
Transfer Learning on Small Datasets for Improved Fall Detection


Abstract
1. Introduction
- Collecting three datasets including accelerometer data for fall detection problem from different devices: the MSBAND watch, the Huawei watch, and the meta-sensor device.
- Conducting an in-depth study of the effectiveness of transfer learning for fall detection using a small data set by creating effective left and right wrist fall detection models.
- Exploring the practicality of applying transfer learning on heterogeneous sensing devices by transferring an existing fall detection model, trained on our MSBAND data set, to a meta-sensor device (in one experiment), as well as a Huawei smartwatch (in another separate experiment), both using a small amount of device specific data.
- Demonstrating the improvement of fall detection using transfer learning to create an ensemble model of both left and right wrists or any additional heterogeneous sensing device.
2. Related Work
2.1. Transfer Learning for General Healthcare
2.2. Transfer Learning for Time-Series Data
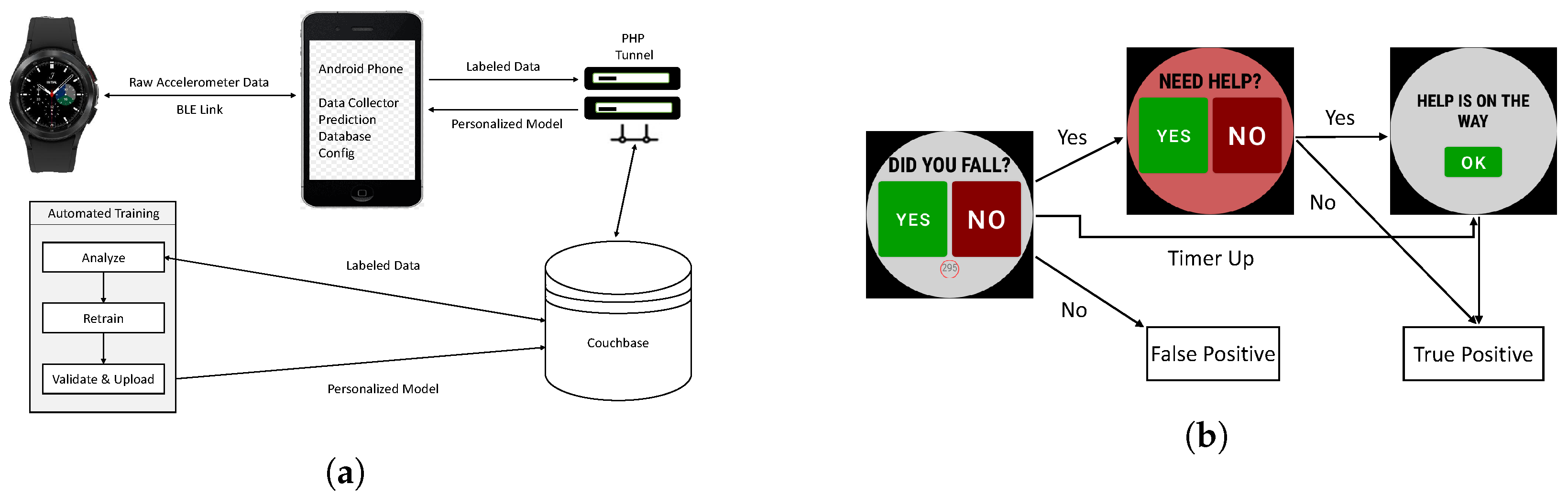
3. SmartFall System Architecture
4. Methodology
4.1. Dataset Collection
4.2. Experimental Settings
| Algorithm 1: Our Transfer Learning Structure |
| Input: Source Domain Data Source_Data, Target Domain Data Target_Data Organize Source_Data And Target_Data Into Data Windows Initialize Models NN_TL And NN_TFS Train NN_TL On Source_Data Data Windows Freeze NN_TL’s Precursory Layers Evaluate NN_TL And NN_TFS On Target_Data Data Windows Compare The Evaluation Results Of NN_TL And NN_TFS On Target_Data |
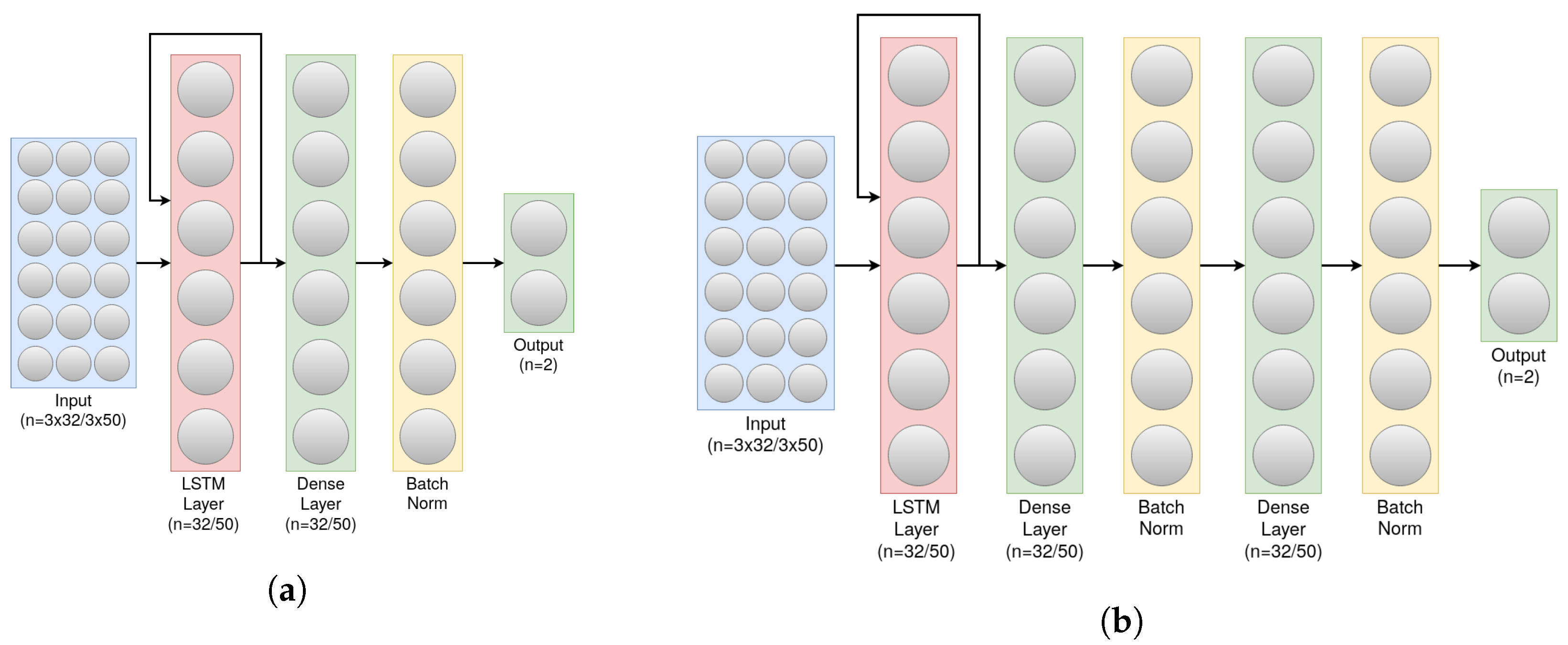
4.3. Model Training and Parameters Tuning
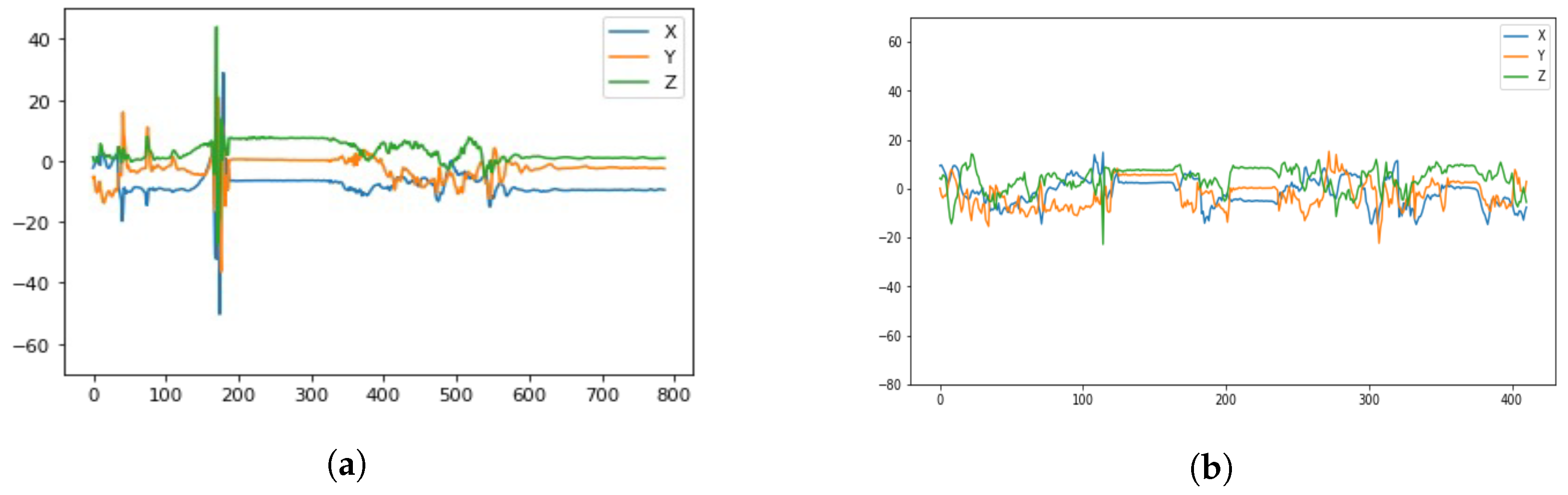
- Window_Size: The number of consecutive data entries that will be fed to the LSTM classifier at once. For example, if the window size is 35 (meaning the length of a single input block is 35 time-consecutive data entries), then the classifier will be fed a tensor of the shape 35 × 3 (since we have 3 coordinates for acceleration for each entry) to give a single classification for. This snapshot of a particular window size represents one sample of time series data as shown in Figure 1a.
- Step_Size: The difference between two consecutive data blocks (each block comprised of Window_Size data entries). For example, say we have 37 data entries, with a Window_Size of 35 and a Step_Size of 1, then, we would have 3 different data blocks, them being [1, 35], [2, 36] and [3, 37], which means we have an overlap of 34 entries between each 2 consecutive data entries. If Step_Size was 2, then we would have 2 different data blocks, them being [1, 35] and [3, 37] (the middle block would be skipped since our step is 2), with an overlap of 33 entries between every 2 consecutive entries (Window_Size − Step_Size is the general number of overlapping entries).
- Smooth_Window: The way we have our model make a final prediction is by predicting over the last Smooth_Window: data blocks, and then average (take the median of) the predictions and use that average as the final fall probability. The motivation behind the smooth window is to take into account a wider scope of predictions, better covering pre-fall, and post-fall data points. This will also ensure that we do not miss any clustered spikes related to fall and we do not just take a single spike as a fall prediction.
- Fall Threshold: After having the averaged fall probability from the most recent smooth window, if its value is greater than Fall Threshold:, then we classify the window as a fall, otherwise we classify it as a non-fall.
- Window_Size: We tried a multitude of different values, and found that the optimal value is the same as the number of data entries sensed within 1 second (the duration of a fall), meaning that the optimal value for the MSBAND model was 32, as the MSBand is at 32 Hz, and the optimal value for the meta-sensor model was 50, as the meta-sensor is at 50 Hz. This seemed to be the sweet spot that captures enough data for accurate classification, any value below that gave a worse classification accuracy, and any value beyond that did not increase the classification accuracy by a noticeable amount. F1-scores for the different Window_Size values can be found in Table 1, where the optimal values are in bold.
- Step_Size: Out of all the values, a step of 1 seemed to perform the best, which indicates that high overlap and small increments between the consecutive data blocks is important for a good performance, as all the higher values gave worse results. F1-scores for the different Step_Size values can be found in Table 2, where the optimal values are in bold.
- Smooth_Window: As explained before, we want to capture the notion of both pre-fall and post-fall occurrence in order to help us better classify falls and have less false positives, and exactly matching that intuition, a broader smooth window of about 2 seconds of sensed data entries (64 for MSBand and 100 for meta-sensor) out-performed both shorter and longer smooth windows. F1-scores for the different Smooth_Window values can be found in Table 3, where the optimal values are in bold.
- Fall_Threshold: Different values in increments of 10% were tried, starting from 10% and ending at 90%, and the fall threshold of 40% performed the best as it had the best balance of accurate true-positive classification while avoiding as many false-positives as possible. This value wasn’t picked solely through experimentation, but also by looking at the prediction probability of the classifier over the test set, we can see that for the fall data, the classifier predicts values above 40%, and for non-fall data, it predicts values below 40%. F1-scores for the different Fall_Threshold values can be found in Table 4, where the optimal values are in bold.
- All layers are fully connected; using drop-out/convolution layers made the performance of the model slightly worse, hence, why we do not use any of those layers.
- The activation function of the dense layers is Relu, and the last layer uses sigmoid which is commonly used for binary classification.
- The default Keras Library’s Binary Cross-Entropy loss function as well as the default Adam optimizer were used as the loss function and optimizer of the network, as those two worked well in our older version of classifier.
- The number of neurons in the LSTM layer, as well as the output dimensions of the dense layers were always set to the number of data entries sensed in one second, similarly to Window_Size, as that generally gave the best result.
5. Experiments and Results
5.1. Left Wrist to Right Wrist Transfer Learning with Meta-Sensor
- 1.
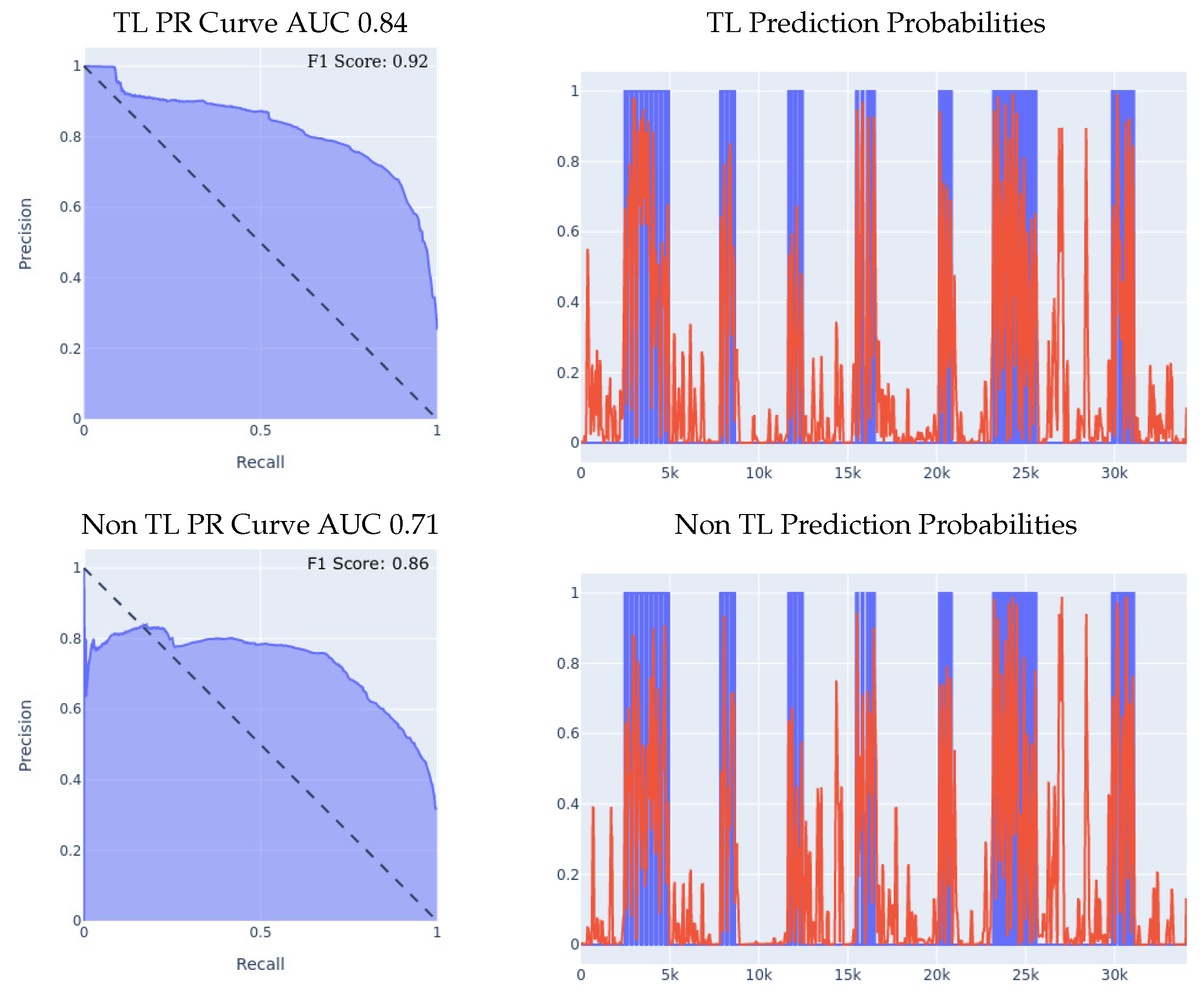
- Meta-sensor Experiment I: In the first of the two experiments, we split the right wrist’s dataset into two sets, one of them being a training dataset comprised of 70% of all the data, and the remaining 30% is the test dataset. The content of the two datasets was such that for each of the 8 people in the full dataset, 70% of that person’s data was in the training set, and the remaining 30% was in the test set, which means that this experiment’s main goal is to try and evaluate how well does the model personalize to these specific 8 people after seeing a portion of their data during the training process. After splitting the data in the described manner, we built two different classifiers using the right wrist training data, the first of which was built from scratch using the right wrist training dataset only. The second classifier was built using transfer learning by having the left wrist classifier as a base model and then training that base model on the right wrist training dataset. Results are presented in Figure 5. We can clearly see the effectiveness of transfer learning over building a model from scratch throughout all 3 presented metrics. If we look at the PR curve, we can see that the transfer learning model’s PR curve is more complete and covers more area resulting in a higher AUC. We then evaluated both classifiers’ performance on the right wrist test dataset.If we look at the prediction probabilities plot, we can see similar true positive classifications between the two models (keep in mind that the prediction threshold for a fall is 0.4), however, we can also see that the transfer learning model has fewer false positive classification instances, for example, if we look at the entries from 12k to 15k in the x-axis, we can see that the non-transfer learning model predicted them falsely as falls (the real label is in blue, the predicted value is in red, a red value higher than 0.4 means a fall prediction), while the transfer learning model predicted them correctly as non-falls.Finally, if we look at the F1 scores, we can see that the transfer learning model achieved an F1 score that is higher by 8% than the non-transfer learning model as shown in Table 5.
- 2.
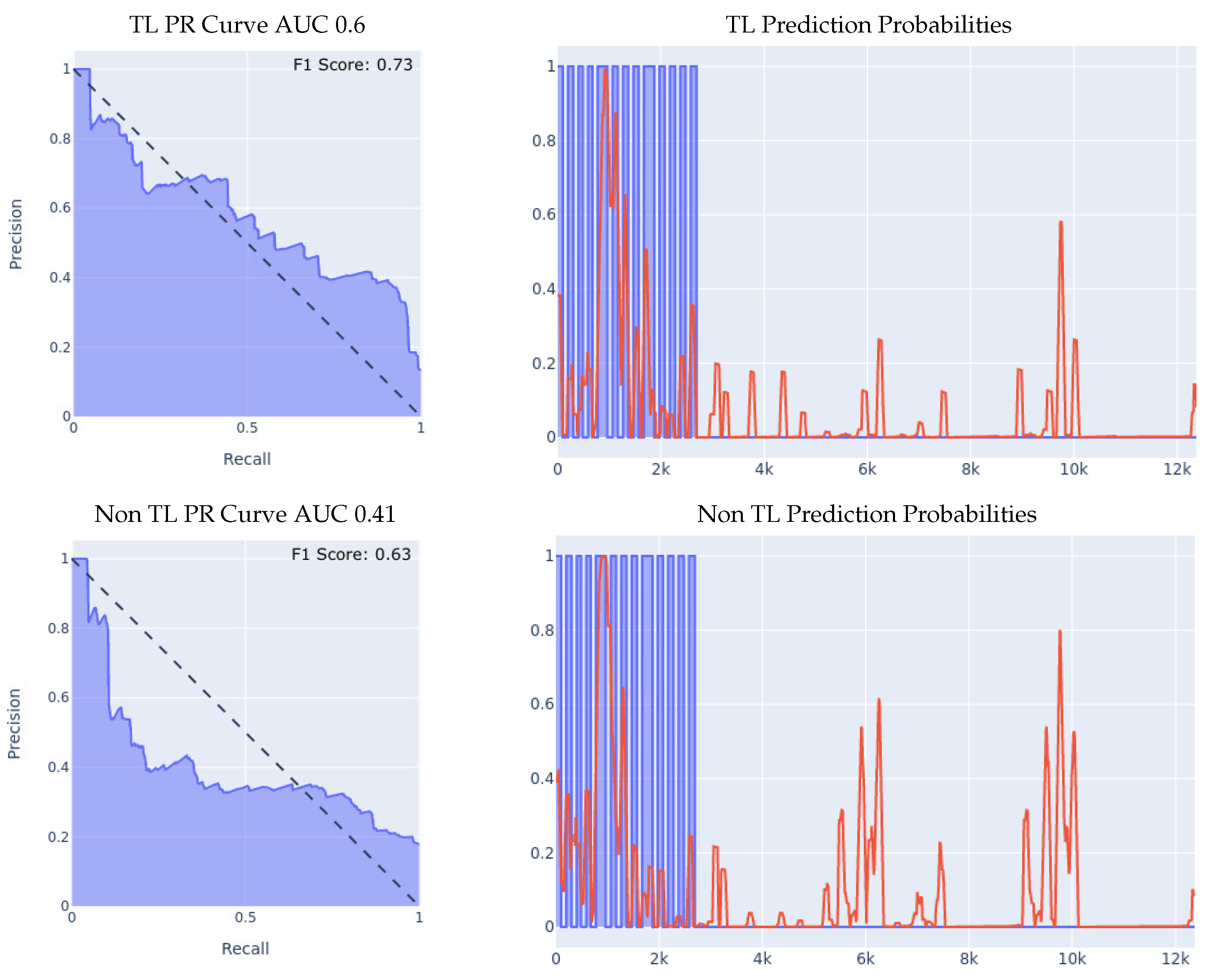
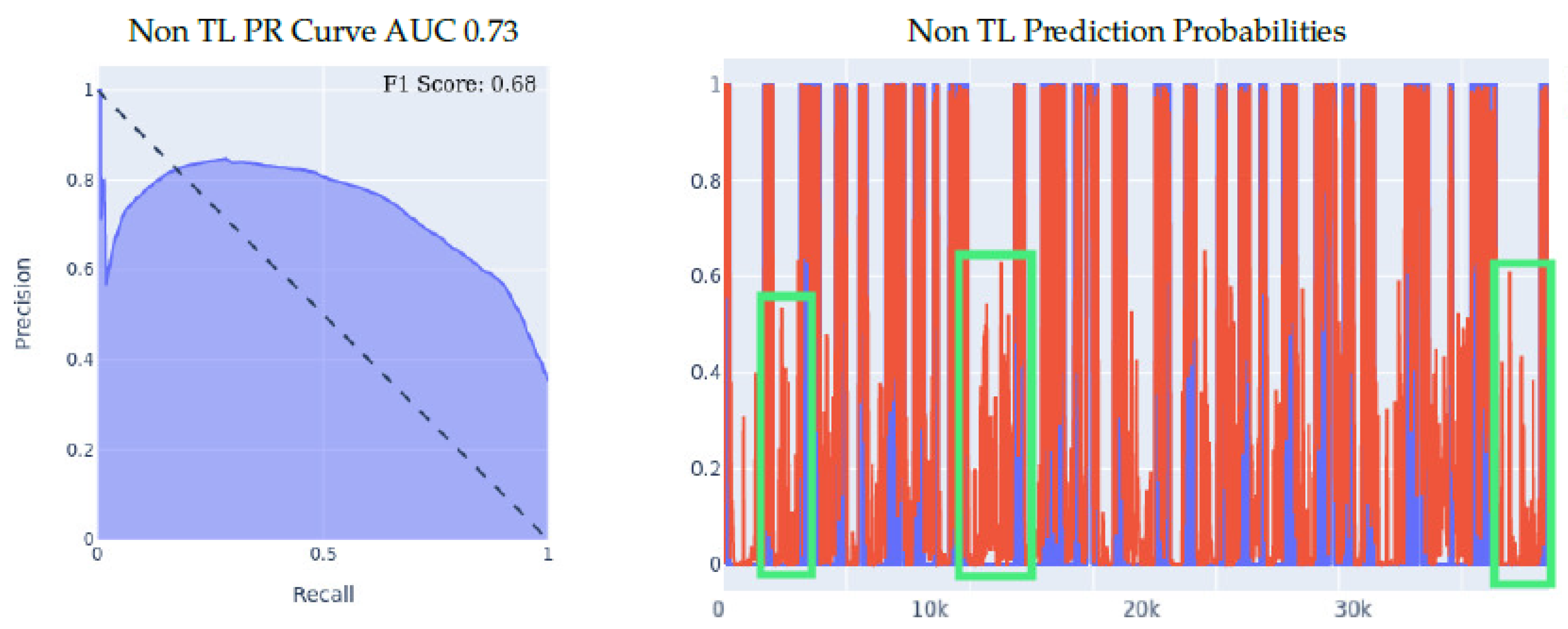
- Meta-sensor Experiment II: In this experiment, we conducted what we call leave-one-person-out cross-validation, which, as its name suggests, is a cross-validation method in which, for each person involved in the meta-sensor dataset, we train the model either from scratch, or using the transfer learning methodology, on a dataset that is comprised of all the people but the one specific person, and then test the resulting model on the remaining person’s data. As mentioned, we do this process for each of the 8 people involved in the full meta-sensor dataset. As opposed to the first experiment, when testing a model in this experiment, the model would have not trained on any data of the person it is being tested on.The result of training and testing using a leave-one-out strategy is shown in Figure 6. The PR Curve and Prediction plots are taken from a random iteration of the cross-validation process and are representative of the average iteration. The evaluation results of a single iteration are based on a dataset of one person only, hence the number of data entries in the leave-one-person-out cross-evaluation results are always significantly less than the prior 70/30 Train/Test experiment, as the evaluation results in that experiment are on 30% of the entire dataset. Again, we can clearly see the effectiveness of transfer learning over building a model from scratch throughout all 3 presented metrics. If we look at the PR curve, we can see that the transfer learning model’s PR curve is more complete and covers more area resulting in a higher AUC, even though both models do not achieve the best result, however, the improvement from using transfer learning is substantial, as it made the PR curve over half of the area, while in the non-transfer learning case, it covered less. If we look at the prediction probabilities plot, we can see similar true positive classifications between the two models with the transfer learning model being slightly better, and we can see that the non-transfer learning model has many more prediction peaks and much sharper spikes in the non-fall area, resulting in more false positive predictions. Finally, if we look at the F1 Scores, we can see that the transfer learning model achieved an averaged F1 score that is higher by almost 10% than the non-transfer learning model as shown in Table 5.
5.2. MSBAND to Meta-Sensor/Huawei Transfer Learning
5.2.1. MSBAND to Meta-Sensor
- 1.
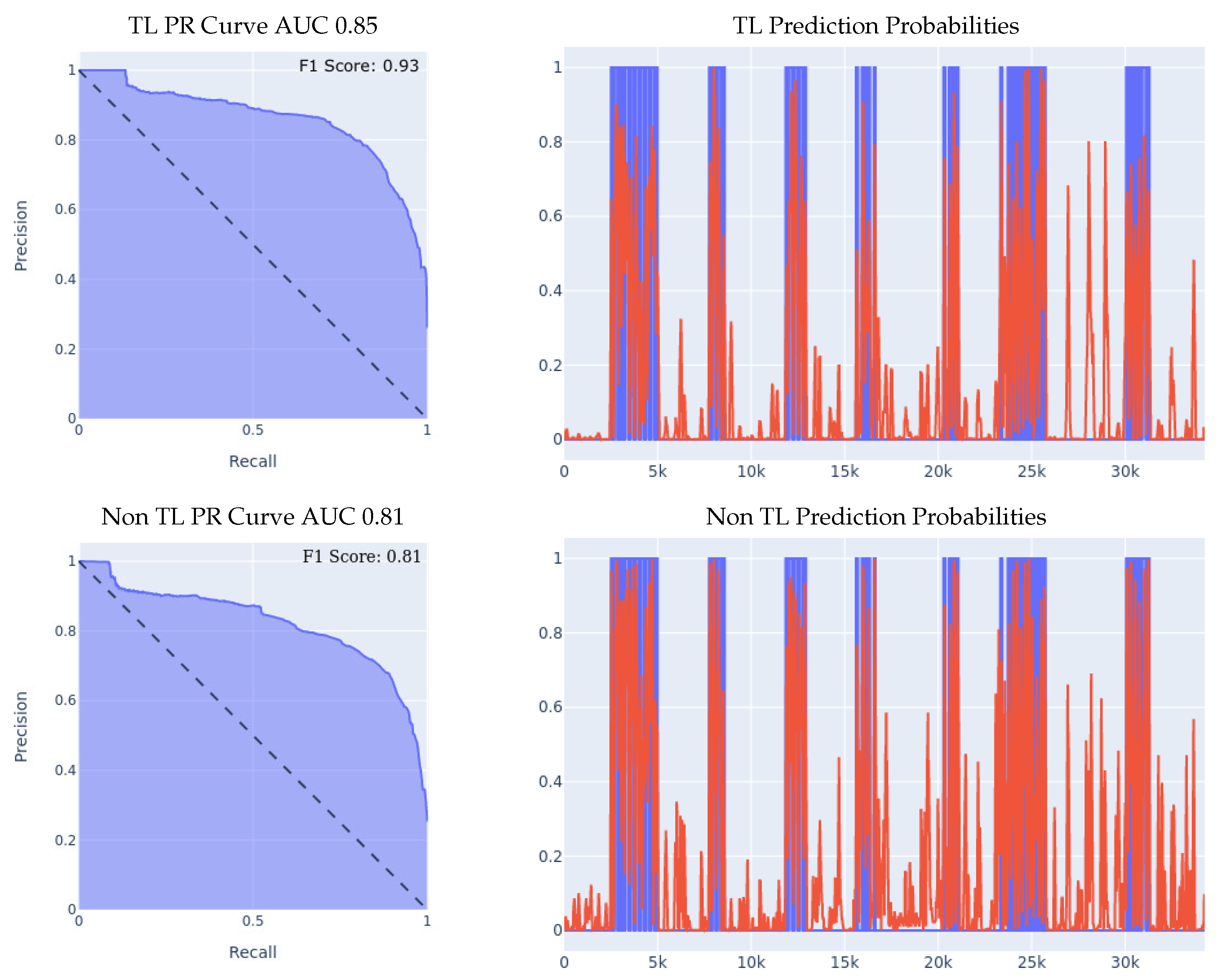
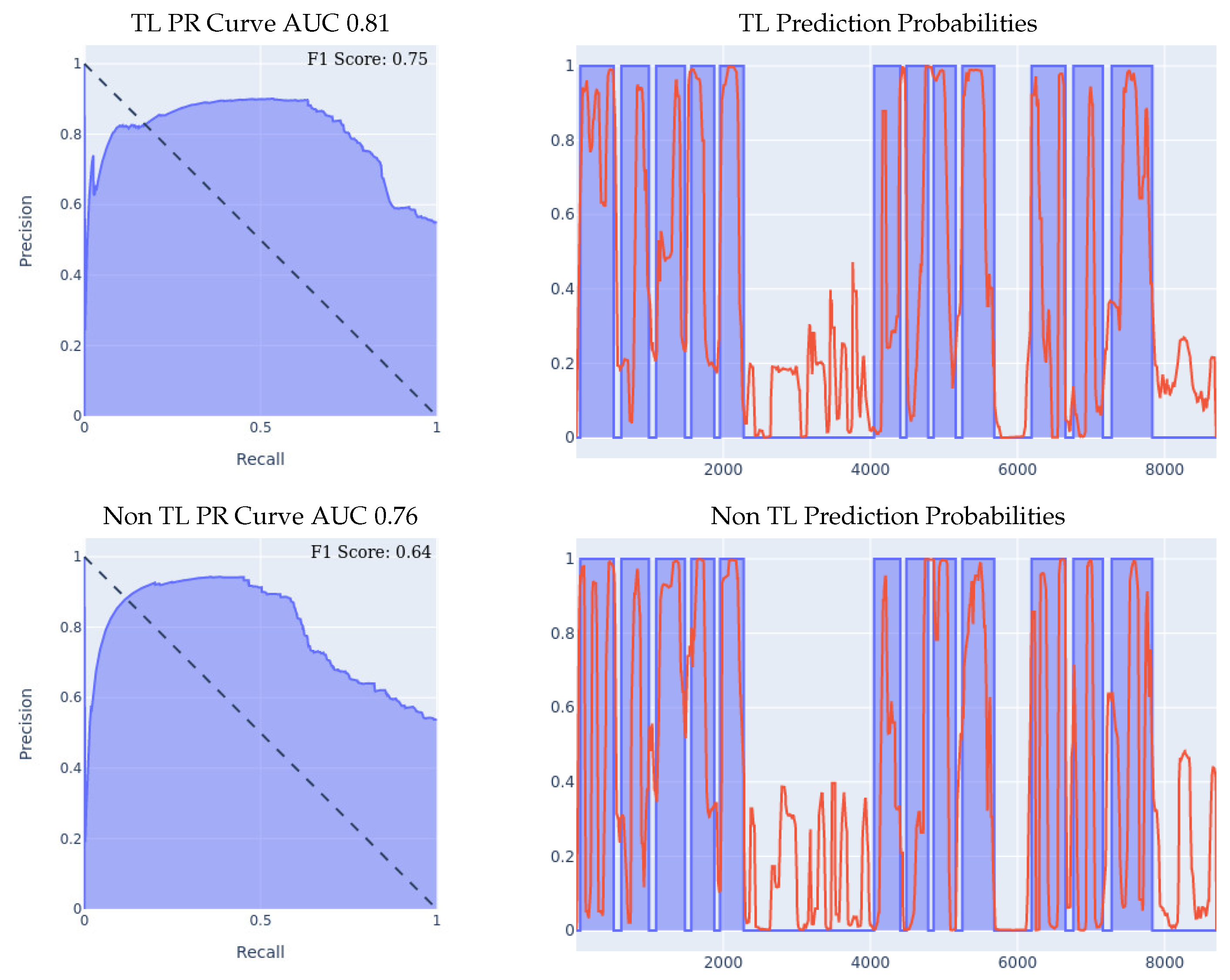
- MSBAND to Meta-Sensor Experiment I: In this experiment, we conduct the exact same 70/30 Train/Test split experiment as we did in the first experiment of Section 5.1. The classifiers’ performance on the left wrist dataset is shown in Figure 7.We can see the effectiveness of transfer learning over building a model from scratch throughout all 3 presented metrics. If we look at the PR curve, we can see that the transfer learning model’s PR curve is slightly more complete and covers more area resulting in a higher AUC. If we look at the prediction probabilities plot, we can see that the transfer learning model has fewer false positive classification instances, for example, if we look at the entries from 13k all the way up to 23k in the x axis, we can see that the non-transfer learning model predicted a lot of the non-fall entries as falls, while the transfer learning model predicted them correctly as non-fall, resulting in a much lower false positive rate. Finally, if we look at the F1 Scores, we can see that the transfer learning model achieved an F1 score that is higher by 12% than the non-transfer learning model, breaking into the 90% range as shown in Table 5.
- 2.
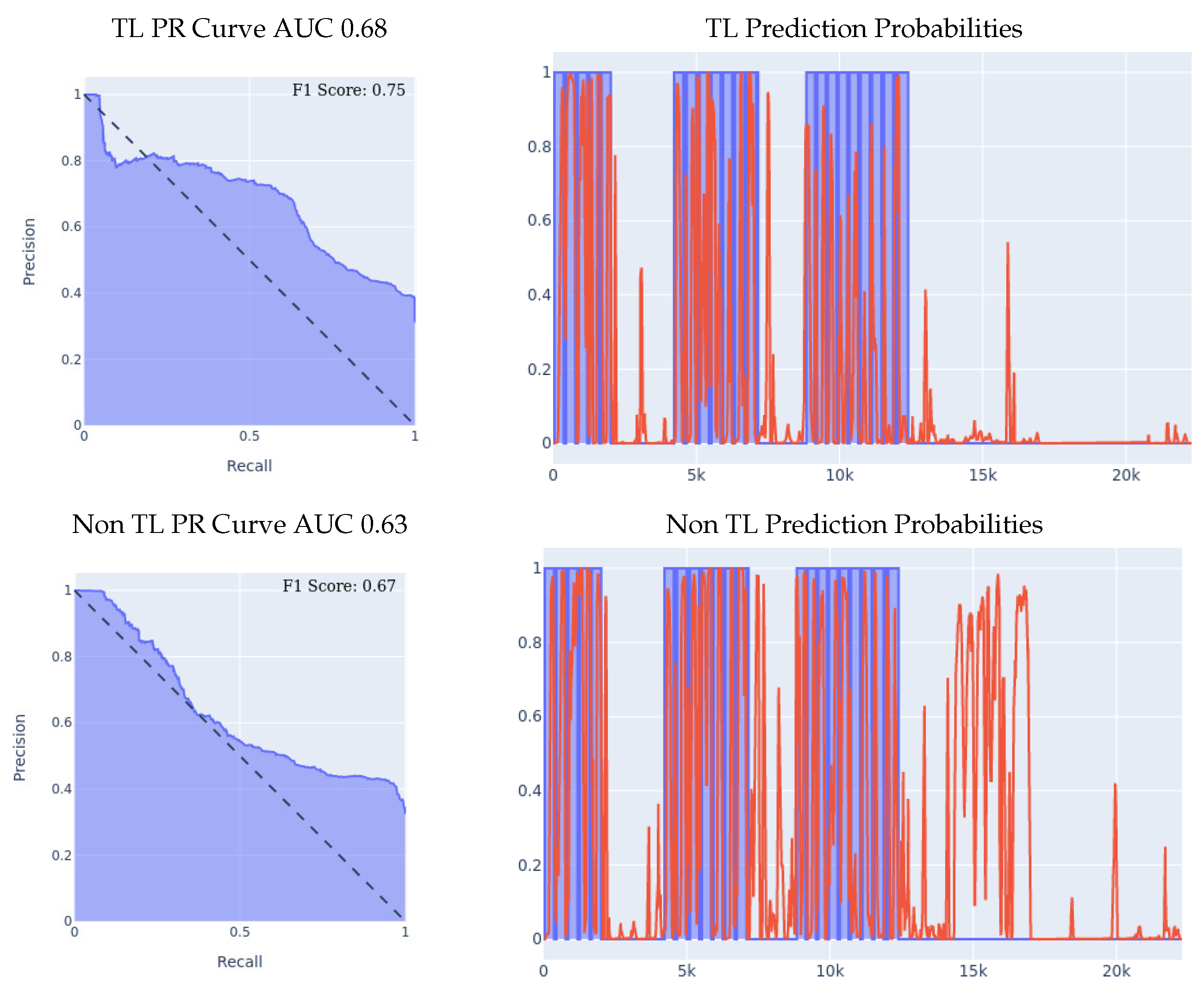
- MSBAND to Meta-Sensor Experiment II: We conduct the exact same leave-one-person-out cross-validation experiment as we did in the second experiment of Section 5.1 with the MSBAND and left meta-sensor datasets.We compare the results of the two models as shown in Figure 8. The results we obtained show an even higher gap between the transfer learning model and the non-transfer learning model than the experiment we reported in Section 5.1. Again, we can clearly see the effectiveness of transfer learning over building a model from scratch throughout all 3 presented metrics. If we look at the prediction probabilities plot, we can see that the non-transfer learning model has many more prediction peaks and much sharper spikes in the non-fall area, resulting in more false positive predictions in the non-transfer learning case. The F1 Scores with the transfer learning are higher by over 14% than the non-transfer learning model in this experiment as shown in Table 5.
5.2.2. MSBAND to Huawei
- 1.
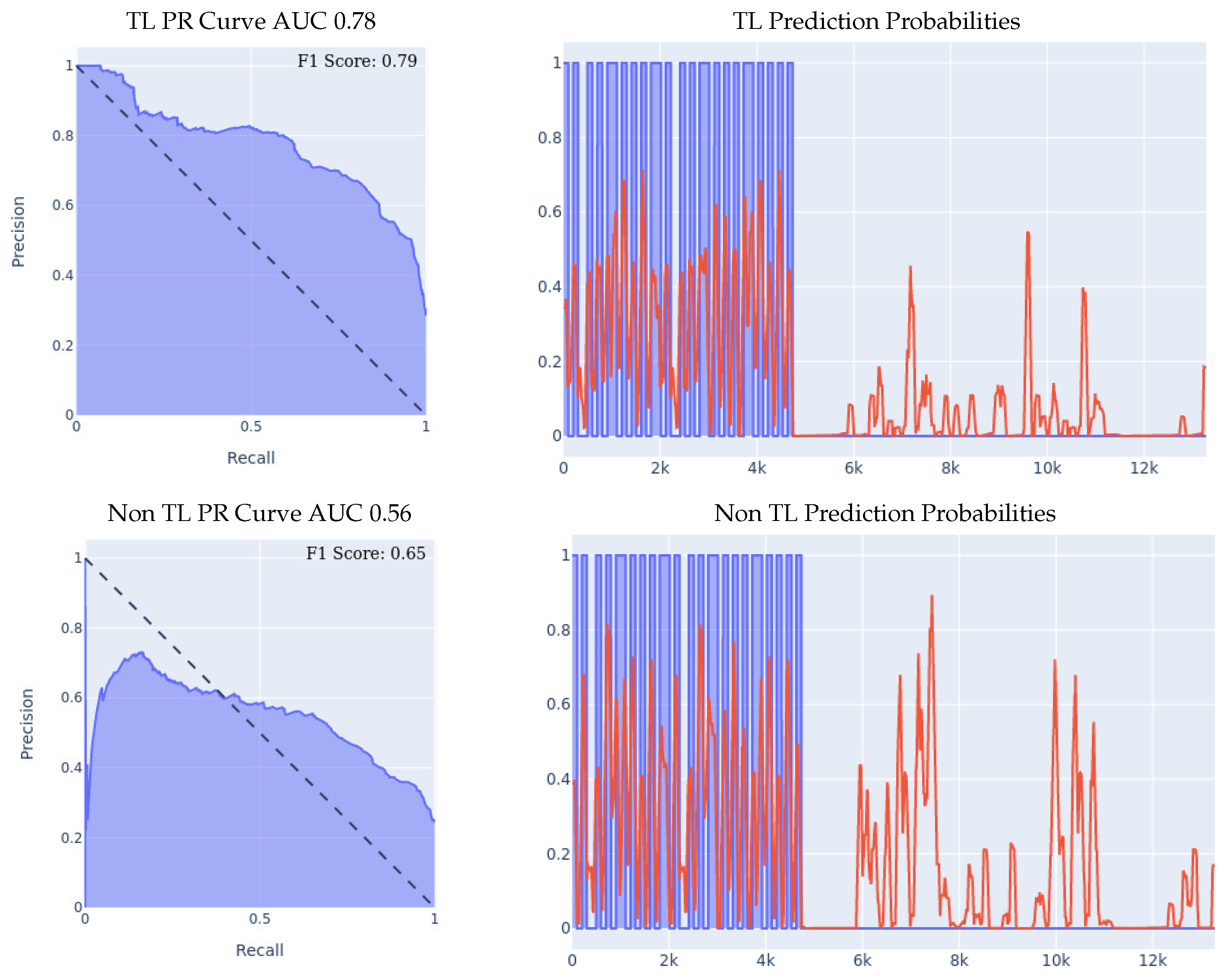
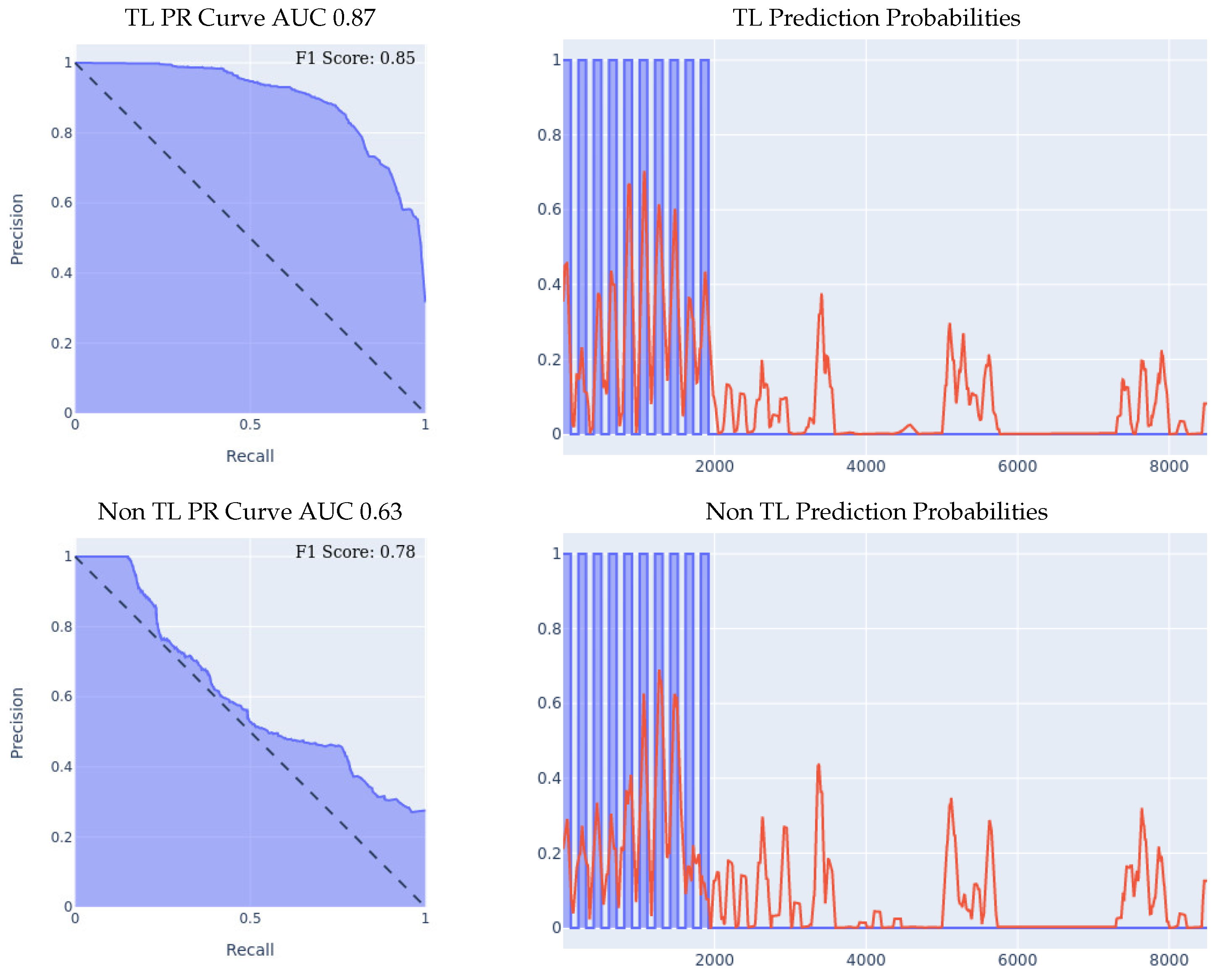
- MSBAND to Huawei Experiment I: the results of the 70/30 Train/Test experiment are presented in Figure 9. We can see the effectiveness of transfer learning over building a model from scratch throughout all three presented metrics.If we look at the prediction probabilities plot, we can see that the transfer learning model has fewer false positive classification instances, for example, if we look at the entries from 12k to 15k on the x axis, we can see that the transfer learning model has much less false positive predictions. The transfer learning model achieved an F1 score that is higher by 14% than the non-transfer learning model as shown in Table 5. Note that in the transfer learning case, the F1 score is not as high as the AUC might imply, and that is because the F1 score is a metric that is focused on the false positive rate and not on the general accuracy, which is an important metric for our evaluation since false positives are a big limitation for our problem.
- 2.
- MSBAND to Huawei Experiment II: the results of the leave-one-person-out cross validation experiment are presented in Figure 10. If we look at the prediction probabilities plot, we can see that the transfer learning model has fewer false positive classification instances, for example, from 8k onwards, we can see that the transfer learning model has no false positive predictions, while the non-transfer learning model has two false positives, and even though on the entries from 2k to 4k on the x axis, both classifiers have two false positive classifications, the transfer learning classifier’s prediction threshold value (the red line) only starts spiking prior to the fall close to entry 4000, in a sense capturing the pre-fall concept, while the non-transfer learning model spikes all through the non-fall range. Finally, if we look at the F1 Scores, we can see that the transfer learning model achieved an F1 score that is higher by 10% than the non-transfer learning model as shown in Table 5.
- 3.
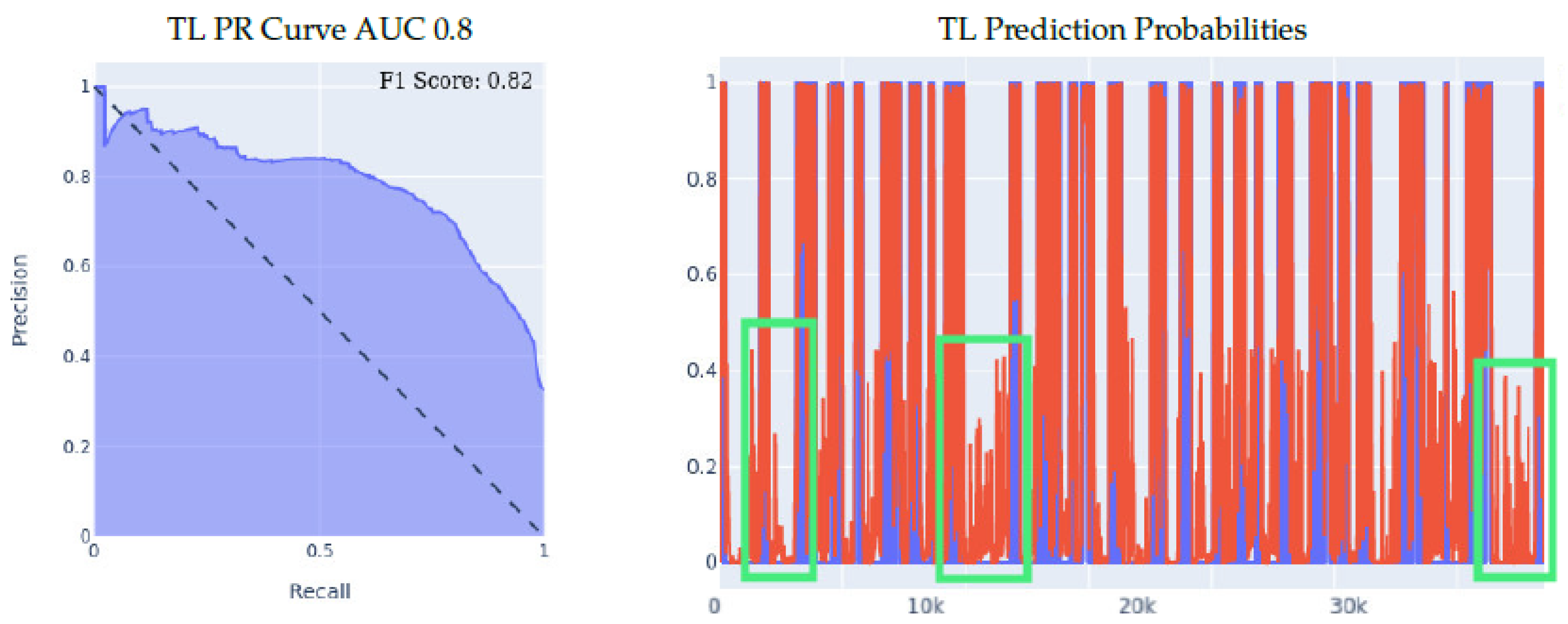
- MSBAND to Huawei real-time experiment: in this experiment, we present the results of real-time predictions of the transfer learning model against the trained-from-scratch model on a dataset collected via user feedback by a lab volunteer. The dataset contains 25 falls and a series of ADL tasks. The results of the experiment are presented in Figure 11. The transfer learning model achieves a slightly better PR Curve with a slightly higher AUC. If we look at the prediction probabilities plot, we can see that the transfer learning predictions overall are less aggressive, which results in predicting much fewer false positives as seen in entries 13k onwards; however, we can also see that the non-transfer learning model’s aggressiveness actually makes it cover true positives (specifically in ranges 5k–7k and 9k–12k) slightly better than the transfer learning model, resulting in an F1 score gap of 8% in favor of the transfer learning model as shown in Table 5.
5.3. Combined Left and Right Wrist Transfer Learning
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Falls Are the Leading Cause of Death in Older Americans. Available online: https://www.cdc.gov/media/releases/2016/p0922-older-adult-falls.html (accessed on 17 June 2019).
- Facts About Falls. Available online: https://www.cdc.gov/falls/facts.html (accessed on 17 June 2019).
- 2017 Profile of Older Americans. Available online: https://acl.gov/sites/default/files/AgingandDisabilityinAmerica/2017OlderAmericansProfile.pdf (accessed on 17 June 2019).
- Preventing Falls in Hospitals. Available online: https://www.ahrq.gov/professionals/systems/hospital/fallpxtoolkit/index.html (accessed on 18 November 2019).
- Tacconi, C.; Mellone, S.; Chiari, L. Smartphone-based applications for investigating falls and mobility. In Proceedings of the 2011 5th International Conference on Pervasive Computing Technologies for Healthcare (PervasiveHealth) and Workshops, Dublin, Ireland, 23–26 May 2011; pp. 258–261. [Google Scholar] [CrossRef]
- Chen, L.; Li, R.; Zhang, H.; Tian, L.; Chen, N. Intelligent fall detection method based on accelerometer data from a wrist-worn smart watch. Measurement 2019, 140, 215–226. [Google Scholar] [CrossRef]
- Medical Life Alert Systems. Available online: http://www.lifealert.com (accessed on 20 December 2022).
- Mobilehelp Smart. Available online: https://www.mobilehelp.com/pages/smart (accessed on 18 November 2019).
- Apple Watch Series 4. Available online: http://www.apple.com/apple-watch-series-4/activity/ (accessed on 18 April 2019).
- RightMinder—Fall Detection for Android Smartwatches and Android Phones. Available online: https://mhealthspot.com/2017/03/rightminder-android-wear-app-seniors/ (accessed on 14 December 2022).
- Mauldin, T.R.; Ngu, A.H.; Metsis, V.; Canby, M.E. Ensemble Deep Learning on Wearables Using Small Datasets. ACM Trans. Comput. Healthcare 2021, 2, 1–30. [Google Scholar] [CrossRef]
- Mauldin, T.R.; Canby, M.E.; Metsis, V.; Ngu, A.H.; Rivera, C.C. SmartFall: A Smartwatch-Based Fall Detection System Using Deep Learning. Sensors 2018, 18, 3363. [Google Scholar] [CrossRef] [PubMed]
- Seraji-Bzorgzad, N.; Paulson, H.; Heidebrink, J. Neurologic examination in the elderly. Handb. Clin. Neurol. 2019, 167, 73–88. [Google Scholar] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Bahdanau, D.; Chorowski, J.; Serdyuk, D.; Brakel, P.; Bengio, Y. End-to-end attention-based large vocabulary speech recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4945–4949. [Google Scholar]
- Zhu, X.J. Semi-Supervised Learning Literature Survey. 2005. Available online: https://pages.cs.wisc.edu/~jerryzhu/pub/ssl_survey.pdf (accessed on 1 December 2022).
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 1–40. [Google Scholar] [CrossRef]
- Maqsood, M.; Nazir, F.; Khan, U.; Aadil, F.; Jamal, H.; Mehmood, I.; Song, O.y. Transfer learning assisted classification and detection of Alzheimer’s disease stages using 3D MRI scans. Sensors 2019, 19, 2645. [Google Scholar] [CrossRef]
- Shin, H.C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef]
- Byra, M.; Wu, M.; Zhang, X.; Jang, H.; Ma, Y.J.; Chang, E.Y.; Shah, S.; Du, J. Knee menisci segmentation and relaxometry of 3D ultrashort echo time cones MR imaging using attention U-Net with transfer learning. Magn. Reson. Med. 2020, 83, 1109–1122. [Google Scholar] [CrossRef]
- Tang, X.; Du, B.; Huang, J.; Wang, Z.; Zhang, L. On combining active and transfer learning for medical data classification. IET Comput. Vis. 2019, 13, 194–205. [Google Scholar] [CrossRef]
- Zeng, M.; Li, M.; Fei, Z.; Yu, Y.; Pan, Y.; Wang, J. Automatic ICD-9 coding via deep transfer learning. Neurocomputing 2019, 324, 43–50. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Marcus, D.S.; Fotenos, A.F.; Csernansky, J.G.; Morris, J.C.; Buckner, R.L. Open access series of imaging studies: Longitudinal MRI data in nondemented and demented older adults. J. Cogn. Neurosci. 2010, 22, 2677–2684. [Google Scholar] [CrossRef]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. Decaf: A deep convolutional activation feature for generic visual recognition. In Proceedings of the INTERNATIONAL Conference on Machine Learning. PMLR, Bejing, China, 22–24 June 2014; pp. 647–655. [Google Scholar]
- Palanisamy, K.; Singhania, D.; Yao, A. Rethinking CNN models for audio classification. arXiv 2020, arXiv:2007.11154. [Google Scholar]
- Koike, T.; Qian, K.; Kong, Q.; Plumbley, M.D.; Schuller, B.W.; Yamamoto, Y. Audio for Audio is Better? An Investigation on Transfer Learning Models for heart sound classification. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 74–77. [Google Scholar]
- Gemmeke, J.F.; Ellis, D.P.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio set: An ontology and human-labeled dataset for audio events. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar]
- Ni, J.; Sarbajna, R.; Liu, Y.; Ngu, A.H.; Yan, Y. Cross-modal knowledge distillation for Vision-to-Sensor action recognition. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 4448–4452. [Google Scholar]
- Ni, J.; Ngu, A.H.; Yan, Y. Progressive Cross-modal Knowledge Distillation for Human Action Recognition. In Proceedings of the 30th ACM International Conference on Multimedia, Lisbon, Portugal, 10 October 2022; pp. 5903–5912. [Google Scholar]
- Li, F.; Shirahama, K.; Nisar, M.A.; Huang, X.; Grzegorzek, M. Deep Transfer Learning for Time Series Data Based on Sensor Modality Classification. Sensors 2020, 20, 4271. [Google Scholar] [CrossRef]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef]
- Gikunda, P.; Jouandeau, N. Homogeneous Transfer Active Learning for Time Series Classification. In Proceedings of the 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), Virtually Online, 13–15 December 2021; pp. 778–784. [Google Scholar] [CrossRef]
- Morales, F.J.O.n.; Roggen, D. Deep Convolutional Feature Transfer across Mobile Activity Recognition Domains, Sensor Modalities and Locations; Association for Computing Machinery: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Zhou, X.; Zhai, N.; Li, S.; Shi, H. Time Series Prediction Method of Industrial Process with Limited Data Based on Transfer Learning. IEEE Trans. Ind. Informatics 2022, 1–10. [Google Scholar] [CrossRef]
- Villar, J.R.; de la Cal, E.; Fañez, M.; González, V.M.; Sedano, J. User-centered fall detection using supervised, on-line learning and transfer learning. Prog. Artif. Intell. 2019, 8, 453–474. [Google Scholar] [CrossRef]
- Ngu, A.H.; Gutierrez, M.; Metsis, V.; Nepal, S.; Sheng, Q.Z. IoT Middleware: A Survey on Issues and Enabling Technologies. IEEE Internet Things J. 2017, 4, 1–20. [Google Scholar] [CrossRef]
- Ngu, A.H.H.; Eyitayo, J.S.; Yang, G.; Campbell, C.; Sheng, Q.Z.; Ni, J. An IoT Edge Computing Framework Using Cordova Accessor Host. IEEE Internet Things J. 2022, 9, 671–683. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Kumar, V.; Choudhary, A.; Cho, E. Data augmentation using pre-trained transformer models. arXiv 2020, arXiv:2003.02245. [Google Scholar]
- Kuroyanagi, I.; Hayashi, T.; Adachi, Y.; Yoshimura, T.; Takeda, K.; Toda, T. Anomalous Sound Detection with Ensemble of Autoencoder and Binary Classification Approaches. Technical Report. DCASE2021 Challenge. 2021. Available online: https://dcase.community/documents/challenge2021/technical_reports/DCASE2021_Kuroyanagi_96_t2.pdf (accessed on 1 December 2022).
- Mariani, G.; Scheidegger, F.; Istrate, R.; Bekas, C.; Malossi, C. Bagan: Data augmentation with balancing gan. arXiv 2018, arXiv:1803.09655. [Google Scholar]
- Li, X.; Metsis, V.; Wang, H.; Ngu, A. TTS-GAN: A Transformer-Based Time-Series Generative Adversarial Network; Lecture Notes in Computer Science; Springer Science and Business Media Deutschland GmbH, Texas State University: San Marcos, TX, USA, 2022; Volume 13263. [Google Scholar]
- Kidger, P.; Morrill, J.; Foster, J.; Lyons, T. Neural controlled differential equations for irregular time series. Adv. Neural Inf. Process. Syst. 2020, 33, 6696–6707. [Google Scholar]
- Hasani, R.; Lechner, M.; Amini, A.; Rus, D.; Grosu, R. Liquid time-constant networks. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 22 February–1 March 2021; Volume 35, pp. 7657–7666. [Google Scholar]
- Liu, Y.; Gong, C.; Yang, L.; Chen, Y. DSTP-RNN: A dual-stage two-phase attention-based recurrent neural network for long-term and multivariate time series prediction. Expert Syst. Appl. 2020, 143, 113082. [Google Scholar] [CrossRef]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.X.; Yan, X. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MSBAND | Meta-Sensor | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Value | 15 | 20 | 32 | 40 | 50 | Value | 30 | 40 | 50 | 60 | 70 |
| F1-Score | 0.8 | 0.85 | 0.93 | 0.91 | 0.92 | F1-Score | 0.75 | 0.76 | 0.81 | 0.81 | 0.8 |
| MSBAND | Meta-Sensor | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Value | 1 | 3 | 5 | 7 | 9 | Value | 1 | 3 | 5 | 7 | 9 |
| F1-Score | 0.93 | 0.9 | 0.87 | 0.88 | 0.86 | F1-Score | 0.81 | 0.77 | 0.79 | 0.75 | 0.73 |
| MSBAND | Meta-Sensor | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Value | 20 | 40 | 64 | 80 | 100 | Value | 20 | 60 | 100 | 130 | 160 |
| F1-Score | 0.83 | 0.89 | 0.93 | 0.86 | 0.87 | F1-Score | 0.69 | 0.75 | 0.81 | 0.75 | 0.78 |
| MSBAND | Meta-Sensor | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Value | 0.1 | 0.3 | 0.4 | 0.7 | 0.9 | Value | 0.1 | 0.3 | 0.4 | 0.7 | 0.9 |
| F1-Score | 0.68 | 0.85 | 0.93 | 0.81 | 0.67 | F1-Score | 0.6 | 0.76 | 0.81 | 0.73 | 0.65 |
| Experiment | Transfer Learning | Dataset Split Strategy | F1 Score (%) |
|---|---|---|---|
| ✓ | 0.92 | ||
| meta-sensor Experiment I | × | Train/Test: 70/30 | 0.86 |
| ✓ | 0.73 | ||
| meta-sensor Experiment II | × | cross-validation | 0.63 |
| ✓ | 0.93 | ||
| MSBAND to meta-sensor Experiment I | × | Train/Test: 70/30 | 0.81 |
| ✓ | 0.79 | ||
| MSBAND to meta-sensor Experiment II | × | cross-validation | 0.65 |
| ✓ | 0.82 | ||
| MSBAND to Huawei Experiment I | × | Train/Test: 70/30 | 0.68 |
| ✓ | 0.75 | ||
| MSBAND to Huawei Experiment II | × | cross-validation | 0.64 |
| ✓ | 0.75 | ||
| MSBAND to Huawei real-time experiment | × | 100% Test | 0.67 |
| ✓ | 0.85 | ||
| Combined Left and Right wrist experiment | × | cross-validation | 0.78 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maray, N.; Ngu, A.H.; Ni, J.; Debnath, M.; Wang, L. Transfer Learning on Small Datasets for Improved Fall Detection. Sensors 2023, 23, 1105. https://doi.org/10.3390/s23031105
Maray N, Ngu AH, Ni J, Debnath M, Wang L. Transfer Learning on Small Datasets for Improved Fall Detection. Sensors. 2023; 23(3):1105. https://doi.org/10.3390/s23031105
Chicago/Turabian StyleMaray, Nader, Anne Hee Ngu, Jianyuan Ni, Minakshi Debnath, and Lu Wang. 2023. "Transfer Learning on Small Datasets for Improved Fall Detection" Sensors 23, no. 3: 1105. https://doi.org/10.3390/s23031105
APA StyleMaray, N., Ngu, A. H., Ni, J., Debnath, M., & Wang, L. (2023). Transfer Learning on Small Datasets for Improved Fall Detection. Sensors, 23(3), 1105. https://doi.org/10.3390/s23031105