Abstract
A light field camera can capture light information from various directions within a scene, allowing for the reconstruction of the scene. The light field image inherently contains the depth information of the scene, and depth estimations of light field images have become a popular research topic. This paper proposes a depth estimation network of light field images with occlusion awareness. Since light field images contain many views from different viewpoints, identifying the combinations that contribute the most to the depth estimation of the center view is critical to improving the depth estimation accuracy. Current methods typically rely on a fixed set of views, such as vertical, horizontal, and diagonal, which may not be optimal for all scenes. To address this limitation, we propose a novel approach that considers all available views during depth estimation while leveraging an attention mechanism to assign weights to each view dynamically. By inputting all views into the network and employing the attention mechanism, we enable the model to adaptively determine the most informative views for each scene, thus achieving more accurate depth estimation. Furthermore, we introduce a multi-scale feature fusion strategy that amalgamates contextual information and expands the receptive field to enhance the network’s performance in handling challenging scenarios, such as textureless and occluded regions.
1. Introduction
With the continuous development of computer vision technology, people are increasingly interested in enhanced 3D technology. In this regard, depth estimation as a fundamental task of 3D vision is of extreme research importance, as it can extract the depth information of a scene from an image. This technique is widely applied in a variety of fields, such as autonomous driving [1], drone navigation [2,3], and 3D reconstruction [4,5], making more intelligent and more effective decisions possible with accurate depth information. In addition, depth estimation can further enhance the user’s 3D experience together with such applications as virtual reality and augmented reality [6,7]. Accurate estimations of depth information are particularly important since depth information is crucial for the interaction and perception capabilities of intelligent systems in various domains. However, when an object in the scene occludes another and only part of the object or surface is visible in the occluded area, it can lead to incomplete information, and thus accurate depth estimation is totally impossible. Yet, the accurate estimation of the relative positions between objects is hard, and occluded scenes would bring difficulty into depth estimation. Solving this problem and improving the depth estimation accuracy of occluded regions will have a positive impact on the overall performance. Therefore, the research on depth estimation for occluded scenes is of great significance.
There are various techniques for depth estimation, including monocular depth estimation [8,9,10] and multi-view stereo matching. Monocular depth estimation involves estimating depth information from a single image or video frame. Due to the absence of geometric constraints from additional viewpoints, monocular depth estimation often faces challenges in accurately inferring depth, especially for distant objects or in scenes with ambiguous texture patterns. Multi-view stereo matching utilizes multiple images captured from different viewpoints for more robust depth estimation. By leveraging disparities between corresponding points in these images, the multi-view stereo method can overcome some of the limitations of monocular depth estimation and provide more accurate depth maps. The depth estimation of light field images can be viewed as a particular multi-view stereo matching method. The unique feature is that the light field image is a type of four-dimensional data set consisting of dense and regular scene samples. This allows for multiple representations of the light-field image, such as epiplane images (EPIs), sub-aperture images (SAIs), and macropixels. This enables the design of more novel methods for the depth estimation of light field images. The light field camera stands out as a distinct camera type capable of collecting and recording light from different directions of a scene. Its unique approach allows users to modify the focal plane or point of view after capturing an image. Modern handheld light field cameras [11] typically employ microlens arrays to capture multi-view images, resulting in dense and regular scene sampling. This characteristic contributes to achieving more accurate depth estimation that traditional multi-view stereo matching methods cannot achieve. One notable advantage of light field cameras is that they are not affected by ambient lighting conditions. This feature makes depth estimation possible even in low-light environments, differentiating light field cameras from conventional ones.
However, light field cameras also possess certain limitations, and the narrow baseline between their sub-aperture images is obviously one of them. This characteristic may bring noise into disparity images, affecting depth estimation accuracy. A trade-off exists between the spatial and angular resolution of light field cameras due to the hardware constraints placed on the image sensor. To address these limitations and achieve accurate depth mapping, Herb et al. [12] proposed a multi-view reconstruction model using kernel parametrization to relax low-rankness, leading to a large-scale convex optimization problem. Jeon et al. [13] utilized the phase shift theorem to estimate sub-aperture image displacement at subpixel levels, introducing a series of methods to improve the accuracy and noise immunity of the cost volume. Zhang et al. [14] explored the application of the geometric structure of 3D lines in light fields for triangulation and stereo matching, presenting a simple yet effective algorithm to enhance depth estimation accuracy. Though these methods show promise, their practicality is uncertain due to the computational complexity. Wanner et al. [15] addressed this issue using local data terms and structural tensor methods for fast depth estimation. However, such fast methods often sacrifice accuracy. In the wake of the development of deep learning, recent proposals have emerged based on convolutional neural networks (CNNs) for depth estimation [16,17]. However, these methods utilize horizontal, vertical, and diagonal views to construct the epi, and while the use of partial views can be effective in reducing computation time, this may not effectively utilize the full information of the light field, hence resulting in a limited improvement in the accuracy of depth estimation.
This paper proposes a new depth estimation network (FPattNet) for light field images. While the full views are input into the network, the attention mechanism is utilized to improve the performance of depth estimation by assigning different weights to each view according to the scene, and the multi-scale feature fusion strategy is utilized to improve the accuracy at the occlusion. Our main contributions are as follows:
- Occlusion awareness: The depth estimation network is specifically designed to handle occluded scenes. We employ a multi-scale feature fusion strategy that amalgamates contextual information from various levels, enabling the model to handle challenging scenarios, such as textureless and occluded regions.
- Scene-specific depth estimation: The optimal combination of views for accurate depth estimation can vary from scene to scene. With this view selection module, our network can dynamically adapt its focus to the most relevant information in each scene.
2. Related Work
On the basis of light filed images, depth estimation methods can be roughly classified into optimization-based methods and learning-based depth estimation methods. Moreover, since the light field image quality affects the depth estimation results, we briefly review the image quality. Thus, it is possible to undertake better preprocessing based on the image quality.
2.1. Quality Assessment of Light Filed Image
Shi et al. [18] introduced the Blind Quality Evaluator of Light Field Images, which utilizes tensor theory to explore the 4D structure characteristics of light field images (LFIs) and proposes Tensor Spatial Characteristic Features for spatial quality and the Tensor Structure Variation Index for angular consistency to assess LFI quality. Shi et al. [19] addressed the challenging problem of Light Field Image Quality Assessment by proposing a No-Reference Light Field Image Quality Assessment scheme. The method quantifies LFI quality degradation by evaluating spatial quality and angular consistency. Zhou et al. [20] proposed a novel tensor-oriented no-reference light field image quality evaluator based on tensor theory. They consider the inherent high-dimensional characteristics of LFI and evaluated quality degradation in both spatial and angular dimensions. Meng et al. [21] proposed a full-reference light field image quality evaluation index that accurately reflects the angular–spatial characteristics of light field data by extracting key refocused images and combining their features with chrominance information.
2.2. Optimization-Based Depth Estimation Methods
Traditional optimization-based depth estimation methods mainly construct depth maps using corresponding algorithms, and then optimize the depth maps using optimization algorithms to improve accuracy, whereas deep learning algorithms benefit from the development of computer hardware and mathematical theory. They only need to input the light field data into the neural network, which can learn the relevant model and perform depth estimation. In contrast, traditional optimization-based methods deal well with problems such as occlusion and noise. However, the drawbacks are that their algorithms are extremely complex and the initial construction is very time-consuming. In addition, when using traditional methods, we need to build different algorithms for different scenes, resulting in less generality in the models compared with deep learning methods. Deep learning methods are efficient and fast with more model generality, but lack specificity in specific scenarios.
Traditional optimization-based depth estimation methods can be divided into three categories: multi-viewpoint stereo matching-based depth estimation methods, EPI-based depth estimation methods, and refocusing-based depth estimation methods.
2.2.1. Methods Based on Multi-View Stereo Matching
The depth estimation method based on multi-view stereo matching evolved from the traditional 2D image stereo constraint. Traditional 2D image stereo matching requires two cameras at a fixed distance to capture the scene simultaneously and obtain a disparity map. The advent of light field cameras makes it possible to acquire disparity from multiple views using a single device, and the camera parameters are fixed. Bishop and Favaro were among the first to estimate depth from multiple views and demonstrated that the method could be implemented on each pixel of a single light field image [22]. Yu et al. investigated geometric relationships in baseline space and introduced an image segmentation algorithm to improve the stereo-matching results [23] further. However, Yu’s method produces significant errors when there is an occlusion in the scene. Park and Lee [24] used communication and scattering cues that were robust to occlusion and noise as constraints, and introduced two data costs: a finite angular entropy cost and a finite adaptive scattering cost. However, these methods do not overcome the problem of the small baselines of light field cameras. Jeon et al. [13] proposed a multi-view cost–volume matching algorithm to evaluate the matching cost, and Heber et al. [12] proposed a new perspective-bending PCA matching condition to improve the sensitivity of the algorithm to subtle pixel-level differences. To further address the occlusion problem, Chen et al. [25] used a superpixel-based regularization method to detect partially occluded regions. They also used confidence maps of labeled regions and edge intensity weights to improve the accuracy of occlusion boundary detection.
2.2.2. Methods Based on EPI
Depth estimation using pairs of polar plane images was first proposed by Bolles et al. [26] in 1987. They used a camera to photograph closely spaced images in a specific scene. They simplified the depth measurement by converting the 3D into 2D through processing steps. Based on this, Matousek et al. [27] proposed a dynamic programming-based algorithm to find the corresponding depth by extracting rows of similar intensity in EPI. In other studies, Criminisi et al. [28] used an EPI volume and a dense horizontal rectification time volume. They generated a set of EPI volumes with the same depth using linear translation. In contrast to the EPI-based approach described above, Wanner [15] and Goldluecke used the dominant direction of the EPI to estimate depth in their structural tensor approach. However, this method is not sensitive to noise and occlusion. In addition, the depth estimation method based on the EPI of 2D images may lead to significant estimation errors due to very dark and bright image features. Tao et al. [29] proposed a dense depth estimation method based on a complete 4D light field EPI, combined with scattered focus and corresponding depth cues, to obtain better depth maps from light field images. They obtained the scatter focus cues by calculating the spatial variance after angular integration. Similarly, Zhang et al. [14] proposed a method that uses a rotating parallelogram operator (SPO) to locate lines in the EPI and calculate their orientations for local depth estimation. This method can further handle occlusion and has better robustness to noise. In addition, Zhang et al. [14] combined multi-directional SPO with edge directions to improve depth estimation near the occlusion boundary, and demonstrated that the optimal EPI direction is parallel to the occlusion boundary.
2.2.3. Refocusing-Based Methods
Light field images contain information about multiple viewpoints in a scene, and objects of different depths correspond to different disparity values in different viewpoint images. Different focusing effects can be obtained by ordering these images by specific methods. Mousier et al. [30] used the relationship between camera calibration parameters and raw data to convert the full-focus images of light field images into depth maps. The full-focus image of the light field image was transformed into a depth map using the relationship. However, since all passive color cameras have low-contrast regions, the solid color background looks the same regardless of the presence of focus, which means that texture is completely lost in the solid color background. The depth estimation method based on refocusing has better results for textures in complex scenes, but has disadvantages such as time-consuming algorithm design and serious computational difficulty.
These traditional methods require extensive optimization calculations for different scenarios, and there is a trade-off between performance and computational efficiency in traditional methods. In this paper, we use a learning approach to represent depth estimation as a supervised learning task using convolutional neural networks while balancing the efficiency and performance of light field depth estimation to achieve a fast and accurate light field depth estimation algorithm.
2.3. Learning-Based Depth Estimation Methods
By learning methods, we can quickly obtain depth maps of light field images and network models with better robustness to occlusions and noise. This approach can effectively control the balance between accuracy and computational cost. Heber et al. [31] extended their previous work on EPI in 2017 using 3D operations instead of 2D operations and RGB-EPI-based neural networks for depth estimation. Shin et al. [16] applied multi-stream networks to their convolutional neural network model to address the problem of insufficient data. Pock et al. [32] proposed a new convolutional neural network model that learns the four-dimensional light field and the corresponding four-dimensional depth field and builds end-to-end mapping, and then uses higher-order regularization in subsequent processing to further refine the depth field and obtain accurate depth values. Tsai et al. [33] implemented the cost volume by shifting each sub-aperture image based on stereo matching, and used cost volume for the first time for light field depth estimation. Chen et al. [34] constructed a cost volume using sub-aperture images of four branches, horizontally, vertically, and diagonally, and utilized an attention mechanism to achieve intra-branch and inter-branch feature fusion. Wang et al. [35] proposed a fast cost constructor that realizes the handling of occlusion by dynamically adjusting the pixels of different views. Wang et al. [36] proposed a disentangling mechanism for light fields by rearranging the sub-aperture images of the light field into macro-pixel images, applying the disentangling mechanism to quickly construct a cost volume.
Since the actual receptive field in the deep network is much smaller than the theoretical receptive field [33], the main problem of current learning-based methods is that they do not effectively utilize global contextual information. In this paper, the expansion of the receptive field is achieved using a feature pyramid network that establishes horizontal connections between different levels of the feature pyramid, and fuses low-level features into high-level features to achieve the extraction of global contextual information. In this way, the accuracy of depth estimation is improved.
3. Methodology
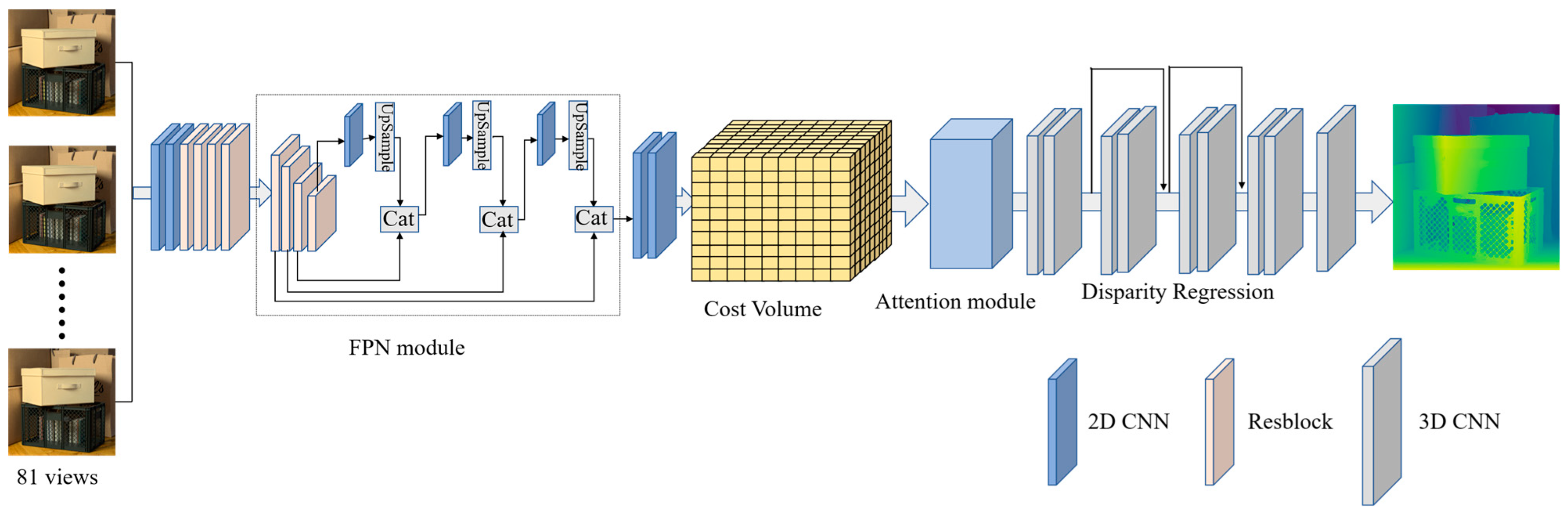
We propose FPattNet, an efficient network designed specifically for light field depth estimation, striking a balance between performance and computational efficiency. The architecture of FPattNet is illustrated in Figure 1, where it takes all sub-aperture images in the light field as input and generates a corresponding disparity map for the central view as output. In the initial stage, the input images undergo feature extraction with two basic convolution blocks, followed by four residual blocks that extract deep features. To expand the receptive field and capture more global information, dilated convolutions [37,38] are applied in the last two residual blocks [39]. Additionally, we incorporate a feature pyramid network [40] to extract contextual information from the input images and construct the cost volume [33] using the feature maps obtained from the feature pyramid output. To reduce redundancy between views and optimize the utilization of available information, we introduce an attention mechanism into the network. This mechanism learns the importance of each view and guides the network to assign different weights to each view, effectively leveraging the sub-aperture images for accurate depth estimation. Finally, we obtain disparity maps by aggregating the cost volume using 3D convolution and performing disparity regression. The detailed structure of FPattNet can be found in Table 1.
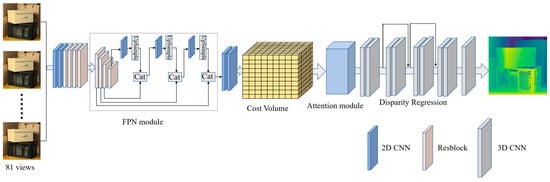
Figure 1.
Architecture of the proposed method.

Table 1.
The detailed structure of our FPattNet. H and W represents the height and width of the input image, respectively. N denotes the number of views and D denotes the number of candidate parallaxes. conv2D, ResBlock2D, Conv3D and ResBlock3D denote the 2D convolution, 2D residual block, 3D convolution and 3D residual block, respectively.
3.1. Feature Extraction and Feature Pyramid Network
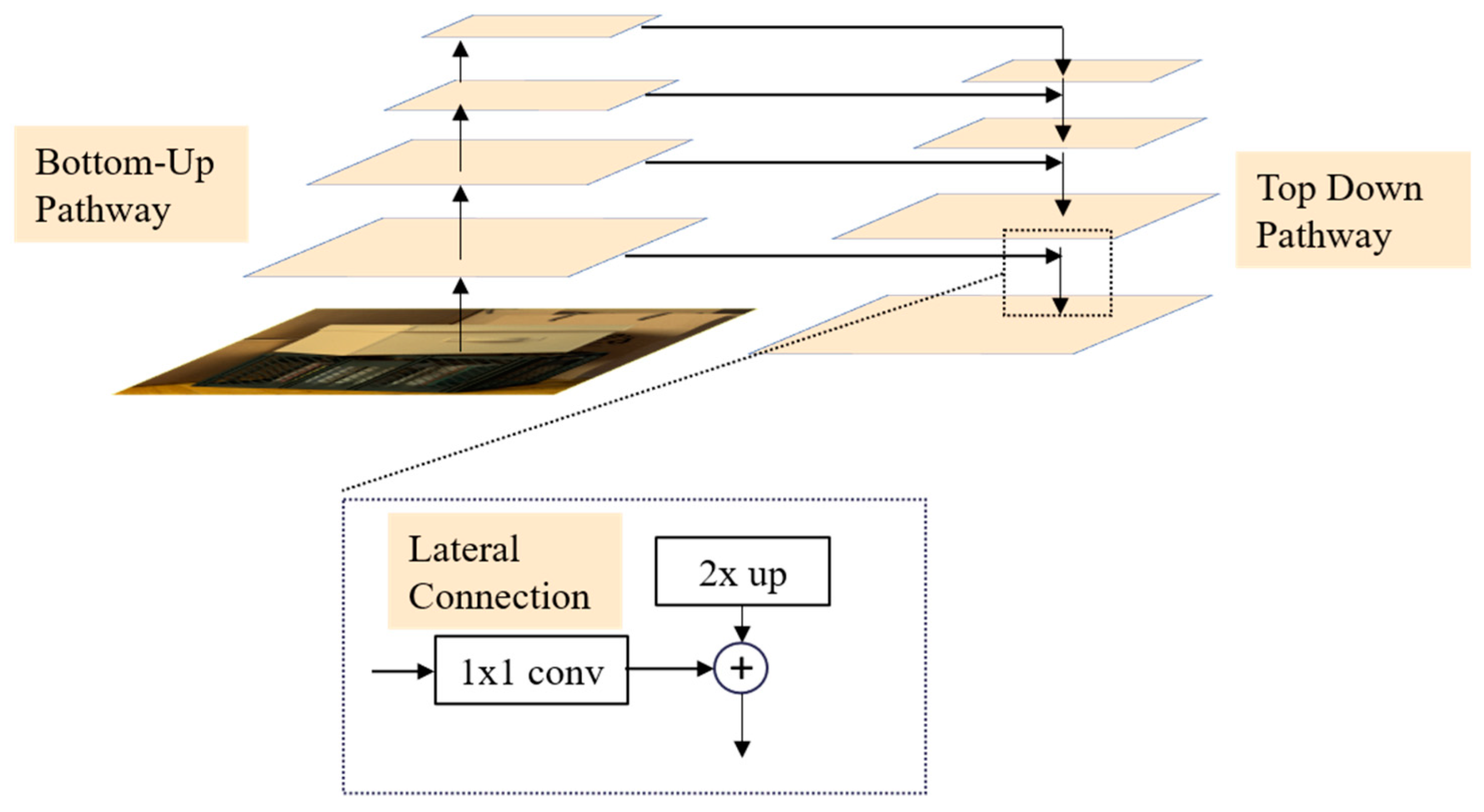
For accurate depth estimation, we leverage the effectiveness of residual blocks for feature extraction. However, the limited receptive field of convolutional neural networks presents challenges in extracting meaningful features, especially in weakly textured or occluded regions. To overcome this limitation, we incorporate a feature pyramid network (FPN) that captures global contextual information by establishing lateral connections between different levels in the feature pyramid, allowing lower-level features to be integrated into higher-level features. This enables the model to comprehend the scene at multiple scales, facilitating more robust depth estimation.
The structure of the feature pyramid network is depicted in Figure 2. Initially, the FPN module generates four feature maps of varying scales by downsampling the output feature map from the last residual block. These feature maps form a feature pyramid, providing representations at different levels of detail. Subsequently, top-down paths and lateral connections are employed to fuse the feature maps from different levels. This fusion process involves bilinear interpolation for upsampling and 1 × 1 convolutions for dimension adjustment. Ultimately, the features at the bottom of the feature pyramid serve as the output of the FPN module. This hierarchical representation enables a comprehensive understanding of the scene at different scales and captures the relationships between various objects. Consequently, our network achieves more accurate depth estimation, particularly in specialized regions, thereby enhancing overall performance.
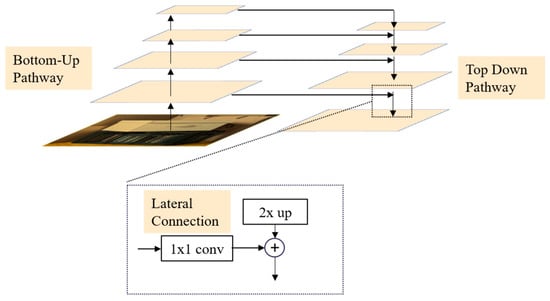
Figure 2.
Structure of feature pyramid network.
3.2. Construction Cost Volume
The utilization of a cost volume plays a crucial role in enhancing the accuracy of depth estimation [41,42]. By considering multiple viewpoints of the same scene, the model can effectively explore the disparity space and improve estimation quality. Due to the limited perception boundary of convolutional neural networks and their failure in integrating information from multiple viewpoints, the estimation of disparities with feature maps can lead to inaccuracies, particularly for larger disparities that exceed the network’s receptive field. To overcome this limitation, we construct cost volumes and leverage 3D convolutional neural networks (3DCNN) for cost volume aggregation. This approach allows the model to gather pixel information from larger spatial locations, thereby overcoming the limitation of the receptive field. Consequently, the model can effectively consider pixel correlations across different viewpoints and flexibly explore the disparity space.
In this study, we construct the cost volume by shifting the output feature maps of the feature pyramid across a predetermined range of disparities and concatenating them along the channel dimension. Specifically, given a light field feature F and a candidate disparity , we shift the feature map of each view based on the angular coordinates (u, v) of the respective view and the chosen disparity value. Subsequently, we concatenate all the shifted features to construct the cost volume. This process is mathematically described by the following equation:
where denotes the shift characteristic of the view (u, v) at disparity d, and denotes the cost tensor when the disparity is d.
The final cost volume is a 4D tensor with the shape of D × H × W × N, where D denotes the range of disparity, H and W are the height and width of the feature map, respectively, and N is the number of channels of the feature map. The disparity range is set to −4 to 4, and 17 levels of disparity are sampled uniformly between them. Finally, accurate subpixel disparity maps are obtained by aggregating cost volumes and disparity regression.
3.3. View Selection Module
Light field images, comprising multiple views from different directions, do not contribute equally to accurate depth estimation due to various factors such as occlusions, complex textures, and lighting variations. Moreover, different scenes may require different combinations of views for optimal depth estimation. To overcome these challenges and enhance depth estimation accuracy, we propose a novel attentional view selection module that dynamically adjusts the contribution of views based on scene characteristics and requirements.
Incorporating the Convolutional Block Attention Module (CBAM) [33,43] into our network allows us to integrate both channel attention and spatial attention modules. This integration enables us to adaptively recalibrate the feature response of each view, taking into account its importance in both the channel and spatial domains. By utilizing the CBAM attention mechanism, we can identify and select the most beneficial views for depth estimation, achieving improved accuracy while reducing computational costs.
3.4. Disparity Regression and Loss
To obtain aggregated information in the disparity dimension and spatial dimension of the cost volume, we used a 3D convolution-based architecture [41]. Specifically, we constructed a 3D convolutional neural network using eight 3 × 3 × 3 convolutional layers to extract feature information from the custom.
Next, we used soft argmin [44] for disparity estimation. When using cost volume for disparity estimation, the traditional method normally obtains the final disparity map by operating on the cost volume. However, the argument operation is not derivable, and so cannot be trained by backpropagation directly. To solve this problem, we adopt the soft margin method. Unlike the traditional argument, soft is a derivable operator and thus can be optimized through backpropagation during training. Specifically, for each pixel location, we multiply the disparity values in the cost volume with the corresponding normalized probabilities, and weight them to sum and obtain the final disparity values. The predicted disparity calculation formula is defined as:
where the softmax is calculated as:
In light field depth estimation, smoothed L1 loss is commonly used as a loss function to measure the difference between the predicted depth map and the true depth map. The smoothed L1 loss function is commonly used, which resists the effects of outliers during training and maintains sensitivity to gradients while reducing overfitting [38]. Disparity loss is defined as:
where N is the number of predicted labeled pixels, is the true disparity value, and is the predicted disparity value.
4. Experiment and Discussion
In this section, we first introduce the dataset used for training, then describe the implementation details, demonstrate the effectiveness of the attention module and the feature pyramid network for improving the performance of depth estimation through ablation experiments, and finally compare with the mainstream methods with qualitative and quantitative results.
4.1. 4D Light Field Dataset
This experiment uses the New HCI light field dataset [45], which consists of light field images of 24 scenes. The dataset is divided into four subsets: “additional”, “training”, “test”, and “stratified”. All light field images are generated by the Blender renderer and contain multiple types of scenes, such as occlusion scenes and fine-textured scenes. Each scene has a 9 × 9 light field multi-view sequence with an angular resolution of 9 × 9 and a spatial resolution of 512 × 512 for each light-field photo. In addition, each scene is provided with profiles for camera settings and disparity range, as well as a true depth map.
4.2. Implementation Details
In this experiment, we select a subset of the New HCI light field dataset for training and testing. Specifically, we select 16 scenes from this dataset as the training set, where the “additional” subset provides high-quality multi-view light field images, and the “stratified” and “training” subsets provide additional light field images that can be used to validate the network performance. We select four scenes from the “test” subset for the final test. In network training, we randomly select 32 × 32 grayscale blocks as training samples and use data enhancement methods [16] including view shifting, rotation, and scaling techniques. A full 512 × 512 image is used for validation and testing. Our network utilizes the Keras API of the TensorFlow framework and Adam as the optimizer, with the batch size set to 32. Specifically, the first 200,000 iterations take a learning rate of 0.001, and the next 20,000 iterations are fine-tuned with a learning rate of 0.0001. The entire training process was performed on an NVIDIA RTX 3090 GPU, and the training lasts about 100 h.
4.3. Evaluation
For an accurate quantitative evaluation of the depth estimation performance, two metrics, BadPix(ε) and MSE × 100, were employed, as suggested by prior works [45].
The BadPix metric measures the percentage of pixels for which the absolute disparity value exceeds a specific threshold between the predicted result and the ground truth label. Typically, thresholds of ε = 0.01, 0.03, and 0.07 are chosen to evaluate the performance at different levels of precision. A lower BadPix value indicates higher accuracy in the depth estimation algorithm.
The BadPix calculation formula is defined as:
The MSE × 100 metric represents the mean square error between the predicted depth map and the ground truth label, multiplied by a factor of 100. This metric quantifies the overall difference between the estimated depth map and the actual depth values. A lower MSE × 100 value indicates a higher level of accuracy in the depth estimation results.
The formula for calculating MSE is:
A comprehensive quantitative and visual comparison was conducted with twelve state-of-the-art methods. These methods encompassed four traditional approaches [14,24,46,47] and eight deep learning methods [16,33,34,36,48,49]. The results of the BadPix 0.01, BadPix 0.03, BadPix 0.07 and MSE × 100 metrics obtained by these methods across eight scenes from the validation set are presented in Table 2.
Table 2.
Quantitative results of comparison with the advanced methods on the HCI_4D LF benchmark. The best results are shown in bold and the second best results are underlined.
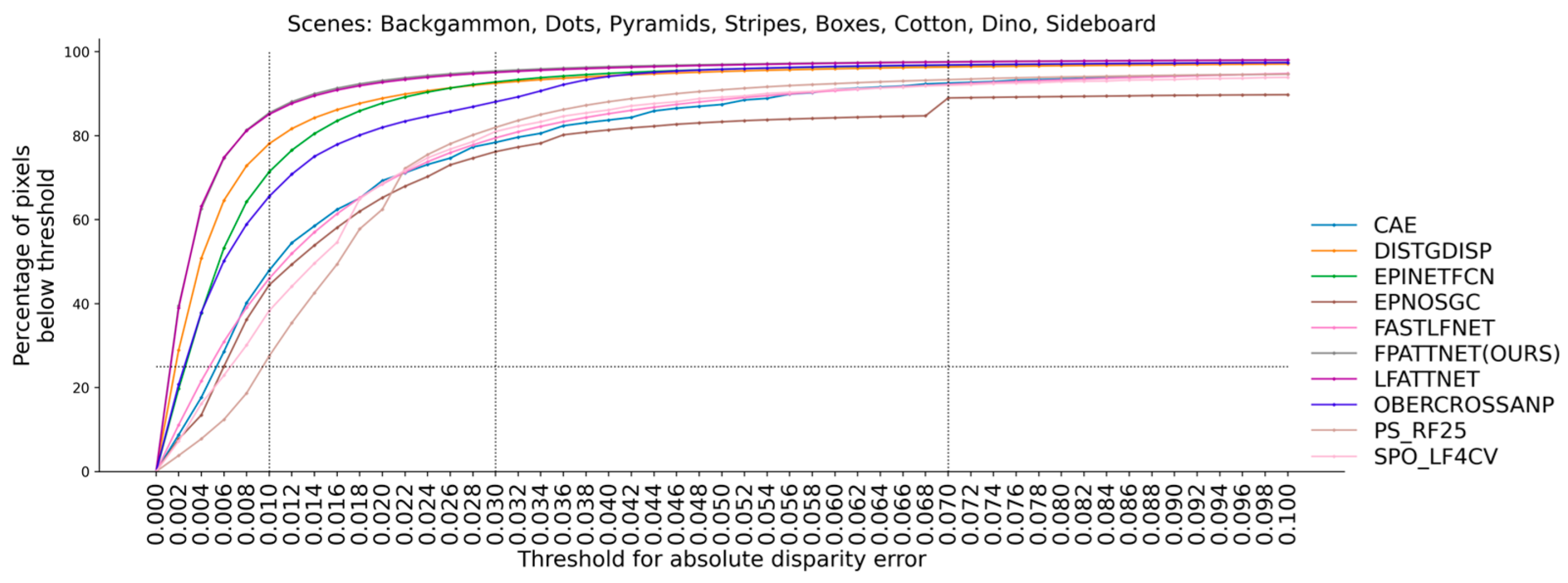
As can be seen from Table 2, our method achieves 11 best and 14 s-best results in 32 columns. As can be seen from Table 3, our method achieves the best results in the eight scenes of the validation set for the average BadPix 0.01, BadPix 0.03 and BadPix 0.07. This suggests that the use of the full view as input, in conjunction with the attention mechanism and multi-scale fusion strategy, can improve the overall depth estimation accuracy. To further analyze the BadPix metric, Figure 3 provides a visual representation. The figure illustrates the percentage of pixels with errors below, the different absolute error thresholds for disparity, as well as the percentage of pixels with errors below, a given threshold relative to the total number of pixels.
Table 3.
Average values of different methods on the validation set. The best results are shown in bold.
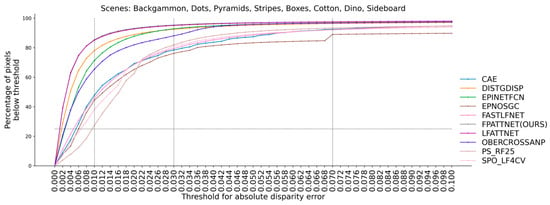
Figure 3.
Comparison of our top-ranked methods on the HCI 4D LF benchmark for the percentage of correct pixels at different BadPix thresholds.
The results depicted in Figure 4 indicate that our method consistently outperforms the other methods across various thresholds, particularly at lower thresholds. This observation suggests that our method exhibits higher accuracy in depth estimation compared to the competing approaches.
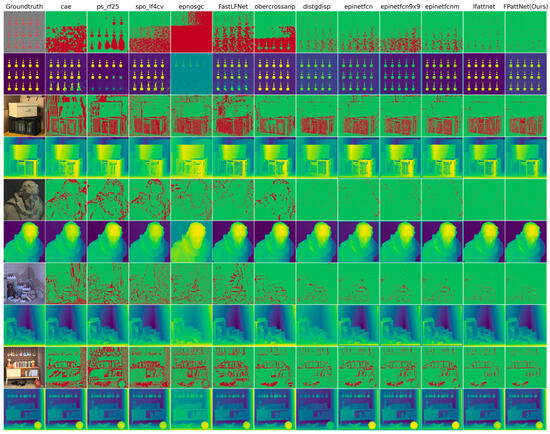
Figure 4.
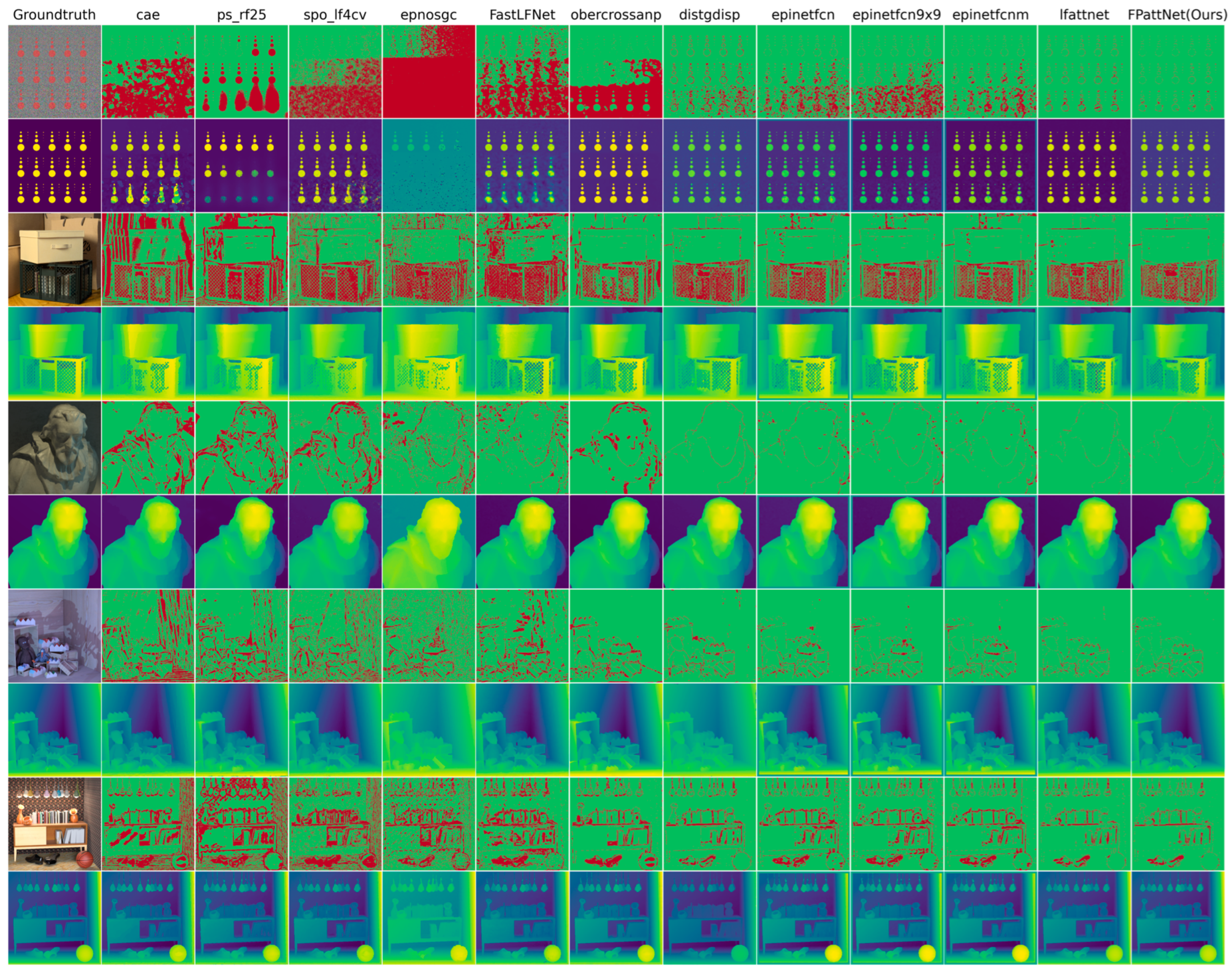
Visual comparison between our method and different LF depth estimation methods on 4D LF benchmarks, including cae [24], ps_rf25 [14], spo_lf4cv [14], epnosgc [49], FastLFNet [48], obercrossanp [47], distgdisp [36], epinetfcn [16], epinetfcn 9 × 9 [16], epinetfcnm [16] and lfattnet [33]. The even-numbered rows show the estimated disparity plots for these methods. In contrast, the odd-numbered rows show the corresponding BadPix 0.03 error maps (pixels with absolute errors greater than 0.03 are marked in red).
Figure 4 and Figure 5 present visual comparisons of different methods in five distinct scenes: dots, box, dino, sideboard, and book. Each scene represents different challenges in depth estimation, such as coplanar circles with clear edge structures in dots, severe occlusion in box and sideboard, and textureless regions, particularly in the book in the scene box.
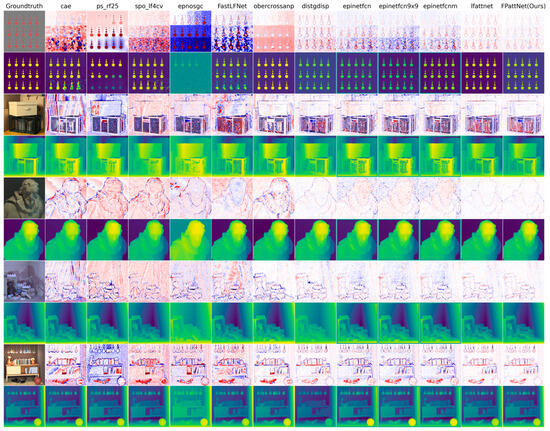
Figure 5.
Visual comparison between our method and different LF depth estimation methods on 4D LF benchmarks, including cae [24], ps_rf25 [46], spo_lf4cv [14], epnosgc [49], FastLFNet [48], obercrossanp [47], distgdisp [36], epinetfc [16], epinetfcn 9 × 9 [16], and epinetfcnm [16] and lfattnet [33]. The even-numbered rows show the estimated disparity plots for these methods. In contrast, the odd-numbered rows show the corresponding MSE error maps (pixels that predict the correct disparity are marked white, with red pixels indicating too far and blue pixels indicating too close).
By examining the BadPix 0.03 bad pixel map, our method consistently exhibits significantly fewer bad pixels compared with the other methods, particularly in scenes with occlusion and textureless regions. This indicates that our method is more effective in the accurate estimation of depth, even in some challenging scenes. In the scene dots, our method captures circular structures with greater precision and minimizes the number of bad pixels. In scenes with severe occlusion, such as box and sideboard, our method demonstrates excellent performance in handling occluded regions and generates more accurate depth maps. Additionally, our method excels in estimating depth in textureless regions, as evidenced by the book in the scene box. While other methods may struggle to estimate depth accurately in such regions, our method manages to capture the depth information more reliably, resulting in fewer bad pixels.
These visual comparisons further validate the effectiveness of our method in achieving accurate depth estimation, particularly in scenes with occlusion and textureless regions. The reduced number of bad pixels highlights the superior performance and robustness of our approach compared with the competing methods.
Figure 6 shows the performance of our method applied to the UrbanLF [50] dataset. Figure 7 shows the 3D point cloud reconstructed with the depth map obtained by different methods, and it is clear that the 3D point cloud reconstructed by our method has better integrity compared with epinetfcn, which is close to ground truth.

Figure 6.
Results of our method for the UrbanLF dataset. The first row represents the image of the center view and the second represents the disparity image.

Figure 7.
Comparison of 3D point clouds generated by different methods in the scenes boxes and sideboard. (a) Ground truth, (b) epinetfcn [16], (c) FPattNet (ours).
4.4. Ablation Experiment
In this section, we demonstrate the effectiveness of the FPN module and attention module with a large number of ablation experiments.
4.4.1. The Effect of the Feature Pyramid Networks
To investigate the impacts of the Feature Pyramid Network (FPN) module on the performance of light field depth estimation, an experiment was conducted in which the FPN module was removed from the original model and retrained. The results, as presented in Table 4, demonstrate that the FPattNet model achieved a decrease of 0.521 in average Mean Squared Error (MSE) and a decrease of 3.881 in BadPix values. These findings suggest that incorporating the FPN module can significantly enhance the overall performance of the depth estimation algorithm.
Table 4.
BadPix 0.03 and MSE (multiplied by 100) implemented by different variants of our FPattNet on the HCI 4D LF benchmark. “w/o-FPN” means that the feature pyramid module is not used in the model. The best results are shown in bold.
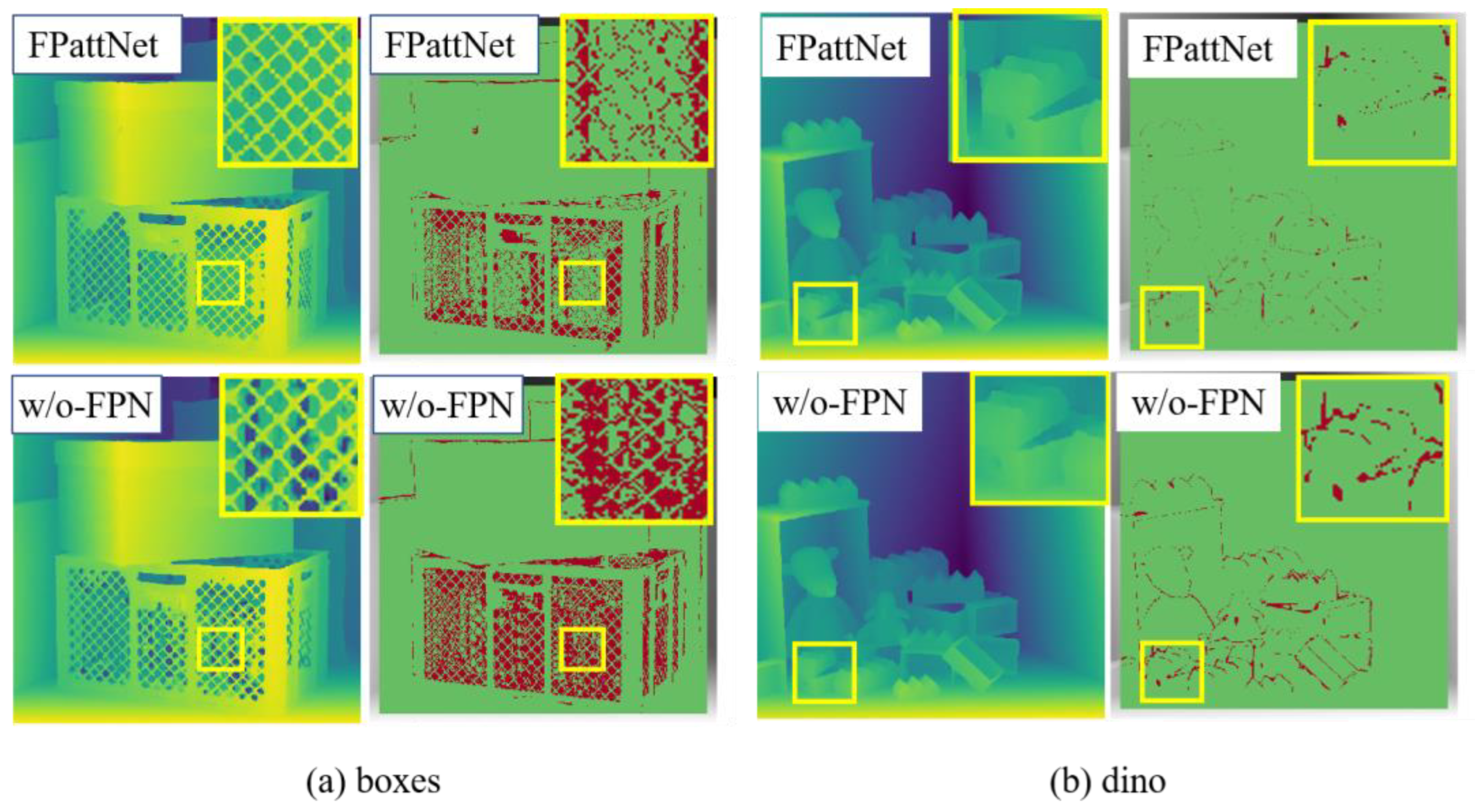
Additionally, Figure 8 provides a visual comparison of the disparity and bad pixel maps between the models with and without the FPN module in the Boxes and Dino scenes. The figure clearly illustrates that the utilization of the FPN module leads to a substantial improvement in depth estimation accuracy, particularly in heavily occluded regions and textureless regions. This improvement can be attributed to the multi-layer architecture of the FPN module, which facilitates feature extraction at various scales. Consequently, the network can capture rich semantic information and effectively model structures and textures of different sizes. In contrast, traditional single-scale methods often struggle to capture complete depth information in occluded regions. By integrating the FPN module, the network can model occluded regions at multiple scales, compensating for the lack of information in occluded and weakly textured regions, thereby resulting in more precise depth estimates.
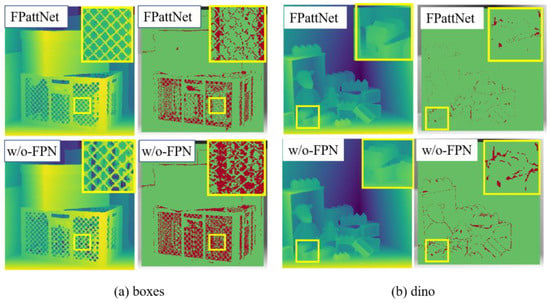
Figure 8.
Visual comparison of our method on scenes (a) boxes and (b) dino with/without FPN. The first column shows the estimated disparity map and the second column shows the BadPix 0.03 error maps.
4.4.2. The Effect of the View Selection Module
To validate the effectiveness and superiority of the view selection module, an experiment was conducted to investigate its impact on the performance of light field depth estimation. In this experiment, the Convolutional Block Attention Module (CBAM) was removed from the original model and retrained. The results, as presented in Table 5, demonstrate a notable improvement in the network’s performance when the attention mechanism is applied. The average Mean Squared Error (MSE) and BadPix values in the eight scenarios with the attention mechanism decreased by 0.379 and 4.836, respectively, compared with the variant without the attention mechanism. The introduction of the attention mechanism enables the network to dynamically select and emphasize the most valuable views for depth estimation. As shown in Figure 9, the view weights differ from scene to scene. This is accomplished by dynamic weight assignment to each view based on its respective contribution. Views with higher contributions are assigned higher weights, allowing the network to better utilize the depth information provided. Conversely, views with lower contributions are given lower weights, thereby minimizing their impact on the final depth estimation results. Focusing on the most informative views, this adaptive weighting of views improves the accuracy and robustness of depth estimation.
Table 5.
BadPix 0.03 and MSE (multiplied by 100) implemented by different variants of our FPattNet on the HCI 4D LF benchmark. “w/o-ATT” means that the attentional view selection module is not used in the model. The best results are shown in bold.

Figure 9.
Attention maps in different scenes; the darker the color, the greater the weight.
The qualitative results depicted in Figure 10 visually prove the effectiveness of the attention mechanism in enhancing depth estimation accuracy. The comparison clearly illustrates that the introduction of the attention mechanism significantly improves the accuracy of depth estimation.
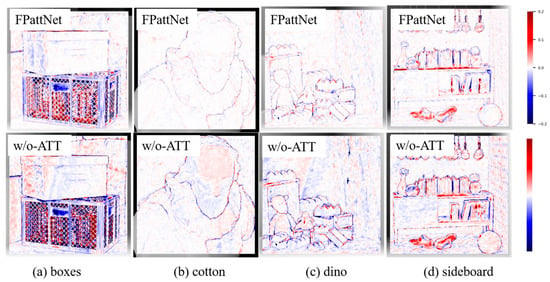
Figure 10.
Visual comparison of our method on scenes (a) boxes, (b) cotton, (c) dino, and (d) sideboard with/without using the attention mechanism. The first row shows the MSE error maps when the attention mechanism is used, and the second row shows the MSE error maps when the attention mechanism is not used. (Pixels that predict the correct disparity are marked white, with red pixels indicating too far and blue pixels indicating too close).
5. Conclusions
This paper introduces a novel light field depth estimation network that integrates a feature pyramid and an attention mechanism. These additions are designed to enhance the accuracy and robustness of depth estimation, particularly in challenging scenarios. The attention mechanism dynamically adjusts and assigns the weights to each view in the light field image, allowing the network to effectively utilize informative views while minimizing the impact of less reliable ones. This adaptive weighting scheme improves depth estimation accuracy, especially in regions with occlusion and weak texture. Additionally, our feature pyramid module plays a crucial role in capturing contextual information and aggregating features at multiple scales. This multi-scale analysis enables a comprehensive understanding of the scene, leading to improved depth estimation performance. By considering features at different scales, our method effectively captures fine details and accurately estimates depth, even in challenging regions.
Extensive experiments validate the superiority of our method over existing light field depth estimation methods. Our approach outperforms others, generating high-quality depth maps that result in refined and detailed 3D point clouds.
Author Contributions
Conceptualization, X.L. and M.X.; methodology, X.L. and M.X.; software, M.X. and C.L.; validation, X.L. and C.L.; formal analysis, M.X. and C.L.; investigation, M.X.; resources, M.X.; data curation, M.X.; writing—original draft preparation, M.X. and C.L.; writing—review and editing, X.L.; visualization, M.X.; supervision, X.L.; project administration, X.L. and M.X.; funding acquisition, X.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Key Research and Development Program of China (Grant Number: 2022YFB3606600).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All datasets analyzed in this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- De Jesus, J.C.; Kich, V.A.; Kolling, A.H.; Grando, R.B.; Guerra, R.S.; Drews, P.L.J. Depth-CUPRL: Depth-Imaged Contrastive Unsupervised Prioritized Representations in Reinforcement Learning for Mapless Navigation of Unmanned Aerial Vehicles. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 10579–10586. [Google Scholar]
- Li, C.-C.; Shuai, H.-H.; Wang, L.-C. Efficiency-Reinforced Learning with Auxiliary Depth Reconstruction for Autonomous Navigation of Mobile Devices. In Proceedings of the 2022 23rd IEEE International Conference on Mobile Data Management (MDM), Paphos, Cyprus, 6–9 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 458–463. [Google Scholar]
- Kim, C.; Zimmer, H.; Pritch, Y.; Sorkine-Hornung, A.; Gross, M. Scene Reconstruction from High Spatio-Angular Resolution Light Fields. ACM Trans. Graph. 2013, 32, 73. [Google Scholar] [CrossRef]
- Geiger, A.; Ziegler, J.; Stiller, C. StereoScan: Dense 3d Reconstruction in Real-Time. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; IEEE: New York, NY, USA, 2011; pp. 963–968. [Google Scholar]
- El Jamiy, F.; Marsh, R. Survey on Depth Perception in Head Mounted Displays: Distance Estimation in Virtual Reality, Augmented Reality, and Mixed Reality. IET Image Process. 2019, 13, 707–712. [Google Scholar] [CrossRef]
- Choi, M.-H.; Yi, W.-J.; Choi, S.-E.; Kang, S.-R.; Yoo, J.-Y.; Yang, S.; Kim, J.-E.; Huh, K.-H.; Lee, S.-S.; Heo, M.-S. Markerless Registration for Augmented-Reality Surgical Navigation System Based on Monocular Depth Estimation. Trans. Korean Inst. Electr. Eng. 2021, 70, 1898–1905. [Google Scholar] [CrossRef]
- Tao, Y.; Xiong, S.; Conway, S.J.; Muller, J.-P.; Guimpier, A.; Fawdon, P.; Thomas, N.; Cremonese, G. Rapid Single Image-Based DTM Estimation from ExoMars TGO CaSSIS Images Using Generative Adversarial U-Nets. Remote Sens. 2021, 13, 2877. [Google Scholar] [CrossRef]
- Lore, K.G.; Reddy, K.; Giering, M.; Bernal, E.A. Generative Adversarial Networks for Depth Map Estimation from RGB Video. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; IEEE: New York, NY, USA, 2018; pp. 1258–1266. [Google Scholar]
- Tao, Y.; Muller, J.-P.; Xiong, S.; Conway, S.J. MADNet 2.0: Pixel-Scale Topography Retrieval from Single-View Orbital Imagery of Mars Using Deep Learning. Remote Sens. 2021, 13, 4220. [Google Scholar] [CrossRef]
- Raytrix|3D Light Field Camera Technology. Available online: https://raytrix.de/ (accessed on 1 July 2023).
- Heber, S.; Pock, T. Shape from Light Field Meets Robust PCA. In Computer Vision—ECCV 2014; Lecture Notes in Computer Science; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; Volume 8694, pp. 751–767. ISBN 978-3-319-10598-7. [Google Scholar]
- Jeon, H.-G.; Park, J.; Choe, G.; Park, J.; Bok, Y.; Tai, Y.-W.; Kweon, I.S. Accurate Depth Map Estimation from a Lenslet Light Field Camera. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: New York, NY, USA, 2015; pp. 1547–1555. [Google Scholar]
- Zhang, S.; Sheng, H.; Li, C.; Zhang, J.; Xiong, Z. Robust Depth Estimation for Light Field via Spinning Parallelogram Operator. Comput. Vis. Image Underst. 2016, 145, 148–159. [Google Scholar] [CrossRef]
- Wanner, S.; Goldluecke, B. Globally Consistent Depth Labeling of 4D Light Fields. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; IEEE: New York, NY, USA, 2012; pp. 41–48. [Google Scholar]
- Shin, C.; Jeon, H.-G.; Yoon, Y.; Kweon, I.S.; Kim, S.J. EPINET: A Fully-Convolutional Neural Network Using Epipolar Geometry for Depth from Light Field Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 8–22 June 2018; IEEE: New York, NY, USA, 2018; pp. 4748–4757. [Google Scholar]
- Leistner, T.; Schilling, H.; Mackowiak, R.; Gumhold, S.; Rother, C. Learning to Think Outside the Box: Wide-Baseline Light Field Depth Estimation with EPI-Shift. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Quebec City, QC, Canada, 16–19 September 2019; pp. 249–257. [Google Scholar]
- Shi, L.; Zhao, S.; Chen, Z. Belif: Blind Quality Evaluator of Light Field Image with Tensor Structure Variation Index. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3781–3785. [Google Scholar]
- Shi, L.; Zhou, W.; Chen, Z.; Zhang, J. No-Reference Light Field Image Quality Assessment Based on Spatial-Angular Measurement. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 4114–4128. [Google Scholar] [CrossRef]
- Zhou, W.; Shi, L.; Chen, Z.; Zhang, J. Tensor Oriented No-Reference Light Field Image Quality Assessment. IEEE Trans. Image Process. 2020, 29, 4070–4084. [Google Scholar] [CrossRef] [PubMed]
- Meng, C.; An, P.; Huang, X.; Yang, C.; Shen, L.; Wang, B. Objective Quality Assessment of Lenslet Light Field Image Based on Focus Stack. IEEE Trans. Multimed. 2022, 24, 3193–3207. [Google Scholar] [CrossRef]
- Bishop, T.E.; Favaro, P. The Light Field Camera: Extended Depth of Field, Aliasing, and Superresolution. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 972–986. [Google Scholar] [CrossRef] [PubMed]
- Yu, Z.; Guo, X.; Ling, H.; Lumsdaine, A.; Yu, J. Line Assisted Light Field Triangulation and Stereo Matching. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, NSW, Australia, 1–8 December 2013; IEEE: New York, NY, USA, 2013; pp. 2792–2799. [Google Scholar]
- Williem; Park, I.K.; Lee, K.M. Robust Light Field Depth Estimation Using Occlusion-Noise Aware Data Costs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2484–2497. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Lin, H.; Yu, Z.; Kang, S.B.; Yu, J. Light Field Stereo Matching Using Bilateral Statistics of Surface Cameras. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; IEEE: New York, NY, USA, 2014; pp. 1518–1525. [Google Scholar]
- Bolles, R.; Baker, H.; Marimont, D. Epipolar-Plane Image-Analysis-an Approach to Determining Structure from Motion. Int. J. Comput. Vis. 1987, 1, 7–55. [Google Scholar] [CrossRef]
- Matoušek, M.; Werner, T.; Hlavác, V. Accurate Correspondences from Epipolar Plane Images. In Proceedings of the Computer Vision Winter Workshop, Brno, Czech Republic, 5–7 February 2001; Citeseer: University Park, PA, USA, 2001; pp. 181–189. [Google Scholar]
- Criminisi, A.; Kang, S.B.; Swaminathan, R.; Szeliski, R.; Anandan, P. Extracting Layers and Analyzing Their Specular Properties Using Epipolar-Plane-Image Analysis. Comput. Vis. Image Underst. 2005, 97, 51–85. [Google Scholar] [CrossRef]
- Tao, M.W.; Hadap, S.; Malik, J.; Ramamoorthi, R. Depth from Combining Defocus and Correspondence Using Light-Field Cameras. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, NSW, Australia, 1–8 December 2013; IEEE: New York, NY, USA, 2013; pp. 673–680. [Google Scholar]
- Mousnier, A.; Vural, E.; Guillemot, C. Partial Light Field Tomographic Reconstruction from a Fixed-Camera Focal Stack. arXiv 2015, arXiv:1503.01903. [Google Scholar]
- Heber, S.; Yu, W.; Pock, T. Neural EPI-Volume Networks for Shape from Light Field. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: New York, NY, USA, 2017; pp. 2271–2279. [Google Scholar]
- Heber, S.; Pock, T. Convolutional Networks for Shape from Light Field. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: New York, NY, USA, 2016; pp. 3746–3754. [Google Scholar]
- Tsai, Y.-J.; Liu, Y.-L.; Ouhyoung, M.; Chuang, Y.-Y. Attention-Based View Selection Networks for Light-Field Disparity Estimation. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Assoc Advancement Artificial Intelligence: Palo Alto, CA, USA, 2020; Volume 34, pp. 12095–12103. [Google Scholar]
- Lin, J.C.Z. Attention-Based Multi-Level Fusion Network for Light Field Depth Estimation. Available online: https://aaai.org/papers/01009-attention-based-multi-level-fusion-network-for-light-field-depth-estimation/ (accessed on 23 July 2023).
- Wang, Y.; Wang, L.; Liang, Z.; Yang, J.; An, W.; Guo, Y. Occlusion-Aware Cost Constructor for Light Field Depth Estimation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 19777–19786. [Google Scholar]
- Wang, Y.; Wang, L.; Wu, G.; Yang, J.; An, W.; Yu, J.; Guo, Y. Disentangling Light Fields for Super-Resolution and Disparity Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 425–443. [Google Scholar] [CrossRef] [PubMed]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated Residual Networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 636–644. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: New York, NY, USA, 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 936–944. [Google Scholar]
- Chang, J.-R.; Chen, Y.-S. Pyramid Stereo Matching Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; IEEE: New York, NY, USA, 2018; pp. 5410–5418. [Google Scholar]
- Zbontar, J.; LeCun, Y. Stereo Matching by Training a Convolutional Neural Network to Compare Image Patches. J. Mach. Learn. Res. 2016, 17, 65. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision-Eccv 2018, Pt Vii, Munich, Germany, 8–14 September 2018; International Publishing Ag: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. [Google Scholar]
- Kendall, A.; Martirosyan, H.; Dasgupta, S.; Henry, P.; Kennedy, R.; Bachrach, A.; Bry, A. End-to-End Learning of Geometry and Context for Deep Stereo Regression. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: New York, NY, USA, 2017; pp. 66–75. [Google Scholar]
- Honauer, K.; Johannsen, O.; Kondermann, D.; Goldluecke, B. A Dataset and Evaluation Methodology for Depth Estimation on 4D Light Fields. In Proceedings of the Computer Vision-Accv 2016, Pt Iii, Taipei, Taiwan, 20–24 November 2016; Springer International Publishing Ag: Cham, Switzerland, 2017; Volume 10113, pp. 19–34. [Google Scholar]
- Jeon, H.-G.; Park, J.; Choe, G.; Park, J.; Bok, Y.; Tai, Y.-W.; Kweon, I.S. Depth from a Light Field Image with Learning-Based Matching Costs. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 297–310. [Google Scholar] [CrossRef] [PubMed]
- Schilling, H.; Diebold, M.; Rother, C.; Jaehne, B. Trust Your Model: Light Field Depth Estimation with Inline Occlusion Handling. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE: New York, NY, USA, 2018; pp. 4530–4538. [Google Scholar]
- Huang, Z.; Hu, X.; Xue, Z.; Xu, W.; Yue, T. Fast Light-Field Disparity Estimation with Multi-Disparity-Scale Cost Aggregation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV 2021), Montreal, QC, Canada, 10–17 October 2021; IEEE: New York, NY, USA, 2021; pp. 6300–6309. [Google Scholar]
- Luo, Y.; Zhou, W.; Fang, J.; Liang, L.; Zhang, H.; Dai, G. EPI-Patch Based Convolutional Neural Network for Depth Estimation on 4D Light Field. In Proceedings of the Neural Information Processing (ICONIP 2017), Pt Iii, Guangzhou, China, 14–18 November 2017; Springer International Publishing Ag: Cham, Switzerland, 2017; Volume 10636, pp. 642–652. [Google Scholar]
- Sheng, H.; Cong, R.; Yang, D.; Chen, R.; Wang, S.; Cui, Z. UrbanLF: A Comprehensive Light Field Dataset for Semantic Segmentation of Urban Scenes. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7880–7893. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).