1. Introduction
Roadway and railway networks are important arteries that support the economic well-being of a nation. These networks require regular maintenance because of continuous deterioration from usage and weather cycles. The development of roadway anomalies such as potholes, frost heaves, swelling, rutting, bumps, sags, and cracks can slow traffic, cause ride discomfort, damage vehicles, and create safety issues [
1]. However, transportation agencies cannot afford to monitor the condition of roadways and railways more frequently than needed because of the high cost and slow speed of current methods. Current standard practices require specially equipped profiler vehicles, skilled personnel to operate them, and time-intensive post-processing to classify the ride quality [
2]. The profiler vehicles use geospatial positioning system (GPS) receivers that update 20 times faster than the low-cost GPS receivers in smartphones, and they use real-time inertial measurement units (IMUs) to improve position estimates [
2]. Even so, the profiler vehicles still cannot accurately estimate the roughness of low-speed and urban roads [
3]. Hence, these limitations spurred research to develop alternative means of achieving more automated, frequent, and network-wide monitoring. This naturally led to the idea of using regular vehicles as participatory sensors [
4,
5]. However, there is a gap in research with regard to characterizing the localization accuracy of a participatory sensing method.
1.1. Literature Review
Previous research established that the minimum onboard devices needed to implement anomaly detection and localization include a GPS receiver, an accelerometer, a speed sensor, a timer, a wireless internet transceiver, a microprocessor with digital memory, and a reliable power source [
5]. Connected vehicles already integrate and provide access to such devices, but their full adoption is uncertain. There were many studies exploring methods of roughness classification using smartphones on board regular vehicles because they can provide the same capability as connected vehicles sensors [
6,
7,
8]. When used on connected locomotives, the method can prevent track capacity loss from closures during condition monitoring with specially equipped railway vehicles [
9,
10,
11]. The device orientation may be fixed when using smartphone sensors to emulate this future probe vehicle application. However, methods that intend to use smartphones that are not in a fixed position during the sensing application may apply available methods to estimate their pose if needed [
12].
One disadvantage of the participatory sensing approach is that the integrated GPS receiver of vehicles and smartphones provides a standard positioning service (SPS), where the accuracy and resolution are much lower than those of the specialized monitoring vehicles [
13]. Given this limitation of low-cost GPS, there is a surprising gap in the literature regarding studies to characterize localization errors in a participatory sensing application. Most studies focused on evaluating related problems of characterizing the accuracy of roughness intensity measurements [
14,
15], approximating the international roughness index (IRI) [
16,
17], or classifying segment roughness using machine learning techniques [
18,
19]. A related finding from evaluations of commercial smartphone applications (apps) is that they disagree in IRI estimates and provide inconsistent results [
20].
The global average horizontal error of the SPS was recently measured as approximately 9 m within a 95% confidence interval [
13]. However, those measurements excluded errors due to atmospheric conditions, receiver errors, multipath reflections, terrain masking, and foliage. Testing in urban environments demonstrated that multipath reflections could double the ground-truth distances [
21]. A literature search as of the time of this writing did not find a study that characterized the anomaly localization error from using low-cost GPS receivers on board regular vehicles.
1.2. Goals and Objectives
The goal of this research was to characterize the position accuracy of localizing roadway and railway anomalies by using widely available low-cost sensors. Consequently, the authors developed an iOS
® app and an Android app called PAVVET and RIVET, respectively, which can access all the required sensors on a smartphone [
22]. These apps include smart power management, remote sensing, security features, and other modes that were needed for this and other projects. The standard GPS receiver of smartphones updates at a rate of 1 Hz, whereas the accelerometer samples at a rate of more than 90 Hz, depending on the device model. This difference in update rates causes the apps to tag a block of accelerometer samples with the same GPS coordinates. For example, if the accelerometer updates 90 times per second but the GPS receiver updates only once per second, the system will tag all 90 accelerometer samples with the GPS coordinates from its last update.
Figure 1 illustrates how the resolution gap creates blocks of accelerometer samples with the same geospatial position. Hence, in addition to errors in the geospatial positions reported, the low update rate of low-cost GPS receivers causes a position resolution gap.
Table 1 shows an example of the data collected for a GPS block that contains the peak accelerometer signal Gz highlighted as a g-force value of −1.216 at time instant of 46.768 s. This is called a peak inertial event (PIE).
GPS blocks update asynchronously along the traversal path. Therefore, the geospatial position updates among traversals T1, T2, …, TN will occur at different geospatial positions. Traversing an isolated anomaly will produce a PIE within a GPS block. As shown in
Figure 1, the position of the PIE within a GPS block mirrors the asynchronous GPS updates.
The main contribution of this work is a method to estimate the
position of an anomaly from a hotspot of the low-accuracy and low-resolution GPS coordinates of the associated PIE detected. Previous work addressed the complementary problem of anomaly
detection by using the participatory sensing approach to enhance signal quality [
23]. That is, anomaly detection must occur before estimating its position. This paper addresses the latter. The experiments conducted showed that it is possible to achieve sub-meter localization accuracy from participatory sensors by knowing only the mean GPS update rate, the mean traversal speed, and the mean latency of tagging accelerometer samples with GPS coordinates.
Figure 2 is a graphical abstract of the approach. An additional pavement management application (not shown) is needed for a complete solution to inform regular road maintenance. For example, the anomaly position estimate software can feed its output to existing pavement management systems that require the positions of anomalies as inputs.
The remainder of this paper is organized into four additional sections.
Section 2 develops the error model of localization and describes the experiment design to evaluate the statistical nature of the error components.
Section 3 provides the results from the experiments and determines the goodness-of-fit of hypothesized distributions of the error components. Based on observations of those error distributions,
Section 4 develops a method to estimate the position of an anomaly from many GPS tags of the accelerometer sample associated with the anomaly.
Section 5 provides some concluding remarks about the findings and briefly describes future work to address a shortcoming of the approach.
3. Results
Figure 5 shows the relative geospatial positions of the PIEs from all traversals of each roughness generator. Each circle, diamond, or square shown in
Figure 5 represents a PIE from the traversals of one device or experiment as indicated. The insets label the dimensions of the elliptically shaped PIE clusters. The outliers are indicated within the circular boundaries.
Table 3 summarizes the values of the various parameters derived from the experiments.
The roughness generators labeled as shown were the railroad tracks, the speed bump, and the joint bump. The arrow next to each PIE cluster indicates the direction of travel. It is evident that, regardless of the travel direction, the centers of each PIE cluster were consistently located prior to the roughness generators.
Figure 5a complements
Figure 4b by showing how the geospatial coordinate updates for the GPS blocks to the two traversals are spatially asynchronous. The figure shows the positions of each GPS block along the traversal path of the GP device. The GPS coordinates for run 32 exited the traversal path even though the vehicle remained on the path.
Table 3 lists the number of traversals conducted for each experiment as
N. Statisticians often consider more than 30 trials to be statistically significant [
25]. Even with 18 MnROAD traversals, the GPS distance distributions converged to a typical bell-shaped curve, which facilitated hypothesis testing with a normal distribution. The apps configured the smartphones to sample at their highest rate. The iOS
® models sampled between 91 and 134 Hz, whereas the GP sampled at approximately 385 Hz. The mean sample rate of the GP differed by approximately 1 Hz among the Paved and Unpaved Road experiments. This is due to the statistical nature of the sampling, as discussed in previous work [
23]. The authors plan to publish the collected data in a future journal article [
26].
3.1. Error Distribution
Figure 6 shows the histogram of the GPS distance error
DGT for each experiment as bar charts. The line graph is the best-fit normal distribution to the histogram.
The best fit was determined by solving the following optimization problem:
The counts for values that fall within interval
Xi of histogram bin
i are
Hi. The values of the distribution evaluated at interval
Xi are
Di where the parameters that minimize the sum-of-squares (SOS) error e are the amplitude
α, mean
µ, and variance
σ2. A Pearson’s chi-squared test quantified the goodness-of-fit of the solution by computing the chi-squared statistic.
The parameter k represents the degrees of freedom (df) in statistics. The value of k associated with the chi-squared statistic is the number of histogram bins minus the three parameters α, µ, and σ needed to obtain the best-fit distribution. Hence, the B histogram bins must be at least four so that the df can be at least unity. The number of bins also has an upper bound because the number of bins cannot exceed the number of samples N.
The probability
p that the chi-squared statistic computed is at least as large as the expected value is the area under the chi-squared distribution curve, where
and
Γ (
k/2) is the gamma function in mathematics. The computed probability is known as the
p-value of the hypothesis test [
25]. The most common practice is to reject the hypothesis that the distribution follows the tested distribution when the
p-value is less than 0.05, and to fail to reject the hypothesis otherwise. Intuitively, a large difference between the observed and best-fit distributions results in a large chi-squared statistic that is associated with a low likelihood.
Table 3 lists the
p-values from the chi-squared goodness-of-fit tests of the
DGT distribution for a normal distribution. The null hypothesis is that the distributions follow a normal distribution. None of the tests could reject the hypothesis that the GPS distance error is normally distributed because the
p-values for all experiments were greater than the standard significance of 0.05. This suggests that the alternative hypothesis could be accepted. It is difficult to observe visually that some of the distributions follow a normal distribution because of their large negative bias and large skew. The average GPS resolution gap time
TRES was 0.55 s with a standard deviation of 0.05 s. The GPS resolution gap distance was computed from Equation (3), and
Figure 7 shows the distribution of those distances for each experiment.
Table 3 lists the
p-values from the chi-squared goodness-of-fit tests of the
DRES distribution for a uniform distribution. The
df for this test was the number of histogram bins minus one parameter α needed obtain the best-fit uniform distribution. The hypothesis was that the distributions follow a uniform distribution. Since the
p-values for all experiments were greater than the standard significance of 0.05, none of the tests could reject the hypothesis that the GPS resolution gap distance was uniformly distributed with a positive bias.
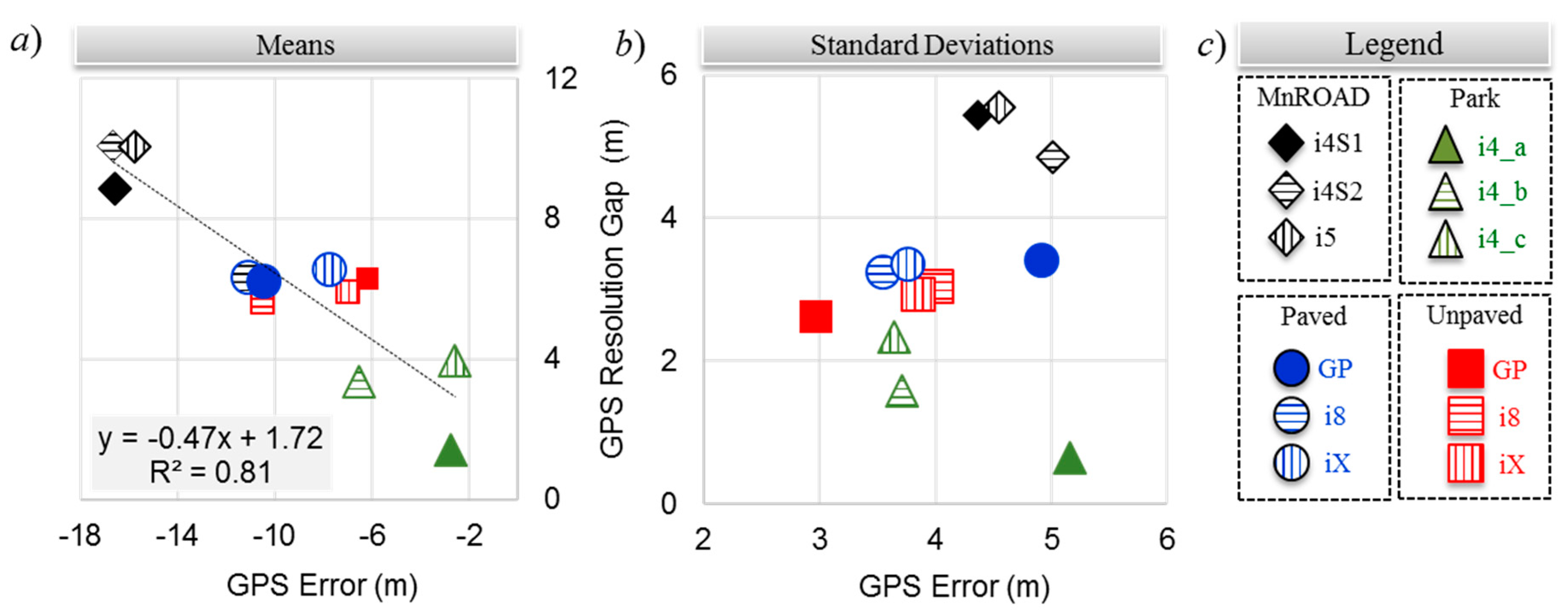
Figure 8a,b compares the means and standard deviations of the GPS distance error and the GPS resolution gap distances, respectively. The legend of
Figure 8c helps with visualizing the error patterns among the smartphones in the four experiment environments. The mean errors tended to cluster with speed. From
Table 3, the mean speeds were approximately 19, 11, and 5 m∙s
−1 for the MnROAD, Paved/Unpaved, and Park Road experiments, respectively. Although three smartphones were in the same spot for the MnROAD, Paved, and Unpaved Road experiments, the difference in their mean errors ranged from less than 1 m to more than 4 m. Except for the highest and lowest speed traversals, the mean GPS resolution gap distance was consistent among smartphones.
Unlike the means of the distance errors, the associated standard deviations did not tend to cluster with speed. The standard deviations ranged from less than 3 m to more than 5 m. The variance was largest for the lowest-speed traversals of the Park Road experiment and the high-speed traversals of the MnROAD experiments. However, the variance for the two higher speeds of the Park Road experiment was consistent with that of the Paved Road and Unpaved Road experiments. Within each testing environment, the variance of the GPS distance error was similar among the iOS® device models, but the differences were more extreme for the Android device. Except for the lowest-speed traversals of the Park Road experiment, the variance of the GPS resolution gap error was consistent among smartphones for the experiments of each environment.
3.2. Residual Error
As observed in
Figure 9a, the GPS distance error, which is the geodesic distance error from the ground truth, varied directly with the mean traversal speed.
Figure 9b shows that the GPS resolution gap distance was even more highly correlated with speed because the coefficient of determination
R2 for the regression equation shown in the inset was close to unity. The correlation with speed is intuitive because the length of a GPS block must be directly proportional to the vehicle’s speed since the GPS blocks are all approximately 1 s long. The implication from the regression model is that distance errors in this application can approach 30 m at highway speeds, making it impractical to locate an anomaly within sight distance.
The mean residual distance error was determined from Equation (2) by using the mean GPS resolution gap distance.
Figure 9c shows the correlation of the residual distance error with speed. Unlike the mean GPS resolution gap distance, the mean residual distance error was not correlated with the mean traversal speed—the
R2 value was only 0.13. This is evidence that the residual distance error must be due to a source that is not related to the movement of the vehicle. The time associated with the mean residual distance error is
tε such that
where
S is the average traversal speed for the GPS block containing the PIE.
Table 4 lists the values for
tε calculated for each smartphone. The negative time bias suggests that the smartphone incurred a time latency in tagging accelerometer values with GPS coordinates.
This is intuitive because the operating system (OS) of a smartphone must take a finite amount of time to calculate the GPS coordinates, fetch those values from an output register after receiving an interrupt, and then store those values to memory along with the accelerometer, speed, and timer samples. This latency is likely to vary among smartphones, depending on the number of process threads running, their processor speeds, and their data bus speeds. From
Table 3, the average value of the GPS tagging latency across all experiments was 0.27 s with a standard deviation of 0.19 s. There was no significant correlation of GPS tagging latency among smartphone models. This suggests that faster processors or bus speeds did not necessarily affect the GPS tagging latency. This suggests that there are other smartphone operational characteristics that cause the GPS tagging latency among smartphones. Identification of those factors will be the focus of future work.
4. Discussion
The nature of the two distance distributions infers a statistical model that can be used to estimate the position of an anomaly. The normal distribution of the GPS distance error suggests that the centroid of the geospatial coordinates of the GPS blocks containing the PIE would be a good starting point for the estimator. Furthermore, computing a centroid enables the detection and removal of outliers due to non-linear errors such as multipath reflections. The latitude and longitude coordinate pair (
θi,
Φi) of a centroid computed from the geospatial positions of
N GPS blocks containing PIEs is
Table 4 lists the geodesic distance from the centroid of each experiment to its respective ground truth as
CGT. A normal distribution of the GPS distance error suggests that the confidence interval of the centroid position is ever-increasing with traversal volume
N. Whereas this method is well suited for participatory sensing vehicles, it is less suitable for situations where only a single or relatively few traversals are available. This participatory sensing approach is robust to GPS errors because it leverages a large volume of traversal data to remove outliers and to continuously increase the precision of estimating a centroid location. For statistical significance and confidence in computing the centroid, the number of traversals used in practice should be at least 30.
From the error model of Equation (1), the estimated position of the anomaly is a distance offset
DX from the centroid, in the direction of travel and along the traversal path such that
where
Tε is the mean time latency of GPS tagging. Both
Tε and
TRES are time delays; thus, they are negative values. Therefore, if
DAX is zero, the estimate will be a positive value, which is a distance ahead of the centroid position. If the mean GPS tagging latency is zero, the estimated position of the anomaly will still be a positive distance away from the centroid position.
The uniform distribution of the PIE position within a GPS block points to the midway position as the best estimate of that error component. This position is equivalent to the product of one-half the mean GPS update interval and the average speed
S for the GPS block containing the PIE. Therefore, the position of the anomaly relative to the centroid position can be estimated as
where
µTGPS is the mean update period of the GPS receiver. All the variables of this equation are deterministic.
Table 4 lists the estimated distance
DX from the computed centroid position by using the values of
Tε estimated for each smartphone. The distance
CGT from the centroid to the ground truth was measured. Hence, the error
EX of the distance estimates was determined, and the results are listed in
Table 4.
The mean error of the distance estimate across all devices was 2 cm, and the standard deviation was 78 cm. For all experiments of this study, the mean of the standard deviations of the traversal speeds was 0.4 m∙s
−1. The standard deviation of the distance estimate is proportional to the choice of speed interval from which the system selects traversal data. The recommended practice is to determine the mean traversal speed of a detected anomaly and then select traversal data that is within a few m∙s
−1 of the mean to satisfy the confidence interval desired for the application. The confidence interval
CI of the distance estimate is
where
Zα = 1.96 for a 95% confidence interval,
σX is the standard deviation of the distance estimate, and
N is the number of traversals used. From Equation (11),
σX depends on the standard deviations of the traversal speed, the time latency of GPS tagging, and the GPS update interval. Hence, the confidence interval of the estimate will increase in proportion to the standard deviation of the speed interval used for data selection and decrease by the square root of the number of traversals used.
A limitation of this approach is that, without further tests, the mean GPS tagging latency of a device is unknown. At relatively low speeds, the average latency may be sufficiently small to ignore because the ground truth will be within sight distance. However, this may not be the case at highway speeds. Determining the latency will require experiments like those described in this paper. However, such experiments are very time-consuming, and they must be conducted for each smartphone used in practice. Another alternative is to guess a time latency and then correct for it after discovering the actual position of ground truths with known coordinates. Such ground truths can be manhole covers, utility covers, speed cushions, drainage provisions, crowned intersecting streets, and sudden grade changes. It is also possible to write software to measure the average latency in tagging accelerometer samples with GPS positions. Those developments will be the focus of future work.
5. Conclusions
Roadway anomalies such as potholes, frost heaves, swelling, and cracking can worsen rapidly with dynamic vehicle loading and weather cycles. Therefore, transportation agencies need to frequently scan the network for anomalies and repair them before they cause safety issues and vehicle damage. Current methods of scanning for anomalies are too expensive to scale for more frequent and network-wide coverage. Consequently, many studies emerged to develop methods of using regular vehicles to measure ride quality data. However, regular vehicles must have the appropriate devices on board to enable a practical solution. Future deployments of connected vehicles will have all the required communications, computing, and sensing capabilities including a low-cost GPS receiver, an accelerometer, a speed sensor, and a high-resolution timer. Meanwhile, researchers and commercial software app providers used smartphones to evaluate different methods that use their embedded low-cost GPS receivers, accelerometers, and timers.
One finding of this research is that low-cost GPS receivers produce a large error spread in anomaly localization when collecting data with smartphones on board vehicles. The authors conducted 12 sets of experiments with many traversals of an isolated rough spot in four different environments. The longitudinal GPS error spread ranged from 21 m to 32 m, and the lateral error spread ranged from 9 m to 15 m. The experiments showed that the geodesic distance error increased linearly with traversal speed. The error exceeded 16 m at arterial speeds of 18.8 m∙s−1 (42 mph). A regression of the trend suggested that the error can exceed 27 m at highway speeds of 31.3 m∙s−1 (70 mph). Such a large error will be beyond the human sight distance.
This work contributes a method to estimate the position of anomalies with greater accuracy when using low-cost GPS receivers on board regular vehicles. The method leverages the large volume of participatory sensing data to calculate an outlier-free centroid of the GPS position tags of a peak inertial event (PIE) produced in the accelerometer signal while traversing an anomaly. The estimated position is a simple function of the average traversal speed, the GPS update interval, and the system latency in tagging accelerometer samples with GPS coordinates. The experiments determined that, with a good estimate of the system latency, the method can provide sub-meter accuracy. Future work will explore methods of automatically estimating the system latency. This will lead to the development of a server-side application that can provide ever-increasing accuracy of estimating the position of anomalies using connected vehicles.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}