Abstract
Food additives are utilized in countless food products available for sale. They enhance or obtain a specific flavor, extend the storage time, or obtain a desired texture. This paper presents an automatic classification system for five food additives based on their absorbance in the ultraviolet domain. Solutions with different concentrations were created by dissolving a measured additive mass into distilled water. The analyzed samples were either simple (one additive solution) or mixed (two additive solutions). The substances presented absorbance peaks between 190 nm and 360 nm. Each substance presents a certain number of absorbance peaks at specific wavelengths (e.g., acesulfame potassium presents an absorbance peak at 226 nm, whereas the peak associated with potassium sorbate is at 254 nm). Therefore, each additive has a distinctive spectrum that can be used for classification. The sample classification was performed using deep learning techniques. The samples were associated with numerical labels and divided into three datasets (training, validation, and testing). The best classification results were obtained using CNN (convolutional neural network) models. The classification of the 404 spectra with a CNN model with three convolutional layers obtained a mean testing accuracy of 92.38% ± 1.48%, whereas the mean validation accuracy was 93.43% ± 2.01%.
1. Introduction
Food additive use has increased since the twenty-first-century lifestyle demands a quicker pace for everyday activities [1,2]. Humans do not have as much time as their ancestors for cropping vegetables, breeding animals, and preparing meals. Their usual routine revolves around work, home duties, and leisure activities. Although people do not grow their crops, they still need food for survival.
Food is nowadays easily accessible [3]. Basic ingredients and packed products can be bought from local markets and supermarkets, whereas fresh cooked products are available in restaurants, pastries, and bakeries. Most products can also be ordered through delivery applications [4,5].
The downside of buying cooked/packed food products is not knowing the ingredients and their quality. Also, products may contain one or more food additives [6]. Food additives are extremely important for the food industry. These substances counteract spoilage, prolong the storage duration, or give the product a distinguished flavor, color, or texture [7]. The use of food additives has increased the variety of food products available for sale [7], has allowed consumers to taste local food products from distant countries [8], and has allowed companies to produce large quantities of food without the risk of food spoilage within the production-delivery period. Food additives are considered safe for consumption considering the acceptable daily intake (ADI). The ADI is the estimated quantity of a certain additive that a person can consume daily without any health risks [9].
Six categories of food additives were identified based on their functionality: preservatives, coloring agents (natural or synthetic colorants), flavoring agents (sweeteners, flavor enhancers), texturizing agents (emulsifiers, stabilizers), nutritional agents (vitamins), and other additives (catalysts) [7]. Aspartame, acesulfame potassium, and saccharin are some commonly used sweeteners, whereas sodium benzoate and potassium sorbate are preservatives [10]. Preservatives fight bacteria within food and prevent the product from spoilage for longer periods than normal, whereas sweeteners provide a sweet taste and fewer calories (or none) than other sugar types [7].
Aspartame is a non-saccharide artificial sweetener that is rapidly metabolized when consumed. The digestive enzymes transform it into methanol, phenylalanine, and aspartic acid [11]. It is commonly used to provide a sweet taste to beverages and food products. The ADI established by the FDA (US Food and Drug Administration) is 50 mg/kg of body weight (bw) per day, whereas according to the EFSA (European Food Safety Authority), the recommended ADI is 40 mg/kg bw/day [12]. Acesulfame potassium (AceK) is a chemically synthesized sweetener considered safe for human consumption. The ADI recommended by the JECFA (Evaluations of the Joint FAO/WHO Expert Committee on Food Additives) is 0–15 mg/kg bw/day. It is commonly used for confectionary products, including sweets and candies.
Saccharin, another artificial sweetener, is also used in sweets (cookies, jams) and soda drinks. It is a white crystalline powder, 300–400 times sweeter than table sugar, with an ADI of 0–5 mg/kg bw, according to JECFA. Two of the most exhaustively used preservatives are sodium benzoate and potassium sorbate. These additives fight against yeast and molds within pickled vegetables, fruit products, cheese, and soft drinks [13,14]. The ADI recommended by JECFA is 0–25 mg/kg bw for potassium sorbate and 0–5 mg/kg bw for sodium benzoate.
Even though these substances are considered harmless, multiple studies have been performed on sweeteners [15,16,17,18], preservatives [19,20], and other food additives [21] to identify the effects of additives on health. Notwithstanding aspartame being considered safe for consumption, its effects on health are still very much debated. Studies have shown that aspartame consumption may impair the growth of the placenta in impregnated mice [12], affect the extravillous trophoblasts of pregnant rodents [22], and influence fertility for women of reproductive age [23]. Similarly, research studies on mice indicate that AceK might increase the risk of atherosclerosis [24], and saccharine consumption during metformin therapy could hinder the effect of the anti-diabetes medication [25]. Reported results have also illustrated that preservatives may have inhibitory effects at the molecular level [14]. Another study identified consumers’ perceptions and knowledge of food additives [26].
Various methods have been identified for the determination of food additives. Some techniques can detect only a certain additive [27,28], whereas others can simultaneously determine multiple substances [29,30,31]. The artificial sweetener, aspartame, has been detected using surface-enhanced Raman spectroscopy [27]. The analyzed samples were prepared by dissolving aspartame in mineral water samples (flavored and unflavored). The results highlight that the technique can detect aspartame within 15 s, even for samples containing other additives (flavored water samples).
Electrochemical sensors have also been employed for additive detection. These sensors were based on a molecularly imprinted polymer and could determine acesulfame potassium (AceK) concentrations between 0.1 and 17 μm in real samples [28].
Capillary electrophoresis is one technique that allows the separation and quantification of different artificial sweeteners. The technique has been used to concomitantly determine four artificial sweeteners within dietetic soft drinks and tabletop sweetener samples. It provides rapid and accurate results and does not require elaborate sample preparation, making it appropriate for food quality applications [29].
Simultaneous detection of food additives was also performed using liquid chromatography/tandem mass chromatography. This method was used to identify ten sweeteners in alcoholic/non-alcoholic beverages and food products [30]. Colorimetry was used for the quantification of sodium benzoate in juice, wine, and vinegar samples for low limits of detection of 2 μM [32], whereas terahertz spectroscopy was combined with SVM (support vector machine) for the identification of six food additives based on coumarin [33]. The proposed methods obtained are reliable, accurate, and more efficient than other detection methods.
Over the past few years, analysis methods have been combined with machine/deep learning techniques for determining food additives or other substances within food products. Sodium benzoate and potassium sorbate were concurrently ascertained using ultraviolet spectrophotometry, the backpropagation neural network algorithm, and partial least squares regression (PLS) [34]. Sugar content in wine grapes was assessed using VNIR-SWIR (visible and near-infrared and short-wave infrared) spectroscopy and machine learning algorithms such as SVM, SVR (support vector regression), CNN (convolutional neural network), and other techniques [35]. In contrast, the determination of aflatoxin B1 in maize was accomplished using NIR (near-infrared) spectroscopy, Markov transition field (MTF) image coding, and a CNN [36]. Infrared spectroscopy and CNN were also used for the classification of Italian pasta [37], melamine and cyanuric acid detection [38], yali pear inspection [39], and polysaccharide detection [40].
Considering the large number of studies that analyze the effects of food additives [15,16,17,18,19,20,21] and the various methods that are used for the additives’ identification [27,28,29,30,31], it can be stated that the identification, classification, and analysis of food additives are important, up-to-date subjects of research.
This work uses artificial neural networks (ANNs) and CNN algorithms to identify and classify food additives based on the spectra recorded in the ultraviolet region of the electromagnetic spectrum. Ultraviolet spectroscopy is combined with neural network algorithms to identify five food additives: two preservatives (sodium benzoate and potassium sorbate) and three artificial sweeteners (aspartame, acesulfame potassium, and saccharin). The objective was to analyze and categorize the spectrum of one-additive solutions and two-additive solutions using coupling spectroscopy with neural network algorithms.
2. Materials and Methods
This study aimed to classify five additives based on their ultraviolet (UV) spectrum. According to the Beer–Bouguer–Lambert Law, the absorbance of a liquid sample depends on the molar concentration (molarity) of the solution, the optical path, and the molar absorptivity. Since the molar concentration influences absorbance, spectra with different absorbance values can be acquired for each additive, constructing a varied and large database.
Liquid samples were prepared by dissolving the additives into distilled water. Two types of samples were prepared. The first category included samples that contained only one food additive dissolved in distilled water (simple solutions). The second category consisted of samples created by mixing two food additives previously dissolved in distilled water (mixed solutions or two-additive solutions). Table A1 presents the five food additives that were selected for this study (three sweeteners and two preservatives).
2.1. UV-Visible Spectrophotometer
The liquid samples were analyzed using the Jasco V-750 UV-Visible Spectrophotometer (Hachioji, Tokyo, Japan). This device has a wavelength range between 190 and 900 nm, with a wavelength accuracy of ±0.2 nm at 656.1 nm. The spectral bandwidth is 1 nm, with photometric accuracies of ±0.0015 Abs (for 0 to 0.5 Abs) and ±0.0025 Abs (for 0.5 to 1 Abs) [41].
Before the spectrum acquisition, the baseline was recorded using distilled water in both the sample and reference cuvettes. The first measurements were performed using simple solutions. To initiate the spectrum acquisition, 3 cm3 of the sample was deposited in the sample cuvette using a pipette. The cuvette was cleaned after each solution using distilled water.
2.2. Simple Solutions
The simple solutions were prepared by diluting each additive in 5 cm3 of distilled water. Table A2 presents the calculated and measured mass of solute necessary for obtaining five solutions. Lower concentrations required small quantities of additives, which could not be measured using the laboratory scale (the device could measure quantities down to 0.0001 g). Therefore, concentrated solutions were diluted. The molar concentrations were halved by mixing 1.5 cm3 of the concentrated sample with 1.5 cm3 of distilled water. Table 1 presents the maximum and the minimum molar concentration and the number of samples that were analyzed for each additive. A total of 193 spectra were acquired for one-additive solutions.

Table 1.
Molar concentrations for simple solutions.
2.3. Two-Additives Solutions
The two-additive solutions were obtained by combining two samples of similar or different concentrations. For each sample, the mass of the substance was measured and then the substance was dissolved in 5 cm3 of distilled water. The mixture was prepared by adding 2 cm3 of the first sample and 2 cm3 of the second. Since both samples contained distilled water when the samples were combined, the molar concentrations of each substance were halved when the samples were combined. Ten different mixtures (Table 2) were obtained with the five additives.
Table 2.
Molar concentrations for mixed solutions.
2.4. Deep Learning Techniques
The classification of the additives was performed using deep learning techniques. Deep learning methods process large amounts of data, identifying patterns within the dataset to provide precise predictions. One of the most famous deep learning algorithms is CNN (convolutional neural network). This algorithm automatically determines the input dataset’s important features without external supervision. CNN has been successfully used for texture feature detection [42], hyperspectral image classification [43], medical diagnosis [44], and facial recognition [45] and has also been associated with optical techniques for food analysis [37,38,39]. The most popular CNN architectures are AlexNet, GoogLeNet, ResNet, X-ception, Inception-V4, and others [46].
The structure of a neural network was developed based on the human brain and the nervous system. A CNN is constructed using several convolutional layers followed by sub-sampling layers (pooling layers), a flatten layer, and multiple fully connected layers [39]. The convolutional layer is built of convolutional filters known as kernels. The kernel size defines the filter mask’s dimensions applied to the input dataset. For a 1D-CNN, the kernel size could be set to 3, 5, or larger values, whereas for a 2D-CNN, the kernel size would have to be two-dimensional (e.g., 3 × 3).
The convolutional layers create feature maps that are sub-sampled by the pooling layer. In other words, the pooling layers save the most significant features within pooled featured maps. The methods that could be used in a pooling layer are max pooling, average pooling, global average pooling, gate pooling, global max pooling, and others [39]. In some cases, these layers decrease the general performance of the network. A pooling layer saves the most important features but focuses on determining the correct location of the feature, resulting in relevant information loss [46].
The data within the pooled feature maps must be delivered to the fully connected layers, but firstly, it needs to pass through a flattening process, transforming the pooled featured maps into a vector [46]. The flatten layer is connected to fully connected layers. These layers are positioned at the end of the network, with all the neurons from one layer being connected to all the neurons from the preceding layer. The fully connected layers are also the main parts of an ANN (artificial neural network). Therefore, a CNN could be described as an ANN with one or more convolutional and pooling layers.
ANNs present an input layer and one or more hidden and output layers. Each layer presents neurons that are defined by weights and a bias. Data are passed from one layer to another depending on the output of each neuron. Neurons are activated based on non-linear activation functions such as Sigmoid, Tanh (hyperbolic tangent), ReLU (Rectified Linear Unit), Leaky ReLU, or NoisyReLU [46]. The most utilized activation function is ReLU due to its low computational load. This function converts the input data into positive numbers [46].
The classification is performed at the end of the fully connected layer. The output layer employs loss functions to establish the error between real and predicted outputs. The real outputs are also called labels, whereas the predicted outputs are known as predictions. Loss functions that can be utilized include cross-entropy (Softmax), Euclidean, Mean Square Error (MSE), Hinge, and others. The Softmax loss function is used for assessing the performances of a model, the Euclidean loss function is used for regression applications, and the Hinge loss function is utilized for binary classification [46].
The loss functions can be minimized using optimizers. These methods are mathematical functions that enhance the performance of the network. Adam (Adaptive Moment Estimation) is the most commonly used optimizer due to its low computational load and memory efficiency [46]. Other optimizers include Momentum, Mini-Batch Gradient Descent, Stochastic Gradient Descent, and Batch Gradient Descent [46]. Other parameters influencing the network’s performances are batch size and the number of epochs. The batch size defines a subset of samples the network uses before the model parameters are updated. The number of epochs can be defined as the number of iterations for which the model would be trained.
A CNN needs to learn the dataset’s features to assess new data and make predictions. Therefore, the input dataset is split into three datasets, each used for a different purpose. The training dataset helps the network learn the most significant features and usually contains 80% of the dataset. The rest of the data are used to calculate the accuracy of the network by comparing the predictions with the actual classes. The results obtained after testing are represented as confusion matrixes. A third dataset (the unseen data) can be used for validation to eliminate the possibility of data overfitting.
A CNN model can obtain good training and testing results, but when faced with new unseen data, it might be unable to correctly classify the data. Overfitting might appear due to many correlated parameters [46], the training dataset size may be too reduced or may contain irrelevant information. The opposite effect might also appear and is known as underfitting. In this case, the model is not trained enough, so it cannot associate the input data with the correct output.
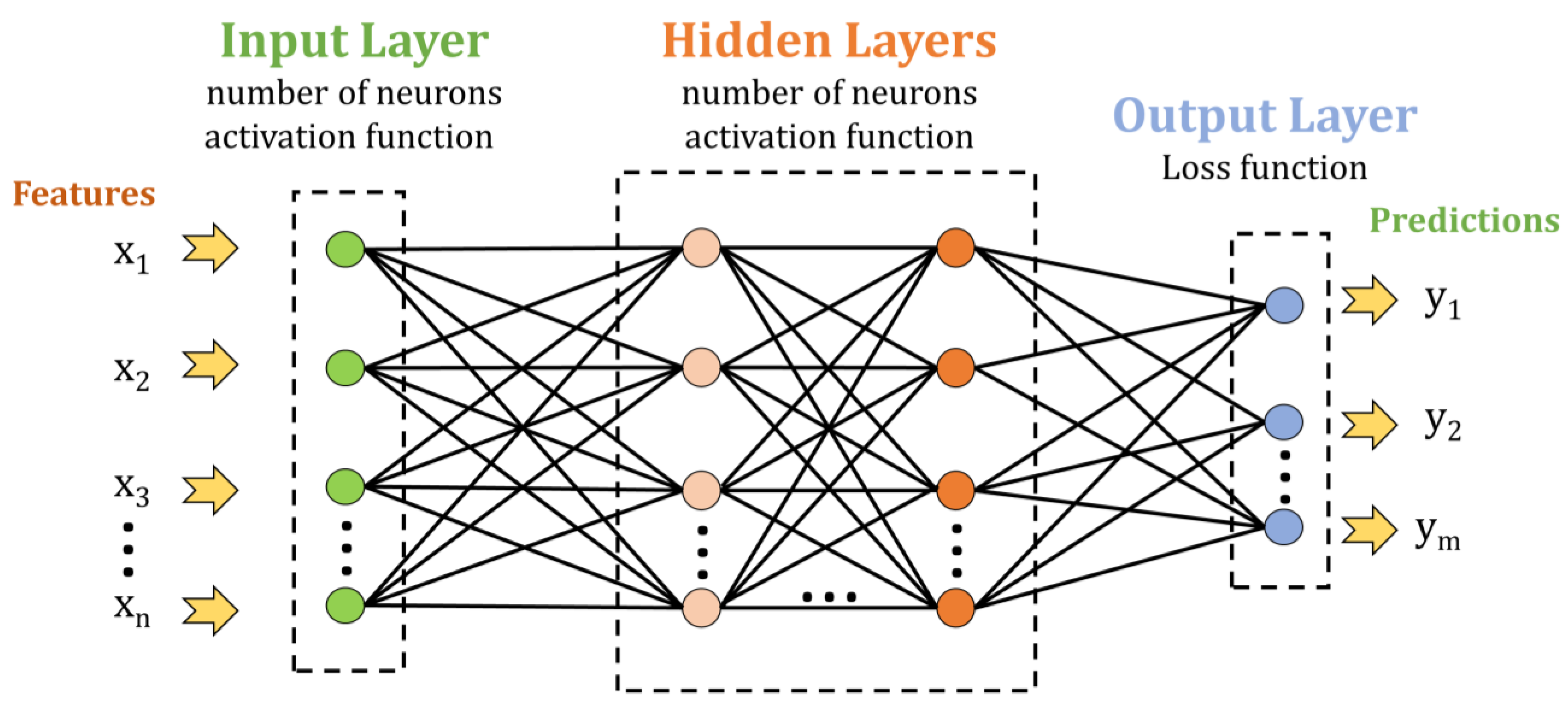
This study tested several ANN and CNN architectures to establish which would be more appropriate for classifying UV spectra. The architecture selection was performed using trial-and-error until the best performance was achieved. Sequential models for ANN and CNN were implemented in the Python programming language [47]. The initial classification was performed using an ANN since their sequential model only contains an input layer, hidden layers, and an output layer, as is presented in Figure 1.
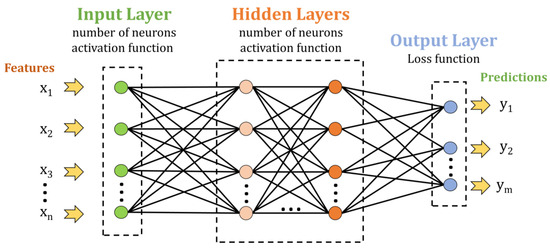
Figure 1.
General architecture of ANN model with an input layer, multiple hidden layers, and an output layer.
The validation accuracy was tested for a network with one and two hidden layers. The input layer was a fully connected layer with 128 neurons that used an ReLU activation function. The hidden layers were also fully connected layers that contained 256 neurons and that used ReLU as an activation function. The number of neurons in the output layer varied because the network was tested initially for one-additive solutions (the output layer contained 5 neurons), for two-additive solutions (10 neurons), and for all the samples (15 neurons).
Convolutional and pooling layers were added to the ANN model. The CNN was built with one, two, and three convolutional layers, followed by pooling layers to test how the accuracy changes with the increase in convolutional layers. The performances of the model were also tested without pooling layers.
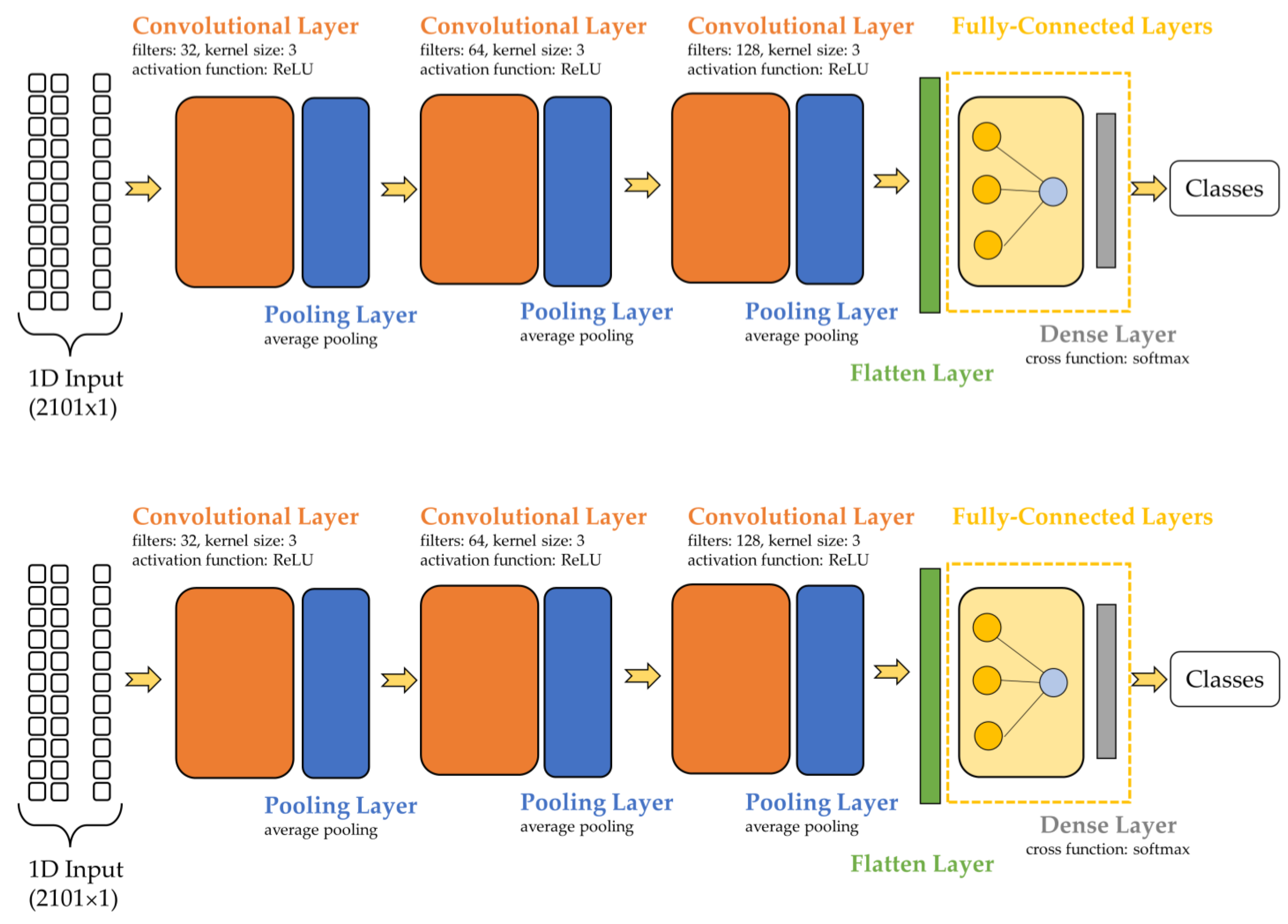
The sequential model for the CNN is presented in Figure 2. The first convolutional layer presented 32 filters, a kernel size of 3, and an ReLU activation function. The second and third layers were similar, differing only in the number of filters (second layer 64, third layer 128). The methods used for the pooling layer included average pooling for the 1-dimensional dataset. A flatten layer was positioned between the convolutional and fully connected layers. The input layer was built using 128 neurons and an ReLU activation function. The hidden layers of the ANN used the ReLU activation function and had 256 neurons per layer. The cross-function utilized in the output layer was Softmax.
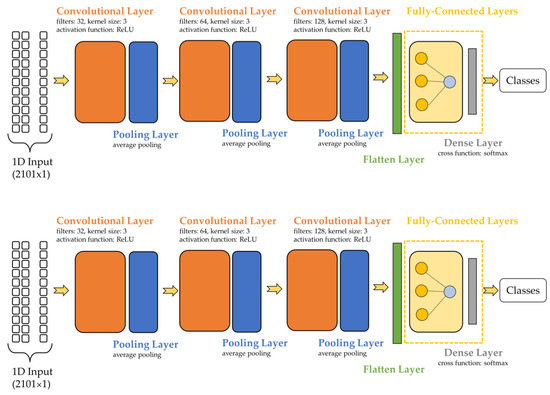
Figure 2.
CNN with three convolutional layers followed by pooling layers.
3. Results
3.1. UV Spectra of Simple Solutions
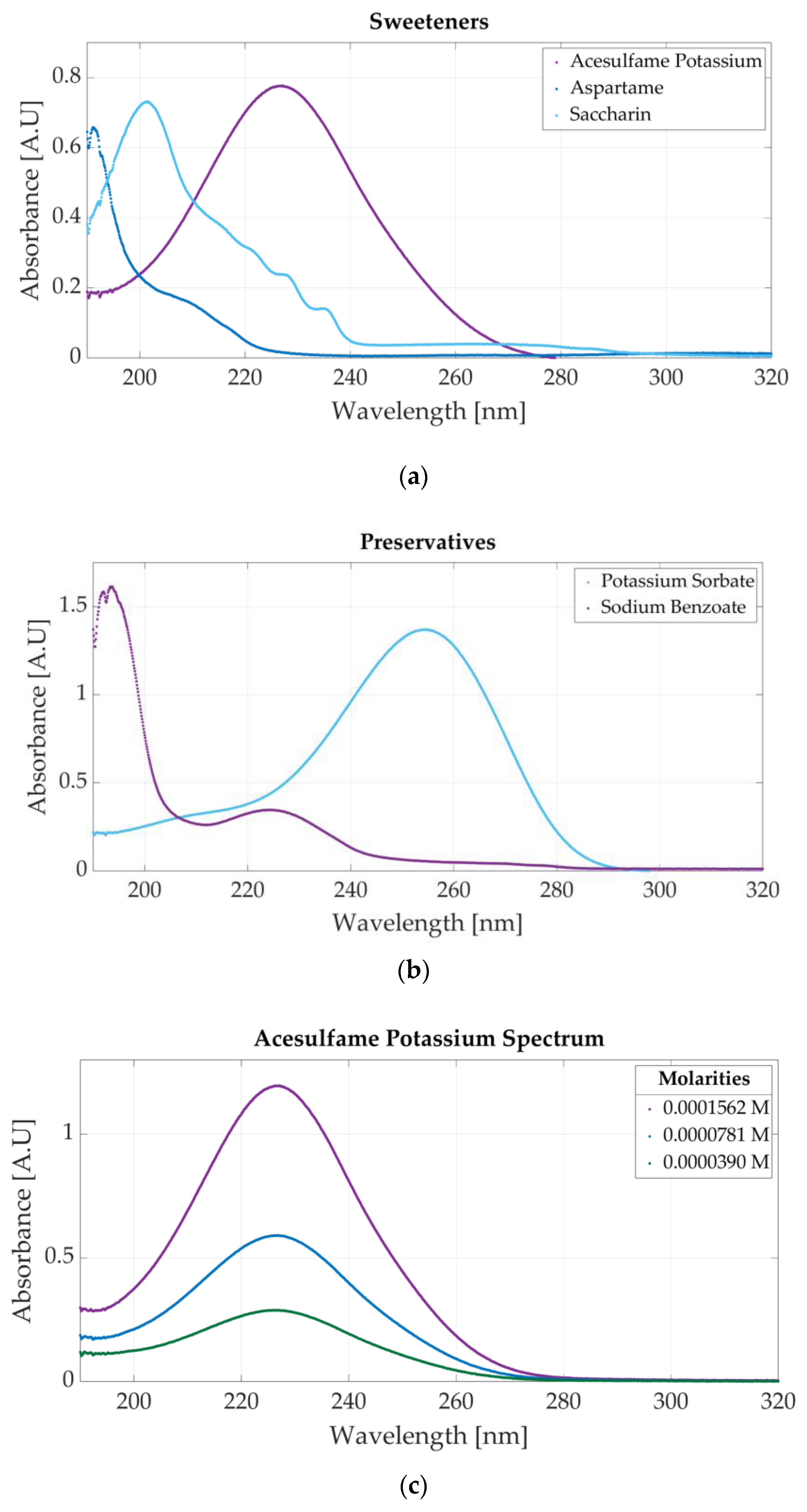
The spectrometric measurements performed using the Jasco V-750 UV-Visible Spectrophotometer (Hachioji, Tokyo, Japan) show that each additive has a specific spectrum, making their classification possible. The spectrum of the sweeteners is presented in Figure 3a. The molar concentrations of the samples are 0.0000625 M acesulfame potassium, 0.00000976 M aspartame, and 0.0000117 M saccharin. Acesulfame potassium presents an absorbance peak at 226 nm, aspartame at 191 nm, and saccharin at 201 nm.
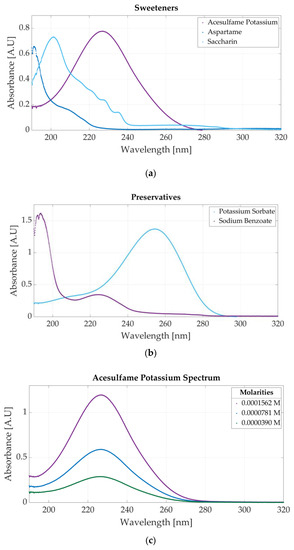
Figure 3.
Ultraviolet spectra of food additives: (a) UV spectrum of acesulfame potassium, aspartame, and saccharin; (b) UV spectrum of sodium benzoate and potassium sorbate; (c) spectra for three molar concentrations of acesulfame potassium obtained through dilutions.
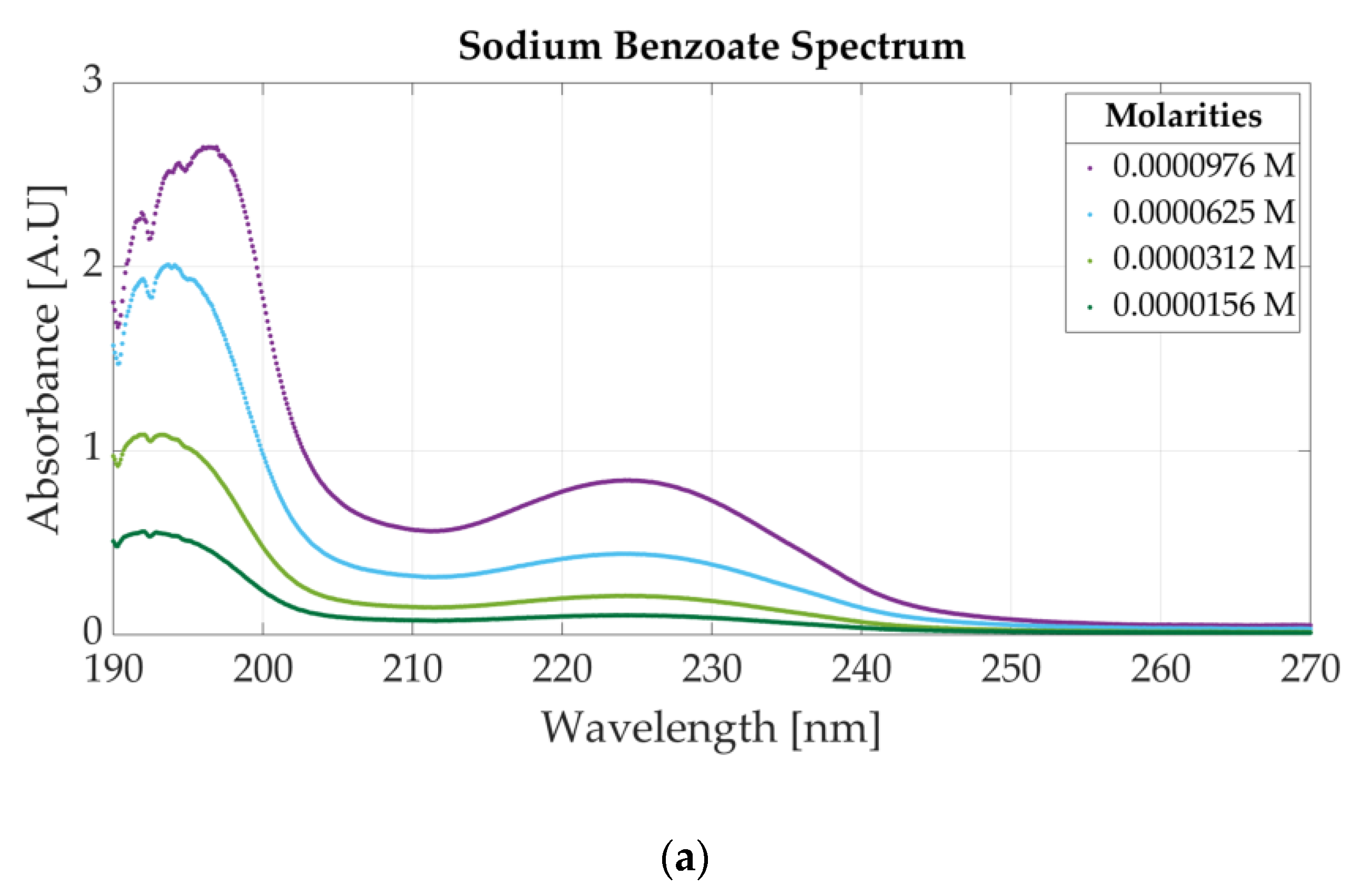
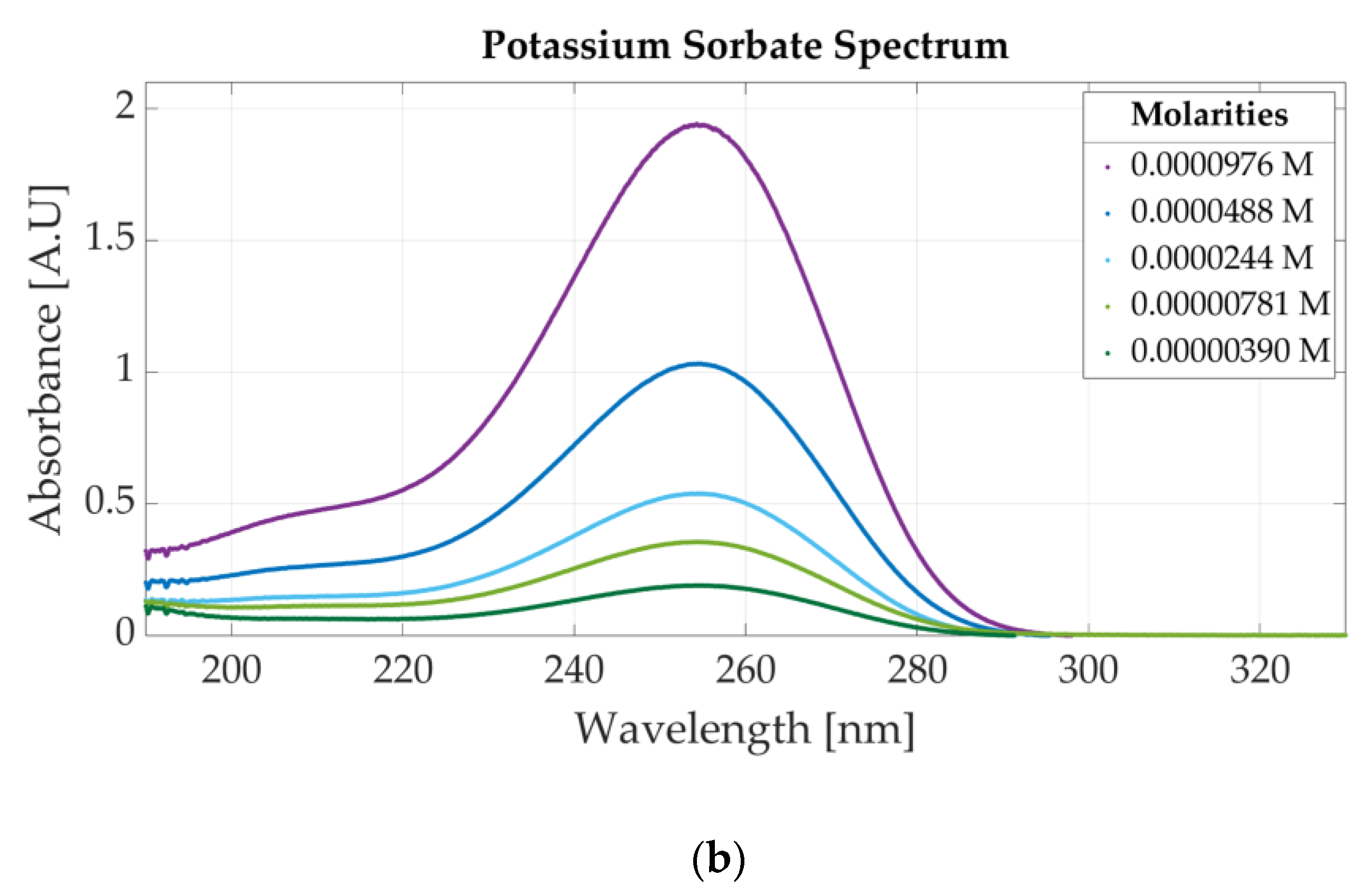
Figure 3b presents the ultraviolet spectrum for a sample of 0.0000312 M potassium sorbate and 0.0000468 M sodium benzoate. The absorbance peak specific to potassium sorbate appears at 254 nm, whereas sodium benzoate has two peaks located at 193 nm and 224 nm. The spectra of four solutions of acesulfame potassium are represented in Figure 3c. The three solutions are obtained by diluting a sample of 0.0001562 M acesulfame potassium. For these solutions, the only change that appears is related to the value of the absorbance peak given by the Beer–Bouguer–Lambert Law. The change in absorbance due to a molar concentration change can also be observed in Figure A1a for four samples of sodium benzoate and Figure A1b for five samples of potassium sorbate.
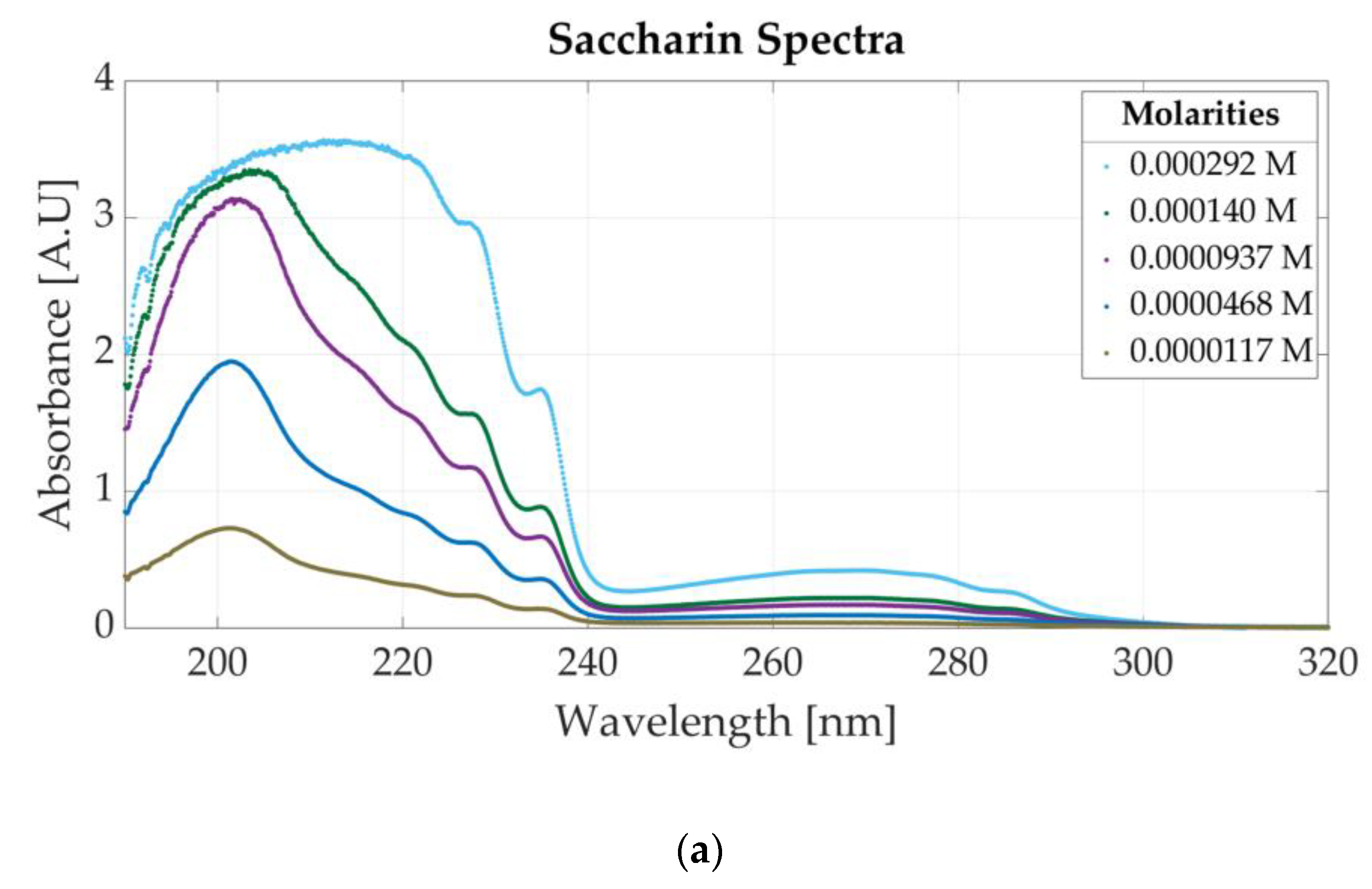
Figure 4a presents the spectrum of six saccharin samples with different molar concentrations. The molar concentrations of the samples vary between 0.000292 M and 0.0000117 M. For lower concentrations than 0.0001 M, the absorbance peak located at 201 nm is visible. For higher concentrations of saccharin (e.g., 0.000292 M), high absorbance values appear in the left part of the spectrum (190 to 240 nm), which might indicate the saturation of the photodetector. Based on the results, the dynamic absorbance range is concluded to vary between 0 and 3 absorbance units (A.U). For absorbance values higher than 3 A.U, the photodetector can no longer accurately measure the absorbance values within 190 nm and 240 nm. Therefore, for concentrations higher than 0.0000937 nm, the absorbance peak associated with saccharine is at 269 nm.
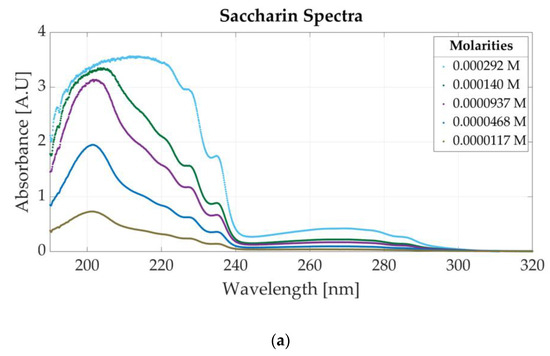
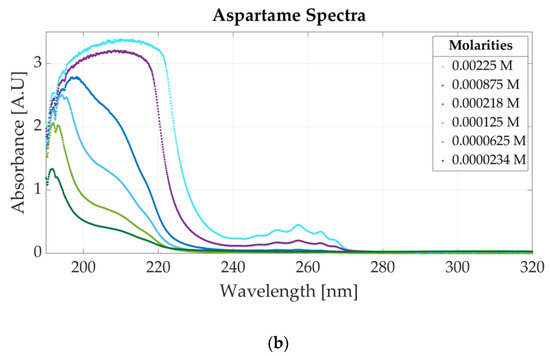
Figure 4.
Ultraviolet spectra of food additives: (a) UV spectra for different concentrations of saccharin; (b) UV spectrum for different concentrations of aspartame.
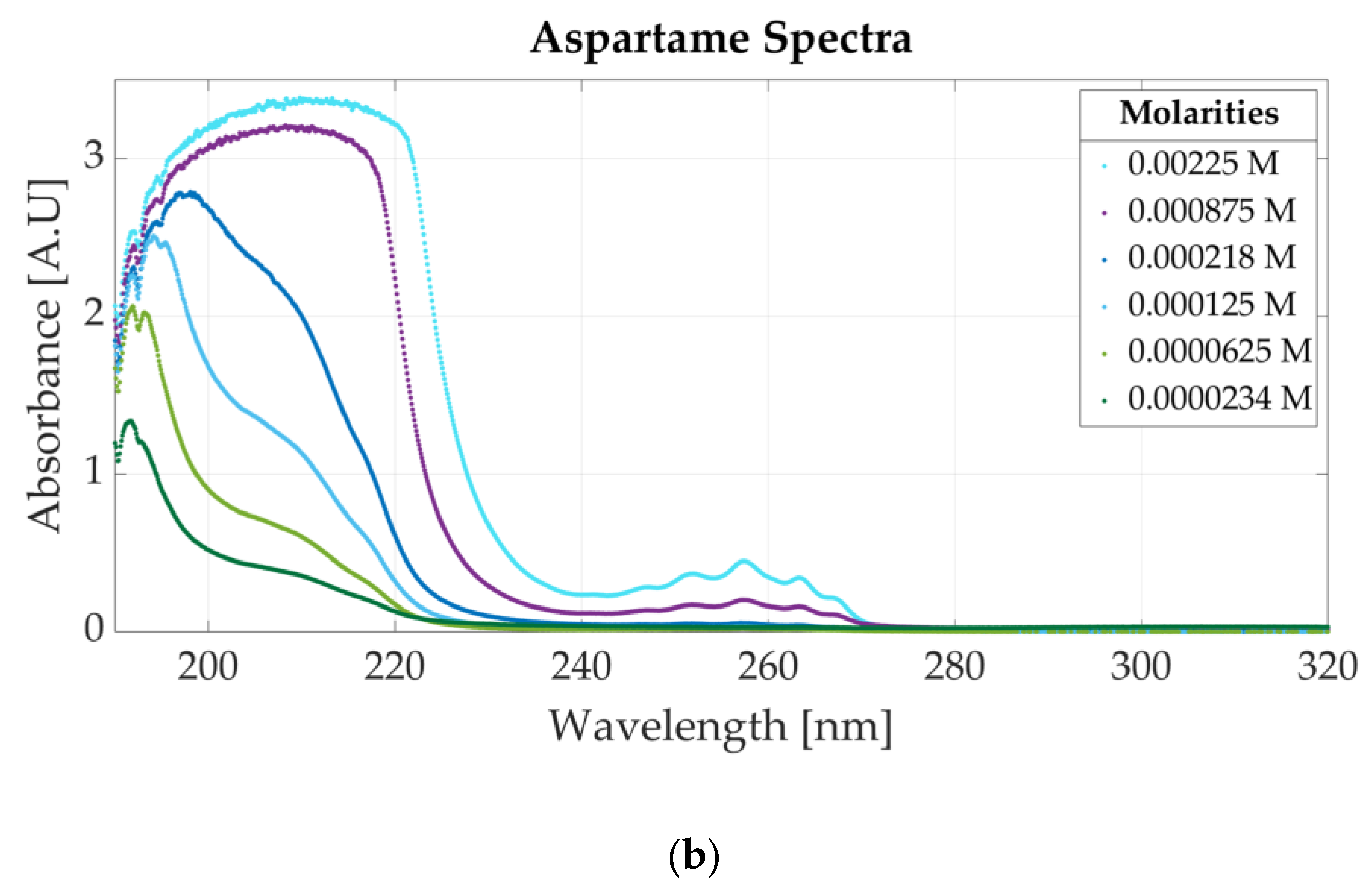
Similarly, Figure 4b represents the spectrum of six samples of aspartame with molar concentrations between 0.00225 M and 0.0000234 M. For concentrations higher than 0.0002 M, five peaks appear within 240 nm and 270 nm (the highest being located at 257 nm), whereas on the right side of the spectrum, high absorbance values are measured (the 191 nm peak is no longer visible). The five peaks are no longer visible for a concentration of aspartame lower than 0.0002 M, but a peak appears between 190 and 200 nm.
3.2. UV Spectra of Two-Additive Solutions
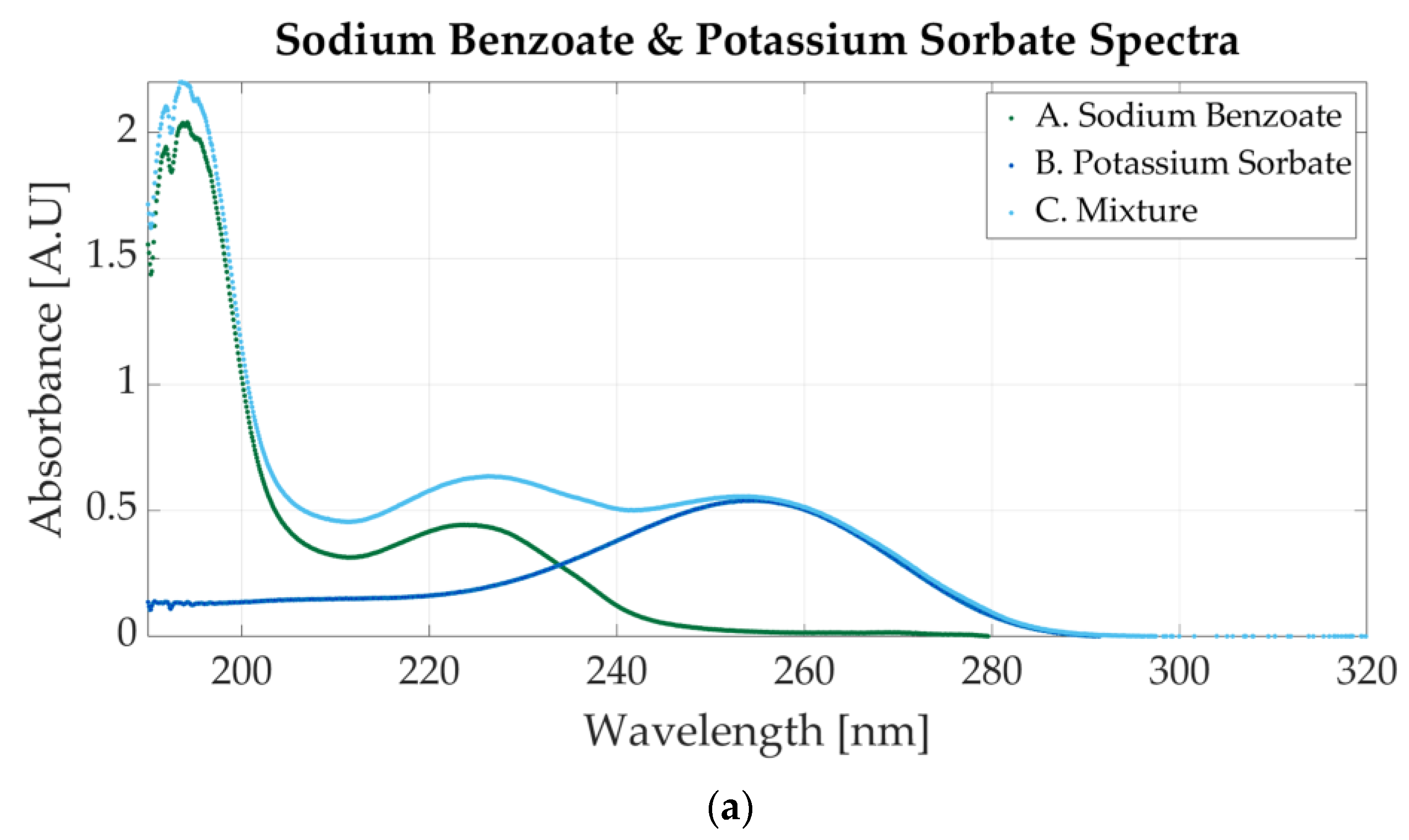
Figure 5a shows the spectrum of a mixture of sodium benzoate and potassium sorbate and the spectra of two simple solutions (one for sodium benzoate and one for potassium sorbate). The mixture contains 0.0000488 M sodium benzoate and 0.0000244 M potassium sorbate. The one-additive solutions have similar molar concentrations to those of the mixture (0.0000427 M for sodium benzoate and 0.0000244 for potassium sorbate).
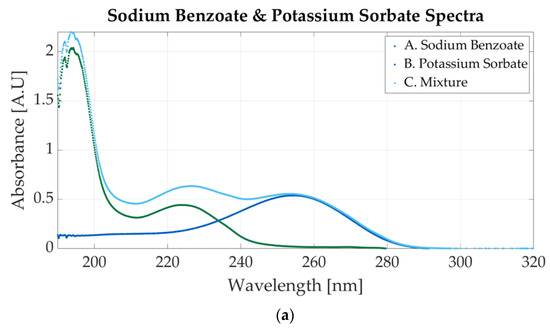
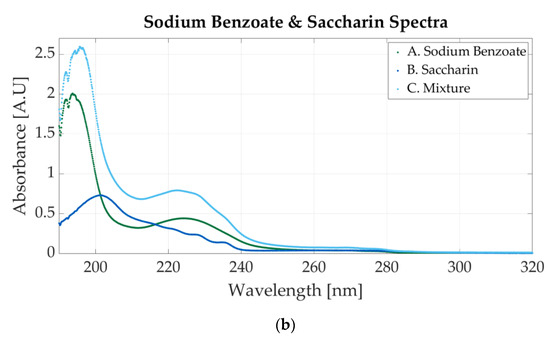
Figure 5.
Ultraviolet spectra of food additives. (a) A. Sodium benzoate, 0.0000427 M; B. potassium sorbate, 0.0000244 M; C. 0.0000488 M sodium benzoate and 0.0000244 M potassium sorbate; (b) A. sodium benzoate, 0.0000546 M; B. saccharin, 0.0000117 M; C. 0.000058 M sodium benzoate and 0.0000117 M potassium sorbate.
The spectra of one-additive samples do not match the spectra of the mixture, because the concentrations of sodium benzoate are different (0.0000488 M in the mixture and 0.0000427 M in the simple solution). The one-additive spectra represented are not the spectra of the two solutions that were mixed. When two samples are combined, the molar concentration of each sample is halved (if using equal parts of each solution) due to the distilled water in the samples. Therefore, the spectra of the one-additive solutions, before the mixture, would have had higher absorbance peaks (compared to the mixture).
Figure 5a shows that the absorbance values for simple solutions and for the mixtures have similar values, which indicates that they are not the spectra of the two pure samples that were mixed. The one-additive solutions are presented to highlight that the mixture spectra contain the absorbance peaks representative of each additive. Potassium sorbate has an absorbance peak at 254 nm, whereas sodium benzoate presents two peaks at 224 nm and 193 nm, as presented in Figure 3b. The three peaks are also visible in the mixture’s representation.
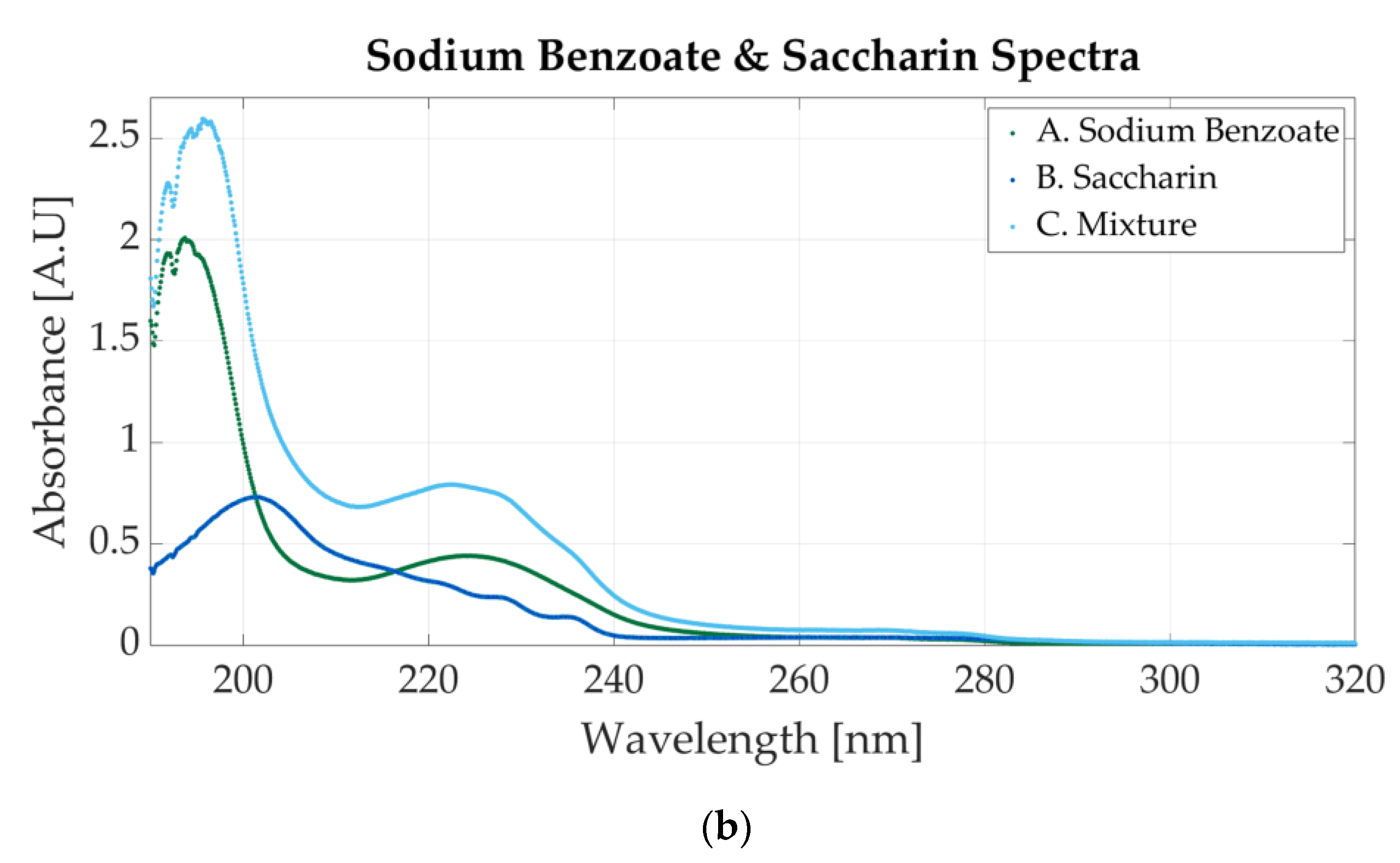
Sodium benzoate is also mixed with saccharin. The spectrum is represented in Figure 5b. The molar concentrations for the one-additive solutions are 0.0000546 M sodium benzoate and 0.0000117 M saccharin. The mixture contains 0.000058 M sodium benzoate and 0.0000117 M. In the mixture’s spectrum, two peaks are visible. Those peaks are specific to sodium benzoate, but the peak around 224 also presents light waves within 220 nm and 240 nm that appear in the saccharin samples’ spectrum.
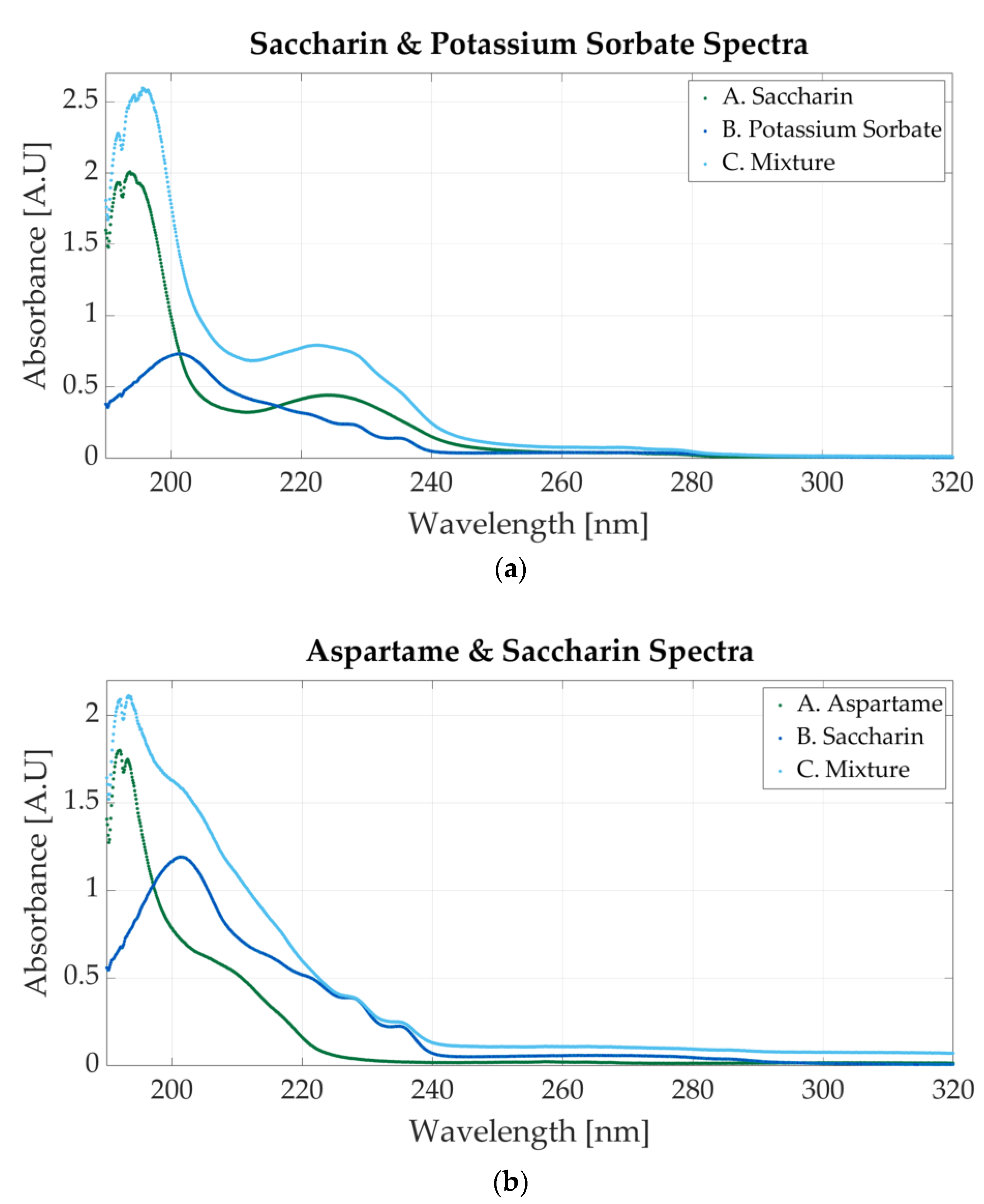
Figure 6a shows the spectrum of a solution with 0.0000117 M potassium sorbate and 0.0000546 saccharin. The peak located at 201 nm is representative of saccharin, whereas the one positioned at 254 nm is clear evidence of the presence of potassium sorbate. The spectra for the one-additive solutions are also represented. The molar concentration of the potassium sorbate solution is 0.0000127, whereas the molar concentration of the saccharin solution is 0.000058 M.
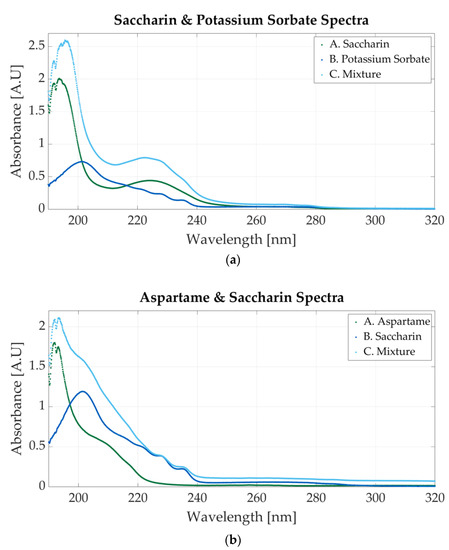
Figure 6.
Ultraviolet spectrum of food additives. (a) A. Saccharin, 0.0000546 M; B. potassium sorbate, 0.0000117 M; C. 0.000058 M sodium benzoate and 0.0000127 M potassium sorbate; (b) A. aspartame, 0.000039 M; B. saccharin, 0.0000234 M; C. 0.000039 M aspartame and 0.0000195 M saccharin.
Figure 6b represents the first mixture containing saccharin and aspartame. The molar concentration of the samples is 0.000039 M aspartame and 0.0000195 M saccharine. The spectrum presents only one peak located around 191 nm, but a second peak, less outlined, appears at 201 nm. This peak, alongside the other two peaks within 220 nm and 240 nm, is specific to saccharin.
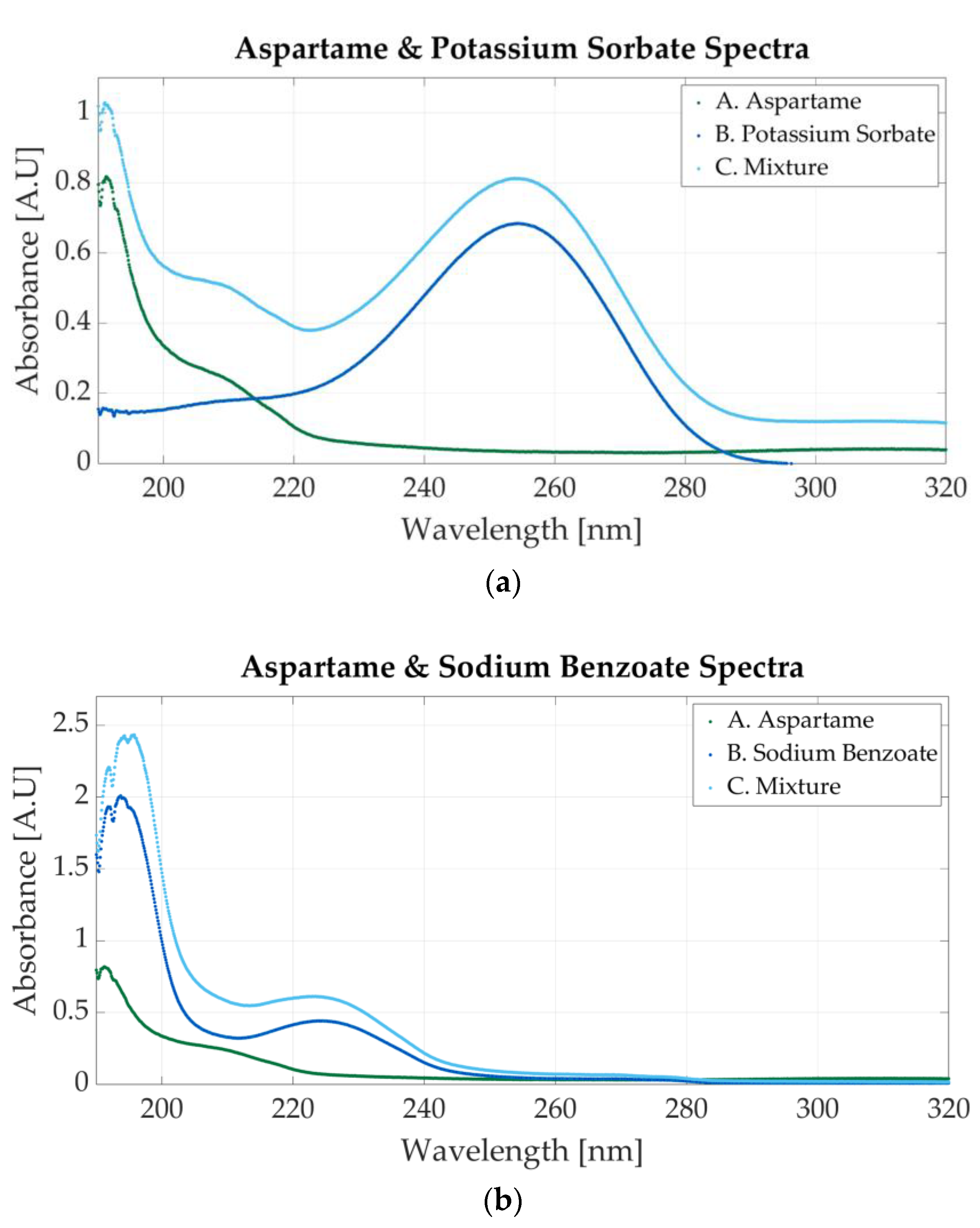
The spectra of two aspartame mixtures are presented in Figure 7. The first mixed solution is prepared using aspartame and potassium sorbate. The spectrum is represented in Figure 7a. The molar concentration of the sample is 0.0000915 M aspartame and 0.0000915 M potassium sorbate. The peak located at 254 nm indicates the presence of potassium sorbate, whereas the 201 nm peak is specific to aspartame. Figure 7b shows the spectrum of a mixture of aspartame and sodium benzoate. The molar concentrations of the samples are 0.0000145 M aspartame and 0.000058 M sodium benzoate. The presence of either substance might cause a peak between 190 and 200 nm since both additives present absorbance peaks in that region.
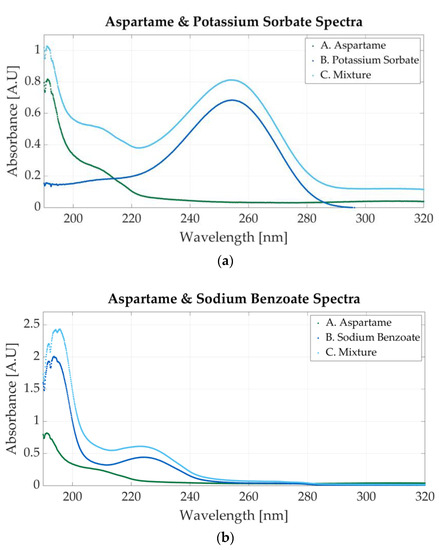
Figure 7.
Ultraviolet spectra of food additives. (a) A. Aspartame, 0.0000117 M; B. potassium sorbate, 0.0000156 M; C. 0.0000915 M aspartame and 0.0000915 M potassium sorbate; (b) A. aspartame, 0.0000117 M; B. sodium benzoate, 0.0000546 M; C. 0.0000145 M aspartame and 0.000058 M sodium benzoate.
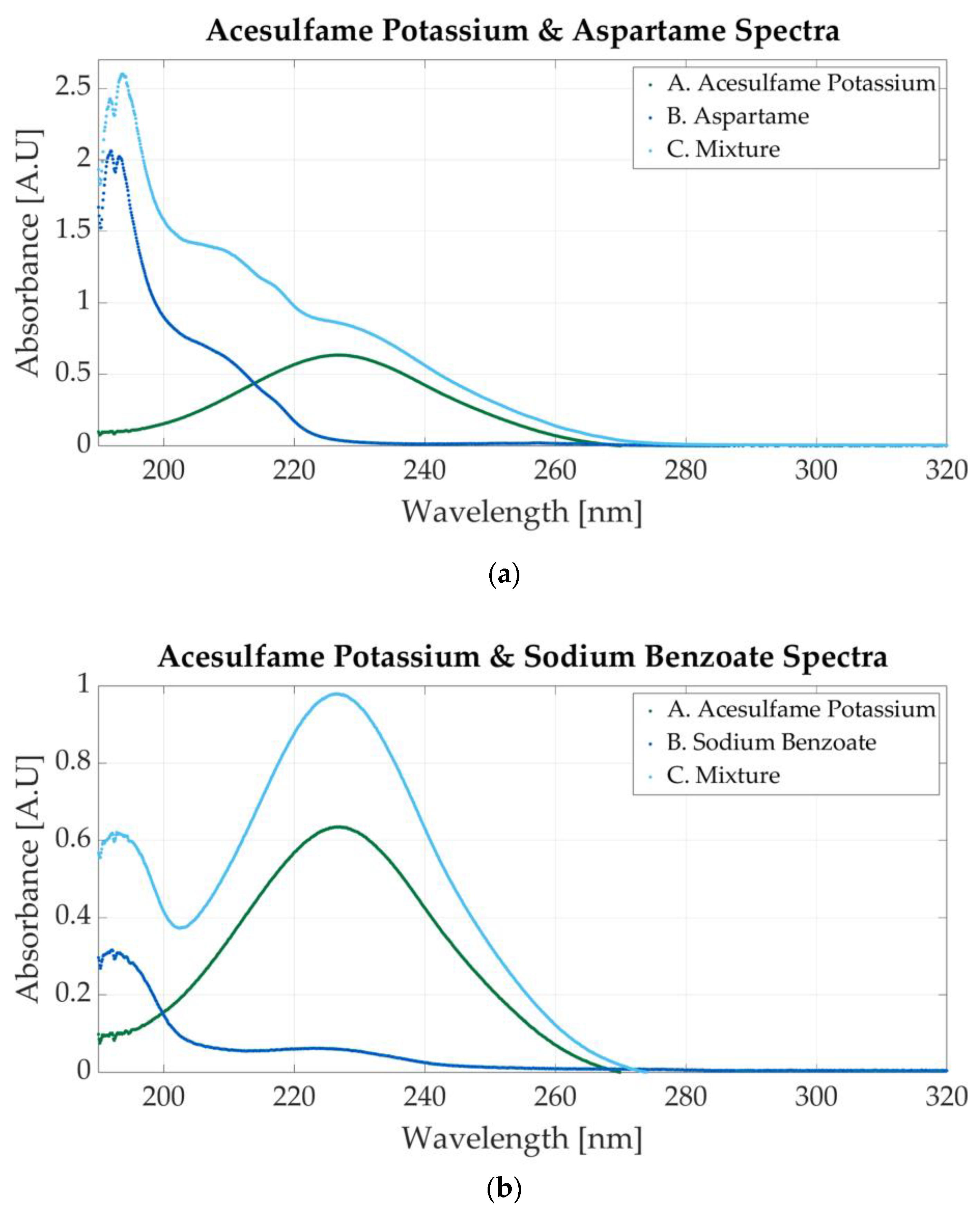
Figure 8a illustrates the spectrum of the mixture between acesulfame potassium and aspartame. The spectrum of the mixtures presents a peak at 191 nm (specific to aspartame) and a slight peak around 226 nm peak (specific to acesulfame potassium). The molar concentration of the sample is 0.00058 M acesulfame potassium and 0.000029 M aspartame.
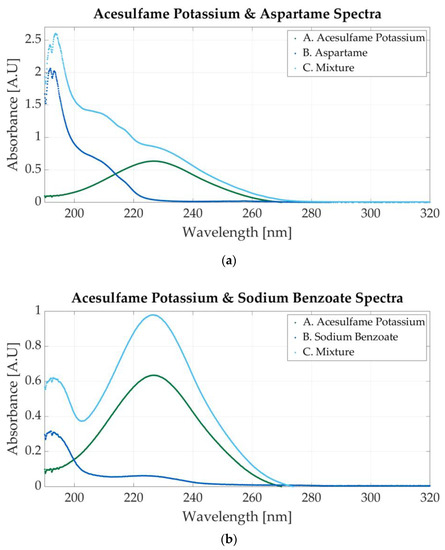
Figure 8.
Ultraviolet spectra of food additives. (a) A. Acesulfame potassium, 0.00005 M; B. aspartame, 0.0000625 M; C. 0.000058 M acesulfame potassium and 0.000029 M aspartame; (b) A. acesulfame potassium, 0.00005 M; B. sodium benzoate, 0.00000683 M; C. 0.0000585 M acesulfame potassium and 0.00000732 M sodium benzoate.
The mixture in Figure 8b contains 0.0000585 M acesulfame potassium and 0.00000732 M sodium benzoate. The absorbance peaks for acesulfame and sodium benzoate are very close. In Figure 3a,b, acesulfame presents an absorbance peak at 226 nm, whereas sodium benzoate peaks at 224 nm. The peak in the mixture’s spectrum may indicate the presence of both substances. The concentration of the additives is important. The spectrum represented in Figure 8b contains a low concentration of sodium benzoate (0.00000732 M); therefore, it can be stated that the peaks located at 226 nm are caused by acesulfame. A second peak at 193 nm is surely an indicator of sodium benzoate.
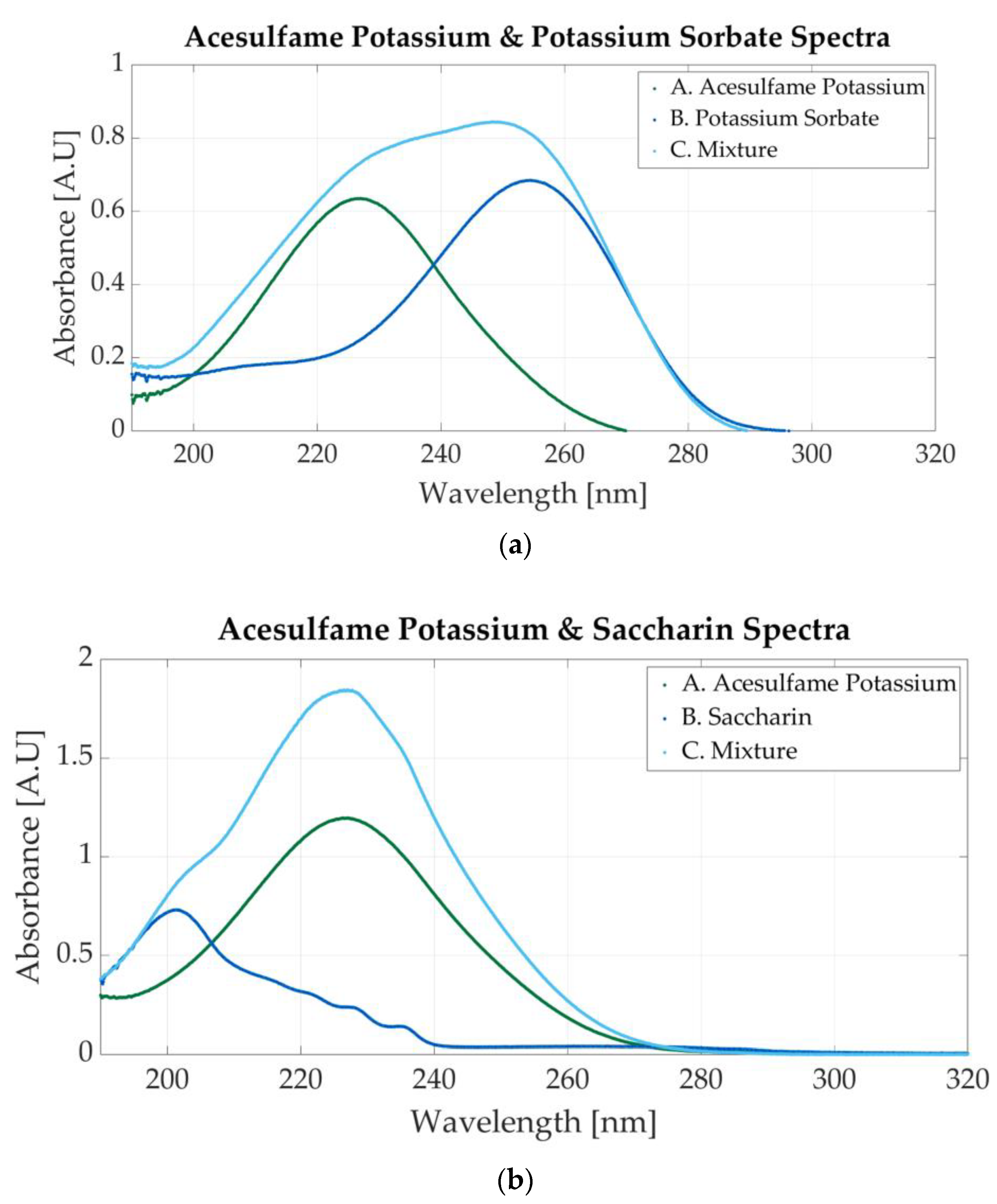
Two more mixtures can be prepared with the additives. The first is composed of acesulfame potassium and potassium sorbate and is composed of acesulfame potassium and potassium sorbate, and the second is composed of acesulfame potassium and saccharin. The spectrum of a mixture of 0.0000585 M AceK and 0.0000219 M sodium benzoate is presented in Figure 9a. The absorbance peaks of acesulfame and potassium sorbate (226 nm and 254 nm, respectively) are located very close; therefore, the peak within this region is wider. The FWHM (full-width at half-maximum) is approximately 45 nm.
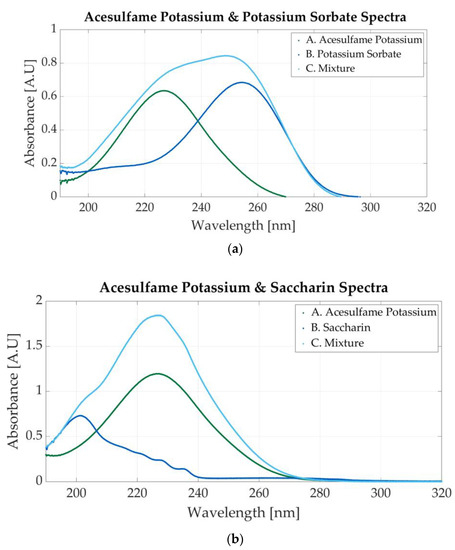
Figure 9.
Ultraviolet spectra of food additives. (a) A. Acesulfame potassium, 0.00005; B. potassium sorbate, 0.0000156 M; C. 0.0000585 M acesulfame potassium and 0.0000219 M potassium sorbate; (b) A. acesulfame potassium, 0.000156 M; B. saccharin, 0.0000117 M; C. 0.000234 M acesulfame potassium and 0.0000145 M saccharin.
Acesulfame potassium is also mixed with saccharine. The molar concentration of the sample is 0.000234 M acesulfame potassium and 0.0000145 M saccharin. The absorbance peak at 226 nm is more prominent than the 201 nm peak because the molar concentration of acesulfame potassium is higher than that of saccharin. Both peaks indicate the presence of additives within the mixture, as can be seen in Figure 9b.
3.3. Classification Results for One-Additive Solutions
The database for one-additive solutions contained 193 data samples (26 for acesulfame potassium, 41 for aspartame, 38 for sodium benzoate, 32 for potassium sorbate, and 56 for saccharin). The database was divided into three datasets: one for training, one for testing, and one for validating the model. The data division was accomplished according to the number of samples for each category. For each class, 20% of the data were allocated for testing, while the remaining data were divided into 80% for training and 20% for validation. Therefore, the training dataset contained 122 samples, the testing dataset contained 42 samples, and the remaining 29 were used for validation.
The first classification was performed on one-additive solutions. A numerical label between 1 and 5 was associated with each additive (1—acesulfame potassium, 2—aspartame, 3—sodium benzoate, 4—potassium sorbate, 5—saccharin). The label was utilized for the additive classification. The classification results for the testing process are displayed in confusion matrices. In these matrices, the actual labels are represented vertically, whereas the predicted labels of the analyzed samples are represented horizontally.
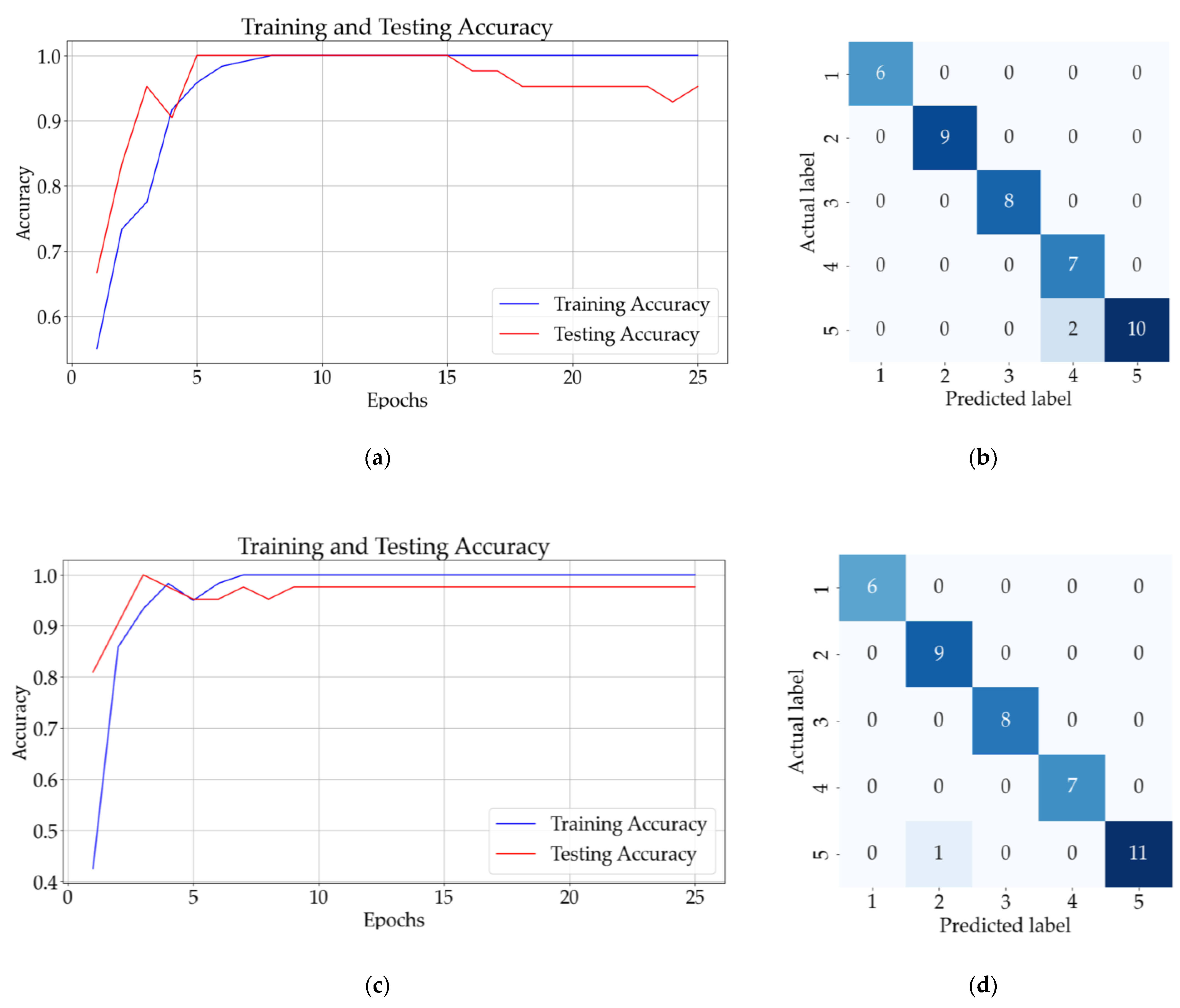
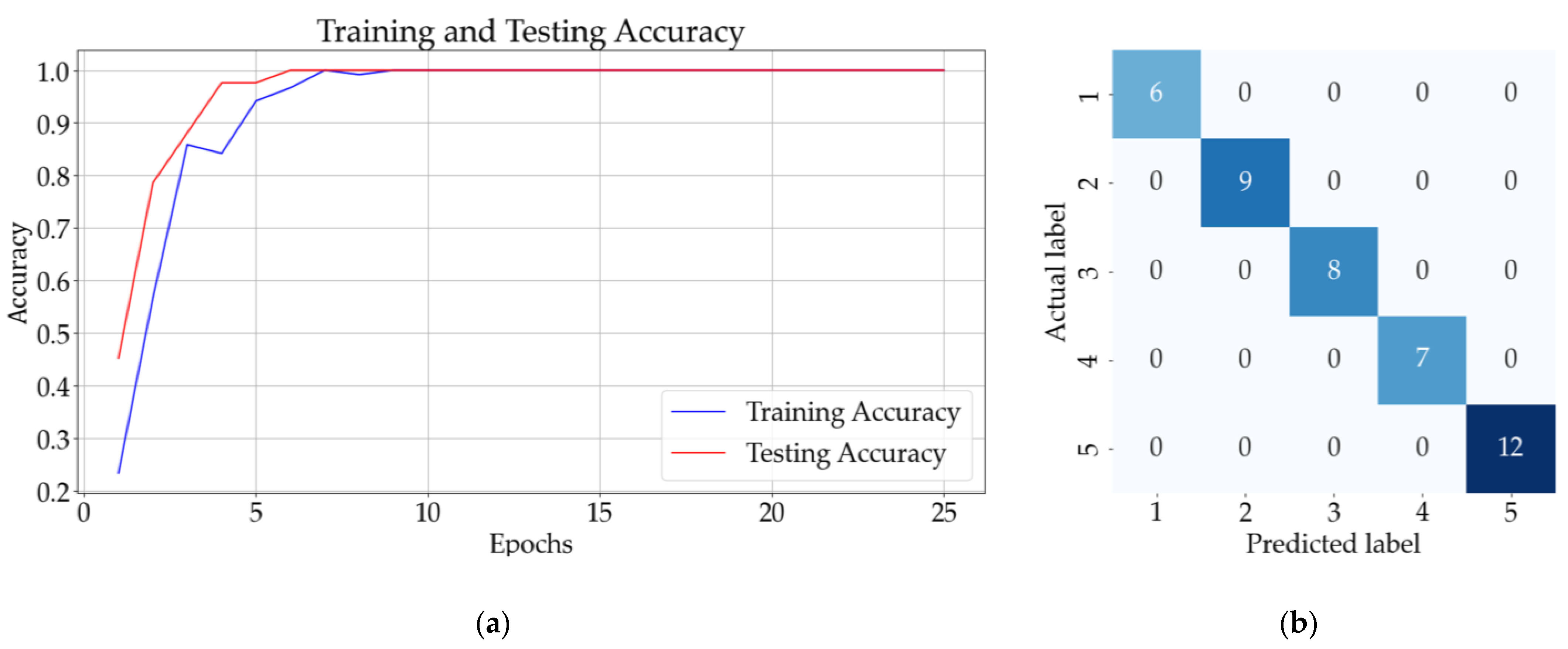
Figure 10 presents the result for classifying the one-additive solutions using ANN and CNN. Figure 10a presents the accuracy of the ANN model (with a hidden layer) after 25 epochs, whereas Figure 10b presents the confusion matrix obtained for the testing dataset. The results for the CNN model with three hidden layers and no pooling layers are presented in Figure 10c,d, and the results for the CNN model with three hidden layers and three pooling layers are presented in Figure 11a,b.
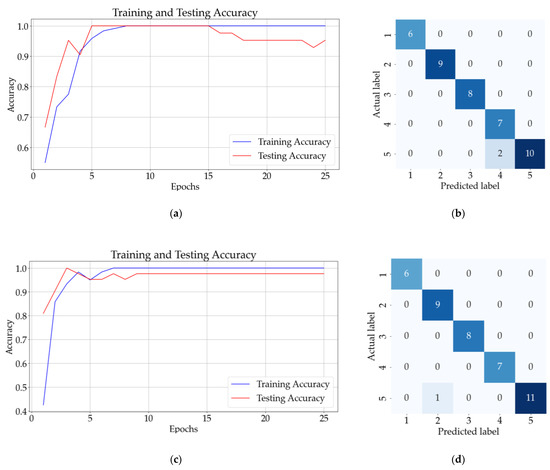
Figure 10.
Results for one-additive solutions: (a) training and testing accuracy for 25 epochs for ANN with one hidden layer; (b) confusion matrix (ANN); (c) training and testing accuracy for CNN with three convolutional layers and no pooling layers; (d) confusion matrix (CNN).
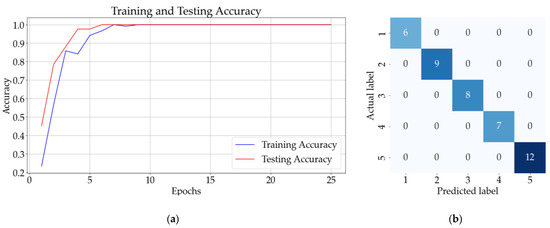
Figure 11.
Results for one-additive solutions: (a) training and testing accuracy CNN with three convolutional layers followed by three pooling layers; (b) confusion matrix for CNN with three convolutional layers and three pooling layers.
Figure 10b shows that the ANN model incorrectly classified a sample from class 5 (saccharin) as belonging to class 2 (potassium sorbate). On the other hand, Figure 10d and Figure 11b illustrate that the CNN without the pooling layer incorrectly classified a sample from class 5 and the CNN model with pooling layers correctly identified all 42 samples.
The best mean accuracy for the testing of the model was obtained for ANN with two hidden layers. For ten consecutive classifications, the mean validation accuracy for this model was 99.67%, with a standard deviation of 1.02%. The same mean testing accuracy was obtained for a CNN with 3 convolutional layers and three pooling layers and the CNN with 3 convolutional layers and no pooling layers. The mean testing accuracy of the other models is presented in Table 3.
Table 3.
The testing accuracy of the neural networks for one-additive solutions.
The classification performances of the models were tested using unseen data. The validation dataset for one-additive solutions consisted of 20% of each class of additives. The division of the database was performed randomly each time. A total of 31 samples (4 samples from class 1, 7 from class 2, 7 from class 3, 4 from class 5, and 9 from class 5) were used for the testing of the model’s classification performances.
The number of correctly classified samples was divided into the total number of samples used for testing. The mean validation accuracy was calculated for 10 successive classifications. The CNN model with one convolutional layer (no pooling layers) and the CNN with two convolutional layers followed by pooling layers were able to correctly identify 99.67% of the samples with a standard deviation of 1.02 %. The mean validation accuracy for the rest of the models is shown in Table 4.
Table 4.
The mean validation accuracy of the neural networks for one-additive solutions.
3.4. Classification Results for Two-Additive Solutions
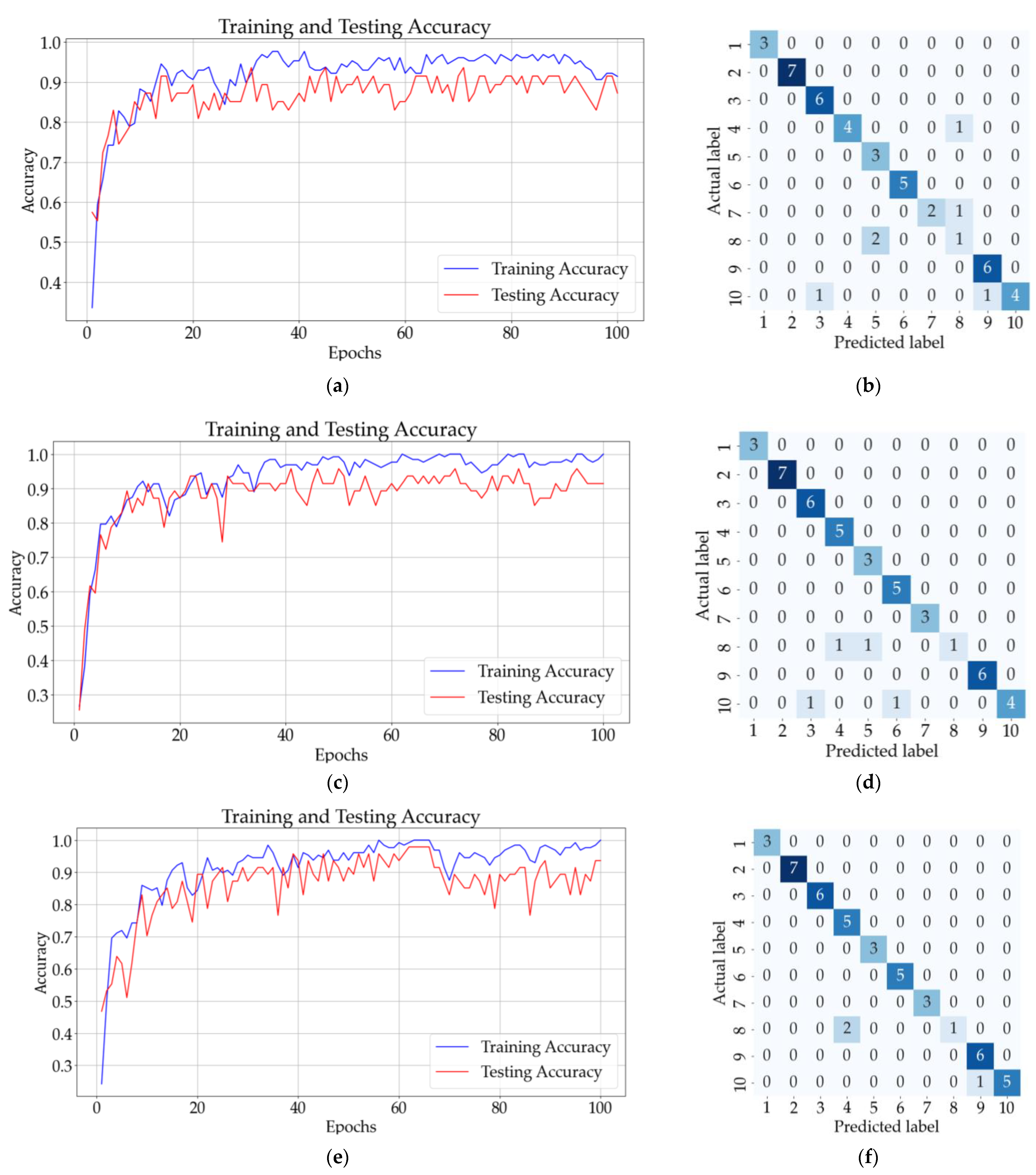
The second classification was conducted on two-additive solutions. The 211 spectra have been labeled with values between 1 and 10 (the numerical labels are presented in Table 2). The classification results for ANN and CNN are presented in Figure 12. The confusion matrix from Figure 12b shows that six samples (one from class 4, one from class 7, two from class 8, and two from class 10) were incorrectly classified using ANN with one hidden layer. The testing accuracy for the ANN model, after 100 epochs, was 88%, as is presented in Figure 12a.
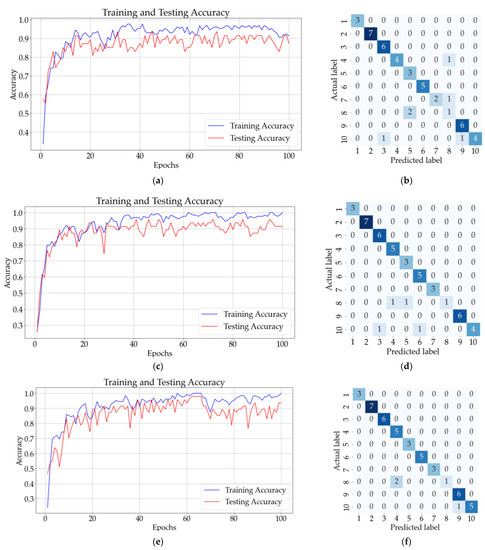
Figure 12.
Results for two-additive solutions: (a) training and testing accuracy for ANN with one hidden layer; (b) confusion matrix (ANN); (c) training and testing accuracy for CNN with three convolutional layers and no pooling layers; (d) confusion matrix for CNN (no pooling layers); (e) training and testing accuracy of CNN with three convolutional layers followed by three pooling layers; (f) confusion matrix for CNN (with pooling layers).
Figure 12c shows the confusion matrix for the CNN model with three convolutional layers and no pooling layers. Two samples from 8 were incorrectly classified as belonging to classes 4 and 5. The testing accuracy of the CNN, after 100 epochs, was 91%, as shown in Figure 12c. Figure 12f illustrates that the CNN with three convolutional layers followed by a pooling layer correctly classified all the samples apart from two samples belonging to class 8 and one sample belonging to class 10. The mean validation accuracy of the model for ten successive classifications was 92.22%, with a standard deviation of 4.3%. Table 5 presents the mean testing accuracy of the tested neural networks for two-additive solutions.
Table 5.
The mean testing accuracy of the neural networks for two-additive solutions.
The models were tested with 36 new samples (3 samples from class 1, 5 from class 2, 4 from class 3, 4 from class 4, 2 from class 5, 4 from class 6, 2 from class 7, 2 from class 8, 5 from class 5, and 5 from class 10). Table 6 shows that the ANN models obtained validation accuracies lower than 90% with high standard deviations. The results indicate that the new samples could not be correctly identified, which was expected since the mean testing accuracy was also low and had high standard deviation (Table 5, ANN with two hidden layers, 88.88% ± 7.04%).
Table 6.
The mean validation accuracy of the neural networks for two-additive solutions.
On the other hand, the CNN model with one convolutional layer followed by the pooling layer obtained high validation and testing results. The mean testing accuracy was 91.94% ± 4.02% (Table 5), whereas the mean validation accuracy was 94.16% ± 3.05% (Table 6). The CNN with two convolutional layers and pooling layers was able to correctly identify 93.88% ± 4.3% of the samples but obtained only a 90.83% ± 6% (high standard deviation) testing accuracy.
Consequently, it is considered that the best results for the classification of two-additive solutions can be obtained using a CNN model with one convolutional layer followed by a pooling layer (91.94% mean testing accuracy, 94.16% mean validation accuracy).
3.5. The Classification of All Solutions
All the spectra (193 spectra for one-additive solutions and 211 spectra for two-additive solutions) were reunited to test the neural network’s accuracy using simple solutions and mixtures. One-additive solutions were labeled with values from 1 to 5, whereas two-additive solutions were labeled with values between 6 and 15 (the order of the samples was not changed).
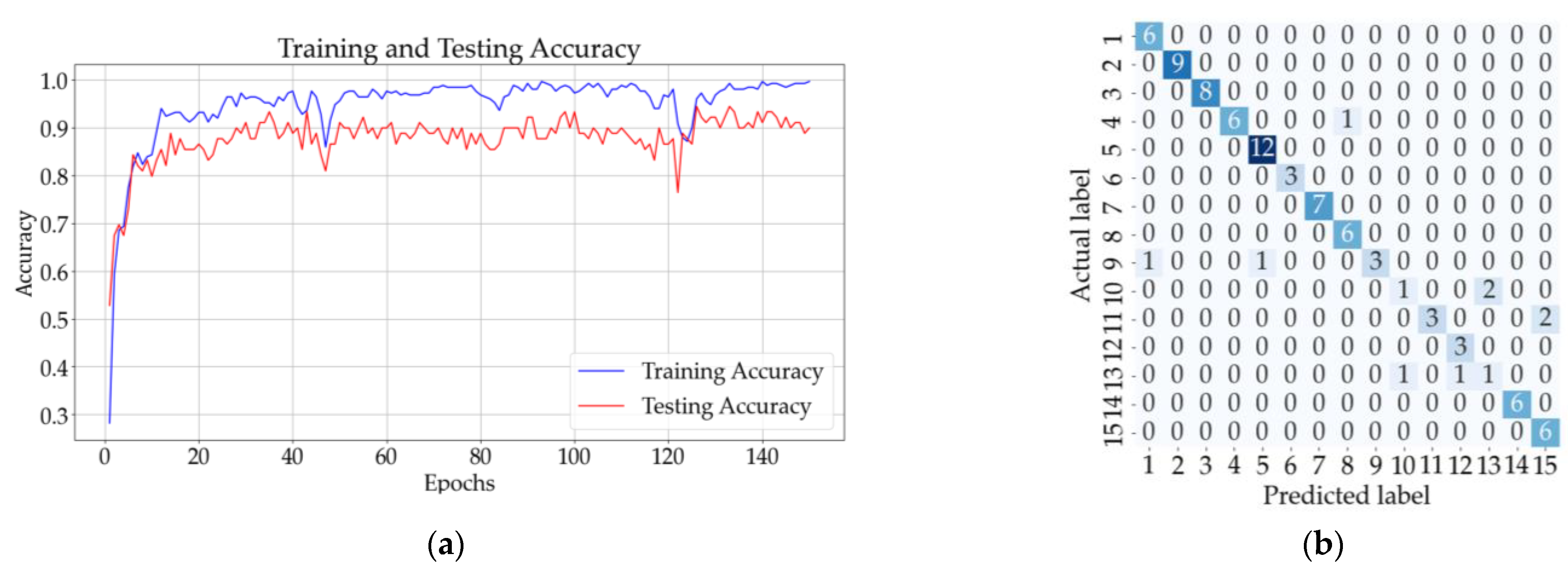
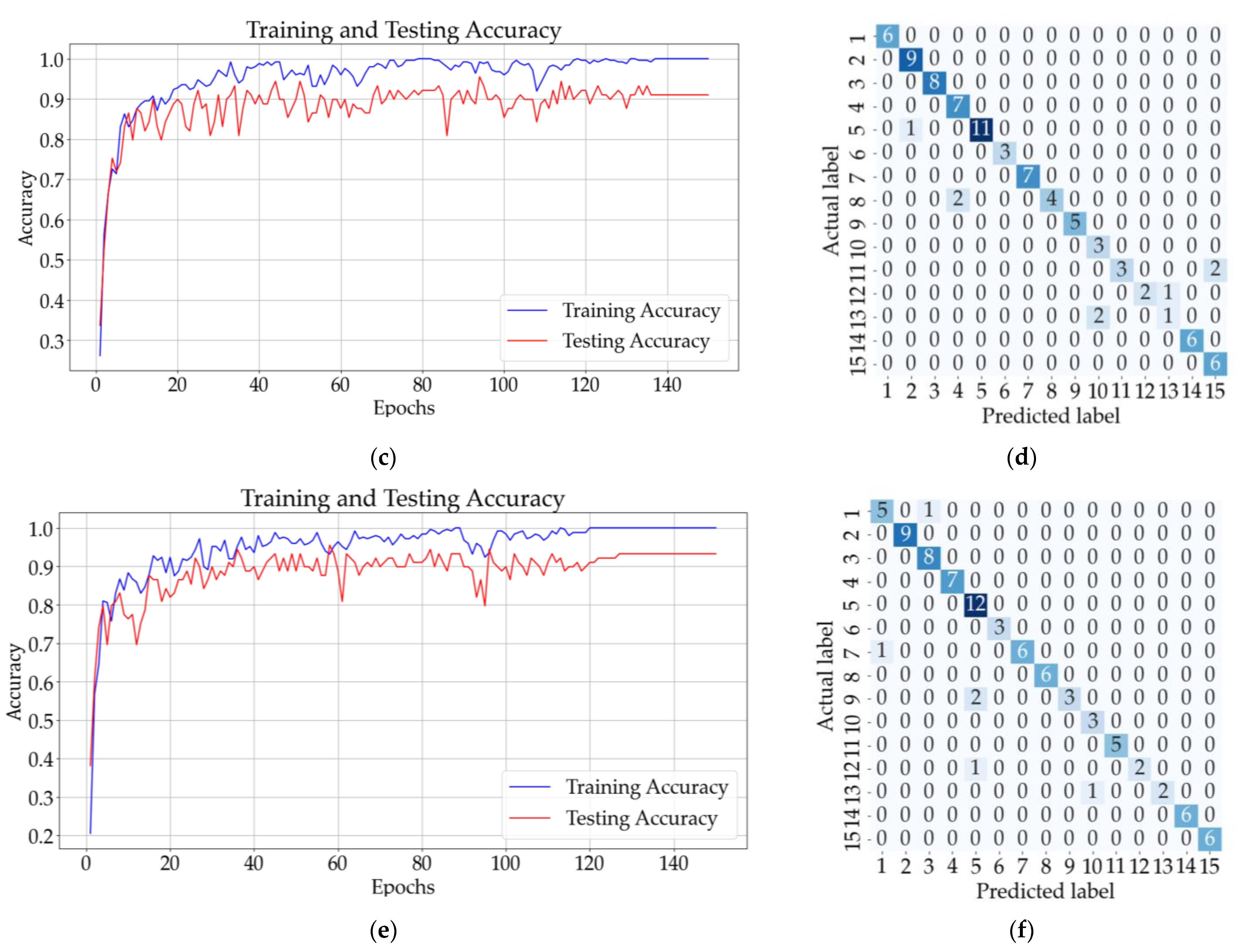
Figure 13b shows that eight samples from classes 9, 10, 11, and 13 were incorrectly classified using the ANN with one hidden layer. The testing accuracy of the model was 90% after the 150 epochs. The CNN model with three convolutional layers and no pooling layers had a testing accuracy of 91%, and according to the confusion matrix illustrated in Figure 13d, only eight samples were incorrectly classified. The testing accuracy increased for the CNN with three convolutional and pooling layers (92%), but the confusion matrix from Figure 13f shows that five samples from classes 7, 9, 12, and 13 could not be classified correctly.
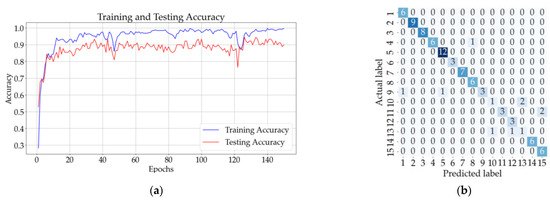
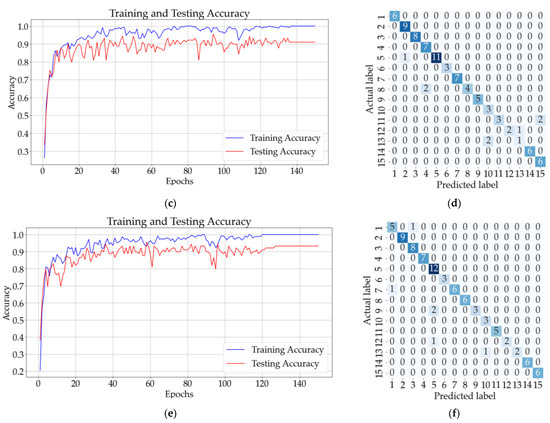
Figure 13.
Results for all solutions: (a) training and testing accuracy for ANN with one hidden layer; (b) confusion matrix (ANN); (c) training and testing accuracy for CNN with three convolutional layers and no pooling layers; (d) confusion matrix for CNN (no pooling layers); (e) training and testing accuracy CNN with three convolutional layers followed by three pooling layers; (f) confusion matrix for CNN (with pooling layers).
The mean testing accuracy of the ANN and CNN models is presented in Table 7. The highest mean validation accuracy was obtained for the CNN model with three convolutional layers and no pooling layers (92.38% ± 1.48%). The mean validation accuracies for the other models are illustrated in Table 8.
Table 7.
The mean testing accuracy of the neural networks for all samples.
Table 8.
The mean validation accuracy of the neural networks for all samples.
The models were also tested using new unseen data. A total of 67 samples were used to determine which model correctly identified the most samples in ten successive classifications. The mean validation accuracy for the eight models is shown in Table 8. The best results were obtained for CNN models with 1, 2 (with and without pooling), and 3 layers.
3.6. Analysis of Variance
The accuracy data presented in Table 3, Table 4, Table 5, Table 6, Table 7 and Table 8 (for testing and validation) were analyzed using a statistical method known as ANOVA (analysis of variance). ANOVA was necessary to establish if there was a significant statistical difference between the accuracy of the algorithms used for the spectra classification. The parametric one-way ANOVA assumes that the datasets are normally distributed, whereas the Kruskal–Wallis H method (known as one-way ANOVA (analysis of variance) on ranks) is a non-parametric test that can be used with nonnormally distributed data [48].
Firstly, a Shapiro–Wilk test was performed to determine the normality of the data. The Shapiro–Wilk results for one-additive solutions are presented in Table 9 (testing results and validation results). The hypothesis of normality is rejected when the p-value is less than or equal to 0.05. Based on the values in Table 9, the datasets were not considered to be normally distributed.
Table 9.
Shapiro–Wilk results for one-additive solutions.
The non-parametric ANOVA on ranks was applied on the data. The null hypothesis, that all the classes are equal, is accepted for p-values higher than 0.05. The analysis shows statistical differences between the accuracy of the techniques for testing (p = 0.02301), whereas, for validation, no difference is found (p = 0.29759). The results do not indicate which algorithms are more significant than the others (for testing), but it shows that the classification algorithm that is selected is relevant for obtaining higher accuracies.
The analysis was continued with a post hoc test. The Dunn test is commonly used if the Kruskal–Wallis method shows significant differences among the classes. Table 10 presents the Dunn test’s results for one-additive solutions (testing). The results (p = 0.42153) indicate that the ANN with two hidden layers (ANN2), the CNN with three convolutional layers (CNN3), and the CNN with two convolutional layers followed by pooling layers (CNN2*) were statistically different compared to the ANN with one hidden layer (ANN1). Statistically, the ANN2, CNN3, and CNN2* would obtain better-accuracy results for the classification of one-additive solutions. The results were compared with a significance level of 0.05 (5%).
Table 10.
Dunn test results for one-additive solutions (testing).
The normality of the accuracy datasets was also tested for two-additive solutions and for all the samples. The results are presented in Table 11 and Table 12. The normality test was followed by a one-way ANOVA since the normality condition was fulfilled.
Table 11.
Shapiro–Wilk results for two-additive solutions.
Table 12.
Shapiro–Wilk results for all samples.
The one-way ANOVA results are shown in Table 13 (for testing) and Table 14 (for validation). The results reveal that there was a statistically significant difference in the validation accuracy datasets F(7, 27) = [2.7], p = 0.01526 (two-additive dataset) and F(7, 27) = [ 2.7078], p = 0.01503 (all samples dataset). The analysis was continued with a post hoc tests to determine which classes (algorithms) presented a significant difference. The selected post hoc test was Tukey’s HSD (Honestly Significant Difference). Based on the number of groups, the degree of freedom calculated using ANOVA (Table 14), and the significance level (0.05), the critical value of the Tukey’s HSD test was 4.41.
Table 13.
One-way ANOVA results (testing dataset).
Table 14.
One-way ANOVA results (validation dataset).
The results within Table 15 were compared with the critical value. The test revealed that the mean value of the accuracy was significantly different between ANN2 and CNN with two convolutional layers (CNN2) (q = 4.4252, 95%). Statistically, the CNN2 algorithm would obtain better results for the classification of the two-additive samples.
Table 15.
Tukey’s HSD test results for two-additive solutions (validation).
The Tukey results for the validation dataset (all the samples) are shown in Table 16. The critical value remained the same as the one calculated for two-additive solutions (4.41). The test revealed that the mean value of the accuracy was significantly different between the CNN with one hidden layer followed by a pooling layer (CNN1*) and CNN1 and CNN2 (q = 4.7673, 95%). Statistically, the CNN1* algorithm would obtain better results for the classification of all the samples.
Table 16.
Tukey’s HSD test results for all samples (validation).
4. Discussion
This study proposes a classification method for food additives based on their absorbance in the ultraviolet domain. Spectroscopy is a non-invasive method that has been employed in various domains, such as chemistry [49], food quality control [50], veterinary diagnosis [51], wine classification [52], and water monitoring [53]. Studies [34,54] have shown that food additives exhibit strong absorbance features at wavelengths shorter than 360 nm. Therefore, UV spectroscopy can be considered a suitable approach for their classification. The use of spectroscopy alongside neural network algorithms has been reported in the literature to determine sodium benzoate and potassium sorbate in beverages [34].
Similar to [34], this work focuses on the classification of sodium benzoate and potassium sorbate and three additional additives that function as sweeteners (acesulfame potassium, aspartame, and saccharine). The spectra of solutions with different molar concentrations were acquired using the Jasco V-750 UV-Visible Spectrophotometer. The spectral database contained 404 spectra, 193 spectra for solutions containing only one additive and 211 for the mixture of two additives.
The classification of the samples was performed using ANN and CNN models. The performances of the models were tested for different architectures. The ANN was tested for 1 and 2 hidden layers, whereas the CNN models were built with 1, 2, or 3 convolutional layers followed or not by pooling layers.
Three classifications were performed. The first one included only simple solutions. As depicted in Table 5 and Table 6, the best model that can be used for the classification of the one-additive solutions was the CNN with two convolutional layers followed by pooling layers. The mean validation and testing accuracy was 99.67% ± 1.02%.
For the classification of two-additive spectra, the best results were obtained with the CNN model with one convolutional layer followed by a pooling layer. The model obtained high validation and testing results. The mean testing accuracy was 91.94% ± 4.02% (Table 7), whereas the mean validation accuracy was 94.16% ± 3.05% (Table 8).
The last classification was performed on the entire database. The CNN model with three convolutional layers was the best choice for the classifications of the 404 spectra, obtaining a mean testing accuracy of 92.38% ± 1.48%. The model also performed well on unseen data, obtaining a validation accuracy of 93.43% ± 2.01% for the classification of the 15 classes of substances. The overall results show that CNN obtained better results than ANN for spectra classification without signs of overfitting or underfitting. Also, the ANOVA analyses followed by post hoc tests indicate that, statistically, the best classification accuracies can be obtained using CNN algorithms.
Future research will focus on three main aspects. The first one regards the dimensions of the spectral dataset. A total of 404 spectra were used for this study. The spectra were acquired for one-additive solutions (193 spectra) and two-additive solutions (211 spectra). For a one-additive solution, more than 25 spectra were acquired for each of the five classes, whereas for two-additive solutions, the minimum number of samples per class was 12. It is desired to enlarge the database with more spectra for two-additive solutions to include at least 25 samples per class and see the changes that appear in the spectrum when mixing solutions with other molar concentrations than the ones presented in this study. Adding supplementary spectra for two-additive solutions could improve the model’s training and validation accuracy.
Secondly, the spectrum of new mixtures could be included in the dataset. Table 17 shows all the possible mixtures that can be obtained by mixing 3, 4, or 5 additives. The sample preparation and spectrum acquisition are time-consuming processes. The mass of the solute needs to be measured, the quantity of the solvent needs to be accurately measured to obtain the desired molar concentration, and dilutions need to be prepared to obtain various concentrations and absorbance values. Considering the average time per sample to be 7 min, it would require 5425 min (approximately 90 h) to prepare at least 25 solutions per class and acquire their spectra.
Table 17.
Number of possible mixtures and estimated preparation time.
Future research could include other food additives, such as coloring agents, texturizing agents, or nutritional agents. The analysis of samples containing five or more additives is crucial because, usually, in food products/beverages, there are more than two additives. The ingredients found within a product are important because they assist customers in apprehending what they are consuming. Identifying food additives is important since their long-term effects are still very disputed [14,22,23,24]. Also, studies have researched the influence of nutritional labels on people’s food choices [55], the importance of front-of-pack nutritional labels [56], and the awareness of consumers regarding food additives [26]. Therefore, the aim to continue this study to analyze real samples and their classification is a current and essential subject that would be very advantageous since spectroscopy is a non-invasive technique requiring small samples. Using deep learning methods would allow the classification of many samples with minimum human assistance, delivering fast results.
Author Contributions
Conceptualization, R.G. and L.S.; methodology, L.S. and R.M.T.; software, C.S.; validation, R.M.T., C.S., L.S. and R.G.; formal analysis, I.-A.P. and R.M.T.; investigation, I.-A.P. and C.S.; resources, C.S.; data curation, I.-A.P.; writing—original draft preparation, I.-A.P.; writing—review and editing, I.-A.P., L.S., R.M.T. and R.G.; visualization, I.-A.P.; supervision, R.M.T. and L.S.; project administration, R.M.T.; funding acquisition, R.M.T. All authors have read and agreed to the published version of the manuscript.
Funding
This paper was financially supported by “Network of excellence in applied research and innovation for doctoral and postdoctoral programs/InoHubDoc”, a project co-funded by the European Social Fund financing agreement no. POCU/993/6/13/153437.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are available upon request from the corresponding authors.
Acknowledgments
This paper was financially supported by “Network of excellence in applied research and innovation for doctoral and postdoctoral programs/InoHubDoc”, a project co-funded by the European Social Fund financing agreement no. POCU/993/6/13/153437.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Table A1 presents the selected food additives alongside the molecular formula and molar mass. The molar mass is necessary for the calculation of the molar concentration of the samples. It is important to select the volume of the solvent and calculate the mass of the solute that needs to be dissolved into the solvent to obtain a sample with the desired molar concentrations.
Table A1.
Food additives.
Table A1.
Food additives.
| Food Additive | Type of Additive | Molar Mass (g/mol−1) | Molecular Formula |
|---|---|---|---|
| Acesulfame Potassium | Sweetener | 202.242 | C4H4KNO4S |
| Aspartame | Sweetener | 294.3 | C14H18N2O5 |
| Saccharin | Sweetener | 183.18 | C7H5NO3S |
| Potassium Sorbate | Preservative | 150.22 | C6H7KO2 |
| Sodium Benzoate | Preservative | 144.11 | C7H5NaO2 |
Table A2 presents the calculated and measured mass of the solute necessary for obtaining a specific molar concentration for each one of the five additives.
Table A2.
Mass of solute.
Table A2.
Mass of solute.
| Food Additive | Molar Concentration (M) | Calculated Mass (g) | Measured Mass (g) |
|---|---|---|---|
| Acesulfame Potassium | 0.1 | 0.1006 | 0.1006 |
| Aspartame | 0.01 | 0.0147 | 0.0144 |
| Saccharin | 0.1 | 0.0915 | 0.0916 |
| Potassium Sorbate | 0.1 | 0.0751 | 0.0752 |
| Sodium Benzoate | 0.9 | 0.0648 | 0.06483 |
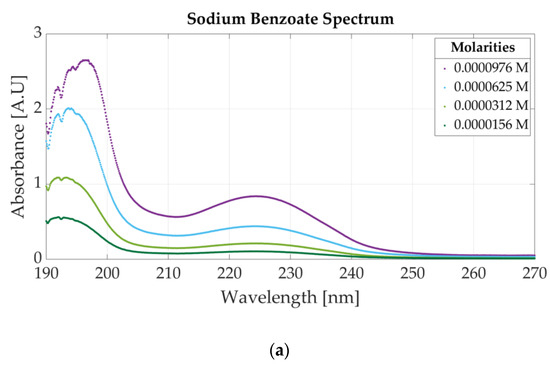
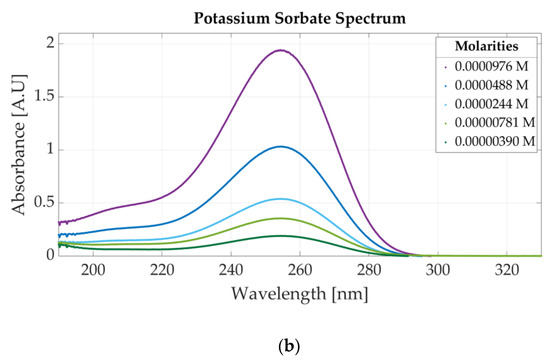
Figure A1.
Ultraviolet spectra of food additives: (a) UV spectrum for four concentrations of sodium benzoate: (b) UV spectrum for five concentrations of potassium sorbate.
Figure A1.
Ultraviolet spectra of food additives: (a) UV spectrum for four concentrations of sodium benzoate: (b) UV spectrum for five concentrations of potassium sorbate.
References
- Dunford, E.K.; Miles, D.R.; Popkin, B. Food Additives in Ultra-Processed Packaged Foods: An Examination of US Household Grocery Store Purchases. J. Acad. Nutr. Diet. 2023, 123, 889–901. [Google Scholar] [CrossRef] [PubMed]
- Djupegot, I.L.; Nenseth, C.B.; Bere, E.; Bjørnarå, H.B.T.; Helland, S.H.; Øverby, N.C.; Torstveit, M.K.; Stea, T.H. The association between time scarcity, sociodemographic correlates and consumption of ultra-processed foods among parents in Norway: A cross-sectional study. BMC Public Health 2017, 17, 447. [Google Scholar] [CrossRef]
- Jackson, P.; Viehoff, V. Reframing convenience food. Appetite 2016, 98, 1–11. [Google Scholar] [CrossRef]
- Duffy, E.W.; Lo, A.; Hall, M.G.; Taillie, L.S.; Ng, S.W. Prevalence and demographic correlates of online grocery shopping: Results from a nationally representative survey during the COVID-19 pandemic. Public Health Nutr. 2022, 25, 3079–3085. [Google Scholar] [CrossRef]
- Zatz, L.Y.; Moran, A.J.; Franckle, R.L.; Block, J.P.; Hou, T.; Blue, D.; Greene, J.C.; Gortmaker, S.; Bleich, S.N.; Polacsek, M.; et al. Comparing Online and In-Store Grocery Purchases. J. Nutr. Educ. Behav. 2021, 53, 471–479. [Google Scholar] [CrossRef] [PubMed]
- Sadler, C.R.; Grassby, T.; Hart, K.; Raats, M.; Sokolović, M.; Timotijevic, L. Processed food classification: Conceptualisation and challenges. Trends Food Sci. Technol. 2021, 112, 149–162. [Google Scholar] [CrossRef]
- Branen, A.L.; Davidson, P.M.; Salminen, S.; Thorngate, J. Food Additives; CRC Press: Boca Raton, FL, USA, 2001. [Google Scholar]
- Dieye, M.; Ndiaye, N.D.; Bassama, J.; Mertz, C.; Bugaud, C.; Diatta, P.; Cissé, M. Storage Time as an Index for Varietal Prediction of Mango Ripening: A Systemic Approach Validated on Five Senegalese Varieties. Foods 2022, 11, 3759. [Google Scholar] [CrossRef]
- Mathiyalagan, S.; Mandal, B.K. A review on assessment of acceptable daily intake for food additives. Biointerface Res. Appl. Chem. 2020, 10, 6033–6038. [Google Scholar] [CrossRef]
- Wu, L.; Zhang, C.; Long, Y.; Chen, Q.; Zhang, W.; Liu, G. Food additives: From functions to analytical methods. Crit. Rev. Food Sci. Nutr. 2022, 62, 8497–8517. [Google Scholar] [CrossRef]
- Ahmad, S.Y.; Friel, J.K.; Mackay, D.S. Effect of sucralose and aspartame on glucose metabolism and gut hormones. Nutr. Rev. 2020, 78, 725–746. [Google Scholar] [CrossRef]
- Huang, S.-Y.; Sun, R.; Chen, Y.-C.; Kang, L.; Wang, C.-T.; Chiu, C.-F.; Wu, H.-T. Aspartame consumption during pregnancy impairs placenta growth in mice through sweet taste receptor-reactive oxygen species-dependent pathway. J. Nutr. Biochem. 2023, 113, 109228. [Google Scholar] [CrossRef] [PubMed]
- Bensid, A.; El Abed, N.; Houicher, A.; Regenstein, J.M.; Özogul, F. Antioxidant and antimicrobial preservatives: Properties, mechanism of action and applications in food—A review. Crit. Rev. Food Sci. Nutr. 2022, 62, 2985–3001. [Google Scholar] [CrossRef] [PubMed]
- Esimbekova, E.N.; Asanova, A.A.; Kratasyuk, V.A. Alternative Enzyme Inhibition Assay for Safety Evaluation of Food Preservatives. Life 2023, 13, 1243. [Google Scholar] [CrossRef] [PubMed]
- Landrigan, P.J.; Straif, K. Aspartame and cancer—New evidence for causation. Environ. Health 2021, 20, 42. [Google Scholar] [CrossRef]
- Debras, C.; Chazelas, E.; Srour, B.; Druesne-Pecollo, N.; Esseddik, Y.; de Edelenyi, F.S.; Agaësse, C.; De Sa, A.; Lutchia, R.; Gigandet, S.; et al. Artificial sweeteners and cancer risk: Results from the NutriNet-Santé population-based cohort study. PLoS Med. 2022, 19, e1003950. [Google Scholar] [CrossRef]
- Higgins, K.A.; Mattes, R.D. A randomized controlled trial contrasting the effects of 4 low-calorie sweeteners and sucrose on body weight in adults with overweight or obesity. Am. J. Clin. Nutr. 2019, 109, 1288–1301. [Google Scholar] [CrossRef]
- Shalaby, A.M.; Ibrahim, M.A.A.H.; Aboregela, A.M. Effect of aspartame on the placenta of adult albino rat. A histological and immunohistochemical study. Ann. Anat. Anat. Anz. 2019, 224, 133–141. [Google Scholar] [CrossRef]
- Dehghan, P.; Mohammadi, A.; Mohammadzadeh-Aghdash, H.; Dolatabadi, J.E.N. Pharmacokinetic and toxicological aspects of potassium sorbate food additive and its constituents. Trends Food Sci. Technol. 2018, 80, 123–130. [Google Scholar] [CrossRef]
- Magomya, A.M.; Yebpella, G.G.; Okpaegbe, U.C.; Oko, O.J.; Gambo, S.B. Analysis and Health Risk Assessment of Sodium Benzoate and Potassium Sorbate in Selected Fruit Juice and Soft Drink Brands in Nigeria. Int. J. Pharm. Chem. 2020, 6, 54. [Google Scholar] [CrossRef]
- Sambu, S.; Hemaram, U.; Murugan, R.; Alsofi, A.A. Toxicological and Teratogenic Effect of Various Food Additives: An Updated Review. BioMed Res. Int. 2022, 2022, 6829409. [Google Scholar] [CrossRef]
- Rodrigues, H.; Silva, C.; Martel, F. The effects of aspartame on the HTR8/SVneo extravillous trophoblast cell line. Reprod. Biol. 2022, 22, 100678. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.-C.; Yeh, Y.-C.; Lin, Y.-F.; Au, H.-K.; Hsia, S.-M.; Chen, Y.-H.; Hsieh, R.-H. Aspartame Consumption, Mitochondrial Disorder-Induced Impaired Ovarian Function, and Infertility Risk. Int. J. Mol. Sci. 2022, 23, 12740. [Google Scholar] [CrossRef] [PubMed]
- Lin, C.-H.; Li, H.-Y.; Wang, S.-H.; Chen, Y.-H.; Chen, Y.-C.; Wu, H.-T. Consumption of Non-Nutritive Sweetener, Acesulfame Potassium Exacerbates Atherosclerosis through Dysregulation of Lipid Metabolism in ApoE−/− Mice. Nutrients 2021, 13, 3984. [Google Scholar] [CrossRef]
- Singh, A.; Rourk, K.; Bernier, A.; de Lartigue, G. Non-Nutritive Sweetened Beverages Impair Therapeutic Benefits of Metformin in Prediabetic Diet-Induced Obese Mice. Nutrients 2023, 15, 2472. [Google Scholar] [CrossRef] [PubMed]
- Bearth, A.; Cousin, M.-E.; Siegrist, M. The consumer’s perception of artificial food additives: Influences on acceptance, risk and benefit perceptions. Food Qual. Preference 2014, 38, 14–23. [Google Scholar] [CrossRef]
- Buyukgoz, G.G.; Bozkurt, A.G.; Akgul, N.B.; Tamer, U.; Boyaci, I.H. Spectroscopic detection of aspartame in soft drinks by surface-enhanced Raman spectroscopy. Eur. Food Res. Technol. 2015, 240, 567–575. [Google Scholar] [CrossRef]
- Singh, R.; Singh, M. Molecularly imprinted electrochemical sensor for highly selective and sensitive determination of artificial sweetener Acesulfame-K. Talanta Open 2023, 7, 100194. [Google Scholar] [CrossRef]
- Bergamo, A.B.; da Silva, J.A.F.; de Jesus, D.P. Simultaneous determination of aspartame, cyclamate, saccharin and acesulfame-K in soft drinks and tabletop sweetener formulations by capillary electrophoresis with capacitively coupled contactless conductivity detection. Food Chem. 2011, 124, 1714–1717. [Google Scholar] [CrossRef]
- Chang, C.-S.; Yeh, T.S. Detection of 10 sweeteners in various foods by liquid chromatography/tandem mass spectrometry. J. Food Drug Anal. 2014, 22, 318–328. [Google Scholar] [CrossRef]
- Duarte, L.M.; Paschoal, D.; Izumi, C.M.; Dolzan, M.D.; Alves, V.R.; Micke, G.A.; Dos Santos, H.F.; de Oliveira, M.A. Simultaneous determination of aspartame, cyclamate, saccharin and acesulfame-K in powder tabletop sweeteners by FT-Raman spectroscopy associated with the multivariate calibration: PLS, iPLS and siPLS models were compared. Food Res. Int. 2017, 99, 106–114. [Google Scholar] [CrossRef]
- Zhang, H.; Yang, H.; Liu, P.; Qin, X.; Liu, G. Colorimetric quantification of sodium benzoate in food by using d-amino acid oxidase and 2D metal organic framework nanosheets mediated cascade enzyme reactions. Talanta 2022, 237, 122906. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Ma, L.; Tang, Z.; Yu, L.X. Identification of coumarin-based food additives using terahertz spectroscopy combined with manifold learning and improved support vector machine. J. Food Sci. 2022, 87, 1108–1118. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Zhang, J.; Zhang, Z.; Liu, X.; Fan, J.; Liu, W.; Zhang, X. Simultaneous ultraviolet spectrophotometric determination of sodium benzoate and potassium sorbate by BP-neural network algorithm and partial least squares. Optik 2020, 201, 163529. [Google Scholar] [CrossRef]
- Kalopesa, E.; Karyotis, K.; Tziolas, N.; Tsakiridis, N.; Samarinas, N.; Zalidis, G. Estimation of Sugar Content in Wine Grapes via In Situ VNIR–SWIR Point Spectroscopy Using Explainable Artificial Intelligence Techniques. Sensors 2023, 23, 1065. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Deng, J.; Jiang, H. Markov Transition Field Combined with Convolutional Neural Network Improved the Predictive Performance of Near-Infrared Spectroscopy Models for Determination of Aflatoxin B1 in Maize. Foods 2022, 11, 2210. [Google Scholar] [CrossRef]
- Sun, P.; Wang, J.; Dong, Z. CNN–LSTM Neural Network for Identification of Pre-Cooked Pasta Products in Different Physical States Using Infrared Spectroscopy. Sensors 2023, 23, 4815. [Google Scholar] [CrossRef]
- Joshi, R.; Gg, L.P.; Faqeerzada, M.A.; Bhattacharya, T.; Kim, M.S.; Baek, I.; Cho, B.-K. Deep Learning-Based Quantitative Assessment of Melamine and Cyanuric Acid in Pet Food Using Fourier Transform Infrared Spectroscopy. Sensors 2023, 23, 5020. [Google Scholar] [CrossRef]
- Hao, Y.; Li, X.; Zhang, C.; Lei, Z. Online Inspection of Browning in Yali Pears Using Visible-Near Infrared Spectroscopy and Interpretable Spectrogram-Based CNN Modeling. Biosensors 2023, 13, 203. [Google Scholar] [CrossRef]
- Przybył, K.; Koszela, K.; Adamski, F.; Samborska, K.; Walkowiak, K.; Polarczyk, M. Deep and Machine Learning Using SEM, FTIR, and Texture Analysis to Detect Polysaccharide in Raspberry Powders. Sensors 2021, 21, 5823. [Google Scholar] [CrossRef]
- Jasco V-750 UV-Visible Spectrophotometer. Available online: https://jascoinc.com/products/spectroscopy/uv-visible-nir-spectrophotometers/specifications/ (accessed on 5 July 2023).
- Barburiceanu, S.; Meza, S.; Orza, B.; Malutan, R.; Terebes, R. Convolutional Neural Networks for Texture Feature Extraction. Applications to Leaf Disease Classification in Precision Agriculture. IEEE Access 2021, 9, 160085–160103. [Google Scholar] [CrossRef]
- Miclea, A.V.; Terebes, R.; Meza, S. One dimensional convolutional neural networks and local binary patterns for hyperspectral image classification. In Proceedings of the 2020 IEEE International Conference on Automation, Quality and Testing, Robotics (AQTR), Cluj-Napoca, Romania, 21–23 May 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Barburiceanu, S.; Terebeș, R. Automatic detection of melanoma by deep learning models-based feature extraction and fine-tuning strategy. IOP Conf. Ser. Mater. Sci. Eng. 2022, 1254, 012035. [Google Scholar] [CrossRef]
- Ben Fredj, H.; Bouguezzi, S.; Souani, C. Face recognition in unconstrained environment with CNN. Vis. Comput. 2021, 37, 217–226. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Van Rossum, G.; Drake, F.L., Jr. Python Reference Manual; Centrum voor Wiskunde en Informatica Amsterdam: Amsterdam, The Netherlands, 1995. [Google Scholar]
- MacFarland, T.W.; Yates, J.M. Kruskal–Wallis H-Test for Oneway Analysis of Variance (ANOVA) by Ranks. In Introduction to Nonparametric Statistics for the Biological Sciences Using R; Springer International Publishing: Cham, Switzerland, 2016; pp. 177–211. [Google Scholar] [CrossRef]
- Hajirasouliha, F.; Omidi, H.; Omid, N.J.; Dorkoosh, F.A. UV spectroscopy: A novel method for determination of degree of substitution of phthaloyl group as amine protector in chitosan. Z. Phys. Chem. 2023, 237, 663–673. [Google Scholar] [CrossRef]
- Venturini, F.; Fluri, S.; Baumgartner, M. Dataset of Fluorescence EEM and UV Spectroscopy Data of Olive Oils during Ageing. Data 2023, 8, 81. [Google Scholar] [CrossRef]
- Coelho, M.L.; França, T.; Mateus, N.L.F.; da Costa Lima, S.M., Jr.; Cena, C.; Ramos, C.A.D.N. Canine visceral leishmaniasis diagnosis by UV spectroscopy of blood serum and machine learning algorithms. Photodiagnosis Photodyn. Ther. 2023, 42, 103575. [Google Scholar] [CrossRef]
- Philippidis, A.; Poulakis, E.; Kontzedaki, R.; Orfanakis, E.; Symianaki, A.; Zoumi, A.; Velegrakis, M. Application of Ultraviolet-Visible Absorption Spectroscopy with Machine Learning Techniques for the Classification of Cretan Wines. Foods 2020, 10, 9. [Google Scholar] [CrossRef]
- Nissen, M.; Doherty, B.; Hamperl, J.; Kobelke, J.; Weber, K.; Henkel, T.; Schmidt, M.A. UV Absorption Spectroscopy in Water-Filled Antiresonant Hollow Core Fibers for Pharmaceutical Detection. Sensors 2018, 18, 478. [Google Scholar] [CrossRef]
- Fernandes, V.N.O.; Fernandes, L.B.; Vasconcellos, J.P.; Jager, A.V.; Tonin, F.G.; de Oliveira, M.A.L. Simultaneous analysis of aspartame, cyclamate, saccharin and acesulfame-K by CZE under UV detection. Anal. Methods 2013, 5, 1524–1532. [Google Scholar] [CrossRef]
- Penzavecchia, C.; Todisco, P.; Muzzioli, L.; Poli, A.; Marangoni, F.; Poggiogalle, E.; Giusti, A.M.; Lenzi, A.; Pinto, A.; Donini, L.M. The influence of front-of-pack nutritional labels on eating and purchasing behaviors: A narrative review of the literature. Eat. Weight Disord. Stud. Anorexia Bulim. Obes. 2022, 27, 3037–3051. [Google Scholar] [CrossRef]
- Muzzioli, L.; Penzavecchia, C.; Donini, L.M.; Pinto, A. Are Front-of-Pack Labels a Health Policy Tool? Nutrients 2022, 14, 771. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).