Abstract
Defect detection on steel surfaces with complex textures is a critical and challenging task in the industry. The limited number of defect samples and the complexity of the annotation process pose significant challenges. Moreover, performing defect segmentation based on accurate identification further increases the task’s difficulty. To address this issue, we propose VQGNet, an unsupervised algorithm that can precisely recognize and segment defects simultaneously. A feature fusion method based on aggregated attention and a classification-aided module is proposed to segment defects by integrating different features in the original images and the anomaly maps, which direct the attention to the anomalous information instead of the irregular complex texture. The anomaly maps are generated more confidently using strategies for multi-scale feature fusion and neighbor feature aggregation. Moreover, an anomaly generation method suitable for grayscale images is introduced to facilitate the model’s learning on the anomalous samples. The refined anomaly maps and fused features are both input into the classification-aided module for the final classification and segmentation. VQGNet achieves state-of-the-art (SOTA) performance on the industrial steel dataset, with an I-AUROC of 99.6%, I-F1 of 98.8%, P-AUROC of 97.0%, and P-F1 of 80.3%. Additionally, ViT-Query demonstrates robust generalization capabilities in generating anomaly maps based on the Kolektor Surface-Defect Dataset 2.
1. Introduction
Defect detection is crucial and indispensable in the industrial manufacturing process. Presently, professionally trained inspectors primarily conduct product defect detection. However, manual inspection is susceptible to subjective biases, low efficiency, lengthy training periods, and high labor costs. With the rapid advancements in computer vision and industrial automation, employing computer vision to replace manual inspection is increasingly becoming the mainstream strategy for industrial defect detection. Notably, high-accuracy defect detection algorithms are essential for the automatic identification of defects. Currently, defect detection methods can be categorized into two types, which are traditional descriptor-based [1,2] and deep learning-based methods [3,4,5,6,7,8,9,10], respectively. Traditional methods typically rely on handcrafted features, including texture-based, shape-based, and color-based detection methods [11,12]. These methods do not require large datasets to learn features, while their adaptability is relatively lower due to the lack of expert knowledge compared with deep learning-based methods. Although requiring large datasets for training, deep learning algorithms deliver powerful feature extraction capabilities by different trained models. According to the tasks of defect detection, deep learning-based methods are classified into supervised, semi-supervised, and unsupervised methods [13]. At present, the detection of surface defects in steel frequently involves manually annotated anchor boxes, employing supervised object detection algorithms to concurrently accomplish defect detection, classification, and localization tasks [14,15,16]. However, in cases where defect classification is unnecessary and only defect detection and localization are required, supervised object detection algorithms necessitate a significantly substantial workload. Although object detection algorithms exhibit remarkable performance in defect localization compared to image segmentation algorithms, they are often inferior to the latter in segmenting the defect regions. Since unsupervised anomaly detection algorithms can perform defect identification and localization tasks using only normal samples, unsupervised anomaly detection algorithms also hold a significant place in the field of defect detection on the surface of steel. However, it is still a challenge for unsupervised algorithms to precisely localize and segment defects with complex backgrounds due to the lack of prior knowledge about defect samples, such as shape, color, size, and semantic information. In current industrial manufacturing, the surface of steel presents complex textures for decorative purposes and corrosion prevention, such as spangle texture on the galvanized steel, which varies in size and often exhibits irregular shapes [17]. Although texture recognition has been investigated for these kinds of steel surfaces [17], studies of defect detection in such textures have not yet been reported. There are two main challenges to precisely recognizing and segmenting defects in this kind of steel: (1) Complex texture background: The size of the texture on steel surfaces is variable and not uniform, which results in complex texture information and obstructs the recognition and accurate positioning of defects, especially tiny defects. Moreover, the complex texture also induces a time-consuming annotation process. (2) illumination variation: Illumination variation, such as overexposed and underexposed conditions, significantly affects the recognition of defects.To address these challenges, we propose VQGNet (ViT-Query with GalvaNet), an unsupervised algorithm that can precisely recognize and segment defects simultaneously. A feature fusion method, GalvaNet, based on an aggregated attention and a classification-aided module is proposed to segment defects by integrating different features in the original images and anomaly maps. In the aggregated attention module, we designed three components: the image weighting scheme (IWS), multi-scale biaxial cross-attention (MBCA), and coordinate spatial attention (CSA). The IWS aims to dynamically weight the input anomaly map and original image; MBCA is designed to enhance the selection of multi-scale features under complex textures; and CSA strengthens the model’s ability to extract the coordinate and spatial information of features. GalvaNet can generate the refined anomaly map through learning from the original image, including defect-free and defective images with the original size and anomaly maps during training. Moreover, the anomaly maps are generated more confidently via ViT-Query, a method based on vision transformer (ViT) [18] trained on text–image matching tasks, multi-scale feature fusion, and neighbor feature aggregation. An improved synthetic anomaly generation method suitable for grayscale images is also introduced to facilitate the model’s learning on anomalous samples. In summary, our main contributions are as follows:
- We propose VQGNet, an unsupervised defect detection approach on complex textured surfaces of steel.
- A feature fusion method named GalvaNet is proposed, which can improve the performance of segmentation of complex textured steel surfaces.
- We design three components: the image weighting scheme (IWS), multi-scale biaxial cross-attention (MBCA), and coordinate-spatial attention (CSA). The IWS aims to dynamically weight the input anomaly map and original image; MBCA is designed to enhance the selection of multi-scale features under complex textures; and CSA strengthens the model’s ability to extract the coordinate and spatial information of features.
- An anomaly detection algorithm based on a ViT backbone named ViT-Query, which is enriched with semantic information, multi-feature fusion, and neighbor feature aggregation methods, is proposed as an encoder to generate more confident anomaly maps.
- A method for creating synthetic anomaly images from grayscale images is also proposed, enabling the rapid and cost-effective generation of a large number of synthetic defects on spangled surfaces.
2. Related Work
2.1. Unsupervised Anomaly Detection
Unsupervised anomaly detection (UAD) is widely applied as a method of out-of-distribution detection, categorized into three main types: reconstruction-based, flow-based, and embedding-based methods. Reconstruction-based methods are commonly used for anomaly detection in images and video surveillance. Generative models, such as autoencoders (AEs) [19] and generative adversarial networks (GANs) [20], are designed to identify anomalies by comparing the deviations between reconstructed normal and anomalous data. DRÆM [21] features a dual-subnetwork architecture with the reconstruction subnetwork trained to detect and reconstruct semantically plausible anomalies and preserve non-anomalous regions. Liu et al. [22] employed a straightforward architecture comprising a feature extractor, adapter, anomaly feature generator, and discriminator. To improve the model’s generalization, they processed extracted image features, combined them with artificially generated anomalous maps using Gaussian noise, and fused them to produce final anomalous feature maps. Secondly, flow-based methods are another method for unsupervised anomaly detection, normalizing flows to assess data density and assign low likelihoods to anomalies. Rudolph et al. [23] proposed Differnet to improve the performance of models by normalizing flows at multiple scales to capture size variations of defects. Gudovskiy et al. [24] and Rudolph et al. [25] further develop Differnet by constructing multi-scale feature pyramids and introducing fully convolutional cross-scale flow modules, which optimize information exchange and expand receptive fields for precise anomaly localization. Thirdly, embedding-based methods construct a reference gallery of typical data representations and identify anomalies by contrasting them against this established reference. Initially, deep neural networks are used to derive data representations via SVM classification [26]. Recently, the investigation focused on leveraging pre-trained feature extractors from expansive datasets, aiming to pinpoint distinctive features more effectively. Various methodologies, such as k-nearest neighbors (KNN) clustering, memory banks, and bag-of-features, are utilized to assemble these features. PatchCore [27] implements a KNN algorithm on patch-level features to improve efficiency and reduce the potential for anomaly generalization prior to constructing the memory bank. Based on the foundational aspects of PatchCore, PNI [28] integrates comprehensive contextual and positional data for better recognition performance and couples them with a refinement module that follows the initial anomaly map generation to improve the accuracy of segmentation. MemSeg [29] incorporates feature information from normal images into an improved U-Net architecture to enhance the model’s detection and segmentation performance. Although unsupervised anomaly detection has achieved outstanding performance in defect recognition tasks, its performance in defect segmentation and localization tasks is still unsatisfactory, especially for images with complex backgrounds.
2.2. Anomaly Simulation-Based Methods
To enhance the segmentation ability of unsupervised models, the generation of artificial anomalies during training has been attempted recently. Li et al. [30] and Song et al. [31] employed a “copy and paste” strategy that involves small rectangular sections of an image that are randomly duplicated and reinserted to simulate structural defects with varying sizes, aspect ratios, and orientations to introduce structural discrepancies. AnomalyDiffusion [32], a few-shot learning method, utilizes diffusion models to learn the characteristics of a small number of anomaly samples and generate more realistic anomaly samples with pixel-level annotations. However, these methods primarily focus on creating either structural or textural anomalies, which may not be effective for datasets with complex backgrounds.
2.3. Attention Mechanism
Attention mechanisms are often used to enhance the accuracy of supervised semantic segmentation tasks. To improve the defect segmentation capability of unsupervised anomaly detection algorithms in complex textured backgrounds, introducing attention mechanisms seems to be a good choice. Attention mechanisms were first introduced by Xu et al. [33] for computer vision in 2015. They proposed a novel theory of visual attention that significantly enriched the research landscape. Subsequently, attention mechanisms were developed by Hu et al. [34]. They proposed a spatial attention that dynamically regulates pixel-level weights across feature maps by adjusting the weights of each feature channel. A convolutional block attention module (CBAM) [35] and spatial, channel squeeze, and excitation (SCSE) [34] have been developed to merge spatial and channel attention and introduce additional information for further optimizing the performance. Coordinate attention (CA) [36] captures the cross-channel information and incorporates direction-aware and position-sensitive details, enabling the model to more accurately locate the target areas. EMA [37] introduces a new branch based on coordinate attention to perform 3 × 3 convolution and cross-attention structures to improve the performance of the original attention mechanism. MCA [38] performs strip convolutions on the x-axis and y-axis, respectively, then computes multi-head cross-attention on the obtained feature maps. Current attention mechanisms are often designed for single attributes, with few combining multiple attributes and being applicable to complex textured surfaces.
3. Proposed Method
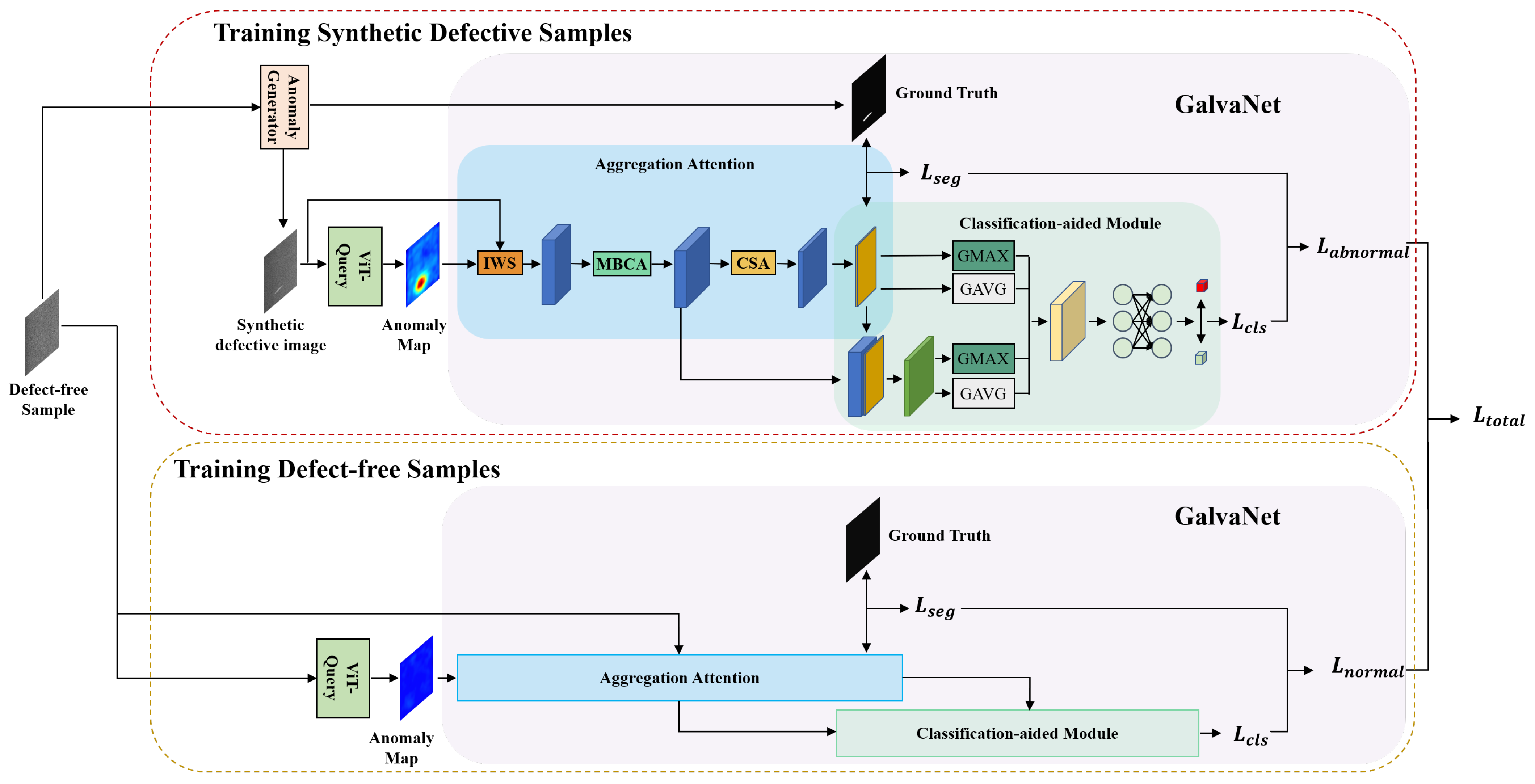
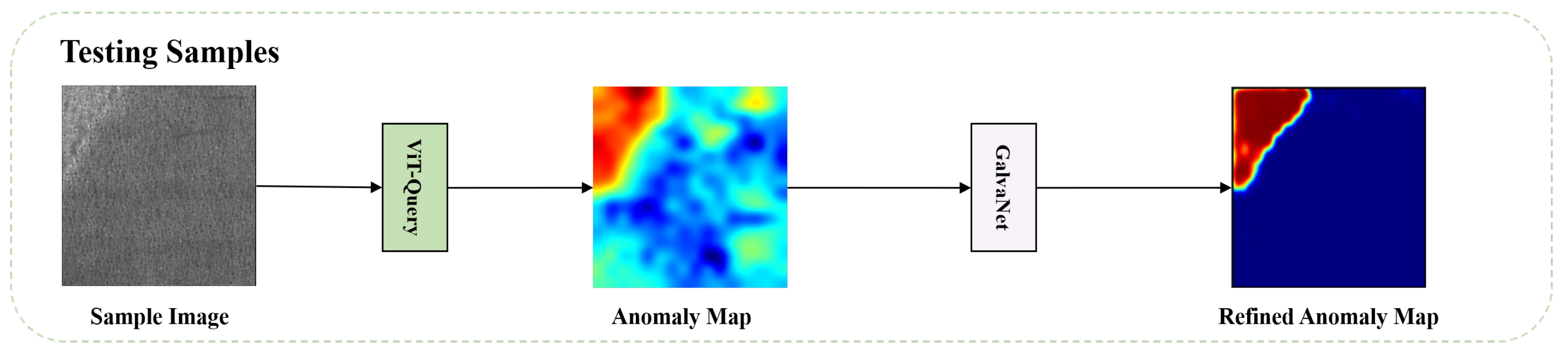
In this section, we present our new framework for recognizing and segmenting defects, VQGNet. The training and testing process is illustrated in Figure 1 and Figure 2, respectively. VQGNet comprises several fundamental components, which we will delineate in the subsequent sections: the anomaly map generation module ViT-Query (Section 3.1), an anomaly generator (Section 3.2), the main multi-task network architecture GalvaNet (Section 3.3), and the loss function (Section 3.4).
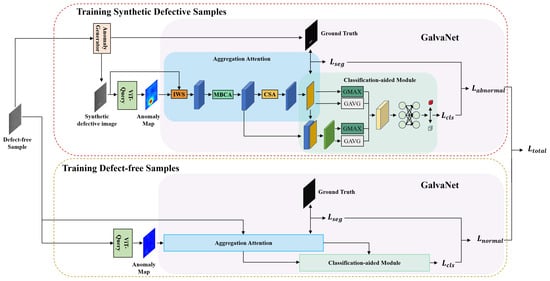
Figure 1.
Training process of VQGNet.
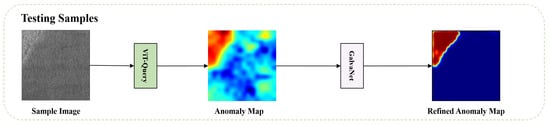
Figure 2.
Testing process of VQGNet.
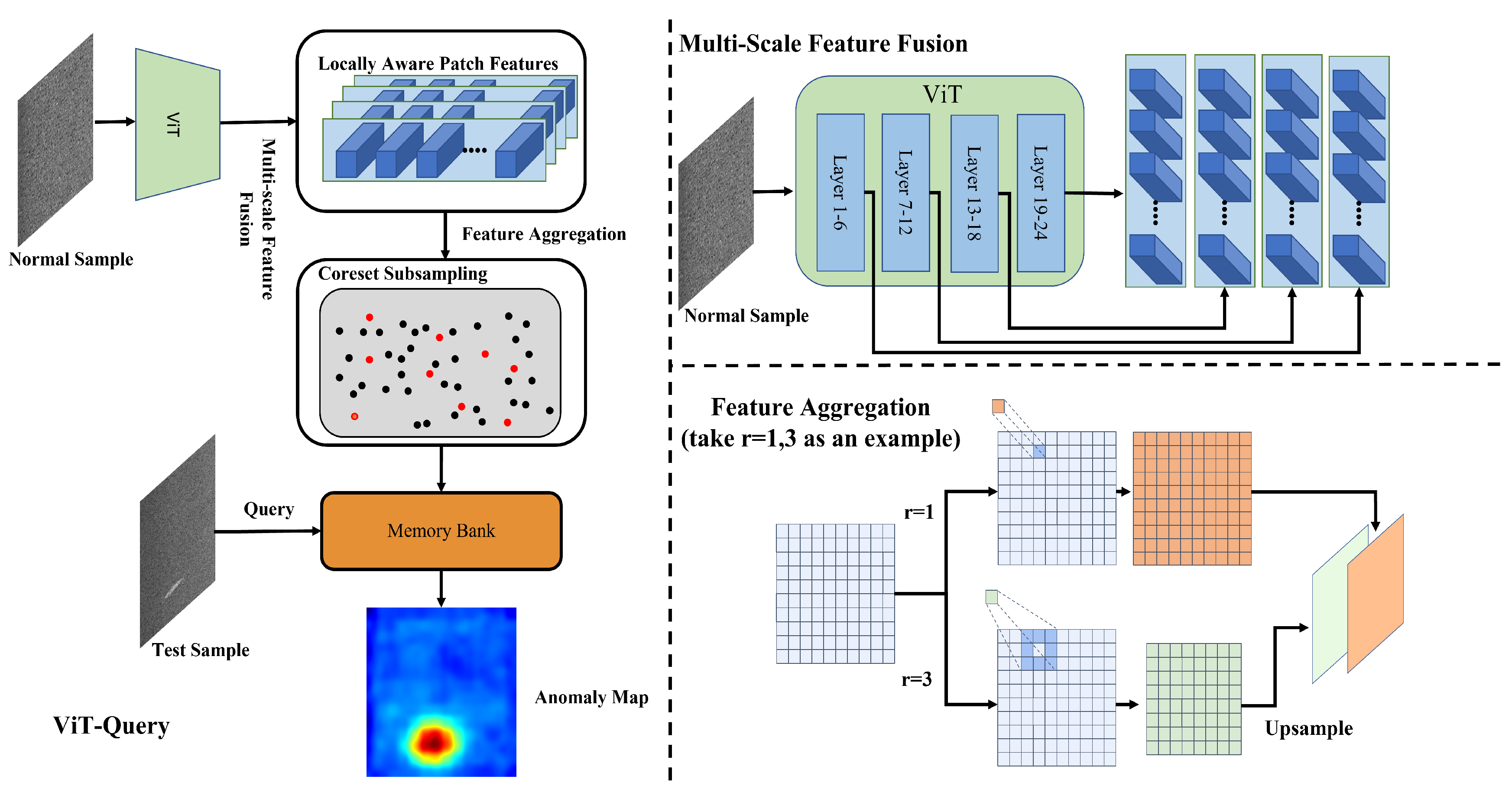
3.1. ViT-Query
Feature extraction: Compared to PatchCore’s utility of WideResNet50 [39] pre-trained on ImageNet [40], ViT-Query utilizes ViT trained on text–image matching tasks to extract features from normal input images. The model will have the ability to discriminate more high-level semantic information after being trained on the task. We divide the ViT into 4 stages, with each stage comprising six layers. This structuring allows for more specialized processing and feature extraction at different levels of the transformer, enhancing the model’s ability to capture and utilize hierarchical semantic information effectively. And, we concatenate the features from every stage, as shown in Figure 3. I is the normal image, represents the feature extracted by stage i, and L is the list of features of the image.The process can be represented as follows:
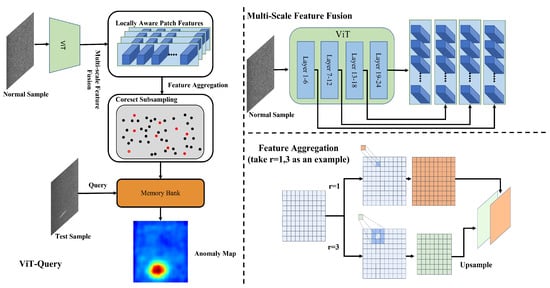
Figure 3.
Framework of ViT-Query.
Neighbor feature aggregation: Using a patch token with multiple aggregation degrees instead of a single patch size is more effective in representing anomalies of varying sizes. This approach results in high-quality anomaly scores. Inspired by Li et al. [41], unlike PatchCore’s directly utilization of kernel aggregation, for i th patch token extracted by ViT’s chosen stage j, we utilize a kernel to obtain the aggregated neighborhood patch token through the function and upsample the aggregated patch token into the same size as the initial, as shown in Figure 3. , and are the channel height and width of the initial features, respectively. Then, we concatenate the aggregated patch token. is the list of aggregated features. The process can be represented as follows:
Coreset sampling: When the feature map size and number increase, the memory bank requirements expand, and the inference time rises significantly. ViT-Query addresses this issue by employing greedy coreset subsampling, which reduces the quantity of features. Coreset subsampling produces a subset by utilizing the iterative greedy approximation [42].
Anomaly Detection: With the downsampled patch level feature memory bank , ViT-Query queries the anomaly score s via the maximum distance between input patch features in its patch collection and its nearest neighbor in :
During the testing process, there may be rare occurrences where the normal features in memory bank are close to the test features , but these normal features have a low similarity to other normal features. Therefore, the anomaly score needs to be adjusted using the following Formula (7) proposed by PatchCore [27]:
is the b nearest patch-features in for test patch-feature .
3.2. Anomaly Generator
On the surfaces of steel with complex textures, defects occur in various forms. There are usually small areas of irregularity and large areas of regular defects on the surfaces, and there is a problem of limited and impossible coverage of all defects during the process of data collection, which significantly limits the use of supervised learning methods for modeling. We have designed a more effective strategy, an anomaly generator, to composite defective samples and introduce them during the training process. These synthetic defective samples, based on the principle of random noise and random shape generation, exhibit randomness in the specific locations of defects. The anomaly synthesis strategy proposed consists of three steps: generate a mask, add representation information, and generate synthetic defect images, as shown in Figure 4.

Figure 4.
Defective image synthesis strategy.
Generate mask: In creating anomalies, we start by generating two-dimensional Perlin noise [43], which is then binarized using a threshold T to produce a binary mask. This mask contains random peaks and valleys, which allows model to extract the features of continuous regions or blocks within the image. To composite small-scale irregular defects on the surfaces of steel, further processing is applied to the binarized mask Perlin noise. Multiple connected domain modules within the mask are retained and ensure that each preserved region block has a minimum area of . These regions are also randomly located due to the randomness of noise. The regions will be scaled by a random scale factor to alter the size of the regions. These preserved regions serve as labels for forged defects, effectively mimicking the small-scale irregularities commonly encountered in industrial environments. For regular defects, a different approach is needed. We generate binary masks with a regular-shaped area, as shown in Figure 4. The masks generated during this process are defined as .
Add representation information: In the process of generating the mask image with the defect information, two methods are introduced to add the defect information, filling the with value , which is out of the distribution. The reference images form the texture dataset DTD [44]. We assume that the grayscale of a normal image of steel with complex textures conforms to a Gaussian distribution. The value is calculated as follows:
and are the mean and variance of the normal imput image, respectively. is the function used to obtain the grayscale value of corrdinate . and are the functions used to calculate the mean and variance of the image’s grayscale value, respectively. is the value of the inverse function of the standard normal distribution function at p. is a uniform distribution function. The in this method is as follows:
⊙ is the element-wise multiply operation. For the method utilizing the value to add the information of defects, image is a random image from the chosen images. is expressed as follows:
Generate synthetic defect images: This step inverts the binarized mask to . After that, it computes the element product on and the original image I to obtain the image and obtain the augmented image . The process is based on the following formula:
Using the above strategy, we obtain synthetic anomaly images from the perspectives of texture and structure. Due to the randomness of defect types and positions on steel with complex textures, our synthetic defects will appear anywhere in the image, maximizing the similarity between synthetic anomaly samples and real anomaly samples. Compared to RGB images, which have colors, grayscale images only have 255 grayscale values. Owing to this characteristic of grayscale images, when we use out-of-distribution grayscale values to fill the image and create defects, the resulting images are more likely to resemble real defect images, as shown in Figure 5.

Figure 5.
Examples of synthetic defect images.
3.3. GalvaNet
In this section, we introduce a novel network architecture, GalvaNet, which consists of two stages, aggregation attention and the classification-aided module, as shown in Figure 1. This model utilizes synthetic defective images and anomaly maps derived from ViT-Query as network inputs. The purpose of GalvaNet is to leverage the valuable global information from the ViT-Query and enhance the accuracy of defect segmentation and localization. Essentially, this approach aims to augment the model’s capacity to acquire local information while performing segmentation tasks [45].
Image weighting scheme (IWS): During the aggregated attention stage, GalvaNet adopts the synthetic defective images and anomaly maps obtained from the ViT-Query as its input. It is cumbersome and inefficient work to set the weight ratio of two inputs manually. To address this issue, GalvaNet employs a channel attention mechanism to integrate input images with anomaly maps, as opposed to utilizing it to re-weight features. It operates by learning the importance of each channel in the input feature map. By dynamically adjusting channel weights, the model can effectively focus on task-relevant information while suppressing irrelevant or noisy channels [46].
In the context of the described mechanism, the input feature maps and the anomaly maps obtained from ViT-Query serve as the basis for channel attention. The channel attention mechanism integrates these inputs through two fully connected layers and employs average pooling operations to perform channel-level weighted fusion. This fusion process generates a new feature map with enhanced feature representation, emphasizing important channels and suppressing less-relevant ones. Compared with the direct weighting of the input image and the anomaly map, the model can adaptively assign weights to different inputs to improve the segmentation performance of the model. The channel attention mechanism expression is as follows:
where represents the sigmoid activation function, represents the ReLU activation function, represents the average pooling operation, represents the synthetic defect image, represents the anomaly map, and are the weight matrices of two fully connected layers. The input images weighted by channel attention can be represented as follows:
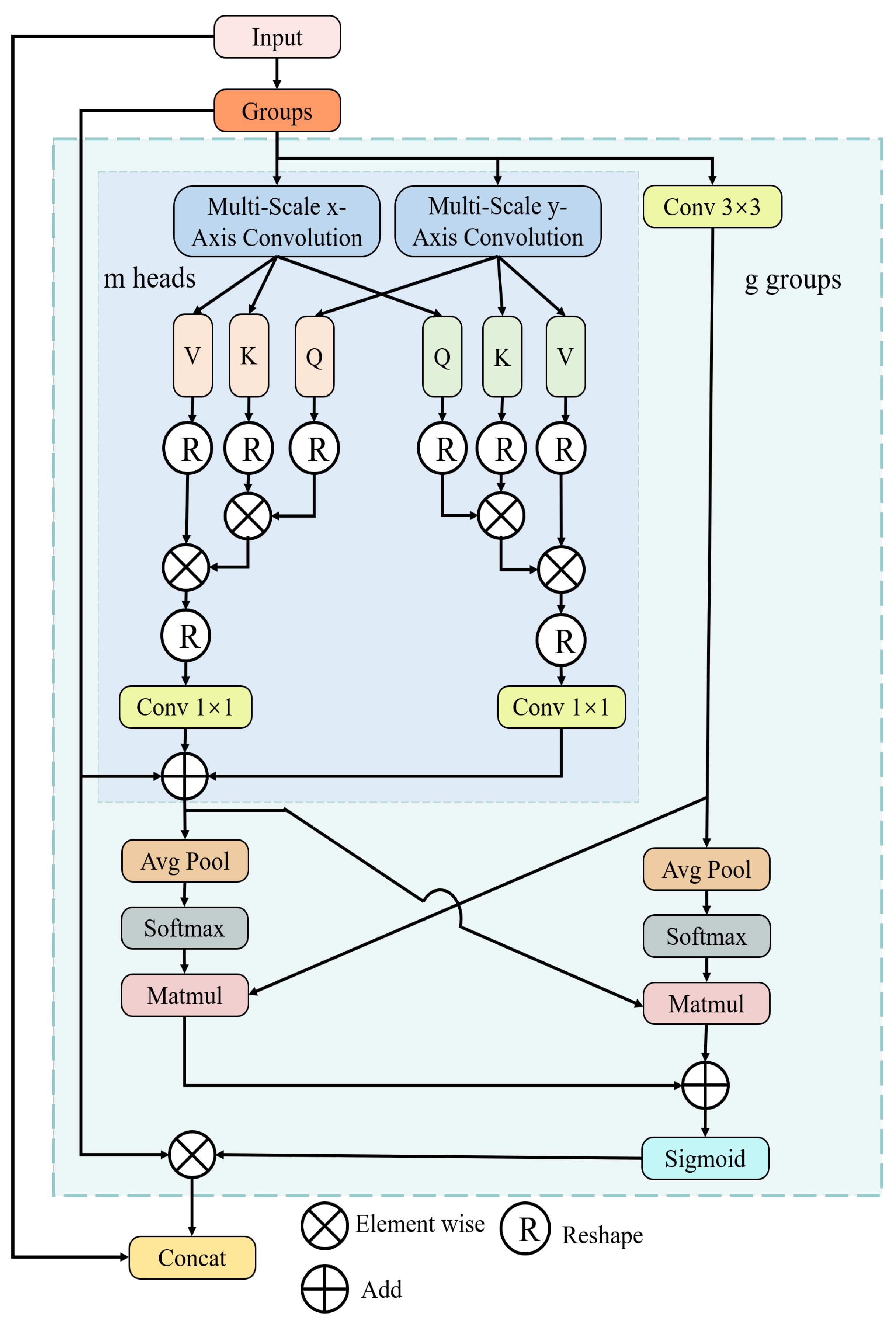
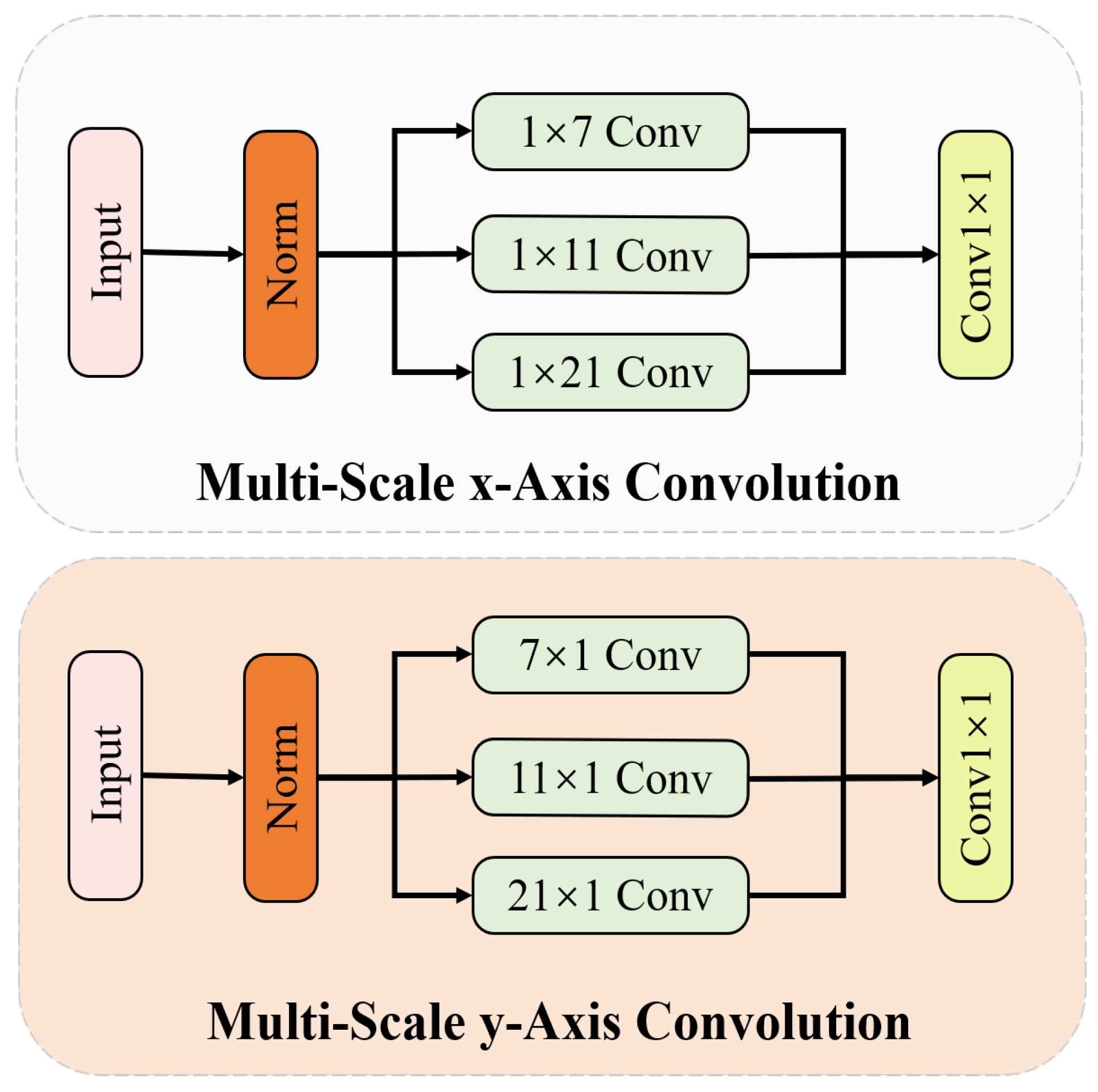
Multi-scale biaxial cross-attention (MBCA): Inspired by EMA and MCA, we design a novel method named multi-scale biaxial cross-attention that integrates multi-scale features and axial features, aiming to better segment defect regions of various sizes and shapes. As illustrated in Figure 6, MBCA utilizes convolutional kernels of different sizes and shapes to capture local information from various defect regions as comprehensively as possible, thereby enhancing the model’s ability to represent defect features. The MBCA module divides the input feature map into g groups, and each set should pass through three branches. The specific feature extraction method of the multi-scale x-axis convolution and multi-scale y-axis convolution is illustrated in Figure 7. When performing feature extraction with axial cross-attention, each input feature map needs to undergo LayerNorm, followed by three strip convolutions of different shapes and then a convolution operation. The formulation can be written as follows:
where and denote the output of multi-scale axis convolution and is a 1D convolution operation. The specific kernel size is shown in Figure 7. Then, and are utilized to calculate the multi-head cross-attention between them. The calculation process can be written as follows:
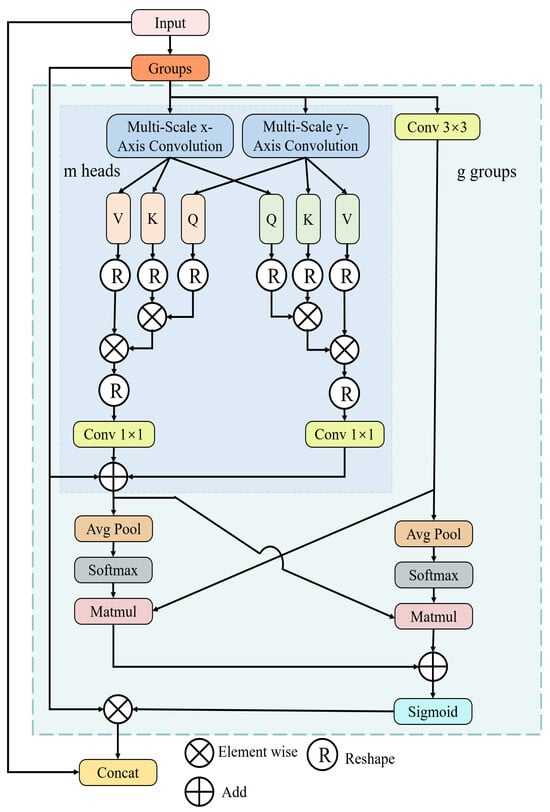
Figure 6.
The architecture of multi-scale biaxial cross-attention.
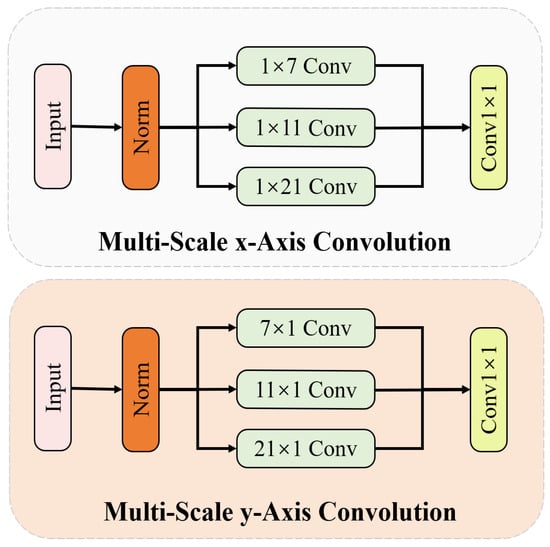
Figure 7.
The architecture multi-scale axis convolution.
MA is multi-head cross-attention. when and are obtained, the output of biaxis cross-attention is calculated as follows:
We represent the feature map obtained through the 3 × 3 convolutional kernel as . We apply the and operations to obtain their respective attention matrices as follows:
After that, we use cross multiplication to obtain their feature maps enhanced by the attention matrices, as shown in the following formula:
The feature map improved by MBCA attention can be computed through the following process:
Since the reweighted matrix is calculated based on groups and there is no communication between groups, we aim to introduce global feature information. Therefore, we concatenate the input matrix with the objects to perform global feature fusion as follows:
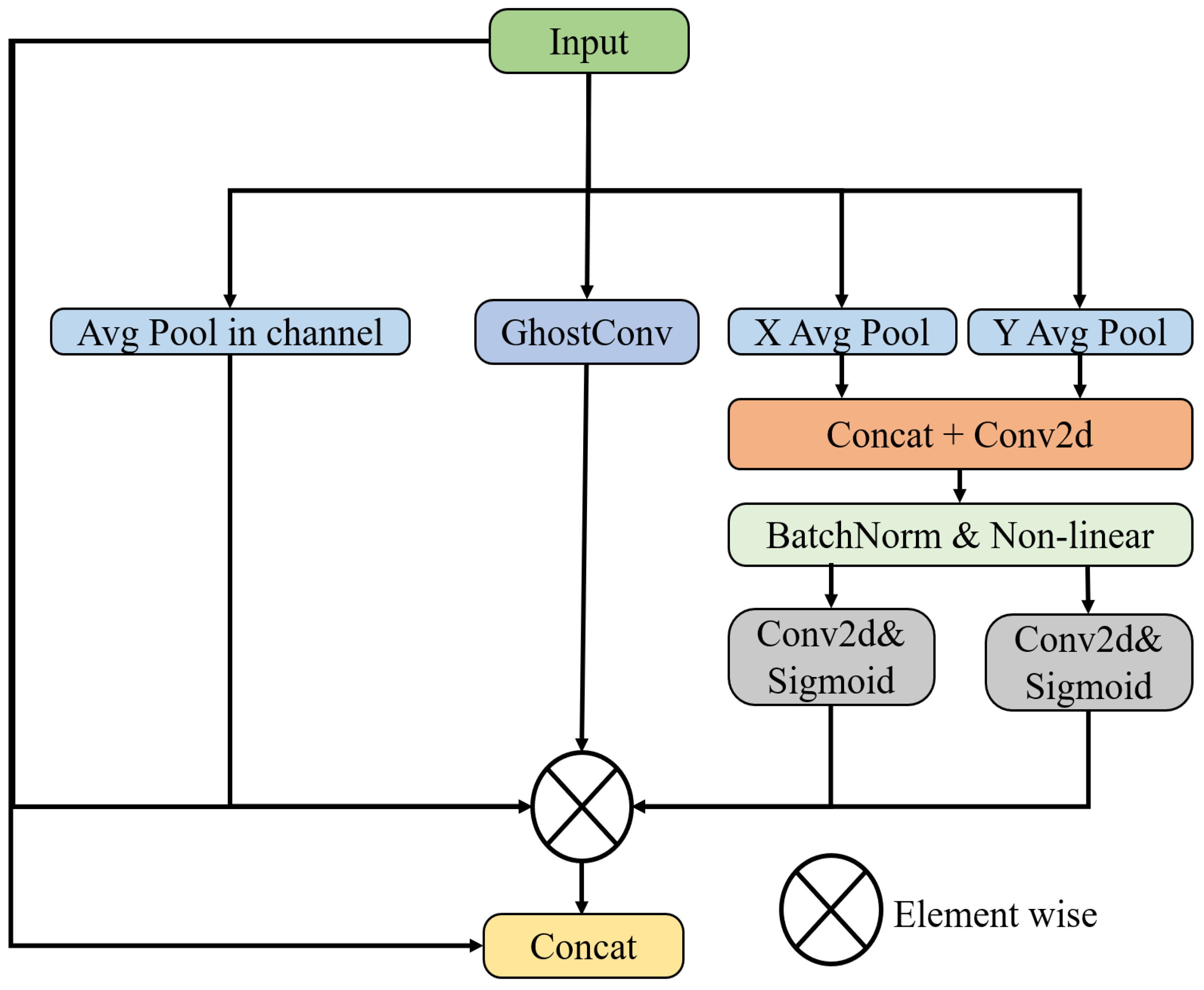
Coordinate spatial attention (CSA): After obtaining the feature map, based on coordinate attention and spatial attention, coordinate spatial attention is introduced to improve GalvaNet’s perception of coordinates and space. In this module, based on the spatial and coordinate attention mechanism, the model dynamically adjusts the weights of each position in the feature map regarding the spatial attention mechanism, allowing the model to focus more on important information (such as object boundaries) and texture [35]. Additionally, the coordinate attention focuses on the position information at different features through the computation of each position’s coordinate encoding to depict the feature map positions [36], thereby enhancing the model’s ability to utilize position information and improve its generalization capability. Therefore, our proposed attention fusion module assists the model in better focusing on spatial and positional information in the feature map, thereby enhancing and the segmentation performance of GalvaNet. The process of CSA is shown in Figure 8. First, we obtain the attention matrix of the feature map at the coordinate level:
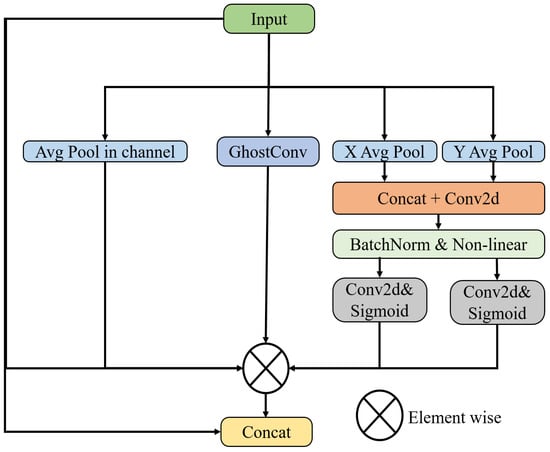
Figure 8.
Framwork of CSA.
In Formula (29), and represent the max pooling and average pooling of the input feature maps, respectively. The Concat operation represents concatenating the obtained feature maps in the channel dimension. In Formula (30), after passing through the deep convolutional module, the feature map that focuses more on image position information obtained through coordinate attention is denoted as . This process involves computing the coordinate encoding for each position, such as row and column indices, to generate a unique weight matrix, where represent the height, width, and number of channels of the input feature map, respectively. Then, represents the feature map with the enhanced spatial information obtained. CSA also uses AVG to compute the attention matrix of the input feature map at the spatial level to enhance the model’s ability to capture spatial features, as follows:
We believe that the galvanized steel surfaces with complex textures have many overlapping features, so GhostConv [47] is introduced to obtain more non-redundant features as shown in Formula (32):
Finally, we multiply the obtained attention matrix by the input feature map and stitch the multiplied matrix and the input feature map into channels to obtain the feature map . The feature map, enhanced by the coordinate spatial attention mechanism, is mapped back to a single channel as the segmentation mask output:
The remaining network structure details of aggregated attention are shown in Table 1.

Table 1.
Architecture details for aggregated attention.
Classification-aided module (CAM): We aim for GalvaNet to have better interpretability and to generate more accurate anomaly maps, which is designed to improve the segmentation performance by incorporating a classification task. The fundamental requirement for a high-quality anomaly map is to ensure that its users recognize anomalies clearly, which in turn improves segmentation performance. The classification-aided module is shown in Table 2.
Table 2.
Architecture details for classification-aided module.
The feature processing and classification pipeline begins with the fusion of the single-channel mask output from the aggregated attention part and the 1024-channel feature map obtained from the deep convolutional modules. This fusion, conducted along the channel dimension, yields a comprehensive 1025-channel feature map. Subsequently, this fused feature map undergoes dimensionality reduction through convolutional processing, refining it into a more manageable 32-channel feature map. Next, both the 32-channel feature map and the single-channel mask go through global max pooling (GMP) operations and global average pooling (GAP) operations. These pooling operations are simultaneously utilized for both the features and the mask, yielding 64-dimensional feature representations for each. This parallel processing ensures that both global image features and segmentation-specific details are effectively captured and represented.
Simultaneously, the single-channel mask, representing segmentation details, utilizes the same pooling operations, generating a two-dimensional feature representation. These features encapsulate segmentation-specific information, contributing to a more comprehensive feature vector.
Following the pooling operations, the 64-dimensional feature representations from the feature map and the mask are concatenated with the 2-dimensional segmentation feature, resulting in a 66-dimensional feature vector. This concatenation effectively integrates information from different processing stages, combining both global image features and localized segmentation details. Finally, this 66-dimensional feature vector is input into a multi-layer perceptron (MLP) network for classification.
3.4. Loss Function
This loss [48] takes into account the loss of defect segmentation and the classification of defective images, placed at the end of the network for gradient-based descent algorithms, enabling simultaneous end-to-end learning. Unlike their approach [48], we did not prohibit the loss from the classification module from backpropagating to the segmentation module during loss propagation. The unified loss is defined as follows:
and represent the losses of segmentation and classification, respectively, utilizing cross-entropy loss. acts as an additional weight for classification loss, and balances each sub-network’s contribution to the final loss. It is important to note that and complement the learning rate in stochastic gradient descent (SGD) rather than replacing it. By averaging the segmentation loss over all pixels, predominantly non-anomalous pixels, helps balance both losses, which may vary in scale.
To address the challenge of performing classification tasks on an anomaly map obtained from the aggregated attention part, we aim for a smooth transition in the balance factor associated with their respective loss functions. We express the transition process of this balancing factor as follows:
In this context, n denotes the current epoch index and signifies the total number of training epochs. Failure to gradually balance the losses may result in gradient explosions during the learning process. This gradual transition in training emphasis from segmentation to classification is termed dynamically balanced loss.
4. Experiments and Results
4.1. Dataset
Applying unsupervised anomaly detection algorithms to detect defects on steel surfaces with complex textures is an emerging and critical task. However, there is currently no dataset that is specifically available for this task. Therefore, we utilized a UR5 robot to hold an industrial area scan camera produced by DAHENG IMAGING, version number MER-2000-19U3M, to capture high-resolution images of a galvanized sheet, ensuring that the distance between the camera and the sheet was kept constant. Additionally, we placed linear light sources on both sides and adjusted their brightness to simulate the light and shadow variations in the actual production environment. The specific system and equipment placement are shown in Figure 9. We captured te complex texture the galvanized sheet, known as spangle. The collected data were annotated at the pixel level by members of our team using ImageJ. We used the ImageJ’s smear pattern to mark the location of the defect. We named this collected and annotated dataset ’Spangles’. To our knowledge, this is the first visual image-based dataset for the detection of defects on galvanized sheet surfaces. We relied on our data acquisition system to collect 1521 images of galvanized sheets with varying texture densities. However, considering that some unsupervised defect detection methods tend to consume significant GPU and memory resources, we also aimed to complete the task with as few normal images as possible. We selected four different types of galvanized sheets with significant texture differences for our training set, with each type containing 25 images, totaling 100 images. The detailed information about this dataset is as follows:
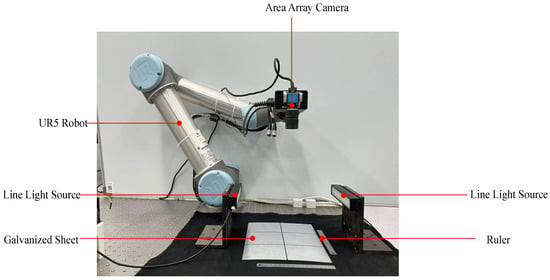
Figure 9.
The surface defect collecting system for galvanized plates captures images of the galvanized plates using an area array camera operated by a UR5 robot under the illumination of an online light source.
Spangles: The dataset consists of 690 galvanized sheet images with a resolution of 1024 × 1024. Among these, 297 images exhibit defects and 393 images are defect-free. Approximately 43.04% of the images are anomalous. The training set includes only 100 defect-free images, with 25 images from each level, which are classified into four levels based on the spangle density of the galvanized sheets, from largest to smallest, as levels 1 to 4. The remaining images are included in the test set. Based on the empirical classification, among the defect images, 200 images have tiny defects (small-area cat whiskers and small zinc dross) and 97 images have major defects (notch marks, horizontal stripes, zinc ash imprint oil spots, large-area cat whiskers, and large zinc dross). Examples of the dataset are shown in Figure 10.

Figure 10.
Spangle partial image visualization.
To further investigate the generalization of our method, we also utilized the Kolektor Surface-Defect Dataset 2 (KSDD2) [48] to evaluate the effectiveness of our algorithm.
4.2. Experimental Configuration
This algorithm is implemented using a device with an Ubuntu 22.04 OS, Intel 12700K CPU, NVidia GeForce RTX 4090 graphic card, and 64 GB of memory, as shown in Table 3. Apart from replicating the Memseg, PNI, and SimpleNet directly in the official source code, all other comparative experiments were implemented using Anomalib [49].
Table 3.
Experiment environment parameters.
For ViT-Query, the feature aggregation parameter r is . For GalvaNet, the training hyperparameters for the network are as follows: a dilation convolutional kernel size of 7 trained with SGD, with no momentum and with no weight decay. Regarding the training of the network, we employ an automatic adjustment mechanism for the weights of segmentation loss and classification loss. These weights are automatically adjusted every epoch, starting with a segmentation loss weight of 1.0 and a classification loss weight of 0. The loss function used for training is BCEWithLogitsLoss [50].
To assess the performance of the methods, we adopted the area under the receiver operator curve (AUROC) and the F1-score as metrics. The AUC value represents the area under the ROC curve. By applying different thresholds, multiple sets of coordinates can be obtained and calculated, as shown in Equation (38). Here, TN denotes the number of samples correctly classified as negative cases, and FN denotes the number of samples incorrectly classified as negative cases. This evaluation metric effectively measures the model’s ability to recognize positive samples [51] and can be computed as follows:
4.3. Results on Spangles
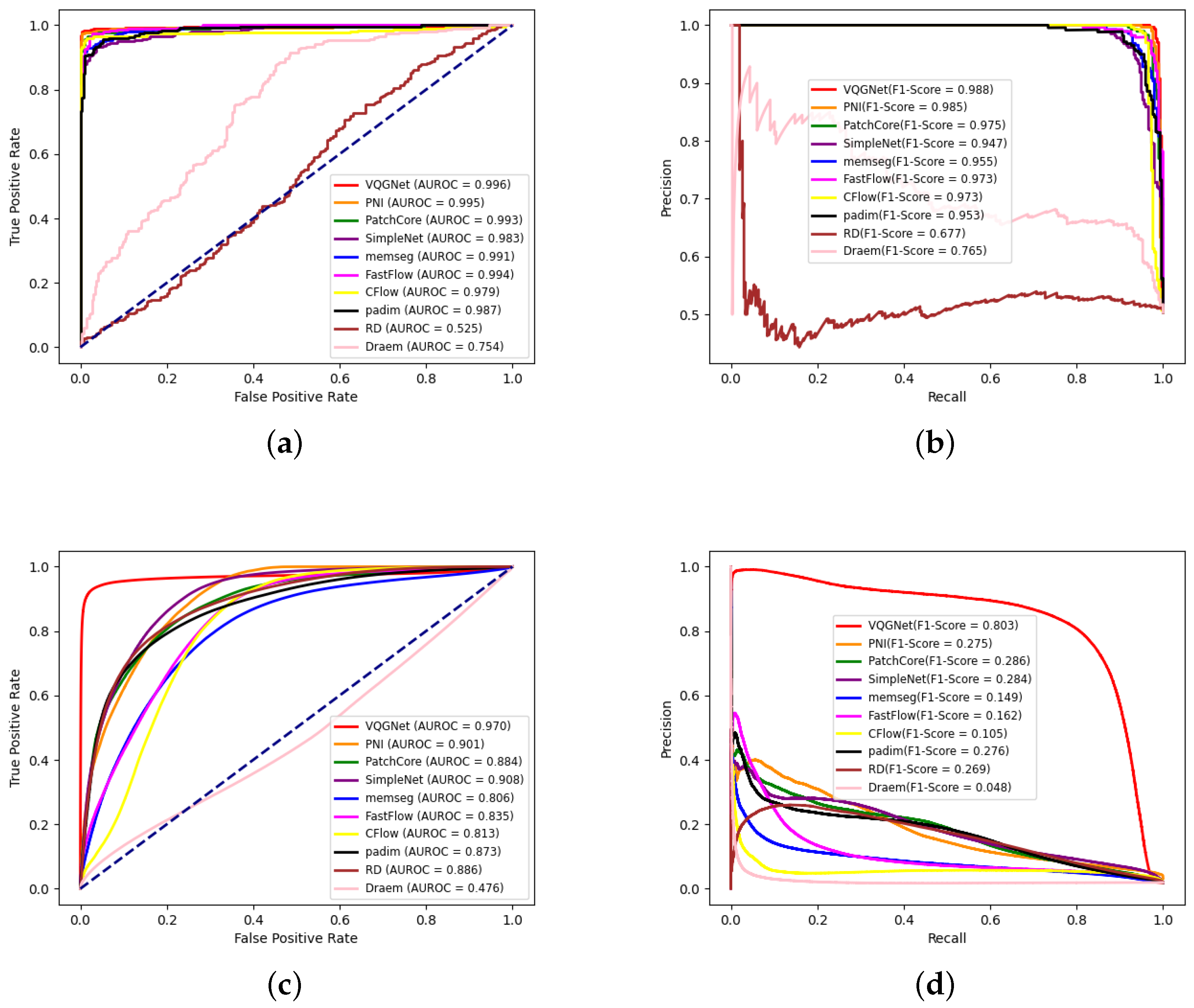
The experiment results of anomaly detection in spangles are presented in Table 4. We compared our proposed GalvaNet algorithm with several conventional algorithms (DRÆM, reverse distillation (RD) [52], Padim [53], CFlow, FastFlow [54], PatchCore, PNI, SimpleNet, Memseg) in terms of image-level AUROC (I-AUROC), image-level F1-score (I-F1), pixel-level AUROC (P-AUROC), and pixel-level F1-score (P-F1). It can be observed that the majority of the unsupervised anomaly detection algorithms demonstrated satisfactory performance at the image level. The proposed VQGNet algorithm demonstrated an anomaly detection performance of 99.6% I-AUROC, 98.8% I-F1, and an anomaly localization performance of 97.0% P-AUROC and 80.3 P-F1, surpassing PNI by 0.1% and 0.3%, respectively, at the image level. Although FastFlow, based on a powerful transformer, and SimpleNet, combining representation and generative methods, also show superior performance, our proposed algorithm outperforms them. Additionally, at the pixel level, the P-AUROC and P-F1 are improved by 6.2% and 51.7% over the second-best SimpleNet and Patchcore, respectively. The seemingly counterintuitive changes in I-AUROC and the F1-score are due to the focus on detecting small defects in galvanized sheets. The dataset contains a large number of small defects, leading to variations in P-AUROC and P-F1 across the different algorithms.
Table 4.
Comparison results on spangles. Anomaly detection and localization performance are measured based on I-AUROC [%], I-F1 [%], P-AUROC [%], and P-F1 [%], respectively.
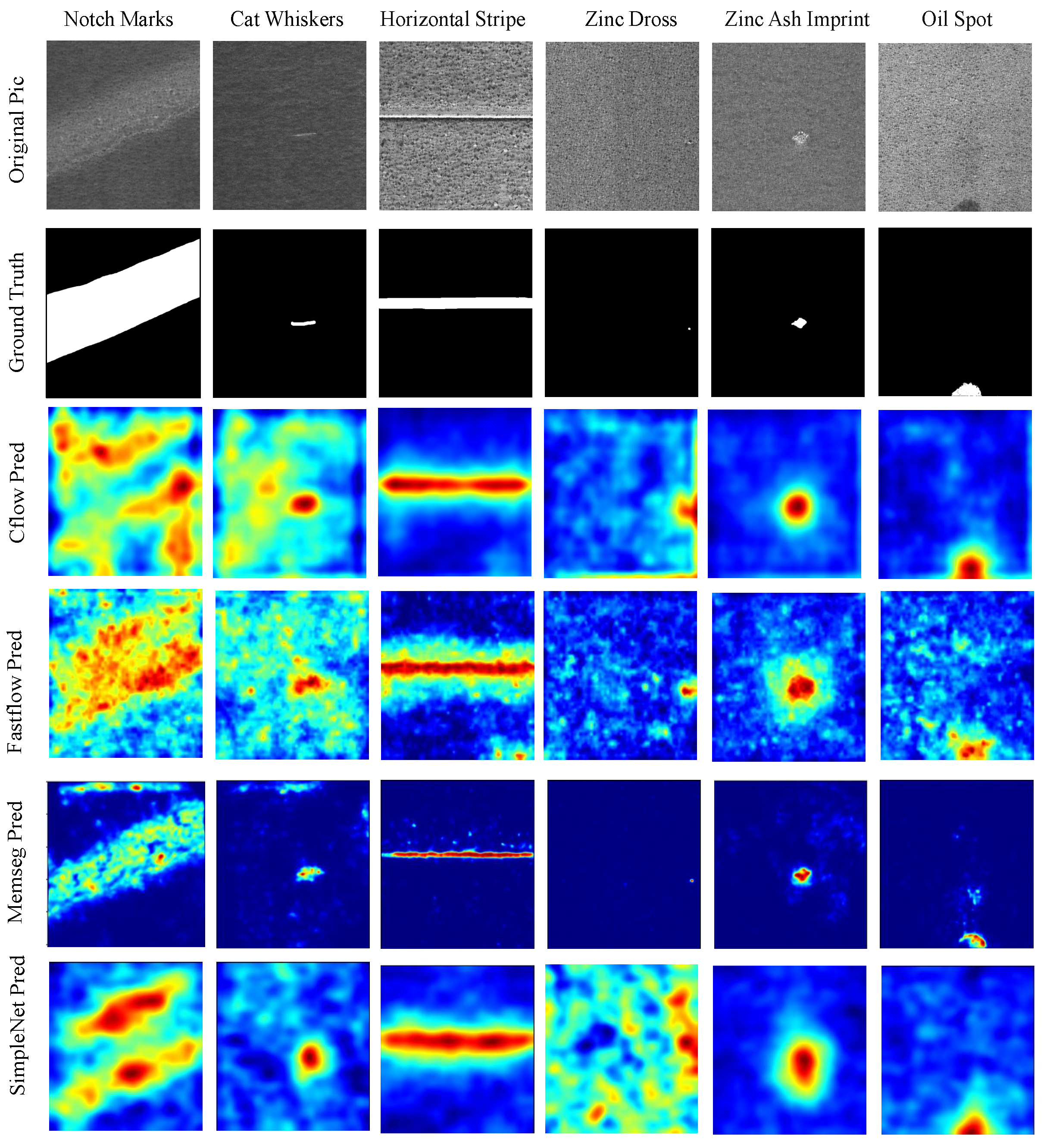
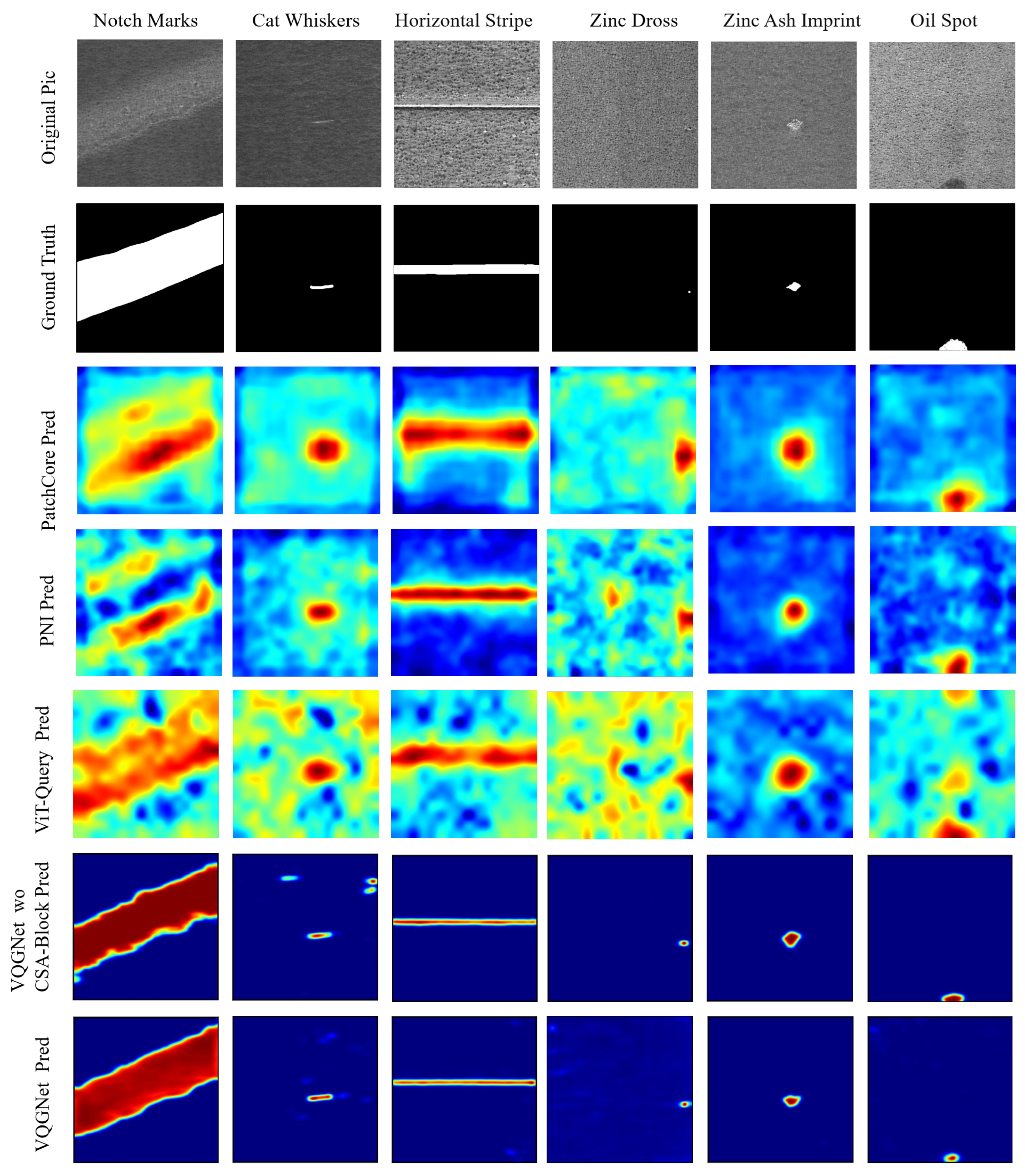
Nonetheless, the improvements in P-AUROC and P-F1 are still remarkable. We believe this is because the synthetic defect images used in network training effectively handled various complex defects occurring in real texture images, learning more precise localization information. As shown in Figure 11, Figure 12 and Figure 13, compared to the visual results of the other algorithms’ anomaly maps, the visual results of VQGNet are significantly better. The visual results of VQGNet are mostly within the key areas indicated by ViT-Query’s visualization, specifically the red regions. This suggests that ViT-Query’s anomaly map provides sufficient prior knowledge of GalvaNet. ViT-Query tends to focus more on global information in the task of anomaly detection on galvanized surfaces, while its attention to local information is relatively weaker. This explains why, despite ViT-Query’s high classification metrics, its segmentation metrics are less satisfactory. However, it is reassuring that ViT-Query provides a rough range for the segmentation results, within which we can perform a more detailed search. ViT-Query exhibits good performance in certain areas with significant defects, such as notch marks, and it better indicates the locations of defects compared to the other algorithms. Leveraging the enhanced defect recognition capability gained from normal images and synthetic defect images, GalvaNet produces a superior Anomaly Map, even though VQGNet may lose some information.
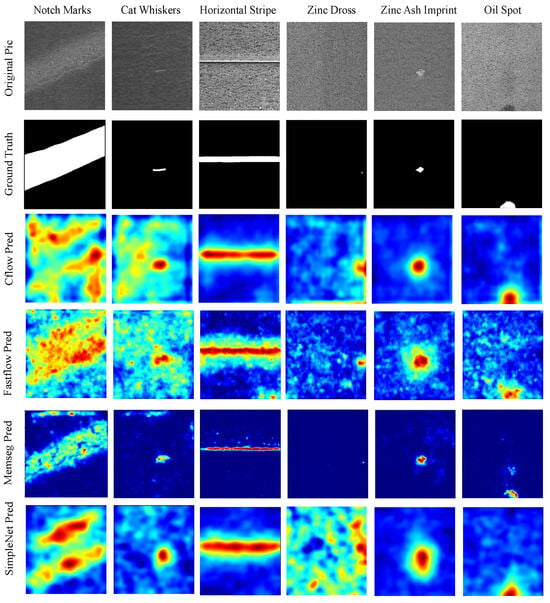
Figure 11.
Visualization of defect segmentation results on spangles. PatchCore, PNI, and VQGNet’s visual results are presented in Figure 13.
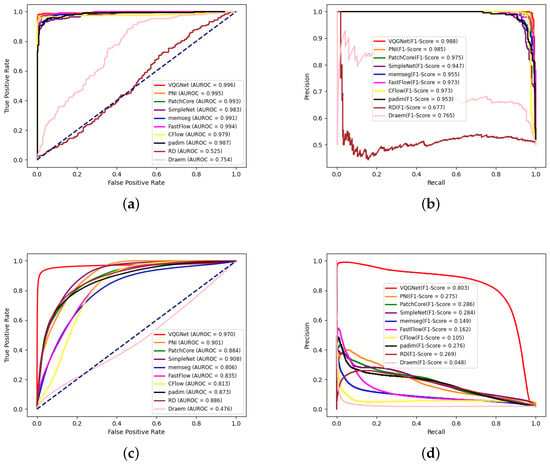
Figure 12.
ROC and precision–recall curves at the image level and pixel level of all algorithms on spangles. (a) Image-level ROC curves; (b) image-level precision–recall curves; (c) pixel-level ROC curves; (d) pixel-level precision–recall curves.
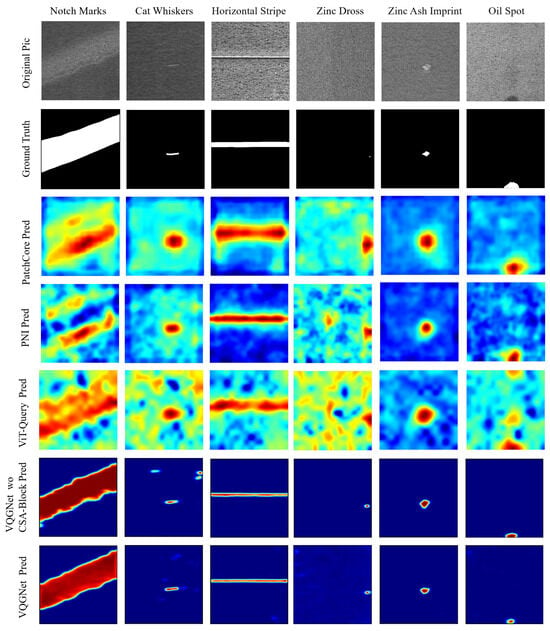
Figure 13.
Visualization of defect segmentation results on spangles.
We also draw ROC and precision–recall curves at the image level and pixel level of all methods, as shown in Figure 12. On the image level, VQGNet, PNI, and PatchCore achieve a similar performance, and VQGNet is slightly better than PNI and PatchCore. On the pixel-level, the AUC of VQGNet is much larger than that of other methods. Based on the precision–recall curves, VQGNet reaches a higher precision than that of other methods with the same recalls.
4.4. Comparative Experiments on KSDD2
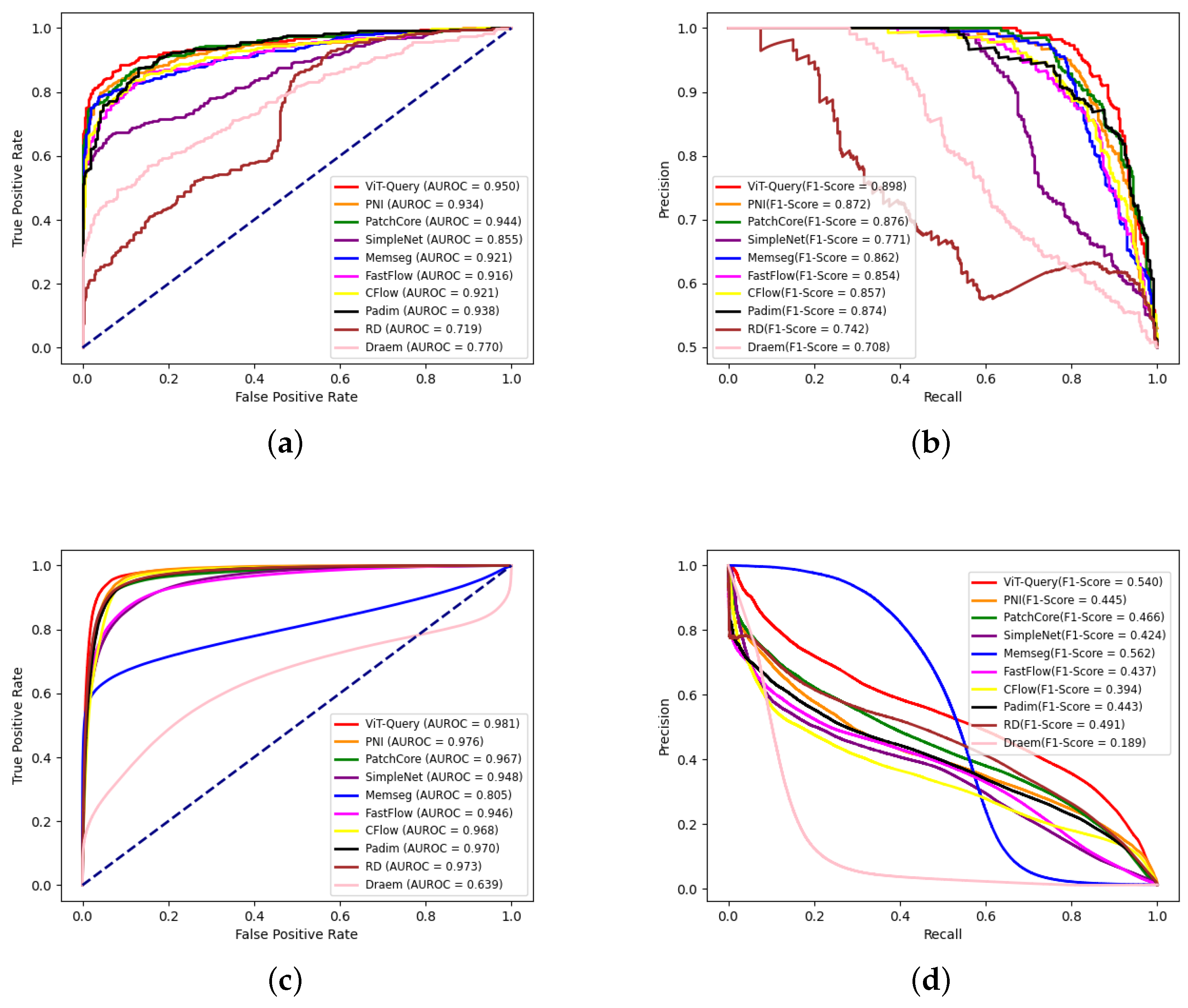
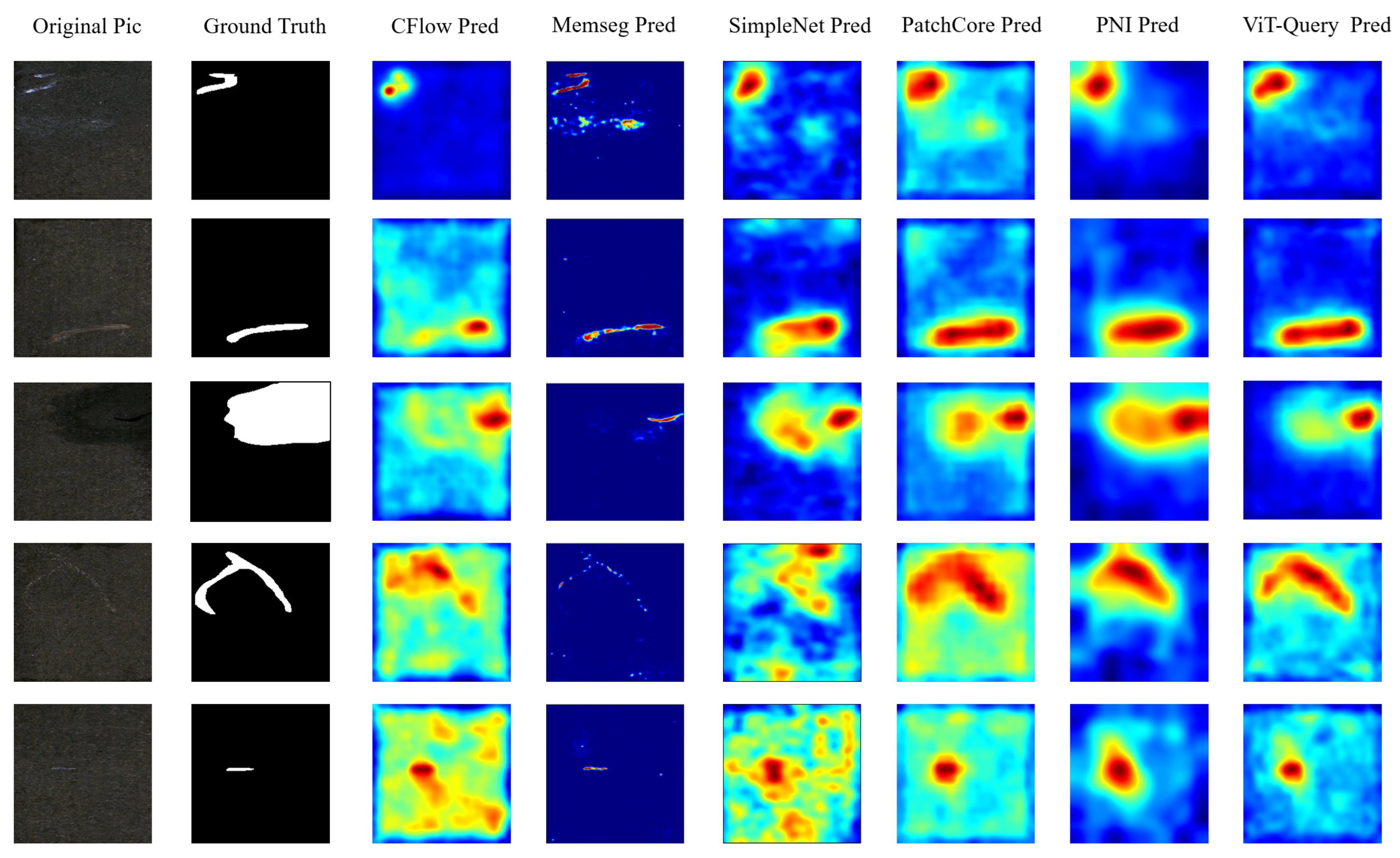
To explore the perceptual encoding capability of ViT-Query for RGB images, we conducted comparative experiments on the KSDD2 dataset. To balance the normal and abnormal samples in the dataset, we selected 356 images in the training set and 356 images with and without defects as the test set. Under this experimental setup, we conducted unsupervised defect detection. Table 5 shows that our model achieved state-of-the-art results, but our method ranked second in terms of P-F1 score. Compared to PatchCore, ViT-Query improved by 0.6% in I-AUROC and 2.1% in I-F1. Additionally, compared to PNI, our method improved by 0.5% in P-AUROC. We also draw ROC and precision–recall curves at the image-level and pixel-level of all the methods, as shown in Figure 14. Figure 14 clearly shows that our method has a certain advantage over the other algorithms. We plotted the visualized results of the experiments in Figure 15. Our algorithm demonstrates superior segmentation performance for various types of defects. It is apparent that the ViT-based ViT-Query more accurately delineates defect shapes compared to the ResNet-based PatchCore and PNI. Moreover, our method demonstrates better generalization compared to MemSeg’s over-segmentation.
Table 5.
Comparison results on KolektorSDD2. Anomaly detection and localization performance are measured based I-AUROC [%], I-F1 [%], P-AUROC [%], and P-F1 [%], respectively.
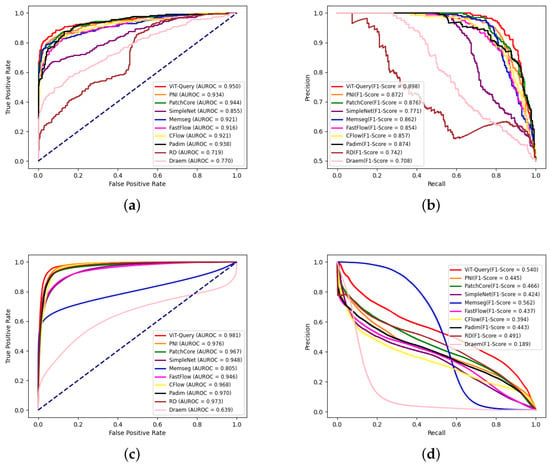
Figure 14.
ROC and precision–recall curve at the image and pixel levels of all algorithms on KSDD2. (a) Image-level ROC curves; (b) image-level precision–recall curves; (c) pixel-level ROC curves; (d) pixel-level precision–recall curves.
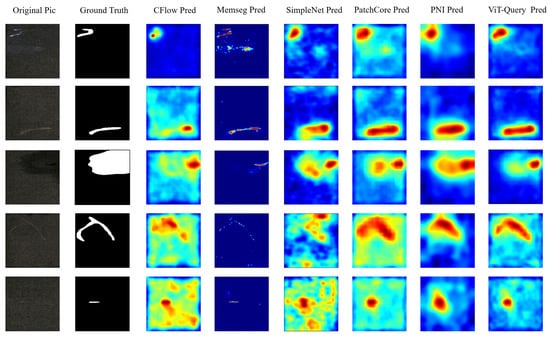
Figure 15.
Visualization of defect segmentation results on KSDD2.
4.5. Ablation Study
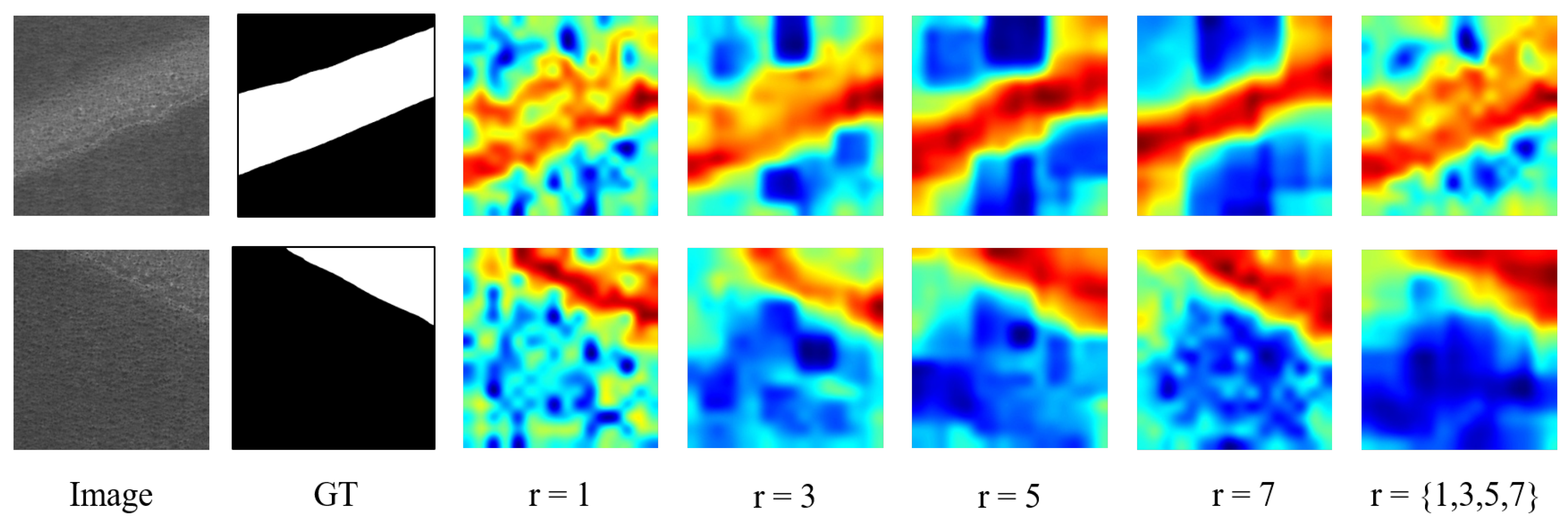
Effects of the neighbor feature aggregation parameter r: As shown in the Table 6, choosing different sizes of kernels for neighborhood feature aggregation significantly affects the performance of ViT-Query. The experimental results indicate that with , ViT-Query achieves better comprehensive results in I-AUROC, I-F1, P-AUROC, and P-F1 compared to other settings. During the experimental process, we observed that using small kernels for neighbor feature aggregation is more sensitive to small-scale features and the boundaries within the image (i.e., the boundary between defect areas and normal areas). However, due to the texture of the steel surface, this approach is prone to misjudgment. On the other hand, larger kernels tend to capture defect features over a larger area, but this leads to poorer segmentation performance at the boundary between defect areas and normal areas, as shown in Figure 16.
Table 6.
Ablation study of kernel aggregation results based on size of spangles.
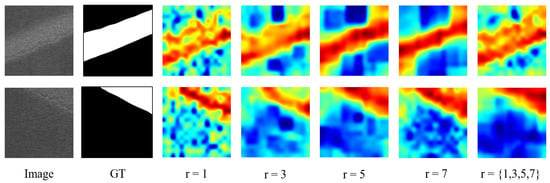
Figure 16.
Visualization of the aggregation of different kernel sizes.
Ablation study on modules of GalvaNet: We conducted an ablation study to verify the effects of three components in our proposed GalvaNet algorithm, IWS, MBCA, and CSA. The results are presented in Table 7. The following observations can be made:
Table 7.
The ablation study results of the module of GalvaNet on CASE spangles. Anomaly detection and localization performance are measured in I-AUROC [%], I-F1 [%], P-AUROC [%], and P-F1 [%], respectively.
- The baseline model, which excludes these three components, is essentially equivalent to ViT-Query.
- Integrating high-resolution image information with the IWS to train GalvaNet without CSA and MBCA significantly increases P-F1 from 44.7% to 71.8%. However, simply adding attention mechanisms to channels for weighted integration can cause global information to be biased towards specific channels, thereby affecting the global information in the anomaly map. This resulted in a decline in the classification performance, with I-AUROC and I-F1 dropping from 99.4% and 98.4% to 95.1% and 85.1%, respectively. When we turn our attention to the visualized anomaly map in Figure 13, we make the following observations: When we do not add the CSA and MBCA, the remaining model (GalvaNet without CSA, MBCA) relies more on the anomaly map provided by ViT-Query. Based on the visualization results of the cat whiskers, we can observe that because the channel attention performs weighted operations across the entire channel, the remaining model gives high attention to some secondary focus areas provided by ViT-Query’s anomaly map.
- Introducing the CSA after the IWS to focus on the spatial and coordinate information of the original high-resolution images and the anomaly maps allowed us to better integrate global and local features. This approach aimed to maintain classification performance while also improving segmentation tasks. Segmentation performance saw substantial improvements, with P-AUROC and P-F1 rising from 91.2% and 71.8% to 96.0% and 75.0%, respectively. By introducing CSA, the model can better learn the rich semantic information within the anomaly map and balance it with the defect segmentation capability obtained from normal images and synthetic defect images. Thus, after adding CSA, the shape of the defect areas is more similar to the ground truth, and the anomaly scores in the normal areas are lower, as shown in Figure 13.
- When we introduced MBCA to VQGNet, which already includes IWS and CSA, we found that the model’s image-level metrics surpassed those of ViT-Query, with improvements of 0.2% in I-AUROC and 0.4% in I-F1. Additionally, at the pixel level, P-AUROC and P-F1 improved by 1% and 5.3%, respectively.
- Overall, these modules collectively enhance the model’s ability to classify and segment anomalies at both the image level and the pixel level. After incorporating all the proposed modules, a significant improvement in the model is observed: I-AUROC and I-F1 improved by 0.2% and 0.4%, respectively, while P-AUROC and P-F1 improved by 2.7% and 35.6%, respectively.
5. Conclusions
In this paper, we propose VQGNet, an unsupervised anomaly detection method that can precisely recognize and segment defects in complexly textured steel simultaneously. GalvaNet, as a main component of VQGNet, comprises IWS, MBCA, CSA, and CAM. It detects and segments defects by integrating various features from both the original image and the anomaly map. IWS dynamically weights the input anomaly map and original image, MBCA enhances the ability to select multi-scale features, and CSA strengthens the model’s ability to extract the coordinate and spatial information of features. The refined anomaly maps and fused features are both input into the CAM for the final classification and segmentation. ViT-Query is proposed to generate the anomaly maps more confidently via multi-scale feature fusion and neighbor feature aggregation. Moreover, an anomaly generation method suitable for grayscale images is introduced to facilitate the model’s learning on the anomalous samples. A series of experiments is carried out using real, complexly textured steel images. VQGNet achieves state-of-the-art (SOTA) performance on the collected spangle dataset, with an I-AUROC of 99.6%, I-F1 of 98.8%, P-AUROC of 97.0%, and P-F1 of 80.3%. Moreover, ViT-Query shows that ViT-Query achieved a P-AUROC of 94.3% and a P-F1 of 44.7% on the spangles dataset and state-of-the-art performance on KSDD2, which demonstrates that compared to other unsupervised anomaly detection algorithms, ViT-Query can obtain anomaly maps with a higher reliability. Furthermore, the ablation studies further confirmed the contributions of the IWS, MBCA, and CSA components in GalvaNet, highlighting their roles in enhancing defect segmentation and maintaining a high classification accuracy. The visual examples of the anomaly generator demonstrate that our generated defects bear a significant similarity to real defects.
The limitations of our study are as follows. In this work, we did not integrate GalvaNet with every algorithm due to the observed variation in the distribution ranges of the anomaly maps produced using different methods. Directly normalizing these maps would affect the anomaly scores of certain anomalous images, thereby compromising the fairness and effectiveness of the analysis. Consequently, GalvaNet was not employed as a universal module; rather, it was specifically combined with ViT-Query to develop VQGNet. Additionally, our empirical results indicate that while VQGNet enhances predictive performance, this improvement comes at the expense of increased computational resource usage and reduced inference speed.
Overall, VQGNet showcases a promising approach for accurate and efficient anomaly detection and segmentation in complexly textured steel, offering valuable insights for future research and applications in this domain.
In the future, we hope to further improve the segmentation effect of the algorithm on panels with complex textures and improve our algorithm for use on other kinds of materials with complex textures.
Author Contributions
Conceptualization, Y.W. and R.Y. (Rui Yang); methodology, R.Y. (Ronghao Yu) and Y.L.; software, R.Y. (Ronghao Yu); validation, R.Y. (Ronghao Yu) and Y.L.; formal analysis, Y.W. and R.Y. (Ronghao Yu); investigation, R.Y. (Ronghao Yu); resources, Y.W.; data curation, Y.L.; writing—original draft preparation, R.Y. (Ronghao Yu); writing—review and editing, Y.W.; visualization, R.Y. (Ronghao Yu) and Y.L.; supervision, Y.W.; project administration, Y.W.; funding acquisition, Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data and code will be available upon request.
Acknowledgments
Ronghao Yu and Yun Liu would like to express their gratitude to Yingna Wu and Rui Yang for their guidance and funding support.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Xu, Y.; Liu, Q.; Xu, J.; Xiao, R.; Chen, S. Review on multi-information acquisition, defect prediction and quality control of aluminum alloy GTAW process. J. Manuf. Process. 2023, 108, 624–638. [Google Scholar] [CrossRef]
- Çağdaş Seçkin, A.; Seçkin, M. Detection of fabric defects with intertwined frame vector feature extraction. Alex. Eng. J. 2022, 61, 2887–2898. [Google Scholar] [CrossRef]
- Wen, R.; Yao, Y.; Li, Z.; Liu, Q.; Wang, Y.; Chen, Y. LESM-YOLO: An Improved Aircraft Ducts Defect Detection Model. Sensors 2024, 24, 4331. [Google Scholar] [CrossRef]
- Amarbayasgalan, T.; Ryu, K.H. Unsupervised Feature-Construction-Based Motor Fault Diagnosis. Sensors 2024, 24, 2978. [Google Scholar] [CrossRef]
- Feng, B.; Cai, J. PCB Defect Detection via Local Detail and Global Dependency Information. Sensors 2023, 23, 7755. [Google Scholar] [CrossRef]
- Yan, R.; Zhang, R.; Bai, J.; Hao, H.; Guo, W.; Gu, X.; Liu, Q. STMS-YOLOv5: A Lightweight Algorithm for Gear Surface Defect Detection. Sensors 2023, 23, 5992. [Google Scholar] [CrossRef]
- Jiang, Z.; Zhang, Y.; Wang, Y.; Li, J.; Gao, X. FR-PatchCore: An Industrial Anomaly Detection Method for Improving Generalization. Sensors 2024, 24, 1368. [Google Scholar] [CrossRef]
- Yang, W.; Qiu, Y.; Liu, W.; Qiu, X.; Bai, Q. Defect prediction in laser powder bed fusion with the combination of simulated melt pool images and thermal images. J. Manuf. Process. 2023, 106, 214–222. [Google Scholar] [CrossRef]
- Presa, S.; Saiz, F.A.; Barandiaran, I. A Fast Deep Learning Based Approach for Unsupervised Anomaly Detection in 3D Data. In Proceedings of the 2022 7th International Conference on Frontiers of Signal Processing (ICFSP), Paris, France, 7–9 September 2022; pp. 6–13. [Google Scholar] [CrossRef]
- Saiz, F.A.; Alfaro, G.; Barandiaran, I.; Graña, M. Generative Adversarial Networks to Improve the Robustness of Visual Defect Segmentation by Semantic Networks in Manufacturing Components. Appl. Sci. 2021, 11, 6368. [Google Scholar] [CrossRef]
- Zhou, Y.; Chang, B.; Zou, H.; Sun, L.; Wang, L.; Du, D. Online visual monitoring method for liquid rocket engine nozzle welding based on a multi-task deep learning model. J. Manuf. Syst. 2023, 68, 1–11. [Google Scholar] [CrossRef]
- Raghavan, U.; Albert, R.; Kumara, S. Near linear time algorithm to detect community structures in large-scale networks. Phys. Rev. E 2007, 76, 036106. [Google Scholar] [CrossRef]
- Sun, L.; Tan, C.; Hu, S.J.; Dong, P.; Freiheit, T. Quality detection and classification for ultrasonic welding of carbon fiber composites using time-series data and neural network methods. J. Manuf. Syst. 2021, 61, 562–575. [Google Scholar] [CrossRef]
- Zhao, B.; Chen, Y.; Jia, X.; Ma, T. Steel surface defect detection algorithm in complex background scenarios. Measurement 2024, 237, 115189. [Google Scholar] [CrossRef]
- Huang, B.; Ding, Y.; Liu, G.; Tian, G.; Wang, S. ASD-YOLO: An aircraft surface defects detection method using deformable convolution and attention mechanism. Measurement 2024, 238, 115300. [Google Scholar] [CrossRef]
- Suo, X.; Zhang, J.; Liu, J.; Yang, D.; Zhou, F. Anomaly Detection in Annular Metal Turning Surfaces Based on a Priori Information and a Multi-Scale Self-Referencing Template. Sensors 2023, 23, 6807. [Google Scholar] [CrossRef]
- Ma, H.; Zong, D.; Wu, Y.; Yang, R. Automatically recognizing and grading spangle on the galvanized steels surface based on convolutional neural network. Mater. Today Commun. 2023, 34, 105272. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Bank, D.; Koenigstein, N.; Giryes, R. Autoencoders. arXiv 2020, arXiv:2003.05991. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Zavrtanik, V.; Kristan, M.; Skočaj, D. Draem-a discriminatively trained reconstruction embedding for surface anomaly detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8330–8339. [Google Scholar]
- Liu, Z.; Zhou, Y.; Xu, Y.; Wang, Z. Simplenet: A simple network for image anomaly detection and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 20402–20411. [Google Scholar]
- Rudolph, M.; Wandt, B.; Rosenhahn, B. Same same but differnet: Semi-supervised defect detection with normalizing flows. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 1907–1916. [Google Scholar]
- Gudovskiy, D.; Ishizaka, S.; Kozuka, K. Cflow-ad: Real-time unsupervised anomaly detection with localization via conditional normalizing flows. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 98–107. [Google Scholar]
- Rudolph, M.; Wehrbein, T.; Rosenhahn, B.; Wandt, B. Fully Convolutional Cross-Scale-Flows for Image-based Defect Detection. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 1829–1838. [Google Scholar]
- Erfani, S.M.; Rajasegarar, S.; Karunasekera, S.; Leckie, C. High-dimensional and large-scale anomaly detection using a linear one-class SVM with deep learning. Pattern Recognit. 2016, 58, 121–134. [Google Scholar] [CrossRef]
- Roth, K.; Pemula, L.; Zepeda, J.; Schölkopf, B.; Brox, T.; Gehler, P. Towards total recall in industrial anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14318–14328. [Google Scholar]
- Bae, J.; Lee, J.H.; Kim, S. Pni: Industrial anomaly detection using position and neighborhood information. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 6373–6383. [Google Scholar]
- Yang, M.; Wu, P.; Liu, J.; Feng, H. MemSeg: A semi-supervised method for image surface defect detection using differences and commonalities. arXiv 2022, arXiv:2205.00908. [Google Scholar] [CrossRef]
- Li, C.-L.; Sohn, K.; Yoon, J.; Pfister, T. Cutpaste: Self-supervised learning for anomaly detection and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9664–9674. [Google Scholar]
- Song, J.; Kong, K.; Park, Y.-I.; Kim, S.-G.; Kang, S.-J. AnoSeg: Anomaly segmentation network using self-supervised learning. arXiv 2021, arXiv:2110.03396. [Google Scholar]
- Hu, T.; Zhang, J.; Yi, R.; Du, Y.; Chen, X.; Liu, L.; Wang, Y.; Wang, C. AnomalyDiffusion: Few-Shot Anomaly Image Generation with Diffusion Model. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–28 February 2024. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 2048–2057. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Ouyang, D.; He, S.; Zhan, J.; Guo, H.; Huang, Z.; Luo, M.; Zhang, G.L. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Shao, H.; Zeng, Q.; Hou, Q.; Yang, J. MCANet: Medical Image Segmentation with Multi-Scale Cross-Axis Attention. arXiv 2023, arXiv:2312.08866. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Li, X.; Huang, Z.; Xue, F.; Zhou, Y. MuSc: Zero-Shot Industrial Anomaly Classification and Segmentation with Mutual Scoring of the Unlabeled Images. arXiv 2024, arXiv:2401.16753. [Google Scholar]
- Sinha, S.; Zhang, H.; Goyal, A.; Bengio, Y.; Larochelle, H.; Odena, A. Small-gan: Speeding up gan training using core-sets. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 9005–9015. [Google Scholar]
- Perlin, K. An image synthesizer. ACM Siggraph Comput. Graph. 1985, 19, 287–296. [Google Scholar] [CrossRef]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; Vedaldi, A. Describing textures in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3606–3613. [Google Scholar]
- Bearman, A.; Ferrari, V.; Russakovsky, O. What’s the point: Semantic segmentation with point supervision. In Proceedings of the ECCV, Amsterdam, The Netherlands, 11–14 October 2016; pp. 1–11. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1577–1586. [Google Scholar]
- Božič, J.; Tabernik, D.; Skočaj, D. Mixed supervision for surface-defect detection: From weakly to fully supervised learning. Comput. Ind. 2021, 129, 103459. [Google Scholar] [CrossRef]
- Akcay, S.; Ameln, D.; Vaidya, A.; Lakshmanan, B.; Ahuja, N.; Genc, U. Anomalib: A deep learning library for anomaly detection. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 1706–1710. [Google Scholar]
- Lou, H.; Li, S.; Zhao, Y. Detecting community structure using label propagation with weighted coherent neighborhood propinquity. Phys. A 2013, 392, 3095–3105. [Google Scholar] [CrossRef]
- García-Pérez, A.; Ziegenbein, A.; Schmidt, E.; Shamsafar, F.; Fernández-Valdivielso, A.; Llorente-Rodríguez, R.; Weigold, M. CNN-based in situ tool wear detection: A study on model training and data augmentation in turning inserts. J. Manuf. Syst. 2023, 68, 85–98. [Google Scholar] [CrossRef]
- Deng, H.; Li, X. Anomaly detection via reverse distillation from one-class embedding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9737–9746. [Google Scholar]
- Defard, T.; Setkov, A.; Loesch, A.; Audigier, R. Padim: A patch distribution modeling framework for anomaly detection and localization. In Proceedings of the International Conference on Pattern Recognition, Virtual, 10–11 January 2021; Springer: Cham, Switzerland, 2021; pp. 475–489. [Google Scholar]
- Yu, J.; Zheng, Y.; Wang, X.; Li, W.; Wu, Y.; Zhao, R.; Wu, L. Fastflow: Unsupervised anomaly detection and localization via 2d normalizing flows. arXiv 2021, arXiv:2111.07677. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).