
A Machine-Learning-Based Method for Identifying the Failure Risk State of Fissured Sandstone under Water–Rock Interaction

 ,
,
Abstract
:1. Introduction
2. Methodology
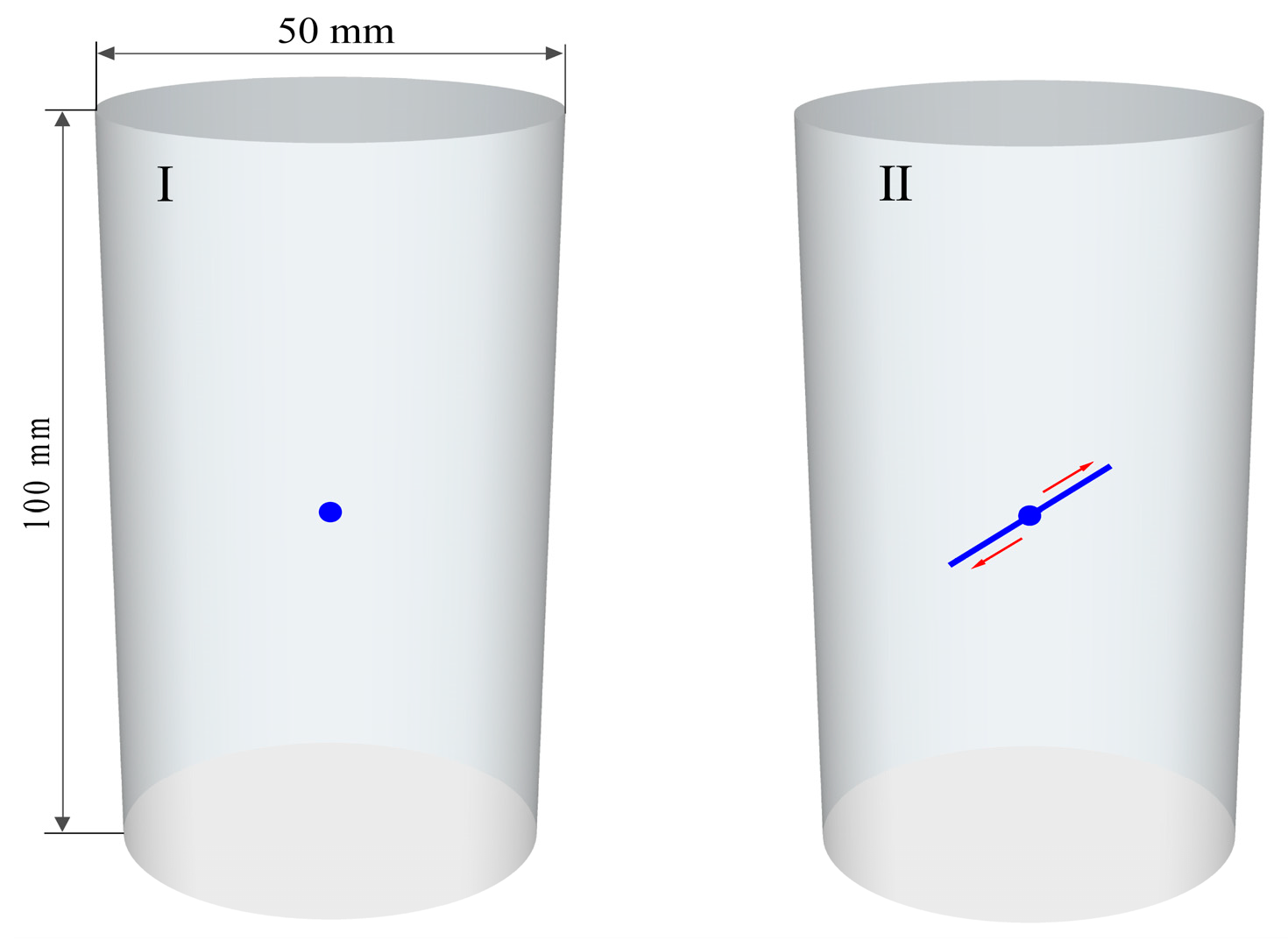
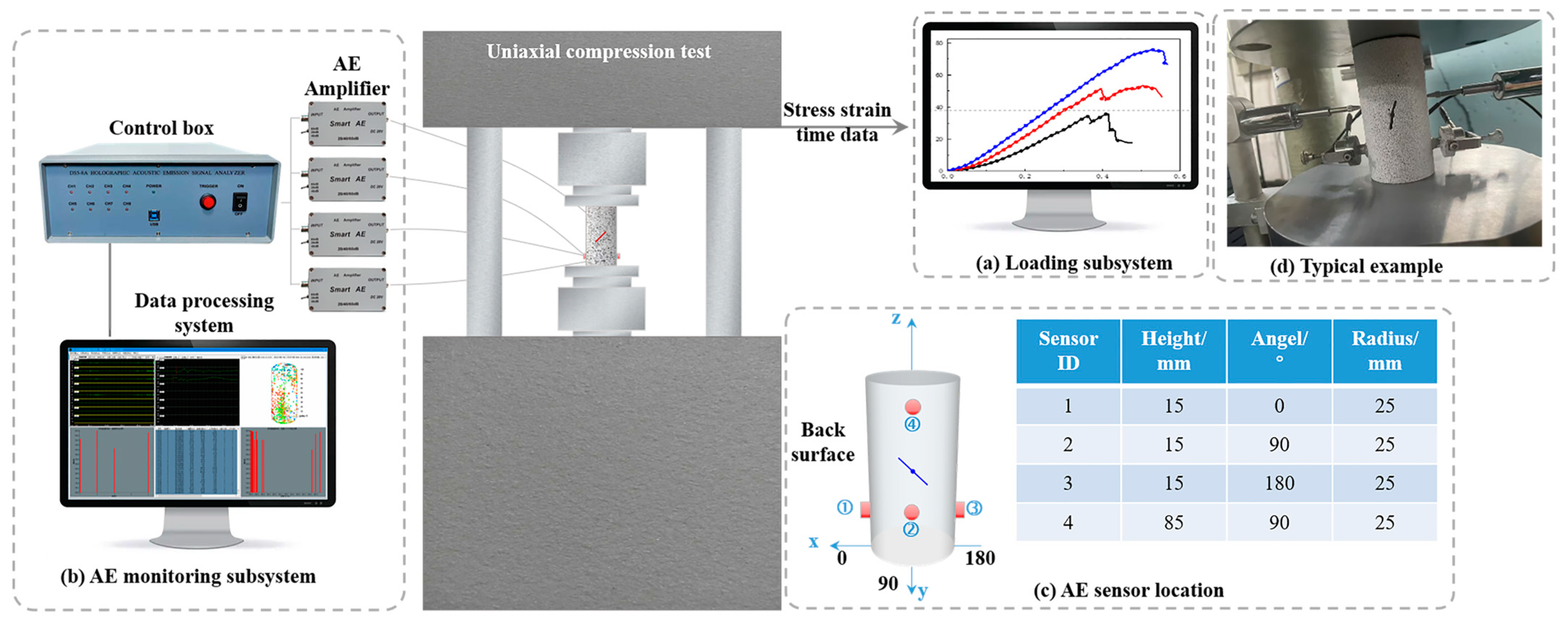
2.1. Material Preparation and Experiment Setup
2.1.1. Material Preparation
2.1.2. Uniaxial Compression Test of Fissured Sandstone
2.2. Machine Learning Models
2.2.1. Random Forest
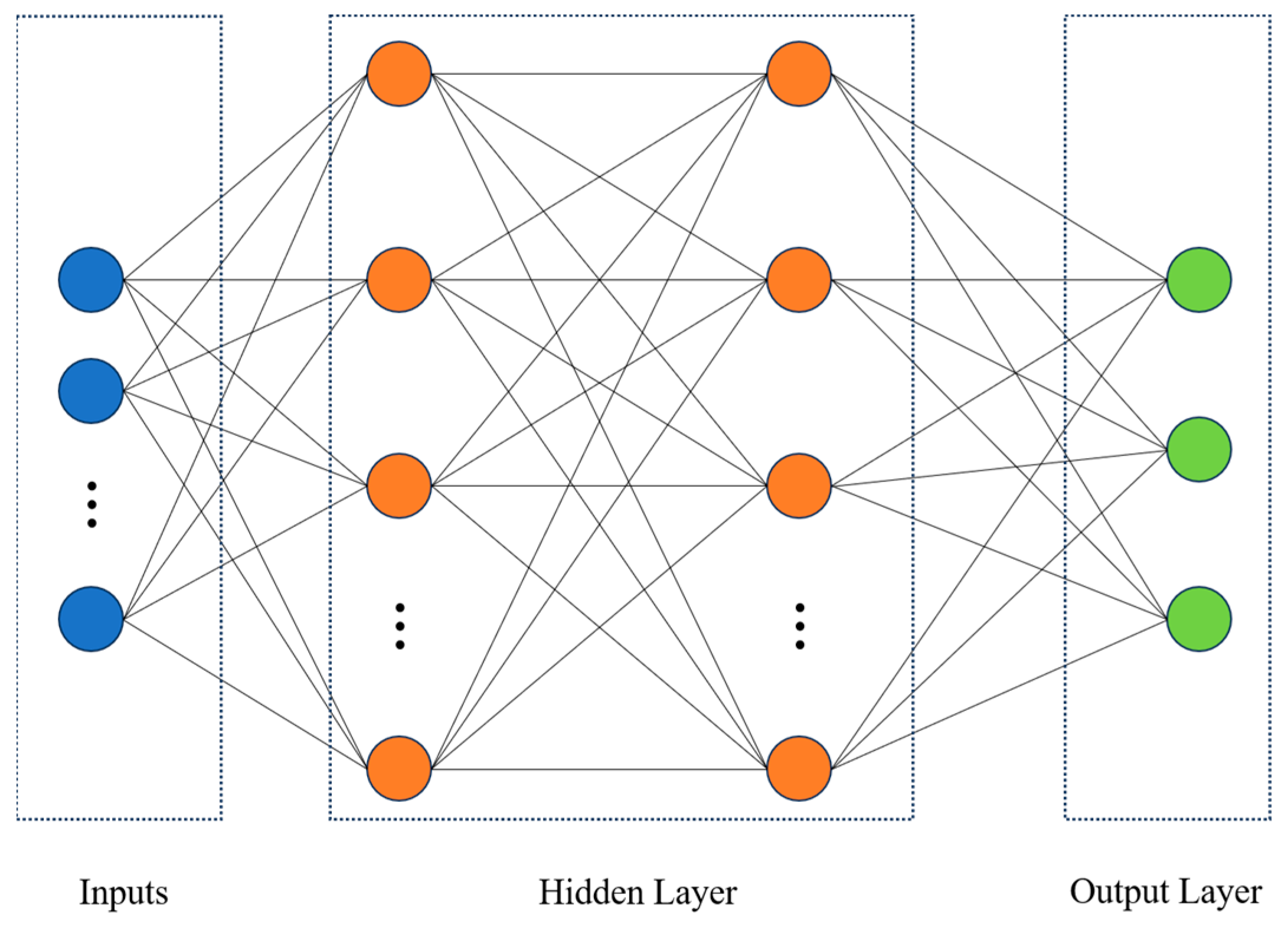
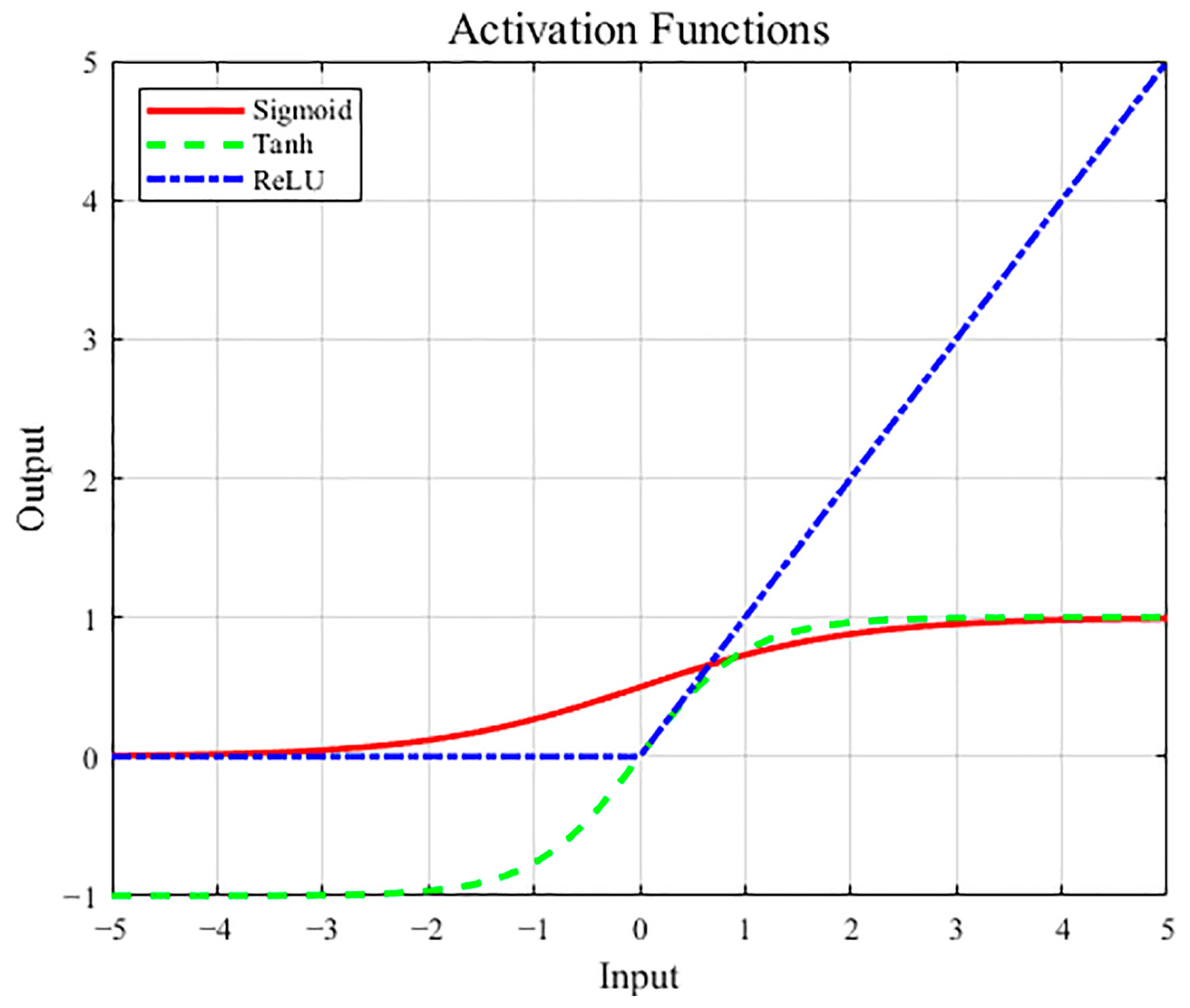
2.2.2. Multilayer Perceptron
2.2.3. AdaBoost
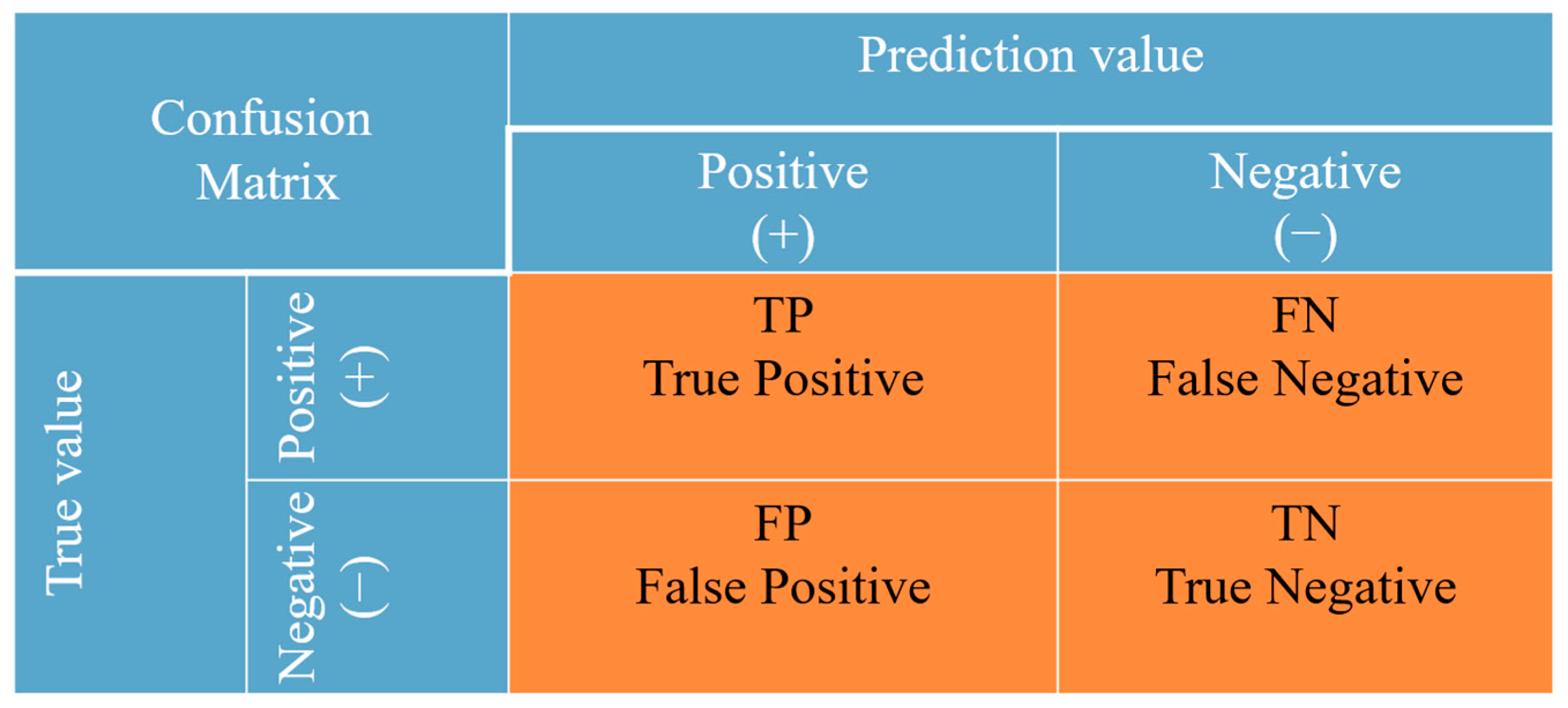
2.2.4. Model Performance Evaluation Metrics
3. Analysis of Instability Precursor Information in Fissured Sandstone
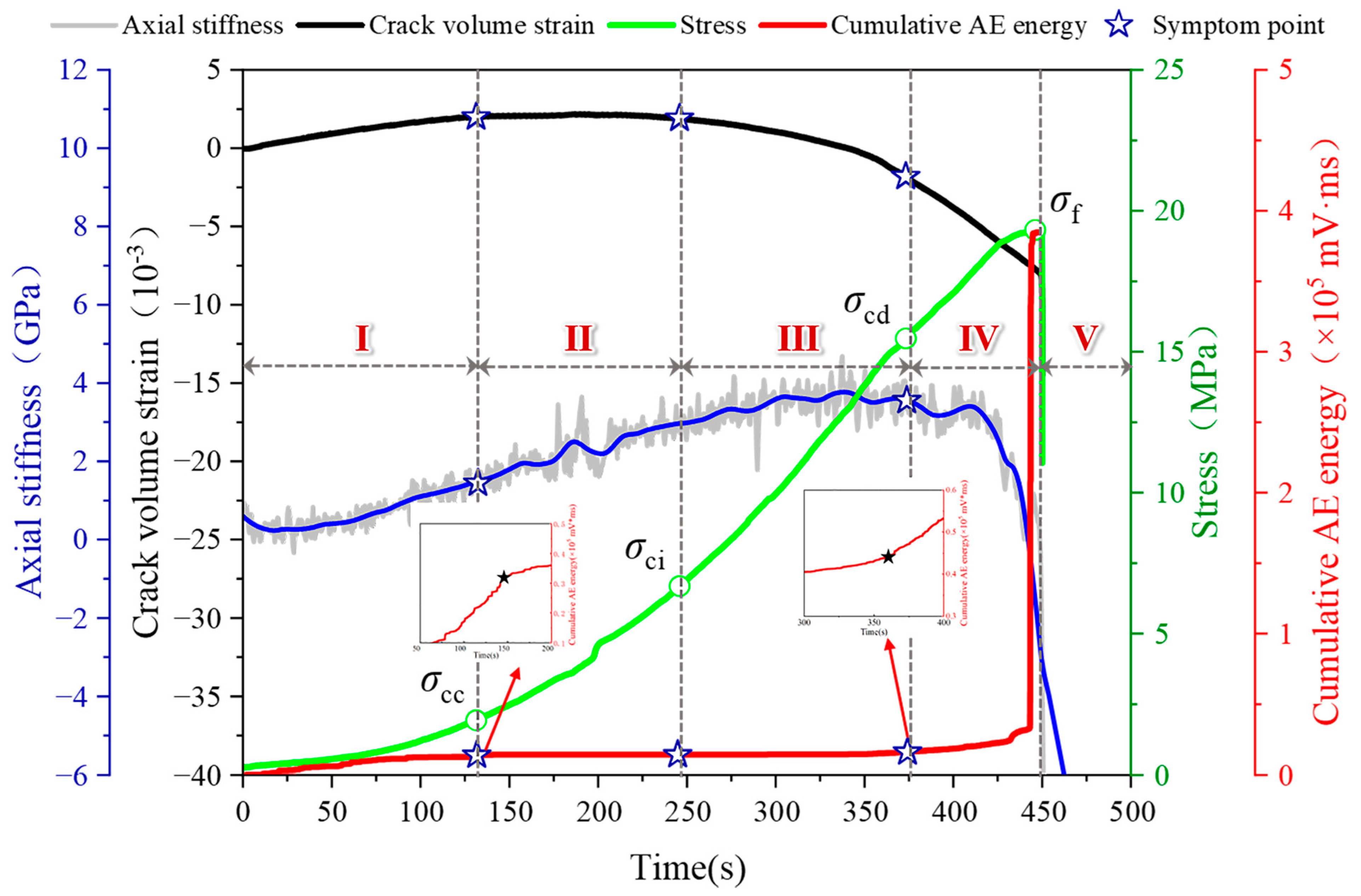
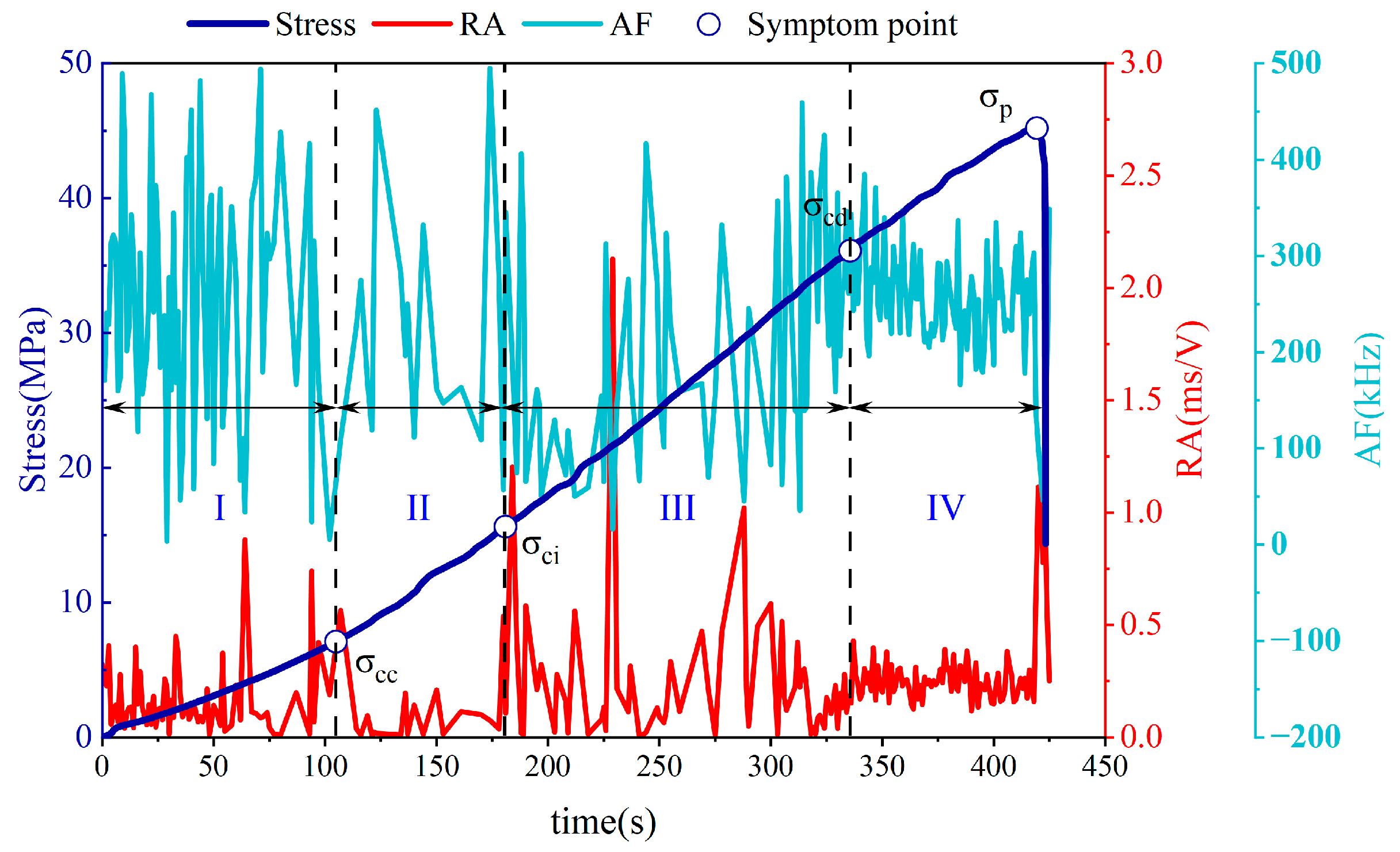
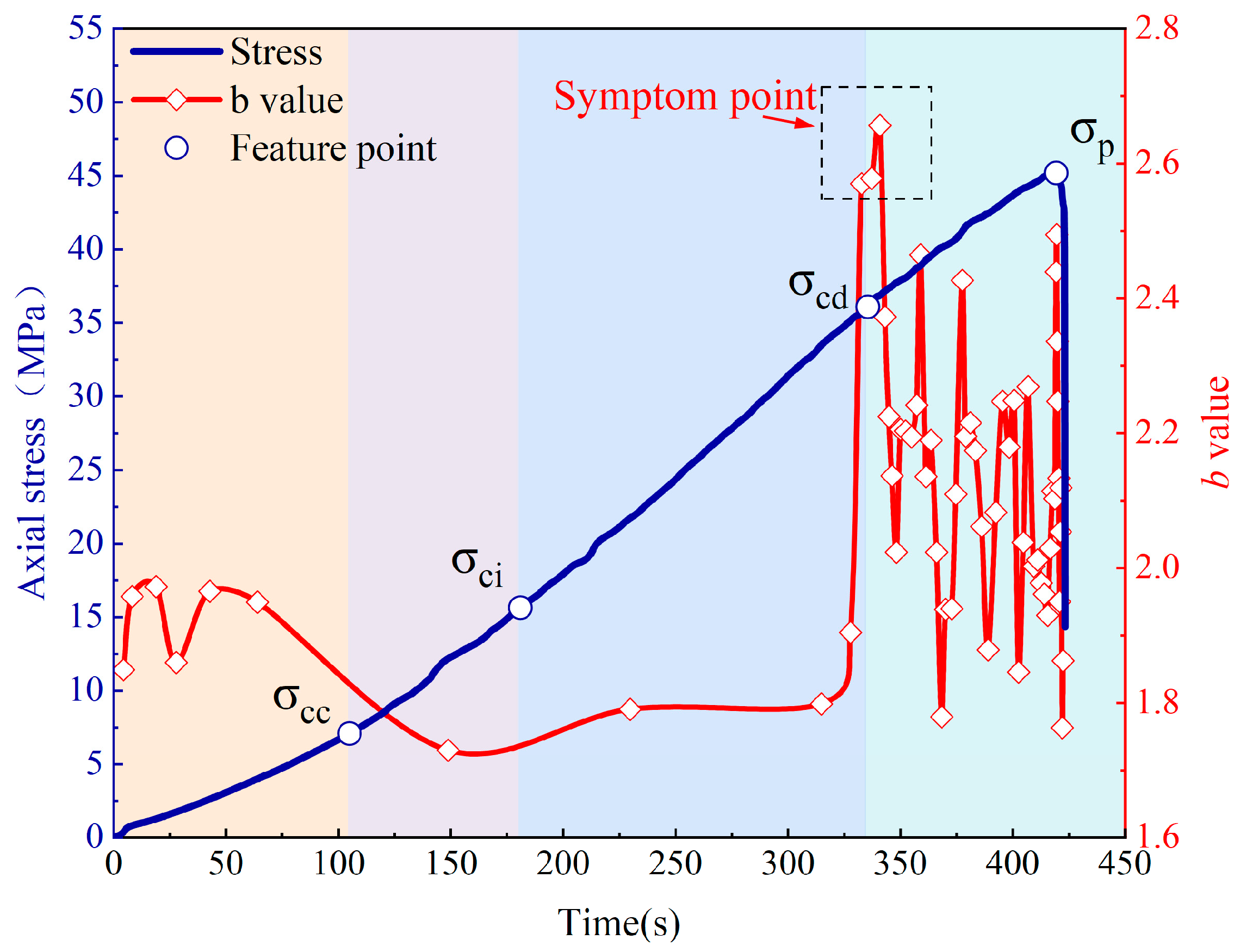
3.1. Failure Stage Division of Fissured Sandstone
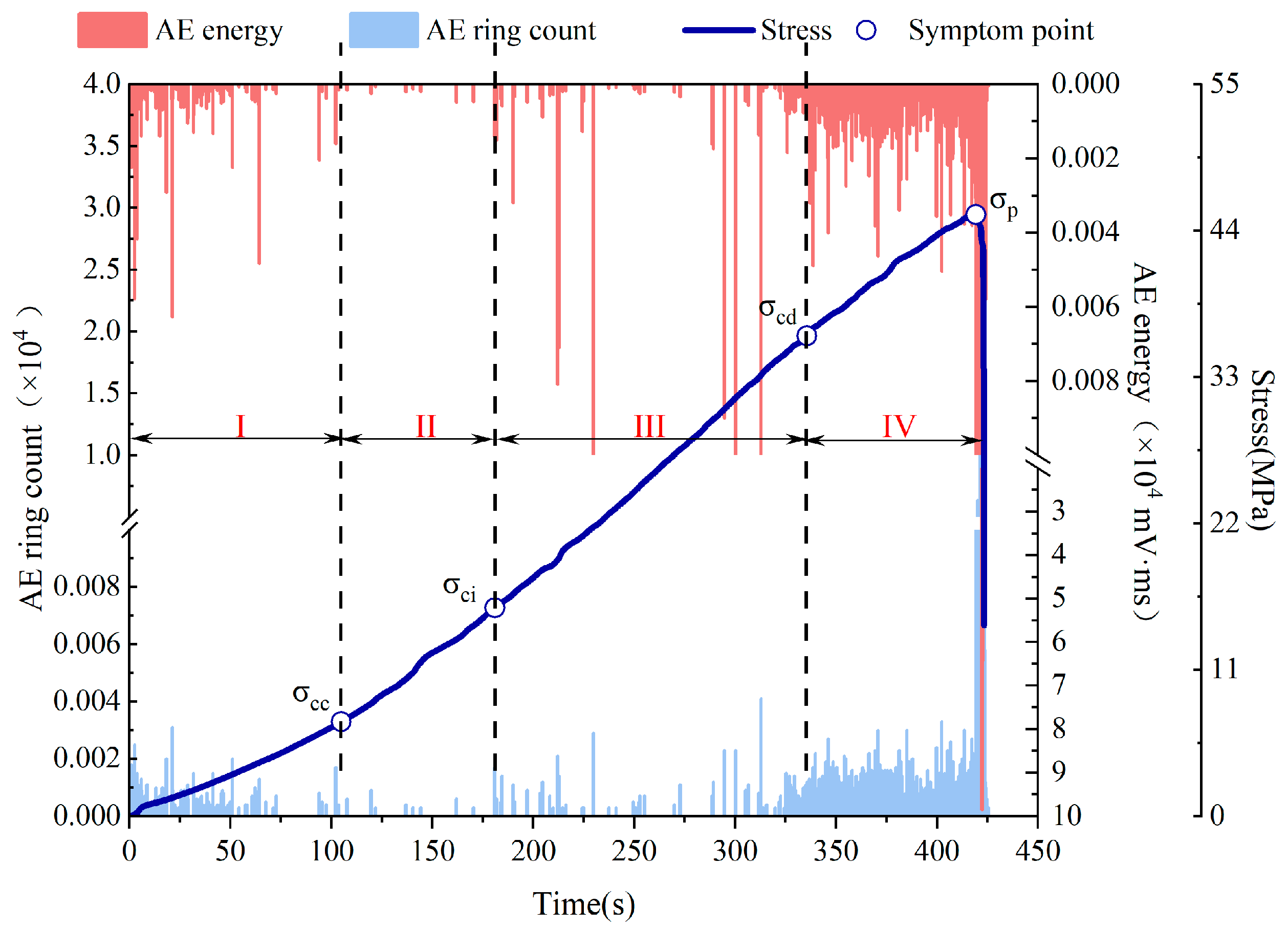
3.2. AE Energy and AE Ringing Count Characterization
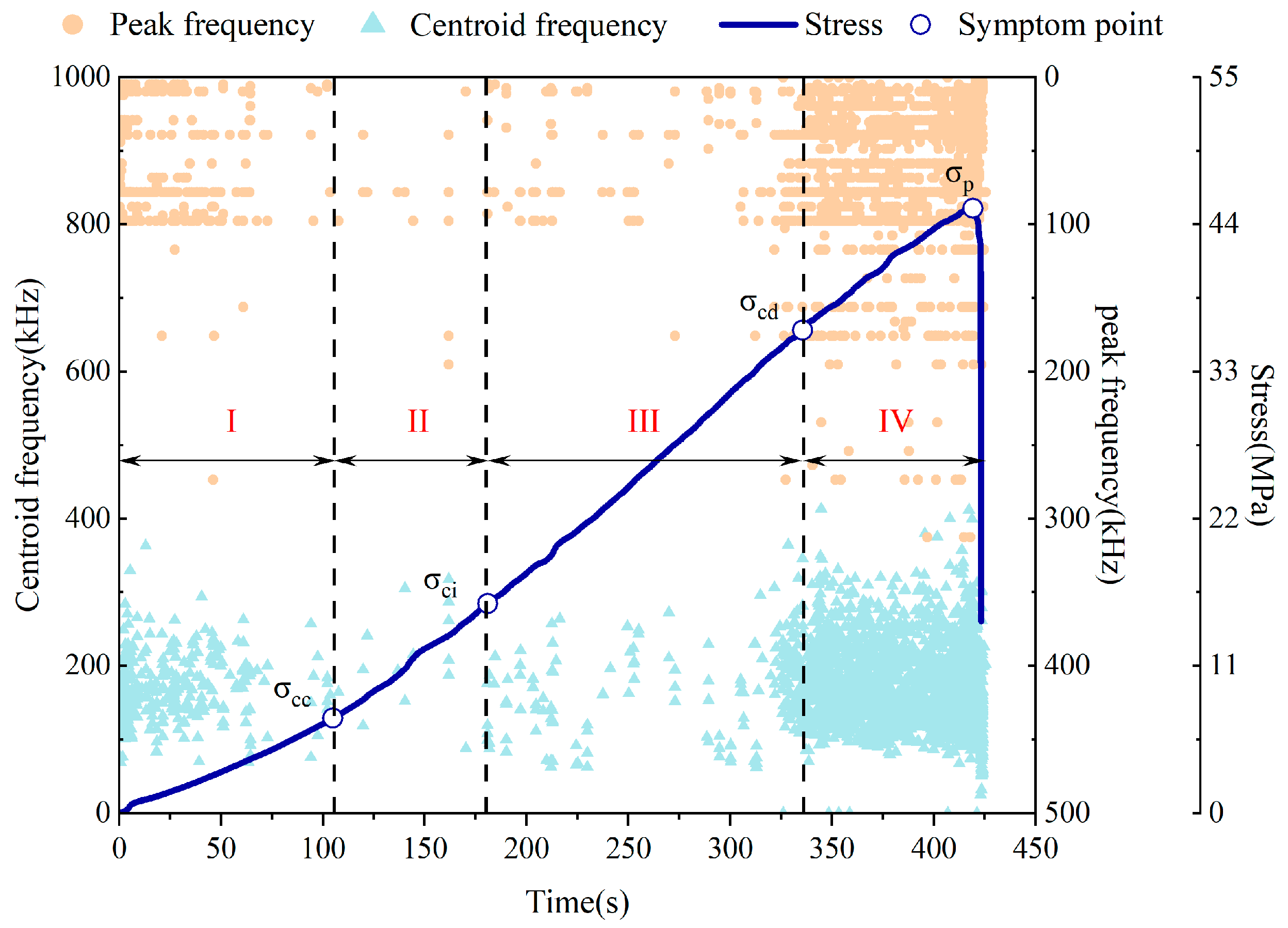
3.3. Centroid Frequency and Peak Frequency Characterization
3.4. RA Value and AF Value Characterization
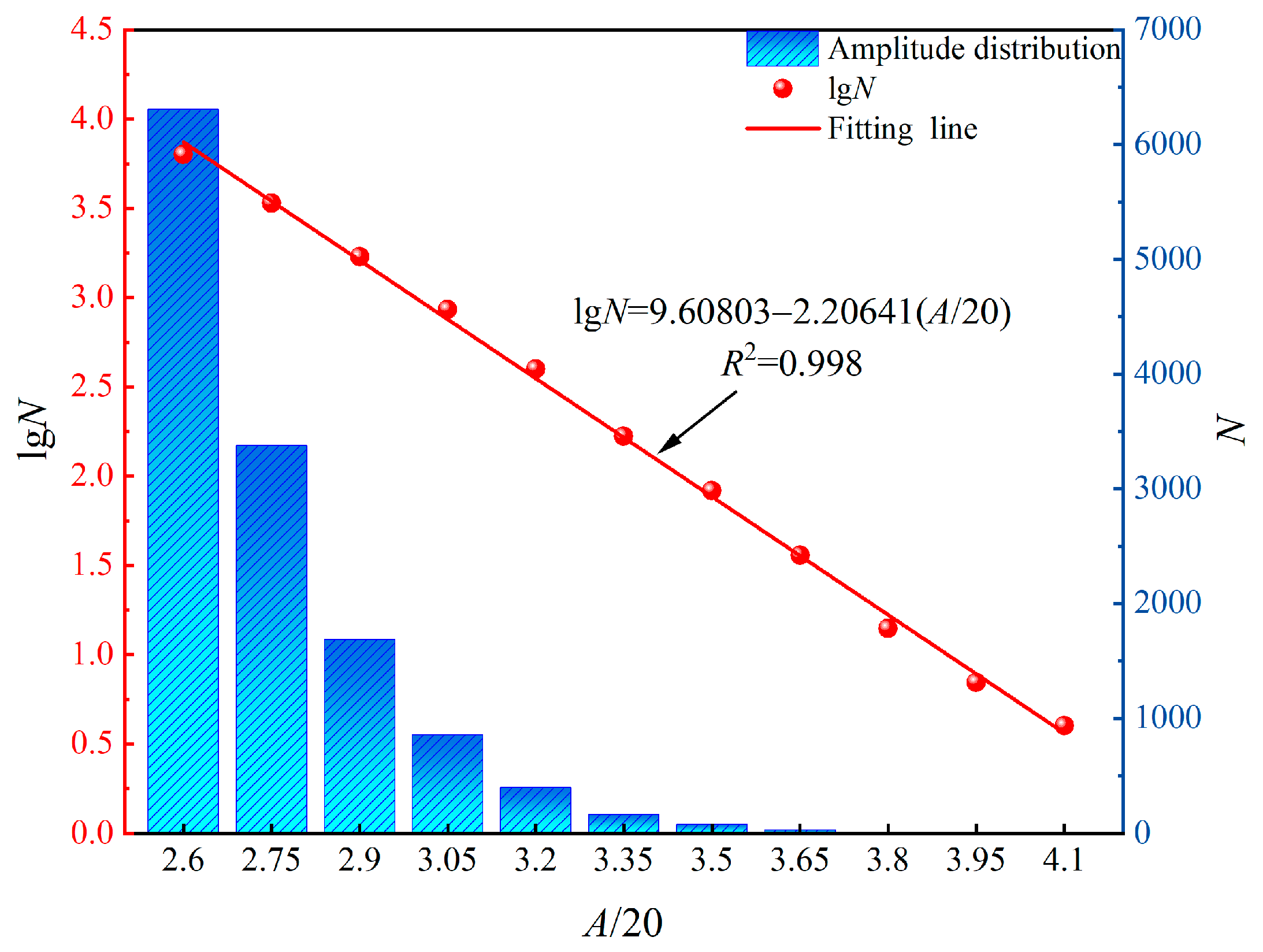
3.5. b Value Characterization
4. Development of Instability State Identification Model Based on Precursor Information
4.1. Data Acquisition
4.2. Data Preprocessing
4.3. Dataset Establishment
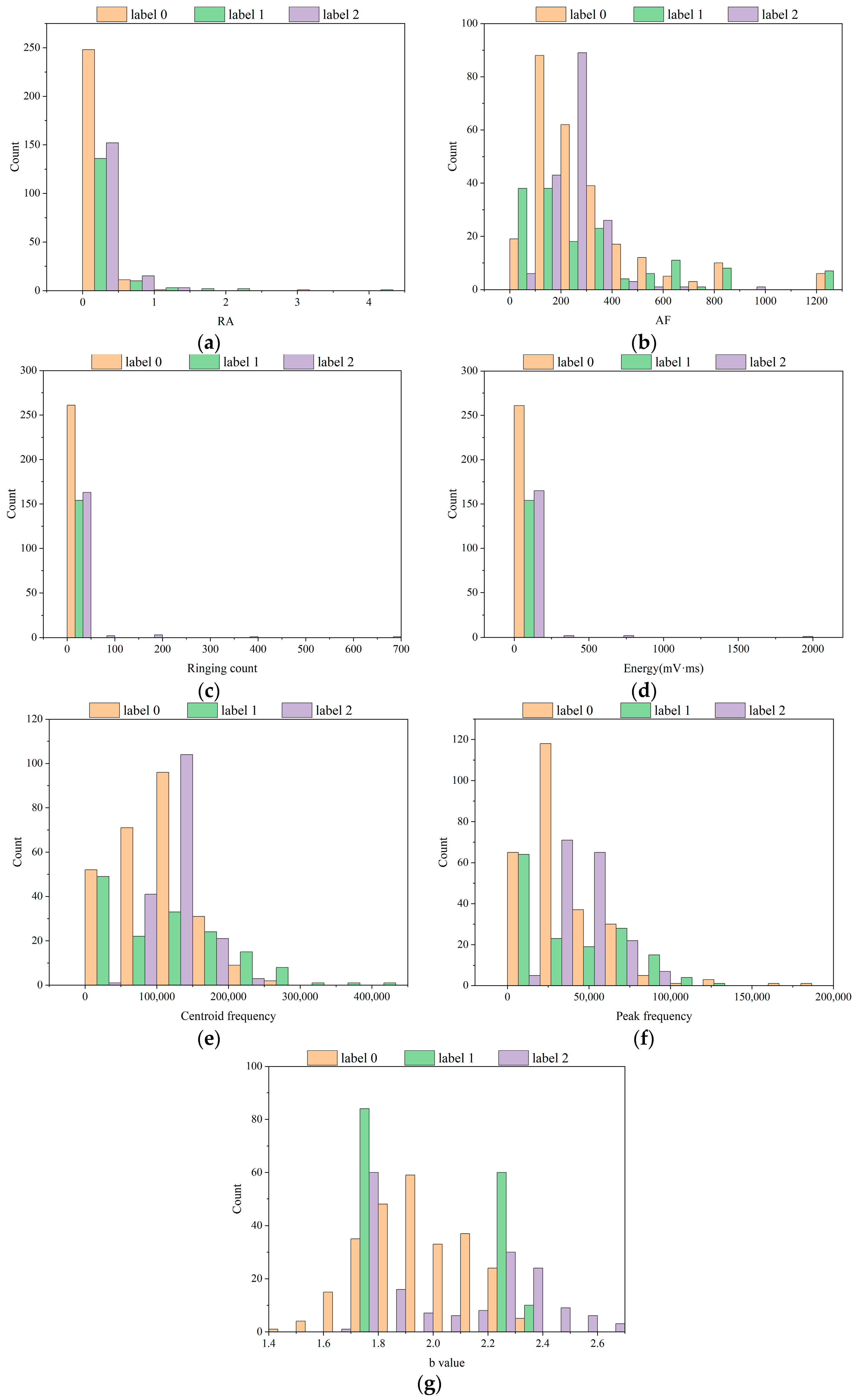
4.4. Dataset Distribution
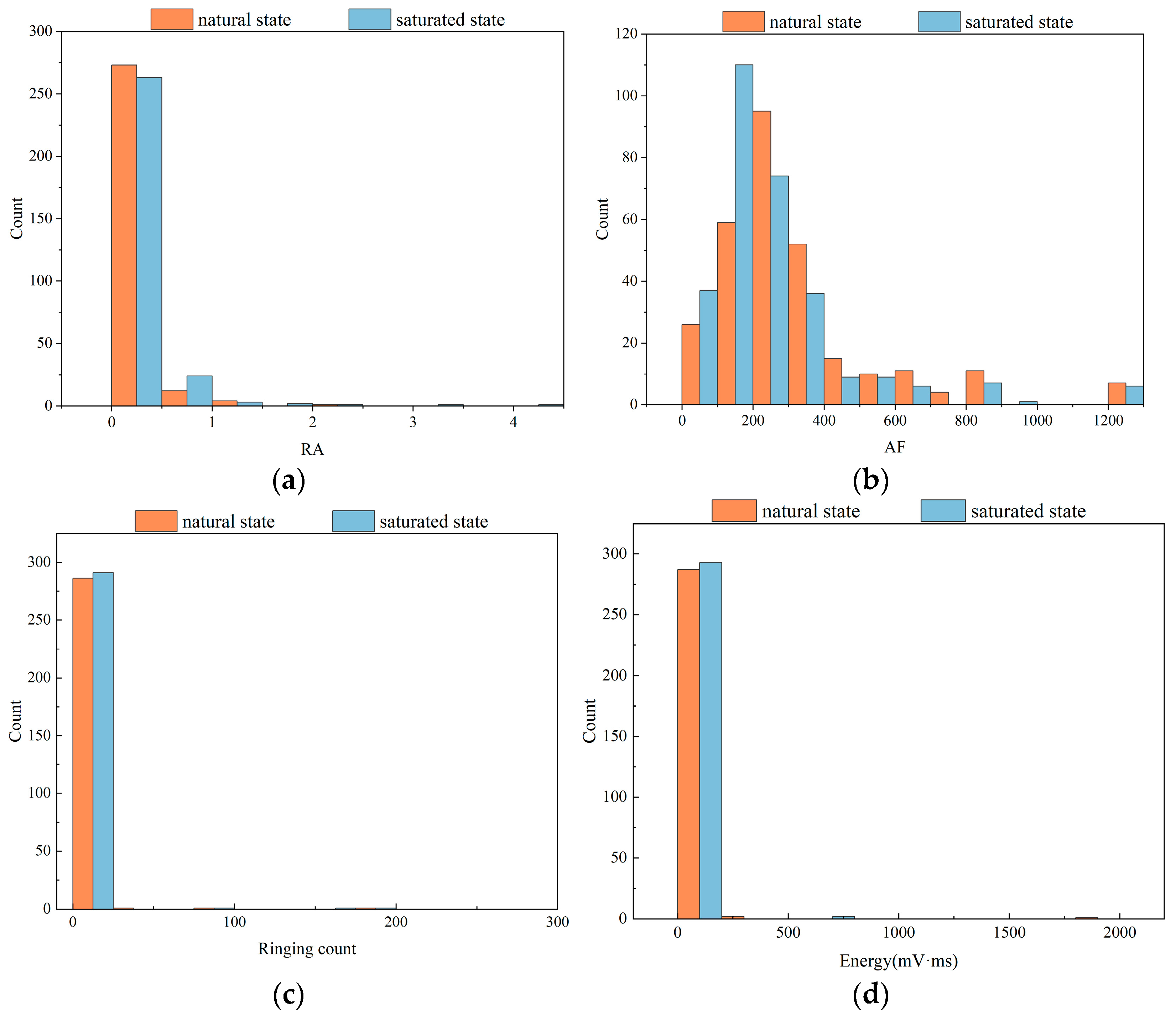
4.4.1. Data Distribution of Different States
4.4.2. Data Distribution of Different Instability Risk States
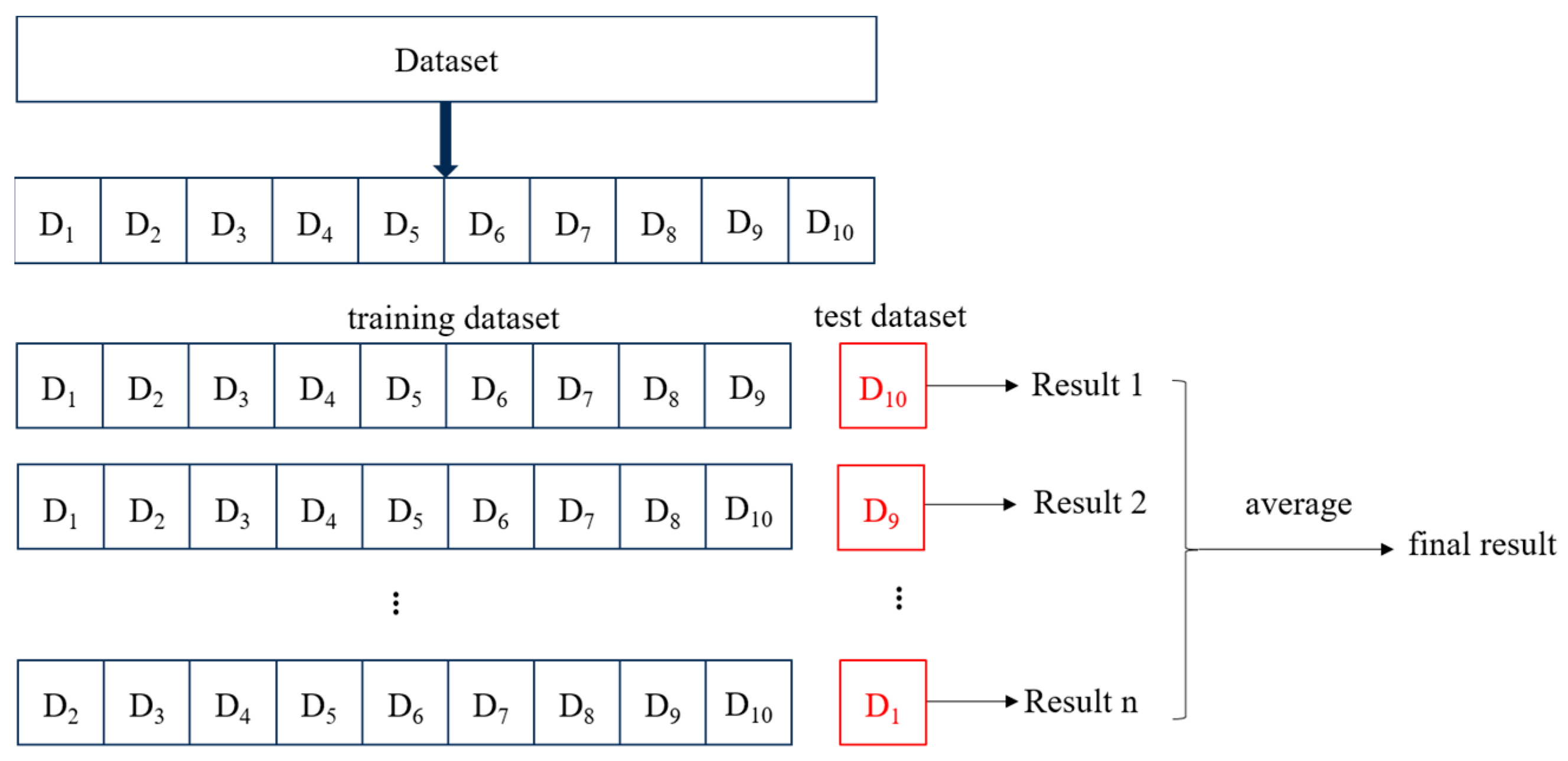
4.5. Dataset Splitting
4.6. Hyperparameter Splitting
4.7. Model Training
5. Performance Analysis and Input Feature Valuation of Machine Learning Models
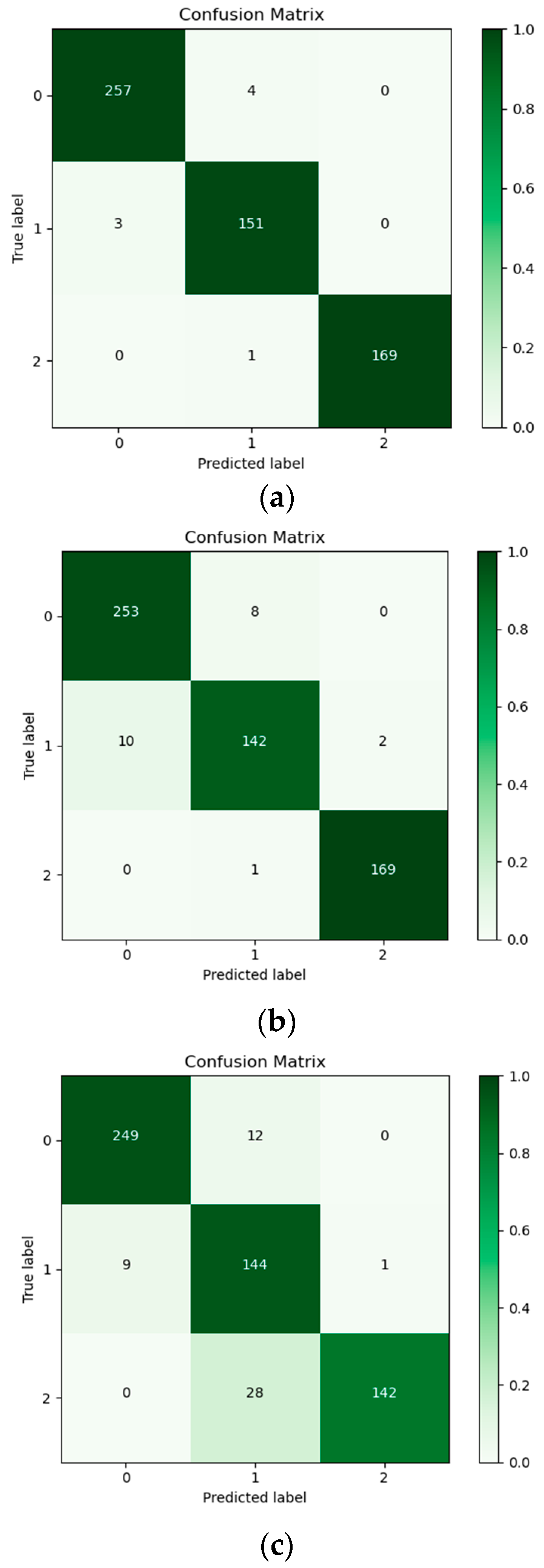
5.1. Models’ Performance
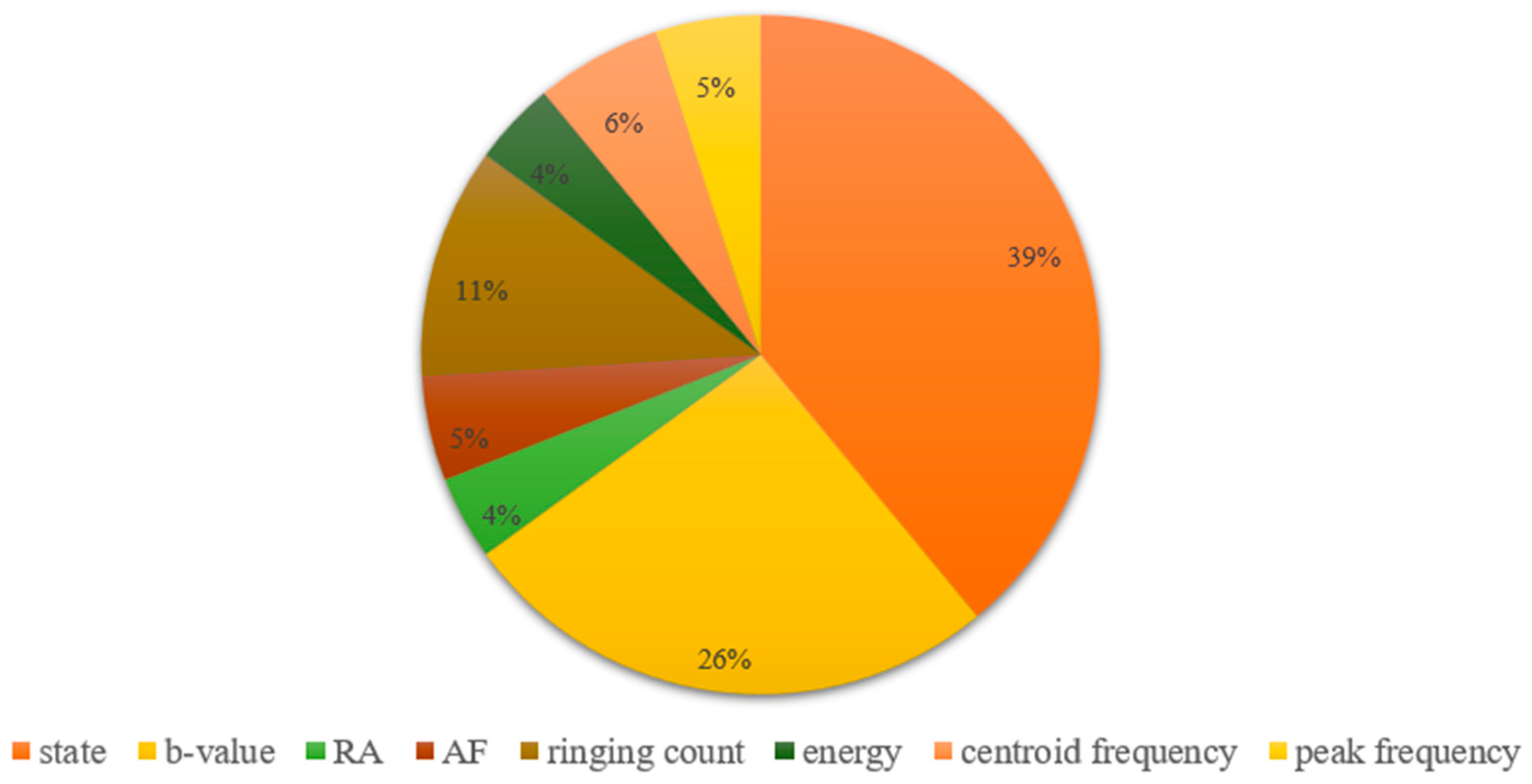
5.2. Importance Analysis of Model Input Features
5.3. Correlation Analysis of Model Input Features
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, P.; Tang, S.; Liang, X.; Zhang, Y.; Tang, C. The Influence of Immersed Water Level on the Short-and Long-Term Mechanical Behavior of Sandstone. Int. J. Rock Mech. Min. 2021, 138, 104631. [Google Scholar] [CrossRef]
- Zhao, K.; Yang, D.; Zeng, P.; Huang, Z.; Wu, W.; Li, B.; Teng, T. Effect of Water Content on the Failure Pattern and Acoustic Emission Characteristics of Red Sandstone. Int. J. Rock Mech. Min. 2021, 142, 104709. [Google Scholar] [CrossRef]
- Behnia, A.; Chai, H.K.; Shiotani, T. Advanced Structural Health Monitoring of Concrete Structures with the Aid of Acoustic Emission. Constr. Build. Mater. 2014, 65, 282–302. [Google Scholar] [CrossRef]
- Sagar, R.V.; Prasad, B.R. A Review of Recent Developments in Parametric Based Acoustic Emission Techniques Applied to Concrete Structures. Nondestruct. Test. Eval. 2012, 27, 47–68. [Google Scholar] [CrossRef]
- Yang, J.; Mu, Z.-L.; Yang, S.-Q. Experimental Study of Acoustic Emission Multi-Parameter Information Characterizing Rock Crack Development. Eng. Fract. Mech. 2020, 232, 107045. [Google Scholar] [CrossRef]
- Zhang, D.; Li, S.; Bai, X.; Yang, Y.; Chu, Y. Experimental Study on Mechanical Properties, Energy Dissipation Characteristics and Acoustic Emission Parameters of Compression Failure of Sandstone Specimens Containing En Echelon Flaws. Appl. Sci. 2019, 9, 596. [Google Scholar] [CrossRef]
- Niu, Y.; Zhou, X.-P.; Zhou, L.-S. Fracture Damage Prediction in Fissured Red Sandstone under Uniaxial Compression: Acoustic Emission b-Value Analysis. Fatigue Fract. Eng. Mater. Struct. 2020, 43, 175–190. [Google Scholar] [CrossRef]
- Chmel, A.; Shcherbakov, I. A Comparative Acoustic Emission Study of Compression and Impact Fracture in Granite. Int. J. Rock Mech. Min. Sci. 2013, 64, 56–59. [Google Scholar] [CrossRef]
- Chmel, A.; Shcherbakov, I. Temperature Dependence of Acoustic Emission from Impact Fractured Granites. Tectonophysics 2014, 632, 218–223. [Google Scholar] [CrossRef]
- Li, D.; Wang, E.; Kong, X.; Ali, M.; Wang, D. Mechanical Behaviors and Acoustic Emission Fractal Characteristics of Coal Specimens with a Pre-Existing Flaw of Various Inclinations under Uniaxial Compression. Int. J. Rock Mech. Min. Sci. 2019, 116, 38–51. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, Y.; Hu, L.; Tang, C.; Zheng, H. Predicting Rock Failure with the Critical Slowing down Theory. Eng. Geol. 2021, 280, 105960. [Google Scholar] [CrossRef]
- Wang, C.; Cao, C.; Li, C.; Chuai, X.; Zhao, G.; Lu, H. Experimental Investigation on Synergetic Prediction of Granite Rockburst Using Rock Failure Time and Acoustic Emission Energy. J. Cent. South Univ. 2022, 29, 1262–1273. [Google Scholar] [CrossRef]
- Liang, W.; Luo, S.; Zhao, G.; Wu, H. Predicting Hard Rock Pillar Stability Using GBDT, XGBoost, and LightGBM Algorithms. Mathematics 2020, 8, 765. [Google Scholar] [CrossRef]
- Wang, G.; Zhao, B.; Wu, B.; Zhang, C.; Liu, W. Intelligent Prediction of Slope Stability Based on Visual Exploratory Data Analysis of 77 In Situ Cases. Int. J. Min. Sci. Technol. 2023, 33, 47–59. [Google Scholar] [CrossRef]
- Su, G.; Huang, J.; Xu, H.; Qin, Y. Extracting Acoustic Emission Features That Precede Hard Rock Instability with Unsupervised Learning. Eng. Geol. 2022, 306, 106761. [Google Scholar] [CrossRef]
- Duan, D.; Feng, X.; Zhang, R.; Chen, X.; Zhang, H. Research on Recognition of Quiet Period of Sandstone Acoustic Emission Based on Four Machine Learning Algorithms. Geofluids 2022, 2022, 2133607. [Google Scholar] [CrossRef]
- Zhou, J.; Huang, S.; Tao, M.; Khandelwal, M.; Dai, Y.; Zhao, M. Stability Prediction of Underground Entry-Type Excavations Based on Particle Swarm Optimization and Gradient Boosting Decision Tree. Undergr. Space 2023, 9, 234–249. [Google Scholar] [CrossRef]
- Dong, L.; Tang, Z.; Li, X.; Chen, Y.; Xue, J. Discrimination of Mining Microseismic Events and Blasts Using Convolutional Neural Networks and Original Waveform. J. Cent. South Univ. 2020, 27, 3078–3089. [Google Scholar] [CrossRef]
- Muir, C.; Swaminathan, B.; Almansour, A.S.; Sevener, K.; Smith, C.; Presby, M.; Kiser, J.D.; Pollock, T.M.; Daly, S. Damage Mechanism Identification in Composites via Machine Learning and Acoustic Emission. NPJ Comput. Mater. 2021, 7, 95. [Google Scholar] [CrossRef]
- Adin, V.; Zhang, Y.; Oelmann, B.; Bader, S. Tiny Machine Learning for Damage Classification in Concrete Using Acoustic Emission Signals. In Proceedings of the 2023 IEEE International Instrumentation and Measurement Technology Conference, I2MTC, Kuala Lumpur, Malaysia, 22–25 May 2023; IEEE: New York, NY, USA, 2023. [Google Scholar] [CrossRef]
- Mandal, D.D.; Bentahar, M.; El Mahi, A.; Brouste, A.; El Guerjouma, R.; Montresor, S.; Cartiaux, F.-B. Acoustic Emission Monitoring of Progressive Damage of Reinforced Concrete T-Beams under Four-Point Bending. Materials 2022, 15, 3486. [Google Scholar] [CrossRef]
- Smolnicki, M.; Lesiuk, G.; Stabla, P.; Pedrosa, B.; Duda, S.; Zielonka, P.; Lopes, C.C.C. Investigation of Flexural Behaviour of Composite Rebars for Concrete Reinforcement with Experimental, Numerical and Machine Learning Approaches. Philos. Trans. R. Soc. A-Math. Phys. Eng. Sci. 2023, 381, 20220394. [Google Scholar] [CrossRef]
- Zhang, T.; Mahdi, M.; Issa, M.; Xu, C.; Ozevin, D. Experimental Study on Monitoring Damage Progression of Basalt-FRP Reinforced Concrete Slabs Using Acoustic Emission and Machine Learning. Sensors 2023, 23, 8356. [Google Scholar] [CrossRef] [PubMed]
- Behnia, A.; Ranjbar, N.; Chai, H.K.; Masaeli, M. Failure Prediction and Reliability Analysis of Ferrocement Composite Structures by Incorporating Machine Learning into Acoustic Emission Monitoring Technique. Constr. Build. Mater. 2016, 122, 823–832. [Google Scholar] [CrossRef]
- Bao, Y.; Li, H. Machine Learning Paradigm for Structural Health Monitoring. Struct. Health Monit. 2021, 20, 1353–1372. [Google Scholar] [CrossRef]
- Chai, M.; Hou, X.; Zhang, Z.; Duan, Q. Identification and prediction of fatigue crack growth under different stress ratios using acoustic emission data. Int. J. Fatigue 2022, 160, 106860. [Google Scholar] [CrossRef]
- Wang, X.; Yue, Q.; Liu, X. Bolted Lap Joint Loosening Monitoring and Damage Identification Based on Acoustic Emission and Machine Learning. Mech. Syst. Signal Process. 2024, 220, 111690. [Google Scholar] [CrossRef]
- Muralha, J.; Grasselli, G.; Tatone, B.; Blümel, M.; Chryssanthakis, P.; Jiang, Y. ISRM Suggested Method for Laboratory Determination of the Shear Strength of Rock Joints: Revised Version. Rock Mech. Rock Eng. 2014, 47, 291–302. [Google Scholar] [CrossRef]
- Song, C.; Feng, G.; Bai, J.; Cui, J.; Wang, K.; Shi, X.; Qian, R. Progressive Failure Characteristics and Water-Induced Deterioration Mechanism of Fissured Sandstone under Water–Rock Interaction. Theor. Appl. Fract. Mech. 2023, 128, 104151. [Google Scholar] [CrossRef]
- Dong, L.; Zhang, L.; Liu, H.; Du, K.; Liu, X. Acoustic Emission b Value Characteristics of Granite under True Triaxial Stress. Mathematics 2022, 10, 451. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Multilayer Perceptrons 60|Handbook of Neural Computation|Luis B. Available online: https://www.taylorfrancis.com/chapters/edit/10.1201/9780429142772-60/multilayer-perceptrons-luis-almeida (accessed on 18 April 2024).
- Hao, J.; Ho, T.K. Machine Learning Made Easy: A Review of Scikit-Learn Package in Python Programming Language. J. Educ. Behav. Stat. 2019, 44, 348–361. [Google Scholar] [CrossRef]
- Hackeling, G. Mastering Machine Learning with Scikit-Learn; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. ICML 1996, 96, 148–156. [Google Scholar]
- Dietterich, T.G. An Experimental Comparison of Three Methods for Constructing Ensembles of Decision Trees: Bagging, Boosting, and Randomization. Mach. Learn. 2000, 40, 139–157. [Google Scholar] [CrossRef]
- Cao, Y.; Miao, Q.-G.; Liu, J.-C.; Gao, L. Advance and Prospects of AdaBoost Algorithm. Acta Autom. Sin. 2013, 39, 745–758. [Google Scholar] [CrossRef]
- Belavagi, M.C.; Muniyal, B. Performance Evaluation of Supervised Machine Learning Algorithms for Intrusion Detection. Procedia Comput. Sci. 2016, 89, 117–123. [Google Scholar] [CrossRef]
- Kumar, Y.; Sahoo, G. Study of Parametric Performance Evaluation of Machine Learning and Statistical Classifiers. Int. J. Inf. Technol. Comput. Sci. IJITCS 2013, 5, 57–64. [Google Scholar] [CrossRef]
- Fawcett, T. An Introduction to ROC Analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Marom, N.D.; Rokach, L.; Shmilovici, A. Using the Confusion Matrix for Improving Ensemble Classifiers. In Proceedings of the 2010 IEEE 26-th Convention of Electrical and Electronics Engineers in Israel, Eilat, Israel, 17–20 November 2010; pp. 000555–000559. [Google Scholar] [CrossRef]
- Heydarian, M.; Doyle, T.E.; Samavi, R. MLCM: Multi-Label Confusion Matrix. IEEE Access 2022, 10, 19083–19095. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, Y.; Miao, D. Three-Way Confusion Matrix for Classification: A Measure Driven View. Inform. Sciences 2020, 507, 772–794. [Google Scholar] [CrossRef]
- Colombo, I.S.; Main, I.G.; Forde, M.C. Assessing damage of reinforced concrete beam using “b-value” analysis of acoustic emission signals. J. Mater. Civ. Eng. 2003, 15, 280–286. [Google Scholar] [CrossRef]
- Rao, M.V.M.S.; Lakshmi, K.J.P. Analysis of b-Value and Improved b-Value of Acoustic Emissions Accompanying Rock Fracture. Curr. Sci. India 2005, 89, 1577–1582. [Google Scholar]
- Vabalas, A.; Gowen, E.; Poliakoff, E.; Casson, A.J. Machine Learning Algorithm Validation with a Limited Sample Size. PLoS ONE 2019, 14, e0224365. [Google Scholar] [CrossRef]
- Cai, J.; Luo, J.; Wang, S.; Yang, S. Feature Selection in Machine Learning: A New Perspective. Neurocomputing 2018, 300, 70–79. [Google Scholar] [CrossRef]
- Myers, L.; Sirois, M.J. Spearman Correlation Coefficients, Differences between. In Encyclopedia of Statistical Sciences; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2006. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Confusion Matrix | Predicted Label | |||
|---|---|---|---|---|
| 0 | 1 | 2 | ||
| True label | 0 | 00 | 01 | 01 |
| 1 | 10 | 11 | 12 | |
| 2 | 20 | 21 | 22 | |
| Parameter | Parameter Set for This Model |
|---|---|
| n_estimators | 5 |
| max_depth | 10 |
| min_samples_leaf | 1 |
| min_samples_split | 2 |
| class_weight | balanced |
| criterion | gini |
| Parameter | Parameter Set for This Model |
|---|---|
| hidden_layer_sizes | (30,20) |
| activation | adam |
| solver | adam |
| alpha | 0.1 |
| max_iter | 400 |
| Parameter | Parameter Set for This Model |
|---|---|
| base_estimator | CART decision tree |
| n_estimators | 300 |
| learning_rate | 0.6 |
| algorithm | SAMME |
| random_state | 37 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, J.; Song, C.; Bai, J.; Feng, G.; Shi, X.; Ma, J. A Machine-Learning-Based Method for Identifying the Failure Risk State of Fissured Sandstone under Water–Rock Interaction. Sensors 2024, 24, 5752. https://doi.org/10.3390/s24175752
Qu J, Song C, Bai J, Feng G, Shi X, Ma J. A Machine-Learning-Based Method for Identifying the Failure Risk State of Fissured Sandstone under Water–Rock Interaction. Sensors. 2024; 24(17):5752. https://doi.org/10.3390/s24175752
Chicago/Turabian StyleQu, Jinbo, Cheng Song, Jinwen Bai, Guorui Feng, Xudong Shi, and Junbiao Ma. 2024. "A Machine-Learning-Based Method for Identifying the Failure Risk State of Fissured Sandstone under Water–Rock Interaction" Sensors 24, no. 17: 5752. https://doi.org/10.3390/s24175752