1. Introduction
In recent years, electric vehicle (EV) technology has developed rapidly, driven by breakthroughs in battery technology [
1,
2]. As a substitute for fossil fuel vehicles, EVs have received extensive attention due to their environmentally friendly characteristics [
2,
3,
4,
5]. EVs can reduce traffic pollution emissions and have lower charging costs than refueling, which has been widely accepted and deployed [
6,
7,
8,
9]. However, large-scale numbers of EVs connected to the power grid will bring challenges, such as frequency excursion and voltage fluctuation [
10]. The voltage stability of the distribution network (DN) is an issue that needs to be focused on. The uncontrolled charging process of EVs will affect the voltage stability of the distribution network [
11]. When EVs are connected to the power grid in vehicle-to-grid (V2G) mode, this situation will further deteriorate. In addition, the access of distributed generators (DGs) to the power system changes the direction of power flow, and the injection of active power upstream by distributed generators (DGs) causes voltage rise and interferes with Volt/Var control (VVC) equipment [
12]. The intermittency, randomness, and fluctuation of renewable energy sources (RESs) can cause voltage fluctuations in the distribution network [
13].
VVC is used to improve the voltage stability of the distribution network. In traditional VVC practice, voltage-regulating devices, such as on-load tap changers (OLTCs), voltage regulators (VRs), and switchable capacitor banks (SCBs), are leveraged to mitigate voltage violations [
14]. In [
15], a support vector regression based model predictive control (MPC) method was proposed to optimize the voltage of a distribution network. For the renewable energy access problem controlled by inverters, a multistage method has been widely used for the VVC of distribution networks [
16,
17]. To coordinate VVC equipment and distributed power supply, neural networks and learning-based methods are widely used. An artificial neural network (ANN) based approach was introduced for the VVC of distributed energy resources at the grid edge [
18]. The authors of [
19] proposed a safe off-policy deep reinforcement learning algorithm for VVC in a power distribution system. A model-free approach based on constrained safe deep reinforcement learning was proposed in [
12] to solve the problem of optimal operation of distribution networks. Although the aforementioned research has made some achievements in VVC, they did not consider the effect of electric vehicle charging on voltage stability nor did they consider the possibility of electric vehicles participating in voltage control.
EVs participate in the voltage regulation of distribution networks. On the one hand, the charging behavior of EVs is stimulated by the electricity price; on the other hand, EVs can operate in the V2G mode [
20]. By adjusting the charging power or discharge power of EVs, it is helpful to stabilize the voltage of the distribution network [
21,
22,
23,
24]. Researchers have performed much work on the problem of charging scheduling of electric vehicles. The authors of [
25] proposed an improved binary particle swarm optimization (PSO) approach to solve the problem of the controlled charging of EV with the objective of reducing the charging cost for EV users and reducing the pressure of peak power on the distribution network. To avoid the limitations of deterministic methods in terms of models and parameters and their inability to handle real-time uncertainty, deep reinforcement learning is widely used in the charging scheduling problem for EVs. References [
3,
10] proposed model-free approaches based on deep reinforcement learning and safe deep reinforcement learning, respectively, for the charging scheduling of household electric vehicles. Both consider the uncertainty of the system and do not need an accurate model but only study the charging scheduling problem of home electric vehicles. When faced with the problem of charging EVs on a larger scale, the charging process for EVs is managed by an aggregator or central controller. However, the charging process of EVs is highly uncertain, which requires the estimation and prediction of the charging demand of EVs. Artificial intelligence approaches are currently of interest due to their advantages in dealing with high-dimensional data and non-linear problems. A Q-learning-based prediction method was proposed in [
26] for forecasting the charging load of electric vehicles under different charging scenarios. The authors of [
27] proposed a demand modeling approach based on 3D convolutional generative adversarial networks. Reference [
28] designed a deep learning-based forecasting and classification network to study the long-term and short-term characteristics of the charging behaviors of plug-in EVs. To solve the problem of EV cluster charging, [
29] proposed a hybrid approach to reduce the power loss and improve the voltage profile in the distribution system, and both the vehicle-to-grid and grid-to-vehicle operational modes of EVs were considered in this work. However, the above research only studies the charging problem of electric vehicles from the perspective of demand response (DR). The capacity and access location of the EV charging load will affect the power flow distribution of the distribution network, and disordered electric vehicle charging will reduce the voltage stability of the distribution network. The authors of [
30] proposed an evolutionary curriculum learning (ECL)-based multiagent deep reinforcement learning (MADRL) approach for optimizing transformer loss of life while considering various charging demands of different EV owners. This work only focuses on the life of the transformer and does not directly control the voltage. Reference [
20] proposed a three-layer hierarchical voltage control strategy for distribution networks considering the customized charging navigation of EVs. Although the hourly scheduling results of the OLTC are given the day before, the voltage is controlled in minutes, and frequent voltage regulation will reduce the life of the OLTC.
The above analysis shows that the current research is more concerned with the VVC of DN or DR of EVs, and there are fewer studies that consider both and perform coordinated optimization. However, the studies that do examine the coordinated optimization of both do not consider the actual system comprehensively. The collaborative optimization of EVs, schedulable DGs and VVC devices in an DN system faces some challenges. First, the charging goals of EV users and the goal of maintaining voltage stability in the distribution networks are mutually exclusive. Second, the distribution network has strong uncertainty and nonlinearity, and the charging process of EVs has strong uncertainty due to arrival time, departure time, and electricity price. Third, there are many homogeneous devices controlled by discrete and continuous actions in the system.
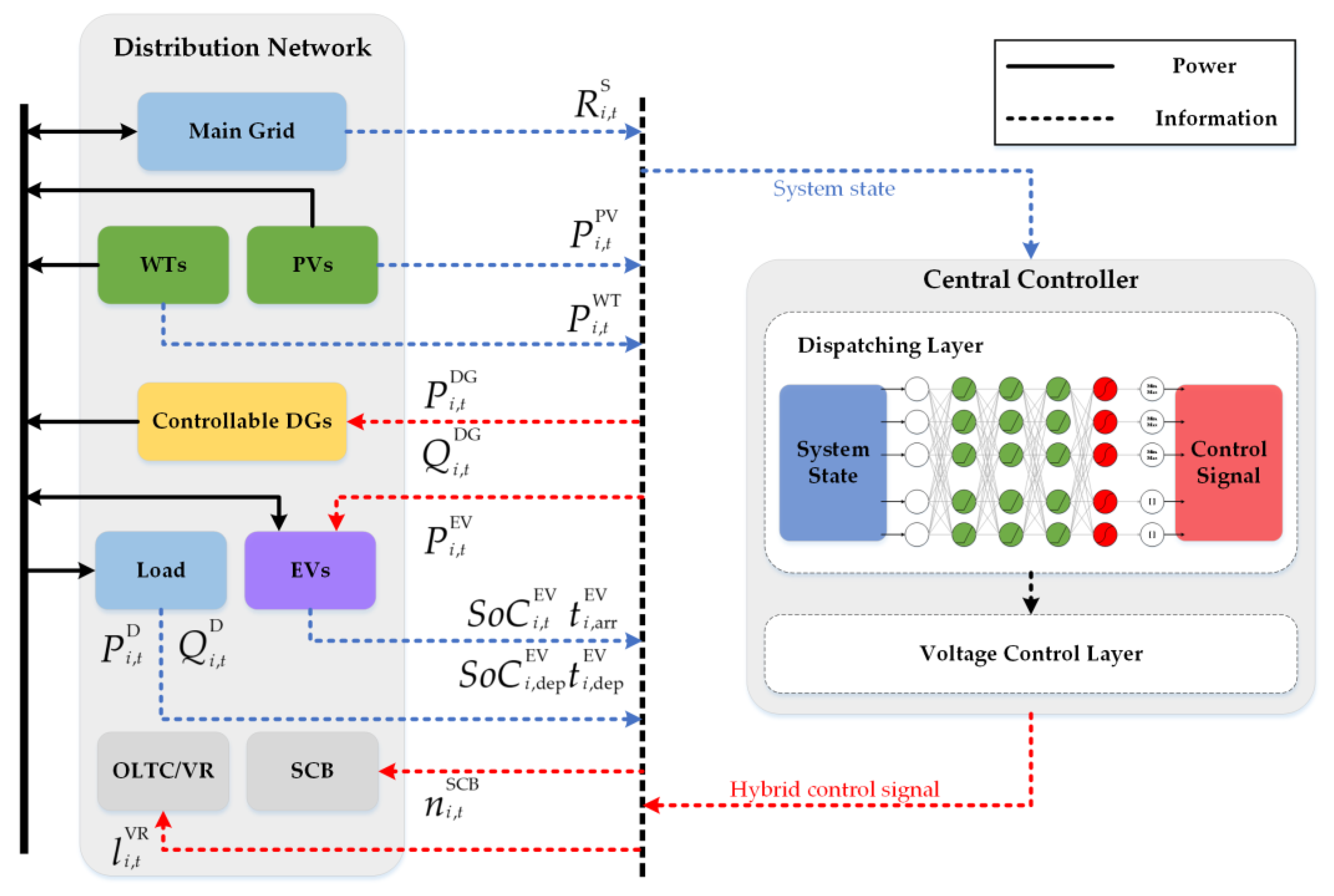
To solve these challenges, we formulate a collaborative EV charging scheduling and voltage control strategy based on DRL to comprehensively schedule the charging of EVs and control the voltage of distribution networks. We establish an MDP model for the charging scheduling of EVs and the voltage control problems of distribution networks. The state variables of the system take into account the uncertainty of the EV charging process, nodal loads, RES generation, and electricity price interacting with the main grid. The purpose is to realize automatic voltage regulation and reduced EV charging cost though the collaborative control of VVC devices and EVs, as well as controllable DGs. The design of the reward function comprehensively considers the charging target of EVs and the voltage control objective of DN. In contrast to the control strategies mentioned in the literature above, which were graded according to time, the proposed control strategy synergistically considers the problem of optimizing the scheduling of EVs and the voltage control of the DN. The collaborative scheduling control strategy consists of two layers; the upper layer manages the charging of electric vehicles and the lower layer regulates the voltage control equipment. The control strategy is output by a designed deep neural network (DNN) and trained using a model-free deep deterministic policy gradient (DDPG) method. A signal rounding block is set up after the output layer of the DNN to obtain the discrete control signals of VVC devices. The main contributions of this work are:
A time-independent two-layer coordinated EV charging and voltage control framework is proposed to minimize EV charging costs and stabilize the voltage of distribution networks.
An MDP with unknown transition probability is established to solve the EV charging problem considering the voltage stabilization of DN. The reward function is reasonably designed to balance the EV charging target and voltage stability target.
The model-free DDPG algorithm is introduced to solve the coordinated optimization problem. A DNN-based policy network is designed to output hybrid continuous scheduling signals and discrete control signals.
The rest of the paper is organized as follows:
Section 2 presents the MDP model and introduces the collaborative scheduling control strategy.
Section 3 encompasses the simulation experiments and analysis.
Section 4 gives the conclusions.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}