
Dilated Heterogeneous Convolution for Cell Detection and Segmentation Based on Mask R-CNN


Abstract
:1. Introduction
- We propose a novel convolutional kernel structure called DHConv that combines the advantages of dilated convolution and HetConv.
- An improved Mask R-CNN, called Mask R-DHCNN, is proposed by replacing the standard convolution of the original Mask R-CNN with the proposed DHConv module, which leads to easy adaptation of variable shapes and sizes in the task of cell detection and segmentation.
- A series of experiments are conducted to verify the effectiveness of the proposed methods on various datasets, and the results show that the proposed method can obtain better performance than some state-of-the-art methods in multiple metrics while maintaining competitive FLOPs and FPS.
2. Related Work
2.1. Dilated Convolution
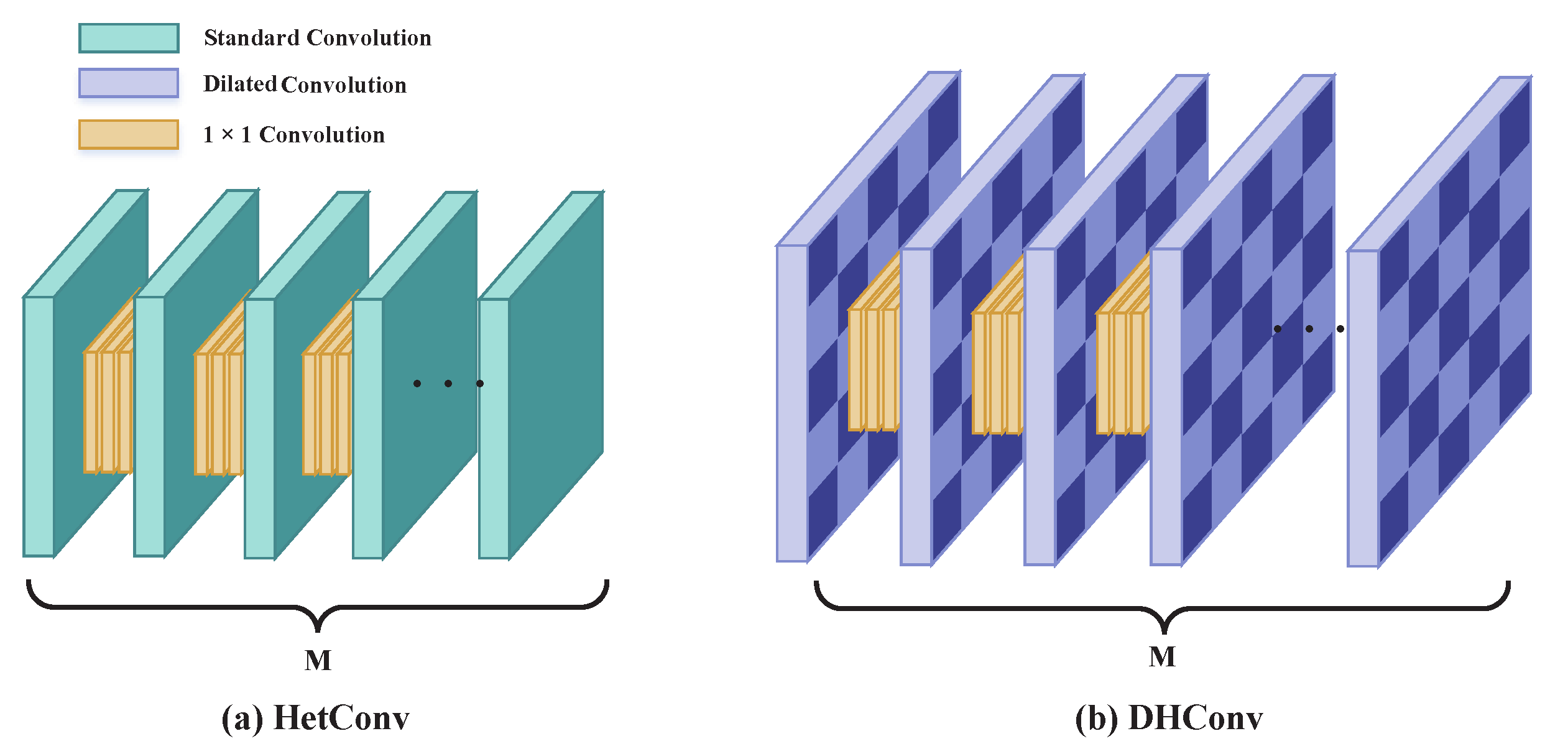
2.2. HetConv
2.3. Mask R-CNN
3. Proposed Method
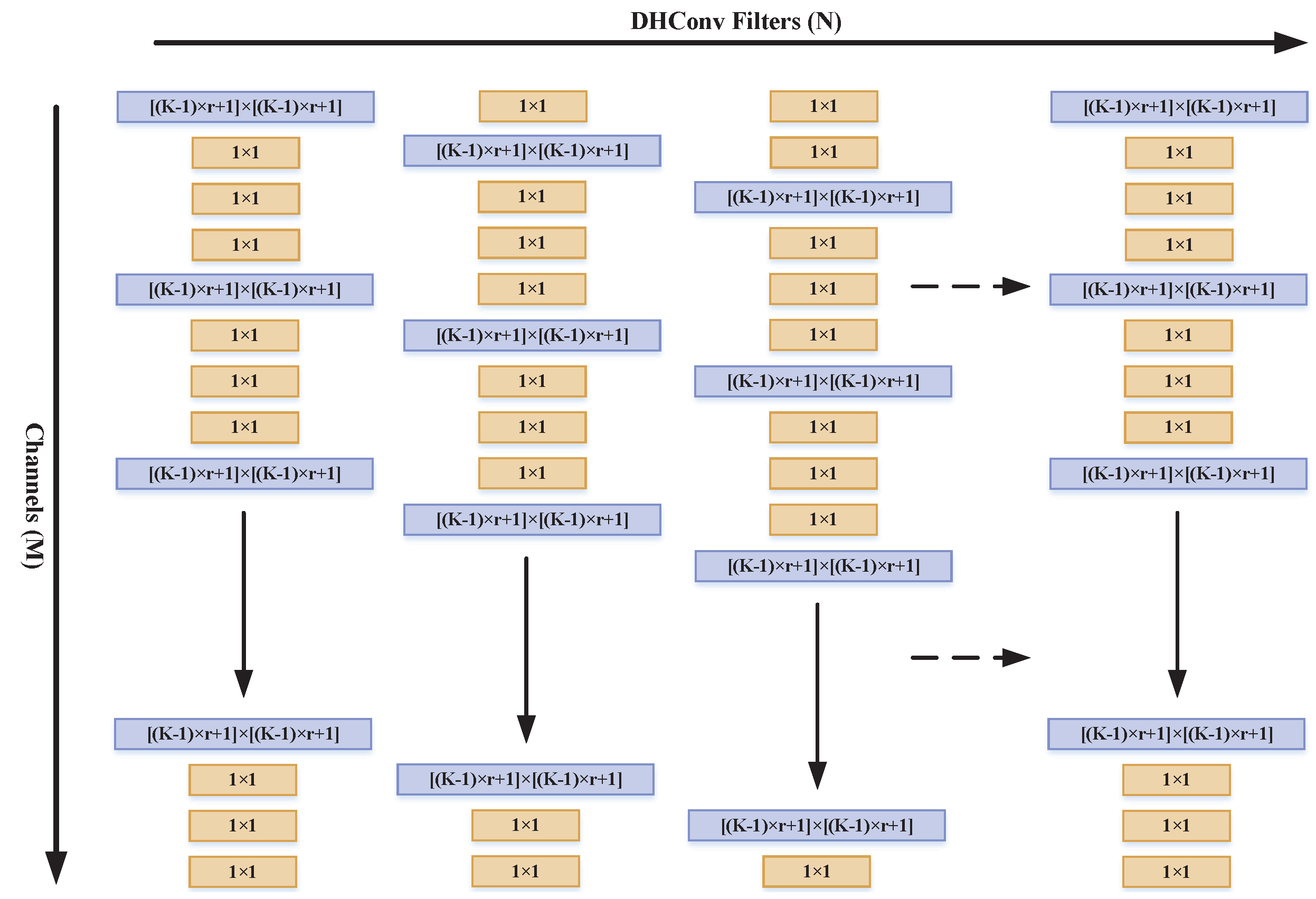
3.1. Dilation Heterogeneous Convolution (DHConv)
3.2. Mask R-DHCNN
4. Experiments and Results
4.1. Experimental Settings
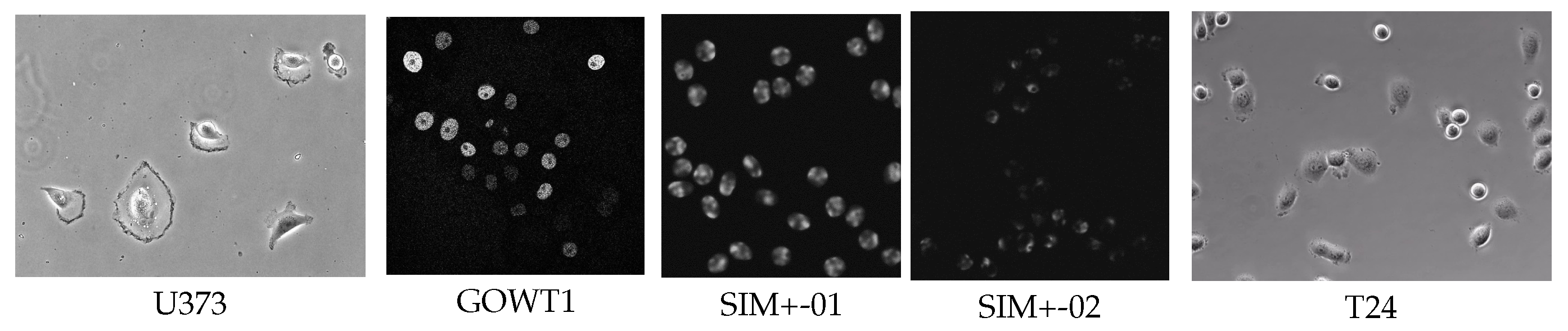
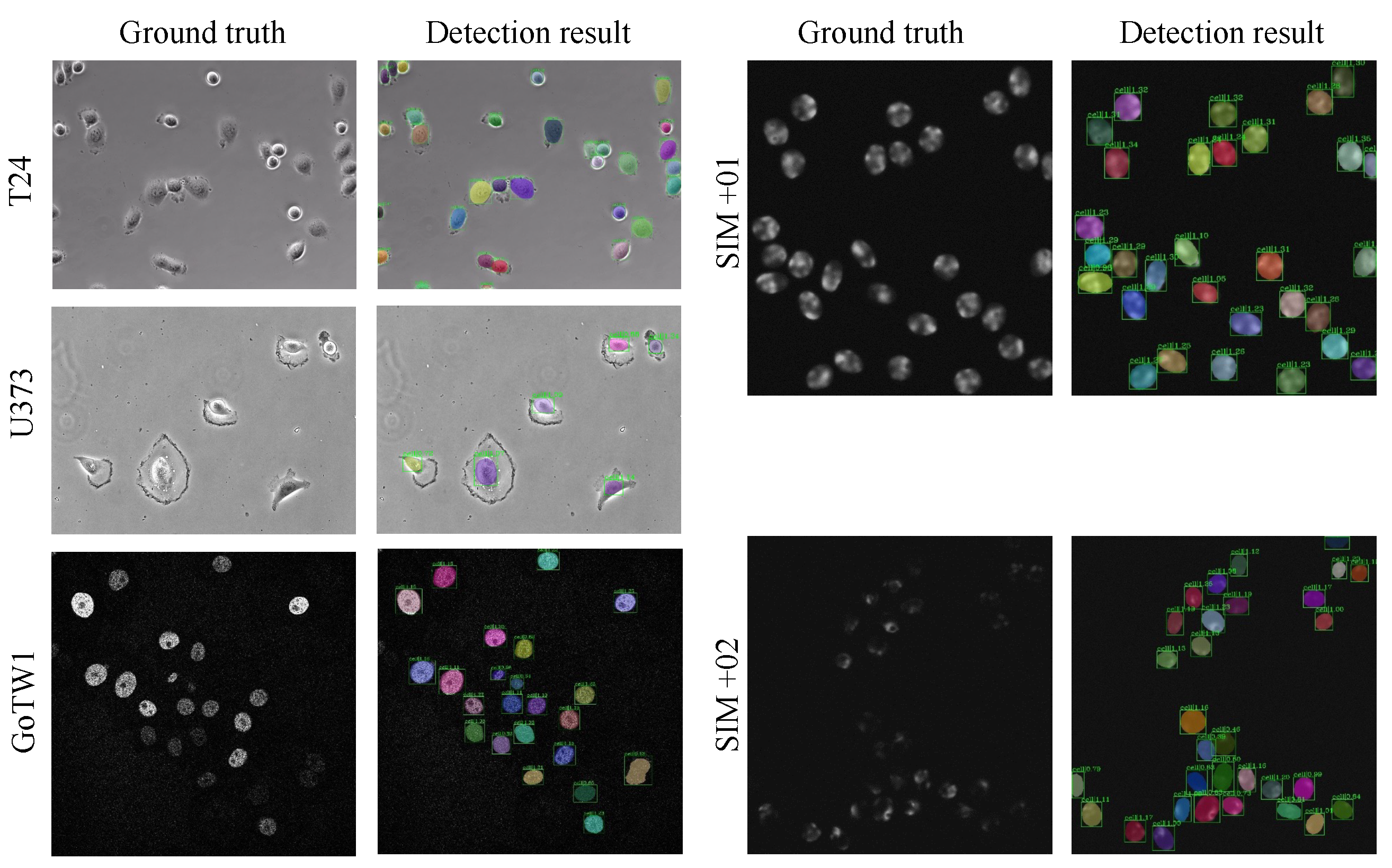
4.2. Datasets
- PhC-C2DH-U373 (U373) comprises images of glioblastoma–astrocytoma cells obtained through phase contrast microscopy. These cells are cultured adherently and video recorded under controlled conditions to provide data for cell tracking and analysis tasks. Due to only subtle differences between two consecutive frames, not all the frames can be considered as training samples for the proposed network. To address this issue, we select one frame from two adjacent images (video frames) as a sample. This operation provided us 230 sample images, among which 184 and 46 images are, respectively, used for training and testing.
- Fluo-N2DH-GOWT1 (GOWT1) was obtained from GFP transfected GOWT1 mouse embryonic stem cells on a flat substrate using a Leica TCS SP5 laser scanning confocal microscope (courtesy of Dr. E. Bártová, Academy of Sciences of the Czech Republic, Brno, Czech Republic). This dataset exhibits characteristics of low contrast and high density under microscope due to factors such as heterogeneous staining, prominent nucleoli, mitoses, cells entering and leaving the field of view, and frequent cell collisions. The dataset also has two image sequences with a total of 368 frames. Similarly, we extract one frame from every two frames and can obtain 184 frames, 147 images for training and 37 images for testing.
- Fluo-N2DH-SIM+ contains simulated cells stained with and without fluorescent chromosomes. The morphology of the cells between the two conditions is quite different. Therefore, both the stained and non-stained images are taken as two separate datasets, Fluo-N2DH-SIM+-01 (short for SIM+-01) and Fluo-N2DH-SIM+-02 (short for SIM+-02). In Fluo-N2DH-SIM+-01, cells are of more complex morphology and low fore-back ground contrast exists. In Fluo-N2DH-SIM+-02, the scale of cells varies greatly, and there are partial occlusions between the cells, which greatly increases the difficulty of segmentation. Moreover, 52 frames and 13 frames from Fluo-N2DH-SIM+-01 (SIM+-01) were selected as training set and testing set, respectively. In Fluo-N2DH-SIM+-02, 120 frames and 13 frames were used for training and testing, respectively.
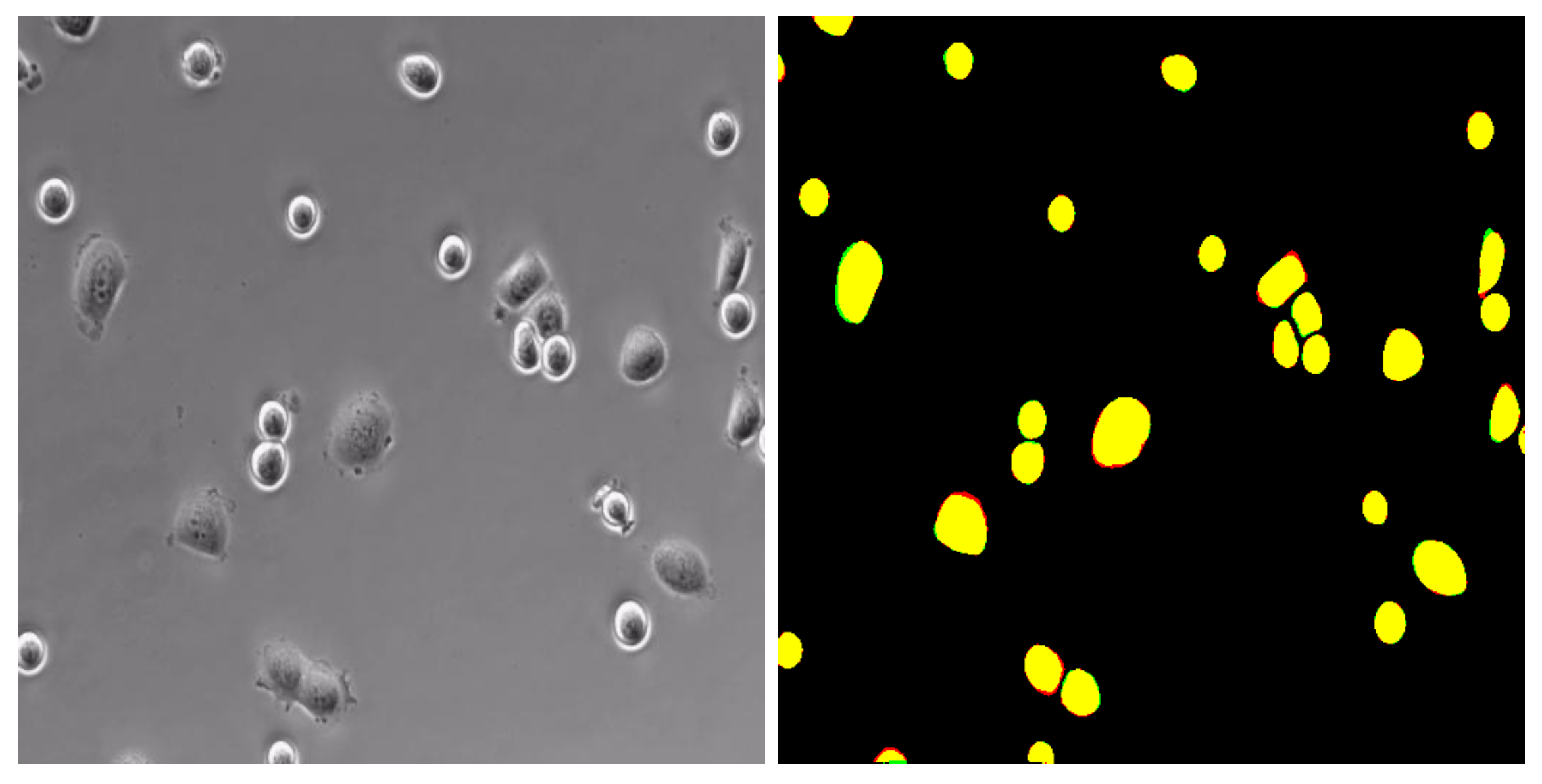
- T24 is a real bladder cancer cell dataset released by the Cancer Cell Institute, University of Cambridge. The cells were cultured in RPMI-1640 medium (HyClone, Logan, UT, USA) supplemented with heat-inactivated FBS (JRH Biosciences, Lenexa, KS, USA), 100 U/mL penicillin, and 100 mg/L streptomycin. Cultures were maintained in a humidified atmosphere of 5% CO2 at 37 °C. Adhesion and overlap between cells were common in these images. In addition, the size of cells varies greatly, making detection and segmentation challenging.
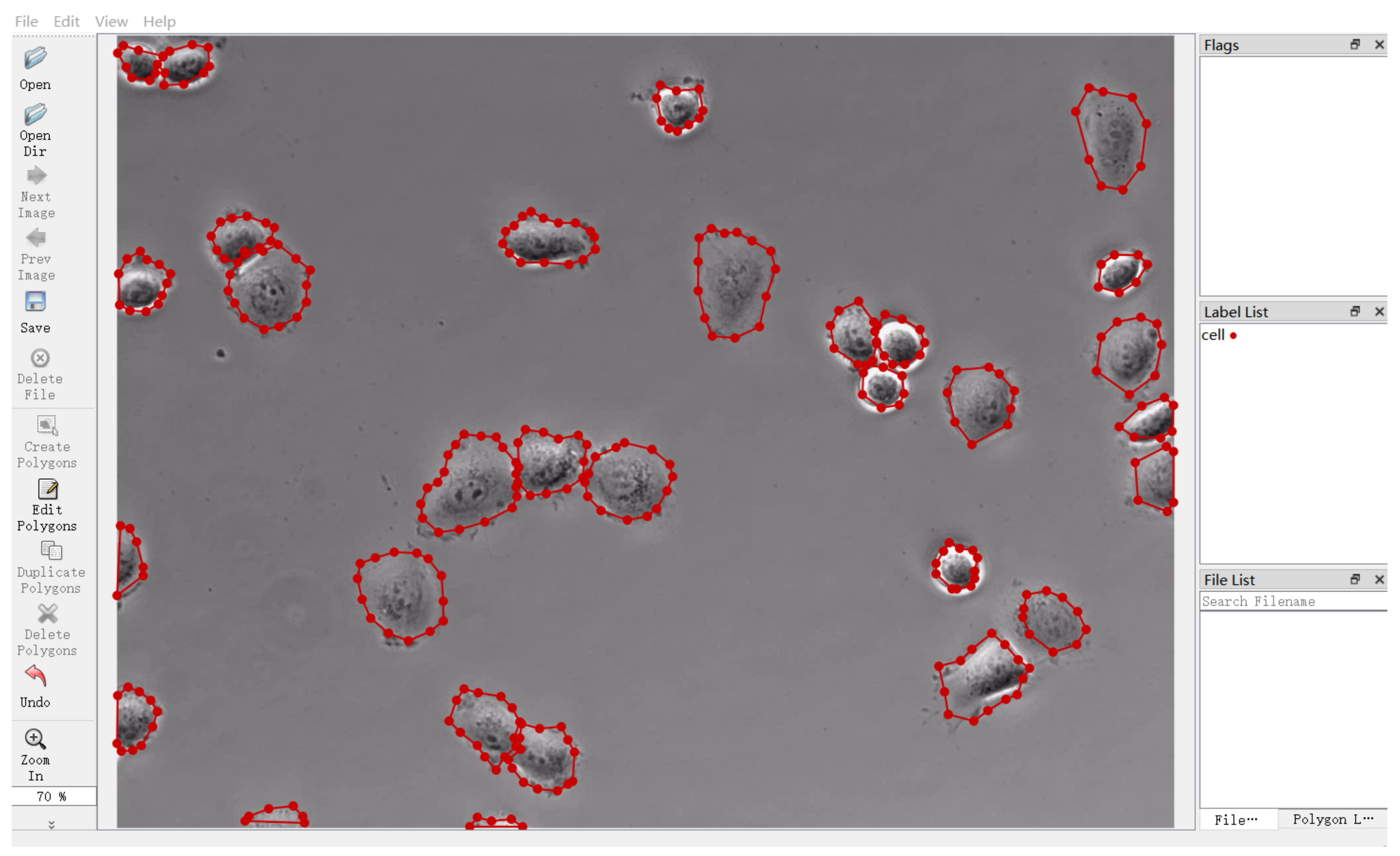
4.3. Data Annotation
4.4. Evaluation Metrics
- : real cells that are correctly identified as real cell objects;
- : non-cell objects that are correctly identified as non-cell objects;
- : non-cell objects that are mistakenly identified as cell objects;
- : real cells that are mistakenly identified as non-cell objects.
- : a measure of the percentage of the correctly classified cell objects in all classifications of cell objects, which is the probability of not misclassifying cell object, i.e.,
- : a measure of the percentage of the correctly classified cell objects in the total real cells, which is the probability of non-missed diagnosis, i.e.,
- : a measure of the proportion of intersection between the model output and the ground truth, i.e.,
- : Recall and Precision are contradictory in evaluating object detection performance as both of them depend on the threshold value of IoU we take to set the TP, FN, TN, and FP. To this end, we calculate the area under the Precision–Recall curve constructed by applying different threshold values to IoU as the average precision of the model, i.e.,where and are the Recall and the dependent Precision, respectively.
- : is commonly used in medical image segmentation tasks. Although is a good index of the model’s segmentation ability, it cannot reflect model performance in both detection and segmentation tasks. Simon et al. [36] proposed that is capable of illustrating the pros and cons of the model in performing detection and segmentation tasks. The definition of is as follows:where x and y are the model prediction and the ground truth, respectively.
4.5. Experiments and Results
4.5.1. Comparison Experiments
4.5.2. Ablation Experiments
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shen, S.P.; Tseng, H.A.; Hansen, K.R.; Wu, R.; Gritton, H.J.; Si, J.; Han, X. Automatic cell segmentation by adaptive thresholding (ACSAT) for large-scale calcium imaging datasets. eNeuro 2018, 5, e0056-18.2018. [Google Scholar] [CrossRef] [PubMed]
- Salihah, A.; Nasir, A.; Mustafa, N.; Fazli, N.; Nasir, M. Application of thresholding technique in determining ratio of blood cells for leukemia detection. In Proceedings of the International Conference on Man-Machine Systems (ICoMMS), Batu Ferringhi, Malaysia, 11–13 October 2009. [Google Scholar]
- Tang, M. Edge detection and image segmentation based on cellular neural network. In Proceedings of the 2009 3rd International Conference on Bioinformatics and Biomedical Engineering, Beijing, China, 11–13 June 2009; pp. 1–4. [Google Scholar]
- Tulsani, H.; Saxena, S.; Yadav, N. Segmentation using morphological watershed transformation for counting blood cells. Int. J. Comput. Appl. Inf. Technol. 2013, 2, 28–36. [Google Scholar]
- Ji, X.; Li, Y.; Cheng, J.; Yu, Y.; Wang, M. Cell image segmentation based on an improved watershed algorithm. In Proceedings of the 2015 8th International Congress on Image and Signal Processing (CISP), Shenyang, China, 14–16 October 2015; pp. 433–437. [Google Scholar]
- Namwong, K.; Polpinit, P.; Wongkham, S.; Saengboonmee, C. Modified watershed transform algorithm for cancer cell segmentation counting. Eng. Appl. Sci. Res. 2016, 43, 370–372. [Google Scholar]
- Chen, Z.; Zheng, K.; Shen, J.; Lin, Y.; Feng, Y.; Xu, J. Sample point classification of abdominal ECG through CNN-Transformer model enables efficient fetal heart rate detection. IEEE Trans. Instrum. Meas. 2023, 73, 6500412. [Google Scholar] [CrossRef]
- Khoshkhabar, M.; Meshgini, S.; Afrouzian, R.; Danishvar, S. Automatic Liver Tumor Segmentation from CT Images Using Graph Convolutional Network. Sensors 2023, 23, 7561. [Google Scholar] [CrossRef] [PubMed]
- Zheng, J.; Liu, H.; Feng, Y.; Xu, J.; Zhao, L. CASF-Net: Cross-attention and cross-scale fusion network for medical image segmentation. Comput. Methods Programs Biomed. 2023, 229, 107307. [Google Scholar] [CrossRef] [PubMed]
- Hu, H.; Guan, Q.; Chen, S.; Ji, Z.; Lin, Y. Detection and Recognition for Life State of Cell Cancer Using Two-Stage Cascade CNNs. IEEE/ACM Trans. Comput. Biol. Bioinform. 2020, 17, 887–898. [Google Scholar] [CrossRef] [PubMed]
- Hu, H.; Liu, A.; Zhou, Q.; Guan, Q.; Li, X.; Chen, Q. An adaptive learning method of anchor shape priors for biological cells detection and segmentation. Comput. Methods Programs Biomed. 2021, 208, 106260. [Google Scholar] [CrossRef] [PubMed]
- Maška, M.; Ulman, V.; Svoboda, D.; Matula, P.; Matula, P.; Ederra, C.; Urbiola, A.; España, T.; Venkatesan, S.; Balak, D.M.; et al. A benchmark for comparison of cell tracking algorithms. Bioinformatics 2014, 30, 1609–1617. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.; Park, J. Centermask: Real-time anchor-free instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 13906–13915. [Google Scholar]
- Chen, X.; Girshick, R.; He, K.; Dollár, P. Tensormask: A foundation for dense object segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2061–2069. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Wu, Z.; Liu, C.; Wen, J.; Xu, Y.; Yang, J.; Li, X. Selecting high-quality proposals for weakly supervised object detection with bottom-up aggregated attention and phase-aware loss. IEEE Trans. Image Process. 2022, 32, 682–693. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. Hypernet: Towards accurate region proposal generation and joint object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 845–853. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Zhu, Y.; Zhao, C.; Wang, J.; Zhao, X.; Wu, Y.; Lu, H. Couplenet: Coupling global structure with local parts for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4126–4134. [Google Scholar]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask Scoring R-CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6409–6418. [Google Scholar]
- Liu, J.; Li, C.; Liang, F.; Lin, C.; Sun, M.; Yan, J.; Ouyang, W.; Xu, D. Inception convolution with efficient dilation search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11486–11495. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2016, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Wang, C.; Fu, Q.; Kou, R.; Huang, F.; Yang, B.; Yang, T.; Gao, M. Techniques and challenges of image segmentation: A review. Electronics 2023, 12, 1199. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Chen, D. Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1091–1100. [Google Scholar]
- Singh, P.; Verma, V.K.; Rai, P.; Namboodiri, V.P. Hetconv: Heterogeneous kernel-based convolutions for deep cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4835–4844. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Wang, S.; Yang, K.J. An Image Scaling Algorithm Based on Bilinear Interpolation with VC++. Tech. Autom. Appl. 2008, 7, 44–45. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 850–859. [Google Scholar]
- Xie, E.; Sun, P.; Song, X.; Wang, W.; Liu, X.; Liang, D.; Shen, C.; Luo, P. Polarmask: Single shot instance segmentation with polar representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12193–12202. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Graham, S.; Vu, Q.D.; Raza, S.E.A.; Azam, A.; Tsang, Y.W.; Kwak, J.T.; Rajpoot, N. Hover-Net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images. Med. Image Anal. 2019, 58, 101563. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Ji, S. Smoothed dilated convolutions for improved dense prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2486–2495. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Methods | AP (%) | Precision (%) | Recall (%) | Dice (%) | FPS |
|---|---|---|---|---|---|---|
| U373 | Baseline | 91.39 ± 0.33 | 87.21 ± 0.30 | 79.31 ± 0.27 | 82.03 ± 0.47 | 4.81 |
| MS R-CNN | 90.12 ± 0.12 | 86.35 ± 0.17 | 78.90 ± 0.25 | 81.87 ± 0.31 | 4.81 | |
| ExtremeNet | 77.75 ± 1.11 | 71.68 ± 1.27 | 60.55 ± 0.89 | 70.11 ± 0.77 | 4.73 | |
| TensorMask | 83.37 ± 1.51 | 79.92 ± 1.93 | 68.31 ± 2.11 | 78.41 ± 0.88 | 2.47 | |
| PolarMask | 88.77 ± 0.10 | 83.09 ± 0.07 | 71.93 ± 0.21 | 80.85 ± 0.13 | 11.79 | |
| CenterMask | 79.33 ± 1.74 | 72.40 ± 1.82 | 61.40 ± 1.19 | 74.90 ± 1.85 | 7.15 | |
| ResNet-50-FPN-ISO | 92.74 ± 0.47 | 88.65 ± 0.19 | 83.04 ± 0.27 | 82.81 ± 0.31 | - | |
| Mask R-DHCNN (Ours) | 92.87 ± 0.53 | 88.26 ± 0.06 | 80.52 ± 0.18 | 84.21 ± 0.80 | 7.00 | |
| GoTW1 | Baseline | 90.64 ± 0.44 | 91.14 ± 0.48 | 87.66 ± 0.23 | 89.65 ± 0.33 | 4.00 |
| MS R-CNN | 88.77 ± 0.64 | 89.26 ± 0.88 | 85.38 ± 0.72 | 86.05 ± 0.59 | 3.95 | |
| ExtremeNet | 84.40 ± 1.03 | 86.75 ± 1.21 | 80.51 ± 0.89 | 82.37 ± 1.22 | 3.90 | |
| TensorMask | 80.09 ± 0.97 | 76.27 ± 1.17 | 70.44 ± 0.82 | 76.27 ± 1.19 | 2.00 | |
| PolarMask | 85.65 ± 0.83 | 87.00 ± 0.77 | 83.43 ± 0.50 | 85.98 ± 0.81 | 9.50 | |
| CenterMask | 78.10 ± 1.56 | 74.51 ± 2.10 | 67.39 ± 1.68 | 73.71 ± 1.40 | 6.13 | |
| ResNet-50-FPN-ISO | 91.18 ± 1.07 | 92.26 ± 0.89 | 90.99 ± 1.14 | 91.05 ± 0.59 | - | |
| Mask R-DHCNN (Ours) | 91.26 ± 0.85 | 91.84 ± 1.23 | 88.99 ± 0.94 | 90.61 ± 0.65 | 6.70 | |
| SIM+01 | Baseline | 93.93 ± 0.69 | 94.06 ± 0.21 | 86.18 ± 0.58 | 87.60 ± 0.40 | 4.10 |
| MS R-CNN | 92.03 ± 0.27 | 93.10 ± 0.89 | 85.86 ± 0.33 | 86.38 ± 0.64 | 4.00 | |
| ExtremeNet | 88.64 ± 1.45 | 90.49 ± 1.29 | 81.30 ± 1.37 | 83.24 ± 1.01 | 3.84 | |
| TensorMask | 87.24 ± 0.93 | 89.94 ± 1.39 | 80.80 ± 1.27 | 83.05 ± 1.71 | 2.15 | |
| PolarMask | 91.19 ± 1.13 | 92.08 ± 0.97 | 84.65 ± 0.48 | 85.74 ± 0.70 | 10.05 | |
| CenterMask | 85.31 ± 1.66 | 88.38 ± 1.02 | 80.29 ± 1.85 | 78.77 ± 1.90 | 6.20 | |
| ResNet-50-FPN-ISO | 94.87 ± 0.44 | 94.79 ± 0.39 | 84.67 ± 0.61 | 89.66 ± 0.57 | - | |
| Mask R-DHCNN (Ours) | 94.04 ± 1.23 | 94.36 ± 0.87 | 88.03 ± 0.42 | 90.13 ± 0.54 | 5.50 | |
| SIM+02 | Baseline | 80.88 ± 1.05 | 83.95 ± 1.06 | 80.69 ± 1.88 | 75.71 ± 1.24 | 3.81 |
| MS R-CNN | 88.43 ± 1.07 | 87.92 ± 1.21 | 85.49 ± 1.53 | 83.10 ± 1.56 | 3.75 | |
| ExtremeNet | 73.22 ± 2.71 | 72.49 ± 1.88 | 70.20 ± 2.47 | 70.17 ± 1.06 | 3.50 | |
| TensorMask | 75.41 ± 0.91 | 74.18 ± 0.54 | 70.77 ± 1.23 | 71.20 ± 1.51 | 2.30 | |
| PolarMask | 78.52 ± 0.99 | 79.06 ± 1.15 | 74.36 ± 1.22 | 74.18 ± 0.85 | 9.23 | |
| CenterMask | 70.63 ± 2.92 | 69.30 ± 3.05 | 67.27 ± 1.87 | 66.98 ± 1.28 | 5.75 | |
| ResNet-50-FPN-ISO | 84.06 ± 0.76 | 85.78 ± 1.02 | 83.37 ± 1.00 | 75.64 ± 0.77 | - | |
| Mask R-DHCNN (Ours) | 82.47 ± 1.11 | 85.71 ± 0.79 | 80.24 ± 2.13 | 78.07 ± 0.94 | 5.61 | |
| T24 | Baseline | 92.25 ± 0.83 | 88.25 ± 0.76 | 85.18 ± 0.73 | 93.81 ± 0.56 | 4.28 |
| MS R-CNN | 91.98 ± 0.07 | 87.67 ± 0.11 | 83.41 ± 0.29 | 93.53 ± 0.31 | 4.29 | |
| ExtremeNet | 81.86 ± 0.88 | 80.88 ± 0.76 | 71.54 ± 0.34 | 79.66 ± 0.50 | 4.12 | |
| TensorMask | 87.53 ± 1.20 | 83.24 ± 1.09 | 76.54 ± 1.52 | 86.33 ± 0.64 | 2.19 | |
| PolarMask | 91.67 ± 0.19 | 86.08 ± 0.20 | 83.10 ± 0.44 | 92.79 ± 0.37 | 10.32 | |
| CenterMask | 82.01 ± 1.14 | 84.80 ± 0.95 | 73.98 ± 1.08 | 80.89 ± 0.74 | 6.42 | |
| ResNet-50-FPN-ISO | 93.41 ± 0.66 | 92.14 ± 0.61 | 83.67 ± 0.71 | 93.82 ± 0.33 | - | |
| Mask R-DHCNN (Ours) | 94.32 ± 0.85 | 91.38 ± 0.56 | 87.15 ± 0.98 | 94.31 ± 0.54 | 6.44 |
| Datasets | Baseline (Mask R-CNN) | HetConv | DConv | DHConv | PQ | FLOPs (G) | FPS |
|---|---|---|---|---|---|---|---|
| U373 | ✓ | 57.53 | 55.37 | 4.81 | |||
| ✓ | ✓ | 57.02 | 46.74 | 7.05 | |||
| ✓ | ✓ | 48.56 | 55.14 | 4.34 | |||
| ✓ | ✓ | 61.24 | 46.75 | 7.00 | |||
| GoTW1 | ✓ | 72.91 | 73.89 | 4.00 | |||
| ✓ | ✓ | 72.20 | 59.46 | 6.71 | |||
| ✓ | ✓ | 61.68 | 74.06 | 3.78 | |||
| ✓ | ✓ | 75.05 | 59.45 | 6.70 | |||
| SIM+-01 | ✓ | 68.26 | 60.23 | 4.10 | |||
| ✓ | ✓ | 69.11 | 50.08 | 5.50 | |||
| ✓ | ✓ | 53.54 | 60.38 | 3.63 | |||
| ✓ | ✓ | 73.96 | 50.13 | 5.50 | |||
| SIM+-02 | ✓ | 46.12 | 70.01 | 3.81 | |||
| ✓ | ✓ | 45.10 | 58.19 | 5.60 | |||
| ✓ | ✓ | 35.68 | 69.25 | 3.52 | |||
| ✓ | ✓ | 49.81 | 57.34 | 4.86 | |||
| T24 | ✓ | 82.87 | 90.74 | 4.28 | |||
| ✓ | ✓ | 80.75 | 70.85 | 6.45 | |||
| ✓ | ✓ | 71.58 | 90.52 | 3.89 | |||
| ✓ | ✓ | 84.15 | 70.88 | 6.44 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, F.; Hu, H.; Xu, H.; Xu, J.; Chen, Q. Dilated Heterogeneous Convolution for Cell Detection and Segmentation Based on Mask R-CNN. Sensors 2024, 24, 2424. https://doi.org/10.3390/s24082424
Hu F, Hu H, Xu H, Xu J, Chen Q. Dilated Heterogeneous Convolution for Cell Detection and Segmentation Based on Mask R-CNN. Sensors. 2024; 24(8):2424. https://doi.org/10.3390/s24082424
Chicago/Turabian StyleHu, Fengdan, Haigen Hu, Hui Xu, Jinshan Xu, and Qi Chen. 2024. "Dilated Heterogeneous Convolution for Cell Detection and Segmentation Based on Mask R-CNN" Sensors 24, no. 8: 2424. https://doi.org/10.3390/s24082424