


A Multi-Source Data Fusion Network for Wood Surface Broken Defect Segmentation

Abstract
:1. Introduction
- Laser profile sensors and cameras are adopted to capture the depth data and image of wooden board. Furthermore, a multi-source data fusion network is designed to recognize the wood broken defect by simultaneously focusing on the depth information and color texture information, to achieve a precise segmentation of the wood broken defects and effectively eliminate the influence of interference;
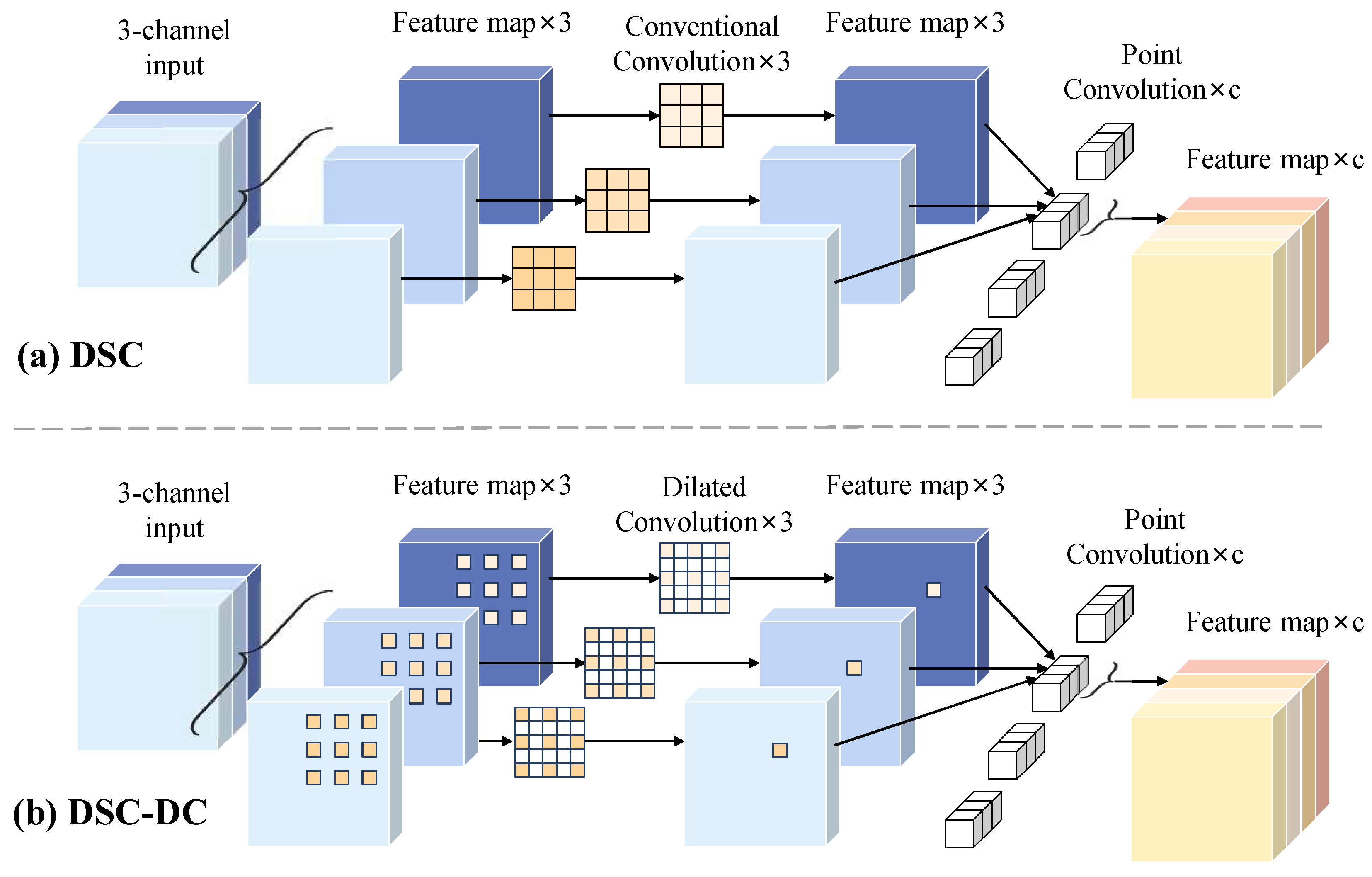
- An improved ResNet34 is developed to efficiently extract multi-level features from wood image and depth data, in which the depthwise separable convolution (DSC) and dilated convolution (DC) are added to reduce feature redundancy and enhance the overall perception of the wood broken defects;
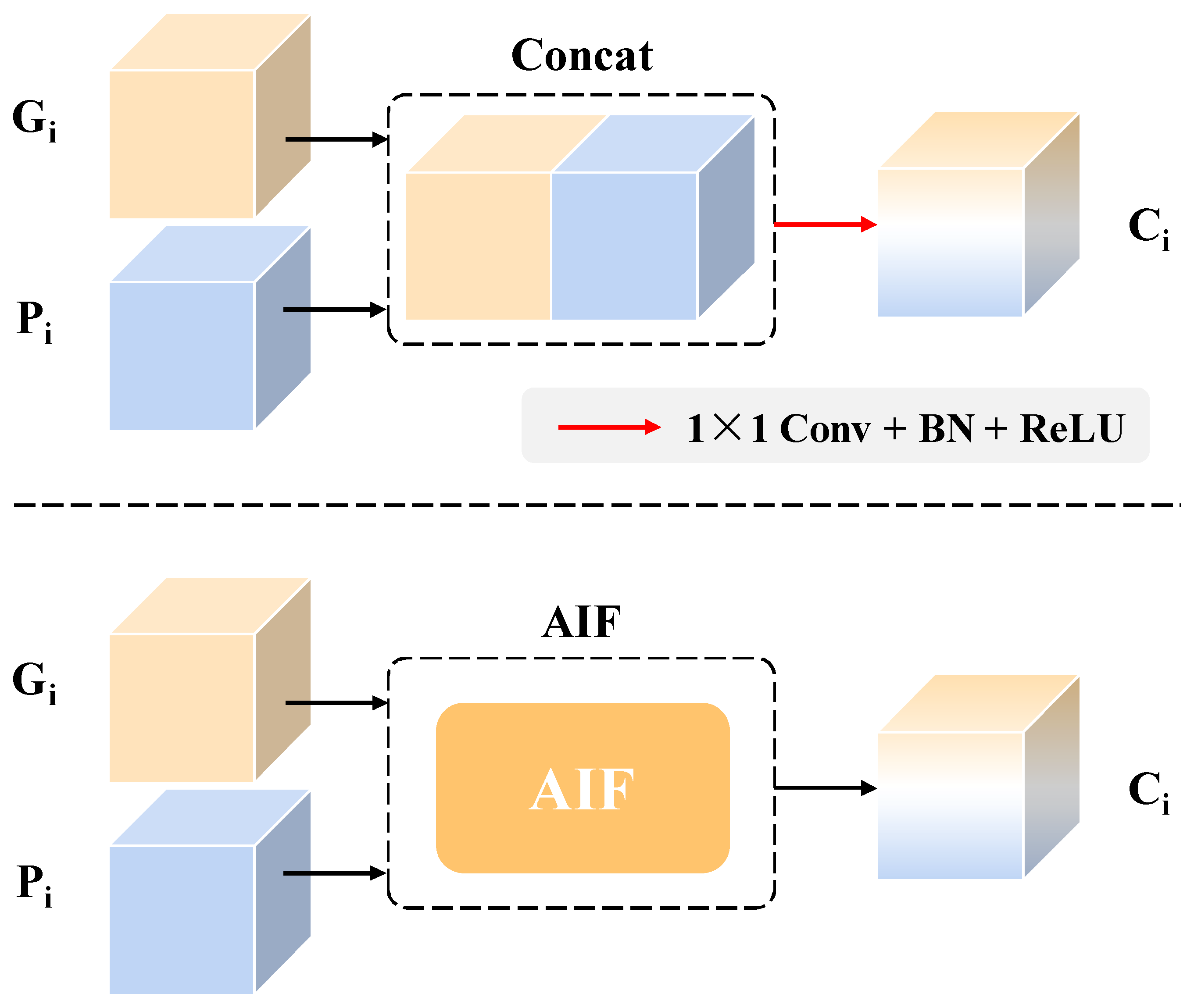
- An adaptive interacting fusion (AIF) module is designed to integrate the features extracted from image and depth data via calculating the weights of different features, achieving accurate feature representation of the broken defect. Additionally, the coordinate attention (CA) is added to further highlight the discriminative effect of depth information.
2. Related Works
2.1. Traditional Wood Defect Detection Approaches
2.2. Deep-Learning-Based Wood Defect Detection Approaches
3. System Overview
3.1. Data Collection
3.2. Wood Broken Defect Dataset
4. Methodology
4.1. Architecture Overview
4.2. Backbone
4.2.1. Res-DSC
4.2.2. Res-DSC-DC
4.3. Adaptive Interacting Fusion
4.4. Loss Function
5. Experiments
5.1. Implementation Details
5.2. Evaluation Metrics
5.3. Experiments on the Selection of Backbone
5.4. Ablation Study
5.5. Experiments on Fusion Methods
5.6. Comparisons of Different Methods
6. Discussion
6.1. Discussion on The Potential Improvement
6.2. Discussion on The Practical Application
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ResNet | Residual network |
| DSC | Depthwise separable convolution |
| DC | Dilated convolution |
| AIF | Adaptive interacting fusion |
| CNN | Convolutional neural networks |
| CA | Coordinate attention |
| BN | Batch normalization and |
| ReLU | ReLU denotes rectified linear units |
| GAP | Global average pool |
| mIoU | Mean intersection over union |
References
- Fang, Y.; Lin, L.; Feng, H.; Lu, Z.; Emms, G. Review of the use of air-coupled ultrasonic technologies for nondestructive testing of wood and wood products. Comput. Electron. Agric. 2017, 137, 79–87. [Google Scholar] [CrossRef]
- Kabouri, A.; Khabbazi, A.; Youlal, H. Applied multiresolution analysis to infrared images for defects detection in materials. NDT E Int. 2017, 92, 38–49. [Google Scholar] [CrossRef]
- Du, X.; Li, J.; Feng, H.; Chen, S. Image reconstruction of internal defects in wood based on segmented propagation rays of stress waves. Appl. Sci. 2018, 8, 1778. [Google Scholar] [CrossRef]
- Qiu, Q.; Qin, R.; Lam, J.; Tang, A.; Leung, M.; Lau, D. An innovative tomographic technique integrated with acoustic-laser approach for detecting defects in tree trunk. Comput. Electron. Agric. 2019, 156, 129–137. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Tu, Y.; Ling, Z.; Guo, S.; Wen, H. An accurate and real-time surface defects detection method for sawn lumber. IEEE Trans. Instrum. Meas. 2021, 70, 2501911. [Google Scholar] [CrossRef]
- Zhu, Y.; Xu, Z.; Lin, Y.; Chen, D.; Zheng, K.; Yuan, Y. Surface defect detection of sawn timbers based on efficient multilevel feature integration. Meas. Sci. Technol. 2024, 35, 046101. [Google Scholar] [CrossRef]
- Lin, Y.; Xu, Z.; Chen, D.; Ai, Z.; Qiu, Y.; Yuan, Y. Wood Crack Detection Based on Data-Driven Semantic Segmentation Network. IEEE/CAA J. Autom. Sin. 2023, 10, 1510–1512. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Funck, J.W.; Zhong, Y.; Butler, D.A.; Brunner, C.C.; Forrer, J.B. Image segmentation algorithms applied to wood defect detection. Comput. Electron. Agric. 2003, 41, 157–179. [Google Scholar] [CrossRef]
- Luo, W.; Sun, L.P. An improved binarization algorithm of wood image defect segmentation based on non-uniform background. J. For. Res. 2019, 30, 1527–1533. [Google Scholar] [CrossRef]
- Chen, L.J.; Wang, K.Q.; Xie, Y.H.; Wang, J.C. The segmentation of timber defects based on color and the mathematical morphology. Optik 2014, 125, 965–967. [Google Scholar] [CrossRef]
- Mahram, A.; Shayesteh, M.G.; Jafarpour, S. Classification of wood surface defects with hybrid usage of statistical and textural features. In Proceedings of the International Conference on Telecommunications and Signal Processing, Prague, Czech Republic, 3–4 July 2012; pp. 749–752. [Google Scholar]
- Li, S.L.; Li, D.J.; Yuan, W.Q. Wood defect classification based on two-dimensional histogram constituted by LBP and local binary differential excitation pattern. IEEE Access 2019, 7, 145829–145842. [Google Scholar] [CrossRef]
- Xie, Y.H.; Wang, J.C. Study on the identification of the wood surface defects based on texture features. Optik-Int. J. Light Electron Opt. 2015, 126, 2231–2235. [Google Scholar]
- Gu, I.Y.; Andersson, H.; Vicen, R. Wood defect classification based on image analysis and support vector machines. Wood Sci. Technol. 2010, 44, 693–704. [Google Scholar] [CrossRef]
- Chang, Z.Y.; Cao, J.; Zhang, Y.Z. A novel image segmentation approach for wood plate surface defect classification through convex optimization. J. For. Res. 2018, 29, 1789–1795. [Google Scholar] [CrossRef]
- Yu, H.L.; Liang, Y.L.; Liang, H.; Zhang, Y.Z. Recognition of wood surface defects with near infrared spectroscopy and machine vision. J. For. Res. 2019, 30, 2379–2386. [Google Scholar] [CrossRef]
- He, T.; Liu, Y.; Xu, C.Y.; Zhou, X.L.; Hu, Z.; Fan, J. A fully convolutional neural network for wood defect location and identification. IEEE Access 2019, 7, 123453–123462. [Google Scholar] [CrossRef]
- He, T.; Liu, Y.; Yu, Y.; Zhao, Q.; Hu, Z. Application of deep convolutional neural network on feature extraction and detection of wood defects. Measurement 2020, 152, 107357. [Google Scholar] [CrossRef]
- Li, D.; Zhang, Z.; Wang, B.; Yang, C.; Deng, L. Detection method of timber defects based on target detection algorithm. Measurement 2022, 203, 111937. [Google Scholar] [CrossRef]
- Meng, W.; Yuan, Y. SGN-YOLO: Detecting Wood Defects with Improved YOLOv5 Based on Semi-Global Network. Sensors 2023, 23, 8705. [Google Scholar] [CrossRef] [PubMed]
- Ge, Y.; Jiang, D.; Sun, L. Wood Veneer Defect Detection Based on Multiscale DETR with Position Encoder Net. Sensors 2023, 23, 4837. [Google Scholar] [CrossRef]
- Xu, Z.; Lin, Y.; Chen, D.; Yuan, M.; Zhu, Y.; Ai, Z.; Yuan, Y. Wood broken defect detection with laser profilometer based on Bi-LSTM network. Expert Syst. Appl. 2024, 242, 122789. [Google Scholar] [CrossRef]
- Yang, L.; Fan, J.; Huo, B.; Li, E.; Liu, Y. A nondestructive automatic defect detection method with pixelwise segmentation. Knowl. Based Syst. 2022, 242, 108338. [Google Scholar] [CrossRef]
- Jiang, X.; Yan, F.; Lu, Y.; Wang, K.; Guo, S.; Zhang, T.; Pang, Y.; Niu, J.; Xu, M. Joint Attention-Guided feature fusion network for saliency detection of surface defects. IEEE Trans. Instrum. Meas. 2022, 71, 2520912. [Google Scholar] [CrossRef]
- Song, G.; Song, K.; Yan, Y. EDRNet: Encoder–decoder residual network for salient object detection of strip steel surface defects. IEEE Trans. Instrum. Meas. 2020, 69, 9709–9719. [Google Scholar] [CrossRef]
- Zhou, X.; Fang, H.; Liu, Z.; Zheng, B.; Sun, Y.; Zhang, J.; Yan, C. Dense attention-guided cascaded network for salient object detection of strip steel surface defects. IEEE Trans. Instrum. Meas. 2021, 71, 5004914. [Google Scholar] [CrossRef]
- Lin, Q.; Li, W.; Zheng, X.; Fan, H.; Li, Z. DeepCrackAT: An effective crack segmentation framework based on learning multi-scale crack features. Eng. Appl. Artif. Intell. 2023, 126, 106876. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, J.; Xu, G.; Li, C.; Gao, G.; Wu, Q. SDDet: An Enhanced Encoder–Decoder Network With Hierarchical Supervision for Surface Defect Detection. IEEE Sens. J. 2022, 23, 2651–2662. [Google Scholar] [CrossRef]
- Li, B.; Wang, T.; Zhai, Y.; Yuan, J. RFIENet: RGB-thermal feature interactive enhancement network for semantic segmentation of insulator in backlight scenes. Measurement 2022, 205, 112177. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Liang, Y.; Li, J.; Zhu, J.; Du, R.; Wu, X.; Chen, B. A Lightweight Network for Defect Detection in Nickel-Plated Punched Steel Strip Images. IEEE Sens. J. 2023, 72, 3505515. [Google Scholar] [CrossRef]
- Wang, X.; Gao, J.; Hou, B.; Wang, Z.; Ding, H.; Wang, J. A Lightweight Modified YOLOX Network Using Coordinate Attention Mechanism for PCB Surface Defect Detection. IEEE Sens. J. 2022, 22, 20910–20920. [Google Scholar]
- Li, W.; Zhang, L.; Wu, C.; Cui, Z.; Niu, C. A New Lightweight Deep Neural Network for Surface Scratch Detection. Int. J. Adv. Manuf. Technol. 2022, 123, 1999–2015. [Google Scholar] [CrossRef] [PubMed]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2016, arXiv:1511.07122. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the Fourth International Conference on 3D Vision, Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Advances in Neural Information Processing Systems; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J., Eds.; NeurIPS: New Orleans, LA, USA, 2021; pp. 12077–12090. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | Type | Number | Output Size |
|---|---|---|---|
| Input | – | – | 512 × 512 × 1 |
| D-Conv1 & I-Conv1 | 7 × 7 Conv, 1s = 2 | 1 | 256 × 256 × 64 |
| 3 × 3 Max-pool, s = 2 | – | 128 × 128 × 64 | |
| D-Conv2 & I-Conv2 | Res-DSC, 2c = 64 | 3 | 128 × 128 × 64 |
| 3 × 3 Max-pool, s = 2 | – | 64 × 64 × 64 | |
| D-Conv3 & I-Conv3 | Res-DSC, c = 128 | 4 | 64 × 64 × 128 |
| 3 × 3 Max-pool, s = 2 | – | 32 × 32 × 128 | |
| D-Conv4 & I-Conv4 | Res-DSC-DC, c = 256 | 2 | 32 × 32 × 256 |
| 3 × 3 Max-pool, s = 2 | – | 16 × 16 × 256 | |
| D-Conv5 & I-Conv5 | Res-DSC-DC, c = 512 | 1 | 16 × 16 × 512 |
| Category | Version |
|---|---|
| GPU | Nvidia GTX 2060S (12 GB, 1470 MHz) (Nvidia, Clara, CA, USA) |
| CPU | Intel i5-12400F (2.5 GHz 4.4 GHz) (Intel, Clara, CA, USA) |
| Programming | Python 3.8.8 + Pytorch 1.10.0 + Cuda 102 |
| Operating system | Windows 11 × 64 |
| Input Types | U-Net Encoder | mIoU (%) | Acc (%) | mRec (%) | mPre (%) | mF1 (%) |
|---|---|---|---|---|---|---|
| Depth Data | ResNet18 | 69.06 | 97.97 | 82.06 | 78.20 | 80.08 |
| ResNet34 | 71.32 | 98.05 | 82.03 | 81.37 | 81.70 | |
| ResNet50 | 70.65 | 97.97 | 84.06 | 78.67 | 81.28 | |
| Image | ResNet18 | 76.85 | 98.53 | 88.56 | 84.01 | 86.23 |
| ResNet34 | 77.19 | 98.64 | 85.81 | 86.87 | 86.34 | |
| ResNet50 | 76.52 | 98.53 | 87.99 | 83.97 | 85.94 | |
| 1 Concat data | ResNet18 | 76.79 | 98.60 | 85.59 | 86.51 | 86.05 |
| ResNet34 | 76.96 | 98.58 | 87.56 | 84.87 | 86.19 | |
| ResNet50 | 76.13 | 98.65 | 83.46 | 88.60 | 85.95 |
| Backbone | Parameters (M) | FLOPs |
|---|---|---|
| ResNet18 | 11.17 | 0.93 × |
| ResNet34 | 21.28 | 1.90 × |
| ResNet50 | 23.50 | 2.12 × |
| ResNet34 | DSC | DC | mIoU | Acc | mRec | mPre | mF1 |
|---|---|---|---|---|---|---|---|
| √ | 76.96 | 98.58 | 87.56 | 84.87 | 86.19 | ||
| √ | √ | 77.25 | 98.67 | 85.02 | 87.82 | 86.39 | |
| √ | √ | 77.32 | 98.58 | 89.40 | 83.78 | 86.50 | |
| √ | √ | √ | 78.56 | 98.76 | 86.75 | 87.88 | 87.31 |
| Backbone | Parameters (M) | FLOPs |
|---|---|---|
| ResNet18 | 11.17 | 0.93 × |
| ResNet34 | 21.28 | 1.90 × |
| Improved ResNet34 (ours) | 10.00 | 0.94 × |
| U-Net Encoder | Data | Fusion Type | mIoU | Acc | mRec | mPre | mF1 |
|---|---|---|---|---|---|---|---|
| Improved ResNet34 | Depth | – | 72.35 | 98.19 | 85.02 | 81.84 | 83.40 |
| Image | – | 77.73 | 98.64 | 87.60 | 86.13 | 86.86 | |
| Depth & Image | AIF (ours) | 79.73 | 98.85 | 87.38 | 88.86 | 88.11 | |
| 1 Concat | 78.56 | 98.76 | 86.75 | 87.88 | 87.31 |
| Methods | Backbone | mIoU (%) | Acc (%) | mRec (%) | mPre (%) | mF1 (%) |
|---|---|---|---|---|---|---|
| U-Net | ResNet50 | 77.70 | 98.64 | 87.14 | 86.89 | 86.70 |
| U-Net | VGG16 | 77.84 | 98.74 | 84.82 | 89.57 | 86.79 |
| PSPNet | ResNet50 | 76.44 | 98.59 | 86.56 | 85.12 | 85.78 |
| PSPNet | MobileNetv2 | 73.61 | 98.36 | 84.62 | 82.78 | 83.68 |
| DeepLabv3 | MobileNetv2 | 75.86 | 98.59 | 84.87 | 85.87 | 85.36 |
| DeepLabv3 | Xception | 71.04 | 98.44 | 76.99 | 88.22 | 76.99 |
| Segformer | MiT-B0 | 78.91 | 98.71 | 89.02 | 86.38 | 87.55 |
| Segformer | MiT-B1 | 77.13 | 98.48 | 90.81 | 82.79 | 86.28 |
| Segformer | MiT-B2 | 76.98 | 98.52 | 88.66 | 84.27 | 86.17 |
| Ours | Improve ResNet34 | 79.73 | 98.85 | 87.38 | 88.86 | 88.11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Y.; Xu, Z.; Lin, Y.; Chen, D.; Ai, Z.; Zhang, H. A Multi-Source Data Fusion Network for Wood Surface Broken Defect Segmentation. Sensors 2024, 24, 1635. https://doi.org/10.3390/s24051635
Zhu Y, Xu Z, Lin Y, Chen D, Ai Z, Zhang H. A Multi-Source Data Fusion Network for Wood Surface Broken Defect Segmentation. Sensors. 2024; 24(5):1635. https://doi.org/10.3390/s24051635
Chicago/Turabian StyleZhu, Yuhang, Zhezhuang Xu, Ye Lin, Dan Chen, Zhijie Ai, and Hongchuan Zhang. 2024. "A Multi-Source Data Fusion Network for Wood Surface Broken Defect Segmentation" Sensors 24, no. 5: 1635. https://doi.org/10.3390/s24051635
APA StyleZhu, Y., Xu, Z., Lin, Y., Chen, D., Ai, Z., & Zhang, H. (2024). A Multi-Source Data Fusion Network for Wood Surface Broken Defect Segmentation. Sensors, 24(5), 1635. https://doi.org/10.3390/s24051635