
No-Reference Image Quality Assessment Combining Swin-Transformer and Natural Scene Statistics

Abstract
:1. Introduction
- We propose an NR-IQA method called STNS-IQA, which employs Swin-Transformer to extract multi-scale features from images, and natural scene statistics to compensate for the information loss caused by image resizing, thus improving the performance of image quality assessment.
- We develop a Feature Enhancement Module (FEM) that enhances global visual information capture using dilated convolution and further introduces deformable convolution to enhance the flexibility and accuracy of feature extraction and improve the network’s ability to perceive the local content of images.
- We propose a Dual-branch Attention (DBA) structure, mechanism that uses channel attention to assign different weights to different feature channels and category specific residual attention to enhance the model’s sensitivity to image content, enabling the model to customize its evaluation for specific content or scene types in an image.
- We conducted evaluations on six benchmark datasets, encompassing both authentic and synthetic distortions, and our findings confirm that our proposed method yields good performance across diverse datasets.
2. Related Work
2.1. FR-IQA
2.2. RR-IQA
2.3. NR-IQA
3. Proposed Methods
3.1. Overview
3.2. Natural Scene Statistics Branch
3.3. Feature Enhancement Module
3.4. Deformable Convolution
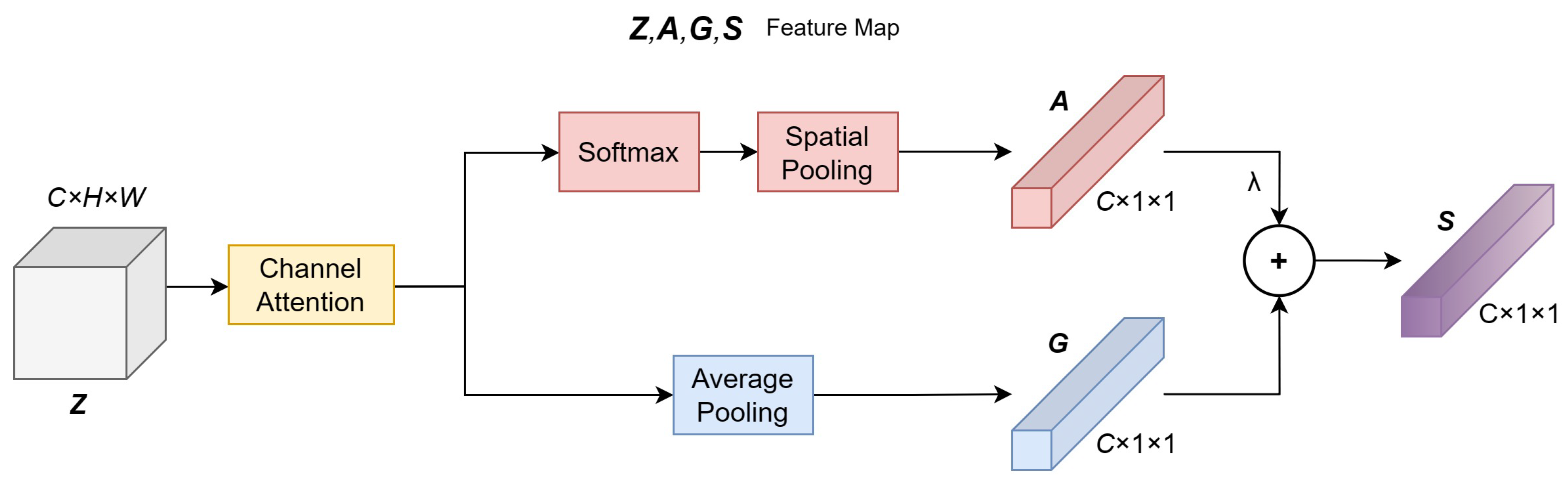
3.5. Dual-Branch Attention Mechanism
3.6. Feature Fusion and Quality Prediction
4. Experiment
4.1. Datasets and Evaluation Metrics
4.2. Implementation Specifics
4.3. Performance Evaluation
4.4. Visual Analysis
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, Z.; Bovik, A.C. Modern image quality assessment. Synth. Lect. Image Video Multimed. Process. 2006, 2, 1–156. [Google Scholar]
- Zhang, F.; Xu, Y. Image quality evaluation based on human visual perception. In Proceedings of the 2009 Chinese Control and Decision Conference, Guilin, China, 17–19 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1487–1490. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Zhang, F.; Ma, L.; Ngan, K.N. Image quality assessment by separately evaluating detail losses and additive impairments. IEEE Trans. Multimed. 2011, 13, 935–949. [Google Scholar] [CrossRef]
- Bae, S.H.; Kim, M. DCT-QM: A DCT-based quality degradation metric for image quality optimization problems. IEEE Trans. Image Process. 2016, 25, 4916–4930. [Google Scholar] [CrossRef]
- Wu, J.; Lin, W.; Shi, G.; Liu, A. Reduced-reference image quality assessment with visual information fidelity. IEEE Trans. Multimed. 2013, 15, 1700–1705. [Google Scholar] [CrossRef]
- Liu, Y.; Zhai, G.; Gu, K.; Liu, X.; Zhao, D.; Gao, W. Reduced-reference image quality assessment in free-energy principle and sparse representation. IEEE Trans. Multimed. 2017, 20, 379–391. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, G.; Sheikh, H.R.; Simoncelli, E.P.; Yang, E.H.; Bovik, A.C. Quality-aware images. IEEE Trans. Image Process. 2006, 15, 1680–1689. [Google Scholar] [CrossRef] [PubMed]
- Zhu, W.; Zhai, G.; Min, X.; Hu, M.; Liu, J.; Guo, G.; Yang, X. Multi-channel decomposition in tandem with free-energy principle for reduced-reference image quality assessment. IEEE Trans. Multimed. 2019, 21, 2334–2346. [Google Scholar] [CrossRef]
- Lee, S.; Park, S.J. A new image quality assessment method to detect and measure strength of blocking artifacts. Signal Process. Image Commun. 2012, 27, 31–38. [Google Scholar] [CrossRef]
- Wang, Z.; Sheikh, H.R.; Bovik, A.C. No-reference perceptual quality assessment of JPEG compressed images. In Proceedings of the International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; IEEE: Piscataway, NJ, USA, 2002; Volume 1. [Google Scholar]
- Marziliano, P.; Dufaux, F.; Winkler, S.; Ebrahimi, T. A no-reference perceptual blur metric. In Proceedings of the International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; IEEE: Piscataway, NJ, USA, 2002; Volume 3. [Google Scholar]
- Marichal, X.; Ma, W.Y.; Zhang, H. Blur determination in the compressed domain using DCT information. In Proceedings of the 1999 International Conference on Image Processing (Cat. 99CH36348), Kobe, Japan, 24–28 October 1999; IEEE: Piscataway, NJ, USA, 1999; Volume 2, pp. 386–390. [Google Scholar]
- Vu, P.V.; Chandler, D.M. A fast wavelet-based algorithm for global and local image sharpness estimation. IEEE Signal Process. Lett. 2012, 19, 423–426. [Google Scholar] [CrossRef]
- Moorthy, A.K.; Bovik, A.C. A two-step framework for constructing blind image quality indices. IEEE Signal Process. Lett. 2010, 17, 513–516. [Google Scholar] [CrossRef]
- Moorthy, A.K.; Bovik, A.C. Blind image quality assessment: From natural scene statistics to perceptual quality. IEEE Trans. Image Process. 2011, 20, 3350–3364. [Google Scholar] [CrossRef] [PubMed]
- Saad, M.A.; Bovik, A.C.; Charrier, C. A DCT statistics-based blind image quality index. IEEE Signal Process. Lett. 2010, 17, 583–586. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Ye, P.; Kumar, J.; Kang, L.; Doermann, D. Unsupervised feature learning framework for no-reference image quality assessment. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1098–1105. [Google Scholar]
- Xue, W.; Zhang, L.; Mou, X. Learning without human scores for blind image quality assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 28 June 2013; pp. 995–1002. [Google Scholar]
- Kang, L.; Ye, P.; Li, Y.; Doermann, D. Convolutional neural networks for no-reference image quality assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1733–1740. [Google Scholar]
- Kang, L.; Ye, P.; Li, Y.; Doermann, D. Simultaneous estimation of image quality and distortion via multi-task convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 2791–2795. [Google Scholar]
- Zhang, W.; Ma, K.; Yan, J.; Deng, D.; Wang, Z. Blind image quality assessment using a deep bilinear convolutional neural network. IEEE Trans. Circuits Syst. Video Technol. 2018, 30, 36–47. [Google Scholar] [CrossRef]
- Ma, K.; Liu, W.; Zhang, K.; Duanmu, Z.; Wang, Z.; Zuo, W. End-to-end blind image quality assessment using deep neural networks. IEEE Trans. Image Process. 2017, 27, 1202–1213. [Google Scholar] [CrossRef] [PubMed]
- Lin, K.Y.; Wang, G. Hallucinated-IQA: No-reference image quality assessment via adversarial learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 732–741. [Google Scholar]
- Varga, D. No-reference image quality assessment with convolutional neural networks and decision fusion. Appl. Sci. 2021, 12, 101. [Google Scholar] [CrossRef]
- Liu, X.; Van De Weijer, J.; Bagdanov, A.D. Rankiqa: Learning from rankings for no-reference image quality assessment. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 1040–1049. [Google Scholar]
- Yang, G.; Zhan, Y.; Wang, Y. Deep Superpixel-Based Network For Blind Image Quality Assessment. arXiv 2021, arXiv:2110.06564. [Google Scholar]
- Su, S.; Yan, Q.; Zhu, Y.; Zhang, C.; Ge, X.; Sun, J.; Zhang, Y. Blindly assess image quality in the wild guided by a self-adaptive hyper network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3667–3676. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Chen, M.; Radford, A.; Child, R.; Wu, J.; Jun, H.; Luan, D.; Sutskever, I. Generative pretraining from pixels. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 July 2020; pp. 1691–1703. [Google Scholar]
- You, J.; Korhonen, J. Transformer for image quality assessment. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1389–1393. [Google Scholar]
- Golestaneh, S.A.; Dadsetan, S.; Kitani, K.M. No-reference image quality assessment via transformers, relative ranking, and self-consistency. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 1220–1230. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Ke, J.; Wang, Q.; Wang, Y.; Milanfar, P.; Yang, F. Musiq: Multi-scale image quality transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5148–5157. [Google Scholar]
- Yang, S.; Wu, T.; Shi, S.; Lao, S.; Gong, Y.; Cao, M.; Wang, J.; Yang, Y. Maniqa: Multi-dimension attention network for no-reference image quality assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1191–1200. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.L.; Yang, Y.B. Sa-net: Shuffle attention for deep convolutional neural networks. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2235–2239. [Google Scholar]
- Zhu, K.; Wu, J. Residual attention: A simple but effective method for multi-label recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 184–193. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Sheikh, H.R.; Sabir, M.F.; Bovik, A.C. A statistical evaluation of recent full reference image quality assessment algorithms. IEEE Trans. Image Process. 2006, 15, 3440–3451. [Google Scholar] [CrossRef] [PubMed]
- Larson, E.C.; Chandler, D.M. Most apparent distortion: Full-reference image quality assessment and the role of strategy. J. Electron. Imag. 2010, 19, 011006. [Google Scholar]
- Ponomarenko, N.; Jin, L.; Ieremeiev, O.; Lukin, V.; Egiazarian, K.; Astola, J.; Vozel, B.; Chehdi, K.; Carli, M.; Battisti, F.; et al. Image database TID2013: Peculiarities, results and perspectives. Signal Process. Image Commun. 2015, 30, 57–77. [Google Scholar] [CrossRef]
- Lin, H.; Hosu, V.; Saupe, D. KADID-10k: A large-scale artificially distorted IQA database. In Proceedings of the 2019 Eleventh International Conference on Quality of Multimedia Experience (QoMEX), Berlin, Germany, 5–9 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–3. [Google Scholar]
- Ghadiyaram, D.; Bovik, A.C. Massive online crowdsourced study of subjective and objective picture quality. IEEE Trans. Image Process. 2015, 25, 372–387. [Google Scholar] [CrossRef] [PubMed]
- Hosu, V.; Lin, H.; Sziranyi, T.; Saupe, D. KonIQ-10k: An ecologically valid database for deep learning of blind image quality assessment. IEEE Trans. Image Process. 2020, 29, 4041–4056. [Google Scholar] [CrossRef] [PubMed]
- Saad, M.A.; Bovik, A.C.; Charrier, C. Blind image quality assessment: A natural scene statistics approach in the DCT domain. IEEE Trans. Image Process. 2012, 21, 3339–3352. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhang, L.; Bovik, A.C. A feature-enriched completely blind image quality evaluator. IEEE Trans. Image Process. 2015, 24, 2579–2591. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Lee, S. Fully deep blind image quality predictor. IEEE J. Sel. Top. Signal Process. 2016, 11, 206–220. [Google Scholar] [CrossRef]
- Zhu, H.; Li, L.; Wu, J.; Dong, W.; Shi, G. MetaIQA: Deep meta-learning for no-reference image quality assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 14143–14152. [Google Scholar]
- Ying, Z.; Niu, H.; Gupta, P.; Mahajan, D.; Ghadiyaram, D.; Bovik, A. From patches to pictures (PaQ-2-PiQ): Mapping the perceptual space of picture quality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3575–3585. [Google Scholar]
- Pan, Z.; Yuan, F.; Lei, J.; Fang, Y.; Shao, X.; Kwong, S. VCRNet: Visual compensation restoration network for no-reference image quality assessment. IEEE Trans. Image Process. 2022, 31, 1613–1627. [Google Scholar] [CrossRef] [PubMed]
- Pan, Z.; Yuan, F.; Wang, X.; Xu, L.; Shao, X.; Kwong, S. No-reference image quality assessment via multibranch convolutional neural networks. IEEE Trans. Artif. Intell. 2022, 4, 148–160. [Google Scholar] [CrossRef]
- Pan, Z.; Zhang, H.; Lei, J.; Fang, Y.; Shao, X.; Ling, N.; Kwong, S. DACNN: Blind image quality assessment via a distortion-aware convolutional neural network. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7518–7531. [Google Scholar] [CrossRef]
- Wang, J.; Fan, H.; Hou, X.; Xu, Y.; Li, T.; Lu, X.; Fu, L. Mstriq: No reference image quality assessment based on swin transformer with multi-stage fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1269–1278. [Google Scholar]
- Shi, J.; Gao, P.; Qin, J. Transformer-based no-reference image quality assessment via supervised contrastive learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; Volume 38, pp. 4829–4837. [Google Scholar]
- You, J.; Yan, J. Explore Spatial and Channel Attention in Image Quality Assessment. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 26–30. [Google Scholar] [CrossRef]
- Ding, K.; Ma, K.; Wang, S.; Simoncelli, E.P. Image quality assessment: Unifying structure and texture similarity. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2567–2581. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.; Min, X.; Tu, D.; Ma, S.; Zhai, G. Blind quality assessment for in-the-wild images via hierarchical feature fusion and iterative mixed database training. IEEE J. Sel. Top. Signal Process. 2023, 17, 1178–1192. [Google Scholar] [CrossRef]
- Ma, K.; Duanmu, Z.; Wang, Z.; Wu, Q.; Liu, W.; Yong, H.; Li, H.; Zhang, L. Group maximum differentiation competition: Model comparison with few samples. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 851–864. [Google Scholar] [CrossRef] [PubMed]
- Ma, K.; Duanmu, Z.; Wu, Q.; Wang, Z.; Yong, H.; Li, H.; Zhang, L. Waterloo exploration database: New challenges for image quality assessment models. IEEE Trans. Image Process. 2016, 26, 1004–1016. [Google Scholar] [CrossRef] [PubMed]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 618–626. [Google Scholar]
- Bosse, S.; Maniry, D.; Müller, K.R.; Wiegand, T.; Samek, W. Deep neural networks for no-reference and full-reference image quality assessment. IEEE Trans. Image Process. 2017, 27, 206–219. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | # of Dist. Images | # of Dist. Types | Distortions Type |
|---|---|---|---|
| LIVE | 799 | 5 | synthetic |
| CSIQ | 866 | 6 | synthetic |
| TID2013 | 3000 | 24 | synthetic |
| KADID-10K | 10,125 | 25 | synthetic |
| CLIVE | 1162 | - | authentic |
| KonIQ-10K | 10,073 | - | authentic |
| Methods | LIVE | CSIQ | TID2013 | KADID-10K | ||||
|---|---|---|---|---|---|---|---|---|
| SROCC | PLCC | SROCC | PLCC | SROCC | PLCC | SROCC | PLCC | |
| DIIVINE [49] | 0.892 | 0.908 | 0.804 | 0.776 | 0.643 | 0.567 | 0.413 | 0.435 |
| BRISQUE [19] | 0.929 | 0.944 | 0.812 | 0.748 | 0.626 | 0.571 | 0.528 | 0.567 |
| ILNIQE [50] | 0.902 | 0.906 | 0.822 | 0.865 | 0.521 | 0.648 | 0.528 | 0.558 |
| BIECON [51] | 0.958 | 0.961 | 0.815 | 0.823 | 0.717 | 0.762 | 0.623 | 0.648 |
| MEON [26] | 0.951 | 0.955 | 0.852 | 0.864 | 0.808 | 0.824 | 0.604 | 0.691 |
| DBCNN [25] | 0.968 | 0.971 | 0.946 | 0.959 | 0.816 | 0.865 | 0.851 | 0.856 |
| TIQA [34] | 0.949 | 0.965 | 0.825 | 0.838 | 0.846 | 0.858 | 0.850 | 0.855 |
| MetaIQA [52] | 0.960 | 0.959 | 0.899 | 0.908 | 0.856 | 0.868 | 0.762 | 0.775 |
| P2P-BM [53] | 0.959 | 0.958 | 0.899 | 0.902 | 0.862 | 0.856 | 0.840 | 0.849 |
| HyperIQA [31] | 0.962 | 0.966 | 0.923 | 0.942 | 0.840 | 0.858 | 0.852 | 0.845 |
| TReS [35] | 0.969 | 0.968 | 0.922 | 0.942 | 0.863 | 0.883 | 0.858 | 0.859 |
| VCRNet [54] | 0.971 | 0.972 | 0.943 | 0.955 | 0.846 | 0.875 | - | - |
| MB-CNN [55] | 0.972 | 0.972 | 0.937 | 0.949 | 0.808 | 0.842 | - | - |
| DACNN [56] | 0.978 | 0.980 | 0.943 | 0.957 | 0.871 | 0.889 | 0.905 | 0.905 |
| MSTRIQ [57] | - | - | - | - | 0.882 | 0.895 | - | - |
| SaTQA [58] | - | - | 0.965 | 0.972 | 0.938 | 0.948 | 0.946 | 0.949 |
| STNS-IQA | 0.977 | 0.979 | 0.966 | 0.976 | 0.908 | 0.922 | 0.922 | 0.926 |
| Methods | CLIVE | KonIQ-10K | ||
|---|---|---|---|---|
| SROCC | PLCC | SROCC | PLCC | |
| DIIVINE [49] | 0.588 | 0.591 | 0.546 | 0.558 |
| BRISQUE [19] | 0.629 | 0.629 | 0.681 | 0.685 |
| ILNIQE [50] | 0.508 | 0.508 | 0.523 | 0.537 |
| BIECON [51] | 0.613 | 0.613 | 0.651 | 0.654 |
| MEON [26] | 0.697 | 0.710 | 0.611 | 0.628 |
| DBCNN [25] | 0.869 | 0.869 | 0.875 | 0.884 |
| TIQA [34] | 0.845 | 0.861 | 0.892 | 0.903 |
| MetaIQA [52] | 0.835 | 0.802 | 0.887 | 0.856 |
| P2P-BM [53] | 0.844 | 0.842 | 0.872 | 0.885 |
| HyperIQA [31] | 0.859 | 0.882 | 0.906 | 0.917 |
| TReS [35] | 0.846 | 0.877 | 0.915 | 0.928 |
| VCRNet [54] | 0.856 | 0.865 | 0.894 | 0.909 |
| SCA-IQA [59] | - | - | 0.916 | 0.931 |
| DACNN [56] | 0.866 | 0.884 | 0.901 | 0.912 |
| MSTRIQ [57] | - | - | 0.946 | 0.954 |
| SaTQA [58] | 0.877 | 0.903 | 0.930 | 0.941 |
| STNS-IQA | 0.864 | 0.890 | 0.923 | 0.933 |
| Method | DBCNN [25] | TIQA [34] | HyperIQA [31] | TReS [35] | DACNN [56] | STNS-IQA |
|---|---|---|---|---|---|---|
| DBCNN [25] | 0 | 0 | −1 | −1 | −1 | −1 |
| TIQA [34] | 0 | 0 | −1 | −1 | −1 | −1 |
| HyperIQA [31] | 1 | 1 | 0 | −1 | −1 | −1 |
| TReS [35] | 1 | 1 | 1 | 0 | −1 | −1 |
| DACNN [56] | 1 | 1 | 1 | 1 | 0 | −1 |
| STNS-IQA | 1 | 1 | 1 | 1 | 1 | 0 |
| Method | GFlops | Params. (M) | CSIQ | TID2013 | KonIQ-10K |
|---|---|---|---|---|---|
| DISTS [60] | 30.69 | 14.72 | 0.929 | 0.830 | - |
| TReS [35] | 8.39 | 34.46 | 0.922 | 0.863 | 0.915 |
| StairIQA [61] | 10.38 | 31.80 | 0.919 | - | 0.921 |
| STNS-IQA | 5.53 | 46.84 | 0.966 | 0.908 | 0.923 |
| Train On | CLIVE | KonIQ-10K | LIVE |
|---|---|---|---|
| Test On | KonIQ-10K | CLIVE | CSIQ |
| WaDIQaM [65] | 0.711 | 0.682 | 0.704 |
| DBCNN [25] | 0.754 | 0.755 | 0.758 |
| HyperIQA [31] | 0.772 | 0.785 | 0.744 |
| TReS [35] | 0.733 | 0.786 | 0.761 |
| STNS-IQA | 0.758 | 0.808 | 0.763 |
| Swin-Transformer | FEM | Deformable Convolution | DBA | NSS Branch | SROCC |
|---|---|---|---|---|---|
| ✓ | 0.912 | ||||
| ✓ | ✓ | 0.915 | |||
| ✓ | ✓ | 0.914 | |||
| ✓ | ✓ | ✓ | 0.919 | ||
| ✓ | ✓ | ✓ | ✓ | 0.921 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 0.923 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Lei, Z.; Li, C. No-Reference Image Quality Assessment Combining Swin-Transformer and Natural Scene Statistics. Sensors 2024, 24, 5221. https://doi.org/10.3390/s24165221
Yang Y, Lei Z, Li C. No-Reference Image Quality Assessment Combining Swin-Transformer and Natural Scene Statistics. Sensors. 2024; 24(16):5221. https://doi.org/10.3390/s24165221
Chicago/Turabian StyleYang, Yuxuan, Zhichun Lei, and Changlu Li. 2024. "No-Reference Image Quality Assessment Combining Swin-Transformer and Natural Scene Statistics" Sensors 24, no. 16: 5221. https://doi.org/10.3390/s24165221