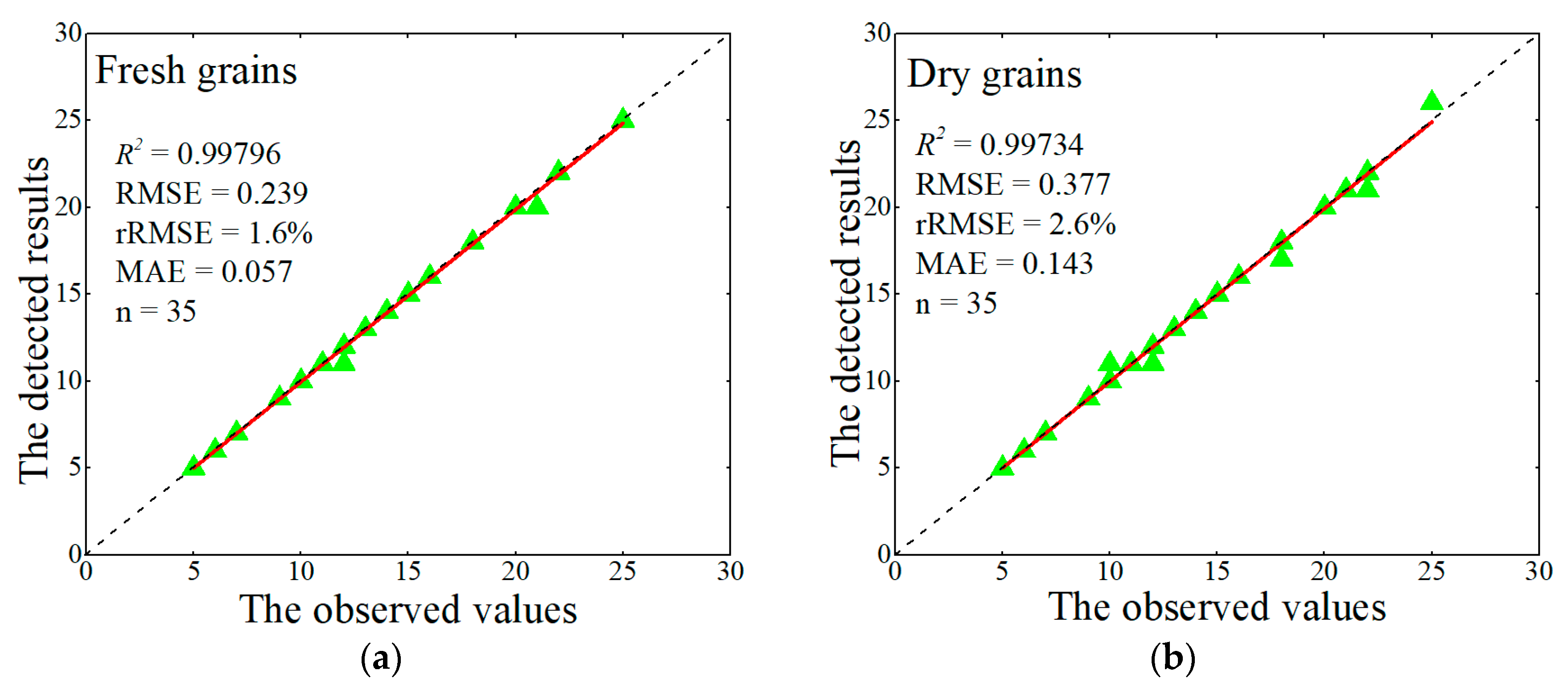
The faster R-CNN [
21] model based on feature pyramid networks (FPN) [
22], which is effective for multi-scale object detections, was used for grain detection. The grain detection model based on Faster R-CNN with FPN was trained using the images of the Original set. For this, the images needed to be preprocessed, as discussed in the following sections.
2.2.1. Image Annotation
To maintain the data consistency and reduce computing memory, the longest side of the images in the Original image set was uniformly scaled to 1280 pixels, and the shortest side was scaled accordingly to the image aspect ratio. The image annotation process was completed using the LabelImg annotation tool [
23]. The annotation process had mainly two steps: drawing a rectangular frame around a grain (
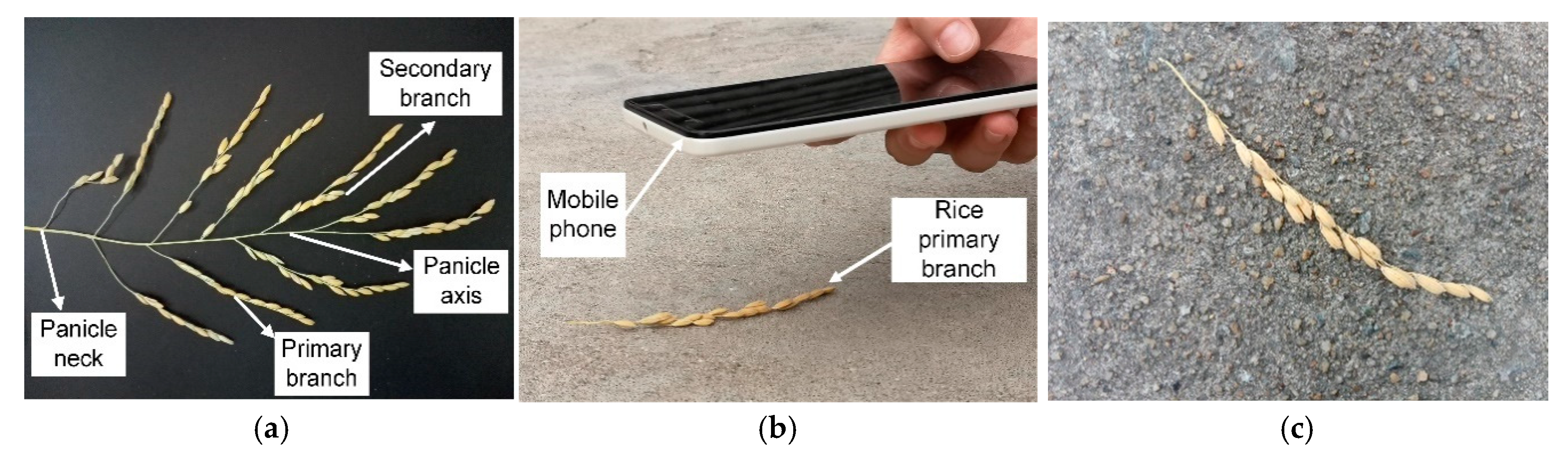
Figure 2a), and storing the labels and coordinates of the rectangular frame in the XML file, in the same format of PASCAL VOC dataset used by ImageNet [
24]. Finally, each image in the dataset had a corresponding XML format annotation file.
When the image was collected, the lighting condition was different. Besides, during image acquisition, the accidental shaking of hand may result in blur occurrence. As the results, the appearance of grains had different scales and clarities in the images, including small scales (
Figure 2b) or large scales (
Figure 2c), blurred conditions (
Figure 2d), and sunny (
Figure 2e) or cloudy environments (
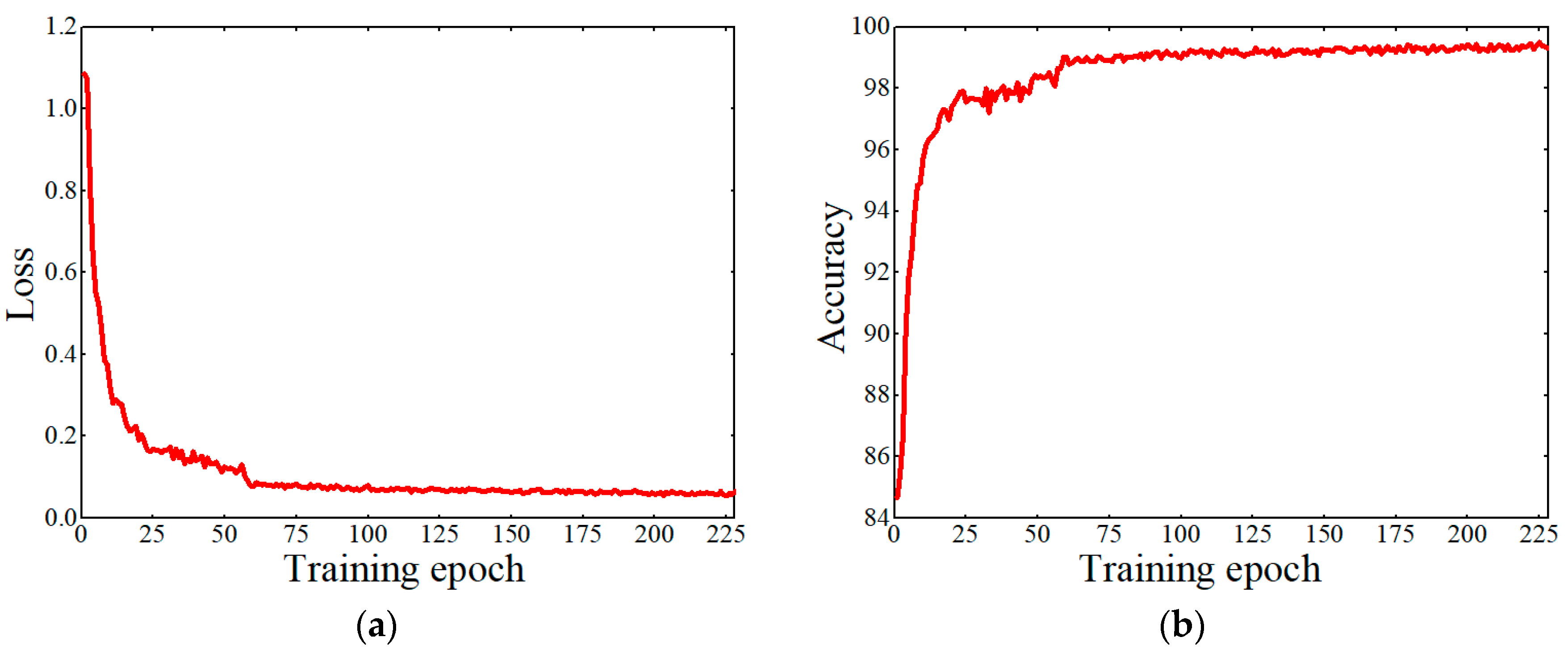
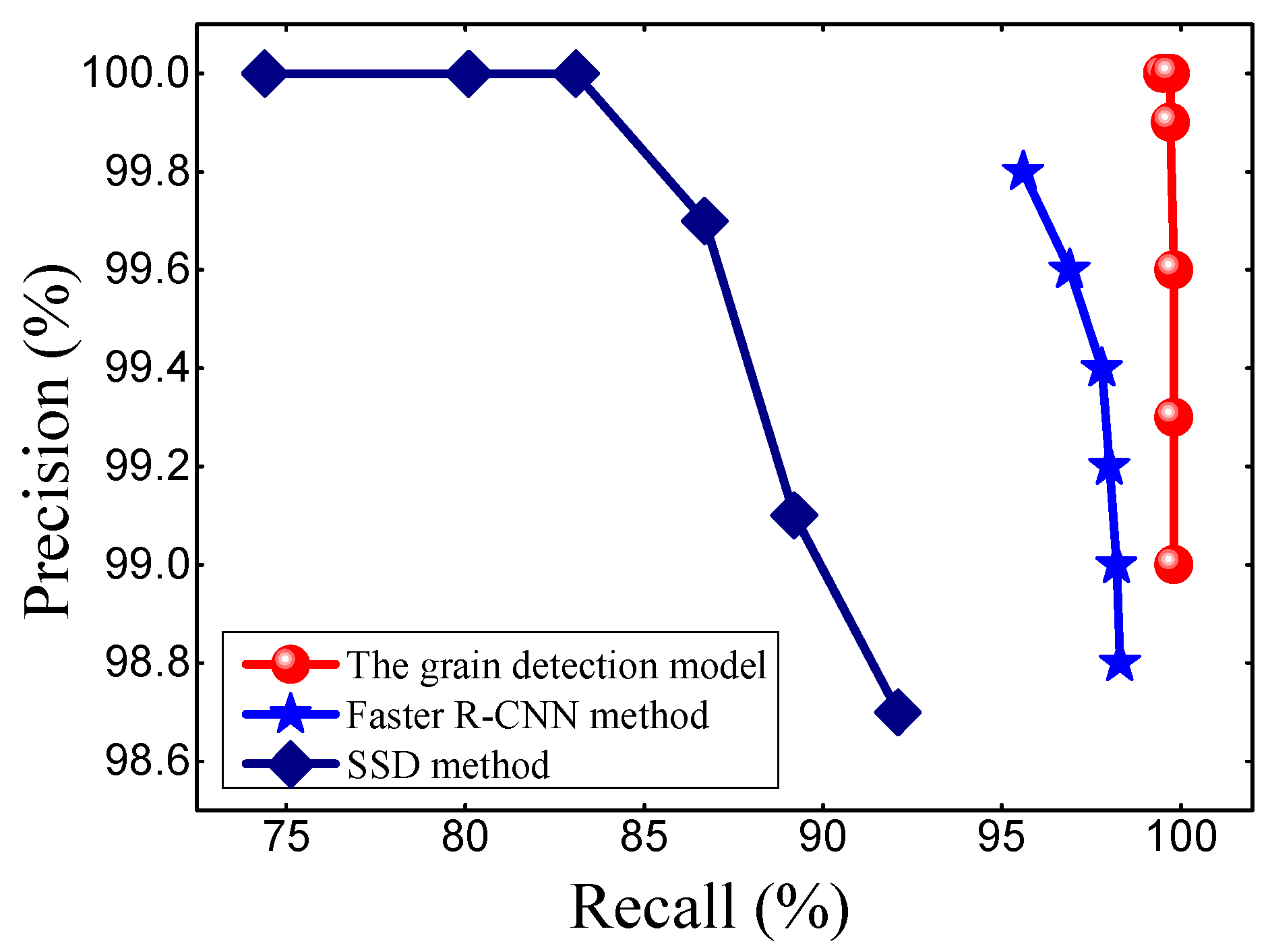
Figure 2f). To increase the robustness of the model, these images were carefully labelled. Also, when the occluded area of grain was more than 90% or when the area of the grain located on the edge of the image was less than 10%, this grain was not labelled. After the annotation process was done, the 796 images in the Original image data set were randomly separated into training, validation, and testing sub-sets with the ratio to the total images of 0.56, 0.24, and 0.2, respectively.
2.2.2. Grain Detection Based on Faster R-CNN with FPN
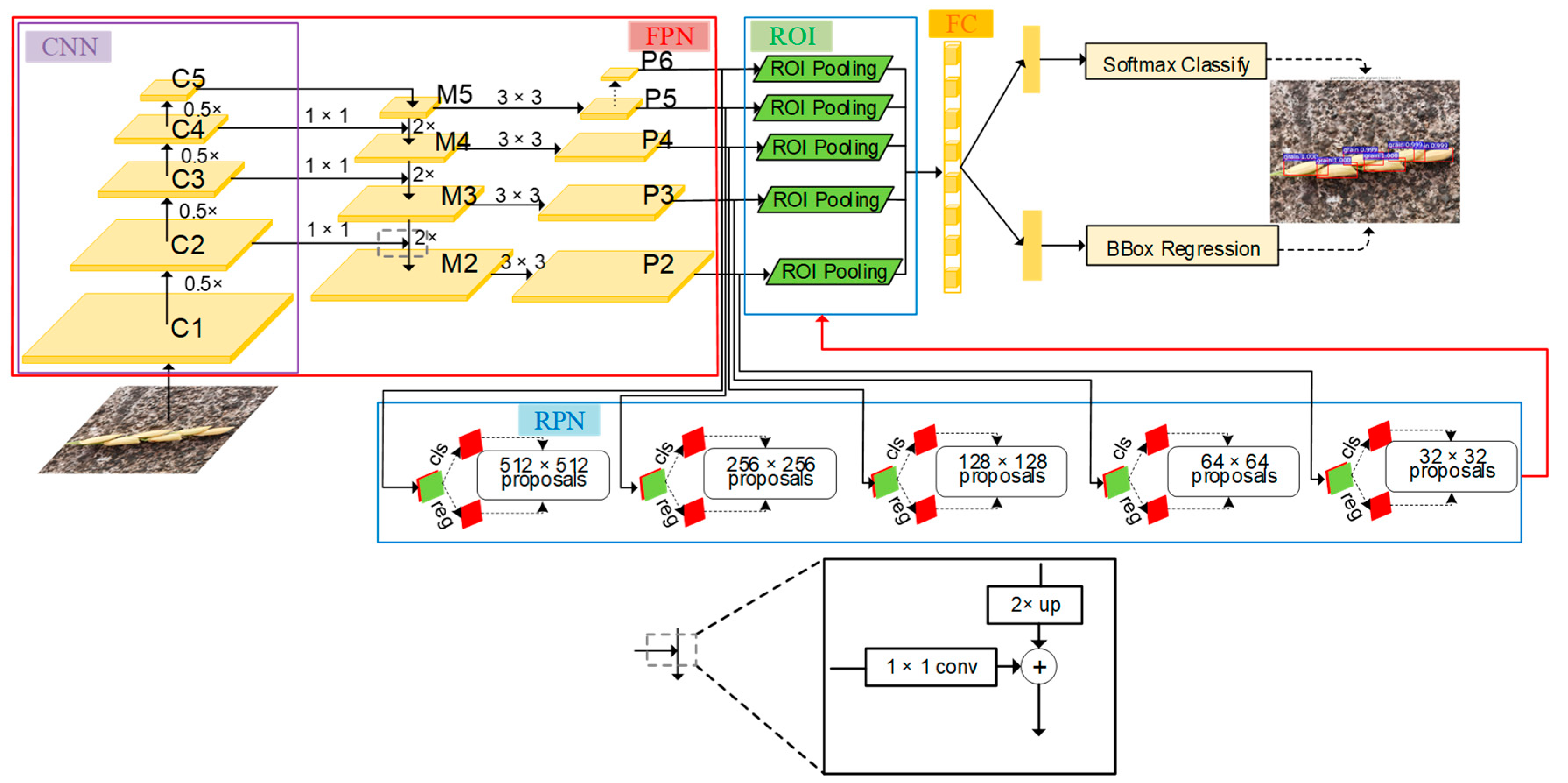
Figure 3 shows a schematic diagram of the Faster R-CNN with FPN network used in this study. Faster R-CNN with FPN was comprised of three parts: FPN for generating multi-scale feature maps, a region proposal network (RPN) using these multi-scale feature maps for generating multi-scale region proposals for objects, and a Fast R-CNN using these multi-scale proposals to detect objects. The backbone CNN extracted multi-scale feature maps of the original images through a set of basic conv+relu+pooling layers. The FPN network uses the inherent multi-scale pyramid structure of the deep convolutional neural network to construct a feature pyramid. Specifically, this is to up-sample the feature map of the highest layer of the convolutional neural network (i.e., 2× large the size) and then add it to the feature map of the lower layer of the convolutional network after 1 × 1 convolution (horizontal connection) to form a layer of the M feature layers. Follow this operation, each layer of the M feature layers was built from top to bottom layer by layer. After each feature layer in the M feature layers undergoes 3 × 3 convolution, the feature pyramid was obtained. The RPN was used to generate multi-scale region proposals through multi-scale feature maps produced by FPN. Both of the multi-scale feature maps and region proposals were fed into an ROI (Region of Interest) pooling layer to obtain the proposal feature maps. The prediction of the grain is carried out through feeding the proposal feature maps into the fully connected layer.
FPN consists of two parts: the first part is the process of bottom-up, and the second part is the fusion process of top-down and lateral connection.
In the bottom-up process, CNN networks are divided into different stages according to the size of the feature map, and the scale ratio of the feature map between each stage differs by two. Among them, each stage corresponds to a feature pyramid level, and the last layer of each stage feature is selected as the feature corresponding to the corresponding level in FPN. Taking ResNet as example, the last residual block layer features of conv2, conv3, conv4, and conv5 layers are selected as the features of FPN, which are recorded as {C2, C3, C4, C5}. The steps of these feature layers relative to the original image are 4, 8, 16, and 32, respectively.
The top-down process uses up-sampling to enlarge the small feature map on the top layer (such as 20) to the same size as the feature map of the previous stage (such as 40). The advantage of this is that it not only utilizes the strong semantic features of the top layer (facilities classification), but also uses the high-resolution information of the bottom layer (facilitates positioning). The up-sampling method can be implemented with the nearest neighbor difference value. In order to combine the high-level semantic features with the bottom-level precise positioning capabilities, a lateral connection structure similar with the residual network is used. The lateral connection merges the features of the upper layer that have the same resolution as the current layer after up-sampling through the addition method. (Here, in order to correct the number of channels, the current layer is subjected to a 1 × 1 convolution operation.) The specific schematic diagram can be seen in the FPN part of
Figure 3.
Specifically, the C5 layer first undergoes 1 × 1 convolution to obtain M5 features. M4 layer was obtained by up-sampling the M5 and then plus the C4 layer after 1 × 1 convolution. Do this process two more times to get M3 and M2, respectively. The M layer features are then subjected to 3 × 3 convolution to obtain the final P2, P3, P4, and P5 layer features. Since each P layer has different scale information relative to the original image, the scale information in the original image was separated to make each P layer process only a single scale information. Specifically, the anchor of the five scales {322, 642, 1282, 2562, 5122} correspond to the five features {P2, P3, P4, P5, P6}. Each feature layer processes three candidate frames with 1:1, 1:2, and 2:1 aspect ratio. P6 is specifically designed for RPN networks and was used to process 512-dimensional candidate boxes. It is obtained by down-sampling from P5.
Each feature layer of the FPN was compared to the features of each level of the image pyramid, thereby the regions of interest (ROI) were mapped to the corresponding feature layers. Taking the input of 224 size pictures as an example, the ROI with width and height will be mapped to the feature level k, and its calculation formula is as follows:
where
k is the feature level,
k0 is 4,
w is the width of the ROI, and
h is the length of the ROI.
In ResNet, the value of k0 is 4, which corresponds to the level of the box with a length and width of 224. If the length and width of the box are divided by 2 related to 224, then the value of k will be reduced by 1, and so on.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}