
Assessing the Cloud-RAN in the Linux Kernel: Sharing Computing and Network Resources

Abstract
:1. Introduction
2. Background and Related Work
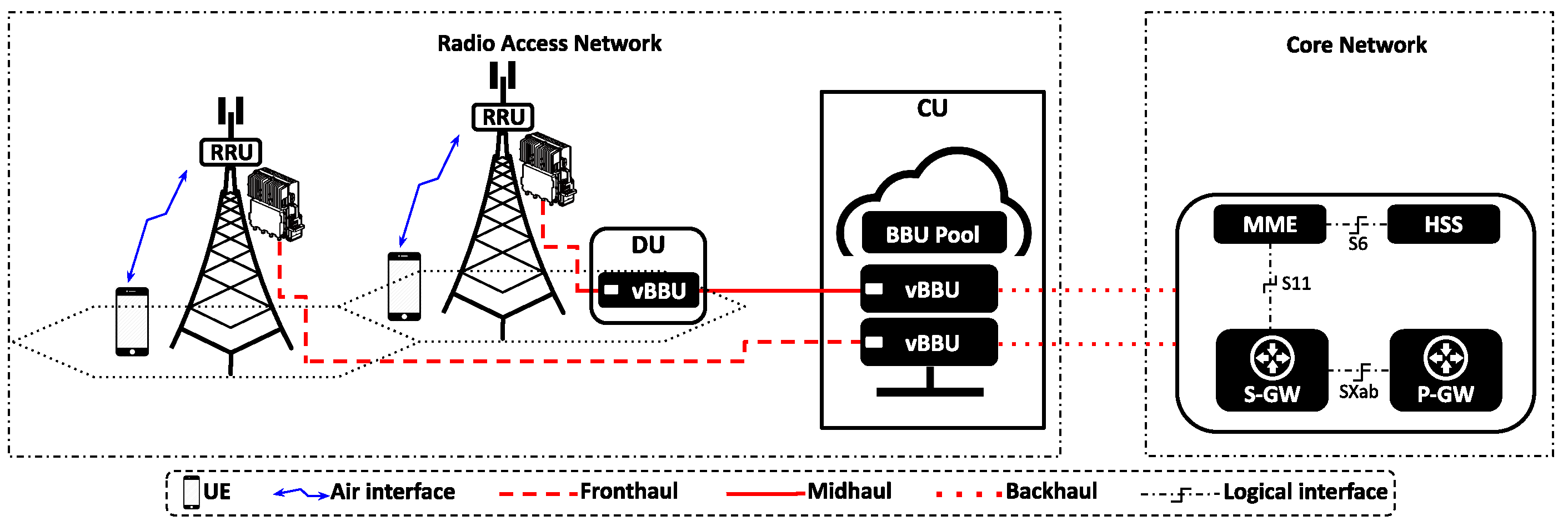
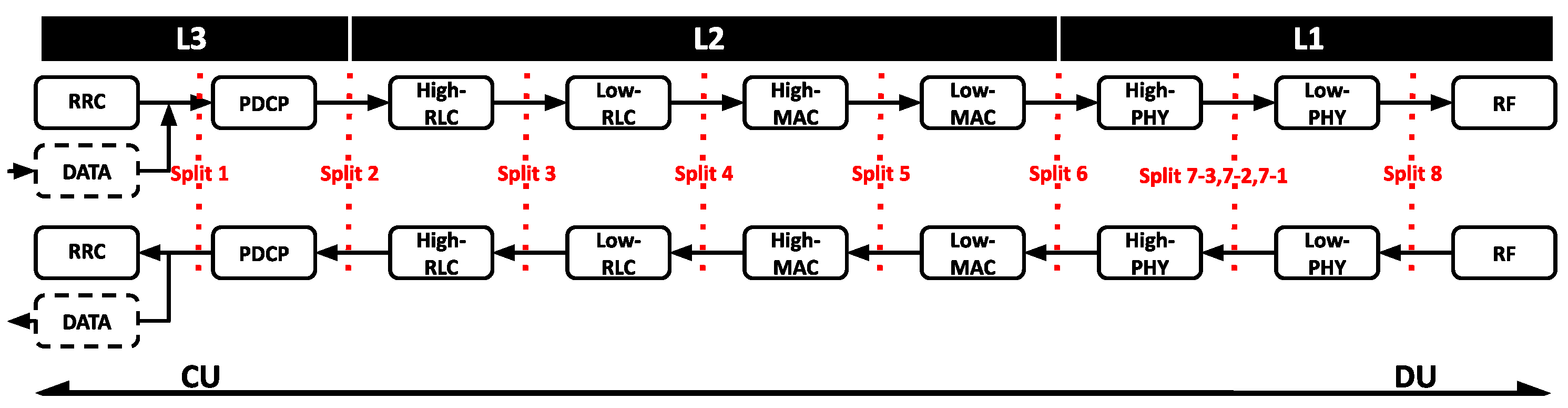
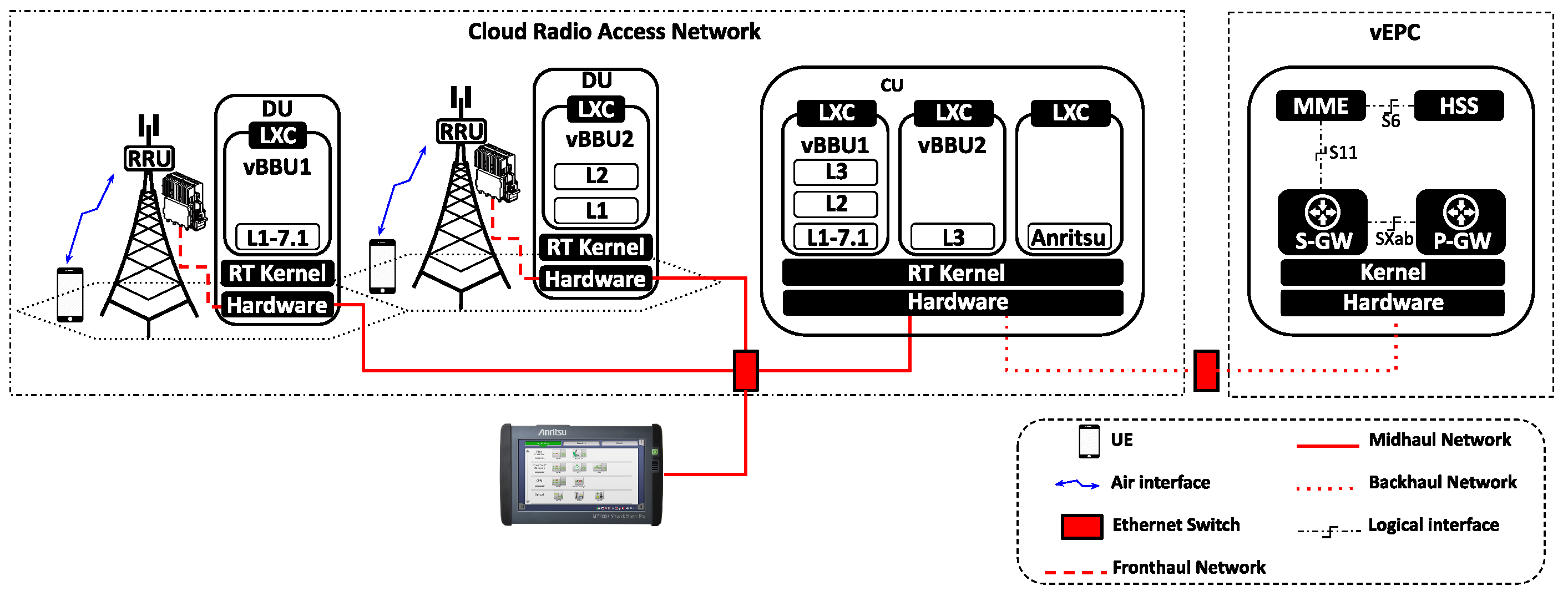
2.1. The Cloud-RAN Architecture
2.2. Hosting vBBU on MEC Servers
2.2.1. Linux as the Host OS for Running vBBUs
2.2.2. Virtualization Environments with RT Support for vBBU Execution
2.3. Resource Sharing in MEC Servers
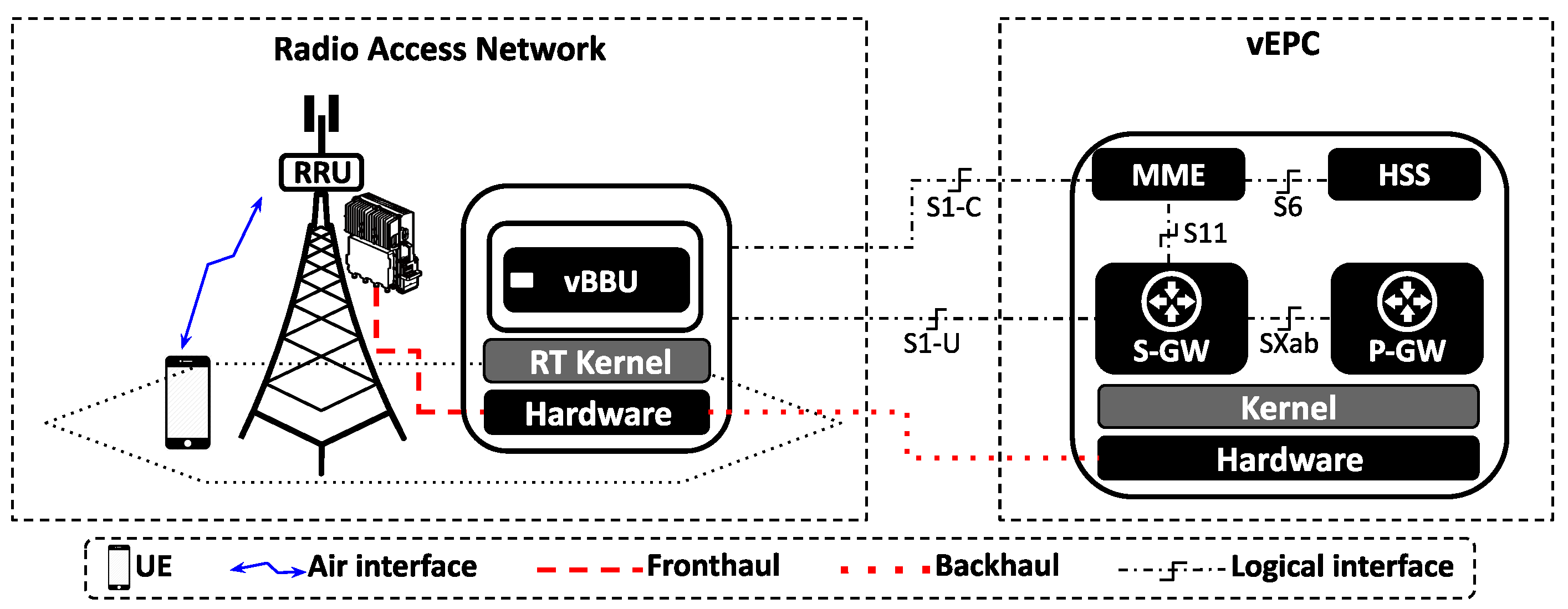
3. System Model: Instantiating the vBBU within the Linux Kernel
3.1. Mobile Network Scenario
3.2. Instantiating the vBBU within the Linux RT-Kernel
3.3. Sharing Computing Resources with User-Space Workloads and Kernel Threads
3.4. Enhancing RT Performance for vBBU Processes with CPU Affinity
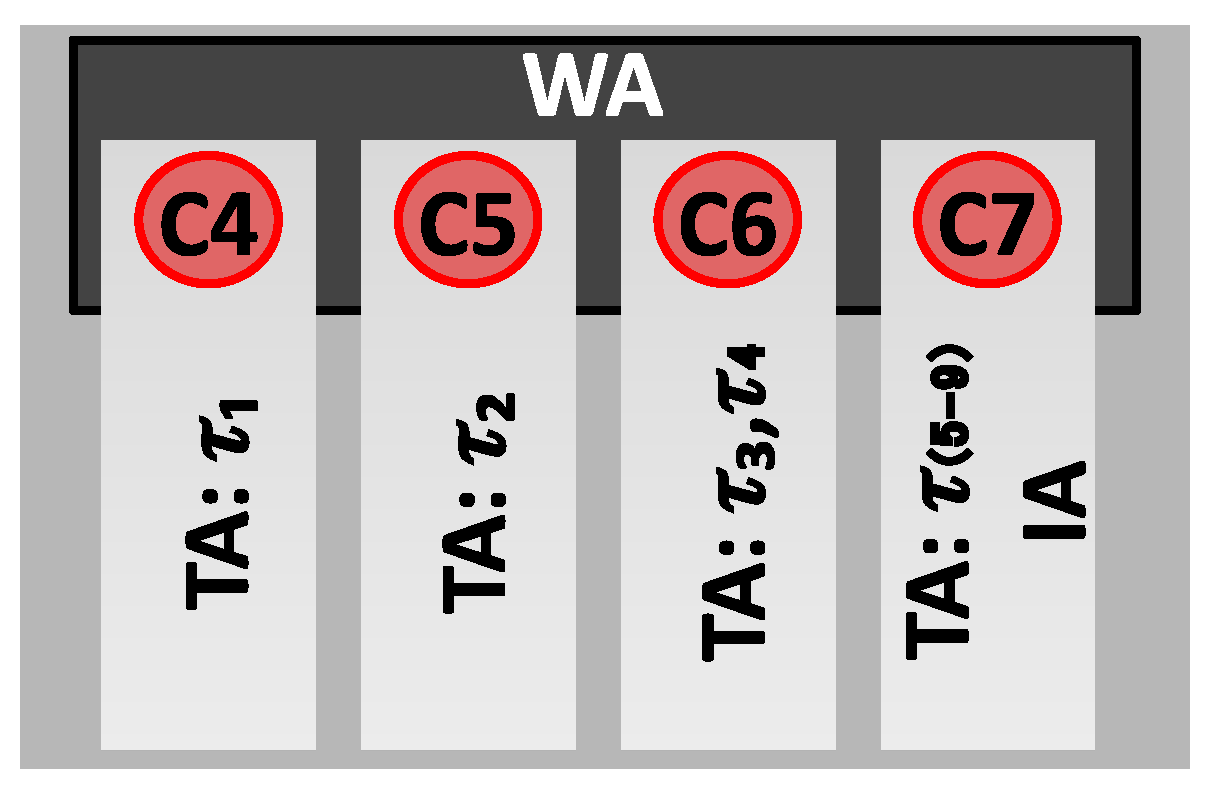
3.5. Mitigating Impact on vBBU RT Performance: Exploring CPU Isolation with Collocated Processes
4. Assessing the vBBU Performance in the Linux Kernel
4.1. Methodology
4.1.1. Experimental Design
4.1.2. Derived Metrics for Evaluation
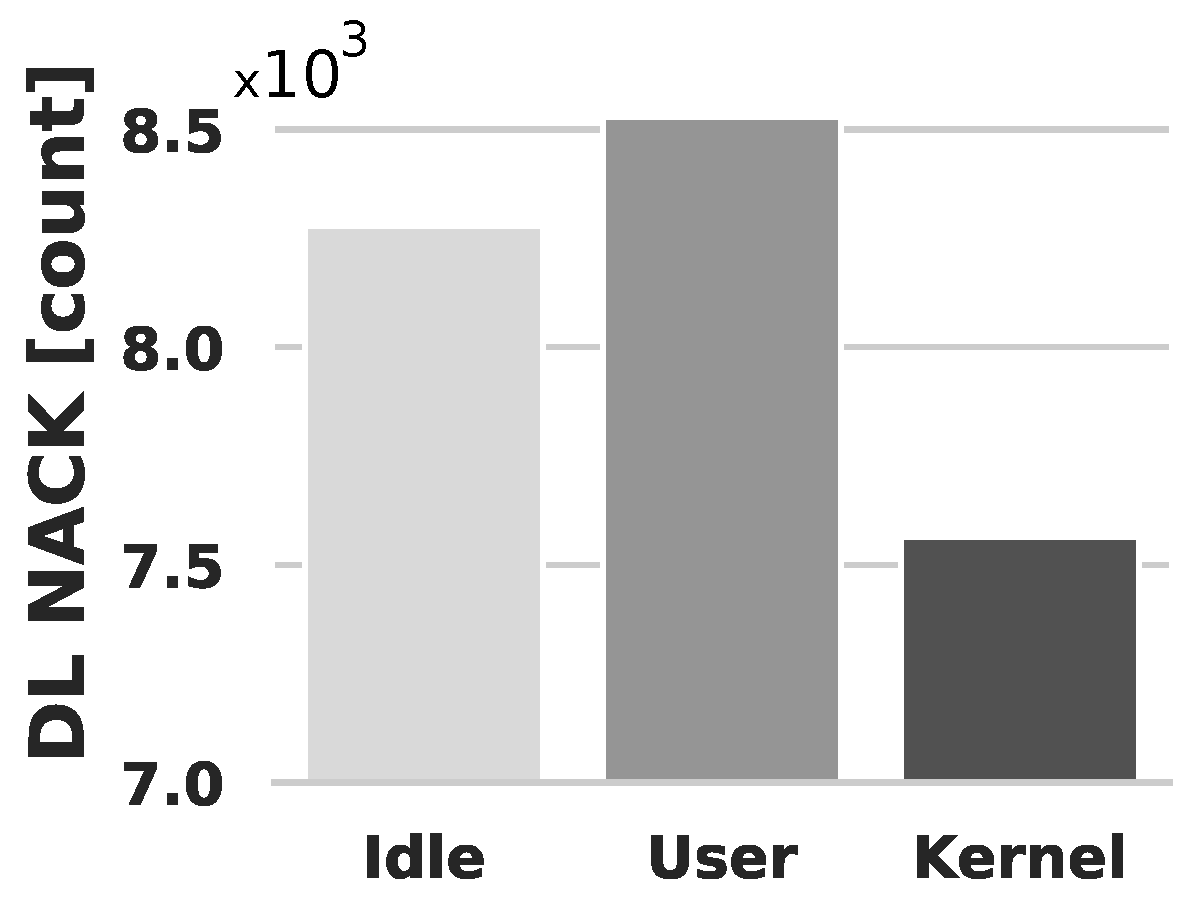
- DL NACK: This metric is part of the DL Data Transmission Process (HARQ ACK/ NACK) [72]. If the UE detects an error in received DL data, it sends a DL NACK to the vBBU, triggering DL data retransmission. NACK counts, which indicate DL re-transmissions, provide valuable insights into the DL data path’s health;
- Scheduling Latency: Measuring the waiting time a process undergoes to obtain CPU-time in the RT-Kernel, scheduling latency is a crucial metric that contributes to task processing latency [41]. Using the Kernel tracing tool BPF Compiler Collection [73], we assessed the scheduling latency for each vBBU thread outlined in Table 1.
4.2. Results and Discussion
4.2.1. Resource Sharing Impact
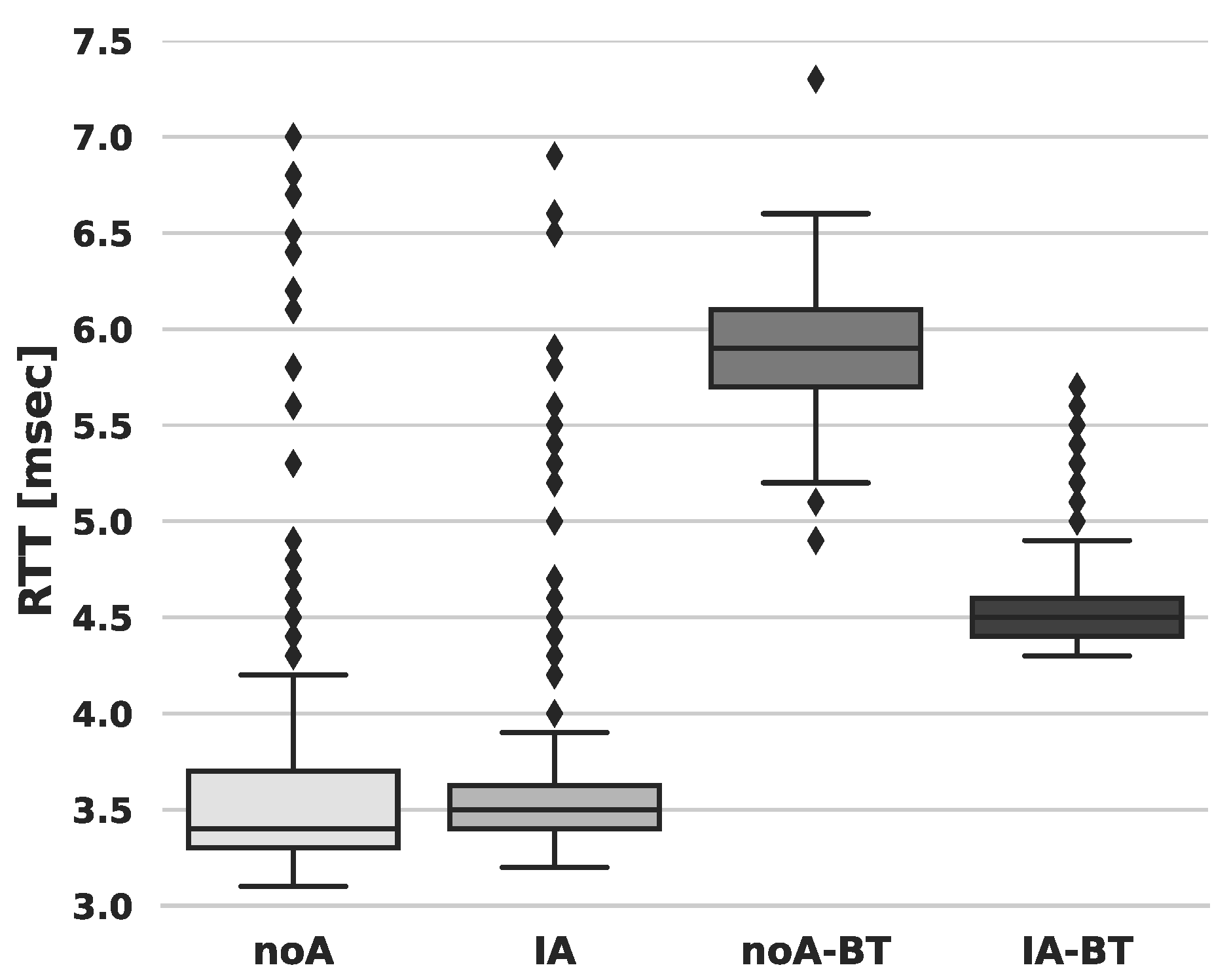
4.2.2. CPU Management Strategies
CPU Affinity
CPU Isolation
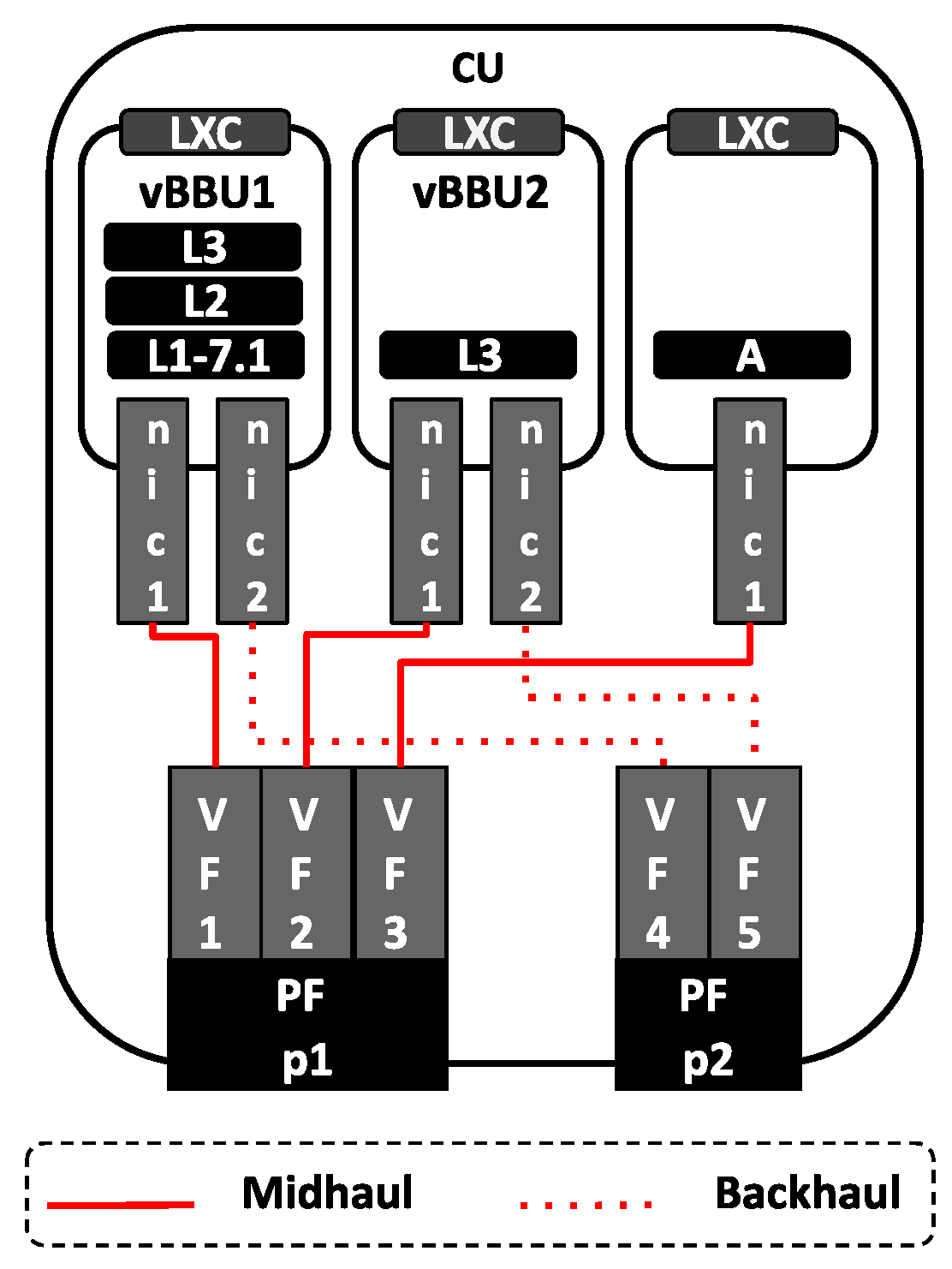
5. Assessing Resource Sharing in the Cloud-RAN Architecture
5.1. Mobile Network Scenario
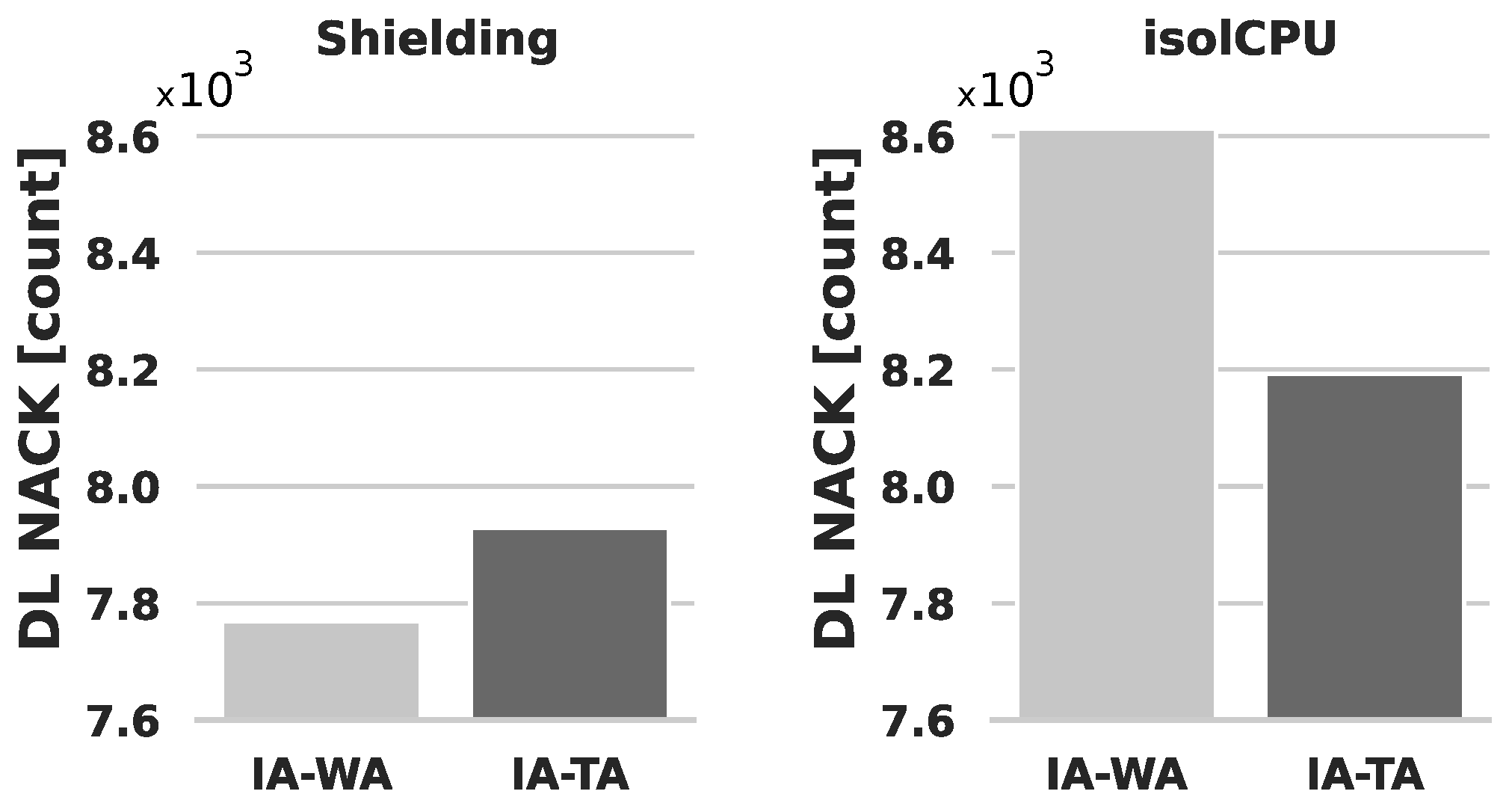
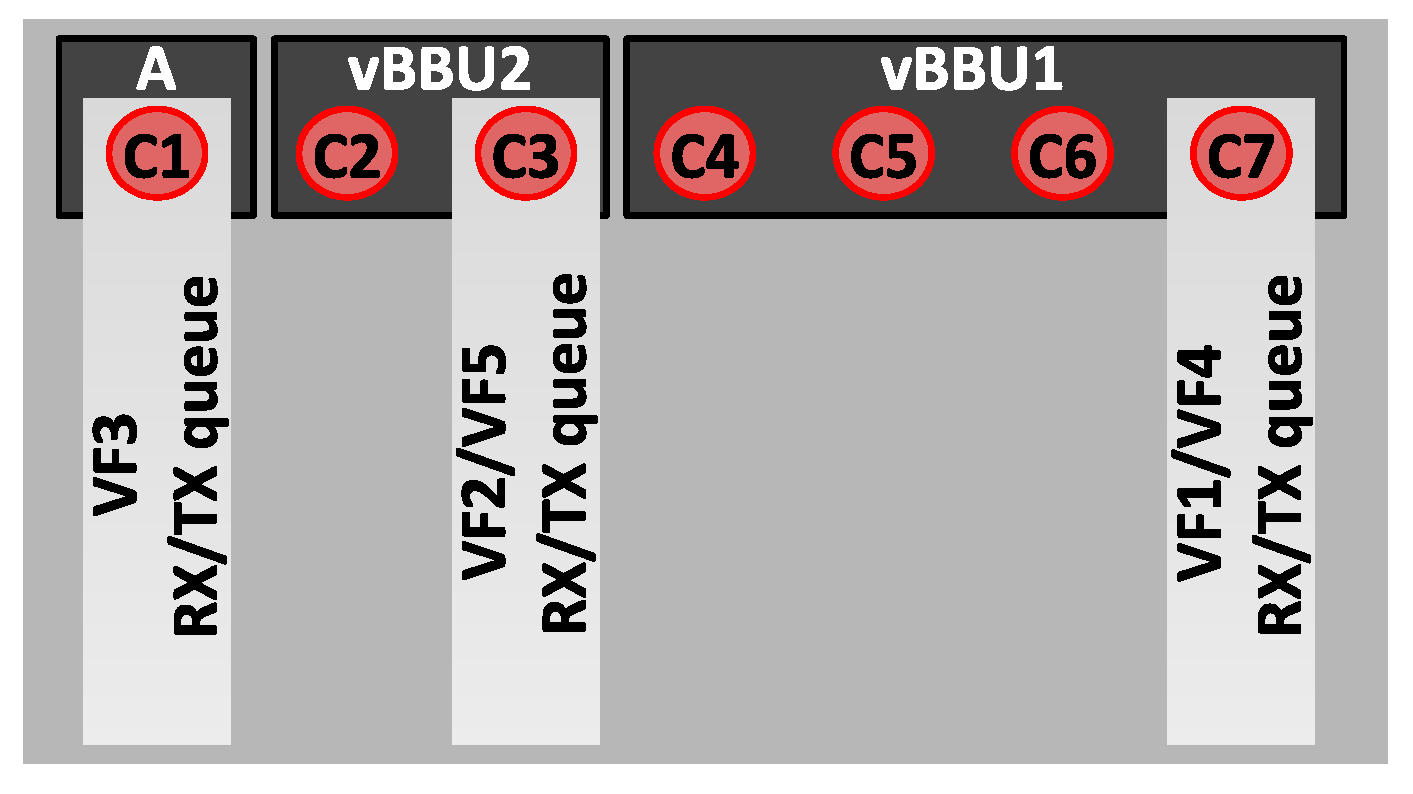
5.2. Sharing Computing Resources at the CU
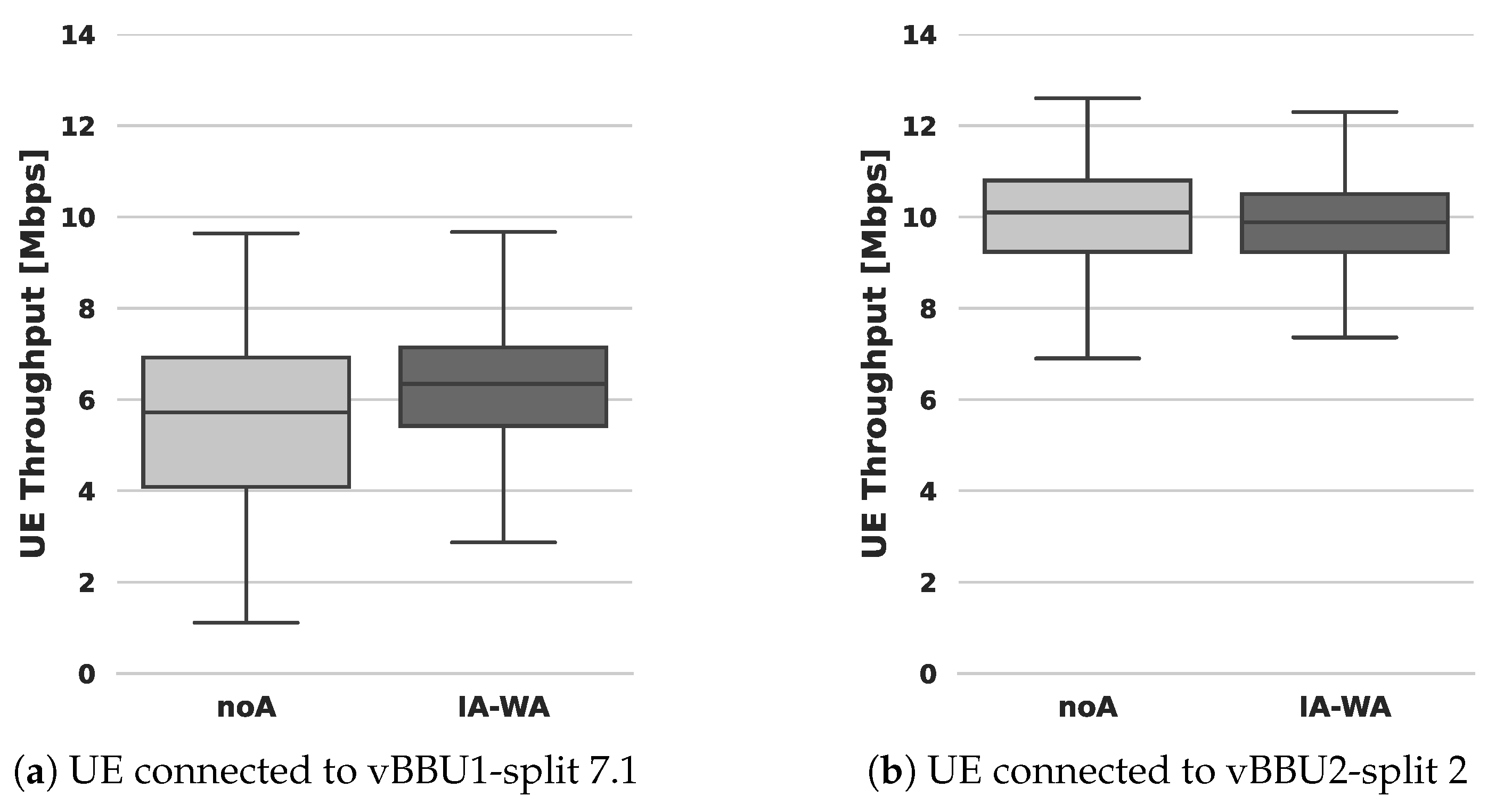
5.3. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Testbed Setup Specifications

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Description |
|---|---|
| UE | OnePlus-5 phone/Software: OxygenOS Version 10.0.1/Oneplus, Shenzhen, China. |
| air interface (as specified by the vBBU) | 25 Physical Resource Blocks (PRB), which provides 5 MHz bandwidth. |
| RRU | Ettus (B210) One antenna port—Single Input Single Output (SISO)/Software: Universal Software Radio Peripheral (USRP) Version: 4.6.0.0-7-gece7c4811/Ettus Research, Austin, TX, USA. |
| Fronthaul | Fast SuperSpeed USB 3.0 connectivity at 5.0 Gbit/s (provided by Ettus (B210)). |
| Monolithic vBBU deployment (see Figure 3) | |
| vBBU | Monolithic eNodeB-LTE implementation from OpenAirInterface (OAI) Version 2.0.0. |
| Edge server | Equipped with eight Intel i7-8750H physical processors at 2.20 GHz, and 32 GiB of memory. |
| Edge server’s OS | Ubuntu 18.04 with low-latency Linux kernel version 5.3.28. |
| Edge server’s NIC | Supermicro AOC-SG-i2 Gigabit Ethernet adapter, equipped with two Intel 82575 Gigabit Ethernet ports/San Jose, CA, USA. |
| Backhaul | physical link at 1 Gbit/s. |
| Cloud-RAN (see Figure 8) | |
| vBBU1 | OpenAirInterface eNodeB–LTE implementation Version 2.0.0, with split 7.1. This functional split uses the NGFI-IF4p5 interface specification [77] |
| vBBU2 | OpenAirInterface eNodeB–LTE implementation Version 2.0.0, with split 2 using the F1 Application Protocol (F1AP) [78,79]. |
| DU | Intel NUC7i7BNB equipped with four Intel Core i7-7567U processors, and 32 GiB of memory. |
| DU’s OS | Ubuntu 16.04 with low-latency Linux kernel version 4.19.58. |
| CU | Edge server equipped with eight Intel i7-8750H physical processors at 2.20 GHz, and 32 GiB of memory. |
| CU’s OS | Ubuntu 20.04 with Linux Kernel low-latency patch version 5.4.0.125.126. |
| Midhaul & Backhaul | Juniper EX4200 Ethernet switch, with physical interfaces at 1 Gbit/ Software: Junos OS Version 12.3R12-S21. |
| Core Network | |
| vEPC | 4G EPC implementation from OAI. |
| vEPC’s host physical machine | Generic server equipped with four Intel i7 processor at 2.20 GHz, and 12 GiB of memory. |
| vEPC’s host OS | Ubuntu 18.04 with generic Linux kernel version 5.3.28. |
References
- Checko, A.; Christiansen, H.L.; Yan, Y.; Scolari, L.; Kardaras, G.; Berger, M.S.; Dittmann, L. Cloud RAN for Mobile Networks—A Technology Overview. IEEE Commun. Surv. Tutor. 2015, 17, 405–426. [Google Scholar] [CrossRef]
- Mosnier, A. Embedded/Real-Time Linux Survey. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=0c81e1915ba80e319739b988ee74a31ef853c7b6 (accessed on 20 December 2023).
- Karachatzis, P.; Ruh, J.; Craciunas, S.S. An Evaluation of Time-Triggered Scheduling in the Linux Kernel. In Proceedings of the RTNS ’23: 31st International Conference on Real-Time Networks and Systems, New York, NY, USA, 7–8 June 2023; pp. 119–131. [Google Scholar] [CrossRef]
- Yodaiken, V. The rtlinux manifesto. In Proceedings of the 5th Linux Expo, Raleigh, NC, USA, 18–22 May 1999. [Google Scholar]
- Ubuntu. Linux Low Latency. Available online: https://packages.ubuntu.com/search?keywords=linux-lowlatency (accessed on 5 April 2024).
- Foundation, T.L. PREEMPT_RT Patch. Available online: https://wiki.linuxfoundation.org/realtime/start (accessed on 5 April 2024).
- Nikaein, N.; Knopp, R.; Kaltenberger, F.; Gauthier, L.; Bonnet, C.; Nussbaum, D.; Ghaddab, R. OpenAirInterface: An open LTE network in a PC. In Proceedings of the 20th Annual International Conference on Mobile Computing and Networking, Maui, HI, USA, 7–11 September 2014; pp. 305–308. [Google Scholar]
- Harutyunyan, D.; Riggio, R. Flex5G: Flexible Functional Split in 5G Networks. IEEE Trans. Netw. Serv. Manag. 2018, 15, 961–975. [Google Scholar] [CrossRef]
- Alba, A.M.; Velásquez, J.H.G.; Kellerer, W. An adaptive functional split in 5G networks. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Paris, France, 29 April–2 May 2019; pp. 410–416. [Google Scholar] [CrossRef]
- Azariah, W.; Bimo, F.A.; Lin, C.W.; Cheng, R.G.; Jana, R.; Nikaein, N. A survey on open radio access networks: Challenges, research directions, and open source approaches. arXiv 2022, arXiv:2208.09125. [Google Scholar]
- Abeni, L.; Cucinotta, T.; Pinczel, B.; Mátray, P.; Srinivasan, M.K.; Lindquist, T. On the Use of Linux Real-Time Features for RAN Packet Processing in Cloud Environments. In Proceedings of the High Performance Computing. ISC High Performance 2022 International Workshops; Anzt, H., Bienz, A., Luszczek, P., Baboulin, M., Eds.; Springer: Cham, Switzerland, 2022; pp. 371–382. [Google Scholar]
- Xu, C.; Zhao, Z.; Wang, H.; Shea, R.; Liu, J. Energy Efficiency of Cloud Virtual Machines: From Traffic Pattern and CPU Affinity Perspectives. IEEE Syst. J. 2017, 11, 835–845. [Google Scholar] [CrossRef]
- Iorgulescu, C.; Azimi, R.; Kwon, Y.; Elnikety, S.; Syamala, M.; Narasayya, V.; Herodotou, H.; Tomita, P.; Chen, A.; Zhang, J.; et al. PerfIso: Performance Isolation for Commercial Latency-Sensitive Services. In Proceedings of the 2018 USENIX Annual Technical Conference (USENIX ATC 18), Boston, MA, USA, 11–13 July 2018; pp. 519–532. [Google Scholar]
- Cinque, M.; Cotroneo, D.; De Simone, L.; Rosiello, S. Virtualizing mixed-criticality systems: A survey on industrial trends and issues. Future Gener. Comput. Syst. 2022, 129, 315–330. [Google Scholar] [CrossRef]
- Åsberg, M.; Nolte, T.; Kato, S.; Rajkumar, R. ExSched: An External CPU Scheduler Framework for Real-Time Systems. In Proceedings of the 2012 IEEE International Conference on Embedded and Real-Time Computing Systems and Applications, Seoul, Republic of Korea, 19–22 August 2012; pp. 240–249. [Google Scholar] [CrossRef]
- Valsan, P.K.; Yun, H.; Farshchi, F. Taming Non-Blocking Caches to Improve Isolation in Multicore Real-Time Systems. In Proceedings of the 2016 IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS), Vienna, Austria, 11–14 April 2016; pp. 1–12. [Google Scholar] [CrossRef]
- Ruiz, A.P.; Rivas, M.A.; Harbour, M.G. CPU Isolation on the Android OS for Running Real-Time Applications. In Proceedings of the JTRES ’15: 13th International Workshop on Java Technologies for Real-Time and Embedded Systems, New York, NY, USA, 7–8 October 2015. [Google Scholar] [CrossRef]
- Angui, B.; Corbel, R.; Rodriguez, V.Q.; Stephan, E. Towards 6G zero touch networks: The case of automated Cloud-RAN deployments. In Proceedings of the 2022 IEEE 19th Annual Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 8–11 January 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Habibi, M.A.; Han, B.; Nasimi, M.; Kuruvatti, N.P.; Fellan, A.; Schotten, H.D. Towards a Fully Virtualized, Cloudified, and Slicing-Aware RAN for 6G Mobile Networks. In 6G Mobile Wireless Networks; Wu, Y., Singh, S., Taleb, T., Roy, A., Dhillon, H.S., Kanagarathinam, M.R., De, A., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 327–358. [Google Scholar] [CrossRef]
- 3GPP TR 38.801, Study on New Radio Access Technology: Radio Access Architecture and Interfaces. 2017. Available online: https://portal.3gpp.org/desktopmodules/Specifications/SpecificationDetails.aspx?specificationId=3056 (accessed on 5 April 2024).
- Larsen, L.M.P.; Checko, A.; Christiansen, H.L. A Survey of the Functional Splits Proposed for 5G Mobile Crosshaul Networks. IEEE Commun. Surv. Tutor. 2019, 21, 146–172. [Google Scholar] [CrossRef]
- IEEE Std 1914.1-2019; Standard for Packet-based Fronthaul Transport Network. IEEE: Piscataway, NJ, USA, 2019.
- Joda, R.; Pamuklu, T.; Iturria-Rivera, P.E.; Erol-Kantarci, M. Deep Reinforcement Learning-Based Joint User Association and CU–DU Placement in O-RAN. IEEE Trans. Netw. Serv. Manag. 2022, 19, 4097–4110. [Google Scholar] [CrossRef]
- Tomaszewski, L.; Kukliński, S.; Kołakowski, R. A New Approach to 5G and MEC Integration. In Proceedings of the Artificial Intelligence Applications and Innovations. AIAI 2020 IFIP WG 12.5 International Workshops; Maglogiannis, I., Iliadis, L., Pimenidis, E., Eds.; Springer: Cham, Switzerland, 2020; pp. 15–24. [Google Scholar]
- Reghenzani, F.; Massari, G.; Fornaciari, W. The Real-Time Linux Kernel: A Survey on PREEMPT_RT. ACM Comput. Surv. 2019, 52, 36. [Google Scholar] [CrossRef]
- RTAI. RTAI-the Real-Time Application Interface for Linux. Available online: https://www.rtai.org/ (accessed on 20 December 2023).
- Kaltenberger, F.; Wagner, S. Experimental analysis of network-aided interference-aware receiver for LTE MU-MIMO. In Proceedings of the 2014 IEEE 8th Sensor Array and Multichannel Signal Processing Workshop (SAM), Coruna, Spain, 22–25 June 2014; pp. 325–328. [Google Scholar] [CrossRef]
- Alyafawi, I.; Schiller, E.; Braun, T.; Dimitrova, D.; Gomes, A.; Nikaein, N. Critical issues of centralized and cloudified LTE-FDD radio access networks. In Proceedings of the 2015 IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015; pp. 5523–5528. [Google Scholar]
- Bhaumik, S.; Chandrabose, S.P.; Jataprolu, M.K.; Kumar, G.; Muralidhar, A.; Polakos, P.; Srinivasan, V.; Woo, T. CloudIQ: A framework for processing base stations in a data center. In Proceedings of the 18th Annual International Conference on Mobile Computing and Networking, Istanbul, Turkey, 22–26 August 2012; pp. 125–136. [Google Scholar]
- Fajjari, I.; Aitsaadi, N.; Amanou, S. Optimized Resource Allocation and RRH Attachment in Experimental SDN based Cloud-RAN. In Proceedings of the 2019 16th IEEE Annual Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 11–14 January 2019; pp. 1–6. [Google Scholar]
- Younis, A.; Tran, T.X.; Pompili, D. Bandwidth and Energy-Aware Resource Allocation for Cloud Radio Access Networks. IEEE Trans. Wirel. Commun. 2018, 17, 6487–6500. [Google Scholar] [CrossRef]
- Nikaein, N. Processing Radio Access Network Functions in the Cloud: Critical Issues and Modeling. In Proceedings of the MCS ’15: 6th International Workshop on Mobile Cloud Computing and Services, New York, NY, USA, 11 September 2015; pp. 36–43. [Google Scholar] [CrossRef]
- Huang, S.; Luo, Y.; Chen, B.; Chung, Y.; Chou, J. Application-Aware Traffic Redirection: A Mobile Edge Computing Implementation Toward Future 5G Networks. In Proceedings of the 2017 IEEE 7th International Symposium on Cloud and Service Computing (SC2), Los Alamitos, CA, USA, 22–25 November 2017; pp. 17–23. [Google Scholar] [CrossRef]
- Xi, S.; Xu, M.; Lu, C.; Phan, L.T.X.; Gill, C.; Sokolsky, O.; Lee, I. Real-time multi-core virtual machine scheduling in Xen. In Proceedings of the 2014 International Conference on Embedded Software (EMSOFT), New Delhi, India, 12–17 October 2014; pp. 1–10. [Google Scholar] [CrossRef]
- Struhár, V.; Behnam, M.; Ashjaei, M.; Papadopoulos, A.V. Real-Time Containers: A Survey. In Proceedings of the 2nd Workshop on Fog Computing and the IoT (Fog-IoT 2020); Cervin, A., Yang, Y., Eds.; OpenAccess Series in Informatics (OASIcs): Dagstuhl, Germany, 2020; Volume 80, pp. 7:1–7:9. [Google Scholar] [CrossRef]
- Abeni, L.; Balsini, A.; Cucinotta, T. Container-Based Real-Time Scheduling in the Linux Kernel. SIGBED Rev. 2019, 16, 33–38. [Google Scholar] [CrossRef]
- Nikaein, N.; Schiller, E.; Favraud, R.; Knopp, R.; Alyafawi, I.; Braun, T. Towards a Cloud-Native Radio Access Network. In Advances in Mobile Cloud Computing and Big Data in the 5G Era; Mavromoustakis, C.X., Mastorakis, G., Dobre, C., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 171–202. [Google Scholar] [CrossRef]
- Mao, C.N.; Huang, M.H.; Padhy, S.; Wang, S.T.; Chung, W.C.; Chung, Y.C.; Hsu, C.H. Minimizing Latency of Real-Time Container Cloud for Software Radio Access Networks. In Proceedings of the 2015 IEEE 7th International Conference on Cloud Computing Technology and Science (CloudCom), Vancouver, BC, Canada, 30 November–3 December 2015; pp. 611–616. [Google Scholar] [CrossRef]
- Cinque, M.; De Tommasi, G. Work-in-Progress: Real-Time Containers for Large-Scale Mixed-Criticality Systems. In Proceedings of the 2017 IEEE Real-Time Systems Symposium (RTSS), Paris, France, 5–8 December 2017; pp. 369–371. [Google Scholar] [CrossRef]
- Han, W.T.; Knopp, R. OpenAirInterface: A Pipeline Structure for 5G. In Proceedings of the 2018 IEEE 23rd International Conference on Digital Signal Processing (DSP), Shanghai, China, 19–21 November 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Foukas, X.; Nikaein, N.; Kassem, M.M.; Marina, M.K.; Kontovasilis, K. FlexRAN: A Flexible and Programmable Platform for Software-Defined Radio Access Networks. In Proceedings of the CoNEXT ’16: 12th International on Conference on Emerging Networking EXperiments and Technologies, New York, NY, USA, 12–15 December 2016; pp. 427–441. [Google Scholar] [CrossRef]
- Cavicchioli, R.; Capodieci, N.; Bertogna, M. Memory interference characterization between CPU cores and integrated GPUs in mixed-criticality platforms. In Proceedings of the 2017 22nd IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Limassol, Cyprus, 12–15 September 2017; pp. 1–10. [Google Scholar] [CrossRef]
- Burns, A.; Davis, R.I. A Survey of Research into Mixed Criticality Systems. ACM Comput. Surv. 2017, 50, 1–37. [Google Scholar] [CrossRef]
- De, P.; Mann, V.; Mittaly, U. Handling OS jitter on multicore multithreaded systems. In Proceedings of the 2009 IEEE International Symposium on Parallel and Distributed Processing, Chengdu, China, 10–12 August 2009; pp. 1–12. [Google Scholar] [CrossRef]
- Reghenzani, F.; Massari, G.; Fornaciari, W. Mixed Time-Criticality Process Interferences Characterization on a Multicore Linux System. In Proceedings of the 2017 Euromicro Conference on Digital System Design (DSD), Vienna, Austria, 30 August–1 September 2017; pp. 427–434. [Google Scholar] [CrossRef]
- Barletta, M.; Cinque, M.; De Simone, L.; Della Corte, R. Achieving isolation in mixed-criticality industrial edge systems with real-time containers. In Proceedings of the 34th Euromicro Conference on Real-Time Systems (ECRTS 2022). Schloss Dagstuhl-Leibniz-Zentrum für Informatik, Modena, Italy, 5–8 July 2022. [Google Scholar]
- Burns, A.; Davis, R.I. Mixed Criticality Systems—A Review. Available online: https://www-users.york.ac.uk/~ab38/review.pdf (accessed on 20 December 2023).
- Liu, L.; Wang, H.; Wang, A.; Xiao, M.; Cheng, Y.; Chen, S. Mind the Gap: Broken Promises of CPU Reservations in Containerized Multi-Tenant Clouds. In Proceedings of the SoCC ’21: ACM Symposium on Cloud Computing, New York, NY, USA, 1–4 November 2021; pp. 243–257. [Google Scholar] [CrossRef]
- Taleb, T.; Samdanis, K.; Mada, B.; Flinck, H.; Dutta, S.; Sabella, D. On Multi-Access Edge Computing: A Survey of the Emerging 5G Network Edge Cloud Architecture and Orchestration. IEEE Commun. Surv. Tutor. 2017, 19, 1657–1681. [Google Scholar] [CrossRef]
- Foukas, X.; Radunovic, B. Concordia: Teaching the 5G VRAN to Share Compute. In Proceedings of the 2021 ACM SIGCOMM 2021 Conference, New York, NY, USA, 23–27 August 2021; SIGCOMM ’21. pp. 580–596. [Google Scholar] [CrossRef]
- Nikaein, N.; Marina, M.K.; Manickam, S.; Dawson, A.; Knopp, R.; Bonnet, C. OpenAirInterface: A Flexible Platform for 5G Research. SIGCOMM Comput. Commun. Rev. 2014, 44, 33–38. [Google Scholar] [CrossRef]
- Gomez-Miguelez, I.; Garcia-Saavedra, A.; Sutton, P.D.; Serrano, P.; Cano, C.; Leith, D.J. In Proceedings of the SrsLTE: An Open-Source Platform for LTE Evolution and Experimentation, New York, NY, USA, 3–7 October 2016; WiNTECH ’16. pp. 25–32. [CrossRef]
- De Oliveira, D.B.; De Oliveira, R.S. Timing analysis of the PREEMPT RT Linux kernel. Software Pract. Exp. 2016, 46, 789–819. [Google Scholar] [CrossRef]
- Abeni, L.; Kiraly, C. Investigating the network performance of a real-time Linux Kernel. In Proceedings of the 15th Real Time Linux Workshop (RTLWS 2013), Lugano, Switzerland, 28–31 October 2013. [Google Scholar]
- Emmerich, P.; Raumer, D.; Beifuß, A.; Erlacher, L.; Wohlfart, F.; Runge, T.M.; Gallenmüller, S.; Carle, G. Optimizing latency and CPU load in packet processing systems. In Proceedings of the 2015 International Symposium on Performance Evaluation of Computer and Telecommunication Systems (SPECTS), Chicago, IL, USA, 26–29 July 2015; pp. 1–8. [Google Scholar] [CrossRef]
- Wu, W.; Crawford, M.; Bowden, M. The performance analysis of linux networking—Packet receiving. Comput. Commun. 2007, 30, 1044–1057. [Google Scholar] [CrossRef]
- Beifuß, A.; Raumer, D.; Emmerich, P.; Runge, T.M.; Wohlfart, F.; Wolfìnger, B.E.; Carle, G. A study of networking software induced latency. In Proceedings of the 2015 International Conference and Workshops on Networked Systems (NetSys), Agadir, Morocco, 13–15 May 2015; pp. 1–8. [Google Scholar] [CrossRef]
- Love, R. Kernel Korner: CPU Affinity. Linux J. 2003, 2003, 8. [Google Scholar]
- Ribeiro, C.P.; Castro, M.; Marangonzova-Martin, V.; Méhaut, J.F.; De Freitas, H.C.; da Silva Martins, C.A.P. Evaluating CPU and memory affinity for numerical scientific multithreaded benchmarks on multi-cores. IADIS Int. J. Comput. Sci. Inf. Syst. (IJCSIS) 2012, 1, 79–93. [Google Scholar]
- Kafshdooz, M.M.; Taram, M.; Assadi, S.; Ejlali, A. A compile-time optimization method for WCET reduction in real-time embedded systems through block formation. ACM Trans. Archit. Code Optim. (TACO) 2016, 12, 1–25. [Google Scholar] [CrossRef]
- Ghatrehsamani, D.; Denninnart, C.; Bacik, J.; Amini Salehi, M. The Art of CPU-Pinning: Evaluating and Improving the Performance of Virtualization and Containerization Platforms. In Proceedings of the ICPP ’20: 49th International Conference on Parallel Processing-ICPP, New York, NY, USA, 17–19 August 2020. [Google Scholar] [CrossRef]
- Bharti, C.; Kanagarathinam, M.R.; Srivastava, S.K.; Lee, M.; Han, J.; Oh, W. CAA: CLAT Aware Affinity Scheduler for Next Generation Mobile Networks. In Proceedings of the 2019 16th IEEE Annual Consumer Communications Networking Conference (CCNC), Las Vegas, NV, USA, 11–14 January 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Gutiérrez, C.S.V.; Juan, L.U.S.; Ugarte, I.Z.; Vilches, V.M. Real-time Linux communications: An evaluation of the Linux communication stack for real-time robotic applications. arXiv 2018, arXiv:1808.10821. [Google Scholar]
- Derr, S. CPUSETS. Available online: https://www.kernel.org/doc/Documentation/cgroup-v1/cpusets.txt (accessed on 21 March 2023).
- Delgado, R.; Choi, B.W. New Insights Into the Real-Time Performance of a Multicore Processor. IEEE Access 2020, 8, 186199–186211. [Google Scholar] [CrossRef]
- Kroah-Hartman, G. Linux Kernel in a Nutshell: A Desktop Quick Reference; O’Reilly Media, Inc.: Newton, MA, USA, 2006. [Google Scholar]
- Kim, S.; Park, H.S. A Multi-core Based Real-time Scheduler Supporting Periodic and Sporadic Threads and Processes. Int. J. Control. Autom. Syst. 2023, 21, 3048–3056. [Google Scholar] [CrossRef]
- Mortimer, M. iperf3 Documentation. Available online: https://buildmedia.readthedocs.org/media/pdf/iperf3-python/latest/iperf3-python.pdf (accessed on 21 November 2023).
- King, C. Stress-ng. Available online: https://wiki.ubuntu.com/Kernel/Reference/stress-ng (accessed on 21 November 2023).
- Anritsu. Anritsu MT1000A Network Master Pro Tester. Available online: https://www.anritsu.com/en-us/test-measurement/products/mt1000a (accessed on 21 November 2023).
- Giacobbi, G. The GNU Netcat Project. Available online: http://netcat.sourceforge.net (accessed on 21 November 2023).
- 3GPP. Evolved Universal Terrestrial Radio Access (E-UTRA); Medium Access Control (MAC) Protocol Specification. Available online: https://portal.3gpp.org/desktopmodules/Specifications/SpecificationDetails.aspx?specificationId=2437 (accessed on 21 November 2023).
- IO-Visor. BPF Compiler Collection (BCC). Available online: https://github.com/iovisor/bcc (accessed on 21 November 2023).
- Krzywinski, M.; Altman, N. Visualizing samples with box plots. Nat. Methods 2014, 11, 119–121. [Google Scholar] [CrossRef] [PubMed]
- Ho, A.; Smith, S.; Hand, S. On deadlock, livelock, and forward progress. In Technical Report UCAM-CL-TR-633; University of Cambridge, Computer Laboratory: Cambridge, UK, 2005. [Google Scholar] [CrossRef]
- Claassen, J.; Koning, R.; Grosso, P. Linux containers networking: Performance and scalability of kernel modules. In Proceedings of the NOMS 2016-2016 IEEE/IFIP Network Operations and Management Symposium, Istanbul, Turkey, 25–29 April 2016; pp. 713–717. [Google Scholar]
- Knopp, R. Overview of Functional Splits in OAI. Available online: https://www.openairinterface.org/docs/workshop/5_OAI_Workshop_20180620/KNOPP_OAI-functional-splits.pdf (accessed on 21 November 2023).
- 3GPP. 5G; NG-RAN; F1 Application Protocol (F1AP) (3GPP TS 38.473 Version 15.2.1 Release 15). Available online: https://www.etsi.org/deliver/etsi_ts/138400_138499/138473/15.02.01_60/ts_138473v150201p.pdf (accessed on 21 November 2023).
- OAI. F1 Interface. Available online: https://gitlab.eurecom.fr/oai/openairinterface5g/wikis/f1-interface (accessed on 20 December 2022).











| Thread | Time Requirement | Description | Index |
|---|---|---|---|
| ru-thread | RT | Radio unit processing | |
| lte-softmodem | RT | L1–L2 processing | |
| fep_processing | RT | Front End Process—RX | |
| feptx_thread | RT | Front End Process—TX | |
| TASK_GTPV1_U | non-RT | GTP tunneling | |
| TASK_UDP | non-RT | UDP socket | |
| TASK_S1AP | non-RT | S1 channel | |
| TASK_SCTP | non-RT | SCTP channel | |
| TASK_RRC | non-RT | RRC channel |
| Thread | 0–1 (microseconds) | 2–3 (microseconds) | 4–7 (microseconds) | 8–15 (microseconds) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Idle | User | Kernel | Idle | User | Kernel | Idle | User | Kernel | Idle | User | Kernel | |
| ru-thread | 93.8 | 53.1 | 90.9 | 0.4 | 41.9 | 4.8 | 0.1 | 1 | 0.3 | 5.7 | 4 | 3.9 |
| lte-softmodem | 99.4 | 49.5 | 91.6 | 0.3 | 49.1 | 7.8 | 0.01 | 0.7 | 0.2 | 0.3 | 0.6 | 0.4 |
| fep_processing | 99.3 | 63 | 89.7 | 0.4 | 35 | 9.3 | 0.05 | 1.1 | 0.5 | 0.3 | 0.9 | 0.4 |
| feptx_thread | 99.4 | 51.4 | 76.1 | 0.5 | 44.8 | 23 | 0.03 | 3.5 | 0.7 | 0.03 | 0.1 | 0.1 |
| TASK_GTP | 98.6 | 58.6 | 84.8 | 0.8 | 38.1 | 10.7 | 0.4 | 2 | 3 | 0.2 | 1.1 | 1.2 |
| UDP_TASK | 95.2 | 52 | 77.9 | 1 | 41.4 | 12.9 | 2.8 | 4.4 | 3.7 | 0.8 | 2 | 1.8 |
| Thread | 0–1 (microseconds) | 2–3 (microseconds) | 4–7 (microseconds) | 8–15 (microseconds) | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Idle | User | Kernel | Idle | User | Kernel | Idle | User | Kernel | Idle | User | Kernel | |||||||||||||
| WA | TA | WA | TA | WA | TA | WA | TA | WA | TA | WA | TA | WA | TA | WA | TA | WA | TA | WA | TA | WA | TA | WA | TA | |
| ru-thread | 93.5 | 93.3 | 45.7 | 52.9 | 78.8 | 81.6 | 0.4 | 0.3 | 49.2 | 41.1 | 17.2 | 15.4 | 0.1 | 0.1 | 1.4 | 1.7 | 0.7 | 0.6 | 5.9 | 6.2 | 3.6 | 4 | 3.3 | 2.3 |
| lte-softmodem | 99.3 | 99.1 | 28.6 | 49.2 | 74.2 | 80.9 | 0.5 | 0.3 | 57.1 | 49 | 19.3 | 17.4 | 0.03 | 0 | 14.3 | 0.6 | 0 | 0.9 | 0.2 | 0.1 | 0 | 0.8 | 6.4 | 0.4 |
| fep_processing | 98.8 | 99.2 | 45.4 | 56.7 | 70.3 | 60.1 | 0.5 | 0.2 | 46.8 | 39.7 | 25 | 33.8 | 0.02 | 0 | 5.5 | 1.8 | 3.1 | 4.3 | 0.5 | 0.6 | 2 | 1.7 | 1.42 | 1.6 |
| feptx_thread | 99.3 | 99.7 | 47 | 53.4 | 72 | 54.4 | 0.7 | 0.3 | 49.7 | 45.6 | 26.2 | 42.8 | 0.05 | 0 | 3 | 0.9 | 1.7 | 2.2 | 0.02 | 0 | 0.2 | 0.1 | 0.1 | 0.4 |
| TASK_GTP | 94.4 | 6.4 | 46.9 | 2.3 | 75.6 | 1.04 | 0.8 | 86.3 | 43.8 | 89.6 | 17.9 | 90.5 | 3.3 | 6 | 4.9 | 3.3 | 3.9 | 3.9 | 1.3 | 1 | 3.8 | 4.4 | 2.3 | 4.3 |
| UDP_TASK | 95.4 | 90.8 | 22.9 | 38.7 | 57.4 | 51.3 | 1.4 | 6.2 | 65.2 | 53.5 | 35.8 | 40.7 | 2 | 1.3 | 7.8 | 5.4 | 4.4 | 3.4 | 1 | 1 | 3.7 | 1.5 | 2.1 | 3.8 |
| Thread | 0–1 (microseconds) | 2–3 (microseconds) | 4–7 (microseconds) | 8–15 (microseconds) | ||||
|---|---|---|---|---|---|---|---|---|
| Kernel | Kernel | Kernel | Kernel | |||||
| IA-WA | IA-TA | IA-WA | IA-TA | IA-WA | IA-TA | IA-WA | IA-TA | |
| ru-thread | 89.4 | 90.8 | 6.5 | 4.5 | 0.4 | 0.34 | 3.5 | 4.3 |
| lte-softmodem | 81 | 93.4 | 7.2 | 5.4 | 0.8 | 0.2 | 1.5 | 0.3 |
| fep_processing | 86.3 | 80.2 | 11.2 | 17.7 | 0.6 | 0.8 | 0.8 | 1.2 |
| feptx_thread | 72.9 | 75.9 | 15.6 | 23.4 | 1.2 | 0.4 | 1.4 | 0.1 |
| TASK_GTP | 74.6 | 0.1 | 9.3 | 56.4 | 4.7 | 32.6 | 2.2 | 4.5 |
| UDP_TASK | 62.5 | 49.4 | 6.2 | 2.7 | 23 | 32.5 | 3.5 | 14.2 |
| Thread | 0–1 (microseconds) | 2–3 (microseconds) | 4–7 (microseconds) | 8–15 (microseconds) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Shielding | isolCPU | Shielding | isolCPU | Shielding | isolCPU | Shielding | isolCPU | |||||||||
| IA-WA | IA-TA | IA-WA | IA-TA | IA-WA | IA-TA | IA-WA | IA-TA | IA-WA | IA-TA | IA-WA | IA-TA | IA-WA | IA-TA | IA-WA | IA-TA | |
| ru-thread | 92.8 | 93.9 | 92 | 93.1 | 0.3 | 0.3 | 0.3 | 0.3 | 0.2 | 0.2 | 0.2 | 0.3 | 6.4 | 5.4 | 7.1 | 6.2 |
| lte-softmodem | 98.6 | 98.4 | 100 | 98.4 | 0.5 | 0.4 | 0 | 0.4 | 0.2 | 0.2 | 0 | 0.2 | 0.4 | 0.4 | 0 | 0.4 |
| fep_processing | 98.1 | 98.3 | 98.1 | 98.5 | 0.7 | 0.4 | 0.7 | 0.2 | 0.1 | 0.1 | 0.2 | 0.1 | 0.8 | 1 | 0.9 | 1 |
| feptx_thread | 98.7 | 99 | 98.5 | 99 | 0.6 | 0.4 | 0.9 | 0.4 | 0.2 | 0.1 | 0.3 | 0.1 | 0.2 | 0.2 | 0.2 | 0.2 |
| TASK_GTP | 96.8 | 93.5 | 96.8 | 93.5 | 0.7 | 4.7 | 0.7 | 4.7 | 1.6 | 1.2 | 1.6 | 1.2 | 0.6 | 0.2 | 0.6 | 0.2 |
| UDP_TASK | 92.6 | 88.4 | 92.4 | 89 | 1 | 5.9 | 1 | 6 | 4.8 | 4.4 | 4.8 | 3.7 | 1.4 | 0.7 | 1.3 | 0.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ocampo, A.F.; Fida, M.-R.; Elmokashfi, A.; Bryhni, H. Assessing the Cloud-RAN in the Linux Kernel: Sharing Computing and Network Resources. Sensors 2024, 24, 2365. https://doi.org/10.3390/s24072365
Ocampo AF, Fida M-R, Elmokashfi A, Bryhni H. Assessing the Cloud-RAN in the Linux Kernel: Sharing Computing and Network Resources. Sensors. 2024; 24(7):2365. https://doi.org/10.3390/s24072365
Chicago/Turabian StyleOcampo, Andres F., Mah-Rukh Fida, Ahmed Elmokashfi, and Haakon Bryhni. 2024. "Assessing the Cloud-RAN in the Linux Kernel: Sharing Computing and Network Resources" Sensors 24, no. 7: 2365. https://doi.org/10.3390/s24072365