
Three-Dimensional Reconstruction with a Laser Line Based on Image In-Painting and Multi-Spectral Photometric Stereo †




Abstract
:1. Introduction
- (1)
- Through the improvement of the network proposed by Isola [17], we propose a Generative Adversarial Network based on image in-painting to realize the effective estimation of the pixel values at the locations covered by the laser line in the multi-spectral image;
- (2)
- The proposed network can effectively extract the laser line in the multi-spectral image;
- (3)
- Through adding certain U-Net-like structures to the generator of GAN, the proposed network can produce stable results;
- (4)
- Based on the proposed network and Fan’s [16] algorithm, we achieve accurate 3D reconstruction using a multispectral image with a laser line.
2. Related Work
2.1. Introduction of Multi-Spectral Photometric Stereo
2.2. Introduction of Photometric Stereo Algorithm Based on Laser Line Correction
2.3. Laser Line Extraction Algorithms
2.4. Image In-Painting Algorithms Based on Deep Learning
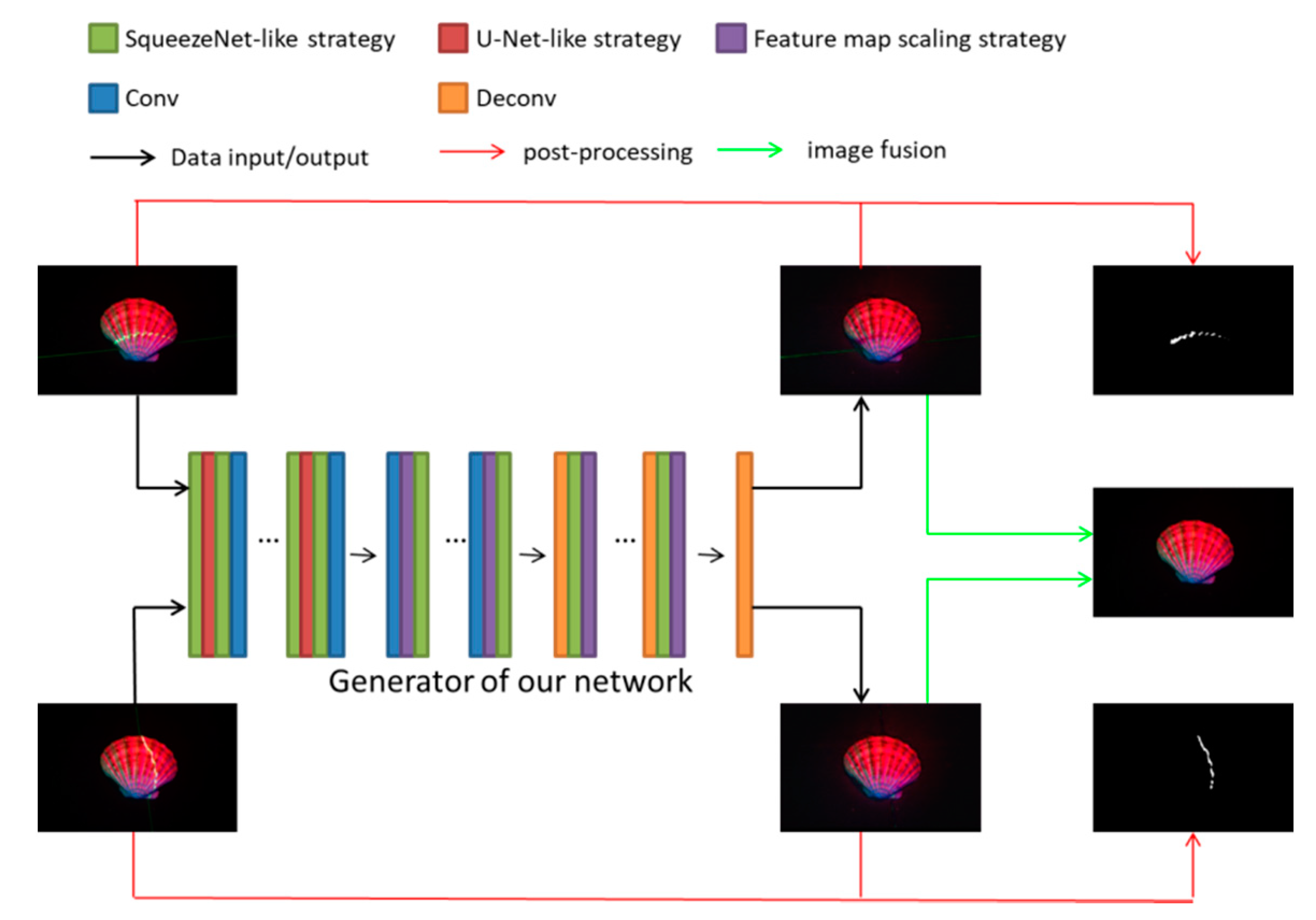
3. Method
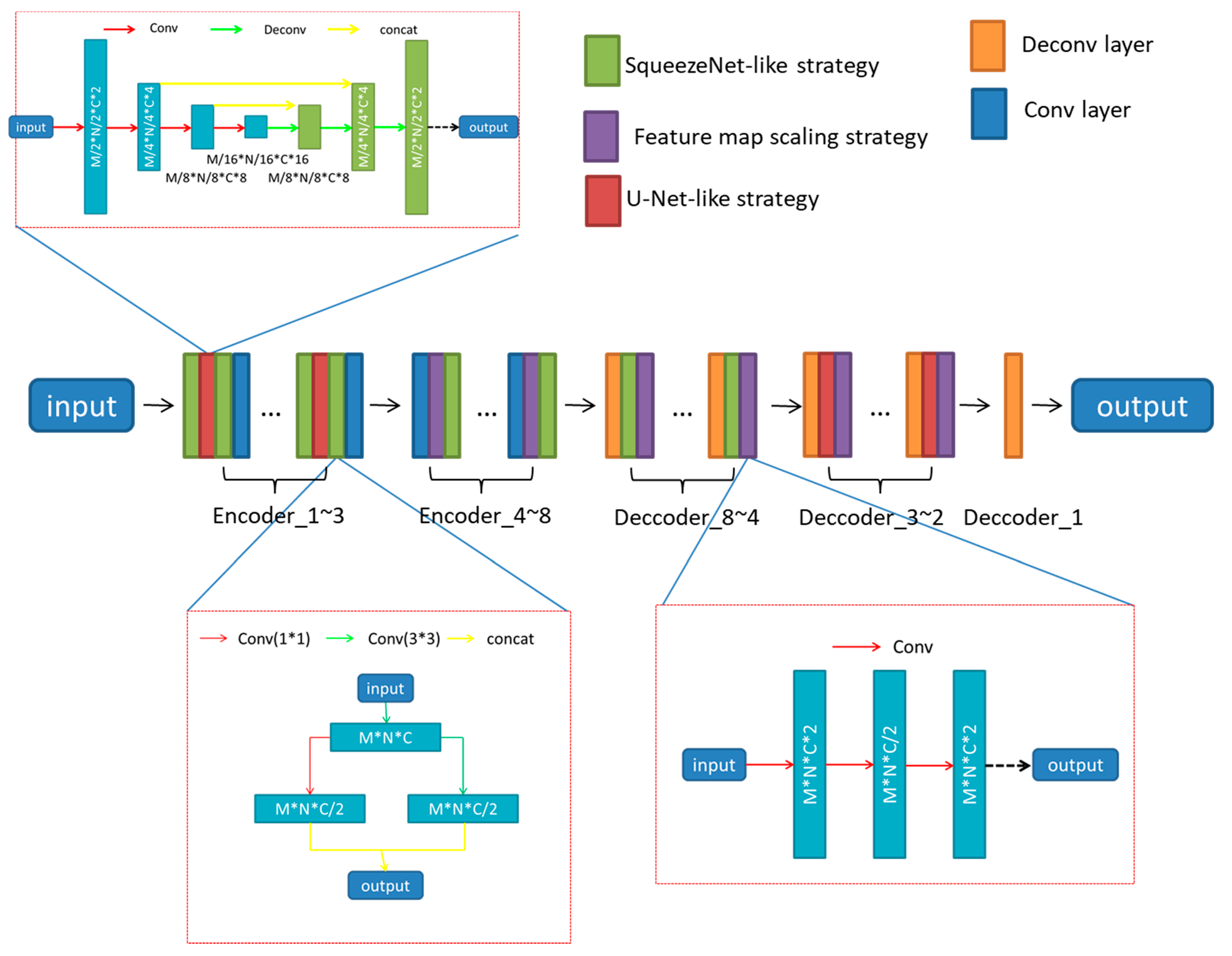
3.1. Architecture
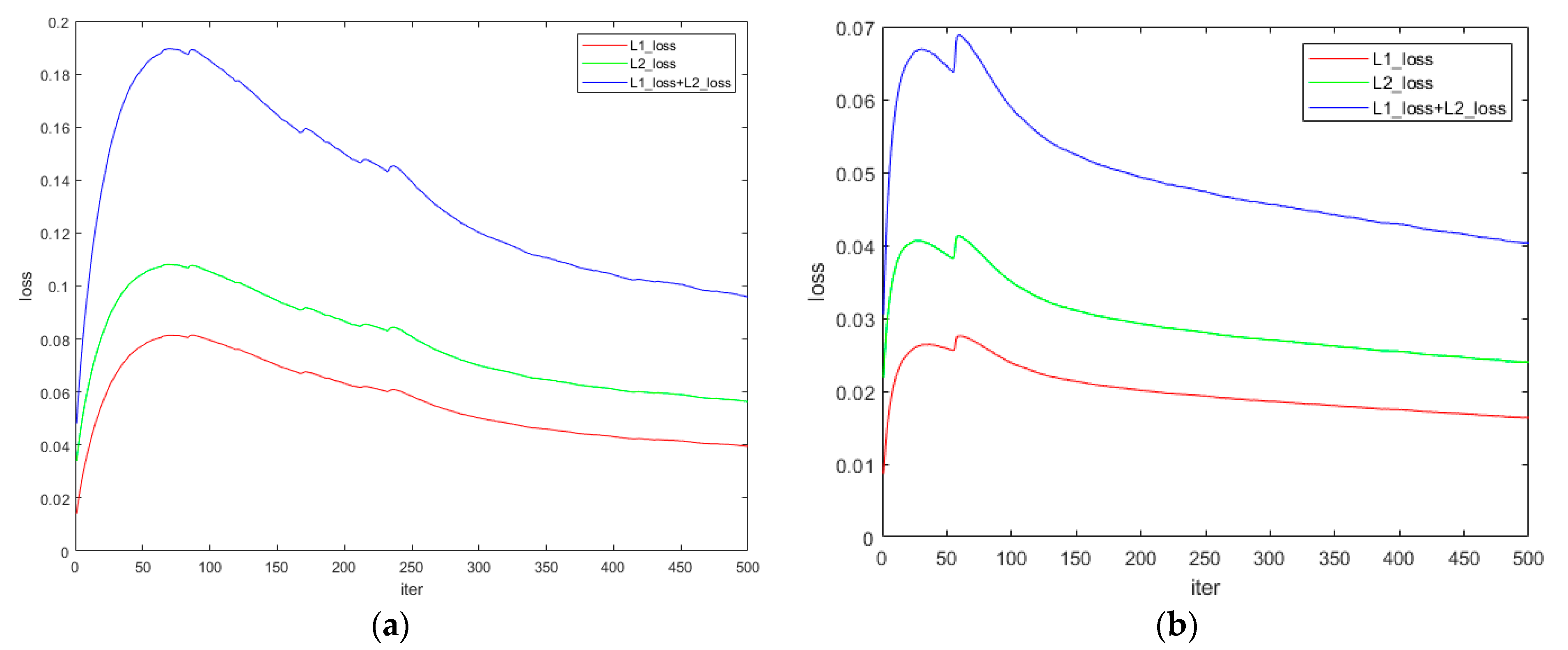
3.2. Training
4. Experiments
4.1. Dataset
4.1.1. Rendered Image Dataset
4.1.2. Real-World Images
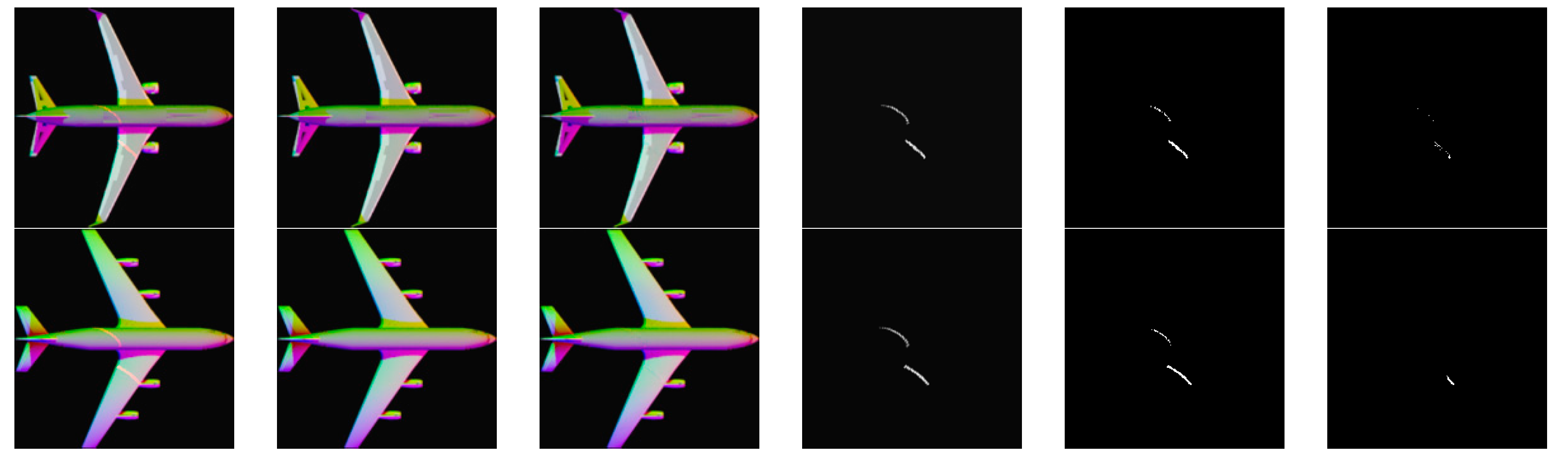
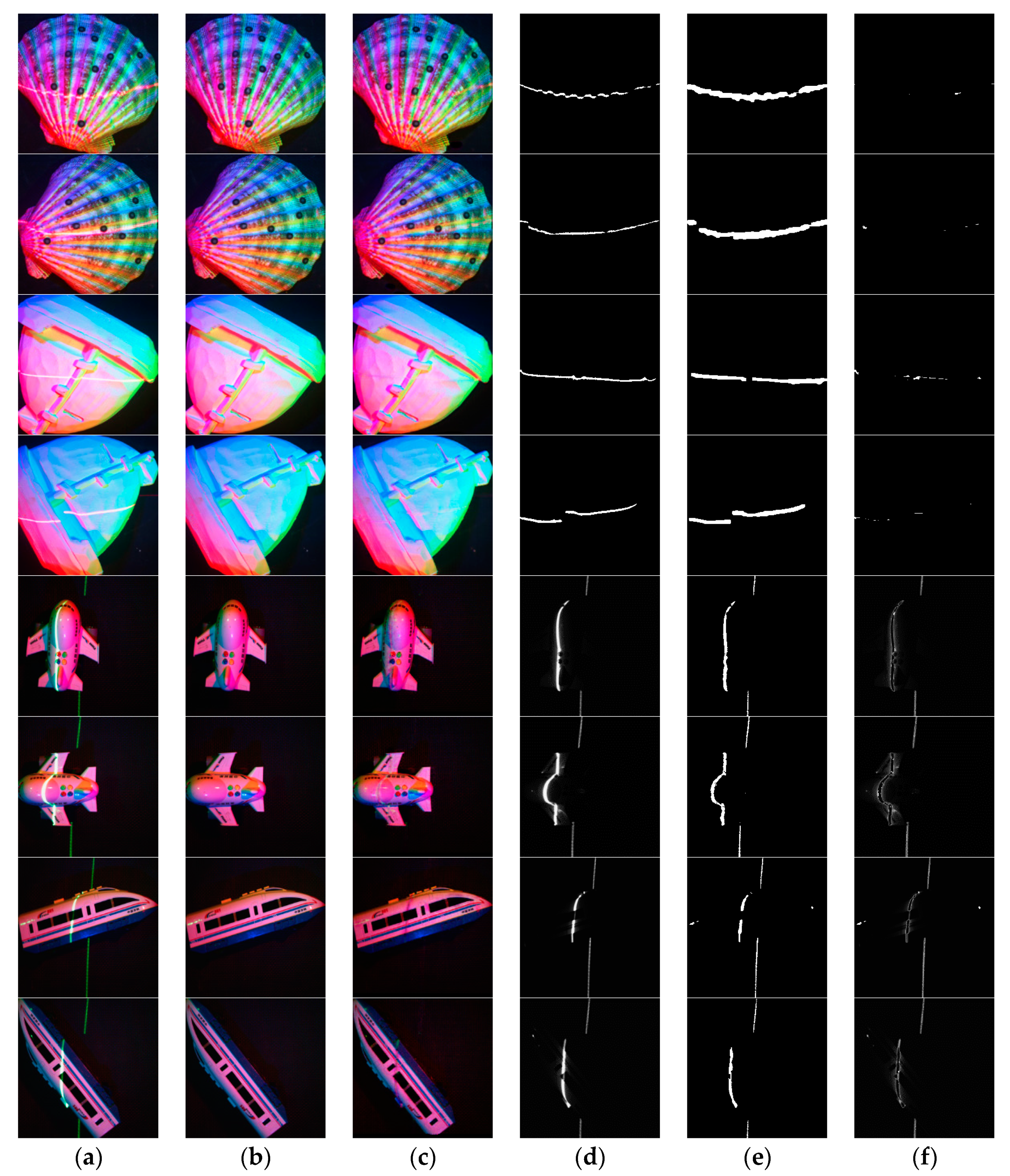
4.2. Laser Line Extraction Results
4.2.1. Extraction Results of Laser Lines in Rendered Images
4.2.2. Extraction Results of Laser Lines in Real-World Images
4.3. Analysis and Discussion
4.3.1. Comparison with the Results of Isola’s Network
4.3.2. Analysis of the Added Strategy
4.3.3. Comparison with Other Image In-Painting Algorithms
4.4. Reconstruction Results Using Multi-Spectral Photometric Stereo
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zeng, H.; Chen, Y.; Zhang, Z.; Wang, C.; Li, J. Reconstruction of 3D Zebra Crossings from Mobile Laser Scanning Point Clouds. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1899–1902. [Google Scholar]
- Cui, Y.; Li, Q.; Yang, B.; Xiao, W.; Chen, C.; Dong, Z. Automatic 3-D Reconstruction of Indoor Environment with Mobile Laser Scanning Point Clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3117–3130. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Wang, N.; Fu, Q.; Zhang, Y.; Wang, M. Research on 3D Reconstruction Method Based on Laser Rotation Scanning. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 4–7 August 2019; pp. 1600–1604. [Google Scholar]
- Woodham, R.J. Photometric method for determining surface orientation from multiple images. Opt. Eng. 1980, 19, 139–191. [Google Scholar] [CrossRef]
- Torresani, L.; Hertzmann, A.; Bregler, C. Nonrigid Structure-from-Motion: Estimating Shape and Motion with Hierarchical Priors. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 878–892. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Wu, Q.; Wang, S. Research on 3D Reconstruction Based on Multiple Views. In Proceedings of the 2018 13th International Conference on Computer Science & Education (ICCSE), Colombo, Sri Lanka, 8–11 August 2018; pp. 1–5. [Google Scholar]
- Lu, L.; Qi, L.; Luo, Y.; Jiao, H.; Dong, J. Three-Dimensional Reconstruction from Single Image Base on Combination of CNN and Multi-Spectral Photometric Stereo. Sensors 2018, 18, 764. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ju, Y.; Qi, L.; Zhou, H.; Dong, J.; Lu, L. Demultiplexing Colored Images for Multispectral Photometric Stereo via Deep Neural Networks. IEEE Access 2018, 6, 30804–30818. [Google Scholar] [CrossRef]
- Ju, Y.; Dong, X.; Wang, Y.; Qi, L.; Dong, J. A dual-cue network for multispectral photometric stereo. Pattern Recognit. 2020, 100, 0031–3203. [Google Scholar] [CrossRef]
- Ju, Y.; Qi, L.; He, J.; Dong, X.; Gao, F.; Dong, J. MPS-Net: Learning to recover surface normal for multispectral photometric stereo. Neurocomputing 2020, 375, 62–70. [Google Scholar] [CrossRef]
- Christensen, P.H.; Shapiro, L.G. Three-dimensional shape from color photometric stereo. Int. J. Comput. Vis. 1994, 13, 213–227. [Google Scholar] [CrossRef]
- Ikeda, O.; Duan, Y. Color Photometric Stereo for Albedo and Shape Reconstruction. In Proceedings of the 2008 IEEE Workshop on Applications of Computer Vision, Copper Mountain, CO, USA, 7–9 January 2008; pp. 1–6. [Google Scholar]
- Ikeda, O. Color photometric stereo for directional diffuse object. In Proceedings of the 2009 Workshop on Applications of Computer Vision (WACV), Snowbird, UT, USA, 7–8 December 2009; pp. 1–6. [Google Scholar]
- Anderson, R.; Stenger, B.; Cipolla, R. Color photometric stereo for multicolored surfaces. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2182–2189. [Google Scholar]
- Fan, H.; Qi, L.; Wang, N.; Dong, J.; Chen, Y.; Yu, H. Deviation correction method for close-range photometric stereo with nonuniform illumination. Opt. Eng. 2017, 56, 103102. [Google Scholar] [CrossRef] [Green Version]
- Fan, H.; Qi, L.; Ju, Y.; Dong, J.; Yu, H. Refractive laser triangulation and photometric stereo in underwater environment. Opt. Eng. 2017, 56, 113101. [Google Scholar] [CrossRef] [Green Version]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Available online: https://www.2grobotics.com/ (accessed on 20 September 2018).
- Mölder, A.; Martens, O.; Saar, T.; Land, R. Laser Line Detection with Sub-Pixel Accuracy. Elektron. Elektrotechnika 2014, 20, 132–135. [Google Scholar] [CrossRef] [Green Version]
- Chmelarova, N.; Chmelar, P.; Beran, L.; Rejfek, L. Improving precision of laser line detection in 3D range scanning systems. In Proceedings of the 2016 26th International Conference Radioelektronika (RADIOELEKTRONIKA), Kosice, Slovakia, 19–20 April 2016; pp. 207–212. [Google Scholar]
- Li, Y.; Zhou, J.; Huang, F.; Liu, L. Sub-Pixel Extraction of Laser Stripe Center Using an Improved Gray-Gravity Method. Sensors 2017, 17, 814. [Google Scholar] [CrossRef] [Green Version]
- Ta, H.N.; Kim, D.; Lee, S. A novel laser line detection algorithm for robot application. In Proceedings of the 2011 11th International Conference on Control, Automation and Systems, Gyeonggi-do, Korea, 26–29 October 2011; pp. 361–365. [Google Scholar]
- Song, W.; Hu, X.; Fu, J.; Zhou, Q.; Zhou, T.; Si, P. The method of hybrid-laser image spot extracts based on HSV space SVD for power transmission line detection. In Proceedings of the 2016 IEEE International Conference on Information and Automation (ICIA), Ningbo, China, 1–3 August 2016; pp. 1361–1364. [Google Scholar]
- Chmelar, P.; Dobrovolny, M. The Laser Line Detection for Autonomous Mapping Based on Color Segmentation. Int. J. Mech. Mater. Eng. 2013, 7, 1654–1658. [Google Scholar]
- Liu, H.; Jiang, B.; Xiao, Y.; Yang, C. Coherent Semantic Attention for Image In-painting. In Proceedings of the International Conference on Computer Vision (ICCV 2019), Seoul, Korea, 27 October–2 November 2019; pp. 4170–4179. [Google Scholar]
- Hong, X.; Xiong, P.; Ji, R.; Fan, H. Deep Fusion Network for Image Completion. arXiv 2019, arXiv:1904.08060. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative Image In-painting with Contextual Attention. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar] [CrossRef] [Green Version]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T. Free-Form Image In-painting with Gated Convolution. In Proceedings of the International Conference on Computer Vision (ICCV 2019), Seoul, Korea, 27 October–2 November 2019; pp. 4471–4480. [Google Scholar]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.Z.; Ebrahimi, M. EdgeConnect: Generative Image In-painting with Adversarial Edge Learning. arXiv 2019, arXiv:1901.00212. [Google Scholar]
- Zeng, Y.; Lin, Z.; Yang, J.; Zhang, J.; Shechtman, E.; Lu, H. High-Resolution Image In-painting with Iterative Confidence Feedback and Guided Upsampling. The 16th European Conference on Computer Vision (ECCV 2020). arXiv 2020, arXiv:2005.11742. [Google Scholar]
- Huang, J.-B.; Kang, S.B.; Ahuja, N.; Kopf, J. Image completion using planar structure guidance. ACM Trans. Graph. 2014, 33, 1–10. [Google Scholar] [CrossRef]
- Yang, J.; Qi, Z.; Shi, Y. Learning to Incorporate Structure Knowledge for Image In-painting. The thirty-fourth AAAI Conference on Artifieial Intelligence (AAAI 2020). arXiv 2020, arXiv:2002.04170. [Google Scholar]
- Liu, H.; Jiang, B.; Song, Y.; Huang, W.; Yang, C. Rethinking Image In-Painting via a Mutual Encoder-Decoder with Feature Equalizations. The 16th European Conference on Computer Vision (ECCV 2020). arXiv, 2020; arXiv:2007.06929. [Google Scholar]
- Ren, J.; Xu, L.; Yan, Q.; Sun, W. Shepard Convolutional Neural Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems—Volume 1 (NIPS’15); MIT Press: Cambridge, MA, USA, 2015; pp. 901–909. [Google Scholar]
- Li, J.; Wang, N.; Zhang, L.; Du, B.; Tao, D. Recurrent Feature Reasoning for Image In-Painting. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16 November 2020; pp. 7757–7765. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference Learn, Represent (ICLR), San Diego, CA, USA, 5–8 May 2015. [Google Scholar]
- Criminisi, A.; Pérez, P.; Toyama, K. Region Filling and Object Removal by Exemplar-Based Image Inpainting. IEEE Trans. Image Process. 2004, 13, 1200–1212. [Google Scholar] [CrossRef] [PubMed]
- Criminisi, A.; Perez, P.; Toyama, K. Object removal by exemplar-based inpainting. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003. [Google Scholar]
- Lu, C.; Feng, J.; Lin, Z.; Yan, S. Exact Low Tubal Rank Tensor Recovery from Gaussian Measurements. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Input_Channels | Output_Channels |
|---|---|---|
| Encoder_1 | 3 | 64 |
| Encoder_2 | 64 | 128 |
| Encoder_3 | 128 | 256 |
| Encoder_4 | 256 | 512 |
| Encoder_5~8 | 512 | 512 |
| Decoder_8~5 | 512 | 512 |
| Decoder_4 | 512 | 256 |
| Decoder_3 | 256 | 128 |
| Decoder_2 | 128 | 64 |
| Decoder_1 | 64 | 3 |
| Image | MSE of Our Result | MSE of the Result of Criminisi’s Algorithm When the Parameter “patch_size” Is | |||
|---|---|---|---|---|---|
| 3 | 5 | 7 | 9 | ||
| (1) | 0.0040 | 0.0073 | 0.0065 | 0.0060 | 0.0057 |
| (2) | 0.0037 | 0.0083 | 0.0083 | 0.0094 | 0.0084 |
| (3) | 0.0030 | 0.0055 | 0.0050 | 0.0052 | 0.0055 |
| (4) | 0.0044 | 0.0068 | 0.0071 | 0.0068 | 0.0060 |
| (5) | 0.0035 | 0.0075 | 0.0072 | 0.0066 | 0.0050 |
| (6) | 0.0032 | 0.0082 | 0.0057 | 0.0053 | 0.0056 |
| (7) | 0.0031 | 0.0079 | 0.0086 | 0.0037 | 0.0025 |
| (8) | 0.0059 | 0.0088 | 0.0083 | 0.0078 | 0.0061 |
| (9) | 0.0081 | 0.0140 | 0.0123 | 0.0132 | 0.0147 |
| (10) | 0.0049 | 0.0125 | 0.0113 | 0.0091 | 0.0104 |
| (11) | 0.0066 | 0.0114 | 0.0098 | 0.0096 | 0.0102 |
| (12) | 0.0066 | 0.0127 | 0.0102 | 0.0098 | 0.0095 |
| (13) | 0.0085 | 0.0092 | 0.0104 | 0.0094 | 0.0090 |
| (14) | 0.0076 | 0.0163 | 0.0152 | 0.0131 | 0.0100 |
| Image | MSE of Our Result | MSE of the Result of Lu’s Algorithm |
|---|---|---|
| (1) | 0.0081 | 0.0231 |
| (2) | 0.0049 | 0.0267 |
| (3) | 0.0066 | 0.0259 |
| (4) | 0.0066 | 0.0266 |
| (5) | 0.0085 | 0.0279 |
| (6) | 0.0076 | 0.0307 |
| Image | MSE of Our Result | MSE of the Result of Zeng’s Algorithm When the Parameter “Line width” Is Set to | ||
|---|---|---|---|---|
| 9 | 13 | 17 | ||
| (1) | 0.0081 | 0.0141 | 0.0120 | 0.0131 |
| (2) | 0.0049 | 0.0113 | 0.0079 | 0.0082 |
| (3) | 0.0066 | 0.0090 | 0.0103 | 0.0113 |
| (4) | 0.0066 | 0.0078 | 0.0098 | 0.0093 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, L.; Zhu, H.; Dong, J.; Ju, Y.; Zhou, H. Three-Dimensional Reconstruction with a Laser Line Based on Image In-Painting and Multi-Spectral Photometric Stereo. Sensors 2021, 21, 2131. https://doi.org/10.3390/s21062131
Lu L, Zhu H, Dong J, Ju Y, Zhou H. Three-Dimensional Reconstruction with a Laser Line Based on Image In-Painting and Multi-Spectral Photometric Stereo. Sensors. 2021; 21(6):2131. https://doi.org/10.3390/s21062131
Chicago/Turabian StyleLu, Liang, Hongbao Zhu, Junyu Dong, Yakun Ju, and Huiyu Zhou. 2021. "Three-Dimensional Reconstruction with a Laser Line Based on Image In-Painting and Multi-Spectral Photometric Stereo" Sensors 21, no. 6: 2131. https://doi.org/10.3390/s21062131
APA StyleLu, L., Zhu, H., Dong, J., Ju, Y., & Zhou, H. (2021). Three-Dimensional Reconstruction with a Laser Line Based on Image In-Painting and Multi-Spectral Photometric Stereo. Sensors, 21(6), 2131. https://doi.org/10.3390/s21062131