Vision-Based Suture Tensile Force Estimation in Robotic Surgery

Abstract
:1. Introduction
2. Related Works
2.1. Vision-Based Force Estimation
2.2. Inception-Resnet V2
3. Materials and Methods
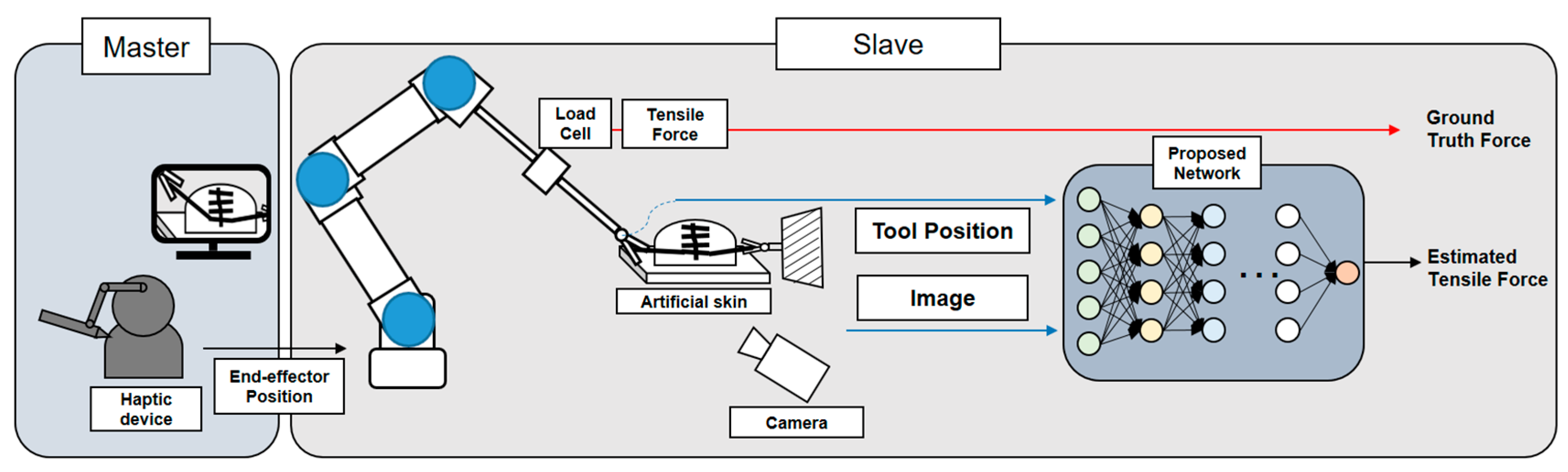
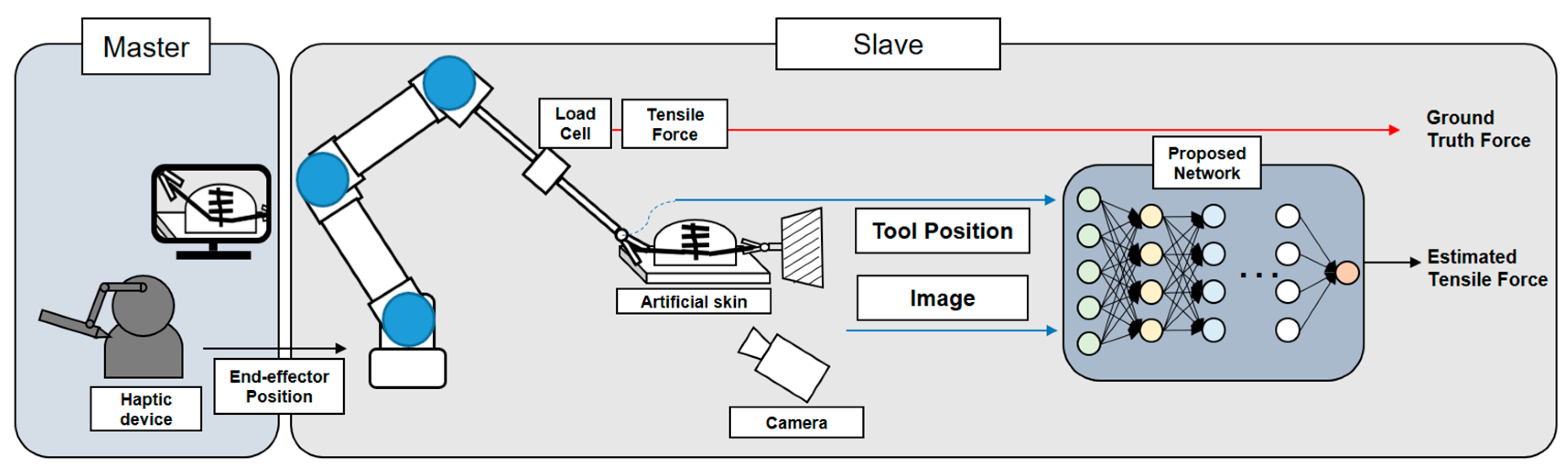
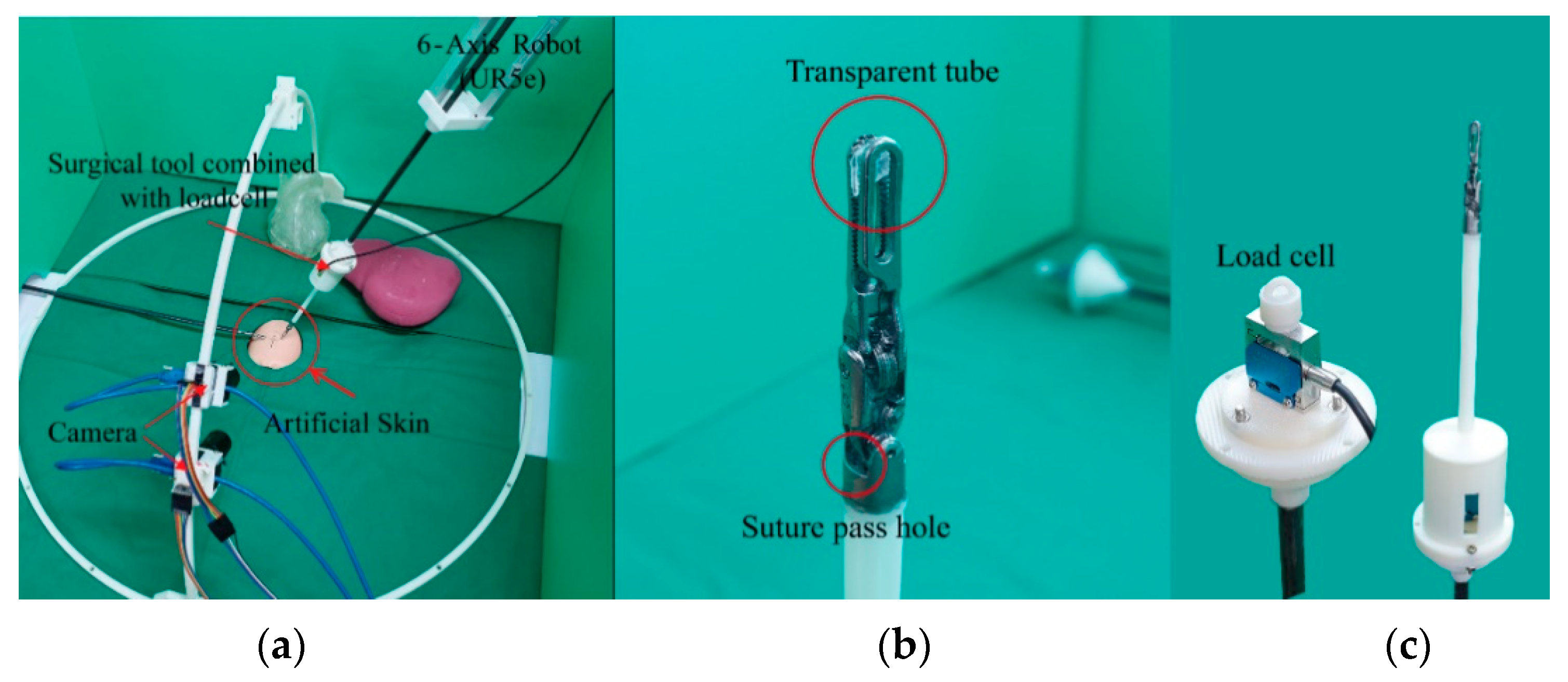
3.1. Overall Operating System
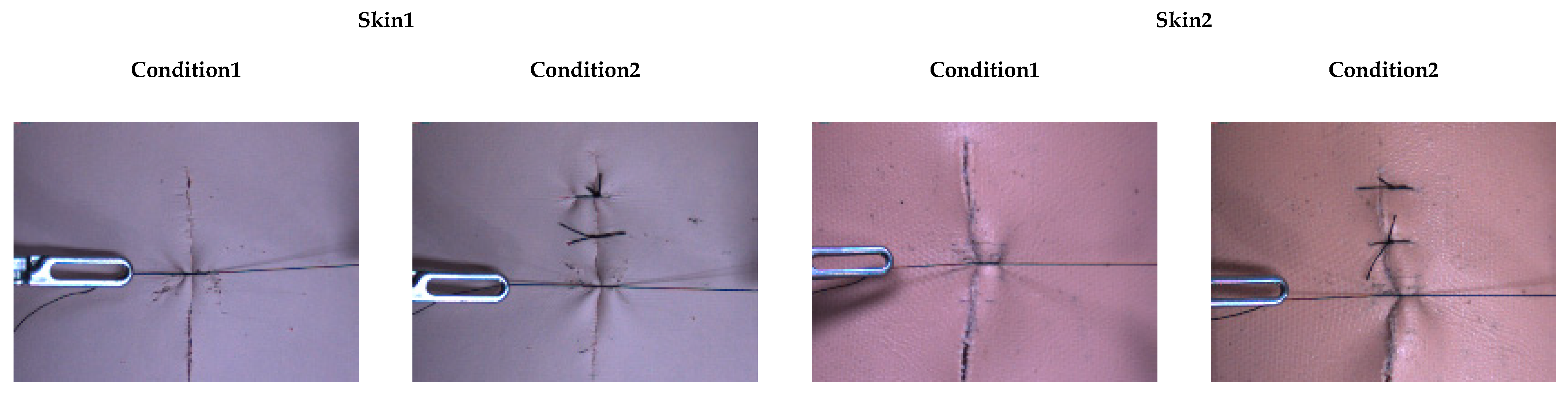
3.2. Dataset
3.3. Image Augmentation and Data Preprocessing
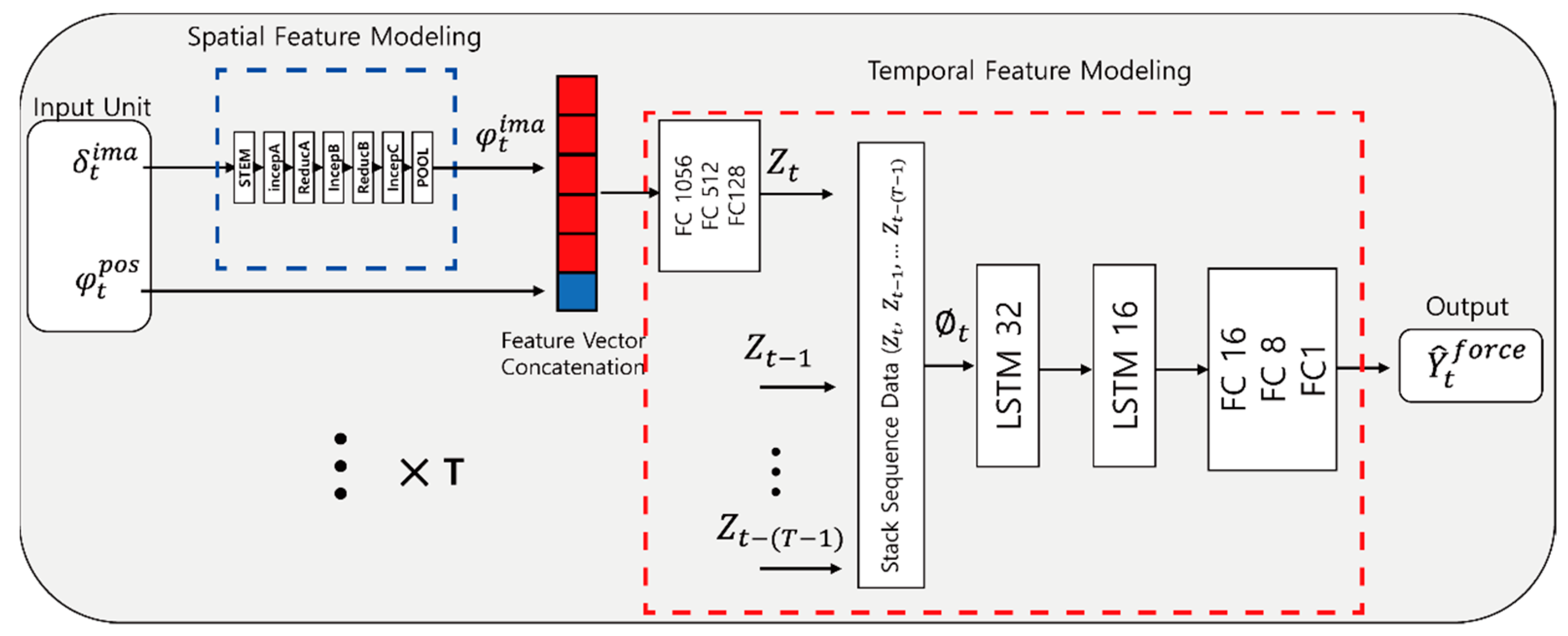
3.4. Feature Modeling Using Proposed Network
3.4.1. Spatial Feature Modeling
3.4.2. Temporal Feature Modeling
4. Results
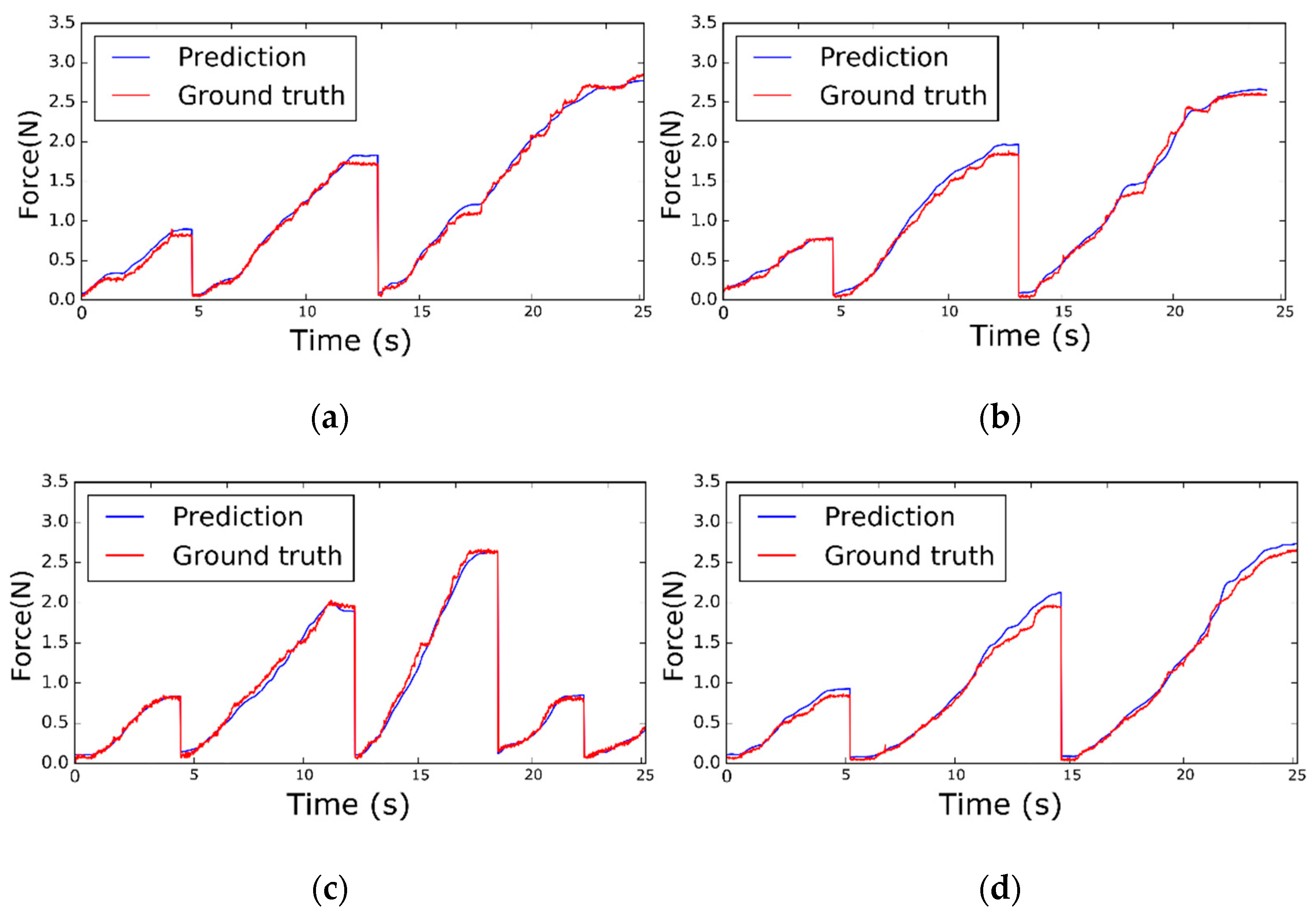
4.1. Results for Soft Objects and Conditions
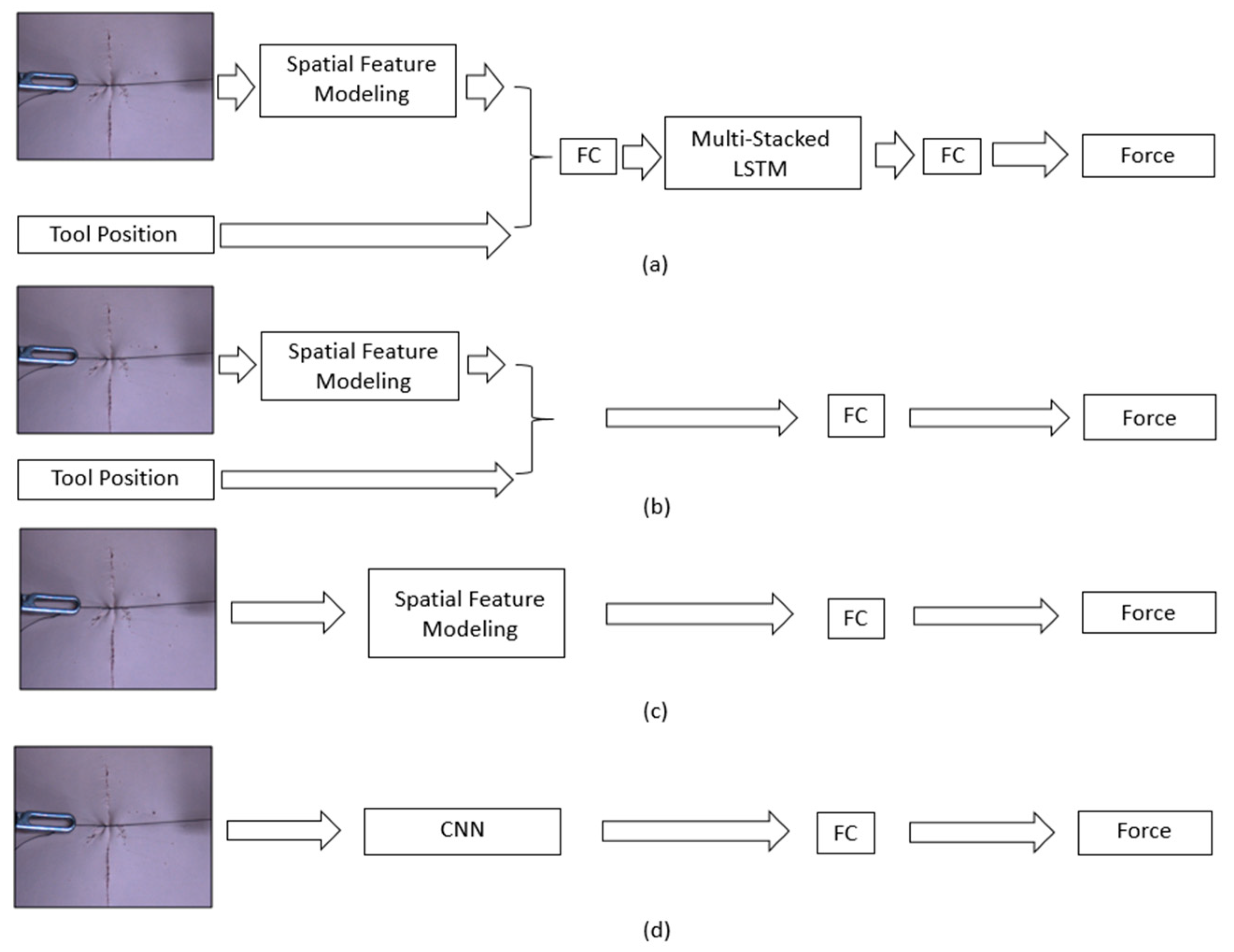
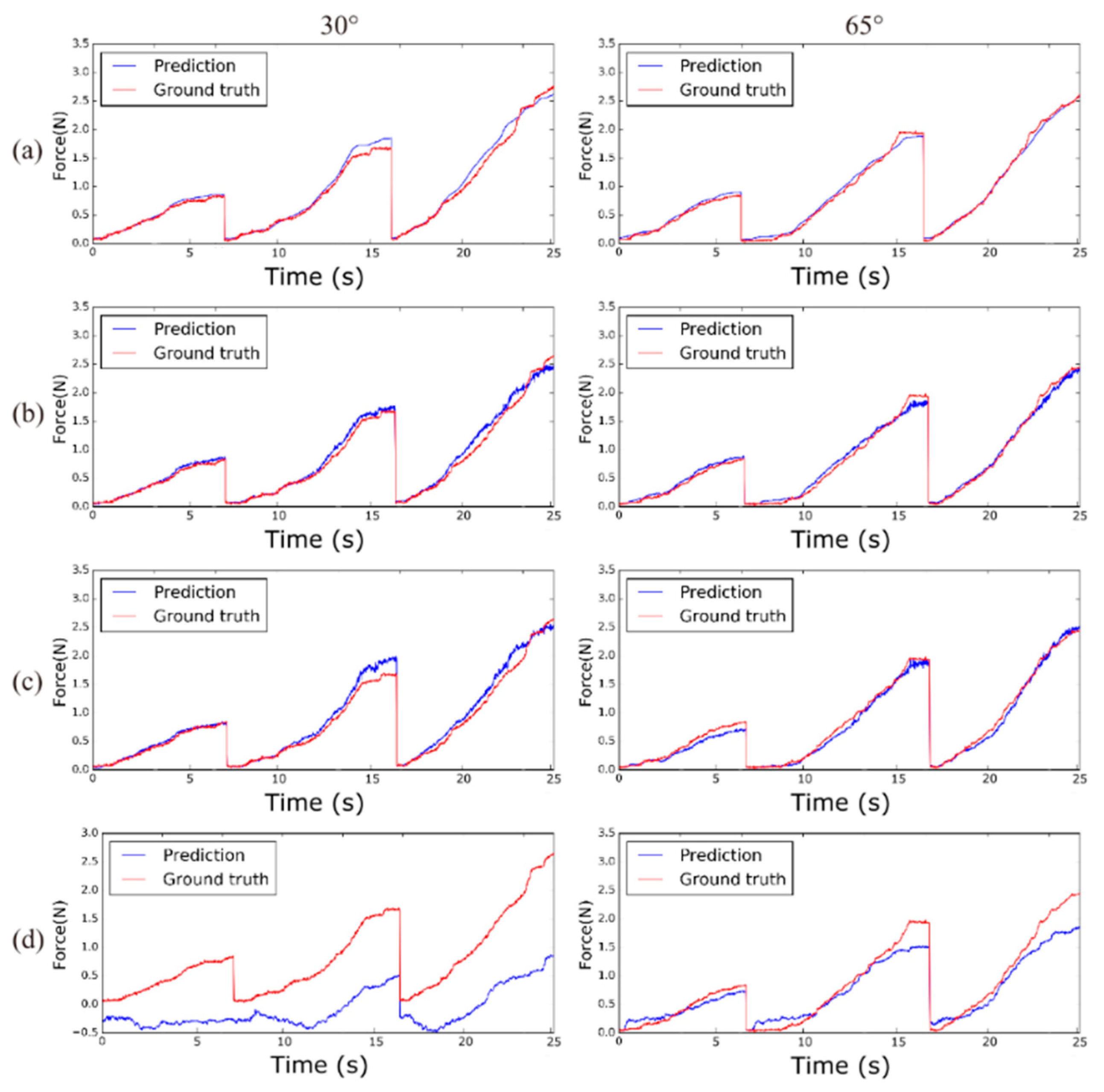
4.2. Comparison of Results by Networks
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gomes, P. Surgical robotics: Reviewing the past, analysing the present, imagining the future. Robot. Comput. Manuf. 2011, 27, 261–266. [Google Scholar] [CrossRef]
- Marbán, A.; Casals, A.; Fernández, J.; Amat, J. Haptic Feedback in Surgical Robotics: Still a Challenge. In Proceedings of the First Iberian Robotics Conference (ROBOT2013), Madrid, Spain, 28–29 November 2013; pp. 245–253. [Google Scholar] [CrossRef]
- Bayle, B.; Joinié-Maurin, M.; Barbé, L.; Gangloff, J.; de Mathelin, M. Robot Interaction Control in Medicine and Surgery: Original Results and Open Problems. In Computational Surgery and Dual Training: Computing, Robotics and Imaging; Garbey, M., Bass, B.L., Berceli, S., Collet, C., Cerveri, P., Eds.; Springer: New York, NY, USA, 2014; pp. 169–191. [Google Scholar] [CrossRef]
- Leblanc, K.A. Laparoscopic incisional and ventral hernia repair: Complications? how to avoid and handle. Hernia 2004, 8, 323–331. [Google Scholar] [CrossRef] [PubMed]
- Melinek, J.; Lento, P.; Moalli, J. Postmortem analysis of anastomotic suture line disruption following carotid endarterectomy. J. Forensic Sci. 2004, 49, 1–5. [Google Scholar] [CrossRef]
- Anup, R.; Balasubramanian, K. Surgical Stress and the Gastrointestinal Tract. J. Surg. Res. 2000, 92, 291–300. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marban, A.; Srinivasan, V.; Wojciech, S.; Fernández, J.; Casals, A. A recurrent convolutional neural network approach for sensorless force estimation in robotic surgery. Biomed. Signal Process. Control. 2019, 50, 134–150. [Google Scholar] [CrossRef] [Green Version]
- Abiri, A.; Askari, S.J.; Tao, A.; Juo, Y.-Y.; Dai, Y.; Pensa, J.; Candler, R.; Dutson, E.P.; Grundfest, W.S. Suture Breakage Warning System for Robotic Surgery. IEEE Trans. Biomed. Eng. 2019, 66, 1165–1171. [Google Scholar] [CrossRef] [PubMed]
- Reiley, C.E.; Akinbiyi, T.; Burschka, D.; Chang, D.C.; Okamura, A.M.; Yuh, D.D. Effects of visual force feedback on robot-assisted surgical task performance. J. Thorac. Cardiovasc. Surg. 2008, 135, 196–202. [Google Scholar] [CrossRef] [Green Version]
- Stephens, T.K.; O’Neill, J.J.; Kong, N.J.; Mazzeo, M.V.; Norfleet, J.E.; Sweet, R.M.; Kowalewski, T.M. Conditions for reliable grip force and jaw angle estimation of da Vinci surgical tools. Int. J. Comput. Assist. Radiol. Surg. 2019, 14, 117–127. [Google Scholar] [CrossRef]
- Shi, C.; Li, M.; Lv, C.; Li, J.; Wang, S. A High-Sensitivity Fiber Bragg Grating-Based Distal Force Sensor for Laparoscopic Surgery. IEEE Sens. J. 2020, 20, 2467–2475. [Google Scholar] [CrossRef]
- Lim, S.-C.; Park, J.; Lee, H.-K. Grip force measurement of forceps with fibre Bragg grating sensors. Electron. Lett. 2014, 50, 733–735. [Google Scholar] [CrossRef]
- Zhao, B.; Nelson, C.A. A sensorless force-feedback system for robot-assisted laparoscopic surgery. Comput. Assist. Surg. 2019, 24, 36–43. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Zi, B.; Wang, D.; Qian, J.; You, W.; Yu, L. External Force Self-Sensing Based on Cable-Tension Disturbance Observer for Surgical Robot End-Effector. IEEE Sens. J. 2019, 19, 5274–5284. [Google Scholar] [CrossRef]
- Hwang, W.; Lim, S.-C. Inferring Interaction Force from Visual Information without Using Physical Force Sensors. Sensors 2017, 17, 2455. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beruvides, G.; Quiza, R.; del Toro, R.; Castaño, F.; Haber, R.E. Correlation of the holes quality with the force signals in a mi-crodrilling process of a sintered tungsten-copper alloy. Int. J. Precis. Eng. Man. 2014, 15, 1801–1808. [Google Scholar] [CrossRef]
- Huang, Z.; Tu, Y.; Meng, S.; Sabau, C.; Popescu, C.; Sabau, C. Experimental study on shear deformation of reinforced concrete beams using digital image correlation. Eng. Struct. 2019, 181, 670–698. [Google Scholar] [CrossRef] [Green Version]
- Kennedy, C.W.; Desai, J.P. A vision-based approach for estimating contact forces: Applications to robot-assisted surgery. Appl. Bionics Biomech. 2005, 2, 53–60. [Google Scholar] [CrossRef]
- Wang, X.; Ananthasuresh, G.; Ostrowski, J.P. Vision-based sensing of forces in elastic objects. Sens. Actuators A Phys. 2001, 94, 142–156. [Google Scholar] [CrossRef]
- Greminger, M.A.; Nelson, B.J. Modeling elastic objects with neural networks for vision-based force measurement. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2003), Las Vegas, NV, USA, 27–31 October 2003; pp. 1278–1283. [Google Scholar] [CrossRef]
- Karimirad, F.; Chauhan, S.; Shirinzadeh, B. Vision-based force measurement using neural networks for biological cell mi-croinjection. J. Biomech. 2014, 47, 1157–1163. [Google Scholar] [CrossRef]
- Kim, W.; Seung, S.; Choi, H.; Park, S.; Ko, S.Y.; Park, J.-O. Image-based force estimation of deformable tissue using depth map for single-port surgical robot. In Proceedings of the 12th International Conference on Control, Automation and Systems (ICCAS 2012), Jeju Island, Korea, 17–21 October 2012; pp. 1716–1719. [Google Scholar]
- Zhang, S.; Wang, S.; Jing, F.; Tan, M. A Sensorless Hand Guiding Scheme Based on Model Identification and Control for Industrial Robot. IEEE Trans. Ind. Inform. 2019, 15, 5204–5213. [Google Scholar] [CrossRef]
- Giannarou, S.; Ye, M.; Gras, G.; Leibrandt, K.; Marcus, H.J.; Yang, G.-Z. Vision-based deformation recovery for intraoperative force estimation of tool–tissue interaction for neurosurgery. Int. J. Comput. Assist. Radiol. Surg. 2016, 11, 929–936. [Google Scholar] [CrossRef] [Green Version]
- Naeini, F.B.; Makris, D.; Gan, D.; Zweiri, Y. Dynamic-Vision-Based Force Measurements Using Convolutional Recurrent Neural Networks. Sensors 2020, 20, 4469. [Google Scholar] [CrossRef] [PubMed]
- Yuan, W.; Dong, S.; Adelson, E.H. GelSight: High-Resolution Robot Tactile Sensors for Estimating Geometry and Force. Sensors 2017, 17, 2762. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Donlon, E.; Dong, S.; Liu, M.; Li, J.; Adelson, E.; Rodriguez, A. GelSlim: A High-Resolution, Compact, Robust, and Calibrated Tactile-sensing Finger. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2018), Madrid, Spain, 1–5 October 2018; pp. 1927–1934. [Google Scholar]
- Gessert, N.; Bengs, M.; Schlüter, M.; Schlaefer, A. Deep learning with 4D spatio-temporal data representations for OCT-based force estimation. Med. Image Anal. 2020, 64, 101730. [Google Scholar] [CrossRef] [PubMed]
- Shin, H.; Cho, H.; Kim, D.; Ko, D.-K.; Lim, S.-C.; Hwang, W. Sequential Image-Based Attention Network for Inferring Force Estimation Without Haptic Sensor. IEEE Access 2019, 7, 150237–150246. [Google Scholar] [CrossRef]
- Lee, D.-H.; Hwang, W.; Lim, S.-C. Interaction Force Estimation Using Camera and Electrical Current Without Force/Torque Sensor. IEEE Sens. J. 2018, 18, 8863–8872. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef] [Green Version]
- Neupert, C.; Matich, S.; Scherping, N.; Kupnik, M.; Werthschutzky, R.; Hatzfeld, C. Pseudo-Haptic Feedback in Teleoperation. IEEE Trans. Haptics 2016, 9, 397–408. [Google Scholar] [CrossRef]
- Bourcier, T.; Chammas, J.; Gaucher, D.; Liverneaux, P.; Marescaux, J.; Speeg-Schatz, C.; Mutter, D.; Sauer, A. Robot-Assisted Simulated Strabismus Surgery. Transl. Vis. Sci. Technol. 2019, 8, 26. [Google Scholar] [CrossRef]
- Kim, D.-H.; Lu, N.; Ma, R.; Kim, Y.-S.; Kim, R.-H.; Wang, S.; Wu, J.; Won, S.M.; Tao, H.; Islam, A.; et al. Epidermal Electronics. Science 2011, 333, 838–843. [Google Scholar] [CrossRef] [Green Version]
- Karabulut, R.; Sonmez, K.; Turkyilmaz, Z.; Bagbanci, B.; Basaklar, A.C.; Kale, N. An In Vitro and In Vivo Evaluation of Tensile Strength and Durability of Seven Suture Materials in Various pH and Different Conditions: An Experimental Study in Rats. Indian J. Surg. 2010, 72, 386–390. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feng, R.; Gu, J.; Qiao, Y.; Dong, C. Suppressing Model Overfitting for Image Super-Resolution Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW 2019), Long Beach, CA, USA, 16–17 June 2019; pp. 1964–1973. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations (ICLR), San Diego, CA, USA, 5–8 May 2015. [Google Scholar]
- Talasaz, A.; Trejos, A.L.; Patel, R.V. The role of direct and visual force feedback in suturing using a 7-DOF dual-arm teleoperated system. IEEE Trans. Haptics 2016, 10, 276–287. [Google Scholar] [CrossRef] [PubMed]
- Chu, C. Mechanical properties of suture materials: An important characterization. Ann. Surg. 1981, 193, 365. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Soft Object | Condition | RMSE (N) | Max-AE (N) |
|---|---|---|---|
| Skin1 | 1 | 0.07227 | 0.3286 |
| Skin1 | 2 | 0.08065 | 0.4531 |
| Skin2 | 1 | 0.07174 | 0.2479 |
| Skin2 | 2 | 0.07847 | 0.2993 |
| All test dataset | 0.07578 | 0.4531 | |
| Model | Test Camera View Angle Accuracy | |||||
|---|---|---|---|---|---|---|
| 90° | 65° | 55° | 30° | All Views | ||
| Proposed network | RMSE | 0.0959 | 0.0627 | 0.0744 | 0.0983 | 0.0758 |
| Max-AE | 0.3249 | 0.2110 | 0.256 | 0.4531 | 0.4531 | |
| Comparison network 1 | RMSE | 0.1011 | 0.0682 | 0.0766 | 0.1108 | 0.0816 |
| Max-AE | 0.3995 | 0.2941 | 0.3244 | 0.4396 | 0.4396 | |
| Comparison network 2 | RMSE | 0.1348 | 0.0777 | 0.08729 | 0.1395 | 0.1005 |
| Max-AE | 0.6662 | 0.3784 | 0.3567 | 0.5730 | 0.6662 | |
| Comparison network 3 | RMSE | 0.6458 | 0.2214 | 0.2617 | 0.6428 | 0.4055 |
| Max-AE | 1.179 | 0.7819 | 0.7457 | 1.6452 | 1.6452 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, W.-J.; Kwak, K.-S.; Lim, S.-C. Vision-Based Suture Tensile Force Estimation in Robotic Surgery. Sensors 2021, 21, 110. https://doi.org/10.3390/s21010110
Jung W-J, Kwak K-S, Lim S-C. Vision-Based Suture Tensile Force Estimation in Robotic Surgery. Sensors. 2021; 21(1):110. https://doi.org/10.3390/s21010110
Chicago/Turabian StyleJung, Won-Jo, Kyung-Soo Kwak, and Soo-Chul Lim. 2021. "Vision-Based Suture Tensile Force Estimation in Robotic Surgery" Sensors 21, no. 1: 110. https://doi.org/10.3390/s21010110
APA StyleJung, W.-J., Kwak, K.-S., & Lim, S.-C. (2021). Vision-Based Suture Tensile Force Estimation in Robotic Surgery. Sensors, 21(1), 110. https://doi.org/10.3390/s21010110