


Deep-Q-Network-Based Packet Scheduling in an IoT Environment

Abstract
1. Introduction
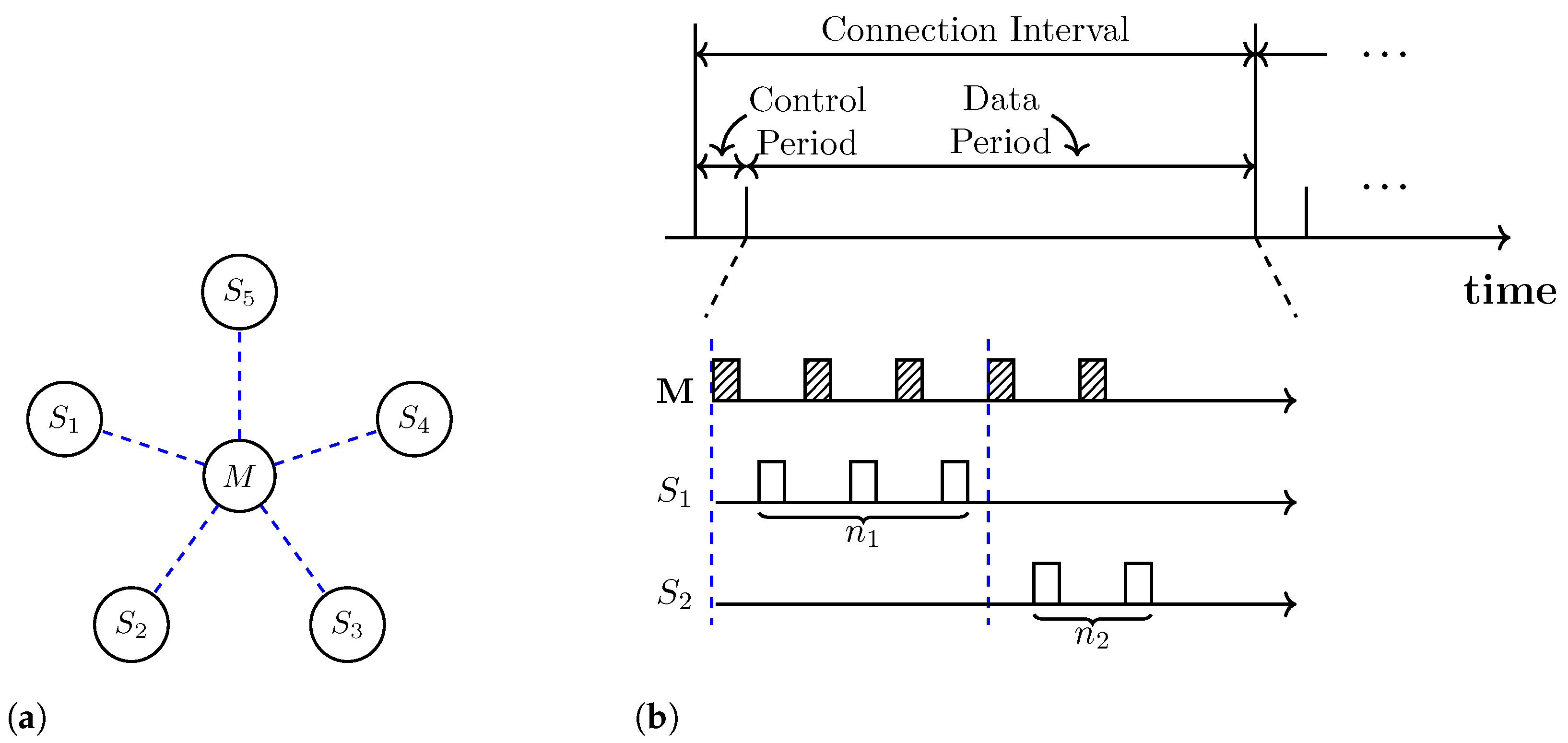
2. System Model
2.1. Network Model
2.2. Problem Formulation
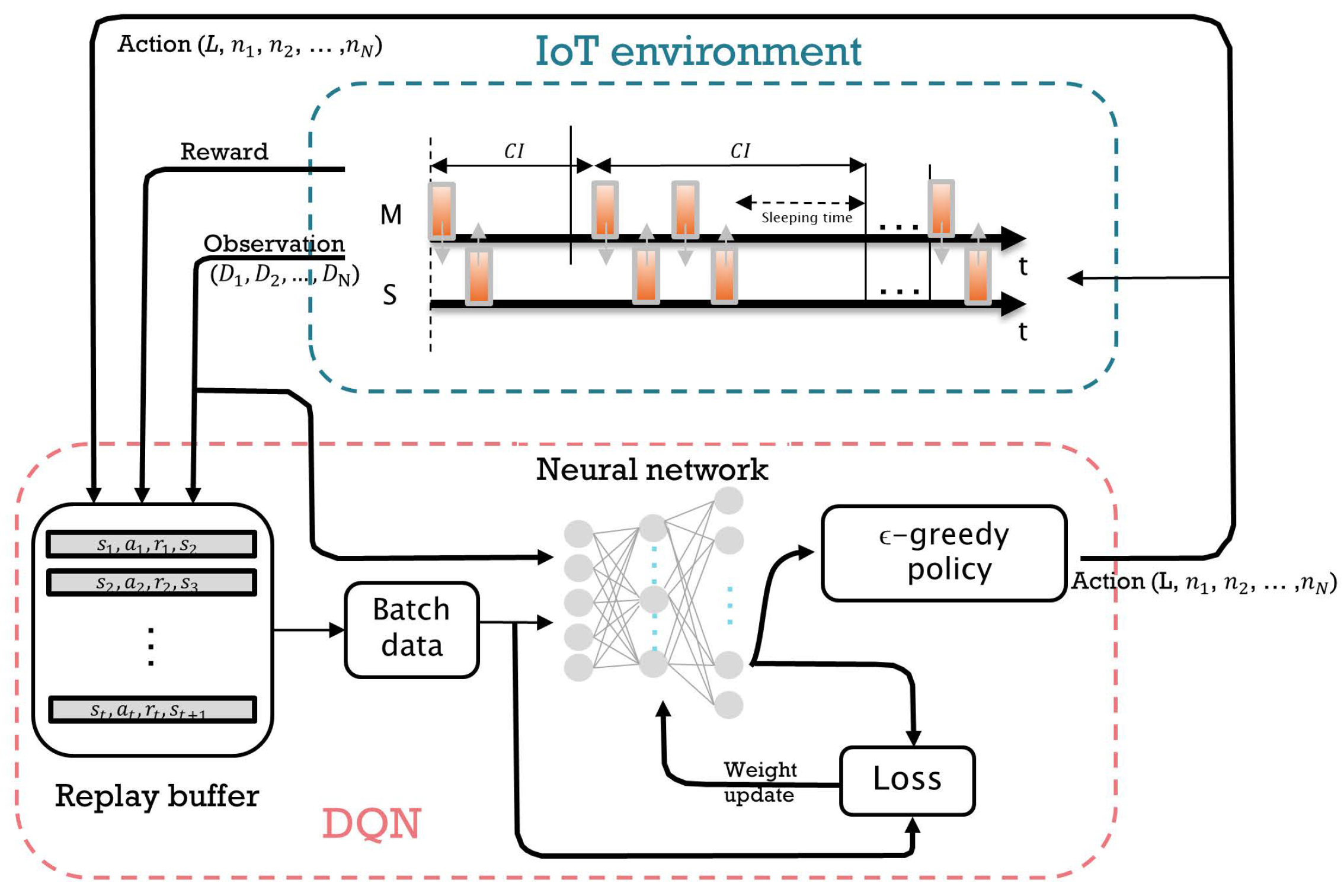
3. DQN-Based Scheduling Algorithm
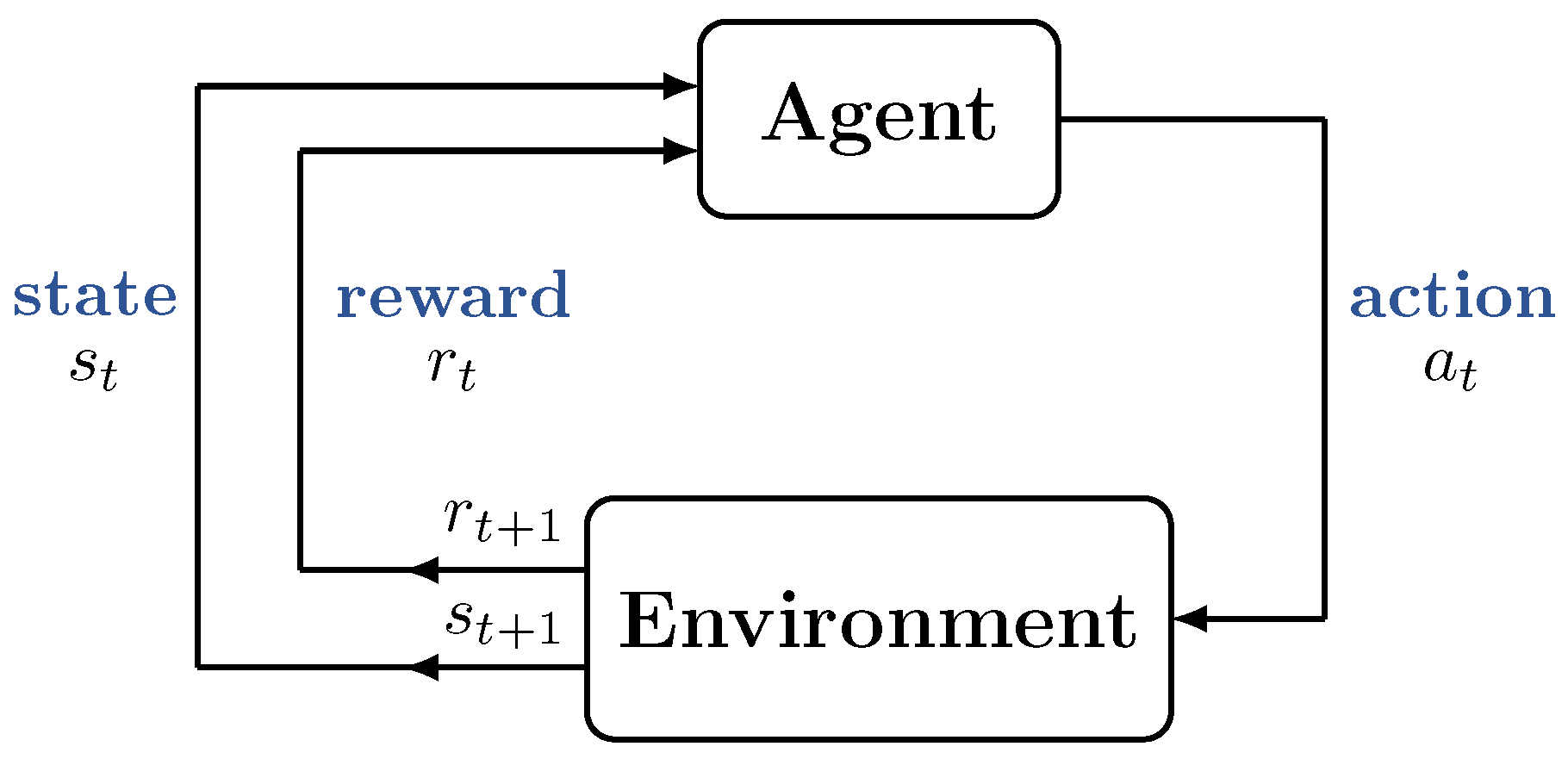
3.1. Reinforcement Learning
3.2. DQN-Based Scheduling Algorithm
3.2.1. States
3.2.2. Actions
3.2.3. Rewards
| Algorithm 1: scheduling algorithm. |
|
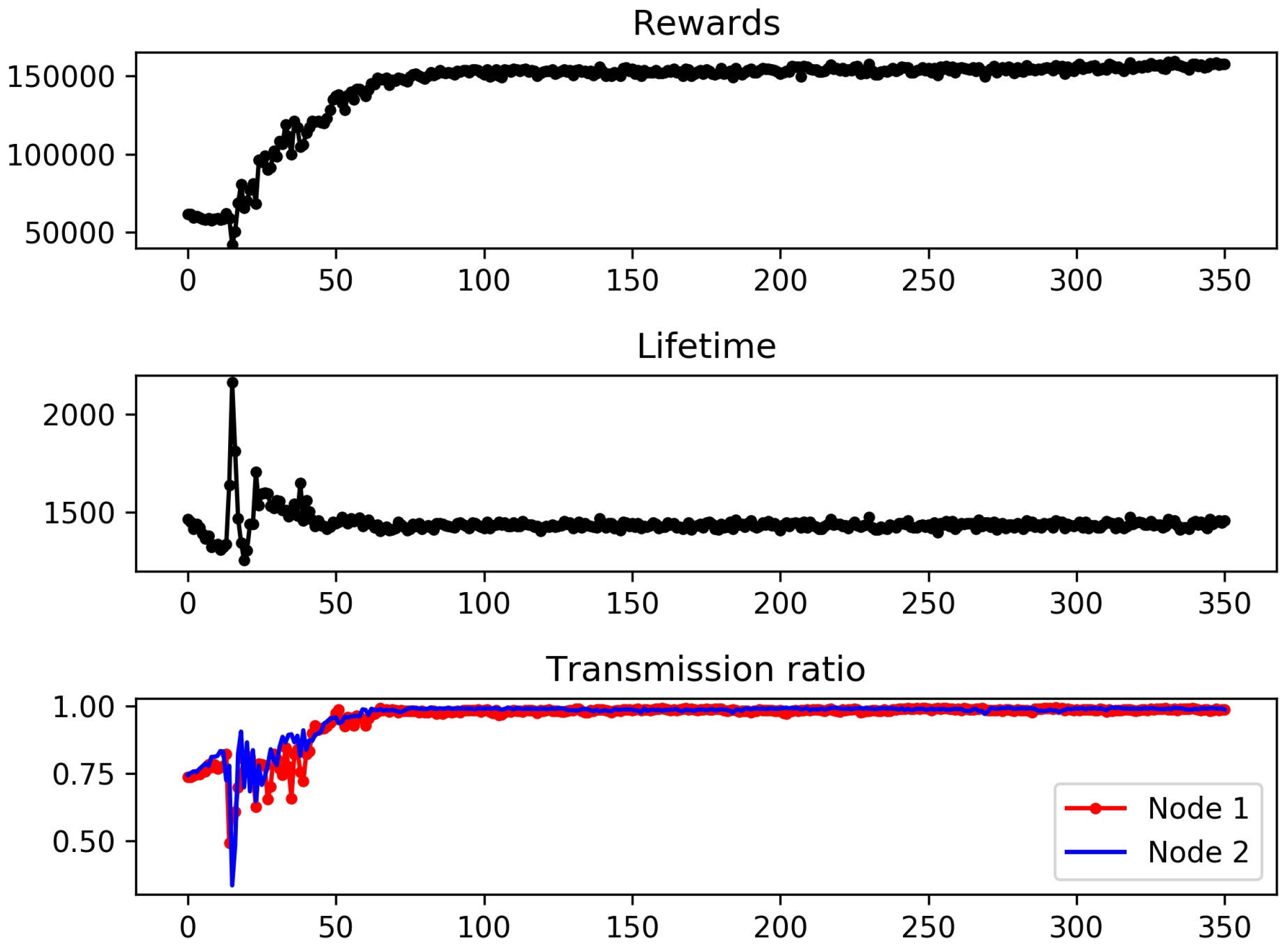
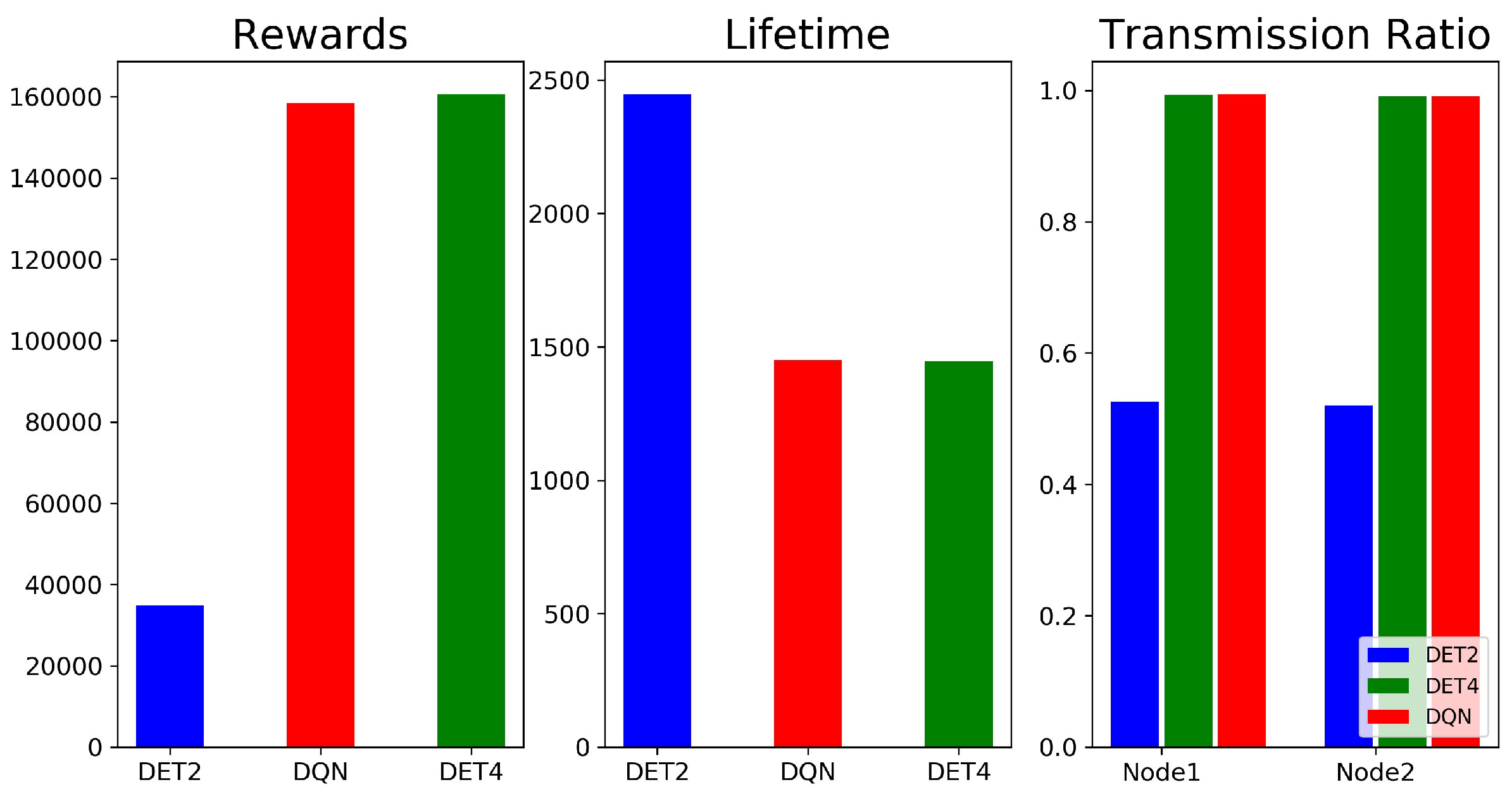
4. Numerical Results and Discussion
5. Related Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BLE | Bluetooth Low Energy |
| CI | Connection Interval |
| DNN | Deep Neural Network |
| DQN | Deep Q-Network |
| IoT | Internet of Things |
| IIoT | Industrial Internet of Things |
| QoS | Quality of Service |
| RL | Reinforcement Learning |
| WSN | Wireless Sensor Network |
References
- Atzori, L.; Iera, A.; Morabito, G. The Internet of Things: A survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Sethi, P.; Sarangi, S.R. Internet of Things: Architectures, protocols, and applications. J. Electr. Comput. Eng. 2017, 2017. [Google Scholar] [CrossRef]
- Balaji, S.; Nathani, K.; Santhakumar, R. IoT technology, applications and challenges: A contemporary survey. Wirel. Pers. Commun. 2019, 108, 363–388. [Google Scholar] [CrossRef]
- Yick, J.; Mukherjee, B.; Ghosal, D. Wireless sensor network survey. Comput. Netw. 2008, 52, 2292–2330. [Google Scholar] [CrossRef]
- Kandris, D.; Nakas, C.; Vomvas, D.; Koulouras, G. Applications of wireless sensor networks: An up-to-date survey. Appl. Syst. Innov. 2020, 3, 14. [Google Scholar] [CrossRef]
- Sudevalayam, S.; Kulkarni, P. Energy harvesting sensor nodes: Survey and implications. IEEE Commun. Surv. Tutor. 2010, 13, 443–461. [Google Scholar] [CrossRef]
- Sachan, S.; Sharma, R.; Sehgal, A. Energy efficient scheme for better connectivity in sustainable mobile wireless sensor networks. Sustain. Comput. Inform. Syst. 2021, 30, 100504. [Google Scholar] [CrossRef]
- Jones, C.E.; Sivalingam, K.M.; Agrawal, P.; Chen, J.C. A survey of energy efficient network protocols for wireless networks. Wirel. Netw. 2001, 7, 343–358. [Google Scholar] [CrossRef]
- Bhandari, S.; Zhao, H.P.; Kim, H.; Khan, P.; Ullah, S. Packet scheduling using SVM models in wireless communication networks. J. Internet Technol. 2019, 20, 1505–1512. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhai, D.; Zhang, R.; Wang, Y. Deep neural network based channel allocation for interference-limited wireless networks. In Proceedings of the 2019 IEEE 20th International Conference on High Performance Switching and Routing (HPSR), Xi’an, China, 26–29 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Xu, S.; Liu, P.; Wang, R.; Panwar, S.S. Realtime scheduling and power allocation using deep neural networks. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, G.; Nie, J.; Peng, Y.; Zhang, Y. Deep reinforcement learning for scheduling in an edge computing-based industrial internet of things. Wirel. Commun. Mob. Comput. 2021, 2021. [Google Scholar] [CrossRef]
- Chen, J.H.; Chen, Y.S.; Jiang, Y.L. Energy-efficient scheduling for multiple latency-sensitive Bluetooth Low Energy nodes. IEEE Sens. J. 2017, 18, 849–859. [Google Scholar] [CrossRef]
- Bluetooth, S. Specification of the Bluetooth System v4. 2; Bluetooth SIG: Kirkland, WA, USA, 2014; Volume 27. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT press: Cambridge, MA, USA, 2018. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Matloff, N. Introduction to Discrete-Event Simulation and the Simpy Language; Department of Computer Science, University of California at Davis: Davis, CA, USA, 2008; Volume 2, pp. 1–33. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv e-prints. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Jones, A. Survey: Energy efficient protocols using radio scheduling in wireless sensor network. Int. J. Electr. Comput. Eng. 2020, 10. [Google Scholar] [CrossRef]
- Malekpourshahraki, M.; Desiniotis, C.; Radi, M.; Dezfouli, B. A survey on design challenges of scheduling algorithms for wireless networks. Int. J. Commun. Netw. Distrib. Syst. 2022, 28, 219–265. [Google Scholar] [CrossRef]
- Qiu, T.; Zheng, K.; Han, M.; Chen, C.P.; Xu, M. A data-emergency-aware scheduling scheme for Internet of Things in smart cities. IEEE Trans. Ind. Inf. 2017, 14, 2042–2051. [Google Scholar] [CrossRef]
- Feng, J.; Zhao, H. Energy-balanced multisensory scheduling for target tracking in wireless sensor networks. Sensors 2018, 18, 3585. [Google Scholar] [CrossRef]
- Dementyev, A.; Hodges, S.; Taylor, S.; Smith, J. Power consumption analysis of Bluetooth Low Energy, ZigBee and ANT sensor nodes in a cyclic sleep scenario. In Proceedings of the 2013 IEEE International Wireless Symposium (IWS), Beijing, China, 14–18 April 2013; pp. 1–4. [Google Scholar] [CrossRef]
- Shan, G.; Roh, B.H. Advertisement interval to minimize discovery time of whole BLE advertisers. IEEE Access 2018, 6, 17817–17825. [Google Scholar] [CrossRef]
- Ghamari, M.; Villeneuve, E.; Soltanpur, C.; Khangosstar, J.; Janko, B.; Sherratt, R.S.; Harwin, W. Detailed examination of a packet collision model for Bluetooth Low Energy advertising mode. IEEE Access 2018, 6, 46066–46073. [Google Scholar] [CrossRef]
- Giovanelli, D.; Milosevic, B.; Farella, E. Bluetooth Low Energy for data streaming: Application-level analysis and recommendation. In Proceedings of the 2015 6th International Workshop on Advances in Sensors and Interfaces (IWASI), Gallipoli, Italy, 18–19 June 2015; pp. 216–221. [Google Scholar] [CrossRef]
- Fu, X.; Lopez-Estrada, L.; Kim, J.G. A Q-learning-based approach for enhancing energy efficiency of Bluetooth Low Energy. IEEE Access 2021, 9, 21286–21295. [Google Scholar] [CrossRef]
- Rioual, Y.; Le Moullec, Y.; Laurent, J.; Khan, M.I.; Diguet, J.P. Reward function evaluation in a reinforcement learning approach for energy management. In Proceedings of the 2018 16th Biennial Baltic Electronics Conference (BEC), Tallinn, Estonia, 8–10 October 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Collotta, M.; Pau, G. Bluetooth for Internet of Things: A fuzzy approach to improve power management in smart homes. Comput. Electr. Eng. 2015, 44, 137–152. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Connection interval length (L) | s |
| Discretized delay levels | 20 |
| Packet arrival rate () | /s |
| Transmission speed of link | 1 Mbps |
| Interframe space (IFS) | ms |
| Master packet size | 12 bytes |
| Slave packet size | 37 bytes |
| Packet lifetime () | 2–4 s |
| Initial battery capacity | |
| Energy consumed by transmitting/receiving a data packet | |
| Energy consumed by transmitting/receiving an empty/control packet |
| States | Action | Frequency |
|---|---|---|
| ((0,0,0,0,0), (0,0,0,0,0)) | (29,0,0) | 3.275 |
| ((0,0,0,0,0), (16,0,0,0,0)) | (30,0,1) | 0.425 |
| ((19,0,0,0,0), (0,0,0,0,0)) | (31,1,0) | 0.35 |
| ((16,0,0,0,0), (0,0,0,0,0)) | (31,1,0) | 0.35 |
| ((10,0,0,0,0), (0,0,0,0,0)) | (31,1,0) | 0.35 |
| ((0,0,0,0,0), (11,0,0,0,0)) | (30,0,1) | 0.325 |
| ((17,0,0,0,0), (0,0,0,0,0)) | (31,1,0) | 0.325 |
| ((15,0,0,0,0), (0,0,0,0,0)) | (31,1,0) | 0.325 |
| ((0,0,0,0,0), (4,0,0,0,0)) | (30,0,1) | 0.325 |
| ((20,0,0,0,0), (0,0,0,0,0)) | (31,1,0) | 0.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, X.; Kim, J.G. Deep-Q-Network-Based Packet Scheduling in an IoT Environment. Sensors 2023, 23, 1339. https://doi.org/10.3390/s23031339
Fu X, Kim JG. Deep-Q-Network-Based Packet Scheduling in an IoT Environment. Sensors. 2023; 23(3):1339. https://doi.org/10.3390/s23031339
Chicago/Turabian StyleFu, Xing, and Jeong Geun Kim. 2023. "Deep-Q-Network-Based Packet Scheduling in an IoT Environment" Sensors 23, no. 3: 1339. https://doi.org/10.3390/s23031339
APA StyleFu, X., & Kim, J. G. (2023). Deep-Q-Network-Based Packet Scheduling in an IoT Environment. Sensors, 23(3), 1339. https://doi.org/10.3390/s23031339