Abstract
Most of the commercial nighttime pedestrian detection (PD) methods reported previously utilized the histogram of oriented gradient (HOG) or the local binary pattern (LBP) as the feature and the support vector machine (SVM) as the classifier using thermal camera images. In this paper, we propose a new feature called the thermal-position-intensity-histogram of oriented gradient (TPIHOG or THOG) and developed a new combination of the THOG and the additive kernel SVM (AKSVM) for efficient nighttime pedestrian detection. The proposed THOG includes detailed information on gradient location; therefore, it has more distinctive power than the HOG. The AKSVM performs better than the linear SVM in terms of detection performance, while it is much faster than other kernel SVMs. The combined THOG-AKSVM showed effective nighttime PD performance with fast computational time. The proposed method was experimentally tested with the KAIST pedestrian dataset and showed better performance compared with other conventional methods.
1. Introduction
For the commercialization of the advanced driver assistance system (ADAS), the most important factors are reliability and robustness, and pedestrian detection (PD) is certainly one of the ADAS functions that require high reliability and robustness. For a robust and reliable PD, reasonable performance even in the nighttime is important because more than half of pedestrian-related accidents occur in the nighttime, even though the volume of traffic is much less than in the daytime [1,2].
For effective nighttime PD, most studies used a thermal camera sensor because it visualizes objects using the infrared (IR) heat signature and it does not depend on lighting conditions. Among several types of thermal cameras, the far infrared (FIR) sensor is commonly used for PD in the nighttime because thermal radiation from pedestrian peaks in the FIR spectrum [3]. Compared with visible images, FIR images are robust against illumination variation but are significantly affected by weather because FIR sensors capture temperature changes in the output images. For example, pedestrians appear brighter than the background in cold days while they appear darker in hot days [1]. Furthermore, FIR images only contain a single channel of intensity information; thus, information on these images is not as detailed as that of visible images.
Similar to PD using visible images, PD using FIR images also consists of two steps: feature extraction and classification. In the feature extraction step, the features developed for daytime PD can also be used for nighttime PD. For example, local binary patter (LBP) [4] and its variations, such as the HOG-LBP [1,5], center-symmetric LBP (CSLBP) [6], and oriented CSLBP (OCSLBP) [7] were also proposed as daytime PD features. However, the LBP-based features have only orientation information of pixel intensity; therefore, they are sensitive to lighting conditions. On the other hand, there are some methods that use the shape of pedestrians as features. Dai et al. [8] utilized the joint shape and appearance cue to find the exact locations of pedestrians. Wang et al. [9] extracted the features using a shape describer and Zhao et al. [3] proposed the shape distribution histogram (SDH). These shape-based features simply used only pixel intensity information and employed background subtraction methods for fixed camera images. Therefore, shape-based features are not suitable for vehicle environment where complex background is not fixed.
As a robust feature for pedestrian detection, the histograms of oriented gradient (HOG) [10] is one of the most popular PD features and its variations have been proposed [11]. Co-occurrence HOG (CoHOG) is one of the extensions of the HOG and it utilizes pair of orientations for computing histogram feature [12]. N. Andavarapu et al. [13] proposed weighted CoHOG (W-CoHOG) that considers gradient magnitude factor to extracting CoHOG. Spatio-temporal HOG (SPHOG), which contains motion information, is proposed for image sequences with fixed camera [14]. Scattered difference of directional gradient (SDDG) that extracts local gradient information along the certain direction is also proposed for IR images [15]. Kim et al. proposed position-intensity HOG (PIHOG or HOG) that includes not only HOG but also the detail position and intensity information for vehicle detection [16]. Theses HOG based features utilize only the gradient information based on color images or do not consider the thermal intensity information which is important cue for pedestrian detection in nighttime.
To address these problems of conventional features, we propose a thermal position intensity HOG (TPIHOG or THOG). The THOG is the extended version of HOG and it is applied for pedestrian detection in nighttime. Unlike the HOG, the proposed THOG has thermal intensity information and can be computed more simply than HOG.
With respect to the classification, the linear support vector machine (linear SVM) is widely used as classifier in many studies, such as in [17,18,19] because it is fast and has reasonably good performance. The kernel SVM has better classification performance than the linear SVM but requires a longer computation time owing to kernel expansion [20,21,22]. However, the additive kernel SVM (AKSVM) has better performance than the linear SVM and also has a classification speed comparable with the linear SVM [20,23,24]. Recently, deep learning has also been applied to object detection system.
Kim et al. utilize convolutional neural network (CNN) for nighttime PD using visible images [25]. Liu et al. and Wagner et al applied fusion architectures to CNN which fuse the visible channel feature and thermal channel features for multispectral PD [26,27]. Cai et al. generates the candidates using saliency map and used deep belief network (DBN) as a classifier for vehicle detection in nighttime [28]. John et al. used Fuzzy C-means clustering for generating candidates and CNN for verification for PD in thermal images [29]. However, the deep learning based method requires dataset with large clean annotations and training procedure, which takes too much time to converge [30]. In addition, GPU is necessary for the training of deep learning, but it is not suitable for implement autonomous system because the system needs to be embedded system [31].
In this study, we propose a combination of the THOG and the AKSVM (THOG-AKSVM) to achieve improved performance for nighttime PD in terms of PD performance compared with conventional methods.
2. Preliminary Fundamentals
Position Intensity Histogram of Oriented Gradient (HOG)
The HOG is defined as the histogram of the magnitude sum for gradient orientations in a cell and it is widely used as an effective feature for PD or vehicle detection (VD). The HOG feature, however, has the limitation that information on gradient position in the cell is lost and the pixel intensity information is not used. Recently, the HOG has been proposed to address this problem and shows better detection performance than HOG for vehicle detection [16]. The HOG contains not only the HOG but also additional information about gradient Position and pixel Intensity. The HOG consists of three parts: the Position (P) part, the Intensity (I) part, and the conventional HOG. The P part of the HOG is extracted by computing the average position of each orientation bin. That is, if denotes the orientation of the gradient at position of the -th cell and the orientation bin of the gradient is defined by
where is the number of bins and , then the averages of and positions of the -th bin () in the -th cell are defined by
where denotes the cell size and is the binary function which returns 1 if the input argument is true and 0 if the argument is false. Then the P part of the -th cell in HOG is , where and .
The I part of the HOG can be defined in terms of the pixel intensity of vehicle images. There are a variety of shapes and sizes of vehicles, but all types of vehicles have low intensity values in some common areas, such as tires and bottom of the vehicles. Using this knowledge, the intensity invariant region (IIR) was proposed in [16]. The IIR is defined as the region of pixels in which the corresponding standard deviation is relatively low. Then, the I part is defined as the summation of standard normal deviation values in the IIR. A detailed procedure for extracting the I part of the HOG is explained as follows. When a set of positive vehicle images is given, where is the number of the training images in ; is the vehicle image and all the images in are resized to images of same size and aligned; is the intensity value of th pixel value of and is the image size, the mean and standard deviation of the vehicle images are defined as
where denotes component-wise multiplication. In Equation (4), low means that the corresponding region has similar intensity values over all types of vehicles including sedans, trucks or sport utility vehicles (SUVs). Therefore, the region with low standard deviation can be used as a distinctive cue for classifying vehicles. This region was defined as IIR and a new feature was extracted from the IIR [19]. To determine the IIR, the values of are divided into intervals and the binary mask is constructed as
where is
Finally, the I part of the HOG is the feature for the IIR region masked by of standard normal deviate image . That is, if the test image is given, then is computed by
and the I part is defined by
where
Figure 1 is an example of computing I part using 4 IIR masks from testing images.

Figure 1.
Examples of computing I part using 4 IIR masks [16].
Finally, the HOG is defined as a concatenation of the three parts, the HOG, the P part and the I part.
3. Proposed Method
Figure 2 shows some examples of pedestrians in thermal images. As shown in the figure, pedestrian detection using a thermal sensor is quite different from PD using a visible sensor owing to the characteristics of the thermal images.

Figure 2.
Examples of thermal images in KAIST dataset.
In thermal images, pedestrians appear brighter than the background and they do not include any color information, only silhouettes. In addition, their intensities vary according to changes in the weather because the thermal sensors visualize temperature radiation from the objects in the images. Therefore, it is important to extract features that can reliably capture pedestrian silhouette under various weather conditions in thermal images.
In previous works [1,5], the HOG was popularly used for nighttime pedestrian detection because it captures the appearance of pedestrians by stacking gradient information. However, in this paper, a new feature called the THOG is proposed to improve nighttime PD performance of the HOG. The proposed THOG is based on the HOG [16] and it is developed so that the THOG has more distinctiveness than the HOG when thermal sensors are used. The THOG includes not only thermal gradient information but also its locations and thermal intensities. The THOG is not a simple application of the HOG to thermal images, but it is redesigned to handle PD problems in thermal images.
In addition, instead of the linear SVM, the additive kernel support vector machine (AKSVM) is used as a classifier to enhance the detection performance, as well as the detection time.
3.1. Thermal Position Intensity Histogram of Oriented Gradient (THOG)
The HOG takes longer time and thus, computationally more expensive than the HOG since the HOG requires additional pixel-wise computation to compute the mean of pixel locations. However, the pixel-wise computation in the HOG is not suitable for commercial PD because it requires real time operation. Thus, in the proposed THOG, the cell-wise approach, and not the pixel-wise approach, was adopted to reduce the computational time. Since the cell values have already been computed in extracting the HOG, less computation is required to compute the THOG compared with the conventional HOG.
Furthermore, unlike the I part based on the IIR in [16], the I part in this paper was increased such that it has the same size as the orientation channel of the HOG. This is because the I part in the original work [16] used only 4 values from the 4 IIR masks as features and it had relatively small effects on the PD performance compared with the P or the HOG parts.
The THOG consists of four parts: the T part, the Position (P) part, the Intensity (I) part, and the conventional HOG. In the conventional HOG, we used the HOG of [32] which has 27 gradient channels (18 signed orientations, 9 unsigned orientations) and 4 gradient energy channels using different normalization methods. A detailed description of these four parts is presented in following subsections.
3.1.1. T Channel Part
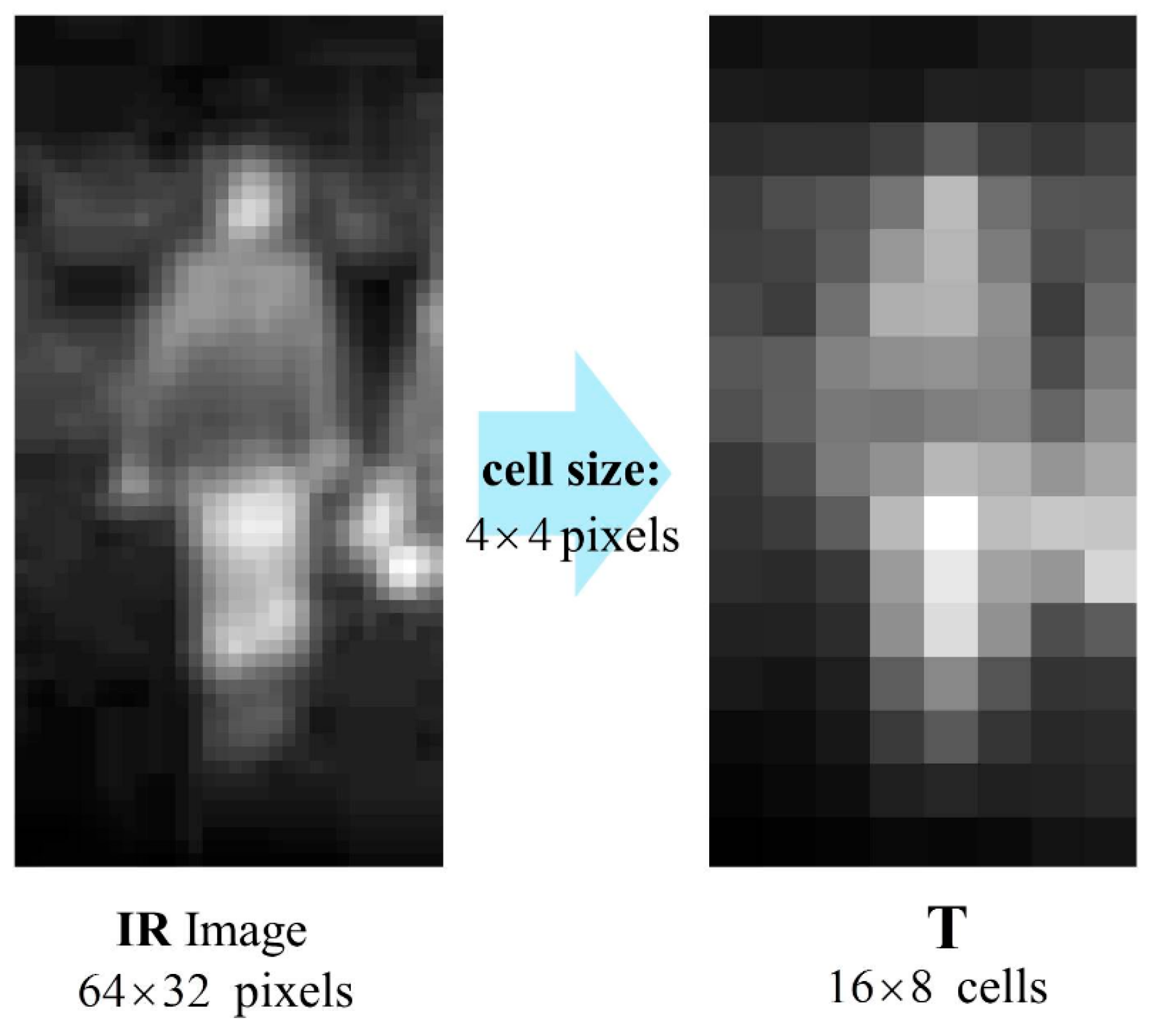
For the first part of the THOG, we used the T channel proposed in [33]. The T channel is defined as an aggregated version of a thermal image. For example, given IR images and cell size, the T channel has cells and the value in each cell is the sum of pixel intensities within the cell. Figure 3 shows an example of an IR image and its T channel.
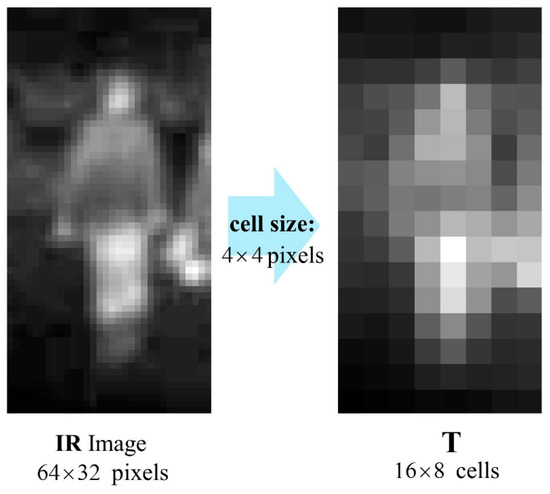
Figure 3.
Example of IR image and its T channel.
Unlike the visible image, the pedestrians have higher pixel intensity values than backgrounds in IR images. Thus, T channel that consists of aggregations of IR intensities can play an important role in classifying pedestrians from other objects.
3.1.2. Position Part
In the P part of the THOG, cell locations of the gradients and not pixel locations, are used unlike in the HOG. In the feature implementation, the HOG consists of multiple orientation channels and each channel contains the bin value for the corresponding orientation of a cell histogram. In Figure 4, shown are the examples of HOG that has cells with 9 gradient orientations.

Figure 4.
Example of HOG channels with 9 orientations.
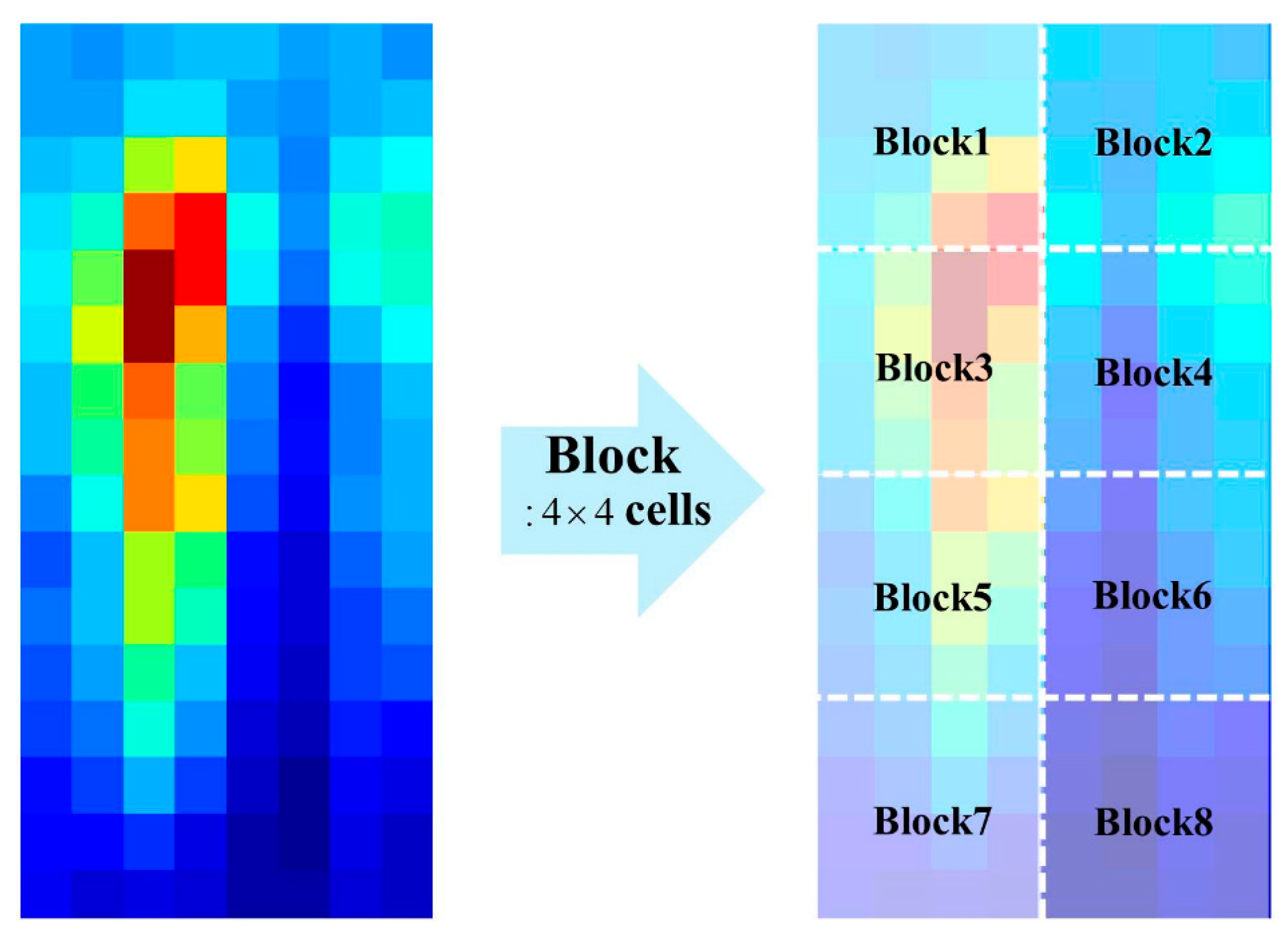
In Figure 4, the values in each channel denote the bin values of cell histogram for the corresponding orientation. For example, the first channel of the HOG contains the first bin value of the cell histogram. In computing the P part of the THOG, we divide the HOG cells into several blocks as shown in Figure 5.
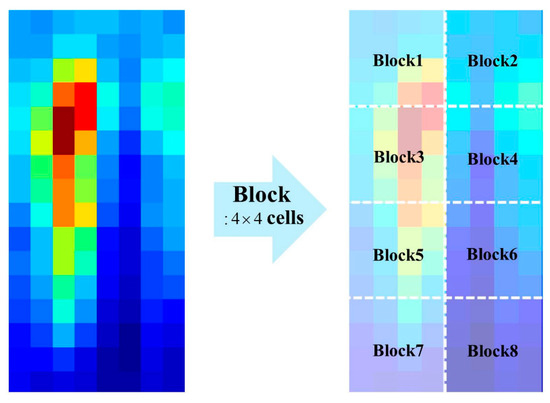
Figure 5.
Example of dividing HOG into 8 blocks.
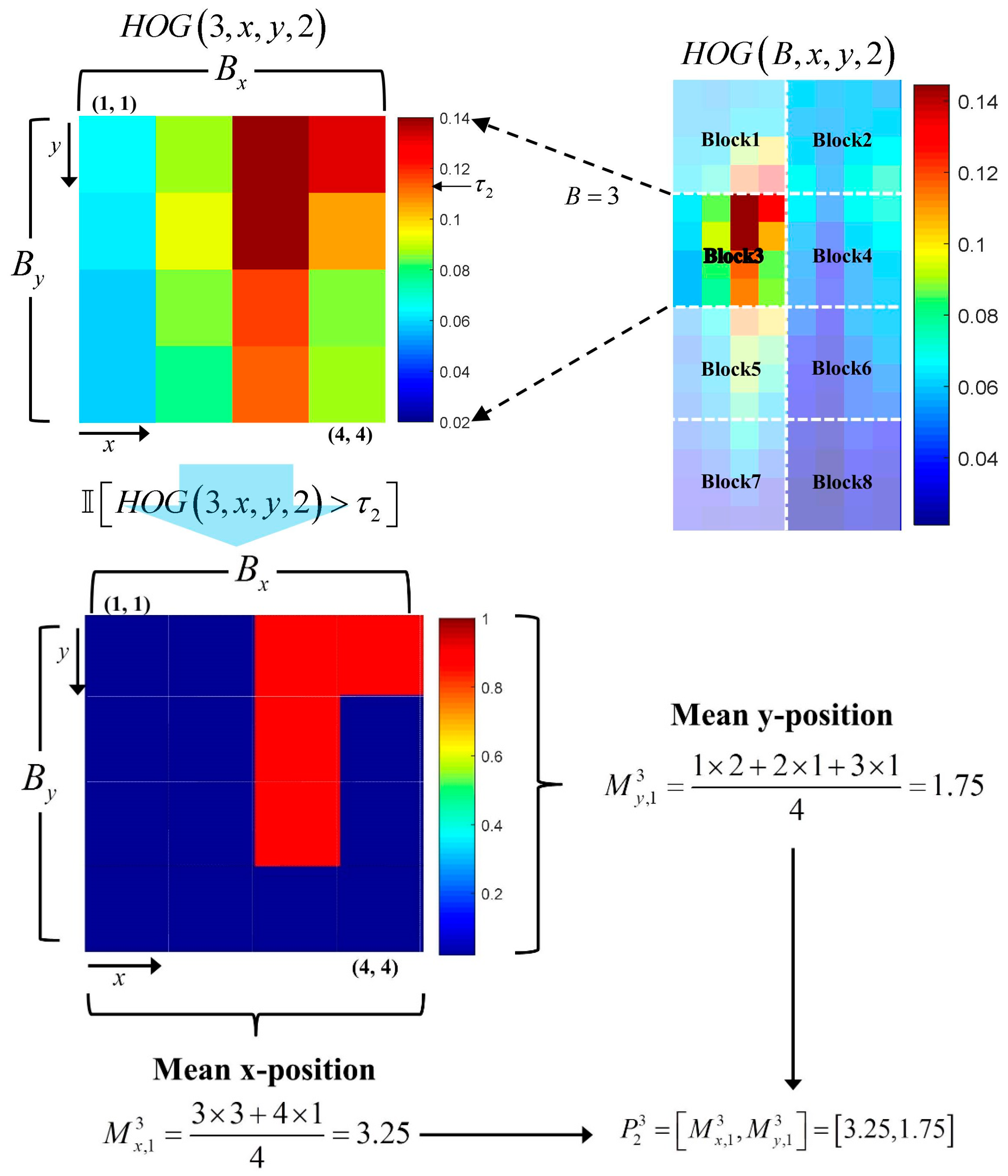
The P part is defined as the location in which each orientation component exists in a block. Assuming that is the value of a cell located at of the th block in the th orientation channel, then the P part is defined by
where
where is the threshold for each orientation. Figure 6 shows an example of the computation of the two values for , the 3rd block in the second orientation channel, when the block size is cells with 9 orientations.
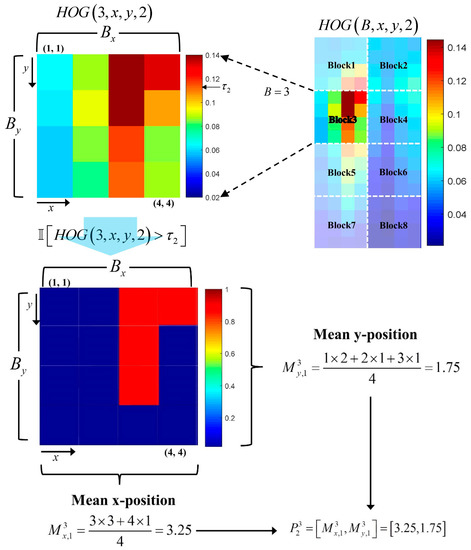
Figure 6.
Example of P part extraction.
In Figure 6, only the cells with values of that exceed the threshold are used to compute the P part of the THOG. Similarly, the P part contains location information of each orientation channel and is computed by
where .
For the sake of better understanding of P part, the HOG and P part are visualized in Figure 7, Figure 8 and Figure 9. Shown in Figure 7 are the examples of pedestrians IR images and they are adopted from KAIST pedestrian dataset [33].

Figure 7.
Examples of pedestrian IR images in KAIST pedestrian dataset [33].
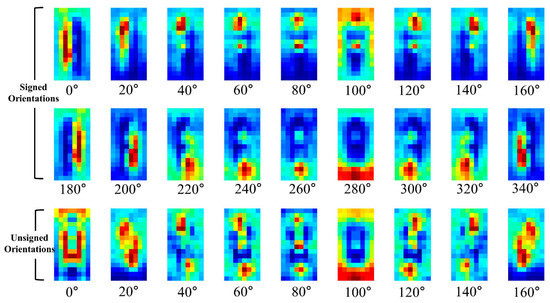
Figure 8.
Average gradient channels of HOG for pedestrians.
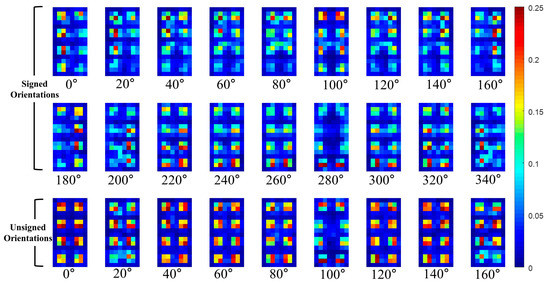
Figure 9.
Average of P parts of THOG for pedestrians.
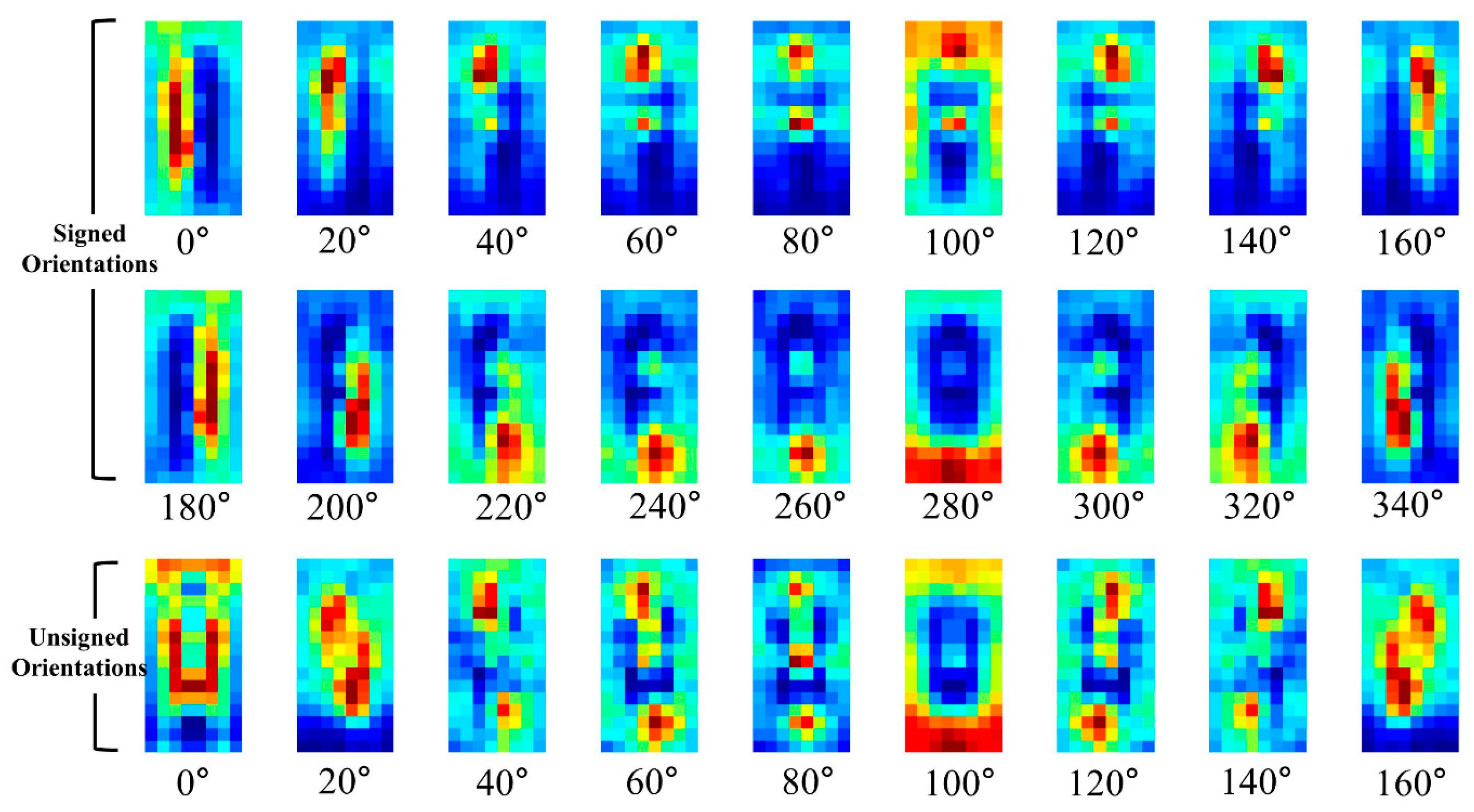
The average HOG channels for training pedestrian data are visualized in Figure 8. The average channels are computing using cropped IR images of 2244 pedestrians. In the figure, the first two rows indicate the HOGs for signed 18 orientations while the third row indicates the HOGs for unsigned 9 orientations.
In Figure 8, the closer the cell is to the red color, the higher the corresponding HOG. As shown in the figure, pedestrians have specific cell parts that have relatively high values for each orientation channel. The conventional HOG uses only these values as the feature but the THOG also uses the cell locations of the orientations as well for nighttime PD.
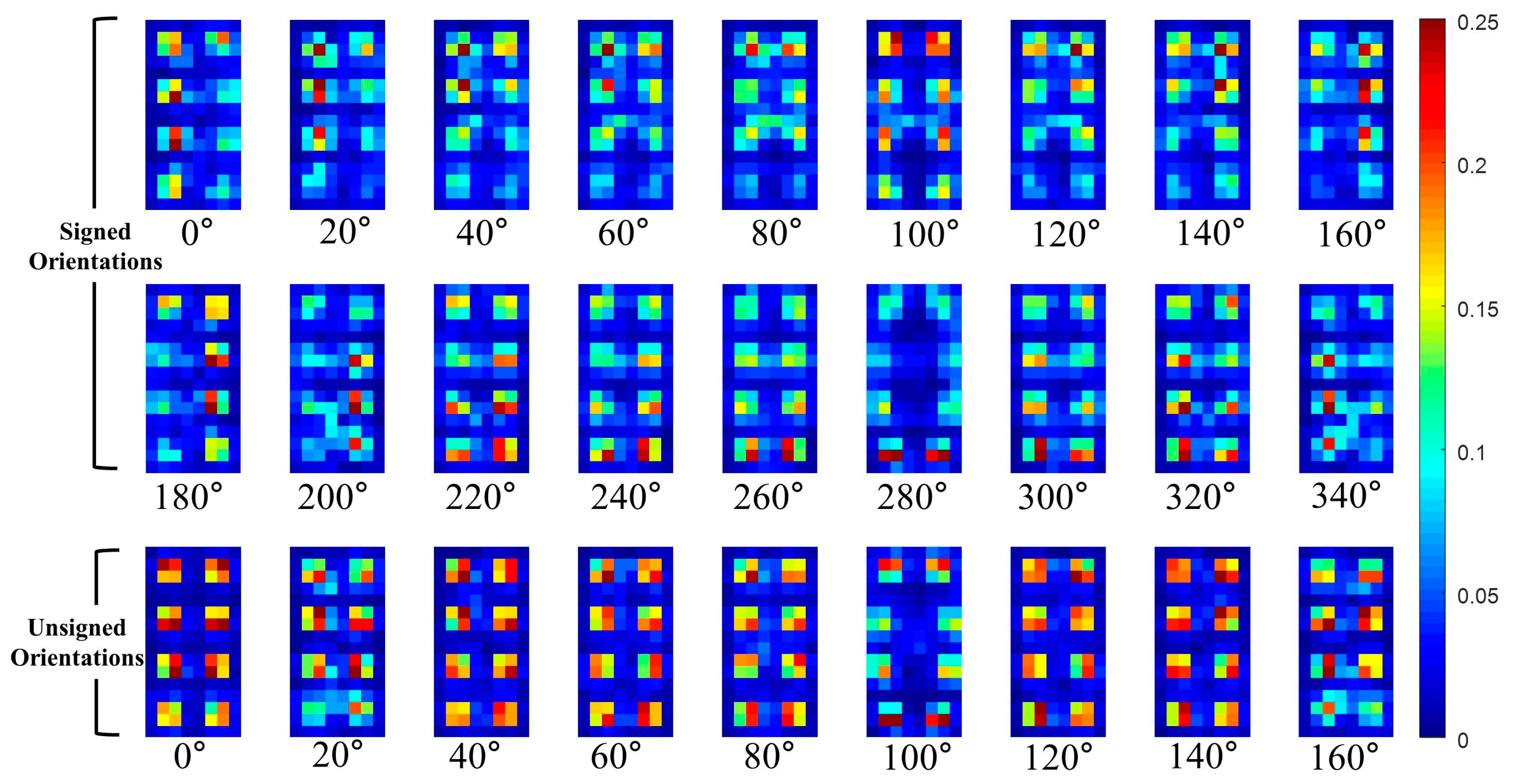
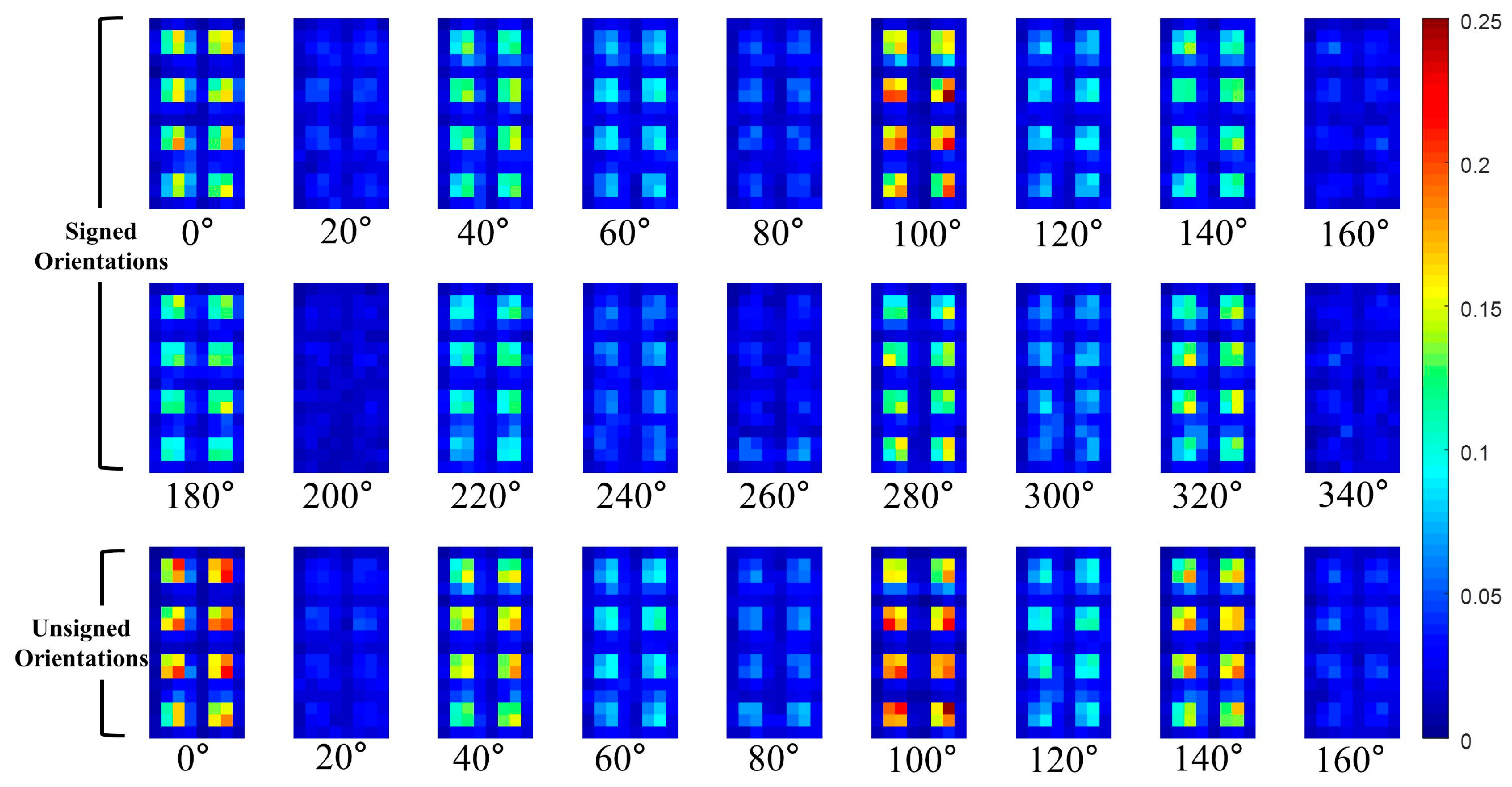
In this paper, the P part of the THOG is extracted from non-overlapped blocks that comprising of 4 × 4 cells. For example, assuming the HOG has 31 channels (18 signed orientations, 9 unsigned orientations, 4 different normalizations), the size of the HOG is cells and it has blocks. The P part of the THOG is extracted from each block and the P part has additional 496 values. Figure 9 and Figure 10, show the visualization of the average of the THOG for pedestrians and non-pedestrians, respectively. In Figure 9 and Figure 10, the average P parts are computed for 2244 pedestrian images and 5000 non-pedestrian images, respectively. All the images are cropped IR images.
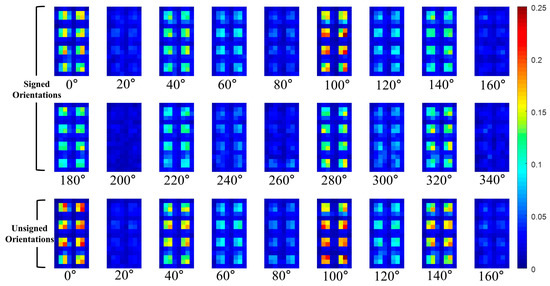
Figure 10.
Average of P parts of THOG for non-pedestrians.
As shown in Figure 9 and Figure 10, the average P parts of the pedestrians are focused on a couple of cell locations for each block. In particular, the average P parts of the pedestrians are mostly larger than those of the non-pedestrians except for unsigned orientation of and . Instead, the average P parts of the non-pedestrians usually have lower values than those of pedestrians. Further, in the orientations of and , the P parts of non-pedestrians have the values close to 0 and they are not included in computation of P parts. This difference between the two classes provides the THOG with discriminatory power for robust PD compared with the HOG.
3.1.3. Intensity Part
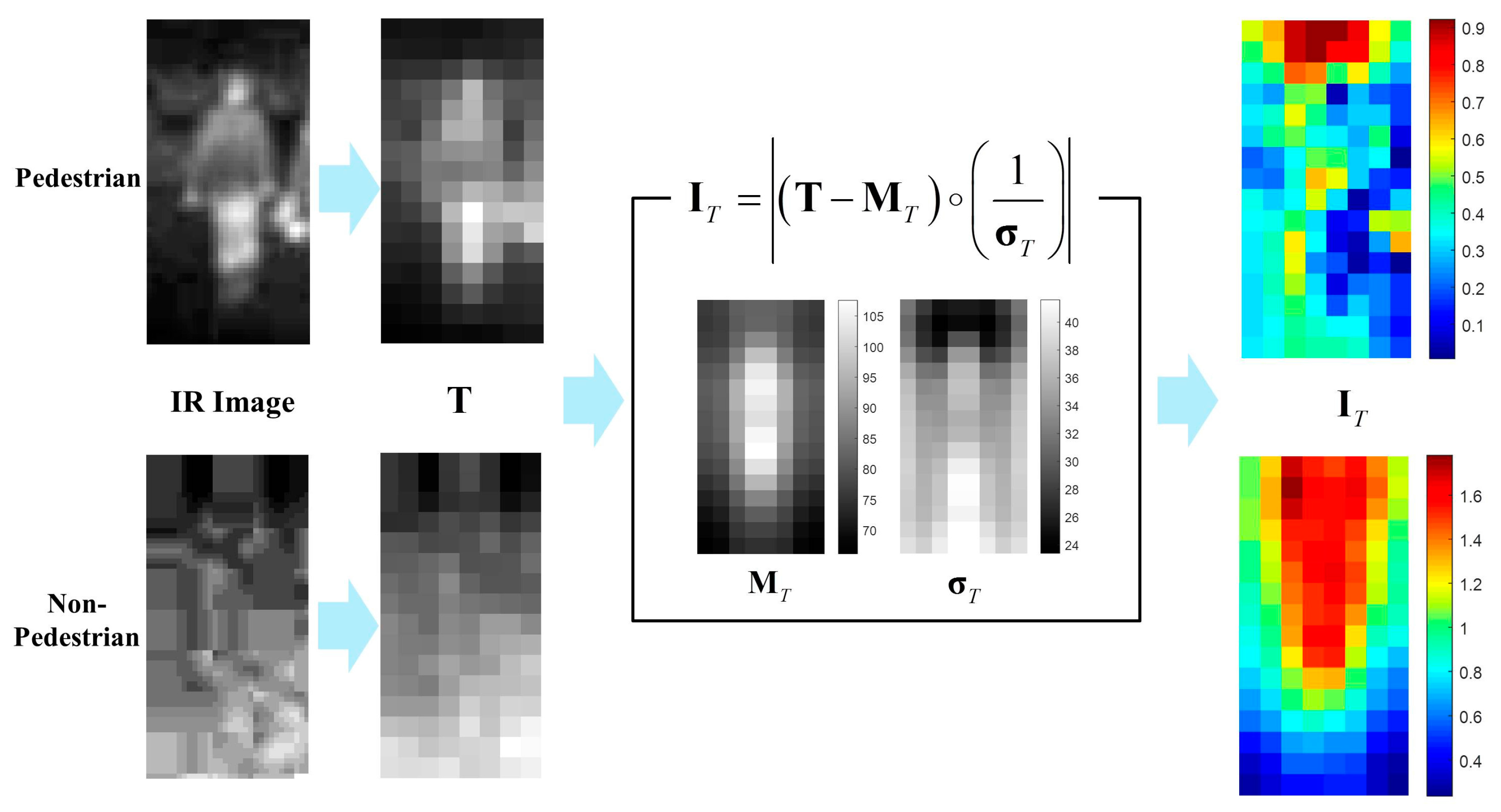
The conventional I part of the HOG is defined as a partial pixel-wise sum of the standard deviate image [16] within the IIR. Thus, the evaluation of the I part requires pixel-wise computation; however, it is obviously computationally expensive for real-time application. Furthermore, the conventional I part in [16] is 4 dimensions long and too short compared with 3968 () dimensions of the HOG, thereby producing minimal effect on the PD performance. In this paper, a modified version of the I part is developed for the PD in thermal images. Rather than using IIR masks, the new I part is directly computed from a normal standard deviate image of the set of T channels which are computed from training pedestrian data ( cropped IR images of pedestrians). Therefore, the feature length of the I part is the same as that of the T channel. That is, given the T channel set of pedestrian images where the superscript ‘+’ means the positive pedestrian samples, is the number of the T channels in and . and are the mean and standard deviation of , respectively, and the I part for a testing T channel is computed by
How to compute the I part from both pedestrian and non-pedestrian testing images is summarized in Figure 11.
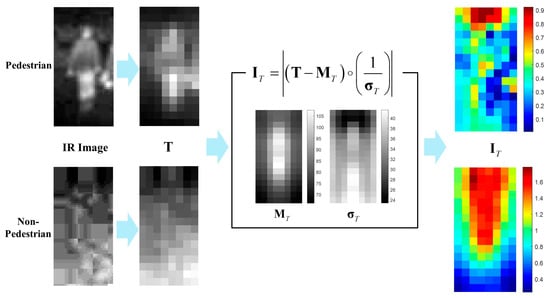
Figure 11.
Example of computing I part from testing images.
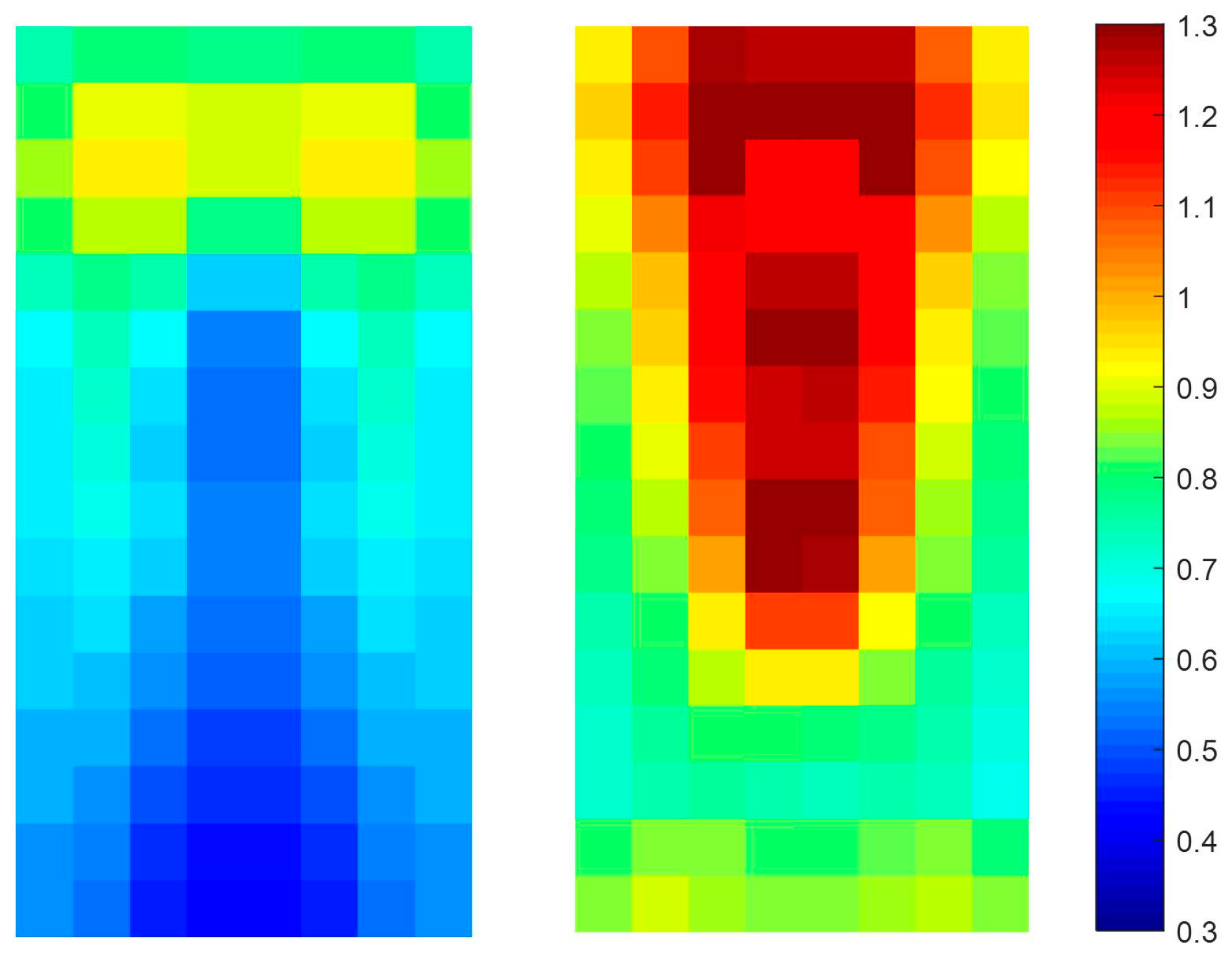
Shown in Figure 11 is the average of I parts for pedestrians and non-pedestrians. The images are cropped IR images of testing dataset of KAIST pedestrians Dataset.
As shown in Figure 12, most of the average I parts for pedestrian images are less than 1. In particular, the parts corresponding to the lower body are less than 0.7. On the other hand, the average I parts for non-pedestrian generally are larger than 0.7 and the parts corresponding to the upper body have the values larger than 1. This difference provides the I parts with strong discriminatory power between pedestrians and non-pedestrians. Further, the extraction of the I part is a cell-wise computation and does not require the additional computation for developing the histogram; therefore, the proposed I part is computationally more efficient than that of the conventional HOG [16].
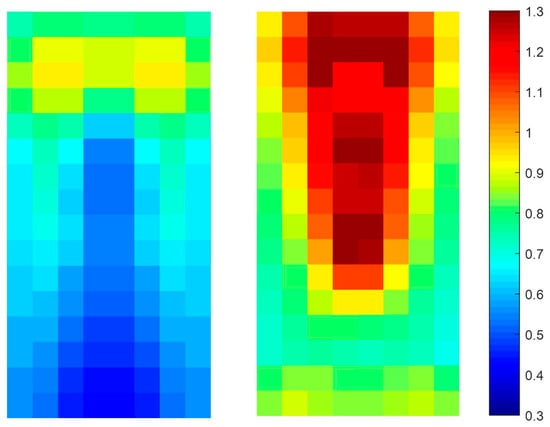
Figure 12.
Average I part for testing images(Left: pedestrian, Right: non-pedestrian).
3.2. Additive Kernel SVM (AKSVM)
The SVM is one of the popular binary classifiers used in object detection in computer vision. Given the training set with samples, the SVM is trained to classify input data as positive () class or negative () class where and . If input data is mapped to a higher dimensional feature space as then the decision function of the SVM is defined by
where , , is the weight and is the bias. The SVM is trained by finding optimal solutions of and which maximizes the margin between the two classes. It can also be trained in dual space using the kernel trick with . After training the SVM in dual space, the decision function (11) can be evaluated by
where denotes a set of support vectors. If the of Equation (15) is nonlinear, the kernel SVM performs better than the linear SVM in classification. However, it requires the high computation and memory resource owing to the kernel computation with its support vectors for every testing.
However, the additive kernels (AK) enable fast computation of the decision function, while maintaining the robust performance of the kernel SVM [23,24]. The AK is defined as the kernel that can be decomposed into a summation of dimension-wise components and it is represented by where and . Various AKs have been reported and they include the linear kernel , intersection kernel , the generalized intersection kernel and the kernel defined as
The decision function of the SVM in Equation (15) with the AK can be represented by
where
and is a one-dimensional function of . In Equation (20), the , are given; therefore the output of can be pre-computed for all possible input data and computed output values are stored in look-up-table (LUT) for each . Assuming the is the LUT that consists of sampled values from , of Equation (20) can be simply approximated as
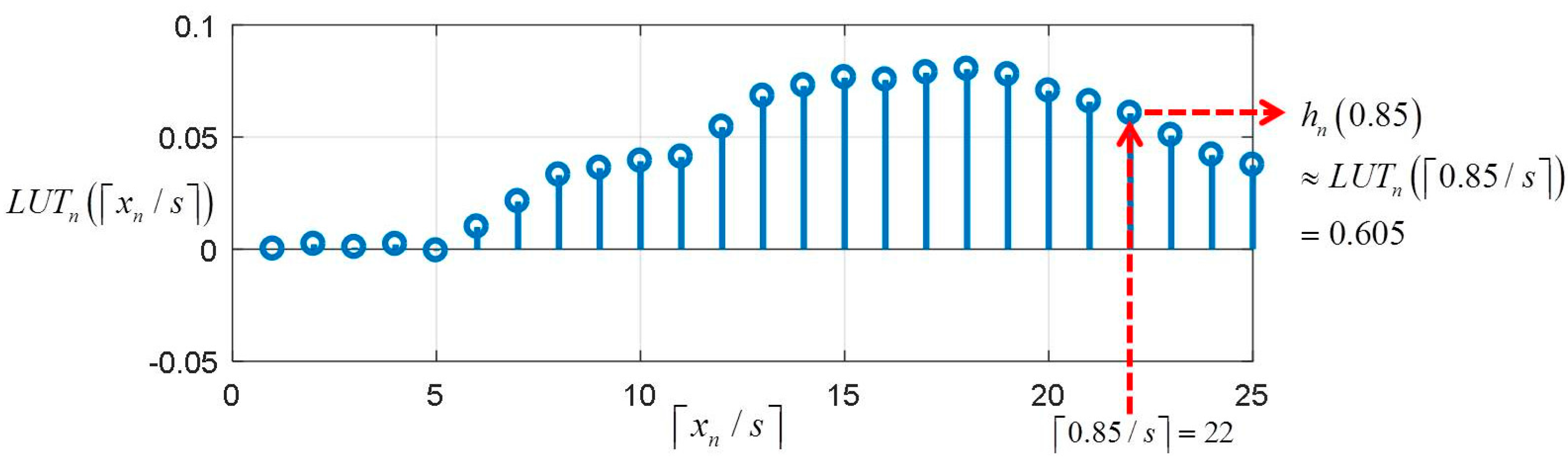
where is the sampling interval on . Figure 13 shows an example of of retrieving value of from . In Figure 13, the size of is and the values of are sampled from with sample interval .
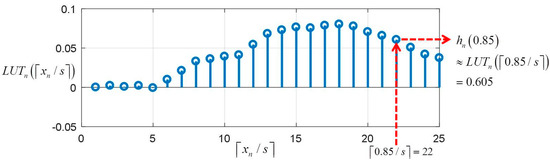
Figure 13.
Example of retrieving value of from for .
Therefore, using the LUTs of , testing of Equation (20) can be simplify carried out as the summation of values taken from the s without kernel computation as
3.3. THOG-AKSVM for Nighttime PD
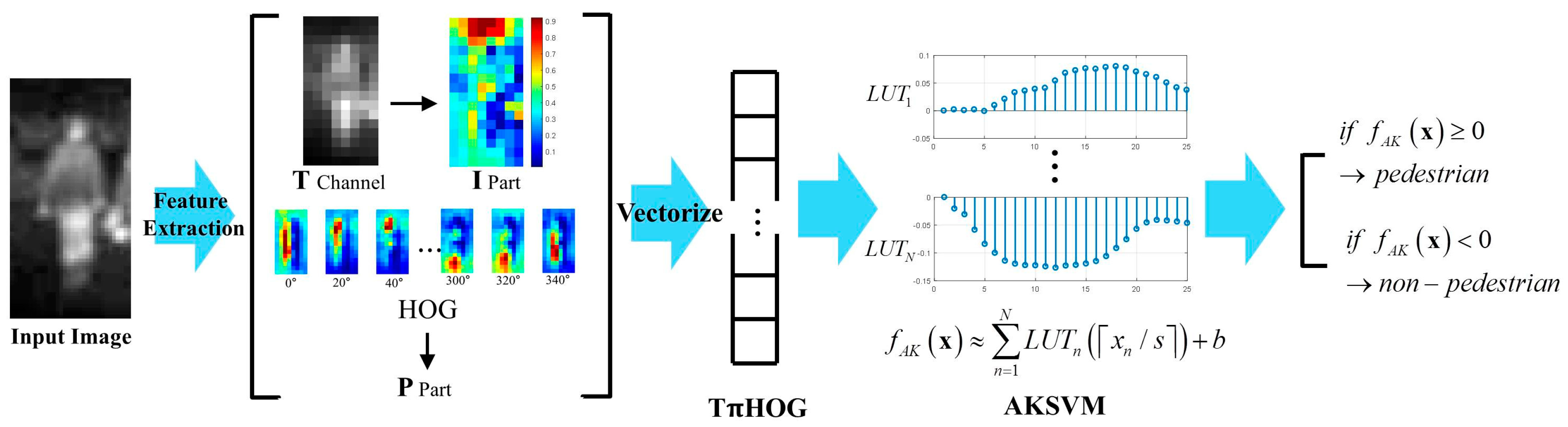
In this subsection, how to combine AKSVM with THOG for nighttime PD is explained. The test process of the combination of AKSVM with THOG is summarized in Figure 14.
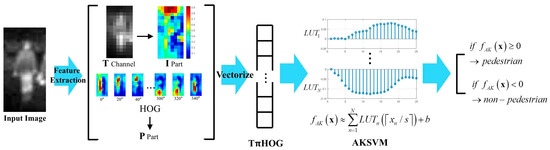
Figure 14.
Test process of THOG-AKSVM for nighttime PD.
As shown in the figure, the HOG and T channel are extracted from input IR image first. Then P and I parts are extracted from HOG and T channel, respectively. All these features are vectorized and THOG is completed by concatenating these vectorized features (T channel, P part, I part, HOG). Then, the score of each component in THOG is read off from the LUT and the total score of THOG is computed by summing the scores of the component features. Finally, if the total score is larger than 0, the input image is classified as pedestrian. Otherwise, it is classified as non-pedestrian.
4. Experimental Results
In this section, the proposed method is applied to the KAIST pedestrian dataset [14] and its performance is compared with other conventional methods. The KAIST pedestrian dataset consists of a number of pairs of visible-thermal images that are aligned in the image size of . The dataset images were taken by both visible and thermal sensors (FIR) in the day and nighttime at three locations (Campus, Road, Downtown). In this experiment, we use images in the nighttime of the KAIST dataset for training and testing. In the nighttime dataset, there are 838 training images with 1122 annotations and 797 test images.
In this experiment, we set the size of the ROI image to pixels, the cell size of the HOG to pixels, and the block size of the THOG to cells. The AKSVM classifiers are trained with THOGs of training set using the LibSVM MATLAB toolbox [24,34]. For LUTs of AKSVM, we used the LUT of and . Piotr’s Computer Vision Toolbox [35] is also used for feature extraction and testing.
For testing, sliding window approach is employed to detect pedestrians with various scales. In the sliding window approach, the step size is fixed to the cell size and scale ratio is set to 1.09 , which result in 8 scales per octave. As in [36,37], we narrow down the search area by restricting the y-coordinate of the center of search window to lie within 210th and 355th pixel in y-axis. Shown in Figure 15 is an example of our sliding window approach for pedestrian detection. In the figure, the yellow boxes denote the search window, green boxes are the detection results and the red lines denote the boundaries of search region within which the y-coordinate of the center of search window is restricted.

Figure 15.
Example of detecting pedestrians of multiple scales using sliding window approach.
We compare the detection performance of the proposed method with other conventional methods [10,19] using ROC curve and the log-average miss rate. The ROC curve shows the detection performance by plotting miss rate against the false positive per image (FPPI). The lower is the ROC curve, the better the detection performance. The log-average miss rate (MR) is the average of miss rate for FPPI of on the log scale. For comparison, we choose HOG-LinearSVM and the ACF-T-THOG [33] as a base line and the state-of-the-art, respectively. ACF-T-THOG utilizes pairs of visible-thermal images of nighttime and extracted ACF from visible images, T-THOG form thermal images. Except ACF-T-THOG, all SVM based classifier (LinearSVM, AKSVM) are trained with thermal images.
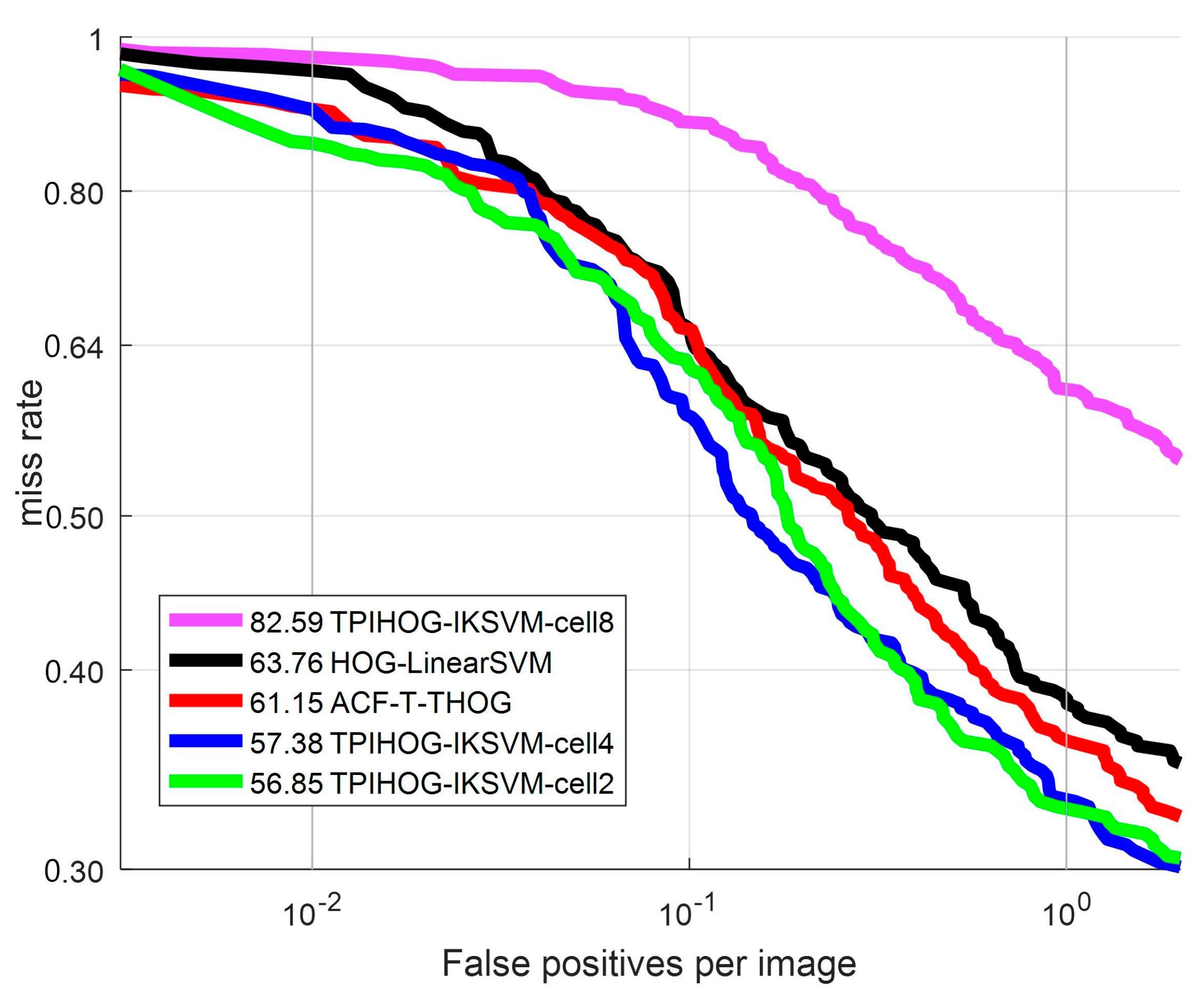
Then, the effect of the cell size on detection performance in analyzed. The ROC curves of THOG with AKSVM are plotted while varying the cell size in Figure 16. The intersection kernel in Equation (16) is used. The subsequent results (Log average MR, time per frame) are summarized in Table 1. In this experiment, we set the number of blocks for P part as 8 blocks per orientation layer as Figure 5.
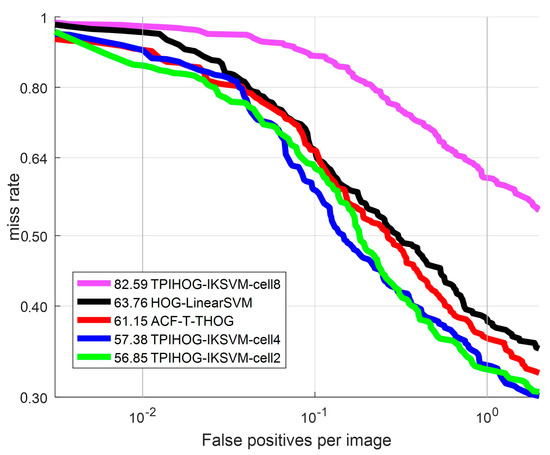
Figure 16.
ROC curve: Comparison of classifiers with different cell size.

Table 1.
Detailed information of feature-classifier.
As shown in Table 1 and Figure 16, the smaller the cell size of THOG is, the better detection performance is obtained. THOG-IKSVM-cell8 spends comparable detection time with ACF-T-THOG but it demonstrates about 30% higher Log average MR than ACF-T-HOG and HOG-LinearSVM. On the other hand, THOG-IKSVM-cell2 demonstrates the best performance among all the competing methods but its detection speed is about 20 times slower than THOG-IKSVM-cell4. Considering the trade-off between the detection performance (log average MR) and detection time, the recommended cell size is 4.
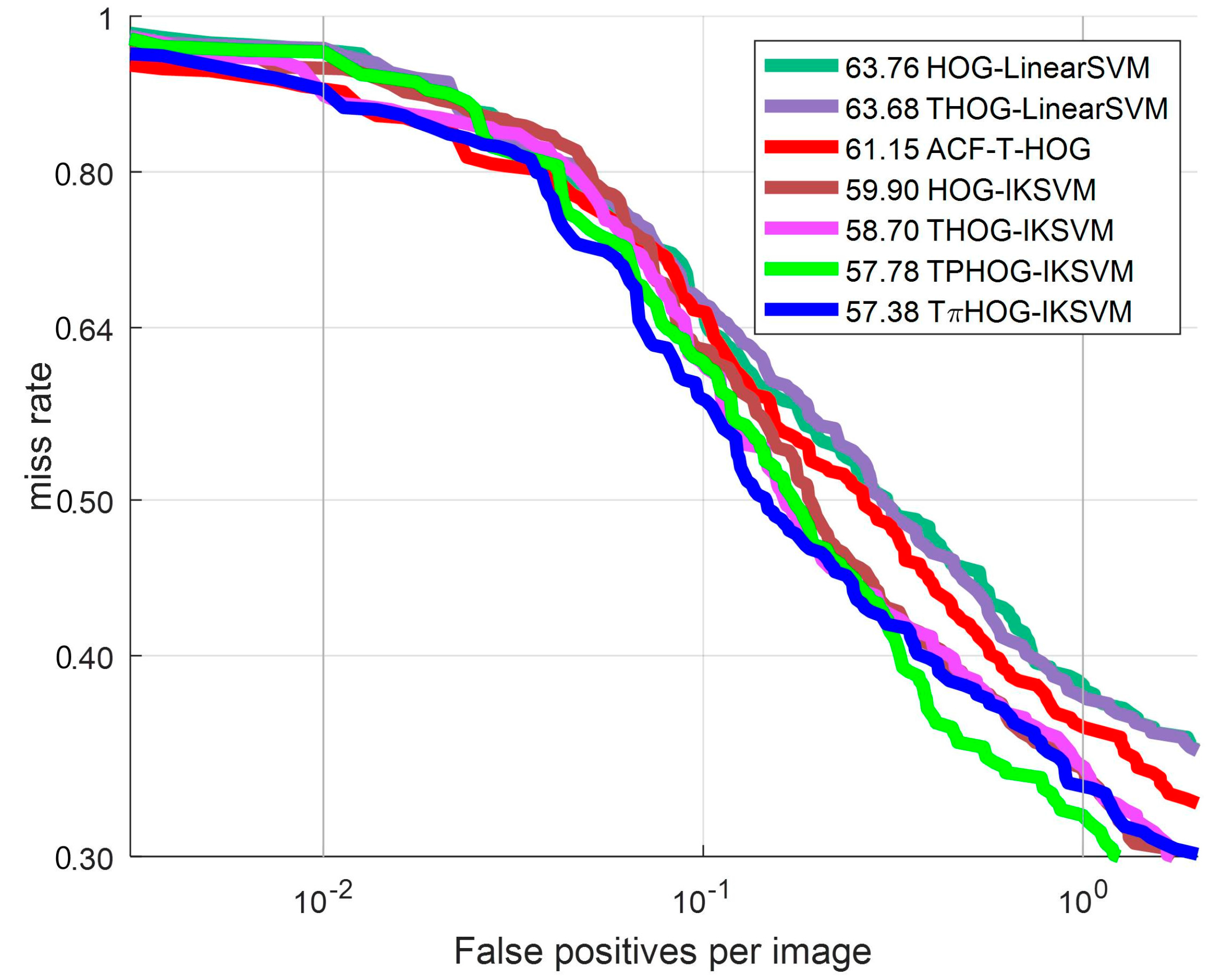
To compare the discriminating power of the feature, we plot the ROC curves for several feature combinations with IKSVM in Figure 17. Table 2 presents the detailed information of the feature-classifier combinations used in experiments.
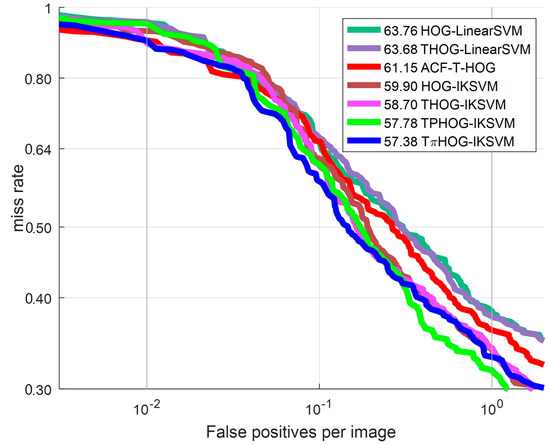
Figure 17.
ROC curve: Comparison of feature.
Table 2.
Detailed information of feature-classifier.
As shown in Figure 17, the THOG-LinearSVM performs better than the HOG-LinearSVM by 0.08% in terms of the log average MR. and THOG-IKSVM shows better detection performance than HOG-IKSVM by 1.2%. From this result, it can be observed that adding the T channel to the HOG improves detection performance from the conventional HOG. To examine the effect of the additive kernel, we measure the detection performance of the THOG-IKSVM. As shown in Figure 17 and Table 2, THOG-IKSVM demonstrates improved performance from THOG-LinearSVM indicating that the additive kernel resulted in significant improved detection performance of the SVM by 4.98% from the linear kernel.
Finally, we measure the detection performance using the TPHOG and the THOG in connection with the AKSVM. The TPHOG which adds the P part to THOG demonstrates 0.92% enhancement from THOG-IKSVM. The THOG which adds I part to TPHOG demonstrates improved performance from TPHOG by 0.4% and outperforms all other methods. From these experimental results, it can be seen that the THOG-AKSVM enhance the performance of conventional method in terms of both feature and classifier performance.
In terms of detection speed, the THOG-IKSVM takes more computational time than HOG-IKSVM by 1.06 s. To be specific, adding P part takes 0.8 s more time than HOG while I part and T channels requires additional 0.1 s compared with HOG.
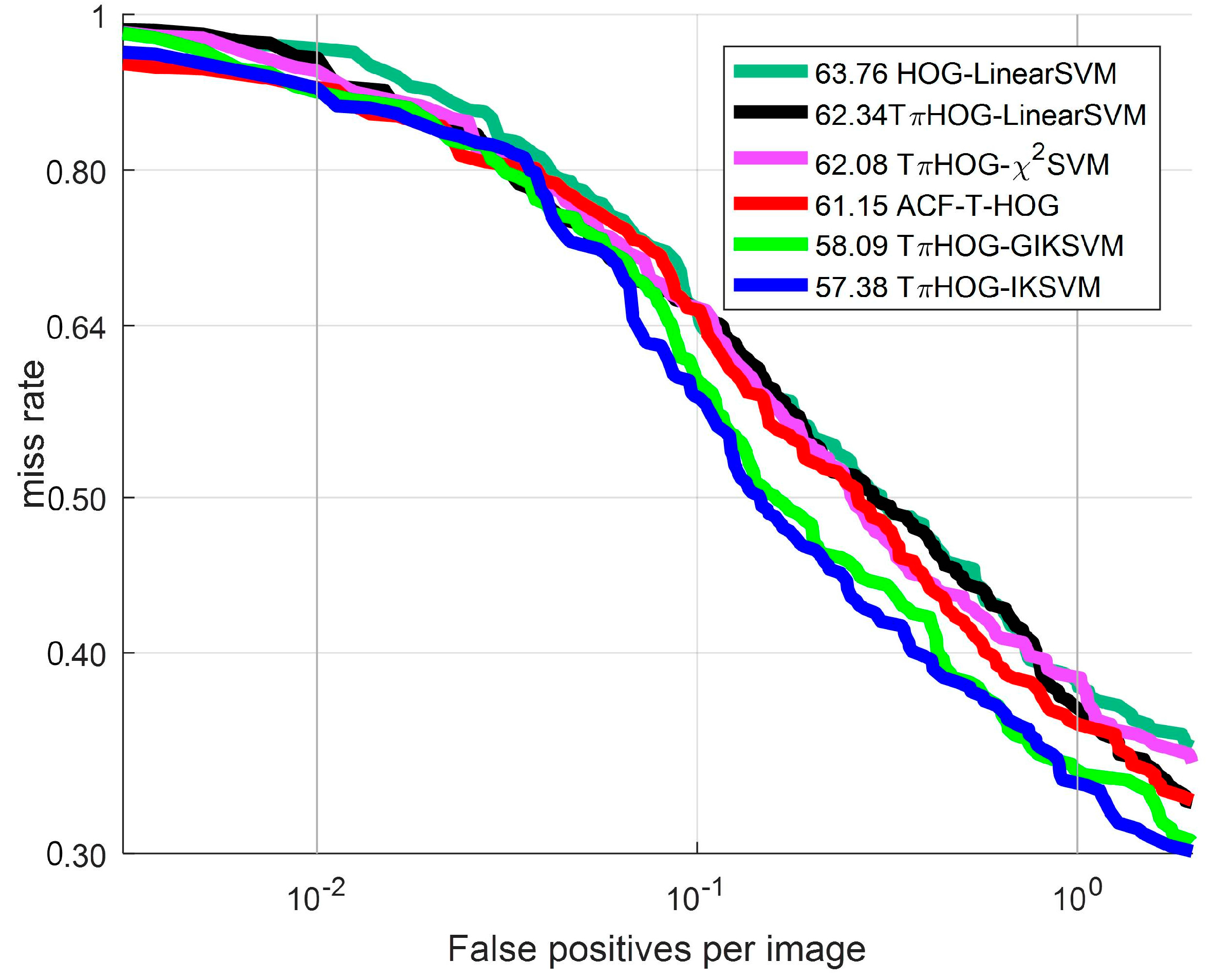
Shown in Figure 18, shown are the ROC curves for the THOG with four different additive kernels: linear kernel, intersection kernel , generalized intersection kernel and kernel . The computational time of THOG-AKSVMs in Figure 16 are the same as one of THOG-IKSVM of Table 2 because they are performed with LookupTable of same size in this experiment.
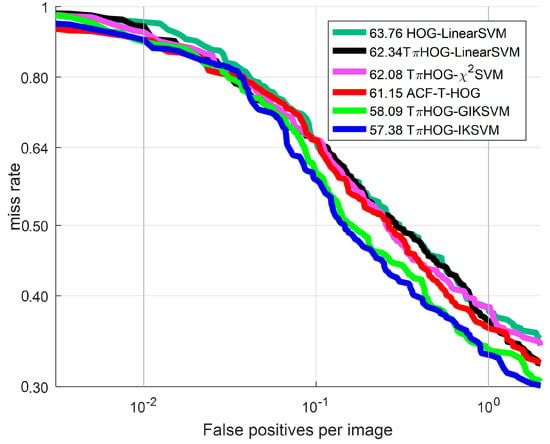
Figure 18.
ROC curve: Comparison of additive kernel
As shown in Figure 18, all types of TPIHOG-AKSVMs performs bettrer than the HOG-LinearSVM and THOG-LinearSVM. Among the AKSVMs, the THOG-IKSVM and THOG-GIKSVM demonstrate the significant improvement from the THOG-LinearSVM, and they also perform better than the ACF-T-HOG. In Figure 19, the examples of the detection results for THOG-IKSVM and ACF-T-THOG are compared

Figure 19.
Detection results on test images of KAIST DB.
As shown in Figure 19, the ACF-T-THOG generates a lot of false positives to the vertical objects such as headlight or buildings. On the other hand, the proposed method shows good detection results with no false positive.
5. Conclusions
In this paper, a novel night-time pedestrian detection method using a thermal camera has been proposed. A new feature named THOG was developed and it was combined with AKSVM. The proposed THOG has more robust discriminative power than HOG because it uses not only the gradient information but also cell location of the gradient for each orientation channel. The proposed method was applied to KAIST pedestrian dataset and results show that its detection performance improved compared with other conventional methods for pedestrian detection in the nighttime. A comparison of experimental results with KAIST pedestrian dataset shows that the THOG performs better than the HOG in the distinctiveness of feature and the THOG-AKSVM shows better performance than other conventional methods.
Acknowledgments
This work was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science and Technology under Grant NRF-2016R1A2A2A05005301.
Author Contributions
Jeonghyun Baek and Euntai Kim designed the algorithm, and carried out the experiment, analyzed the result, and wrote the paper; Sungjun Hong and Jisu Kim analyzed the data and gave helpful suggestion on this research.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hurney, P.; Waldron, P.; Morgan, F.; Jonses, E.; Glavin, M. Night-time Pedestrian Classification with Histograms of Oriented Gradients-Local Binary Patterns Vectors. IET Intell. Transp. Syst. 2015, 9, 75–85. [Google Scholar] [CrossRef]
- European Road Safety Observatory. Traffic Safety Basis Facts 2012—Pedestrian. Available online: http://roderic.uv.es/bitstream/handle/10550/30206/BFS2012_DaCoTA_INTRAS_Pedestrians.pdf?sequence=1&isAllowed=y (accessed on 11 August 2017).
- Zhao, X.Y.; He, Z.X.; Zhang, S.Y.; Liang, D. Robust pedestrian detection in thermal infrared imagery using a shape distribution histogram feature and modified sparse representation classification. Pattern Recognit. 2015, 48, 1947–1960. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution Gray-scale and Rotation Invariant Texture Classification with Local Binary Patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Wang, X.; Han, T.X.; Yan, S. An HOG-LBP Human Detector with Partial Occlusion Handling. In Proceedings of the 2009 IEEE 12th Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–4 October 2009. [Google Scholar]
- Ko, B.; Kim, D.; Nam, J. Detecting Humans using Luminance Saliency in Thermal Images. Opt. Lett. 2012, 37, 4350–4352. [Google Scholar] [CrossRef] [PubMed]
- Jeong, M.R.; Kwak, J.; Son, E.; Ko, B.; Nam, J. Fast Pedestrian Detection using a Night Vision System for Safety Driving. In Proceedings of the 2014 International Conference on Computer Graphics, Imaging and Visualization (CGIV), Singapore, 6–8 August 2014. [Google Scholar]
- Dai, C.; Zheng, Y.; Li, X. Pedestrian Detection and Tracking in Infrared Imagery Using Shape and Appearance. Comput. Vis. Image Underst. 2007, 106, 288–299. [Google Scholar] [CrossRef]
- Wang, J.; Chen, D.; Chen, H.; Yang, J. On Pedestrian Detection and Tracking in Infrared Videos. Pattern Recognit. Lett. 2012, 33, 775–785. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian Detection: An Evaluation of the State of the Art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Watanabe, T.; Ito, S.; Yokoi, K. Co-occurrence histograms of oriented gradients for pedestrian detection. In Proceedings of the 2009 Conference on Pacific-Rim Symposium on Image and Video Technology, Tokyo, Japan, 13–16 January 2009; pp. 37–47. [Google Scholar]
- Andavarapu, N.; Vatsavayi, V.K. Weighted CoHOG (W-CoHOG) Feature Extraction for Human Detection. In Proceedings of Fifth International Conference on Soft Computing for Problem Solving; Springer: Singapore, 2016; Volume 437, pp. 273–283. [Google Scholar]
- Hua, C.; Makihara, Y.; Yagi, Y. Pedestrian detection by using a spatio-temporal histogram of oriented gradients. IEICE Trans. Inf. Syst. 2013, 96, 1376–1386. [Google Scholar] [CrossRef]
- Qi, B.; John, V.; Liu, Z.; Mita, S. Pedestrian detection from thermal images with a scattered difference of directional gradients feature descriptor. In Proceedings of the 17th IEEE Conference on Intelligent Transportation System (ITSC), Qingdao, China, 8–11 October 2014; pp. 2168–2173. [Google Scholar]
- Kim, J.; Baek, J.; Kim, E. A Novel On-road Vehicle Detection Method Using HOG. IEEE Trans. Intell. Transp. Syst. 2015, 16, 3414–3429. [Google Scholar] [CrossRef]
- Xu, F.; Liu, X.; Fujimura, K. Pedestrian Detection and Tracking with Night Vision. IEEE Trans. Intell. Transp. Syst. 2005, 6, 63–71. [Google Scholar] [CrossRef]
- Bertozzi, M.; Broggi, A.; Del Rose, M.; Felisa, M.; Rakotomamonjy, A.; Suard, F. A Pedestrian Detector Using Histograms of Oriented Gradients and a Support Vector Machine Classifier. In Proceedings of the IEEE Conference on Intelligent Transportation System Conference (ITSC), Seattle, WA, USA, 30 September–3 October 2007. [Google Scholar]
- O’Malley, R.; Jones, E.; Glavin, N. Detection of Pedestrians in Far-Infrared Automotive Night Vision Using Region-Growing and Clothing Distortion Compensation. Infrared Phys. Technol. 2010, 53, 439–449. [Google Scholar] [CrossRef]
- Baek, J.; Kim, J.; Kim, E. Fast and Efficient Pedestrian Detection via the Cascade Implementation of an Additive Kernel Support Vector Machine. IEEE Trans. Intell. Transp. Syst. 2017, 16, 3414–3429. [Google Scholar] [CrossRef]
- O’Malley, R.; Glavin, M.; Jones, E. An Efficient Region of Interest Generation Technique for Far-Infrared Pedestrian Detection. In Proceedings of the International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 9–13 January 2008; pp. 1–2. [Google Scholar]
- Sun, H.; Wang, C.; Wang, B. Night Vision Pedestrian Detection Using a Forward-looking Infrared Camera. In Proceedings of the 2011 International Workshop on Multi-Platform/Multi-Sensor Remote Sensing and Mapping (M2RSM), Xiamen, China, 10–12 January 2011; pp. 1–4. [Google Scholar]
- Maji, S.; Berg, A.C.; Malik, J. Efficient Classification for Additive Kernel SVMs. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 66–77. [Google Scholar] [CrossRef] [PubMed]
- Vedaldi, A.; Zisserman, A. Efficient Additive Kernels via Explicit Feature Maps. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 480–492. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.H.; Hong, H.G.; Park, K.R. Convolutional Neural Network-Based Human Detection in Nighttime Images Using Visible Light Camera Sensors. Sensors 2017, 17, 1065. [Google Scholar]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D.N. Multispectral deep neural networks for pedestrian detection. arXiv, 2016; arXiv:1611.02644. [Google Scholar]
- Wagner, J.; Fischer, V.; Herman, M.; Behnke, S. Multispectral pedestrian detection using deep fusion convolutional neural networks. In Proceedings of the 24th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN), Bruges, Belgium, 27–29 April 2016; pp. 509–514. [Google Scholar]
- Cai, Y.; Sun, X.; Wang, H.; Chen, L.; Jiang, H. Night-Time Vehicle Detection Algorithm Based on Visual Saliency and Deep Learning. J. Sens. 2016, 2016, 8046529. [Google Scholar] [CrossRef]
- John, V.; Mita, S.; Liu, Z.; Qi, B. Pedestrian detection in thermal images using adaptive fuzzy C-means clustering and convolutional neural networks. In Proceedings of the 14th IAPR International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 18–22 May 2015; pp. 246–249. [Google Scholar]
- Biswas, S.K.; Milanfar, P. Linear support tensor machine with LSK channels: Pedestrian detection in thermal infrared images. IEEE Trans. Image Process. 2017, 22, 4229–4242. [Google Scholar] [CrossRef] [PubMed]
- Choi, E.; Lee, W.; Lee, K.; Kim, J.; Kim, J. Real-time pedestrian recognition at night based on far infrared image sensor. In Proceedings of the 2nd International Conference on Communication and Information Processing, Singapore, 26–29 November 2016; pp. 115–119. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; Kweon, I. Multispectral Pedestrian Detection: Benchmark Dataset and Baseline. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Chang, C.-C.; Linm, C.-J. LIBSVM: A Library for Support Vector Machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Doll´ar, P. Piotr’s Computer Vision Matlab Toolbox (PMT). Available online: http://vision.ucsd.edu/pdollar/toolbox/doc/index.html (accessed on 2 December 2016).
- Daniel Costea, A.; Nedevschi, S. Semantic channels for fast pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2360–2368. [Google Scholar]
- Baek, J.; Hong, S.; Kim, J.; Kim, E. Bayesian learning of a search region for pedestrian detection. Multimed. Tools Appl. 2016, 75, 863–885. [Google Scholar] [CrossRef]






© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).