1. Introduction
Autonomous driving has gotten increased attention from the researchers and industrial community alike over the last 10–15 years. Even if the problem has long been investigated by researchers (demonstrated by examples such as ALVINN [
1]), it was catalysed by the DARPA Grand and Urban challenges (held in 2005 and 2007, respectively) and resulting in many detailed research works (e.g., [
2,
3]). In addition to the advancement on algorithmic aspect of autonomous driving, these competitions also lead to the advancement on sensor side, with development of multi-beam lidar sensors such as the Velodyne range of devices [
4] conceived and prototyped during the Grand Challenge [
5]. Since then, a significant amount of research has been carried out addressing different aspects of autonomous driving such as object detection [
6,
7], localisation [
8], tracking [
9], intention estimation [
10], as well as end-to-end deep-learning based approaches (e.g., [
11]). In addition to the research explicitly addressing autonomous driving, a lot of closely-related research has also been carried out in the area of Advanced Driver Assistance Systems (ADAS); for example, Martinez et al. [
12] investigated approaches for driving style recognition.
Traffic infrastructure and rules have evolved over a century, with human road user being the centre piece. While being in traffic scenarios ranging from residential neighbourhoods to motorways, we as humans continuously use the understanding of other humans’ behaviour, be it other drivers, bicyclists, pedestrians, etc., to keep ourselves and those sharing the roads with us safe. A detailed discussion on how our implicit understanding of behaviour, and subtle cues (e.g., eye contact, or the difference between a pedestrian talking to another near a curb, and then turning away and moving in the direction of road) are imperative for, or enhance, safety and efficiency in our everyday traffic is presented in [
13].
In this paper, we focus on the task of entering a roundabout in the face of traffic already present inside (the roundabout). Roundabouts play a very important role in modern traffic infrastructure. Studies have shown that roundabouts reduce traffic accidents (in comparison to signal-controlled intersections), can reduce delays and improve traffic flows, and even have lower long-term cost compared to signal-controlled intersections [
14]. As humans, we instinctively consider numerous factors such as the number of oncoming vehicles, their positions, speeds, even lengths, etc. to manoeuvre ourselves to enter roundabouts in a safe, efficient and smooth way. From an autonomous vehicles’ perspective, estimating agent (other vehicles present inside the roundabout) intention in terms of intended exit-direction, as well as agent’s future state in a roundabout, is not trivial but is imperative to make its manoeuvre to enter the roundabout safe, efficient (efficiency in this context not only includes time, but also smoothness of ride and minimisation of wear and tear to brakes, etc.) and smooth. We therefore, in this paper, investigate and propose methods for modelling traffic in roundabouts and predicting agent behaviour and future state (inside roundabouts). The proposed approaches are based on a setup where perception data is acquired by a lidar sensors located at the centre of a roundabout.
Modelling of behaviour and prediction of motion has long been of interest for the scientific community. It is applicable especially in domains where humans and intelligent systems co-exist [
15], for instance service robotics, and assisted as well as autonomous driving. Other application areas of motion prediction include traffic monitoring, surveillance systems, etc. Consequently, comprehensive surveys have also been conducted on the subject. A survey which addresses motion-prediction applications in intelligent vehicles is presented in [
16]. The survey is focused towards modelling approaches (mathematical models and algorithms, etc. that define how agent motion is modelled and how the predictions can be made) and proposes categorisation of these approaches into three main categories, namely physics-based, manoeuvre-based, and interaction-aware approaches. Physics-based approaches are relatively more parametric in nature, and are based on physical-models governing agent motion. Manoeuvre-based approaches consider motion patterns executed by agents while interaction-aware approaches also take into account interaction of manoeuvring entities with each other. The study argues that physics-based methods are computationally fast but are suitable for short-term predictions (typically not more than a second), whereas the manoeuvre-based and interaction-aware approaches allow for longer-term predictions but interaction-aware techniques are computationally expensive and thus not compatible with real-time operation requirements for applications such as risk-assessment in autonomous driving. Our method for motion modelling and state prediction is most closely related to the middle category i.e. manoeuvre-based as (which becomes apparent in
Section 3) our method is based on comparing query trajectories to modelled or previously recorded real-world agent trajectories using a particle filter classifier.
Another comprehensive survey on motion-trajectory prediction that reviews over 170 works is presented in [
15]. The study is more focused towards human motion but also considers bicycle and vehicles, and presents a systematic and deep (i.e., detailed) categorisation approach for motion-prediction methods. The authors of the study argued that the most basic level at which the works on motion prediction can be categorised is in terms of contextual cues and modelling approaches. They divide the modelling approaches into three main categories, i.e. physics based, pattern based and planning based. On a broader level, physics-based approaches model and predict motion based on physical-motion mathematical models. Pattern-based approaches exploit pattens in sequences of motion displayed by agents, and planning-based approaches go one step ahead by also taking into account longer-term goals of agents in motion prediction estimates. To make it more intuitively clear, Rudenko et al. [
15] argued that these three categories of modelling approaches follow
sense-predict,
sense-learn-predict, and
sense-reason-predict schemes, respectively. More interesting and novel however is the categorisation in terms of contextual cues proposed by Rudenko et al. [
15]. The contextual cues include internal and external stimuli in relation to the agent in question, dynamics in the environment and properties of the static aspects of an environment itself. With respect to a target agent, the stimuli include position, orientation, velocity, and semantics such as age, gender, etc., whereas with respect to the environment presence of obstacles, map-awareness and affordances are considered, to name a few. In terms of contextual cues, our current study is based on motion state as we use heading angle, lateral offset and position as feature attributes. We also study the effect of taking vehicle size into account, while doing state prediction, thus our method has the ability to incorporate agent semantics into motion prediction. Our method is unaware of dynamics in the environment and assumes affordances to priority for vehicles (or an agent which is) already inside a roundabout with respect to any vehicles wanting to enter in future.
We describe our motion modelling and state prediction method in detail in
Section 3, but before that, some related literature is presented in the following section.
3. Method
We propose a method for estimation of future position of an agent. The estimation is based on current agent state (position and speed) and its predicted future intentions. Below, we first describe three ways to model agent paths (or more specifically traffic flow in a roundabout in our context) in
Section 3.1, proceeded by intention estimation (
Section 3.2) and position prediction (
Section 3.4) using these models.
3.1. Modelling Agent Paths—Case of a Roundabout
The three models for agent intention estimation and consequent position prediction are based on: (i) geometric-model of a roundabout; (ii) a data-driven mean model of the roundabout; and (iii) a model based on a set of reference trajectories traversed by agents at the roundabout.
Here, it is worth mentioning that the models (for behaviour modelling) and method (for state prediction) we propose in this study do not strictly depend on the choice of perception sensor employed to acquire vehicle motion data. Even if the current study employs an infrastructural perception sensor (a multi-beam lidar, to be more specific), our approach is based on vehicle motion information. In long-term future, such information might become available via telematics. However, full-scale deployment of autonomous vehicles is expected to take a very long time [
13]. In the mean time, autonomous and connected vehicles are expected to share the roads with more conventional human-driven vehicles. During this transition period, infrastructural perception sensors can be installed in urban environments but their cost prohibits their widespread use. In this scenario, it is beneficial to study and compare different road-infrastructure (roundabout for the case at hand) models to compare the gain and loss in terms of generality, ease of building a model, etc. for applications such as behaviour modelling and state prediction. This is the rationale for the three models (based on roundabout geometry only, mean paths traversed by vehicles, and a set of actual vehicle trajectories, respectively) proposed as follows.
3.1.1. Geometric Model of a Roundabout
The first proposed method to model a roundabout, and the most generalisable, is based solely on roundabout geometry, as also suggested in [
16]. A large body of literature exists in the form of standards as well as research studies addressing types, geometric design, safety, speeds and other aspects related to roundabouts. For instance, authors in [
32] describes different types of roundabouts, i.e., large, compact, double, etc. Roundabout safety, causes of accidents, and ways to mitigate them have been addressed in several studies (e.g., [
33,
34,
35,
36]). Such geometric models are easy to generate using, for instance, CAD drawings, satellite imagery, an image acquired using a drone, etc., and taking into account traffic flow direction, speed limits, etc. at the roundabout. This ease makes such models interesting to be investigated for applications in assisted and autonomous driving.
The roundabout at which the data (explained in more detail in
Section 3.5) for this study were acquired lies at the intersection of a university campus (with 30 km/h as speed limit) and a suburban zone (with 50 km/h as speed limit) and is a single-lane roundabout. Geometrical design characteristics such as minimum central island diameter and circulating carriageway width are presented in [
37]. The study places the lowest acceptable central-island diameter and carriageway width for such speeds at 10 m and 7.6 m, respectively, and encourages larger central-island diameters for better safety. Similarly, a technical report by Federal Highway Administration (Washington, DC, USA) [
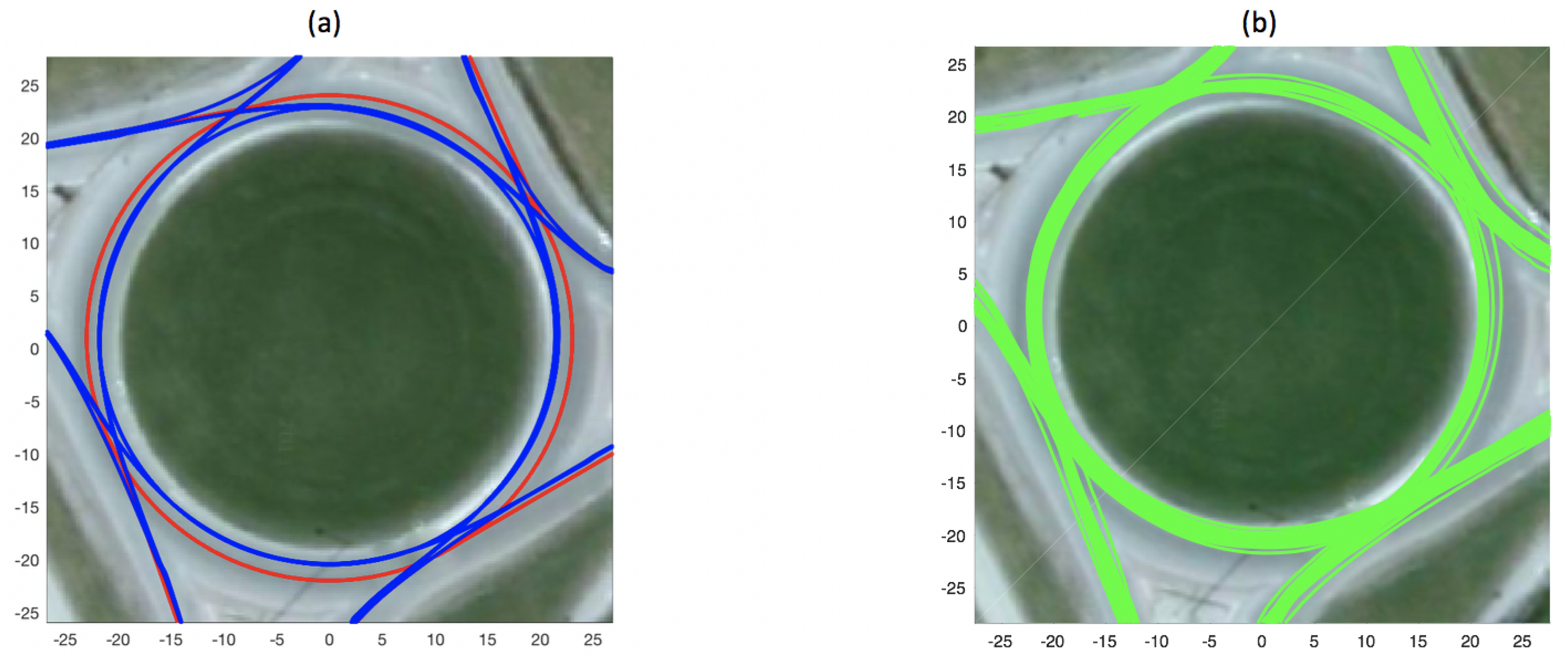
38] demonstrates the optimal paths that drivers are expected to take in single-lane roundabouts, such as the one used to acquire data in our study. Keeping these studies in mind and the geometry of the roundabout at hand, models for trajectories excepted to be taken by vehicles entering and exiting at each of the four legs (16 cases in total) were constructed and are used as the first of the three models in our study. The model is presented as red trajectories in
Figure 1a.
3.1.2. Using a Set of Reference Trajectories
The second model that we propose to model agent paths inside a roundabout takes a
wisdom-of-the-crowd approach and uses a set of
n actual vehicle trajectories (traversed by vehicles inside the roundabout) for each of the 16 cases of vehicle entry/exit combination as the roundabout model. The model therefore is less generalisable compared to the geometric model presented above, as the trajectories recorded inside a single specific roundabout would represent vehicles’ behaviour only in that roundabout. This modelling approach was also used in our previous study [
39]. A set of reference trajectories constituting such a roundabout model is presented in
Figure 1b.
3.1.3. Data-Driven Model of a Roundabout
The third model that we propose for a roundabout is neither explicitly based on the roundabout geometry nor on recorded trajectories themselves, but instead is based on mean paths taken by vehicles inside a roundabout. Such a model lies in the middle of the first two proposed models (i.e., geometric and set of reference trajectories) in terms of generality, and therefore also provides a middle ground for comparing the proposed models.
The data-driven model used in this study was constructed by recording vehicle trajectories over 40 min in the roundabout, and then calculating average paths taken by each of the 16 combinations of vehicle entry and exit location (i.e., for entry and exit at each of the four legs). The model is represented by blue trajectories in
Figure 1a.
3.2. Classification of Exit Direction
Having one of the above three models at hand, as a new query trajectory begins to comes in, the first task is to predict what exit direction is the agent expected to take (to leave the roundabout) so that more precise predictions such as future agent state can be estimated. For the purpose of exit direction classification, we use and build upon our previous work [
39], where we proposed exit direction classification using a decision-tree based as well as a particle-filtering based approach, using heading angle, lateral position offset and speed as feature attributes. The study showed that, in a multi-class problem such as the roundabout, the particle-filtering based approach performed better.
The work presented in [
39] proposes exit-direction classification based on a set of reference trajectories and hence is comparable to the model presented in
Section 3.1.2 above. This means that the number
n of reference trajectories in the model is not fixed and can change depending on factors such as availability of data and complexity of problem at hand, and can usually range between a few tens to a few hundreds [
39]. The fundamental difference, in terms of exit direction classification, when compared to the other two models presented in
Section 3.1.1 and
Section 3.1.3 is that in these two cases the reference trajectories in the model are fixed to one trajectory per class, i.e., a total of 16 trajectories in each model for the case of roundabout.
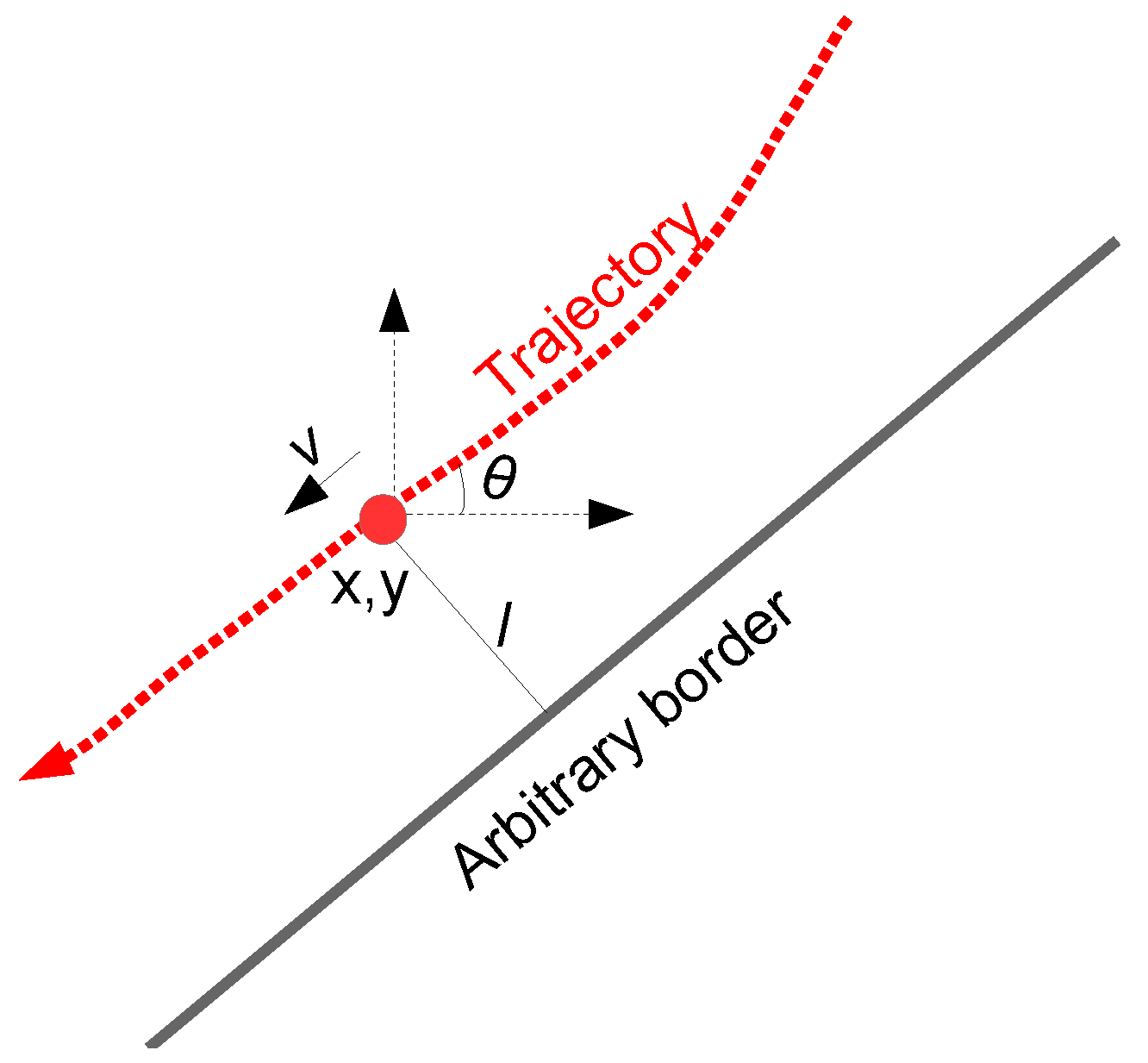
In our previous study [
39], heading angle
was found to be the most discriminative feature attribute and lateral position offset
l was also found to perform well, whereas, speed
v was the least discriminative feature attribute. For the sake of consistency with the findings of our previous study, we use
as our primary feature set for the results presented in this paper. In the current study, we also investigate position (i.e.,
x, y coordinates) as a feature attribute (and briefly comment on it in
Section 5.5). A depiction of the feature attributes is presented in
Figure 2. It is worth mentioning here that the current study does not aim to compare different feature attributes, but instead focuses on modelling of roundabouts and employing such models in exit-direction classification and future state prediction for vehicles in a roundabout.
Using particle-filter based classification, the classifier output a probability of an incoming query trajectory to belong to each of the reference trajectories (i.e., 16 trajectories in case of the geometric and the data-driven, and
n trajectories in the case of the set-of-reference-trajectories model) present in the roundabout models being used. The details on particle-filter classification method can be found in [
39] but they are also summarised below for the sake of completion.
3.3. The Particle-Filter Classifier
As described in [
39], we discretise an environment of interest (the roundabout in our case) using a grid of physical locations. Such a discretisation, for the case of the roundabout at hand, is shown in
Figure 3, with each cell being 0.6 m wide (A discussion on the effect of larger grid-cell width is presented in [
39]. In general, wider grid cells result in inferior performance by the classifier.) and 10 m in length. The behaviour model
B, for any of the three roundabout models presented in
Section 3.1, consists of the average feature attribute values (for each trajectory) inside each grid cell, and can be denoted as follows:
The belief of a query trajectory to belong to the reference trajectories (for any of the three models), given the grid cells are described by d, is represented by the set of M number of particles .
Each of the M number of particles, and its associated weight , in the set represents the belief for the query trajectory to belong to one of the reference trajectories. At the beginning, a particle set is randomly generated with all available reference trajectories uniformly represented. Initial weights are all assigned equal values of .
For each change of location in terms of d, the particle set is then recursively updated as follows:
Make the observation , i.e., measuring the feature attributes at current grid location of the query vehicle.
Calculate new weight for each particle depending on consistency between
and the belief represented by the respective particle.
Draw m particles, with replacement, employing updated particle weights.
At any given grid location in which a query agent falls at a given time, the sum of probabilities of particles representing reference trajectories in each of the possible (i.e., 16) categories represents the belief of the query instance to belong to that category.
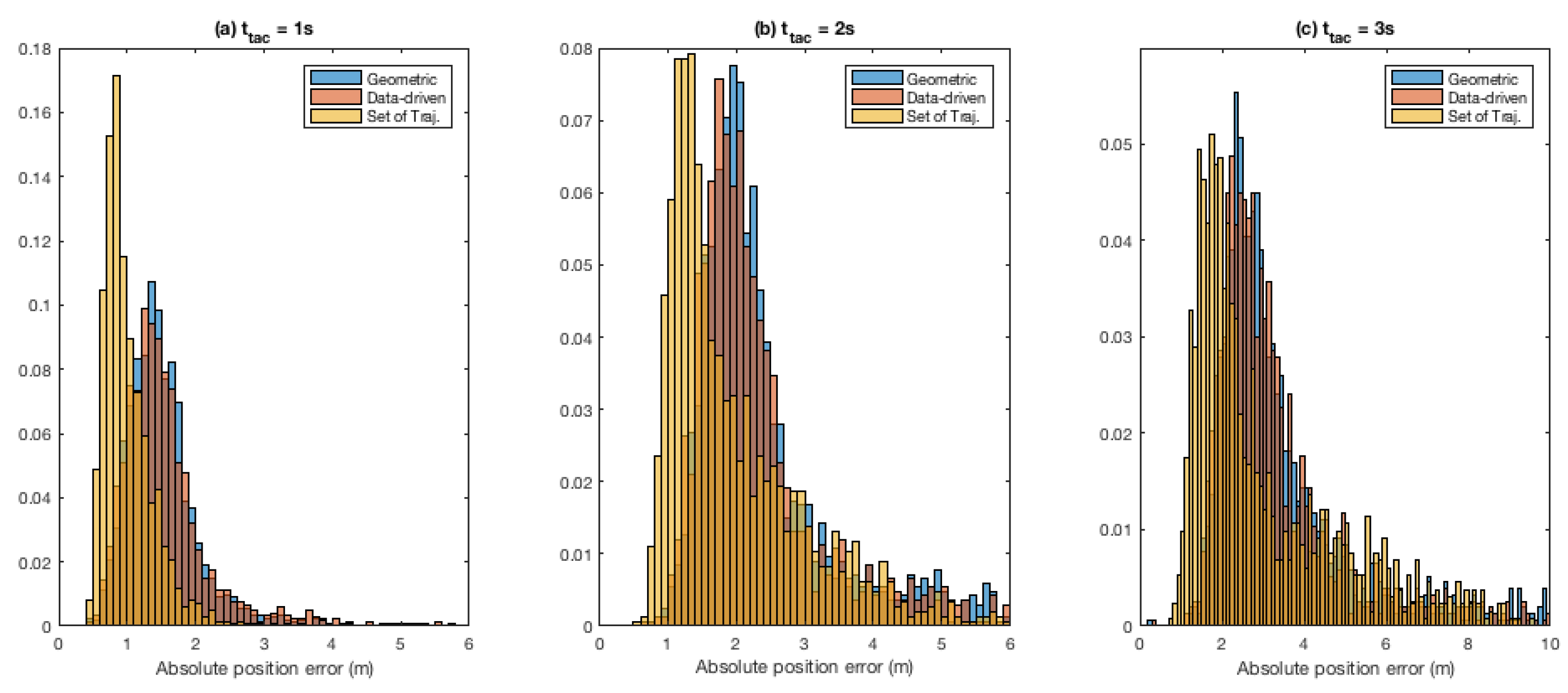
3.4. State Prediction in Tactical Timeframe
As mentioned in
Section 1, even for human drivers, when approaching a traffic light, a dilemma zone exists between 2.5 and 5.5 s before arriving at the traffic light, where it is difficult for a driver to decide between stopping or not, when seeing a yellow light [
25]. In the context of the current study,
tactical timeframe refers to such a timeframe and we denote it by
.
Given a tactical time window
and current speed
of a query vehicle, the state prediction amounts to estimating the position of the vehicle
into the future. For the geometric and data-driven roundabout models (cf.
Section 3.1.1 and
Section 3.1.3), the state prediction is done by traveling along the corresponding reference trajectory (of the winning class, out of the total 16) with a uniform speed value
for time
. In the case of the set-of-reference-trajectories roundabout model (cf.
Section 3.1.2), as each of the 16 classes is represented by multiple reference trajectories, a position is predicted in the same manner
s into the future (for each reference trajectory represented in the particle set), and then a weighted average is performed on the predicted position estimates to arrive at a consolidated future position estimate. In this way, in the set-of-reference-trajectories model, general speed and acceleration patterns demonstrated by vehicles in the roundabout are taken into account in state prediction implicitly.
Figure 4 depicts a demonstrative experiment for exit-direction classification (described above in
Section 3.2) as well as state prediction, for a single query vehicle trajectory at a roundabout (for
= 1 s). The figure shows the predicted exit direction (shown in the figure once every ten estimates, for clarity) as well as the ground-truth and predicted positions while the query vehicle remains inside the roundabout. It is worth mentioning here that, for this experiment, the roundabout model used is the one based on a set of reference trajectories (cf.
Section 3.1).
3.5. Experimental Setup
Below, we describe details about the dataset used for experimentation as well as different experiments performed to compare the proposed roundabout models, validate the corresponding state prediction, etc.
3.5.1. Dataset
The dataset used for experimentation consists of real-world traffic data, acquired at a busy roundabout that has four legs, and a central-island diameter of 40 m. The dataset was acquired by Kucner et al. [
30] and Fan et al. [
40] by placing a Velodyne HDL-64E multi-beam lidar sensor at centre of the roundabout for 2 h and scanning at 10 Hz (i.e., ten 360
scans per second), in Sweden (the traffic flow is therefore
right-hand.) The dataset consists of 1694 vehicle trajectories, extracted from the raw point-cloud data captured by the lidar sensor. Sample trajectories from the dataset are shown in
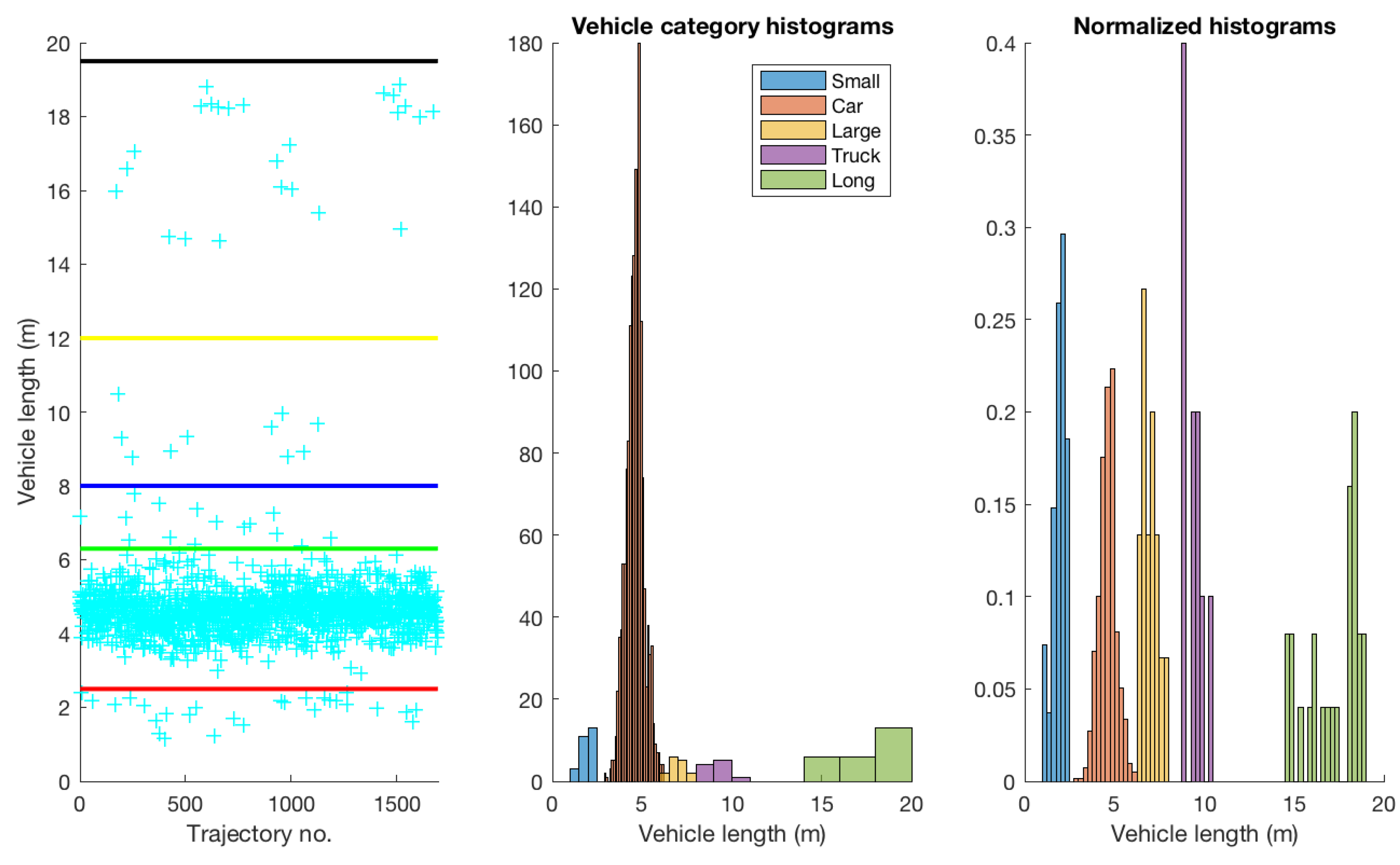
Figure 1b. The dataset contains different vehicle types. We categorised the vehicles based on their length (for vehicle-category based experiments described later in
Section 3.5.5) into five categories namely:
small vehicles (below 2.5 m) such as motorcycles;
cars (between 2.5 and 6.3 m), including not only cars but also SUVs, etc.;
large vehicles (between 6.3 and 8 m) such as vans/mini-busses;
trucks (between 8 and 12 m) e.g. trucks typically in a single body; and
long vehicles (above 12 m) typically consisting of a prime mover and one or more trailers.
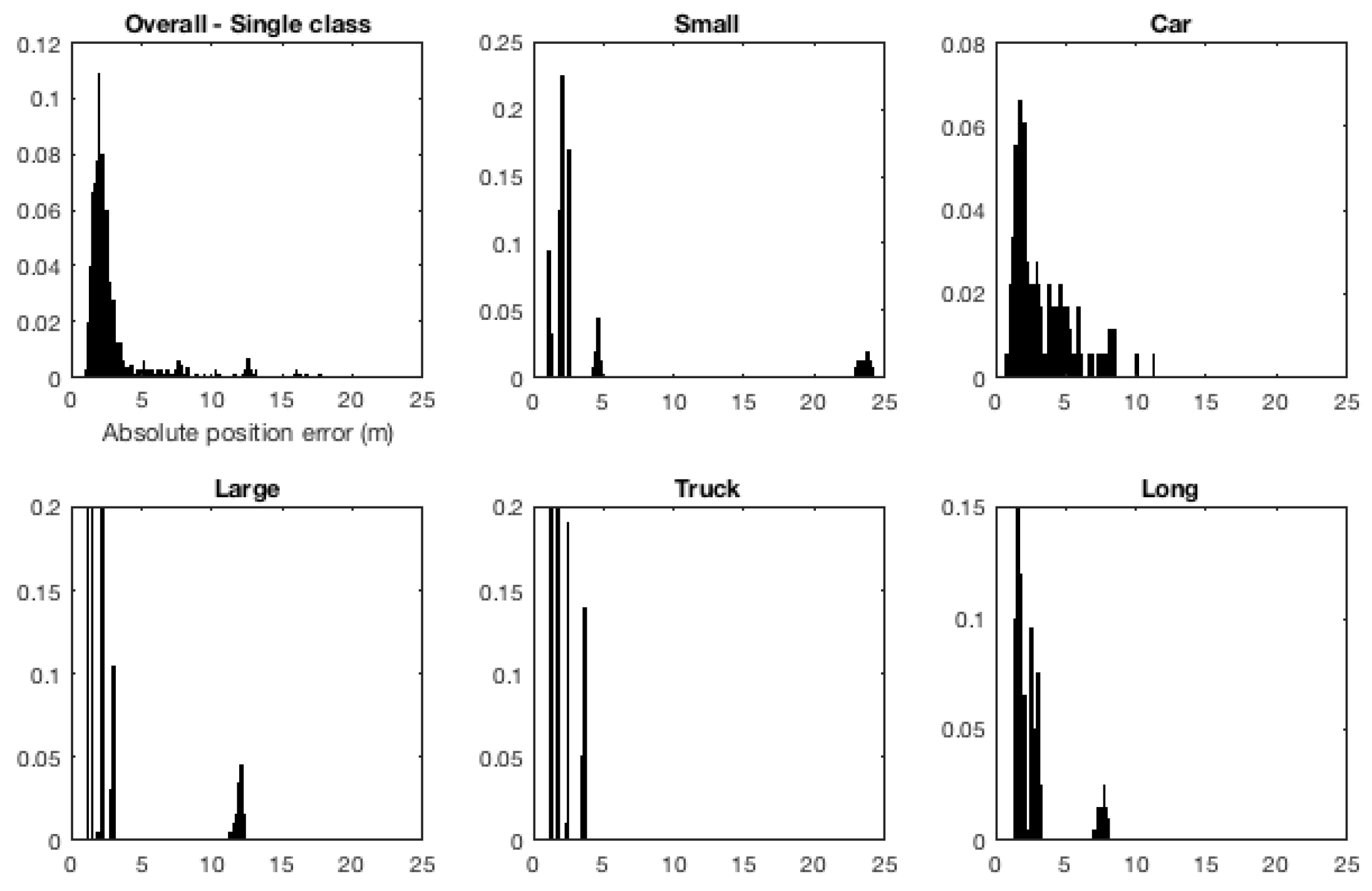
Figure 5 shows the distribution of different vehicle types in the dataset. Not surprisingly, the majority of vehicles in the dataset belong to the car category, with 1617 vehicles (out of the total 1694 in the dataset). Other categories contained much fewer vehicles: 27 small, 15 large, 10 truck, and 25 long vehicles. A question might arise here as to why were the vehicles in the large and truck categories considered as two separate categories and not a single one. The reason for this is that van busses and light cargo vehicles are physically different compared to heavy single-body trucks (and are therefore expected to behave differently on road).
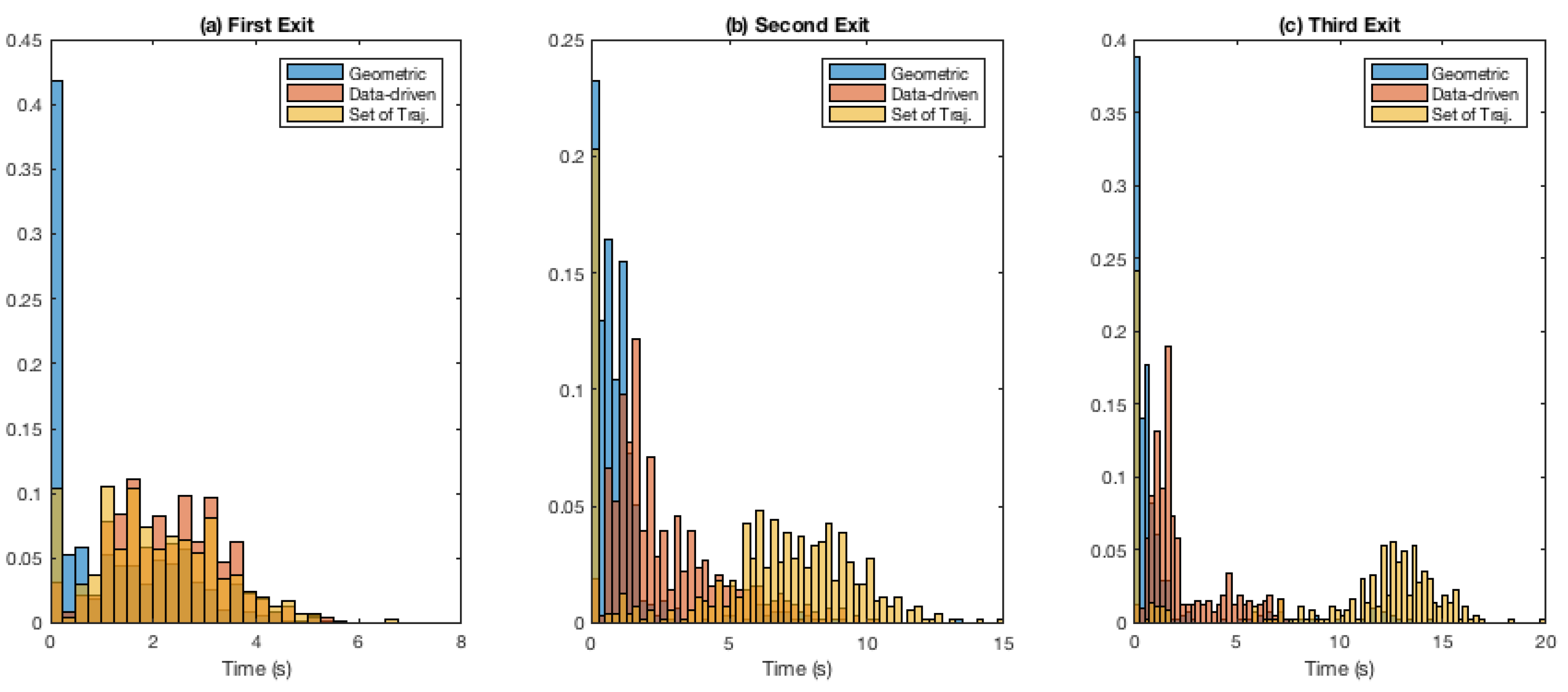
3.5.2. Evaluation of Exit Direction and State Prediction Results
We report the result of exit-direction classification in terms how early in time, before a query vehicle takes its ground-truth exit, the exit prediction by the proposed algorithms converged (to the correct exit) and stayed robust. The reason for using exit time as reference for exit-direction classification is twofold. Firstly, in terms of tactical decision making, time leading to a final event is of importance (for instance, in the case of a dilemma zone at traffic lights [
25], as mentioned in
Section 1). Secondly, the lengths of vehicle trajectories in the roundabout use case at hand differ significantly in case a vehicle (regardless of entry direction) takes the first, second or third corresponding exit. Therefore, time, taking vehicle exit from the roundabout as reference, serves as a more meaningful measure of correct exit-direction classification, compared to, for instance, time or distance traveled measured from vehicle entry into the roundabout. Here, it is worth mentioning that our previous work [
39] used distance (from convergence to exit from the roundabout) as a measure of exit-direction classification performance.
The state prediction evaluation results are presented in terms of mean absolute Euclidean distance error between predicted ( into) future positions and the ground-truth position that the vehicle actually arrived at into future.
Here, it is worth mentioning that for the exit-classification and state-prediction results presented in upcoming
Section 4.1 and
Section 4.2, 15% (i.e., 254) of the 1694 trajectories were randomly chosen as reference trajectories and the remaining (1440) were used for validation. Seeding for the random choice of the 15% reference trajectories was kept fixed for the sake of consistency between experiments.
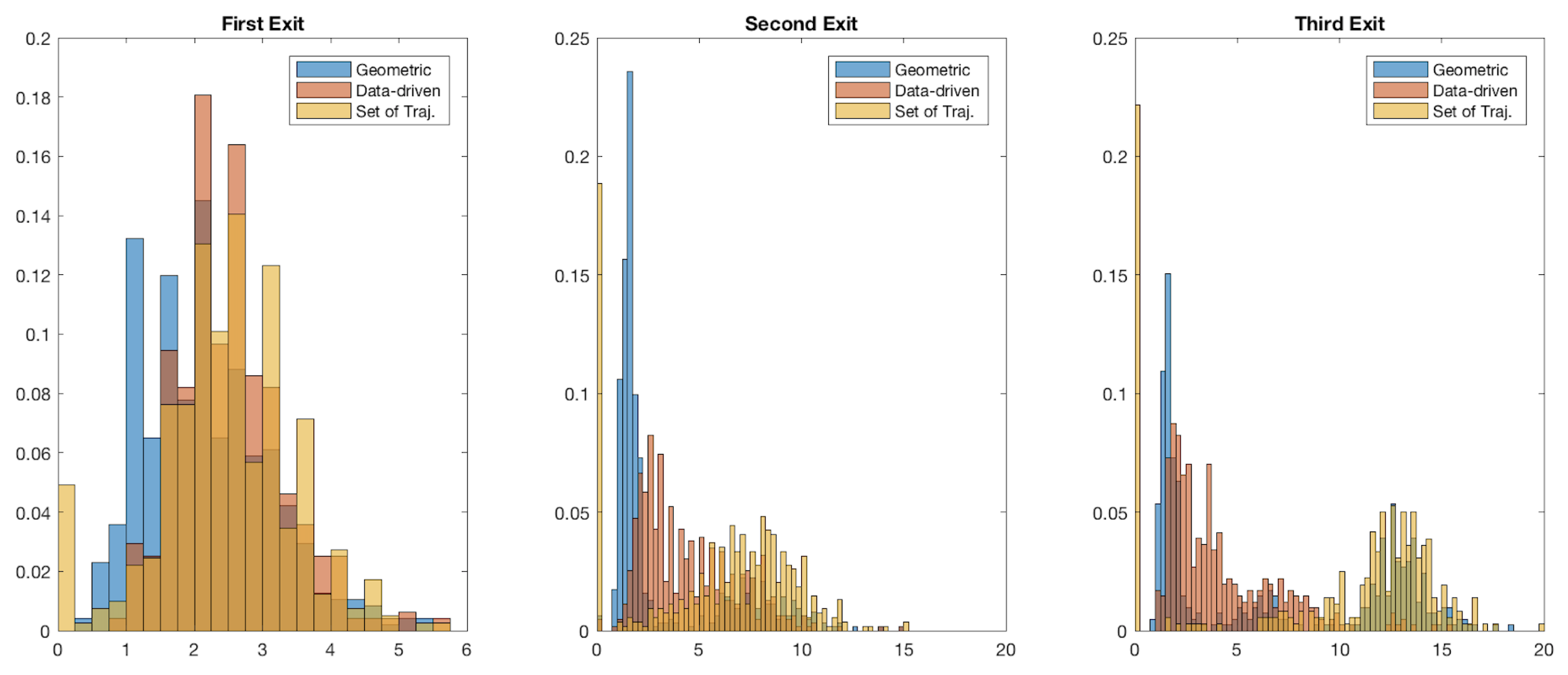
3.5.3. Comparison of the Three Roundabout Models
The three roundabout models presented in
Section 3.1 are compared with each other in terms of how well each model can be employed for exit-direction classification and state prediction using the (time since convergence, and position error) measures described above in
Section 3.5.2.
3.5.4. Tactical Time Widows
Instead of limiting to a single value of
to compare the three roundabout models, results are reported for the following tactical time windows:
Here, it is worthing mentioning that, while it would be interesting to experiment with longer values of , the roundabout at hand is too small to provide sufficient data points for meaningfully investigating larger values at all relative exits (i.e., first, second or third exit, regardless of the entry direction).
3.5.5. Tactical Prediction Based on Vehicle Type
Intuitively, one can argue that inside traffic, different-sized vehicles would behave differently. A motorcyclist will manoeuvre his/her vehicle differently compared to an SUV, or compared to a long vehicle consisting of a prime mover and multiple trailers, for instance. We report results on state prediction using different vehicle categories (cf.
Section 3.5.1) as separate, as well as when considering them as just one general group.
6. Conclusions
This paper presents methods for on-road agent behaviour prediction and state estimation in the context of roundabout traffic scenario. The agent behaviour prediction is in terms of classifying which exit direction an agent inside the roundabout is expected to take, and the state estimation refers to the predicted future position of an agent after a given time. The paper also presents three models to model traffic inside a roundabout and compares them in terms of both the exit-direction classification and the state prediction. Among the three models, i.e., geometric (which can be generated using drawings or satellite images, etc.), data-driven, and based on a set of reference trajectories, experimental results indicate that the model based on a set of reference trajectories is better suited, in terms of both the early and robust exit-direction classification and more accurate state prediction. Experiments carried out in this study for state prediction by categorising vehicles into classes based on vehicle size indicate that such a categorisation can effect, and in some cases enhance, the state prediction accuracy.
In the future, we intend to investigate recognition of vehicle category based on behaviour only, and study the usage of deep learning for agent behaviour recognition in comparison to the filtering-based classifier employed in the current study. We also plan to use the methods proposed in the current study to develop a simulation where autonomous vehicles adjusts their manoeuvres in the face of real on-coming traffic in a roundabout and compare it to human behaviour (i.e., recorded human manoeuvres in the same situation).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}