1. Introduction
Transportation is an essential part of human lives and a significant portion of a country’s economy comes from the transportation industry. While being a source of safe and fast travel, lack of driver vigilance, fatigue, and drowsiness may lead to accidents involving injuries and fatalities [
1]. Driver drowsiness is responsible for a large number of accidents in the world. Different studies report 20% to 50% of accidents are related to driver fatigue and drowsiness on certain roads [
2,
3]. Drowsiness is when someone feels dizzy or experiences involuntary sleep, primarily due to a lack of sleep or mental or physical fatigue. It can be particularly hazardous when there is a need for a consistently high level of attention, such as in industrial work, mining, and driving to avoid unwanted and life-threatening events [
4,
5]. When it comes to drowsy driving, it has severe implications for road safety. Along with other contributing factors such as speeding, drinking, and driving, and not wearing seat belts or helmets, drowsy or fatigued driving is also considered a major source of road accidents [
6,
7].
Over the last few years, physical and life losses because of road accidents have increased. According to reports on road safety [
8], out of 1.35 million mortalities, approximately 37% of people die yearly due to drivers’ drowsiness in road accidents. Overall, it is the eighth leading cause of death and ranked the first cause of mortalities for people aged between 5 and 29. Taking energy drinks, coffee, or stopping to take a short nap while traveling for a long time helps drivers stay alert, but the effect remains for the short term [
9]. Moreover, these remedies may only be effective when a driver is aware of fatigue [
10].
1.1. Research Objectives
Keeping with the above discussion, a driver’s acts are critical to road security, both for the driver and other people traveling on roads. Due to its significant importance in saving lives, driver drowsiness detection has received increased attention lately. Several studies are found in the literature that focus on detecting different levels of alertness in drivers using unique facial cues such as head poses, eye movement, and other facial expressions [
11,
12]. While ongoing research shows promising advancements, core challenges, such as accurate and real-time drowsiness detection, still need to be addressed. Current driver yawning detection systems are either expensive or need more robustness [
13,
14].
Drowsiness among drivers causes injuries and sometimes the death of millions of people annually; there is a need to develop a system with high accuracy, precision, and robustness. Detection of drowsiness is a critical factor for successfully preventing road accidents. The objective of this research is to propose a deep neural network model that performs relatively better in terms of accuracy and other measures.
1.2. Research Contributions
This study aims to propose a more accurate driver drowsiness detection method to reduce road accidents. The following are the major contributions of this study:
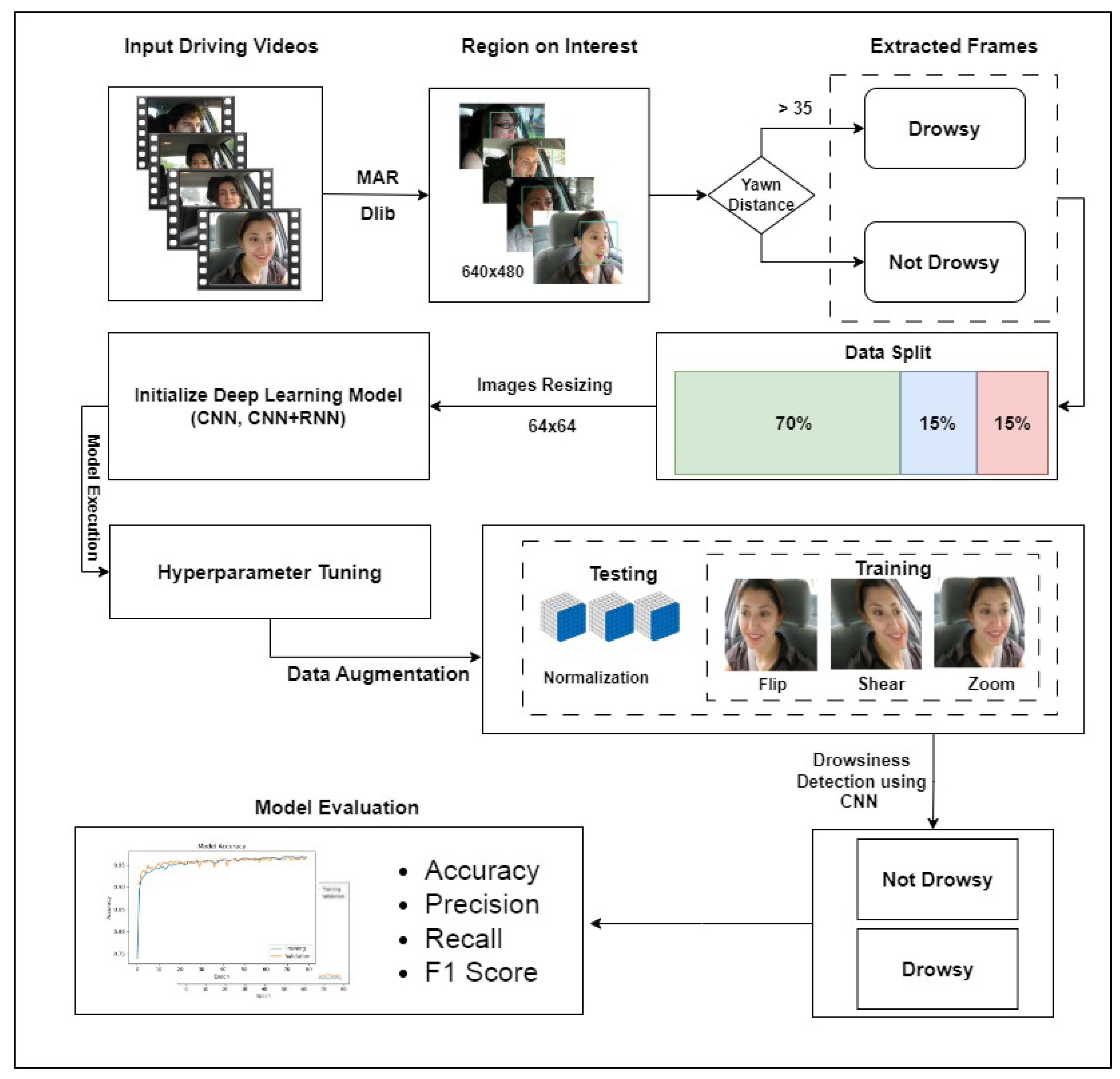
A deep convolutional neural network (CNN) is designed in this study for driver drowsiness detection. The model is optimized regarding the number of layers, neurons in each layer, etc. In addition, a hybrid deep learning model CNN-RNN (recurrent neural network) that combines CNN and RNN deep learning models is also used.
Experiments involve using the publicly available YawDD dataset. To reduce the impact of smaller datasets, data augmentation is used. Separate experiments are performed using augmented and original datasets for performance comparison.
For model training, facial features like the mouth aspect ratio (MAR) are used, which are extracted using the Dlib library. The effectiveness of the proposed model is evaluated using multiple performance metrics such as precision, recall, and F1 score. Moreover, performance comparison with existing state-of-the-art models is also carried out.
The remaining part of this study is organized as follows.
Section 2 presents the literature review on driver drowsiness detection.
Section 3 describes the methodology, while experimental results are explained in
Section 4. Lastly,
Section 5 presents the conclusion and future recommendations.
2. Literature Review
Driver drowsiness detection techniques fall into three main categories. The first category is the biological feature technique that involves analyzing physiological signals [
15], skin temperature, and galvanic skin response (GSR) to measure physical conditions that change with the level of drowsiness or fatigue [
16,
17,
18,
19]. The second category is vehicle movement indicator techniques specifically focused on driving applications to detect abnormal driving behavior due to fatigue or drowsiness, such as random braking, lane positioning, abnormal speeding, and abnormal steering. We can observe these kinds of behavior with the help of different sensors in the vehicle [
2,
19,
20]. Vehicle movement indicator techniques have several restrictions such as road shape, vehicle type, driver expertise, and the situation, and more importantly, it needs more time to acquire all these parameters [
14,
21]. Both categories are invasive, requiring extra equipment or sensors to detect drowsiness [
13]. The stated limitation makes both techniques inappropriate to implement in real-time. Consequently, most studies focus on the third category, which uses the behavioral features of drivers.
The behavioral feature technique is noninvasive and involves computer vision for drowsiness detection. For real-time visual analysis of behavioral features, a camera is needed [
11,
12]. Behavioral measures such as unusual eye movement, facial expression, yawing, and head orientation are measured without attaching any additional equipment. Consequently, behavioral feature analysis is a cost-effective and easy-to-use solution.
Notably, the integration of deep learning techniques has significantly enhanced signal and image processing tasks in real word problems [
22]. Deep learning has also witnessed remarkable advancements in the field of object detection [
23]. These advancements have revolutionized various industries, including autonomous vehicles [
24], security systems [
25], and healthcare [
26]. In recent years, deep learning has spearheaded a revolution in drowsiness detection across all categories, encompassing behavioral, biological, and vehicle movement indicators. The substantial impact of deep learning on these critical aspects of drowsiness detection has been transformative [
2]. This study also considers behavioral features to detect drowsiness. Below, the relevant literature on drowsiness detection using deep learning and computer vision is discussed.
The use of spatial and temporal features is predominant in existing studies that utilize the behavioral data of drivers. For example, the study [
27] used spatiotemporal data to detect fatigue among drivers by analyzing facial features. The authors proposed a fusion-based system to detect yawns, head pose estimation, and detection of somnolence. Three datasets were used for analysis: YawDD, DEAP, and MiraclHB. YawDD and MiraclHB contain behavioral features, whereas the DEAP dataset analyzes human emotional states, psychological signals, and electroencephalography (EEG). The proposed model achieved recall and precision of 84% and 85%, respectively. Similarly, ref. [
28] focused on early drowsiness detection using temporal features. Occlusion criteria were used that measure the distance between the centers of the pupil and the horizontal length of the eye. The researcher used a support vector machine (SVM) classifier on publicly available benchmark data and achieved 89% accuracy.
Along the same lines, ref. [
29] proposed a novel approach with two streams—a spatial– temporal graph convolutional network. The method leverages both spatial and sequential features. The two-stream framework employed in the method captures spatial and temporal features as well as first-order and second-order information at the same time. The anticipated method was evaluated on the YawDD and NTHU-DDD datasets, achieving an impressive average accuracy of 93.4% and 92.7%, respectively, demonstrating the feasibility and effectiveness of the method.
Another study [
30] considered the most significant temporal features to detect drowsiness precisely. A novel algorithm was proposed using linear SVM for classification and the Dlib library to extract facial features for experimental analysis. A rarest IMM face dataset was used that contained all images with the open eyes of drivers. Samples of individuals related to diverse civilizations, colors, and environments were added to make the dataset more challenging and realistic. Occlusion is applied on each incoming frame while preprocessing to overcome the chances of false prediction. After handling the occlusion situation, the proposed system achieved 94.2% accuracy with open eyes.
Along the same lines, ref. [
31] used temporal and spatial face features to detect drowsiness. The UTA-RLDD dataset used for experimentation has 30 h of videos of 60 participants with three classes: alert, low vigilant, and drowsy. In this study, two different models were proposed. The first model is based on a long short-term memory (LSTM) architecture for temporal feature extraction, and the second uses CNN and LSTM for spatial feature extraction. The Dlib library containing linear SVM classifier was used for temporal features with 79.9% accuracy; however, due to the multiple feature matrix, the computational time was increased. For spatial features, the Softmax classifier was used to obtain more accurate results, i.e., 97.5% accuracy.
According to [
32], information related to the mouth and eyes is needed to classify them. This information is essential to obtain fast results and detect drowsiness states in drivers. In this regard, the study adopted a MTCNN model for drowsiness detection. Two public datasets were combined and used in this study including the YawDD video dataset of various people from various ethnic backgrounds, and the NTHU-DDD dataset containing five different scenarios, and each frame was labeled as ‘fatigue’ or ‘not fatigue’. The Dlib algorithm was implemented to detect the face, mouth, and eye regions. The experiments were performed at constant frame rates to calculate fatigue. As a result, the model achieved 98.81% accuracy.
Moreover, ref. [
33] aimed to extract spatial and temporal features to detect drowsiness among drivers. The researchers proposed a new deep learning framework to collect drowsiness information from the spatial-temporal domain. The publicly available NTHU-DDD dataset was used for experimentation involving different participants with and without eyeglasses and variant illuminations. Different experiments were performed initially where the proposed approach achieved 82.8% accuracy with 3DcGAN. Additional experiments showed improved performance with an 87.1% accuracy using 3DcGAN+TLABiLSTM and 91.2% accuracy using 3DcGAN+TLABiLSTM and refinement. Similarly, ref. [
34] employed a combination of multitask convolutional neural network (MTCNN) for face recognition and Dlib for locating facial key points. For extracting fatigue feature vectors from the facial key points of each frame, a temporal feature sequence was constructed and fed into an LSTM network to obtain an ultimate fatigue feature value. The proposed model achieved an average accuracy of 88% and 90% for YawDD and self-built datasets, respectively.
Real-time driver drowsiness detection is a challenging task, and a few studies have endeavored to perform this task. For example, ref. [
35], drivers’ vigilance status was studied on real-time data using deep learning. The authors used the Haar-cascade method and CNN with the UTA-RLDD dataset, and five-fold validation was applied at a rate of 8.4 frames per second. The dataset contains real states of active and drowsy faces, so the trained model was expected to be more accurate and realistic. The selected CNN has low complexity too. The added novelty in the work is the creation of a custom dataset containing 122 videos of 10 participants. Various tuning hyperparameters were applied to achieve significant accuracy. On batch sizes of 200 and 500 epochs, it showed the best accuracy. The experimental results showed a 96.8% accuracy.
The study [
36] presented a real-time system to analyze consecutive video frames using information entropy to detect fatigue. An improved YOLOv3-tiny CNN was used to capture facial regions. A geometric area called the face feature triangle (FFT) using the Dlib toolkit, facial landmarks, and coordinates of the facial regions were used to capture the relevant facial information. By utilizing the FFT, a face feature vector (FFV) is created that encapsulates all the necessary information to determine the fatigue state of the drivers. The proposed algorithm achieved a detection speed of over 20 frames per second with an accuracy rate of 94.32%. Ref. [
37] collected real-time data for drowsiness detection and performed various experiments to validate it. Two hundred and twenty-three subjects participated, and frames were labeled into four classes. For experiments, data from 10 participants containing 245 videos each with 5 min duration were taken and split into a three to one ratio for training and validation. Various experiments were performed where a maximum accuracy of 64% was achieved.
Detecting drowsiness with open eyes is a challenging task. Ref. [
30] used computer vision to detect real-time drowsiness among drivers. The system used eye blink duration as a key indicator for the accident avoidance system. The proposed approach detects the open and closed states of the eyes based on the eye aspect ratio (EAR). Experimental analysis of the YawDD dataset demonstrated that the system achieved an accuracy of approximately 92.5%.
The authors created a curated dataset of 50 subjects, 30 males and 20 females, with varying illumination conditions in [
38]. Four deep convolutional neural networks (DCNNs) named Xception, ResNet101, InceptionV4, and ResNext101 with feature pooling methods were applied to this dataset. Most experiments achieved a 90% accuracy, but these models require significant computational resources. A low-complexity MobileNetV2 CNN was trained to maximize efficiency to overcome this problem. Weibull-based ResNext101 and MobileNetV2 models achieved 93.80% and 90.50% accuracy, respectively. Experiments were also performed on the benchmark dataset NTHU-DDD with the proposed algorithm that achieved an 84.21% accuracy.
The study [
19] proposed a reliable fatigue detection system built on the CNN model. The study also proposed a fusion method to measure multiple physical features. The fusion method includes Haarlike, 68-Landmarkmodels, PERCLOS, and the MAR ratio. The VGG16 convolutional neural network for fatigue feature learning and the single-shot multi-box detector algorithm were adopted for better speed and accuracy. The VGG16 model helps to overcome the problems of poor environment, lighting conditions, and drivers wearing glasses to provide flexibility. Using four states of mouth, the experiments showed 90% accuracy on NTHU-DDD and other datasets.
In [
39], the RLDD dataset was presented with the videos of 60 participants, of which 51 were male, and 9 were female. There are 180 videos, each 10 min long, with three alerts for low vigilance and drowsy classes. The researchers used five-fold experiments at a 4:1 training–testing ratio. The model was trained on 7000 blink sequences with a learning rate of 0.000053. Initially, the LSTM network achieved 61.4% accuracy, then experiments on the HM-LSTM network showed a 4% increase in accuracy and achieved 65.2% accuracy. Experiments also indicated that the HM-LSTM network performed well compared to fully connected layers and human judgment.
Table 1 provides a comparative summary of the discussed research works. The existing literature on driver drowsiness using facial features indicates that there is still room for improvement in driver drowsiness detection to improve the robustness and reliability of these approaches. Behavioral drowsiness detection is a difficult task. There is a need to develop a more effective and robust drowsiness detection approach.
4. Results and Discussions
Six experiments are conducted on the complete dataset. We have proposed three deep neural network architectures for training and analysis. Each model is trained with and without data augmentation. The design of a deep learning model for drowsiness detection is based on several key factors and considerations, primarily to ensure its accuracy, efficiency, and real-world applicability. As we have the data in the form of frames of videos and we have binary class problems, that is the reason we develop these model architectures.
The findings of each experiment are discussed in this section. These experiments aim to achieve maximum classification accuracy and optimized performance for other quantitative measures for drowsiness detection among drivers. To measure the effect and performance of deep learning architecture in predicting yawning among drivers, the performance is assessed using standard metrics like accuracy, confusion matrix, precision, recall, and F1 score. We have used these measures to compare our solution with the relevant existing literature.
4.1. Experiments with Deep CNN Architecture
The deep CNN base architecture model is used in the experiments using training and validation data. The model accuracy and loss graphs for the proposed CNN model without data augmentation are shown in
Figure 7. It can be observed that the model starts with zero training accuracy; however, it improves as the number of epochs proceeds.
Figure 8 shows training and validation accuracy and loss for the CNN-1 model using the augmented data. Results show that model training and validation accuracy show a very similar trend as the number of epochs increases, contrary to the graphs on the original data where the model training and validation accuracy and loss have different trends.
Table 10 shows the training and validation of the proposed CNN-1 model without and with data augmentation. In the first experiment without data augmentation, the proposed model achieved a 96.34% accuracy rate for testing and 99.69% in training, respectively. Similarly, in the second experiment with data augmentation, the proposed architecture achieved a 95.99% accuracy rate for testing data and 96.85% for training, respectively. Experimental results show that the proposed architecture without data augmentation has achieved the highest accuracy.
The performance evaluation matrix, including precision, recall, and F1 score for both classes of the dataset, are shown in
Table 11. The precision score by the proposed CNN model without data augmentation is 0.9728 for the drivers belonging to the ‘not_yawning’ class and 0.9480 for the drivers belonging to the ‘yawning’ class indicating that 97.28% of the instances predicted as ‘Not Yawning’ are actually ‘Not Yawning’ and 94.80% of the instances predicted as ‘Yawning’ are actually ‘Yawning’.
Similarly, the recall for the ‘Not Yawning’ class is 0.9680. For the ‘Yawning’ class, it is 0.9558, indicating 96.80% and 95.58% of instances were correctly predicted as ‘Not Yawning’ and ‘Yawning’, respectively. The F1 score is considered more reliable, especially for scenarios where the class distribution is imbalanced, as it combines both precision and recall. The F1 score is 0.9704 (97.04%) for 1409 instances for the ‘not_yawning’ class and 0.9519 (95.19%) for 860 instances for the ‘yawning’ class, respectively. It shows that there is a significant balance between precision and recall.
For experiments involving data augmentation, the results of the CNN-1 model are slightly different. The precision score by the CNN-1 model is 0.9551 for the ‘not_yawning’ class and 0.9683 for the ‘yawning’ class, which indicates that 95.51% of the instances predicted as ‘Not Yawning’ are actually ‘Not Yawning’ and 96.83% of the instances predicted as ‘Yawning’ are actually ‘Yawning’. Similarly, the recall for the ‘Not Yawning’ class is 0.9815. For the ‘Yawning’ class, it is 0.9244, indicating 98.15% and 92.% instances are correctly predicted as ‘Not Yawning’ and ‘Yawning’, respectively. The F1 score is 0.9682 (96.82%) for 1409 instances for the ‘not_yawning’ class and 0.9459 (95.59%) for 860 instances for the ‘yawning’ class, respectively; it shows that there is a significant balance between precision and recall.
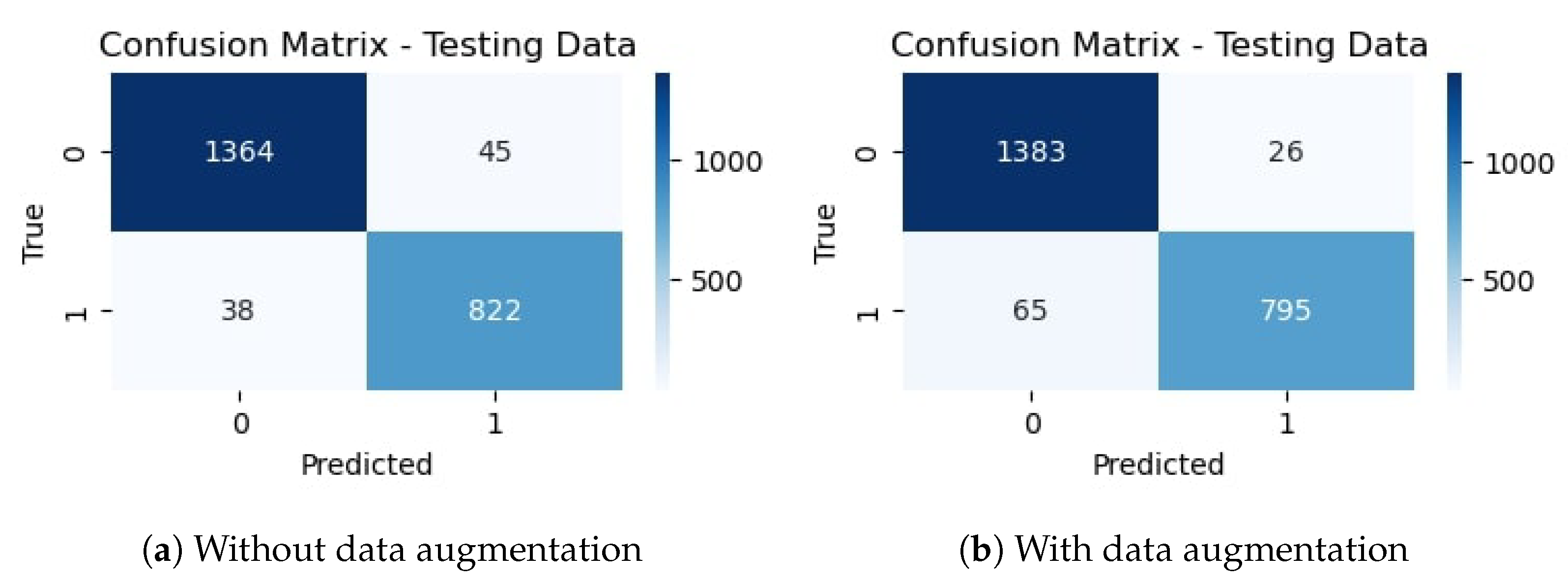
The confusion matrix for the proposed CNN-1 model without data augmentation is given in
Figure 9a. It indicates that out of 2269 testing images, 2186 are classified correctly by the proposed CNN model. It means the accuracy rate for the model is 96.34%. Similarly,
Figure 9b shows the confusion matrix for the proposed architecture with data augmentation, which indicates that out of 2269 testing images, 2178 are correctly classified. It means that the accuracy rate for the model is 95.99%.
4.2. Experiments with Deep CNN-2 Architecture
The deep CNN-2 base architecture model is used in the experiments using training and validation data. The model accuracy and loss graphs for the proposed CNN-2 model without data augmentation are shown in
Figure 10. Similar to the previous model, it starts with zero training accuracy, but improves as the number of epochs proceeds.
Figure 11 shows training and validation accuracy and loss for the CNN-2 model using the augmented data. Similar to CNN-1, CNN-2 model training and validation accuracy shows a very similar trend as the number of epochs increases, contrary to the graphs on the original data where the model training and validation accuracy and loss have different trends.
Table 12 shows the training and validation of the proposed CNN-2 model without and with data augmentation. In the first experiment without data augmentation, the proposed CNN-2 model achieved a 96.69% accuracy rate for testing and 99.41% in training, respectively. Similarly, in the second experiment with data augmentation, the proposed CNN-2 architecture achieved a 95.50% accuracy rate for testing data and 95.94% for training, respectively. Experimental results show that the proposed architecture without data augmentation has achieved the highest accuracy.
The performance evaluation matrix, including precision, recall, and F1 score for both classes of the dataset, are shown in
Table 13. The precision score by the proposed CNN-2 model without data augmentation is 0.9730 for the drivers belonging to the ‘not_yawning’ class and 0.9569 for the drivers belonging to the ‘yawning’ class indicating that 97.30% of the instances predicted as ‘Not Yawning’ are actually ‘Not Yawning’ and 95.69% of the instances predicted as ‘Yawning’ are actually ‘Yawning’. Similarly, the recall for the ‘Not Yawning’ class is 0.9737. For the ‘Yawning’ class, it is 0. 9558, indicating 97.37% and 95.58% instances were correctly predicted as ‘Not Yawning’ and ‘Yawning’, respectively. The F1 score is 0.9733 (97.33%) for 1409 instances for the ‘not_yawning’ class and 0.9563 (95.63%) for 860 instances for the ‘yawning’ class, respectively. It shows that there is a significant balance between precision and recall.
For experiments involving data augmentation, the results of the CNN-2 model are slightly different. The precision score by the CNN-2 model is 0.9516 for the ‘not_yawning’ class and 0.9610 for the ‘yawning’ class, which indicates that 95.16% of the instances predicted as ‘Not Yawning’ are actually ‘Not Yawning’ and 96.10% of the instances predicted as ‘Yawning’ are actually ‘Yawning’. Similarly, the recall for the ‘Not Yawning’ class is 0.9772. For the ‘Yawning’ class, it is 0.9186, indicating 97.72% and 91.86% instances are correctly predicted as ‘Not Yawning’ and ‘Yawning’, respectively. The F1 score is 0.9642 (96.42%) for 1409 instances for the ‘not_yawning’ class and 0.9393 (93.93%) for 860 instances for the ‘yawning’ class, respectively; it shows that there is a significant balance between precision and recall.
The confusion matrix for the proposed CNN-2 model without data augmentation is given in
Figure 12a. It indicates that out of 2269 testing images, 2194 are classified correctly by the proposed CNN-2 model. It means the accuracy rate for the model is 96.69%. Similarly,
Figure 12b shows the confusion matrix for the proposed architecture with data augmentation, which indicates that out of 2269 testing images, 2167 are correctly classified. It means that the accuracy rate for the model is 95.50%.
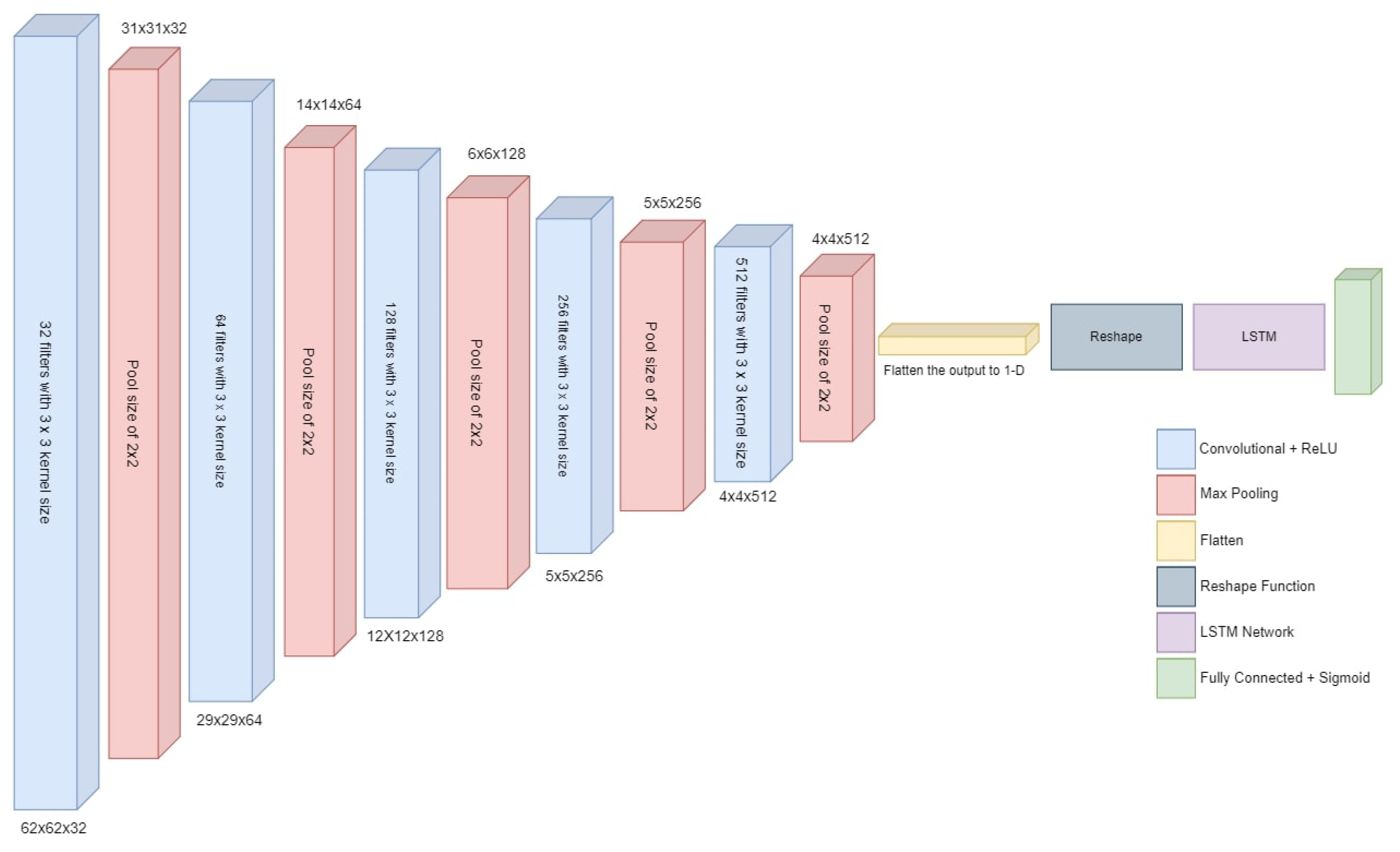
4.3. Experiments with Deep CNN-RNN Architecture
In the third and fourth experiments, we implement hybrid deep CNN-RNN architecture for driver drowsiness detection. The model accuracy and loss graphs of the hybrid model without data augmentation are shown in
Figure 13. It is observed that the model starts poorly with training accuracy, but improves as the number of epochs proceeds. The best accuracy is obtained with 47 epochs, but after that, the training and validation accuracy start reducing.
Figure 14 shows training and validation accuracy and loss of hybrid CNN-RNN with data augmentation. It can be seen that contrary to the behavior of the model on the original data where training and validation curves have different trends, model training and validation curves show very similar trends as the number of epochs grow.
Table 14 shows the training and validation accuracy of the hybrid CNN-RNN model using data augmentation and no augmentation. The proposed hybrid model obtained a 95.24% accuracy without augmentation and 97.55% training accuracy. On the other hand, with data augmentation, it achieved 95.64% and 96.28% accuracy for testing and training, respectively. Results show that results are better if the model is trained on the original dataset without data augmentation.
Results regarding precision, recall, and F1 score are given in
Table 15. The precision score for the proposed CNN-RNN model without data augmentation is 0.9514 for the ‘not_yawning’ class and 0.9541 for the ‘yawning’ class, indicating that 95.14% of the instances predicted as ‘Not Yawning’ are actually ‘Not Yawning’ and 95.41% of the instances predicted as ‘Yawning’ are actually ‘Yawning’. Similarly, the recall for the ‘Not Yawning’ and ‘Yawning’ classes is 0.9730 and 0.9186, respectively, indicating 97.30% and 91.86% instances are correctly predicted. The F1 score is 0.9621 (96.21%) for 1409 instances for the ‘not_yawning’ class and 0.9360 (93.60%) for 860 instances for the ‘yawning’ class, respectively, showing that the model does not have overfitting.
The precision score for the CNN-RNN model using augmented data is 0.9517 for the ‘not_yawning’ class and 0.9646 for the ‘yawning’ class. Results indicate that 95.17% and 96.46% of the ‘Not Yawning’ and ‘Yawning’ classes are predicted correctly. In the same way, recall scores of 0.9794 and 0.9186 for not yawning and yawning indicate superior results. F1 scores of 0.9654 (96.54%) for 1409 instances of the ‘not_yawning’ class and 0.9410 (95.10%) for 860 instances of the ‘yawning’ class, respectively, also show a balance between precision and recall.
The confusion matrix for the proposed CNN model without data augmentation in
Figure 15a indicates that out of 2269 testing images, 2161 are classified correctly by the hybrid CNN-RNN model. It indicates that the accuracy rate for the model is 95.24%. Similarly,
Figure 15b shows the confusion matrix for the proposed architecture with data augmentation, which indicates that out of 2269 testing images, 2170 are correctly classified showing an accuracy rate for the model is 95.64%.
4.4. Computational Time of Models
We set the batch size to 32 for training and the number of epochs to 80 and trained the models on the YawDD dataset.
Table 16 provides the training time of all models employed in this study.
Firstly, two variants of CNN were considered. CNN-1, without data augmentation, exhibited a training and testing time of 3.24 h. When data augmentation techniques were applied to CNN-1, the time increased slightly to 3.70 h. On the other hand, CNN-2, which is another variant of the CNN architecture, required 2.89 h for training and testing without data augmentation and 3.01 h when data augmentation was incorporated. These results demonstrate that CNN-2 was generally more time-efficient compared to CNN-1, while data augmentation increased training time for both architectures.
Additionally, a hybrid CNN-RNN architecture was assessed, again with and without data augmentation. Without data augmentation, this architecture demanded 3.74 h for training and testing, making it one of the most time-consuming options in this study. The introduction of data augmentation increased the time marginally to 3.82 h.
4.5. Comparison with Existing Studies
This study primarily focuses on the effectiveness of our model in detecting drowsiness indicators within the scope of the provided dataset. The performance of the proposed CNN model is compared with relevant studies available in the literature for the detection of drowsiness among drivers.
Table 17 shows the performance comparison results. This study used the YawDD dataset for experimental analysis, so we are considering only those existing studies for comparison that have used the YawDD dataset for experiments. Based on classification accuracy, the proposed CNN model outperforms existing studies on driver drowsiness detection.
To capture facial regions in complex driving conditions, [
36] used improved YOLOv3-tiny CNN. The proposed algorithm in this study achieved an accuracy rate of 94.32% at a detection speed of over 20 frames per second. In [
34], the authors employed a combination of MTCNN for face detection and Dlib for locating facial key points. The proposed model achieves an 88% average accuracy. A real-time fatigue detection system has been developed that calculates eye blink duration as a key indicator for accident avoidance systems. The experimental analysis on the YawDD dataset shows that it achieves an accuracy of 92.5% [
30]. Lastly, [
29] proposed an approach using two streams of spatial-temporal graph convolutional networks for driver drowsiness detection. The model leverages spatial and temporal features and achieved 93.4% accuracy on the YawDD dataset.
4.6. Discussion
This study proposes a deep CNN model for accurately detecting driver drowsiness from videos. In addition, a hybrid model comprising CNN and RNN is also designed for performance comparison. Drivers’ behavioral features are utilized to train and test the models. Moreover, to resolve the data imbalance problem, data augmentation is also utilized. A summary of results employing both models and data augmentation is presented in
Table 18. It shows that the average accuracy for both models is very close. The CNN model achieves an average accuracy of 98.01% without data augmentation, which is higher than the average accuracy of the hybrid CNN-RNN model for all experiments.
Experimental results indicate that in general, the results of deep CNN, which only considers spatial features, perform slightly better than the hybrid deep CNN-RNN model, which considers spatial-temporal features. Performance measures like precision, recall, and F1 score are also considered to compare the results. Overall, both models achieve amazing performance with and without data augmentation, showing a very close difference. Although we achieve better accuracy without data augmentation, it is a powerful technique to enhance model performance and generalization ability. When we look at the training validation graphs, we can conclude that after data augmentation, the accuracy might be reduced, but the generalization of the models is enhanced.
While this research has demonstrated the effectiveness of the deep learning model for drowsiness detection, it is essential to acknowledge certain limitations that are associated with the use of DLib and the potential impacts of these limitations in real-world scenarios [
45]. In real-world scenarios, it is challenging to ensure that a driver maintains a consistent head orientation toward the installed camera. DLib, like many other vision-based methods, primarily focuses on a single point of monitoring, typically the driver’s face. This approach does not consider the broader context of the driver’s behavior, which may include fatigue-related cues from other parts of the body (e.g., body posture or hand movements).
Drowsiness among drivers causes injuries and deaths of millions of people annually, so there is a need to develop a system with high accuracy, precision, and recall. Detection of drowsiness is the key factor for successfully preventing road accidents. This study focused on drowsiness detection among drivers using deep learning architectures. We try to develop a more accurate model for predicting yawning or drowsiness among drivers. The results show that the proposed architectures, which only consider spatial features, perform better without data augmentation on the selected dataset. Overall, all three models show exceptional performance with and without data augmentation, showing a very close difference.
Existing research works on drowsiness detection provide various deep learning architectures and report results regarding accuracy, sensitivity, etc. This study makes a difference in the following context:
- i
Behavioral feature-based drowsiness detection: While drowsiness detection using facial features is a known area of research, our study specifically focuses on using behavioral features, such as yawning, as a means to detect drowsiness. This approach offers a novel perspective on addressing drowsiness detection, which complements existing methods.
- ii
Three deep learning architectures: We propose and compare two deep learning architectures, a deep CNN and a hybrid CNN-RNN, for drowsiness detection. Using a hybrid architecture that considers spatial and temporal features is innovative and can potentially lead to more robust results, especially in dynamic scenarios like drowsy driving.
- iii
Data augmentation: Our study highlights the impact of data augmentation techniques on model performance. This analysis, coupled with the focus on behavioral features, contributes to the novelty of our research. It demonstrates that data augmentation is a valuable tool in enhancing the generalization of models in this context.
- iv
Comparison with existing studies: Our research includes a comparison with existing studies, specifically on the same YawDD dataset. By achieving better accuracy compared to these existing studies, our research showcases a novel and effective approach to drowsiness detection among drivers.
Overall, the novelty of the study lies in the unique combination of using behavioral features, proposing three deep learning architectures, analyzing the impact of data augmentation, and achieving higher accuracy compared to existing studies, all within the context of addressing drowsiness detection among drivers.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}