1. Introduction
In the past, the technology and algorithm of hardware has not been well developed. Related work about facial reconstruction and recognition are mainly based on 2D image processing. In recent years, developments in neural networks and statistics have greatly influenced the field of computer vision. Benefitting from mature techniques and lower costs of computers, fast computing speed is no longer leaving researchers in the dust. Therefore, the applications of 3D point cloud are broadly used in object detection [
1,
2,
3], reconstruction [
4,
5] and recognition [
6,
7].
As the rapid development of artificial intelligence (AI) and the internet of things (IoT), personal privacy is getting a lot of discussion. In recent years, researchers have studied intensively on protecting personal data facilitatively. Furthermore, the most relevant issue is facial analysis, which can be applied to facial recognition for high security systems [
8,
9,
10], health care [
11,
12], law enforcement [
13,
14], etc. Recently, 3D face reconstruction has been a major trend and challenging work in computer vision field, which provides comprehensive face geometry and invariant to illumination compared with 2D imaging. However, previous works [
15,
16,
17,
18] show that 3D face reconstruction approaches are mainly based on 2D images, for example, shape from motion (SFM) [
19], shape from shading (SFS) [
20], multi-view geometry [
18], etc. In addition, these strategies may require complicated instrument establishing, which is time consuming, and the accuracy of reconstruction models are often affected by illumination variations. S. Zhang et al. [
21] proposed a method that reconstructed dense 3D face point clouds by applying a radial basis function (RBF) with a single depth image of Kinect data. The first stage aligned the depth data with RGB image. Then, detecting facial region by using the Haar Cascade Classifier [
22], the raw face point cloud can be obtained. To acquire more accurate face point cloud, the second stage applied K-means clustering [
23] to divide the clusters into facial regions and others. After that, the authors employed k Dimensional-tree (kD-tree) to find the neighborship and distance between points to perform interpolation based on RBF. The result [
21] shows that the number of points is ten times denser than the initial point cloud. However, the accuracy might be affected by facial orientation when performing facial recognition because only a single frame is taken. In this paper, we present an algorithm that reconstructs the whole head point cloud from multi-view geometry. Not only are the ears preserved, but insignificant parts like shoulders are removed. The procedures are done without any RGB information, which verify the feasibility of 3D face reconstruction/recognition in a low-light environment or a fully dark situation.
A 3D point cloud is composed of several points in a three-dimensional space which represents the shape and surface of an object. Moreover, features such as curvature and normal are also included. Point clouds can be acquired directly from a stereo camera, laser scanner or light detection and ranging (LiDAR). Nowadays, the research and related algorithm of 3D point cloud processing are trending issues, since data acquisition is no longer difficult. As autonomous cars are increasingly driving on the road, safety is the most concerned topic for drivers. Building a reliable vehicle to satisfy customers, multiple sensors such as LiDAR and cameras are necessary to be equipped and several modules based on these devices must be integrated. The related sensing algorithms such as object detection and environment perception are bound up with 3D point clouds. In regard to [
24], the authors reviewed the techniques used in autonomous car for point cloud processing, including the overview of map creation, localization and perception modules. To integrate these modules for security, 3D point cloud learning such as reconstruction, classification and segmentation are elementary tasks to deal with.
In the study of point cloud pre-processing techniques, feature extraction is the most significant process which help us to detect certain types of points with different information. Fast point feature histogram (FPFH), which is a descriptor that can represent features of local area, was proposed by Rusu, et al. [
25]. Given a point cloud, then searching k-nearest neighbors (kNN) in the sphere with a selected radius for each point. The surface normal can be estimated between the point pairs. Point feature histogram (PFH) at a query point is related to its neighbors and the normal of surrounding points. Considering the angular variation of point pairs, local features can be described by using PFH. However, this approach may be very time-consuming.
While performing facial feature extraction, normal and curvature will be the essential concepts to analyze a 3D point cloud set. Principal component analysis (PCA) is the most commonly used method and is simple to realize [
26]. The dimensionality may be quite high when dealing with a massive dataset. PCA is also a dimension-reducing approach that simplifies the data by reducing the number of less important variables. Moreover, information of the original dataset can still be hold by its covariance matrix. The concept of PCA can not only be used in 2D images, but it also be extended to extract 3D point cloud features by computing the eigenvalues and eigenvectors of the covariance matrix [
27]. In this paper, the PCA is applied for extracting features from a face point cloud to measure similarity and detect the position of important parts of the face, e.g., nose tip and eyes, which possess higher variations of curvature.
As mentioned above, the applications of 3D face recognition have developed rapidly in our life. The advantages of face recognition with an additional dimension can be summarized [
28]: (a) invariant to illumination, pose, viewpoint; and (b) potential for higher recognition accuracy because the features such as normal and curvature on faces are better described rather than a 2D image. According to the type of facial point cloud matching strategies, there are several categories.
Spatial geometry approach: Nunes et al. [
29] performed face recognition by using a face curvature map (FCM) and experimenting with the VAP RGB-D Face Database. Projecting the 3D point cloud data on 2D image and representing features such as normal and curvature index with different colors. The similarity determination is done by FCM histogram matching. Medioni et al. [
30] acquired 3D facial shapes from passive stereo sensor that recovered depth information with mesh of triangles. Then, they performed face recognition using ICP to match the face surface. However, the system set-up needs a large working envelope and requires two calibrated cameras, which is too complicated to implement.
Deep learning approach: Jhuang et al. [
31] experimented with Kinect and estimated normal and curvature of face point cloud by using the Point Cloud Library (PCL). The PCL is an open-source library for point cloud processing, including filtering, registration, model fitting, object segmentation, etc. After that, a deep belief network (DBN) with 800 training epochs is adopted to train these extracted features. Finally, the pre-trained model is used to identify whether the input face point cloud feature is same person. The experiment proved that the accuracy might decrease with the increment of hidden layers. However, this approach poses a heavy loading of computation and a huge training dataset is needed.
Local features approach: Lee et al. [
32] performed face recognition using curvature at eight feature points on face. Calculating the relationship of distances and angles between these points, that is, relative features. In the recognition stage, a feature-based support vector machine (SVM) is applied for classification. However, the paper didn’t mention how the feature points are detected. In other words, the points were probably located manually.
In this paper, we present a complete procedure from the very front data acquisition to the face point cloud reconstruction, and finally apply the untrained 3D point cloud data to facial recognition. Briefly, a robust stitching method for multi-view face point cloud reconstruction is applied to rebuild a much denser 3D face point cloud with high-density, numerous-feature points. The reconstruction models are taken as reference models. Next, certain feature extractions, as well as a similarity score, are used to recognize whether the input 3D point cloud is the most similar as one of the models in database. The algorithm presented in this paper is to verify the feasibility of 3D face reconstruction and recognition, which is applied for some specific fields such as our laboratory and office. Hence, we collect our own data set with total 1412 frames in the testing phase. The result shows that the algorithm is competitive with a processing time of less than 0.23 s and a high accuracy of almost 100%. Besides, all algorithms are implemented with low-cost devices. The CPU of the device is i7-6700HQ. Any GPU capacity and complicated deep learning algorithm was not applied. The main contributions of this work include: (a) ROI confinement techniques for precise head segmentation by K-means clustering; (b) computing efficiently and alignment skills for multi-view point clouds registration by ICP; (c) simple method to detect outliers by DBSCAN and face feature extraction; and (d) a novel face registration similarity score is presented to evaluate 3D face point cloud recognition.
2. 3D Point Cloud Preprocessing
To self-contain this work, in this section, numerous fundamental algorithms will be illustrated briefly. The well-known Microsoft Kinect v2 is employed to acquire the body point cloud from different views. The multi-view 3D point clouds are going to rebuild a high-density model. Point cloud registration using ICP plays an important role in reducing the deviation of distance between point clouds. In addition, approaches for feature extraction, segmentation and denoising will also be introduced.
2.1. Principal Component Analysis (PCA)
As previously mentioned, feature extraction is the significant process when dealing with massive data. PCA [
26,
27] is a dimension-reducing approach that simplifies the data by reducing the number of variables. The number of features in data is regarded as the dimensionality of point set. Extracting important components from the features, that is, reducing the dimensionality which make the composition of data not too complex and convenient to analyze.
The main concept of PCA is to find a vector in feature space that the largest variance of data can be acquired through orthogonal projection. The projected data in lower dimensions still preserve the information which is held by the original data. The features such as normal and curvature can be obtained by calculating the eigenvalue and eigenvector of covariance matrix in the point set.
Let
be point set with value of X, Y and Z in 3D space, the mean is represented as:
Then, a 3-by-3 covariance matrix can be calculated as:
Based on the symmetric property of Equation (2), the covariance matrix can be further rewritten as:
where
is an orthogonal matrix which is composed of eigenvectors,
is a diagonal matrix which is consisted of eigenvalues.
Moreover,
can be represented as follows:
where the components in Equation (4) are eigenvalues satisfying
.
The eigenvectors of covariance matrix are principal directions that are mutually orthogonal. Besides, the principal curvature which is associated with the first principal component will be applied in the later sections. It can be defined as:
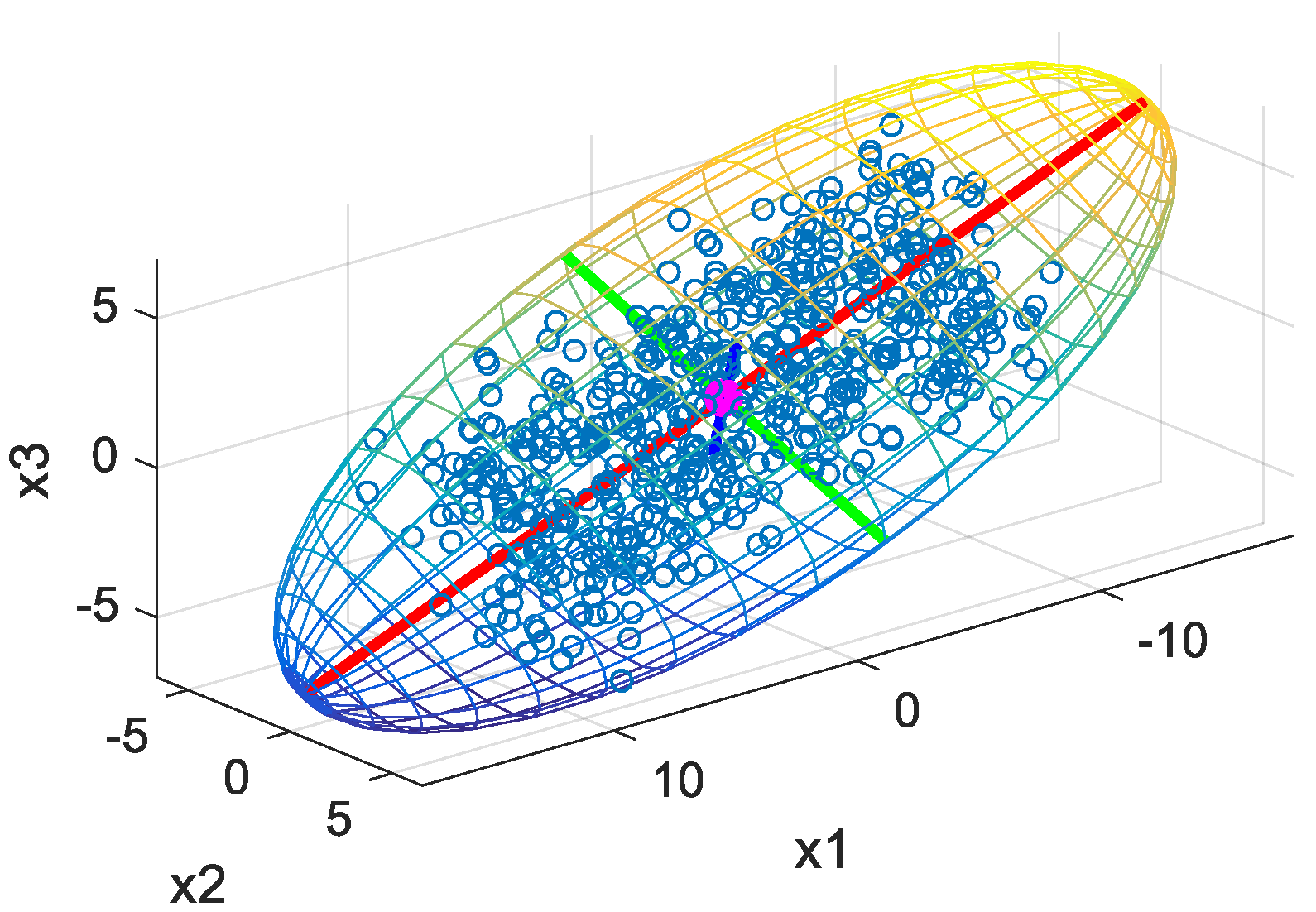
Given a 3D point cloud data set, the first principal component corresponds to the orientation of greatest variance as the red line shown in
Figure 1. The green and blue lines are associated with second and third principal component, respectively.
2.2. k-Nearest Neighbor (kNN)
In this paper, the kNN algorithm [
33] is used to search the k-nearest points of every point in a model set to predict the relationship between model set and data set for point cloud registration or in itself to perform PCA. It is a straightforward approach that is simple to implement.
To achieve the goal of classification by using kNN, a kD-tree [
34] needs to be built in advance for the purpose of reducing nearest neighbor searching time. A kD-tree is a binary search tree in
dimensional space which divides the data into subsets. While the process can hardly be interpreted in 3D space. However, the rule of classification and kD-tree construction in 2D space is obvious to realize. Assume that there are seven points
as shown in
Figure 2a. The request is inserting a query point
to find its nearest neighbor. According to the rules of kD-tree construction, each node in
Figure 2b divides the points with maximum invariance.
Following these rules, the nearest neighbors, that is, closest points near a query point can be found. The searching computation time is remarkably reduced due to the characteristic of binary space partitioning. In addition, the kNN algorithm can be implemented rapidly.
2.3. Iterative Closest Point (ICP)
In this paper, ICP [
34] is the most significant algorithm which is applied for facial point cloud reconstruction and recognition. While performing facial reconstruction, ICP is used to make the surface of point clouds stitched to each other. Besides, while performing face recognition, the angle of view of face point cloud need to be considered. The accuracy may not be desirable without point cloud registration. Therefore, ICP algorithm plays an important role in point cloud preprocessing.
The aim of ICP algorithm is to best align the point set through spatial transformation, that is, point cloud registration shown in
Figure 3. Regarding the point set as rigid body, ICP minimizes the Euclidean distance between the two point clouds through iterations. Precise registration is achieved through ICP. In this study, only the head part point clouds will be considered from the whole frame, since the point clouds are going to be segmented by pre-processing. As a result, the size of the point cloud can be reduced dramatically and therefore the computation loading is affordable.
In 3D space, there are six degrees of freedom, including three-axis translations and three-axis rotations, respectively. The objective function according to the goal of ICP algorithm mentioned above can be defined as:
where
is data set and
is model set. The transformation pair,
and
are rotation matrix and translation vector, respectively. However, outliers may lead to the failure of point cloud registration. Weights for each pair
is considered in Equation (6) to avoid the effect caused by outliers. It can be defined as:
where
is the distance between point pair of nearest neighbor and
is maximum distance in the whole point pairs.
Equation (7) illustrates that weight approaches 0 while the distance between point pair is large. Otherwise, it approaches 1. Outliers and inliers can be more clearly distinguished during ICP iterations by applying the concept of weighting.
The centroids of the two point cloud sets are computed as follows:
The optimal translation vector is computed as:
Let
and
. Taking Equation (9) into Equation (6) and substituting
and
into
and
, the objective function can be rearranged as:
Let
, the middle term in Equation (10) become
. Applying the singular value decomposition (SVD) on
yields
where
is diagonal matrix. The optimal rotation matrix is selected as:
The optimal transformation pair, and is solved based on Equations (9) and (12), respectively.
2.4. K-Means Clustering
K-means clustering [
23] is an unsupervised learning algorithm which the clusters are based on data without ground truth. The point cloud can be partitioned into parts by using this approach. Given
points and
clusters, then
centroids will be randomly selected. Computing the Euclidean distances between every point and centroid to initially determine every point belongs to the nearest cluster which possess the minimum distance between the centroid. Moreover, the centroids are not fixed. The goal of K-means clustering is to minimize sum of square difference of distance between points and centroids in each group. The objective function can be written as:
where
are group centroids,
are points in the dataset, and
are the associated designated groups.
In this paper, a K-means clustering algorithm is applied to segment the upper body point cloud into head and other parts. The detailed processing technique will be introduced in the next section.
2.5. Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
DBSCAN [
35] is also a clustering algorithm which is based on density. However, different from K-means clustering, DBSCAN doesn’t need to specify quantity of clusters in advance and outliers can be distinguished. In addition, the clusters can be any shape.
There are two parameters that need to be specified, the radius of neighborhood, and the minimum number of points, . The clustering algorithm can be summarized as follows:
Expand a circle with radius
at every point. If the number of points more than
are included in the circle, define the centroid as core point and form a cluster as the blue points shown in
Figure 4;
If the number of points less than
are included in the circle but another core point is reachable, the centroid will still be involved in a cluster. The centroid is defined as edge point. For example, the green points shown in
Figure 4;
If there are no points in the circle except for itself as the red points shown in
Figure 4. The points are defined as outliers.
In this paper, the DBSCAN is applied to remove outliers. The detailed processing technique will be introduced in the next section.
3. 3D Face Point Cloud Reconstruction
In regard to 3D point cloud acquisition, the Microsoft Kinect v2 is set up in our laboratory with indoor and normal light environment. Since any RGB information of the image is not used, the point clouds acquired from depth sensor will not be affected even in dark environments. Lightning is not a problem for data acquisition. The only thing that one needs to be careful about is that the depth sensor should not be irradiated by sun illumination directly because the sensor may not work, and a large part of point cloud will be lost.
The illustration of the initial configuration and setup of Microsoft Kinect v2 is shown in
Figure 5. The distance between model and sensor is approximately 90 cm and the associated density of point cloud is optimal via test. It is recommended that the average distance between points in the point cloud should not exceed 2 mm. Most of the texture such as the eyes, nose and mouth can be clearly revealed. If the model is too close to the sensor, due to the limit of the field of view (FOV) of the depth sensor, the face point may not be collected properly. On the contrary, if the model is placed too far from the depth sensor, sparse point cloud will be obtained, in which the point cloud may not describes the face detail texture clearly.
For all the test members taken as the data base, multi-view face point clouds are going to reconstruct a denser model set first. For a single test member, there are five total point clouds needed; the front view, turn left 30 degrees, turn left 60 degrees, turn right 30 degrees and turn right 60 degrees relative to the depth camera, respectively. An example illustration of the model data set collection is shown in
Figure 6. To simplify naming confusion of point cloud, let A be the point cloud corresponding to
Figure 6a, B be the point cloud corresponding to
Figure 6b, and so on. These abbreviations will be used in
Section 3.2.
The reconstruction technique can be divided into three parts; head segmentation, point cloud registration and denoising.
3.1. Head Segmentation
Since the point cloud not only contains face model we need, certain background objects within the range of 5 m [
36] in front of depth camera are also included. Thus, establishing a region of interest (ROI) is necessary to focus on the model processing and to remove meaningless background objects. According to the initial configuration shown in
Figure 5, preliminary filtering can be applied by using the intrinsic function in MATLAB based on [
37], the function “pcdenoise”. The function is applied for the point cloud noise removal after initially acquiring the data set. There are two parameters needing to be specified; the number of nearest neighbor points and the outlier threshold. The first one evaluates the mean of average distance between all points and specified number of nearest points. The second parameter specifies the standard deviation from mean average distance to neighbors of all points. Once the mean distance from a query point to its neighbors is larger than the threshold, it is considered an outlier. Removing the outliers and a lower-noise point cloud can be acquired, which is enough for the following point cloud processing such as 3D face reconstruction and recognition. The preliminary filtering result is shown below.
Figure 7 shows the ROI point cloud before and after noise removal. It is obvious that most of the sparse outliers can be removed.
Because the dimension of the head may be different for every test member, it is hard to set a fixed ROI, which may include unnecessary parts such as the neck, arm and chest, when applying the head segmentation directly. Therefore, a further precise head segmentation is needed.
First, in order to achieve the precise head segmentation, refining a ROI which confines a smaller region is needed. Note that the ROI has a longer length in the Z axis and symmetry in the X axis and Y axis to prepare for precise segmentation through the K-means algorithm later. Regarding the determination of the ROI, the mean values of X and Y coordinate in ROI point cloud is calculated. Next, extending 12 cm back-and-forth and left-and-right with respect to the mean, as the blue and white lines shown in
Figure 8a,b, respectively. After that, the region of 5 cm from top of the point cloud is excluded to preserve the face without hair. Finally, the region with 35 cm height from the forehead is preserved.
Figure 8 gives the complete illustration of rough segmentation as mentioned above. Later, K-means clustering is applied for further precise head segmentation.
Based on the rough segmentation completed, K-means clustering is ready for further precise head segmentation. Referring to
Figure 8a,b, it evidently shows that there is an obvious gap between the chin and neck. Besides, according to the shape, narrow region along X and Y direction and longer length along Z direction bounded by the red bounding box in
Figure 8, which means that head can be simply segmented with two clusters implemented by K-means clustering.
Figure 9 demonstrates the results of precise head segmentation and verifies that the presented segmentation algorithm described in
Section 3.1 is suitable even for different people. Head can be simply segmented with setting two clusters for K-means clustering because it is applicable to the human body contour. The point cloud marked in red and green is the result of implementing K-means clustering.
Next, the clusters marked in red are going to be discarded and then the complete head point clouds can be extracted accordingly. These four models are then further used for 3D face reconstruction as presented in
Section 3.2.
3.2. Point Cloud Registration
To integrate the segmented point cloud into a complete face point cloud, the ICP algorithm is used for multi-view point clouds registration. Note that the given two point cloud sets without initial alignment may diverge during iteration because the distance between two point cloud sets is too far, which leads to the failure of nearest neighbor searching. The alignment technique will be introduced later.
Therefore, we detect the nose tip of A, B, D point cloud in
Figure 6 by using shape index with curvature. According to [
38], shape index is used to determine the shape of a 3D object. The shape index at a point
can be defined as:
where
is the principal curvature as shown in Equation (5) and
is the third curvature which is associated with the third principal component, it can be written as:
Based on the definition of shape index in Equation (14), it can represent the local shape of an object continuously between concave and convex. The shape index is larger while the local shape is similar to a dome or spherical cap. Therefore, nose tip is the point with the larger value of shape index, shown as the red points shown in
Figure 10.
The angle of rotation of C and E point cloud in
Figure 6 is larger so that the nose tip may not be involved. However, we detect the point with maximum or minimum value along X direction, as the red points shown in
Figure 11.
After reference points for initial alignment are found, four times ICP registration is to be performed. The alignment techniques and matching steps are summarized as:
First matching the front-view point cloud (A point cloud) with B point cloud in
Figure 6b. Transforming B’s nose tip to the same position as A’s nose tip for initial alignment. Let it be Recon 1 Cloud after performing ICP. The result of registration and deviation are shown as
Figure 12.
Detecting the point with minimum value along X direction in Recon 1 Cloud and translating the point found in
Figure 11a to the same position as this point for initial alignment. Let it be Recon 2 Cloud after performing ICP. The result of registration and deviation are shown in
Figure 13.
So far, the reconstruction of the left half of the face is completed. The reconstruction approach is same for the right half of the face. Detecting the nose tip in Recon 2 Cloud, then translating D’s nose tip to the location same as this point for initial alignment. Let it be Recon 3 Cloud after performing ICP. The result of registration and deviation are shown in
Figure 14. However, the deviation is larger as shown in
Figure 14b, which may be affected by the sparser distribution of points and more outliers in the right face.
Translating the point found in
Figure 11b to the same position as the point with the maximum value along X direction in Recon 3 Cloud for initial alignment. Then, let it be the Recon 4 Cloud after performing ICP. The result of registration and deviation are shown in
Figure 15.
The techniques of 3D facial point cloud reconstruction have been illustrated above in detail. However, the growing outliers may lead to misclassification while performing face recognition. As a consequence, point cloud denoising is necessary to remove the outliers. Related processing will be introduced in
Section 3.3.
3.3. Point Cloud Denoising
Since the reconstructed model contains many outliers as shown in
Figure 15a, the aforementioned DBSCAN is used for noise removal. Regarding outlier removal, the trick is, only the X-Z plane information is adopted. It is the projection of the Recon 4 Cloud onto the X-Z plane. Apply DBSCAN algorithm to this 2D point cloud. The result is shown in
Figure 16, where the red point clouds are going to be discarded and the green ones are going to be preserved. By applying the same procedure, the final face point cloud reconstruction of all the models are shown in
Figure 17.
The models are reconstructed from five multi-view point clouds, namely, the models shown in
Figure 17 in this paper are still point clouds but not mesh. To statistically analyze the point clouds before and after reconstruction, the nearest neighbor search is applied to compute average distance of the point clouds. Taking the average of sum of the distance between each point and its nearest neighbor, average distance can be acquired. It can be represented as:
where
is the number of points and
is the minimum distance between point pair of nearest neighbor.
The comparison between original point cloud and reconstruction model is tabulated in
Table 1. It shows that the average distance between each point and its nearest neighbor is lower between and after reconstruction. The denser the point cloud, the more features can provide. The textures can also be present clearly with dense reconstruction model.
These reconstruction models displayed in
Figure 17 will be taken as the model set in database. The complete flowchart of face reconstruction and recognition is summarized as in
Figure 18.
Among the part of 3D point cloud facial reconstruction, the preprocessing steps from the very beginning can be summarized as the blue block diagram at the left block shown in
Figure 19. The registration steps are shown in the orange block diagram on the upper right block of
Figure 19. The reconstruction point cloud denoising steps are shown in the green block diagram at the lower right part of
Figure 19.
The reconstruction point clouds will be taken as models in database for face recognition. Calculating the similarity score of the data set from current shot and comparing it with each model set in the database will be the next milestone. The most similar candidates can be chosen after comparing the scores. The similarity score and criterion for 3D face recognition will be introduced in the next section.
5. Experiment Verification
The five frames {A, B, C, D, E} in
Section 3 are acquired in multi-view geometry, which is applied for model point cloud reconstruction only. The reconstruction point cloud in
Figure 17 will be taken as model 1–4 in database. The schematic illustration is shown in
Figure 20.
However, this section illustrates the experimental verification to test the feasibility of 3D face recognition, which is applied for some specific fields such as our laboratory and office for security purpose. To simplify naming confusion, models in database are named as Model 1–4 and the testing point clouds for 3D face recognition are named as Member 1–6. The schematic illustration is shown in
Figure 21.
To test the feasibility of recognition using similarity score, we acquired plenty of data sets to perform 3D facial recognition. Among the Member point cloud, Member 1–4 correspond to the same person as Model 1–4. In the testing phase, each frame of the Member point cloud will be registered with Models 1–4 and a similarity score with every Model is evaluated. In addition, to test whether the member not in database can still be classified or not, there are Member 5 and Member 6 not in database as shown in
Figure 22, which have 280 and 237 frames, respectively. Each frame of Members 5–6 will also be registered with Models 1–4 and similarity score with every Model is evaluated.
The quantity of data set is tabulated in
Table 2 so that it’s easier to understand. There are total of 1412 frames in data set to test the feasibility of 3D face recognition using similarity score.
To simulate the situation of 3D facial recognition on smart devices and to challenge whether the 3D point cloud face recognition are robust against pose and rotation or not, the rotation range
in roll/pitch angles is considered, which is illustrated in
Figure 23. Indeed, the facial similarity score will be the highest if the face is facing the sensor without obvious rotations. However, the presented 3D facial recognition can still work properly with
in roll/pitch angles owing to the feature aligned ICP registration. Related experiments demonstrate that even in the presence of facial rotations, the developed face recognition algorithm can also provide good accuracy.
Taking each data set as input, calculating the face similarity score mentioned in
Section 4.2 with every model set in database. The criteria for facial point cloud recognition are listed as follows:
Identify as the same person if face similarity score with data set from current shot and one of model set in database is greater than 80, namely, ;
If a data set from the current shot has face similarity score larger 80 with more than two model set, identifying the model with highest score, which means the most similar model in the database;
Otherwise, none of the models will be identified if the data set from the current shot has a face similarity score less than 80 with every model set.
The criteria above are inductions according to our experiment. In the experiment, we found that curvature is the most important parameter which reveals the difference between the data set and model set. In addition, the recognition similarity score helps us widen the difference in highest score and second highest score. Thus, we define the values of each parameter in similarity score are:
The result of 3D face recognition and processing time is shown in
Figure 24.
Figure 24a–d shows the accuracy between Member 1 to Member 4 and every model set. There are 12 frames of Member 1 recognized as none, which the face similarity score is less than 80. The accuracy is 94.03%. Every data set of Member 2 is recognized as Model 2, the accuracy is 100%. In
Figure 24c, there are 19 frames of Member 3 recognized as none, the accuracy is 90.95%. Besides, only one frame of Member 4 is misclassified as none, the accuracy is 99.49%. In addition, the average processing time is also computed and displayed on the title. The similarity score can be evaluated within less than 0.23 s with the algorithm presented in this paper.
The result of 3D face recognition with members not in database is shown in
Figure 25.
Figure 25c,d show the experiment with the member not in the database. It is evident that none of Member 5 and Member 6 is classified as model because none of the face similarity score of data set is greater than 80. Members not in the database are not misclassified and thereby the examination accuracy is 100%.
According to the result of 3D face recognition and processing time as shown in
Figure 24 and
Figure 25, it proves that the algorithm is competitive with fast computation and high accuracy.
Table 3 summarize the relationship between model, frames of member and accuracy.































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}