
Deep Learning-Based Fish Detection Using Above-Water Infrared Camera for Deep-Sea Aquaculture: A Comparison Study

 and
and
Abstract
1. Introduction
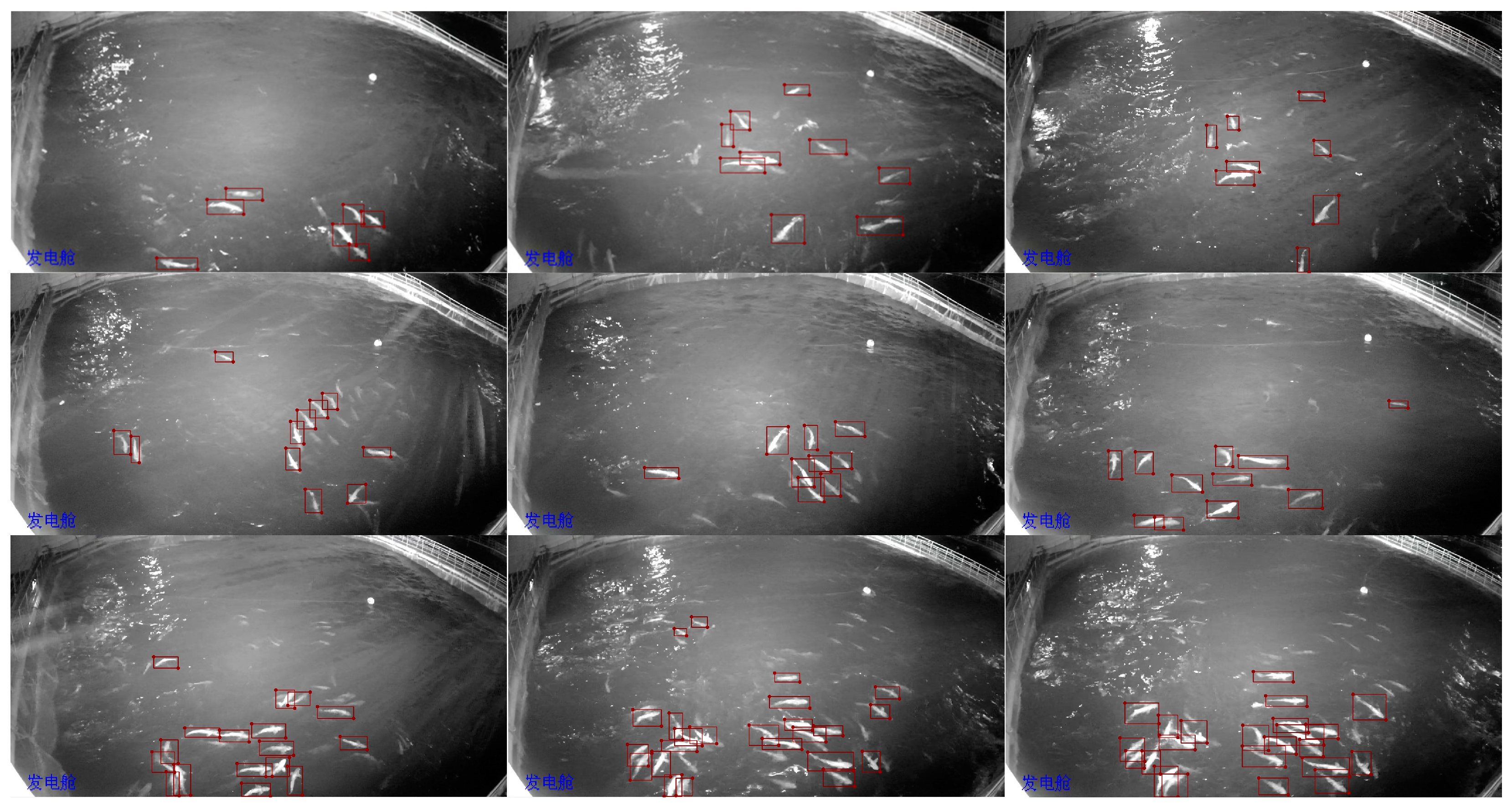
- Based on the above-water infrared camera, a dataset for deep-sea aquaculture fish detection was constructed, comprising 400 images and 2830 individual fish.
- Using our fish dataset, we compared the performances of Faster R-CNN and YOLOv5 and explored the influence of five different backbone networks (including VGG16, ResNet34, ResNet50, MobileNetV2, and EfficientNetB0), as well as different learning rates, feature extraction layers, and data augmentation strategies, on fish detection precision.
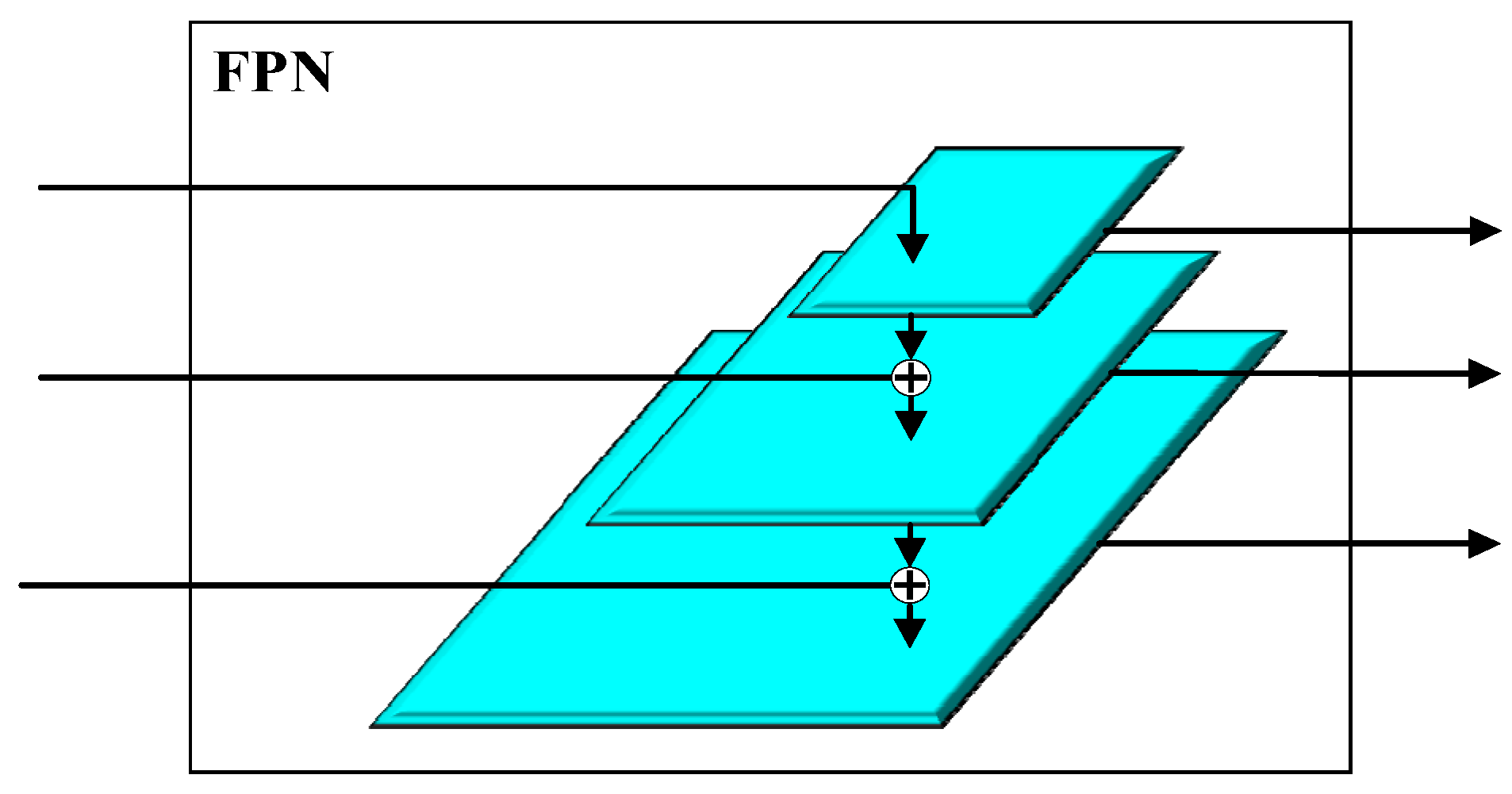
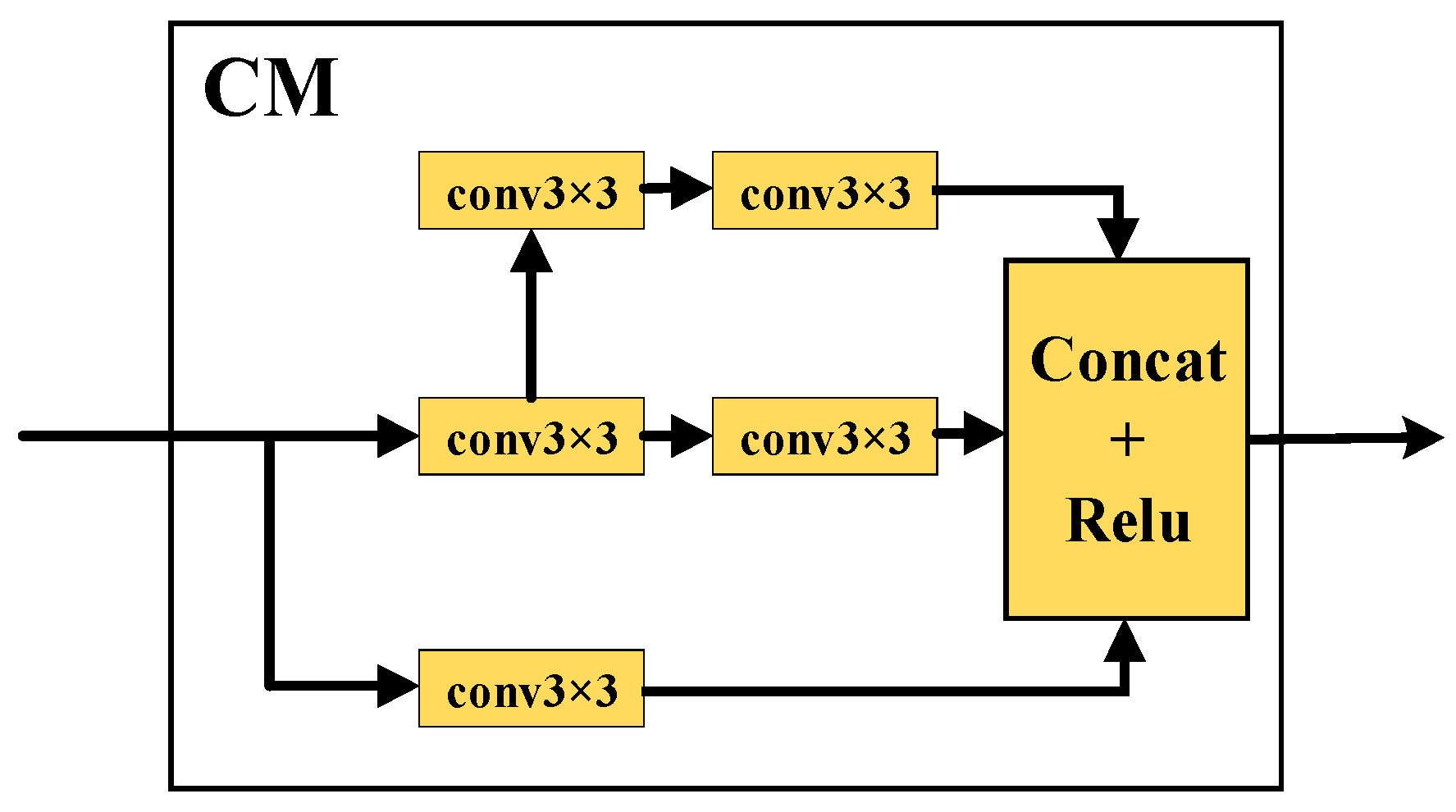
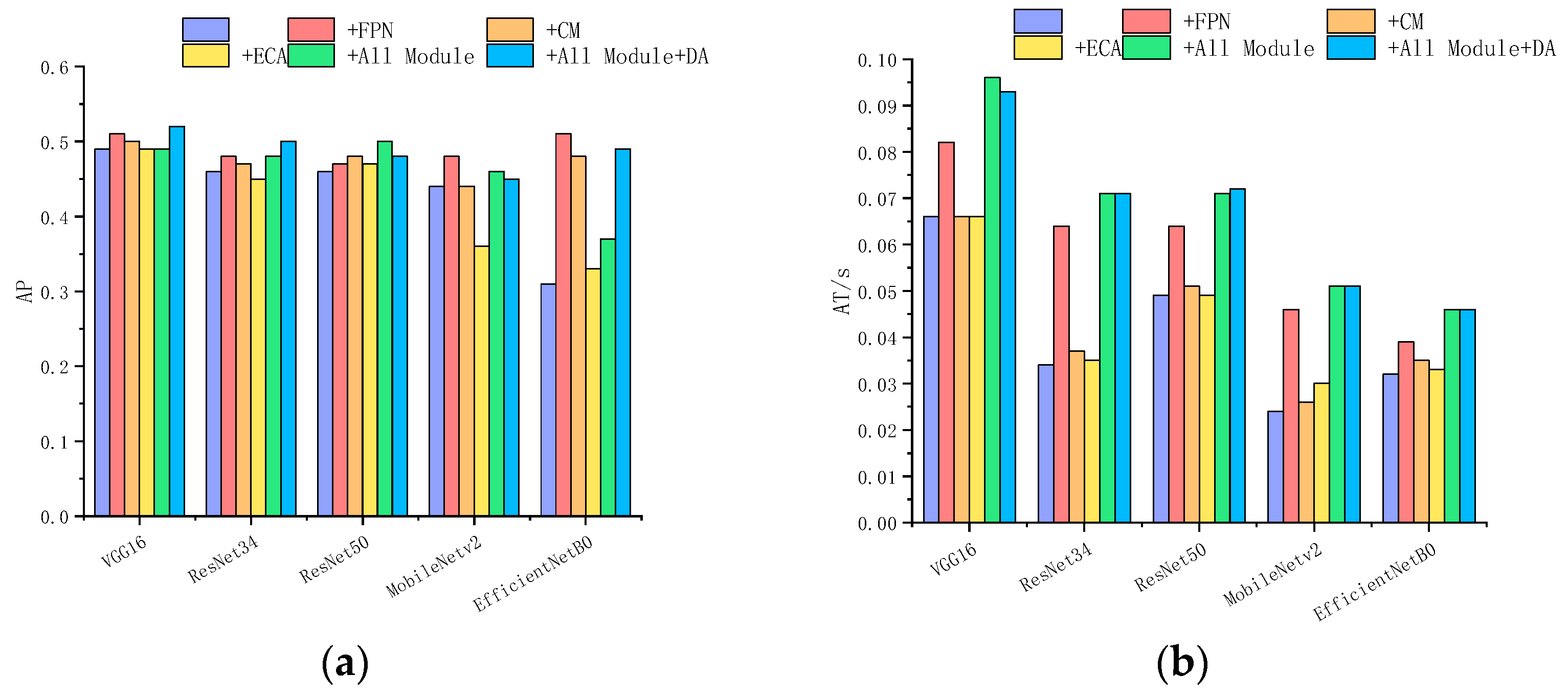
- Furthermore, we investigated the impact on fish detection performance by integrating individual modules into Faster R-CNN, including the FPN, CM, ECA-Net, and the effect of the combined networks.
2. Materials and Methods
2.1. Data Gathering
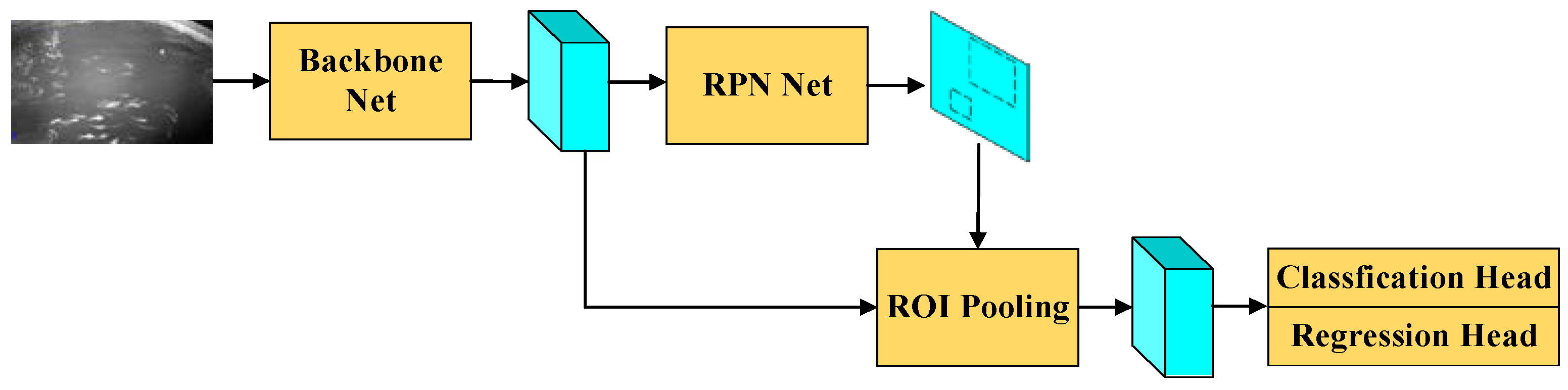
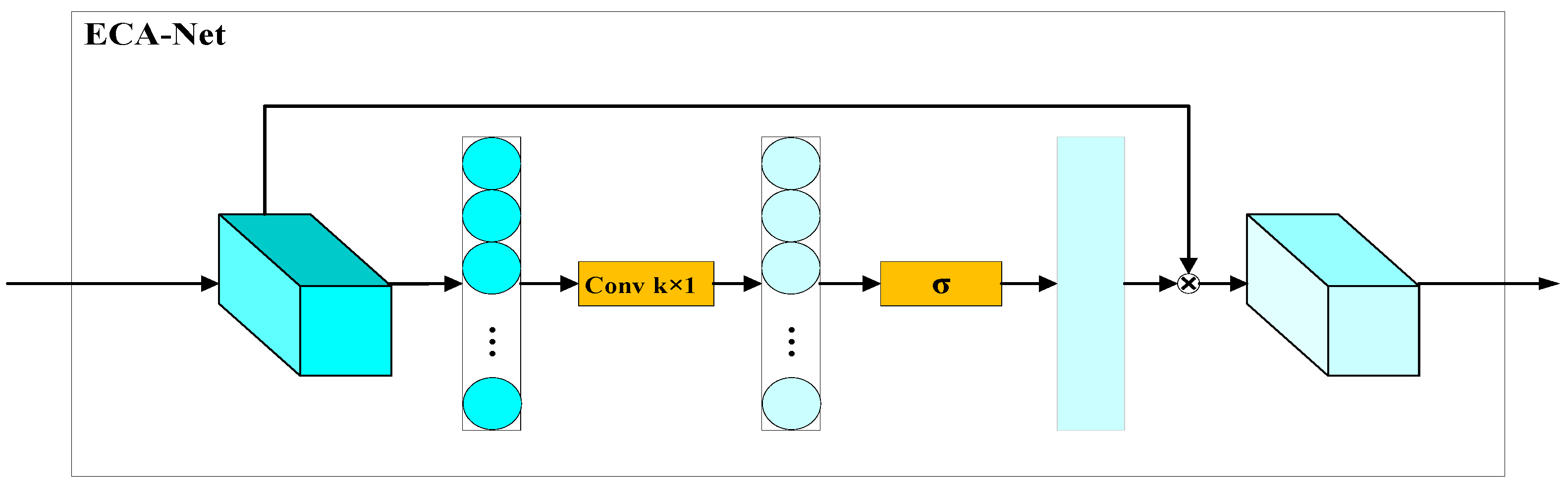
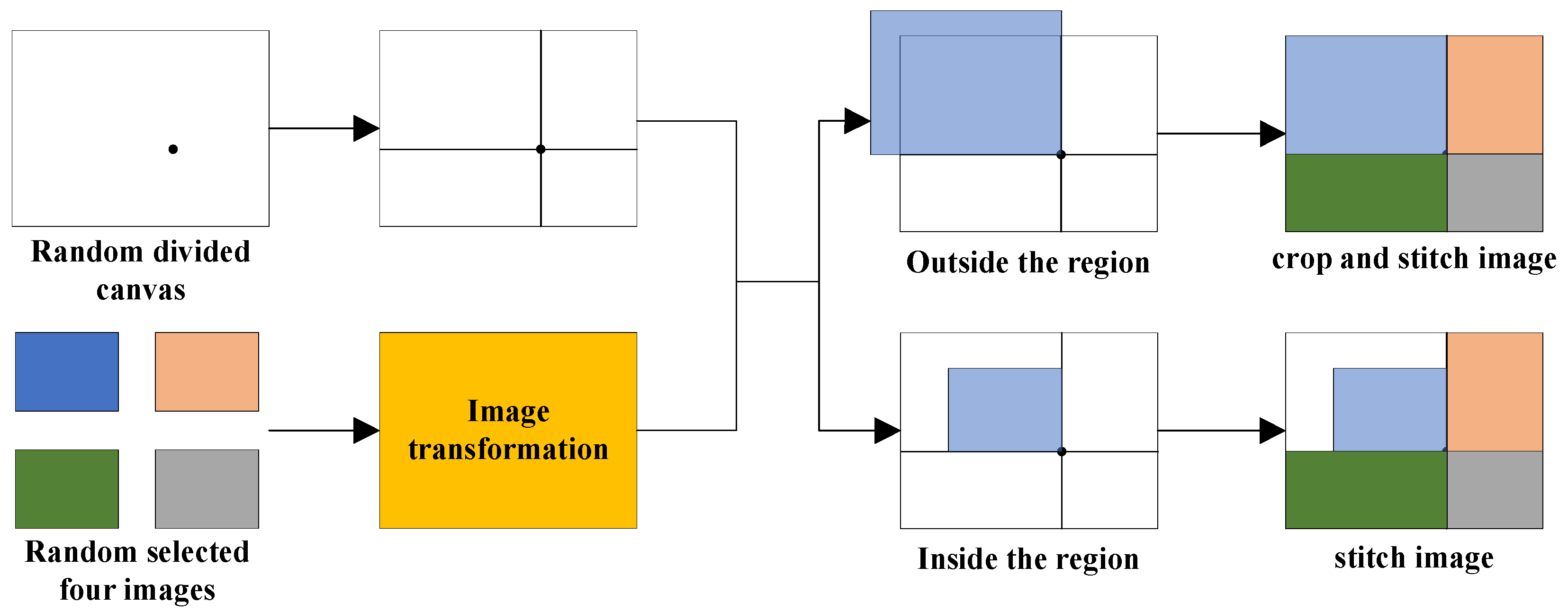
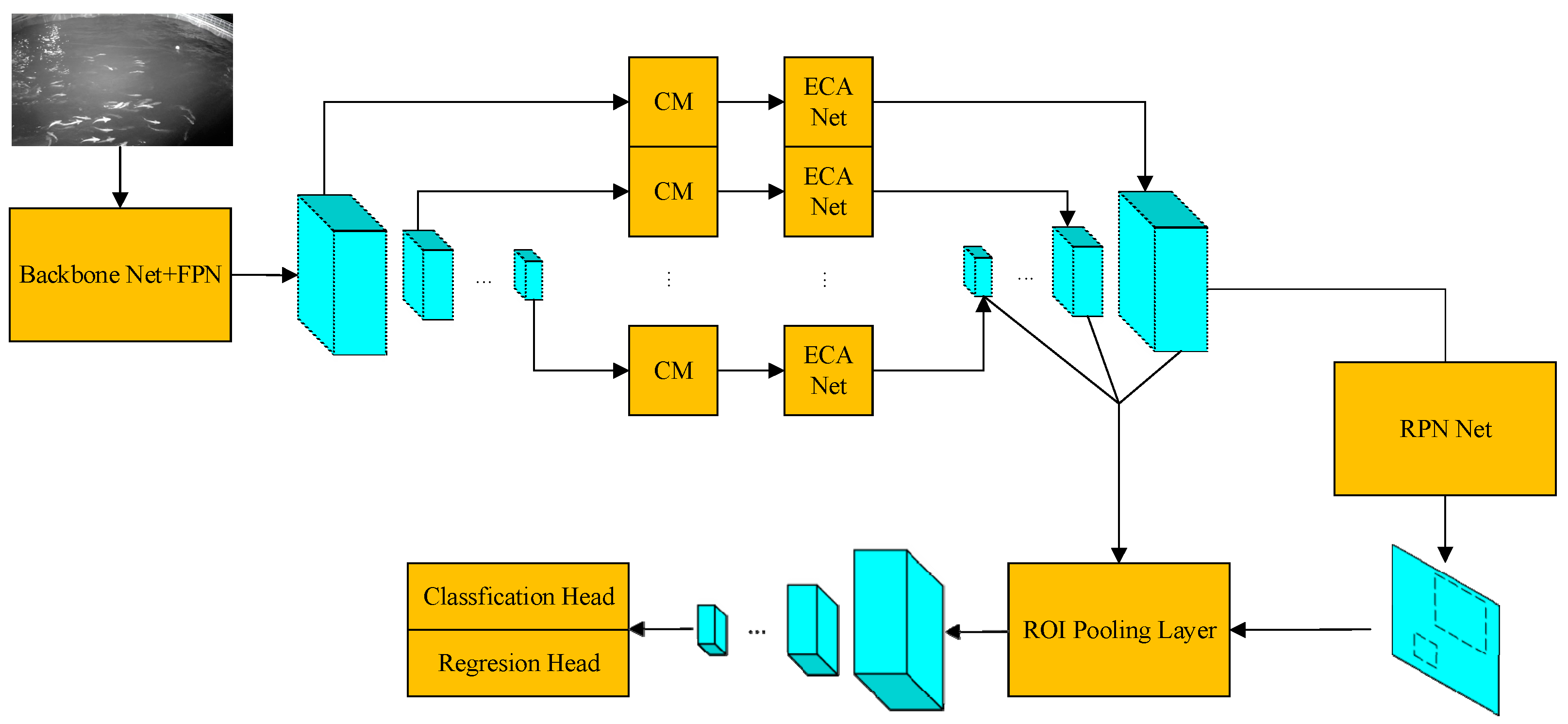
2.2. Network Modules for Fish Detection
3. Experimental Setup and Results
3.1. Comparison Experiments between Faster RCNN and YOLOv5
3.2. Comparison Experiments under Different Learning Rates
3.3. Comparison Experiments under Different Backbone Networks
3.4. Comparison Experiments by Integrating Different Modules
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Food and Agriculture Organization. The State of World Fisheries and Aquaculture 2022 (SOFIA): Towards Blue Transformation; Food & Agriculture Organization of the United Nations (FAO): Rome, Italy, 2022. [Google Scholar]
- Naylor, R.; Fang, S.; Fanzo, J. A Global View of Aquaculture Policy. Food Policy 2023, 116, 102422. [Google Scholar] [CrossRef]
- Willis, S.; Bygvraa, D.A.; Hoque, M.S.; Klein, E.S.; Kucukyildiz, C.; Westwood-Booth, J.; Holliday, E. The Human Cost of Global Fishing. Mar. Policy 2023, 148, 105440. [Google Scholar] [CrossRef]
- Wei, Y.; Wei, Q.; An, D. Intelligent Monitoring and Control Technologies of Open Sea Cage Culture: A Review. Comput. Electron. Agric. 2020, 169, 105119. [Google Scholar] [CrossRef]
- Yu, J.; Yan, T. Analyzing Industrialization of Deep-Sea Cage Mariculture in China: Review and Performance. Rev. Fish. Sci. Aquac. 2023, 31, 483–496. [Google Scholar] [CrossRef]
- Yassir, A.; Jai Andaloussi, S.; Ouchetto, O.; Mamza, K.; Serghini, M. Acoustic Fish Species Identification Using Deep Learning and Machine Learning Algorithms: A Systematic Review. Fish. Res. 2023, 266, 106790. [Google Scholar] [CrossRef]
- Yang, L.; Liu, Y.; Yu, H.; Fang, X.; Song, L.; Li, D.; Chen, Y. Computer Vision Models in Intelligent Aquaculture with Emphasis on Fish Detection and Behavior Analysis: A Review. Arch. Comput. Methods Eng. 2021, 28, 2785–2816. [Google Scholar] [CrossRef]
- Li, D.; Wang, Q.; Li, X.; Niu, M.; Wang, H.; Liu, C. Recent Advances of Machine Vision Technology in Fish Classification. ICES J. Mar. Sci. 2022, 79, 263–284. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A Discriminatively Trained, Multiscale, Deformable Part Model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), Computational and Biological Learning Society, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Lin, T.Y.; Belongie, M.M. Microsoft Coco: Common Objects in Context. In Computer Vision, Proceedings of the ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Zurich, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision, Proceedings of the ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Deng, J.; Guo, J.; Ververas, E. Retinaface: Single-Shot Multi-Level Face Localisation in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5203–5212. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Najibi, M.; Samangouei, P.; Chellappa, R.; Davis, L.S. SSH: Single Stage Headless Face Detector. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Rosales, M.A.; Palconit, M.G.B.; Almero, V.J.D.; Concepcion, R.S.; Magsumbol, J.-A.V.; Sybingco, E.; Bandala, A.A.; Dadios, E.P. Faster R-CNN Based Fish Detector for Smart Aquaculture System. In Proceedings of the 2021 IEEE 13th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment, and Management (HNICEM), Manila, Philippines, 28–30 November 2021. [Google Scholar]
- Muksit, A.A.; Hasan, F.; Hasan Bhuiyan Emon, M.F.; Haque, M.R.; Anwary, A.R.; Shatabda, S. YOLO-Fish: A Robust Fish Detection Model to Detect Fish in Realistic Underwater Environment. Ecol. Inform. 2022, 72, 101847. [Google Scholar] [CrossRef]
- Tamou, B.; Benzinou, A.; Nasreddine, A. Multi-Stream Fish Detection in Unconstrained Underwater Videos by the Fusion of Two Convolutional Neural Network Detectors. Appl. Intell. 2021, 51, 5809–5821. [Google Scholar] [CrossRef]
- Zeng, L.; Sun, B.; Zhu, D. Underwater Target Detection Based on Faster R-CNN and Adversarial Occlusion Network. Eng. Appl. Artif. Intell. 2021, 100, 104190. [Google Scholar] [CrossRef]
- Knausgård, K.M.; Wiklund, A.; Sørdalen, T.K.; Halvorsen, K.T.; Kleiven, A.R.; Jiao, L.; Goodwin, M. Temperate Fish Detection and Classification: A Deep Learning Based Approach. Appl. Intell. 2022, 52, 6988–7001. [Google Scholar] [CrossRef]
- Li, J.; Liu, C.; Lu, X.; Wu, B. CME-YOLOv5: An Efficient Object Detection Network for Densely Spaced Fish and Small Targets. Water 2022, 14, 2412. [Google Scholar] [CrossRef]
- Salman, A.; Siddiqui, S.A.; Shafait, F.; Mian, A.; Shortis, M.R.; Khurshid, K.; Ulges, A.; Schwanecke, U. Automatic Fish Detection in Underwater Videos by a Deep Neural Network-Based Hybrid Motion Learning System. ICES J. Mar. Sci. 2020, 77, 1295–1307. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
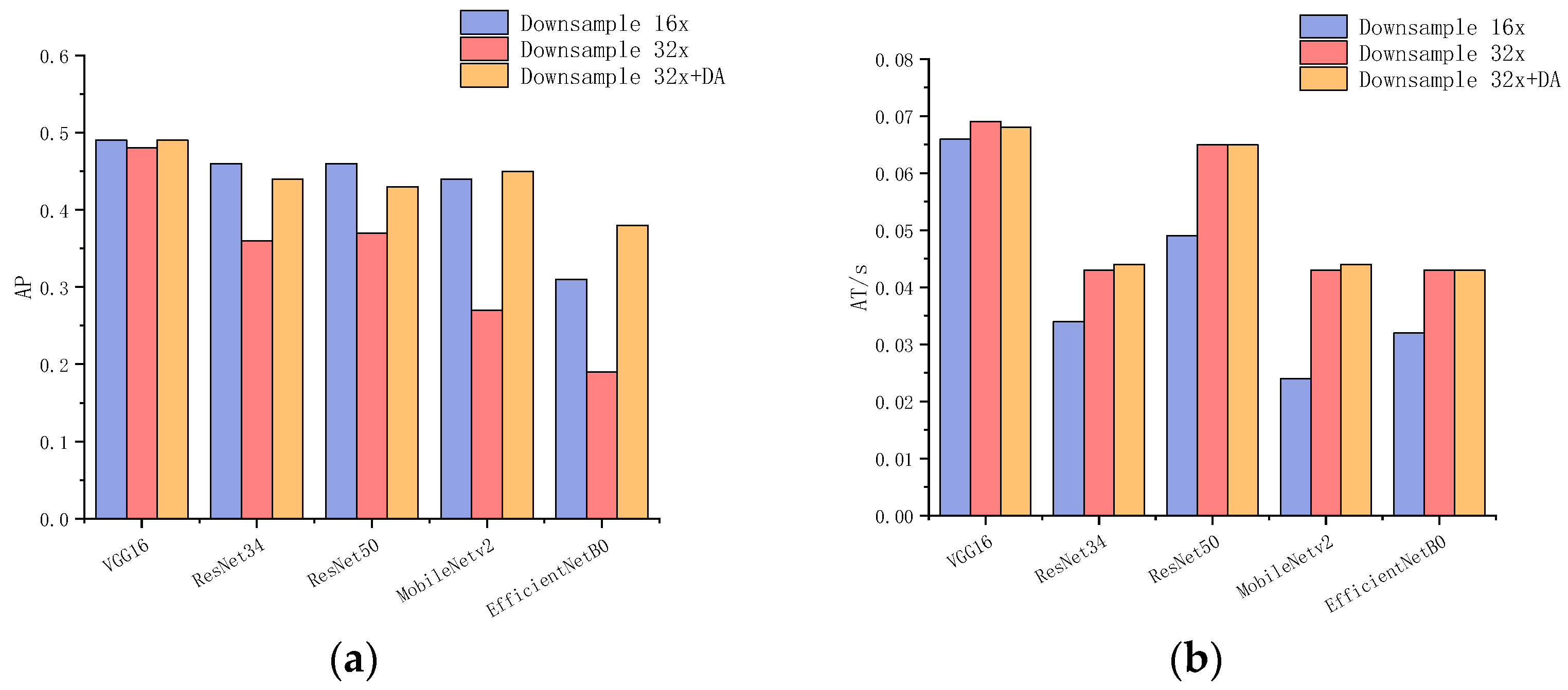{kind=link}
{kind=link}
| Name | Method | Dataset | AP50 |
|---|---|---|---|
| Faster R-CNN [28] | Faster R-CNN-based | underwater, fishpond | 0.78 |
| YOLO-Fish [29] | YOLO-based | underwater, wild environment | 0.77 |
| Multi-stream Faster R-CNN [30] | Faster R-CNN-based | underwater, wild environment | 0.74 |
| CME-YOLOv5 [33] | YOLO-based | underwater, hydropower stations, and fish breeding station | 0.949 |
| deep neural network-based hybrid motion learning [34] | R-CNN-based | underwater, wild environment | lack of data |
| Our work | Faster R-CNN-based | above-water, deep sea truss-structure net cage | 0.85 |
| FPN | CM | ECA-Net | |||
|---|---|---|---|---|---|
| Input | Output | Input | Output | Input | Output |
| F_00 | F_10 | F_10 | F_20 | F_20 | F_30 |
| F_01 | F_11 | F_11 | F_21 | F_21 | F_31 |
| F_02 | F_12 | F_12 | F_22 | F_22 | F_32 |
| Model | AP | AP50 | AT(s) |
|---|---|---|---|
| YOLOv5 | 0.33 | 0.68 | 0.014 |
| Faster RCNN | 0.48 | 0.85 | 0.069 |
| Learning Rate | AP | AP50 | AP75 |
|---|---|---|---|
| LR-0.005 | 0.48 | 0.85 | 0.48 |
| LR-0.01 | 0.49 | 0.85 | 0.52 |
| LR-0.025 | 0.50 | 0.86 | 0.52 |
| LR-adaptive | 0.48 | 0.85 | 0.49 |
| Backbone | DR | AP | AP50 | AP75 | AT(s) | PS(M) |
|---|---|---|---|---|---|---|
| VGG16+L10 | 16 | 0.49 | 0.85 | 0.50 | 0.066 | 36.78 |
| VGG16+L13 | 32 | 0.48 | 0.85 | 0.48 | 0.069 | 43.86 |
| VGG16+L13+DA | 32 | 0.49 | 0.84 | 0.54 | 0.068 | 43.86 |
| ResNet34+L27 | 16 | 0.46 | 0.83 | 0.48 | 0.034 | 22.68 |
| ResNet34+L33 | 32 | 0.36 | 0.74 | 0.28 | 0.043 | 50.43 |
| ResNet34+L33+DA | 32 | 0.44 | 0.79 | 0.42 | 0.044 | 50.43 |
| ResNet50+L40 | 16 | 0.46 | 0.83 | 0.48 | 0.049 | 70.49 |
| ResNet50+L49 | 32 | 0.37 | 0.76 | 0.30 | 0.065 | 165.23 |
| ResNet50+L49+DA | 32 | 0.43 | 0.78 | 0.42 | 0.065 | 165.23 |
| MobileNetv2+L14 | 16 | 0.44 | 0.83 | 0.39 | 0.024 | 6.51 |
| MobileNetv2+L19 | 32 | 0.27 | 0.70 | 0.14 | 0.043 | 82.35 |
| MobileNetv2+L19+DA | 32 | 0.45 | 0.82 | 0.41 | 0.044 | 82.35 |
| EfficientNetB0+L16 | 16 | 0.31 | 0.73 | 0.19 | 0.032 | 13.91 |
| EfficientNetB0+L18 | 32 | 0.19 | 0.54 | 0.05 | 0.043 | 84.14 |
| EfficientNetB0+L18+DA | 32 | 0.38 | 0.79 | 0.29 | 0.043 | 84.14 |
| Feature Extraction Nodules | AP | AP50 | AP75 | AT(s) | PS(M) |
|---|---|---|---|---|---|
| VGG16 | 0.49 | 0.85 | 0.50 | 0.066 | 36.78 |
| VGG16+FPN | 0.51 | 0.85 | 0.57 | 0.082 | 24.13 |
| VGG16+CM | 0.50 | 0.85 | 0.54 | 0.066 | 38.99 |
| VGG16+ECA | 0.49 | 0.86 | 0.51 | 0.066 | 36.78 |
| VGG16+All Module | 0.49 | 0.85 | 0.52 | 0.096 | 25.79 |
| VGG16+All Module+DA | 0.52 | 0.86 | 0.60 | 0.63 | 0.093 |
| ResNet34 | 0.46 | 0.83 | 0.48 | 0.034 | 22.68 |
| ResNet34+FPN | 0.48 | 0.85 | 0.53 | 0.064 | 24.55 |
| ResNet34+CM | 0.47 | 0.84 | 0.48 | 0.037 | 23.23 |
| ResNet34+ECA | 0.45 | 0.83 | 0.44 | 0.035 | 22.68 |
| ResNet34+All Module | 0.48 | 0.84 | 0.55 | 0.071 | 26.21 |
| ResNet34+All Module+DA | 0.50 | 0.82 | 0.57 | 0.61 | 0.071 |
| ResNet50 | 0.46 | 0.83 | 0.48 | 0.049 | 538 |
| ResNet50+FPN | 0.47 | 0.83 | 0.48 | 0.064 | 193 |
| ResNet50+CM | 0.48 | 0.84 | 0.49 | 0.051 | 605 |
| ResNet50+ECA | 0.47 | 0.84 | 0.47 | 0.049 | 538 |
| ResNet50+All Module | 0.50 | 0.84 | 0.51 | 0.071 | 205 |
| ResNet50+All Module+DA | 0.48 | 0.82 | 0.55 | 0.59 | 0.072 |
| MobileNetv2 | 0.44 | 0.83 | 0.39 | 0.024 | 6.51 |
| MobileNetv2+FPN | 0.48 | 0.84 | 0.50 | 0.046 | 16.85 |
| MobileNetv2+CM | 0.44 | 0.83 | 0.40 | 0.026 | 6.58 |
| MobileNetv2+ECA | 0.36 | 0.79 | 0.27 | 0.030 | 6.51 |
| MobileNetv2+All Module | 0.46 | 0.83 | 0.47 | 0.051 | 18.51 |
| MobileNetv2+All Module+DA | 0.45 | 0.85 | 0.54 | 0.63 | 0.051 |
| EfficientNetB0 | 0.31 | 0.73 | 0.19 | 0.032 | 13.91 |
| EfficientNetB0+FPN | 0.51 | 0.85 | 0.57 | 0.039 | 19.22 |
| EfficientNetB0+CM | 0.48 | 0.85 | 0.51 | 0.035 | 14.23 |
| EfficientNetB0+ECA | 0.33 | 0.74 | 0.22 | 0.033 | 13.91 |
| EfficientNetB0+All Module | 0.37 | 0.79 | 0.25 | 0.046 | 20.88 |
| EfficientNetB0+All Module+DA | 0.49 | 0.84 | 0.53 | 0.63 | 0.046 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, G.; Yao, Z.; Hu, Y.; Lian, A.; Yuan, T.; Pang, G.; Huang, X. Deep Learning-Based Fish Detection Using Above-Water Infrared Camera for Deep-Sea Aquaculture: A Comparison Study. Sensors 2024, 24, 2430. https://doi.org/10.3390/s24082430
Li G, Yao Z, Hu Y, Lian A, Yuan T, Pang G, Huang X. Deep Learning-Based Fish Detection Using Above-Water Infrared Camera for Deep-Sea Aquaculture: A Comparison Study. Sensors. 2024; 24(8):2430. https://doi.org/10.3390/s24082430
Chicago/Turabian StyleLi, Gen, Zidan Yao, Yu Hu, Anji Lian, Taiping Yuan, Guoliang Pang, and Xiaohua Huang. 2024. "Deep Learning-Based Fish Detection Using Above-Water Infrared Camera for Deep-Sea Aquaculture: A Comparison Study" Sensors 24, no. 8: 2430. https://doi.org/10.3390/s24082430
APA StyleLi, G., Yao, Z., Hu, Y., Lian, A., Yuan, T., Pang, G., & Huang, X. (2024). Deep Learning-Based Fish Detection Using Above-Water Infrared Camera for Deep-Sea Aquaculture: A Comparison Study. Sensors, 24(8), 2430. https://doi.org/10.3390/s24082430