


Semi-Autonomic AI LF-NMR Sensor for Industrial Prediction of Edible Oil Oxidation Status

 ,
,  ,
, 
Abstract
:1. Introduction
1.1. Importance of Evaluation of Oxidation of Edible Oils
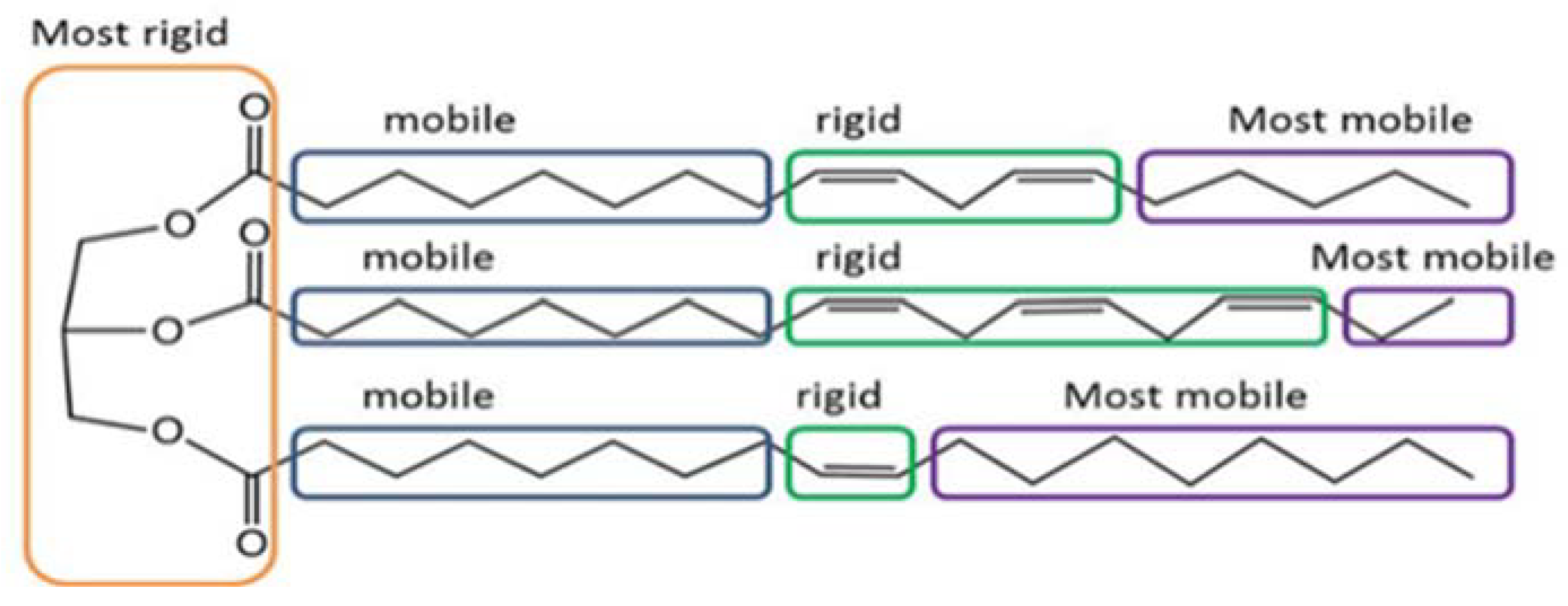
1.2. Oxidation Process of Edible Oils
1.3. Available Technologies for Evaluation of Oil Oxidation
1.4. 1H Low-Field NMR Relaxation Sensor Technology
1.5. Machine Learning (ML) Technology
2. Materials and Methods
2.1. Materials
2.2. Thermal Oxidation
2.3. Conventional Standard Wet Chemistry Analyses
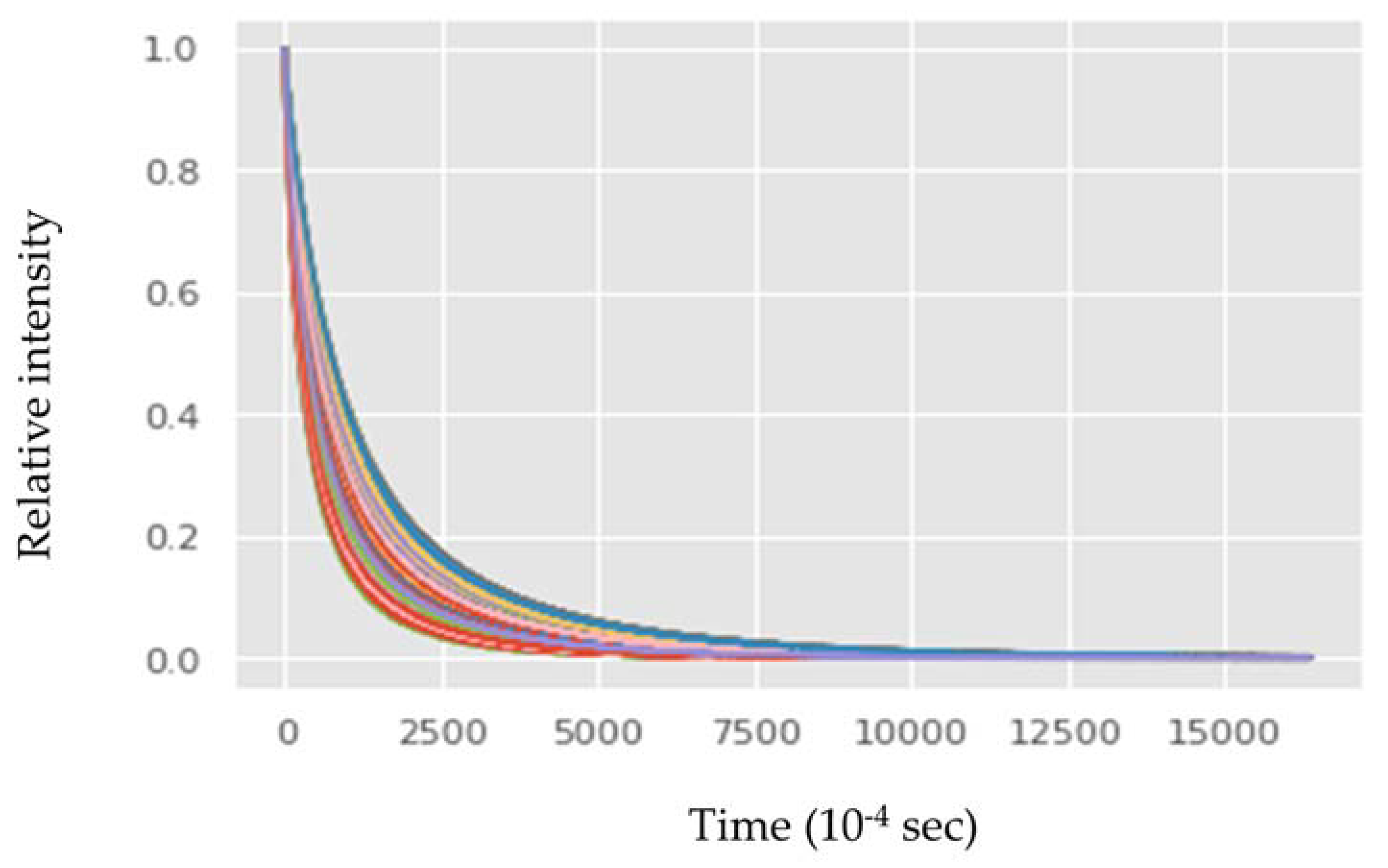
2.4. Low-Field NMR Relaxation Analysis
2.5. Self-Diffusion
2.6. Machine Learning Methodology
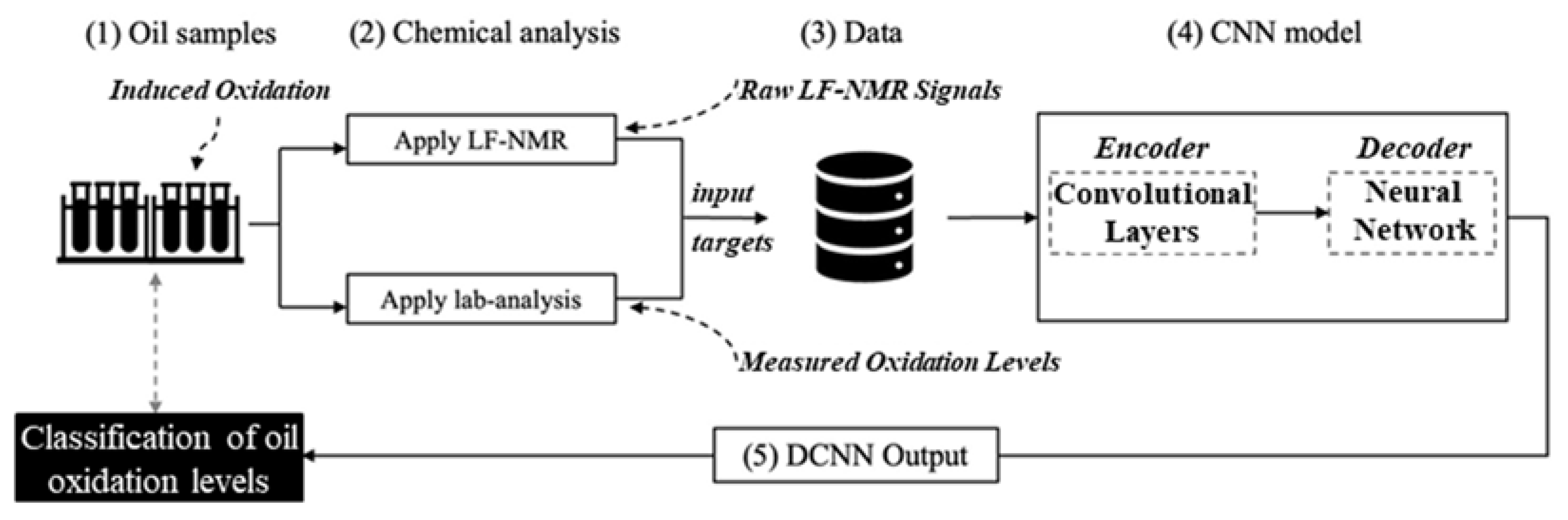
2.6.1. Nuclear Magnetic Resonance Acquisition, Labeling, and CNN Training
2.6.2. The Linseed Oil Oxidation Analyses Database
2.6.3. Criteria for Dividing Oil Samples into ‘Good’, ‘Fair’, and ‘Bad’ Oil Categories of Oil Oxidation
2.7. Convolutional Neural Network (CNN) Architecture
3. Results and Discussion
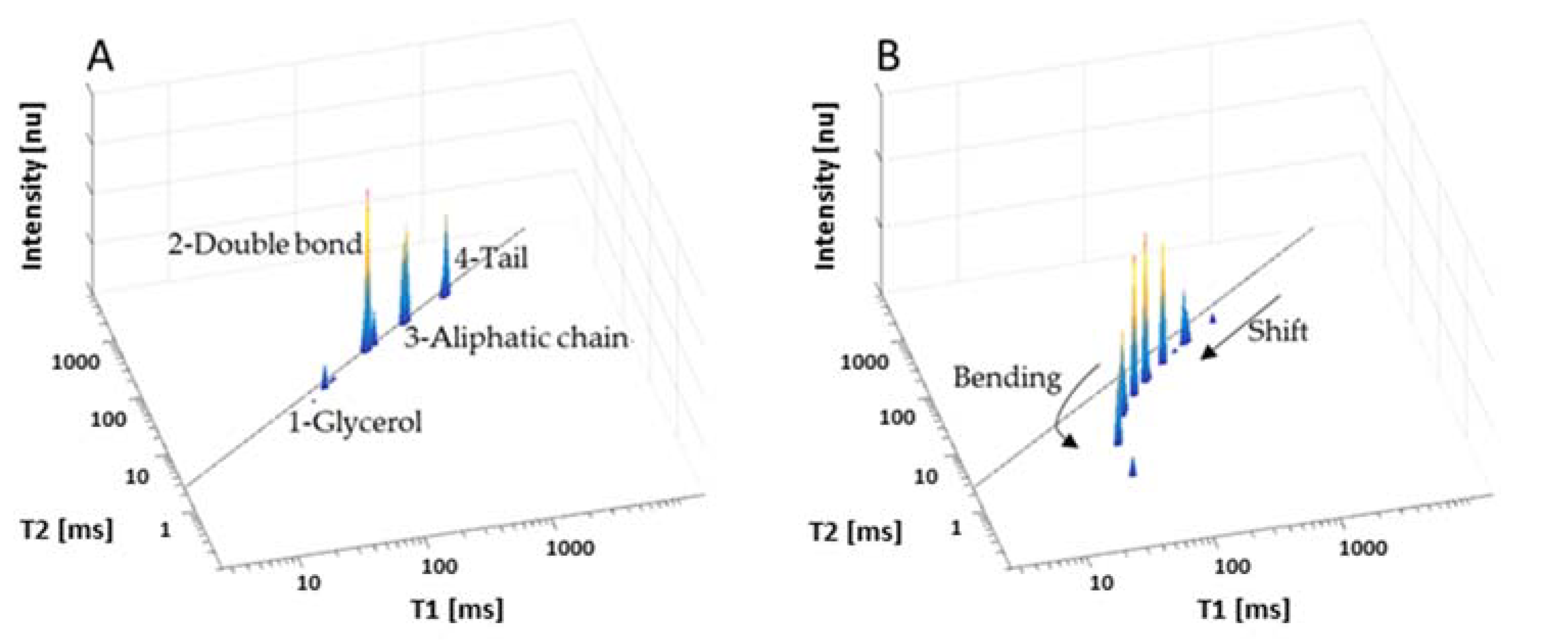
3.1. Low-Field NMR Relaxation Curves of Thermally Induced LSO Oxidation
3.2. The Application
4. Conclusions
5. Patents
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Patterson, E.; Wall, R.; Fitzgerald, G.F.; Ross, R.P.; Stanton, C. Health Implications of High Dietary Omega-6 Polyunsaturated Fatty Acids. J. Nutr. Metab. 2012, 2012, e539426. [Google Scholar] [CrossRef]
- Ruxton, C.H.S.; Reed, S.C.; Simpson, M.J.A.; Millington, K.J. The health benefits of omega-3 polyunsaturated fatty acids: A review of the evidence. J. Hum. Nutr. Diet. 2004, 17, 449–459. [Google Scholar] [CrossRef] [PubMed]
- Lacombe, R.J.S.; Chouinard-Watkins, R.; Bazinet, R.P. Brain docosahexaenoic acid uptake and metabolism. Mol. Aspects Med. 2018, 64, 109–134. [Google Scholar] [CrossRef] [PubMed]
- Resende, M.T.; Linder, C.; Wiesman, Z. 1H LF-NMR Energy Relaxation Time Characterization of the Chemical and Morphological Structure of PUFA-Rich Linseed Oil During Oxidation With and Without Antioxidants. Eur. J. Lipid Sci. Technol. 2019, 121, 1800339. [Google Scholar] [CrossRef]
- Resende, M.T.; Linder, C.; Wiesman, Z. Alkyl Tail Segments Mobility as a Marker for Omega-3 Polyunsaturated Fatty Acid-Rich Linseed Oil Oxidative Aging. J. Am. Oil Chem. Soc. 2020, 97, 1283–1297. [Google Scholar] [CrossRef]
- Hwang, H.-S. Application of NMR Spectroscopy for Foods and Lipids. In Advances in NMR Spectroscopy for Lipid Oxidation Assessment; Hwang, H.-S., Ed.; SpringerBriefs in Food, Health, and Nutrition; Springer International Publishing: Cham, Switzerland, 2017; pp. 11–13. ISBN 978-3-319-54196-9. [Google Scholar]
- Gonzalez Viejo, C.; Fuentes, S. Digital Detection of Olive Oil Rancidity Levels and Aroma Profiles Using Near-Infrared Spectroscopy, a Low-Cost Electronic Nose and Machine Learning Modelling. Chemosensors 2022, 10, 159. [Google Scholar] [CrossRef]
- Jacobsen, C. Some strategies for the stabilization of long chain n-3 PUFA-enriched foods: A review. Eur. J. Lipid Sci. Technol. 2015, 117, 1853–1866. [Google Scholar] [CrossRef]
- Nielsen, N.C.; Beyer, M. Analysis of Snacks Products using Multinuclear Low-Field NMR Sensor Technology. Available online: http://www.nanonord.dk/media/1350/white-paper-v6.pdf (accessed on 9 February 2023).
- Choe, E.; Min, D.B. Mechanisms and Factors for Edible Oil Oxidation. Compr. Rev. Food Sci. Food Saf. 2006, 5, 169–186. [Google Scholar] [CrossRef]
- Choe, E.; Min, D.b. Chemistry of Deep-Fat Frying Oils. J. Food Sci. 2007, 72, R77–R86. [Google Scholar] [CrossRef]
- Aust, S.D.; Morehouse, L.A.; Thomas, C.E. Role of metals in oxygen radical reactions. J. Free Radic. Biol. Med. 1985, 1, 3–25. [Google Scholar] [CrossRef]
- Berman, P.; Meiri, N.; Linder, C.; Wiesman, Z. 1H low field nuclear magnetic resonance relaxometry for probing biodiesel autoxidation. Fuel 2016, 177, 315–325. [Google Scholar] [CrossRef]
- Gromadzka, J.; Wardencki, W. Trends in edible vegetable oils analysis. part A. Determination of different components of edible oils—A review. Pol. J. Food Nutr. Sci. 2011, 61, 33–43. [Google Scholar] [CrossRef]
- Lazzari, M.; Chiantore, O. Drying and oxidative degradation of linseed oil. Polym. Degrad. Stab. 1999, 65, 303–313. [Google Scholar] [CrossRef]
- Barriuso, B.; Astiasarán, I.; Ansorena, D. A review of analytical methods measuring lipid oxidation status in foods: A challenging task. Eur. Food Res. Technol. 2013, 236, 1–15. [Google Scholar] [CrossRef]
- Velasco, J.; Andersen, M.L.; Skibsted, L.H. Electron spin resonance spin trapping for analysis of lipid oxidation in oils: Inhibiting effect of the spin trap alpha-phenyl-N-tert-butylnitrone on lipid oxidation. J. Agric. Food Chem. 2005, 53, 1328–1336. [Google Scholar] [CrossRef]
- Merkx, D.W.H.; Hong, G.T.S.; Ermacora, A.; van Duynhoven, J.P.M. Rapid Quantitative Profiling of Lipid Oxidation Products in a Food Emulsion by 1H NMR. Anal. Chem. 2018, 90, 4863–4870. [Google Scholar] [CrossRef]
- Resende, M.T.; Campisi-Pinto, S.; Linder, C.; Wiesman, Z. Multidimensional Proton Nuclear Magnetic Resonance Relaxation Morphological and Chemical Spectrum Graphics for Monitoring and Characterization of Polyunsaturated Fatty-Acid Oxidation. J. Am. Oil Chem. Soc. 2019, 96, 125–135. [Google Scholar] [CrossRef]
- Rudszuck, T.; Förster, E.; Nirschl, H.; Guthausen, G. Low-field NMR for quality control on oils. Magn. Reson. Chem. 2019, 57, 777–793. [Google Scholar] [CrossRef]
- Blümich, B. Introduction to compact NMR: A review of methods. TrAC Trends Anal. Chem. 2016, 83, 2–11. [Google Scholar] [CrossRef]
- Barbosa, L.L.; Kock, F.V.C.; Silva, R.C.; Freitas, J.C.C.; Lacerda, V., Jr.; Castro, E.V.R. Application of Low-Field NMR for the Determination of Physical Properties of Petroleum Fractions. Energy Fuels 2013, 27, 673–679. [Google Scholar] [CrossRef]
- Guo, J.-C.; Zhou, H.-Y.; Zeng, J.; Wang, K.-J.; Lai, J.; Liu, Y.-X. Advances in low-field nuclear magnetic resonance (NMR) technologies applied for characterization of pore space inside rocks: A critical review. Pet. Sci. 2020, 17, 1281–1297. [Google Scholar] [CrossRef]
- dos Santos, V.R.; Goncalves, V.; Deng, P.; Ribeiro, A.C.; Teigao, M.M.; Dias, B.; Mendes Pinto, I.; Gallo, J.; Peng, W.K. Novel time-domain NMR-based traits for rapid, label-free Olive oils profiling. NPJ Sci. Food 2022, 6, 59. [Google Scholar] [CrossRef]
- Hahn, E.L. Spin Echoes. Phys. Rev. 1950, 80, 580–594. [Google Scholar] [CrossRef]
- Carr, H.Y.; Purcell, E.M. Effects of Diffusion on Free Precession in Nuclear Magnetic Resonance Experiments. Phys. Rev. 1954, 94, 630–638. [Google Scholar] [CrossRef]
- Meiboom, S.; Gill, D. Modified Spin-Echo Method for Measuring Nuclear Relaxation Times. Rev. Sci. Instrum. 1958, 29, 688–691. [Google Scholar] [CrossRef]
- Abragam, A. The Principles of Nuclear Magnetism; Clarendon Press: Oxford, UK, 1961; ISBN 978-0-19-852014-6. [Google Scholar]
- Campisi-Pinto, S.; Levi, O.; Benson, D.; Cohen, M.; Resende, M.T.; Saunders, M.; Linder, C.; Wiesman, Z. Analysis of the Regularization Parameters of Primal–Dual Interior Method for Convex Objectives Applied to 1H Low Field Nuclear Magnetic Resonance Data Processing. Appl. Magn. Reson. 2018, 49, 1129–1150. [Google Scholar] [CrossRef]
- Campisi-Pinto, S.; Levi, O.; Benson, D.; Resende, M.T.; Saunders, M.; Linder, C.; Wiesman, Z. Simulation-Based Sensitivity Analysis of Regularization Parameters for Robust Reconstruction of Complex Material’s T1 − T21H LF-NMR Energy Relaxation Signals. Appl. Magn. Reson. 2020, 51, 41–58. [Google Scholar] [CrossRef]
- Berman, P.; Leshem, A.; Etziony, O.; Levi, O.; Parmet, Y.; Saunders, M.; Wiesman, Z. Novel 1H low field nuclear magnetic resonance applications for the field of biodiesel. Biotechnol. Biofuels 2013, 6, 55. [Google Scholar] [CrossRef]
- Berman, P.; Levi, O.; Parmet, Y.; Saunders, M.; Wiesman, Z. Laplace inversion of low-resolution NMR relaxometry data using sparse representation methods. Concepts Magn. Reson. Part A 2013, 42, 72–88. [Google Scholar] [CrossRef]
- Berman, P.; Meiri, N.; Colnago, L.A.; Moraes, T.B.; Linder, C.; Levi, O.; Parmet, Y.; Saunders, M.; Wiesman, Z. Study of liquid-phase molecular packing interactions and morphology of fatty acid methyl esters (biodiesel). Biotechnol. Biofuels 2015, 8, 12. [Google Scholar] [CrossRef]
- Resende, M.T.; Osheter, T.; Linder, C.; Wiesman, Z. Proton Low Field NMR Relaxation Time Domain Sensor for Monitoring of Oxidation Stability of PUFA-Rich Oils and Emulsion Products. Foods 2021, 10, 1385. [Google Scholar] [CrossRef]
- Iwahashi, M.; Kasahara, Y. Dynamic molecular movements and aggregation structures of lipids in a liquid state. Curr. Opin. Colloid Interface Sci. 2011, 16, 359–366. [Google Scholar] [CrossRef]
- Colnago, L.A.; Wiesman, Z.; Pages, G.; Musse, M.; Monaretto, T.; Windt, C.W.; Rondeau-Mouro, C. Low field, time domain NMR in the agriculture and agrifood sectors: An overview of applications in plants, foods and biofuels. J. Magn. Reson. 2021, 323, 106899. [Google Scholar] [CrossRef]
- Guillén, M.D.; Ruiz, A. Monitoring of heat-induced degradation of edible oils by proton NMR. Eur. J. Lipid Sci. Technol. 2008, 110, 52–60. [Google Scholar] [CrossRef]
- Stejskal, E.O.; Tanner, J.E. Spin Diffusion Measurements: Spin Echoes in the Presence of a Time-Dependent Field Gradient. J. Chem. Phys. 1965, 42, 288–292. [Google Scholar] [CrossRef]
- Osheter, T.; Linder, C.; Wiesman, Z. Time Domain (TD) Proton NMR Analysis of the Oxidative Safety and Quality of Lipid-Rich Foods. Biosensors 2022, 12, 230. [Google Scholar] [CrossRef]
- Ancora, D.; Milavec, J.; Gradišek, A.; Cifelli, M.; Sepe, A.; Apih, T.; Zalar, B.; Domenici, V. Sensitivity of Proton NMR Relaxation and Proton NMR Diffusion Measurements to Olive Oil Adulterations with Vegetable Oils. J. Agric. Food Chem. 2021, 69, 12081–12088. [Google Scholar] [CrossRef]
- Osheter, T.; Campisi-Pinto, S.; Resende, M.T.; Linder, C.; Wiesman, Z. 1H LF-NMR Self-Diffusion Measurements for Rapid Monitoring of an Edible Oil’s Food Quality with Respect to Its Oxidation Status. Molecules 2022, 27, 6064. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Oord, A.; Li, Y.; Babuschkin, I.; Simonyan, K.; Vinyals, O.; Kavukcuoglu, K.; Driessche, G.; Lockhart, E.; Cobo, L.; Stimberg, F. Parallel wavenet: Fast high-fidelity speech synthesis. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 3918–3926. [Google Scholar]
- Lal, A.; Chiang, Z.D.; Yakovenko, N.; Duarte, F.M.; Israeli, J.; Buenrostro, J.D. Deep learning-based enhancement of epigenomics data with AtacWorks. Nat. Commun. 2021, 12, 1507. [Google Scholar] [CrossRef]
- Rai, V.; Quang, D.X.; Erdos, M.R.; Cusanovich, D.A.; Daza, R.M.; Narisu, N.; Zou, L.S.; Didion, J.P.; Guan, Y.; Shendure, J.; et al. Single-cell ATAC-Seq in human pancreatic islets and deep learning upscaling of rare cells reveals cell-specific type 2 diabetes regulatory signatures. Mol. Metab. 2020, 32, 109–121. [Google Scholar] [CrossRef]
- Gemmeke, J.F.; Ellis, D.P.W.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio Set: An ontology and human-labeled dataset for audio events. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2017, New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Kong, Q.; Cao, Y.; Iqbal, T.; Wang, Y.; Wang, W.; Plumbley, M.D. Panns: Large-scale pretrained audio neural networks for audio pattern recognition. IEEEACM Trans. Audio Speech Lang. Process. 2020, 28, 2880–2894. [Google Scholar] [CrossRef]
- Kriman, S.; Beliaev, S.; Ginsburg, B.; Huang, J.; Kuchaiev, O.; Lavrukhin, V.; Leary, R.; Li, J.; Zhang, Y. Quartznet: Deep Automatic Speech Recognition with 1D Time-Channel Separable Convolutions. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Barcelona, Spain, 2020; pp. 6124–6128. [Google Scholar]
- Li, J.; Lavrukhin, V.; Ginsburg, B.; Leary, R.; Kuchaiev, O.; Cohen, J.M.; Nguyen, H.; Gadde, R.T. Jasper: An end-to-end convolutional neural acoustic model. arXiv 2019, arXiv:190403288. [Google Scholar]
- Buenrostro, J.; Wu, B.; Chang, H.; Greenleaf, W. ATAC-seq: A Method for Assaying Chromatin Accessibility Genome-Wide. Curr. Protoc. Mol. Biol. Ed. Frederick M Ausubel Al 2015, 109, 21–29. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Chaudhary, N.; Misra, S.; Kalamkar, D.; Heinecke, A.; Georganas, E.; Ziv, B.; Adelman, M.; Kaul, B. Efficient and Generic 1D Dilated Convolution Layer for Deep Learning. arXiv 2021, arXiv:210408002. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:151107122. [Google Scholar]
- van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:160903499. [Google Scholar]
- Van Den Oord, A.; Kalchbrenner, N.; Kavukcuoglu, K. Pixel recurrent neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 19–24 June 2016; pp. 1747–1756. [Google Scholar]
- Meiri, N.; Berman, P.; Colnago, L.A.; Moraes, T.B.; Linder, C.; Wiesman, Z. Liquid-phase characterization of molecular interactions in polyunsaturated and n-fatty acid methyl esters by 1H low-field nuclear magnetic resonance. Biotechnol. Biofuels 2015, 8, 96. [Google Scholar] [CrossRef]
- Symoniuk, E.; Ratusz, K.; Krygier, K. Comparison of the oxidative stability of linseed (Linum usitatissimum L.) oil by pressure differential scanning calorimetry and Rancimat measurements. J. Food Sci. Technol. 2016, 53, 3986–3995. [Google Scholar] [CrossRef]
- Frankel, E.N. Methods to determine extent of oxidation. In Lipid Oxidation; Elsevier: Amsterdam, The Netherlands, 2012; pp. 99–127. ISBN 978-0-9531949-8-8. [Google Scholar]
- Bock, S.; Weiß, M. A Proof of Local Convergence for the Adam Optimizer. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]



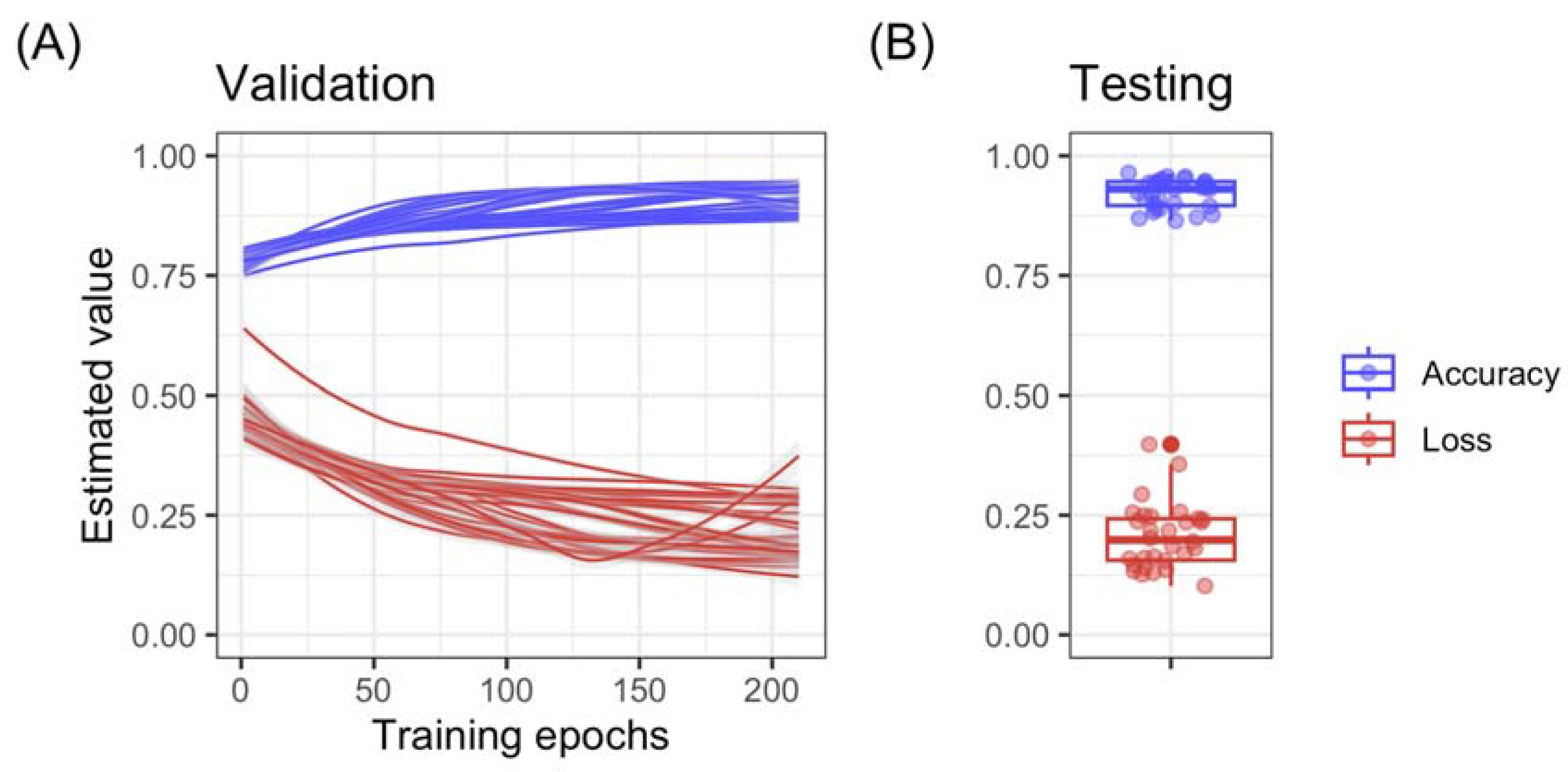

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | D 1 Range (×10−9 m2/s) | PV 2 Range (mmol/kg) | Total Samples |
|---|---|---|---|
| ‘Good’ | >0.03 | <20 | 126 |
| ’Fair’ | 0.02–0.03 | 20–50 | 77 |
| ‘Bad’ | ≤0.02 | ≥50 | 187 |
| Oxidation Class | ||||
|---|---|---|---|---|
| Bad | Fair | Good | Overall | |
| Number of repetitions (n) | 30 | 30 | 30 | 30 |
| Support (n of samples) | 126 | 77 | 187 | 390 |
| Total number of tests | 3780 | 2310 | 5610 | 11,700 |
| Precision (%) (median, [IQR 1]) | 97% [87%, 0.98%] | 88% [84%, 90%] | 94% [93%, 96%] | 93% [87%, 96%] |
| Recall (%) (median, [IQR 1]) | 98% [96%, 100%] | 77% [59%, 83%] | 97% [96%, 98%] | 96% [83%, 98%] |
| F1-score (median, [IQR 1]) | 0.96 [0.91, 0.98] | 0.81 [0.69, 0.86] | 0.96 [0.95, 0.97] | 0.95 [0.86, 0.96] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Osheter, T.; Campisi Pinto, S.; Randieri, C.; Perrotta, A.; Linder, C.; Weisman, Z. Semi-Autonomic AI LF-NMR Sensor for Industrial Prediction of Edible Oil Oxidation Status. Sensors 2023, 23, 2125. https://doi.org/10.3390/s23042125
Osheter T, Campisi Pinto S, Randieri C, Perrotta A, Linder C, Weisman Z. Semi-Autonomic AI LF-NMR Sensor for Industrial Prediction of Edible Oil Oxidation Status. Sensors. 2023; 23(4):2125. https://doi.org/10.3390/s23042125
Chicago/Turabian StyleOsheter, Tatiana, Salvatore Campisi Pinto, Cristian Randieri, Andrea Perrotta, Charles Linder, and Zeev Weisman. 2023. "Semi-Autonomic AI LF-NMR Sensor for Industrial Prediction of Edible Oil Oxidation Status" Sensors 23, no. 4: 2125. https://doi.org/10.3390/s23042125
APA StyleOsheter, T., Campisi Pinto, S., Randieri, C., Perrotta, A., Linder, C., & Weisman, Z. (2023). Semi-Autonomic AI LF-NMR Sensor for Industrial Prediction of Edible Oil Oxidation Status. Sensors, 23(4), 2125. https://doi.org/10.3390/s23042125