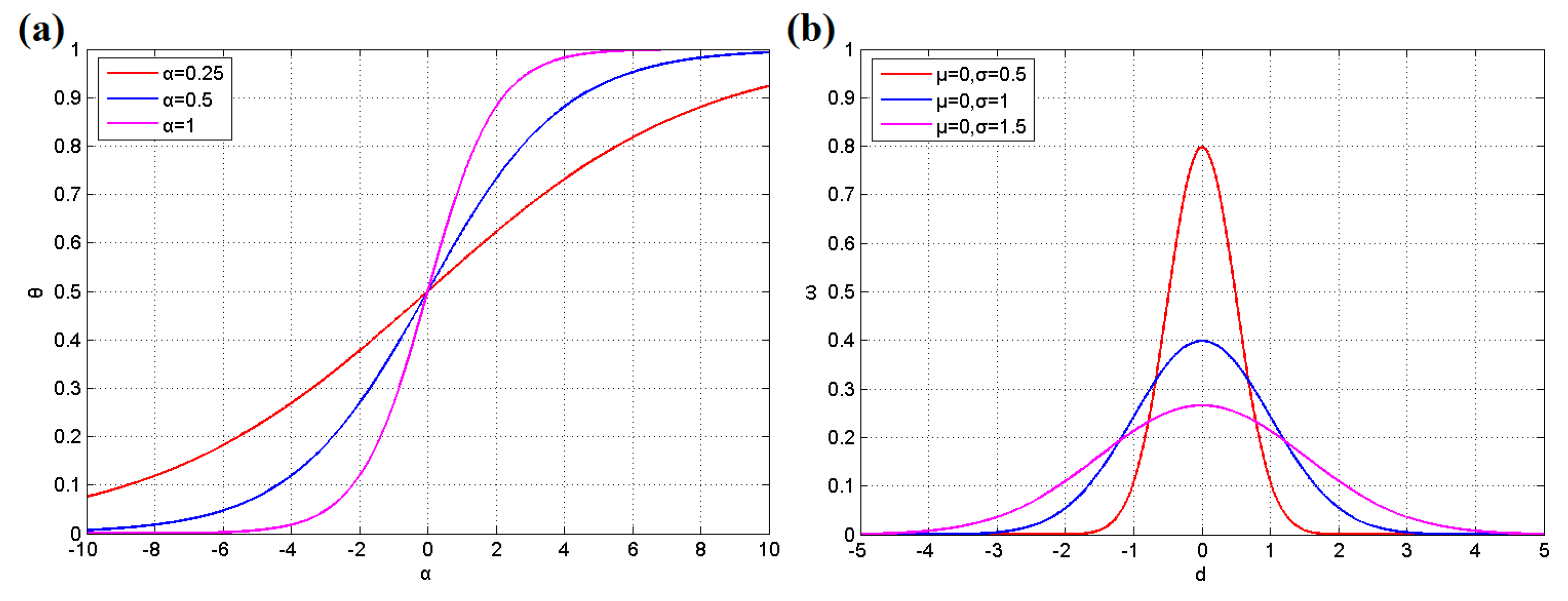
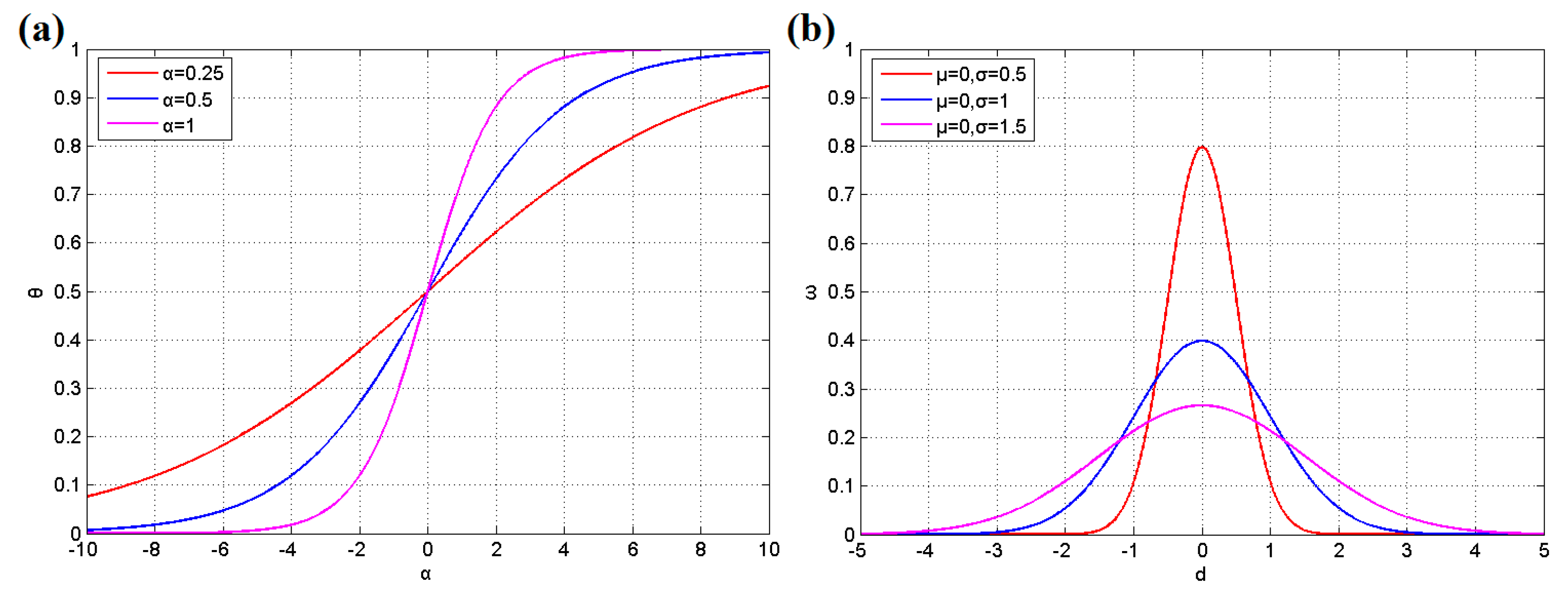
3.2. BN and Learning
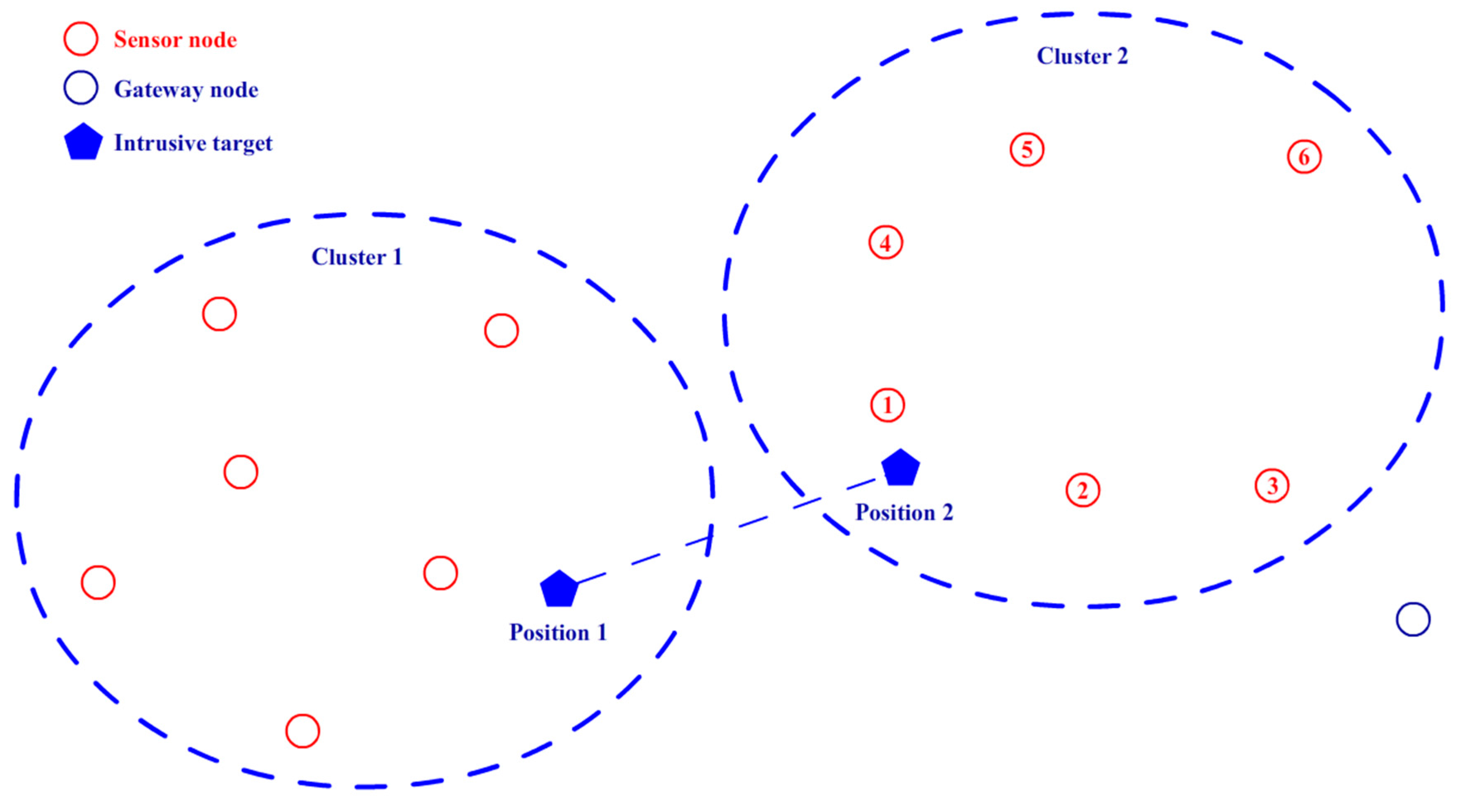
3.3. Node Movement and Target Detection
4. Data Fusion and Energy Control
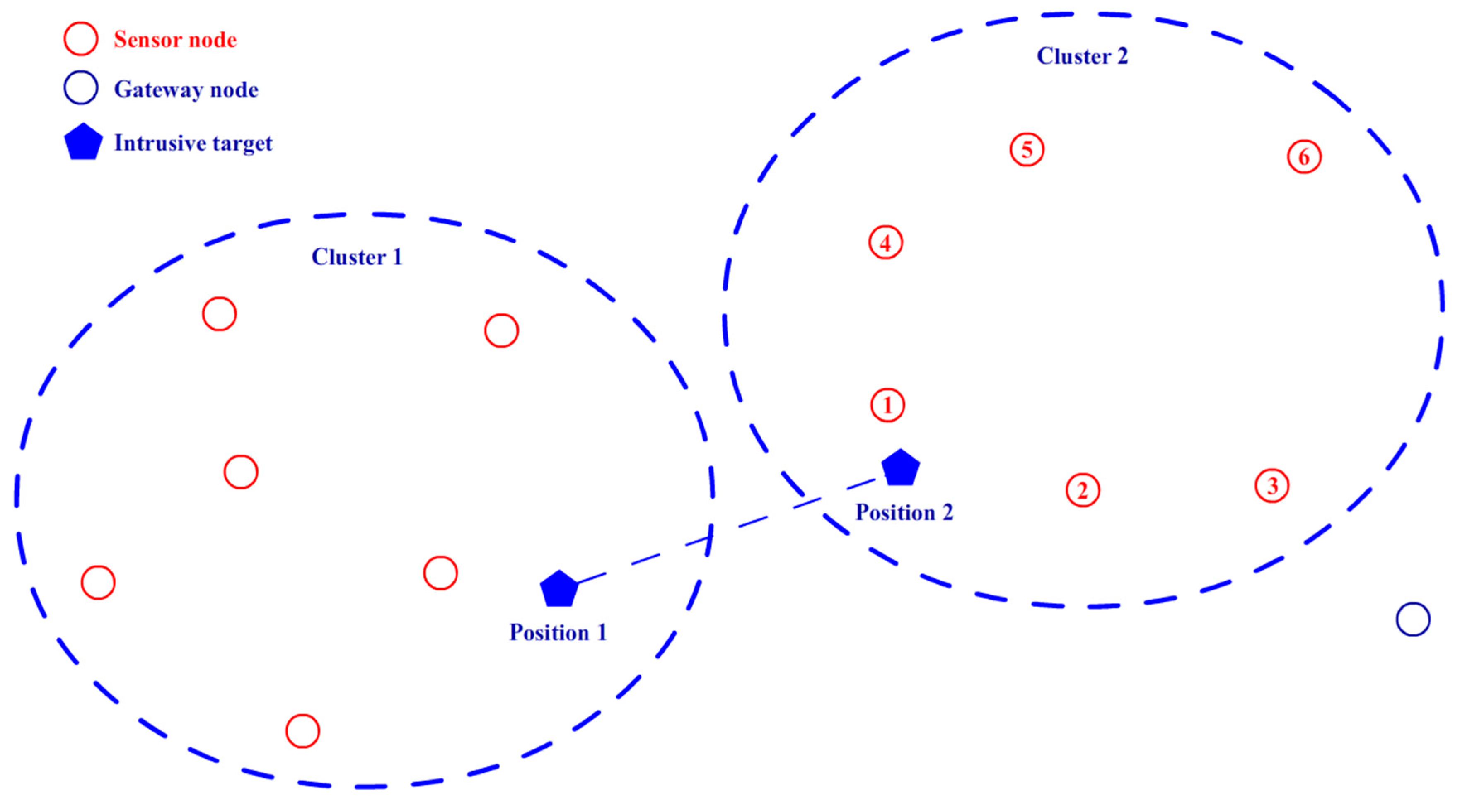
4.1. Clustering Algorithm
| Algorithm 1. Center initialization of the k-means++ algorithm. |
| Input: a set of objects O |
| Output: a set of initial centers , containing k elements |
| procedure K-MEANS++ (O, k) |
| Set all the objects in O as unprocessed, and ; |
| Choose an initial center randomly from the dataset, and |
| while |
| Choose the next initial center , selecting with probability |
| end while |
| return |
| end procedure |
4.2. Target Tracking
4.3. Data Fusion
5. Simulation and Experiments
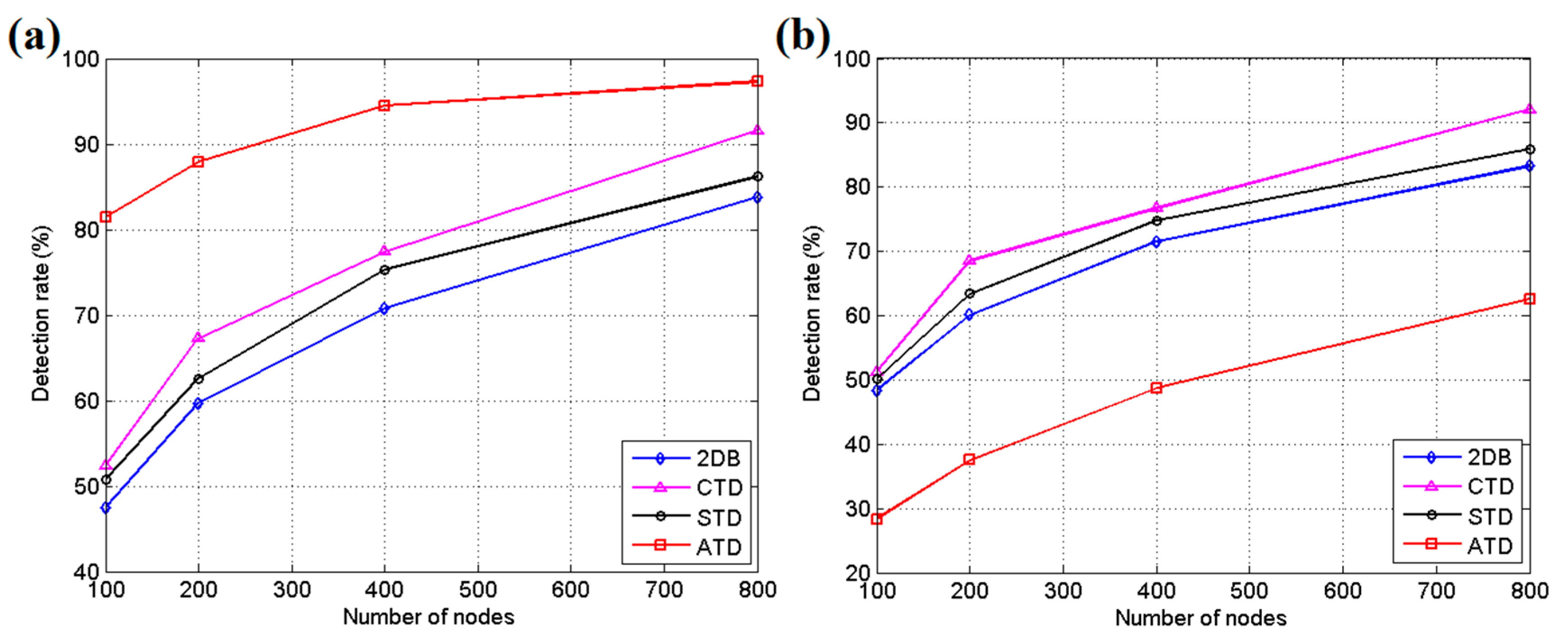
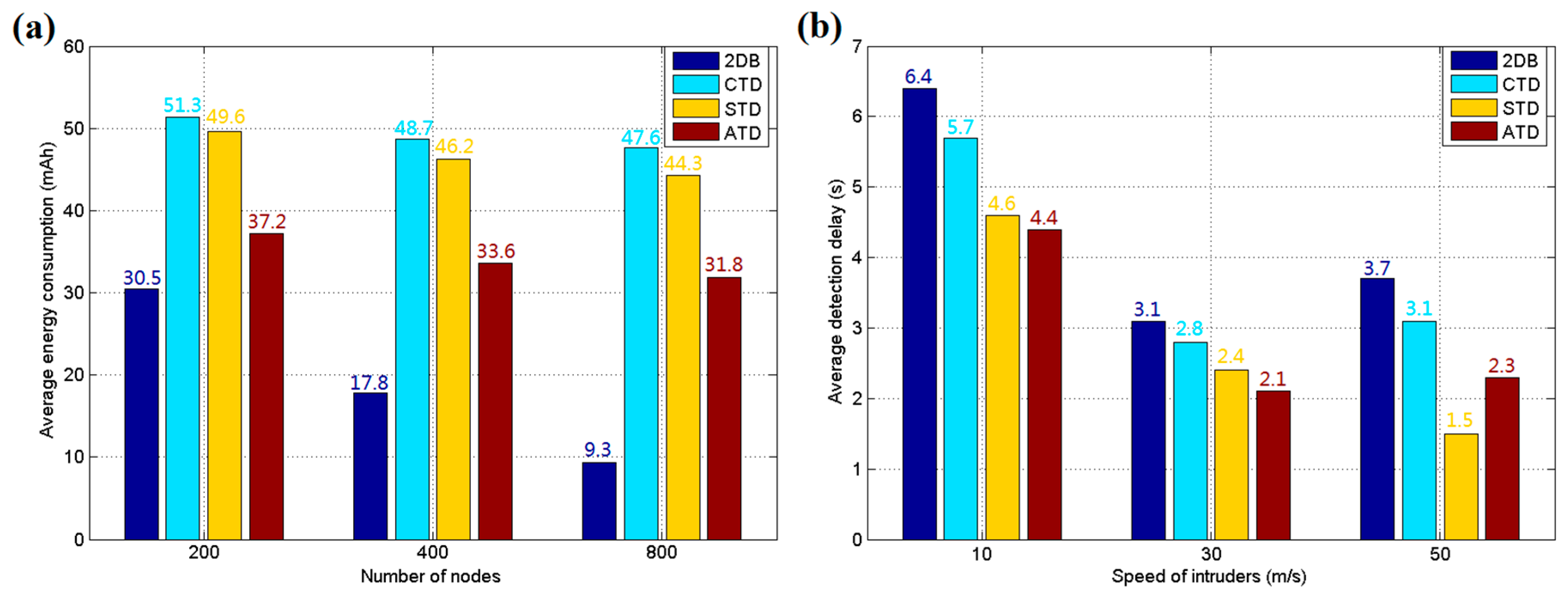
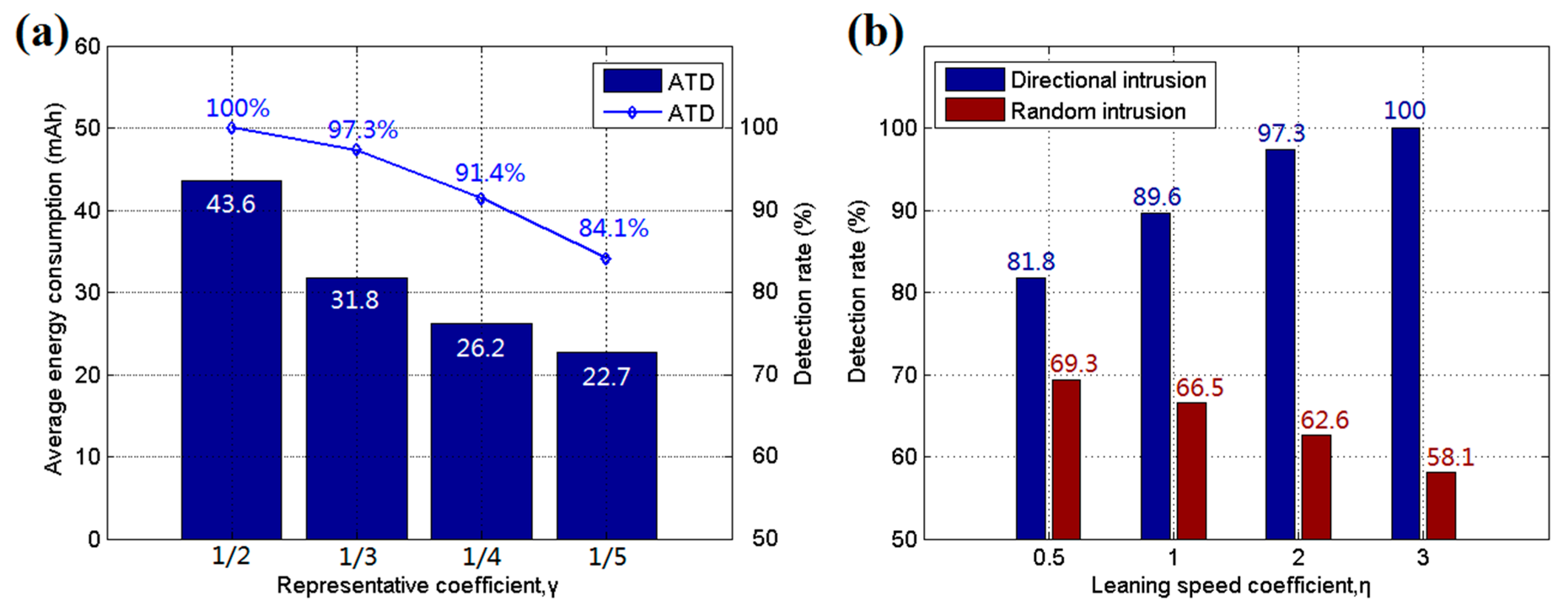
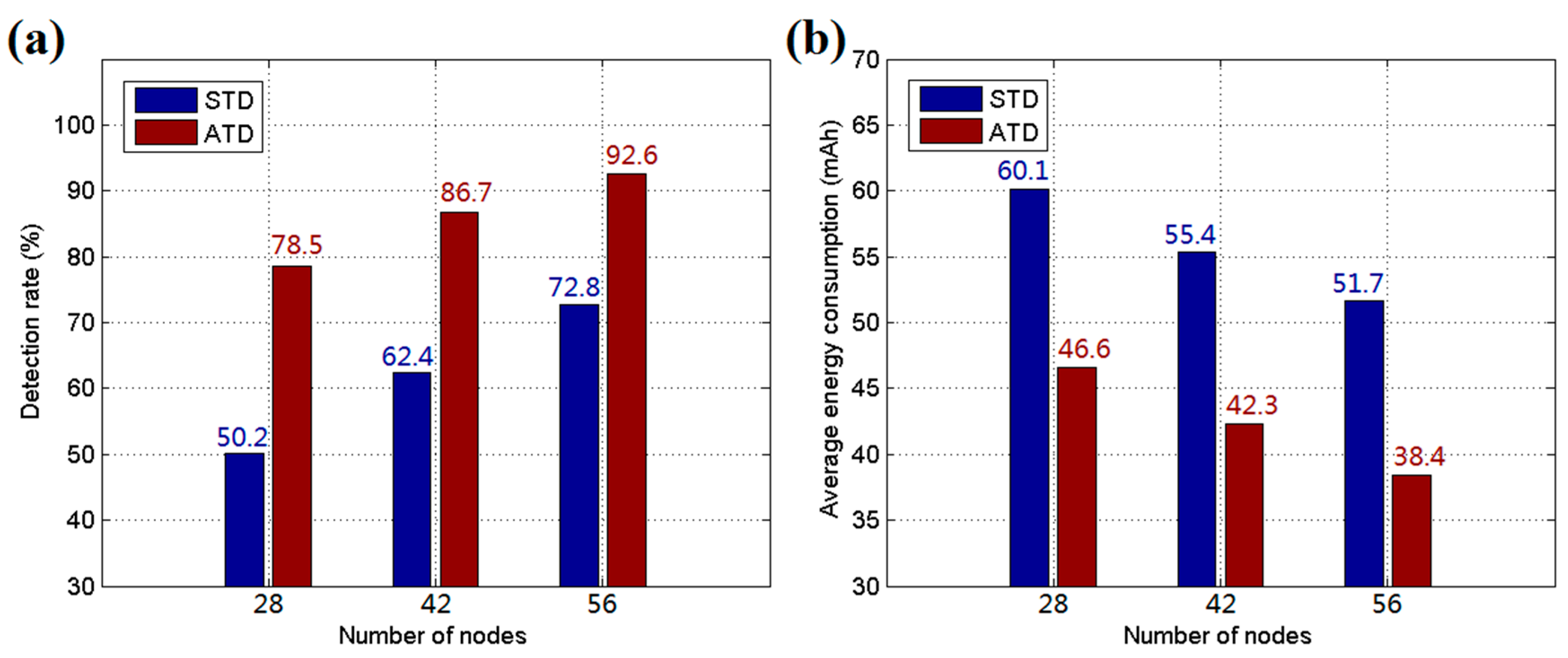
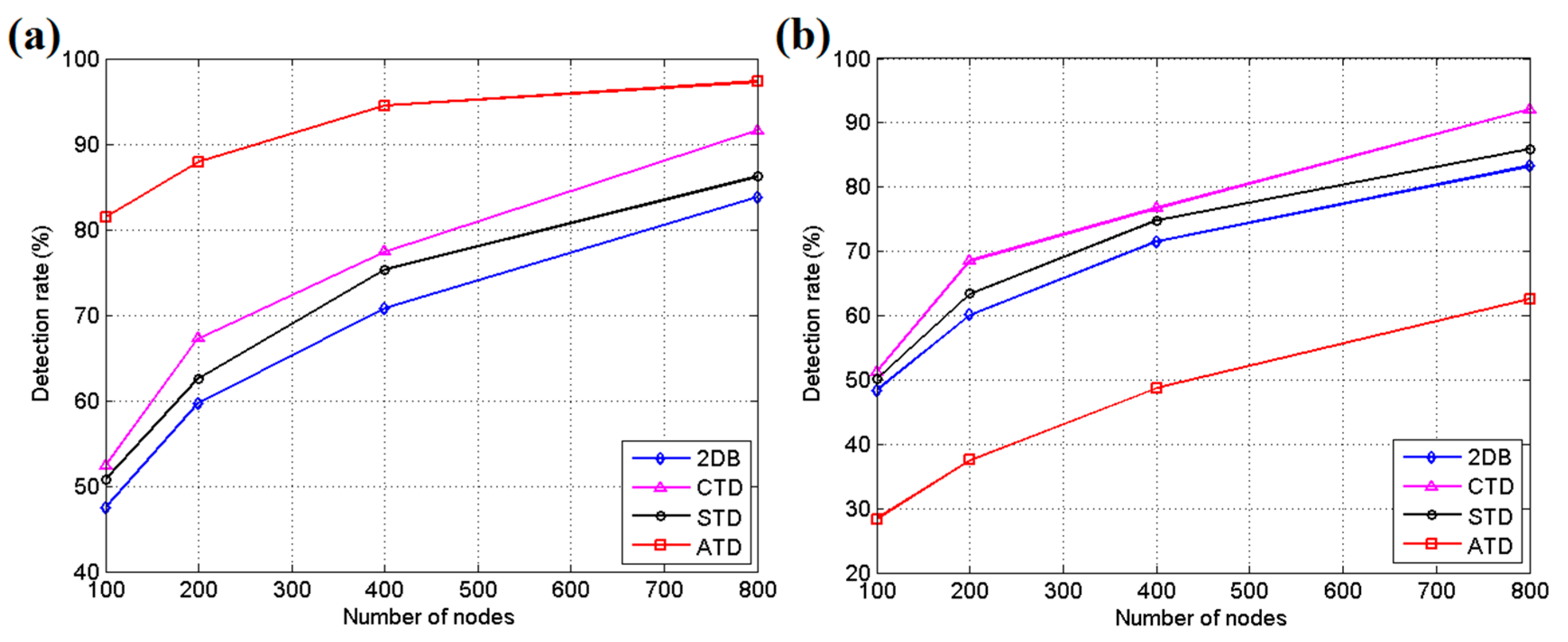
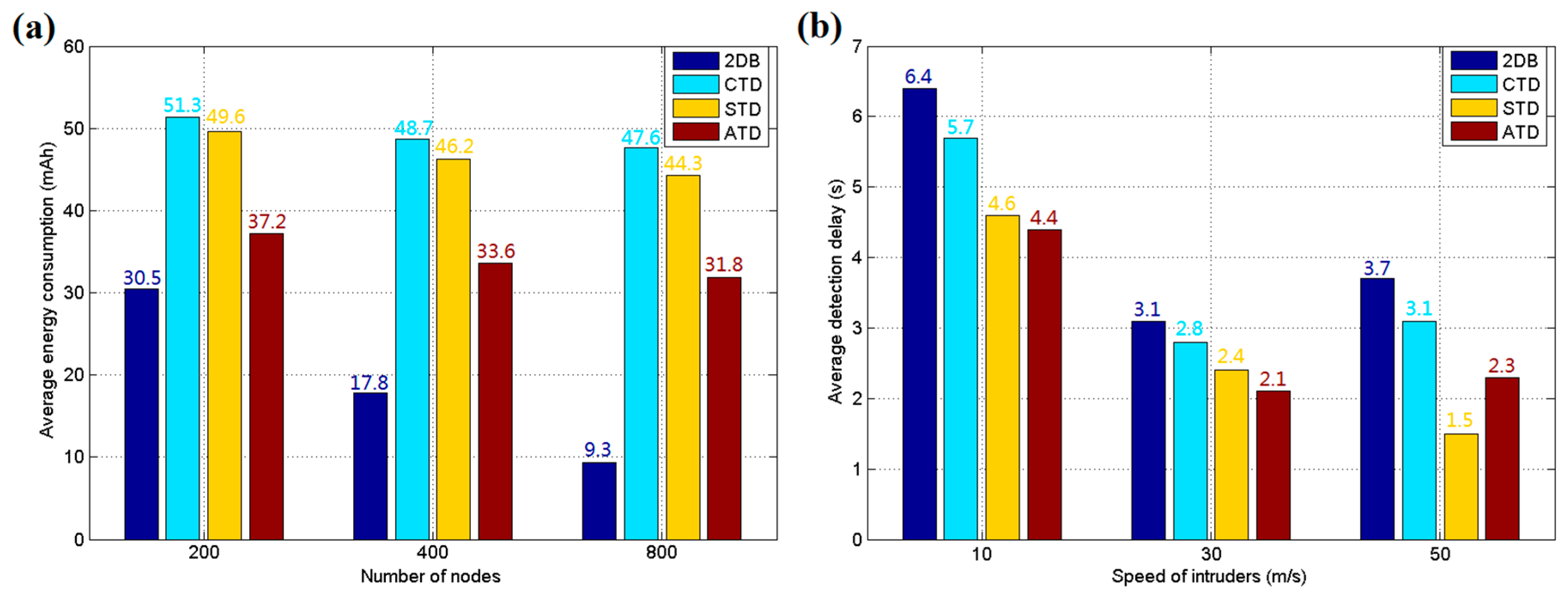
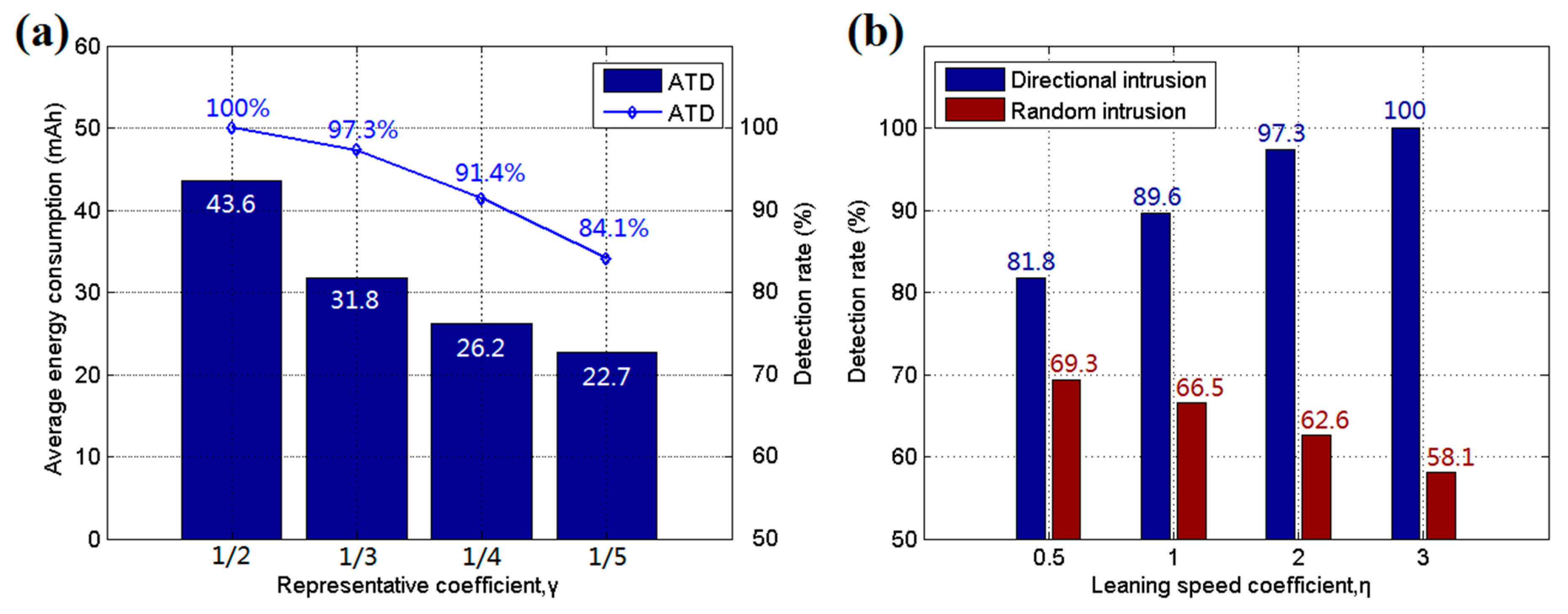
5.1. Simulation Results and Discussion
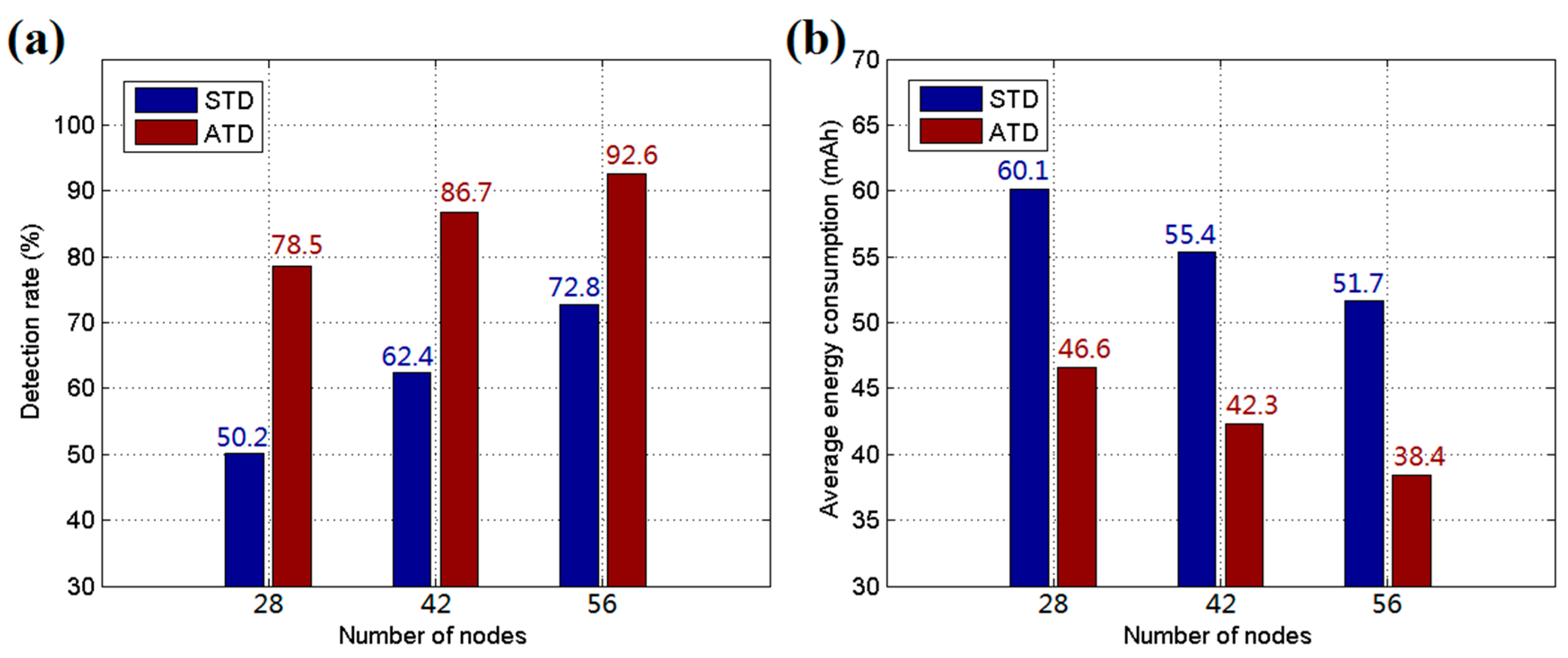
5.2. Implementation and Experiments
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Izadi, D.; Abawajy, J.H.; Ghanavati, S.; Herawan, T. A data fusion method in wireless sensor networks. Sensors 2015, 15, 2964–2979. [Google Scholar] [CrossRef] [PubMed]
- Feng, T.H.; Li, W.T.; Hwang, M.S.A. False Data Report Filtering Scheme in Wireless Sensor Networks: A Survey. Int. J. Netw. Secur. 2015, 17, 229–236. [Google Scholar]
- Shen, V.R.L.; Yang, C.Y.; Chen, C.H. A smart home management system with hierarchical behavior suggestion and recovery mechanism. Comput. Stand. Interfaces 2015, 41, 98–111. [Google Scholar] [CrossRef]
- Chin, T.L.; Chuang, W.C. Latency of collaborative target detection for surveillance sensor networks. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 467–477. [Google Scholar] [CrossRef]
- Hefeeda, M.; Bagheri, M. Forest Fire Modeling and Early Detection using Wireless Sensor Networks. Ad Hoc Sens. Wirel. Netw. 2009, 7, 169–224. [Google Scholar]
- Tung, H C.; Tsang, K.F.; Lam, K.L.; Tung, H.Y.; Li, B.Y.S.; Yeung, L.F.; Ko, K.T.; Lau, W.H.; Rakocevic, V. A mobility enabled inpatient monitoring system using a ZigBee medical sensor network. Sensors 2014, 14, 2397–2416. [Google Scholar] [CrossRef] [PubMed]
- Colombo, A.; Fontanelli, D.; Macii, D.; Palopoli, L. Flexible indoor localization and tracking based on a wearable platform and sensor data fusion. IEEE Trans. Instrum. Meas. 2014, 63, 864–876. [Google Scholar] [CrossRef]
- Feng, T.H.; Shih, N.Y.; Hwang, M.S. A Safety Review on Fuzzy-based Relay Selection in Wireless Sensor Networks. Int. J. Netw. Secur. 2015, 17, 712–721. [Google Scholar]
- Zou, T.; Lin, S.; Feng, Q.; Chen, Y. Energy-Efficient Control with Harvesting Predictions for Solar-Powered Wireless Sensor Networks. Sensors 2016, 16, 53. [Google Scholar] [CrossRef] [PubMed]
- Tian, J.; Zhang, W.; Wang, G.; Gao, X. 2D k-barrier duty-cycle scheduling for intruder detection in wireless sensor networks. Comput. Commun. 2014, 43, 31–42. [Google Scholar] [CrossRef]
- An, Y.K.; Yoo, S.M.; An, C.; Wells, B.E. Rule-based multiple-target tracking in acoustic wireless sensor networks. Comput. Commun. 2014, 51, 81–94. [Google Scholar] [CrossRef]
- Arora, A.; Dutta, P.; Bapat, S.; Kulathumani, V.; Zhang, H.; Naik, V.; Mittal, V.; Cao, H.; Demirbas, M.; Gouda, M.; et al. A line in the sand: A wireless sensor network for target detection, classification, and tracking. Comput. Netw. 2004, 46, 605–634. [Google Scholar] [CrossRef]
- Sikka, P.; Corke, P.; Overs, L. Wireless sensor devices for animal tracking and control. In Proceedings of the 29th Annual IEEE International Conference on Local Computer Networks, Denver, CO, USA, 16–18 November 2004; pp. 446–454. [Google Scholar]
- Howard, A.; Matarić, M.J.; Sukhatme, G.S. Mobile Sensor Network Deployment Using Potential Fields: A Distributed, Scalable Solution to the Area Coverage Problem; Distributed Autonomous Robotic Systems 5; Springer: Fukuoka, Japan, 2002; pp. 299–308. [Google Scholar]
- Batalin, M.A.; Sukhatme, G.S. Sensor network-mediated multi-robot task allocation. In Multi-Robot Systems. From Swarms to Intelligent Automata Volume III; Springer: Cham, Switzerland, 2005; pp. 27–38. [Google Scholar]
- Qi, X.; Wei, P.; Liu, L.; Xie, M.; Cai, G. Wireless sensor networks energy effectively distributed target detection. Int. J. Distrib. Sens. Netw. 2014, 2014. [Google Scholar] [CrossRef]
- Jin, Y.; Ding, Y.; Hao, K.; Jin, Y. An endocrine-based intelligent distributed cooperative algorithm for target tracking in wireless sensor networks. Soft Comput. 2015, 19, 1427–1441. [Google Scholar] [CrossRef]
- Gangwar, P.K.; Singh, Y.; Mohindru, V. An energy efficient zone-based clustering approach for target detection in wireless sensor networks. In Proceedings of the IEEE Recent Advances and Innovations in Engineering (ICRAIE), Jaipur, India, 9–11 May 2014; pp. 1–7. [Google Scholar]
- Calafate, C.T.; Lino, C.; Diaz-Ramirez, A.; Cano, J.C.; Manzoni, P. An integral model for target tracking based on the Use of a WSN. Sensors 2013, 13, 7250–7278. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, D.; Fang, W. Automatic node selection and target tracking in wireless camera sensor networks. Comput. Electr. Eng. 2014, 40, 484–493. [Google Scholar] [CrossRef]
- Sheltami, T.R.; Khan, S.; Shakshuki, E.M.; Menshawi, M.K. Continuous objects detection and tracking in wireless sensor networks. J. Ambient. Intell. Humaniz. Comput. 2016, 7, 489–508. [Google Scholar] [CrossRef]
- Yet, B.; Constantinou, A.; Fenton, N.; Neil, M.; Luedeling, E.; Shepherd, K. A Bayesian network framework for project cost, benefit and risk analysis with an agricultural development case study. Expert Syst. Appl. 2016, 60, 141–155. [Google Scholar] [CrossRef]
- Zhang, G.; Thai, V.V. Expert elicitation and Bayesian Network modeling for shipping accidents: A literature review. Saf. Sci. 2016, 87, 53–62. [Google Scholar] [CrossRef]
- Bianchi, F.M.; Livi, L.; Rizzi, A. Two density-based k-means initialization algorithms for non-metric data clustering. Pattern Anal. Appl. 2015, 19, 754–763. [Google Scholar] [CrossRef]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. k-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, Society for Industrial and Applied Mathematics, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Shahrivari, S.; Jalili, S. Single-pass and linear-time k-means clustering based on MapReduce. Inf. Syst. 2016, 60, 1–12. [Google Scholar] [CrossRef]
- Sepasi, S.; Ghorbani, R.; Liaw, B.Y. A novel on-board state-of-charge estimation method for aged Li-ion batteries based on model adaptive extended Kalman filter. J. Power Sources 2014, 245, 337–344. [Google Scholar] [CrossRef]
- Yazdanian, M.; Mehrizi-Sani, A.; Mojiri, M. Estimation of Electromechanical Oscillation Parameters Using an Extended Kalman Filter. IEEE Trans. Power Syst. 2015, 30, 2994–3002. [Google Scholar] [CrossRef]
- De Angelis, G.; Moschitta, A.; Carbone, P. Positioning Techniques in Indoor Environments Based on Stochastic Modeling of UWB Round-Trip-Time Measurements. IEEE Trans. Intell. Transp. Syst. 2015, 17, 2272–2281. [Google Scholar] [CrossRef]


© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, T.; Li, Z.; Li, S.; Lin, S. Adaptive Energy-Efficient Target Detection Based on Mobile Wireless Sensor Networks. Sensors 2017, 17, 1028. https://doi.org/10.3390/s17051028
Zou T, Li Z, Li S, Lin S. Adaptive Energy-Efficient Target Detection Based on Mobile Wireless Sensor Networks. Sensors. 2017; 17(5):1028. https://doi.org/10.3390/s17051028
Chicago/Turabian StyleZou, Tengyue, Zhenjia Li, Shuyuan Li, and Shouying Lin. 2017. "Adaptive Energy-Efficient Target Detection Based on Mobile Wireless Sensor Networks" Sensors 17, no. 5: 1028. https://doi.org/10.3390/s17051028
APA StyleZou, T., Li, Z., Li, S., & Lin, S. (2017). Adaptive Energy-Efficient Target Detection Based on Mobile Wireless Sensor Networks. Sensors, 17(5), 1028. https://doi.org/10.3390/s17051028