
Blockchain-Based Federated Learning System: A Survey on Design Choices


Abstract
:1. Introduction
1.1. Contributions
- We investigate research papers from the literature and find about 31 design variations researchers often take to solve FL issues in their system.
- We analyze the pros and cons of committing to each design pattern concerning the fundamental FL metrics such as robustness, efficiency, privacy, and fairness.
- We classify the surveyed papers to seek trends of popular design patterns.
- Based on our analysis, we derive several research directions to enhance the quality of future blockchain-based FL systems.
1.2. Related Surveys
1.3. Paper Organization
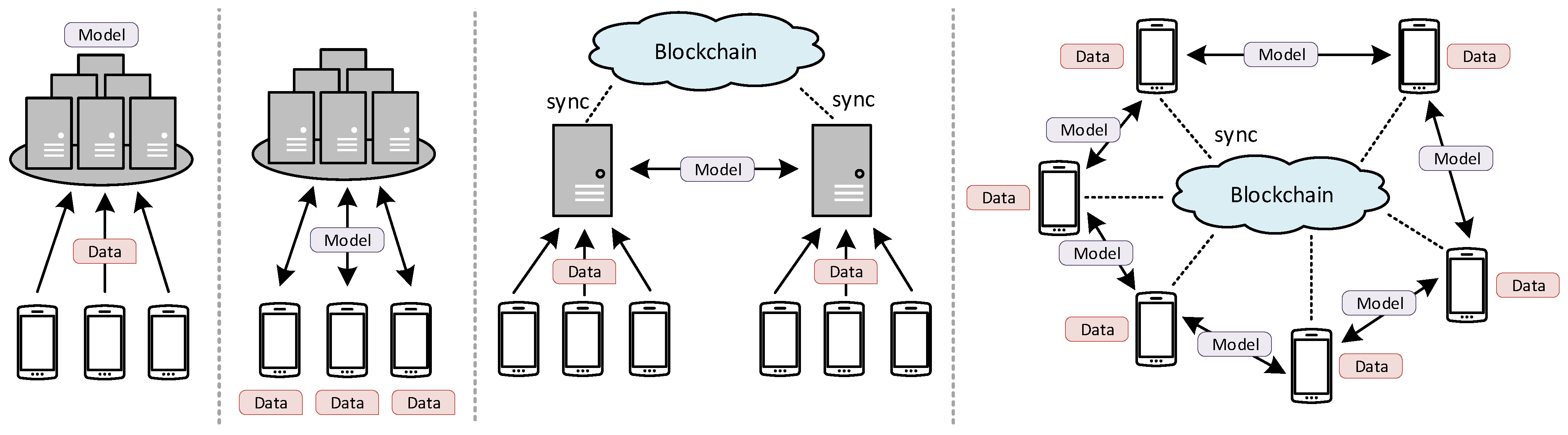
2. Blockchain Integration into Federated Learning
2.1. Brief Overview of Federated Learning System
2.2. Privacy, Security, and Trust Issues in Federated Learning System
2.3. Privacy, Security, and Trust Solutions for Federated Learning System
2.4. Blockchain Roles in Federated Learning System
3. Design Patterns on Blockchain-Based FL System
3.1. Survey Methodology
3.2. Registering FL Clients Strategy
3.2.1. How to Attract Trainers?
3.2.2. How to Choose Trainers?
3.3. Distributing FL Models Strategy
3.3.1. How to Distribute Models?
3.3.2. How to Prevent Model Leakage?
3.4. Training FL Models Strategy
3.4.1. How to Prevent Data Leakage?
3.4.2. How to Make Communication Efficient?
3.5. Validating FL Models Strategy
3.5.1. Who Should Become Reviewers?
3.5.2. How to Select Models for Aggregation?
3.5.3. How to Punish Malicious Actors?
3.6. Aggregating FL Models Strategy
3.6.1. Who Can Become Aggregators?
3.6.2. How to Aggregate Models?
3.6.3. Where Does Aggregation Happen?
4. Analysis on Investigated Design Patterns
4.1. Fundamental Metrics
4.2. Analysis of Registering FL Clients Strategy
4.3. Analysis of Distributing FL Models Strategy
4.4. Analysis of Training FL Models Strategy
4.5. Analysis of Validating FL Models Strategy
4.6. Analysis of Aggregating FL Models Strategy
4.7. Lesson Learned
5. Discussion
5.1. Classifications of Research Papers
5.1.1. Classification of Design-Pattern
5.1.2. Classification of Implementations
5.2. Ideal Design Choices
5.3. Other Research Directions
5.4. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics (PMLR), Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Albrecht, J.P. How the GDPR will change the world. Eur. Data Prot. Law Rev. 2016, 2, 287. [Google Scholar] [CrossRef]
- Yang, T.; Andrew, G.; Eichner, H.; Sun, H.; Li, W.; Kong, N.; Ramage, D.; Beaufays, F. Applied federated learning: Improving google keyboard query suggestions. arXiv 2018, arXiv:1812.02903. [Google Scholar]
- Carlini, N.; Liu, C.; Erlingsson, Ú.; Kos, J.; Song, D. The secret sharer: Evaluating and testing unintended memorization in neural networks. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 14–16 August 2019; pp. 267–284. [Google Scholar]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System; Technical Report; Bitcoin: Las Vegas, NV, USA, 2019. [Google Scholar]
- Wood, G. Ethereum: A secure decentralised generalised transaction ledger. Ethereum Proj. Yellow Pap. 2014, 151, 1–32. [Google Scholar]
- Nguyen, D.C.; Ding, M.; Pham, Q.V.; Pathirana, P.N.; Le, L.B.; Seneviratne, A.; Li, J.; Niyato, D.; Poor, H.V. Federated learning meets blockchain in edge computing: Opportunities and challenges. IEEE Internet Things J. 2021, 8, 12806–12825. [Google Scholar] [CrossRef]
- Ali, M.; Karimipour, H.; Tariq, M. Integration of Blockchain and Federated Learning for Internet of Things: Recent Advances and Future Challenges. Comput. Secur. 2021, 108, 102355. [Google Scholar] [CrossRef]
- Aledhari, M.; Razzak, R.; Parizi, R.M.; Saeed, F. Federated learning: A survey on enabling technologies, protocols, and applications. IEEE Access 2020, 8, 140699–140725. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.; Huang, J.; Liu, X. Cross-Silo Federated Learning: Challenges and Opportunities. arXiv 2022, arXiv:2206.12949. [Google Scholar]
- Karimireddy, S.P.; Jaggi, M.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.U.; Suresh, A.T. Breaking the centralized barrier for cross-device federated learning. Adv. Neural Inf. Process. Syst. 2021, 34, 28663–28676. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. arXiv 2019, arXiv:1912.04977. [Google Scholar]
- Goodfellow, I.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- Shamir, A. How to share a secret. Commun. ACM 1979, 22, 612–613. [Google Scholar] [CrossRef]
- Lee, J.H. BIDaaS: Blockchain based ID as a service. IEEE Access 2017, 6, 2274–2278. [Google Scholar] [CrossRef]
- Ahmad, A.; Saad, M.; Bassiouni, M.; Mohaisen, A. Towards blockchain-driven, secure and transparent audit logs. In Proceedings of the 15th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services, New York, NY, USA, 5–7 November 2018; pp. 443–448. [Google Scholar]
- He, W.; Wei, J.; Chen, X.; Carlini, N.; Song, D. Adversarial example defense: Ensembles of weak defenses are not strong. In Proceedings of the 11th USENIX Workshop on Offensive Technologies (WOOT’17), Vancouver, BC, Canada, 14–15 August 2017. [Google Scholar]
- Dennis, R.; Owen, G. Rep on the block: A next generation reputation system based on the blockchain. In Proceedings of the 10th IEEE International Conference for Internet Technology and Secured Transactions (ICITST), London, UK, 14–16 December 2015; pp. 131–138. [Google Scholar]
- Androulaki, E.; Barger, A.; Bortnikov, V.; Cachin, C.; Christidis, K.; De Caro, A.; Enyeart, D.; Ferris, C.; Laventman, G.; Manevich, Y.; et al. Hyperledger fabric: A distributed operating system for permissioned blockchains. In Proceedings of the EuroSys’18: Thirteenth EuroSys Conference, Porto, Portugal, 23–26 April 2018; pp. 1–15. [Google Scholar]
- Wang, J.; Li, M.; He, Y.; Li, H.; Xiao, K.; Wang, C. A blockchain based privacy-preserving incentive mechanism in crowdsensing applications. IEEE Access 2018, 6, 17545–17556. [Google Scholar] [CrossRef]
- Li, M.; Weng, J.; Yang, A.; Lu, W.; Zhang, Y.; Hou, L.; Liu, J.N.; Xiang, Y.; Deng, R.H. Crowdbc: A blockchain-based decentralized framework for crowdsourcing. IEEE Trans. Parallel Distrib. Syst. 2018, 30, 1251–1266. [Google Scholar] [CrossRef]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečnỳ, J.; Mazzocchi, S.; McMahan, H.B.; et al. Towards federated learning at scale: System design. arXiv 2019, arXiv:1902.01046. [Google Scholar]
- CoinMarketCap. Today’s Cryptocurrency Prices by Market Cap. 2021. Available online: https://bit.ly/3cupQJe (accessed on 1 February 2021).
- Kim, H.; Park, J.; Bennis, M.; Kim, S.L. Blockchained on-device federated learning. IEEE Commun. Lett. 2019, 24, 1279–1283. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y.; Huang, X.; Dai, Y.; Maharjan, S.; Zhang, Y. Blockchain and federated learning for privacy-preserved data sharing in industrial IoT. IEEE Trans. Ind. Inform. 2019, 16, 4177–4186. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Blockchain empowered asynchronous federated learning for secure data sharing in internet of vehicles. IEEE Trans. Veh. Technol. 2020, 69, 4298–4311. [Google Scholar] [CrossRef]
- Baliga, A.; Subhod, I.; Kamat, P.; Chatterjee, S. Performance evaluation of the quorum blockchain platform. arXiv 2018, arXiv:1809.03421. [Google Scholar]
- Ethereum Foundation. The Merge. 2023. Available online: https://ethereum.org/en/roadmap/merge/ (accessed on 1 February 2023).
- Passerat-Palmbach, J.; Farnan, T.; Miller, R.; Gross, M.S.; Flannery, H.L.; Gleim, B. A blockchain-orchestrated federated learning architecture for healthcare consortia. arXiv 2019, arXiv:1910.12603. [Google Scholar]
- Li, Z.; Liu, J.; Hao, J.; Wang, H.; Xian, M. CrowdSFL: A secure crowd computing framework based on blockchain and federated learning. Electronics 2020, 9, 773. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Zhang, W.; Lu, Q.; Yu, Q.; Li, Z.; Liu, Y.; Lo, S.K.; Chen, S.; Xu, X.; Zhu, L. Blockchain-based Federated Learning for Device Failure Detection in Industrial IoT. IEEE Internet Things J. 2020, 8, 5926–5937. [Google Scholar] [CrossRef]
- Fan, S.; Zhang, H.; Zeng, Y.; Cai, W. Hybrid Blockchain-Based Resource Trading System for Federated Learning in Edge Computing. IEEE Internet Things J. 2020, 8, 2252–2264. [Google Scholar] [CrossRef]
- Toyoda, K.; Zhang, A.N. Mechanism design for an incentive-aware blockchain-enabled federated learning platform. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 395–403. [Google Scholar]
- Desai, H.B.; Ozdayi, M.S.; Kantarcioglu, M. Blockfla: Accountable federated learning via hybrid blockchain architecture. arXiv 2020, arXiv:2010.07427. [Google Scholar]
- Awan, S.; Li, F.; Luo, B.; Liu, M. Poster: A reliable and accountable privacy-preserving federated learning framework using the blockchain. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 2561–2563. [Google Scholar]
- Mendis, G.J.; Wu, Y.; Wei, J.; Sabounchi, M.; Roche, R. A blockchain-powered decentralized and secure computing paradigm. IEEE Trans. Emerg. Top. Comput. 2020, 9, 2201–2222. [Google Scholar] [CrossRef] [Green Version]
- Mugunthan, V.; Rahman, R.; Kagal, L. BlockFLow: An Accountable and Privacy-Preserving Solution for Federated Learning. arXiv 2020, arXiv:2007.03856. [Google Scholar]
- Benet, J. Ipfs-content addressed, versioned, p2p file system. arXiv 2014, arXiv:1407.3561. [Google Scholar]
- Liu, L.; Hu, Y.; Yu, J.; Zhang, F.; Huang, G.; Xiao, J.; Wu, C. Training Encrypted Models with Privacy-preserved Data on Blockchain. In Proceedings of the 3rd International Conference on Vision, Image and Signal Processing, Vancouver, BC, Canada, 26–28 August 2019; pp. 1–6. [Google Scholar]
- Liu, Y.; Peng, J.; Kang, J.; Iliyasu, A.M.; Niyato, D.; Abd El-Latif, A.A. A secure federated learning framework for 5G networks. IEEE Wirel. Commun. 2020, 27, 24–31. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Cui, L.; Su, X.; Ming, Z.; Chen, Z.; Yang, S.; Zhou, Y.; Xiao, W. CREAT: Blockchain-assisted Compression Algorithm of Federated Learning for Content Caching in Edge Computing. IEEE Internet Things J. 2020, 9, 14151–14161. [Google Scholar] [CrossRef]
- Wu, C.; Xiao, J.; Huang, G.; Wu, F. Galaxy Learning—A Position Paper. arXiv 2019, arXiv:1905.00753. [Google Scholar]
- Ouyang, L.; Yuan, Y.; Wang, F.Y. Learning Markets: An AI Collaboration Framework Based on Blockchain and Smart Contracts. IEEE Internet Things J. 2020, 9, 14273–14286. [Google Scholar] [CrossRef]
- Kumar, S.; Dutta, S.; Chatturvedi, S.; Bhatia, M. Strategies for Enhancing Training and Privacy in Blockchain Enabled Federated Learning. In Proceedings of the 6th IEEE International Conference on Multimedia Big Data (BigMM), New Delhi, India, 24–26 September 2020; pp. 333–340. [Google Scholar]
- Zhang, Z.; Xu, K.; Li, Q.; Liu, X.; Li, L.; Wu, B.; Guo, Y. Seccl: Securing collaborative learning systems via trusted bulletin boards. IEEE Commun. Mag. 2020, 58, 47–53. [Google Scholar] [CrossRef]
- Hu, Y.; Xia, W.; Xiao, J.; Wu, C. GFL: A Decentralized Federated Learning Framework Based On Blockchain. arXiv 2020, arXiv:2010.10996. [Google Scholar]
- Majeed, U.; Hong, C.S. FLchain: Federated learning via MEC-enabled blockchain network. In Proceedings of the 20th IEEE Asia-Pacific Network Operations and Management Symposium (APNOMS), Matsue, Japan, 18–20 September 2019; pp. 1–4. [Google Scholar]
- Korkmaz, C.; Kocas, H.E.; Uysal, A.; Masry, A.; Ozkasap, O.; Akgun, B. Chain FL: Decentralized Federated Machine Learning via Blockchain. In Proceedings of the 2nd IEEE International Conference on Blockchain Computing and Applications (BCCA), Antalya, Turkey, 2–5 November 2020; pp. 140–146. [Google Scholar]
- Ramanan, P.; Nakayama, K. Baffle: Blockchain based aggregator free federated learning. In Proceedings of the 2020 IEEE International Conference on Blockchain (Blockchain), Rhodes, Greece, 2–6 November 2020; pp. 72–81. [Google Scholar]
- Moore, C.; O’Neill, M.; O’Sullivan, E.; Doröz, Y.; Sunar, B. Practical homomorphic encryption: A survey. In Proceedings of the 2014 IEEE International Symposium on Circuits and Systems (ISCAS), Melbourne, Australia, 1–5 June 2014; pp. 2792–2795. [Google Scholar]
- Zhou, H.; Wornell, G. Efficient homomorphic encryption on integer vectors and its applications. In Proceedings of the 2014 IEEE Information Theory and Applications Workshop (ITA), San Diego, CA, USA, 9–14 February 2014; pp. 1–9. [Google Scholar]
- Ethereum. Types—Solidity Documentations. 2021. Available online: https://bit.ly/2VJrXDn (accessed on 22 July 2021).
- Gupta, M. Solidity Gas Optimization Tips. 2018. Available online: https://bit.ly/3fZvGDy (accessed on 22 July 2021).
- Felix Johannes, M. Hardened Model Aggregation for Federated Learning Backed by Distributed Trust Towards Decentralizing Federated Learning Using a Blockchain. Master’s Thesis, Uppsala University, Uppsala, Sweden, 2020. [Google Scholar]
- Zhang, Z.; Yang, T.; Liu, Y. SABlockFL: A blockchain-based smart agent system architecture and its application in federated learning. Int. J. Crowd Sci. 2020, 4, 133–147. [Google Scholar] [CrossRef]
- Rathore, S.; Pan, Y.; Park, J.H. BlockDeepNet: A Blockchain-based secure deep learning for IoT network. Sustainability 2019, 11, 3974. [Google Scholar] [CrossRef] [Green Version]
- El Rifai, O.; Biotteau, M.; de Boissezon, X.; Megdiche, I.; Ravat, F.; Teste, O. Blockchain-Based Federated Learning in Medicine. In Proceedings of the 18th International Conference on Artificial Intelligence in Medicine, AIME 2020, Minneapolis, MN, USA, 25–28 August 2020; pp. 214–224. [Google Scholar]
- Arachchige, P.C.M.; Bertok, P.; Khalil, I.; Liu, D.; Camtepe, S.; Atiquzzaman, M. A trustworthy privacy preserving framework for machine learning in industrial iot systems. IEEE Trans. Ind. Inform. 2020, 16, 6092–6102. [Google Scholar] [CrossRef]
- Smahi, A.; Li, H.; Yang, Y.; Yang, X.; Lu, P.; Zhong, Y.; Liu, C. BV-ICVs: A privacy-preserving and verifiable federated learning framework for V2X environments using blockchain and zkSNARKs. J. King Saud-Univ.-Comput. Inf. Sci. 2023; 101542, in press. [Google Scholar]
- Heiss, J.; Grünewald, E.; Tai, S.; Haimerl, N.; Schulte, S. Advancing Blockchain-based Federated Learning through Verifiable Off-chain Computations. In Proceedings of the 2022 IEEE International Conference on Blockchain (Blockchain), Espoo, Finland, 22–25 August 2022; pp. 194–201. [Google Scholar]
- Qi, M.; Wang, Z.; Wu, F.; Hanson, R.; Chen, S.; Xiang, Y.; Zhu, L. A blockchain-enabled federated learning model for privacy preservation: System design. In Proceedings of the Information Security and Privacy: 26th Australasian Conference, ACISP 2021, Virtual Event, 1–3 December 2021; pp. 473–489. [Google Scholar]
- Xuan, S.; Jin, M.; Li, X.; Yao, Z.; Yang, W.; Man, D. DAM-SE: A blockchain-based optimized solution for the counterattacks in the internet of federated learning systems. Secur. Commun. Netw. 2021, 2021, 9965157. [Google Scholar] [CrossRef]
- Li, C.; Shen, Q.; Xiang, C.; Ramesh, B. A Trustless Federated Framework for Decentralized and Confidential Deep Learning. In Proceedings of the 2022 IEEE 1st Global Emerging Technology Blockchain Forum: Blockchain & Beyond (iGETblockchain), Irvine, CA, USA, 7–11 November 2022; pp. 1–6. [Google Scholar]
- Irolla, P.; Châtel, G. Demystifying the membership inference attack. In Proceedings of the 12th CMI Conference on Cybersecurity and Privacy (CMI), Copenhagen, Denmark, 28–29 November 2019; pp. 1–7. [Google Scholar]
- Hu, Y. GFL Framework. 2021. Available online: https://bit.ly/3cjsi3D (accessed on 11 March 2021).
- Morsbach, F.J. DecFL. 2021. Available online: https://bit.ly/3cpHtsl (accessed on 11 March 2021).
- Rifai, O.E. Solidity-fl. 2021. Available online: https://bit.ly/2OF8kZc (accessed on 11 March 2021).
- Haimerl, N. Advancing Blockchain Based Federated Learning Through Verifiable Off Chain Computations. 2023. Available online: https://github.com/NikolasHaimerl/Advancing-Blockchain-Based-Federated-Learning-Through-Verifiable-Off-Chain-Computations (accessed on 1 February 2023).
- SuperLi. Decentralized Neural Network Using Blockchain. 2023. Available online: https://github.com/s-elo/DNN-Blockchain (accessed on 1 February 2023).
- Wu, C.; Zhang, F.; Wu, F. Distributed modelling approaches for data privacy preserving. In Proceedings of the 5th IEEE International Conference on Multimedia Big Data (BigMM), Singapore, 11–13 September 2019; pp. 357–365. [Google Scholar]
- Shamir, O.; Srebro, N.; Zhang, T. Communication-efficient distributed optimization using an approximate newton-type method. In Proceedings of the ICML’14: Proceedings of the 31st International Conference on International Conference on Machine Learning, PMLR, Beijing, China, 21–26 June 2014; pp. 1000–1008. [Google Scholar]
- Bernstein, J.; Wang, Y.X.; Azizzadenesheli, K.; Anandkumar, A. signSGD: Compressed optimisation for non-convex problems. In Proceedings of the 5th International Conference on Machine Learning (PMLR), Stockholm, Sweden, 10–15 July 2018; pp. 560–569. [Google Scholar]
- Vukolić, M. The quest for scalable blockchain fabric: Proof-of-work vs. BFT replication. In Proceedings of the International Workshop on Open Problems in Network Security, Zurich, Switzerland, 29 October 2015; pp. 112–125. [Google Scholar]
- Thibault, L.T.; Sarry, T.; Hafid, A.S. Blockchain scaling using rollups: A comprehensive survey. IEEE Access 2022, 10, 93039–93054. [Google Scholar] [CrossRef]
- Alief, R.N.; Putra, M.A.P.; Gohil, A.; Lee, J.M.; Kim, D.S. FLB2: Layer 2 Blockchain Implementation Scheme on Federated Learning Technique. In Proceedings of the 2023 IEEE International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Bali, Indonesia, 20–23 February 2023; pp. 846–850. [Google Scholar]
- Zhao, Y.; Zhao, J.; Jiang, L.; Tan, R.; Niyato, D.; Li, Z.; Lyu, L.; Liu, Y. Privacy-preserving blockchain-based federated learning for IoT devices. IEEE Internet Things J. 2020, 8, 1817–1829. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Issues | Type | Possible Solutions | Blockchain Contributions |
|---|---|---|---|
| Model Leakage | P | Use encryption, client registration, and model auditing log. | Use the smart contract for registration and auditing. |
| Data Leakage | P | Employ differential privacy on local models. | - |
| Poisoning | S | Use reputation system, evaluate the local model updates before aggregation. | Build a reputation system and aggregation protocol on top of the smart contract. |
| Malicious Server | S | Make FL becomes less centralized. | Provide a platform for decentralization. |
| Low Motivations | T | Incentivize the clients based on their training contributions. | The digital token in the blockchain can be used as an incentive mechanism. |
| Client Dropouts | T | Employ deposit to punish intentional dropouts. | The digital token can also be used as a deposit mechanism. |
| Low Trust | T | - | Can be used as a trusted platform due to its high integrity guarantee. |
| Design | R | Reason | E | Reason | P | Reason | F | Reason |
|---|---|---|---|---|---|---|---|---|
| NoInc. | −1 | encourage malicious behavior | ✗ | – | ✗ | – | −2 | not fair for honest clients |
| Flat. | +1 | encourage honest behaviour | −1 | need little computation to distribute rewards | ✗ | – | −1 | well-trained models subsidize poor-trained models |
| ConRe. | +2 | encourage even honest behaviour | −2 | need to calculate contributions from all clients | ✗ | – | +1 | clients are rewarded based on their contributions |
| Open. | −1 | most likely to include malicious trainers | ✗ | – | ✗ | – | +1 | all clients can equally become trainers |
| Res. | +1 | less likely to include malicious trainers | −1 | must add filtering algorithm for trainer candidates | −1 | clients need to disclose private info about themselves | −1 | only qualified clients can become trainers |
| OC | −1 | no log on models | ✗ | – | ✗ | – | −1 | hard to audit |
| Blo. | +2 | models are safely recorded in the blockchain | −2 | storing huge models in the blockchain is costly | −1 | all blockchain nodes can see the models | +1 | all blockchain nodes can audit the models |
| IPFS | +1 | hash of the model is stored in the blockchain | −1 | storing only hashes is cheaper | −1 | all blockchain and storage nodes can see the models | +1 | all blockchain and storage nodes can audit the models |
| NoPrev. | −1 | attackers can obtain models | ✗ | – | −1 | attackers can obtain models | −1 | attackers can obtain models |
| Enc. | +1 | models are protected from third party | −1 | additional steps are required for encryption | +1 | models are protected from leakage | +1 | only eligible entities can see the models |
| NoPrev. | ✗ | – | ✗ | – | −1 | attackers may obtain private data | ✗ | – |
| DP | −1 | decrease models’ accuracy | −1 | additonal steps to add noise during training | +1 | private data is secured | ✗ | – |
| HE | ✗ | does not affect robustness | −1 | perform training on encrypted models is complex | +1 | private data is secured | ✗ | – |
| NoComp. | ✗ | – | ✗ | – | ✗ | – | ✗ | – |
| Comp. | ✗ | – | +1 | can safe a lot of bandwidth | ✗ | – | ✗ | – |
| NoVer. | −1 | malicious models can jeopardize the global model | ✗ | – | ✗ | – | −2 | malicious models may outperform honest models |
| Sin. | +1 | models are verified by a reviewer | −1 | require simple single-validation | −1 | models are leaked to single reviewer | −1 | may not fair if the reviewer is compromised |
| All. | +3 | models are peer-reveiwed by all clients | −3 | models must be transferred to all clients | −3 | all clients know each others’ model | +2 | hard to compromise when validated by all clients |
| Boa. | +2 | models are verified by few reviewers | −2 | models need to be delivered to few reviewers | −2 | models are leaked to few reviewers | +1 | sligthly difficult to compromise few reviewers |
| Ran. | +1 | reducing the chance of malicious models to be selected | −1 | need to have a trustable random oracle | ✗ | – | ✗ | – |
| Repo. | +1 | reducing the chance of malicious models to be selected | −1 | need to build a mediator for accusers and victims | ✗ | – | ✗ | – |
| Vot. | +1 | reducing the chance of malicious models to be selected | −1 | need to build a voting mechanism for all clients | ✗ | – | ✗ | – |
| Con. | +2 | have a higher chance to exclude malicious models | −2 | need to calculate contribution for each client | ✗ | – | ✗ | – |
| NoPun. | −1 | may encourage malicous behaviour | ✗ | – | ✗ | – | −1 | malicious entities does not get punishment |
| Repu. | +1 | encourage honest behaviour | −1 | needs additional credit score processing | −1 | clients are most likely to use the same account | +1 | malcious entity is punished socially |
| Depo. | +1 | encourage honest behaviour | −1 | needs additional deposit processing | ✗ | – | +1 | malicious entity is punished economically |
| Sin. | −1 | malicious aggregator can compromise the global model | ✗ | – | ✗ | – | −1 | not fair if the aggregator is malicious |
| Mul. | +1 | slightly difficult for a malicious aggregator to corrupt the global model | −1 | models need to be distributed to all aggregators | −1 | many nodes obtain information about the global models | +1 | the robust aggregation process boosts clients’ trust |
| Syn. | ✗ | – | −1 | must wait for slow trainers | ✗ | – | ✗ | – |
| Asy. | ✗ | – | +1 | aggregate without waiting | ✗ | – | ✗ | – |
| Off. | ✗ | – | ✗ | – | ✗ | – | ✗ | – |
| On. | +1 | the aggregation process becomes hard-to-tamper | −1 | smart contract code execution is costly and complex | −1 | all blockchain nodes can see the aggregation process | +1 | the aggregation process can be audited |
| Ref. | Trainer Reward | Trainer Selection | Model Leak | Distribution | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Flat | DQ | MQ | Vot. | Spe. | Open | Repu. | Dep. | Auth. | Lot. | Pub. | Sym. | HE | OC | Blo. | IPFS | |||
| [31] | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ||
| [37] | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ | ||
| [30] | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | ||
| [49] | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ||
| [50] | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ||
| [57] | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ||
| [39] | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ||
| [58] | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ||
| [36] | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | ||
| [42] | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ||
| [35] | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | ||
| [47] | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ||
| [52] | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ||
| [38] | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ||
| [59] | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ||
| [60] | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ||
| [46] | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | ||
| [33] | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ||
| [45] | ✗ | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ||
| [41] | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ | ||
| [48] | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ||
| [44] | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ||
| [61] | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | ||
| [34] | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ||
| [51] | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ||
| [62] | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ||
| [63] | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ||
| [64] | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ||
| [65] | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ||
| [66] | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ||
| Ref. | Data Leak | Effc. | Reviewer | Model Selection | Punishment | Aggregator | Method | Location | ||||||||||
| DP | HE | Comp. | Sin. | All. | Boa. | Ran. | Repo. | Vot. | Con. | Dep. | Repu. | Sin. | Mul. | Syn. | Asy. | On. | Off. | |
| [31] | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [37] | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [30] | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [49] | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [50] | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ |
| [57] | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✓ |
| [39] | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✓ |
| [58] | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ |
| [36] | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ |
| [42] | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✓ | ✗ |
| [35] | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [47] | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [52] | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ |
| [38] | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ |
| [59] | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✓ |
| [60] | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ |
| [46] | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [33] | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [45] | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ |
| [41] | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [48] | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [44] | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [61] | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [34] | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [51] | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ |
| [62] | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ |
| [63] | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ |
| [64] | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [65] | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✓ |
| [66] | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| Ref. | Environment | Evaluation | Dependencies | Ava. | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Impl. | L | T | # FL Nodes | Acc. | Sca. | GC | FL Algorithm | ML Library | ML Dataset | ||
| [31] | ✓ | ✓ | ✗ | 3 | ✓ | ✓ | ✓ | FedAvg | SYFT | BCWD, HDD | ✗ |
| [37] | ✓ | ✓ | ✗ | up to 40 | ✗ | ✓ | ✗ | FedAvg | PyTorch | BCWD | ✗ |
| [30] | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| [49] | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | FedAvg, Distilation | ✗ | MNIST, CIFAR-10 | [68] |
| [50] | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | DANE | ✗ | ✗ | ✗ |
| [57] | ✓ | ✗ | ✓ | 3 | ✓ | ✗ | ✓ | FedAvg | Tensorflow | MNIST | [69] |
| [39] | ✓ | ✗ | ✗ | up to 100 | ✓ | ✗ | ✓ | FedAvg | ✗ | Adult, KDD | ✗ |
| [58] | ✓ | ✓ | ✗ | 10 | ✓ | ✗ | ✗ | FedAvg | ✗ | ✗ | ✗ |
| [36] | ✓ | ✓ | ✓ | up to 10 | ✗ | ✓ | ✓ | FedAvg, signSGD | ✗ | CIFAR-10 | ✗ |
| [42] | ✓ | ✗ | ✗ | up to 300 | ✓ | ✗ | ✗ | FedAvg | Tensorflow | MNIST, CIFAR-10 | ✗ |
| [35] | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | FedAvg | ✗ | ✗ | ✗ |
| [47] | ✓ | ✗ | ✗ | up to 5 | ✓ | ✗ | ✗ | FedAvg | Hyperas | MNIST | ✗ |
| [52] | ✓ | ✓ | ✗ | up to 128 | ✓ | ✓ | ✓ | Model chunking | Keras, Tensorflow | NYC Taxi | ✗ |
| [38] | ✓ | ✓ | ✗ | up to 6 | ✓ | ✓ | ✗ | Fusion | Tensorflow | MNIST, NASA Glenn | ✗ |
| [59] | ✓ | ✓ | ✗ | 10 | ✓ | ✓ | ✗ | FedAvg | Tensorflow | PASCAL VOC 2012 | ✗ |
| [60] | ✓ | ✓ | ✗ | 15 | ✓ | ✗ | ✗ | FedAvg | Numpy | NIDDK | [70] |
| [46] | ✓ | ✓ | ✗ | up to 7 | ✓ | ✗ | ✓ | Fusion/Ensemble | Keras | MNIST | ✗ |
| [33] | ✓ | ✓ | ✗ | 5 | ✓ | ✓ | ✗ | CDW FedAvg | Leaf | Air Conditioning Data | ✗ |
| [45] | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| [41] | ✓ | ✓ | ✗ | up to 11 | ✓ | ✗ | ✓ | FedAvg | Numpy | MNIST | ✗ |
| [48] | ✓ | ✓ | ✗ | up to 30 | ✓ | ✗ | ✗ | FedAvg | Keras, sklearn | MNIST | ✗ |
| [44] | ✓ | ✗ | ✗ | 30 | ✓ | ✓ | ✗ | FedAvg | ✗ | MovieLens | ✗ |
| [61] | ✓ | ✓ | ✓ | 5 | ✓ | ✓ | ✓ | FedAvg | ✗ | MNIST | ✗ |
| [34] | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| [51] | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | Online FedAvg | Tensorflow, PyTorch | MNIST, CIFAR-10 | ✗ |
| [62] | ✓ | ✓ | ✗ | up to 30 | ✓ | ✓ | ✓ | FedAvg | Tensorflow | MNIST, BelgiumTS | ✗ |
| [63] | ✓ | ✓ | ✗ | 8 | ✓ | ✓ | ✗ | Zokrates Learning | ✗ | UCI Daily Sport | [71] |
| [64] | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✓ | ✗ | ✗ | Diabetes, Cancer | ✗ |
| [65] | ✓ | ✓ | ✗ | 50 | ✓ | ✓ | ✗ | FedAvg | PyTorch, PySyft | MNIST | ✗ |
| [66] | ✓ | ✓ | ✗ | 5 | ✓ | ✗ | ✗ | ✗ | ✗ | CIFAR, TinyImageNet | [72] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oktian, Y.E.; Lee, S.-G. Blockchain-Based Federated Learning System: A Survey on Design Choices. Sensors 2023, 23, 5658. https://doi.org/10.3390/s23125658
Oktian YE, Lee S-G. Blockchain-Based Federated Learning System: A Survey on Design Choices. Sensors. 2023; 23(12):5658. https://doi.org/10.3390/s23125658
Chicago/Turabian StyleOktian, Yustus Eko, and Sang-Gon Lee. 2023. "Blockchain-Based Federated Learning System: A Survey on Design Choices" Sensors 23, no. 12: 5658. https://doi.org/10.3390/s23125658