
Towards a Safe Human–Robot Collaboration Using Information on Human Worker Activity



Abstract
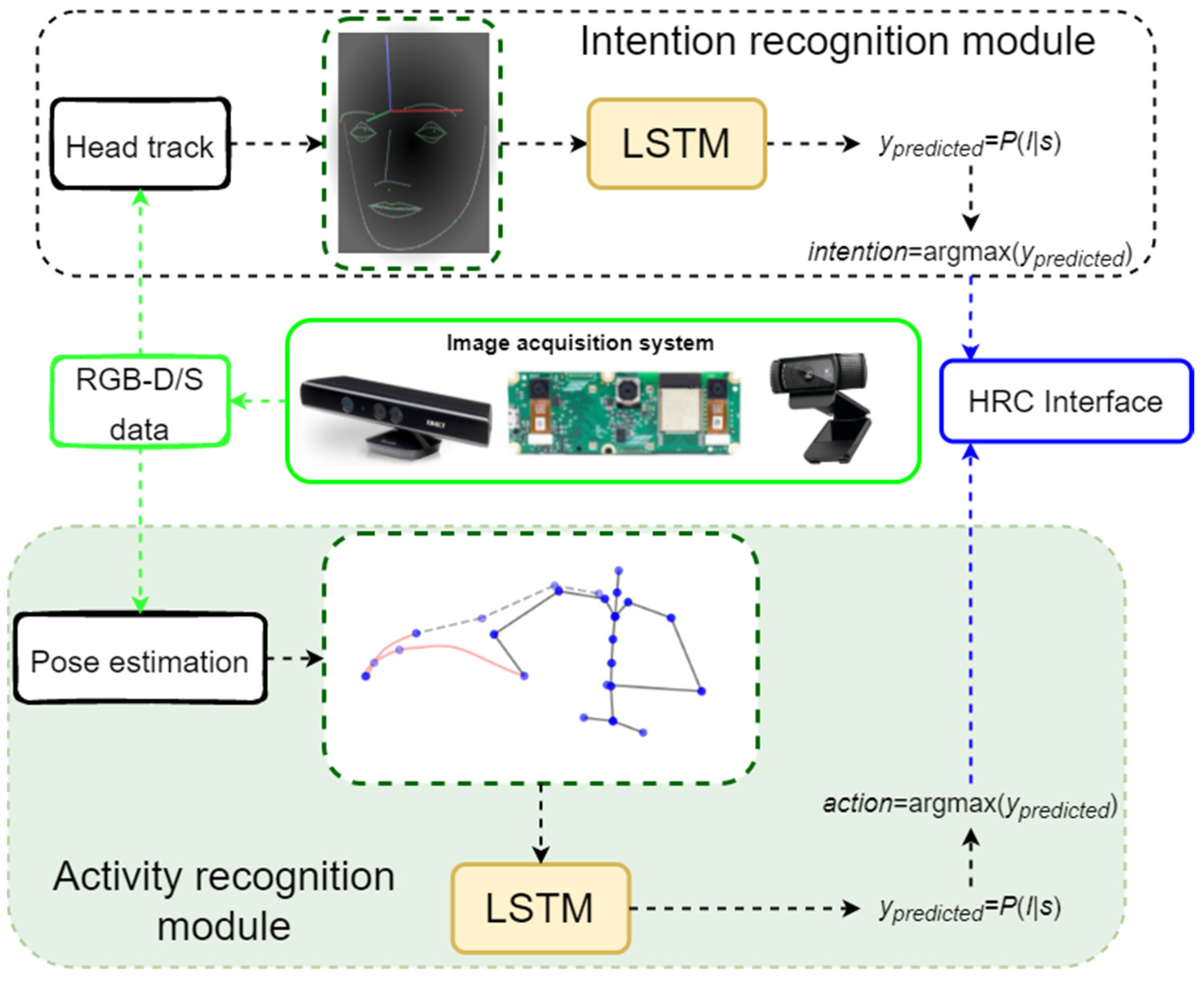
:1. Introduction
- Section 2: Through an overview, the model is introduced, and certain pose estimation models are described and explained. We present an overview of the dataset used for the activity recognition. Furthermore, the algorithms and explanations that summarize the work performed for the purpose of action recognition are discussed, and finally, the overall framework of the system’s simulation and visualization is explained;
- Section 3: In this section, the training and overall results of the system are discussed;
- Section 4: In the final section of this paper, we summarize the work conducted and propose future directions for the field.
2. Materials and Methods
2.1. Pose Estimation
2.2. Dataset
2.3. Dimensionality Reduction
2.4. Human Activity Recognition
2.5. Simulation and Visualization Environment
3. Results and Discussions
3.1. Dimensionality Reduction Results
3.2. Action Recognition Model Training Results
- The dataset appears to be unbalanced. The Assemble System action comprises most of the dataset;
- Actions, such as Assemble System and No Action, are very similar in terms of motion and show little variance;
- A large portion of every action class is predicted as No Action. The explanation for this trend lies in the fact that the beginning and end of each action starts with the same motion properties.
3.3. Online Performance Results
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mincă, E.; Filipescu, A.; Cernega, D.; Șolea, R.; Filipescu, A.; Ionescu, D.; Simion, G. Digital Twin for a Multifunctional Technology of Flexible Assembly on a Mechatronics Line with Integrated Robotic Systems and Mobile Visual Sensor—Challenges towards Industry 5.0. Sensors 2022, 22, 8153. [Google Scholar] [CrossRef] [PubMed]
- Abdulrahman, A.; Richards, D.; Bilgin, A.A. Exploring the influence of a user-specific explainable virtual advisor on health behaviour change intentions. Auton. Agents Multi-Agent Syst. 2022, 36, 25. [Google Scholar] [CrossRef] [PubMed]
- Castro-Rivera, J.; Morales-Rodríguez, M.L.; Rangel-Valdez, N.; Gómez-Santillán, C.; Aguilera-Vázquez, L. Modeling Preferences through Personality and Satisfaction to Guide the Decision Making of a Virtual Agent. Axioms 2022, 11, 232. [Google Scholar] [CrossRef]
- Dhou, K.; Cruzen, C. An innovative chain coding mechanism for information processing and compression using a virtual bat-bug agent-based modeling simulation. Eng. Appl. Artif. Intell. 2022, 113, 104888. [Google Scholar] [CrossRef]
- Saeed, I.A.; Selamat, A.; Rohani, M.F.; Krejcar, O.; Chaudhry, J.A. A Systematic State-of-the-Art Analysis of Multi-Agent Intrusion Detection. IEEE Access 2020, 8, 180184–180209. [Google Scholar] [CrossRef]
- Schmitz, A. Human–Robot Collaboration in Industrial Automation: Sensors and Algorithms. Sensors 2022, 22, 5848. [Google Scholar] [CrossRef]
- Stipancic, T.; Koren, L.; Korade, D.; Rosenberg, D. PLEA: A social robot with teaching and interacting capabilities. J. Pac. Rim Psychol. 2021, 15, 18344909211037019. [Google Scholar] [CrossRef]
- Wang, L.; Majstorovic, V.D.; Mourtzis, D.; Carpanzano, E.; Moroni, G.; Galantucci, L.M. Proceedings of the 5th International Conference on the Industry 4.0 Model for Advanced Manufacturing, Belgrade, Serbia, 1–4 June 2020; Lecture Notes in Mechanical Engineering; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Lasota, P.A.; Fong, T.; Shah, J.A. A Survey of Methods for Safe Human-Robot Interaction. Found. Trends Robot. 2017, 5, 261–349. [Google Scholar] [CrossRef]
- Ajoudani, A.; Zanchettin, A.M.; Ivaldi, S.; Albu-Schäffer, A.; Kosuge, K.; Khatib, O. Progress and prospects of the human–robot collaboration. Auton. Robot. 2018, 42, 957–975. [Google Scholar] [CrossRef] [Green Version]
- Semeraro, F.; Griffiths, A.; Cangelosi, A. Human–robot collaboration and machine learning: A systematic review of recent research. Robot. Comput.-Integr. Manuf. 2023, 79, 102432. [Google Scholar] [CrossRef]
- Ogenyi, U.E.; Liu, J.; Yang, C.; Ju, Z.; Liu, H. Physical Human–Robot Collaboration: Robotic Systems, Learning Methods, Collaborative Strategies, Sensors, and Actuators. IEEE Trans. Cybern. 2019, 51, 1888–1901. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bi, Z.; Luo, M.; Miao, Z.; Zhang, B.; Zhang, W.; Wang, L. Safety assurance mechanisms of collaborative robotic systems in manufacturing. Robot. Comput.-Integr. Manuf. 2021, 67, 102022. [Google Scholar] [CrossRef]
- Chandrasekaran, B.; Conrad, J.M. Human-robot collaboration: A survey. In Proceedings of the SoutheastCon 2015, Fort Lauderdale, FL, USA, 9–12 April 2015; pp. 1–8. [Google Scholar] [CrossRef]
- Mukherjee, D.; Gupta, K.; Chang, L.H.; Najjaran, H. A Survey of Robot Learning Strategies for Human-Robot Collaboration in Industrial Settings. Robot. Comput.-Integr. Manuf. 2022, 73, 102231. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Shaikh, M.; Chai, D. RGB-D Data-Based Action Recognition: A Review. Sensors 2021, 21, 4246. [Google Scholar] [CrossRef] [PubMed]
- Banos, O.; Galvez, J.-M.; Damas, M.; Pomares, H.; Rojas, I. Window Size Impact in Human Activity Recognition. Sensors 2014, 14, 6474–6499. [Google Scholar] [CrossRef] [Green Version]
- Maeda, G.; Ewerton, M.; Neumann, G.; Lioutikov, R.; Peters, J. Phase estimation for fast action recognition and trajectory generation in human–robot collaboration. Int. J. Robot. Res. 2017, 36, 1579–1594. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar] [CrossRef]
- Dallel, M.; Havard, V.; Baudry, D.; Savatier, X. InHARD—Industrial Human Action Recognition Dataset in the Context of Industrial Collaborative Robotics. In Proceedings of the IEEE International Conference on Human-Machine Systems (ICHMS), Rome, Italy, 7–9 September 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Carreira, J.; Noland, E.; Hillier, C.; Zisserman, A. A short note on the kinetics-700 human action dataset. arXiv 2019, arXiv:1907.06987. [Google Scholar]
- Ullah, A.; Muhammad, K.; Del Ser, J.; Baik, S.W.; de Albuquerque, V.H.C. Activity Recognition Using Temporal Optical Flow Convolutional Features and Multilayer LSTM. IEEE Trans. Ind. Electron. 2018, 66, 9692–9702. [Google Scholar] [CrossRef]
- Li, S.; Fan, J.; Zheng, P.; Wang, L. Transfer Learning-enabled Action Recognition for Human-robot Collaborative Assembly. Procedia CIRP 2021, 104, 1795–1800. [Google Scholar] [CrossRef]
- Fazli, M.; Kowsari, K.; Gharavi, E.; Barnes, L.; Doryab, A. HHAR-net: Hierarchical Human Activity Recognition using Neural Networks. In Intelligent Human Computer Interaction—IHCI 2020; Springer: Cham, Switzerland, 2021; pp. 48–58. [Google Scholar] [CrossRef]
- Moniz, A.B. Intuitive Interaction Between Humans and Robots in Work Functions at Industrial Environments: The Role of Social Robotics. In Social Robots from a Human Perspective; Springer: Cham, Switzerland, 2015; pp. 67–76. [Google Scholar] [CrossRef]
- Jerbic, B.; Stipancic, T.; Tomasic, T. Robotic bodily aware interaction within human environments. In Proceedings of the SAI Intelligent Systems Conference (IntelliSys), London, UK, 10–11 November 2015; pp. 305–314. [Google Scholar] [CrossRef]
- Huang, J.; Huo, W.; Xu, W.; Mohammed, S.; Amirat, Y. Control of Upper-Limb Power-Assist Exoskeleton Using a Human-Robot Interface Based on Motion Intention Recognition. IEEE Trans. Autom. Sci. Eng. 2015, 12, 1257–1270. [Google Scholar] [CrossRef]
- Orsag, L.; Stipancic, T.; Koren, L.; Posavec, K. Human Intention Recognition for Safe Robot Action Planning Using Head Pose. In HCI International 2022—Late Breaking Papers. Multimodality in Advanced Interaction Environments: HCII 2022; Springer: Cham, Switzerland, 2022; pp. 313–327. [Google Scholar] [CrossRef]
- Matsumoto, Y.; Ogasawara, T.; Zelinsky, A. Behavior recognition based on head pose and gaze direction measurement. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2000) (Cat. No.00CH37113), Takamatsu, Japan, 31 October–5 November 2002; pp. 2127–2132. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, H.; Geng, J.; Jiang, W.; Deng, X.; Miao, W. An information fusion method based on deep learning and fuzzy discount-weighting for target intention recognition. Eng. Appl. Artif. Intell. 2022, 109, 104610. [Google Scholar] [CrossRef]
- Cubero, C.G.; Rehm, M. Intention Recognition in Human Robot Interaction Based on Eye Tracking. In Human-Computer Interaction—INTERACT 2021: INTERACT 2021; Springer: Cham, Switzerland, 2021; pp. 428–437. [Google Scholar] [CrossRef]
- Lindblom, J.; Alenljung, B. The ANEMONE: Theoretical Foundations for UX Evaluation of Action and Intention Recognition in Human-Robot Interaction. Sensors 2020, 20, 4284. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Hao, J. Intention Recognition in Physical Human-Robot Interaction Based on Radial Basis Function Neural Network. J. Robot. 2019, 2019, 4141269. [Google Scholar] [CrossRef]
- Awais, M.; Saeed, M.Y.; Malik, M.S.A.; Younas, M.; Asif, S.R.I. Intention Based Comparative Analysis of Human-Robot Interaction. IEEE Access 2020, 8, 205821–205835. [Google Scholar] [CrossRef]
- Fan, J.; Zheng, P.; Li, S. Vision-based holistic scene understanding towards proactive human–robot collaboration. Robot. Comput.-Integr. Manuf. 2022, 75, 102304. [Google Scholar] [CrossRef]
- Stipancic, T.; Jerbic, B. Self-adaptive Vision System. In Emerging Trends in Technological Innovation—DoCEIS 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 195–202. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Liu, H.; Wang, L.; Gao, R.X. Deep learning-based human motion recognition for predictive context-aware human-robot collaboration. CIRP Ann. 2018, 67, 17–20. [Google Scholar] [CrossRef]
- Zhang, R.; Lv, Q.; Li, J.; Bao, J.; Liu, T.; Liu, S. A reinforcement learning method for human-robot collaboration in assembly tasks. Robot. Comput.-Integr. Manuf. 2022, 73, 102227. [Google Scholar] [CrossRef]
- Sadrfaridpour, B.; Wang, Y. Collaborative Assembly in Hybrid Manufacturing Cells: An Integrated Framework for Human–Robot Interaction. IEEE Trans. Autom. Sci. Eng. 2017, 15, 1178–1192. [Google Scholar] [CrossRef]
- Moutinho, D.; Rocha, L.F.; Costa, C.M.; Teixeira, L.F.; Veiga, G. Deep learning-based human action recognition to leverage context awareness in collaborative assembly. Robot. Comput.-Integr. Manuf. 2023, 80, 102449. [Google Scholar] [CrossRef]
- Rahman, S.M.; Wang, Y. Mutual trust-based subtask allocation for human–robot collaboration in flexible lightweight assembly in manufacturing. Mechatronics 2018, 54, 94–109. [Google Scholar] [CrossRef]
- Mavsar, M.; Denisa, M.; Nemec, B.; Ude, A. Intention Recognition with Recurrent Neural Networks for Dynamic Human-Robot Collaboration. In Proceedings of the 20th International Conference on Advanced Robotics (ICAR), Ljubljana, Slovenia, 6–10 December 2021; pp. 208–215. [Google Scholar] [CrossRef]
- Nemec, B.; Mavsar, M.; Simonic, M.; Hrovat, M.M.; Skrabar, J.; Ude, A. Integration of a reconfigurable robotic workcell for assembly operations in automotive industry. In Proceedings of the IEEE/SICE International Symposium on System Integration (SII), Narvik, Norway, 9–12 January 2022; pp. 778–783. [Google Scholar] [CrossRef]
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. 2014, 46, 33. [Google Scholar] [CrossRef]
- Tan, H.H.; Lim, K.H. Vanishing Gradient Mitigation with Deep Learning Neural Network Optimization. In Proceedings of the 7th International Conference on Smart Computing & Communications (ICSCC), Sarawak, Malaysia, 28–30 June 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Hu, Z.; Zhang, J.; Ge, Y. Handling Vanishing Gradient Problem Using Artificial Derivative. IEEE Access 2021, 9, 22371–22377. [Google Scholar] [CrossRef]
- Kim, S.; Wimmer, H.; Kim, J. Analysis of Deep Learning Libraries: Keras, PyTorch, and MXnet. In Proceedings of the IEEE/ACIS 20th International Conference on Software Engineering Research, Management and Applications (SERA), Las Vegas, NV, USA, 25–27 May 2022; pp. 54–62. [Google Scholar] [CrossRef]
- Pyvovar, M.; Pohudina, O.; Pohudin, A.; Kritskaya, O. Simulation of Flight Control of Two UAVs Based on the “Master-Slave” Model. In Integrated Computer Technologies in Mechanical Engineering—2021: ICTM 2021; Springer: Cham, Switzerland, 2022; pp. 902–907. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action ID | Meta-Action Label |
|---|---|
| 0 | No action 1 |
| 1 | Consult sheets |
| 2 | Turn sheets |
| 3 | Take screwdriver |
| 4 | Put down screwdriver |
| 5 | Pick in front 1 |
| 6 | Pick left 1 |
| 7 | Take measuring rod |
| 8 | Put down measuring rod |
| 9 | Take component |
| 10 | Put down component |
| 11 | Assemble system 1 |
| 12 | Take subsystem |
| 13 | Put down subsystem |
| Dimensionality Reduction Method | Resulting Number of Feature Points | Comment |
|---|---|---|
| None 1 | 63 | N/A |
| Visual inspection 2 | 51 | N/A |
| PCA | 27 | Human worker symmetry is compromised 3 |
| Metric | Model with 51 Input Features | Model with 27 Input Features |
|---|---|---|
| Precision | 0.709 | 0.709 |
| Recall | 0.699 | 0.694 |
| F1-Score | 0.686 | 0.680 |
| Subclass | Accuracy (%) |
|---|---|
| Picking In Front | ~63% |
| Picking Left | ~67% |
| No Action | ~39% |
| Assemble System | ~38% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Orsag, L.; Stipancic, T.; Koren, L. Towards a Safe Human–Robot Collaboration Using Information on Human Worker Activity. Sensors 2023, 23, 1283. https://doi.org/10.3390/s23031283
Orsag L, Stipancic T, Koren L. Towards a Safe Human–Robot Collaboration Using Information on Human Worker Activity. Sensors. 2023; 23(3):1283. https://doi.org/10.3390/s23031283
Chicago/Turabian StyleOrsag, Luka, Tomislav Stipancic, and Leon Koren. 2023. "Towards a Safe Human–Robot Collaboration Using Information on Human Worker Activity" Sensors 23, no. 3: 1283. https://doi.org/10.3390/s23031283
APA StyleOrsag, L., Stipancic, T., & Koren, L. (2023). Towards a Safe Human–Robot Collaboration Using Information on Human Worker Activity. Sensors, 23(3), 1283. https://doi.org/10.3390/s23031283