Abstract
With the widespread application of unmanned aerial vehicle (UAV) formation technology, it is very important to maintain good communication quality with the limited power and spectrum resources that are available. To maximize the transmission rate and increase the successful data transfer probability simultaneously, the convolutional block attention module (CBAM) and value decomposition network (VDN) algorithm were introduced on the basis of a deep Q-network (DQN) for a UAV formation communication system. To make full use of the frequency, this manuscript considers both the UAV-to-base station (U2B) and the UAV-to-UAV (U2U) links, and the U2B links can be reused by the U2U communication links. In the DQN, the U2U links, which are treated as agents, can interact with the system and they intelligently learn how to choose the best power and spectrum. The CBAM affects the training results along both the channel and spatial aspects. Moreover, the VDN algorithm was introduced to solve the problem of partial observation in one UAV using distributed execution by decomposing the team q-function into agent-wise q-functions through the VDN. The experimental results showed that the improvement in data transfer rate and the successful data transfer probability was obvious.
1. Introduction
As a new technology, unmanned aerial vehicle (UAV) technology has been widely used in civil, public and military fields [1]. The effectiveness and potential of UAVs for coastal-zone applications were elaborated in a review [2]. The execution latency has been decreased and the computation performance has been improved for the mobile edge computing networks by integrating UAVs into the research [3]. By poring over a large amount of literature, Ref. [4] provided a novel insight into cyber physical systems in UAV networks. To maximize the quality of the experience of real-time video streaming, the authors of [5] designed the power control, the movement and the video resolution of the UAV to base station and UAV user links. Using the Stackelberg dynamic game, Ref. [6] came up with a resource pricing and trading scheme to realize edge computing resource allocation between UAVs and edge computing stations. Despite only one single UAV being able to finish some difficult tasks, the possibility of mission failure was relatively high, as tasks were getting more complex and diversified. Multi-UAV applications have attracted widespread attention and achieved remarkable accomplishments in some situations where one UAV may not suffice. To make full use of the advantages of the UAV, multi-UAV formations have been designed and widely used in many fields. The UAV formation technology has become an important research topic in the world because it is highly three-dimensional, informationalized and electronized. The UAV formation technology is mainly applied in data fusion, physical verification platform technologies, formation control, task assignment, flight path planning, communication networking and virtual and information perception. For a multi-UAV formation, multisource information fusion and information perception are the most important applications. The routing problem of multiple UAVs to realize remote sensing and area coverage in the shortest time was studied in [7]. To respond quickly to a disaster scenario, the authors of [8] evaluated open source and commercial software solutions for 3D reconstructions of disaster scenarios. The authors of Ref. [9] constructed a mobile sensing system based on multi-UAVs, which captured the variance of the air quality index at the meter level and plotted its corresponding fine-grained distribution. The authors of Ref. [10] solved the problem of cooperative control based on multi-UAV systems. Based on a multi-UAV wireless cache network, a new joint communication scheduling and trajectory method was proposed in [11]. To enhance the throughput of the network and minimize the data transmission time for a multi-hop UAV relay network, Ref. [12] addressed the packet routing problem. The authors of Ref. [13] solved the topology control problem for a UAV swarm network. Compared to other wireless networks, the topology of multi-UAV formation networks will always change as the positions of nodes, the amount of nodes and links are not fixed. The changes in position and speed can lead to intermittent connections between each one [1]. Both [14] and [15] agreed that the improvement of communication rate and the assurance of communication quality were necessary on account of the rapid different complexities and changing task surroundings. Reasonable resource allocation is an effective method to achieve these goals.
To address the problem of resource allocation, the random method is one of the traditional methods and has recently been put into use in joint power and spectrum resource distribution by a number of researchers. In general, the random method serves as a baseline for comparison. For instance, powers are evenly assigned to every transmitter and the subchannels are distributed randomly to the devices in the literature [16]. In addition to the random method, in the work of [17], Wentao Zhao et al. randomly assigned channels to every device to device pair, and then chose one power from the candidate power list that could maximize the data transfer rate of the system. The random method is superior in working speed but inferior in improving the communication capacity and transmission quality of the system. A resource optimization method combining spectrum and speed is proposed in reference [18]. In order to meet the requirements of high average spectral efficiency and to maximize the minimum average energy, the authors of [19] worked on optimizing the transmitted power and trajectory of UAVs and the power splitting ratio of the ground terminals.
Deep learning (DL) has been widely used in areas such as natural language processing and computer vision [20], as well as machine translation and automatic speech recognition [21]. The progress of reinforcement learning (RL) and deep convolutional neural networks (CNN) enabled machine learning (ML) to acquire unprecedented results in visual areas, for instance playing Atari games [22], image classification [23] and face recognition [24]. For the convolutional layer of one CNN, a single neuron is related to only a few adjacent neurons. One convolutional layer usually represents a few feature maps, and every feature map consists of certain rectangular neurons. The authors of [25] proved that some suitable learning mechanisms can help capture correlations and improve the performance of a CNN without additional oversight. The combination of deep learning and reinforcement learning is also known as deep reinforcement learning (DRL). Recently, DRL has also been put into use in the resource assignment problem of wireless networks. Compared to the traditional methods, DRL has its own superiority [26]. Dealing with large systems, a deep Q-network (DQN) is used to find a channel access strategy in the study [27]. A good strategy can be found directly from historical observations without knowing prior system information. Contrary to the above work, and to ensure the quality of communication, this manuscript considers the joint power and spectrum optimization of a UAV formation flight to maximize the transmission rate and increase the successful data transfer probability based on a DQN. The main contributions of this paper are as follows:
- Resource optimization based on the three-dimensional distribution of multiple UAVs, which is different from a random [28] or flat distribution [29] of UAVs, as used in the previous study. The multi-UAVs were located successively at edges or the eight vertices of a cube and kept a cube formation during their flight;
- In order to achieve joint power and channel resource optimization for the UAV formation, a DQN was used. Moreover, a CNN was used after the state data were preprocessed in the training process;
- Based on a DQN, the convolutional block attention module (CBAM) and value decomposition network (VDN) modules were introduced to further realize system performance improvement. The CBAM worked at the CNN layer to capture correlations of the feature map along both the channel and spatial aspects, and the VDN worked as the reward mechanism. The experimental results proved the effectiveness of the introduction of the CBAM and VDN.
2. System Model
In this chapter, the scenario of a multi-UAV formation network and the data transmission model are introduced, respectively. In the channel model, both the small-scale and large-scale fading is included and the optimization objective function is given last.
2.1. Scenario Setting
It was assumed that the multi-UAVs kept the flying formation during the execution of a task. The whole UAV network consisted of multi-UAVs and one base station (BS). The multi-UAVs were located at the eight vertices or edges of one cube. There were two data transmission modes, and the spectrum availability was limited. For the UAV network, M orthogonal uplinks were pre-assigned to M UAVs to perform the UAV to base station (U2B) data transfer, and N pairs of UAV to UAV (U2U) links performed the U2U data transfer. The U2B links could be reused by the U2U links to make full use of the frequency. In one time slot, as agreed, one U2B link only used one uplink and multiple U2U links could reuse the same uplink; however, one U2U link could only occupy one uplink. The value was used as the binary indicator matrix and if the nth U2U link reused the mth uplink resource, otherwise . , and were used to represent the locations of the kth UAV, the jth UAV and the BS, respectively. Then, the distance between the kth and the jth UAV is calculated as follows:
Similarly, the distance between the kth UAV and the BS is calculated as
2.2. Modeling the Line of Sight Probability
In this part, the channel model used in the multi-UAV formation network is introduced. The channel model consists of the channel model of the U2U and U2B data transfer. The U2U and U2B links are different due to the different line-of-sight (LoS) characteristics and the elevation angle in the actual environment.
For the U2U channel model, the free space channel model of the U2U link was used in the multi-UAV formation network. The values and denote the transmitter and receiver power of the nth U2U link reusing the mth uplink. The relationship between them can be expressed as
where h is the constant channel gains factor related to the amplifier and antenna, is the distance between the transmitter and receiver UAVs of the nth U2U link and is the channel path loss constant. The receiver interference of the nth U2U link consists of the data that comes from the nth U2B link and other U2U links that reuse the same mth uplink. is labeled as the transmitter power of the mth U2B link, and, then, the receiver interference of the nth U2U link is expressed as follows.
where is labeled as the transmitter power of the U2U link, indicates whether the U2U link reuses the mth uplink and is the variance of the additive white Gaussian noise (AWGN) with a mean equal to zero. The data transfer rate of the U2U link can be calculated as follows.
For the U2B channel model, the model of air-to-ground (ATG) propagation adopts the U2B data transmission proposed in the existing literature [30,31]. To predicte the ATG path loss, [32] designed a statistical propagation model. In time slot t, the path loss of LoS and non-line-of-sight (NLoS) of the kth U2U link is indicated as
where is the distance between the BS and transmitter UAV of the U2U link, the values and are attenuation factors that are caused by the LoS and NLoS transmission, respectively. The value is the free space path loss that is expressed as follows.
where f is the carrier frequency. Recommended by the International Telecommunication Union (ITU), as mentioned in the reference [33], the probability of the LoS link data transfer is expressed as
where and are constants that are related to the environment and is the elevation angle of the kth UAV. The sight probability model is adapted to the low-altitude aerial platforms of the UAV network. This probability is closely related to three statistical parameters in the environment: the average number of buildings per unit area; the proportion of construction land area in the total land area; the building height distribution based on the Rayleigh probability density function. The average path loss in decibels (dB) is expressed as follows.
The average power received by the BS from the mth U2B link is denoted as
where is the transmitter power of the mth U2B link. Similarly, is labeled as the transmitter power of the nth U2U link that reuses the mth uplink. The interference received by the BS from the U2U links is calculated as
Therefore, the signal-to-interference-plus-noise-ratio (SINR) of the mth U2B link is calculated as
where is the variance of the AWGN with a mean equal to zero. The data transfer rate of the mth U2B link is expressed as
2.3. The Problem Optimization Objective
This section details the optimization objective of the multi-UAV formation network. The goal of this manuscript was to improve the successful data transfer probability of the U2U links and realize the maximization of the system data transfer rate. The optimization objective is modeled as
where stands for the maximum transmitter power used by the UAVs, and stand for the transmitter power of the nth U2U and mth U2B links, respectively. In view of the fact that the distances from the UAVs to the BS are longer than those between each UAV, the maximum power is adopted by the U2B link transmitters to guarantee the quality of the data transfer. For the sake of maximizing the data transfer rate and generating less interference to the system, each U2U link ought to choose the appropriate power and spectrum. Three power levels were set to be used by the U2U links. Then, and are the arguments to be optimized. The optimization function consists of the rate of U2U links, U2B links and the transmission time limit. The optimization function at each time slot t that was used as the reward function in the proposed DQN mechanism is expressed as follows.
where a,b and are the percentage of each part. If the data in the U2U links are transmitted successfully within the transmission time Ts, it is classed as a successful data transfer. The value is the remaining time left to finish the data transfer in the U2U links and it is initialized to T. The third section is initialized to zero, which means the transmitters have a lot of time to transmit data to obtain a bigger reward function . If the remaining time gets shorter, the reward function can reduce due to the increase in the failure data transfer probability.
3. The Proposed Method
This section details the joint spectrum and power allocation method based on a DQN in the multi-UAV formation network. The process of the DQN method is introduced first, and, then the algorithm of the CBAM and the VDN module is added, based on the DQN.
3.1. Introduction of the DQN
The multi-UAV movement problem could be modeled as the constrained Markov decision process (CMDP) problem, giving a moving area that is classical in order to solve RL tasks with constraints. The maximum cumulative long-term discounted reward can be obtained after the agents are well trained to execute the best action strategy. In the multi-UAV formation network, the whole network corresponds to the environment in the RL method, and each U2U link is regarded as an agent. An action is labelled with and it includes two parameters of the action space A. Each U2U transmitter makes an action choice according to the current state , and the environment feedbacks a reward and the next state . Therefore, state, action, reward and the next state are the main transitions in RL. The value A is a set of M uplinks and three power levels. The state contains the channel information in the U2B links and U2U links , the interference from the U2U links , the uplink reuse indicator of the U2U links B, the time left to transmit data and the data left to transmit . The set of all states is called the state space S.
For a given state , in each time slot the U2U link transmitter needs to select an action according to the strategy . In regular Q-learning, the decision-making strategy is carried out by a q-function. Once a state–action pair is determined, the q-value reward is calculated after selecting one action. To find the optimization strategy to maximize the cumulative reward, once the q-value is calculated, the action selection strategy can be carried out according to the following expression
So, the optimization strategy can be denoted as
For a specific action and state, the maximum Q-value, i.e, the expected accumulative discount reward, is expressed as
where is the discount coefficient that is needed to strike a balance between current and future decisions. Equation (17) is the total cost for the optimization. According to Equation (15), each UAV can choose the most appropriate power and spectrum based on its remaining data transmission time and the system interference.
In the multi-UAV formation problem, the state and action space will be very large, which makes it is difficult to use regular Q-learning as some Q-values are seldom updated. As a combination of RL and a deep network, the DQN has been widely used. A DQN can take a state as the input and output all the action values . It can then select the action with the maximum value as the next action. The values of are the parameters of the neural network (NN) and are called the Q-network. As is well-known, in the study of [22], Mnih et al. introduced target networks and experience replay to achieve a better performance for the DQN algorithm. The output of target network in the DQN is written as
where are the coefficients of the target network and are updated according to the Q-network after certain steps. The coefficients of the Q-network are updated according to the gradient descent policy to loss function. The loss function is shown as below.
where D is a memory buffer that is used to store all the transitions . Referring to the experience replay method, in order to reduce the data correlation, fixed batch transitions are randomly selected from D in every training period. As the input of the Q-network, parameters of the Q-network are updated while training the data.
3.2. The DQN with the CBAM
Research [22] has proven that the introduction of the experience replay and target network has greatly improved the performance of the DQN. In this system, the state data are converted into a square matrix to train the CNN. On this basis of the DQN, the CBAM is added, which consists of two important submodules: channel and spatial. The channel submodule adopts both average-pooling and max-pooling outputs, processed by a shared network. The outputs are then processed by the spatial submodule. In the spatial submodule, passing through the pooling layer, the output data of the channel submodule are put into a convolution layer. The following details the operation of the submodules.
Let and represent the average-pool and max-pool operations, respectively. Two different descriptors are generated after the pooling operation, acting on the UAV states. The channel attention data can be obtained after the pooling results are both processed by the following shared network. The shared network consists of a multi-layer perceptron (MLP) that has one hidden layer, and the size of the hidden activation is , where r is the reduction ratio. The output feature data are summed element-wise after the shared network. So, the channel attention operation can be expressed as
where represents the sigmoid function, and are the weights of the shared network and they are shared for both inputs’ pooling results, and .
The spatial attention graph is generated by using the spatial relationships of the features that focus on ‘where’ the useful information is. The spatial attention is supplement to the channel attention. For the spatial attention, the average-pooling and max-pooling operations are applied first to concatenate the channel attention outputs to a resultful characteristic descriptor. Then, the descriptor is processed by a convolution layer to obtain the spatial attention data . So, the spatial attention operation can be expressed as
where represents the sigmoid function and f denotes a convolution operation.
3.3. The DQN with the VDN
Section 3.2 details the optimization of the network from the channel and spatial aspects, and this section looks at improving the system performance in terms of the reward mechanism. Due to partial observability, the spurious rewards problem exists in both the fully centralized and decentralized mechanisms. To avoid the spurious reward data produced by the naive independent agents, a VDN is introduced while training the individual agents. The operation is to obtain agent-wise value functions by decomposing the team value function. Based on team rewards, the system can acquire optimal linear decomposition learning. The total Q-gradient is propagated backward by the deep neural network (DNN) representing the function of each agent-wise value.
For the multi-UAV formation network, distributed across n UAVs, the observations and actions are labeled as n-dimensional tuples of observations in O and actions in A.
The additive decomposition can be expressed by the following equation.
where the represent every agent’s own observations and is learned by back propagating gradients according to the joint summation reward, rather than the specific reward of agent i, is the history tuple of one agent. For the improved summation reward, are action–value functions that consist of all particular rewards of the UAVs, without any other constraints. The overall architecture is shown in Figure 1.
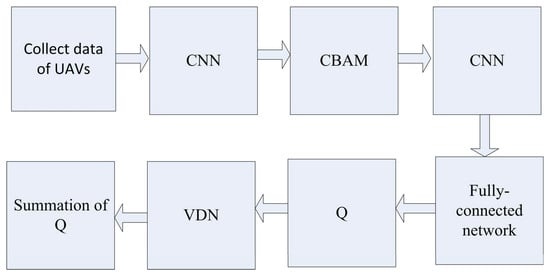
Figure 1.
The overall improved DQN architecture with the CBAM and VDN.
3.4. Training and Validation
Algorithm 1 is the flow of the entire training architecture. The buffer capacity D is , the training step M is 40000 and every 2000 steps represents one episode. The value is 0.99 and K is 50. The value of the Q-function is 1. The programming language is python and it was written and executed on PyCharm Community Edition 2019.2.2 x64 using Xeon Silver 4110 CPU @ 2.10 GHz @ 2.10 GHz. The network layer is detailed in the simulation section. The communication rate and time delay were designed in the Q-function, in order to maximize the Q-function and obtain a better training effect, and the CBAM and VDN were added, respectively. The algorithm is based on a pure DQN without 1 and 2 modules. Any module can be embedded into the network quickly. The CBAM affects the training results along both channel and spatial aspects. With the VDN, the action selection for the UAVs is based on the global observations of all UAVs. While in the validation architecture, every transmitter of the U2U link adopts the action that can maximize the evaluation Q-value, based on the well-trained target network at every time step. Accordingly, the results of one episode were recorded and are shown in the simulation section.
| Algorithm 1 The improved DQN for multi-UAV formation resource optimization with the CBAM and VDN (training stage) |
|
4. Simulation
The selection of the simulation parameters are based on existing works [18] and 3GPP specifications [34]. Multiple UAVs were arranged as a cube formation in a three-dimensional 2 km × 2 km × 2 km area. The main parameters are shown in Table 1. In the training stage, the size of the input and output CNN layer convolution kernel was 3 with a padding of 1. The global average-pool and max-pool operator in the CBAM module was 6 ∗ 6 and the channel ratio r was 16. To verify the generalization of the proposed method, scenarios with different numbers of UAVs were tested. To prove the validity of the proposed method, first the experiment with only a traditional DQN was executed, then, the CBAM and VDN were embedded separately and lastly both the CBAM and VDN were embedded simultaneously. The experimental results were recorded, analyzed and compared to the random and multichannel access methods proposed in [17] and [27], respectively. For the random method, the uplinks and power were randomly allocated to the UAVs. For the multichannel access method, the power used by every UAV was not changed, and the accumulated discounted reward was maximized to realize the optimization of the channel allocation.

Table 1.
Simulation parameters.
Figure 2 shows how the average U2B link data transfer rate varied with the number of UAVs. More interference was generated as the number of UAVs increased, which caused the decrease in the average data transfer rate. The average data transfer rate, obtained using the random and multichannel access methods, was always lower than that obtained by other methods, especially the DQN with CBAM or with both the VDN and CBAM. From this it can be inferred that the improved DQN with CBAM method, or the method with both the VDN and CBAM, will maintain a high communication rate as more UAVs are added to the multi-UAV formation.
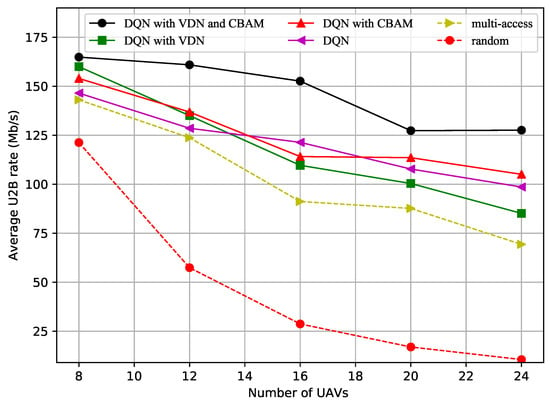
Figure 2.
Average U2B rate vs. number of UAVs.
Figure 3 shows how the successful data transfer probability of the U2U links varied with the number of UAVs. More interference was generated as the number of UAVs increased, which caused the decrease in the successful data transfer probability. The successful data transfer probability obtained using the random method was always the lowest. When there were only 8 UAVs, the successful data transfer probability using the multichannel access method was not low, but it went down quite fast as the number of UAVs increases. From this figure, it can be inferred that the improved DQN with VDN method, or the method with both the VDN and CBAM, will maintain a high successful data transfer probability, as more UAVs are added to the multi-UAV formation.
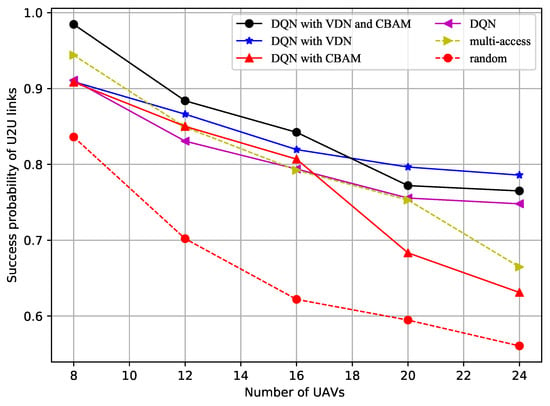
Figure 3.
Success probability of the U2B links vs. number of UAVs.
In order to figure out why the proposed improved DQN mechanisms showed superior performances, the power selection situations of the different methods with a different number of UAVs over time were recorded. Shown in Figure 4, Figure 5 and Figure 6, the probability of the power selection with 8, 12 and 16 UAVs for three situations was drawn, respectively. By observing these three figures, it can be inferred that because the UAVs can wisely select different powers, less interference is generated in the system. In addition, when the number of UAVs in the formation varies, the UAVs automatically adjust the number of lowest or highest power users.
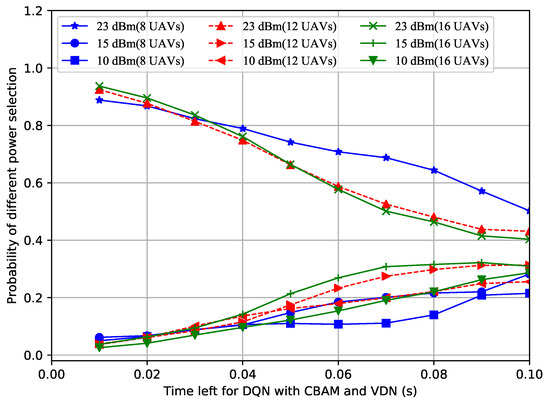
Figure 4.
Probability of power selection vs. remaining time for the DQN with the CBAM and VDN.
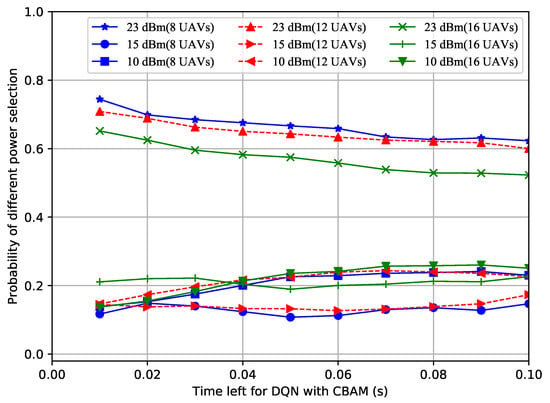
Figure 5.
Probability of power selection vs. remaining time for the DQN with CBAM.
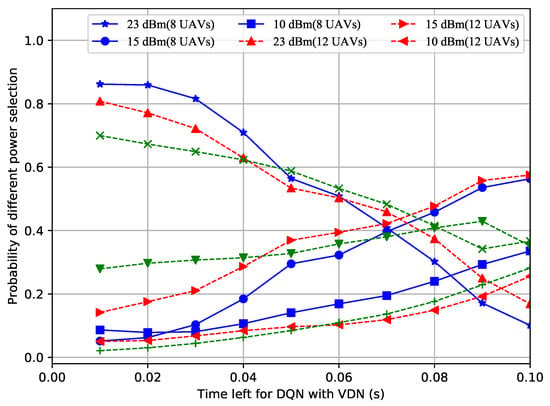
Figure 6.
Probability of power selection vs. remaining time for the DQN with VDN.
Finally, Figure 7 and Figure 8 show how the reward and loss varied in the overtraining step, respectively, to show the convergence of the proposed DQN and the improved DQN. The axis label “training step()” represents every number times 100 or 1000, with a maximum of 40,000 training steps. With 40,000 training steps, the reward and loss gradually converged, despite some fluctuations. From Figure 7, the reward was bigger in the improved DQN than that in the DQN method. In Figure 8, the lowest points of loss are marked. It is obvious that the DQN with the VDN or CBAM always reached the lowest point earlier than with the DQN alone, and the method with both the VDN and CBAM was the earliest one. The two figures further illustrate the effectiveness and convergence of the improved method.
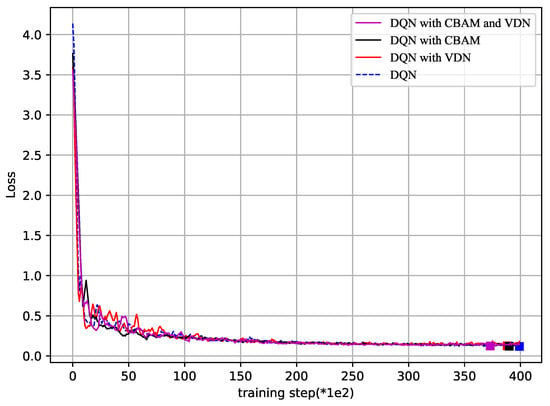
Figure 7.
Loss vs. training step (*1e2).
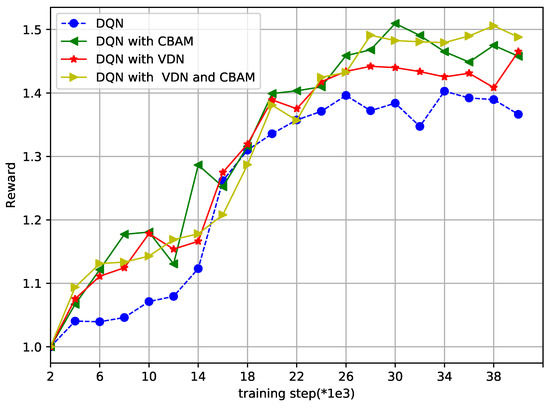
Figure 8.
Reward vs. training step (*1e3).
5. Conclusions
- This manuscript focuses on the realization of joint power and spectrum resource optimization using a DQN mechanism for a multi-UAV formation communication network, in which the UAVs are located in 3D forms when the multi-UAVs are on a mission. The objective was to maximize the transmission rate and increase the successful data transfer probability simultaneously.
- The main idea was that the U2U links were treated as agents and the CBAM and VDN were further introduced based on the DQN. Compared to the random and multichannel access methods, the DQN method slightly improved system performance, and the introduction of the CBAM and VDN further improved the data transfer rate of the U2B links and the successful data transfer probability of the U2B links.
- The reason for the performance improvement is that the UAVs could intelligently choose the appropriate power and frequency based on the remaining time and the number of UAVs. The authors drew the conclusion that the superiority of the proposed method became more and more obvious as the number of UAVs in the formation increased.
- This model can be used in agricultural or military applications, such as disaster relief, environmental detection, remote situational awareness, deception and jamming. Even if a few UAVs break down, the overall capability of the UAVs will not be affected. However, the speed is low and the mobility and self-defense ability is poor. If the number of UAVs is small, they are easy to detect and intercept, and the different flight altitudes will affect the communication quality between the UAVs and the ground base station. In this work, the formation of the UAVs remained the same during the execution of tasks, and future work could focus on the situation with changing formations.
Author Contributions
Conceptualization, J.L.; methodology, J.L.; software, J.L.; validation, J.L. and S.L.; formal analysis, C.X. and S.L.; investigation, C.X. and S.L.; resources, J.L.; data curation, J.L., S.L. and C.X.; writing—original draft preparation, J.L.; writing—review and editing, C.X. and S.L.; visualization, J.L.; supervision, S.L.; project administration, J.L., S.L. and C.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| DQN | deep Q-network; |
| UAVs | unmanned aerial vehicles; |
| U2B | UAV-to-base station; |
| U2U | UAV-to-UAV; |
| CBAM | convolutional block attention module; |
| VDN | value decomposition network; |
| DL | deep learning; |
| RL | reinforcement learning; |
| ML | machine learning; |
| DRL | deep reinforcement learning; |
| CNN | convolutional neural network; |
| BS | base station; |
| LoS | line-of-sight; |
| AWGN | additive white Gaussian noise; |
| NLoS | non-line-of-sight; |
| ITU | International Telecommunication Union; |
| SINR | signal-to-interference-plus-noise ratio; |
| CMDP | constrained Markov decision process; |
| NN | neural network; |
| ATG | air-to-ground. |
References
- Gupta, L.; Jain, R.; Vaszkun, G. Survey of Important Issues in UAV Communication Networks. IEEE Commun. Surv. Tutor. 2016, 18, 1123–1152. [Google Scholar] [CrossRef]
- Richard, A.; Abiodunmusa, A.; Bernard, E.; Jerry, A. Unmanned Aerial Vehicle (UAV) applications in coastal zone management. Environ. Monit. Assess. 2021, 193, 1–12. [Google Scholar]
- Fuhui, Z.; Rose, Q.H.; Zan, L.; Wang, Y. Mobile Edge Computing in Unmanned Aerial Vehicle Networks. IEEE Wirel. Commun. 2020, 27, 140–146. [Google Scholar]
- Wang, H.; Zhao, H.; Zhang, J. Survey on Unmanned Aerial Vehicle Networks: A Cyber Physical System Perspective. IEEE Commun. Surv. Tutor. 2020, 22, 1027–1070. [Google Scholar]
- binti Burhanuddin, L.A.; Liu, X.; Deng, Y.; Challita, U.; Zahemszky, A. QoE Optimization for Live Video Streaming in UAV-to-UAV Communications via Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2022, 71, 5358–5370. [Google Scholar] [CrossRef]
- Xu, H.; Huang, W.; Zhou, Y.; Yang, D.; Li, M.; Han, Z. Edge Computing Resource Allocation for Unmanned Aerial Vehicle Assisted Mobile Network with Blockchain Applications. IEEE Trans. Wirel. Commun. 2021, 20, 3107–3121. [Google Scholar]
- Avellar, G.S.; Pereira, G.A.; Pimenta, L.C.; Iscold, P. Multi-UAV routing for area coverage and remote sensing with minimum time. Sensors 2015, 15, 27783–27803. [Google Scholar] [CrossRef]
- Verykokou, S.; Ioannidis, C.; Athanasiou, G.; Doulamis, N.; Amditis, A. 3D reconstruction of disaster scenes for urban search and rescue. Multimed. Tools Appl. 2018, 77, 9691–9717. [Google Scholar] [CrossRef]
- Yang, Y.; Zheng, Z.; Bian, K.; Song, L.; Han, Z. Real-time profiling of fine-grained air quality index distribution using UAV sensing. IEEE Internet Things J. 2018, 5, 186–198. [Google Scholar] [CrossRef]
- Belkacem, K.; Munawar, K.; Muhammad, S.S. Distributed cooperative control of autonomous multi-agent UAV systems using smooth control. J. Syst. Eng. Electron. 2020, 31, 1297–1307. [Google Scholar]
- Chai, S.; Lau, V.K.N. Multi-UAV Trajectory and Power Optimization for Cached UAV Wireless Networks With Energy and Content Recharging-Demand Driven Deep Learning Approach. IEEE J. Sel. Areas Commun. 2021, 39, 3208–3224. [Google Scholar]
- Ding, R.; Chen, J.; Wu, W.; Liu, J.; Gao, F.; Shen, X. Packet Routing in Dynamic Multi-Hop UAV Relay Network: A Multi-Agent Learning Approach. IEEE Trans. Veh. Technol. 2022, 71, 10059–10072. [Google Scholar]
- Taehoon, Y.; Sangmin, L.; Kyeonghyun, Y.; Hwangnam, K. Reinforcement Learning Based Topology Control for UAV Networks. Sensors 2023, 23, 921. [Google Scholar]
- Qian, L.P.; Zhang, H.; Wang, Q.; Wu, Y.; Lin, B. Joint multi-domain resource allocation and trajectory optimization in UAV-assisted maritime IoT networks. IEEE Internet Things J. 2023, 10, 539–552. [Google Scholar] [CrossRef]
- Dai, X.; Duo, B.; Yuan, X.; Tang, W. Energy-efficient UAV communications: A generalized propulsion energy consumption model. IEEE Wirel. Commun. Lett. 2022, 11, 2150–2154. [Google Scholar] [CrossRef]
- Kai, C.; Li, H.; Xu, L.; Li, Y.; Jiang, T. Joint subcarrier assignment with power allocation for sum rate maximization of D2D communications in wireless cellular networks. IEEE Trans. Veh. Technol. 2019, 68, 4748–4759. [Google Scholar] [CrossRef]
- Zhao, W.T.; Wang, S.W. Resource allocation for device-to-device communication underlaying cellular networks: An alternating optimization method. IEEE Commun. Lett. 2015, 19, 1398–1401. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, H.; Di, B.; Song, L. Cellular UAV-to-X Communications: Design and Optimization for Multi-UAV Networks. IEEE Trans. Wirel. Commun. 2019, 18, 1346–1359. [Google Scholar]
- Gitae, P.; Kisong, L. Optimization of the Trajectory, Transmit Power, and Power Splitting Ratio for Maximizing the Available Energy of a UAV-Aided SWIPT System. Sensors 2022, 22, 9081. [Google Scholar]
- Gomez-Alanis, A.; Peinado, A.M.; Gonzalez, J.A.; Gomez, A.M. A gated recurrent convolutional neural network for robust spoofing detection. IEEE-ACM Trans. Audio Speech Lang. Process. 2019, 27, 1985–1999. [Google Scholar] [CrossRef]
- Shao, J.T.; Zheng, J.J.; Zhang, B. Deep convolutional neural networks for thyroid tumor grading using Ultrasound B-mode Images. J. Acoust. Soc. Am. 2020, 148, 1529–1535. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Xu, G.; Li, G.; Guo, S.; Zhang, T.; Li, H. Secure decentralized image classification with multiparty homomorphic encryption. IEEE Trans. Circuits Syst. Video Technol. 2023. [Google Scholar] [CrossRef]
- Liu, W.; Kou, K.; Miao, J.; Cai, Z. Quaternion scalar and vector norm decomposition: Quaternion PCA for color face recognition. IEEE Trans. Image Process. 2023, 32, 446–457. [Google Scholar] [CrossRef]
- Jie, H.; Li, S.; Samuel, A.; Gang, S.; Wu, E. Squeeze-and-Excitation Networks. Available online: https://arxiv.org/abs/1709.01507 (accessed on 5 April 2018).
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D.I. Applications of Deep Reinforcement Learning in Communications and Networking: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef]
- Wang, S.; Liu, H.; Gomes, P.H.; Krishnamachari, B. Deep reinforcement learning for dynamic multichannel access. In Proceedings of the International Conference on Computing, Networking and Communications, Silicon Valley, CA, USA, 26–29 January 2017. [Google Scholar]
- Jie, L.; Sai, L.; Abdul, H.S. Joint Channel and Power Assignment for UAV Swarm Communication based on Multi-agent DRL. IEICE Trans. Commun. 2022, E105-B, 1249–1257. [Google Scholar]
- Jie, L.; Xiaoyu, D.; Sai, L. DQN-based decentralized multi-agent JSAP resource allocation for UAV swarm communication. J. Syst. Eng. Electron. 2023, 34. [Google Scholar]
- Al-Hourani, A.; Kandeepan, S.; Lardner, S. Optimal LAP Altitude for Maximum Coverage. IEEE Wirel. Commun. Lett. 2014, 3, 569–572. [Google Scholar] [CrossRef]
- Athukoralage, D.; Guvenc, I.; Saad, W.; Bennis, M. Regret Based Learning for UAV Assisted LTE-U/WiFi Public Safety Networks. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016. [Google Scholar]
- Al-Hourani, A.; Kandeepan, S.; Jamalipour, A. Modeling air-to-ground path loss for low altitude platforms in urban environments. In Proceedings of the IEEE Global Communications Conference, Austin, TX, USA, 8–12 December 2014. [Google Scholar]
- Propagation Data and Prediction Methods Required for the Design of Terrestrial Broadband Radio Access Systems Operating in a Frequency Range from 3 to 60 GHz. Geneva, Switzerland, P.1410-5, P Series. Available online: https://www.itu.int/rec/R-REC-P.1410-5-201202-I/en (accessed on 23 February 2012).
- Enhanced LTE Support for Aerial Vehicles, Release 15. Release 15, Document 3GPP TS 36.777. Available online: https://www.3gpp.org/ftp/Specs/archive/36_series/36.777/ (accessed on 20 December 2017).








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).