1. Introduction
Anonymous networks play an important role in safeguarding user identities and privacy. Existing anonymous networks include onion routing (Tor) [
1], garlic routing [
2], the Mix Network [
3], and the Invisible Internet Project (I2P) [
4]. Notably, Tor and the Mix Network are two common types of anonymous networks. Tor routes data through a series of intermediary nodes, in which it emphasizes preventing the associations of communication partners [
1]. On the other hand, the Mix Network employs multiple routers to shuffle and randomize encrypted messages [
3]. By using these networks, both ends can communicate without sharing identities such as IP addresses.
The demand for using anonymous networks has increased. For instance, approximately two million users accessed Tor in the first quarter of 2020 [
1]. In legitimate cases, users may access services like file sharing while preserving anonymity. On the other hand, anonymity can result in misbehavior in cyberspaces, which includes cyber attacks. For example, packets targeting the Darknet are suspicious and usually generated by malware or attackers searching for vulnerabilities [
5]. Moreover, investigations into the Tor network unveiled that malware and counterfeits have been circulating [
6]. The authors proposed to detect distributed denial of services (DDoSs) by evaluating Darknet traffic [
7]. Not only do attackers exploit anonymous networks to attack non-anonymous entities, but the Tor network itself is subject to denial of service (DoS) attacks, which may lead to the loss of bandwidth resources [
8]. Furthermore, attempts to deanonymize clients, locate servers within the Tor network, and reduce the service availability of the Tor network have become the targets of attackers [
9]. These trends imply that attackers have abused anonymous networks, although there are legitimate use cases. Therefore, efforts to detect anonymous traffic are necessary for preventing adversarial affairs, and our work assumes anonymous traffic is an anomaly.
Blocking the IP addresses that are involved in anonymous traffic has been one tactic [
10]. When encountering suspected anonymous traffic, the IP address of the incoming traffic is compared against each blocked IP address. However, this approach can be expensive and performs poorly whenever the list is outdated [
11]. Alternatively, in research, there have been attempts to trace clients that use the Tor network. In this study, the researchers controlled a Tor router and a server in the Tor network to generate purposefully modified packets. When the controlled Tor router observes modified packets, the client’s identity can be linked and confirmed. Nonetheless, this approach requires control over Tor routers and over the deployment of servers in the Tor network, which can undermine the Tor network’s functionalities. In summary, these aspects demonstrate that detecting anonymous traffic remains a challenge.
To improve the efficiency of traffic analysis, researchers have inspected anonymous traffic by focusing on packet characteristics and stream patterns [
12]. Recently, machine learning and deep learning-based methods have been explored for analyzing anonymous traffic. Extensive studies have been performed on supervised learning [
12,
13,
14]. In supervised learning approaches, the objective is to learn an approximation of
, where the given datasets are represented as
, where
is the feature set and where
denotes the corresponding label [
15]. Classifiers, a subset of supervised learning algorithms, are heavily employed to compute boundaries that categorize samples into distinct regions. In the deep learning field, classifiers are constructed with complex structures that are capable of processing features in high dimensions. While classifiers achieve high performance on static data, those types of models exhibit shortcomings upon deployment in real time. For instance, their real-time deployment in the realm of IDS shows vulnerability to the obfuscated features of dynamic network traffic [
16]. The performance evaluation of some machine learning- and deep learning-based models displayed a high false positive rate in classifying Darknet traffic [
13]. Moreover, due to the limited availability of public datasets, researchers have needed help accessing data about anonymous network traffic [
17,
18]. Consequently, training detection models can be challenging.
Regarding the existing challenges, the motivations can be summarized as follows:
The generation of anonymous traffic, often linked to adversarial activities on the Internet, underscores the necessity of its detection for maintaining cybersecurity.
While supervised learning algorithms are widely utilized to examine anonymous traffic, especially classifiers designed for predictive tasks, they still face challenges. These challenges include limitations in adapting to unpredictable network conditions and significant time and resource demands, such as a lengthy training time and dependence on labeled data. By applying feature engineering, we focus on extracting packet- and timing-related features, which are crucial for differentiating between anonymous and non-anonymous traffic.
By addressing the adaptability of the Markov decision process (MDP) to dynamic environments, we implement a classification system based on the MDP principles and outcomes of feature engineering. The result is a robust classification system that can efficiently detect anonymous traffic with a simplified architecture.
Based on the motivations, the contributions are summarized as follows. In this work, we differentiated between anonymous and benign network traffic by incorporating packet and timing features. These features distinguish effectively between anonymous and benign traffic, as well as pave the way for subsequent experiments in anonymous traffic detection. Furthermore, we applied the Markov decision process (MDP) framework to the classification system, thereby enhancing decision-making tasks and system resilience by strategically designing actions, states, and rewards. We also introduced a classification model characterized by a simplified structure with reduced resource demands. The efficiency of these reductions is validated through decreased training times and performance evaluations. An accuracy rate exceeding 80% is anticipated by leveraging our framework’s architecture.
We arrange the structure of the paper as follows. Initially,
Section 2 delves into the Tor network and Darknet technical details. This section also introduces supervised learning-based detection approaches and explains the applications of reinforcement learning frameworks in the network domains. Subsequently,
Section 3 discusses the proposed reinforcement learning-based system. Following
Section 3,
Section 4 explains the system development and testing processes. Finally, the paper is concluded by summarizing critical findings related to the proposed system.
3. Methodology
This section explains the network environment in which the proposed detection system will be deployed and the adapted MDP framework to detect anonymous traffic.
3.1. Network Environment
3.1.1. Pattern Information Processing
In network environments, detecting anonymous traffic in real time is challenging due to its encryption features. Rather than examining each packet, our system identifies patterns based on sequences of packets, or ‘flows’, characterized by consistent source and destination IP addresses and ports [
12]. Within this context, the pattern information is related to packet statistics, such as flow length in bytes and timing statistics, including the flow duration and time elapsed between the arrival of consecutive packets. As real-time training data are unavailable, the system computes these features as soon as it captures a flow. For instance, to determine the average packet size within a flow, it divides the total byte counts by the total packet counts.
3.1.2. Flow Pattern Visualization
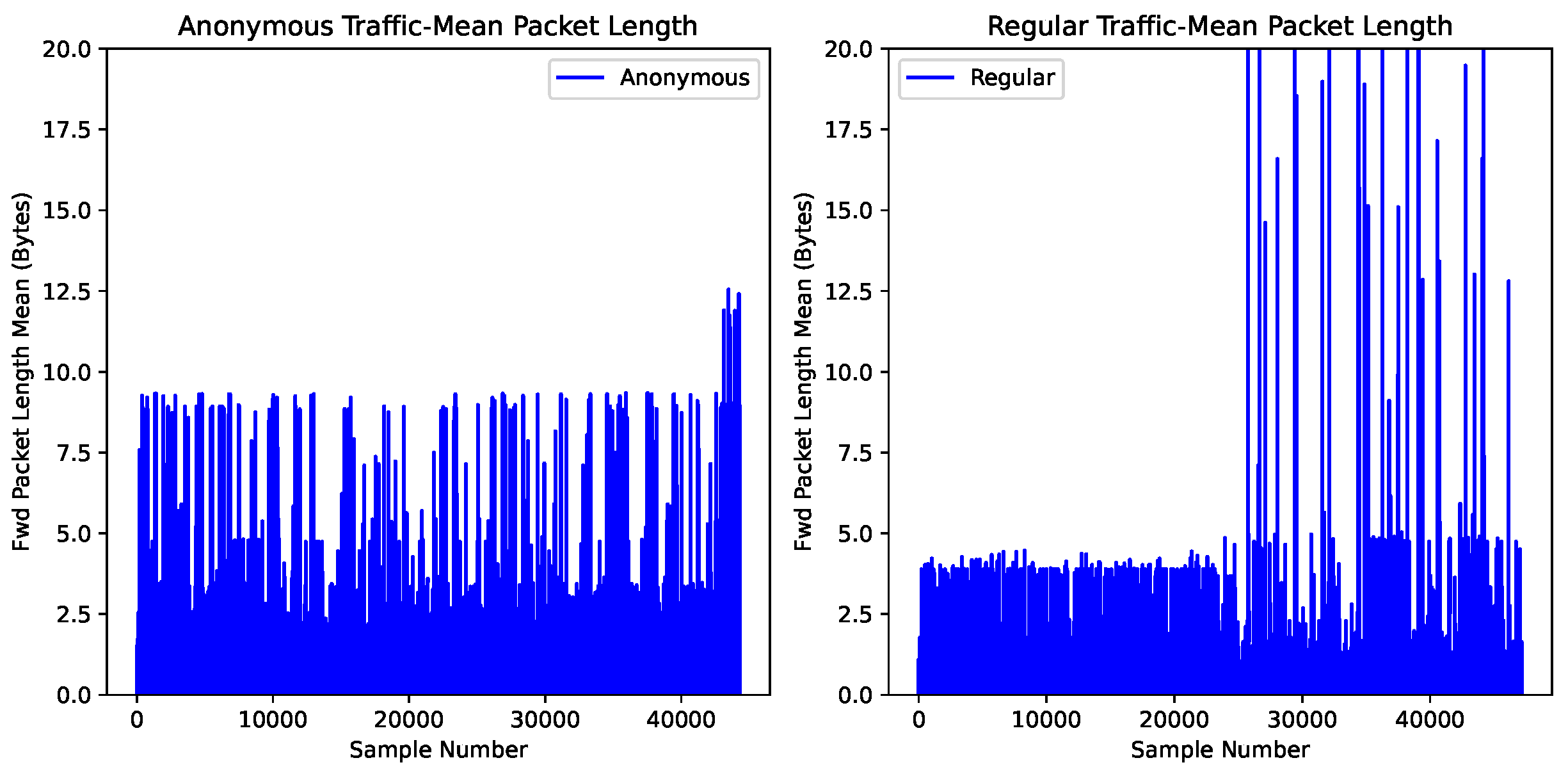
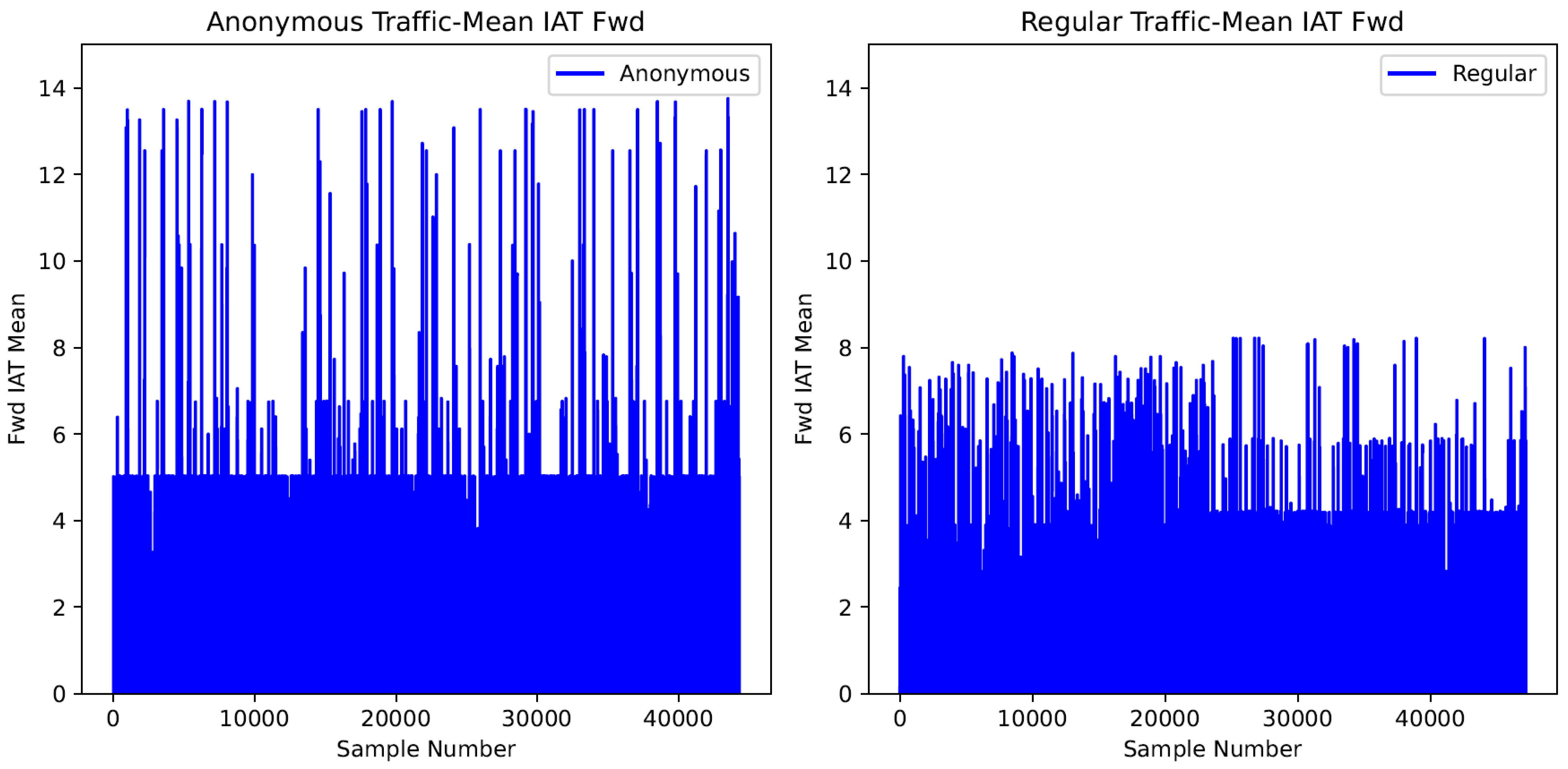
Figure 1 and
Figure 2 visualize the differences in the timing and packet patterns of anonymous and regular traffic flows, respectively. The horizontal axis marks the number of samples, while the vertical axis records the feature value of each sample. The feature values are standardized to unit variance to minimize the bias imposed by the maximum and minimum values.
Figure 1 displays the mean packet length in a flow. It can be seen that the feature values of approximately 40,000 samples vibrate in the range between 0 and 12.5. For regular traffic, the majority of samples range from zero to five, although some feature values exceed five along the vertical axis.
Figure 1 displays the mean packet length in a flow. In the figure, the feature values of approximately 40,000 samples vibrate between 0 and 12.5. Most samples range from zero to five for regular traffic, although some feature values exceed five along the vertical axis.
Figure 2 displays one of the timing-based features, or the mean inter-arrival time of two consecutive packets in the forward direction. The plot of anonymous traffic in
Figure 2 indicates that the feature values of approximately 40,000 anonymous traffic samples range between 0 and 14. For regular traffic, the feature values of all regular traffic samples range from zero to eight.
The results imply that anonymous traffic flows exhibit different timing and packet-based patterns than non-anonymous traffic. Hence, analyzing the packet and timing-based features of anonymous traffic paves the road toward detecting anonymous traffic.
3.2. MDP Environment Descriptions
MDP is a standard framework for addressing sequential decision-making problems [
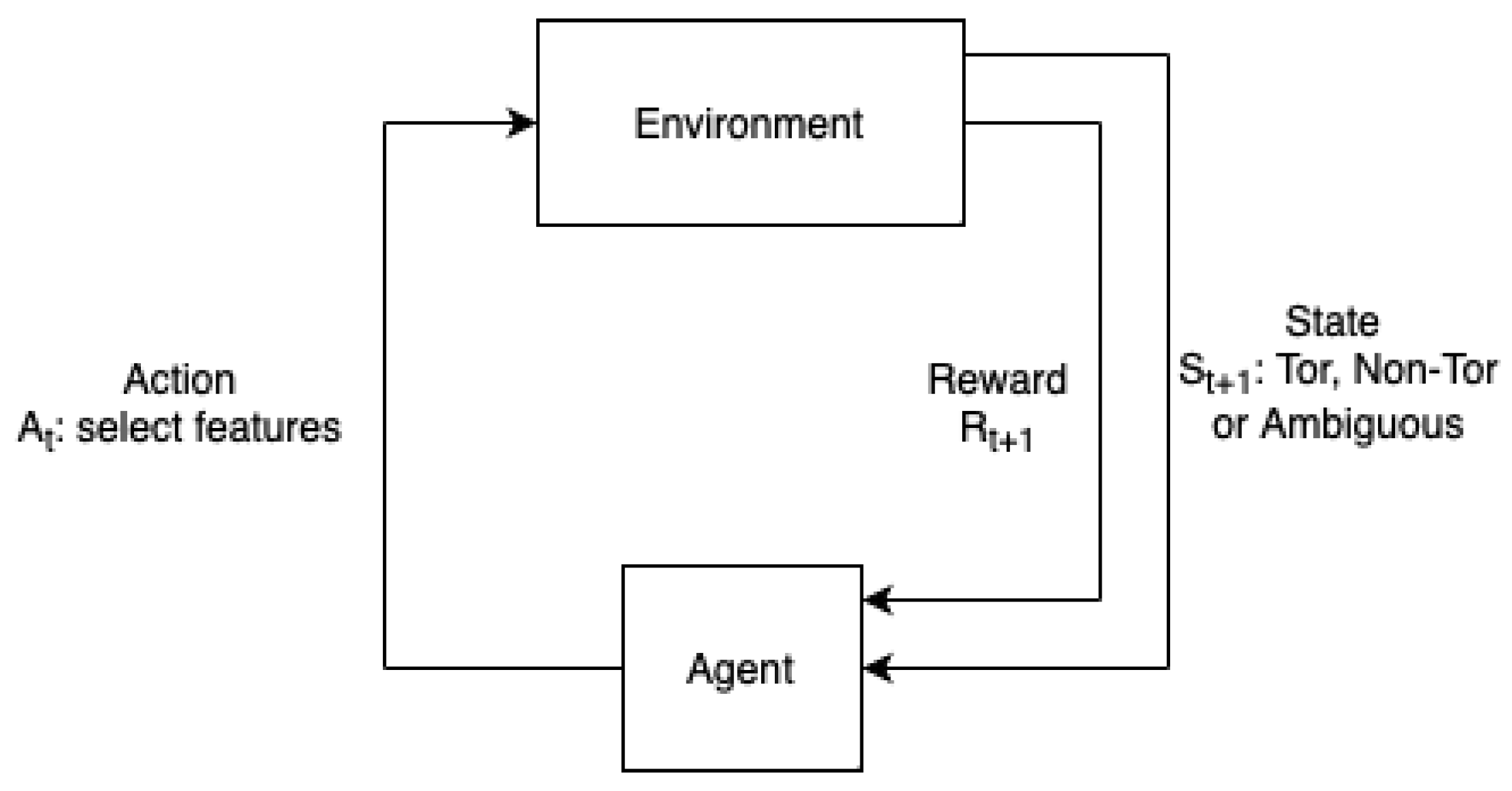
30]. An MDP framework consists of a quadruple denoted as (S, A, r, p). In the quadruple, element S represents a state space with a finite set of states, A represents the action space with a finite set of actions, r is the reward value received upon executing an action, and p is a transition probability. Subsequently, the proposed detection system simulates the MDP framework, as depicted in
Figure 3. In
Figure 3, the process involves selecting a set of features, e.g., the average length of packets in a flow, by the system, according to the current policy. Next, following the execution of action
, the environment sends the reward to the agent, resulting in a transition to another state. This design addresses the interactions between the agent and the environment.
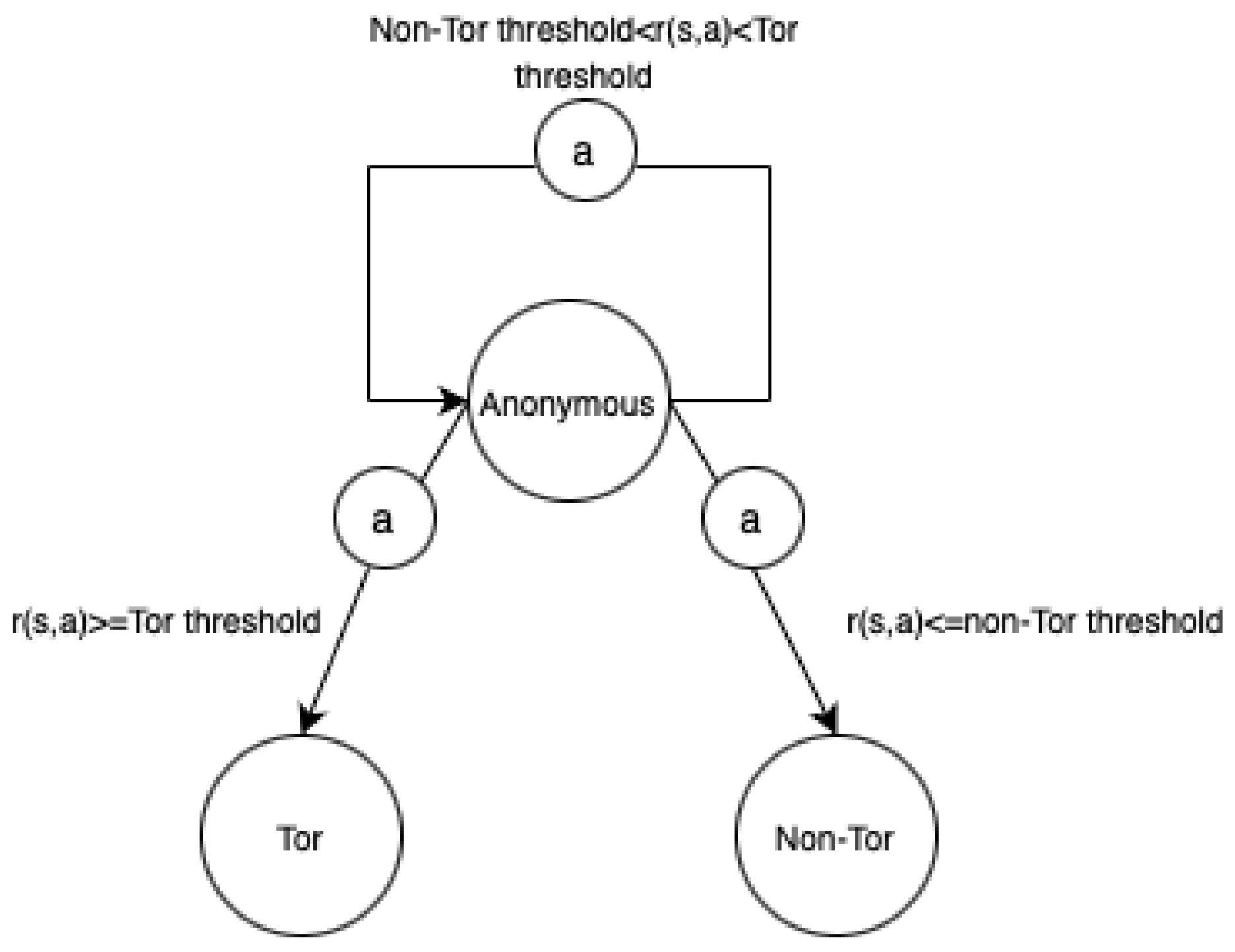
State S: The state space contains three states: Tor, non-Tor, and ambiguous. The state space is interpreted as . In S, s1 represents a vague state, s2 represents a Tor state, and s3 represents a non-Tor state. The initial state of the agent is ambiguous, meaning that the agent has no clue about the behavior of the detected traffic. As such, the agent’s goal is to identify an answer to leave the ambiguous state. Accordingly, the Tor and non-Tor states are considered goal states. The agent assumes that the Tor network generates the current traffic when reaching the Tor state. The current traffic flow is recognized as non-Tor when transiting to the non-Tor state.
This design replaces the conventional labels used for classification tasks with these model states, allowing the system to process the observed network traffic differently.
Action A: The agent’s action is to select features. The action space is defined as , where and . The subscript n represents the number of actions, and t is the number of features each action selects.
To rank features based on feature importance, the feature selection techniques provided by the
Scikit-learn library [
31] are used to select features. Those selection techniques include Recursive Feature Elimination (RFE), Recursive Feature Elimination with Cross-Validation (RFECV), the random forest classifier, the mutual information-based SelectKBest library, and Support Vector Machine (SVM). The rationale for selecting these techniques will be revealed in
Section 4.
Based on this design, the action space size is five. The first, second, third, fourth, and fifth actions select features ranked by RFE, RFECV, the random forest classifier, the SelectKBest API with mutual information, and SVM.
Table 3 summarizes the action space. We reveal and discuss the feature rankings and the selected features in
Section 4:
Heuristic reward function: The heuristic reward function reflects an agent’s action. Our system calculates the reward value by taking the linear summation of weighted feature values as the input to the hyperbolic tangent function. This design of the reward function bounds the reward values within the range between −1 and 1. Precisely, the scalar value of the immediate reward is calculated as:
In Equation (
2), parameter w represents the weight of each feature, and variable f is the feature value. The scalar sum of each product of the feature value and the corresponding weight is the input to the hyperbolic tangent function. Specifically, the formula of the hyperbolic tangent function is as follows:
where
e is the natural exponent and the variable
x is the input to the hyperbolic tangent function, or
in Formula (
2). Finally, the reward function is written as follows:
Environment model: The model of the environment is the transition probability. The conditional probability of transiting to the next state is
. Based on an environment model, an agent’s interactions with the environment can be model-based or model-free. For instance, the environment model in balancing a pendulum can be approximated by knowledge about kinematics. However, an explicit model, given the definitions of state, action a, and reward functions, has yet to be identified among the recorded network flows in CIC-Darknet2020 [
14]. Thus, the agent is expected to make decisions and interact with the environment without being aware of an environment model.
3.3. Threshold Setting
A two-threshold system distinguishes between Tor and non-Tor traffic flow samples, with each threshold tuned explicitly to its respective traffic type. Setting these thresholds aims to calibrate the system’s sensitivity toward identifying Tor traffic. For example, a higher threshold for Tor traffic may decrease the sensitivity, leading to fewer Tor traffic flows being detected. Another goal is to minimize the dependence on labels. Instead of contrasting the computed results with predefined labels, the system compares the results with tuned thresholds. This methodology enables the system to decide whether a specific result exceeds or falls below the set threshold, which facilitates the identification of traffic types in a lightweight manner.
Figure 4 illustrates the horizontal axis on which the Tor and non-Tor thresholds are tuned. Since the experiment considers Tor samples as the Positive Class, the endpoint with the value of 1 denotes Tor samples, and the endpoint with the value of −1 denotes non-Tor samples. Additionally, the value of the Tor threshold is greater than that of the non-Tor threshold. Besides, the segmentation forms three intervals. The first interval is located on the left side of the non-Tor threshold. The middle interval is located between the non-Tor and Tor thresholds. The third interval is situated on the right side of the Tor threshold. Samples with reward values that are distributed on the right side of the Tor threshold are identified as Tor. On the other hand, samples distributed on the left side of the non-Tor threshold towards −1 are detected as non-Tor traffic. Lastly, the middle interval indicates ambiguous samples, meaning the system cannot extract sufficient information to decide. In the above configuration, the system distinguishes Tor and non-Tor flows in an unsupervised mode by setting the thresholds, and the labels are substituted with threshold values.
Note that the distances from each threshold to either endpoint do not contribute to the decision-making process.
3.4. System Diagram
Initially, the agent is placed in the ambiguous state in
Figure 5 and selects the first action in the action space specified in
Table 3. After choosing the first action, the environment assigns the immediate reward, and the agent compares it with the two thresholds. There are three comparison outcomes: lower than the non-Tor threshold, higher than the Tor threshold, and higher than the non-Tor threshold, but lower than the Tor threshold (the middle interval in
Figure 4).
Figure 5 illustrates the transition diagram consisting of three states (Tor, Non-Tor, and Anonymous), where each vertex represents a distinct state and each edge denotes a transition triggered by an action, or (
a), along with the associated reward value, or (
).
3.5. Detection Algorithm
The MDP framework is implemented as a modified transition probability set. Based on the equation below, the probability of transiting to an ambiguous state is one if the reward is less than the Tor threshold and more significant than the non-Tor threshold. The probability of transiting to the Tor state is one if the reward value exceeds the Tor threshold. The transition probability of transiting to the non-Tor state is one if the reward value is lower than the non-Tor threshold. On the other hand, in either the Tor or non-Tor state, the agent reaches the goal and re-initiates in the ambiguous state.
Algorithm 1 describes the transitions between states according to the actions, rewards, states, state transitions, and thresholds. In the adapted MDP framework, the agent aims to arrive at either a Tor or non-Tor state from the ambiguous state. After executing an action, a reward value higher than the Tor threshold or lower than the non-Tor threshold triggers a decision, and the agent departs the ambiguous state. After departing the ambiguous state, the workflow of the current traffic concludes. In turn, the agent moves back to the ambiguous state to analyze the upcoming traffic flows. However, subsequent actions, i.e., the second through the fifth action, are selected until the agent exits the ambiguous state. If the agent remains ambiguous after selecting all five actions, the agent cannot decide and neglects the traffic flow.
Ambiguous traffic flows are recorded in a buffer. Elements in the buffer require further analysis, depending on factors such as respective Intrusion-Detection System policies.
| Algorithm 1 Transitions between states. |
- 1:
procedure Transition() ▹ Function - 2:
for i in 0, len(feature_set), batch_size) do // Create batches - 3:
// Calculate reward value of each sample in the batch - 4:
- 5:
for j in range(len(batch_features), batch_size) do - 6:
if then ▹ Classified as Tor - 7:
- 8:
else if then ▹ Classified as non_Tor - 9:
- 10:
else ▹ Classified as Ambiguous - 11:
while do - 12:
if then - 13:
▹ Further processing required - 14:
- 15:
- 16:
▹
|
4. Experiment
This section delineates the development and testing of the proposed method. The raw dataset was preprocessed in the development phase, and features were ranked according to the feature engineering techniques. In the last stage of the development phase, we trained five single-layer perceptrons and utilized each perceptron’s corresponding weights in the input layer as the reward function’s parameters in Equation (
2). In the testing phase, the system’s performance was gauged based on the accuracy, recall, and precision. Lastly, the system performance was compared against the performance of conventional classifiers.
4.1. Dataset Processing
4.1.1. Raw Dataset
The CIC-Darknet2020 dataset is a labeled dataset that summarizes the statistics of bidirectional anonymous and non-anonymous traffic flows [
14]. We used these historical statistics to develop the MDP framework.
The researchers extracted packet- and timing-based features using the
CICFlowMeter [
14] tool. Timing-based features include packet inter-arrival time, idle time, and bytes per second. Packet-based features include pattern information about the packet size and contents.
There are four types of labels: non-Tor, non-VPN, Tor, and VPN. We consider VPN traffic anonymous because VPN traffic is encrypted, although VPN traffic is tunneled and generated by different means than that of the Tor traffic. Therefore, the Tor and VPN labels are merged as Tor types, while the non-Tor and non-VPN labels are incorporated into the non-Tor type, resulting in two labels.
Table 4 summarizes the raw dataset.
To elaborate, the number of flow records is 141,530, while the number of features is 83. The number of flows labeled as non-Tor and Tor is 117,219 and 24,311, respectively.
4.1.2. Cleaning and Preprocessing
The raw dataset was converted to a pandas dataframe for preprocessing and cleaning.
In the cleaning phase, samples that contain infinite values and “Not a Number” entries were dropped. Then, the features that share the same value among all samples were discarded. The resulting number of features was 62, and the number of samples was reduced from 141,530 to 141,483. To further simplify the feature set, the Feature Selection with Variance Thresholding (VarianceThreshold) technique in the
Scikit-learn library (abbreviated as
sklearn) [
31] was applied. Specifically, the VarianceThreshold technique removes features with a variance below a specified threshold. In the experiment, the threshold was set at 30%. After running the VarianceThreshold, four features were further eliminated, resulting in 58 features.
The label distributions of the raw dataset are skewed, as shown in
Table 4. Basically, samples labeled as non-Tor are quite abundant, while the number of Tor samples is 24,311 and only accounts for 17.18% of the 141,483 samples. To balance the dataset, the non-Tor samples whose indexes range from 0 to 69,999 were eliminated. Next, we generated 20,000 synthetic data by duplicating the samples labeled as Tor or VPN.
After cleaning and balancing, the finalized dataset contains 91,483 samples and 58 features. As
Table 5 displays, the final dataset contains 47,172 Tor samples and 44,311 non-Tor samples, both of which account for approximately 48.4% of the 91,483 samples. Lastly, the number of features is 58.
4.1.3. Label Encoding
Since there are two types of labels, the Bernoulli Equation was applied. The Bernoulli Equation is defined as and , where X is a random variable and p is the probability of X being equal to 1. As a result, an integer of either 0 or 1 replaces each categorical label. Since anonymous traffic is defined as an anomaly, each Tor label is replaced with the integer 1 (Positive Class), and each non-Tor label is replaced with the integer 0 (Negative Class). This step was achieved through the Label Encoding method in the sklearn library.
However, to facilitate the separations between non-Tor and Tor samples, the labels belonging to the Negative Class were converted from 0 to −1. To perform the conversion, the formula applied is represented as follows: . After applying the formula, the labels in the Positive Class are represented as the integer 1, and the labels in the Negative Class are replaced with the integer −1.
4.2. Action Space Construction
The dimensionality of our action space is two, encompassing a multitude of actions. Each action within this space is defined as a feature selection technique in the sklearn library, and each action selects a specific set of features. Upon processing the raw dataset, it is imperative to finalize the total number of actions available within this action space along with the specific number of features selected by each individual action.
4.2.1. Determining the Number of Actions
According to
Table 3, the random forest classifier (RF), Recursive Feature Elimination (RFE), Recursive Feature Elimination with Cross-Validation (RFECV), mutual information, and Support Vector Machine (SVM) were chosen for defining each action and utilized to rank the feature importance.
In the experiment, a higher importance ranking indicates that a feature is more likely to contribute to the predictive performance. Since the feature importance ranking is based on importance scores, the experiment adopts RF to generate the importance scores and measure the amount of information contained in each feature to reduce the uncertainty. Also, RF was applied to the RFE and RFECV APIs as their score function. Subsequently, the RFE and RFECV techniques were leveraged to recursively eliminate features containing less information about the target variables. Additionally, the mutual information technique was employed to measure the relevance between a feature and the target variable. Lastly, as 58 features are involved, SVM was utilized to reduce over-fitting and improve robustness.
The experiment has determined the composition of the action space, which now comprises five actions: Random Forest (RF), Recursive Feature Elimination (RFE), Recursive Feature Elimination with Cross-Validation (RFECV), mutual information, and Support Vector Machine (SVM).
4.2.2. Determining the Number of Features Selected by Each Action
After determining the number of actions, the number of features selected by each action was determined. When selecting the number of features for each action, one explicit method is to include as much information as possible, for example feeding all of the 58 features. However, this method may incur undesired data volume. Another approach is to include fewer features. To determine the optimal number of features selected by each action, we evaluated the accuracy by using the random forest classifier. The random forest classifier was chosen as it generates importance scores. In addition, it is used as the score function of the Recursive Feature Elimination and the Recursive Feature Elimination techniques with Cross-Validation in the experiment.
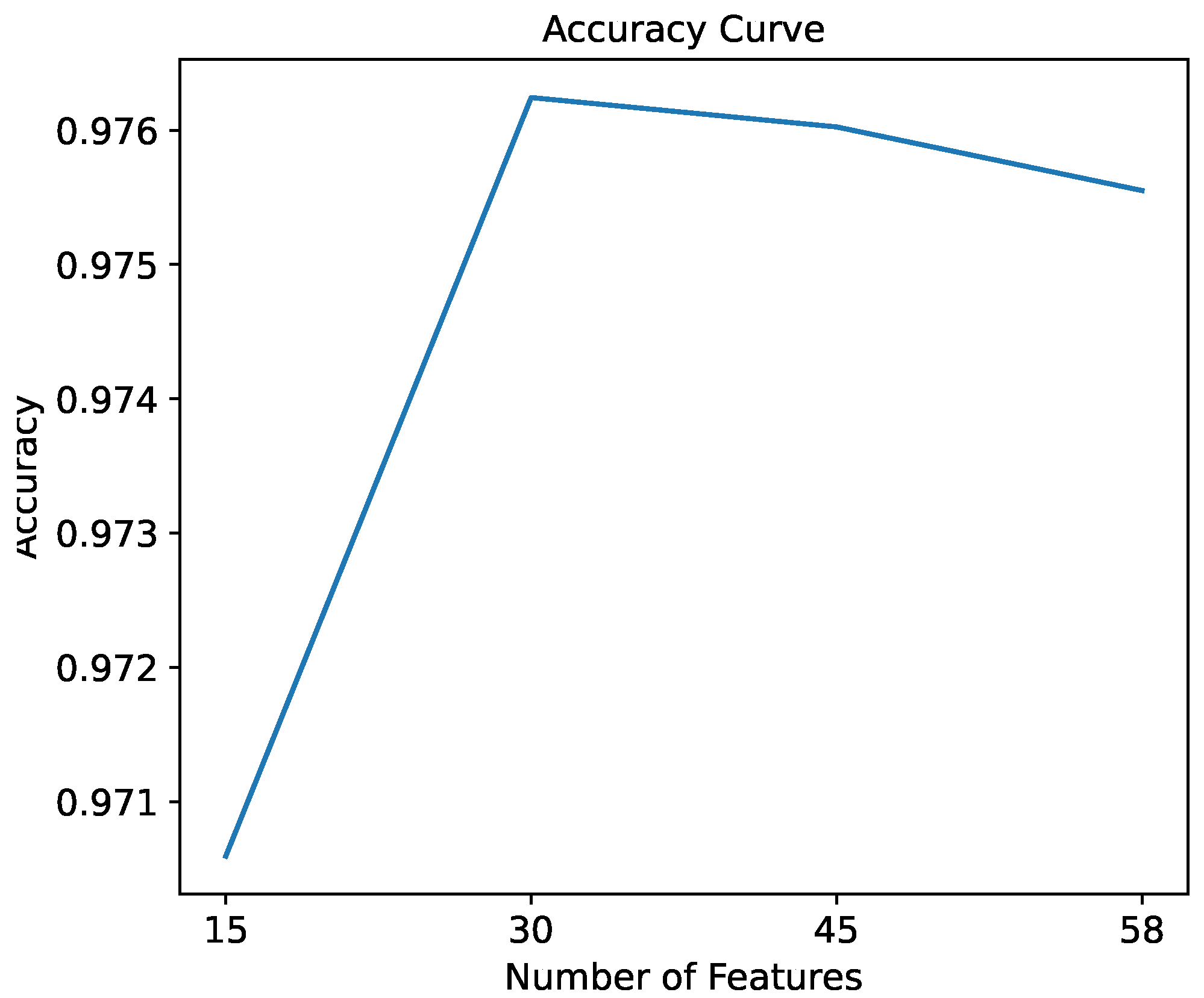
The classification accuracy of the random forest classifier was measured regarding the number of features. In the evaluation process, initiating the experiment with 15 features, the number of features was increased gradually in increments of 15 until all 58 features were used.
Figure 6 depicts the resulting accuracy curve. The accuracy improved from 0.9746 when selecting 15 features to 0.9774 when selecting 30 features. Nonetheless, the accuracy saturated when more than 30 features were selected. This trend indicates that the accuracy improves as the number of features is increased within a specific range. However, selecting more features did not improve the performance further. Therefore, the number of features selected by each action was determined to be 15. This decision balances between maximizing input information while minimizing complexity and computational demands.
4.2.3. Determining the Specific Features Selected by Each Action
After determining the number of features each action should select, the experimentation focused on identifying which 15 out of the 58 features would be most appropriate for each action. We explored two main strategies: randomly selecting 15 features from the 58 available features and the selection based on the highest importance scores. The random selection approach revealed that the number of possible combinations for selecting 15 features from 58 is approximately , a figure that is impractical to solve due to its vast scale. To address this challenge, we adopted a second approach that prioritizes feature selection based on importance scores. This method utilized feature selection APIs in the sklearn library, incorporating techniques such as Recursive Feature Elimination (RFE), Recursive Feature Elimination with Cross-Validation (RFECV), mutual information, Random Forest Classification, and Support Vector Machine (SVM). By selecting the top-15 ranked features as determined by each technique, the action space was refined to consist of five actions, each selecting 15 features with the highest importance scores. This strategy concluded the construction of the action space.
4.3. Feature Selection Process
The feature selection process was initiated by searching for the most appropriate parameter set. The grid search on the random forest classifier was applied. The parameters to be searched are displayed in
Table 6.
The result of the grid search is as follows. The number of estimators is 125, the maximum depth 15, the minimum number of samples to split a node 2, and the minimum number of samples in a leaf node 1.
We used the resulting configuration of the random forest classifier as the score function of RFE and RFECV. The number of folds of the cross-validations in RFECV was set to three. Subsequently, the random forest classifier with the same parameter configuration, as mentioned in
Table 7, was built based on the processed dataset. As for the SelectKBest API, the mutual information technique was used as its score function. Finally, an SVM with a linear kernel was built based on the processed dataset.
By applying these feature selection techniques, the 15 features with the highest 15 ranks were derived.
Table 8 displays the ranking results.
For RFE, the most crucial feature was identified as Bwd Packet Length Min, while the feature with the 15th rank was Idle Min. Similarly, for RFECV, the most crucial feature was flow duration, while the feature ranked 15th was Flow IAT Mean. Furthermore, there are standard features that RFE, RFECV, SelectKBest, and RF select. Features such as Bwd Packet Length Min, Flow Packets/s, and Flow IAT Max were consistently determined as informative for distinguishing between Tor and non-Tor traffic.
4.4. Reward Function Experimentation
At first, the reward function was defined as a linear equation. Furthermore, the endeavor was to compute the weights of the linear equation such that the aggregate of weighted feature values separates the Tor and non-Tor samples around a threshold of zero. Nonetheless, the calculations imply that the correspondence between the weights and the labels was intricate. Therefore, non-linearity was introduced to facilitate the separation of Tor and non-Tor samples.
Hyperbolic Tangent-Based Reward Function
A single-layer neural network was harnessed to implement the reward function, as mentioned in Equation (
2). Specifically, the weights of the reward function were derived from the trained neural network. The activation function at the output layer serves to add the non-linearity. In each instance of the single-layer neural network, the input layer contains 15 neurons, while the output layer has 1 neuron. The hyperbolic tangent function is employed at the output layer to map the linearly weighted summation of feature values onto a single value.
Prior to the training process, the feature values of each sample underwent standardization to reach unit variance. The reason for executing standardization is that many feature values have a vast range. For instance, the
idle max feature has a maximum value of
, whereas the
Bwd Packet Length Min feature has a maximum value of 1350. Accordingly, the
StandardScaler class of
sklearn [
31] was leveraged to bring all feature values to the same scale.
During the training phase, each neural network was trained in a supervised manner using the
PyTorch library. Stochastic gradient descent (SGD) with a learning rate of 0.001 was employed as the optimizer. It was observed that the loss stopped decreasing after 30 epochs. Consequently, each neural network was trained within 30 epochs in a trial. However, another observation indicated that the weights in each training trial varied, even when the same feature set was applied. To determine the influence of those variations on the detection accuracy, the performance of each trained neural network was tested. The result exhibited that varying weights across trials did not reduce the accuracy, provided the feature sets were used consistently across trials. As a result, the weights produced by the last run were finalized as the weights of each reward function. The results of the reward functions are recorded in
Table 9.
Regarding the correlations between the rankings of feature weights and the rankings of feature importance, the results showcase that the rankings of the weights did not align with the rankings of feature importance generated by the sklearn feature selection techniques. For instance, within the feature set selected via RFE, Idle Min had the lowest ranking and the third-highest weight of 0.1763. Meanwhile, Flow IAT Max was ranked at the top position by SelectKBest. However, it had the third-highest weight. This discrepancy suggests that the weights in a neural network and the importance of features are different metrics in evaluating the contributions of the features to predictive performance.
Based on
Table 9, the reward function corresponding to each action is represented as
. Hence, the reward of
was calculated as
, where the weight set was transposed and multiplied by the features selected by action
. According to Equation (
4), the reward value of selecting the features ranked by RFE is calculated as
4.5. Threshold Probing
4.5.1. Adjusting Threshold Values
Adjusting the sensitivity to Tor traffic requires setting appropriate thresholds. We initiated with the first action set to select features as ranked by Recursive Feature Elimination (RFE), with the expectation that the target thresholds would be close to 0. The probing began at this baseline. A nested loop was employed for the probing process, where the outer loop adjusted the non-Tor threshold from −1 to 1 and the inner loop varied the Tor threshold within the same range, both utilizing an incremental step of 0.02. The results from this threshold probing indicated that the optimal accuracy was achieved when the non-Tor threshold was set at −0.3.
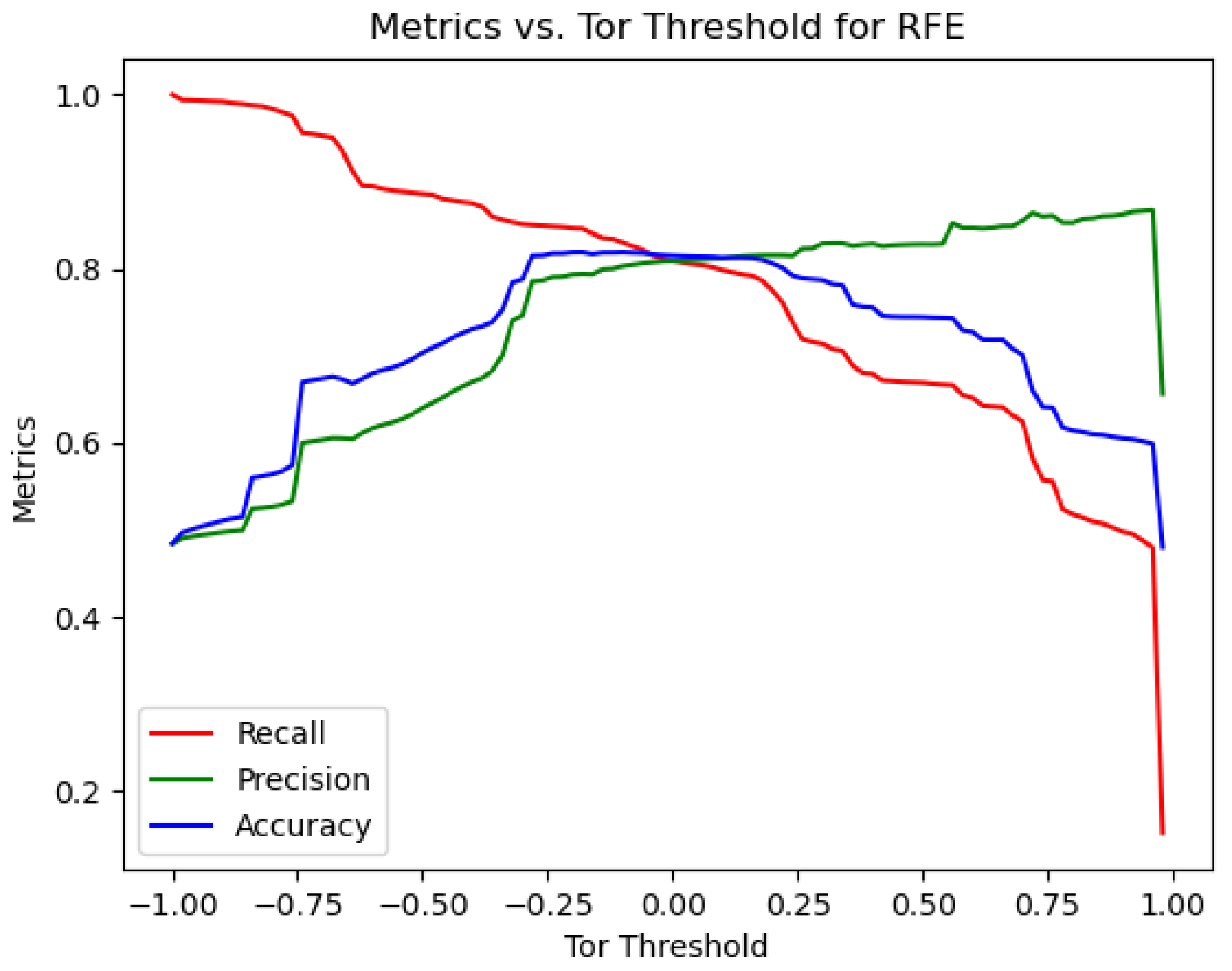
As depicted in
Figure 7, the highest accuracy was reached in the range between −0.25 and 0.2. Taking into account the width of this ambiguous interval and the intersection point of accuracy, recall, and precision metrics, the Tor threshold was set at −0.3. Consequently, the Tor and non-Tor thresholds were finalized at −0.1 and −0.3, respectively, marking the end of the threshold optimization process.
4.5.2. Adjusting the Action Sequence
We adjusted the sequence of actions to be applied at the ambiguous state to improve accuracy. Different from
Table 3, the action space can be arranged as in
Table 10.
The first action (Number 1) in the sequence had the highest impact on accuracy to the extent of 5 to 10%. However, adjusting the action sequence while keeping the first action fixed trivializes the accuracy improvement.
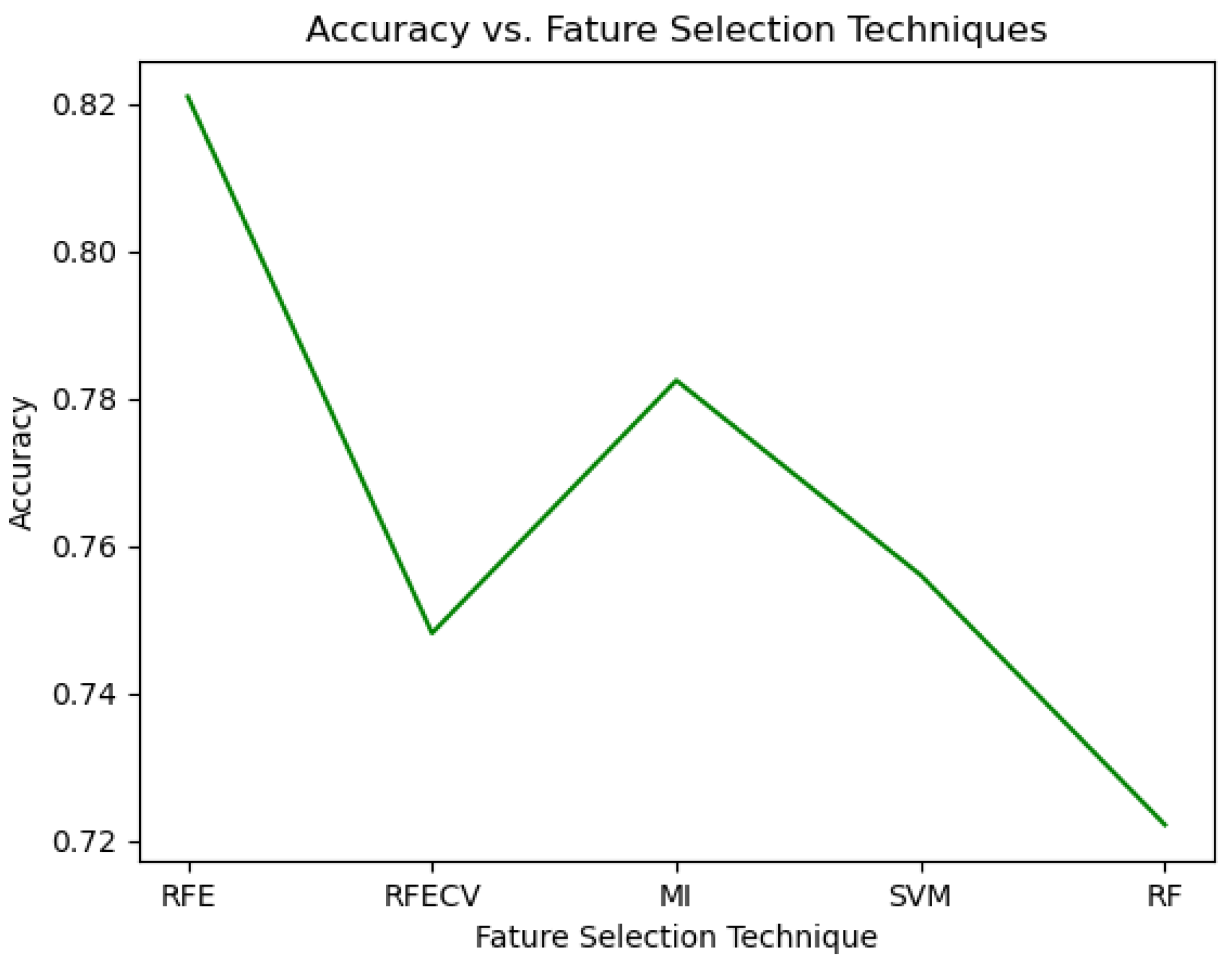
The experiment recorded the maximum accuracy of positioning the RFE, RFECV, mutual information, random forest classifier, or SVM at the first.
Figure 8 shows the trends. Arranging Recursive Feature Elimination (RFE) as the first position in the action space yielded the highest accuracy at 82%, whereas employing features ranked by the random forest classifier led to the lowest accuracy, recorded at 72.2%.
The final action space is defined as , where is RFE, is RFECV, is mutual information, is SVM, and is random forest.
4.6. Model Deployment and Testing
The workflow of the testing procedure is divided into four phases as shown in
Figure 9.
In phase 1, the saved and trained perceptrons were loaded from the .pth files, and the training process was detailed in
Section 4.4. Phase 2 involved extracting the features listed in
Table 8 from the cleaned dataset. These features were then standardized for processing in the proceeding phases. In the third phase, a supervised testing procedure was conducted. Specifically, a reward value was obtained in every step, and the reward value was compared with the pre-defined thresholds. The state to which the agent transits was then compared with the known label for the current sample. If the state and label matched, the sample was correctly identified. Conversely, the samples would be misclassified if the state and label did not match. In the final phase, the model performance was gauged based on the precision, recall, and accuracy metrics. The results of these metrics are recorded in
Table 11.
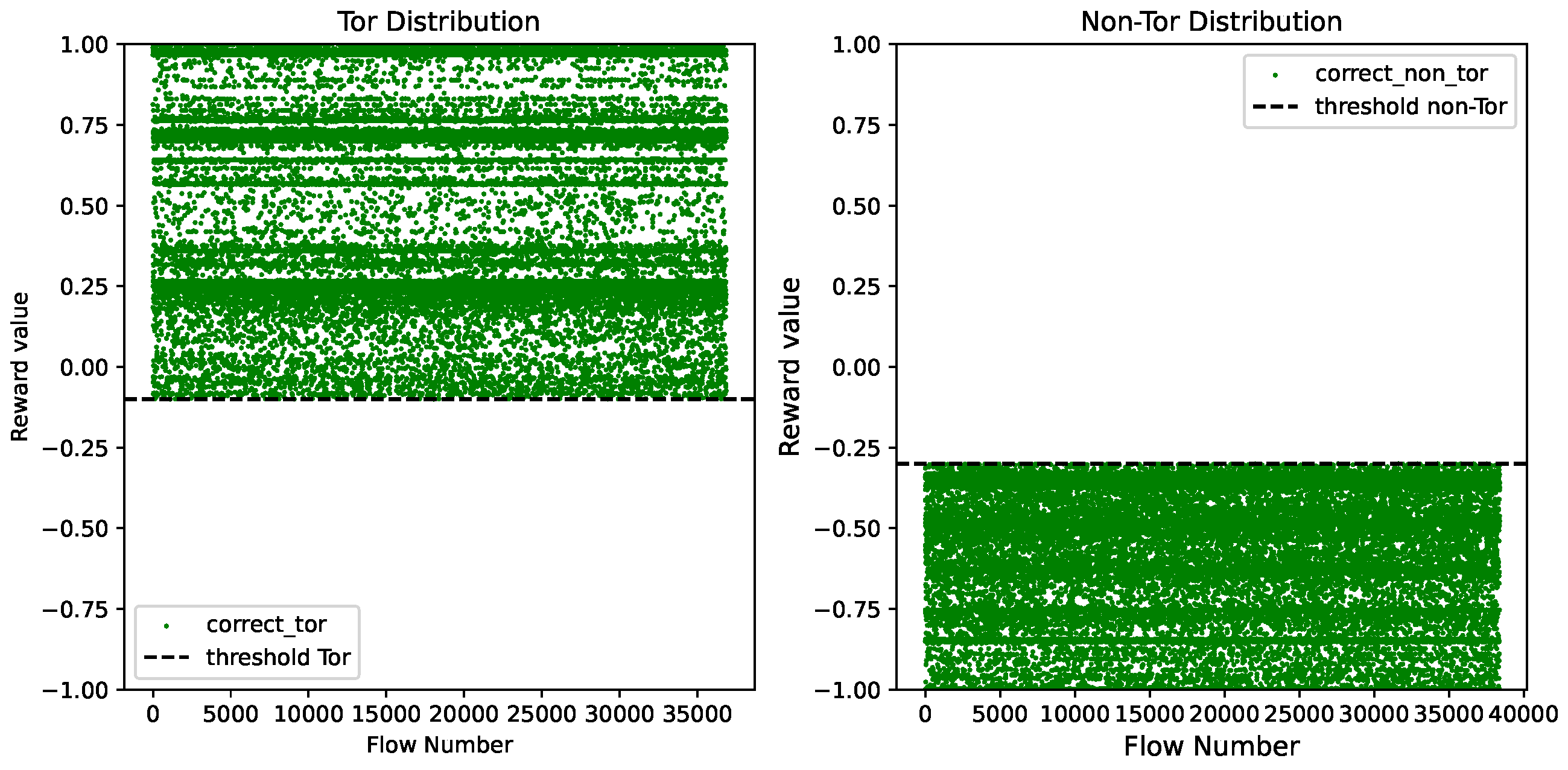
Additionally, we visualize in
Figure 10 the reward value distributions of Tor and non-Tor traffic samples when the Tor threshold was set at −0.1 and the non-Tor threshold was set at −0.3.
Figure 10 demonstrates that the Tor and non-Tor thresholds effectively separated the reward values of Tor and non-Tor samples into two regions.
4.7. System Performance Comparisons
In addition to model testing, the performance of the proposed system was assessed against other baselines by the accuracy. The baselines included the CNN model (DeepImage) described in [
14], the stacking ensemble model developed by [
13], the random forest classifier implementation in our experiment, the improved decision tree algorithm (Tor-IDS) mentioned in [
25], and the random forest tested on the Anon17 dataset [
18].
Table 12 lists the comparison results.
The comparison results highlight the outstanding performance of supervised baselines in identifying Tor traffic patterns. Among these models, the improved decision tree algorithm [
25] and the random forest implementation [
18] had the highest accuracy at up to 0.99, followed closely by the ensemble model at 0.98, the random forest classifier in our experiment at 0.97, and the DeepImage model at 0.95. It is worth noting that, while the proposed model trailed behind these supervised models in terms of accuracy, it achieved an accuracy level exceeding 80%. This discrepancy indicates that ensemble and decision tree-based models in fully supervised modes can process static data and predict patterns with a high efficiency. In contrast, the proposed model targets operating in an unsupervised mode. This strategy addresses the challenges posed by the absence of labeled data in real-time network environments. As a trade-off, the proposed model was developed with a single dataset and will function in the absence of the labeled dataset upon deployment. Furthermore, each instance of the single-layer neural network has a simple structure and rapid training time. With continued improvements, the accuracy is considered satisfactory in this study. Ultimately, those aspects make deployments of this system in real-time situations more practical and robust.
5. Conclusions
Anonymous networks preserve user anonymity by relaying data through a distributed network. Using tools such as the Tor network makes the transmitted data hard to read and trace for third parties. However, traffic originating from anonymous networks can be suspicious or malevolent. Therefore, the real-time detection of anonymous traffic is crucial, yet inherently complex. This work has implemented a real-time system for detecting anonymous traffic using a labeled dataset containing 141,530 samples. Instead of relying on traditional classifiers, features most informative about Tor and non-Tor traffic were extracted. These important features were then used to construct a tuple comprising information about the system’s state, action, reward, and transition. Based on this tuple, we implemented a system with a simplified structure utilizing a single-layer feed-forward neural network for classification tasks. During deployment, the system continuously monitors network flows and analyzes relevant features. It makes decisions by reward signals and compares each reward signal against predefined thresholds. Depending on the comparison results, the agent transitions to one of the following states: the Tor, Non-Tor, or ambiguity. In the testing phase, the model was gauged in a supervised manner. The result indicates that the model’s accuracy for detecting anonymous traffic is 82%, which could have implications for network security and privacy.
In future work, we aim to develop robust methods for detecting traffic generated by Darknet protocols within the Tor network, along with distinguishing between benign and malicious anonymous traffic. This endeavor would involve refining the analytical techniques, which may contribute to strengthening cybersecurity measures.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}