In this section, we first provide an overview of the proposed method. Subsequently, we present the hybrid encoder incorporating ConvNeXt Transformer and region-aware spatial attention module. Further, we introduce the self-adaptive multi-scale feature fusion attention module. Lastly, we delineate the components of the loss function.
3.1. Overview
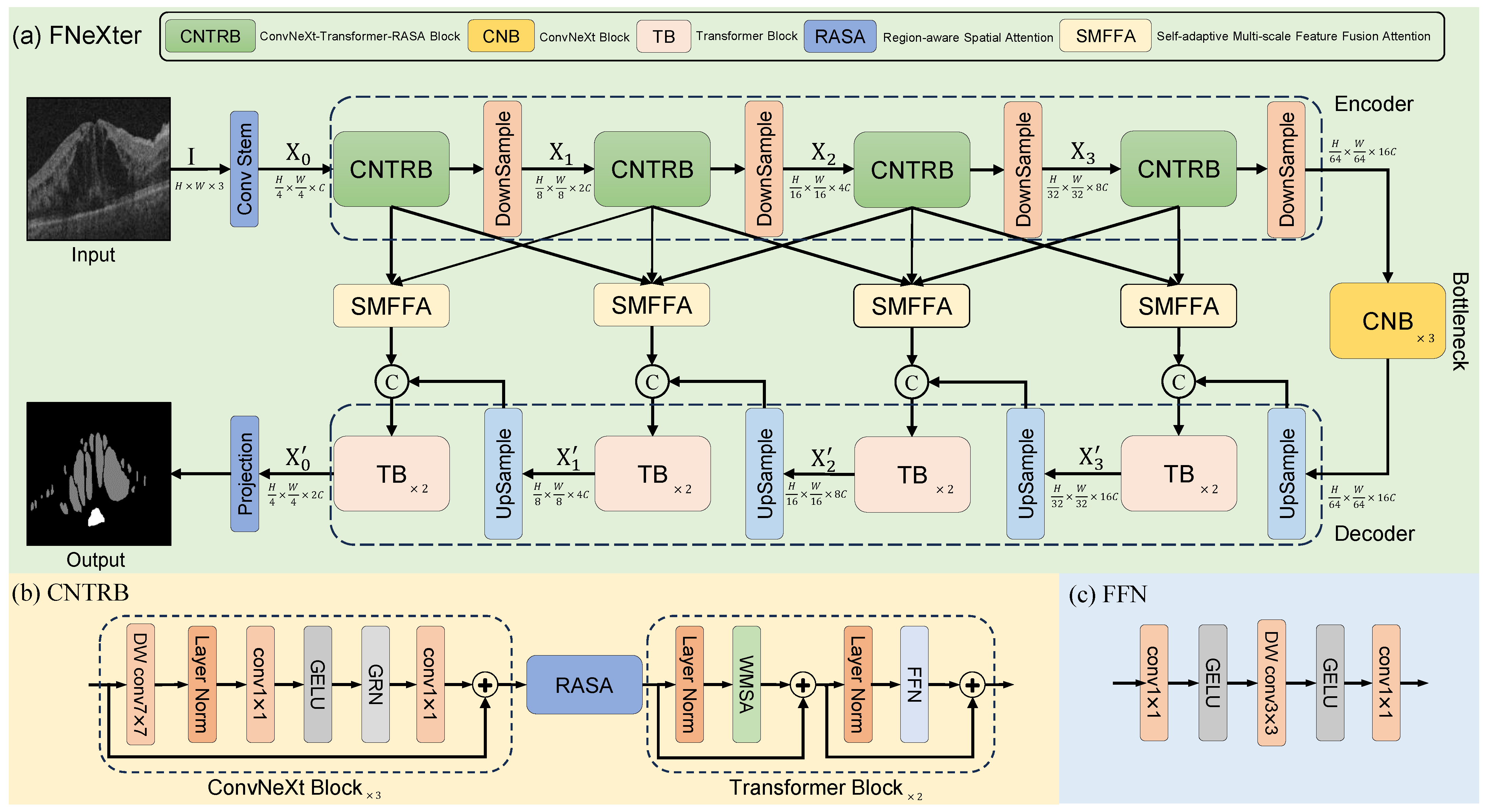
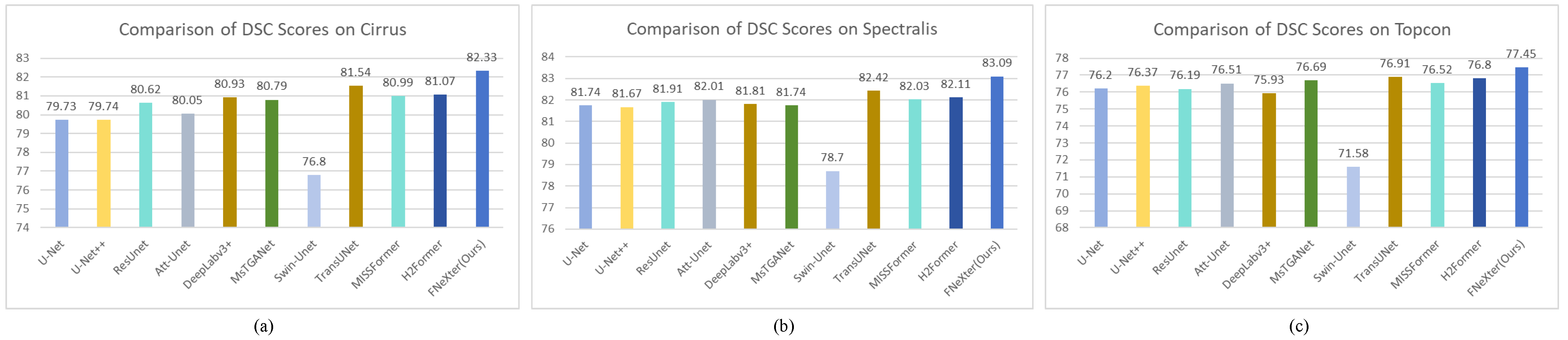
The architecture of the model is depicted in
Figure 1, consisting of an encoder, a bottleneck, and a decoder. Specifically, given an input image
, where
H,
W, and 3 denote the height, width, and channel count, respectively, the image is first processed through a Convolutional Neural Network module termed stem. This includes a
convolutional layer with a stride of 2, serving to extract initial features and implement downsampling. Consequently, this produces a feature map of a resolution quartered from the original image, having a channel dimension, C, of 96. It can also be denoted as
.
Subsequently, the feature map undergoes progressive deep feature extraction via four encoder stages. Each stage consists of a ConvNeXt module, a Transformer module, and a region-aware spatial attention module. After each encoder stage, a downsampling layer composed of LayerNorm and a convolutional layer with a stride of 2 is utilized. This serves to halve the spatial dimensions of the feature map and double the channel count. Consequently, the feature representation from the stage in the encoder is given as where indexes the four stages. Thirdly, the feature maps pass through a bottleneck layer composed of three ConvNeXt blocks, where further feature extraction and combination take place. Subsequently, the feature maps from the bottleneck layer are fed into the decoder section for continued feature extraction and upsampling operations. Each stage of the decoder is made up of two Transformer blocks. After each decoder stage, the feature maps are processed through an upsampling layer, which employs bilinear interpolation followed by a convolutional operation, doubling the spatial dimensions while halving the channel count. We also employ a self-adaptive multi-scale feature fusion attention module to enhance the skip connections, allowing for a better fusion of multi-scale features from adjacent encoder stages while preserving both global and local information. Finally, a convolutional layer is used to generate the segmentation results.
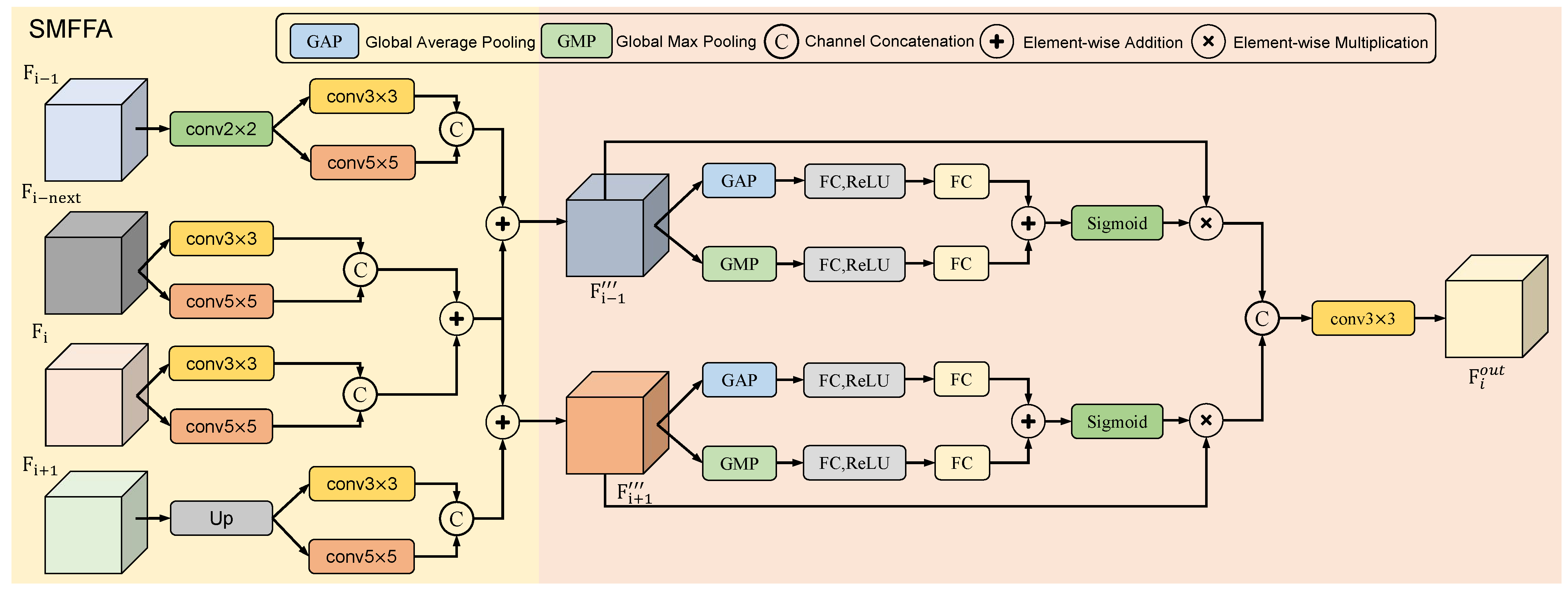
3.3. Self-Adaptive Multi-Scale Feature Fusion Attention
In the U-Net architecture, the output from each stage of the encoder is concatenated with the output from the corresponding stage of the decoder, an operation commonly referred to as skip connection. The skip connections allow for the integration of low-level and high-level features, mitigating information loss and enhancing the model’s performance. To further integrate multi-scale features and enhance the model’s ability to learn global contextual information, we introduce the self-adaptive multi-scale feature fusion attention (SMFFA). Many researchers have proposed methods for feature fusion, such as the hierarchical attention module (HAM) introduced by Tao et al. [
32], which employs different fusion methods to integrate feature maps of varying channel-spatial ratios to learn discriminative features. Differently from the SAM, our SMFFA approach fuses a broader range of multi-scale features, enhancing multi-scale information and diverse features. Additionally, we enhance spatial features in the feature extraction encoder stages, and in SMFFA, further augment important multi-scale features through attention mechanisms. Building upon the foundation of skip connections, SMFFA is capable of adaptively fusing and extracting multi-scale features from adjacent stages. The detailed definition is as follows: For the output feature map of each encoder stage
where
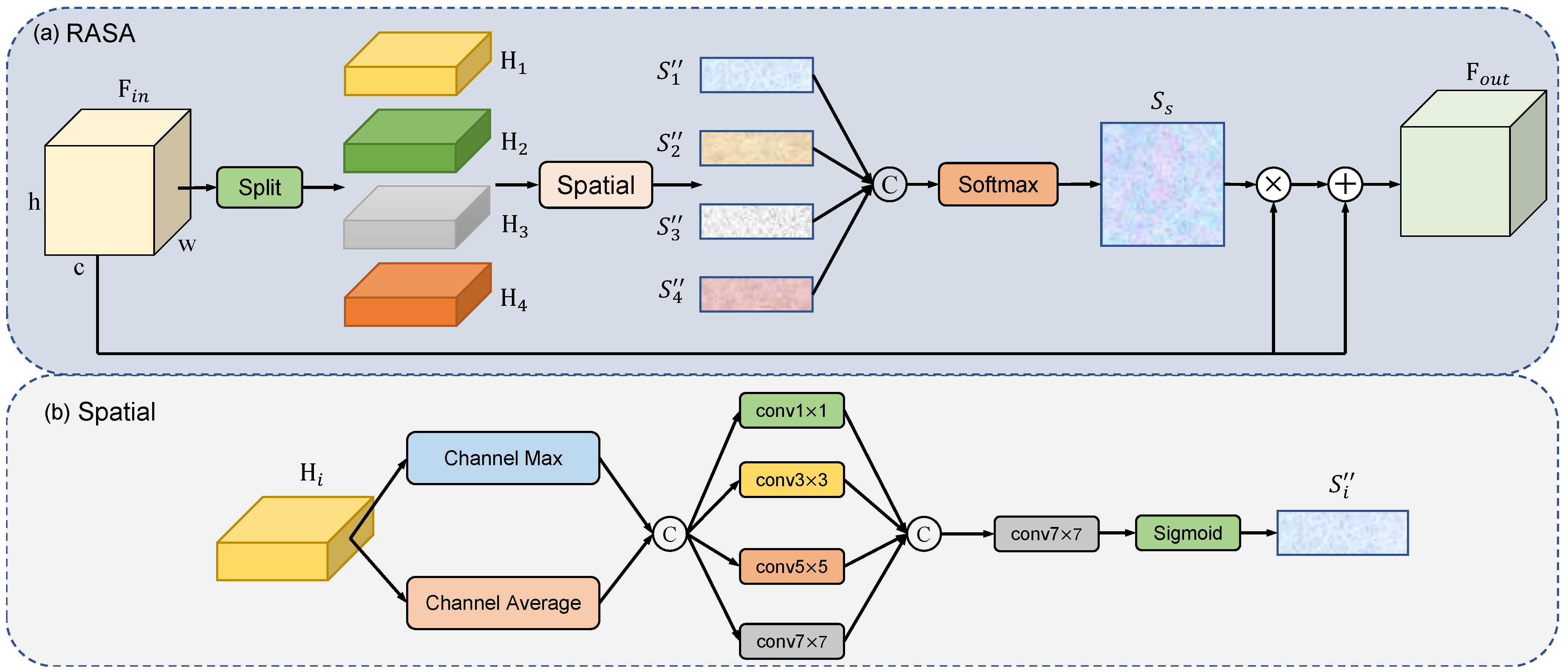
indexes the four stages. As illustrated in
Figure 3, for feature
, we merge it with the feature of its neighboring stage. For the SMFFA of the second stage and third stage, the feature is fused with the features from both the preceding and the succeeding stages. However, for the SMFFA of the first stage and fourth stage, the feature is only fused with the feature from its immediate neighboring stage.
For the SMFFA at encoder stage
i where
, we fuse the current stage feature
and additional feature
, the preceding stage feature
, and the succeeding stage feature
. To better leverage the advantages of the encoder architecture and fuse features across multiple scales and layers, we introduce an additional feature
extracted right after the ConvNeXt module of the current encoder stage, in addition to the output feature
at each stage. This strategy aims to harness the strengths of both the ConvNext and Transformer modules in feature processing. For the preceding stage feature
, we apply a convolutional layer with a kernel size of
and a stride of 2 to perform downsampling, halving the spatial resolution of the feature map. For the succeeding stage feature
, we employ bilinear interpolation to perform upsampling, doubling the spatial size of the feature map.
To effectively integrate multi-scale features, we employ convolutional layers with kernel sizes of
and
to process the aforementioned four features. For feature
, we apply both layers to
yielding two features each with channel dimension reduced to
. These are then concatenated along the channel dimension to produce
. Similar operations are applied to
to obtain
. Likewise,
and
are processed to obtain
and
, respectively.
where
represents one of the several features described previously, specifically belonging to the set {
}. Meanwhile,
denotes the output feature map after processing, and belongs to the set {
}. By employing these two convolutional layers with kernel sizes of
and
, the model is further enabled to capture features across multiple scales, allowing the network to recognize both fine-grained and coarser patterns within OCT images. Additionally, this operation enhances the model’s ability to capture more contextual information, providing a more comprehensive representation of the data and enriching the feature space. Subsequently, for the current encoder stage, the concatenated features
and
undergo element-wise addition to yield the final feature
for the current stage.
where ⊕ denotes element-wise addition. Subsequently, the processed feature of the current stage,
, is element-wise added to the features of the adjacent preceding and succeeding stages,
and
, respectively. The sum of
and
yields a preliminarily fused multi-scale feature
. Similarly, the sum of
and
results in another preliminarily fused multi-scale feature
. By subjecting four features from adjacent stages to convolutional and concatenation operations, the model gains enhanced multi-scale feature representation. This not only allows for the more precise recognition of detailed information but also aids in capturing global contextual information, thereby preserving semantic richness across different scales and rendering a more comprehensive feature representation.
To better process the fused features, we utilize channel attention to further enhance important multi-scale features. For the fused feature
, we first apply Global Average Pooling (GAP) and Global Max Pooling (GMP) operations. The outputs from these operations are then passed to respective fully connected layers. These are subsequently processed through a ReLU activation function and another fully connected layer, enabling the model to learn a compact representation. Finally, the processed features from both paths are summed and passed through a sigmoid activation function to learn attention weights. The attention weights are element-wise multiplied with the input fused feature to obtain the attention-modulated feature
. Through this attention module, essential features within the fused representation are further emphasized. This enables the model to adaptively learn and selectively extract salient channel features, thereby enhancing the specificity of feature extraction.
where
and
denotes fully connected layer.
denotes sigmoid activation function. ⊗ denotes element-wise multiplication. Similarly, the feature
undergoes attention processing as described in the above equations, resulting in an attention-modulated feature represented by
. Ultimately, we concatenate the two attention-enhanced fused features and pass them through a
convolutional layer for dimension reduction, yielding the final fused feature
, which is then relayed to the corresponding stage of the decoder.
As depicted in
Figure 3, the aforementioned operations collectively form our self-adaptive multi-scale feature fusion attention (SMFFA). Through our proposed SMFFA, we have enhanced the traditional skip connections by merging distinct features from adjacent encoder stages. Firstly, within the current encoder stage, we fuse the features processed by ConvNeXt with the final output features of the entire stage. This operation facilitates multi-level feature extraction, as ConvNeXt primarily focuses on local, detailed features, while the final stage output captures more global and high-level semantic information. This enhances the model’s robustness to various types of data. Secondly, all features from adjacent stages undergo processing through convolutional layers with different kernel sizes, preserving semantic richness across multiple scales. Furthermore, our SMFFA effectively fuses multi-scale and multi-level features across multiple stages, enabling the model to capture both fine-grained and coarser features. This assists the model in understanding the global context and capturing local details. Finally, we employ an attention mechanism to adaptively learn the significant features within the fused representation, allowing the model to focus on the most relevant features. In summary, this module automatically fuses multi-scale features from adjacent encoder stages and, via the attention mechanism, adaptively extracts significant features from the fused representation, thereby amplifying the model’s capability to learn global and contextual multi-scale representative features.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}