
A Two-Stage Data Association Approach for 3D Multi-Object Tracking



Abstract
:1. Introduction
- ID switches (IDS): the number of times tracks are associated with wrong detections;
- False Positives (FP): the number of times real objects are missed detected;
- False Negatives (FN): the number of times the tracking algorithm reports tracks in places where there are no real objects present.
- Our main contribution is the adaptation of an image-based tracking method to the 3D setting. In details, we exploit a kinematically feasible motion model, which is unavailable in 2D, to facilitate the prediction of objects’ poses. This motion model defines the minimal state vector needed to be tracked.
- Extensive experiment carried out in various datasets proves the effectiveness of our approach. In fact, our better performance, compared to AB3DMOT-style models, show that adding a certain degree of re-identification can improve the tracking performance while keeping the added complexity to the minimum.
- Our implementation is available at https://github.com/quan-dao/track_with_confidence accessed on 21 April 2021.
2. Related Work
3. Method
3.1. Problem Formulation
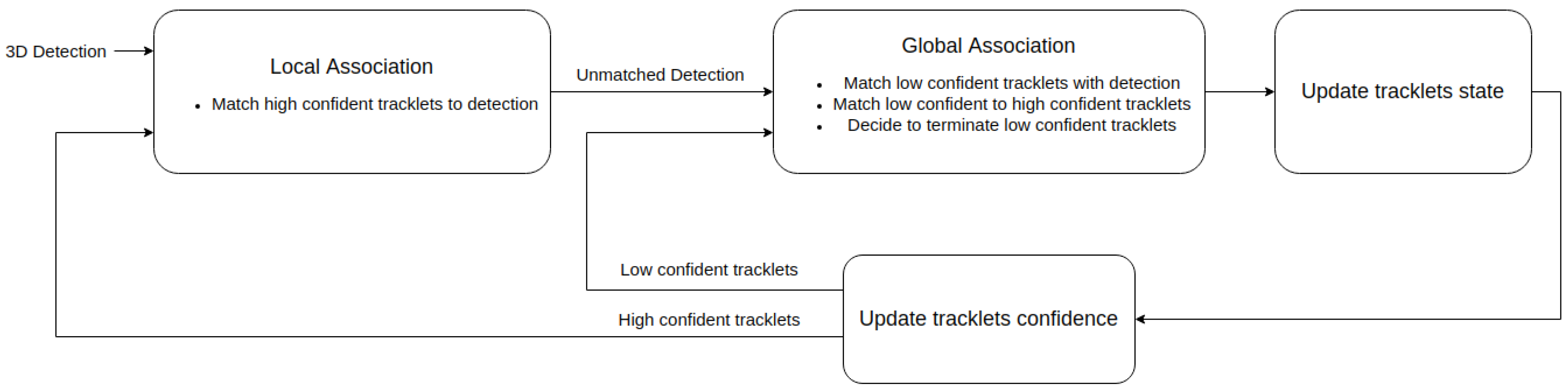
3.2. Two-Stage Data Association
3.2.1. Tracklet Confidence Score
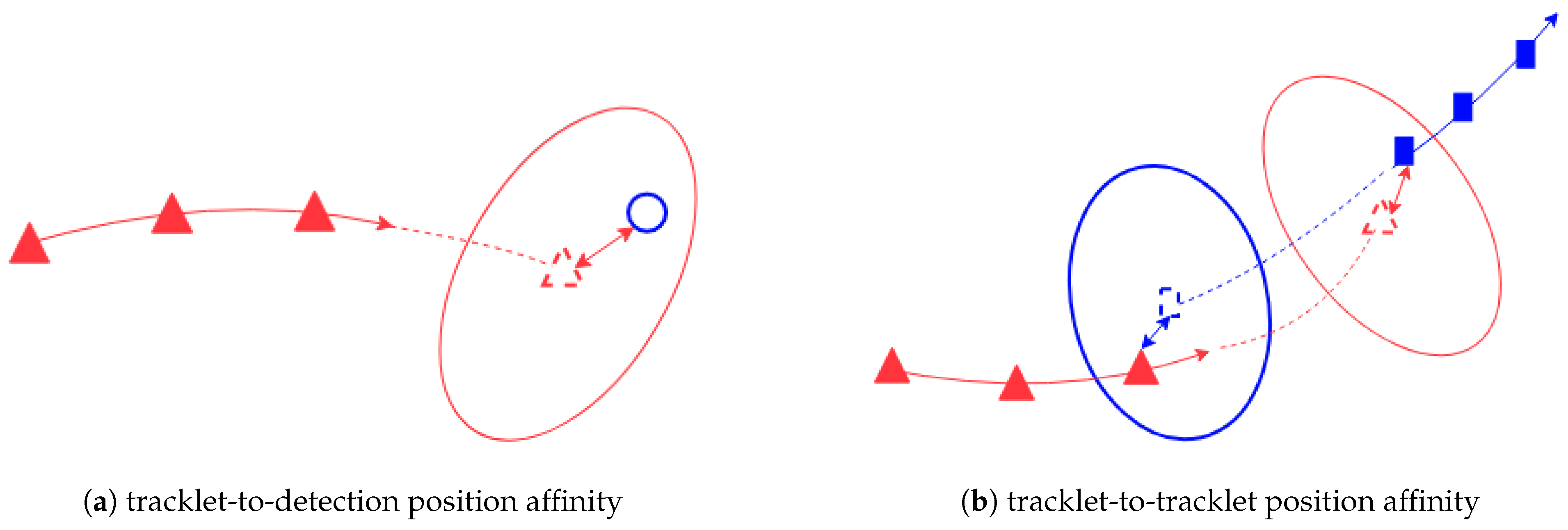
3.2.2. Affinity Function
- Mahalanobis distance between the last state of propagated forward in time and the first state of ;
- Mahalanobis distance between the first state of propagated backward in time and the last state of .
3.2.3. Local Association
3.2.4. Global Association
- Matching low-confident tracklets with high-confident ones;
- Matching low-confident tracklets with detections left over by the local association stage;
- Deciding to terminate low-confident tracklets.
3.3. Motion Model and State Vector
3.4. Complexity Analysis
| Algorithm 1: Greedy algorithm for solving LAP |
 |
4. Experiments
4.1. Tuning the Hyper Parameters
- Performs a coarse grid search with the expected percentile of distribution in the set which means the value of is in the set , while keeping the rest of hyper parameters unchanged. Please note that here the value of the threshold is just half of the corresponding value in Distribution Table. This is because the motion affinity is scaled by half in our implementation to reduce its dominance over the size affinity.
- Once a performance peak is identified at , a fine grid search is performed on the set
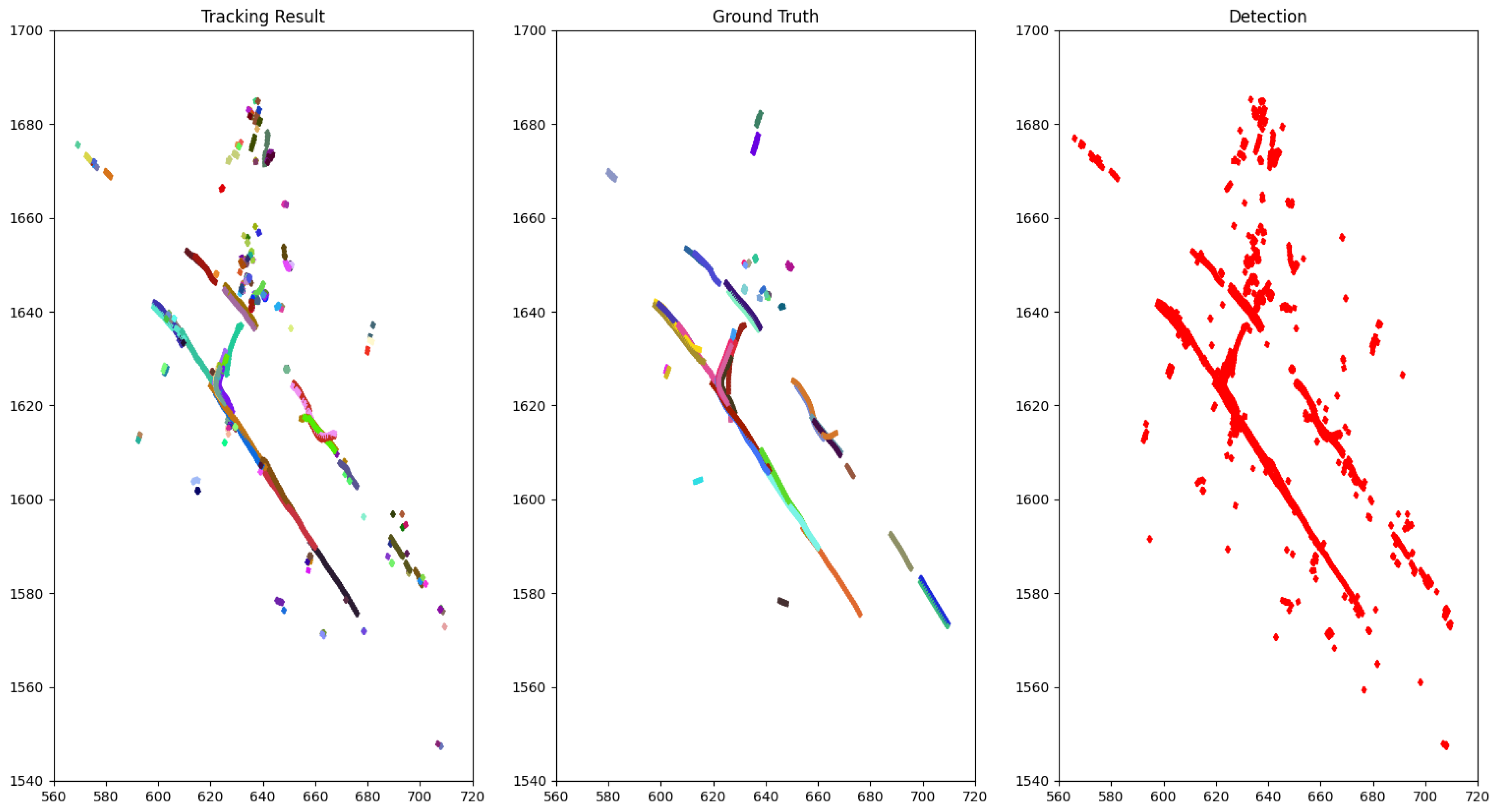
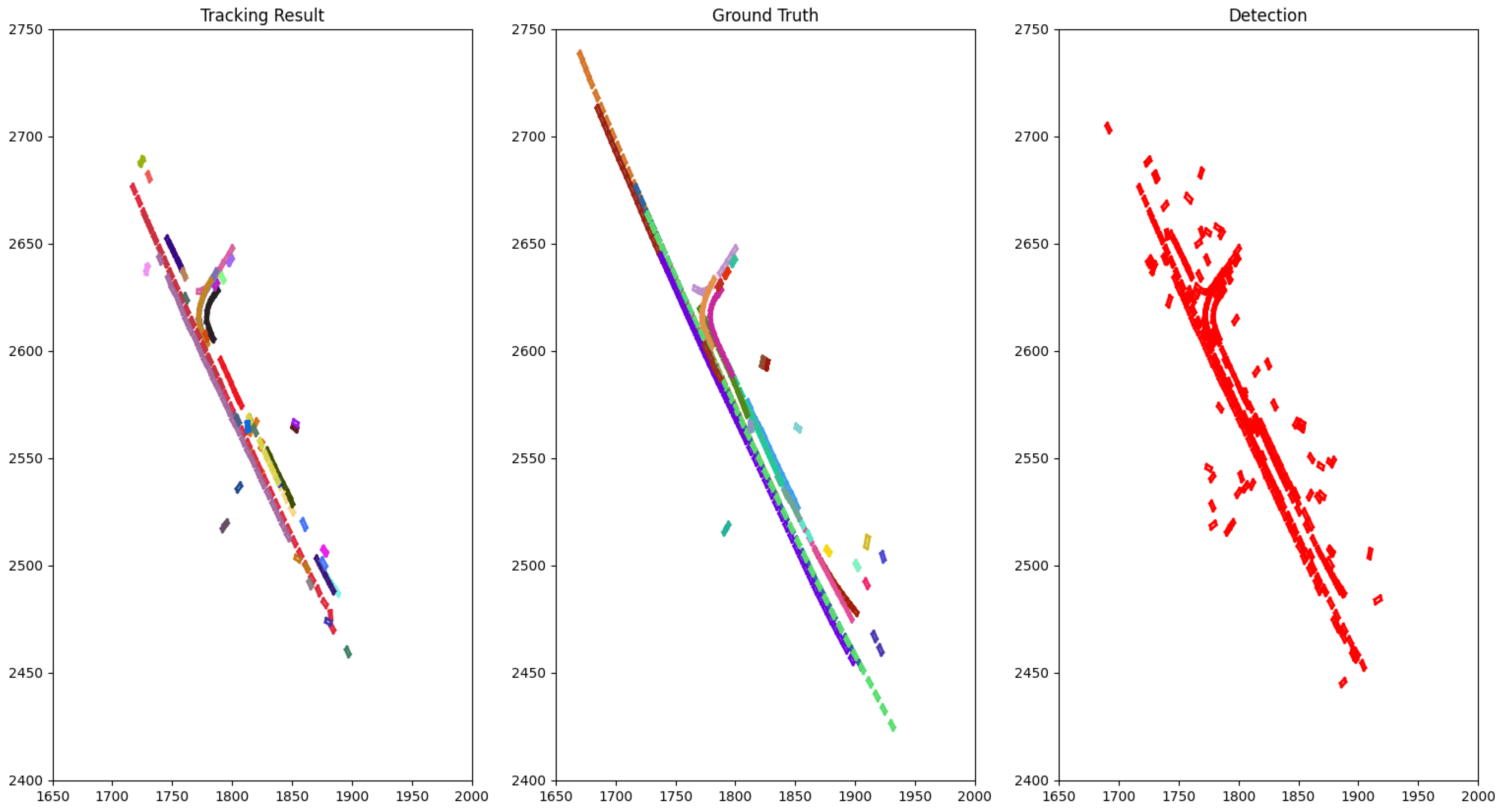
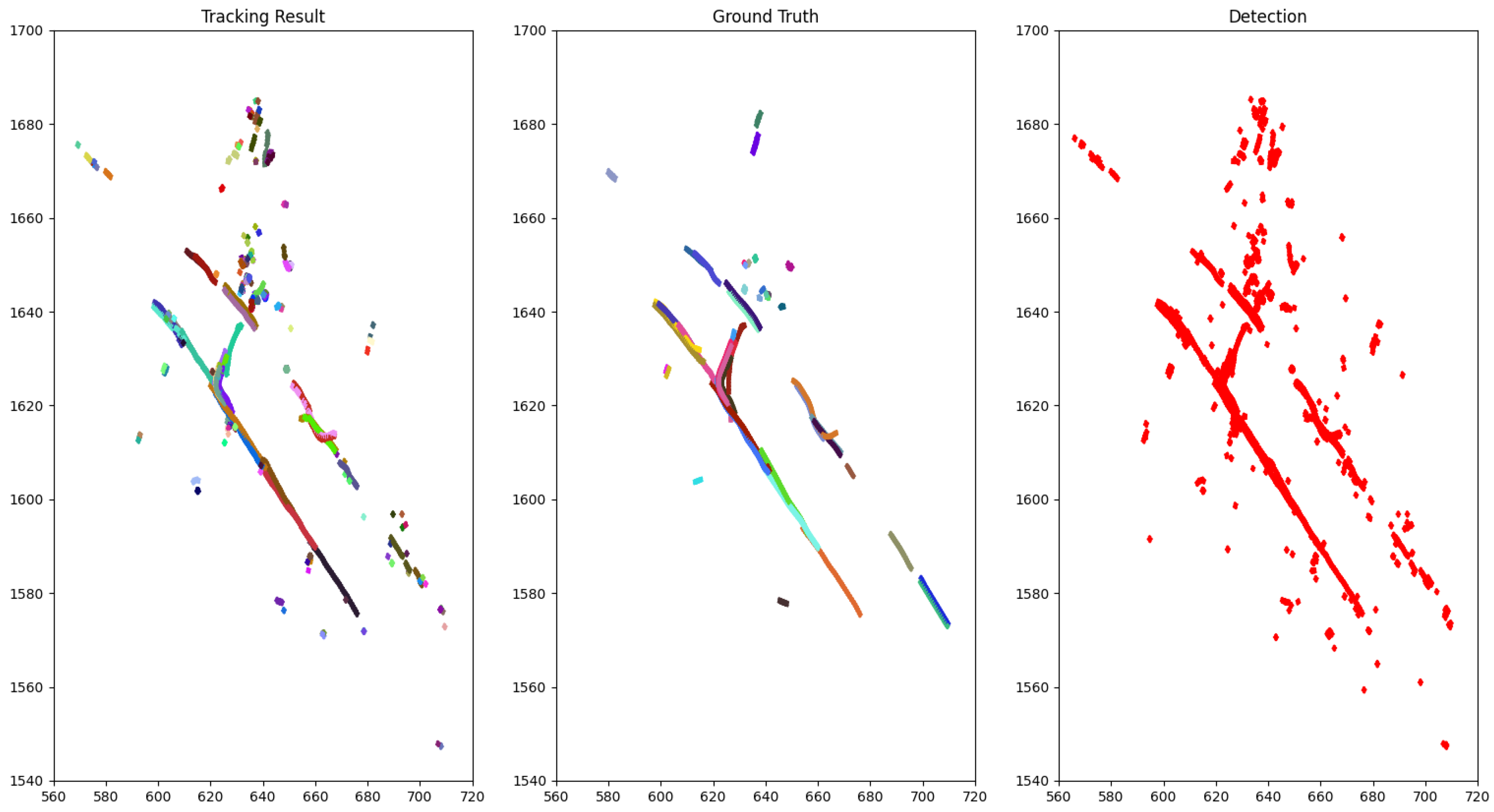
4.2. Tracking Results
4.3. Ablation Study
- Two stages of data association (local and global). Each stage is formulated as a LAP and solved by a greedy matching algorithm [15].
- The affinity function the sum of position affinity and size affinity (as in Equation (4)).
- The motion model is Constant Turning Rate and Velocity (CTRV) for car-like objects (cars, buses, trucks, trailers, bicycles) and Constant Veloctiy (CV) for pedestrians.
- As mentioned in Section 4.1, the value of hyperparameters are set as follows: (in Equation (3)), tracklet confidence threshold , and the affinity threshold (in Equation (11))
5. Conclusions and Perspectives
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| MOT | Multi-Object Tracking |
| IoU | Intersection over Union |
| LAP | Linear Assignment Problem |
| CTRV | Constant Turning Rate and Velocity |
| CV | Constant Velocity |
| AMOTA | Average Multi-Object Tracking Accuracy |
| AMOTP | Average Multi-Object Tracking Precision |
| MT | Mostly Track |
| ML | Mostly Lost |
| FP | False Positive |
| FN | False Negative |
| IDS | ID Switches |
| FRAG | Fragment |
| FPS | Frames Per Second |
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Scheidegger, S.; Benjaminsson, J.; Rosenberg, E.; Krishnan, A.; Granström, K. Mono-camera 3d multi-object tracking using deep learning detections and pmbm filtering. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 433–440. [Google Scholar]
- Weng, X.; Wang, J.; Held, D.; Kitani, K. AB3DMOT: A Baseline for 3D Multi-Object Tracking and New Evaluation Metrics. arXiv 2020, arXiv:2008.08063. [Google Scholar]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Liang, M.; Yang, B.; Zeng, W.; Chen, Y.; Hu, R.; Casas, S.; Urtasun, R. PnPNet: End-to-End Perception and Prediction with Tracking in the Loop. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 11553–11562. [Google Scholar]
- Yin, T.; Zhou, X.; Krähenbühl, P. Center-based 3d object detection and tracking. arXiv 2020, arXiv:2006.11275. [Google Scholar]
- Luo, W.; Yang, B.; Urtasun, R. Fast and furious: Real time end-to-end 3d detection, tracking and motion forecasting with a single convolutional net. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3569–3577. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. Nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2446–2454. [Google Scholar]
- Garcia-Fernandez, A.F.; Williams, J.L.; Granstrom, K.; Svensson, L. Poisson Multi-Bernoulli Mixture Filter: Direct Derivation and Implementation. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 1883–1901. [Google Scholar] [CrossRef] [Green Version]
- kuang Chiu, H.; Prioletti, A.; Li, J.; Bohg, J. Probabilistic 3D Multi-Object Tracking for Autonomous Driving. arXiv 2020, arXiv:2001.05673. [Google Scholar]
- Zhu, B.; Jiang, Z.; Zhou, X.; Li, Z.; Yu, G. Class-balanced grouping and sampling for point cloud 3d object detection. arXiv 2019, arXiv:1908.09492. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Ding, Z.; Hu, Y.; Ge, R.; Huang, L.; Chen, S.; Wang, Y.; Liao, J. 1st Place Solution for Waymo Open Dataset Challenge—3D Detection and Domain Adaptation. arXiv 2020, arXiv:2006.15505. [Google Scholar]
- Ge, R.; Ding, Z.; Hu, Y.; Wang, Y.; Chen, S.; Huang, L.; Li, Y. AFDet: Anchor Free One Stage 3D Object Detection. arXiv 2020, arXiv:2006.12671. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 10529–10538. [Google Scholar]
- Cheng, S.; Leng, Z.; Cubuk, E.D.; Zoph, B.; Bai, C.; Ngiam, J.; Song, Y.; Caine, B.; Vasudevan, V.; Li, C.; et al. Improving 3D Object Detection through Progressive Population Based Augmentation. arXiv 2020, arXiv:2004.00831. [Google Scholar]
- Bae, S.H.; Yoon, K.J. Robust online multi-object tracking based on tracklet confidence and online discriminative appearance learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1218–1225. [Google Scholar]
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A survey on 3d object detection methods for autonomous driving applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef] [Green Version]
- Geiger, A.; Lauer, M.; Wojek, C.; Stiller, C.; Urtasun, R. 3d traffic scene understanding from movable platforms. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1012–1025. [Google Scholar] [CrossRef] [Green Version]
- Leal-Taixé, L.; Milan, A.; Reid, I.; Roth, S.; Schindler, K. Motchallenge 2015: Towards a benchmark for multi-target tracking. arXiv 2015, arXiv:1504.01942. [Google Scholar]
- Mauri, A.; Khemmar, R.; Decoux, B.; Ragot, N.; Rossi, R.; Trabelsi, R.; Boutteau, R.; Ertaud, J.Y.; Savatier, X. Deep Learning for Real-Time 3D Multi-Object Detection, Localisation, and Tracking: Application to Smart Mobility. Sensors 2020, 20, 532. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bae, S.H.; Yoon, K.J. Confidence-based data association and discriminative deep appearance learning for robust online multi-object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 595–610. [Google Scholar] [CrossRef]
- Yang, H.; Wen, J.; Wu, X.; He, L.; Mumtaz, S. An efficient edge artificial intelligence multipedestrian tracking method with rank constraint. IEEE Trans. Ind. Inform. 2019, 15, 4178–4188. [Google Scholar] [CrossRef]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The CLEAR MOT metrics. EURASIP J. Image Video Process. 2008, 2008, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Leal-Taixé, L.; Milan, A.; Schindler, K.; Cremers, D.; Reid, I.; Roth, S. Tracking the trackers: An analysis of the state of the art in multiple object tracking. arXiv 2017, arXiv:1704.02781. [Google Scholar]
- Leal-Taixé, L.; Canton-Ferrer, C.; Schindler, K. Learning by tracking: Siamese CNN for robust target association. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Paris, France, 12 September 2016; pp. 33–40. [Google Scholar]
- Chang, S.; Li, W.; Zhang, Y.; Feng, Z. Online siamese network for visual object tracking. Sensors 2019, 19, 1858. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weng, X.; Wang, Y.; Man, Y.; Kitani, K.M. Gnn3dmot: Graph neural network for 3d multi-object tracking with 2d-3d multi-feature learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6499–6508. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method Name | Tracking Method | AMOTA | Object Detector | mAP |
|---|---|---|---|---|---|
| NuScenes | CenterPoint [9] | Greedy closest-point matching | 0.650 | CenterPoint | 0.603 |
| PMBM | Poisson Multi-Bernoulli Mixture filter [14] | 0.626 | CenterPoint | 0.603 | |
| StanfordIPRL-TRI [15] | Hungarian algorithm with Mahalanobis distance as cost function and Kalman Filter | 0.550 | MEGVII [16] | 0.519 | |
| AB3DMOT [6] | Hungarian algorithm with 3D IoU as cost function and Kalman Filter | 0.151 | MEGVII | 0.519 | |
| CenterTrack | Greedy closest-point mathcing | 0.108 | CenterNet [17] | 0.388 | |
| Waymo | HorizonMOT [18] | 3-stage data associate, each stage is an assignment problem solved by Hungarian algorithm | 0.6345 | AFDet [19] | 0.7711 |
| CenterPoint | Greedy closest-point matching | 0.5867 | CenterPoint | 0.7193 | |
| PV-RCNN-KF | Hungarian algorithm and Kalman Filter | 0.5553 | PV-RCNN [20] | 0.7152 | |
| PPBA AB3DMOT | Hungarian algorithm with 3D IoU as cost function and Kalman Filter | 0.2914 | PointPillars and PPBA [21] | 0.3530 |
| Dataset | Method | AMOTA↑ | AMOTP↓ | MT↑ | ML↓ | FP↓ | FN↓ | IDS↓ | FRAG↓ |
|---|---|---|---|---|---|---|---|---|---|
| KITTI (val) | Ours | 0.415 | 0.691 | NA | NA | 766 | 3721 | 10 | 259 |
| AB3DMOT [6] | 0.377 | 0.648 | NA | NA | 696 | 3713 | 1 | 93 | |
| NuScenes (val) | Ours | 0.583 | 0.748 | 3617 | 1885 | 13,439 | 28,119 | 512 | 511 |
| StanfordIPRL-TRI [15] | 0.561 | 0.800 | 3432 | 1857 | 12,140 | 28,387 | 679 | 606 | |
| Waymo (test @ L2) | Ours | 0.365 | 0.263 | NA | NA | 0.089 | 0.533 | 0.014 | NA |
| PPBA-AB3DMOT | 0.291 | 0.270 | NA | NA | 0.171 | 0.535 | 0.003 | NA |
| Class of Objects | Our Runtime (fps) | AB3DMOT’s Runtime (fps) |
|---|---|---|
| Car | 115 | 186 |
| Pedestrian | 497 | 424 |
| Cyclist | 1111 | 1189 |
| Method | AMOTA↑ | AMOTP↓ | MT↑ | ML↓ | FP↓ | FN↓ | IDS↓ | FRAG↓ |
|---|---|---|---|---|---|---|---|---|
| Default | 0.583 | 0.748 | 3617 | 1885 | 13,439 | 28,119 | 512 | 511 |
| Hungarian for LAP | 0.587 | 0.743 | 3609 | 1880 | 13,667 | 28,070 | 596 | 573 |
| No ReID | 0.583 | 0.748 | 3616 | 1882 | 13,429 | 28,100 | 504 | 510 |
| Global assoc only | 0.327 | 0.924 | 2575 | 2244 | 26,244 | 38,315 | 4215 | 3038 |
| Const Velocity only | 0.567 | 0.781 | 3483 | 1966 | 12,649 | 29,427 | 718 | 606 |
| No size affinity | 0.581 | 0.748 | 3595 | 1904 | 13,423 | 28,448 | 512 | 508 |
| 3D IoU as affinity | 0.535 | 0.898 | 3090 | 2075 | 9168 | 33,041 | 550 | 528 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dao, M.-Q.; Frémont, V. A Two-Stage Data Association Approach for 3D Multi-Object Tracking. Sensors 2021, 21, 2894. https://doi.org/10.3390/s21092894
Dao M-Q, Frémont V. A Two-Stage Data Association Approach for 3D Multi-Object Tracking. Sensors. 2021; 21(9):2894. https://doi.org/10.3390/s21092894
Chicago/Turabian StyleDao, Minh-Quan, and Vincent Frémont. 2021. "A Two-Stage Data Association Approach for 3D Multi-Object Tracking" Sensors 21, no. 9: 2894. https://doi.org/10.3390/s21092894
APA StyleDao, M.-Q., & Frémont, V. (2021). A Two-Stage Data Association Approach for 3D Multi-Object Tracking. Sensors, 21(9), 2894. https://doi.org/10.3390/s21092894