Abstract
A robust wood material crack detection algorithm, sensitive to small targets, is indispensable for production and building protection. However, the precise identification and localization of cracks in wooden materials present challenges owing to significant scale variations among cracks and the irregular quality of existing data. In response, we propose a crack detection algorithm tailored to wooden materials, leveraging advancements in the YOLOv8 model, named ICDW-YOLO (improved crack detection for wooden material-YOLO). The ICDW-YOLO model introduces novel designs for the neck network and layer structure, along with an anchor algorithm, which features a dual-layer attention mechanism and dynamic gradient gain characteristics to optimize and enhance the original model. Initially, a new layer structure was crafted using GSConv and GS bottleneck, improving the model’s recognition accuracy by maximizing the preservation of hidden channel connections. Subsequently, enhancements to the network are achieved through the gather–distribute mechanism, aimed at augmenting the fusion capability of multi-scale features and introducing a higher-resolution input layer to enhance small target recognition. Empirical results obtained from a customized wooden material crack detection dataset demonstrate the efficacy of the proposed ICDW-YOLO algorithm in effectively detecting targets. Without significant augmentation in model complexity, the mAP50–95 metric attains 79.018%, marking a 1.869% improvement over YOLOv8. Further validation of our algorithm’s effectiveness is conducted through experiments on fire and smoke detection datasets, aerial remote sensing image datasets, and the coco128 dataset. The results showcase that ICDW-YOLO achieves a mAP50 of 69.226% and a mAP50–95 of 44.210%, indicating robust generalization and competitiveness vis-à-vis state-of-the-art detectors.
1. Introduction
Since ancient times, wooden materials have been extensively utilized due to their practicality, renewability, and eco-friendly properties, resulting in the construction of numerous historically and aesthetically significant ancient buildings. Statistics reveal that over 70% of ancient structures in China feature wooden frameworks [1]. Over time and with environmental changes, ancient buildings have undergone various forms of deterioration, with cracks emerging as the most prevalent issue. The causes of such cracks within wooden structures are multifaceted and deleterious, often exacerbated by financial constraints and limitations in repair techniques, thereby significantly impeding the sustainable development of wooden architectural components within ancient structures, ultimately leading to structural collapse in certain instances. Consequently, preservation efforts and research endeavors focusing on protective measures for wooden architectural heritage have garnered considerable attention.
Within wooden structure inspections, non-destructive testing methodologies play a pivotal role in defect identification within architectural constructions. Non-destructive testing methodologies offer enhanced efficiency and reduced destructiveness compared to conventional measurement techniques, encompassing methodologies such as laser scanning [2], ultrasonic testing [3], and visual inspections. Among these methodologies, instruments reliant on ultrasonic and electromagnetic waves exhibit limited detection ranges and fewer discernible categories. At the same time, vision-based non-contact methodologies boast superior detection speeds, real-time performance, and accuracy. Recently, vision-based non-destructive testing technologies have witnessed a burgeoning promotion, successfully facilitating crack detection on metallic surfaces in industrial settings, thereby markedly decreasing operational costs vis-à-vis alternative detection methodologies. Furthermore, the advent of deep learning (DL) has elicited favorable responses in crack detection research, with DL object detection technologies gradually permeating the domain of non-destructive testing within wooden structures [4,5,6,7,8]. Present research predominantly harnesses convolutional neural networks and YOLO series models to discern and categorize wooden architectural sites [9,10], wood, and wooden utensils [11,12] by extracting texture features and analysis of color attributes.
The identification and localization of cracks within wooden edifices pose significant challenges attributable to the multifarious causes and diverse array of damage types, notably the disordered distribution of cracks. The principal obstacles encountered in crack detection via DL include reconciling model complexity with accuracy. Key issues in the design of detection models encompass excessively intricate architectures, suboptimal detection rates for minute cracks, and stringent criteria about the quality of input data sources [13,14,15].
This study explores an optimized detection model, to augment the efficacy of DL-based object detection technology in the non-destructive assessment of wooden structures for crack detection. The YOLO series detectors are characterized as single-stage object detectors [16], notable for their exceptional processing speed and real-time performance compared to the two-stage detectors within the CNN series.
Consequently, this paper proposes a lightweight object detection algorithm based on the improved YOLOv8 [17], designed for crack detection in wooden materials. We initiate by designing a feature optimization module composed of GSConv and GS bottleneck [18] to enhance feature fusion and processing capabilities. Within this framework, GSConv emerges as a pivotal component capable of significantly reducing the model’s complexity while preserving its efficacy. Within the refined YOLO network architecture, modifications are made to the neck network, drawing upon the principles of the gather–distribute (GD) mechanism [19], aimed at bolstering the capacity for feature fusion. Concurrently, the retention of small target features is ensured by establishing connections between layers with heightened sampling rates, thereby amplifying the precision in identifying minute crack targets within the YOLO network. Moreover, the convergence speed was further enhanced by incorporating Wise-IoU [20], featuring a dual-layer attention mechanism and dynamic gradient gain characteristics. Lastly, a dataset specifically tailored for crack detection in wooden materials was curated.
The primary contributions of this study can be delineated as follows:
- We propose a feature optimization module composed of GSConv and GS Bottleneck that enhances feature fusion and processing capabilities and balances the price and performance of the algorithm.
- We designed the network architecture using the GD mechanism, incorporating autonomously designed modules. This redesign notably enhances the information fusion capability of the neck network without significantly increasing model complexity, thereby efficiently preserving the features of small targets.
- We introduce a Wise-IoU with a dual-layer attention mechanism and dynamic gradient gain characteristics. This introduction accelerates the convergence speed of the model and enables it to adapt to the varying data quality in the dataset.
2. Related Works
Image-based crack detection in wooden materials stands as a multifaceted research domain, integrating disciplines such as image processing, pattern recognition, and DL. Presently, this field exhibits a categorical division into two principal classifications which are crack detection in wooden materials founded on digital image processing methods and crack detection based on DL methodologies. Crack detection approaches originating from digital image processing methods manifest an earlier inception and boast a comparatively mature technological framework. Conversely, methods reliant on DL surfaced at a later juncture, demonstrating heightened potential for advancement.
2.1. Traditional Methods for Wood Crack Detection
Wooden material crack detection constitutes a research domain focused on discerning cracks within wooden materials, grounded in traditional digital image processing. This study employs algorithms of digital image processing to perform feature extraction, thereby contributing to determining the presence of cracks in images or videos. Conventional methodologies for target detection involve introducing the integral image for swift feature computation, proposing the AdaBoost algorithm, and implementing the cascade structure by Viola-Jones [21], utilizing the histogram of oriented gradients (HOG) for facile capture of local shape features [22,23], and employing the deformable part-based model as an extension of HOG, especially adept at detecting occluded objects [24,25]. Meanwhile, some swarm intelligence algorithms, such as harmony search [26,27], cuckoo search [28,29], and sparrow search [30] are widely used to optimize the performance of the detection results.
The scale-invariant feature transform algorithm [31] is utilized extensively in the realm of computer vision for object identification and definition by leveraging local image features. Its applicability extends notably to the task of matching objects or scenes across disparate viewpoints. As the imperatives for heightened precision and computational efficiency escalate within this domain, there exists a persistent drive toward refining existing methodologies. This endeavor manifests in the continuous enhancement of various detection techniques, exemplified by advancements such as the Oriented FAST and Rotated BRIEF (ORB) [32], which offer superior efficiency in contrast to the conventional SIFT approach. Furthermore, contemporary research endeavors have delved into the integration of hybrid models as a means of augmenting the efficacy of target detection processes [33].
2.2. CNN-Based Methods for Wood Crack Detection
Traditional wooden material crack detection, based on digital image processing, encounters significant challenges in extracting complex semantic information related to cracks. These challenges often result in increased rates of false positives and false negatives. The rapid advancement of DL has facilitated the widespread adoption of neural network-based DL methods across various domains. These methods are notably applied in solving equations [34,35,36], performing matrix computations [37,38], and enhancing intelligent control systems [39,40]. In numerous DL models, convolutional neural networks (CNNs) exhibit excellent self-learning capabilities and can adeptly reveal profound semantic insights within images. With the continuous evolution of CNNs and the emergence of high-performance computing devices, areas such as image classification and object detection have witnessed substantial development. This progress has led to the successive introduction of efficient single-stage object detection networks, including YOLO [16], single-shot multi-box detectors [41], and efficient object detection.
Moreover, in the realm of DL, backbone networks serve as feature extractors for detectors, encompassing AlexNet [42], ResNet [43], DenseNet [44], MobileNet [45], ShuffleNet [46], and ShuffleNetV2 [47], among others. There is ongoing research into lightweight network structures [48] to achieve computational acceleration and conserve computational resources.
As a consequence of these advancements, object detection methods rooted in DL have found widespread adoption in the field of wooden material crack detection. The fundamental process can be divided into two stages: training and inference. During the training stage, the initial steps involve collecting a large number of images relevant to wooden material cracks to construct a comprehensive training dataset. Subsequently, data are annotated or preprocessed to adapt to the specific task. Following this, the dataset undergoes preprocessing to enhance data diversity. The processed data are then used as input for the CNN for feature extraction. Finally, features are classified, and this sequential step is iteratively performed during the training process to obtain an optimal model.
3. Methodology
3.1. YOLOv8 over Review
The YOLO model represents an object recognition and localization algorithm grounded in deep neural networks. Its most prominent attribute lies in its high-speed operational capabilities, rendering it particularly suited for real-time systems. This model has garnered significant acclaim and has been extensively employed in the domain of computer vision. YOLOv8 [17] distinguishes itself from its forerunners, such as YOLOv5 [49] and YOLOv7 [50]; it now claims the position of the most innovative computer vision model globally and stands as a highly adaptable platform for customization. The network’s fundamental structure primarily encompasses three key components: the head, backbone, and neck.
In YOLOv8, the enhanced CSPDarknet53 [51] functions as the backbone network, facilitating the generation of five discrete scale features through a sequence of five successive downsampling stages. Furthermore, a seminal design innovation within the YOLO framework is the incorporation of the spatial pyramid pooling (SPP) structure [52]. Inspired by the path aggregation network (PANet) [53], the PAN-FPN architecture is integrated into the neck component of YOLOv8. A comprehensive network structure that harmonizes both top-down and bottom-up components is created in this approach, which through feature fusion blends surface-level positional insights with deep semantic details, thereby enriching the breadth and depth of features.
Within the head structure of the YOLOv8, it embraces a ‘decoupled head’ and incorporates the distribution focal loss (DFL) [54] concept for object classification and bounding box regression predictions. This version refines loss functions, using the vertical federated learning (VFL) [55] loss for classification and the complete intersection over union (CIoU) [56] loss alongside the DFL for regression, each offering distinct features. In addition, anchor-free detection of the YOLOv8 simplifies distinguishing between positive and negative samples, and the task-aligned one-stage object detection (TOOD) [57] is integrated for better sample allocation, which improves both the robustness and detection accuracy of the model.
3.2. Improve the Structure of ICDW-YOLO
3.2.1. The Framework of ICDW-YOLO
Notwithstanding the incorporation of feature pyramid networks (FPNs) [58] and PANet [53] in the current YOLO algorithm for multi-scale feature fusion, a fusion issue persists concerning feature information. Specifically, the fundamental YOLO series algorithms adopt a conventional FPN structure within the neck network segment. Traditional FPN structures are constrained to fully fuse features solely from adjacent layers, with information from other layers being attainable only through indirect recursive methods. This results in escalated algorithmic complexity and a consequential loss of transmitted information. The employed transmission mode may, during computation, lead to a substantial loss of information as the interaction between non-adjacent layers relies solely on the selection of information through intermediate layers, consequently leading to the loss of specific information. Consequently, the information from one layer may effectively aid only adjacent layers, thereby diminishing its support for other non-adjacent layers. Thus, the overall efficacy of information fusion may be restricted.
In light of this, there arises a necessity to introduce the GD mechanism, which systematically gathers and amalgamates information from diverse scales through a unified module, subsequently distributing the fused features across distinct layers [19]. Within this mechanism, the feature alignment module (FAM) [59] and information fusion module (IFM) synergistically aggregate features from disparate hierarchical echelons. The inject module subsequently disburses the amalgamated information throughout diverse layers of the network. This strategic orchestration enables the model to judiciously harness multi-scale features, thus elevating object detection precision while retaining low latency. This approach not only circumvents the inherent information loss observed in traditional FPN structures but also amplifies the information fusion capacity of the neck section without a significant increase in latency. It more judiciously harnesses the features extracted by the backbone network.
Specifically, as elucidated in Figure 1, this study introduces the GD mechanism into the neck part of the original YOLOv8 network. The low-GD is utilized to replace the upsampling fusion stage of PANet, while the high-GD replaces the downsampling fusion stage of PANet. Moreover, the introduction of a higher-resolution B2 layer into low-GD aims to preserve the feature information of small targets as comprehensively as possible. Within low-GD, using the B4 layer as the reference, large feature maps such as the B2 layer and B3 layer undergo downsampling through average pooling, whereas small feature maps like the B5 layer undergo upsampling using bilinear interpolation to standardize the feature map sizes, after which the merged features are acquired. Subsequently, the features obtained through low-GD fusion, namely P3 layer, P4 layer, and P5 layer, undergo feature fusion via high-GD. This procedure effectively enhances information fusion performance and preserves the information features of small targets.
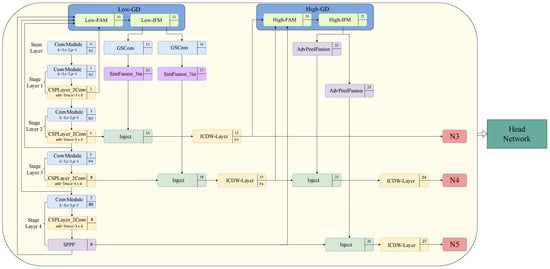
Figure 1.
Network structure of ICDW-YOLO.
Moreover, within the domain of object detectors, the neck serves as a crucial intermediary between CNN’s backbone network and the head network. This facilitates the fusion and processing of features, thereby enhancing the precision and efficiency of detection. In order to effectively balance the model’s performance with its complexity, this study has developed a new module based on the GS Bottleneck framework. This module replaces the CSP Bottleneck with a two-convolution (c2f) model in the neck network and is named the ICDW layer model. Together with the introduction of GSConv, this addition further enhances the cost-effectiveness of model computation.
Therefore, the combination of the GD mechanism, ICDW layer, and GSConv collectively constitute the network architecture optimization of ICDW-YOLO.
3.2.2. ICDW Layer
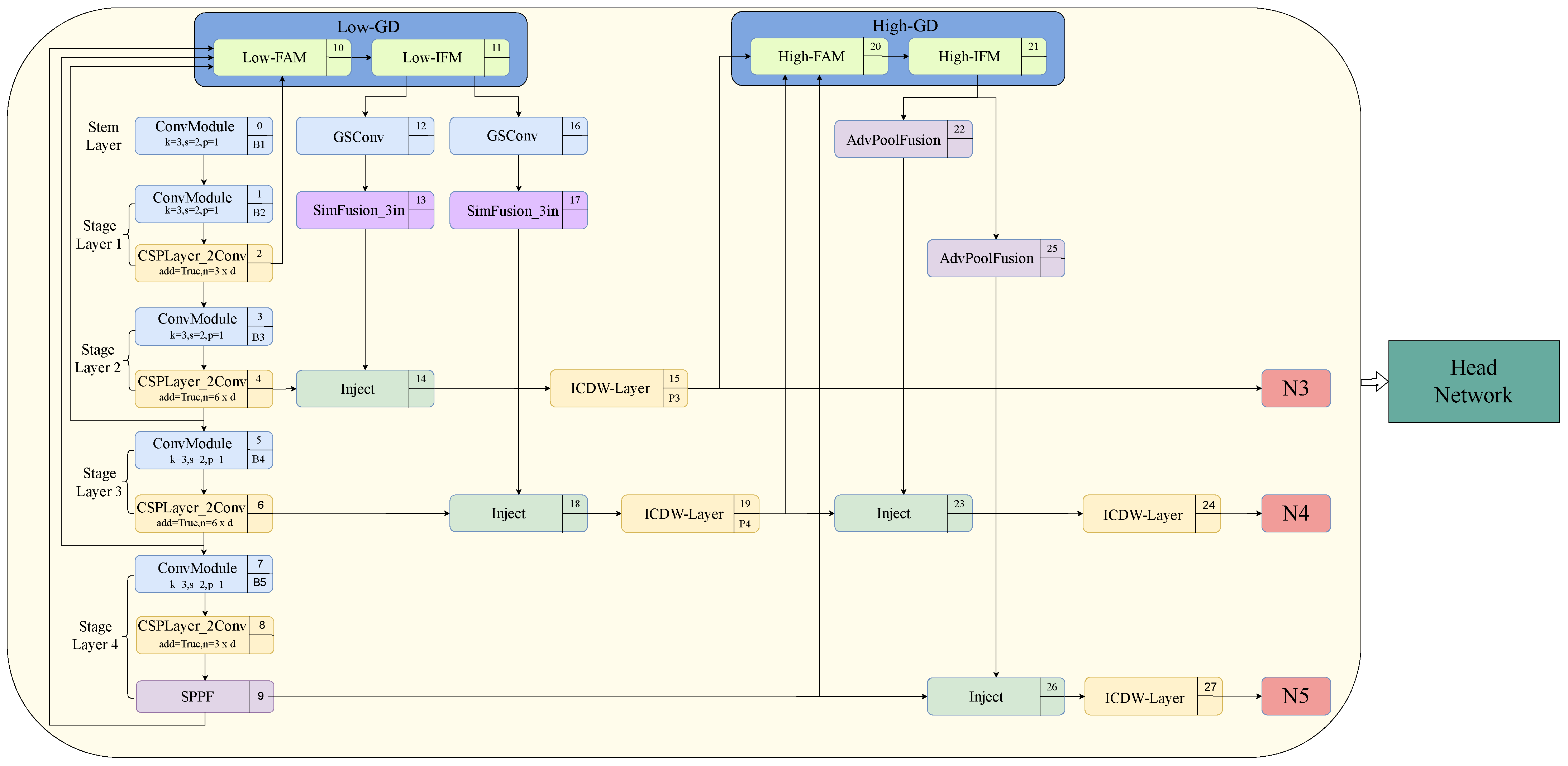
The ICDW layer is primarily designed to replace the c2f module within the original neck network, thereby effectively facilitating feature fusion and processing while also balancing the model’s performance and computational cost. As depicted in Figure 2, the ICDW layer primarily incorporates the GSConv and GS Bottleneck module, which is constructed by stacking GSConv, to enhance the network’s feature extraction capabilities.

Figure 2.
Structure of the GS bottleneck module and ICDW layer.
The integration of GSConv addresses the prevalent computational speed challenge in CNN predictions. With each instance of spatial compression and channel expansion in the feature map, there is a consequential partial loss of semantic information. Sparse convolution (SC) [60] maximally retains implicit connections among channels, whereas depthwise separable convolution (DSC) [61] completely severs these connections. GSConv strives to preserve these connections to the utmost extent possible. The design and implementation of this module effectively enhance the network’s feature fusion capability while reducing computational complexity and inference time.
3.2.3. Wise-IoU
In order to effectively address the negative impact of low-quality data in the training set on the model’s generalization ability, we introduce Wise-IoU [20] in ICDW-YOLO, incorporating a dual-layer attention mechanism constructed based on metrics.
IoU serves as a metric for quantifying the degree of overlap between the predicted box and the ground truth in the target detection task. In this context, and represent the height and width of the intersection area respectively, while denotes the area union. The gradient computation of in backpropagation is elucidated in Equation (2). In such cases, in the absence of overlap between the bounding boxes, i.e., or , the gradient of in backpropagation becomes non-existent, thus the width cannot be updated during training.
In addressing this issue, Wise-IoU separates and according to the paradigm in Equation (3), thus constructing the penalty term as shown in Equation (4). This term significantly amplifies the for ordinary quality anchor boxes and effectively prevents from impeding gradient convergence. This process weakens the penalty of geometric metrics when there is a good overlap between anchor and target boxes, without excessive interference in training, thereby improving the model’s generalization ability.
Moreover, to enhance the regression of bounding boxes and mitigate harmful gradients arising from low-quality training data, we introduce an outlier assessment to evaluate the quality of anchors, as demonstrated in Equation (5), and assign smaller gradient gains to anchors with larger outliers. Ultimately, this results in the realization of a Wise-IoU, which not only introduces a non-monotonic focusing coefficient but also incorporates a dual-layer attention mechanism attentive to distance, as demonstrated in Equations (6) and (7).
In the scenario where , results in , and if the outliers of the anchor boxes satisfy , C is the quality partition standard of the anchor boxes, the anchor boxes gain the highest gradient. Moreover, since is dynamic and the quality partition standard of the anchor boxes is also dynamic, a gradient gain allocation strategy that best fits the current situation occurs at every moment, thus further accelerating the convergence of the model and improving its performance.
4. Experimental Results
4.1. Dataset Preparation and Augmentation
The dataset in this study primarily consists of three components. Firstly, an original dataset for the detection of cracks in wooden materials, to evaluate the model’s performance in this specific domain. Secondly, a dataset intended to assess the model’s generalization capability. This dataset includes a dynamic fireworks detection dataset as well as an aerial image object detection dataset, covering various small targets and targets with dynamic features. Finally, a publicly available dataset is employed for standardizing the evaluation of the model, with the coco128 dataset being selected.
4.1.1. Crack Dataset
Typically, datasets are procured through online searches; nevertheless, the scarcity and heterogeneity of these images are noteworthy. Specific image categories boast publicly accessible datasets characterized by superior quality in comparison to their counterparts. Furthermore, the predominant approach entails the acquisition of images through on-site photography. Owing to the dearth and substandard quality of online images portraying cracks in wooden materials, on-site photography was selected as the preferred methodology. Images capturing fissures in wooden materials for this study were culled from enduring wooden structures dispersed across diverse locales in Hunan Province, China, with a standing history exceeding thirty years. These images were systematically captured from diverse perspectives within environments mirroring natural conditions, encompassing both interior and exterior settings. Diligent efforts were exerted to circumvent excessively shadowed angles and environments.
Due to the necessity of sourcing images of cracks in wooden materials from ancient buildings predominantly constructed of wood, the collection process is inherently challenging, resulting in a limited sample size. Consequently, the initial dataset comprises only 506 images depicting cracks in wooden materials. Given the prevailing uniformity in architectural styles and wood varieties among wooden structures within the same locale, the preliminary screening rigorously eliminated excessively blurred and redundant images. This process culminated in a refined dataset of 406 images, thus affirmatively ensuring dataset quality.
After the initial collection, the images underwent meticulous annotation using the labeling tool. Moreover, owing to the constrained dimensions of the initial dataset, imperative measures encompassing feature augmentation methodologies were instituted to refine image processing, thereby substantively amplifying and elevating its quality. The data augmentation methodology employed in this study adopts a comprehensive framework integrating rotation, blurring, luminosity adjustment, image stretching, and the infusion of Gaussian noise. Post application of feature augmentation, the dataset encompassed a cumulative total of 1617 different images; the effect is shown in Figure 3. As delineated in Table 1, the dataset was partitioned into training, validation, and test subsets, adhering to a proportion of 7:2:1.

Figure 3.
Example of feature enhancement.

Table 1.
Description of the Crack dataset.
4.1.2. Other Dataset
This study introduces additional datasets to assess the model’s performance, generalization capabilities, and applicability in various detection scenarios. A significant concern addressed is the limited diversity and scale within the wooden material dataset, which restricts comprehensive testing of the model’s multifaceted capabilities. While the wooden material crack detection dataset includes both single-object and multi-object detection, it suffers from limited scale and targets that lack dynamic characteristics and substantial scale variation. In contrast, the fire and smoke detection dataset comprises dynamic targets, enabling a thorough evaluation of the ICDW-YOLO model’s proficiency in detecting dynamic objects. This assessment primarily focuses on scenarios where targets display dynamic features, influenced by the mobile nature of embedded platforms during development.
The initial dataset introduced is the Fire and Smoke dataset, as delineated in Table 2, comprising two distinct components. One segment emanates from the publicly available wildfire smoke dataset provided by the State Key Laboratory of Fire Science (SKLFS), University of Science and Technology of China (USTC) [62]. The second segment constitutes a dataset meticulously collected and annotated during our research, denoted as the Fire and Smoke dataset in subsequent discussions.
Table 2.
Descriptions of other datasets.
Furthermore, the DOTAv2-tiny dataset is utilized to evaluate the ICDW-YOLO model’s capacity to identify small and multi-scale targets, especially in contexts demanding multi-object recognition. Given that the Crack dataset is characterized as a single-target dataset with relatively sizable targets, the introduction of the DOTA dataset becomes imperative, encompassing both multi-object and small-object recognition. The DOTA dataset, designed for object detection in aerial images [63], is an extensive collection acquired from diverse platforms and sensors. The DOTAv2 version, presently available in three versions, was selected for experimentation, and given the considerable magnitude of the DOTAv2 dataset, a judiciously chosen subset is employed in this research without compromising the dataset’s integrity. The chosen dataset size is detailed in Table 2, denoted as DOTAv2-tiny in subsequent discussions. Finally, a publicly available dataset is used for standardizing the evaluation of the model, with the coco128 dataset selected, as shown in Table 2.
4.2. Training Parameters and Experimental Environment
In order to ensure methodological robustness, all experiments were rigorously executed under uniform hardware conditions. The experimentation was conducted employing a custom-assembled computer system, which features specific and finely detailed specifications, meticulously elucidated in Table 3, inclusive of an Nvidia GeForce 4060 Ti graphics processing unit endowed with 16 GB of memory (Nvidia, Santa Clara, CA, USA), supplemented by 32 GB of RAM, and powered by an Intel Core i7 processor 14,700 K running at 5.6 GHz across 20 cores (Intel, Santa Clara, CA, USA).
Table 3.
Descriptions of hardware and software.
Setting hyperparameters is pivotal for shaping model performance and ensuring the success of algorithmic enhancements. In the process of refining the YOLOv8 model, it is imperative to uphold uniform hyperparameter configurations. This consistency serves as a linchpin, affirming the efficacy of model advancements and expediting precise performance appraisals conducted both before and after enhancements. The act of adjusting hyperparameters during algorithmic refinement introduces the potential to obscure the origin of performance variations—whether they emanate from the inherent enhancements of the algorithm or result from alterations in the hyperparameters. Consequently, in order to ascertain an unambiguous and rigorous assessment of advancements, this paper steadfastly adheres to a standardized set of hyperparameters, as shown in Table 4.
Table 4.
Hyperparameters for training.
4.3. Evaluation Metrics
In the empirical evaluation of performance metrics, the study incorporated the utilization of average precision (AP), F1 score, and accuracy. The computation of accuracy entails the establishment of a ratio, specifically the division of true positives (TPs) and true negatives (TNs) by the aggregate of identified samples, as explicated in Equation (8). What is noteworthy here is that TPs denote instances correctly predicted as positive, while TNs designate instances accurately predicted as negative. Importantly, false positives (FPs) constitute instances erroneously predicted as positive, and false negatives (FNs) represent instances genuinely positive but erroneously predicted as negative.
Precision and recall have emerged as pivotal metrics in the appraisal of a classification model’s efficacy, particularly in scenarios wherein achieving equilibrium between true positives and false positive predictions is imperative. Precision, delineated in Equation (9), quantifies the accuracy of the model’s positive prognostications. It manifests as the quotient of TPs divided by the summation of TPs and false positives (FPs). Conversely, recall, as articulated in Equation (10), gauges the model’s acumen in identifying true positives from the entire pool of actual positive instances. This is computed as the ratio of TPs to the sum of TPs and false negatives (FNs). Heightened recall underscores the model’s proficiency in capturing a substantial proportion of actual positives. Both metrics are of paramount significance in comprehending the model’s efficacy, with precision affording a nuanced focus on the accuracy of positive predictions, and recall accentuating the entirety of positive instances captured.
Average precision (AP), elucidated in Equation (11), serves as a metric for appraising the model’s capability to accurately categorize objects and sequence them predicated on predicted confidence, conventionally summarized as the mean average precision (mAP) across multiple categories, elucidated in Equation (12). F1 score, as delineated in Equation (13), assumes the role of a harmonic mean, encapsulating precision and recall, thereby furnishing a balanced singular metric catering to false positives and false negatives, particularly salient in scenarios where each error type exerts a substantial impact or in datasets characterized by imbalance. Intersection over union (IoU), explicated in Equation (14), quantifies the precision of object localization by assessing the ratio of the overlapping area between predicted bounding boxes (BDs) and ground truth bounding boxes (BGTs) relative to their union area. Cumulatively, these metrics proffer a holistic evaluation of the object detection model’s capacities, spanning both classification accuracy and object localization precision.
FLOPs (floating point operations) serve as indicators for assessing algorithmic complexity and are commonly used indirectly to gauge the computational speed of neural network models. In the context of convolutional layers, the formula for calculating FLOPs is depicted in Equation (15), where denotes the number of channels in the input tensor of the convolutional layer, represents the number of channels in the output tensor, and K indicates the size of the convolutional kernel. Higher FLOP values typically indicate that the model exhibits a more intricate architecture or necessitates greater computational resources for processing input data, thereby providing a metric to quantify the complexity of the model.
In the evaluation of the model’s inference and recognition speeds, this study adopts FPS (frames per second) as the principal metric, as depicted in Equation (16), where represents the pre-processing time, represents the inference time, and represents the post-processing time. FPS denotes the rate at which the network processes frames per second, indicating either the number of images processed per second or the time required to process a single image, thereby assessing detection speed. A shorter processing time correlates with higher speed.
4.4. Experimental Results and Analysis
4.4.1. Quantitative Comparison and Evaluation
The quantitative evaluation in this article aimed to comprehensively assess the effectiveness of the proposed methodology. Various metrics, including precision, recall, mAP50, mAP50–95, and so on, were calculated using Equations (8)–(16). To address the diversity of instances in the dataset, spanning different distances and encompassing both small and large areas, systematic testing was conducted across various DL models.
This study primarily focuses on utilizing DL models for the detection of cracks in wooden materials, with a specific emphasis on protecting ancient buildings through crack detection. Following a thorough evaluation of the dataset, YOLOv8 was selected as the primary framework due to its performance and efficiency in swiftly detecting instances of cracks in wooden materials of different sizes and orientations. The proposed crack detection model, built upon YOLOv8, exhibited significant enhancements across multiple performance metrics.
In order to thoroughly evaluate the effectiveness of the proposed method, and in consideration of the challenges in aligning evaluation metrics between traditional detection methods and DL-based detection approaches, this analysis encompasses a range of DL-based object detection technologies and their enhancements, including YOLOv5, YOLOv5p6 [49], YOLOv6 [64], YOLOv8, YOLOv8p6 [17], EfficientNetv2 [65], ShuffleNetV2 [47], and RTDETR [66]. Moreover, in order to assess the model’s generalizability across diverse scenarios and varied requirements, experiments were conducted not solely utilizing the Crack dataset, as mentioned previously, but also incorporating the previously described DATAv2-tiny dataset, Fire and Smoke dataset, and coco128 dataset. The comparative performance analysis between the ICDW-YOLO and various models concerning each dataset is detailed in Table 5, and Figure 4.
Table 5.
Quantitative analysis index table for the model.

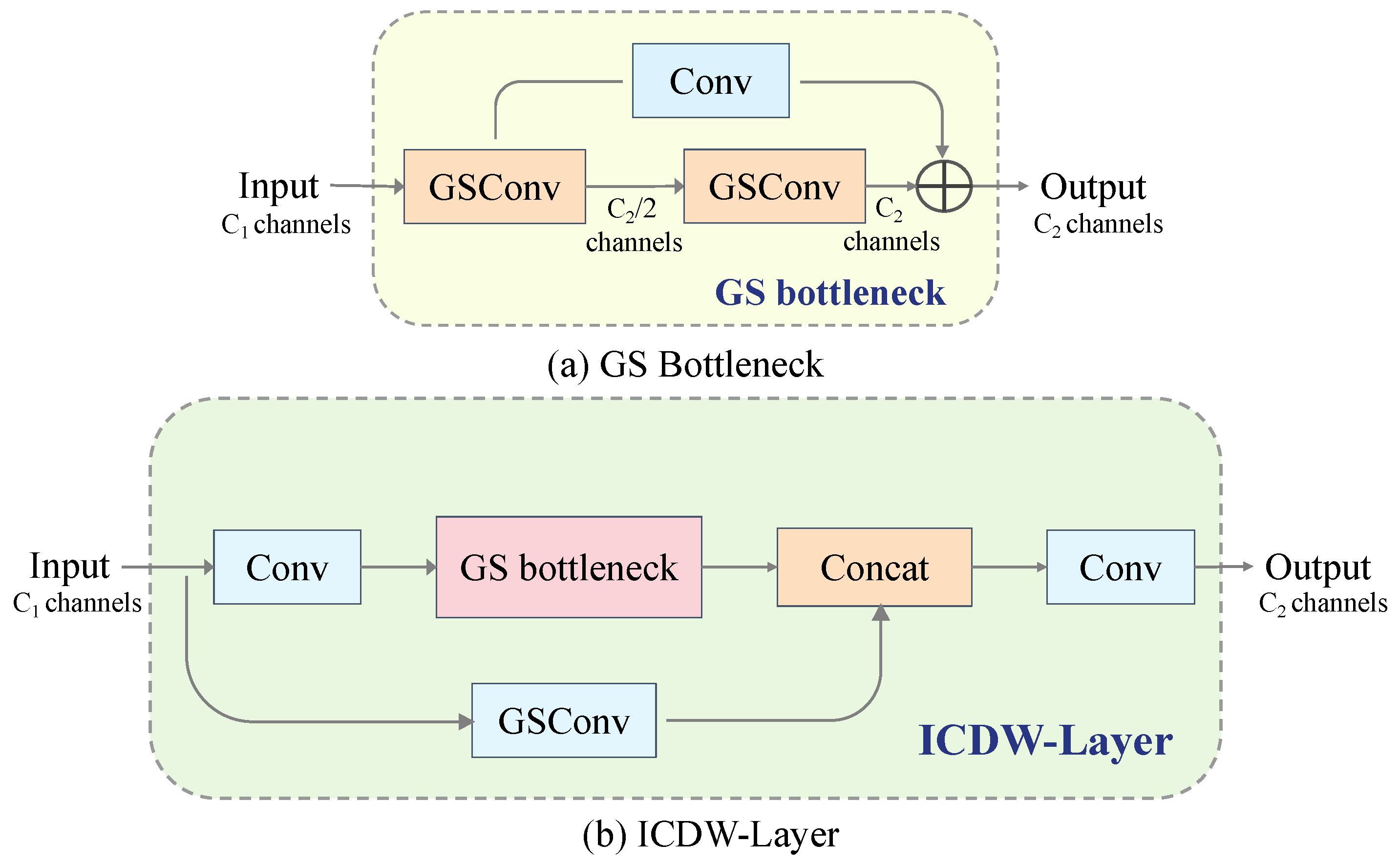
Figure 4.
Graph of the change curve of the model evaluation index. (a) The mAP50 metric change graph of ICDW-YOLO under the Crack dataset. (b) The mAP50 metric change graph of ICDW-YOLO under the coco128 dataset. (c) The mAP50 metric change graph of ICDW-YOLO under the Fire and Smoke dataset. (d) The mAP50 metric change graph of ICDW-YOLO under the DOTAv2-tiny dataset.
The comparative experimental results of the proposed ICDW-YOLO model against various DL-based object detection models on different datasets are presented in Table 5 and Figure 4. In several comparative experiments, RTDETR’s stringent dataset requirements led to poor performance and underfitting on the Crack and DATAv2-tiny datasets. Under identical dataset and training conditions, ICDW-YOLO consistently achieved superior performance metrics, such as precision, recall, and mAP. Specifically, among models of similar complexity, ICDW-YOLO ranked highest for all metrics on the Crack dataset and excelled on datasets like DATAv2-tiny, designed to test detection capabilities in diverse complex environments. It ranked first in precision, recall, mAP50, mAP50–95, and F1 score across multiple datasets.
As detailed in Table 5, on the Crack dataset, ICDW-YOLO maintained inference speed and model complexity without significant increases in FPS or FLOPs, while ranking first in precision, recall, mAP50–95, and F1 score. Its mAP50 was second only to the more complex ShuffleNetV2. On the wooden material detection dataset collected for this study, ICDW-YOLO demonstrated outstanding performance. The model attained precision, recall, mAP50, and mAP50–95 values of 98.756%, 98.013%, 99.201%, and 79.018%, respectively, representing notable enhancements over the original YOLOv8 model.
For more detailed assessments on the DATAv2-tiny and Fire and Smoke datasets, ICDW-YOLO significantly improved performance while maintaining inference speed and without noticeably increasing model complexity. On the DATAv2-tiny dataset, which exhibited significant differences in experimental results, ICDW-YOLO ranked first in precision, recall, mAP50, and F1 score. Finally, on the coco128 dataset, used for a comprehensive evaluation in a small-sample, multi-target environment with scale variations, ICDW-YOLO performed admirably across all five performance metrics. It secured the top position in precision, mAP50, and F1 score, and was second in recall, mAP50, and mAP50–95 only to RTDETR, which has much higher complexity (FLOPs) and lower inference capability (FPS). Compared to the original YOLOv8 model, ICDW-YOLO’s precision increased from 64.601% to 82.128%, recall from 53.456% to 55.181%, mAP50 from 60.256% to 69.226%, and mAP50–95 from 39.627% to 44.210%. Compared to similar models, ICDW-YOLO achieves superior performance with reduced complexity compared to YOLOv6 and attains higher performance without a significant increase in model size compared to the YOLOv8 and YOLOv5 series.
4.4.2. Ablation Study
The ablation experiments are conducted to delineate the contributions and functions of various components within the model, thereby assessing its robustness and performance and providing guidance for optimization and enhancement. This study undertakes a series of ablation experiments aimed at evaluating the effects of the Wise-IoU, and the neck network design method with the GD mechanism, GSConv, and ICDW layer model on the accuracy of detection. Specifically, this research comprises 14 specific ablation experiments on the coco128 and Crack datasets, incorporating the YOLOv8 model, models (a) to (e), and ICDW-YOLO. The detailed findings of these experiments are summarized in Table 6, which extensively assesses the potential enhancements of the YOLOv8 baseline model resulting from these modifications. These assessments are based on various metrics, including precision, recall, mAP50, mAP50–95, and FLOPs.
Table 6.
Results of ablation experiments.
The ablation study suggests that while the YOLOv8 object detection model demonstrates robust performance, its effectiveness may not achieve its utmost potential under certain circumstances. These findings indicate the potential for enhancing model accuracy across diverse contexts by integrating Wise-IoU, ICDW layer, and GSConv into the YOLOv8 network architecture and adopting the neck network design method with the GD mechanism. Specifically, the introduction of Wise-IoU can effectively enhance various metrics of the model without increasing its complexity, while the introduction of GSConv can reduce model complexity to some extent with minimal impact on performance. However, introducing the ICDW layer or GD mechanism alone would significantly increase the model’s size, leading to a considerable rise in complexity as the cost of performance enhancement.
As demonstrated by the experimental data in Table 6, the introduction of either the ICDW layer or the GD mechanism results in a significant increase in model size while simultaneously enhancing performance. For example, the FLOPs on the coco128 dataset increased from 8.7 GFLOPs in the original YOLOv8 model to 12.5 GFLOPs and 20.0 GFLOPs for models (a) and (b), respectively. Notably, model (b) also incorporates GSConv, which aids in reducing model complexity. Conversely, the GD mechanism introduced in model (a) improves performance without substantially increasing complexity by enhancing multi-scale feature fusion capability. Consequently, integrating the GD mechanism and GSConv can effectively counterbalance the increase in model complexity caused by the ICDW layer while preserving the performance enhancements brought by the GD mechanism and ICDW layer. Additionally, the introduction of Wise-IoU further increases the performance of the model without affecting the complexity.
Finally, in terms of outcomes on the coco128 dataset, the ICDW-YOLO model emerges as the most exceptional overall, particularly with the precision and comprehensive performance of the model with complexity and accuracy ranking highest across all models. In comparison to the original YOLOv8 model, its precision, recall, mAP50, and mAP50–95 increased by 17.527%, 1.725%, 8.97%, and 4.583%. Additionally, on the Crack dataset, ICDW-YOLO ranked first in all metrics except recall, where it was only marginally behind model (e), which had a FLOP value nearly twice that of ICDW-YOLO. In comparison to the original YOLOv8 model, its precision, recall, mAP50, and mAP50–95 increased by 2.049%, 1.405%, 0.264%, and 4.392%, respectively.
4.4.3. Quantitative Comparison and Evaluation
Additionally, after the quantitative analysis, this study delved into the detection performance of ICDW-YOLO through qualitative analysis. Initially, to evaluate the crack detection capabilities of ICDW-YOLO for wooden materials, as depicted in Figure 4d, sixteen images showcasing diverse crack patterns, textures, exposure levels, and blur degrees were extracted from the Crack dataset. ICDW-YOLO consistently yielded reliable outcomes for crack detection in wooden materials across varied and intricate conditions.
Moreover, to assess the model’s ability to generalize across different scenarios, as illustrated in Figure 5a,b, sixteen aerial images featuring multiple targets and small objects from the DOTAv2-tiny dataset were selected. Additionally, sixteen images depicting more minor, abrupt, and dynamically evolving smoke plumes induced by wildfires were chosen from the Fire and Smoke dataset. It was noted that ICDW-YOLO not only delivered dependable results for detecting multiple targets and small objects but also exhibited commendable performance in discerning dynamically changing small objects.

Figure 5.
Target detection sample of ICDW-YOLO. (a) Examples of detection results on the Crack dataset. (b) Examples of detection results on the DOTAv2-tiny dataset. (c) Examples of detection results on the Fire and Smoke dataset.
Overall, the dataset proposed in this study constitutes a high-quality resource for crack detection in wooden materials. The ICDW-YOLO model proposed herein demonstrates robustness in detecting objects of varying sizes and compositions, encompassing single and multiple objects, as well as those exhibiting dynamic changes. In the domain of crack detection in wooden materials, ICDW-YOLO adeptly identifies and detects cracks, thereby offering valuable support in the surveillance and preservation of ancient structures.
5. Conclusions
This research presents a refined crack detection algorithm tailored for wooden materials, leveraging enhancements made to YOLOv8. In contrast to YOLOv8n, the algorithmic framework proposed herein initially restructures the neck network by adopting the GD mechanism and replacing the C2f module with the ICDW layer. Subsequently, GSConv is introduced to supplant the convolutional process in the neck network. Wise-IoU is further integrated, which features a dual-layer attention mechanism and dynamic gradient gain attributes to better align with the intricacies of crack detection in wooden materials. Empirical findings demonstrate that the algorithm proposed in this study surpasses existing state-of-the-art algorithms in terms of detection accuracy and exhibits promising experimental outcomes on internally developed and publicly available datasets. Furthermore, it fortifies the equilibrium between algorithmic efficacy and intricacy while enhancing overall performance.
Despite achieving commendable detection accuracy, the proposed algorithm still encounters instances of missed detections and false alarms. The network’s resilience may diminish in response to alterations in lighting conditions. Our future research will prioritize the comprehensive collection of crack images in wooden materials and will further investigate the relationships among factors such as types of wooden materials, quality of data annotation, types of cracks, crack orientations, and their future development trends. Additionally, in-depth studies will be conducted on the impact of various types of cracks in wooden materials on the structural health of buildings. Additionally, the main objective of model research is to accelerate detection speed and robustness while keeping model complexity from significantly increasing, improving real-time detection performance, and integrating multiple data sources to enhance detection accuracy and reliability.
Author Contributions
Conceptualization, J.Z.; data curation, J.Z. and J.N.; formal analysis, J.Z.; funding acquisition, J.Z., J.N., Z.X., and P.Y.; methodology, J.Z.; project administration, P.Y.; resources, P.Y.; software, J.Z.; supervision, Z.X. and P.Y.; validation, J.Z.; Visualization, J.Z. and J.N.; Writing—original draft, J.Z. and J.N.; Writing—review and editing, Z.X. and P.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Jishou University Introduced Personnel and Returned Doctoral Research Funding Project: Key Technologies on Collaborative Information Retrieval for Big Data, the Hunan Student’s Innovation and Entrepreneurship Training Program under grant no. S202310531041, the Hunan Student’s Innovation and Entrepreneurship Training Program under grant no. S202310531073, and the Hunan Student’s Innovation and Entrepreneurship Training Program under grant no. JDCX20241155.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available upon request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Dai, J.; Chang, L.; Qian, W.; Li, X. Damage characteristics of ancient architecture wood members and stress wave nondestructive testing of internal void. J. Beijing Univ. Technol. 2016, 42, 236–244. [Google Scholar]
- Cabaleiro, M.; Lindenbergh, R.; Gard, W.; Arias, P.; Van de Kuilen, J. Algorithm for automatic detection and analysis of cracks in timber beams from LiDAR data. Constr. Build. Mater. 2017, 130, 41–53. [Google Scholar] [CrossRef]
- Yang, H.; Yu, L. Feature extraction of wood-hole defects using wavelet-based ultrasonic testing. J. For. Res. 2017, 28, 395–402. [Google Scholar] [CrossRef]
- Kato, S.; Wada, N.; Shiogai, K.; Tamaki, T.; Kagawa, T.; Toyosaki, R.; Nobuhara, H. Crack Severity Classification from Timber Cross-Sectional Images Using Convolutional Neural Network. Appl. Sci. 2023, 13, 1280. [Google Scholar] [CrossRef]
- Hadiwidjaja, M.L.; Gunawan, P.H.; Prakasa, E.; Rianto, Y.; Sugiarto, B.; Wardoyo, R.; Damayanti, R.; Sugiyanto, K.; Dewi, L.M.; Astutiputri, V.F. Developing Wood Identification System by Local Binary Pattern and Hough Transform Method. J. Phys. Conf. Ser. 2019, 1192, 012053. [Google Scholar] [CrossRef]
- Chang, L.H.; Chang, X.H.; Chang, H.; Qian, W.; Cheng, L.T.; Han, X.L. Nondestructive testing on ancient wooden components based on Shapley value. In Advances in Materials Science and Engineering; Wiley: Hoboken, NJ, USA, 2019; Volume 2019, pp. 1–11. [Google Scholar]
- Hacıefendioğlu, K.; Ayas, S.; Başağa, H.B.; Toğan, V.; Mostofi, F.; Can, A. Wood construction damage detection and localization using deep convolutional neural network with transfer learning. Eur. J. Wood Wood Prod. 2022, 80, 791–804. [Google Scholar] [CrossRef]
- Ehtisham, R.; Qayyum, W.; Camp, C.V.; Plevris, V.; Mir, J.; Khan, Q.U.Z.; Ahmad, A. Computing the characteristics of defects in wooden structures using image processing and CNN. Autom. Constr. 2024, 158, 105211. [Google Scholar] [CrossRef]
- Liu, Y.; Hou, M.; Li, A.; Dong, Y.; Xie, L.; Ji, Y. Automatic Detection of Timber-Cracks in Wooden Architectural Heritage Using YOLOv3 Algorithm. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, XLIII-B2-2020, 1471–1476. [Google Scholar] [CrossRef]
- Ma, J.; Yan, W.; Liu, G.; Xing, S.; Niu, S.; Wei, T. Complex texture contour feature extraction of cracks in timber structures of ancient architecture based on YOLO algorithm. Adv. Civ. Eng. 2022, 2022, 7879302. [Google Scholar] [CrossRef]
- Li, L.; Li, Z.; Han, H.; Yang, L.; Feng, X.; Roli, F.; Xia, Z. Wooden spoon crack detection by prior knowledge-enriched deep convolutional network. Eng. Appl. Artif. Intell. 2023, 126, 106810. [Google Scholar] [CrossRef]
- Qiu, Y.; Ai, Z.; Lin, Y.; Xu, Z.; Liu, X. Detecting Defects of Wooden Boards by Improved YOLOv4-Tiny Algorithm. In Proceedings of the 2021 Chinese Intelligent Systems Conference: Volume III, Fuzhou, China, 16–17 October 2021; Springer: Singapore, 2022; pp. 519–527. [Google Scholar]
- Wang, B.; Yang, C.; Ding, Y.; Qin, G. Detection of wood surface defects based on improved YOLOv3 algorithm. BioResources 2021, 16, 6766–6780. [Google Scholar] [CrossRef]
- Lin, Y.; Xu, Z.; Chen, D.; Ai, Z.; Qiu, Y.; Yuan, Y. Wood Crack Detection Based on Data-Driven Semantic Segmentation Network. IEEE/CAA J. Autom. Sin. 2023, 10, 1510–1512. [Google Scholar] [CrossRef]
- Cao, X.; Li, G. An effective method of wood crack trace and quantity detection based on digital image processing technology. In Proceedings of the 2021 13th International Conference on Machine Learning and Computing, Shenzhen, China, 26 February–1 March 2021; pp. 304–309. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Jocher, G. YOLOv8. Ultralytics: Github. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 May 2023).
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A lightweight-design for real-time detector architectures. J. Real Time Image Process. 2024, 21, 62. [Google Scholar] [CrossRef]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Wang, Y.; Han, K. Gold-YOLO: Efficient object detector via gather-and-distribute mechanism. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2024; Volume 36. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; IEEE: Piscataway, NJ, USA, 2001; Volume 1, p. I. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Wang, X.; Han, T.X.; Yan, S. An HOG-LBP human detector with partial occlusion handling. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 32–39. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–8. [Google Scholar]
- Li, J.; Wong, H.C.; Lo, S.L.; Xin, Y. Multiple object detection by a deformable part-based model and an R-CNN. IEEE Signal Process. Lett. 2018, 25, 288–292. [Google Scholar] [CrossRef]
- Ye, S.; Zhou, K.; Zain, A.M.; Wang, F.; Yusoff, Y. A modified harmony search algorithm and its applications in weighted fuzzy production rule extraction. Front. Inf. Technol. Electron. Eng. 2023, 24, 1574–1590. [Google Scholar] [CrossRef]
- Qin, F.; Zain, A.M.; Zhou, K.Q. Harmony search algorithm and related variants: A systematic review. Swarm Evol. Comput. 2022, 74, 101126. [Google Scholar] [CrossRef]
- Ye, S.Q.; Zhou, K.Q.; Zhang, C.X.; Mohd Zain, A.; Ou, Y. An improved multi-objective cuckoo search approach by exploring the balance between development and exploration. Electronics 2022, 11, 704. [Google Scholar] [CrossRef]
- Zhang, C.X.; Zhou, K.Q.; Ye, S.Q.; Zain, A.M. An Improved Cuckoo Search Algorithm Utilizing Nonlinear Inertia Weight and Differential Evolution for Function Optimization Problem. IEEE Access 2021, 9, 161352–161373. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Zhou, K.Q.; Li, P.C.; Xiang, Y.H.; Zain, A.M.; Sarkheyli-Hägele, A. An improved chaos sparrow search optimization algorithm using adaptive weight modification and hybrid strategies. IEEE Access 2022, 10, 96159–96179. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; IEEE: Piscataway, NJ, USA, 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2564–2571. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Xiao, L.; Liao, B.; Li, S.; Chen, K. Nonlinear recurrent neural networks for finite-time solution of general time-varying linear matrix equations. Neural Netw. 2018, 98, 102–113. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Zheng, L.; Weng, J.; Mao, Y.; Lu, W.; Xiao, L. A new varying-parameter recurrent neural-network for online solution of time-varying Sylvester equation. IEEE Trans. Cybern. 2018, 48, 3135–3148. [Google Scholar] [CrossRef]
- Xiao, L.; Liao, B. A convergence-accelerated Zhang neural network and its solution application to Lyapunov equation. Neurocomputing 2016, 193, 213–218. [Google Scholar] [CrossRef]
- Liao, B.; Zhang, Y. Different complex ZFs leading to different complex ZNN models for time-varying complex generalized inverse matrices. IEEE Trans. Neural Netw. Learn. Syst. 2013, 25, 1621–1631. [Google Scholar] [CrossRef]
- Liao, B.; Zhang, Y. From different ZFs to different ZNN models accelerated via Li activation functions to finite-time convergence for time-varying matrix pseudoinversion. Neurocomputing 2014, 133, 512–522. [Google Scholar] [CrossRef]
- Jin, L.; Zhang, Y.; Li, S.; Zhang, Y. Modified ZNN for Time-Varying Quadratic Programming With Inherent Tolerance to Noises and Its Application to Kinematic Redundancy Resolution of Robot Manipulators. IEEE Trans. Ind. Electron. 2016, 63, 6978–6988. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, S.; Kadry, S.; Liao, B. Recurrent neural network for kinematic control of redundant manipulators with periodic input disturbance and physical constraints. IEEE Trans. Cybern. 2018, 49, 4194–4205. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Chen, J.; Wang, W.; Zhang, D.; Zeb, A.; Nanehkaran, Y.A. Attention embedded lightweight network for maize disease recognition. Plant Pathol. 2021, 70, 630–642. [Google Scholar] [CrossRef]
- Jocher, G. YOLOv5. Ultralytics: Github. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 22 November 2022).
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Wei, K.; Li, J.; Ma, C.; Ding, M.; Wei, S.; Wu, F.; Chen, G.; Ranbaduge, T. Vertical federated learning: Challenges, methodologies and experiments. arXiv 2022, arXiv:2202.04309. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE Computer Society: Piscataway, NJ, USA, 2021; pp. 3490–3499. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Ye, M.; Wang, Z.; Lan, X.; Yuen, P.C. Visible thermal person re-identification via dual-constrained top-ranking. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; Volume 1, p. 2. [Google Scholar]
- Liu, B.; Wang, M.; Foroosh, H.; Tappen, M.; Pensky, M. Sparse convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 806–814. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Zhang, Q.; Lin, G.; Zhang, Y.; Xu, G.; Wang, J. Wildland Forest Fire Smoke Detection Based on Faster R-CNN using Synthetic Smoke Images. Procedia Eng. 2018, 211, 441–446. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 16965–16974. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).